1.hive vs spark-sql
为了给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,hive应运而生,它是运行在Hadoop上的SQL-on-hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,运行效率底,spark sql而是采用内存存储可以减少大量的中间磁盘落地数据。相比hive速度能提高10到100倍。
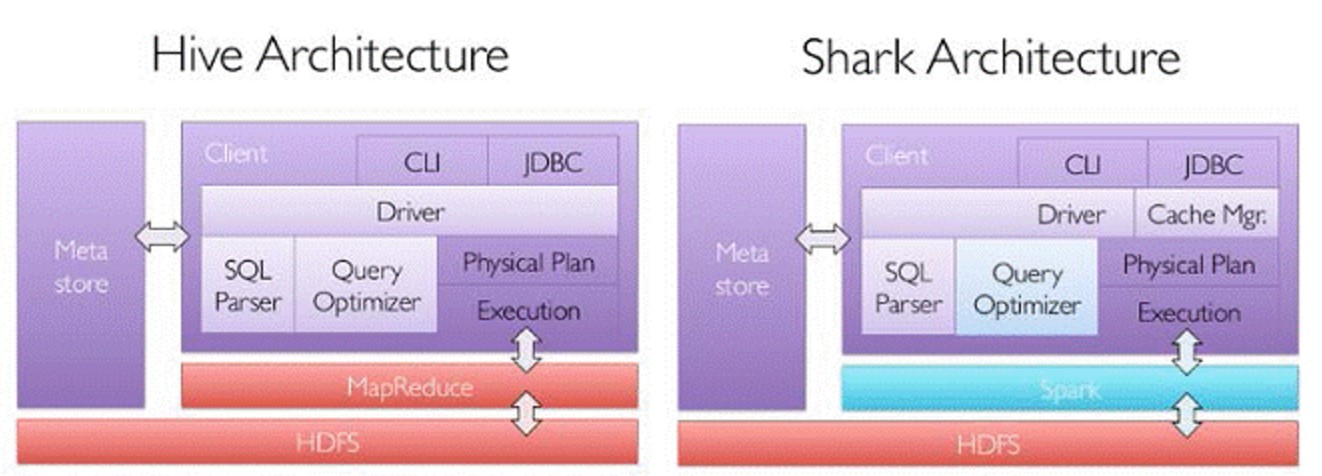
2.集群配置
拷贝hive的配置文件到spark conf的目录下,并删除不必要的信息,增加thrift server配置
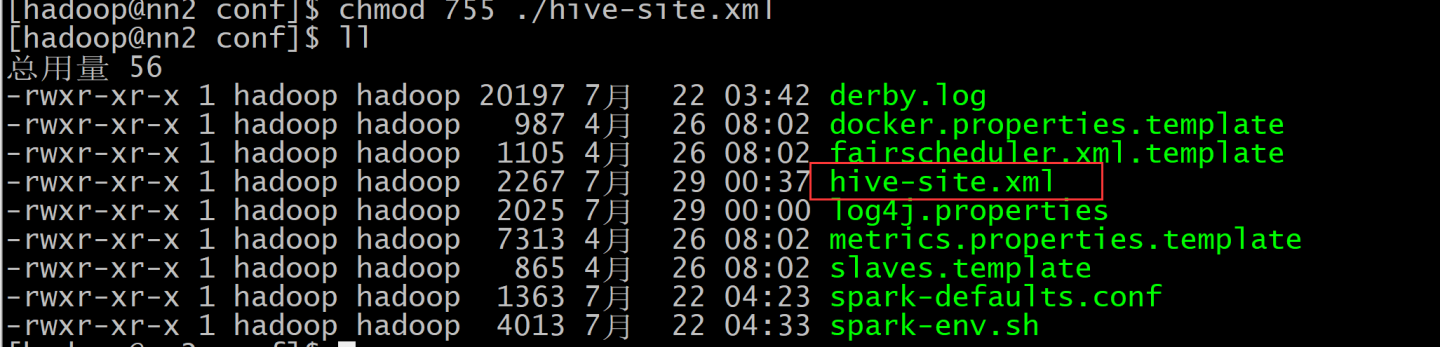
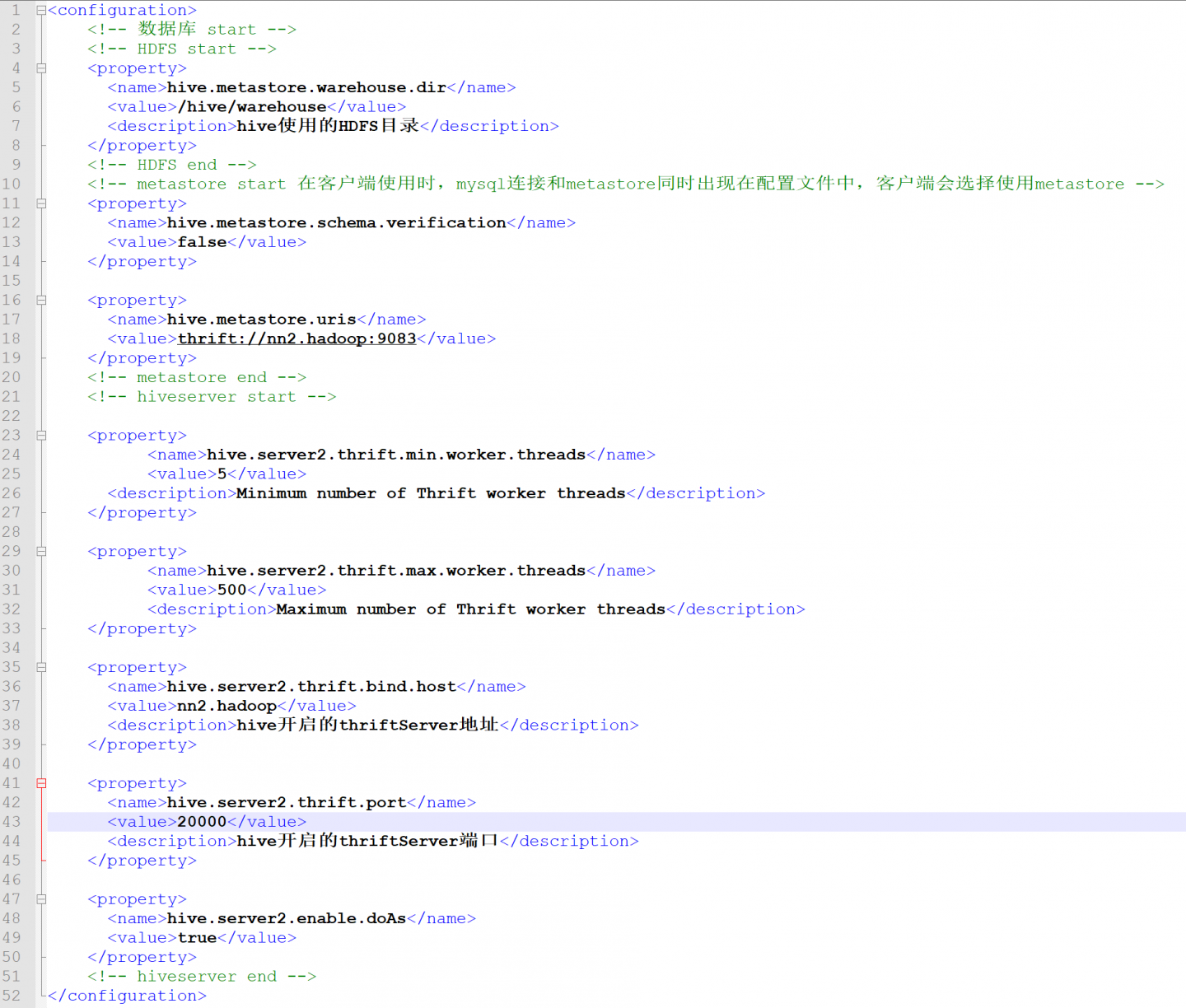
修改conf/hive-site.xml 中的 “hive.metastore.schema.verification”值为false即可解决 “Caused by: MetaException(message:Version information not found in metastore.)
减少日志输出
回复帖子,然后刷新页面即可查看隐藏内容
版权声明:原创作品,允许转载,转载时务必以超链接的形式表明出处和作者信息。否则将追究法律责任。来自海汼部落-青牛,http://hainiubl.com/topics/194



