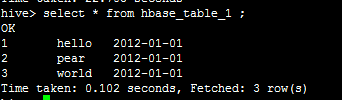
1.创建有分区的表
CREATE TABLE hbase_table_1(key int, value string) partitioned by (day string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val") TBLPROPERTIES ("hbase.table.name" = "xyz");
2.查询源表的记录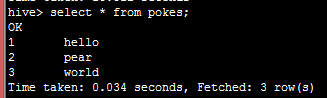
3、将数据插入指定分区的hbase_table_1,执行报错,错误信息如下:
hive> insert overwrite table hbase_table_1 partition (day='2012-01-01') select * from pokes;
Query ID = root_20180322145656_b9e8bd17-2489-41da-a4f3-6d04e42738d3
Total jobs = 3
Launching Job 1 out of 3
Number of reduce tasks is set to 0 since there's no reduce operator
java.io.IOException: java.lang.IllegalArgumentException: Must specify table name
at org.apache.hadoop.hive.ql.exec.FileSinkOperator.checkOutputSpecs(FileSinkOperator.java:1080)
at org.apache.hadoop.hive.ql.io.HiveOutputFormatImpl.checkOutputSpecs(HiveOutputFormatImpl.java:67)
at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:272)
at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:143)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1307)
at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1304)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1920)
at org.apache.hadoop.mapreduce.Job.submit(Job.java:1304)
at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:578)
at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:573)
at java.security.AccessController.doPrivileged(Native Method)
at javax.security.auth.Subject.doAs(Subject.java:422)
at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1920)
at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:573)
at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:564)
at org.apache.hadoop.hive.ql.exec.mr.ExecDriver.execute(ExecDriver.java:428)
at org.apache.hadoop.hive.ql.exec.mr.MapRedTask.execute(MapRedTask.java:142)
at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:214)
at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:100)
at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:1978)
at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:1691)
at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1423)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1207)
at org.apache.hadoop.hive.ql.Driver.run(Driver.java:1197)
at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:226)
at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:175)
at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:389)
at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:781)
at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:699)
at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:634)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at org.apache.hadoop.util.RunJar.run(RunJar.java:221)
at org.apache.hadoop.util.RunJar.main(RunJar.java:136)
Caused by: java.lang.IllegalArgumentException: Must specify table name
at org.apache.hadoop.hbase.mapreduce.TableOutputFormat.setConf(TableOutputFormat.java:195)
at org.apache.hadoop.util.ReflectionUtils.setConf(ReflectionUtils.java:73)
at org.apache.hadoop.util.ReflectionUtils.newInstance(ReflectionUtils.java:133)
at org.apache.hadoop.hive.ql.io.HiveFileFormatUtils.getHiveOutputFormat(HiveFileFormatUtils.java:277)
at org.apache.hadoop.hive.ql.io.HiveFileFormatUtils.getHiveOutputFormat(HiveFileFormatUtils.java:267)
at org.apache.hadoop.hive.ql.exec.FileSinkOperator.checkOutputSpecs(FileSinkOperator.java:1078)
... 37 more
Job Submission failed with exception 'java.io.IOException(java.lang.IllegalArgumentException: Must specify table name)'
FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask