6 SQL语句
6.1 准备工作
创建商品表:
商品表 product
商品编号 主键 自增
商品名称 字符
商品价格 浮点型
商品类别ID
create table product(
pid int not null primary key auto_increment,
pname varchar(500),
price double,
c_id int
);添加测试数据:
INSERT INTO product VALUES(null,' 联想(Lenovo)威6 14英寸商务轻薄笔记本电脑(i7-8550U 8G 256G PCIe SSD FHD MX150 Win10 两年上门)鲨鱼灰',5999,1);
INSERT INTO product VALUES(null,'联想(Lenovo)拯救者Y7000 15.6英寸游戏笔记本电脑(英特尔八代酷睿i5-8300H 8G 512G GTX1050 黑)',5999,1);
INSERT INTO product VALUES(null,'三洋(SANYO)9公斤智能变频滚筒洗衣机 臭氧除菌 空气洗 WiFi智能 中途添衣 Magic9魔力净',2499,1);
INSERT INTO product VALUES(null,'海尔(Haier) 滚筒洗衣机全自动 10公斤变频 99%防霉抗菌窗垫EG10014B39GU1',2499,1);
INSERT INTO product VALUES(null,'雷神(ThundeRobot)911SE炫彩版 15.6英寸游戏笔记本电脑(I7-8750H 8G 128SSD+1T GTX1050Ti Win10 RGB IPS)',6599,1);
INSERT INTO product VALUES(null,'七匹狼休闲裤男2018秋装新款纯棉男士直筒商务休闲长裤子男装 2775 黑色 32/80A',299,2);
INSERT INTO product VALUES(null,'真维斯JEANSWEST t恤男 纯棉圆领男士净色修身青年打底衫长袖体恤上衣 浅花灰 M',35,2);
INSERT INTO product VALUES(null,'PLAYBOY/花花公子休闲裤男弹力修身 秋季适中款商务男士直筒休闲长裤 黑色适中款 31(2.4尺)',128,2);
INSERT INTO product VALUES(null,'劲霸男装K-Boxing 短版茄克男士2018新款休闲舒适棒球领拼接青年夹克|FKDY3114 黑色 185',362,2);
INSERT INTO product VALUES(null,'Chanel 香奈儿 女包 2018全球购 新款蓝色鳄鱼皮小牛皮单肩斜挎包A 蓝色',306830,3);
INSERT INTO product VALUES(null,'皮尔卡丹(pierre cardin)钱包真皮新款横竖款男士短款头层牛皮钱夹欧美商务潮礼盒 黑色横款(款式一)',269,3);
INSERT INTO product VALUES(null,'PRADA 普拉达 女士黑色皮质单肩斜挎包 1BD094 PEO V SCH F0OK0',28512,3);
INSERT INTO product VALUES(null,'好想你 干果零食 新疆特产 阿克苏灰枣 免洗红枣子 玛瑙红500g/袋',21.9,4);
INSERT INTO product VALUES(null,'三只松鼠坚果大礼包1588g每日坚果礼盒干果组合送礼火红A网红零食坚果礼盒8袋装',128,4);
INSERT INTO product VALUES(null,'三只松鼠坚果炒货零食特产每日坚果开心果100g/袋',32.8,4);
INSERT INTO product VALUES(null,'洽洽坚果炒货孕妇坚果零食恰恰送礼每日坚果礼盒(26g*30包) 780g/盒(新老包装随机发货)',149,4);
INSERT INTO product VALUES(null,'今之逸品【拍3免1】今之逸品双眼皮贴双面胶美目舒适隐形立显大眼男女通用 中号160贴',9.9,5);
INSERT INTO product VALUES(null,'自然共和国 原自然乐园 芦荟舒缓保湿凝胶300ml*2(约600g)进口补水保湿舒缓晒后修复面膜',72,5);
INSERT INTO product VALUES(null,'欧莱雅LOREAL 男士火山岩控油清痘洁面膏100ml(洗面奶男 清洁毛孔 祛痘 男士洗面奶)',38.9,null);
INSERT INTO product VALUES(null,'阿拉丁 aladdin 144-62-7 无水草酸 O107180 草酸,无水 500g',88.1,null);
INSERT INTO product VALUES(null,'远东电缆(FAR EAST CABLE)BVVB 2*2.5平方国标家装照明插座用2芯硬护套铜芯电线装潢明线 100米',473,null);6.2 简单查询
1)查询表所有记录
-- 查询所有的商品
select * from product;
-- 查询所有商品的商品名和商品价格
select pname,price from product;2)别名查询,使用的关键字是as(as可以省略)
-- 表别名:
-- 有了表别名,可以通过Navicat提示出表的字段,非常好用
select p.pname,p.price from product p;
--列别名:
select p.pname as name1,p.price price1 from product p;3)去掉重复值
-- 查询有多少种不同的价格
select distinct price from product;4)查询结果是表达式(运算查询)
-- 将所有商品的价格+10元进行显示
select pname,price price1,(price+10) price2 from product;6.3 条件查询
格式:select ... from tablename where ...;
说明:筛选符合条件的行记录。
| 比较运算符 | >、<、<= 、 >=、= 、!=、<> | 大于、小于、大于(小于)等于、不等于 |
|---|---|---|
| BETWEEN...AND... | 显示在某一区间的值(含头含尾) | |
| IN(set) | 显示在in列表中的值,例:in(100,200) | |
| LIKE ‘张pattern’ | 模糊查询,Like语句中,%代表零个或多个任意字符,_代表一个字符,例如:first_name like ‘_a%’; | |
| IS NULL | 判断是否为空 | |
| 逻辑运算符 | and | 多个条件同时成立 |
| or | 多个条件任一成立 | |
| not | 不成立,例:where not(salary>100); |
查询商品名称为“三只松鼠坚果炒货零食特产每日坚果开心果100g/袋”的商品所有信息:
SELECT * FROM product WHERE pname = '三只松鼠坚果炒货零食特产每日坚果开心果100g/袋';查询价格为299商品
SELECT * FROM product WHERE price = 299;查询价格不是800的所有商品
-- 写法1 : 最正常的写法
SELECT * FROM product WHERE price != 800;
-- 写法2 : 比较诡异的写法
SELECT * FROM product WHERE price <> 800;查询商品价格大于60元的所有商品信息
SELECT * FROM product WHERE price > 60;查询商品价格在2000到10000之间所有商品
-- 标准写法
SELECT * FROM product WHERE price >= 2000 AND price <=10000;
-- 简易写法 效果一样
SELECT * FROM product WHERE price BETWEEN 2000 AND 10000;查询商品价格小于2000或大于10000的所有商品
select * from product where price > 10000 or price < 2000;查询商品价格等于 306830 、28512 的商品信息
-- 标准写法
select * from product where price = 306830 or price = 28512;
-- 简写方案
select * from product where price in (306830,28512);查询含有 '霸' 字的所有商品
SELECT * FROM product WHERE pname LIKE '%霸%';查询以'三'开头的所有商品
SELECT * FROM product WHERE pname LIKE '三%';查询第二个字为'想'的所有商品
SELECT * FROM product WHERE pname LIKE '_想%';商品表中没有分类的商品
SELECT * FROM product WHERE c_id IS NULL;查询商品表中有分类的商品
SELECT * FROM product WHERE c_id IS NOT NULL;6.4 排序查询
通过order by语句,可以将查询出的结果进行排序。暂时放置在select语句的最后。
格式:
SELECT * FROM 表名 ORDER BY 排序字段 ASC|DESC;
-- ASC 升序 (默认)
-- DESC 降序1)按照价格降序排序
SELECT * FROM product ORDER BY price DESC;3)在价格排序(降序)的基础上,以分类排序(降序)
SELECT * FROM product ORDER BY price DESC,c_id DESC;3)显示商品的价格(去重),并排序(降序)
SELECT DISTINCT price FROM product ORDER BY price DESC;6.5 聚合查询
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一个单一的值;另外聚合函数会忽略空值。
聚合查询就是先把表的数据聚在一起,统一进行计算后,再得出一个结果的查询方式。
聚合函数:
count:
COUNT()函数进行计数使用
COUNT(*)对表中行的数目进行计数,包含空值(NULL)。
使用COUNT(column)对特定列中具有值的行进行计数,忽略NULL值。
sum:计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
max:计算指定列的最大值,如果指定列是字符串类型,那么使用字符串排序运算;
min:计算指定列的最小值,如果指定列是字符串类型,那么使用字符串排序运算;
avg:计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;
1)count(*) vs count(colume)
-- 查询商品的总条数
SELECT COUNT(*) FROM product;
-- 查询结果:21, count(*) 包含 空值
-- 查询商品类别id的总条数
select count(c_id) from product;
-- 查询结果:18, count(c_id) 不包含c_id为空的记录2)查询价格大于2000商品的总条数
SELECT COUNT(*) FROM product WHERE price > 2000;3)查询分类为 1 的所有商品的总和
SELECT SUM(price) FROM product WHERE c_id = 1;4)查询分类为2所有商品的平均价格
SELECT AVG(price) FROM product WHERE c_id = 2;5)查询商品的最大价格和最小价格
SELECT MAX(price),MIN(price) FROM product;6.6 分组查询
分组查询是指使用group by字句对查询信息进行分组。
格式:
SELECT 查询字段 FROM 表名 GROUP BY 分组字段 [HAVING 分组条件];
-- 分组操作中的having子语句,是用于在分组后对数据进行过滤的,作用类似于where条件。
-- 其中 查询字段只能是 分组字段, 聚合函数,常量 这三种having与where的区别:
having是在分组后对数据进行过滤
where是在分组前对数据进行过滤
having后面可以使用聚合函数(统计函数)
where后面不可以使用聚合函数
1)统计各个分类商品的个数
SELECT c_id ,COUNT(*) FROM product GROUP BY c_id;2) 统计各个分类商品的个数,且只显示个数大于3的信息
SELECT c_id ,COUNT(*) FROM product GROUP BY c_id HAVING COUNT(*) > 3;
--等效于
SELECT c_id ,COUNT(*) as num FROM product GROUP BY c_id HAVING num > 3;3)筛选价格>100 的商品,并统计 统计各个分类商品的个数,且只显示个数大于3的信息
SELECT c_id ,COUNT(*) as num FROM product where price>100 GROUP BY c_id having num > 3;7 多表查询
7.1 表与表的关系
通过之前ER图的讲解,我们知道实体与实体的关系有三种,实体对应表,所以表与表的关系也有三种。
7.1.2 一对一关系
在一对一关系中,A 表中的一行最多只能匹配于 B 表中的一行,反之亦然。如果相关列都是主键或都具有唯一约束,则可以创建一对一关系。
这种关系并不常见,因为一般来说,按照这种方式相关的信息都在一个表中。
除非表字段特别多,拆分表。
7.1.2 一对多关系
一对多关系是最普通的一种关系。在这种关系中,A 表中的一行可以匹配 B 表中的多行,但是 B 表中的一行只能匹配 A 表中的一行。比如:商品类别表和商品表,一个类别可以有多个商品,一个商品只有一个类别。

一对多建表原则:
在从表(多方)创建一个字段,字段作为外键指向主表(一方)的主键。

7.1.3 多对多关系
在多对多关系中,A 表中的一行可以匹配 B 表中的多行,反之亦然。要创建这种关系,需要中间表,将多对多转成两个一对多。
比如:学生表和课程表是多对多关系,如下图:

7.1.4 外键约束
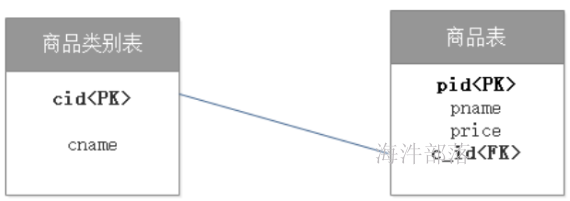
由此看出:
商品类别表的主键作为商品表的外键。
我们通过主表的主键和从表的外键来描述主外键关系,呈现就是一对多关系。
外键特点:
从表外键的值是对主表主键的引用。
从表外键类型,必须与主表主键类型一致。
声明外键约束:
语法:alter table 从表 add [constraint] [外键名称] foreign key (从表外键字段名) references 主表 (主表的主键);
[外键名称] 用于删除外键约束的,一般建议“_fk”结尾
alter table 从表 drop foreign key 外键名称
使用外键目的:保证数据完整性
外键约束示例:
1)创建表
-- 删除表
drop table product;
drop table category;
-- 创建category表
CREATE TABLE category (
cid int,
cname varchar(50) DEFAULT NULL,
PRIMARY KEY (cid)
);
-- 创建product 表,并声明 category 表的cid字段作为外键
-- 要删改category表,必须要先删改product表对应数据
CREATE TABLE product (
pid int(11) NOT NULL AUTO_INCREMENT,
pname varchar(500) DEFAULT NULL,
price double DEFAULT NULL,
cid int(11) DEFAULT NULL,
PRIMARY KEY (pid),
KEY `product_cid_fk` (`cid`),
CONSTRAINT `product_cid_fk` FOREIGN KEY (`cid`) REFERENCES `category` (`cid`)
);2)向分类表中添加数据
insert into category values (1,'家用电器/电脑');3)向商品表中添加已经存在的商品类别的商品
INSERT INTO product VALUES(null,' 联想(Lenovo)威6 14英寸商务轻薄笔记本电脑(i7-8550U 8G 256G PCIe SSD FHD MX150 Win10 两年上门)鲨鱼灰',5999,1);
INSERT INTO product VALUES(null,'联想(Lenovo)拯救者Y7000 15.6英寸游戏笔记本电脑(英特尔八代酷睿i5-8300H 8G 512G GTX1050 黑)',5999,1);
INSERT INTO product VALUES(null,'三洋(SANYO)9公斤智能变频滚筒洗衣机 臭氧除菌 空气洗 WiFi智能 中途添衣 Magic9魔力净',2499,1);
INSERT INTO product VALUES(null,'海尔(Haier) 滚筒洗衣机全自动 10公斤变频 99%防霉抗菌窗垫EG10014B39GU1',2499,1);
INSERT INTO product VALUES(null,'雷神(ThundeRobot)911SE炫彩版 15.6英寸游戏笔记本电脑(I7-8750H 8G 128SSD+1T GTX1050Ti Win10 RGB IPS)',6599,1);4)向商品表中添加不存在的商品类别的商品 (报错,违反了主外键约束)
INSERT INTO product VALUES(null,'七匹狼休闲裤男2018秋装新款纯棉男士直筒商务休闲长裤子男装 2775 黑色 32/80A',299,2);
5)删除指定分类(分类被商品使用) -- 执行异常(因为要删除的商品分类被外检表引用,所以会报错)
delete from category where cid = 1;
6)先删除指定分类的商品表数据,再删除指定分类的类别表数据
delete from product where cid=1;
delete from category where cid = 1;7.2 多表查询
7.2.1 准备数据
重新给商品表和商品类别表初始化数据。
-- 向商品类别表中添加数据
insert into category (cid,cname) values(1,'家用电器/电脑'), (2,'男装/女装/童装/内衣'),(3,'女鞋/箱包/珠宝/钟表'),(4,'食品/酒类/生鲜/特产'),(5,'美妆/个护清洁/宠物');
-- 向商品表中添加数据
INSERT INTO product VALUES(null,' 联想(Lenovo)威6 14英寸商务轻薄笔记本电脑(i7-8550U 8G 256G PCIe SSD FHD MX150 Win10 两年上门)鲨鱼灰',5999,1);
INSERT INTO product VALUES(null,'联想(Lenovo)拯救者Y7000 15.6英寸游戏笔记本电脑(英特尔八代酷睿i5-8300H 8G 512G GTX1050 黑)',5999,1);
INSERT INTO product VALUES(null,'三洋(SANYO)9公斤智能变频滚筒洗衣机 臭氧除菌 空气洗 WiFi智能 中途添衣 Magic9魔力净',2499,1);
INSERT INTO product VALUES(null,'海尔(Haier) 滚筒洗衣机全自动 10公斤变频 99%防霉抗菌窗垫EG10014B39GU1',2499,1);
INSERT INTO product VALUES(null,'雷神(ThundeRobot)911SE炫彩版 15.6英寸游戏笔记本电脑(I7-8750H 8G 128SSD+1T GTX1050Ti Win10 RGB IPS)',6599,1);
INSERT INTO product VALUES(null,'七匹狼休闲裤男2018秋装新款纯棉男士直筒商务休闲长裤子男装 2775 黑色 32/80A',299,2);
INSERT INTO product VALUES(null,'真维斯JEANSWEST t恤男 纯棉圆领男士净色修身青年打底衫长袖体恤上衣 浅花灰 M',35,2);
INSERT INTO product VALUES(null,'PLAYBOY/花花公子休闲裤男弹力修身 秋季适中款商务男士直筒休闲长裤 黑色适中款 31(2.4尺)',128,2);
INSERT INTO product VALUES(null,'劲霸男装K-Boxing 短版茄克男士2018新款休闲舒适棒球领拼接青年夹克|FKDY3114 黑色 185',362,2);
INSERT INTO product VALUES(null,'Chanel 香奈儿 女包 2018全球购 新款蓝色鳄鱼皮小牛皮单肩斜挎包A 蓝色',306830,3);
INSERT INTO product VALUES(null,'皮尔卡丹(pierre cardin)钱包真皮新款横竖款男士短款头层牛皮钱夹欧美商务潮礼盒 黑色横款(款式一)',269,3);
INSERT INTO product VALUES(null,'PRADA 普拉达 女士黑色皮质单肩斜挎包 1BD094 PEO V SCH F0OK0',28512,3);
INSERT INTO product VALUES(null,'好想你 干果零食 新疆特产 阿克苏灰枣 免洗红枣子 玛瑙红500g/袋',21.9,4);
INSERT INTO product VALUES(null,'三只松鼠坚果大礼包1588g每日坚果礼盒干果组合送礼火红A网红零食坚果礼盒8袋装',128,4);
INSERT INTO product VALUES(null,'三只松鼠坚果炒货零食特产每日坚果开心果100g/袋',32.8,4);
INSERT INTO product VALUES(null,'洽洽坚果炒货孕妇坚果零食恰恰送礼每日坚果礼盒(26g*30包) 780g/盒(新老包装随机发货)',149,4);
INSERT INTO product VALUES(null,'今之逸品【拍3免1】今之逸品双眼皮贴双面胶美目舒适隐形立显大眼男女通用 中号160贴',9.9,5);
INSERT INTO product VALUES(null,'自然共和国 原自然乐园 芦荟舒缓保湿凝胶300ml*2(约600g)进口补水保湿舒缓晒后修复面膜',72,5);7.2.2 连接查询
7.2.2.1 交叉连接查询
语法:select * from A,B;
得到的结果集记录数是两个表记录数的乘积。
这样的结果集也称笛卡尔积。
假设集合A={a, b},集合B={0, 1, 2},则两个集合的笛卡尔积为{(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}。
笛卡尔积是很可怕的,比如 A,B两表 个10000条数据,得到的笛卡尔积就有 10000 0000条。
示例:
-- 商品类别 5条数据
select count(*) from category;
-- 商品 18条数据
select count(*) from product;
-- 交叉查询 90条数据
select count(*) from product,category;
-- 详细数据
select * from product,category;7.2.2.2 内连接查询
内链接是查询两个表的交集的部分。
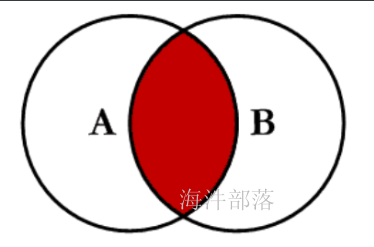
隐式内连接:select * from A,B where 条件;
-- 找两个表中 cid 相对的join在一起
select * from category c,product p where c.cid = p.cid;显示内连接:select * from A inner join B on 条件; (推荐写法)
-- 找两个表中 cid 相对的join在一起
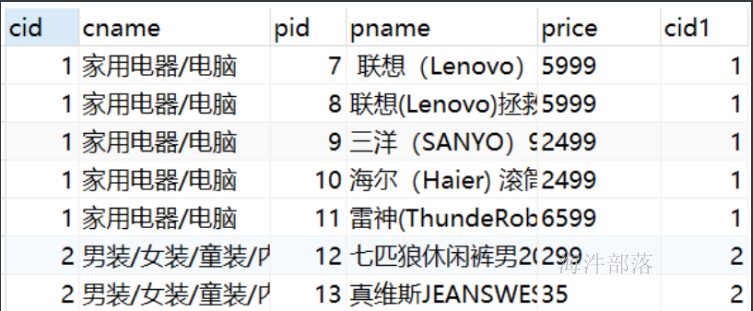
select * from category c inner join product p on c.cid = p.cid;部分内链接结果:
内链接的问题:
向商品类别表插入一条数据
INSERT into category values (6,'手机/运营商/数码');
但是当我关联查询的时候
select DISTINCT c.* from category c inner join product p on c.cid = p.cid;
只能查询出5个类别,这是为什么呢?
商品表只有这5个类别的数据。如何解决? 用外连接。
7.2.2.3 外连接查询
外连接可以把关联查询的两张表的一张表作为主表,另外一张作为从表,而外链接始终保证主表的数据完整。
外连接分三类:左外连接(left outer join)、右外连接(right outer join)和全外连接(full outer join),可以省略outer。
1)左外连接(left join)
语法:select * from A left join B on 条件
A left join B,查询结果A表是全的,B表如果没有和A表匹配的记录,那就以一条null数据填充查询结果。

示例:
-- 使用有连接解决上面的问题
select DISTINCT c.* from category c left join product p on c.cid = p.cid;
-- 同时查看左连接的结果
select * from category c left join product p on c.cid = p.cid;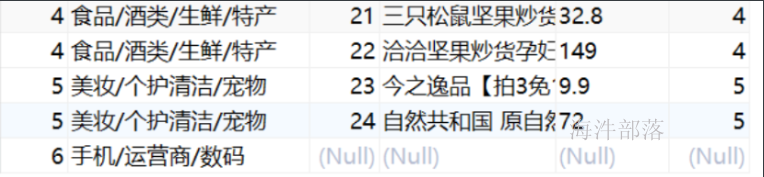
2)右外连接(right join)
语法:select * from A right join B on 条件
A right join B,查询结果B表是全的,A表如果没有和B表匹配的记录,那就以一条null数据填充查询结果。

示例:
-- 用右连接实现上面的查询结果
select * from product p right join category c on c.cid = p.cid;
7.2.2.4 多表查询综合案例
1) 查询价格在一万以内名字中包含 '想' 的商品
隐式内连接
-- 查询价格在一万以内名字中包含 '想' 的商品
select * from category c,product p where c.cid = p.cid and p.price <= 10000 and p.pname like '%想%';
隐式内连接是借助where条件来设定关联关系,所以这样如果一旦where条件变多整体关联关系就很难把控,并且表越多,隐式内连接关联就越乱,多表连接时不建议用。
显式内连接
-- 先通过连接条件生成临时结果,然后再通过where条件筛选出最终结果
select * from category c
inner join product p on c.cid = p.cid -- 此处设置连接条件
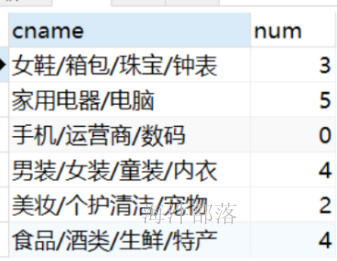
where p.price < 10000 and p.pname like '%想%'; -- 此处设置连接后的筛选条件2)查询所有分类商品的个数
左外连接 :
-- 先通过连接条件生成临时结果,然后再通过group by 汇总出最终结果
select c.cname,count(p.cid) num from category c
left join product p on c.cid = p.cid
group by c.cname;结果 :
7.2.3 子查询
有时一次查询查不出结果,需要将一次查询完的结果作为条件再进行查询。
子查询是指在查询语句中嵌套另一个查询,子查询可以支持多层嵌套。
对于一个普通的查询语句,子查询可以出现在两个位置。
1)出现在 from 语句后当成数据表
-- 统计商品表有多少种不同的类别
select count(distinct cid) from product;
-- 利用子查询对每个类别去重,然后再count
select count(*) from
(select distinct cid from product) t1;
-- 利用子查询按照类别分组得到每个类别,然后再去重
select count(*) from
(select cid from product group by cid) t1;
2)出现在where 条件后作为过滤条件的值
单行单列子查询
-- 类别为 家用电器/电脑的商品名称和价格
select pname, price from product
where cid=(select cid from category where cname='家用电器/电脑');
多行单列子查询
-- 查询商品价格大于5000的类别
select * from category where cid in (select cid from product where price>5000);
使用子查询要注意如下要点:
1)子查询要用括号括起来。
2)把子查询当成数据表时(出现在from 之后),可以为该子查询起别名,尤其是作为前缀来限定数据列时,必须给子查询起别名。
3)把子查询当成过滤条件时,将子查询放在比较运算符的右边,这样可以增强查询的可读性。
8 视图
什么是视图
视图是一张虚拟表
表示一张表的部分数据或多张表的综合数据
其结构和数据是建立在对表的查询基础上
视图中不存放数据
数据存放在视图所引用的原始表中
一个原始表,根据不同用户的不同需求,可以创建不同的视图
为什么使用视图
- 重用SQL语句
- 简化复杂的SQL操作。在编写查询后,可以方便地重用它而不必知道其基本查询细节。
- 使用表的一部分而不是整个表。
- 保护数据。可以授予用户访问表的特定部分的权限,而不是整个表的访问权限。
规定及限制
- 因为视图不包含数据,所以每次使用视图时,都必须处理查询执行时需要的所有检索
- 与表一样,视图必须唯一命名(不能给视图取与别的视图或表相同的名字) 名称_view
- 对于可以创建的视图数目没有限制
- 视图大部分情况都不能更新和删除,比如多表导出、groupby、常量字段等等
视图语法
-- 创建视图
create view view_name as
<select 语句>;
-- 查询视图数据
select 字段1,字段2, ... from view_name
-- 删除视图
drop view view_name;示例:
-- 查询 类别为 家用电器/电脑 且 商品价格>5000的商品信息
select pname, price from product
where cid=(select cid from category where cname='家用电器/电脑') and price > 5000;
-- 查询 类别为 家用电器/电脑 且 商品价格<5000的商品信息
select pname, price from product
where cid=(select cid from category where cname='家用电器/电脑') and price < 5000;发现上面的两个查询有公共的部分,那我们就可以把公共部分创建视图,基于这个视图在来查询相应价格的数据
-- 创建视图 (查询 类别为 家用电器/电脑 的 商品信息)
create view cp1_view as
select pname, price from product
where cid=(select cid from category where cname='家用电器/电脑');
-- 在此基础上,用视图直接筛选价格>5000的商品
select * from cp1_view where price > 5000;
-- 在此基础上,用视图直接筛选价格<5000的商品
select * from cp1_view where price < 5000;筛选价格>5000的商品的结果

筛选价格<5000的商品的结果

删除视图
drop view cp1_view;9 索引
9.1 索引概述
为什么要学索引
如果新华字典没有汉语拼音、偏旁部首目录,你如何查找某个汉字?
一页一页翻找,效率低
如果带着汉语拼音、偏旁部首目录,你如何查找?
先看汉语拼音目录,找到汉字对应的页数,直接找对应页码即可。利用索引检索,效率高
索引是什么
Mysql官方对索引的定义是:索引(Index)是帮助Mysql高效获取数据的数据结构。
提取句子主干就是:索引是数据结构。
索引的目的
索引的目的在于提高查询或检索效率。(拿空间换时间)
索引的优势
提高数据检索效率,降低数据库IO成本。
降低数据排序的成本,降低CPU的消耗。
索引的劣势
索引也是一张表,保存了主键和索引字段,并指向实体表的记录,所以也需要占用内存。
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段, 都会调整因为更新所带来的键值变化后的索引信息 。
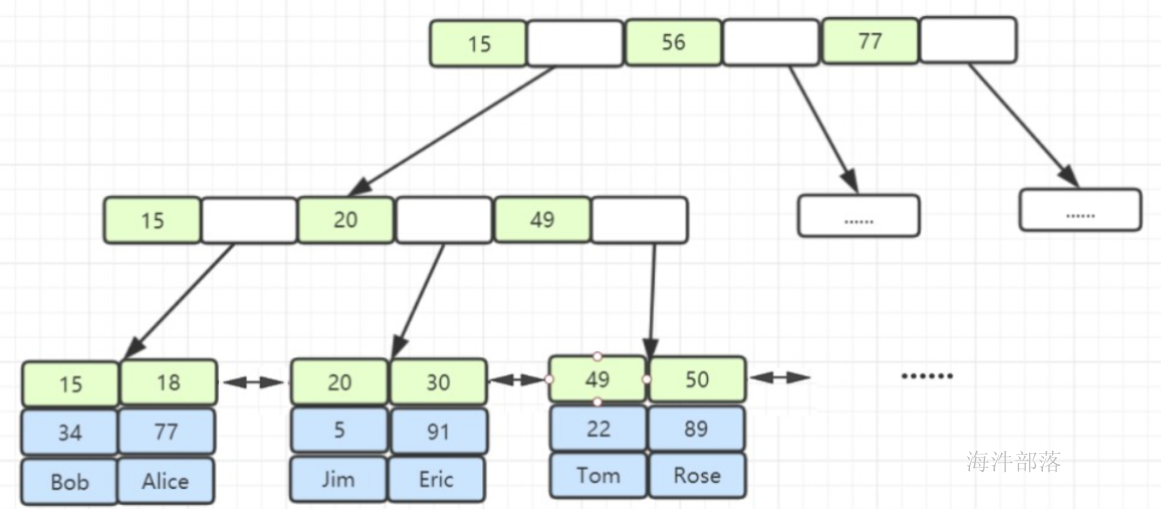
9.2 MySQL的索引存储结构
MySQL默认使用的是B+数存储结构,如下图所示:
其中:
非叶子节点只存储键值。
只有叶子节点才会存储数据,数据存储的是非主键的数据。
叶子节点之间使用双向指针连接,最底层的叶子节点形成了一个双向有序链表。
优势:
范围查询特别方便,只需要在叶子节点利用有序链表查找范围即可。
9.3 MySQL索引分类

9.4 MySQL 索引使用
索引语法

创建索引的方式:
1)查询时总是要按照商品价格作为查询条件时,可以给商品表的商品价格添加一个索引
create INDEX index_product_price on product(price);2)查看某个表的索引
show index from product;
部分结果说明
Table:创建索引的表
Non_unique:索引是否非唯一
Key_name:索引的名称
Column_name:定义索引的列字段
Seq_in_index:该列在索引中的位置
Null:该列是否能为空值
Index_type:索引类型
3)删除索引
DROP INDEX index_product_price on product;
show create table9.5 MySql创建索引的使用技巧
创建索引的指导原则
(一) 按照下列标准选择建立索引的列
- 频繁搜索的列
- 经常用作查询选择的列
- 经常排序、分组的列
- 经常用作连接的列(主键/外键)
(二) 请不要使用下面的列创建索引
- 仅包含几个不同值的列
- 表中仅包含几行
(三) 使用索引时注意事项
- 查询时减少使用*返回全部列,不要返回不需要的列
- 索引应该尽量小,在字节数小的列上建立索引
- WHERE子句中有多个条件表达式时,包含索引列的表达式应置于其他条件表达式之前
- 避免在ORDER BY子句中使用表达式
9.6 索引失效的场景
1)当在查询条件中出现 <>、NOT、in、not exists 时,查询时更倾向于全表扫描。
2)在查询条件中有or 也不走索引,尽量不使用。
3)查询条件使用LIKE通配符
SQL语句中,使用后置通配符会走索引,例如查询姓张的学生(select from student where name LIKE 'hai%'),而前置通配符(select from student where name LIKE '%niu')会导致索引失效而进行全表扫描。
4)在索引列上使用函数 或 计算。
5)索引列数据类型不匹配。比如:字段类型是string, 但条件值不是string。
9.7 关键字
1)union union all两个结果集的数据进行堆叠
union去重
union all不去重,全部数据集都保存
2)distinct去重
将重复字段进行过滤
3)not与exists
exists判断在数据集中是否存在
4) limit
9.8 函数
1)字符串类型函数
CONCAT(s1,s2...sn) 链接字符串
CONCAT_WS(x, s1,s2...sn)间隔符链接
FORMAT(x,n) 字符串格式化,保留小数n位
LOWER(s)转换小写 UPPER转换为大写
trim去除字符串的左右部分的空格
SUBSTRING(s, start, length) /SUBSTR(s,start,length) 截取字符串
REPLACE(s,s1,s2)替换字符串字段
REVERSE翻转
2)数字类型函数
max min avg sum
rand()随机数
mod()余数
floor()向下取整 ceil向上取整
3)日期函数
CURRENT_DATE() 当前日期
CURRENT_TIME() 当前时间
CURRENT_TIMESTAMP()当前时间 相当于上面两个的总体
datediff(dat1,dat2)时间间隔天数
| DATE_ADD(d,INTERVAL expr type) | 计算起始日期 d 加上一个时间段后的日期,type 值可以是:MICROSECONDSECONDMINUTEHOURDAYWEEKMONTHQUARTERYEARSECOND_MICROSECONDMINUTE_MICROSECONDMINUTE_SECONDHOUR_MICROSECONDHOUR_SECONDHOUR_MINUTEDAY_MICROSECONDDAY_SECONDDAY_MINUTEDAY_HOURYEAR_MONTH | SELECT DATE_ADD("2017-06-15", INTERVAL 10 DAY); -> 2017-06-25 SELECT DATE_ADD("2017-06-15 09:34:21", INTERVAL 15 MINUTE); -> 2017-06-15 09:49:21 SELECT DATE_ADD("2017-06-15 09:34:21", INTERVAL -3 HOUR); ->2017-06-15 06:34:21 SELECT DATE_ADD("2017-06-15 09:34:21", INTERVAL -3 HOUR); ->2017-04-15 |
|---|---|---|
DATE_FORMAT(d,f) 格式化 select date_format('2020-10-10 10:10:10','%Y,%m,%d,%H,%i,%s,%r')
%Y,%m,%d,%H,%i,%s,日期 %r 上下午
year month day hour minute second 获取时间中的相应位置的值
4)高级函数
CASE expression WHEN condition1 THEN result1 WHEN condition2 THEN result2 ... WHEN conditionN THEN resultN ELSE result END |
CASE 表示函数开始,END 表示函数结束。如果 condition1 成立,则返回 result1, 如果 condition2 成立,则返回 result2,当全部不成立则返回 result,而当有一个成立之后,后面的就不执行了。 | SELECT CASE WHEN 1 > 0 THEN '1 > 0' WHEN 2 > 0 THEN '2 > 0' ELSE '3 > 0' END ->1 > 0 |
|---|---|---|
| COALESCE(expr1, expr2, ...., expr_n) | 返回参数中的第一个非空表达式(从左向右) | SELECT COALESCE(NULL, NULL, NULL, 'runoob.com', NULL, 'google.com'); |
|---|---|---|
| IF(expr,v1,v2) | 如果表达式 expr 成立,返回结果 v1;否则,返回结果 v2。 | SELECT IF(1 > 0,'正确','错误') ->正确 |
|---|---|---|
| IFNULL(v1,v2) | 如果 v1 的值不为 NULL,则返回 v1,否则返回 v2。 | SELECT IFNULL(null,'Hello Word') ->Hello Word |
|---|---|---|
9.9 行列转换
一、行转列
即将原本同一列下多行的不同内容作为多个字段,输出对应内容。
建表语句
DROP TABLE IF EXISTS tb_score;
CREATE TABLE tb_score(
id INT(11) NOT NULL auto_increment,
userid VARCHAR(20) NOT NULL COMMENT '用户id',
subject VARCHAR(20) COMMENT '科目',
score DOUBLE COMMENT '成绩',
PRIMARY KEY(id)
)ENGINE = INNODB DEFAULT CHARSET = utf8;插入数据
INSERT INTO tb_score(userid,subject,score) VALUES ('001','语文',90);
INSERT INTO tb_score(userid,subject,score) VALUES ('001','数学',92);
INSERT INTO tb_score(userid,subject,score) VALUES ('001','英语',80);
INSERT INTO tb_score(userid,subject,score) VALUES ('002','语文',88);
INSERT INTO tb_score(userid,subject,score) VALUES ('002','数学',90);
INSERT INTO tb_score(userid,subject,score) VALUES ('002','英语',75.5);
INSERT INTO tb_score(userid,subject,score) VALUES ('003','语文',70);
INSERT INTO tb_score(userid,subject,score) VALUES ('003','数学',85);
INSERT INTO tb_score(userid,subject,score) VALUES ('003','英语',90);
INSERT INTO tb_score(userid,subject,score) VALUES ('003','政治',82);查询数据表中的内容(即转换前的结果)
SELECT * FROM tb_score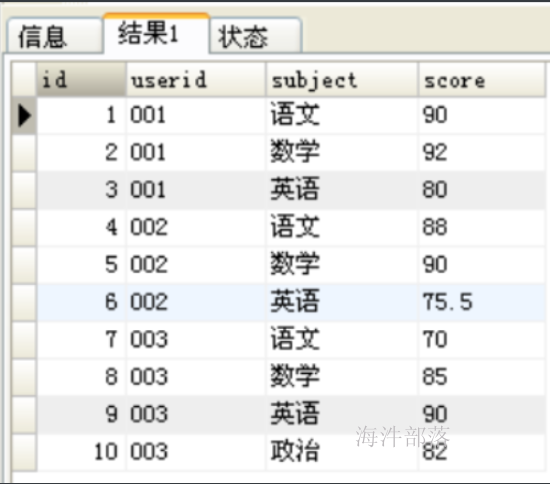
先来看一下转换后的结果:
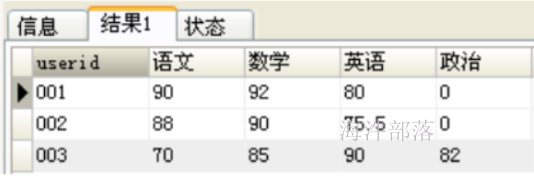
可以看出,这里行转列是将原来的subject字段的多行内容选出来,作为结果集中的不同列,并根据userid进行分组显示对应的score。
1、使用case...when....then 进行行转列
SELECT userid,
SUM(CASE `subject` WHEN '语文' THEN score ELSE 0 END) as '语文',
SUM(CASE `subject` WHEN '数学' THEN score ELSE 0 END) as '数学',
SUM(CASE `subject` WHEN '英语' THEN score ELSE 0 END) as '英语',
SUM(CASE `subject` WHEN '政治' THEN score ELSE 0 END) as '政治'
FROM tb_score
GROUP BY userid2、使用IF() 进行行转列:
SELECT userid,
SUM(IF(`subject`='语文',score,0)) as '语文',
SUM(IF(`subject`='数学',score,0)) as '数学',
SUM(IF(`subject`='英语',score,0)) as '英语',
SUM(IF(`subject`='政治',score,0)) as '政治'
FROM tb_score
GROUP BY userid注意点:
(1)SUM() 是为了能够使用GROUP BY根据userid进行分组,因为每一个userid对应的subject="语文"的记录只有一条,所以SUM() 的值就等于对应那一条记录的score的值。
假如userid ='001' and subject='语文' 的记录有两条,则此时SUM() 的值将会是这两条记录的和,同理,使用Max()的值将会是这两条记录里面值最大的一个。但是正常情况下,一个user对应一个subject只有一个分数,因此可以使用SUM()、MAX()、MIN()、AVG()等聚合函数都可以达到行转列的效果。
(2)IF(subject='语文',score,0) 作为条件,即对所有subject='语文'的记录的score字段进行SUM()、MAX()、MIN()、AVG()操作,如果score没有值则默认为0。
3、合并字段显示:利用group_concat()
SELECT userid,GROUP_CONCAT(`subject`,":",score)AS 成绩 FROM tb_score
GROUP BY userid运行结果:
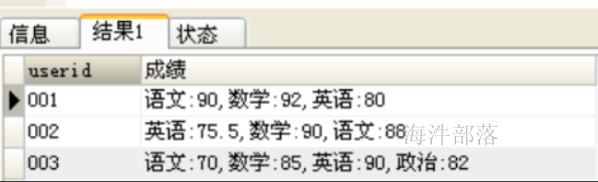
group_concat(),手册上说明:该函数返回带有来自一个组的连接的非NULL值的字符串结果。比较抽象,难以理解。通俗点理解,其实是这样的:group_concat()会计算哪些行属于同一组,将属于同一组的列显示出来。要返回哪些列,由函数参数(就是字段名)决定。分组必须有个标准,就是根据group by指定的列进行分组。结论:group_concat()函数可以很好的建属于同一分组的多个行转化为一个列。
三、列转行
建表语句:
CREATE TABLE tb_score1(
id INT(11) NOT NULL auto_increment,
userid VARCHAR(20) NOT NULL COMMENT '用户id',
cn_score DOUBLE COMMENT '语文成绩',
math_score DOUBLE COMMENT '数学成绩',
en_score DOUBLE COMMENT '英语成绩',
po_score DOUBLE COMMENT '政治成绩',
PRIMARY KEY(id)
)ENGINE = INNODB DEFAULT CHARSET = utf8;插入数据:
INSERT INTO tb_score1(userid,cn_score,math_score,en_score,po_score) VALUES ('001',90,92,80,0);
INSERT INTO tb_score1(userid,cn_score,math_score,en_score,po_score) VALUES ('002',88,90,75.5,0);
INSERT INTO tb_score1(userid,cn_score,math_score,en_score,po_score) VALUES ('003',70,85,90,82);查询数据表中的内容(即转换前的结果)
SELECT * FROM tb_score1
转换后:
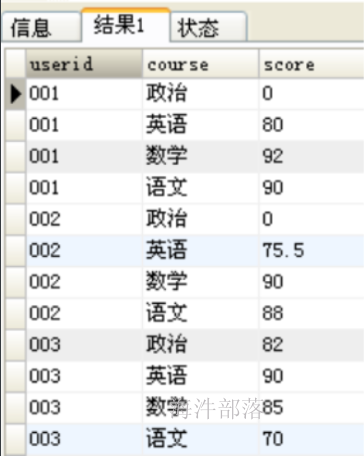
本质是将userid的每个科目分数分散成一条记录显示出来。
直接上SQL:
SELECT userid,'语文' AS course,cn_score AS score FROM tb_score1
UNION ALL
SELECT userid,'数学' AS course,math_score AS score FROM tb_score1
UNION ALL
SELECT userid,'英语' AS course,en_score AS score FROM tb_score1
UNION ALL
SELECT userid,'政治' AS course,po_score AS score FROM tb_score1
ORDER BY userid这里将每个userid对应的多个科目的成绩查出来,通过UNION ALL将结果集加起来,达到上图的效果。
附:UNION与UNION ALL的区别(摘):
1.对重复结果的处理:UNION会去掉重复记录,UNION ALL不会;
2.对排序的处理:UNION会排序,UNION ALL只是简单地将两个结果集合并;
3.效率方面的区别:因为UNION 会做去重和排序处理,因此效率比UNION ALL慢很多;
9.10分组后的topN
准备工作
测试表结构如下:
root:test> show create table test1\G
*************************** 1. row ***************************
Table: test1
Create Table: CREATE TABLE `test1` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) DEFAULT NULL,
`course` varchar(20) DEFAULT NULL,
`score` int(11) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8
1 row in set (0.00 sec)插入数据:
insert into test1(name,course,score)
values
('张三','语文',80),
('李四','语文',90),
('王五','语文',93),
('张三','数学',77),
('李四','数学',68),
('王五','数学',99),
('张三','英语',90),
('李四','英语',50),
('王五','英语',89);查看结果:
root:test> select * from test1;
+----+--------+--------+-------+
| id | name | course | score |
+----+--------+--------+-------+
| 1 | 张三 | 语文 | 80 |
| 2 | 李四 | 语文 | 90 |
| 3 | 王五 | 语文 | 93 |
| 4 | 张三 | 数学 | 77 |
| 5 | 李四 | 数学 | 68 |
| 6 | 王五 | 数学 | 99 |
| 7 | 张三 | 英语 | 90 |
| 8 | 李四 | 英语 | 50 |
| 9 | 王五 | 英语 | 89 |
+----+--------+--------+-------+TOP 1
查询每门课程分数最高的学生以及成绩
1、使用自连接【推荐】
root:test> select a.name,a.course,a.score from
-> test1 a
-> join (select course,max(score) score from test1 group by course) b
-> on a.course=b.course and a.score=b.score;
+--------+--------+-------+
| name | course | score |
+--------+--------+-------+
| 王五 | 语文 | 93 |
| 王五 | 数学 | 99 |
| 张三 | 英语 | 90 |
+--------+--------+-------+
3 rows in set (0.00 sec)2、使用相关子查询
root:test> select name,course,score from test1 a
-> where score=(select max(score) from test1 where a.course=test1.course);
+--------+--------+-------+
| name | course | score |
+--------+--------+-------+
| 王五 | 语文 | 93 |
| 王五 | 数学 | 99 |
| 张三 | 英语 | 90 |
+--------+--------+-------+
3 rows in set (0.00 sec)或者
root:test> select name,course,score from test1 a
-> where not exists(select 1 from test1 where a.course=test1.course and a.score < test1.score);
+--------+--------+-------+
| name | course | score |
+--------+--------+-------+
| 王五 | 语文 | 93 |
| 王五 | 数学 | 99 |
| 张三 | 英语 | 90 |
+--------+--------+-------+
3 rows in set (0.00 sec)TOP N
N>=1
查询每门课程前两名的学生以及成绩
1、使用union all
如果结果集比较小,可以用程序查询单个分组结果后拼凑,也可以使用union all
root:test> (select name,course,score from test1 where course='语文' order by score desc limit 2)
-> union all
-> (select name,course,score from test1 where course='数学' order by score desc limit 2)
-> union all
-> (select name,course,score from test1 where course='英语' order by score desc limit 2);
+--------+--------+-------+
| name | course | score |
+--------+--------+-------+
| 王五 | 语文 | 93 |
| 李四 | 语文 | 90 |
| 王五 | 数学 | 99 |
| 张三 | 数学 | 77 |
| 张三 | 英语 | 90 |
| 王五 | 英语 | 89 |
+--------+--------+-------+
6 rows in set (0.01 sec)2、自身左连接
root:test> select a.name,a.course,a.score
-> from test1 a left join test1 b on a.course=b.course and a.score<b.score
-> group by a.name,a.course,a.score
-> having count(b.id)<2
-> order by a.course,a.score desc;
+--------+--------+-------+
| name | course | score |
+--------+--------+-------+
| 王五 | 数学 | 99 |
| 张三 | 数学 | 77 |
| 张三 | 英语 | 90 |
| 王五 | 英语 | 89 |
| 王五 | 语文 | 93 |
| 李四 | 语文 | 90 |
+--------+--------+-------+
6 rows in set (0.00 sec)3、相关子查询
root:test> select *
-> from test1 a
-> where 2>(select count(*) from test1 where course=a.course and score>a.score)
-> order by a.course,a.score desc;
+----+--------+--------+-------+
| id | name | course | score |
+----+--------+--------+-------+
| 6 | 王五 | 数学 | 99 |
| 4 | 张三 | 数学 | 77 |
| 7 | 张三 | 英语 | 90 |
| 9 | 王五 | 英语 | 89 |
| 3 | 王五 | 语文 | 93 |
| 2 | 李四 | 语文 | 90 |
+----+--------+--------+-------+
6 rows in set (0.01 sec)

