1 单机时代的数据存储解决方案
1.1 单块硬盘
在单机时代,如果把数据一块磁盘一块磁盘的写,有如下问题:
1)单块磁盘写,磁盘读写速度上不去,读写慢;
2)数据写入单块磁盘,一旦磁盘故障导致数据丢失;
在这种情况下,RAID技术就应运而生了。
1.2 RAID
RAID ( Redundant Array of Independent Disks )即独立磁盘冗余阵列,简称为「磁盘阵列」,其实就是用多个独立的磁盘组成在一起形成一个大的磁盘系统,从而实现比单块磁盘更好的存储性能和更高的可靠性。
根据 RAID 算法的不同,RAID 有很多种。下面主要介绍 RAID0、RAID1、RAID10。
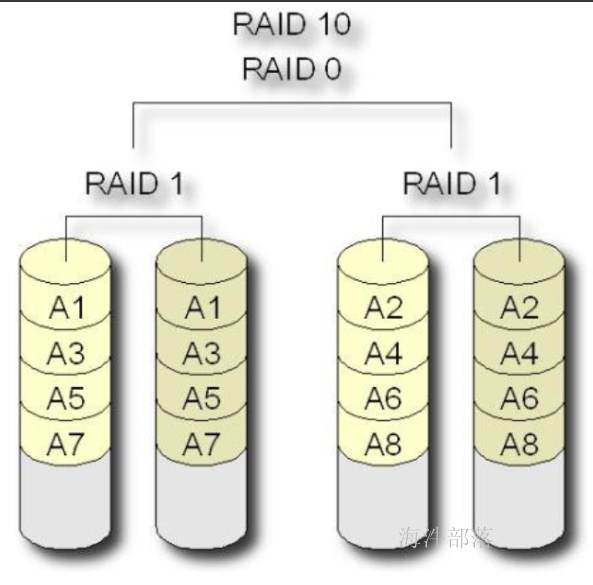
1.2.1 RAID0
RAID0 是一种非常简单的的方式,它将多块磁盘组合在一起形成一个大容量的存储。
假设阵列中有N块磁盘,当写数据时,会将数据分为N份,然后分别写入N块 磁盘中。因此,RAID0将提供非常优秀的读写性能。
优点:
并行写入读取快,空间利用率高。
如果你要读取/写入 2G 的数据,在普通硬盘上,要以单盘的速度读取/写入 2G 的数据。
如果在 4 盘 RAID0 阵列中,每个盘只需读取/写入 500MB 的数据,四个盘可以并行读取/写入,因此理论的读写速度将是单块硬盘的4倍。
缺点:
只要阵列中有一块硬盘坏掉,由于这块硬盘保存着所有数据(每个文件)的某一部分,因此所有数据都将无法读取,整个阵列中的数据将宣告报废。
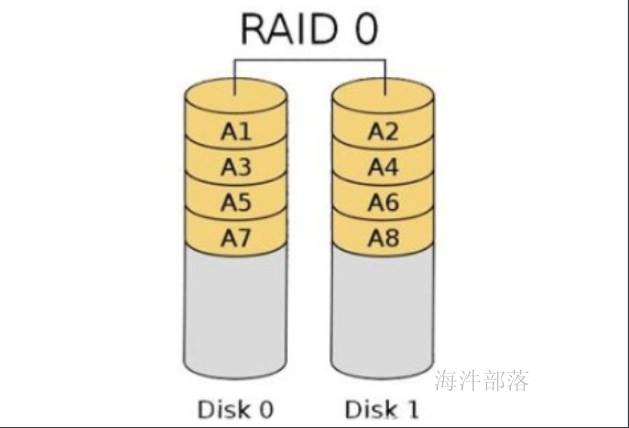
1.2.2 RAID1
RAID1 是磁盘阵列中单位成本最高的一种方式。因为它的原理是在往磁盘写数据的时候,将同一份数据无差别的写两份到磁盘,分别写到工作磁盘和镜像磁盘,那么它的实际空间使用率只有50%了,两块磁盘当做一块用,这是一种比较昂贵的方案。
优点:
数据写入两个磁盘,通过冗余存储实现容错。
缺点:
空间利用率低,读写速度慢。
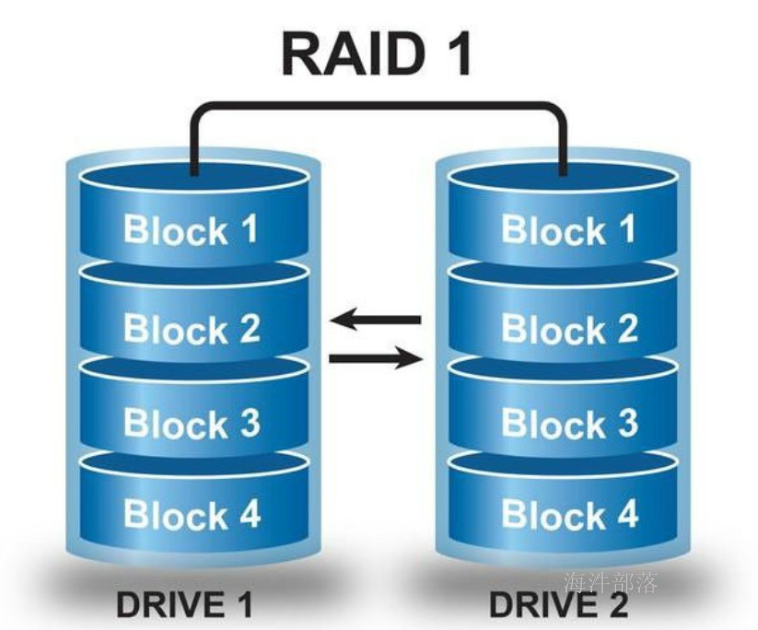
1.2.3 RAID10
RAID10其实就是RAID1与RAID0的一个合体。
先将磁盘阵列组成 RAID1, 再将多个RAID1 组成 RAID0。
读写数据时,可以将数据分N块,并行写入,而且每块数据都有备份。
这样既可以通过冗余存储容错,也可以提高读写的效率。
2 HDFS概述
HDFS是Hadoop Distribute File System 的简称,也就是Hadoop的一个分布式文件系统,用来解决存储问题。
HDFS 可以使用低成本的硬件来搭建。
HDFS 可以对海量的数据进行分布式存储。
HDFS 实现软件RAID10。
HDFS 总思想:化大为小,分而存之And备之。
将大的数据集,划分成 N 个块,再将这些块存到大量独立的机器上,而且每块都有备份,防止数据丢失。
数据集1 -----> N个 数据块 -----> 并行写入集群机器 -------> 同时对每个数据块做备份
数据块(Block):是 HDFS 的最小存储单位。一秒定律来决定大小 --> 150M/S --> 128M。
2.1 HDFS 系统结构组成
HDFS 是一个主(master)/仆(slave)体系结构,从最终用户的角度来看,它就像传统的文件系统一样,可以通过目录路径对文件执行 增、删、改、查 操作。
在 HDFS 体系结构中有两类结点:
一类是 NameNode,又叫“名称结点”;
另一类是 DataNode,又叫“数据结点”。
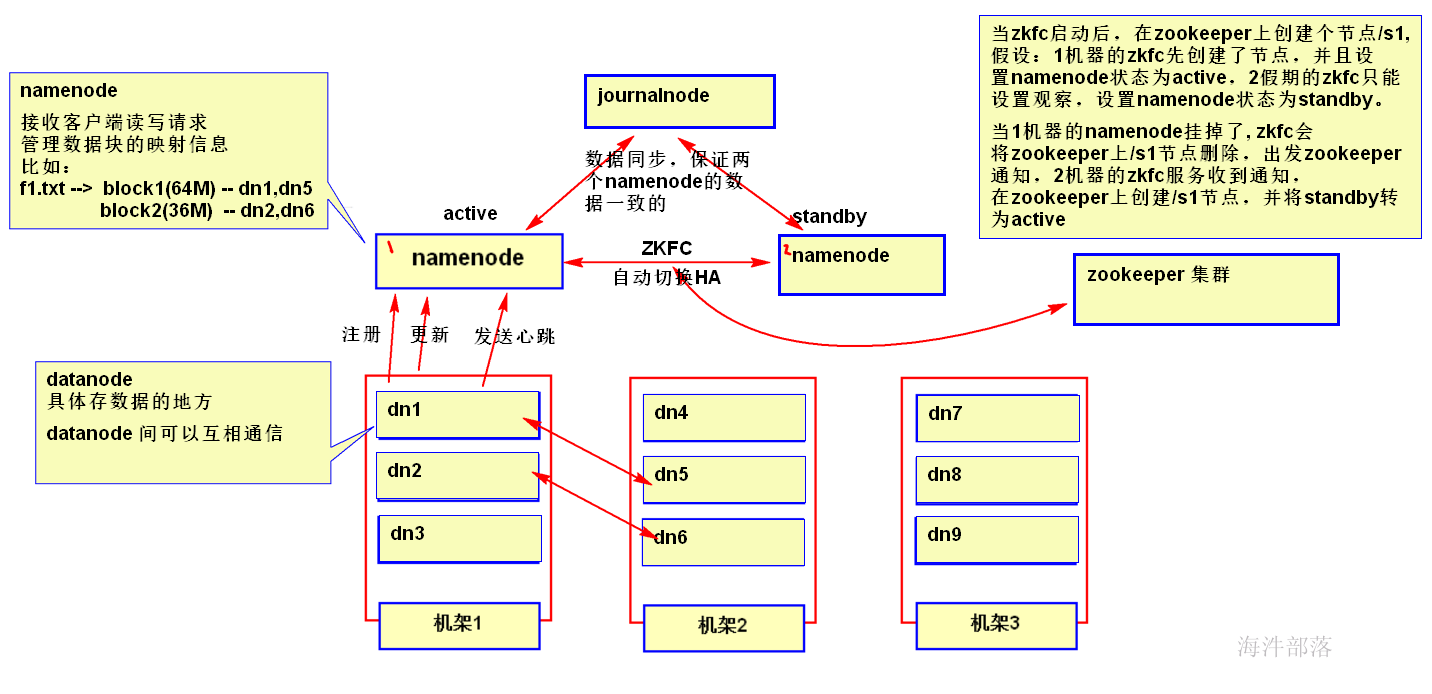
NameNode:
是大领导。管理数据块映射;处理客户端的读写请求。一般有一个active状态的namenode,有一个standby状态的namenode,其中,active状态的NameNode负责所有的客户端操作,standby状态的NameNode处于从属地位,维护着数据状态,随时准备切换。
journalnode:
负责两个状态的namenode进行数据同步,保持数据一致。
ZKFC:
作用是HA自动切换。会将NameNode的active状态信息保存到zookeeper。
DataNode:
干活的。负责存储client发来的数据块block;执行数据块的读写操作。
关系:
1)datanode启动时要在namenode上注册,当datanode改变时,也要通知namenode。datanode 会定期向NameNode发送心跳,告知NameNode 该节点的datanode是活着的。
2)datanode之间可以相互传输数据。
2.2 数据块——block
1)数据块是基本的数据存储单位,一个大文件根据数据块的大小,将文件分为若干个块。
Hadoop1.x是64M, Hadoop2.x是128M,如果机器性能高可配置256M,太大失去了分布式计算的意义。
NameNode存储的文件数据块的元数据信息;而datanode存储块信息对应的数据。
NameNode存储的元数据信息包括:
-
- 文件的存储路径
- 文件大小
- block块大小
- 文件和blickid的映射关系
- 文件的权限
- 上传的用户
- Block数量信息
- Block和DataNode之间的关系信息
2)一个数据块的元数据信息占用namenode内存存储空间为150字节。块越小读取的速度就越快,但是整体占用namenode的空间就越大。
比如:文件188M,
64M一块分3块, 占namenode内存:150*3 = 450字节
1M一块,188块,占namenode内存:150*188 ≈ 30000字节
块的设定要合理。太大,不适宜计算;太小,占namenode内存
3)一个大文件会被拆分成一个个的块,然后存储于不同的机器。对于大规模的集群会存储在不同的机架上,如果一个文件少于Block大小,那么实际占用的空间为其文件的大小。 60M的文件, 块单位64M,实际存储:60M
4)数据块也是基本的读写单位,类似于磁盘的扇区,每次都是读写一个块。读写多个块就合成了一个文件。
5)为了容错,文件的所有数据块都会有副本,也就是说复制的是数据块而不是单独的一个文件被复制了,默认复制3份,可以在hdft-site.xml里进行配置。
2.3 HDFS 的写数据流程
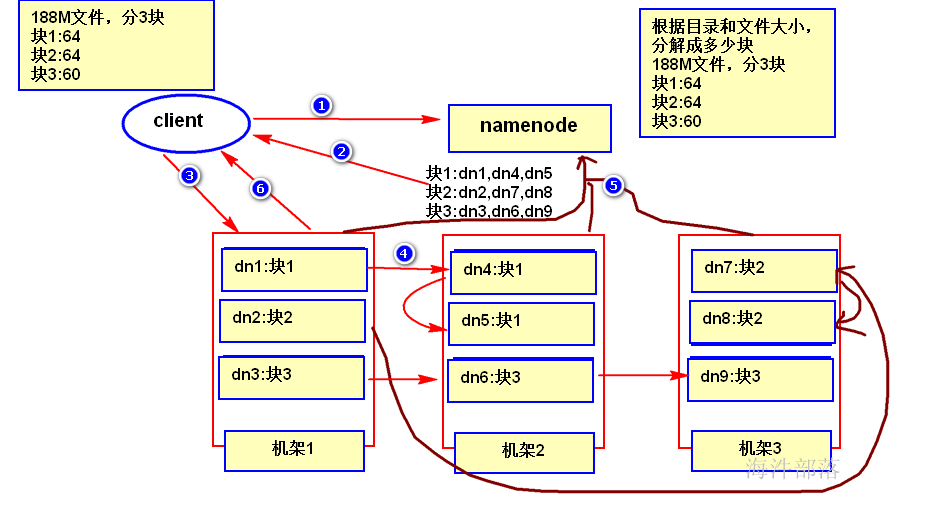
1)客户端发起数据写入请求,告诉namenode要写入的文件信息;
2)namenode 根据客户端的情况(client端所在位置、文件大小)给客户端分配写入数据的位置,也就是写到哪几台机器上;
3)客户端接收到namenode返回的映射信息,向datanode写入数据;
4)datanode复制数据,实现副本写入;
5)副本写入完成之后,各数据节点向namenode上报block信息;
6)datanode通知客户端写操作已完成;
2.4 HDFS 的读数据流程
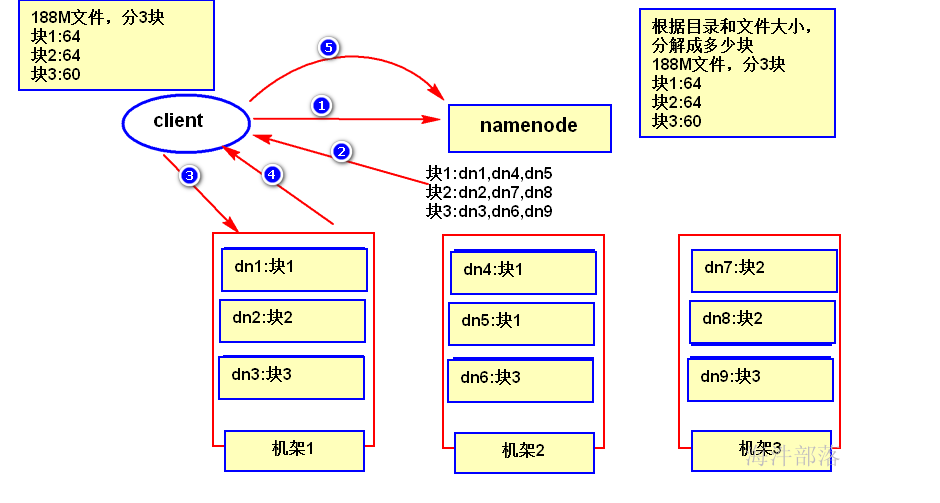
1)客户端发起读数据的请求,通知 namenode 要读取哪个文件; 2)namenode 在内存中检索,找到该文件对应数据块的映射信息(要读取的数据在哪台机器上),并返回给客户端; 3)客户端通过映射信息,到最近的机器找到要读取的数据块; 4)客户端从数据块中读取数据信息并返回给客户端 5)客户端读完数据之后,通知 namenode 已经读取完成;注意: 在读取数据的过程中,如果客户端在与数据结点通信时出现错误,则尝试连接包含此数据块的下一个数据结点。失败的数据结点将被记录,并且以后不再连接。
3 HDFS 安装和初始化
3.1 HDFS规划
namenode:
nn1.hadoop
nn2.hadoop
datanode:
s1.hadoop、
s2.hadoop、
s3.hadoop
3.2 HDFS配置文件及说明
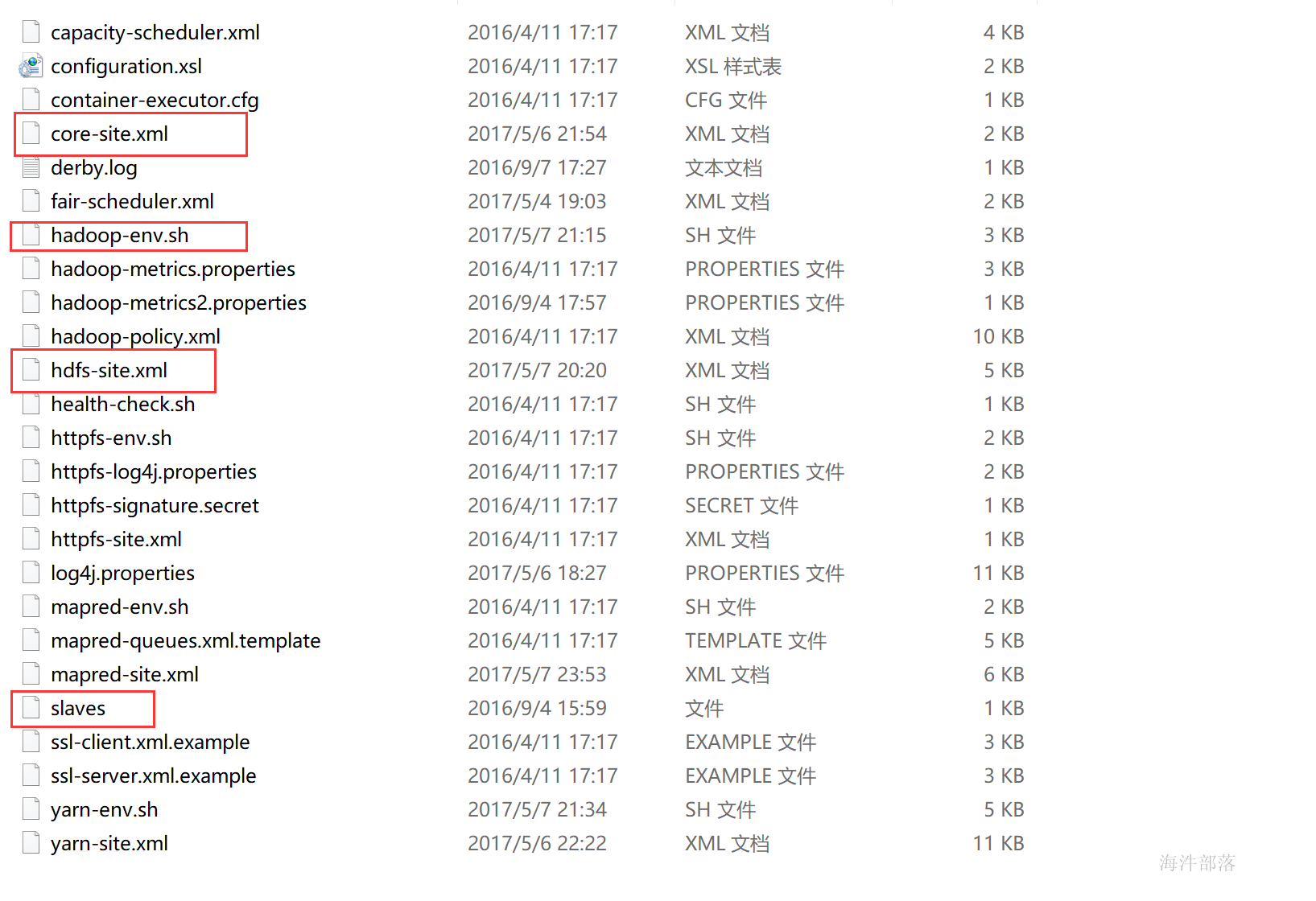
3.2.1 hdfs-site.xml
HA集群需要使用命名空间区分一个HDFS集群。同一个集群中的不同NameNode,使用不同的NameNode ID区分。为了支持所有NameNode使用相同的配置文件,因此在配置参数中,需要把“nameservice ID”作为NameNode ID的前缀。
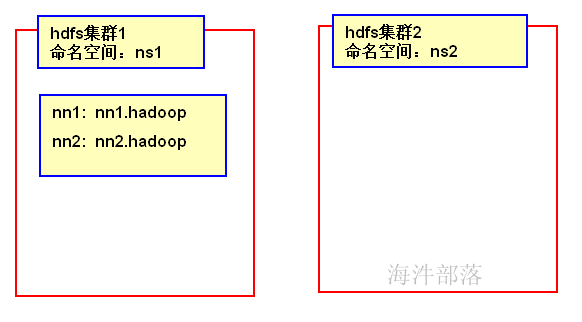
dfs.nameservices 命名空间的逻辑名称。提供服务的NS(nameservices)逻辑名称,与core-site.xml里的对应。如果有多个HDFS集群,可以配置多个命名空间的名称,使用逗号分开即可。
<property>
<name>dfs.nameservices</name>
<value>ns1</value>
<description>提供服务的NS逻辑名称,与core-site.xml里的对应</description>
</property>dfs.ha.namenodes.[nameservice ID] 命名空间中所有NameNode的唯一标示名称。可以配置多个,使用逗号分隔。该名称是可以让DataNode知道每个集群的所有NameNode。当前,每个集群最多只能配置两个NameNode。
<property>
<name>dfs.ha.namenodes.ns1</name>
<value>nn1,nn2</value>
<description>列出该逻辑名称下的NameNode逻辑名称</description>
</property>dfs.namenode.rpc-address.[nameservice ID].[name node ID] 每个namenode监听的RPC地址。
dfs.namenode.http-address.[nameservice ID].[name node ID] 每个namenode监听的http地址。
<!--主要的-->
<property>
<name>dfs.namenode.rpc-address.ns1.nn1</name>
<value>nn1.hadoop:9000</value>
<description>指定NameNode的RPC位置</description>
</property>
<!--主要的-->
<property>
<name>dfs.namenode.http-address.ns1.nn1</name>
<value>nn1.hadoop:50070</value>
<description>指定NameNode的Web Server位置</description>
</property>
<!--主要的-->
<property>
<name>dfs.namenode.rpc-address.ns1.nn2</name>
<value>nn2.hadoop:9000</value>
<description>指定NameNode的RPC位置</description>
</property>
<!--主要的-->
<property>
<name>dfs.namenode.http-address.ns1.nn2</name>
<value>nn2.hadoop:50070</value>
<description>指定NameNode的Web Server位置</description>
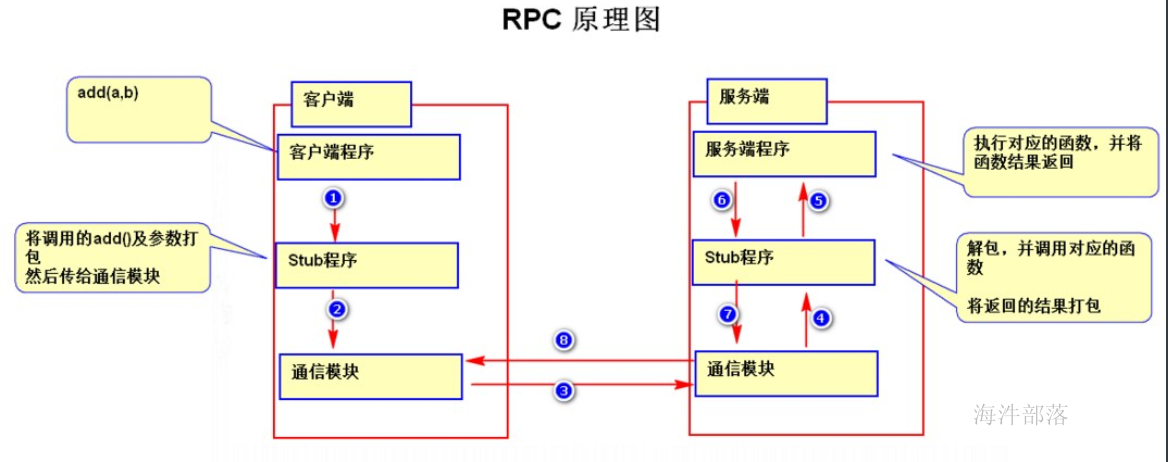
</property>RPC(Remote Procedure Call Protocol)
远程过程调用协议。一个通俗的描述是:客户端在不知道调用细节的情况下,调用存在于远程计算机上的某个对象,就像调用本地应用程序中的对象一样。
目前,主流的平台中都支持各种远程调用技术,以满足分布式系统架构中不同的系统之间的远程通信和相互调用。
主要配置说明
| name | value | description |
|---|---|---|
| dfs.datanode.data.dir | /data1/dfs,/data2/dfs,/data3/dfs,/data4/dfs,/data5/dfs,/data6/dfs | datanode本地文件存放地址 |
| dfs.replication | 3 | 文件复本数 一个文件,可在其他机器共存放3个副本,保证一个文件不只是在一台机器上 ,体现高可用性 |
| dfs.namenode.name.dir | /data1/dfsname,/data2/dfsname,/data3/dfsname | namenode本地文件存放地址 |
| dfs.support.append | TRUE | 是否支持追加,但不支持并发线程往里追加 |
| dfs.permissions.enabled | FALSE | 是否开启目录权限,自己用建议不开启 |
| dfs.nameservices | ns1 | 提供服务的NS逻辑名称,与core-site.xml里的对应,可以配置多个命名空间的名称,使用逗号分开即可。 |
| dfs.ha.namenodes.[nameservice ID] | nn1,nn2 | 命名空间中所有NameNode的唯一标示名称。可以配置多个,使用逗号分隔。该名称是可以让DataNode知道每个集群的所有NameNode。当前,每个集群最多只能配置两个NameNode。 |
| dfs.namenode.rpc-address.ns1.nn1 | nn1.hadoop:9000 | 指定NameNode的RPC位置 |
| dfs.namenode.http-address.ns1.nn1 | nn1.hadoop:50070 | 指定NameNode的Web Server位置 |
| dfs.namenode.rpc-address.ns1.nn2 | nn2.hadoop:9000 | 指定NameNode的RPC位置 |
| dfs.namenode.http-address.ns1.nn2 | nn2.hadoop:50070 | 指定NameNode的Web Server位置 |
| dfs.namenode.shared.edits.dir | qjournal://nn1.hadoop:8485;nn2.hadoop:8485/ns1 | 指定用于HA存放edits的共享存储,通常是namenode的所在机器 |
| dfs.journalnode.edits.dir | /data/journaldata/ | journaldata服务存放文件的地址 |
| fs.trash.interval | 2880 | 垃圾回收周期,单位分钟 |
| dfs.blocksize | 134217728 | 块的大小 |
| dfs.datanode.du.reserved | 2147483648 | 每个存储卷保留用作其他用途的磁盘大小 |
| dfs.datanode.fsdataset.volume.choosing.policy | org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy | datanode数据副本存放的磁盘选择策略, 有2种方式一种是轮询方式 (org.apache.hadoop.hdfs.server.datanode.fsdataset.RoundRobinVolumeChoosingPolicy,为默认方式), 另一种为选择可用空间足够多的磁盘存储方式 (org.apache.hadoop.hdfs.server.datanode.fsdataset.AvailableSpaceVolumeChoosingPolicy) |
| dfs.datanode.available-space-volume-choosing-policy.balanced-space-threshold | 2147483648 | 当选择可用空间足够多的磁盘存储方式才生效,hdfs计算最大可用空间-最小可用空间的差值,如果差值小于此配置,则选择轮询方式存储 |
3.2.2 core-site.xml
主要配置说明
| name | value | description |
|---|---|---|
| io.native.lib.available | TRUE | 开启本地库支持 |
| fs.defaultFS | hdfs://ns1 | 客户端连接HDFS时,默认的路径前缀。默认文件服务的协议和NS(nameservices)逻辑名称,和hdfs-site里的对应此配置替代了1.0里的fs.default.name |
| io.compression.codecs | org.apache.hadoop.io.compress.GzipCodec,org.apache.hadoop.io.compress.DefaultCodec,org.apache.hadoop.io.compress.BZip2Codec,org.apache.hadoop.io.compress.SnappyCodec | 相应编码的操作类,用逗号分隔 |
| ha.zookeeper.quorum | nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 | HA使用的zookeeper地址,用逗号分隔 |
3.2.3 hadoop-env.sh
HADOOP_CLASSPATH:hadoop的classpath
JAVA_LIBRARY_PATH:java加载本地库的地址
HADOOP_HEAPSIZE:java虚拟机使用的最大内存
HADOOP_OPTS:hadoop启动公用参数
HADOOP_NAMENODE_OPTS:namenode专用参数
HADOOP_DATANODE_OPTS:datanode专用参数
HADOOP_CLIENT_OPTS:hadoop client专用参数
3.2.4 slaves
slaves文件里面记录的是集群里所有DataNode的主机名
hadoop-daemons.sh 中用到了 slaves 文件
注意:配置文件里的host改成你自己的
3.3 把hadoop安装包分发到每个机器+解压+创建软链接+修改Hadoop权限
#将Hadoop安装包上传到~hadoop/up
cd ~/upload
rz
#将Hadoop安装包 分发到5台机器的/tmp 目录下
./scp_all.sh ../up/hadoop-2.7.3.tar.gz /tmp/
#批量将Hadoop安装包解压到/usr/local
./ssh_root.sh tar -zxf /tmp/hadoop-2.7.3.tar.gz -C /usr/local
#批量创建软链接
./ssh_root.sh ln -s /usr/local/hadoop-2.7.3 /usr/local/hadoop
# 批量修改解压目录为Hadoop用户和组 z
./ssh_root.sh chown -R hadoop:hadoop /usr/local/hadoop-2.7.3
3.4 把hadoop配置分发到每个机器上,并解压
#将配置文件压缩包上传到~hadoop/up
cd ~/up
rz
#hadoop配置文件地址
ll /usr/local/hadoop/etc/hadoop/
#批量备份hadoop老的配置
./ssh_all.sh mv /usr/local/hadoop/etc/hadoop /usr/local/hadoop/etc/hadoop_back
#批量将自定义的配置拷贝到/tmp 目录下
./scp_all.sh ../up/hadoop.tar.gz /tmp/
#批量将自定义配置 压缩包解压到/usr/local/hadoop/etc/
./ssh_all.sh tar -xzf /tmp/hadoop.tar.gz -C /usr/local/hadoop/etc
#批量检查配置是否正确解压
./ssh_all.sh head /usr/local/hadoop/etc/hadoop/hadoop-env.sh3.5 初始化分布式文件系统HDFS
步骤:
1)启动zookeeper
2)启动 journalnode 2台
3)启动zookeeper客户端,初始化HA的zookeeper信息
4)对nn1上的namenode进行格式化
5)\启动nn1上的namenode****
*6)在nn2上 同步namenode*
*7)启动nn2上的namenode*
*8)启动ZKFC 2台*
*9)启动datanode 3台*
3.5.1 启动zookeeper
#启动zookeeper
./ssh_all_zookeeper.sh /usr/local/zookeeper/bin/zkServer.sh start
#查看zookeeper运行的状态
./ssh_all_zookeeper.sh /usr/local/zookeeper/bin/zkServer.sh status3.5.2 启动 journalnode

在每个要运行的机器上执行 hadoop-daemon.sh start journalnode
cd /usr/local/hadoop/logs/ hadoop相关服务日志文件地址
vim hadoop-hadoop-journalnode-nn1.hadoop.log
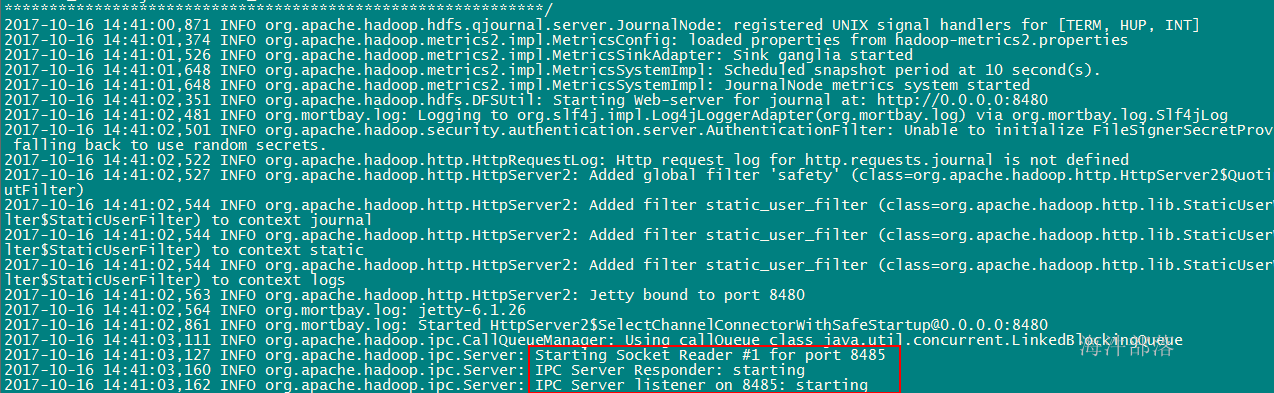
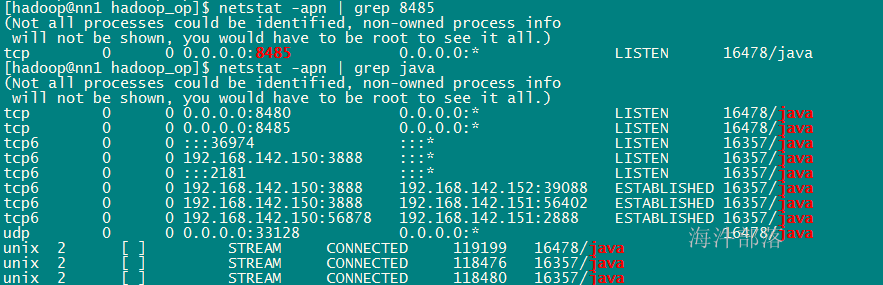
netstat -apn |grep 8485
#在nn1上启动journalnode
hadoop-daemon.sh start journalnode
#在nn2上启动journalnode
hadoop-daemon.sh start journalnode
3.5.3 初始化HA的zookeeper信息
#启动zkclient,并连接zookeeper集群
/usr/local/zookeeper/bin/zkCli.sh -server nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181
#在nn1克隆会话,用hadoop用户执行下面命令,初始化HA的zookeeper信息
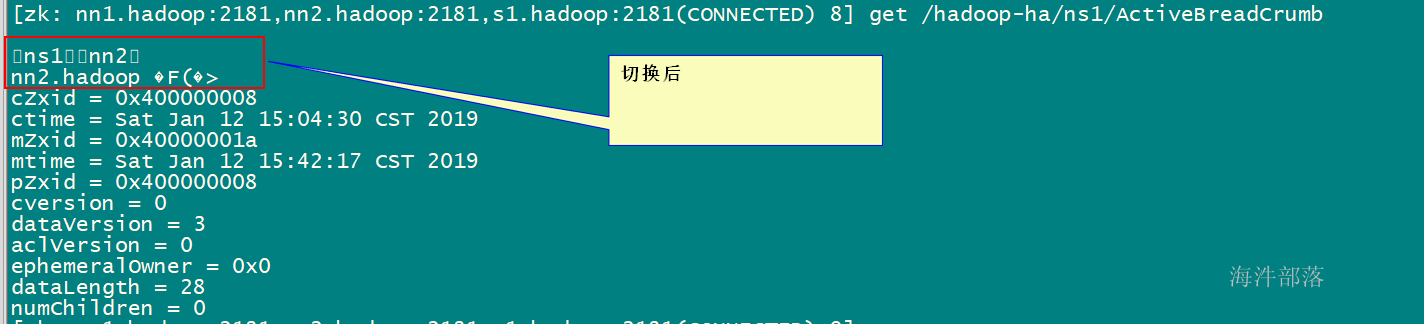
hdfs zkfc -formatZK通过zookeeper客户端查看结点

在nn1上执行 hdfs zkfc -formatZK 初始化HA的zookeeper信息
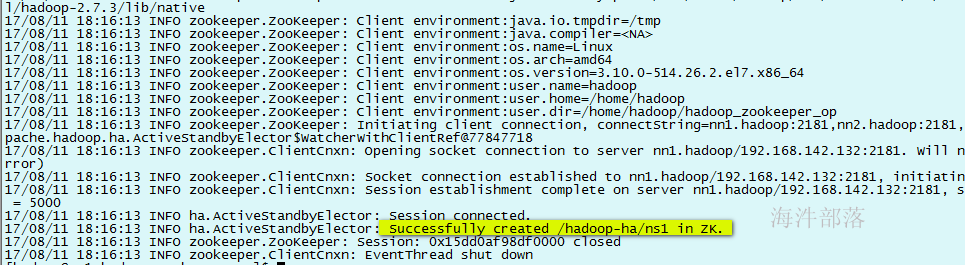
初始化后,通过zookeeper客户端查看结点

4.5.4 对nn1上的namenode进行格式化
初始化一些目录和文件。
在nn1上执行 hadoop namenode -format
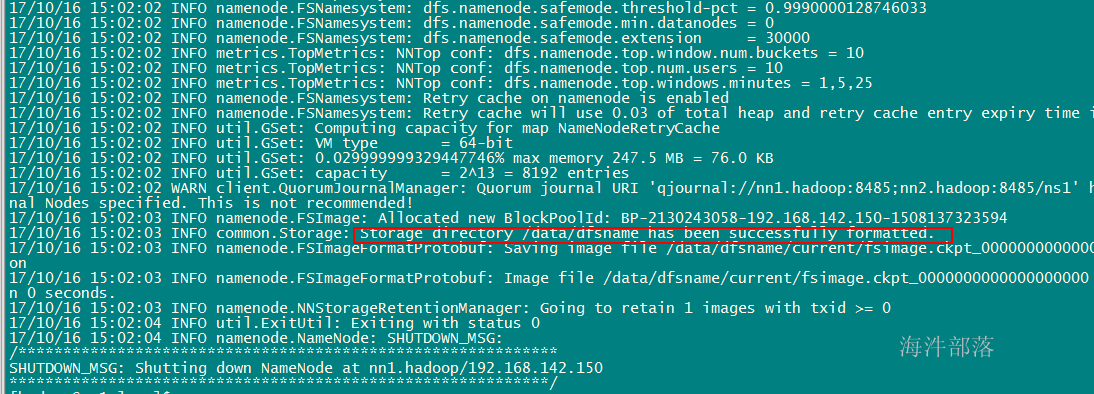
3.5.5 启动nn1上的namenode并观察日志文件
在nn1上执行 hadoop-daemon.sh start namenode
vim /usr/local/hadoop/logs/hadoop-hadoop-namenode-nn1.hadoop.log
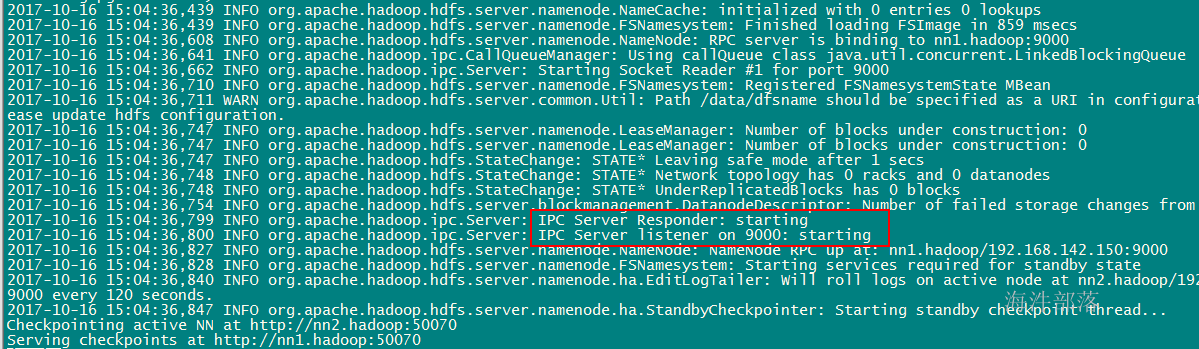
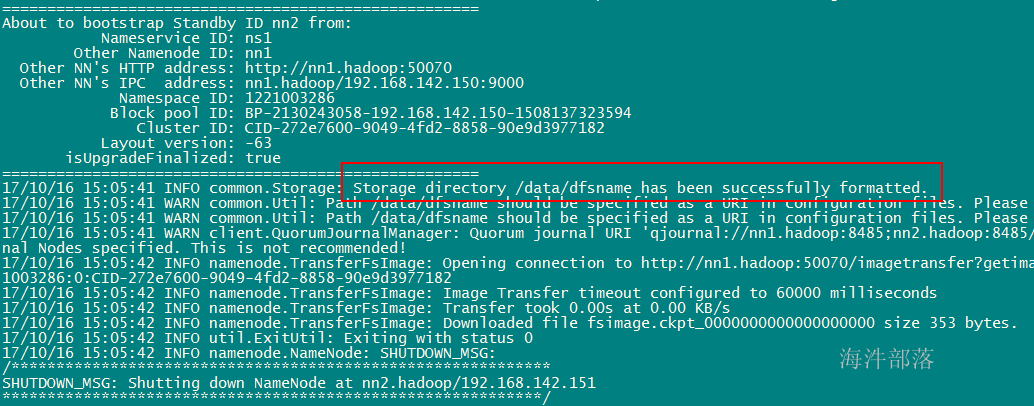
3.5.6 第二个namenode同步第一个namenode状态
在nn2上执行 hadoop namenode -bootstrapStandby
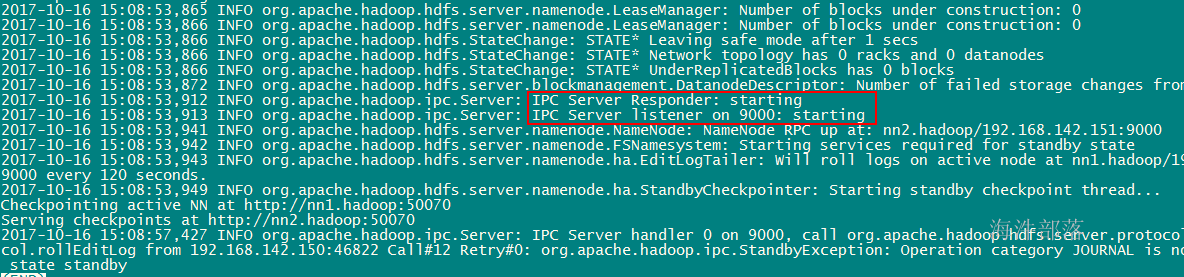
3.5.7 在nn2上启动namenode
在nn2上执行 hadoop-daemon.sh start namenode
vim /usr/local/hadoop-2.7.3/logs/hadoop-hadoop-namenode-nn2.hadoop.log 观察日志
3.5.8 启动ZKFC
在 nn1 和 nn2 分别启动ZKFC,这时两个namenode,一个变成active,一个变成standby
zkfc作用:HA自动切换。
hadoop-daemon.sh start zkfcactive
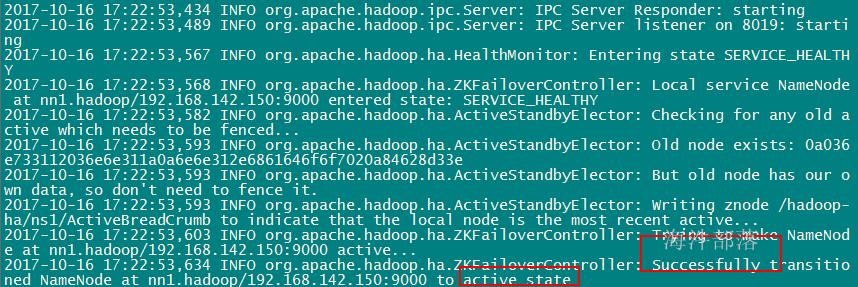
standby
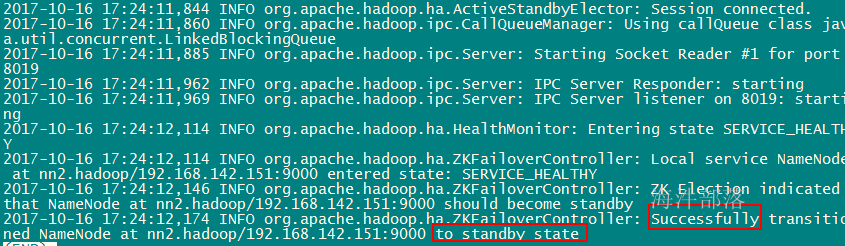
在自己的windows电脑上配置好hosts
C:\Windows\System32\drivers\etc\hosts
192.168.142.160 nn1.hadoop
192.168.142.161 nn2.hadoop
192.168.142.162 s1.hadoop
192.168.142.163 s2.hadoop
192.168.142.164 s3.hadoop
192.168.142.165 s4.hadoop在任何机器上执行hdfs haadmin -getServiceState 可查看HA状态

3.5.9 启动datanode
在nn1上执行hadoop-daemons.sh start datanode 启动s1 s2 s3上的datanode服务,注意这里是hadoop-daemons.sh而不是hadoop-daemon.sh
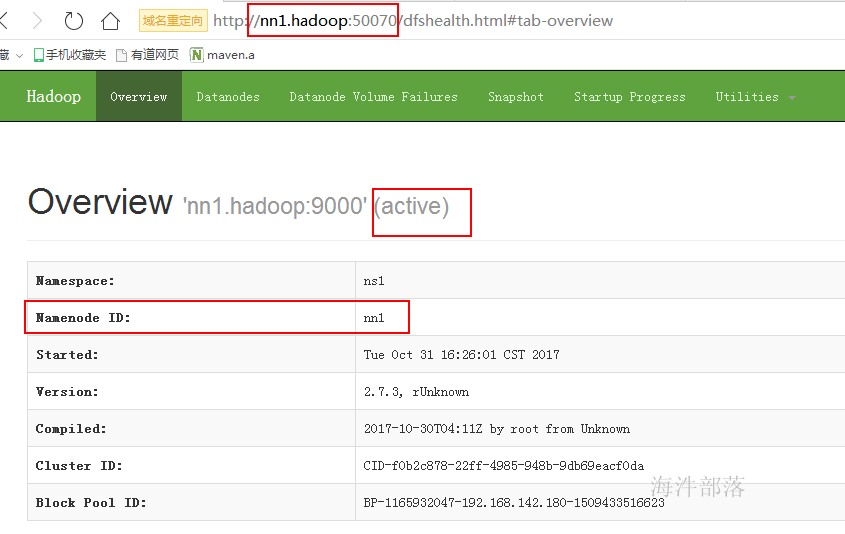
启动完成后看http://nn1.hadoop:50070 页面的状态,查看集群的存储情况和节点信息
http://nn1.hadoop:50070 nn1节点页面
http://nn2.hadoop:50070 nn2节点页面
介绍页面内容
3.5.10 测试新建的HDFS是否有问题
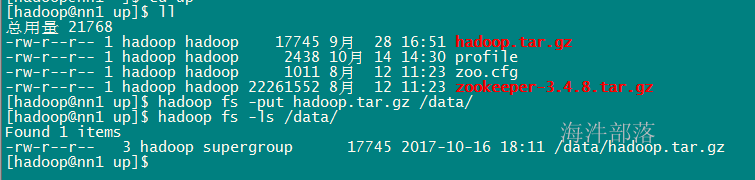
hadoop fs -mkdir /data (等于 hadoop fs -mkdir hdfs://ns1/data)
在hdfs上创建一下data目录
hadoop fs -put ./hadoop.tar.gz /data/
向hdfs上传一个文件进行测试
tail -f /usr/local/hadoop/logs/
hadoop-hadoop-datanode-s2.hadoop.log 查看数据节点的datanode日志
在web页面上查看文件
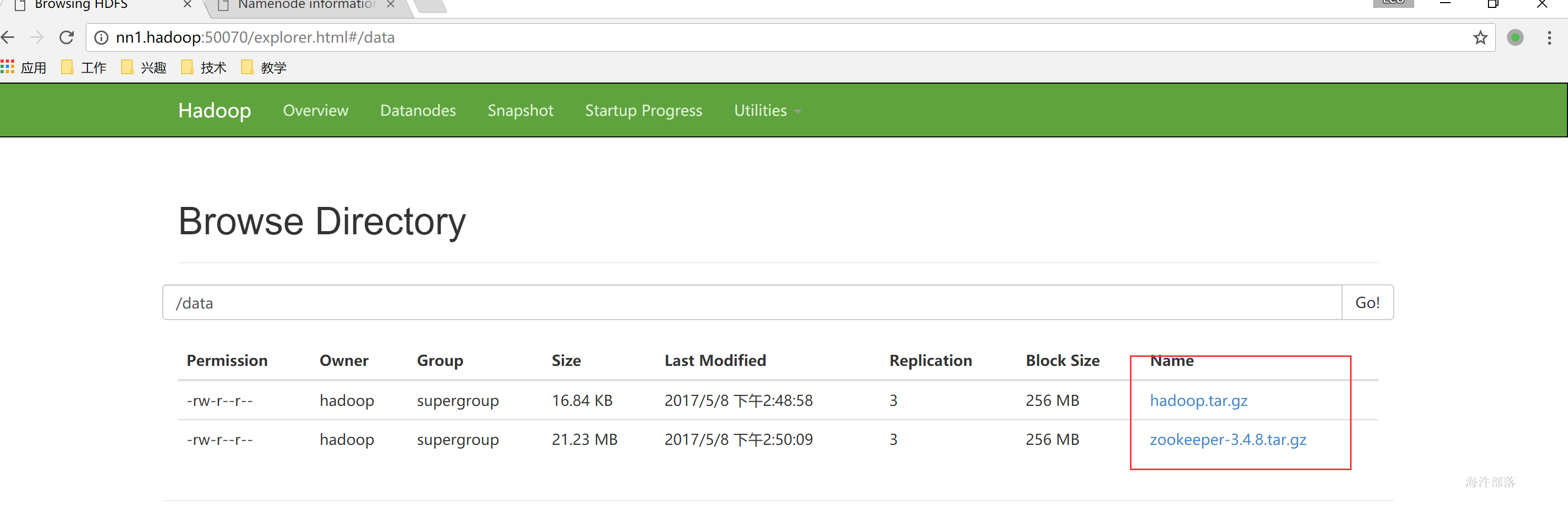
因为有3个副本所以每台机器上使用的容量是一样的

4 已经初始化分布式文件系统HDFS,怎么启动和关闭
#启动分布式文件系统HDFS
/usr/local/hadoop/sbin/start-dfs.sh
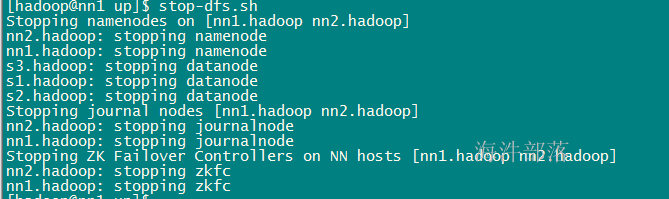
#关闭分布式文件系统HDFS
/usr/local/hadoop/sbin/stop-dfs.sh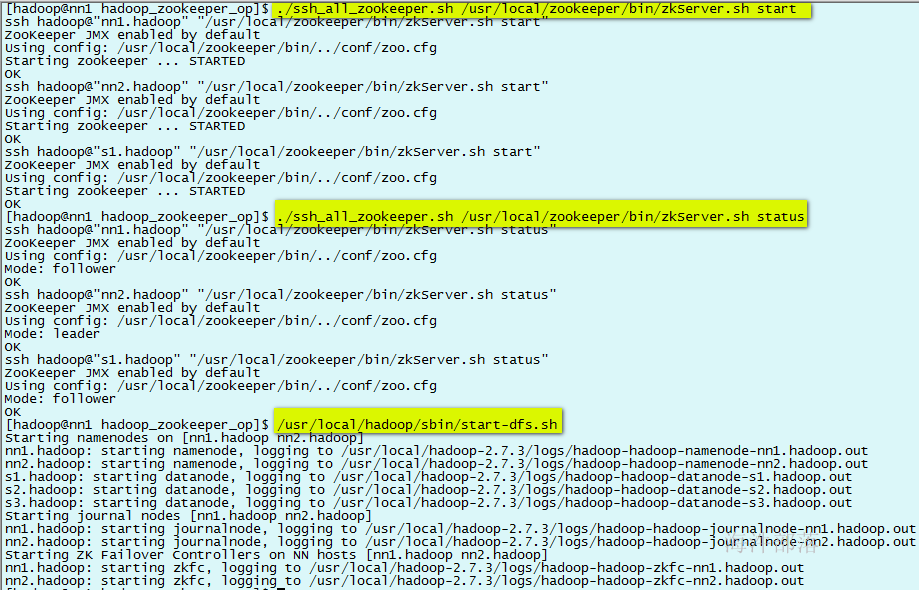
关闭
5 HDFS HA
5.1 带HA的HDFS都包括哪些进程
#查看每个机器上的java进程
./ssh_all.sh jps 
#查看详细进程信息
ps -aux|grep java从里面查看启动信息是否有你自己的配置,就是你配置的hadoop-env.sh里的信息
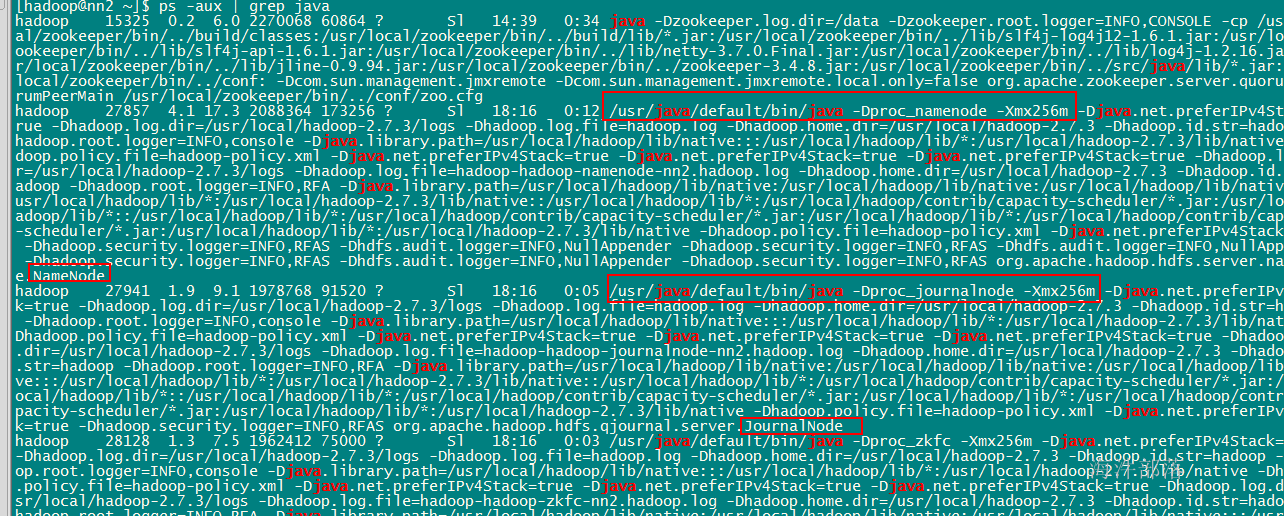
5.2 测试 HDFS HA 切换
注意HA不能切换是因为nn1和nn2的没有安装fuser,可在zkfc日志中看到

先用root用户 ,安装 在nn1和nn2上执行
yum -y install psmisc
重启hdfs集群,在执行HA切换。
切换前

切换后: