1 phoenix原理
1.1 phoenix定位
Phoenix最早是saleforce的一个开源项目,后来成为Apache基金的顶级项目。Phoenix是一个HBASE SQL层(即为HBase的一个SQL引擎),用作应用层和HBASE之间的中间件。Phoeinx可以用标准的JDBC API替代HBASE client API来创建表、插入与查询HBASE中的数据。
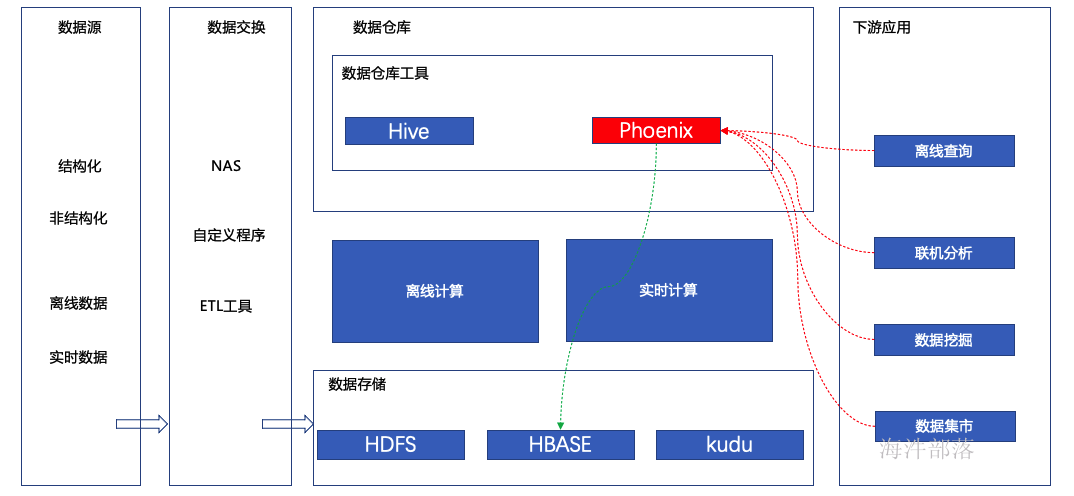
1.2 phoenix在大数据应用处于什么环节
etl工具:
kettle:免费,开源产品,纯 java 编写。
informatica:第二,商业软件,相当专业的etl工具,适合大部分etl场景。
datastage:大哥,商业软件,最专业的etl工具,比 informatica 贵,适合大部分etl场景。
phoenix的出现解决了hbase filter的弱点,内置二级索引查询效率较高,实现SQL on nosql。
1.3 应用场景
Phoenix已与Hadoop其他服务完全集成,如Spark,Hive,Flume和Map Reduce。适合高并发、低延迟、简单查询、二级索引的场景。Phoenix通过结合HBase与SQL两者的优点,在Hadoop中为低延迟应用程序启用OLTP和运营分析。
1.4 SQL支持
Apache Phoenix支持所有标准SQL查询构造,包括SELECT,FROM,WHERE,GROUP BY,HAVING,ORDER BY等。它还支持一整套DML命令以及通过DDL命令创建表和版本化增量更改。
1.5 架构设计
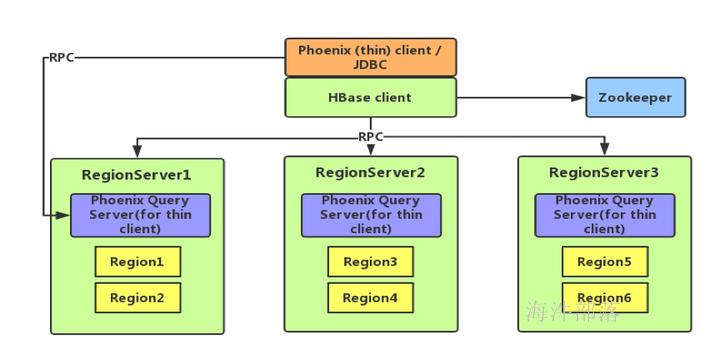
Phoenix 分为 client 和 server,其中 client 又分为 thin(本质上是一个 JDBC 驱动,所依赖的第三方类较少)和非 thin (所依赖的第三方类较多)两种;server 是针对 thin client 而言的,为 standalone 模式,是由一台 Java 服务器组成,代表客户端管理 Phoenix 的连接,可以进行横向扩展。
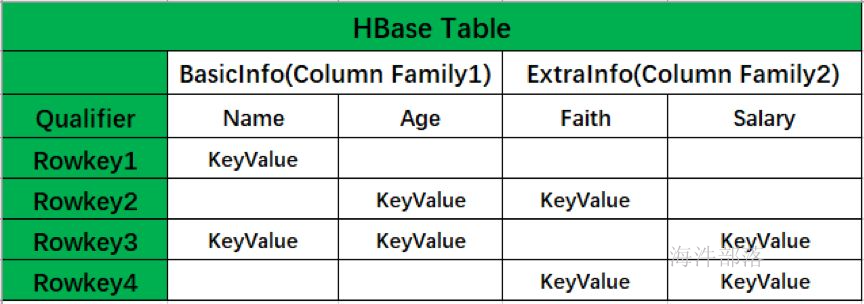
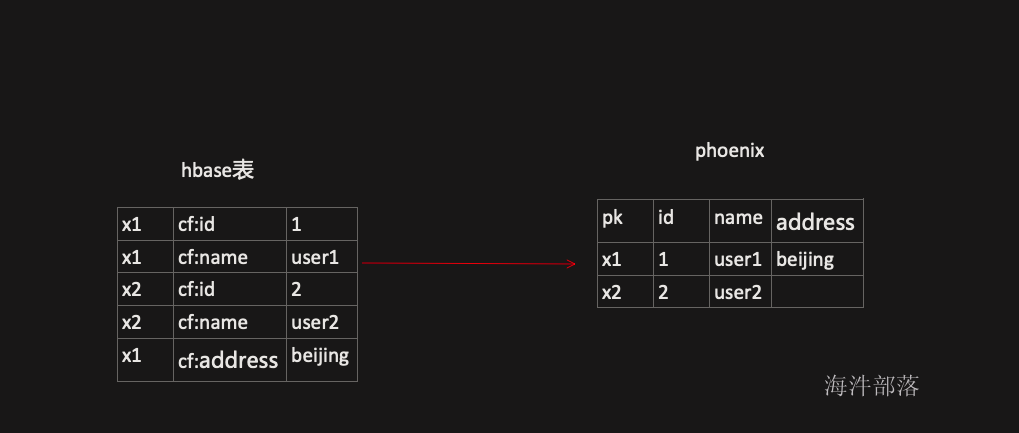
Phoenix 在hbase中引入了一个中间层,将 HBase 非关系型形式转换成关系型数据模型,在创建表时默认会将 PK 与 HBase 中表的 Rowkey 映射起来,PK 支持多字段组合,剩下的列可以根据需求进行选择,列簇如果未显式定义,则会被忽略,Qualifier 会转换成表的字段名。如下图所示:
2. cdh集成phoenix
2.1 下载安装包
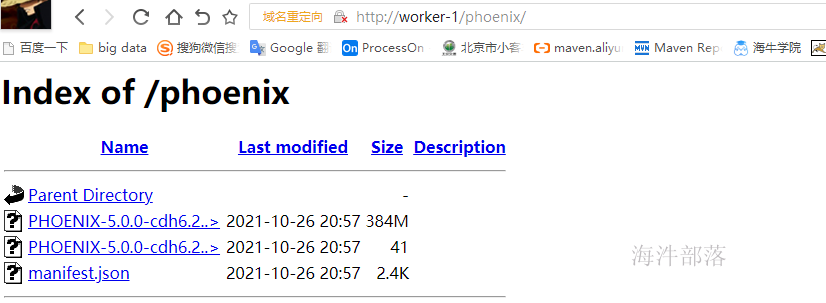
上传安装包服务器,如/opt目录下,然后创建httpd的phoenix目录,然后将phoenix包复制到httpd目录下,用于本地parcel安装。
mkdir /opt/phoenix/
tar -xvf phoenix.tar -C /opt/phoenix/
mkdir /var/www/html/phoenix
cp PHOENIX-5.0.0-cdh6.2.0.p0.1308267-el7.parcel* manifest.json /var/www/html/phoenix
cp PHOENIX-1.0.jar /opt/cloudera/csd/检查http服务是否可以访问
2.2 cdh页面操作
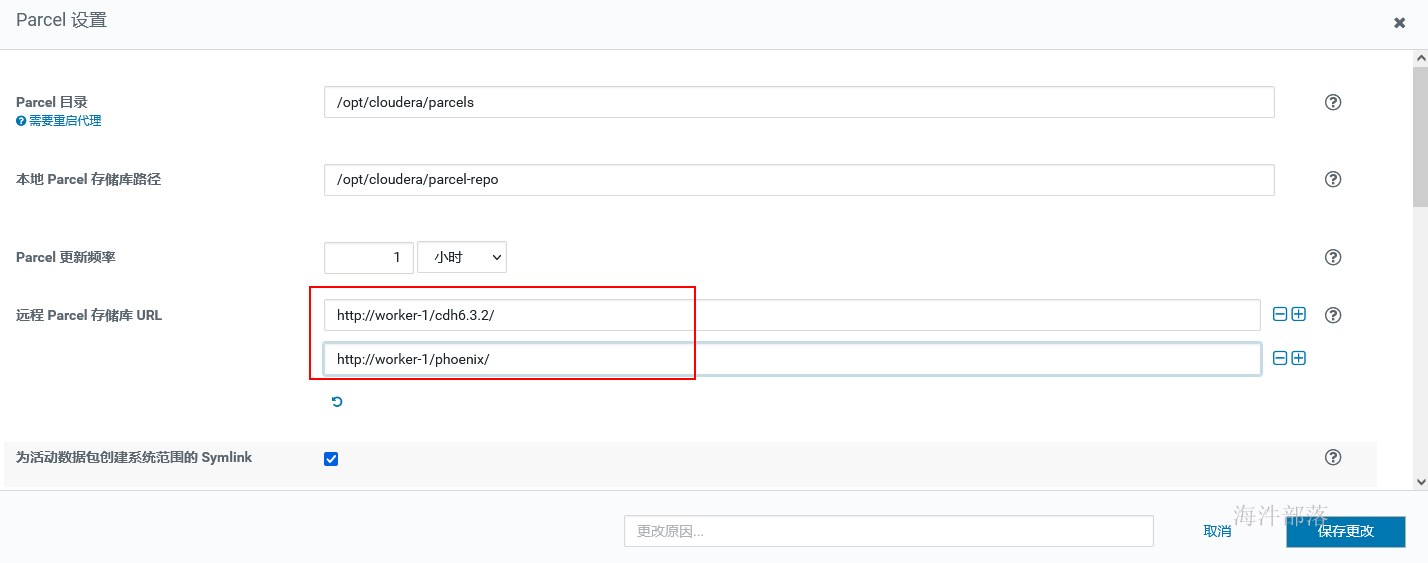
2.2.1 配置parcel

2.2.2 下载激活

分配的位置:

点 激活,再点确定,直到激活完成

2.2.3 重启服务、配置生效
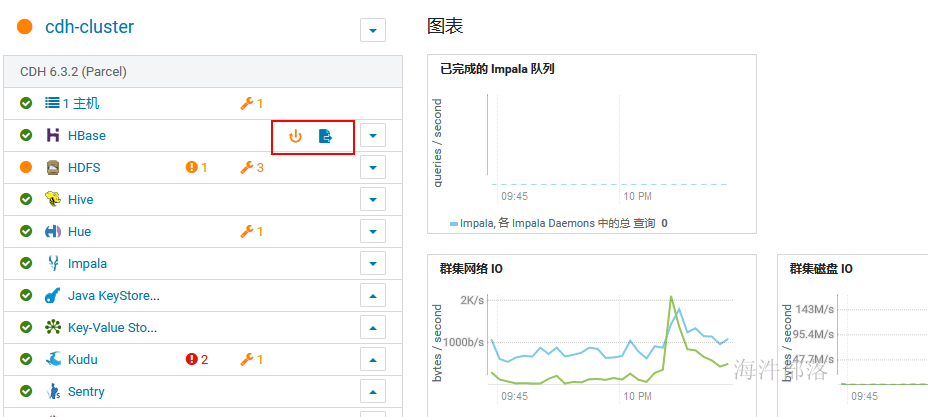
重启过期配置后,集成完成。
3 phoenix登录
3.1 phoenix目录
3.2 配置path
将Phoenix 的bin 目录添加的 /etc/profile 文件的path中,目的是可在任意目录执行。

source /etc/profile 使配置生效

3.3 登录phoenix
# hbase认证
kinit hbase
# 访问zookeeper客户端的 /hbase znode, 读取hbase元数据信息
phoenix-sqlline worker-1:2181:/hbase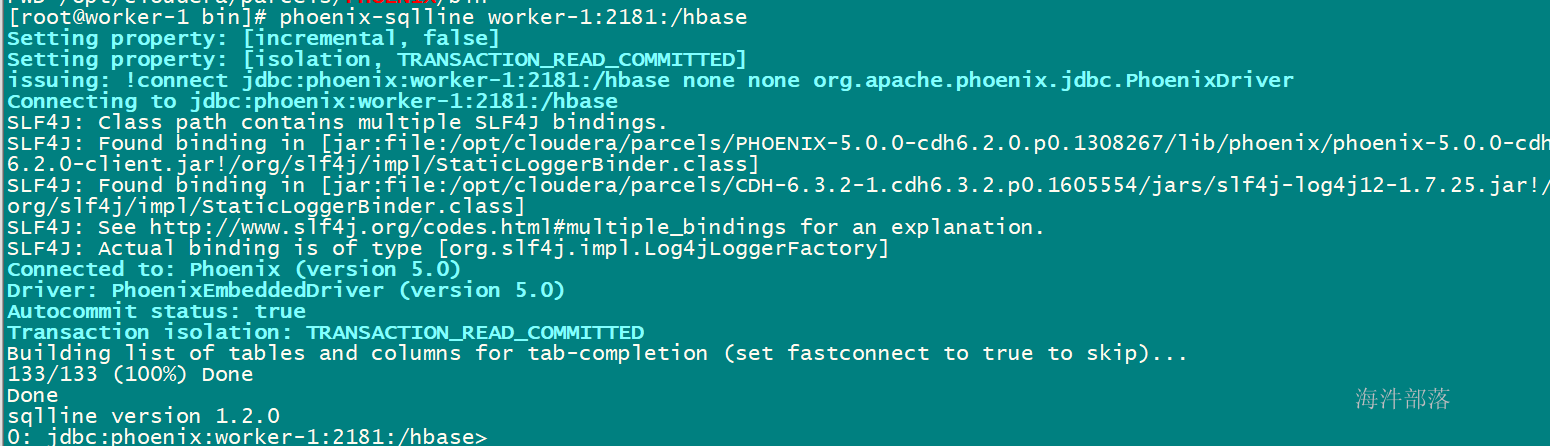
4 phoenix实操
4.1 创建测试表
在phoenix中创建测试表,必须指定主键,主键对应hbase的rowkey。
-- 表名不带双引号,默认转成大写
create table phtest1(
pk varchar not null primary key,
col1 varchar,
col2 varchar,
col3 varchar
);
-- 表名带双引号,不转大写
create table "phtest2"(
pk varchar not null primary key,
col1 varchar,
col2 varchar,
col3 varchar
);
-- 查看表列表
!tables
-- 查看表结构
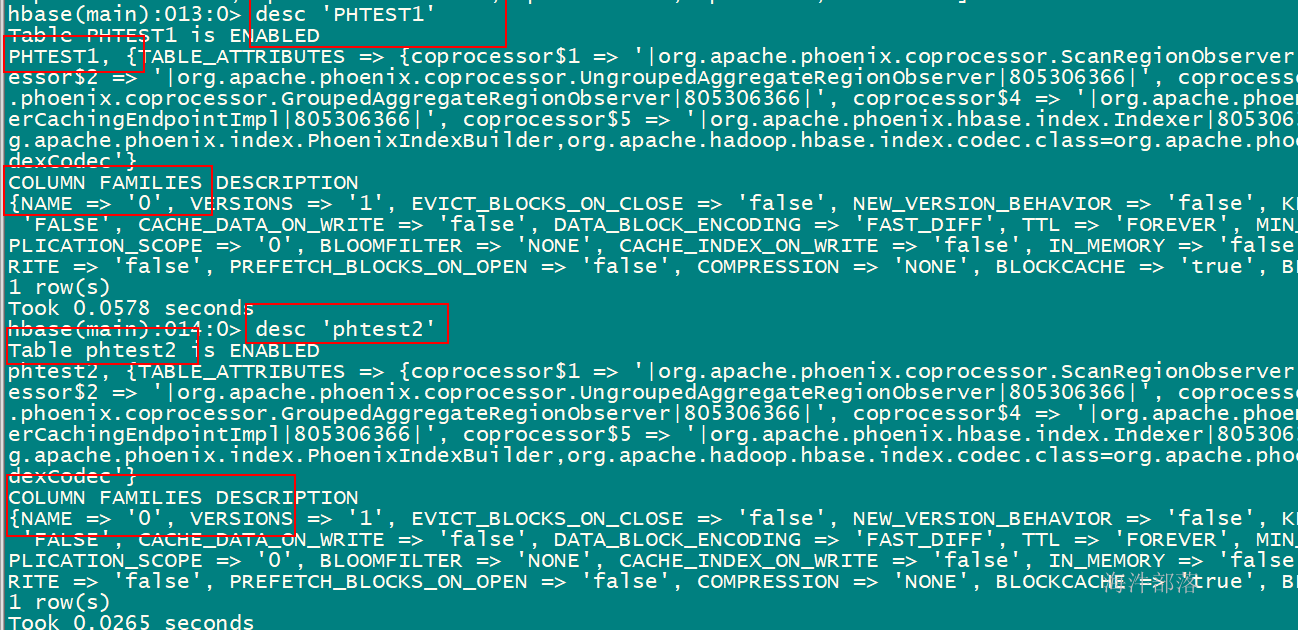
!describe "phtest1"
在hbase shell中查询(phoenix严格区分大小写,所有小写在phoenix中都会被翻译为大写)
4.2 插入/查询数据
-- upsert插入时如果主键已经存在则更新,如果不存在则插入。
-- 数据插入与hbase shell插入数据性质一致,如果插入相同主键的值,则保持最新的一条数据。
-- 直接 values 插入或更新
upsert into PHTEST1 values ('x0001','1','2','3');
upsert into PHTEST1 values ('x0001','1','22','3');
upsert into PHTEST1 values ('x0002','1','2','3');
-- 指定字段插入更新
upsert into PHTEST1 (pk,col1,col2,col3) values ('x0003','1','2','3');
# 查询
select * from PHTEST1;
select col1 from PHTEST1;
select t.col1 from PHTEST1 t;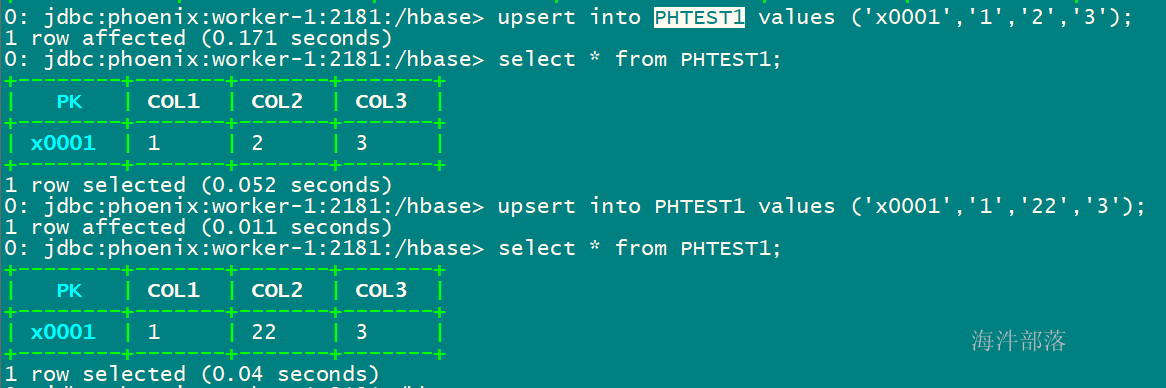
在hbase shell中查询

4.3 测试删除
插入多行,删除其中某一行
-- 插入多行,一次只能插入一行,不能插入多行
upsert into PHTEST1 values ('x0005','2','3','4');
upsert into PHTEST1 values ('x0006','3','4','5');
upsert into PHTEST1 values ('x0007','4','5','6');
-- 查询验证
select * from PHTEST1;
-- 删除一行
delete from PHTEST1 where col1='2';
-- 查询验证
select * from PHTEST1;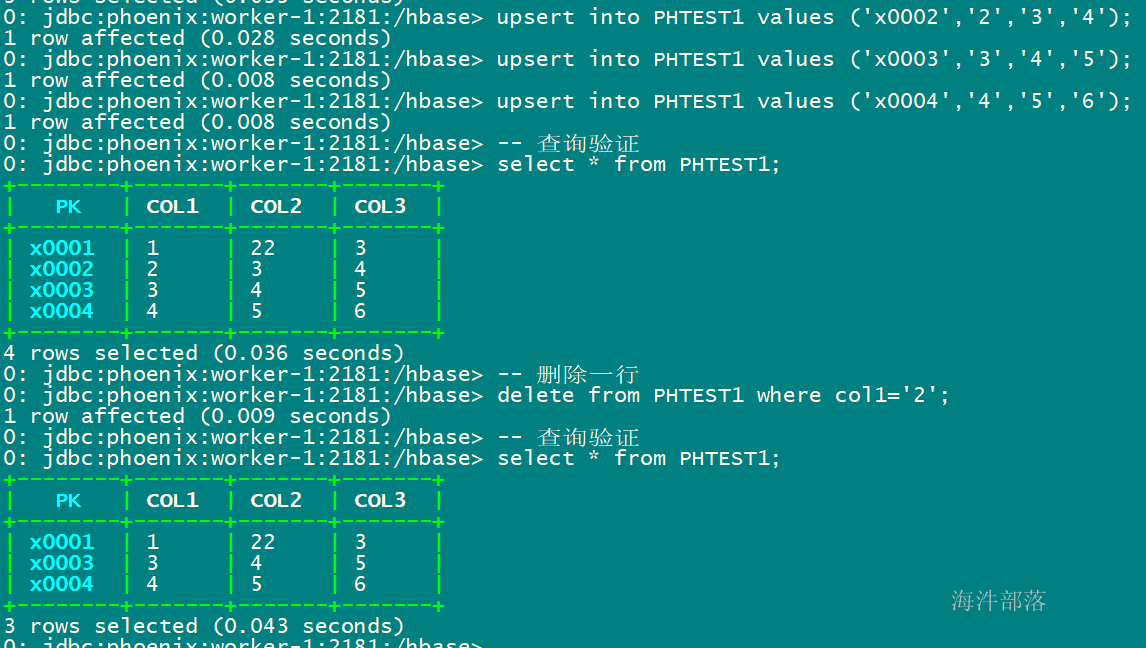
4.4 批量更新
-- 使用select查询结果集批量更新表
-- 创建一张临时表PHTEST2
create table PHTEST2(
pk varchar not null primary key,
col1 varchar,
col2 varchar,
col3 varchar
);
-- 临时表插入数据,比phtest1表多了'x0005'、'x0006'和'x0002'三行,其中'x0003'、'x0004'与phtest1的一致
upsert into PHTEST2 values ('x0001','newvalue','newvalue','newvalue');
upsert into PHTEST2 values ('x0002','newvalue','newvalue','newvalue');
upsert into PHTEST2 values ('x0003','3','4','5');
upsert into PHTEST2 values ('x0004','4','5','6');
upsert into PHTEST2 values ('x0005','newvalue','newvalue','newvalue');
upsert into PHTEST2 values ('x0006','newvalue','newvalue','newvalue');
-- 执行批量更新, 将PHTEST2表的数据覆盖到PHTEST1表
upsert into PHTEST1 select * from PHTEST2;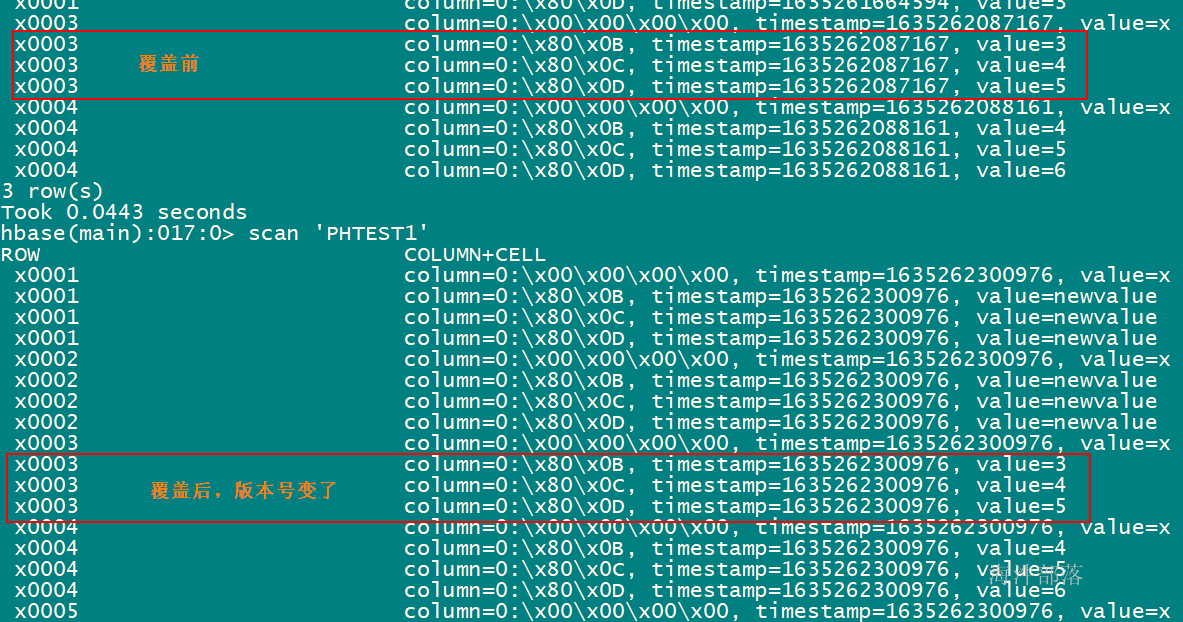
4.5 删除表
drop table PHTEST2;4.6 统计查询
select count(1) from PHTEST1;
select count(distinct col1) from PHTEST1;
select sum(num) from (select col1, count(*) as num from PHTEST1 group by col1) t1;
select col1, count(*) as num from PHTEST1 group by col1 order by num desc;
4.7 数据导入
使用官方提供的数据样例,phoenix数据导入只支持csv文件格式。
# 在客户端外
# 执行SQL文件
# 对标hive的-f test.sql ${hiveconf:batch_date}
phoenix-sqlline worker-1:2181:/hbase STOCK_SYMBOL.sql
# 加载csv文件数据到 STOCK_SYMBOL 表
phoenix-psql -t STOCK_SYMBOL worker-1:2181:/hbase STOCK_SYMBOL.csv
# 注意:
# 1)phoenix数据导入只支持后缀为.csv的文件, csv文件名称不需要和表名称一致,文件名可以小写
# 2)指定的表必须是大写,小写就报错
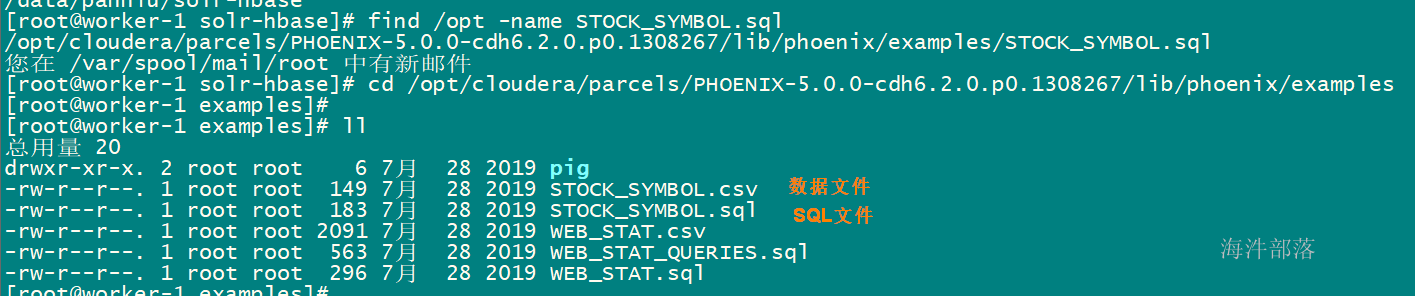
执行SQL文件内的SQL语句:
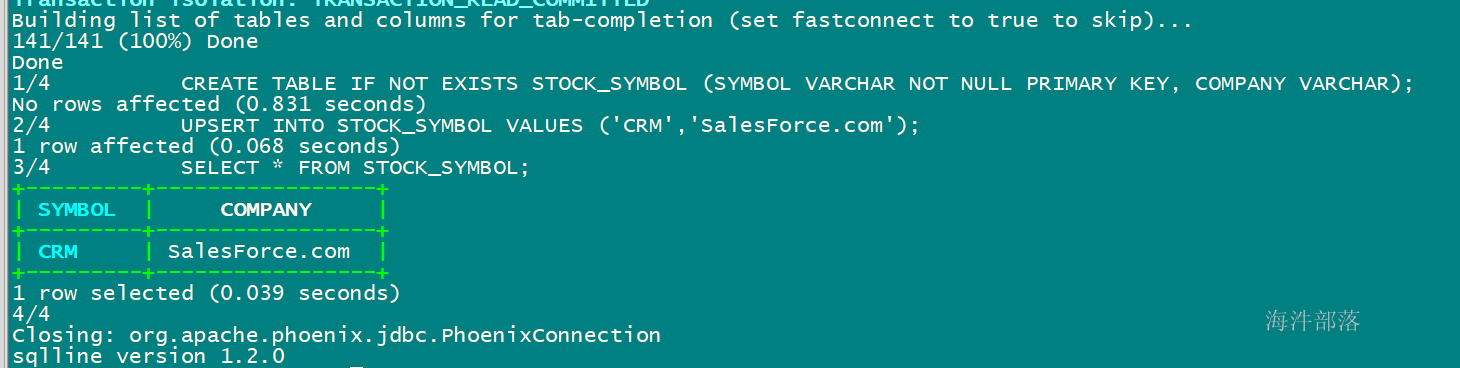
加载csv文件数据到 STOCK_SYMBOL 表后查询:
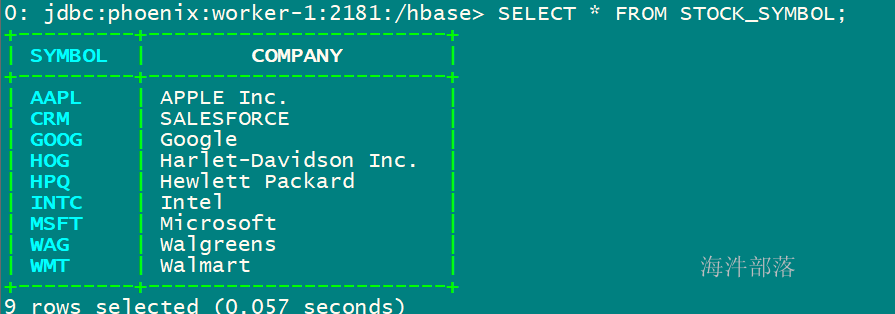
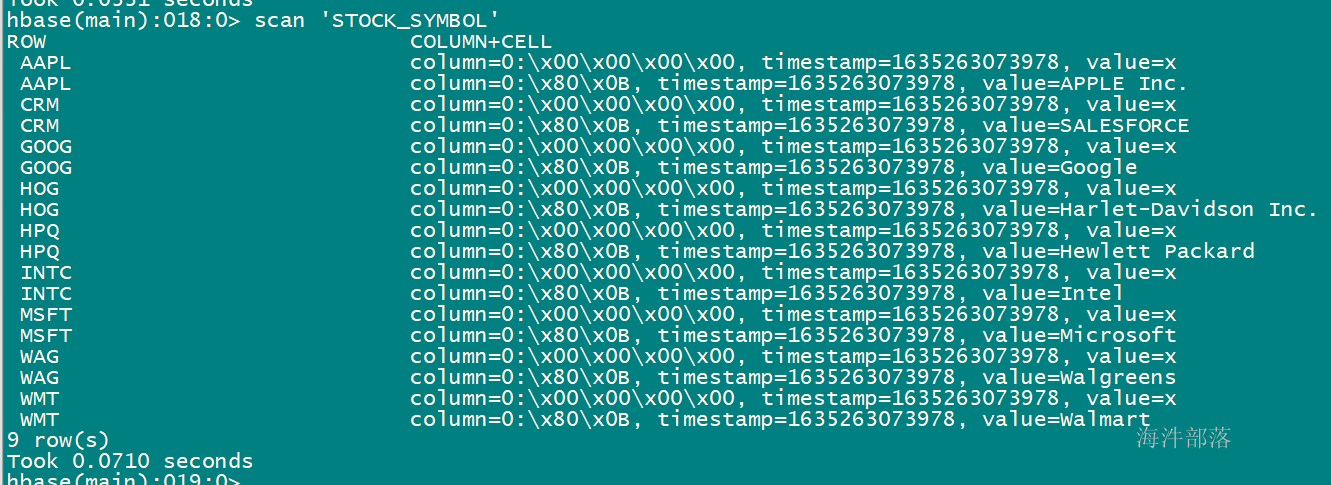
4.8 在phoenix建表时指定列族
-- 用 列族名.字段名
create table "cftest" (
pk varchar not null primary key,
cf1.col1 varchar,
cf2.col2 varchar);
-- 查询时可以不用列族
select col1 from "cftest"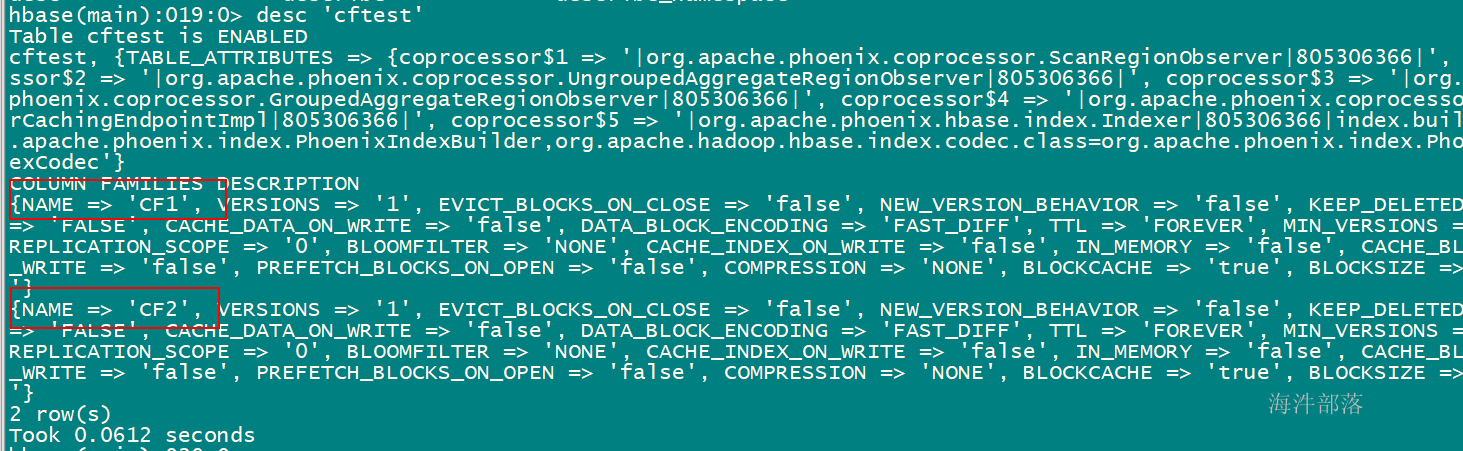
4.9 在phoenix建表时指定压缩格式
-- 在后面可指定压缩格式
create table "comptest" (
pk varchar not null primary key,
cf1.col1 varchar,
cf2.col2 varchar)
compression='snappy';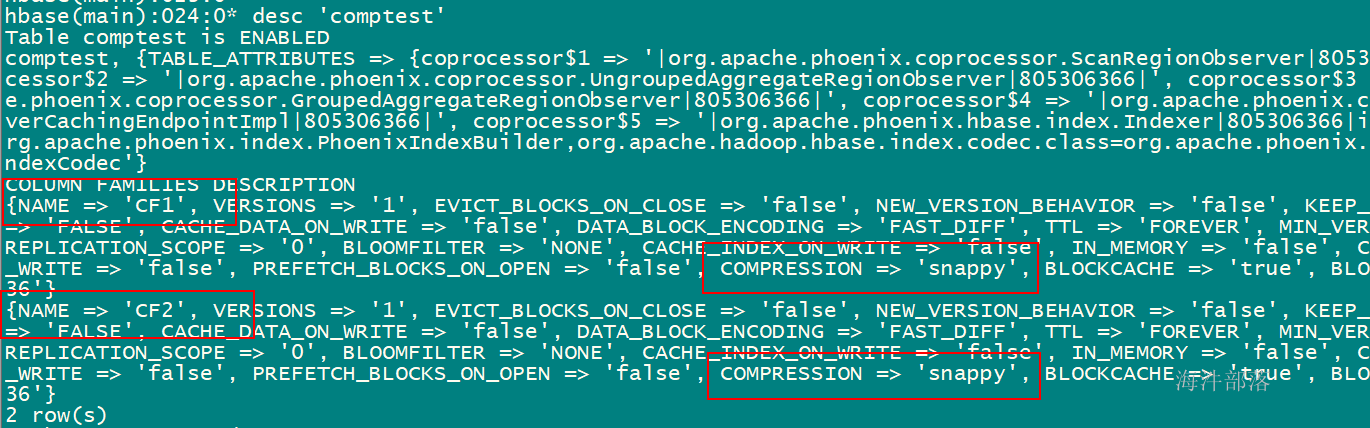
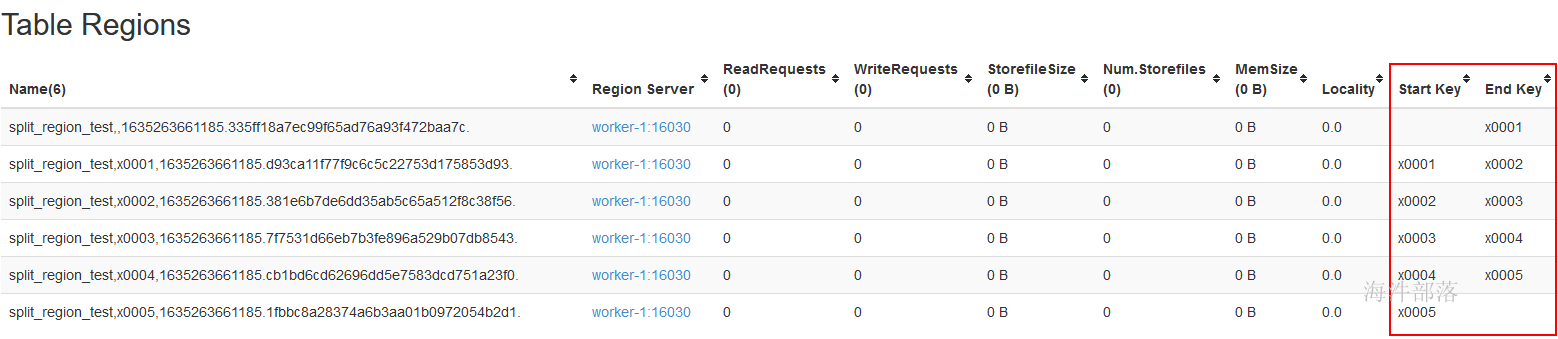
4.10 在phoenix建表时预分region
-- 用 split on ('x0001','x0002','x0003','x0004','x0005') 来进行预分region
-- 其中 on 里面的 是 splitkey
create table "split_region_test" (
pk varchar not null primary key,
cf1.col1 varchar,
cf2.col2 varchar)
compression='snappy'
split on ('x0001','x0002','x0003','x0004','x0005');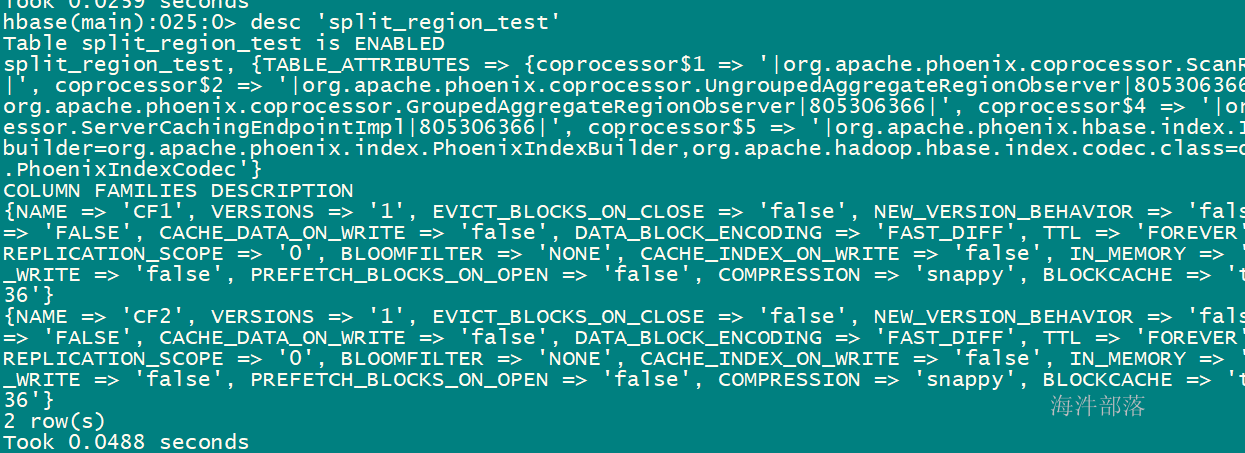
查看hbase web ui:
4.11 phoenix与hbase表关联
1)在hbase中创建带有命名空间的表,并添加数据
# 已知hbase命名空间 xinniu
# 创建带有命名空间的表
create 'xinniu:relatetable',{NAME => 'cf1',COMPRESSION => 'snappy'},{NAME => 'cf2',COMPRESSION => 'snappy'}
# 添加数据
put 'xinniu:relatetable','x0001','cf1:name','user1'
put 'xinniu:relatetable','x0002','cf1:name','user2'
put 'xinniu:relatetable','x0001','cf1:age','20'
put 'xinniu:relatetable','x0002','cf1:age','21'
put 'xinniu:relatetable','x0001','cf2:address','beijing'
put 'xinniu:relatetable','x0002','cf2:address','shanghai'2)在phoenix中创建schema(schema相当于命名空间)
-- 先在phoenix中创建schema,对应hbase的namespace
create schema if not exists "xinniu";执行报错:
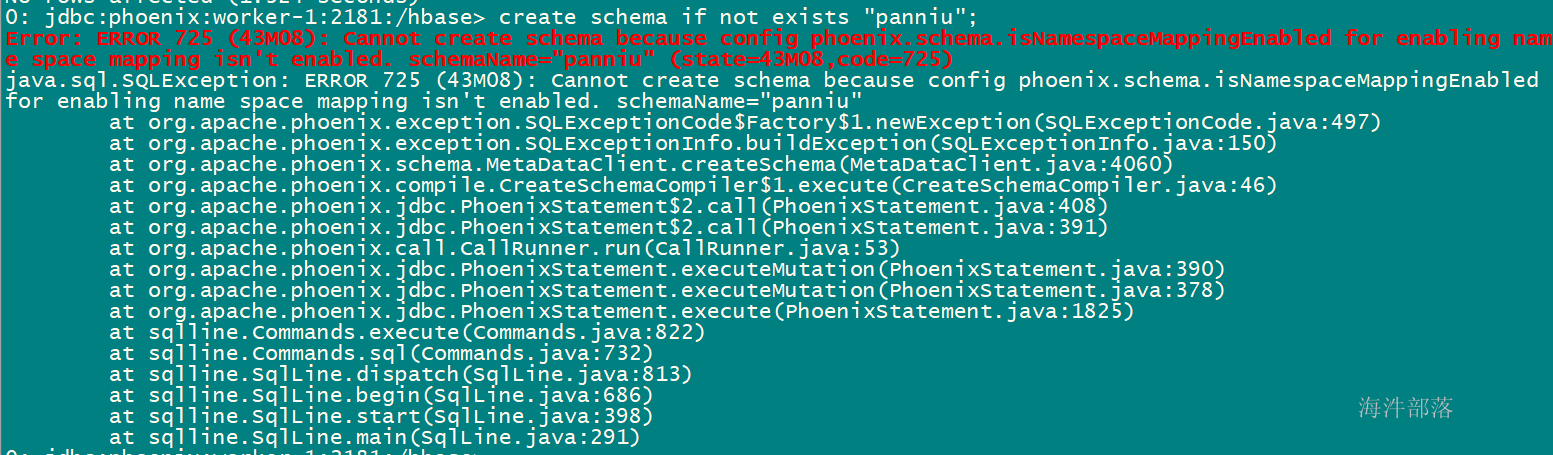
在phoenix中创建schema报错解决方式:在hbase的hbase-site.xml中添加phoenix.schema.isNamespaceMappingEnabled=true和phoenix.schema.mapSystemTablesToNamespace=true
建议在服务端和客户端都添加,用hbase web ui添加配置
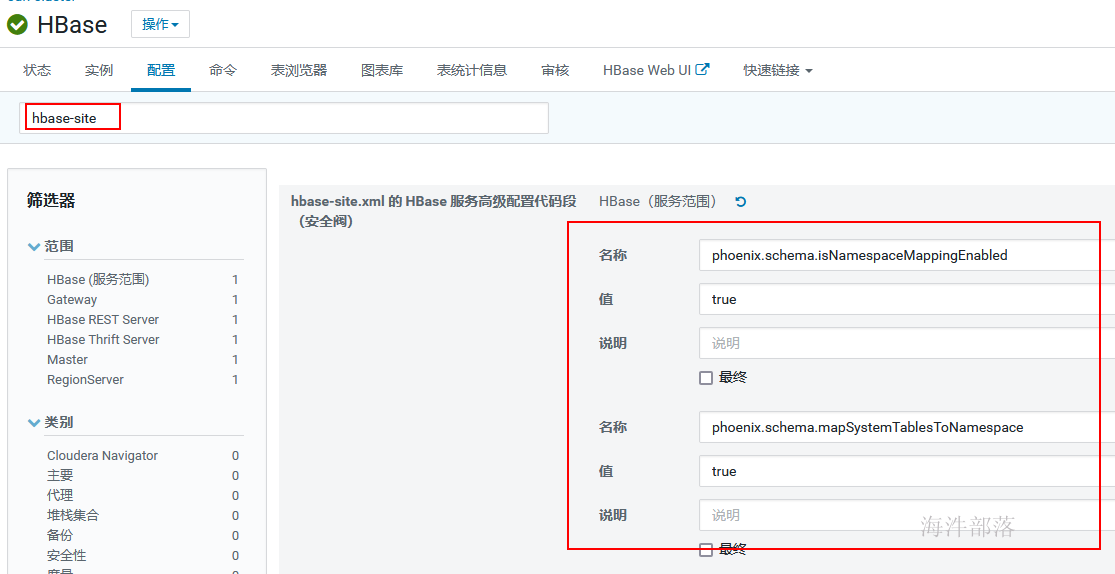
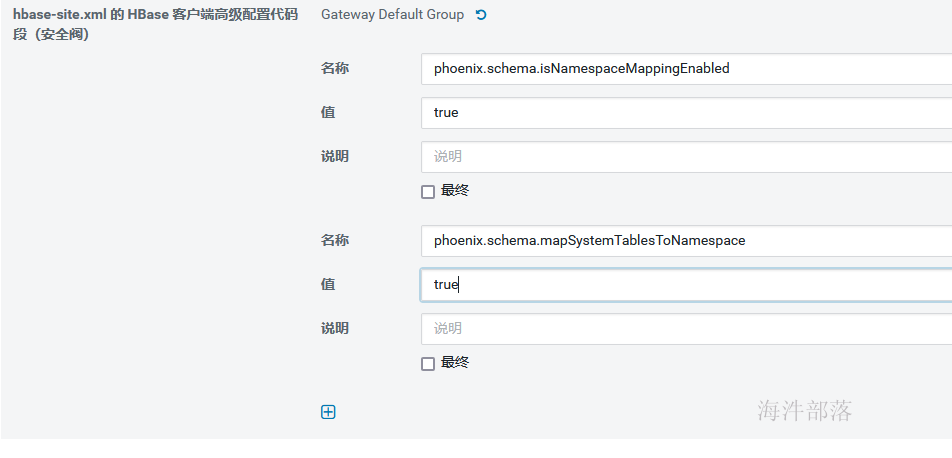
并重启过期配置。
重新进入Phoenix 客户端
-- 退出客户端
!q
-- 进入客户端
phoenix-sqlline worker-1:2181:/hbase
-- 先在phoenix中创建schema,对应hbase的namespace
create schema if not exists "xinniu";3)创建带有命名空间的表
-- 在phoenix创建'xinniu:relatetable'的关联表
-- 其中: column_encoded_bytes=0 是把字段名转成字符串,而不是原来的byte数组
create table "xinniu"."relatetable"(
id varchar not null primary key,
"cf1"."name" varchar,
"cf1"."age" varchar,
"cf2"."address" varchar
) column_encoded_bytes=0;
-- 在phoenix中插入一条数据测试
upsert into "xinniu"."relatetable" (id,"cf1"."name","cf1"."age","cf2"."address") values ('x0003','user3','22','guangzhou');
select * from "xinniu"."relatetable";
select "cf1"."name" from "xinniu"."relatetable";
-- 没有给进行BYTES.tostring
create table "xinniu"."relatetable1"(
id varchar not null primary key,
"cf1"."name" varchar,
"cf1"."age" varchar,
"cf2"."address" varchar
);
upsert into "xinniu"."relatetable1" (id,"cf1"."name","cf1"."age","cf2"."address") values ('x0003','user3','22','guangzhou');建表语句中带有 column_encoded_bytes=0, 从hbase查询,字段名能看得懂:
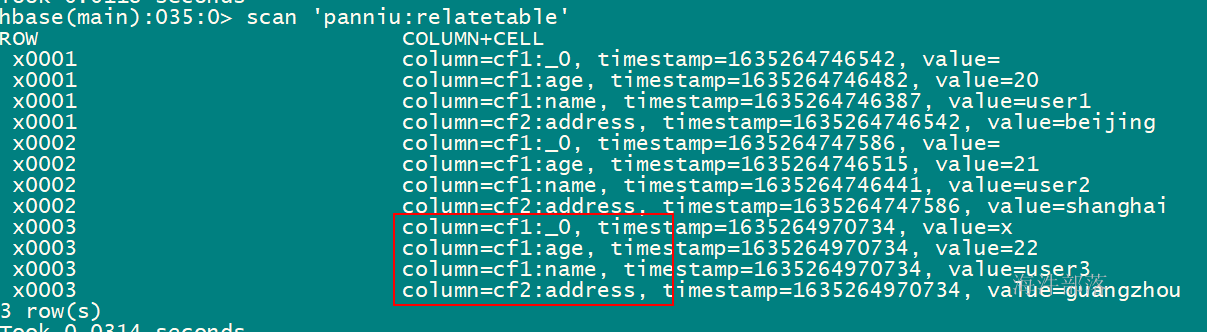
建表语句中不带有 column_encoded_bytes=0, 从hbase查询,字段名看不懂:

4.12 phoenix建表时指定组合rowkey
-- 通过 CONSTRAINT pk primary key ( prefix,id ) 设定联合主键,作为rowkey
-- 当prefix和id作为联合主键, 只在hbase的rowkey中存在, column里没有
-- 建表语句
create table "xinniu"."combinationkey_table" (
prefix varchar not null,
id varchar not null,
col1 varchar,
col2 varchar
CONSTRAINT pk primary key ( prefix,id )
)
column_encoded_bytes=0,
compression='snappy'
split on ('1','2','|');
-- 插入数据
upsert into "xinniu"."combinationkey_table" (prefix,id,col1,col2) values ('1','001','user1','20');
upsert into "xinniu"."combinationkey_table" (prefix,id,col1,col2) values ('1','002','user2','21');
-- 查看表结构
!describe "xinniu"."combinationkey_table"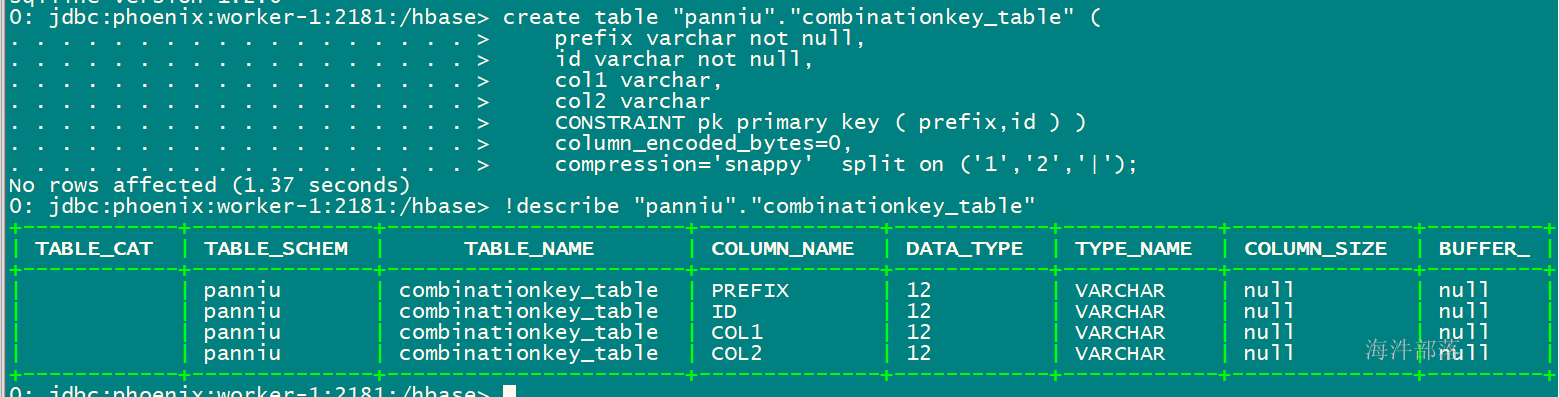
添加数据后:

查看hbase表:

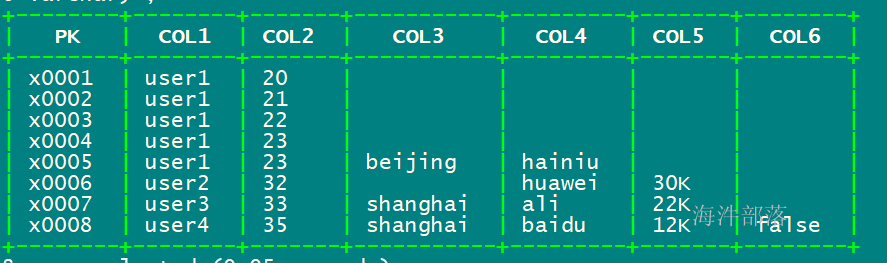
4.13 phoenix实现动态列
-- 创建表
create table "xinniu"."dynamic_table"(
pk varchar not null primary key,
col1 varchar,
col2 varchar
)column_encoded_bytes=0;
-- 插入数据
upsert into "xinniu"."dynamic_table" (pk,col1,col2) values ('x0001','user1','20');
upsert into "xinniu"."dynamic_table" (pk,col1,col2) values ('x0002','user1','21');
upsert into "xinniu"."dynamic_table" (pk,col1,col2) values ('x0003','user1','22');
upsert into "xinniu"."dynamic_table" (pk,col1,col2) values ('x0004','user1','23');
-- 动态插入列
-- 动态插入 col3 和 col4 列
upsert into "xinniu"."dynamic_table" (pk,col1,col2,col3 varchar,col4 varchar) values ('x0005','user1','23','beijing','hainiu');
-- 动态插入 col4 和 col5 列
upsert into "xinniu"."dynamic_table" (pk,col1,col2,col4 varchar,col5 varchar) values ('x0006','user2','32','huawei','30K');
-- 动态插入 col3、col4、col5 列
upsert into "xinniu"."dynamic_table" (pk,col1,col2,col3 varchar,col4 varchar,col5 varchar) values ('x0007','user3','33','shanghai','ali','22K');
-- 动态插入 col3、col4、col5、col6 列
upsert into "xinniu"."dynamic_table" (pk,col1,col2,col3 varchar,col4 varchar,col5 varchar,col6 varchar) values ('x0008','user4','35','shanghai','baidu','12K','false');
-- phoenix中查询动态列
select * from "xinniu"."dynamic_table"(col3 varchar,col4 varchar);
select * from "xinniu"."dynamic_table"(col3 varchar,col4 varchar,col5 varchar) ;
select * from "xinniu"."dynamic_table"(col3 varchar,col4 varchar,col5 varchar,col6 varchar) ;select * from "xinniu"."dynamic_table"(col3 varchar,col4 varchar);

select * from "xinniu"."dynamic_table"(col3 varchar,col4 varchar,col5 varchar) ;

select * from "xinniu"."dynamic_table"(col3 varchar,col4 varchar,col5 varchar,col6 varchar) ;
5 索引
5.1 开启索引
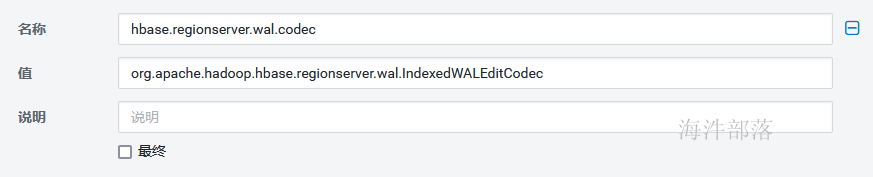
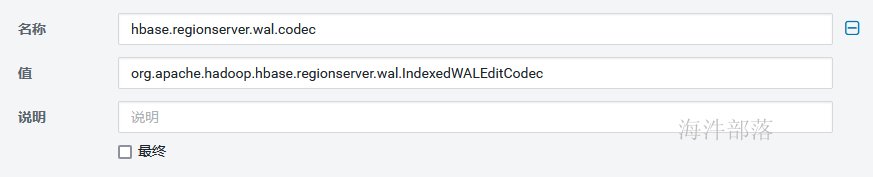
配置hbase-site.xml文件(服务端与客户端),用hbase web ui添加配置hbase.regionserver.wal.codec=org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec
搜索“hbase-site”
在服务端添加
在客户端添加
重启过期配置后,重新进入phoenix 客户端。
5.2 数据准备
-- 创建测试表
create table "xinniu"."testindex"(
pk varchar not null primary key,
col1 varchar
)column_encoded_bytes=0;
-- 插入数据
upsert into "xinniu"."testindex" values ('x1','1');
……
upsert into "xinniu"."testindex" values ('x20000','20000');
-- 编写脚本,生成SQL文件
[root@worker-1 hdfs_test]# vim s1.sh
#! /bin/bash
for((i=1;i<=20000;i++))
do
echo "upsert into \"xinniu\".\"testindex\" values ('x${i}','${i}');" >> testindex.sql
done
-- 执行SQL文件导入表
phoenix-sqlline worker-1:2181:/hbase testindex.sql
--通过导入csv文件的方式将数据导入到表
phoenix-psql -t "xinniu"."testindex" worker-1:2181:/hbase t1.csv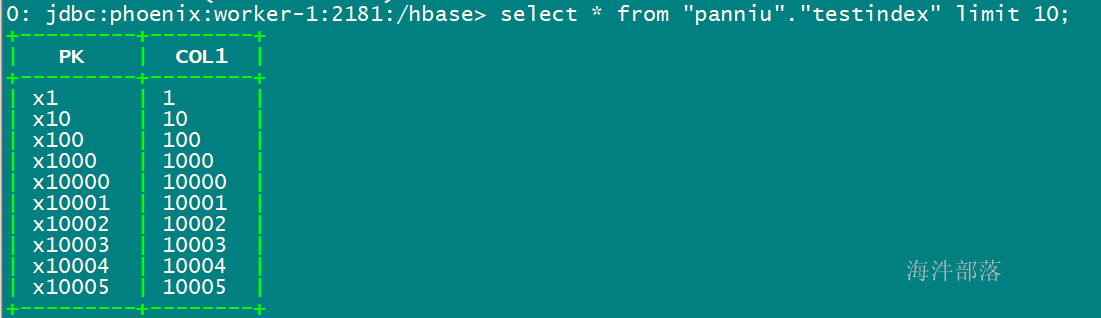
5.3 索引开启前查询
-- 查看执行计划,发现全表扫描
explain select * from "xinniu"."testindex" where COL1 = '200';
-- 查询
select * from "xinniu"."testindex" where COL1 = '200';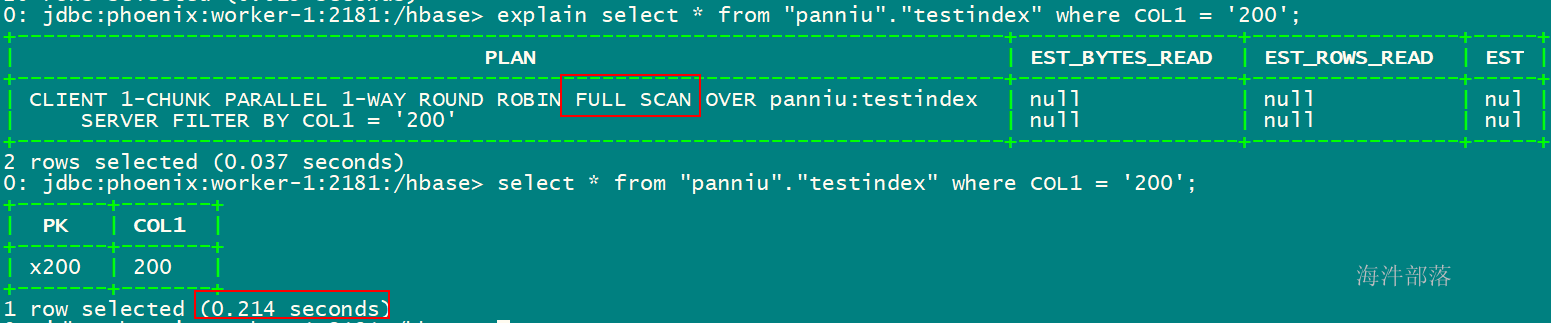
通过执行计划可以发现,查询为FULL SCAN。
5.4 索引操作
-- 基于 COL1字段 创建索引, 当创建完后,索引里存的是已经排序好的COL1数据
create local index myindex on "xinniu"."testindex" (COL1);
-- 查看执行计划,发现不全表扫描
explain select * from "xinniu"."testindex" where COL1 = '200';
select * from "xinniu"."testindex" where COL1 = '200';
-- 删除索引
drop index myindex on "xinniu"."testindex";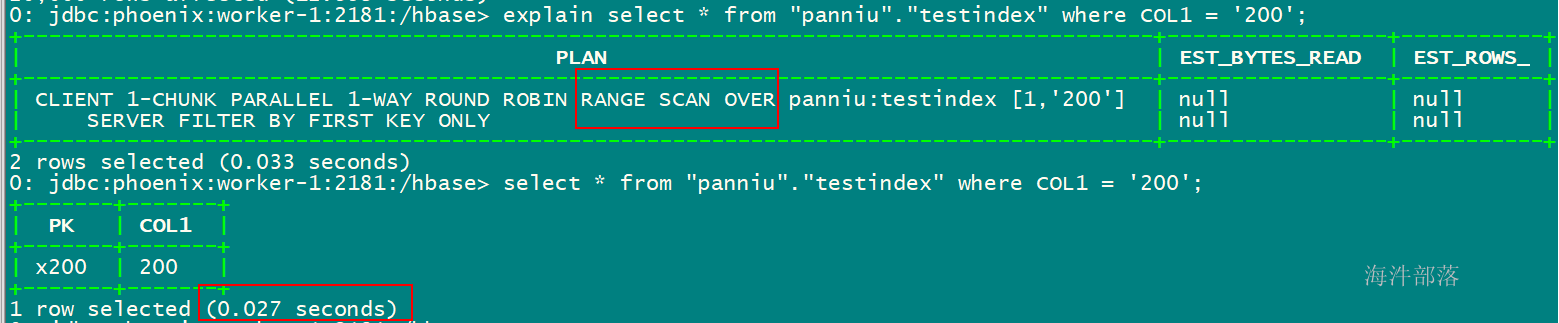
6 api 操作Phoenix
6.1 环境版本信息
cdh6.3.2版本,phoenix5.0.0版本,hbase2.1.0版本
6.2 pom中添加Phoenix依赖
<dependency>
<groupId>org.apache.phoenix</groupId>
<artifactId>phoenix-core</artifactId>
<version>5.0.0-HBase-2.0</version>
</dependency>6.3 相关配置文件
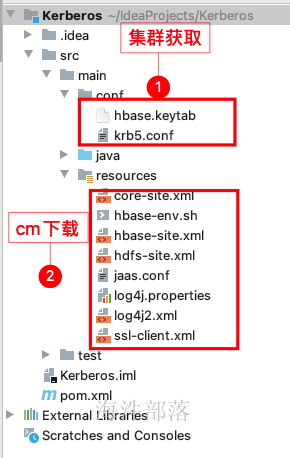
- kerberos配置文件在集群环境下载,krb5.conf为kerberos安装配置时的配置文件,对应路径为/etc/krb5.conf,hbase.keytab为票据文件。
- hbase相关配置文件,在cm界面hbase→操作→下载客户端配置
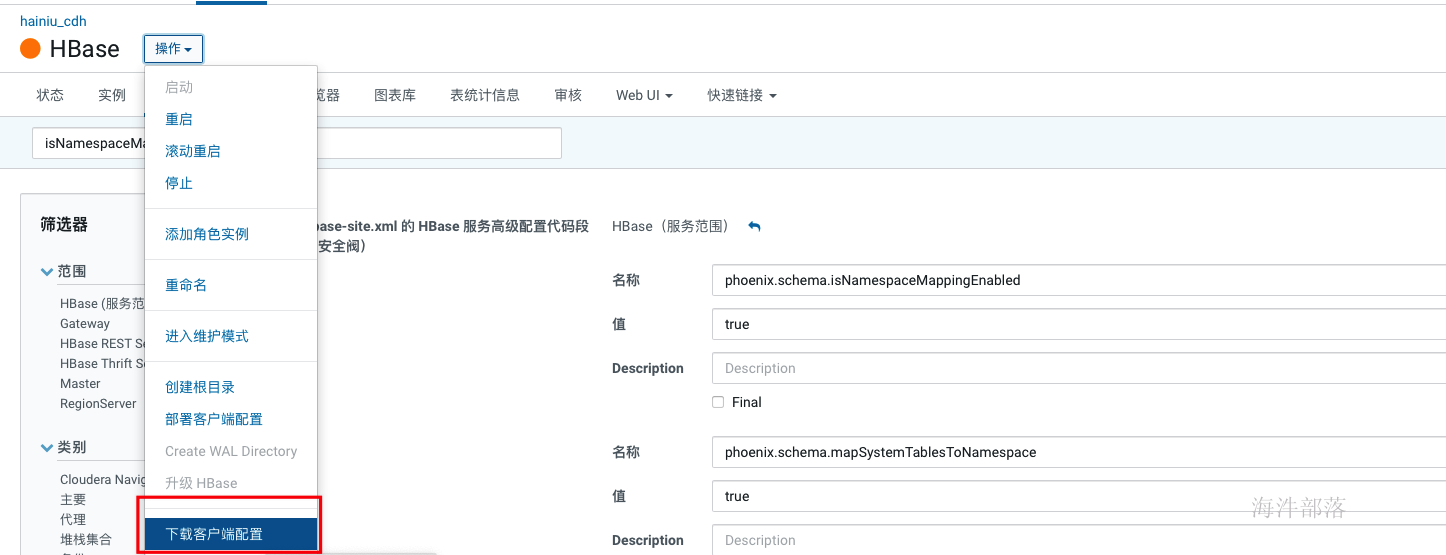
如果在hbase-site.xml中没有 上面两个配置,需要添加到hbase-site.xml文件中
<property>
<name>phoenix.schema.isNamespaceMappingEnabled</name>
<value>true</value>
<description>命名空间开启</description>
</property>
<property>
<name>hbase.regionserver.wal.codec</name>
<value>org.apache.hadoop.hbase.regionserver.wal.IndexedWALEditCodec</value>
<description>二级索引支持</description>
</property>6.4 创建测试表
-- 创建测试表
create table "xinniu"."testindex2"(
pk varchar not null primary key,
col1 varchar
)column_encoded_bytes=0;6.5 代码
package com.hainiu;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.security.UserGroupInformation;
import java.io.IOException;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.sql.Statement;
public class HbaseOpForPhoenix {
static Configuration conf = HBaseConfiguration.create();
public static void main(String[] args) {
String krb5Path = "src/main/conf/krb5.conf";
String principal = "hbase@HAINIU.COM";
String keytabPath = "src/main/conf/hbase.keytab";
kerberosAuth(conf,krb5Path,principal,keytabPath);
writeDataToHbaseByPhoenix();
}
/**
* 通过Phoenix写入hbase表
*/
private static void writeDataToHbaseByPhoenix() {
String url = "jdbc:phoenix:worker-1:2181";
try {
Class.forName("org.apache.phoenix.jdbc.PhoenixDriver");
try(
Connection conn = DriverManager.getConnection(url);
Statement stmt = conn.createStatement();
){
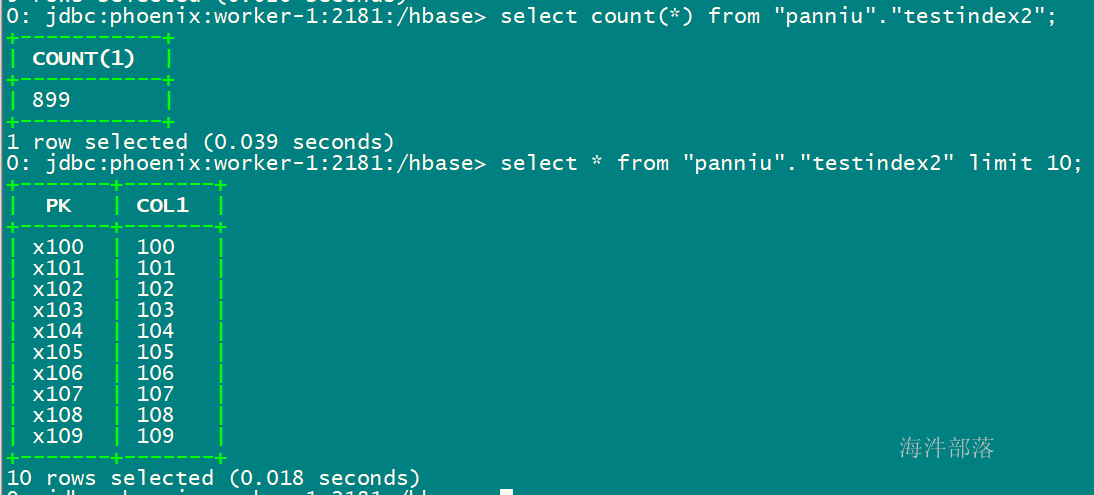
for(int i = 100; i < 999; i++){
String sql = "upsert into \"xinniu\".\"testindex2\" values ('x"+ i + "','" + i + "') ";
stmt.addBatch(sql);
// System.out.println(sql);
}
stmt.executeBatch();
// 提交事务
conn.commit();
}catch (SQLException e){
e.printStackTrace();
}
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* kerberos认证
* @param configuration hadoop配置文件
* @param krb5Path kerberos配置文件(krb5.conf)路径
* @param principal 认证主体名
* @param keytabPath keytab文件路径
*/
public static void kerberosAuth(Configuration configuration, String krb5Path, String principal, String keytabPath){
// 通过系统设置参数设置krb5.conf
System.setProperty("java.security.krb5.conf",krb5Path);
// 指定kerberos 权限认证
configuration.set("hadoop.security.authentication","Kerberos");
// 用 UserGroupInformation 类做kerberos认证
UserGroupInformation.setConfiguration(configuration);
try {
// 用于刷新票据,当票据过期的时候自动刷新
UserGroupInformation.getLoginUser().checkTGTAndReloginFromKeytab();
// 通过 keytab 登录
// 参数1:认证主体
// 参数2:认证文件
UserGroupInformation.loginUserFromKeytab(principal,keytabPath);
UserGroupInformation loginUser = UserGroupInformation.getLoginUser();
System.out.println("loginUser:" + loginUser);
} catch (IOException e) {
e.printStackTrace();
}
}
}
运行时报这样的错误,可忽略
执行插入后,查看表,说明数据已经导入