1 下载es-hadoop插件
es-hadoop 插件下载地址:https://www.elastic.co/cn/downloads/past-releases#es-hadoop
上传es-hadoop插件到集群,并解压和修改权限
cd /opt
# 解压
unzip elasticsearch-hadoop-7.12.1.zip
# 修改权
chmod -R 777 /opt/elasticsearch-hadoop-7.12.1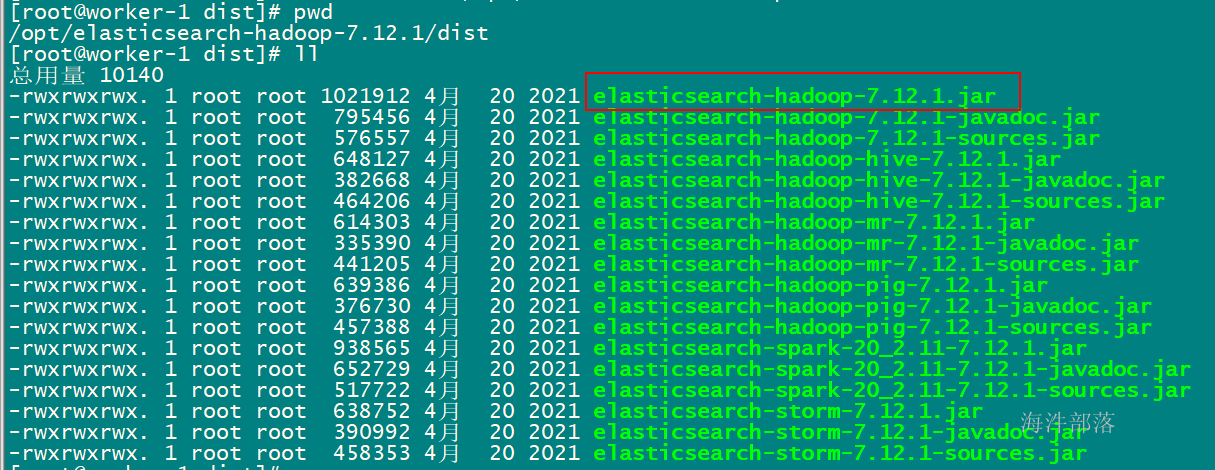
2 准备hive数据
kinit hive
-- 连接hive
beeline -u "jdbc:hive2://worker-1:10000/;principal=hive/worker-1@HAINIU.COM"
-- 创建临时表
create table if not exists xinniu.hivetable(
id string,
col1 string,
col2 int
)
comment 'hive表'
row format delimited fields terminated by '\t';
vim tdata
1 name1 11
2 name2 12
3 name3 13
4 name4 14
5 name5 15
-- 上传hdfs
kinit xinniu
hadoop fs -mkdir -p /data/xinniu/es_input
hadoop fs -put -f tdata /data/xinniu/es_input
hadoop fs -chmod 777 /data/xinniu/es_input
kinit hive
-- 加载数据
load data inpath '/data/xinniu/es_input/tdata' into table xinniu.hivetable;
select * from xinniu.hivetable;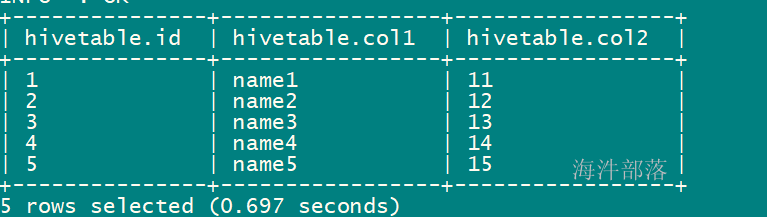
3 导入hive数据到es
1) 使用hive 客户端方式执行(beeline方式不能add jar)
# 认证hive
kinit hive
# 启动hive客户端
hive
# 加载es-hadoop jar包
add jar /opt/elasticsearch-hadoop-7.12.1/dist/elasticsearch-hadoop-7.12.1.jar;
# 加载 commons-httpclient jar包
add jar /opt/cloudera/cm/lib/commons-httpclient-3.1.jar;
# 创建es的hive外表
CREATE EXTERNAL TABLE xinniu.hive2es(
id string,
col1 string,
col2 bigint
)STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler'
TBLPROPERTIES('es.resource'='hivemappinges/_doc',
'es.nodes'='worker-1:9200',
'es.index.auto.create'='TRUE',
'es.index.refresh_interval' = '-1',
'es.index.number_of_replicas' = '0',
'es.batch.write.retry.count' = '6',
'es.batch.write.retry.wait' = '60s',
'es.mapping.name' = 'id:id,col1:col1,col2:col2'
);
# 创建es外表时,字段类型数值设置为bigint,因为es默认数值是bigint,hive的字段类型要和es的类型一致
# es.mapping.name中 id:id 是 hive2es的id对应es的属性id其中:
es.index.refresh_interval:
当数据添加到索引后并不能马上被查询到,等到索引刷新后才会被查询到。 refresh_interval 配置的刷新间隔。
refresh_interval 的默认值是 1s。
当 refresh_interval 为 -1 时,意味着不刷新索引。
当需要大量导入数据到ES中,可以将 refresh_interval 设置为 -1 以加快导入速度。导入结束后,再将 refresh_interval 设置为一个正数,例如1s。
# 创建索引
PUT /news_test
# 设置不刷新
PUT /news_test/_settings
{ "refresh_interval": -1 }
# 添加文档
POST /news_test/_doc/1
{"content":"美国留给伊拉克的是个烂摊子吗"}
# 由于不刷新,查询不出来
GET /news_test/_doc/_search
# 设置每1s刷新
PUT /news_test/_settings
{ "refresh_interval": "1s" }
# 查询出来
GET /news_test/_doc/_searches.index.number_of_replicas:
当需要大量导入数据到es中,需要设置es.index.number_of_replicas=0,目的是减少文档复制造成的开销。可在导入后设置副本数,这样开销小。
2)插入数据到es的hive外表
INSERT OVERWRITE TABLE xinniu.hive2es SELECT id,col1,col2 FROM xinniu.hivetable;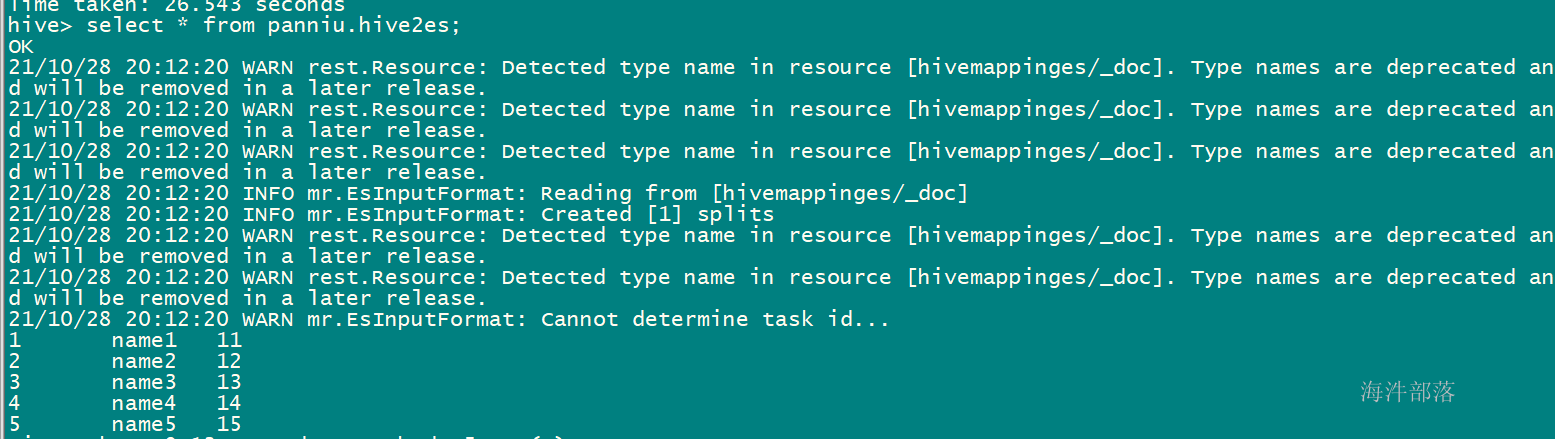
查看es
GET /hivemappinges/_doc/_search
{
"query":{
"match_all": {}
}
}

