1 概述
1.1 为什么要引入lily和solr
在Hbase中,表的RowKey 按照字典排序, 单一的通过RowKey检索数据的方式,不再满足更多的需求,查询成为Hbase的瓶颈,希望像Sql一样快速检索数据,Hbase之前定位的是大表的存储,要进行这样的查询,往往是要通过类似Hive、Pig等系统进行全表的MapReduce计算,这种方式既浪费了机器的计算资源,又因高延迟使得应用黯然失色,于是HBase Secondary Indexing的方案出现了。
1.2 Solr
Solr是一个独立的企业级搜索应用服务器,是Apache Lucene项目的开源企业搜索平台,其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如Word、PDF)的处理。Solr是高度可扩展的,并提供了分布式搜索和索引复制。Solr 4还增加了NoSQL支持,以及基于Zookeeper的分布式扩展功能SolrCloud。它的主要特性包括:高效、灵活的缓存功能,垂直搜索功能,Solr是一个高性能,采用Java5开发,基于Lucene的全文搜索服务器。同时对其进行了扩展,提供了比Lucene更为丰富的查询语言,同时实现了可配置、可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面,是一款非常优秀的全文搜索引擎,Solr可以高亮显示搜索结果,通过索引复制来提高可用性,提供一套强大Data Schema来定义字段,类型和设置文本分析,提供基于Web的管理界面。
检索数据,首先要了解数据的分类,不同类型的数据如何检索
数据总体分为两种:
1)结构化数据:指具有固定格式或有限长度的数据,如数据库,元数据等。
2)非结构化数据:指不定长或无固定格式的数据,如邮件,word文档等磁盘上的文件。
结构化数据查询方法:
数据库搜索
数据库中的搜索很容易实现,通常都是使用sql语句进行查询,而且能很快的得到查询结果。
数据库中的数据存储是有规律的,有行有列而且数据格式、数据长度都是固定的,可以创建索引,通过索引查询。
非结构化数据查询方法:
1)顺序扫描法(Serial Scanning)
所谓顺序扫描,比如要找内容包含某一个字符串的文件,就是一个文档一个文档的看,对于每一个文档,从头看到尾,如果此文档包含此字符串,则此文档为我们要找的文件,接着看下一个文件,直到扫描完所有的文件。如利用windows的搜索也可以搜索文件内容,只是相当的慢。
2)全文检索(Full-text Search)
将文档中的部分信息创建索引,然后通过索引去文档中查找指定信息的过程。
就好比词典。我们通过汉语拼音顺序,给字创建索引目录,当我们要查找某个词语时,先根据汉语拼音顺序找到对应字对应的页码,直接通过页码找到这个词语。这比顺序一页一页翻要快的多。
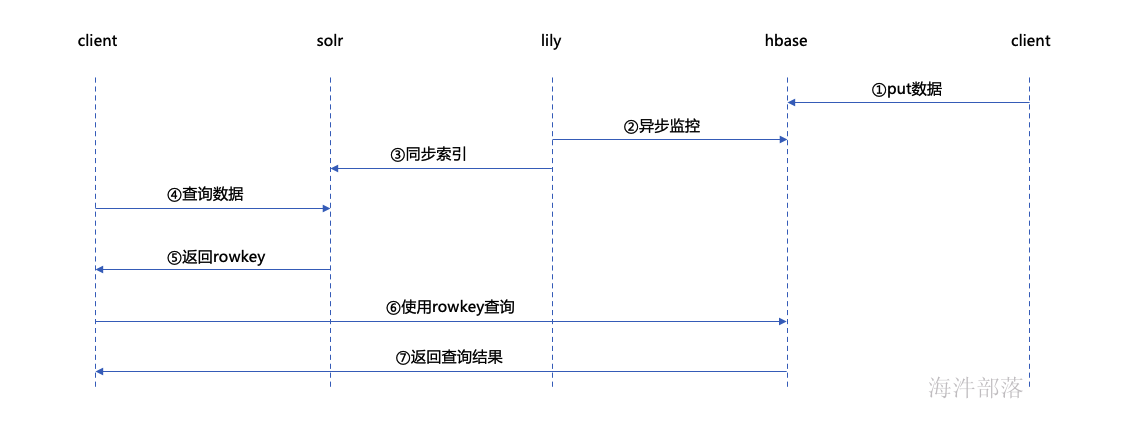
1.3 Key-Value Store Indexer
是Hbase到Solr生成索引的中间工具,在CDH5.3.2中的Key-Value Indexer使用的是Lily HBase Indexer 服务,Lily HBase Indexer是一款灵活的、可扩展的、高容错的、事务性的,并且近实时的处理HBase列索引数据的分布式服务软件。它是NGDATA公司开发的Lily系统的一部分,已开放源代码,Lily HBase Indexer使用SolrCloud来存储HBase的索引数据,当HBase执行写入、更新或删除操作时,Indexer通过HBase的replication功能来把这些操作抽象成一系列的Event事件,并用来保证写入Solr中的HBase索引数据的一致性,并且Indexer支持用户自定义的抽取,转换规则来索引HBase列数据。Solr搜索结果会包含用户自定义的columnfamily:qualifier字段结果,这样应用程序就可以直接访问HBase的列数据。
1.4 hbase+lily+solr架构
2 服务配置
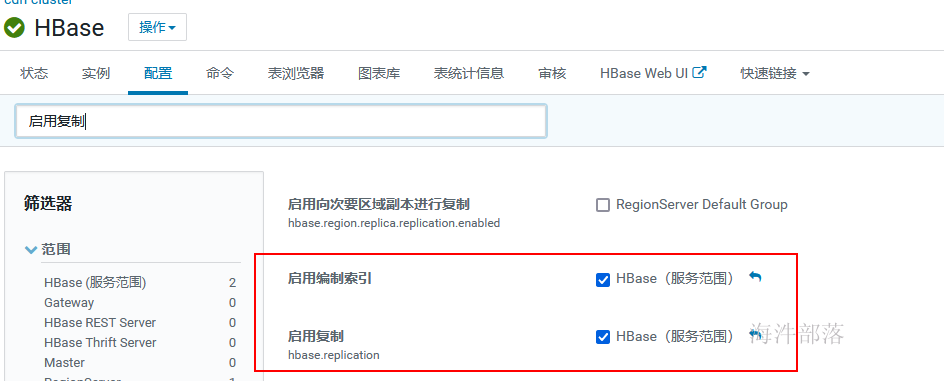
hbase配置文件搜索index,启用编制索引和启用复制。(如果是搭建hbase时已经勾选lily,那默认是启用的)
3 solr
3.1 collection创建脚本
# 用来创建solr collection
vim /data/panniu/solr-hbase/createcollection.sh
# zk节点
ZK="worker-1"
# 要创建的collection名称
COLLECTION="panniu"
# 分片数(分片是提高并行度)
SHARD=1
# 副本数(副本是用来容错的)
REPLICA=1
echo "create solr collection"
rm -rf ${COLLECTION}_tmp/*
# 生成配置文件
solrctl --zk $ZK:2181/solr instancedir --generate ${COLLECTION}_tmp/configs
# 上传配置文件到zk
solrctl --zk $ZK:2181/solr instancedir --create $COLLECTION ${COLLECTION}_tmp/configs
# solr创建collection
solrctl --zk $ZK:2181/solr collection --create $COLLECTION -s $SHARD -r $REPLICA
# 查看collection
solrctl --zk $ZK:2181/solr collection --list其中:
1)zk节点、collection名称是可以换成自己的
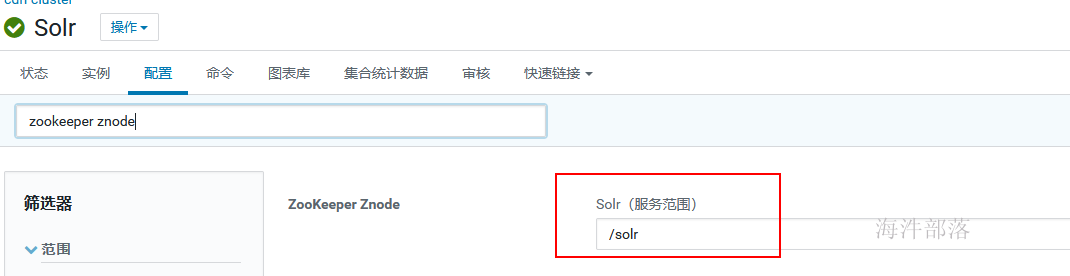
2)$ZK:2181/solr 中的 solr 是和solr内配置的一样的,如果换成自己的,需要修改solr web ui 里的配置并重启solr服务。
3.2 执行创建脚本
sh createcollection.sh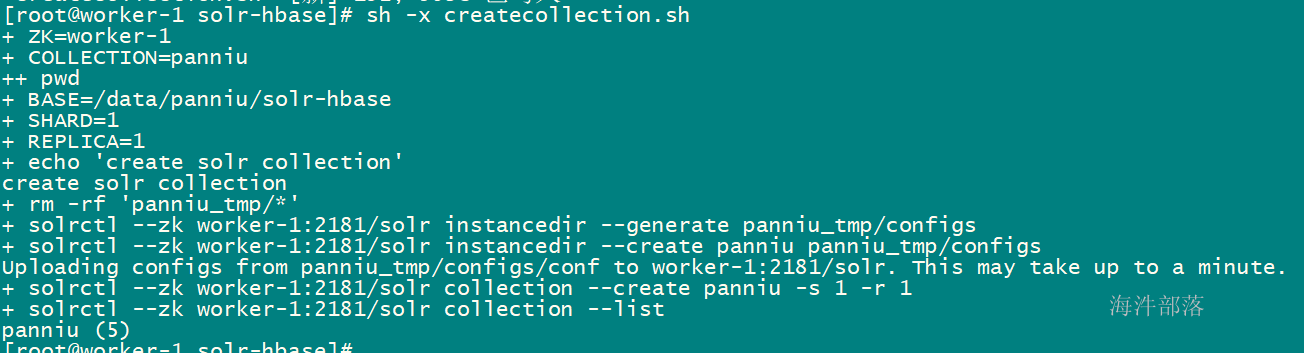
执行完后,查看zookeeper节点:
zookeeper-client -server worker-1:2181

3.3 solr web验证
进入到solr的web ui 页面
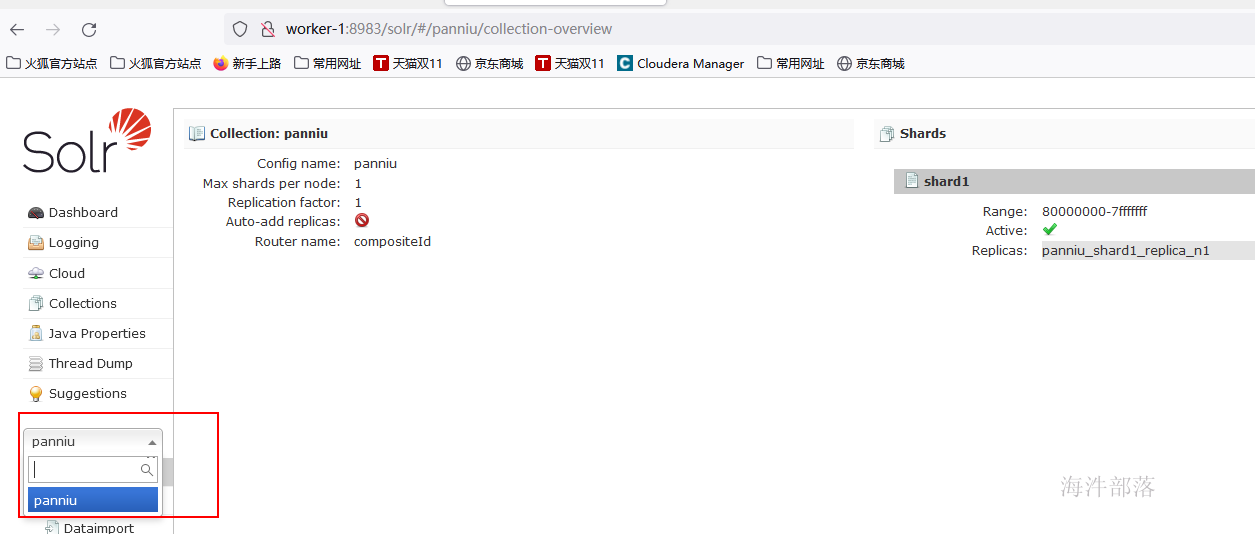
3.4 solr创建field字段
用 curl 请求solr
# 非安全模式(没有kerberos安全认证)
curl -X POST -H 'Content-Type:application/json' -d '{
"add-field":{
"name":"content",
"type":"text_en",
"stored":true,
"indexed":true
}
}' http://worker-1:8983/solr/panniu/schema
# 其中:
# name: 字段的名称
# type: 字段类型, text_en: 英文文本
# stored:是否存储文档
# indexed: 是否有索引
# http://worker-1:8983/solr/panniu/schema 里面的 panniu 是已经创建好的collection名称
# 解析json网站:www.json.cn# 安全模式 用户名和密码可以随意输入
curl --negotiate -u user:passwd -X POST -H 'Content-Type:application/json' -d '{
"add-field":{
"name":"content",
"type":"text_en",
"stored":true,
"indexed":true
}
}' http://worker-1:8983/solr/panniu/schema
查看solr web ui 已经添加了该字段
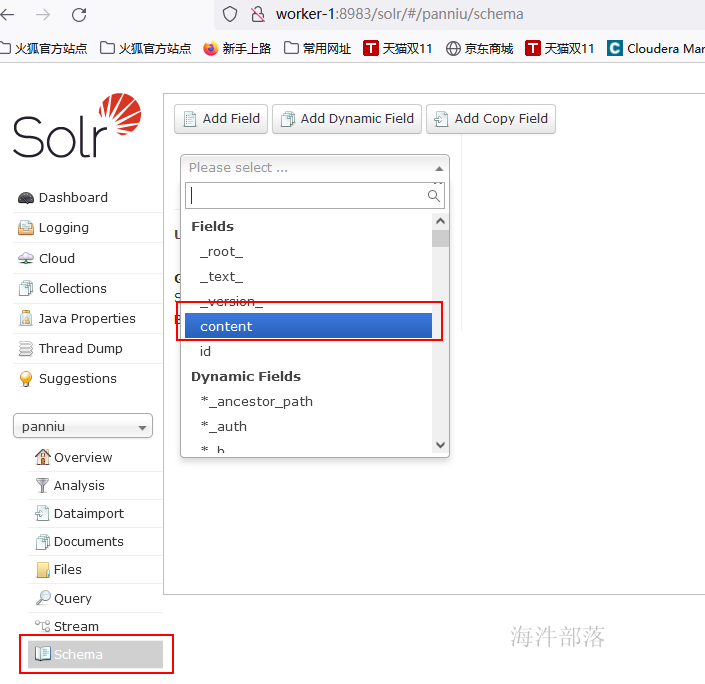
4 lily hbase indexer
4.1 创建临时作业配置目录
mkdir -p /data/panniu/solr-hbase/conf
cd /data/panniu/solr-hbase4.2 准备morphline配置文件(解读)
# 准备morphline配置文件
morphlines : [
{
# morphline配置id,与indexer配置文件中的morphlineID一致
id : morphline1
importCommands : ["org.kitesdk.morphline.**", "com.ngdata.**"]
commands : [
{
extractHBaseCells {
# hbase字段映射
mappings : [
{
# textinfo为hbase对应的列族,content为hbase对应的列名
inputColumn : "textinfo:content"
# 输出列,对应solr中的field字段
outputField : "content"
# solr中字段类型
type : "string"
source : value
}]
}
}
]
}
]正式配置文件
cd /data/panniu/solr-hbase
cat > conf/morphlines.conf << EOF
morphlines : [
{
id : morphline1
importCommands : ["org.kitesdk.morphline.**", "com.ngdata.**"]
commands : [
{
extractHBaseCells {
mappings : [
{
inputColumn : "textinfo:content"
outputField : "content"
type : "string"
source : value
}]
}
}
]
}
]
EOF4.3 准备indexer配置文件
cd /data/panniu/solr-hbase
cat > conf/indexer-config.xml << EOF
<?xml version="1.0"?>
<indexer table="panniu:texthbase" mapper="com.ngdata.hbaseindexer.morphline.MorphlineResultToSolrMapper" mapping-type="row" >
<!-- The relative or absolute path on the local file system to the morphline configuration file. -->
<!-- Use relative path "morphlines.conf" for morphlines managed by Cloudera Manager -->
<param name="morphlineFile" value="conf/morphlines.conf"/>
<!-- The optional morphlineId identifies a morphline if there are multiple morphlines in morphlines.conf -->
<!-- <param name="morphlineId" value="morphline1"/> -->
</indexer>
EOF4.4 执行lily hbase indexer刷新脚本(非安全模式)
本次不操作
# 这是批量刷新脚本,不是实时刷新脚本
vim hbase2solr.sh
# 填入如下内容
COLLECTION='panniu'
ZK='worker-1'
# 删除之前的索引文档
solrctl collection --deletedocs $COLLECTION
config="/etc/hadoop/conf.cloudera.yarn"
parcel="/opt/cloudera/parcels/CDH"
jar="$parcel/lib/hbase-solr/tools/hbase-indexer-mr-*-job.jar"
hbase_conf="/etc/hbase/conf/hbase-site.xml"
opts="'mapred.child.java.opts=-Xmx1024m'"
log4j="$parcel/share/doc/search*/examples/solr-nrt/log4j.properties"
zk="$ZK:2181/solr"
# 分词器
# libjars="lib/lucene-analyzers-smartcn-4.10.3-cdh5.14.2.jar"
# 在安全认证环境下需要打开这行配置
# export HADOOP_OPTS="-Djava.security.auth.login.config=conf/jaas.conf"
hadoop --config $config jar $jar --conf $hbase_conf -D $opts --log4j $log4j --hbase-indexer-file conf/indexer-config.xml --verbose --go-live --zk-host $zk --collection $COLLECTION4.5 安全模式执行lily hbase indexer刷新脚本
# 这是批量刷新脚本,不是实时刷新脚本(需要手动执行)
vim hbase2solr.sh
# 填入如下内容
COLLECTION='panniu'
ZK='worker-1'
solrctl collection --deletedocs $COLLECTION
config="/etc/hadoop/conf.cloudera.yarn"
parcel="/opt/cloudera/parcels/CDH"
jar="$parcel/lib/hbase-solr/tools/hbase-indexer-mr-*-job.jar"
hbase_conf="/etc/hbase/conf/hbase-site.xml"
opts="'mapred.child.java.opts=-Xmx1024m'"
log4j="$parcel/share/doc/search*/examples/solr-nrt/log4j.properties"
zk="$ZK:2181/solr"
# 分词器
# libjars="lib/lucene-analyzers-smartcn-4.10.3-cdh5.14.2.jar"
# 在安全认证环境下需要打开这行配置
export HADOOP_OPTS="-Djava.security.auth.login.config=conf/jaas.conf"
hadoop --config $config jar $jar --conf $hbase_conf -D $opts --log4j $log4j --hbase-indexer-file conf/indexer-config.xml --verbose --go-live --zk-host $zk --collection $COLLECTION创建jaas.conf文件
vim conf/jaas.conf
#填写如下内容(别复制)
Client {
com.sun.security.auth.module.Krb5LoginModule required
useKeyTab=true
keyTab="/data/solr.keytab"
storeKey=true
useTicketCache=false
principal="solr@HAINIU.COM";
};创建solr认证主体和keytab文件
kadmin.local
# 创建solr认证主体
addprinc -pw solr solr@HAINIU.COM
# 生成solr的keytab
xst -norandkey -k /data/solr.keytab solr
exit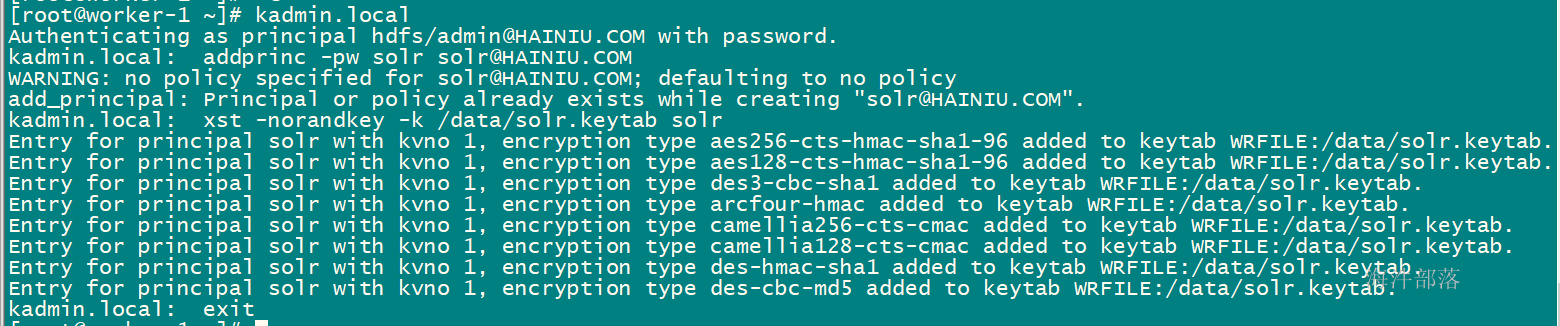
4.6 执行hbase2solr.sh脚本
4.6.1 创建对应HBASE表并添加数据
kinit hbase
hbase shell
# 创建对应的hbase表
create 'panniu:texthbase', 'textinfo'
# 给表添加数据
put 'panniu:texthbase', 'x001', 'textinfo:content', 'content1'
put 'panniu:texthbase', 'x002', 'textinfo:content', 'content2'
put 'panniu:texthbase', 'x003', 'textinfo:content', 'content3'
put 'panniu:texthbase', 'x004', 'textinfo:content', 'content4'
put 'panniu:texthbase', 'x005', 'textinfo:content', 'content5'
4.6.2 修改yarn的配置(如果修改过,无需修改)
由于用hdfs用户执行脚本,需要修改yarn的两个配置参数,否则用hdfs运行报错
最小用户id: 211
禁止的系统用户:删除hdfs
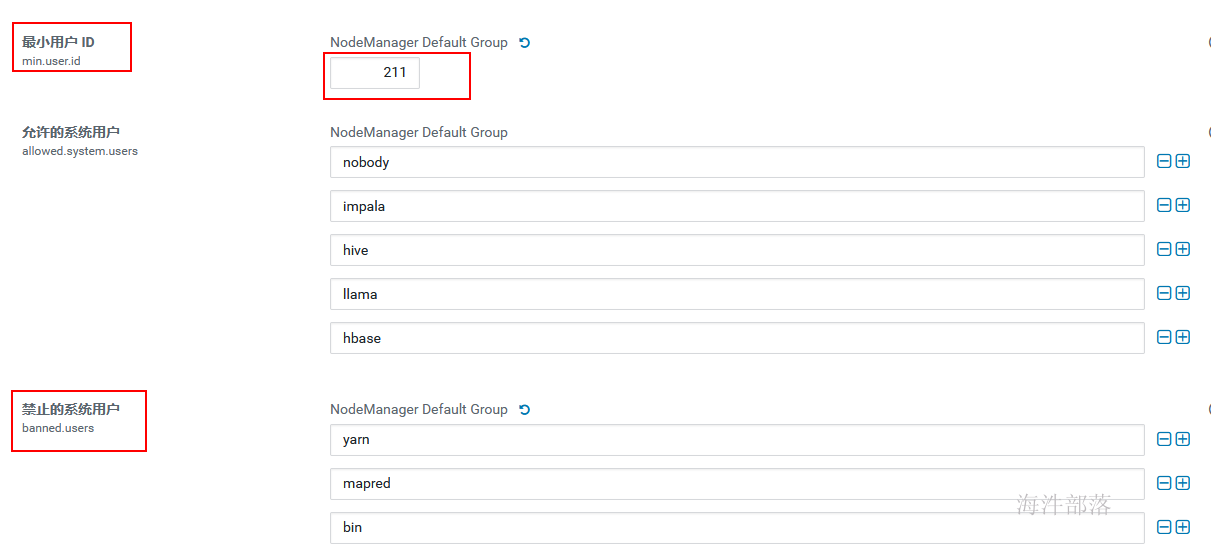
修改完后重启过期配置。
4.6.3 用hdfs执行 脚本
1)用hbase用户给hdfs赋予panniu:texthbase 的所有权限
kinit hbase
hbase shell
grant '@hdfs','RWXCA', 'panniu:texthbase'2)用hdfs执行脚本
[root@worker-1 solr-hbase]# pwd
/data/panniu/solr-hbase
[root@worker-1 solr-hbase]# sh hbase2solr.sh
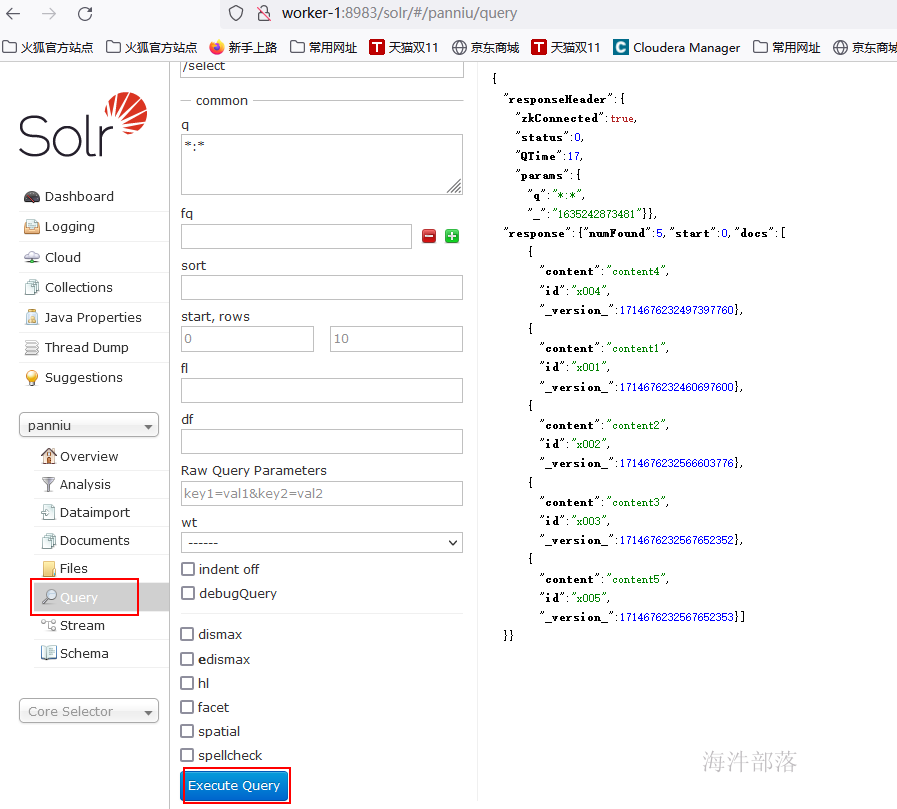
4.7 solr web验证数据
查看字段明细
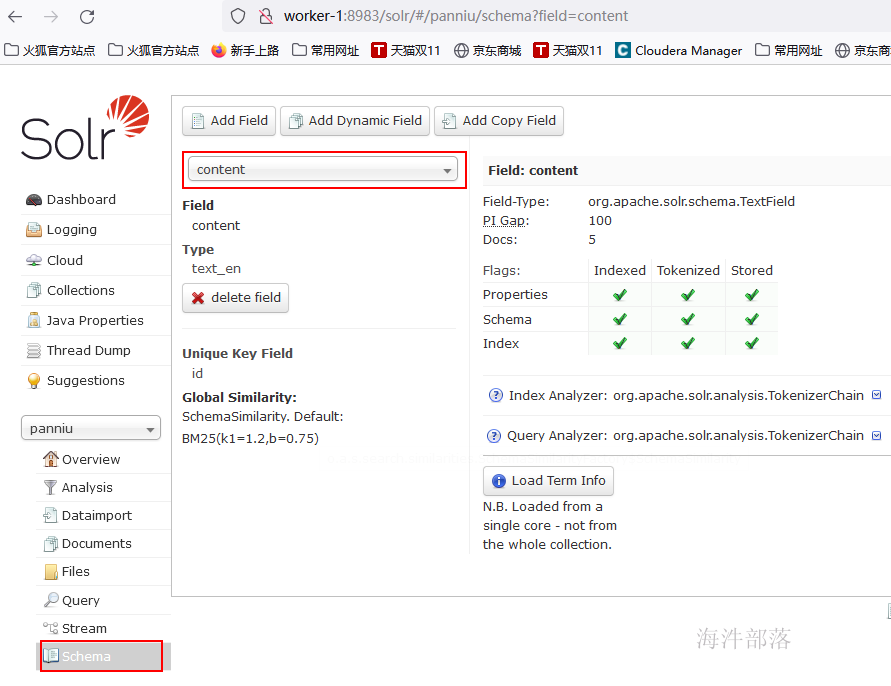
solr查询结果