1 impala操作环境
1.1 impala-shell
# 创建 impala 用户和认证凭证
kadmin.local
addprinc -pw impala impala@HAINIU.COM
xst -norandkey -k /data/impala.keytab impala
exit
# 认证impala
kinit -kt /data/impala.keytab impala
klist
# 默认连接impala方式
impala-shell
# 企业用法:连接impala时指定impalad
#-i:指定impalad节点(可以是任意节点)
#-k:采用kerberos认证方式登录
impala-shell -i worker-1 -k
# 在impala里查看数据库列表, 发现元数据缺失,这是因为impala没有把hive的元数据同步过来,需要同步hive元数据到impala
show databases;
# 同步元数据
invalidate metadata注意:
实际生产环境下,-i参数至关重要,如果有多个并行任务,可以通过-i参数将任务均衡分发到不同的impalad节点上。
1.2 hue操作impala
1.2.1 使用admin admin 登陆,进入管理界面
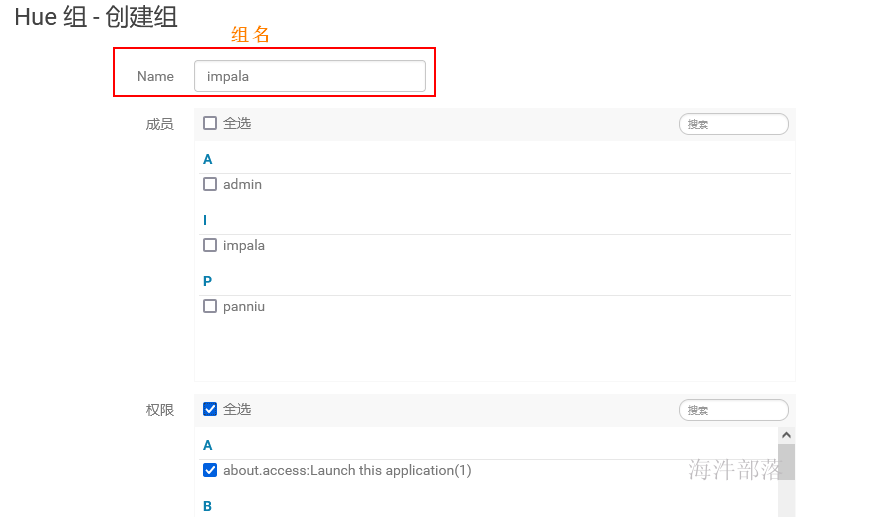
1.2.2 添加组

输入组名和设置权限
1.2.3 添加用户

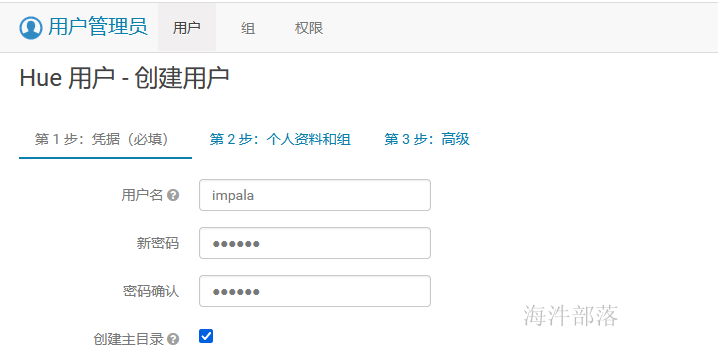
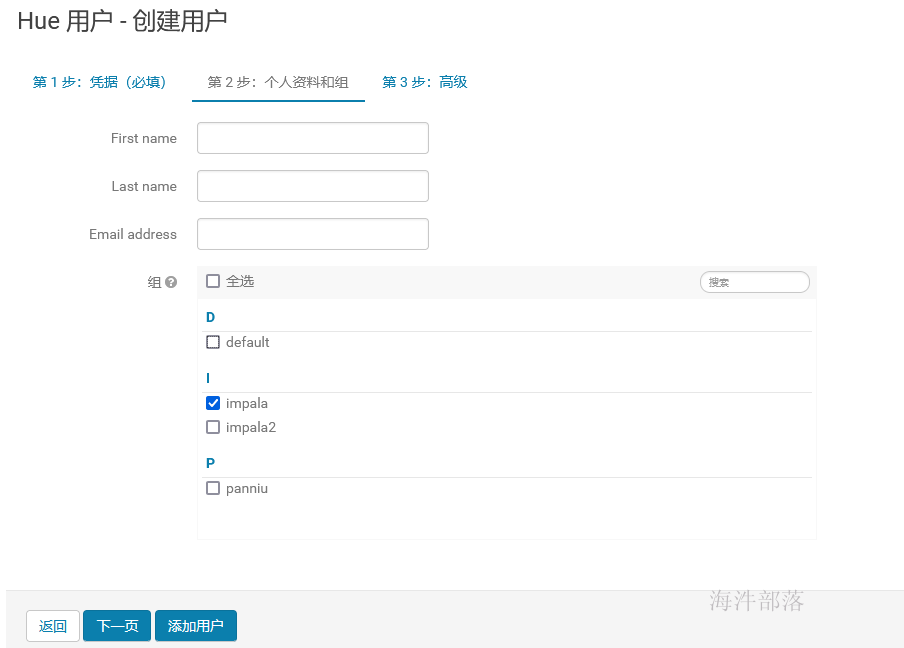
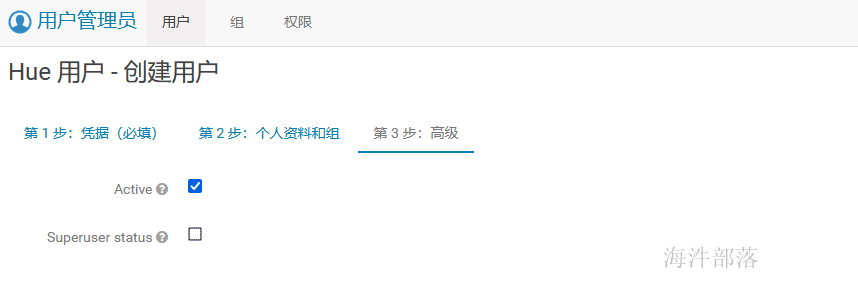
1.2.4 使用impala用户登录
输入 impala impala 登录
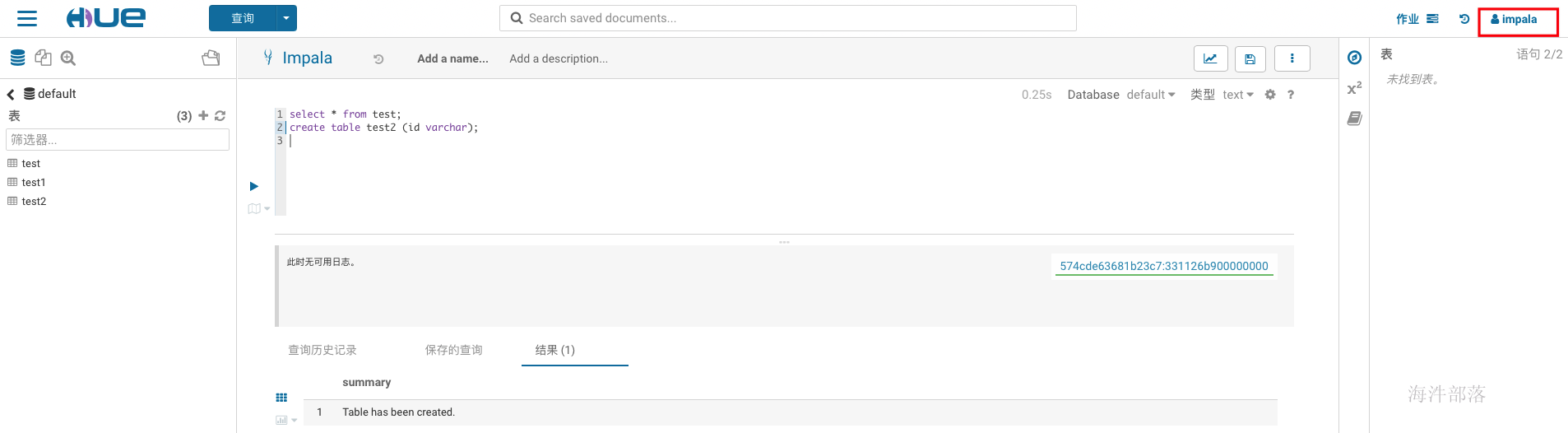
-- 执行测试
select * from test;
create table test2(id string);在安全环境下需要kerberos安全认证与sentry授权,认证与授权参照kerberos+sentry实操
2 impala-shell实操
impala-shell 实操与 hue 实操命令一致。
impala 基本语句与 hive 基本一致。
2.1 创建测试表并加载数据
-- 创建临时表
create table if not exists xinniu.impala_t1(
col1 int,
col2 boolean,
col3 timestamp,
col4 string
)
comment '临时加载表'
row format delimited fields terminated by '\t';
-- 造测试数据
vim tmp1
1 true 2021-08-20 12:20:00 ssd
3 false 2021-08-20 12:30:00 ssm
2 true 2021-08-20 11:30:00 ssc
4 true 2021-08-20 11:20:00 ssa
6 true 2021-08-20 12:20:00 skd
5 false 2021-08-20 12:30:00 smm
8 true 2021-08-20 13:30:00 smc
9 true 2021-08-20 13:20:00 sma
7 true 2021-08-20 14:20:00 smd
10 false 2021-08-20 14:30:00 skm
12 true 2021-08-20 15:30:00 skc
11 true 2021-08-20 15:20:00 ska
-- 用hdfs认证后,上传到hdfs目录
hadoop fs -put tmp1 /user/impala
-- 加载数据
load data inpath '/user/impala/tmp1' overwrite into table xinniu.impala_t1;
-- 创建parquet正式表(基于源表表结构创建)
create table if not exists xinniu.impala_parquet1
stored as parquet
tblproperties ("parquet.compress"="SNAPPY")
as
select * from xinniu.impala_t1
where 1=0;
-- 自己根据字段类型创建
CREATE TABLE xinniu.impala_parquet1 (
col1 INT,
col2 BOOLEAN,
col3 TIMESTAMP,
col4 STRING
)
STORED AS PARQUET
TBLPROPERTIES ('parquet.compress'='SNAPPY') ;
-- 临时表加载数据到正式表
insert overwrite table xinniu.impala_parquet1
select * from xinniu.impala_t1;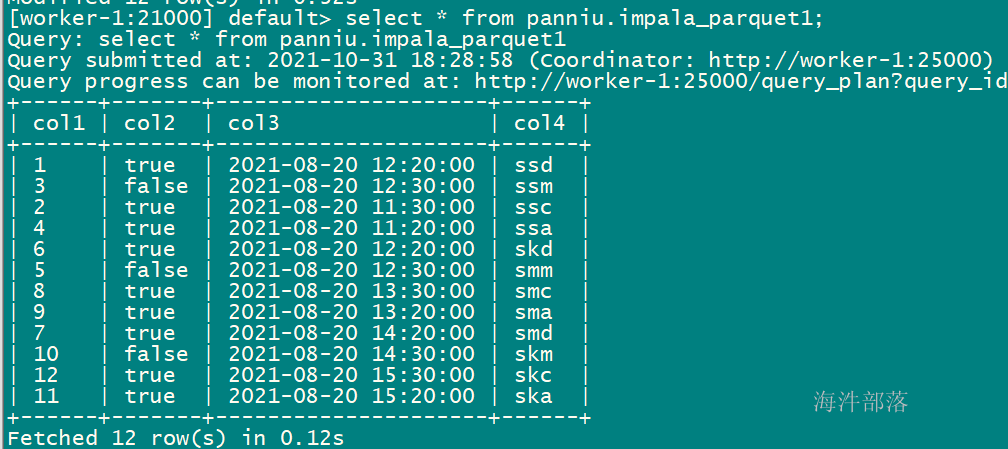
2.2 数据导出
impala不支持 insert overwrite 的方式导出数据,需要使用-o outputpath的方式导出。
#参数解释:
# -i:指定impalad节点
# -k:使用kerberos认证方式
# -q:查询语句(也可以使用-f sql文件的方式)
# -B --output_delimiter:指定输出文件分隔符
# -o:输出文件
# 输出文件字段按照\t分隔
impala-shell -i worker-1 -k -q "select * from xinniu.impala_parquet1 limit 5;" -B --output_delimiter="\t" -o /data/output.txt
# 默认输出
impala-shell -i worker-1 -k -q "select * from xinniu.impala_parquet1 limit 5;" -o /data/output2.txt
# 输出文件字段按照|分隔
impala-shell -i worker-1 -k -q "select * from xinniu.impala_parquet1 limit 5;" -B --output_delimiter="|" -o /data/output1.txt
# 执行SQL文件导出
impala-shell -i worker-1 -k -f test.sql -o /data/output4.txt
# 其中 test.sql 文件中的内容:
select * from xinniu.impala_parquet1 limit 5;默认输出格式:
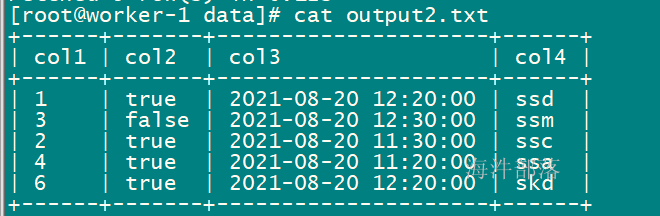
2.3 查询语句
查询语句与hive基本一致
-- 在排序语句中使用offset 即从offset位置开始输出
select * from xinniu.impala_parquet1 order by col1 desc limit 5;
select * from xinniu.impala_parquet1 order by col1 desc limit 5 offset 2;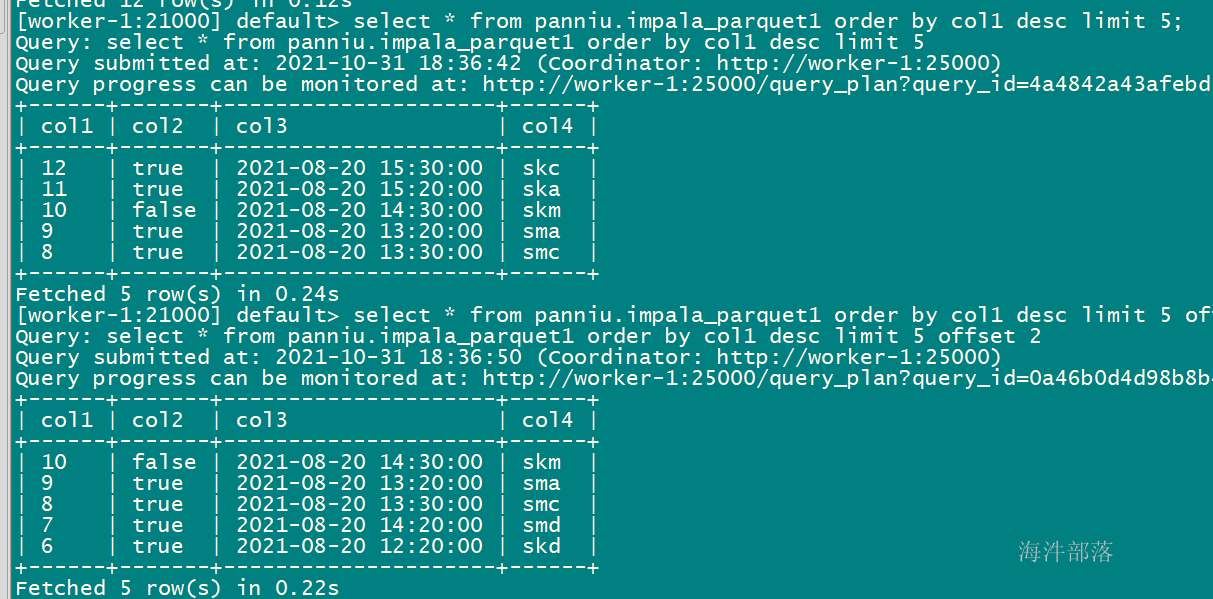
2.4 union与union all
-- union去重 union all不去重
-- union
select * from xinniu.impala_parquet1
union
select * from xinniu.impala_parquet1;
-- union all
select * from xinniu.impala_parquet1
union all
select * from xinniu.impala_parquet1;
-- hive union是有bug的
-- impala的union没有这个bug
select * from xinniu.impala_parquet1 t1 inner join xinniu.impala_parquet1 t2 on t1.col1=t2.col1
union
select * from xinniu.impala_parquet1 t1 inner join xinniu.impala_parquet1 t2 on t1.col1=t2.col1;2.5 日期时间类型
-- hive的orc格式支持date类型
-- 【hive创建的表】
create table if not exists xinniu.hive_orc(
pk string,
col2 timestamp
)
comment 'test date type'
stored as orc
tblproperties ("orc.compress"="SNAPPY");
-- hive的orc格式支持date类型,impala什么格式都不支持date类型,统一使用timestamp
-- 【impala创建的】
create table if not exists xinniu.impala_parquet2(
pk string,
col2 timestamp
)
comment 'test date type'
stored as parquet
tblproperties ("parquet.compress"="SNAPPY");
-- 时间转换
-- 获取当前时间戳
select current_timestamp();
-- hive:2021-07-12 01:34:44.436
-- impala:2021-07-12 01:35:06.752796000
-- 获取1970年1月1日到当前时间的秒数,bigint类型
select unix_timestamp(current_timestamp());
-- typeof() 查看当前函数结果类型
select typeof(unix_timestamp(current_timestamp()));
-- 格式化成字符串
-- 默认格式: yyyy-MM-dd HH:mm:ss
select from_unixtime(unix_timestamp(current_timestamp()));
-- 指定格式
select from_unixtime(unix_timestamp(current_timestamp()), 'yyyyMMdd');
-- 给日期格式字符串或日期时间格式字符串,都可以格式化成指定格式的字符串
select from_unixtime(unix_timestamp('2021-08-20'), "yyyy-MM-dd HH:mm:ss");
select from_unixtime(unix_timestamp('2021-08-20 11:22:33'), "yyyy-MM-dd HHmmss");
select from_timestamp(cast(unix_timestamp(current_timestamp()) as timestamp),"yyyy-MM-dd");
select from_timestamp(cast(unix_timestamp('2021-08-20') as timestamp),"yyyy-MM-dd");
select from_timestamp(cast(unix_timestamp('2021-08-20 11:22:33') as timestamp),"yyyy-MM-dd");
2.6 转码函数
-- 加密
select base64encode('hainiu');
-- 解密
select base64decode('aGFpbml1');
#对数据脱敏的时候
身份证号、手机号、姓名、地址、账号2.7 拼接字符串
-- hive执行
select concat('hello','hainiu'); -- hellohainiu
select concat_ws('_','hello','hainiu'); -- hello_hainiu
select concat('hello','hainiu',null); -- null
select concat_ws('_','hello','hainiu',null); -- hello_hainiu
-- 在impala中concat_ws(),有null出现则结果就为null
-- impala执行
select concat('hello','hainiu'); -- hellohaniu
select concat_ws('_','hello','hainiu'); -- hello_hainiu
select concat('hello','hainiu',null); -- null
select concat_ws('_','hello','hainiu',null); -- null
-- 获取第一个非空的值, 这个和hive用法一样,可作为赋默认值
select coalesce(null, null, 1,2);
2.8 字符串查找
-- 用于匹配子串在字符串中的位置(以1起点), 如果找不到返回0
select instr('/good_detail.action?id=001','/good_detail.action');
select instr('/good_search.action?id=001','/good_detail.action');2.9 元数据同步
由于Impala的架构设计,每一个impalad(coordinator角色)都会缓存一份自己的元数据信息。在impala中执行ddl语句之后,都需要通过catalog服务来广播到集群中的每一个节点。如果刚执行完ddl操作,立即到其他impalad 节点上查询,此时可能无法查到最新的修改。(多个impalad 才能测试出来)
有三种方式可以解决:
2.9.1 开启sync_ddl参数
在ddl语句前开启sync_ddl参数,在ddl语句结束后关闭,当前session有效,优先使用。
-- 影响最小,在一些create insert命令前打开自动同步功能
set SYNC_DDL=true;
create table xinniu.synctable(id string);
-- 在create insert 命令执行后关闭自动同步功能
set SYNC_DDL=false;2.9.2 使用refresh db.tablename 表级增量刷新(推荐)
REFRESH是用于刷新某个表或者某个分区的数据信息,它会重用之前的表元数据,仅仅执行文件刷新操作,它能够检测到表中分区的增加和减少,主要用于表中元数据未修改,数据的修改,例如INSERT INTO、LOAD DATA、ALTER TABLE ADD PARTITION、ALTER TABLE DROP PARTITION等,如果直接修改表的HDFS文件(增加、删除或者重命名)也需要指定REFRESH刷新数据信息。
影响其次并且指定表,如果没有打开sync_dll开关的情况下,优先使用这种方式去刷新元数据。
-- 语法格式:
-- 增量刷新全表
refresh table_name;
-- 仅仅刷新指定分区
refresh [table_name] [PARTITION (key_col1=val1 [, key_col2=val2...])]];
refresh xinniu.synctable;2.9.3 使用invalidate metadata 全量刷新
INVALIDATE METADATA是用于刷新全库或者某个表的元数据,包括表的元数据和表内的文件数据,它会首先清除表的缓存,然后从metastore中重新加载全部数据并缓存,该操作代价比较重,主要用于在hive中修改了表的元数据,需要同步到impalad,例如create table/drop table/alter table add columns等。
注意:使用invalidate metadata 全量刷新,使所有impalad上缓存的元数据无效,尽量少用或者不用,一般生产上不允许使用,即使非要用也是invalidate metadata tablename的方式使用。
-- 影响范围是表
invalidate metadata xinniu.synctable;
-- 影响范围最大,即使已经有元数据的表,也会跟着一起刷新。
invalidate metadata
使用原则:
1)如果只是涉及到表的数据改变,使用refresh [table]
2)如果只是涉及到表的某一个分区数据改变,使用refresh [table] partition [partition]
3)如果涉及到表的schema改变,使用invalidate metadata [table]
4)禁止使用invalidate metadata什么都不加
2.10 解决中文注释乱码问题
修改hive的元数据表
修改编码后,之前创建的不能生效,只有以后创建的才会生效。
-- 修改元数据表编码
-- 修改数据编码为latin1
alter database metastore default character set latin1;
-- 修改表、列、分区、分区键、索引编码
use metastore;
alter table COLUMNS_V2 modify column COMMENT varchar(256) character set utf8;
alter table TABLE_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;
alter table PARTITION_KEYS modify column PKEY_COMMENT varchar(4000) character set utf8;
alter table INDEX_PARAMS modify column PARAM_VALUE varchar(4000) character set utf8;3 impala性能相关
impala关联操作左大右小,如果没有按照左大右小的规则写,impala会使用compute stats来收集join中每张表的统计信息,然后由Impala根据表的大小、列的唯一值数目等来自动优化查询。为了更加精确地获取每张表的统计信息,每次表的数据变更时(如执行insert、load data、add partition、或drop partition等)都要重新执行一遍compute stats。
-- 刷新全表统计信息
compute stats db.tablename;
-- 执行完dml语句时针对分区刷新表统计信息,此种方式只刷新了batch_date这个新增分区的信息到表统计信息中,相比compute stats效率要快
compute incremental stats db.tablename partition (pt in (${batch_date},''));
在执行大批量任务的时候通常会有非常多任务脚本,在任务提交的时候应该轮询发送到不同的imapad节点上进行,而不应该在同一个impalad节点上执行,会导致单一impalad节点的oom,也严重影响并发性能,在执行的过程中通过-i指定impalad的节点。
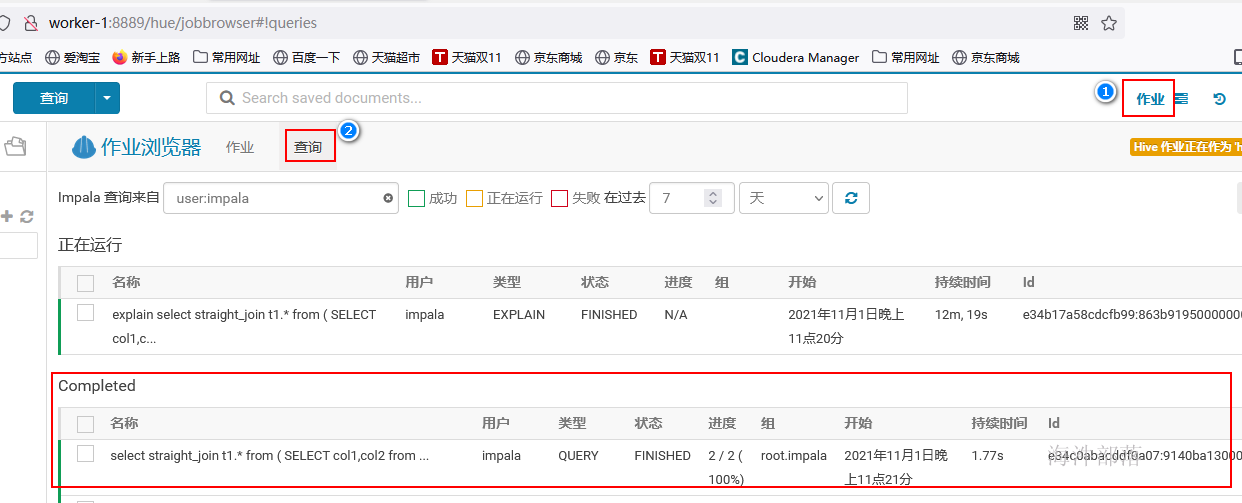
impala-shell -k -i worker-1(impalad节点) -q "select ……" 或者 -f sql文件4 impala执行计划解读
判断是否有表或者列统计信息
# straight_join : 当加了这个,就按照编写的SQL顺序进行join, 不用impala的优化器的优化方案。
# 直接按照当前顺序执行(本身就是左大右小)
explain
select straight_join t1.*
from
(
SELECT col1,col2 from xinniu.impala_t1
) t1
join
(
select col1,col2 from xinniu.impala_t1 limit 5
) t2
on
t1.col1=t2.col1;
# 按照impala的优化器优化方案执行(本身SQL是左小右大,优化器优化后变成左大右小)
explain select *
from
(
select col1,col2 from xinniu.impala_t1 limit 5
) t1
join
(
SELECT col1,col2 from xinniu.impala_t1
) t2
on
t1.col1=t2.col1;
# 直接按照当前顺序执行(本身SQL是左小右大)
explain select straight_join *
from
(
select col1,col2 from xinniu.impala_t1 limit 5
) t1
join
(
SELECT col1,col2 from xinniu.impala_t1
) t2
on
t1.col1=t2.col1;查看执行计划:
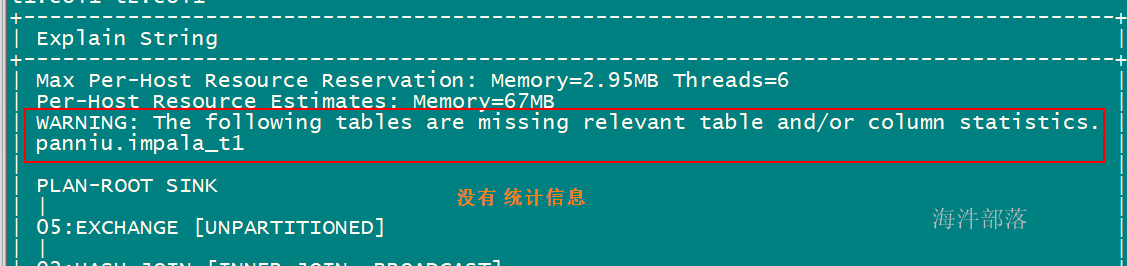
执行统计:
compute stats xinniu.impala_t1;再次查看执行计划,发现警告信息已经没了:
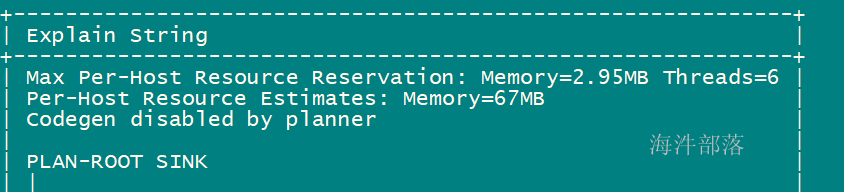
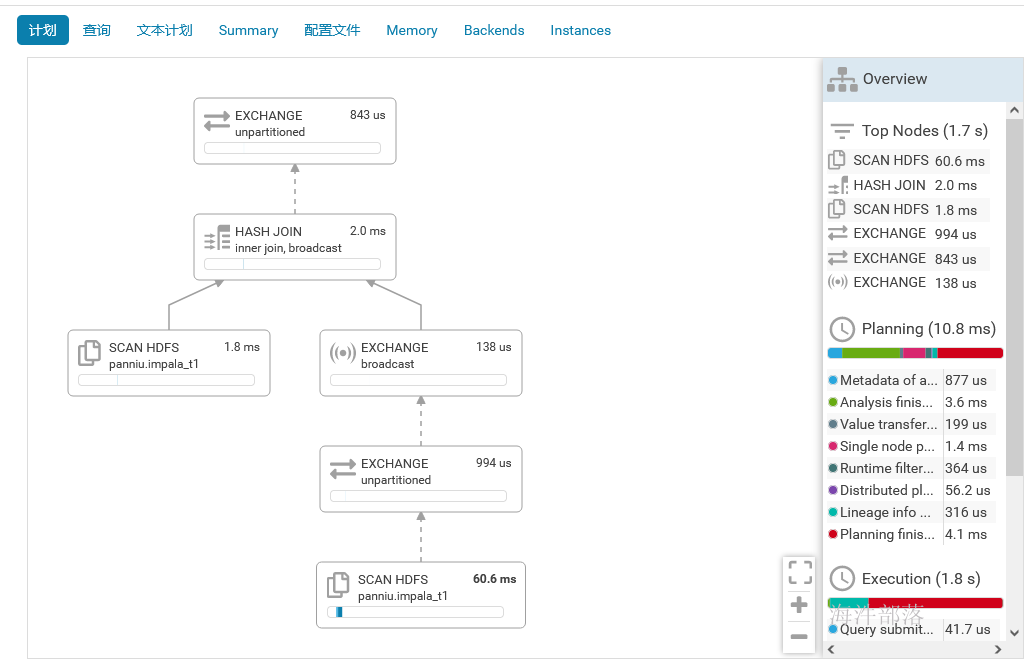
在hue上可以查看执行计划树,并且可以直观的看到每个环节所用的时间。