1 如何找到你执行SQL的Profile文件
在impala中,如果你执行了一个SQL,该如何查看其内部的运行流程,该如何对现有SQL进行优化,这就需要你会查看profile文件。
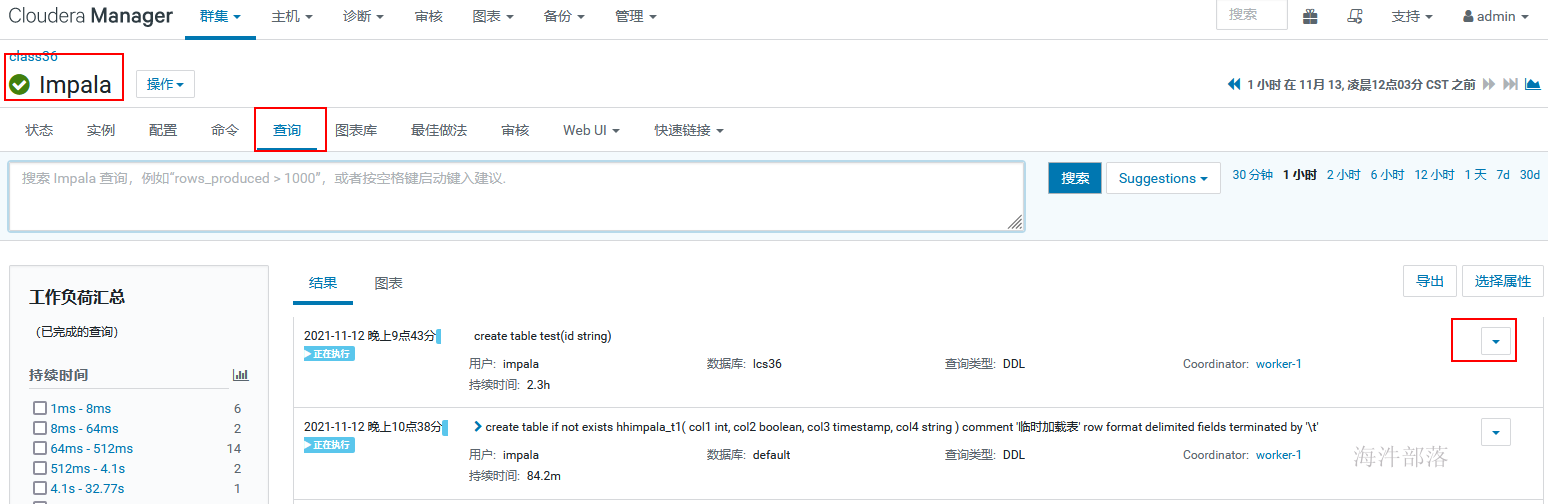
找到你要查看的SQL

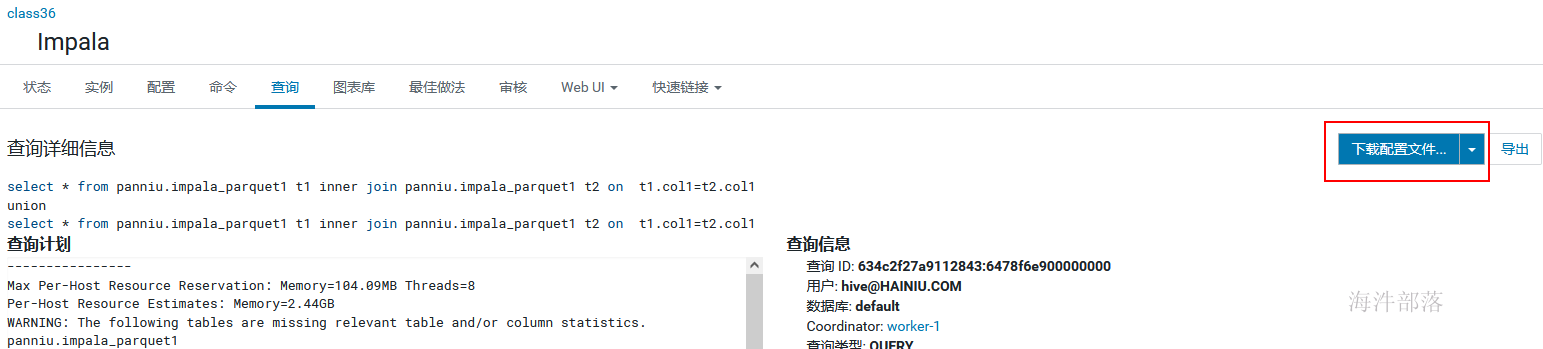
2 分析profile文件
示例SQL:
select * from xinniu.impala_parquet1 t1 inner join xinniu.impala_parquet1 t2 on t1.col1=t2.col1
union
select * from xinniu.impala_parquet1 t1 inner join xinniu.impala_parquet1 t2 on t1.col1=t2.col1;下面从 概要部分、执行计划树、执行概要部分分析
2.1 概要部分
# 查询id:该ID唯一标识在Impala中运行过的SQL,这对于从Impala Daemon日志中用ID查询相关的信息很有用,只需搜索此查询ID,就可以了解SQL运行细节和相关的错误信息。
Query (id=a94622372f612871:2c2019b000000000)
Summary
Session ID: dc49b8ec4ffcd17c:c57aa777c4e1dbba
# 告诉我们连接来自哪里。
# BEESWAX:从impala-shell客户端运行
# HIVESERVER2:从Hue运行
Session Type: BEESWAX
# 开始时间和结束时间, 可以查看运行时长
# hue:运行几秒中,但运行时间会很长,原因是Hue会保持会话打开直到会话关闭或用户运行另一个查询,比正常显示的时间更长
# impala-shell: 基本和运行时长一致
Start Time: 2021-11-12 22:30:36.432669000
End Time: 2021-11-12 22:30:37.682648000
Query Type: QUERY
Query State: FINISHED
# OK表示查询成功执行完成。
Query Status: OK
# 该信息显示运行查询的Impala版本,如果你发现它与你安装的Impala版本不匹配,则说明未正确安装某些部分。
Impala Version: impalad version 3.2.0-cdh6.3.2 RELEASE (build 1bb9836227301b839a32c6bc230e35439d5984ac)
# 运行查询的用户信息
User: hive@HAINIU.COM
Connected User: hive@HAINIU.COM
Delegated User:
Network Address: ::ffff:192.168.88.250:45204
# 在哪个数据库上执行查询的
Default Db: default
# 查询sql,如果查看别人的运行问题,可看这个SQL
Sql Statement: select * from xinniu.impala_parquet1 t1 inner join xinniu.impala_parquet1 t2 on t1.col1=t2.col1
union
select * from xinniu.impala_parquet1 t1 inner join xinniu.impala_parquet1 t2 on t1.col1=t2.col1
# 执行查询的impalad节点,以便上对应节点查看日志
Coordinator: worker-1:22000
Query Options (set by configuration): CLIENT_IDENTIFIER=Impala Shell v3.2.0-cdh6.3.2 (1bb9836) built on Fri Nov 8 07:22:06 PST 2019
Query Options (set by configuration and planner): MT_DOP=0,CLIENT_IDENTIFIER=Impala Shell v3.2.0-cdh6.3.2 (1bb9836) built on Fri Nov 8 07:22:06 PST 2019
Plan: 2.2 执行计划树
# 每个机器最大资源预留
Max Per-Host Resource Reservation: Memory=104.09MB Threads=8
# 每个机器资源预估
Per-Host Resource Estimates: Memory=2.44GB
# Impala在查询计划中给出了警告来提示用户需要在该表上执行COMPUTE STATS来消除这个警告信息。
WARNING: The following tables are missing relevant table and/or column statistics.
xinniu.impala_parquet1
# 分析的SQL
Analyzed query: SELECT * FROM xinniu.impala_parquet1 t1 INNER JOIN
xinniu.impala_parquet1 t2 ON t1.col1 = t2.col1 UNION SELECT * FROM
xinniu.impala_parquet1 t1 INNER JOIN xinniu.impala_parquet1 t2 ON t1.col1 =
t2.col1
# ----执行计划树----
# 查询计划(Query plan)是Impala profile中最重要的部分之一,我们需要知道如何读取它,
# 因为它告诉我们如何扫描(scan)表、交换数据(data exchange)和连接(join)以获得最终结果
# Fragment信息:一个主机,一个实例。
F06:PLAN FRAGMENT [UNPARTITIONED] hosts=1 instances=1
| Per-Host Resources: mem-estimate=68.00KB mem-reservation=0B thread-reservation=1
PLAN-ROOT SINK
| mem-estimate=0B mem-reservation=0B thread-reservation=0
|
12:EXCHANGE [UNPARTITIONED]
| mem-estimate=68.00KB mem-reservation=0B thread-reservation=0
| tuple-ids=4 row-size=64B cardinality=0
| in pipelines: 11(GETNEXT)
|
F05:PLAN FRAGMENT [HASH(col1,col2,col3,col4,col1,col2,col3,col4)] hosts=1 instances=1
Per-Host Resources: mem-estimate=128.07MB mem-reservation=34.00MB thread-reservation=1
11:AGGREGATE [FINALIZE] # 计算聚合的最终结果
| group by: col1, col2, col3, col4, col1, col2, col3, col4
| mem-estimate=128.00MB mem-reservation=34.00MB spill-buffer=2.00MB thread-reservation=0
| tuple-ids=4 row-size=64B cardinality=0
| in pipelines: 11(GETNEXT), 01(OPEN), 04(OPEN)
|
10:EXCHANGE [HASH(col1,col2,col3,col4,col1,col2,col3,col4)]
| mem-estimate=68.00KB mem-reservation=0B thread-reservation=0
| tuple-ids=4 row-size=64B cardinality=0
| in pipelines: 01(GETNEXT), 04(GETNEXT)
| # Fragment信息:一个主机,一个实例。
| # F04:片段ID可以用来在Profile的后面部分找到实际的片段统计信息,它可以告诉我们这个片段在运行时如何运行的详细信息
F04:PLAN FRAGMENT [RANDOM] hosts=1 instances=1
Per-Host Resources: mem-estimate=2.19GB mem-reservation=70.03MB thread-reservation=2 runtime-filters-memory=2.00MB
07:AGGREGATE [STREAMING] # 去重操作
| group by: col1, col2, col3, col4, col1, col2, col3, col4
| mem-estimate=128.00MB mem-reservation=34.00MB spill-buffer=2.00MB thread-reservation=0
| tuple-ids=4 row-size=64B cardinality=0
| in pipelines: 01(GETNEXT), 04(GETNEXT)
|
00:UNION # union操作(不去重的)
| mem-estimate=0B mem-reservation=0B thread-reservation=0
| tuple-ids=4 row-size=64B cardinality=0
| in pipelines: 01(GETNEXT), 04(GETNEXT)
|
|--06:HASH JOIN [INNER JOIN, BROADCAST]
| | hash predicates: t1.col1 = t2.col1
| | fk/pk conjuncts: assumed fk/pk
| | runtime filters: RF002[bloom] <- t2.col1
| | mem-estimate=2.00GB mem-reservation=34.00MB spill-buffer=2.00MB thread-reservation=0
| | tuple-ids=2,3 row-size=64B cardinality=unavailable
| | in pipelines: 04(GETNEXT), 05(OPEN)
| |
| |--09:EXCHANGE [BROADCAST]
| | | mem-estimate=35.97KB mem-reservation=0B thread-reservation=0
| | | tuple-ids=3 row-size=32B cardinality=unavailable
| | | in pipelines: 05(GETNEXT)
| | |
| | F03:PLAN FRAGMENT [RANDOM] hosts=1 instances=1
| | Per-Host Resources: mem-estimate=64.00MB mem-reservation=32.00KB thread-reservation=2
| | 05:SCAN HDFS [xinniu.impala_parquet1 t2, RANDOM]
| | partitions=1/1 files=1 size=1.06KB
| | stored statistics:
| | table: rows=unavailable size=unavailable
| | columns: unavailable
| | extrapolated-rows=disabled max-scan-range-rows=unavailable
| | mem-estimate=64.00MB mem-reservation=32.00KB thread-reservation=1
| | tuple-ids=3 row-size=32B cardinality=unavailable
| | in pipelines: 05(GETNEXT)
| |
| 04:SCAN HDFS [xinniu.impala_parquet1 t1, RANDOM]
| partitions=1/1 files=1 size=1.06KB
| runtime filters: RF002[bloom] -> t1.col1
| stored statistics:
| table: rows=unavailable size=unavailable
| columns: unavailable
| extrapolated-rows=disabled max-scan-range-rows=unavailable
| mem-estimate=64.00MB mem-reservation=32.00KB thread-reservation=1
| tuple-ids=2 row-size=32B cardinality=unavailable
| in pipelines: 04(GETNEXT)
| # 执行 inner join
03:HASH JOIN [INNER JOIN, BROADCAST]
| # join 条件
| hash predicates: t1.col1 = t2.col1
| fk/pk conjuncts: assumed fk/pk
| # join条件字段的filter
| runtime filters: RF000[bloom] <- t2.col1
| mem-estimate=2.00GB mem-reservation=34.00MB spill-buffer=2.00MB thread-reservation=0
| tuple-ids=0,1 row-size=64B cardinality=unavailable
| in pipelines: 01(GETNEXT), 02(OPEN)
|
| # EXCHANGE: 代表网络交换, BROADCAST: 代表将数据广播到其他计算节点
|--08:EXCHANGE [BROADCAST]
| | mem-estimate=35.97KB mem-reservation=0B thread-reservation=0
| | tuple-ids=1 row-size=32B cardinality=unavailable
| | in pipelines: 02(GETNEXT)
| |
| F01:PLAN FRAGMENT [RANDOM] hosts=1 instances=1
| Per-Host Resources: mem-estimate=64.00MB mem-reservation=32.00KB thread-reservation=2
| 02:SCAN HDFS [xinniu.impala_parquet1 t2, RANDOM]
| partitions=1/1 files=1 size=1.06KB
| stored statistics:
| table: rows=unavailable size=unavailable
| columns: unavailable
| extrapolated-rows=disabled max-scan-range-rows=unavailable
| mem-estimate=64.00MB mem-reservation=32.00KB thread-reservation=1
| tuple-ids=1 row-size=32B cardinality=unavailable
| in pipelines: 02(GETNEXT)
|
| # 第一步通常从HDFS扫描(HDFS Scan)开始
01:SCAN HDFS [xinniu.impala_parquet1 t1, RANDOM]
# 表中只有一个分区,Impala也读取一个分区。这并不一定意味着这个表是分区的,如果表没有分区,它也将显示为1/1
# 表/分区下只有一个文件(files=1)
# Impala读取的数据总大小为1.06KB
partitions=1/1 files=1 size=1.06KB
# join条件字段的filter
runtime filters: RF000[bloom] -> t1.col1
# 由于没有执行COMPUTE STATS统计信息,导致可统计的数据
stored statistics:
table: rows=unavailable size=unavailable
columns: unavailable
extrapolated-rows=disabled max-scan-range-rows=unavailable
# mem-estimate: planner分析这个任务需要多少内存
# mem-reservation:planner分析这个任务需要预留多少内存
mem-estimate=64.00MB mem-reservation=32.00KB thread-reservation=1
tuple-ids=0 row-size=32B cardinality=unavailable
in pipelines: 01(GETNEXT)2.3 执行概要部分
# ---执行概要部分---
ExecSummary:
#Hosts:一共用了多少个节点(impalad)
#Avg Time:平均时长,用于评估所有节点平均耗时
#Max Time:最大时长,用于评估是否有某个节点执行任务时长过长
#Rows:实际查询过程中查询了多少行,查出来多少就代表实际是多少,行数的单位为k或者m,比如:1.2k=1200 1.2m=12000000
#Est. #Rows: 执行计划给出的评估行数,如果这里给出的是-1,代表没有表的统计信息
#Peak Mem: 执行过程中实际消耗的内存
#Est. Peak Mem: 执行计划判断需要多少内存
Operator #Hosts Avg Time Max Time #Rows Est. #Rows Peak Mem Est. Peak Mem Detail
-----------------------------------------------------------------------------------------------------------------------------------------------------
F06:ROOT 1 211.843us 211.843us 0 0
12:EXCHANGE 1 130.929us 130.929us 12 0 80.00 KB 68.00 KB UNPARTITIONED
F05:EXCHANGE SENDER 1 828.719us 828.719us 1.91 KB 0
11:AGGREGATE 1 9.295ms 9.295ms 12 0 34.08 MB 128.00 MB FINALIZE
10:EXCHANGE 1 87.501us 87.501us 12 0 80.00 KB 68.00 KB HASH(col1,col2,col3,col4,col1,col2,col3,col4)
F04:EXCHANGE SENDER 1 673.441us 673.441us 1.91 KB 0
07:AGGREGATE 1 3.000ms 3.000ms 12 0 34.28 MB 128.00 MB STREAMING
00:UNION 1 0.000ns 0.000ns 24 0 54.00 KB 0
|--06:HASH JOIN 1 15.679ms 15.679ms 12 -1 34.06 MB 2.00 GB INNER JOIN, BROADCAST
| |--09:EXCHANGE 1 19.297us 19.297us 12 -1 16.00 KB 35.97 KB BROADCAST
| | F03:EXCHANGE SENDER 1 857.362us 857.362us 3.76 KB 0
| | 05:SCAN HDFS 1 5.270ms 5.270ms 12 -1 106.00 KB 64.00 MB xinniu.impala_parquet1 t2
| 04:SCAN HDFS 1 4.398ms 4.398ms 12 -1 106.00 KB 64.00 MB xinniu.impala_parquet1 t1
03:HASH JOIN 1 10.168ms 10.168ms 12 -1 34.06 MB 2.00 GB INNER JOIN, BROADCAST
# 代表网络交换
|--08:EXCHANGE 1 29.293us 29.293us 12 -1 16.00 KB 35.97 KB BROADCAST
| # 代表网络交换(序列化)
| F01:EXCHANGE SENDER 1 113.875us 113.875us 3.76 KB 0
| 02:SCAN HDFS 1 5.587ms 5.587ms 12 -1 106.00 KB 64.00 MB xinniu.impala_parquet1 t2
01:SCAN HDFS 1 3.913ms 3.913ms 12 -1 106.00 KB 64.00 MB xinniu.impala_parquet1 t13 谓词下推
谓词下推,就是在将过滤条件下推到离数据源更近的地方,最好就是在table_scan时就能过滤掉不需要的数据。
谓词下推可用于join的优化。
3.1 inner join
先看个SQL
# 是个inner join, sql表达:先join,拿到join的结果后在where筛选
select
*
from
(
select * from xinniu.impala_t1
) t1
join
(
select * from xinniu.impala_t1
) t2
on
t1.col1=t2.col1
where
t1.col2=true and t2.col4='ssd';但对于innerjoin,左表右表都要满足条件,所以优化器将 inner join的条件下推
# 优化后的SQL
select
*
from
(
select * from xinniu.impala_t1 where col2=true
) t1
join
(
select * from xinniu.impala_t1 where col4='ssd'
) t2
on
t1.col1=t2.col1;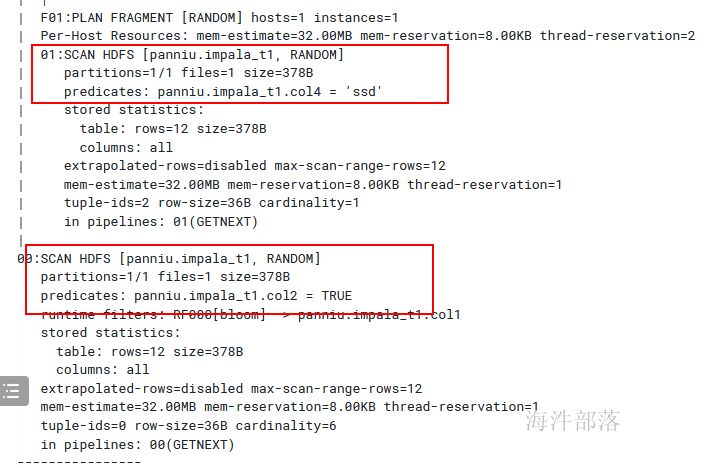
3.2 leftjoin
3.2.1 优化类型1
# t1:select * from xinniu.impala_t1 where t1.col2=true 结果集大于
# t2: select * from xinniu.impala_t1 where t2.col4='ssd'
# 优化成leftjoin, select * from t1 left join t2 on t1.col1=t2.col1 where t2.col4='ssd'
explain select
*
from
(
select * from xinniu.impala_t1
) t1
left join
(
select * from xinniu.impala_t1
) t2
on
t1.col1=t2.col1
where
t1.col2=true and t2.col4='ssd';内部执行计划树:
02:HASH JOIN [LEFT OUTER JOIN, BROADCAST]
# 优化成leftjoin, select * from t1 left join t2 on t1.col1=t2.col1 where t2.col4='ssd'
| hash predicates: xinniu.impala_t1.col1 = xinniu.impala_t1.col1
| fk/pk conjuncts: xinniu.impala_t1.col1 = xinniu.impala_t1.col1
| other predicates: xinniu.impala_t1.col4 = 'ssd'
| mem-estimate=1.94MB mem-reservation=1.94MB spill-buffer=64.00KB thread-reservation=0
| tuple-ids=0,2N row-size=72B cardinality=6
| in pipelines: 00(GETNEXT), 01(OPEN)
|
|--03:EXCHANGE [BROADCAST]
| | mem-estimate=16.00KB mem-reservation=0B thread-reservation=0
| | tuple-ids=2 row-size=36B cardinality=1
| | in pipelines: 01(GETNEXT)
| |
| F01:PLAN FRAGMENT [RANDOM] hosts=1 instances=1
| Per-Host Resources: mem-estimate=32.00MB mem-reservation=8.00KB thread-reservation=2
| 01:SCAN HDFS [xinniu.impala_t1, RANDOM]
| partitions=1/1 files=1 size=378B
| predicates: xinniu.impala_t1.col4 = 'ssd' #【where条件下推到 存储端】
| stored statistics:
| table: rows=12 size=378B
| columns: all
| extrapolated-rows=disabled max-scan-range-rows=12
| mem-estimate=32.00MB mem-reservation=8.00KB thread-reservation=1
| tuple-ids=2 row-size=36B cardinality=1
| in pipelines: 01(GETNEXT)
|
00:SCAN HDFS [xinniu.impala_t1, RANDOM]
partitions=1/1 files=1 size=378B
predicates: xinniu.impala_t1.col2 = TRUE #【where条件下推到 存储端】
stored statistics:
table: rows=12 size=378B
columns: all
extrapolated-rows=disabled max-scan-range-rows=12
mem-estimate=32.00MB mem-reservation=8.00KB thread-reservation=1
tuple-ids=0 row-size=36B cardinality=6
in pipelines: 00(GETNEXT)3.2.2 优化类型2
# 左数据集t1: select * from xinniu.impala_t1 where col2=true 结果集大于
# 右数据集t2: select * from xinniu.impala_t1 where col4='ssd'
# 优化成rightjoin, select * from t1 right join t2 on t1.col1=t2.col1 and t1.col2=true
select
*
from
(
select * from xinniu.impala_t1
) t1
left join
(
select * from xinniu.impala_t1
) t2
on
t1.col1=t2.col1
where
t1.col4='ssd' and t2.col2=true;内部执行计划树:
F02:PLAN FRAGMENT [HASH(xinniu.impala_t1.col1)] hosts=1 instances=1
Per-Host Resources: mem-estimate=2.97MB mem-reservation=2.94MB thread-reservation=1 runtime-filters-memory=1.00MB
# 优化成rightjoin, select * from t1 right join t2 on t1.col1=t2.col1 and t1.col2=true
02:HASH JOIN [RIGHT OUTER JOIN, PARTITIONED]
| hash predicates: xinniu.impala_t1.col1 = xinniu.impala_t1.col1
| fk/pk conjuncts: xinniu.impala_t1.col1 = xinniu.impala_t1.col1
| other predicates: xinniu.impala_t1.col2 = TRUE
| runtime filters: RF000[bloom] <- xinniu.impala_t1.col1
| mem-estimate=1.94MB mem-reservation=1.94MB spill-buffer=64.00KB thread-reservation=0
| tuple-ids=2N,0 row-size=72B cardinality=1
| in pipelines: 01(GETNEXT), 00(OPEN)
|
|--04:EXCHANGE [HASH(xinniu.impala_t1.col1)]
| | mem-estimate=16.00KB mem-reservation=0B thread-reservation=0
| | tuple-ids=0 row-size=36B cardinality=1
| | in pipelines: 00(GETNEXT)
| |
| F01:PLAN FRAGMENT [RANDOM] hosts=1 instances=1
| Per-Host Resources: mem-estimate=32.00MB mem-reservation=8.00KB thread-reservation=2
| 00:SCAN HDFS [xinniu.impala_t1, RANDOM]
| partitions=1/1 files=1 size=378B
| predicates: xinniu.impala_t1.col4 = 'ssd' #【where条件下推到 存储端】
| stored statistics:
| table: rows=12 size=378B
| columns: all
| extrapolated-rows=disabled max-scan-range-rows=12
| mem-estimate=32.00MB mem-reservation=8.00KB thread-reservation=1
| tuple-ids=0 row-size=36B cardinality=1
| in pipelines: 00(GETNEXT)
|
03:EXCHANGE [HASH(xinniu.impala_t1.col1)]
| mem-estimate=16.00KB mem-reservation=0B thread-reservation=0
| tuple-ids=2 row-size=36B cardinality=6
| in pipelines: 01(GETNEXT)
|
F00:PLAN FRAGMENT [RANDOM] hosts=1 instances=1
Per-Host Resources: mem-estimate=33.00MB mem-reservation=1.01MB thread-reservation=2 runtime-filters-memory=1.00MB
01:SCAN HDFS [xinniu.impala_t1, RANDOM]
partitions=1/1 files=1 size=378B
predicates: xinniu.impala_t1.col2 = TRUE #【where条件下推到 存储端】
runtime filters: RF000[bloom] -> xinniu.impala_t1.col1
stored statistics:
table: rows=12 size=378B
columns: all
extrapolated-rows=disabled max-scan-range-rows=12
mem-estimate=32.00MB mem-reservation=8.00KB thread-reservation=1
tuple-ids=2 row-size=36B cardinality=6
in pipelines: 01(GETNEXT)

