1 kudu为何应运而生
kudu 是Cloudera 开源给 Apache的,针对 Hadoop 平台而开发的列式存储管理器,kudu是介于hive与hbase中间的一个组件,解决了hive的随机读写问题,同时提高了hbase的吞吐量与组合查询效率。
Kudu是一种非洲的大羚羊,中文名叫“捻角羚”。
hive痛点:
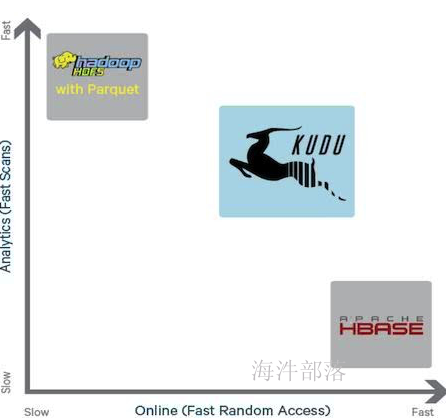
hive可以很高写吞吐量,但是不支持随机读写,支持组合条件查询,但是组合查询效率较低,需要全表扫或者按照分区表扫全部数据。
hbase痛点:
hbase可以支持随机读写,并且随机读写性能很高,但是在组合查询的时候效率很低,需要全表扫描。
kudu的出现折中了hive与hbase的特性,取长补短,介于两者中间。
| hive | hbase | kudu | |
|---|---|---|---|
| 随机读写 | 不支持随机读写 | 支持随机读写,并且非常快 | 支持随机读写,但是没有hbase快 |
| 组合查询 | 支持,但是效率低下 | 支持filter过滤,但是效率非常低,与hive性能相仿,甚至不如hive的分区分桶表 | 支持组合查询,性能比hive高 |
| 分区设计 | 指定分区键或者分布键(分桶) | 按照rowkey分,采用的是range方式分区(region) | 支持hash、range以及hash与range组合分区 |
对比图如下:
2 kudu数据模型
Kudu的设计是面向结构化存储的,数据模型与传统的关系型数据库类似,一个 Kudu集群由多个表组成,每个表由多个字段组成,一个表必须指定一个由若干个(>=1)字段组成的主键,如下图:
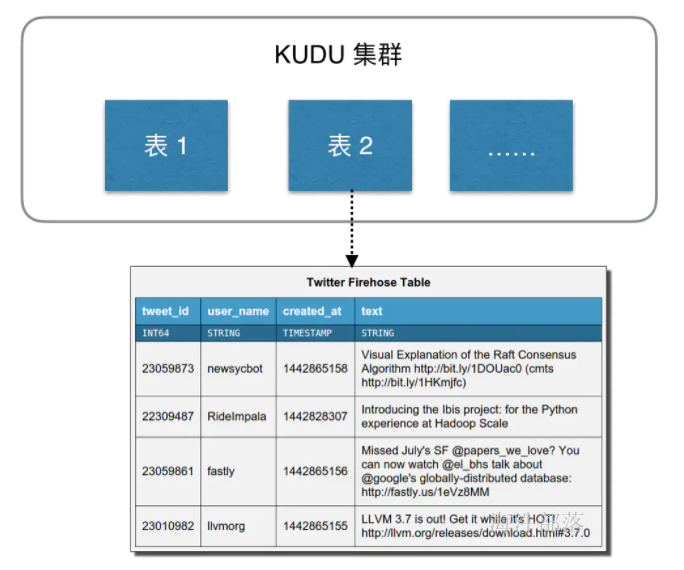
Kudu需要在建表时定义Schema信息,包括定义列(列类型)和主键primary key。
Kudu的数据唯一性依赖与primary key的列组合。
Kudu不支持传统关系型数据库的二级索引。
Kudu表中的每个字段是强类型的,而不是HBase那样所有字段都认为是 bytes。这样做的好处是可以对不同类型数据进行不同的编码。
Kudu的数据类型包括:
boolean, int8, int16, int32, int64
unixtime_micros:(自 Unix 时代以来的 64 位微秒)
float、double、decimal(高精度)
string
binary
随着kudu版本的升级,可能会增加新的数据类型。
3 kudu架构
3.1 kudu网络架构
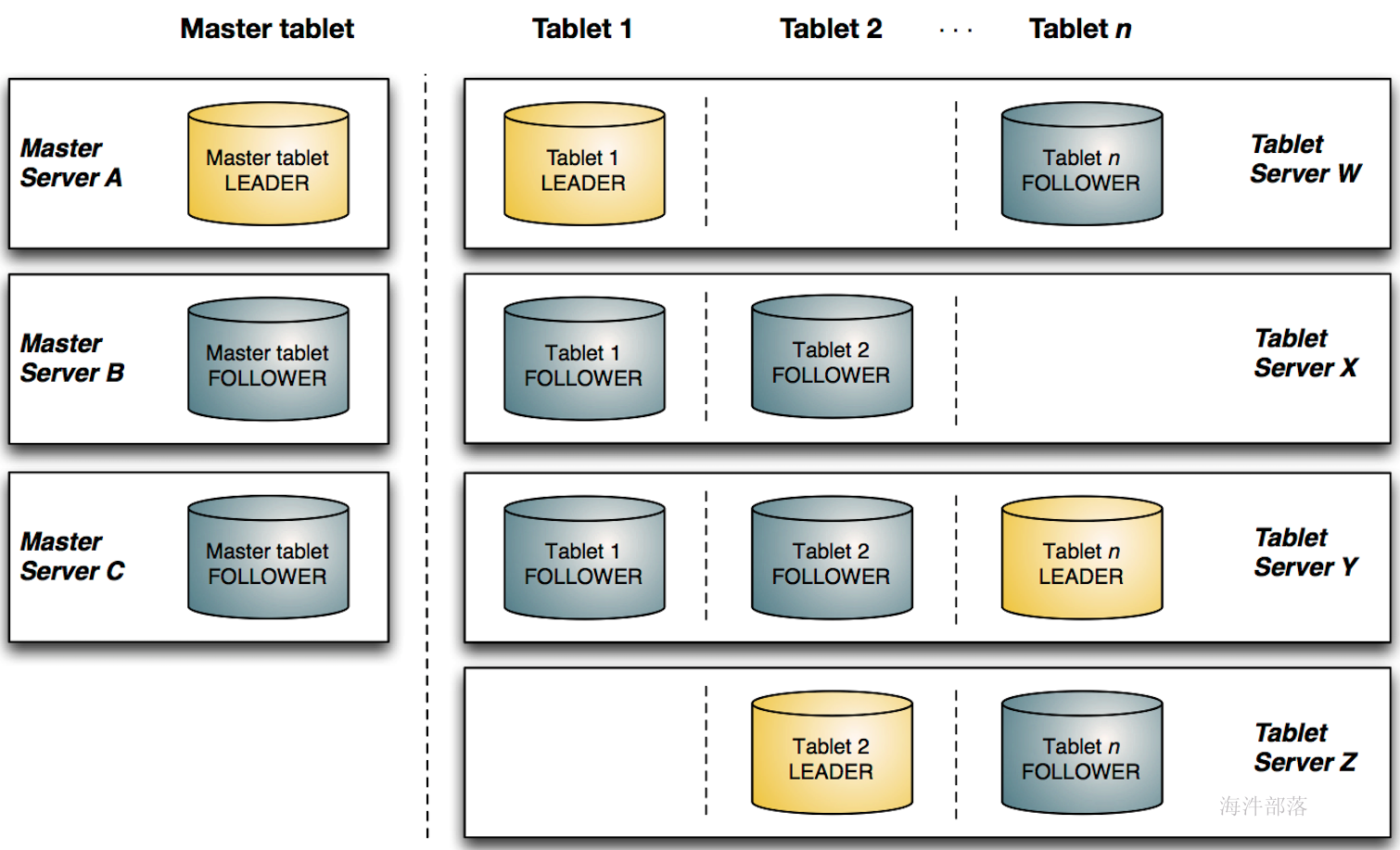
kudu由master server与tablet server两部分组成:
master server:负责集群管理、元数据管理等管理工作。(可理解为HBase中的HMaster角色)
部署多个master server用于master 的容错,但只有一个master提供服务。
tablet server:提供数据存储、数据读写功能。(可理解为HBase中的RegionServer角色)
tablet分为leader与follower多副本机制(为了容错),其中leader负责写服务,follower与leader一起提供读服务。
3.2 kudu内部架构
其中:
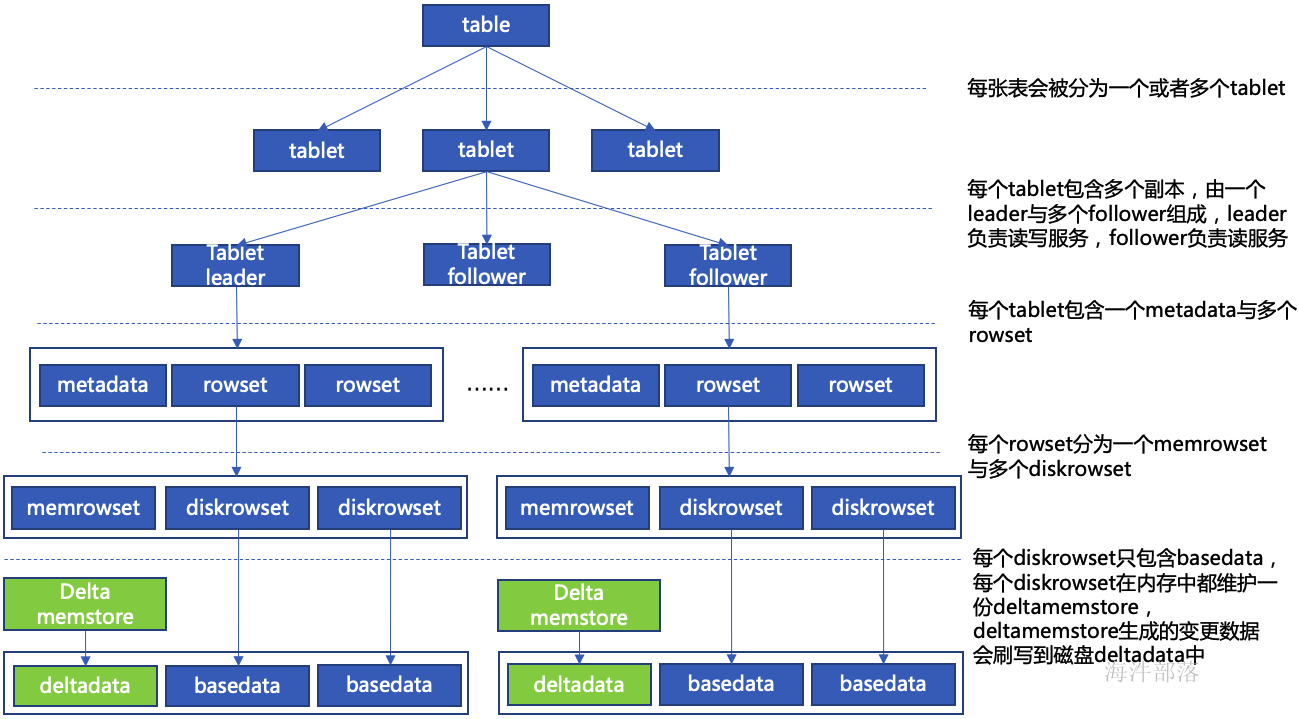
一个table表可以分到多个tablet里,可以理解为一个表分多片存储(一个表的tablet数量是由kudu表的hash或range分区数决定)。
一个tablet有一个leader和多个flower,可以理解为一片里有多个副本,每个副本都一样。
每个tablet包含一个MetaData(存元数据,记录tablet属于哪个表)和若干个RowSet(行集合,存数据)。
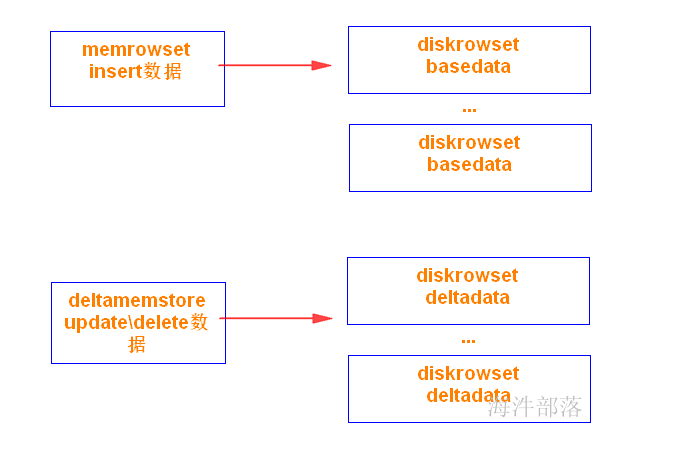
RowSet包含一个MemRowSet和若干个DiskRowSet
MemRowSet:写缓存, 可理解为HBase中的MemStore。
DiskRowSet:
溢写的磁盘文件,可理解为HBase中的HFile(但内部结构不一样)。MemRowSet中的数据按照行试图进行存储,数据结构为B-Tree。MemRowSet中的数据被Flush到磁盘之后,形成DiskRowSet。
DiskRowSet中的数据按照列进行组织,与Parquet类似(用于分析型查询)。每一个Column的数据被存储在一个相邻的数据区域,而这个数据区域进一步被细分成一个个的小的Page单元,对每一个Column Page可采用一些Encoding算法,以及一些通用的Compression算法。
一个DiskRowSet包含两部分数据:基础数据(Base Data),以及变更数据(Deltadata)。更新/删除操作所生成的数据记录,被保存在变更数据部分。
kudu的数据写入也和hbase一样,一行有多个版本(用于快速增删改),即一行insert、update、delete都是在增加版本,后续要进行文件合并。
4 kudu写数据流程
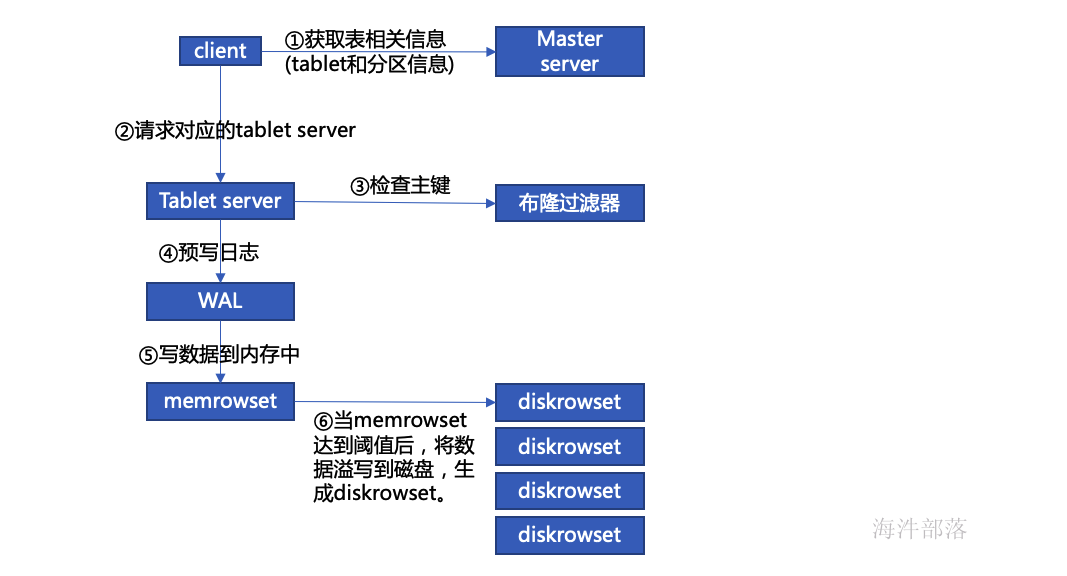
insert写数据流程:
1)从 master 获取表信息以及分区信息,也就是表的元数据信息。
2)通过元数据信息找到对应的 tablet。
3)检查主键是否存在,如果存在抛异常。
a)通过主键确认要写入的数据在哪个 rowset
b)在该范围下通过布隆过滤器再过滤掉不可能存在的rowset
c)最后通过rowset中的 主键索引(B-tree)精确定位key是否存在
4)wal 预写日志(和hbase 一样,防止写入写缓存的数据丢失)
5)当 wal 写入完成后, 开始写数据到 memrowset 中(写缓存中)
6)当写入memrowset 后,通知客户端写成功了。
写数据后续的流程:
1)溢写磁盘
当 memrowset 达到一定阈值的时候,会将 memrowset 中的数据持久化到磁盘上,也就是diskrowset。
2)数据合并
随着持续数据写入,kudu 中的小文件会越来越多,主要包括各个diskrowset 中的basedata(基础数据),还有若干份deltadata(变更数据),小文件的增多会影响 kudu 的性能,特别是deltafile 中还有很多重复的数据,为了提高性能,会进行定期 compaction,compaction 主要包括两部分:
a)deltadata compaction:过多的 deltadata 影响读性能,定期将 deltadata 合并回basedata可以提升性能。在大部分业务场景,频繁变更的字段是集中在少数几个字段中的,而kudu是列式存储的,因此 kudu 还在 deltadata compaction 时做了优化,文件合并时只合并部分变更列到basedata 中对应的列。
b)diskrowset compaction:除deltadata外,还定期将diskrowset 合并,原因是合并时可以将被删除的数据彻底的删除,而且可以减少同样key范围内数据的文件数,提升索引的效率。
5 kudu读数据流程
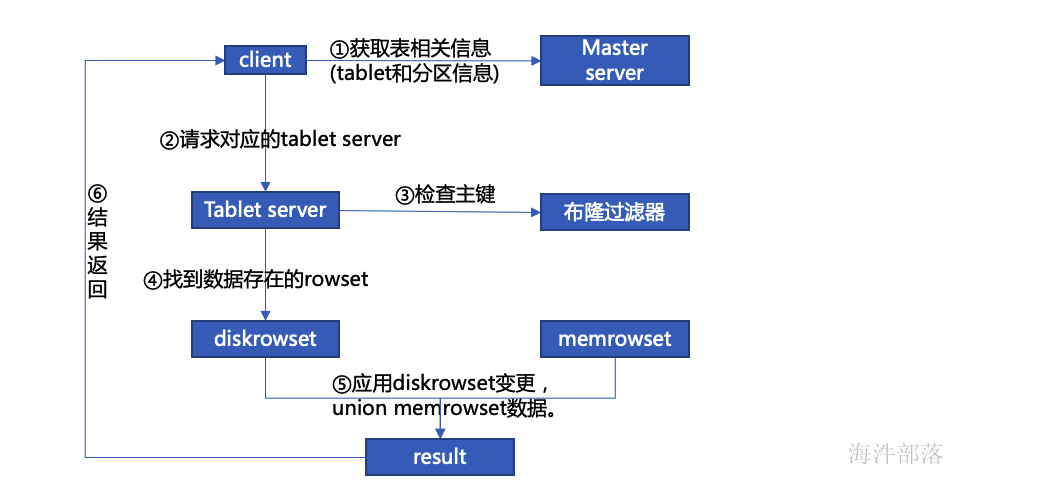
如果主键不存在,返回告诉没有。
如果主键存在,需要查询 insert 和 update 的 内存和磁盘,找出最新版本的数据返回。
insert的内存 memrowset 和 磁盘diskrowset。
update的内存deltamemstore 和 磁盘deltadata。
6 kudu更新数据流程
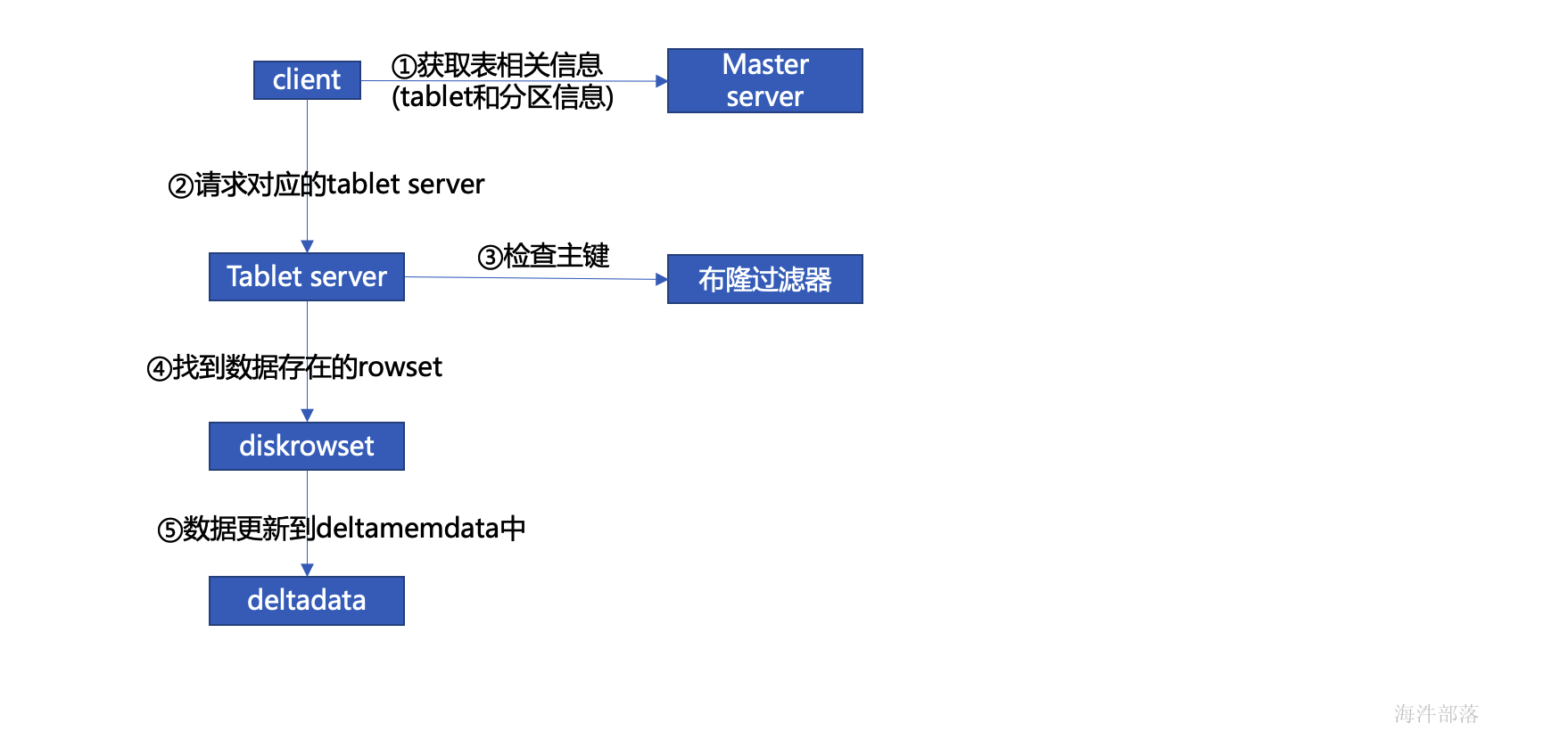
如果主键存在, 那先写入WAL, 再写入 更新的写缓存(Delta Memstore)
当Delta Memstore 达到一定阈值,flush到 磁盘 (deltadata)。


