impala操作kudu 1 建表
1.1 hash分区
优点:
按照字段的Hash值进行分区,由于是Hash分区,数据的写入会被均匀的分散到各个 tablet 中,写入速度快。
缺点:
但是对于顺序读的场景这一策略就不太适用了,因为数据分散,一次顺序读需要将各个 tablet 中的数据分别读取并组合,吞吐量低。
Hash 分区无法应对分区扩展的情况。
1.1.1 建表语句
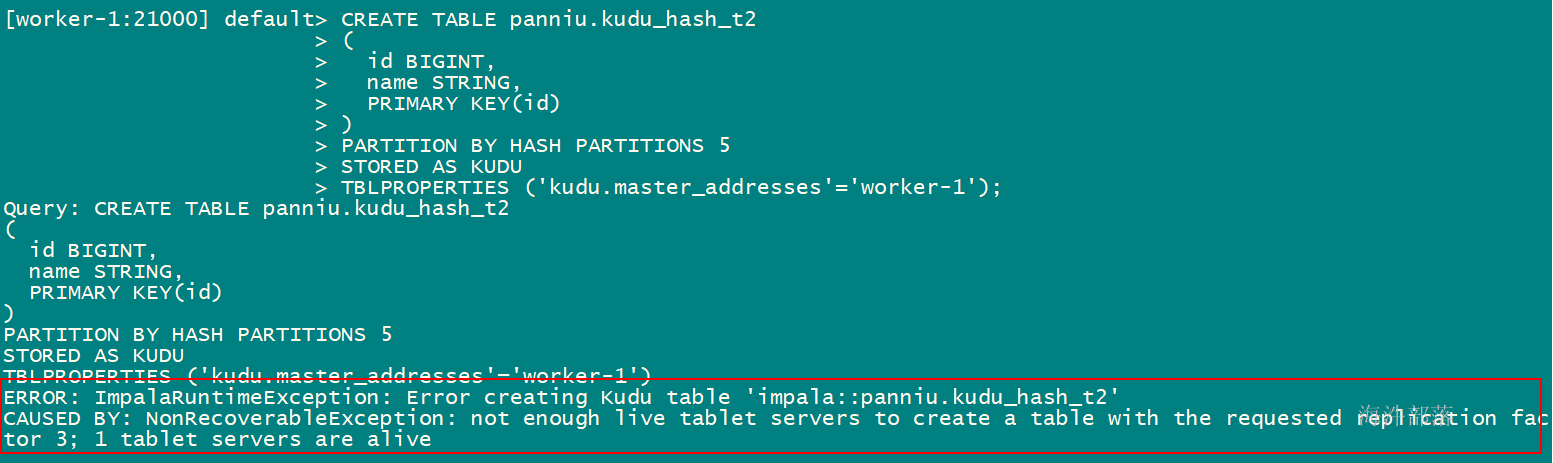
-- 单节点部署时需要指定副本数,否则创建失败。
-- kudu默认副本数为3
CREATE TABLE xinniu.kudu_hash_t1
(
id BIGINT,
name STRING,
PRIMARY KEY(id)
)
PARTITION BY HASH PARTITIONS 5
STORED AS KUDU
TBLPROPERTIES ('kudu.master_addresses'='worker-1','kudu.num_tablet_replicas' = '1');
其中:
1)kudu表中主键必须放在第一个位置,否则报错。
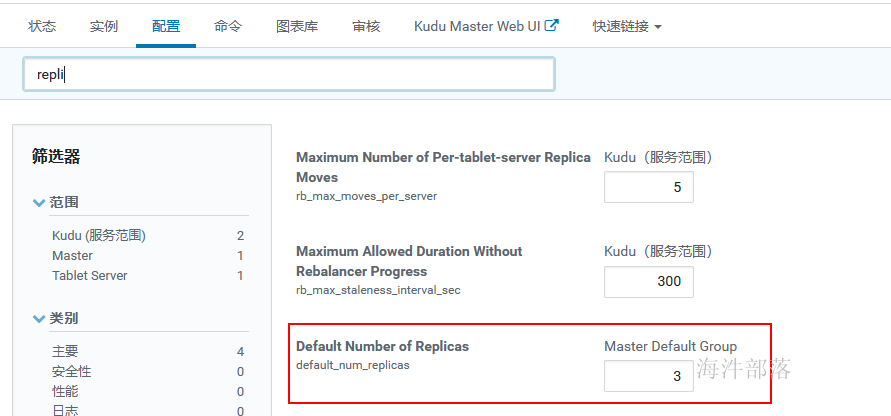
2)kudu.num_tablet_replicas 参数
kudu默认的副本数是3,在kudu的配置文件中设置,当创建表时不指定 kudu.num_tablet_replicas 参数,那默认就是3,由于当前kudu集群就一个节点,所以创建表时不指定就报错。
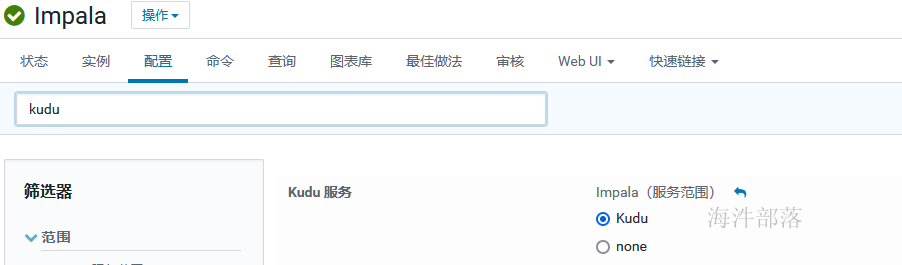
3)kudu.master_addresses 参数
如果集群安装时impala和kudu都安装了,在配置中已经配置好,那就可以省略 kudu.master_addresses 参数
如果后安装的,那需要手动配置
1.1.2 webui查看
kudu → Kudu Master Web UI

进入webUI后,点击 tables 进入表列表页
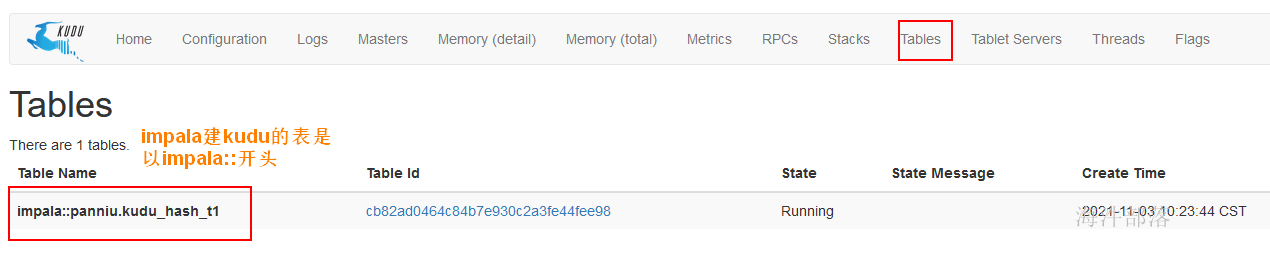
点击链接,进入建表页
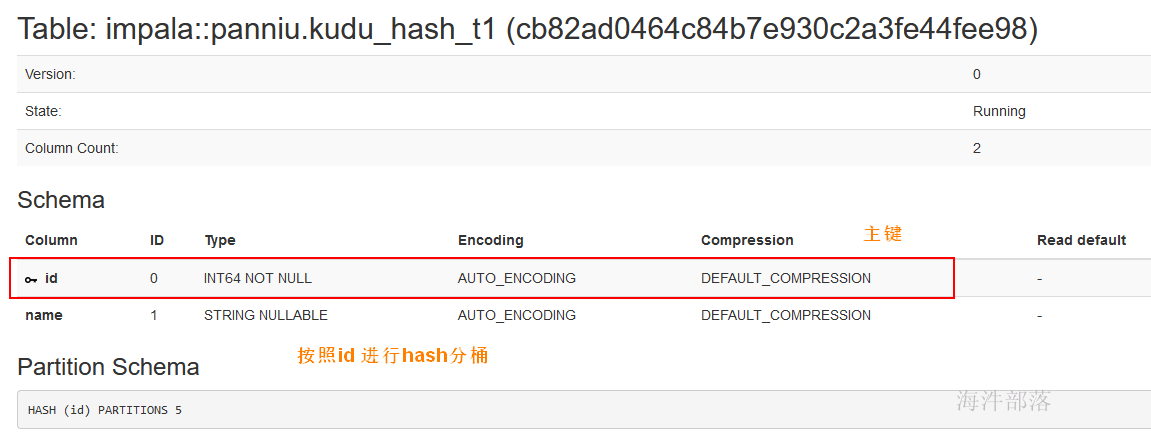
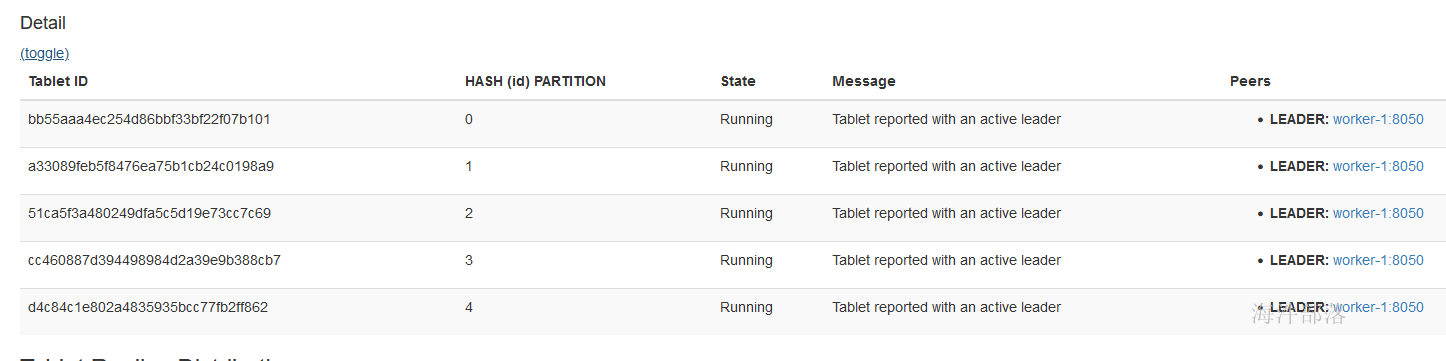
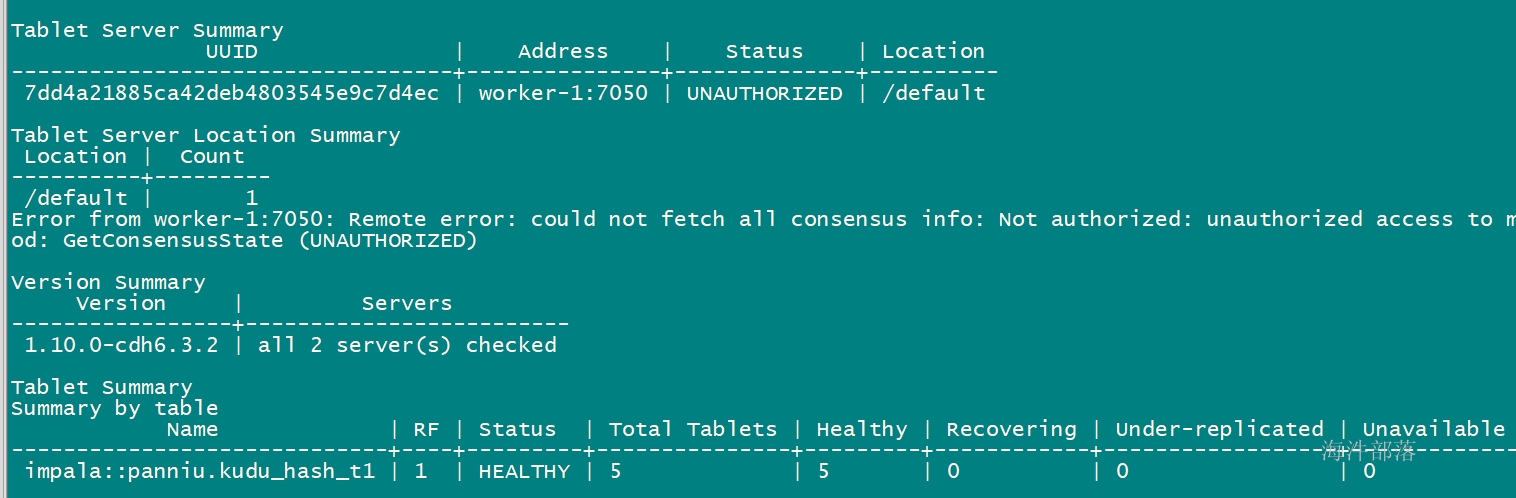
1.1.3 查看表副本数
# 在shell里执行
kudu cluster ksck worker-1部分结果:
1.1.4 查询数据结果集创建表
-- impala源表使用xinniu.impala_parquet1
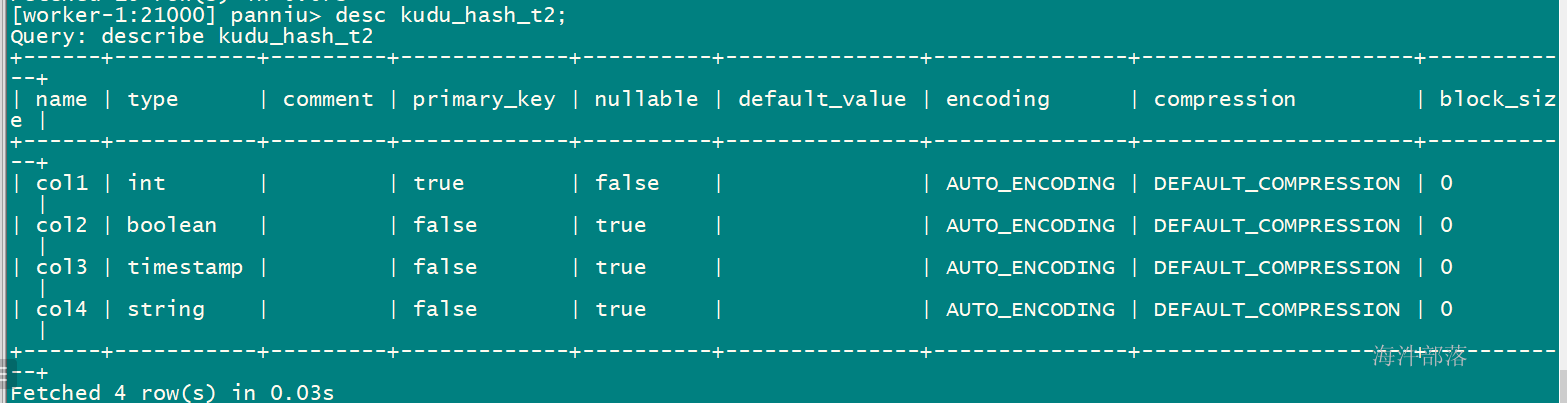
desc xinniu.impala_parquet1;
+------+-----------+---------+
| name | type | comment |
+------+-----------+---------+
| col1 | int | |
| col2 | boolean | |
| col3 | timestamp | |
| col4 | string | |
+------+-----------+---------+
-- 基于xinniu.impala_parquet1 创建 xinniu.kudu_hash_t2
-- 只有主键能分区
create table xinniu.kudu_hash_t2
primary key (col1)
partition by hash (col1) partitions 5
stored as kudu
TBLPROPERTIES ('kudu.num_tablet_replicas' = '1')
as
select col1,col2, col3, col4 from xinniu.impala_parquet1
;
-- 基于xinniu.impala_parquet1 创建 xinniu.kudu_hash_t3
-- 当kudu表是联合主键时, 查询的主键的字段要放在前面,否则报错
create table xinniu.kudu_hash_t3
primary key (col1,col3)
partition by hash (col1) partitions 5
stored as kudu
TBLPROPERTIES ('kudu.num_tablet_replicas' = '1')
as
select col1,col3,col2,col4 from xinniu.impala_parquet1
;1.2 range分区
优点:
按照字段值范围进行分区,HBase 就采用了这种方式,优势是在数据进行批量读的时候,可以把大部分的读变成同一个 tablet 中的顺序读,能够提升数据读取的吞吐量。
按照范围进行分区,我们可以很方便的进行分区扩展。
缺点:
同一个范围内的数据写入都会落在单个 tablet 上,写的压力大,速度慢。
1.2.1 按照value方式指定分区范围
-- 用 value 方式创建的range分区范围,在前区间上自动加1作为后区间。
-- 如果range分区的分区键采用的是数据日期,推荐使用如下方式分区,value=${batch_date}
create table xinniu.kudu_range_t1(
pk string,
col1 int,
col2 boolean,
col3 timestamp,
col4 string,
primary key (pk,col1)
)
partition by range (col1)
(
partition value = 1,
partition value = 3,
partition value = 5,
partition value = 7,
partition value = 9
)
stored as kudu
tblproperties ('kudu.num_tablet_replicas' = '1');
-- 添加分区前可先删除分区,这样可以重复执行
alter table xinniu.kudu_range_t1 drop if exists range partition value = 10;
alter table xinniu.kudu_range_t1 add if not exists range partition value = 10;
其中:
partition by range (col1)
(
partition value = 1,
partition value = 3,
partition value = 5,
partition value = 7,
partition value = 9
)
等效于
partition by range (col1)
(
PARTITION 1 <= VALUES < 2,
PARTITION 3 <= VALUES < 4,
PARTITION 5 <= VALUES < 6,
PARTITION 7 <= VALUES < 8,
PARTITION 9 <= VALUES < 10
)
查看表分区明细:
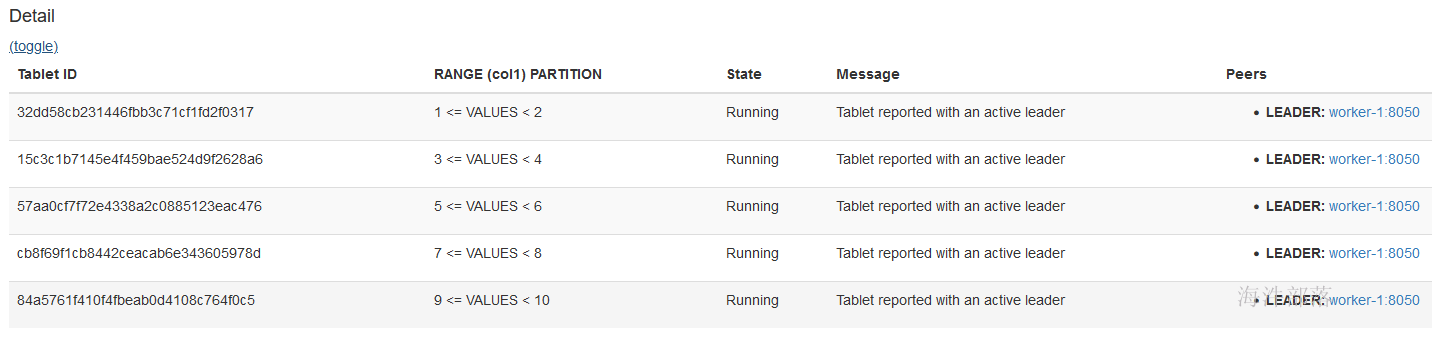
添加分区后,查看分区明细:
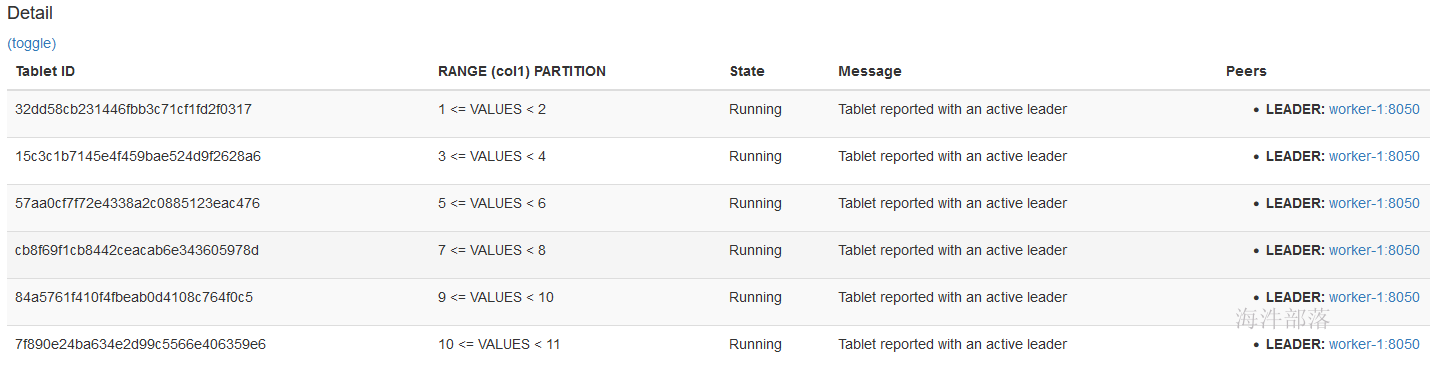
1.2.2 按照values 方式指定分区范围
-- 使用此种方式创建range分区,才能正确按照分区范围建表。
create table xinniu.kudu_range_t2(
pk string,
col1 int,
col2 boolean,
col3 timestamp,
col4 string,
primary key (pk,col1)
)
partition by range (col1)
(
partition VALUES < 1,
partition 1 <= VALUES < 3,
partition 3 <= VALUES < 5,
partition 5 <= VALUES < 7,
partition 7 <= VALUES < 10
)
stored as kudu
tblproperties ('kudu.num_tablet_replicas' = '1');
-- 添加分区前可先删除分区,这样可以重复执行
alter table xinniu.kudu_range_t2 drop if exists range partition 10 <= values < 15;
alter table xinniu.kudu_range_t2 add if not exists range partition 10 <= values < 15;查看表分区明细:
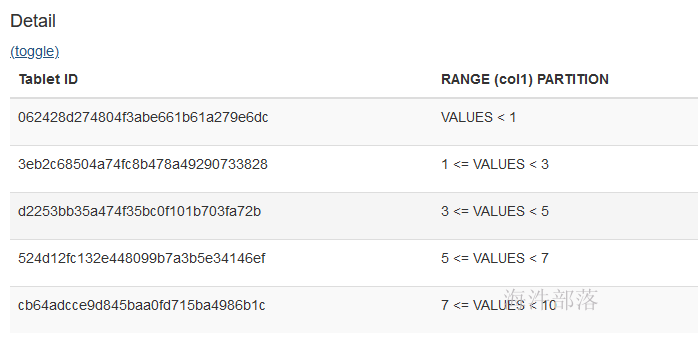
添加分区后,查看分区明细:
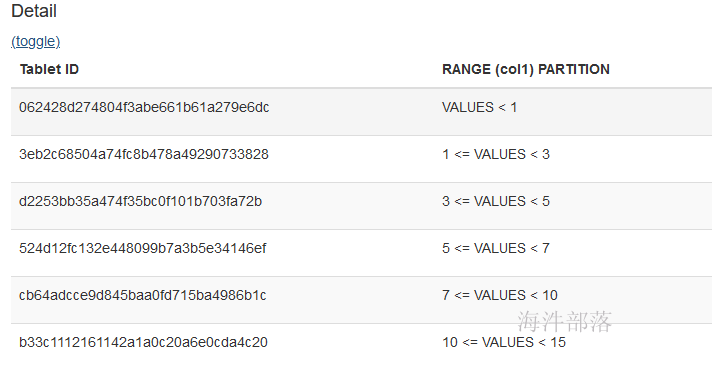
1.3 组合分区
可以组合HASH和RANGE分区以创建更复杂的分区模式。
可以指定零个或多个HASH定义,后跟零个或一个RANGE定义。每个定义可以包含一列或多列。
-- 组合主键必须放在表字段的最前面
-- 分组键必须为主键
create table xinniu.combin_partition_table(
id bigint,
age int,
name string,
primary key (id,age)
)
partition by hash (id) partitions 5,
range (age)
(
partition VALUES < 10,
partition 10 <= VALUES < 20,
partition 20 <= VALUES < 30,
partition 30 <= VALUES < 40,
partition 40 <= VALUES < 60
)
stored as kudu
tblproperties ('kudu.num_tablet_replicas' = '1');
-- 增加分区
alter table xinniu.combin_partition_table add range partition 60 <= values < 100;
-- 删除分区
alter table xinniu.combin_partition_table drop range partition 60 <= values < 100;
查看表分区:
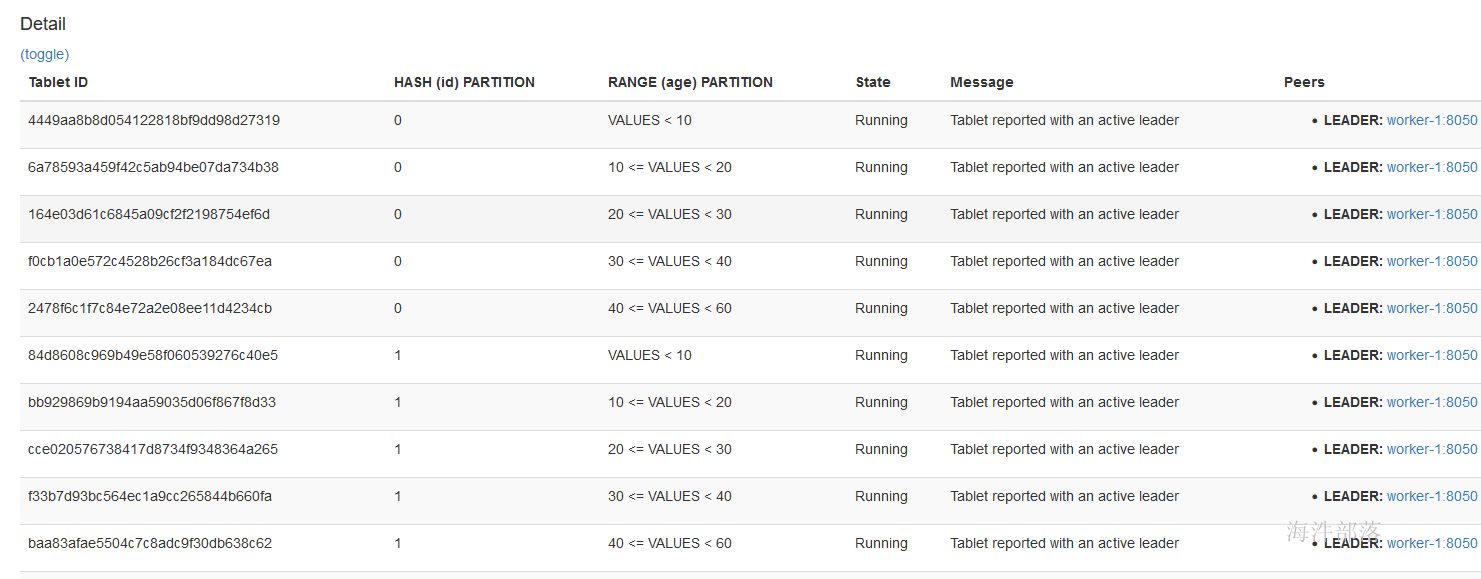
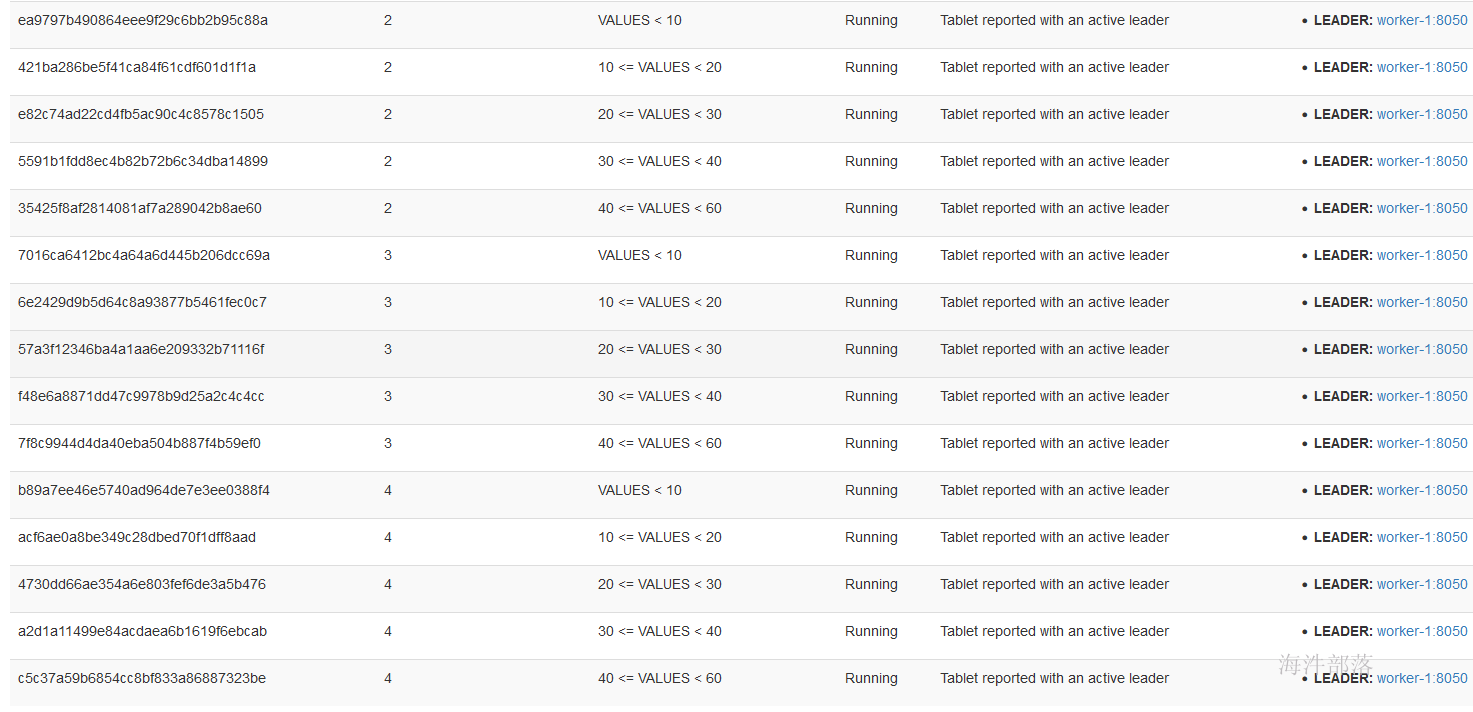
2 插入数据
-- 单条插入
INSERT INTO xinniu.kudu_hash_t1 VALUES (1, "sarah");
-- 多条插入
INSERT INTO xinniu.kudu_hash_t1 VALUES (2, "john"), (3, "jane"), (4, "jim");
-- upsert 如果主键存在则修改,如果不存在则新增
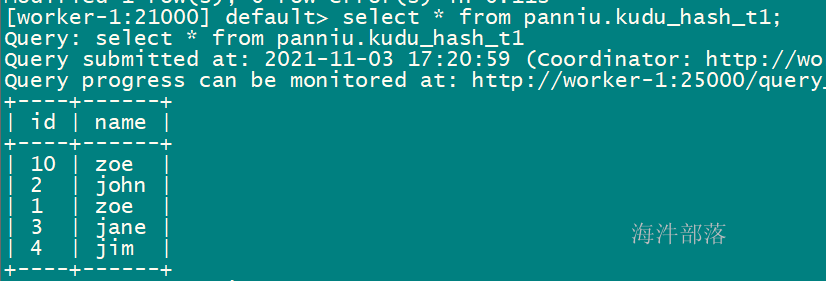
UPSERT INTO xinniu.kudu_hash_t1 VALUES (1, "zoe");
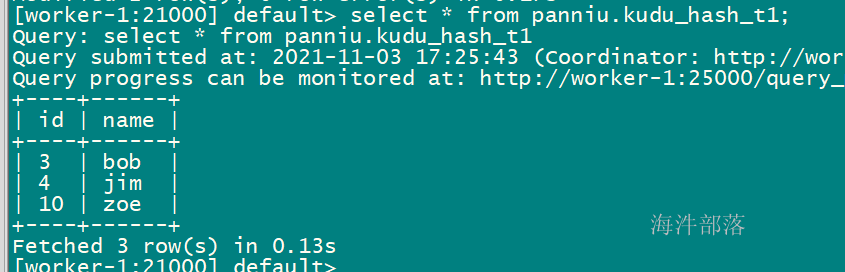
UPSERT INTO xinniu.kudu_hash_t1 VALUES (10, "zoe");插入后查询:
3 修改数据
-- kudu 修改数据也是写入一条update操作
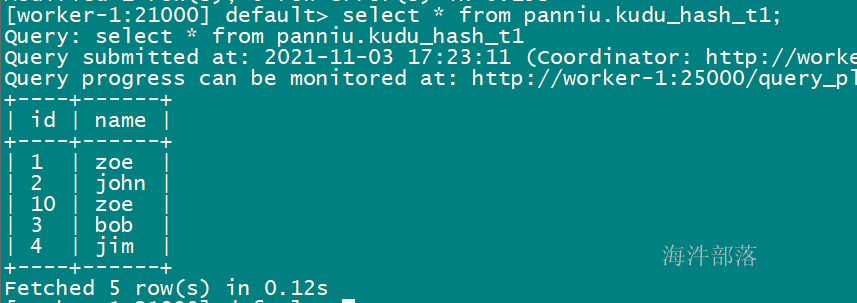
UPDATE xinniu.kudu_hash_t1 SET name="bob" where id = 3;修改后查询:
4 删除数据
-- kudu 修改数据也是写入一条delete操作
DELETE FROM xinniu.kudu_hash_t1 WHERE id < 3;删除后查看:
5 修改表名
-- 修改表名
ALTER TABLE xinniu.kudu_hash_t1 RENAME TO xinniu.kudu_hash_t1_rename;6 查询导入
无论是带有分区还是不带有分区的表,增删改查和查询导入都不要指定分区,这个是kudu自己来根据你设置的分区方式自动写入指定的tablet中。
# 如果主键存在,insert into table ... select ... 失败
insert into table xinniu.kudu_hash_t2 select col1, col2, col3, col4 from xinniu.impala_parquet1 where col1=1;
# 查询kudu_hash_t2数据
select * from kudu_hash_t2;
+------+-------+---------------------+------+
| col1 | col2 | col3 | col4 |
+------+-------+---------------------+------+
| 9 | true | 2021-08-20 13:20:00 | sma |
| 10 | false | 2021-08-20 14:30:00 | skm |
| 2 | true | 2021-08-20 11:30:00 | ssc |
| 8 | true | 2021-08-20 13:30:00 | smc |
| 12 | true | 2021-08-20 15:30:00 | skc |
| 6 | true | 2021-08-20 12:20:00 | skd |
| 7 | true | 2021-08-20 14:20:00 | smd |
| 1 | true | 2021-08-20 12:20:00 | ssd |
| 5 | false | 2021-08-20 12:30:00 | smm |
| 11 | true | 2021-08-20 15:20:00 | ska |
| 3 | false | 2021-08-20 12:30:00 | ssm |
| 4 | true | 2021-08-20 11:20:00 | ssa |
+------+-------+---------------------+------+
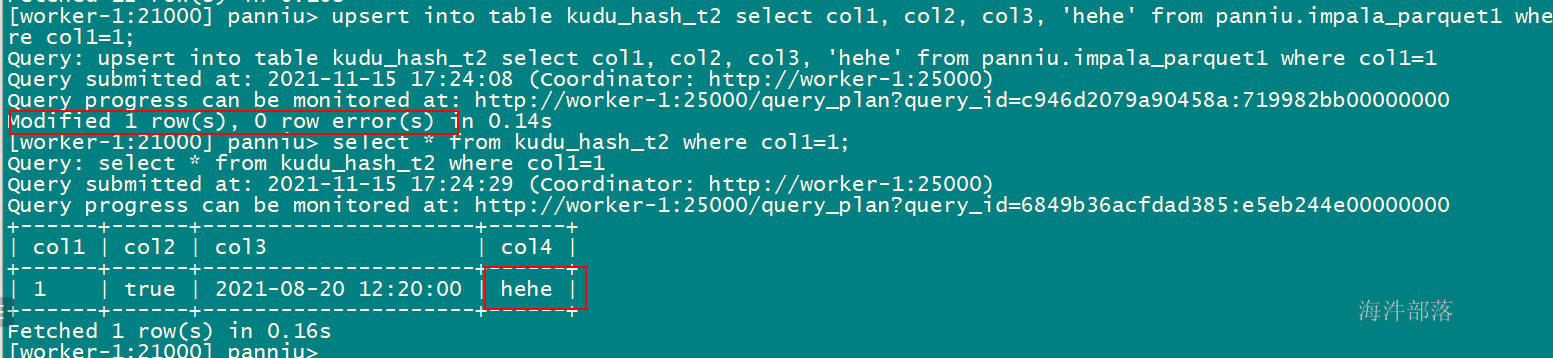
# 如果主键存在更新,upsert into table ... select ... 成功
upsert into table xinniu.kudu_hash_t2 select col1, col2, col3, 'hehe' from xinniu.impala_parquet1 where col1=1;