1 项目pom添加kudu依赖
<!-- 使用cdh自带的仓库-->
<repositories>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
</repositories>
<dependencies>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>3.0.0-cdh6.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>3.0.0-cdh6.3.2</version>
</dependency>
<dependency>
<groupId>org.apache.kudu</groupId>
<artifactId>kudu-client</artifactId>
<version>1.10.0-cdh6.3.2</version>
</dependency>
</dependencies>2 资源配置文件
在cdh webui hbase或yarn中下载客户端配置,并把配置文件上传到工程资源目录下
3 kerberos.properties 配置文件
将集群的 krb5.conf 和 impala.keytab 文件下载到本地并放到 src/main/conf 目录下
在资源目录下创建 kerberos.properties 文件,内部配置内容如下,目的是通过读取properties文件获取kerberos 认证信息
krb5.conf.path=E:/workspaces/scala/class33/hainiuhbase/src/main/conf/krb5.conf
kerberos.user=impala@HAINIU.COM
kerberos.keytab.path=E:/workspaces/scala/class33/hainiuhbase/src/main/conf/impala.keytab4 kerberos 认证代码
/**
* kerberos 安全认证
* @param flag 是否打印认证过程信息
*/
private static void kerberosAuth(boolean flag) {
Properties prop = new Properties();
try {
prop.load(KuduAPI.class.getResourceAsStream("/kerberos.properties"));
String krb5Path = prop.getProperty("krb5.conf.path");
String principal = prop.getProperty("kerberos.user");
String keytabPath = prop.getProperty("kerberos.keytab.path");
//hadoop配置文件
Configuration configuration = new Configuration();
// 通过系统设置参数设置krb5.conf
System.setProperty("java.security.krb5.conf",krb5Path);
// 指定kerberos 权限认证
configuration.set("hadoop.security.authentication","Kerberos");
//打印kerberos认证过程信息
if (flag){
System.setProperty("sun.security.krb5.debug","true");
}
// 用 UserGroupInformation 类做kerberos认证
UserGroupInformation.setConfiguration(configuration);
try {
// 用于刷新票据,当票据过期的时候自动刷新
UserGroupInformation.getLoginUser().checkTGTAndReloginFromKeytab();
// 通过 keytab 登录
// 参数1:认证主体
// 参数2:认证文件
UserGroupInformation.loginUserFromKeytab(principal,keytabPath);
UserGroupInformation loginUser = UserGroupInformation.getLoginUser();
System.out.println("loginUser:" + loginUser);
} catch (IOException e) {
e.printStackTrace();
}
} catch (Exception e) {
e.printStackTrace();
}
}5 kudu api操作
5.1 获取 KuduClient 对象
/**
* 获取 kudu 的客户端对象
* @return
*/
private static KuduClient getKuduClient() {
//设置kudu master地址
String kudumasters = System.getProperty("kuduMasters", "worker-1:7051");
KuduClient kuduClient = null;
// 获取kudu客户端
try {
kuduClient = UserGroupInformation.getLoginUser().doAs(new PrivilegedAction<KuduClient>() {
@Override
public KuduClient run() throws Exception {
final KuduClient client = new KuduClient.KuduClientBuilder(kudumasters).build();
return client;
}
});
} catch (Exception e) {
e.printStackTrace();
}
return kuduClient;
}5.2 创建表
/**
* 创建kudu表
* id 、name、age, id作为主键, 用id做hash分区
* @param kuduClient
* @param tableName
*/
private static void createTable(KuduClient kuduClient, String tableName) {
// 创建 SchemaColums
List<ColumnSchema> columnSchemas = new ArrayList<ColumnSchema>();
// 创建id, 作为主键, snappy压缩
final ColumnSchema idColumnSchema = new ColumnSchema
.ColumnSchemaBuilder("id", Type.INT64)
.key(true)
.compressionAlgorithm(ColumnSchema.CompressionAlgorithm.SNAPPY)
.build();
// 创建 name, snappy压缩
final ColumnSchema nameColumnSchema = new ColumnSchema
.ColumnSchemaBuilder("name", Type.STRING)
.compressionAlgorithm(ColumnSchema.CompressionAlgorithm.SNAPPY)
.build();
// 创建 age, snappy压缩
final ColumnSchema ageColumnSchema = new ColumnSchema.ColumnSchemaBuilder("age", Type.INT32)
.compressionAlgorithm(ColumnSchema.CompressionAlgorithm.SNAPPY)
.build();
// 将创建columnSchema添加到列表里
columnSchemas.add(idColumnSchema);
columnSchemas.add(nameColumnSchema);
columnSchemas.add(ageColumnSchema);
// 设置 按照 id 做hash分区
List<String> hashKeys = new ArrayList<String>();
hashKeys.add("id");
// 创建创建表操作对象
final CreateTableOptions tableOptions = new CreateTableOptions();
// 设置所建kudu表的副本数
tableOptions.setNumReplicas(1);
// 设置安装id进行hash分区, 共三个
tableOptions.addHashPartitions(hashKeys, 3);
// 创建 schema对象
Schema schema = new Schema(columnSchemas);
try {
if(kuduClient.tableExists(tableName)){
System.out.println(tableName + " is exists!");
return;
}
// 创建表
kuduClient.createTable(tableName, schema, tableOptions);
System.out.println(tableName + ": create finished");
} catch (KuduException e) {
e.printStackTrace();
}
}执行创建后,在kudu webui 查看:
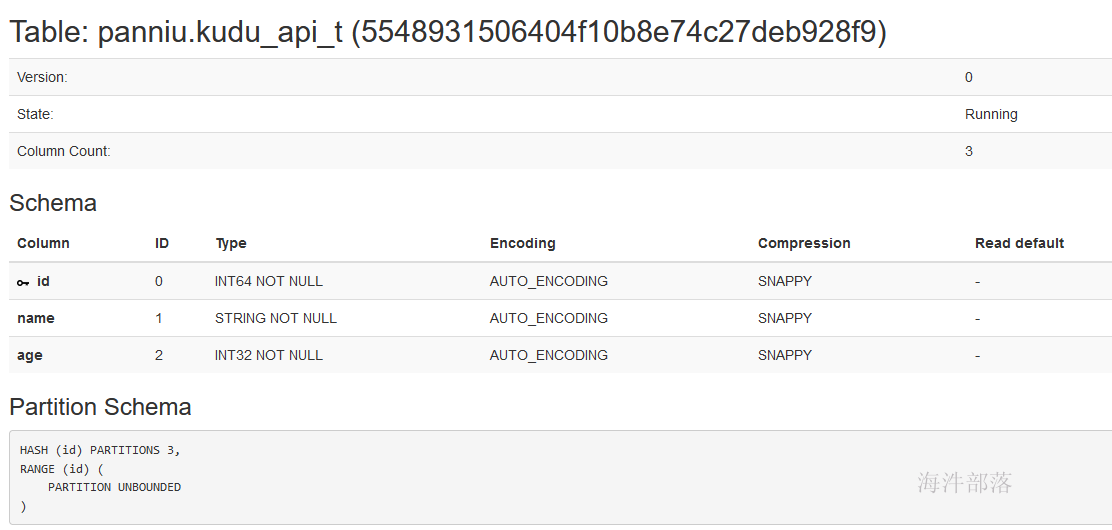
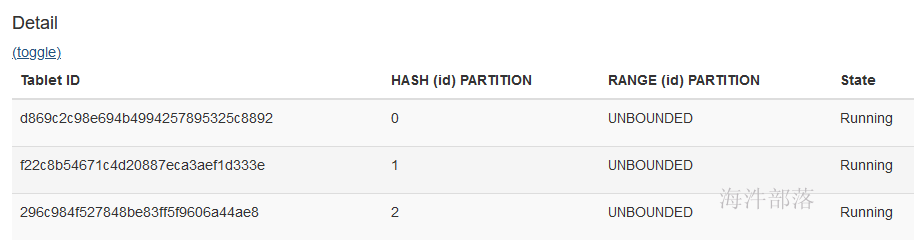
5.2.1 按照id hash分区
CreateTableOptions createTableOptions = new CreateTableOptions();
// 设置一个副本
createTableOptions.setNumReplicas(1);
// 设置 按照 id 来 hash 分区, 分 3 分区
List<String> hashKeys = new ArrayList<>();
hashKeys.add("id");
createTableOptions.addHashPartitions(hashKeys, 3);5.2.2 按照age range分区
/**
* id 、name、age, id,age作为主键, 用age做range分区
* CREATE TABLE panniu.kudu_api_range_t1
* (
* id bigint,
* age int,
* name string,
* PRIMARY KEY(id, age)
* )
* partition by range (age)
* (
* partition 10 <= VALUES < 15,
* partition 15 <= VALUES < 25,
* partition 25 <= VALUES < 30
* )
* STORED AS KUDU
* TBLPROPERTIES ('kudu.num_tablet_replicas' = '1');
* @param kuduClient
*/
private static void createKuduTableWithRange(KuduClient kuduClient) {
String tableNameRange = "xinniu.kudu_api_range_t1";
List<ColumnSchema> columns = new ArrayList<ColumnSchema>();
// 创建 id 的 ColumnSchema对象
// id bigint 、主键、snappy压缩
final ColumnSchema idcs = new ColumnSchema.ColumnSchemaBuilder("id", Type.INT64)
.key(true)
.compressionAlgorithm(ColumnSchema.CompressionAlgorithm.SNAPPY)
.build();
// 创建 age 的 ColumnSchema对象
// age int, 主键、snappy压缩
final ColumnSchema agecs = new ColumnSchema.ColumnSchemaBuilder("age", Type.INT32)
.key(true)
.compressionAlgorithm(ColumnSchema.CompressionAlgorithm.SNAPPY)
.build();
// 创建 name 的 ColumnSchema对象
final ColumnSchema namecs = new ColumnSchema.ColumnSchemaBuilder("name", Type.STRING)
.compressionAlgorithm(ColumnSchema.CompressionAlgorithm.SNAPPY)
.build();
columns.add(idcs);
columns.add(agecs);
columns.add(namecs);
final Schema schema = new Schema(columns);
final CreateTableOptions options = new CreateTableOptions();
// 设置副本数是1
options.setNumReplicas(1);
List<String> keys = new ArrayList<String>();
keys.add("age");
// 设置range分区字段
options.setRangePartitionColumns(keys);
// 循环添加分区范围
int[] lowerArr = {10, 15, 25};
int[] upperArr = {15, 25, 30};
for(int i = 0; i < lowerArr.length; i++){
final int lowerNum = lowerArr[i];
final int upperNum = upperArr[i];
final PartialRow lowerRow = new PartialRow(schema);
lowerRow.addInt("age", lowerNum);
final PartialRow upperRow = new PartialRow(schema);
upperRow.addInt("age", upperNum);
options.addRangePartition(lowerRow, upperRow);
}
// 参数1:表名
// 参数2:schema是列的集合
// 参数3:建表参数
try {
kuduClient.createTable(tableNameRange, schema,options);
} catch (KuduException e) {
e.printStackTrace();
}
}5.2.3 先按照id hash分区,后按age range分区
private static void createKuduTableWithHashAndRange(KuduClient kuduClient) {
String tableNameRange = "xinniu.kudu_api_range_t2";
List<ColumnSchema> columns = new ArrayList<ColumnSchema>();
// 创建 id 的 ColumnSchema对象
// id bigint 、主键、snappy压缩
final ColumnSchema idcs = new ColumnSchema.ColumnSchemaBuilder("id", Type.INT64)
.key(true)
.compressionAlgorithm(ColumnSchema.CompressionAlgorithm.SNAPPY)
.build();
// 创建 age 的 ColumnSchema对象
// age int, 主键、snappy压缩
final ColumnSchema agecs = new ColumnSchema.ColumnSchemaBuilder("age", Type.INT32)
.key(true)
.compressionAlgorithm(ColumnSchema.CompressionAlgorithm.SNAPPY)
.build();
// 创建 name 的 ColumnSchema对象
final ColumnSchema namecs = new ColumnSchema.ColumnSchemaBuilder("name", Type.STRING)
.compressionAlgorithm(ColumnSchema.CompressionAlgorithm.SNAPPY)
.build();
columns.add(idcs);
columns.add(agecs);
columns.add(namecs);
final Schema schema = new Schema(columns);
final CreateTableOptions options = new CreateTableOptions();
// 设置副本数是1
options.setNumReplicas(1);
// 设置按照id hash分区, 5个
List<String> hashKeys = new ArrayList<String>();
hashKeys.add("id");
options.addHashPartitions(hashKeys, 5);
List<String> rangeKeys = new ArrayList<String>();
rangeKeys.add("age");
// 设置range分区字段
options.setRangePartitionColumns(rangeKeys);
// 循环添加分区范围
int[] lowerArr = {10, 15, 25};
int[] upperArr = {15, 25, 30};
for(int i = 0; i < lowerArr.length; i++){
final int lowerNum = lowerArr[i];
final int upperNum = upperArr[i];
final PartialRow lowerRow = new PartialRow(schema);
lowerRow.addInt("age", lowerNum);
final PartialRow upperRow = new PartialRow(schema);
upperRow.addInt("age", upperNum);
options.addRangePartition(lowerRow, upperRow);
}
// 参数1:表名
// 参数2:schema是列的集合
// 参数3:建表参数
try {
kuduClient.createTable(tableNameRange, schema,options);
} catch (KuduException e) {
e.printStackTrace();
}
}5.3 添加数据
/**
* 添加数据
* @param kuduClient
* @param tableName
*/
private static void insertData(KuduClient kuduClient, String tableName) {
KuduSession kuduSession = null;
try{
// 打开kudu表
KuduTable kuduTable = kuduClient.openTable(tableName);
// 打开kudu会话窗口
kuduSession = kuduClient.newSession();
// 设置关闭自动提交
kuduSession.setFlushMode(SessionConfiguration.FlushMode.MANUAL_FLUSH);
// 创建upser对象并添加一行数据
final Upsert upsert1 = kuduTable.newUpsert();
final PartialRow row1 = upsert1.getRow();
row1.addLong("id", 1L);
row1.addString("name", "user1");
row1.addInt("age", 11);
final Upsert upsert2 = kuduTable.newUpsert();
final PartialRow row2 = upsert2.getRow();
row2.addLong("id", 2L);
row2.addString("name", "user2");
row2.addInt("age", 12);
// 执行操作
kuduSession.apply(upsert1);
kuduSession.apply(upsert2);
// 手动提交
kuduSession.flush();
kuduSession.close();
}catch (Exception e){
e.printStackTrace();
}finally {
if(!kuduSession.isClosed()){
try {
kuduSession.close();
} catch (KuduException e) {
e.printStackTrace();
}
}
}
}添加完成后,创建impala表指向kudu表,用impala来查询
-- 创建 impala表
create EXTERNAL table xinniu.impala_kuduapi
stored as kudu
TBLPROPERTIES (
'kudu.table_name' = 'xinniu.kudu_api_t'
);
-- 用impala表查询
select * from xinniu.impala_kuduapi;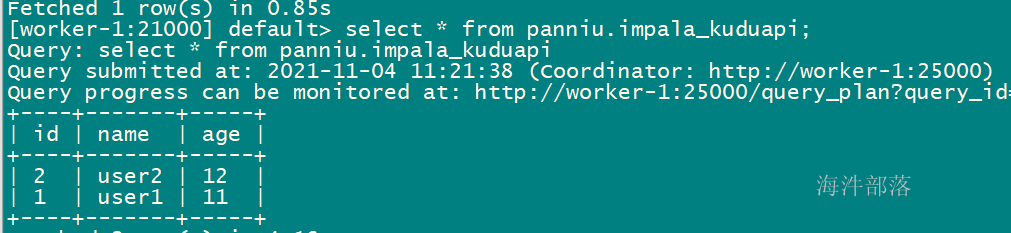
kudu刷写磁盘的三种方式:
AUTO_FLUSH_SYNC(默认):
所有的写入都只有在自动刷新到服务器后才会返回。不会发生批处理,在这种模式下,Flush()函数不会产生任何效果,因为每个应用程序在返回之前已经刷新了缓冲区。
AUTO_FLUSH_BACKGROUND:
每一个应用的KuduSession.apply()函数都会返回的非常快,但是写操作会被发送到后台进程,可能与来自同一会话的其他写入一起进行批处理。如果没有足够的缓冲空间,KuduSession.apply()会阻塞,缓冲空间不可用。因为写入操作是在后台应用进行的的,因此任何错误都将存储在一个会话本地缓冲区中。注意:这个模式可能会导致数据插入是乱序的,这是因为在这种模式下,多个写操作可以并发地发送到服务器。
MANUAL_FLUSH:
每一个应用的KuduSession.apply()函数都会返回的非常快,但是写操作不会发送,直到用户使用flush()函数,如果缓冲区超过了配置的空间限制,KuduSession.apply()函数会返回一个错误。
5.4 查询表
/**
* 扫描全表
* @param kuduClient
* @param tableName
*/
private static void scanTable(KuduClient kuduClient, String tableName) {
try{
// 打开kudu表
final KuduTable kuduTable = kuduClient.openTable(tableName);
// 创建扫描表的对象
final KuduScanner scanner = kuduClient.newScannerBuilder(kuduTable).build();
// 遍历查询结果
for(RowResult rowResult : scanner){
long id = rowResult.getLong("id");
String name = rowResult.getString("name");
int age = rowResult.getInt("age");
System.out.println("id:" + id + ", name:" + name + ", age: " + age);
}
// 关闭scanner
scanner.close();
}catch (Exception e){
e.printStackTrace();
}
}查询结果:
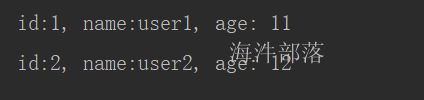
5.5 带有条件的查询
/**
* 实现 带有条件的scan
* 相当于实现: select id, age from kudu_table where id >= 1 and name = user1;
* @param kuduClient
* @param tableName
*/
private static void scanTableBy(KuduClient kuduClient, String tableName) {
try{
// 打开kudu表
final KuduTable kuduTable = kuduClient.openTable(tableName);
// 创建scanner对象
final KuduScanner.KuduScannerBuilder builder = kuduClient.newScannerBuilder(kuduTable);
// 设置查询返回字段列表
List<String> names = new ArrayList<>();
names.add("id");
names.add("age");
builder.setProjectedColumnNames(names);
// 获取id的ColumnSchema
final ColumnSchema idColumnSchema = kuduTable.getSchema().getColumn("id");
// 增加scan筛选条件 id >= 1L
final KuduPredicate idPredicate = KuduPredicate.newComparisonPredicate(idColumnSchema,
KuduPredicate.ComparisonOp.GREATER_EQUAL,
1L);
// 添加scan条件
builder.addPredicate(idPredicate);
// 获取name的columnSchema
final ColumnSchema nameColumnSchema = kuduTable.getSchema().getColumn("name");
// 增加筛选条件 name = user1
final KuduPredicate namePredicate = KuduPredicate.newComparisonPredicate(nameColumnSchema,
KuduPredicate.ComparisonOp.EQUAL,
"user1");
builder.addPredicate(namePredicate);
final KuduScanner kuduScanner = builder.build();
for(RowResult rowResult : kuduScanner){
final long id = rowResult.getLong("id");
// final String name = rowResult.getString("name");
final int age = rowResult.getInt("age");
System.out.println("id:" + id + ", age: " + age);
}
kuduScanner.close();
}catch (Exception e){
e.printStackTrace();
}
}查询结果:

5.6 删除表
/**
* 删除表
* @param kuduClient
* @param tableName
*/
private static void deleteTable(KuduClient kuduClient, String tableName) {
try {
kuduClient.deleteTable(tableName);
System.out.println(tableName + " :删除完成!");
} catch (Exception e) {
e.printStackTrace();
}
}通过kudu webui 查看,发现列表里已经删除:
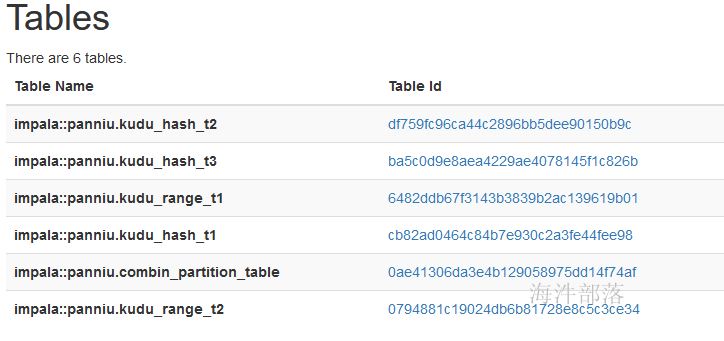
5.7 全部代码
package com.hainiu;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.security.UserGroupInformation;
import org.apache.kudu.ColumnSchema;
import org.apache.kudu.Schema;
import org.apache.kudu.Type;
import org.apache.kudu.client.*;
import java.io.IOException;
import java.security.PrivilegedExceptionAction;
import java.util.ArrayList;
import java.util.List;
import java.util.Properties;
public class KuduAPI {
public static void main(String[] args) {
kerberosAuth(false);
KuduClient kuduClient = getKuduClient();
String tableName = "xinniu.kudu_api_t";
createTable(kuduClient, tableName);
// insertData(kuduClient, tableName);
// scanTable(kuduClient, tableName);
// scanTableBy(kuduClient, tableName);
// deleteTable(kuduClient, tableName);
}
/**
* 实现 带有条件的scan
* 相当于实现: select id, age from kudu_table where id >= 1 and name = user1;
* @param kuduClient
* @param tableName
*/
private static void scanTableBy(KuduClient kuduClient, String tableName) {
try{
// 打开kudu表
final KuduTable kuduTable = kuduClient.openTable(tableName);
// 创建scanner对象
final KuduScanner.KuduScannerBuilder builder = kuduClient.newScannerBuilder(kuduTable);
// 设置查询返回字段列表
List<String> names = new ArrayList<>();
names.add("id");
names.add("age");
builder.setProjectedColumnNames(names);
// 获取id的ColumnSchema
final ColumnSchema idColumnSchema = kuduTable.getSchema().getColumn("id");
// 增加scan筛选条件 id >= 1L
final KuduPredicate idPredicate = KuduPredicate.newComparisonPredicate(idColumnSchema,
KuduPredicate.ComparisonOp.GREATER_EQUAL,
1L);
// 添加scan条件
builder.addPredicate(idPredicate);
// 获取name的columnSchema
final ColumnSchema nameColumnSchema = kuduTable.getSchema().getColumn("name");
// 增加筛选条件 name = user1
final KuduPredicate namePredicate = KuduPredicate.newComparisonPredicate(nameColumnSchema,
KuduPredicate.ComparisonOp.EQUAL,
"user1");
builder.addPredicate(namePredicate);
final KuduScanner kuduScanner = builder.build();
for(RowResult rowResult : kuduScanner){
final long id = rowResult.getLong("id");
// final String name = rowResult.getString("name");
final int age = rowResult.getInt("age");
System.out.println("id:" + id + ", age: " + age);
}
kuduScanner.close();
}catch (Exception e){
e.printStackTrace();
}
}
/**
* 扫描全表
* @param kuduClient
* @param tableName
*/
private static void scanTable(KuduClient kuduClient, String tableName) {
try{
// 打开kudu表
final KuduTable kuduTable = kuduClient.openTable(tableName);
// 创建扫描表的对象
final KuduScanner scanner = kuduClient.newScannerBuilder(kuduTable).build();
// 遍历查询结果
for(RowResult rowResult : scanner){
long id = rowResult.getLong("id");
String name = rowResult.getString("name");
int age = rowResult.getInt("age");
System.out.println("id:" + id + ", name:" + name + ", age: " + age);
}
// 关闭scanner
scanner.close();
}catch (Exception e){
e.printStackTrace();
}
}
/**
* 获取 kudu 的客户端对象
* @return
*/
private static KuduClient getKuduClient() {
//设置kudu master地址
String kudumasters = System.getProperty("kuduMasters", "worker-1:7051");
KuduClient kuduClient = null;
// 获取kudu客户端
try {
kuduClient = UserGroupInformation.getLoginUser().doAs(new PrivilegedAction<KuduClient>() {
@Override
public KuduClient run() throws Exception {
final KuduClient client = new KuduClient.KuduClientBuilder(kudumasters).build();
return client;
}
});
} catch (Exception e) {
e.printStackTrace();
}
return kuduClient;
}
/**
* 删除表
* @param kuduClient
* @param tableName
*/
private static void deleteTable(KuduClient kuduClient, String tableName) {
try {
kuduClient.deleteTable(tableName);
System.out.println(tableName + " :删除完成!");
} catch (Exception e) {
e.printStackTrace();
}
}
/**
* 添加数据
* @param kuduClient
* @param tableName
*/
private static void insertData(KuduClient kuduClient, String tableName) {
KuduSession kuduSession = null;
try{
// 打开kudu表
KuduTable kuduTable = kuduClient.openTable(tableName);
// 打开kudu会话窗口
kuduSession = kuduClient.newSession();
// 设置关闭自动提交
kuduSession.setFlushMode(SessionConfiguration.FlushMode.MANUAL_FLUSH);
// 创建upser对象
final Upsert upsert1 = kuduTable.newUpsert();
final PartialRow row1 = upsert1.getRow();
row1.addLong("id", 1L);
row1.addString("name", "user1");
row1.addInt("age", 11);
final Upsert upsert2 = kuduTable.newUpsert();
final PartialRow row2 = upsert2.getRow();
row2.addLong("id", 2L);
row2.addString("name", "user2");
row2.addInt("age", 12);
// 执行操作
kuduSession.apply(upsert1);
kuduSession.apply(upsert2);
// 手动提交
kuduSession.flush();
kuduSession.close();
}catch (Exception e){
e.printStackTrace();
}finally {
if(!kuduSession.isClosed()){
try {
kuduSession.close();
} catch (KuduException e) {
e.printStackTrace();
}
}
}
}
/**
* 创建kudu表
* id 、name、age, id作为主键, 用id做hash分区
* @param kuduClient
* @param tableName
*/
private static void createTable(KuduClient kuduClient, String tableName) {
// 创建 SchemaColums
List<ColumnSchema> columnSchemas = new ArrayList<ColumnSchema>();
// 创建id, 作为主键, snappy压缩
final ColumnSchema idColumnSchema = new ColumnSchema
.ColumnSchemaBuilder("id", Type.INT64)
.key(true)
.compressionAlgorithm(ColumnSchema.CompressionAlgorithm.SNAPPY)
.build();
// 创建 name, snappy压缩
final ColumnSchema nameColumnSchema = new ColumnSchema
.ColumnSchemaBuilder("name", Type.STRING)
.compressionAlgorithm(ColumnSchema.CompressionAlgorithm.SNAPPY)
.build();
// 创建 age, snappy压缩
final ColumnSchema ageColumnSchema = new ColumnSchema.ColumnSchemaBuilder("age", Type.INT32)
.compressionAlgorithm(ColumnSchema.CompressionAlgorithm.SNAPPY)
.build();
// 将创建columnSchema添加到列表里
columnSchemas.add(idColumnSchema);
columnSchemas.add(nameColumnSchema);
columnSchemas.add(ageColumnSchema);
// 设置 按照 id 做hash分区
List<String> hashKeys = new ArrayList<String>();
hashKeys.add("id");
// 创建创建表操作对象
final CreateTableOptions tableOptions = new CreateTableOptions();
// 设置所建kudu表的副本数
tableOptions.setNumReplicas(1);
// 设置安装id进行hash分区, 共三个
tableOptions.addHashPartitions(hashKeys, 3);
// 创建 schema对象
Schema schema = new Schema(columnSchemas);
try {
if(kuduClient.tableExists(tableName)){
System.out.println(tableName + " is exists!");
return;
}
// 创建表
kuduClient.createTable(tableName, schema, tableOptions);
System.out.println(tableName + ": create finished");
} catch (KuduException e) {
e.printStackTrace();
}
}
/**
* kerberos 安全认证
* @param flag 是否打印认证过程信息
*/
private static void kerberosAuth(boolean flag) {
Properties prop = new Properties();
try {
prop.load(KuduAPI.class.getResourceAsStream("/kerberos.properties"));
String krb5Path = prop.getProperty("krb5.conf.path");
String principal = prop.getProperty("kerberos.user");
String keytabPath = prop.getProperty("kerberos.keytab.path");
//hadoop配置文件
Configuration configuration = new Configuration();
// 通过系统设置参数设置krb5.conf
System.setProperty("java.security.krb5.conf",krb5Path);
// 指定kerberos 权限认证
configuration.set("hadoop.security.authentication","Kerberos");
//打印kerberos认证过程信息
if (flag){
System.setProperty("sun.security.krb5.debug","true");
}
// 用 UserGroupInformation 类做kerberos认证
UserGroupInformation.setConfiguration(configuration);
try {
// 用于刷新票据,当票据过期的时候自动刷新
UserGroupInformation.getLoginUser().checkTGTAndReloginFromKeytab();
// 通过 keytab 登录
// 参数1:认证主体
// 参数2:认证文件
UserGroupInformation.loginUserFromKeytab(principal,keytabPath);
UserGroupInformation loginUser = UserGroupInformation.getLoginUser();
System.out.println("loginUser:" + loginUser);
} catch (IOException e) {
e.printStackTrace();
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
6 impala关联kudu表(非impala创建)
-- impala 关联 已有的非impala创建的kudu表, 那需要指定 kudu.table_name 参数
create EXTERNAL table xinniu.impala_kuduapi
stored as kudu
TBLPROPERTIES (
'kudu.table_name' = 'xinniu.kudu_api_t'
);
插入数据后,可查询结果
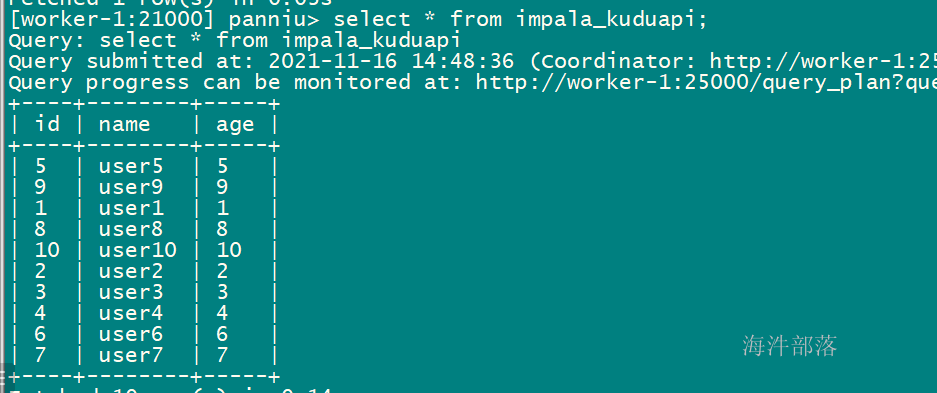
删除impala表,kudu表还存在



