参考官方文档:https://kylin.apache.org/cn/docs31/tutorial/create_cube.html
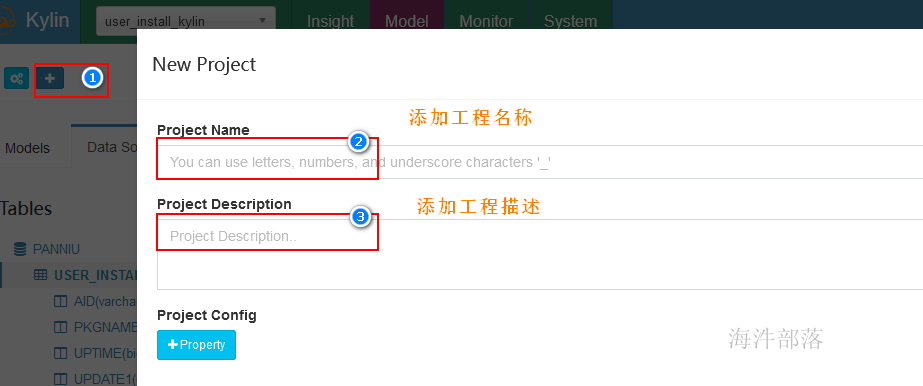
1 创建工程
2 同步hive表
2.1 同步hive表
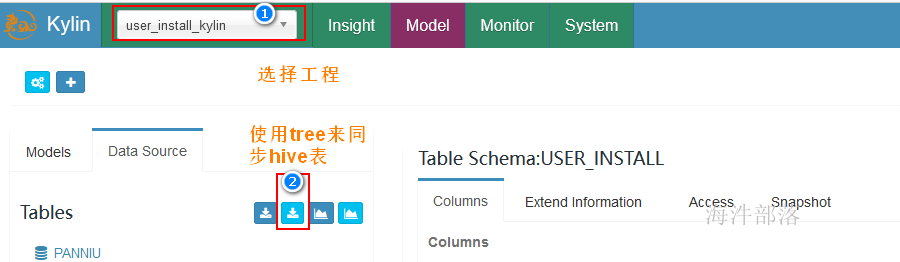
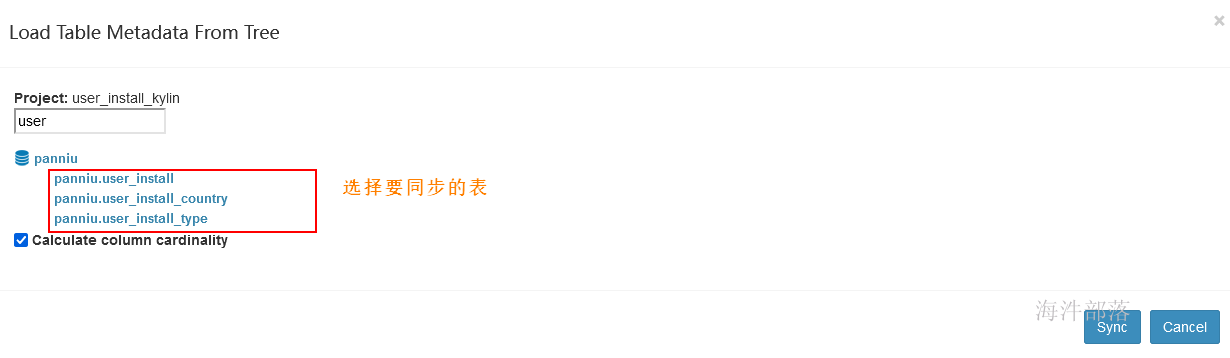
在tree中选择要同步的表(可读选), 然后 点击 “sync” 同步,执行mapreduce任务,可在监控里查看。
默认勾选的是计算表的基数(表中每个字段的 count distinct)
在监控里查看:
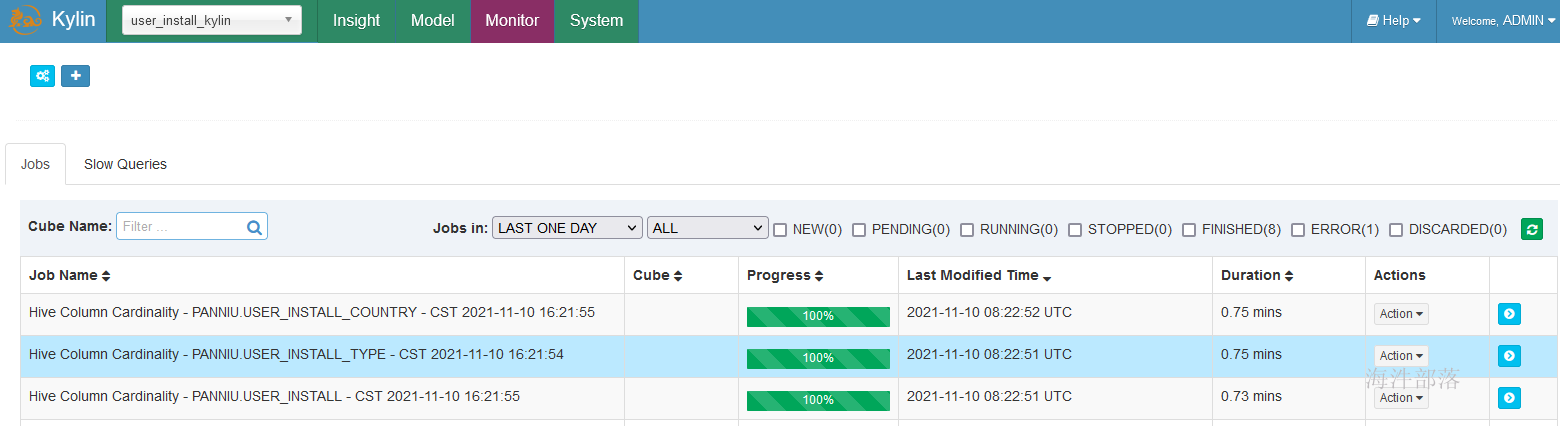
同步完成,刷新页面后展示:
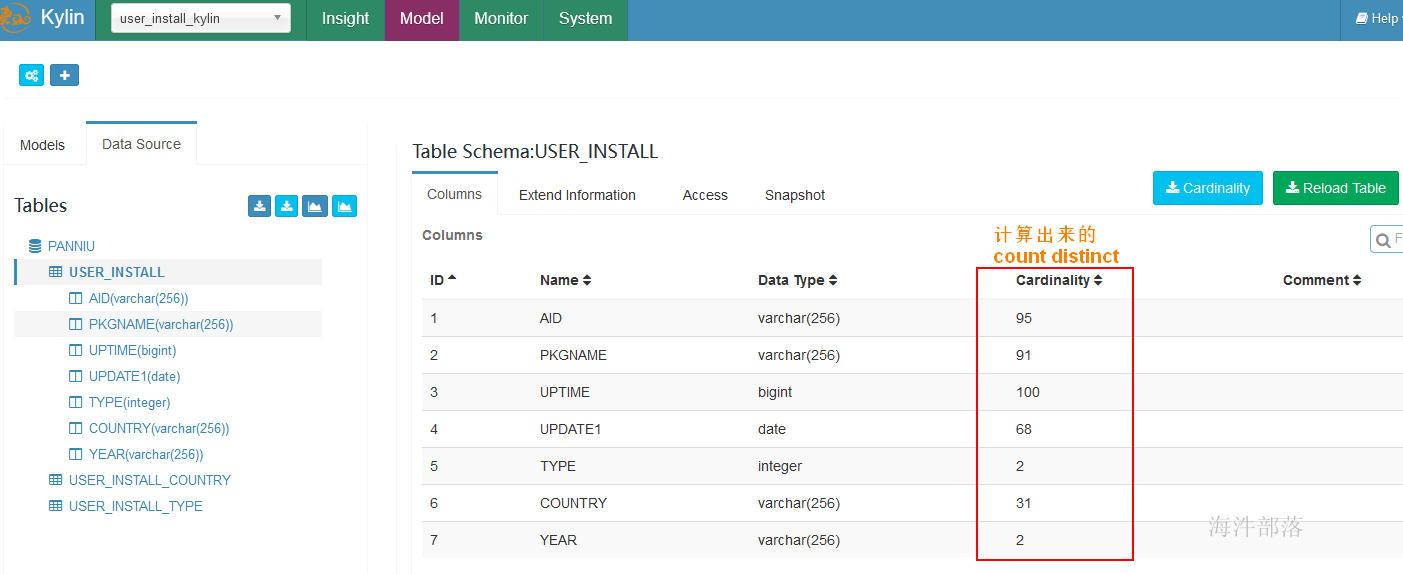
2.2 重载表
当表结构发生变化的时候可以通过reload重载表
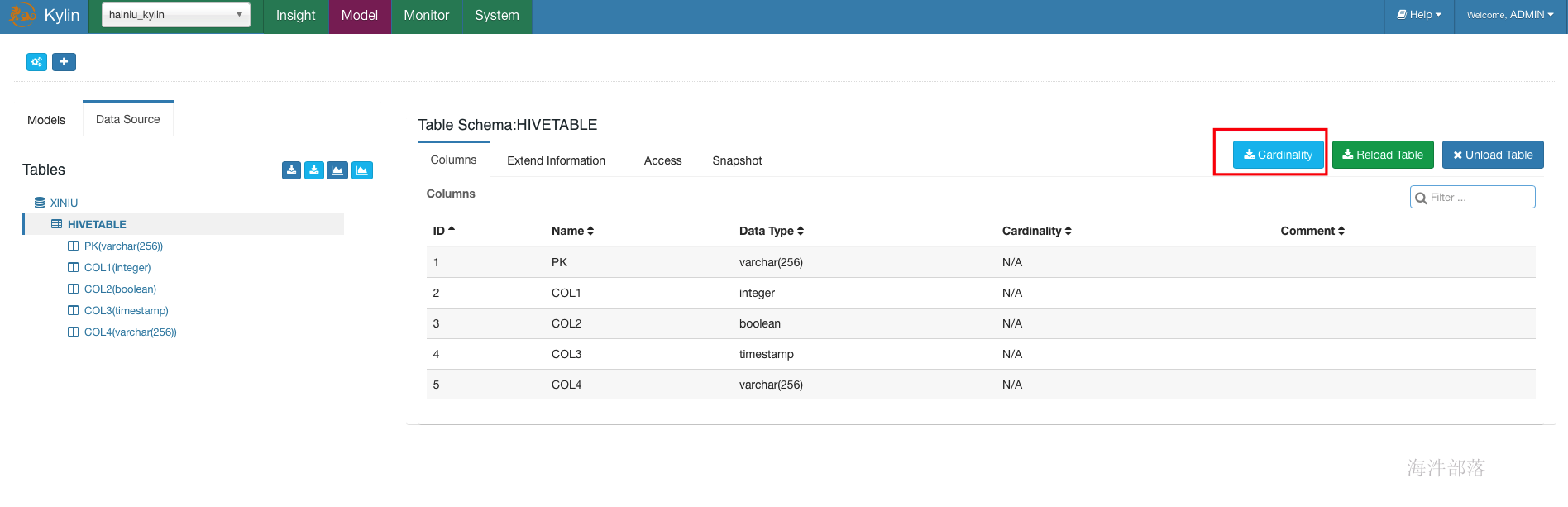
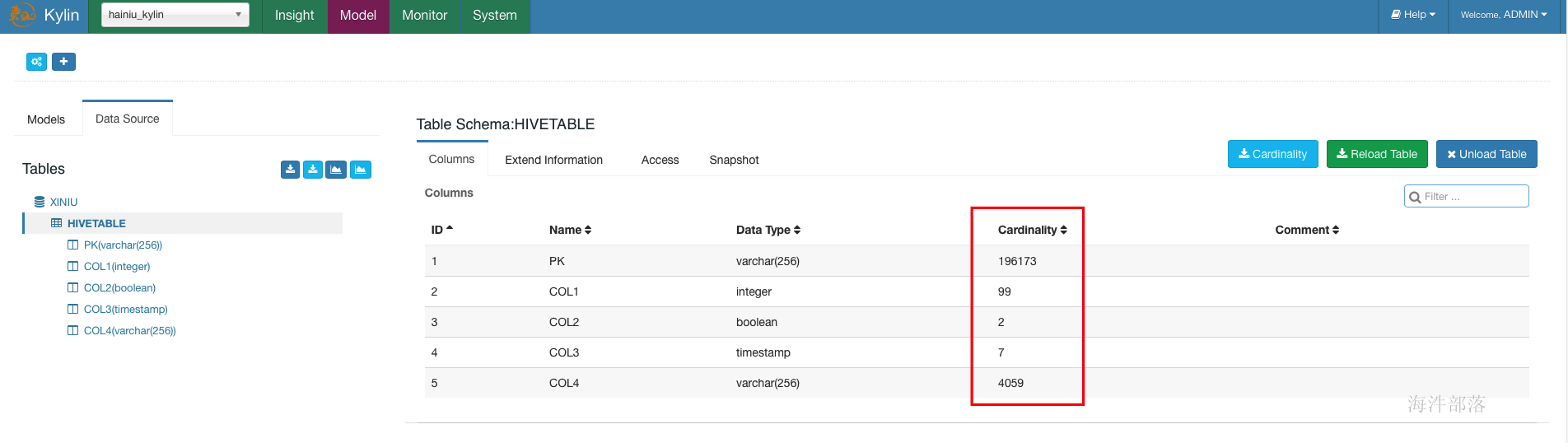
3 查看表字段基数
3.1 执行基数计算
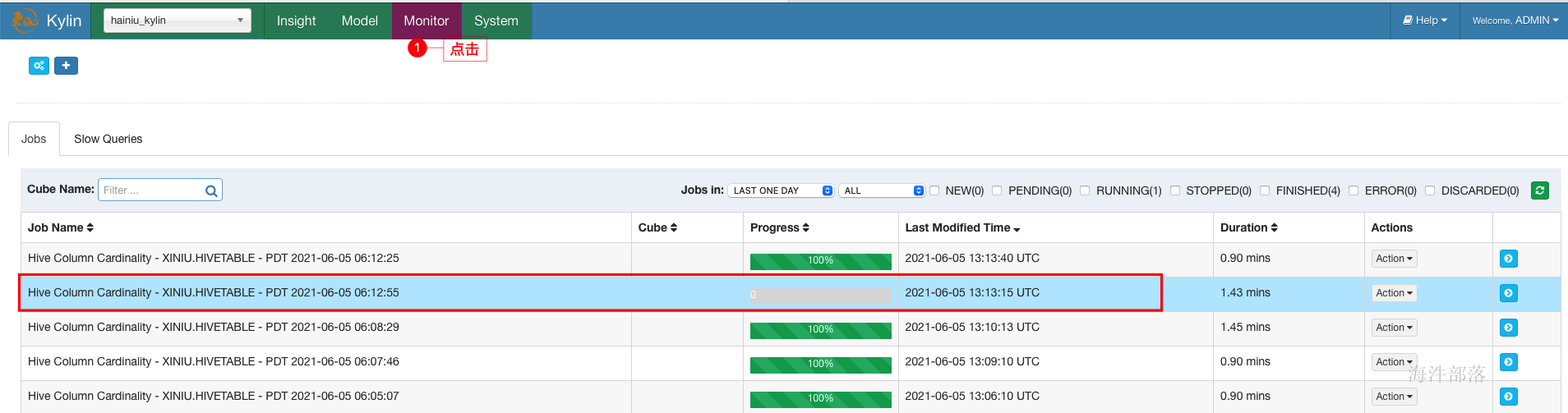
3.2 在监控页查看计算任务
3.3 查看基数
刷新页面后查看
4 定义数据模型
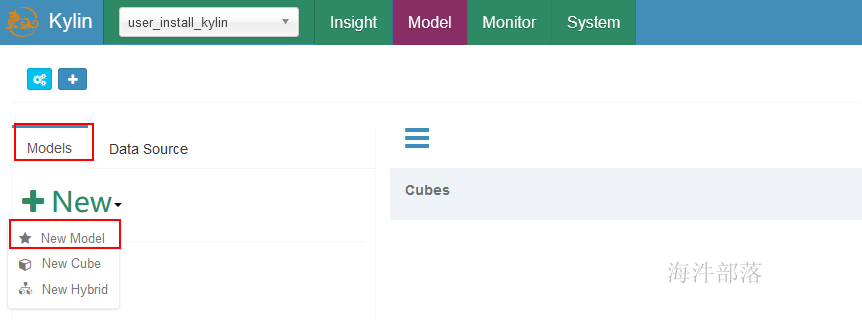
4.1 创建模型
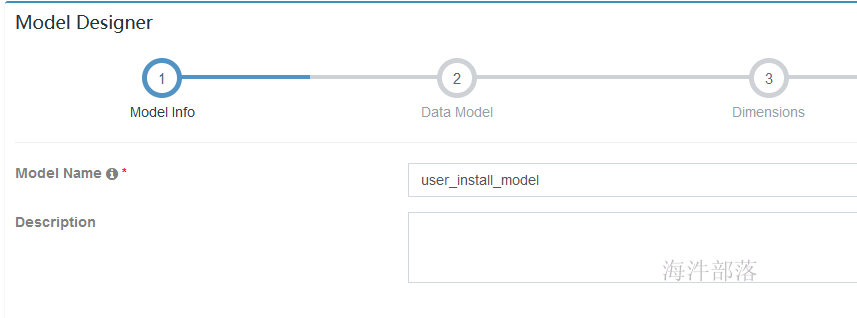
4.2 配置 model info信息
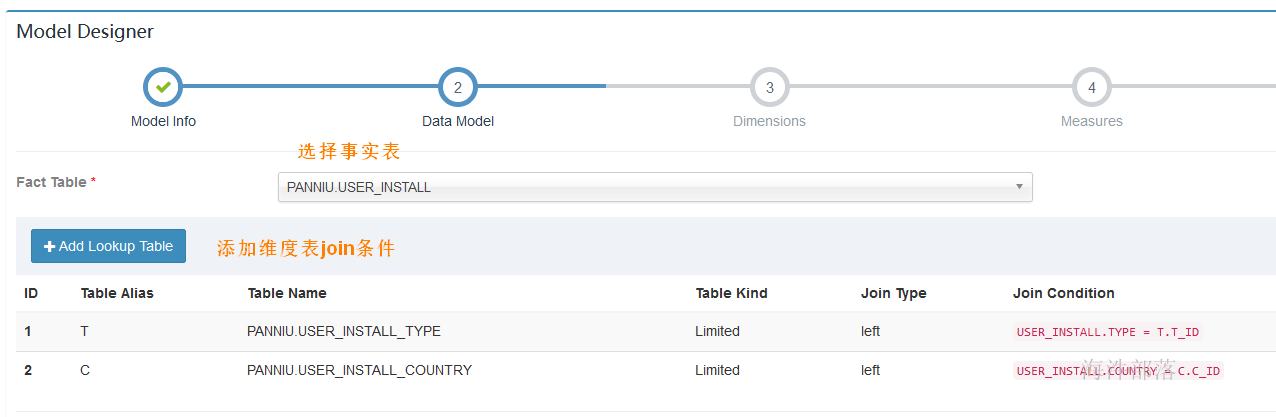
4.3 选择事实表和添加维度表
维度表join可以不添加,具体看业务
4.4 选择维度
选择groupby的字段, 维度是跟统计的业务挂钩的。
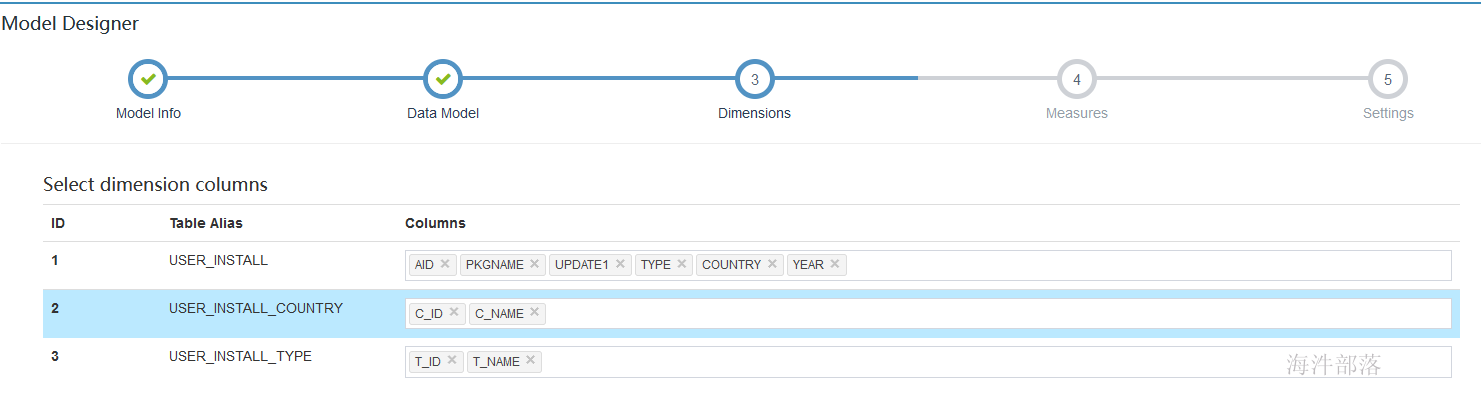
4.5 选择测量列
维度选择完,可在剩余的列里面挑选度量列
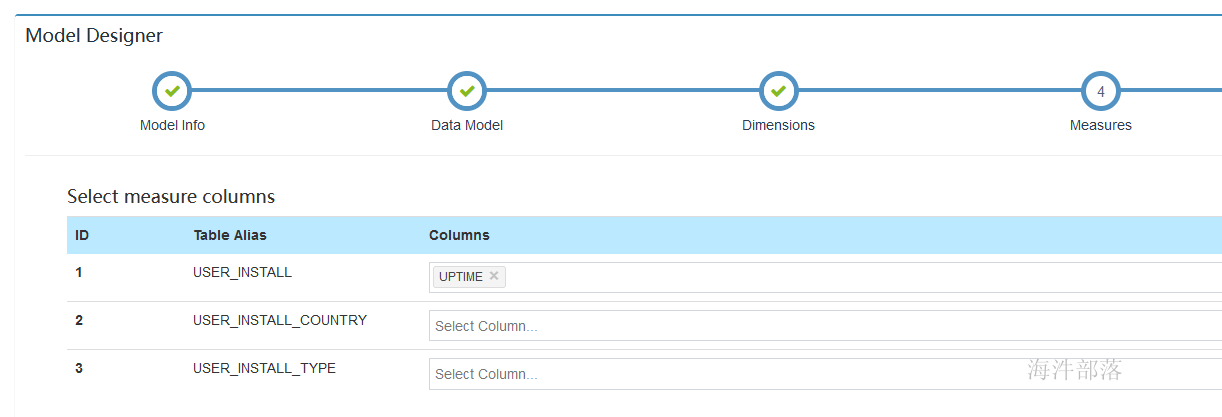
5.6 选择分区
模型已经创建完成
5 创建cube
5.1 新建cube
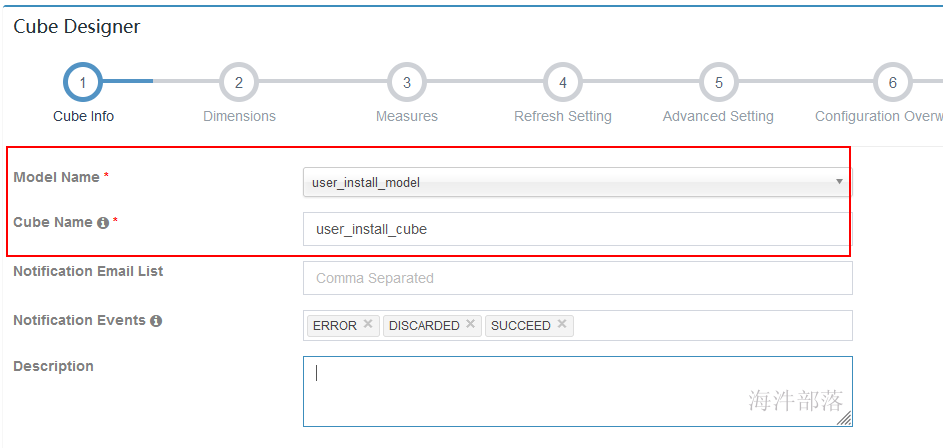
5.2 cube info
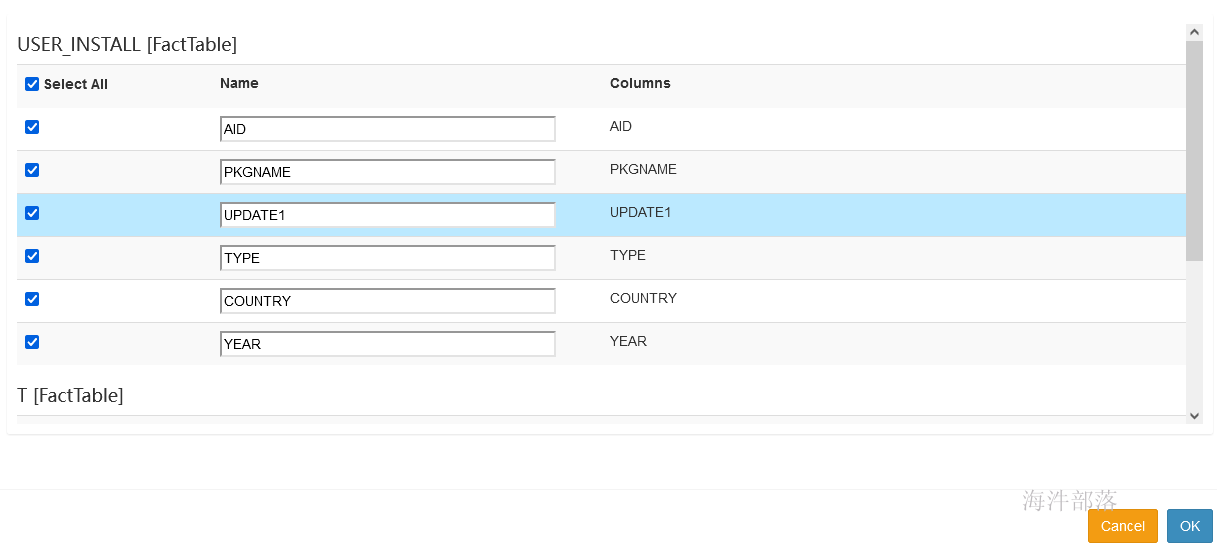
5.3 Dimensions(添加维度列)
本例:全选
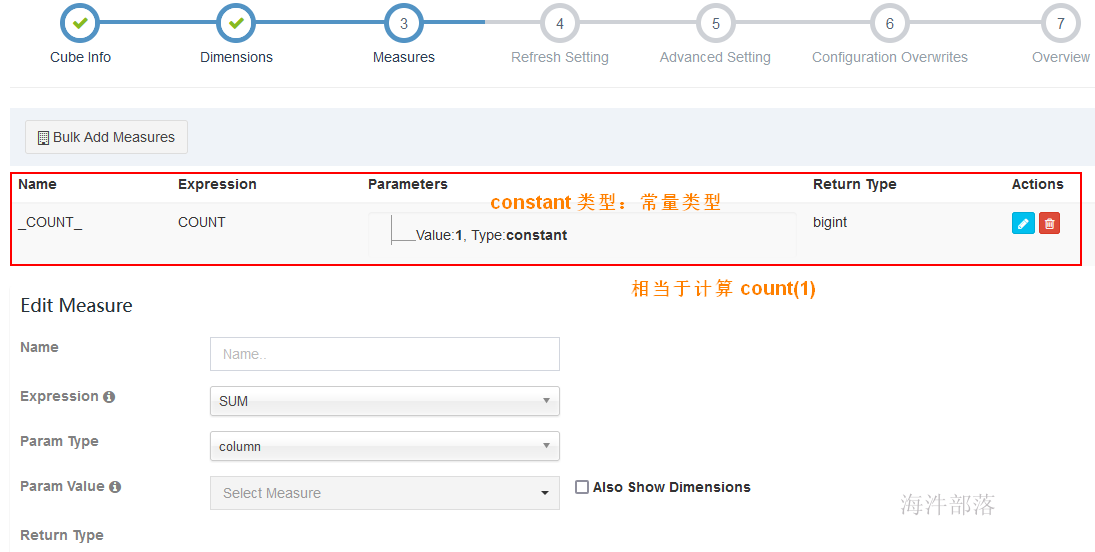
5.4 设置度量
默认自带一个 COUNT 统计
5.4.1 添加count 度量
实现的SQL相当于 : select count(country) from user_install;
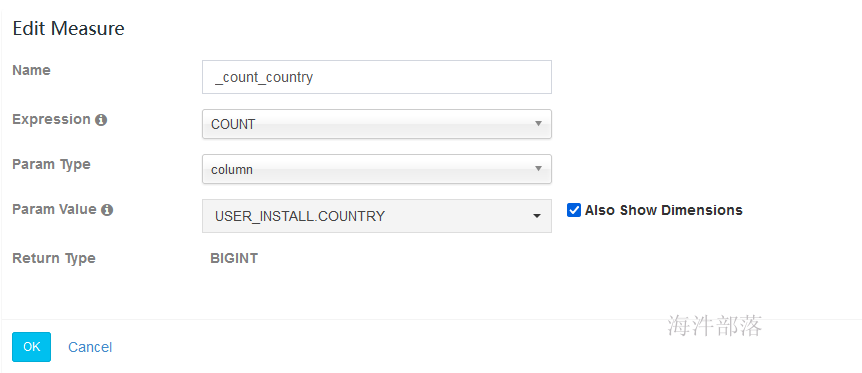
5.4.2 添加count distinct 度量
实现的SQL相当于 : select count(distinct aid) from user_install;
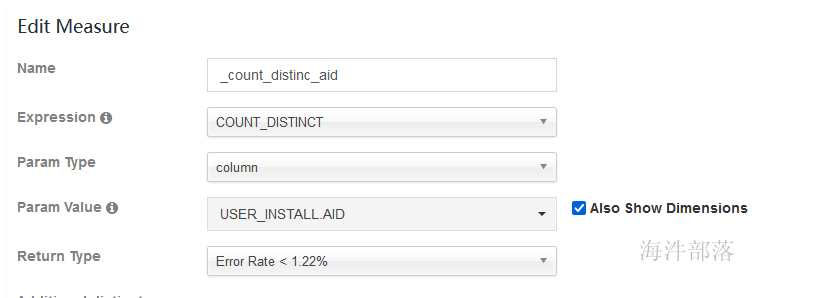
5.4.3 添加topN度量
求group by year 后的 uptime topN
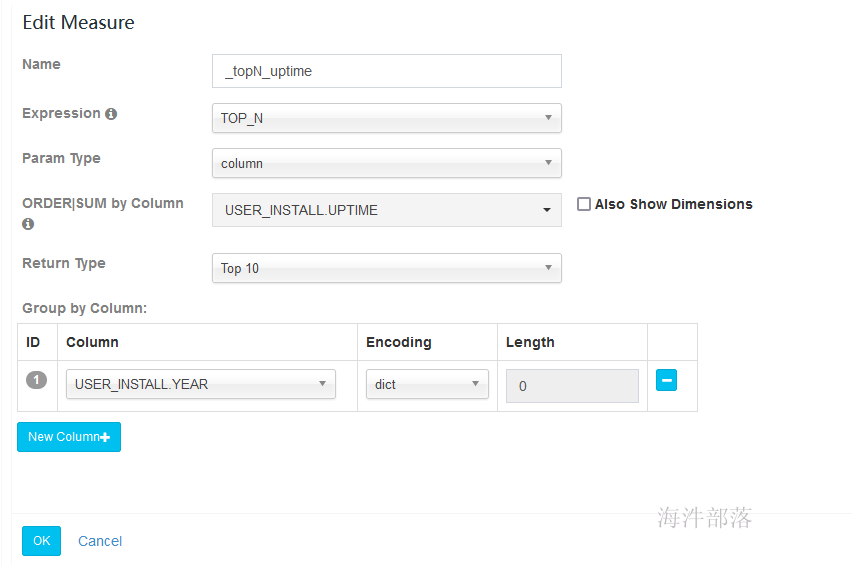
本例添加这些:
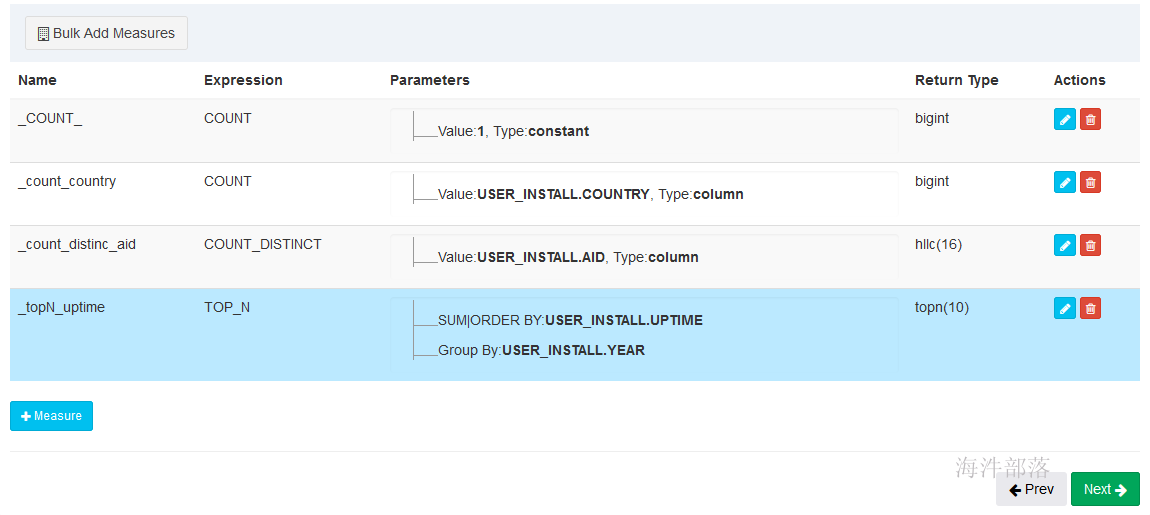
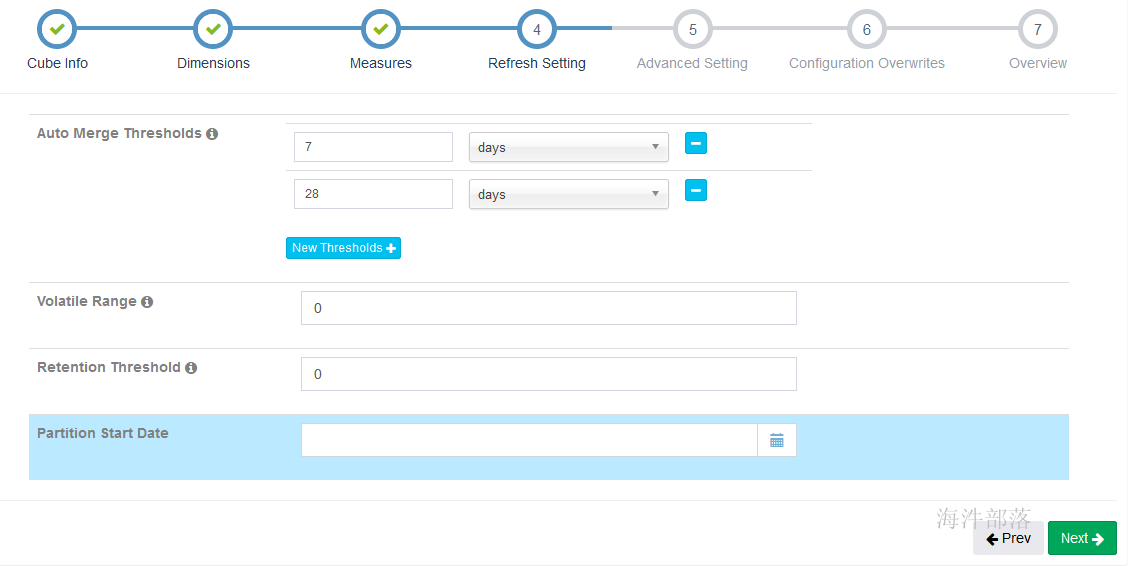
5.5 更新设置(cub合并设置)
Auto Merge Thresholds: 自动合并小的 segments 到中等甚至更大的 segment。如果不想自动合并,删除默认2个选项。
Volatile Range: 默认为0,会自动合并所有可能的 cube segments。
Retention Threshold: 只会保存 cube 过去几天的 segment,旧的 segment 将会自动从头部删除;0表示不启用这个功能。
5.6 高级设置
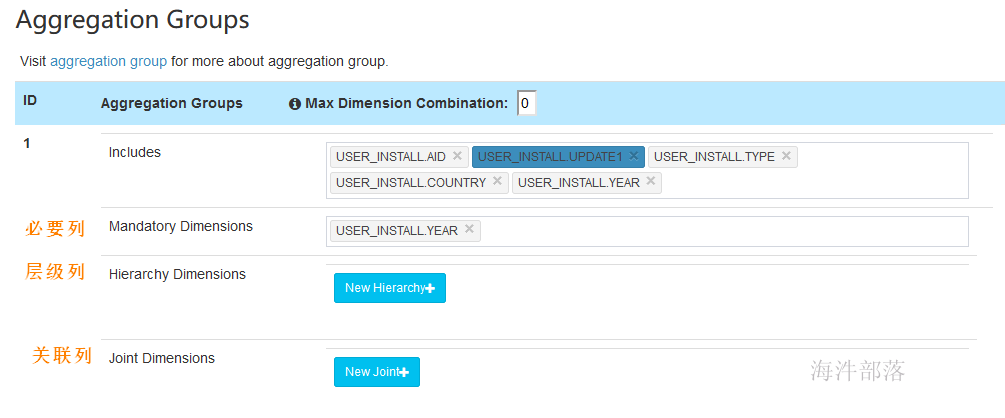
5.6.1 Aggregation Groups
Aggregation Groups: Cube 中的维度可以划分到多个聚合组中。默认 kylin 会把所有维度放在一个聚合组,当维度较多时,产生的组合数可能是巨大的,会造成 Cube 爆炸;如果你很好的了解你的查询模式,那么你可以创建多个聚合组。在每个聚合组内,使用 “Mandatory Dimensions”, “Hierarchy Dimensions” 和 “Joint Dimensions” 来进一步优化维度组合。
Mandatory Dimensions: 必要维度,用于总是出现的维度。例如,如果你的查询中总是会带有 “ORDER_DATE” 做为 group by 或 过滤条件, 那么它可以被声明为必要维度。这样一来,所有不含此维度的 cuboid 就可以被跳过计算。
Hierarchy Dimensions: 层级维度,例如 “国家” -> “省” -> “市” 是一个层级;不符合此层级关系的 cuboid 可以被跳过计算,例如 [“省”], [“市”]. 定义层级维度时,将父级别维度放在子维度的左边。
Joint Dimensions:联合维度,有些维度往往一起出现,或者它们的基数非常接近(有1:1映射关系)。例如 “user_id” 和 “email”。把多个维度定义为组合关系后,所有不符合此关系的 cuboids 会被跳过计算。
5.6.2 rowkey设置
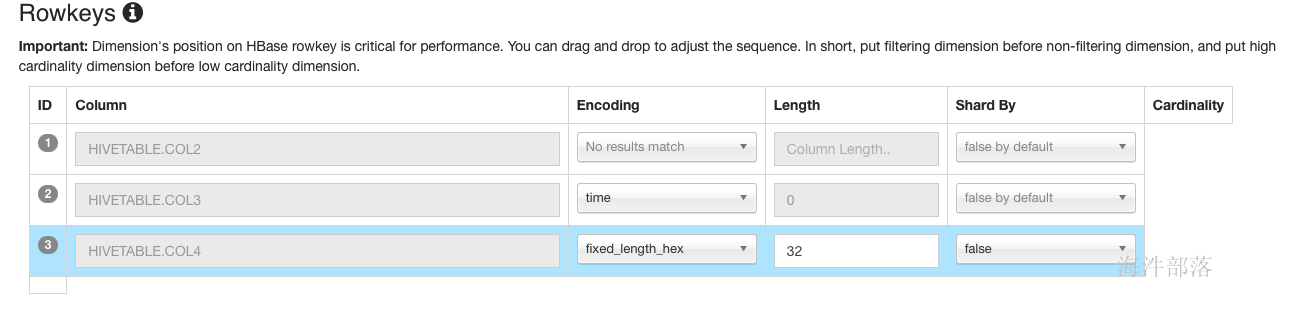
默认是dict,dict只能中低基数(小于100W),如果是超高基数则需要自己设计encoding,并且指定length。
5.6.3 维度白名单

用于设计白名单,选中的列如果被加入白名单,则一定会被构建。
5.6.4 cube引擎

5.6.5 编码字典
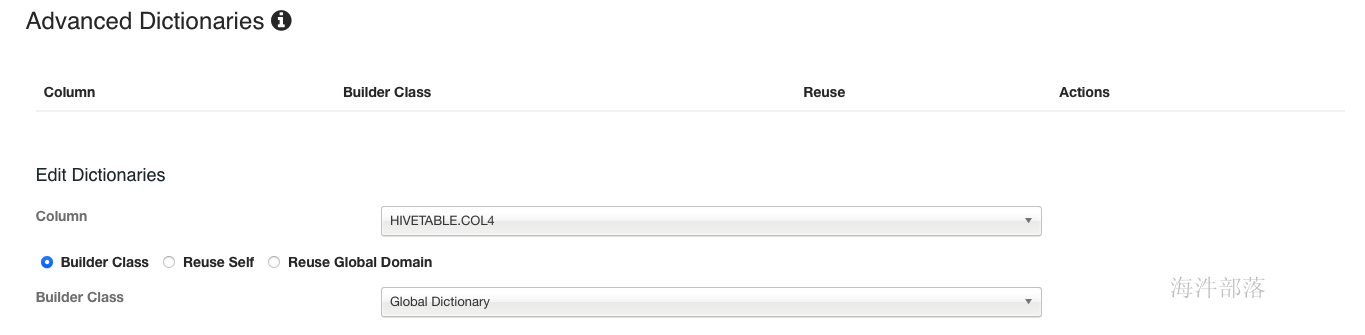
将非integer的列转为integer,用于distinct,且仅限于distinct,因为这种编码是单向编码的,不支持解码。
5.6.6 列族设计

设计多个列族,用于提高hbase的io性能。
5.6.7 创建完成

6 cube构建
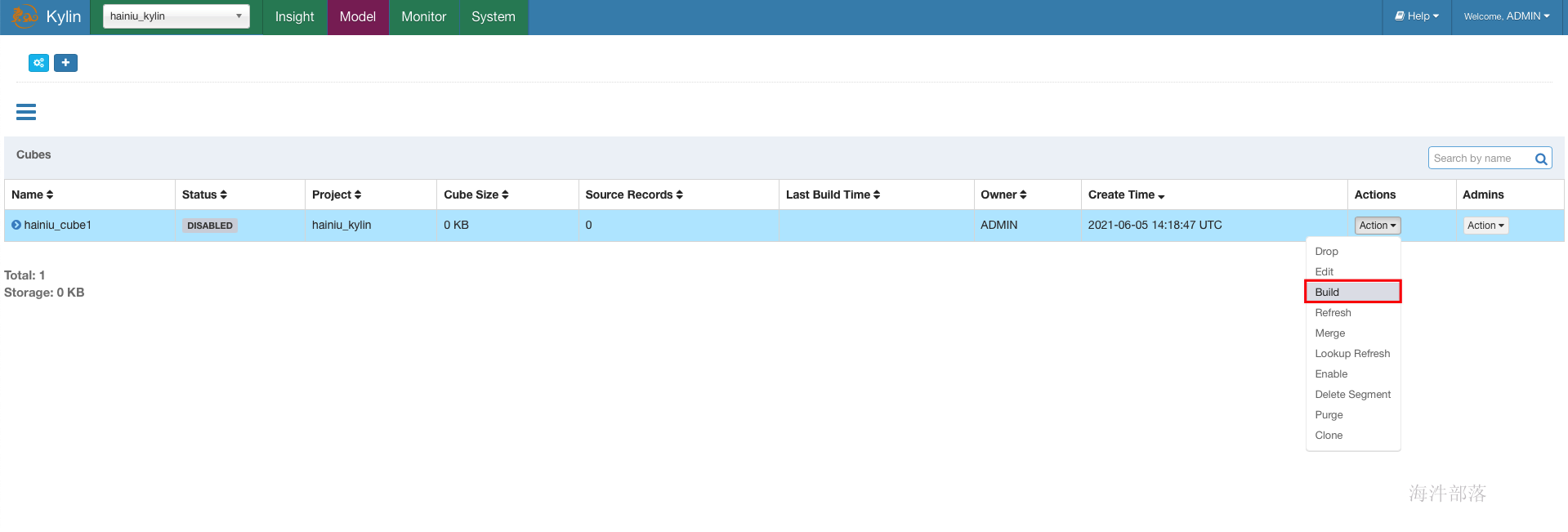
选择开始和结束时间, 这个时间范围是分区的时间范围。
本例数据是 2014和 2015年, 选择的范围只要包含这两个即可
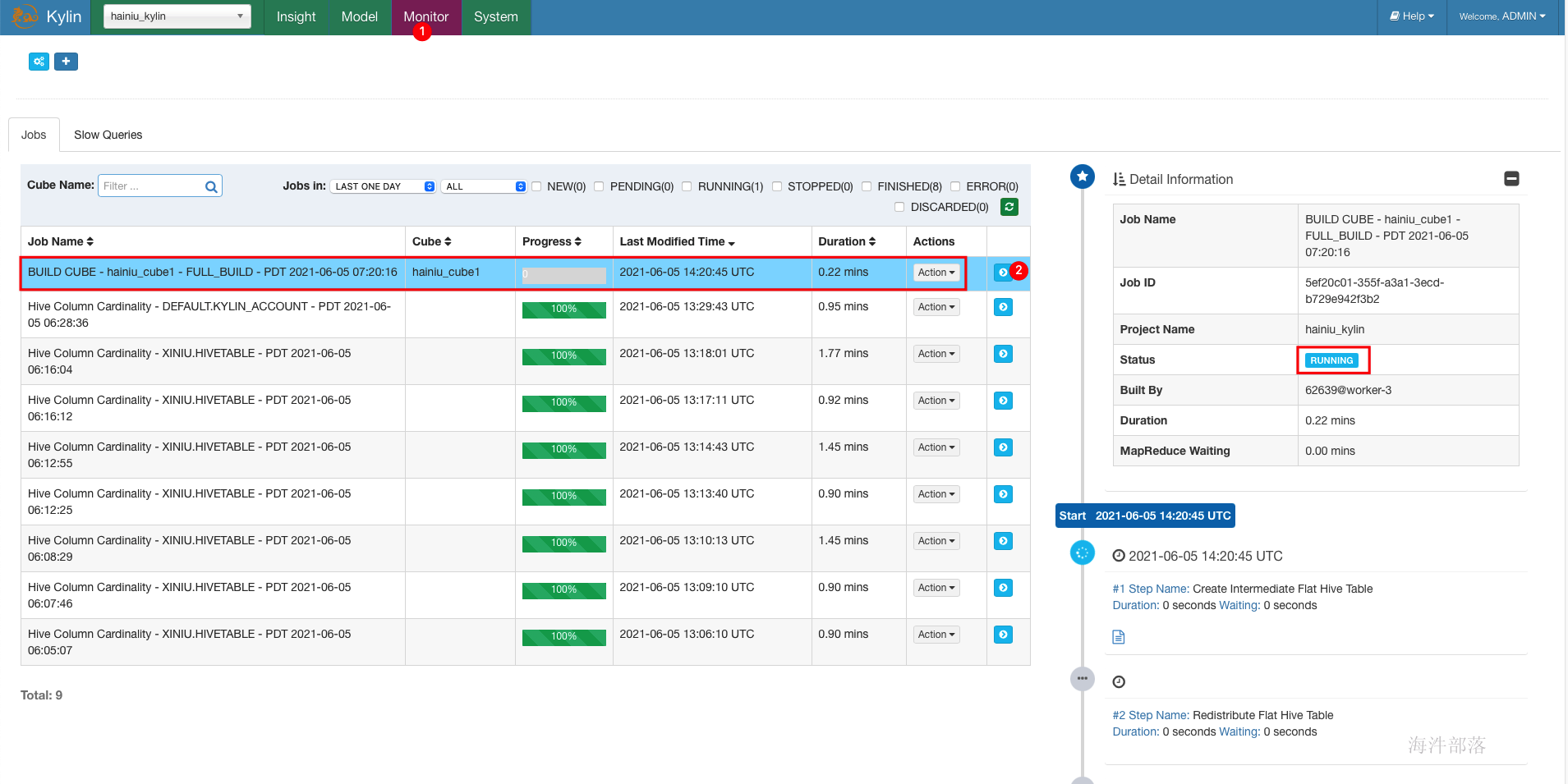

7 通过cube查询
官方文档:https://kylin.apache.org/cn/docs31/tutorial/sql_reference.html
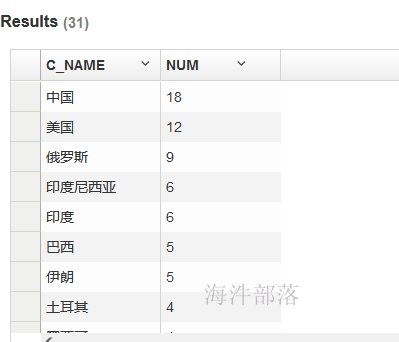
-- 先join 再按照 c_name group by 求 count
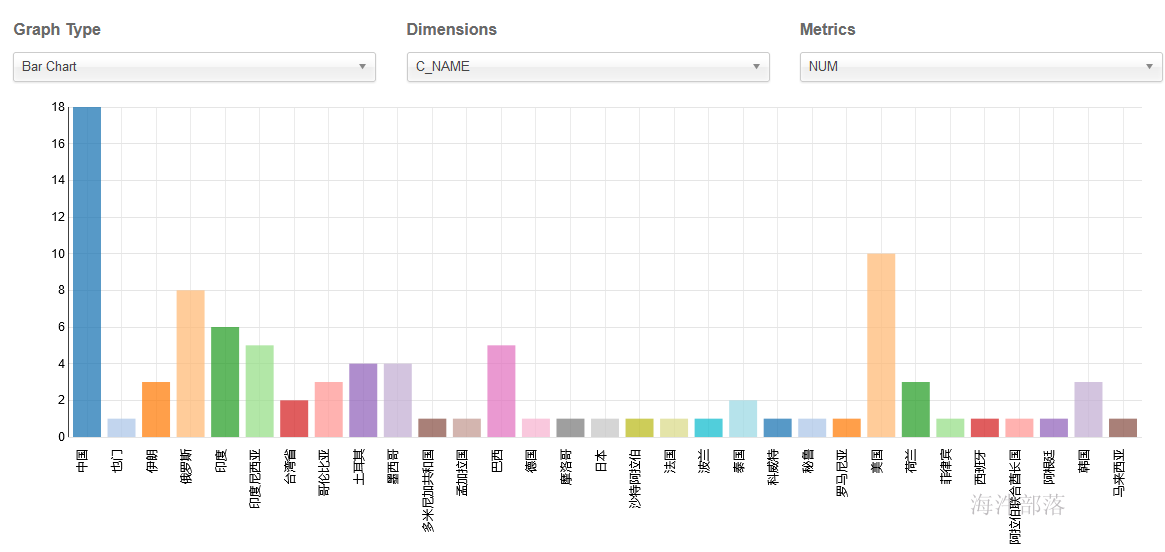
select t3.c_name, count(*) as num from
(
select * from user_install t1
left join user_install_country t2 on t1.country=t2.c_id
) t3 group by t3.c_name order by num desc;
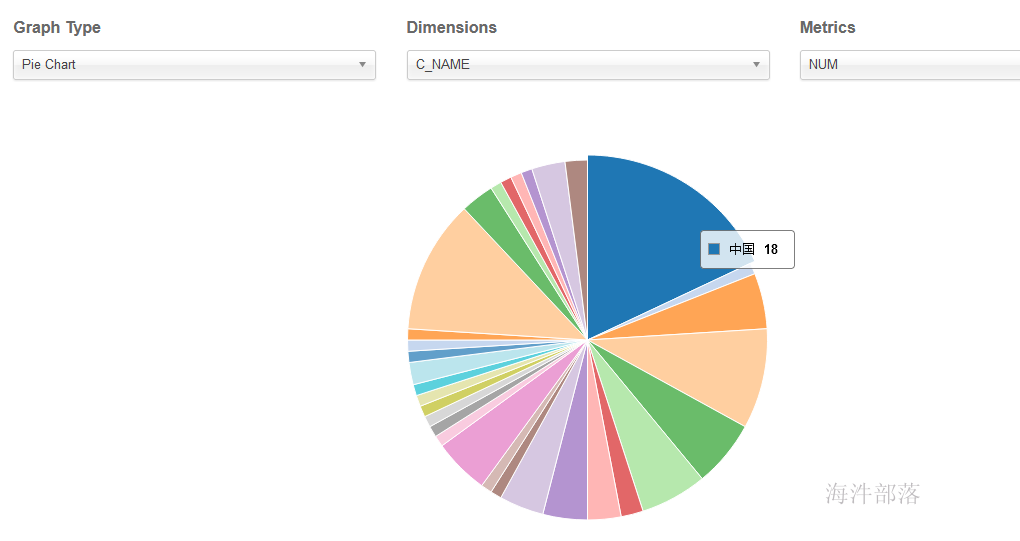
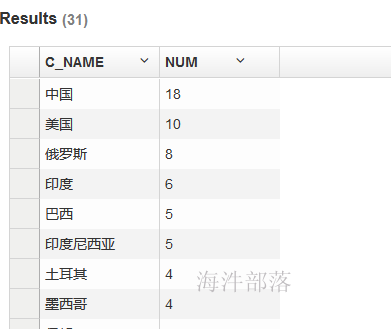
查询结果:
饼图:
-- 先join再按照c_name group by 求 count distinct
select t3.c_name, count(distinct aid) as num from
(
select * from user_install t1
left join user_install_country t2 on t1.country=t2.c_id
) t3 group by t3.c_name order by num desc;查询结果:
柱状图: