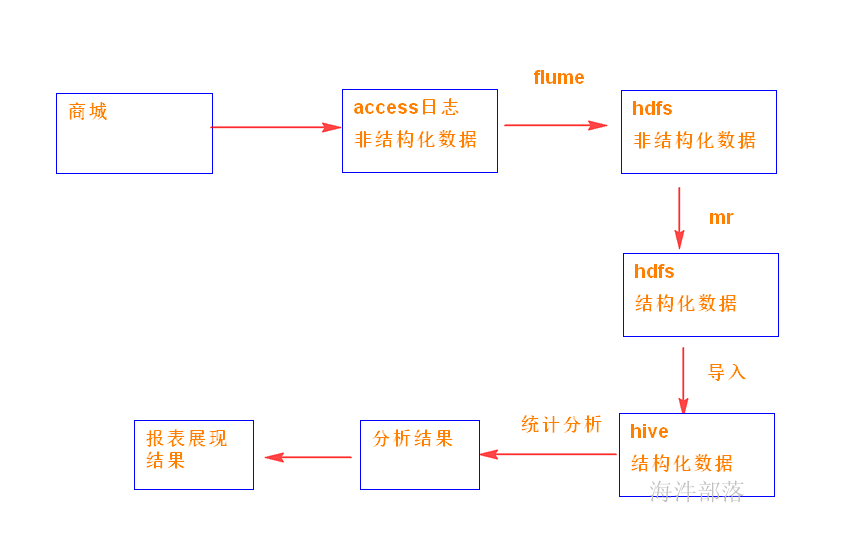
1 flume概述
Flume是一个分布式、可靠、高可用的海量日志聚合系统,支持在系统中定制各类数据发送方,用于收集数据,同时,Flume提供对数据的简单处理,并写到各种数据接收方的能力,Flume 在0.9.x and 1.x之间有较大的架构调整,1.x版本之后的改称Flume NG,0.9.x的称为Flume OG。
flume是分布式的日志收集系统,它将各个服务器中的数据收集起来并送到指定的地方去,比如说送到HDFS、Hbase,简单来说flume就是收集日志的。 flume 作为 cloudera(CDH版本的hadoop) 开发的实时日志收集系统,受到了业界的认可与广泛应用。
Flume两个版本区别:
1)Flume-og
Flume 0.9X版本的统称。
Flume-og采用了多Master的方式,为了保证配置数据的一致性,Flume引入了ZooKeeper用于保存配置文件,在配置文件发生变化时,ZooKeeper可以通知Flume Master节点,Flume Master间可同步数据。
2)Flume-ng
Flume1.X版本的统称。
Flume-ng 取消了集中管理配置的 Master 和 Zookeeper,变为一个纯粹的传输工具。
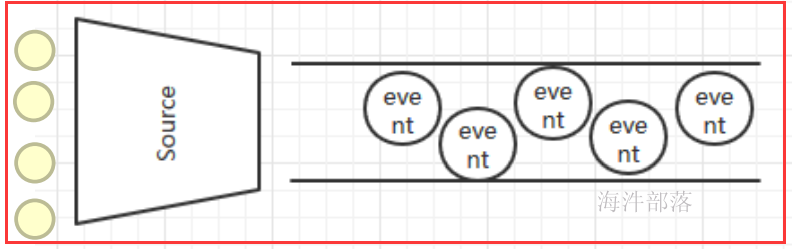
1.1 flume的结构模型
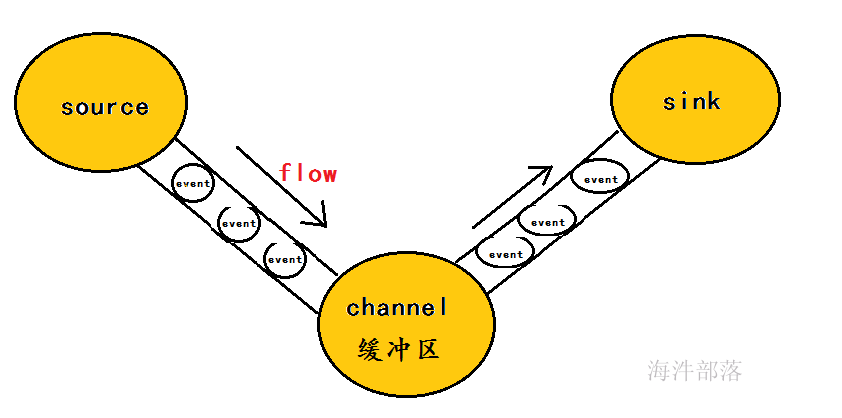
Flume 运行的核心是 Agent,Flume以agent为最小的独立运行单位,一个agent就是一个JVM,含有三个核心组件,分别是source、 channel、 sink,通过这些组件, Event 可以从一个地方流向另一个地方,如下图所示。
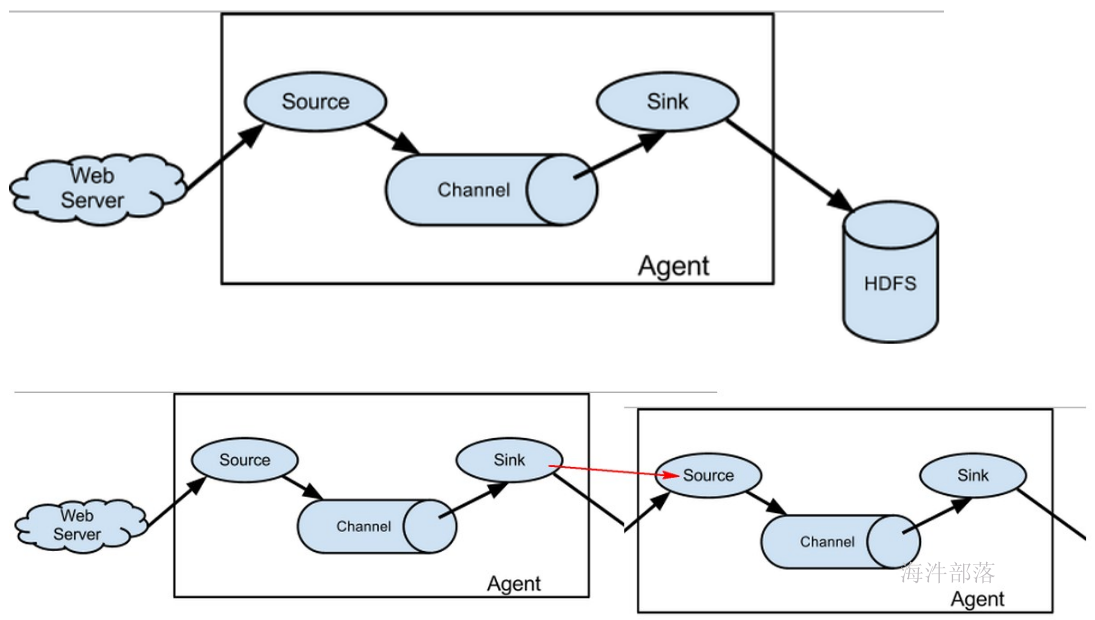
Source:
从Client上收集数据并对数据进行格式化,以Event(事件)的形式传递给单个或多个Channel。
Channel:
短暂的存储容器,将从Source接收到的Event进行缓存直到被Sink消费掉,Channel是Source和Sink之间的桥梁,Channal是一个完整的事务,能保证了数据在收发时的一致性。
Sink:
从Channel中消费数据(Event)并传递到存储容器(Hbase、HDFS)或其他的Source中。
工作流程:
把数据从数据源(source)收集过来,在将收集到的数据送到指定的目的地(sink)。
为了保证输送的过程一定成功,在送到目的地(sink)之前,会先缓存数据(channel),待数据真正到达目的地(sink)后,flume再删除自己缓存的数据。
什么是Event?
1)event将传输的数据进行封装,是flume传输数据的基本单位,如果是文本文件,通常是一行记录。
2)event也是事务的基本单位。
3)event从source,流向channel,再到sink,本身为一个字节数组,并可携带headers(头信息)信息。
4)event代表着一个数据的最小完整单元,从外部数据源来,向外部的目的地去。
Agent:
Flume以 Agent 为最小的独立运行单元,Agent 依赖于 JVM ,一个 Agent 的运行就伴随一个 JVM 实例的产生。
一台机器可以运行多个Agent,一个Agent中可以包含多个Source、Sink。
1.2 flume各组件介绍
Flume提供了大量内置的Source、Channel和Sink类型,不同类型的Source,Channel和Sink可以自由组合.组合方式基于用户设置的配置文件。
1.2.1 Source组件
Source是数据的收集端,负责将数据捕获后进行特殊的格式化,将数据封装到事件(event) 里,然后将事件推入Channel中,Flume提供了各种source的实现,包括Avro Source、Exce Source、Spooling Directory Source、NetCat Source、Syslog Source、Syslog TCP Source、Syslog UDP Source、HTTP Source、HDFS Source,etc。如果内置的Source无法满足需要, Flume还支持自定义Source。
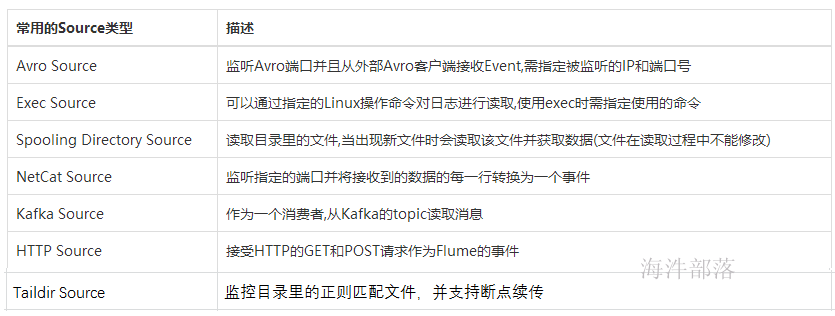
1.2.2 Channel组件
Channel是连接Source和Sink的组件,大家可以将它看做一个数据的缓冲区(数据队列),它可以将事件暂存到内存中也可以持久化到本地磁盘上, 直到Sink处理完该事件,Flume对于Channel,则提供了Memory Channel、JDBC Chanel、File Channel,etc。
MemoryChannel可以实现高速的吞吐,但是无法保证数据的完整性。
MemoryRecoverChannel在官方文档的建议上已经建义使用FileChannel来替换。
FileChannel保证数据的完整性与一致性。

1.2.3 Sink组件
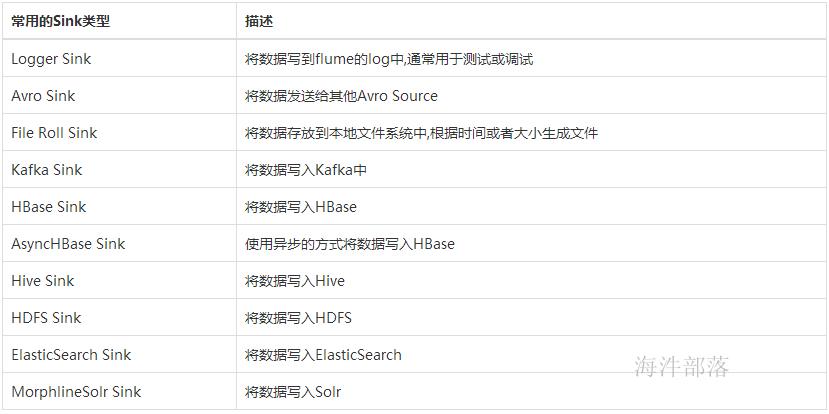
Flume Sink取出Channel中的数据,进行相应的存储文件系统,数据库,或者提交到远程服务器。Flume也提供了各种sink的实现,包括HDFS sink、Logger sink、Avro sink、File Roll sink、Null sink、HBase sink,etc。
Flume Sink在设置存储数据时,可以向文件系统中,数据库中,hadoop中储数据,在日志数据较少时,可以将数据存储在文件系中,并且设定一定的时间间隔保存数据,在日志数据较多时,可以将相应的日志数据存储到Hadoop中,便于日后进行相应的数据分析。
2 flume 安装
集群 → 添加服务, 选择flume
选择依赖的服务
添加主机
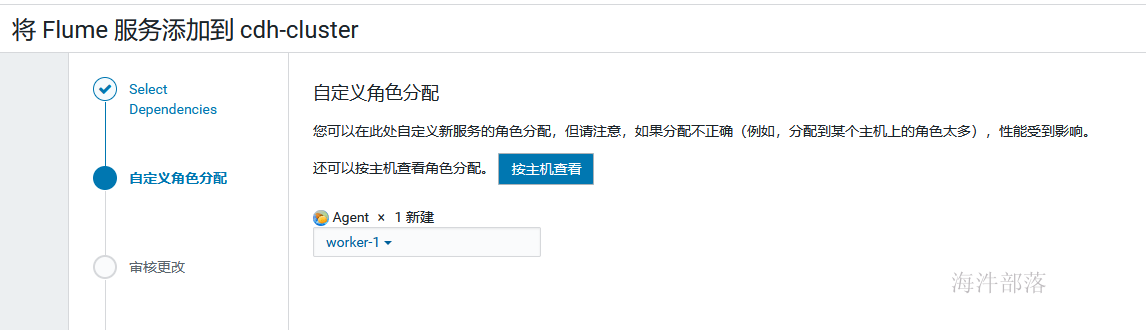
启动服务即可使用。
3 flume应用
flume应用就是学组价的搭配应用,根据各组件的不同,配置内容也不同
可参考官方网站:http://flume.apache.org/FlumeUserGuide.html
3.1 netcat -- memory -- logger
监听一个指定的网络端口,即只要应用程序向这个端口里面写数据,这个source组件就可以获取到信息。
其中:
Source:netcat
Sink:logger
Channel:memory
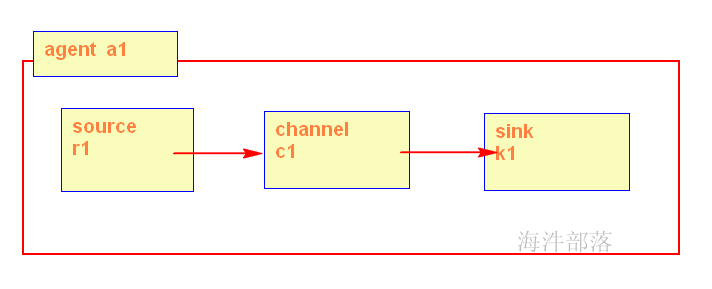
1)从整体上描述代理agent中sources、sinks、channels所涉及到的组件
# 配置Agent
a1.sources = r1
a1.sinks = k1
a1.channels = c12)分别配置三个组件的具体实现
# 配置Source
a1.sources.r1.type = netcat
a1.sources.r1.bind = 192.168.142.160
a1.sources.r1.port = 22222
# 配置Sink
a1.sinks.k1.type = logger
# 配置Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 1003)将三个组件进行连接
# 将三者连接
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c14)启动flume agent a1 服务端
# 每个人用自己的,注意给自己用户权限 /data/xxx/flume
flume-ng agent -n a1 -f /data/xinniu/flume/conf/netcat-conf.properties -Dflume.root.logger=DEBUG,console参数说明:
-n :指定agent名称(与配置文件中代理的名字相同)
-c :指定flume中配置文件的目录
-f :指定配置文件
-Dflume.root.logger=DEBUG,console :设置日志等级
5)使用telnet发送数据
在虚拟机里发送命令
telnet 192.168.142.160 22222
aa bb cc6)在控制台上查看flume收集到的日志数据

3.2 exec -- memory -- hdfs
Exec Source:监听一个指定的命令,获取一条命令的结果作为它的数据源 ;
常用的是tail -F file指令监控一个文件,即只要应用程序向日志(文件)里面写数据,source组件就可以获取到日志(文件)中最新的内容 。

可用此方式进行实时抽取。
配置如下:
Source:exec
Sink:hdfs
Channel:memory
# 配置Agent
a1.sources = f1
a1.channels = c1
a1.sinks = t1
# 配置Source
a1.sources.f1.type = exec
# 配置需要监控的日志输出目录
a1.sources.f1.command = tail -f /data/xinniu/flume/exec/exec.log
# 配置Sink
# 指定目标类型
a1.sinks.t1.type = hdfs
# 使用linux的本地时间
a1.sinks.t1.hdfs.useLocalTimeStamp = true
# 设定HDFS的目录结构
a1.sinks.t1.hdfs.path = hdfs:///user/xinniu/flume-exec/%Y-%m-%d
# 文件的前缀
a1.sinks.t1.hdfs.filePrefix = %Y-%m-%d-%H
# 文件的后缀
a1.sinks.t1.hdfs.fileSuffix = .log
# 设置副本为1
a1.sinks.t1.hdfs.minBlockReplicas = 1
# 不压缩的文本
a1.sinks.t1.hdfs.fileType = DataStream
# 文本格式
a1.sinks.t1.hdfs.writeFormat = Text
# 可以设置一个时间来关闭一个hdfs文件
a1.sinks.t1.hdfs.rollInterval = 0
# 可以设置一个字节数来关闭一个文件
a1.sinks.t1.hdfs.rollSize = 0
# 设置当写入了多少个event的时候就关闭这个文件
a1.sinks.t1.hdfs.rollCount = 5
# 禁止因为超时原因而关闭文件
a1.sinks.t1.hdfs.idleTimeout = 0
# 配置Channel
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
# 将三者连接
a1.sources.f1.channels = c1
a1.sinks.t1.channel = c1其中:
sink 输出到hdfs中,每5个event 生成一个hdfs文件,hdfs文件目录会根据hdfs.path 的配置自动创建。
sink hdfs 配置参数描述:
| 名称 | 描述 |
|---|---|
| hdfs.path | hdfs目录路径 |
| hdfs.filePrefix | 文件前缀。默认值FlumeData |
| hdfs.fileSuffix | 文件后缀 |
| hdfs.rollInterval | 多久时间后close hdfs文件。单位是秒,默认30秒。设置为0的话表示不根据时间close hdfs文件 |
| hdfs.rollSize | 文件大小超过一定值后,close文件。默认值1024,单位是字节。设置为0的话表示不基于文件大小 |
| hdfs.rollCount | 写入了多少个事件后close文件。默认值是10个。设置为0的话表示不基于事件个数 |
| hdfs.fileType | 文件格式, 有3种格式可选择:SequenceFile(默认), DataStream(不压缩) or CompressedStream(可压缩) |
| hdfs.batchSize | 批次数,HDFS Sink每次从Channel中拿的事件个数。默认值100 |
| hdfs.minBlockReplicas | HDFS每个块最小的replicas数字,不设置的话会取hadoop中的配置 |
| hdfs.maxOpenFiles | 允许最多打开的文件数,默认是5000。如果超过了这个值,越早的文件会被关闭 |
| serializer | HDFS Sink写文件的时候会进行序列化操作。会调用对应的Serializer接口,可以自定义符合需求的Serializer |
| hdfs.retryInterval | 关闭HDFS文件失败后重新尝试关闭的延迟数,单位是秒 |
| hdfs.callTimeout | HDFS操作允许的时间,比如hdfs文件的open,write,flush,close操作。单位是毫秒,默认值是10000 |
| hdfs.writeFormat | 序列文件记录的格式。一个文本或writable |
| hdfs.codeC | 压缩编解码器。以下之一:gzip,bzip2,lzo,lzop,snappy |
| hdfs.idleTimeout | 超时之后,非活动文件关闭(0 =禁止自动关闭空闲文件) |
创建监控文件
mkdir /data/xinniu/flume/exec && cd /data/xinniu/flume/exec && touch exec.log && echo 'OK'启动flume agent a1 服务端
flume-ng agent -n a1 -f /data/xinniu/flume/conf/exec-conf.properties -Dflume.root.logger=INFO,Console 监控/data/xinniu/flume/exec/exec.log
往exec.log 追加数据,追加5个之后,会生成新文件
cd /data/xinniu/flume/exec
echo `date` >> exec.logflume就把数据归集到hdfs上, hdfs每5个事件关闭文件,并产生新文件
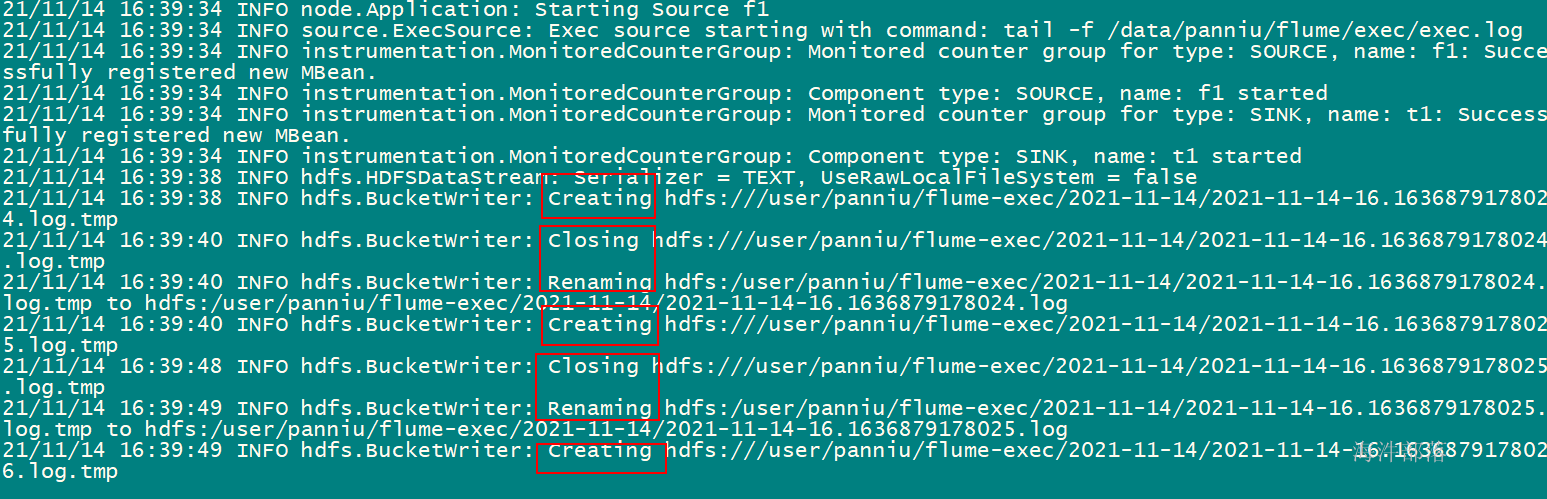
webui查看:
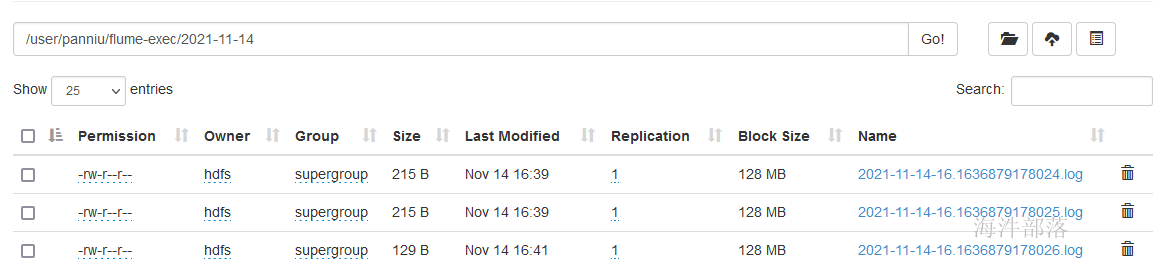
弊端:
ExecSource tail -f 适合固定文件日志的读取,但是这会有一个弊端,就是当你的服务器宕机重启后,此时数据读取还是从头开始,既不支持文件断点续传的功能。
有重复归集数据的风险
在重启后,不追加任何数据情况下,查看发现比之前多,证明重复归集了:
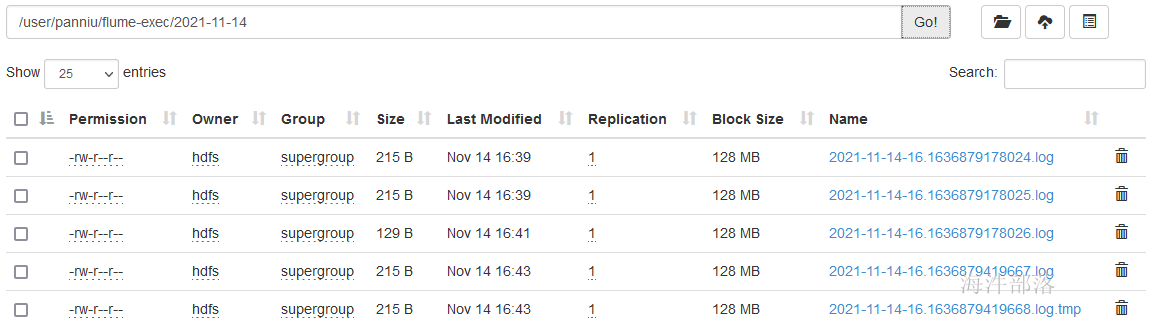
3.3 Taildir Source
Taildir Source:监听一个指定的目录下,指定正则格式的文件的内容,作为它的数据源,并支持断点续传功能 ;
如何支持断点续传的?
有个文件,存储断点续传的位置。
用于实时抽取指定目录下的多个文件。
创建配置文件
vim /data/xinniu/flume/conf/taildir-conf.properties填写如下配置到文件中
配置方式:
Source:Taildir
Sink:hdfs
Channel:file
# Name the components on this agent
a2.sources = f1
a2.channels = c1
a2.sinks = t1
# sources类型
a2.sources.f1.type = taildir
#存储读取文件数据最后位置
a2.sources.f1.positionFile = /data/xinniu/flume/data
a2.sources.f1.filegroups = g1
a2.sources.f1.filegroups.g1 = /data/xinniu/flume/taildir/.*.log
# Describe the sink
a2.sinks.t1.type = hdfs
a2.sinks.t1.hdfs.useLocalTimeStamp = true
a2.sinks.t1.hdfs.path = hdfs:///user/xinniu/flume-taildir/%Y-%m-%d
a2.sinks.t1.hdfs.filePrefix = %Y-%m-%d
a2.sinks.t1.hdfs.writeFormat = Text
a2.sinks.t1.hdfs.fileType = DataStream
a2.sinks.t1.hdfs.rollInterval = 0
a2.sinks.t1.hdfs.rollSize = 0
a2.sinks.t1.hdfs.rollCount = 5
# channals file
a2.channels.c1.type = file
a2.channels.c1.checkpointDir = /data/xinniu/flume/data/checkpoint1
a2.channels.c1.dataDirs = /data/xinniu/flume/data/data1
# Bind the source and sink to the channel
a2.sources.f1.channels = c1
a2.sinks.t1.channel = c1创建监控目录
mkdir -p /data/xinniu/flume/taildir启动flume agent a2 服务端
flume-ng agent -n a2 -f /data/xinniu/flume/conf/taildir-conf.properties -Dflume.root.logger=DEBUG,Console追加N条数据到 t1.log中
echo `date` >> /data/xinniu/flume/taildir/t1.logwebui:

查看/data/xinniu/flume/data/taildir_position.json 文件内容
内部记录了归集到哪个文件的哪个位置

重新启动后,先查看这个文件内容,再进行归集,不会重复归集
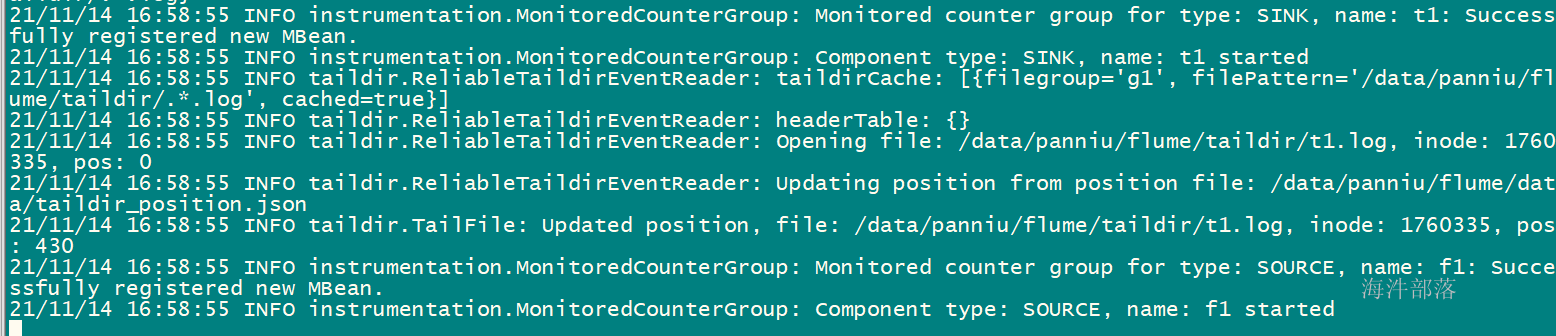
3.4 Spooling Directory Source
Spooling Directory Source:监听一个指定的目录,即只要应用程序向这个指定的目录中添加新的文件,source组件就可以获取到该信息,并解析该文件的内容,然后写入到channle。写入完成后,标记该文件已完成或者删除该文件。

此种方式不是实时抽取,是定时抽取。
flume官网中Spooling Directory Source描述:
Property Name Default Description
channels –
type – The component type name, needs to be spooldir.
spoolDir – Spooling Directory Source监听的目录
fileSuffix .COMPLETED 文件内容写入到channel之后,标记该文件
deletePolicy never 文件内容写入到channel之后的删除策略: never or immediate
fileHeader false Whether to add a header storing the absolute path filename.
ignorePattern ^$ Regular expression specifying which files to ignore (skip)
interceptors – 指定传输中event的head(头信息),常用timestampa1.sources.r1.ignorePattern = ^(.)*\.tmp$ # 跳过.tmp结尾的文件
两个注意事项:
# 1) 拷贝到spool目录下的文件不可以再打开编辑
# 2) 不能将具有相同文件名字的文件拷贝到这个目录下配置如下:
Source:Spooling Directory
Sink:hdfs
Channel:file
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# 指定source源
a1.sources.r1.type = spooldir
# 指定监控的目录
a1.sources.r1.spoolDir = /data/xinniu/flume/spooling
a1.sources.r1.fileHeader = true
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = timestamp
#如果想传完删掉,可以配置
#如果打开这个配置,cp mv 同样的文件到监控的目录下,也可以归集
#如果关闭这个配置,cp mv 同样的文件到监控的目录下,抛异常
#a1.sources.r1.deletePolicy = immediate
# 跳过.tmp结尾的文件
a1.sources.r1.ignorePattern = ^(.)*\\.tmp$
# Describe the sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs:///user/xinniu/flume-spooling/%Y-%m
a1.sinks.k1.hdfs.filePrefix = %Y-%m-%d-%H
a1.sinks.k1.hdfs.fileSuffix = .log
a1.sinks.k1.hdfs.minBlockReplicas = 1
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 0
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 100
a1.sinks.k1.hdfs.callTimeout = 40000
# channals file
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /data/xinniu/flume/data/checkpoint2
a1.channels.c1.dataDirs = /data/xinniu/flume/data/data2
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1其中:
Spooling Directory Source 监听/data/xinniu/flume/spooling 下的是否有新文件,如果有,则读到channel。输出到hdfs中,每100个event 生成一个hdfs文件,hdfs文件目录会根据hdfs.path 的配置自动创建。
创建监控目录
mkdir -p /data/xinniu/flume/spooling启动flume agent a1 服务端
flume-ng agent -n a1 -f /data/xinniu/flume/conf/spooling-conf.properties -Dflume.root.logger=DEBUG,Console监控/data/xinniu/flume/spooling 目录,把文件cp到目录下,flume就开始归集,归集完,把文件重命名为xxx.COMPLETED
cp文件到目标目录(文件不重名)

已经被归集的文件,被重命名

归集后的文件
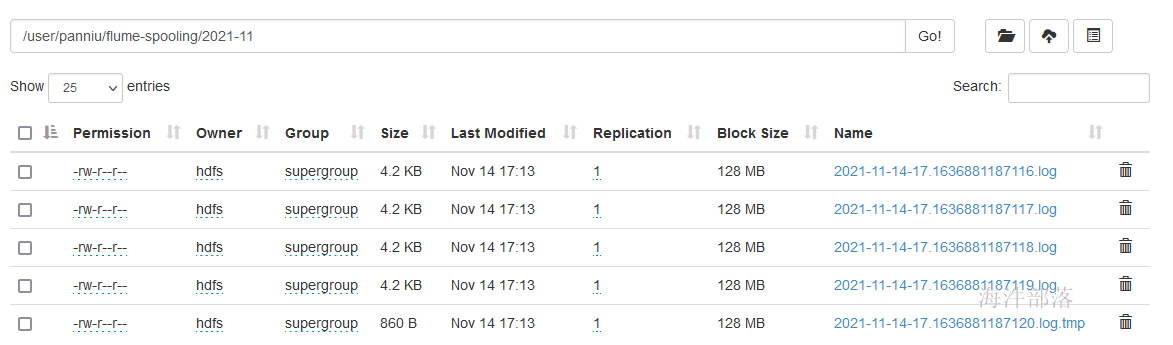
4 access日志归集与处理
4.1 flume归集access.log日志到HDFS
通过flume归集实现将日志写入hdfs用于离线处理
sources:taildir
channel:file
sink:hdfs
hdfs归集: 每5分钟生成一个文件,并且带有snappy压缩;
1)配置
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# sources类型
a1.sources.r1.type = TAILDIR
#存储读取文件数据最后位置
a1.sources.r1.positionFile = /data/xinniu/flume/data/taildir_position_access.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /data/xinniu/flume/access/access.log
# hdfs sink-k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs:///data/xinniu/access_log/%Y/%m%d
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 300
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = access_%Y%m%d
a1.sinks.k1.hdfs.fileSuffix = .log.snappy
# 设置输出压缩
a1.sinks.k1.hdfs.fileType = CompressedStream
# 设置snappy压缩
a1.sinks.k1.hdfs.codeC = snappy
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.callTimeout = 0
# channals file
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /data/xinniu/flume/data/checkpoint_access
a1.channels.c1.dataDirs = /data/xinniu/flume/data/data_access
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c12)配置文件位置
/data/xinniu/flume/conf/access-taildir-conf.properties3)启动flume
启动命令:
flume-ng agent -n a1 -f /data/xinniu/flume/conf/access-taildir-conf.properties -Dflume.root.logger=DEBUG,console后台启动命令:
nohup flume-ng agent -n a1 -f /data/xinniu/flume/conf/access-taildir-conf.properties -Dflume.root.logger=DEBUG,console >> /dev/null 2>&1 &4)生成hdfs目录和文件
4.2 编写mapreduce对归集的access日志做数据清洗
业务字段说明:
#ip地址:
192.168.142.1
#请求用户,没用
-
# 请求时间: yyyyMMddHHmmss
14/Sep/2020:14:43:38 +0800
# 请求url:
GET /getBrandDetailByIdForPage.action?id=13 HTTP/1.1
# 状态码:
200
# 发送给客户端的字节数:
9111
# post请求boby数据:
-
# refer:
http://www.hainiushop.com/index.jsp
# useragent:
Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108
# -
# 用户id
a6a597b4f3b24e16ba87cec919a4162c
# 登录用户名
pan123编写mapreduce程序:
/**
* Access2Text.java
* com.hainiu.mr
* Copyright (c) 2021, 海牛版权所有.
* @author 潘牛
*/
package com.hainiu.mr;
import java.io.IOException;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import java.util.Date;
import java.util.Locale;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
/**
* 读取access日志数据转结构化数据
* @author 潘牛
* @Date 2021年8月10日
*/
public class Access2Text extends Configured implements Tool{
public static class Access2TextMapper extends Mapper<LongWritable, Text, Text, NullWritable>{
SimpleDateFormat sdf1 = new SimpleDateFormat("dd/MMM/yyyy:HH:mm:ss", Locale.ENGLISH);
SimpleDateFormat sdf2 = new SimpleDateFormat("yyyyMMddHHmmss");
Text keyOut = new Text();
@Override
protected void map(LongWritable key, Text value, Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] arr = line.split("\001");
context.getCounter("hainiu", "total line nume").increment(1L);
if(arr.length != 12){
context.getCounter("hainiu", "bad line num").increment(1L);
return;
}
// 0 192.168.142.1
// 1 -
// 2 14/Sep/2020:14:43:38 +0800
// 3 GET /getBrandDetailByIdForPage.action?id=13 HTTP/1.1
// 4 200
// 5 9111
// 6 -
// 7 http://www.hainiushop.com/index.jsp
// 8 Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.108 Safari/537.36
// 9 -
// 10 a6a597b4f3b24e16ba87cec919a4162c
// 11 -
String ip = arr[0];
// 14/Sep/2020:14:43:38 +0800
String timestr = arr[2];
String str = timestr.substring(0, timestr.indexOf(" "));
// timestr.split(" ")[0]
// yyyyMMddHHmmss格式的数据
String format = "";
try {
Date date = sdf1.parse(str);
format = sdf2.format(date);
} catch (ParseException e) {
e.printStackTrace();
}
// GET /getBrandDetailByIdForPage.action?id=13 HTTP/1.1
String reqstr = arr[3];
String[] arr2 = reqstr.split(" ");
String reqType = arr2[0];
String reqUrl = arr2[1];
String status = arr[4];
String body = arr[6];
String refer = arr[7];
String userAgent = arr[8];
String uid = arr[10];
String logonName = arr[11];
StringBuilder sb = new StringBuilder();
sb.append(ip).append("\t")
.append(reqType).append("\t")
.append(format).append("\t")
.append(reqUrl).append("\t")
.append(status).append("\t")
.append(body).append("\t")
.append(refer).append("\t")
.append(userAgent).append("\t")
.append(uid).append("\t")
.append(logonName);
keyOut.set(sb.toString());
context.write(keyOut, NullWritable.get());
}
}
@Override
public int run(String[] args) throws Exception {
Configuration conf = getConf();
Job job = Job.getInstance(conf, "access2text");
// 设置运行的类(linux 运行用)
job.setJarByClass(Access2Text.class);
// 设置mapperclass
job.setMapperClass(Access2TextMapper.class);
job.setNumReduceTasks(0);
// 设置mapper输出keyclass
job.setMapOutputKeyClass(Text.class);
// 设置mapper输出valueclass
job.setMapOutputValueClass(NullWritable.class);
// 设置reducer输出keyclass
job.setOutputKeyClass(Text.class);
// 设置reducer输出的valueclass
job.setOutputValueClass(NullWritable.class);
// 设置读取的输入文件的inputformatclass,默认是文本,可以不设置
job.setInputFormatClass(TextInputFormat.class);
// 设置写入文件的outputformatclass,默认是文本,可以不设置
job.setOutputFormatClass(TextOutputFormat.class);
// 设置输入目录
FileInputFormat.addInputPath(job, new Path(args[0]));
Path outputPath = new Path(args[1]);
// 设置输出目录
FileOutputFormat.setOutputPath(job, outputPath);
// 自动删除输出目录
FileSystem fs = FileSystem.get(conf);
// 如果输出目录存在,就递归删除输出目录
if(fs.exists(outputPath)){
// 递归删除输出目录
fs.delete(outputPath, true);
System.out.println("delete outputPath==> 【" + outputPath.toString() + "】 success!");
}
// 提交job
boolean status = job.waitForCompletion(false);
return status ? 0 : 1;
}
public static void main(String[] args) throws Exception {
// /tmp/access/input_text /tmp/access/output
System.exit(ToolRunner.run(new Access2Text(), args));
}
}运行参数: /tmp/access/input_text /tmp/access/output
运行结果:
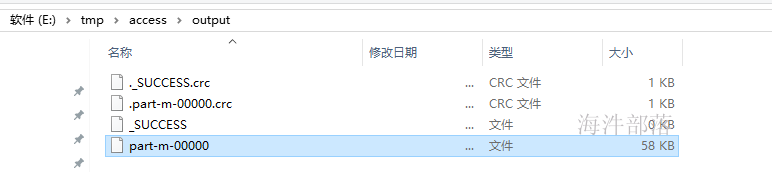
处理好的一行的数据

后续可以基于给数据来建表,用hive统计分析查询