1 创建队列
- 队列是在执行spark、mapreduce等程序,需要用到“队列”参数时使用的。
- 管理员进入安全中心->队列管理页面,点击“创建队列”按钮,创建队列。
2 添加租户
- 租户对应的是Linux的用户,用于worker提交作业所使用的用户。如果linux没有这个用户,worker会在执行脚本的时候创建这个用户。
- 租户编码:租户编码是Linux上的用户,唯一,不能重复(添加租户时没创建linux用户,当用该租户执行工作流时会自动创建,如果之前创建过就不创建了)
- 管理员进入安全中心->租户管理页面,点击“创建租户”按钮,创建租户。
3 创建项目
- 点击"项目管理"进入项目管理页面,点击“创建项目”按钮,输入项目名称,项目描述,点击“提交”,创建新的项目。
项目首页
- 在项目管理页面点击项目名称链接,进入项目首页,如下图所示,项目首页包含该项目的任务状态统计、流程状态统计、工作流定义统计。
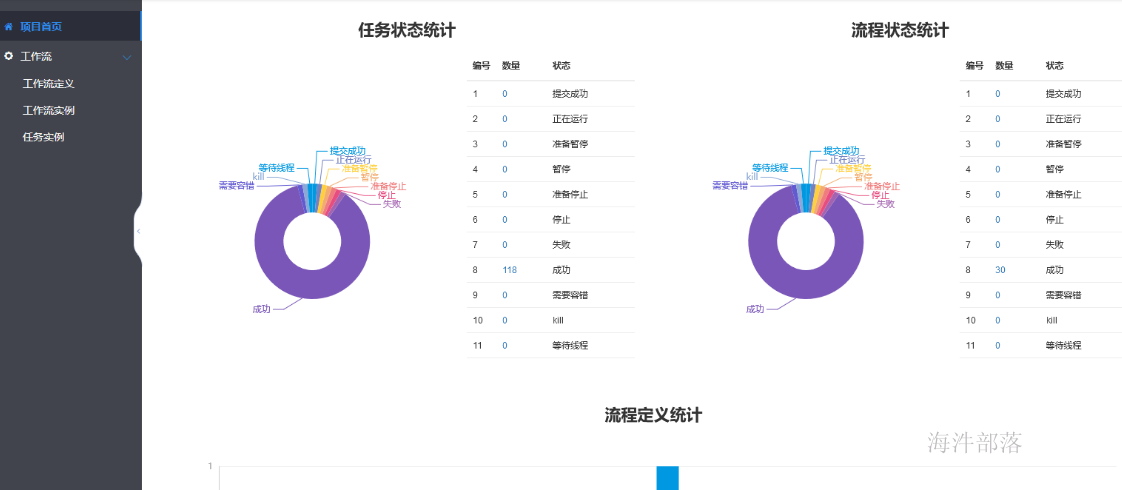
-
任务状态统计:在指定时间范围内,统计任务实例中状态为提交成功、正在运行、准备暂停、暂停、准备停止、停止、失败、成功、需要容错、kill、等待线程的个数
-
流程状态统计:在指定时间范围内,统计工作流实例中状态为提交成功、正在运行、准备暂停、暂停、准备停止、停止、失败、成功、需要容错、kill、等待线程的个数
- 工作流定义统计:统计用户创建的工作流定义及管理员授予该用户的工作流定义
4 工作流定义
4.1 创建工作流定义
-
点击项目管理->工作流->工作流定义,进入工作流定义页面,点击“创建工作流”按钮,进入
工作流DAG编辑
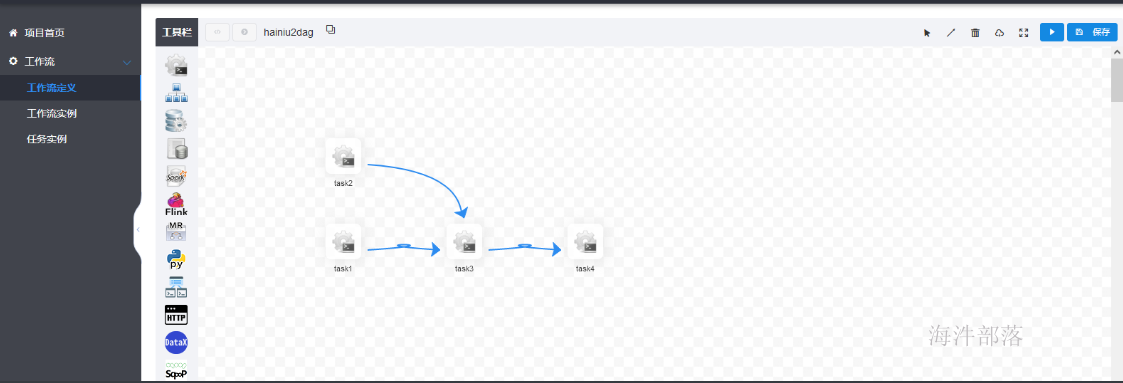
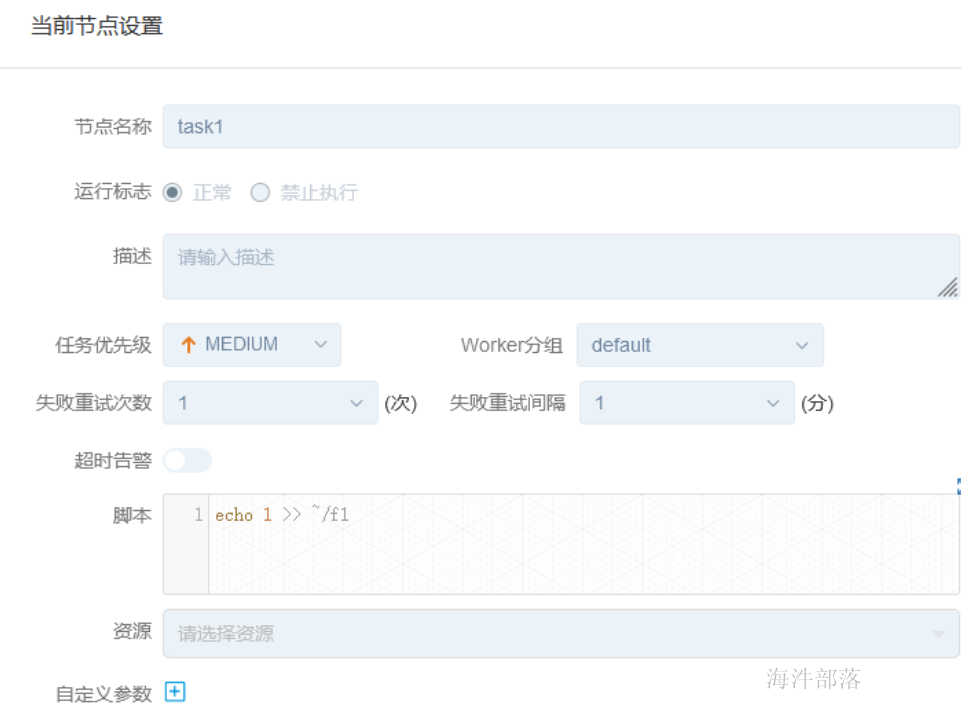
task1--shell:
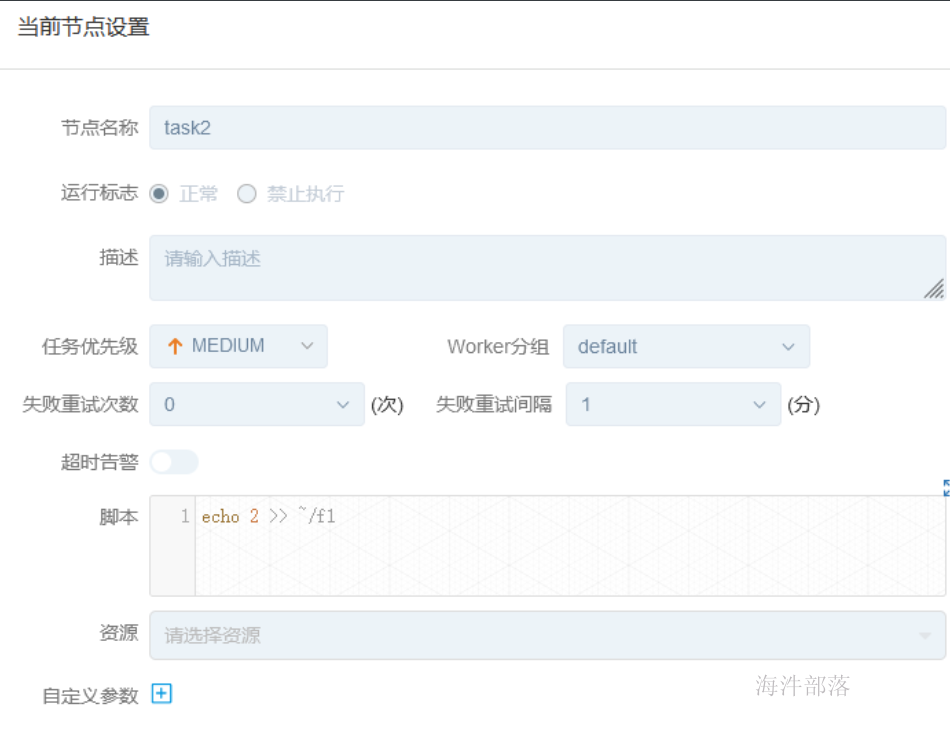
task2--shell:
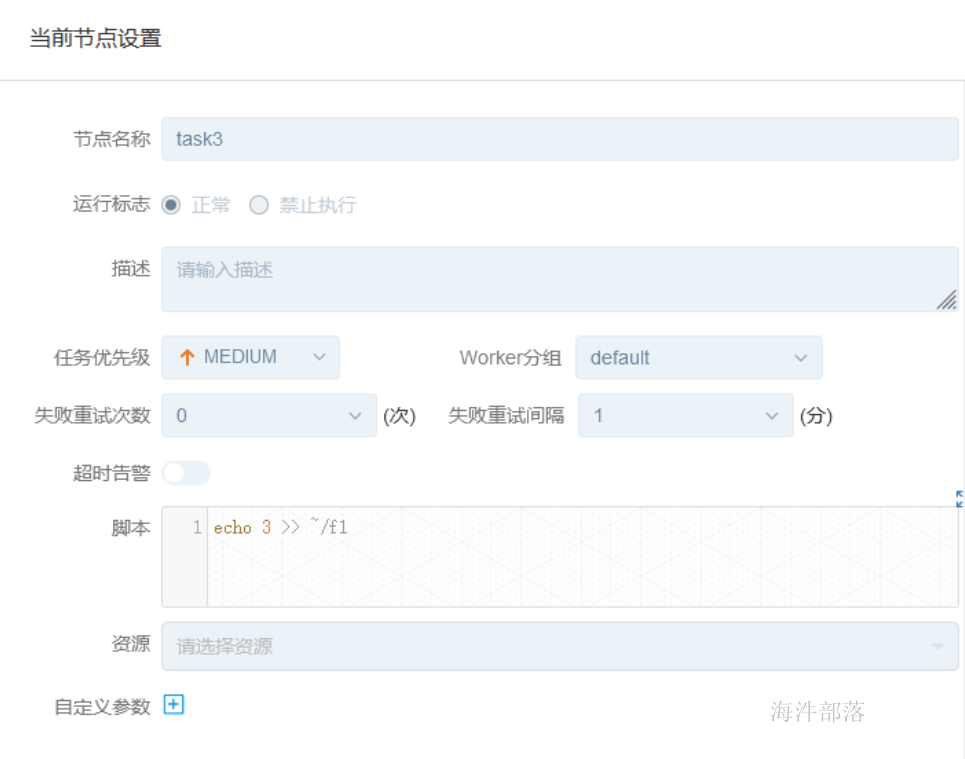
task3-shell:
task4--shell:
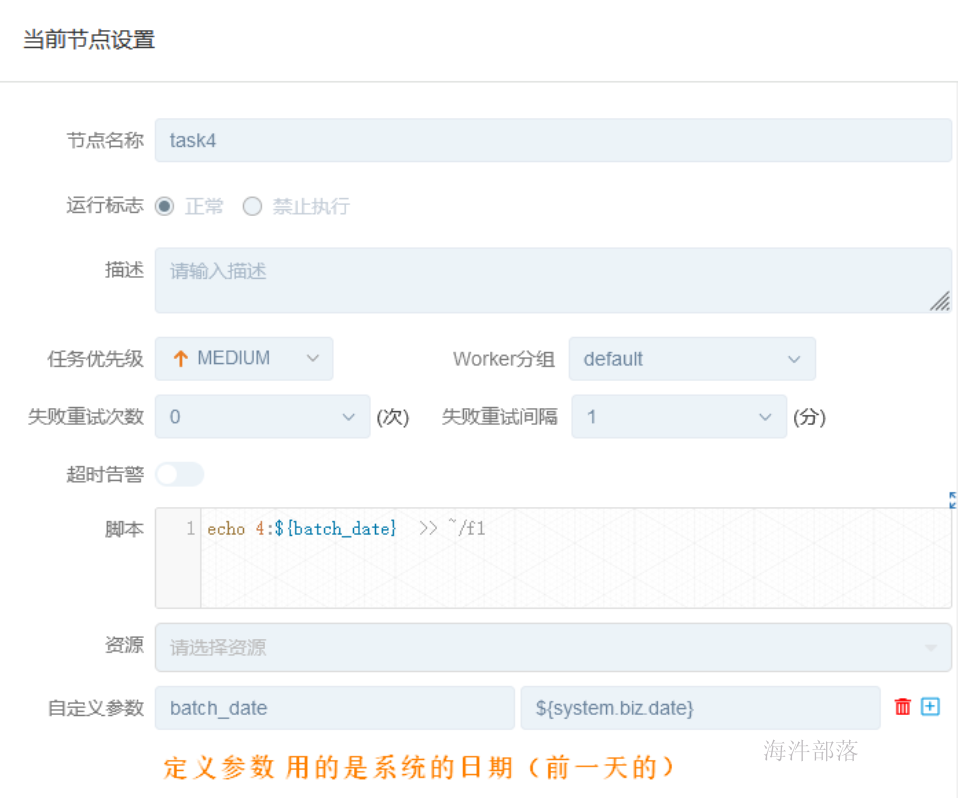
| 变量 | 含义 |
|---|---|
| ${system.biz.date} | 日常调度实例定时的定时时间前一天,格式为 yyyyMMdd,补数据时,该日期 +1 |
| ${system.biz.curdate} | 日常调度实例定时的定时时间,格式为 yyyyMMdd,补数据时,该日期 +1 |
| ${system.datetime} | 日常调度实例定时的定时时间,格式为 yyyyMMddHHmmss,补数据时,该日期 +1 |
保存后,点击 工作流定义,进入工作流定义列表

4.2 工作流上线
工作流定义完成后,是在“下线”状态,需要点击“上线”

4.3 工作流执行
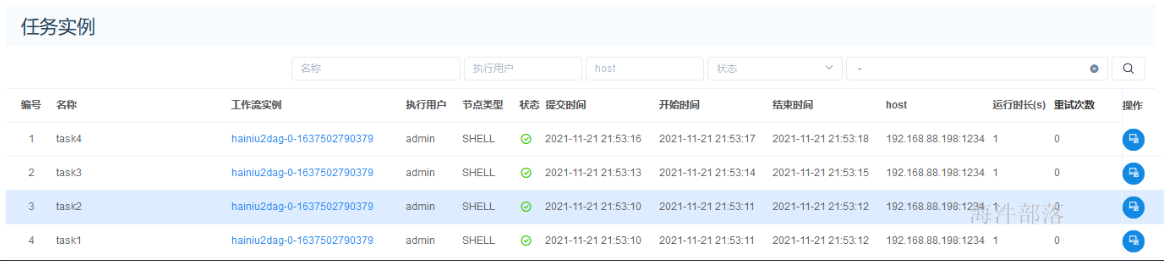
上线之后,可以执行工作流,点击“执行”按钮后,会生成工作流实例 和 任务实例。
工作流实例:

任务实例(一个工作流里定义多个任务):
4.4 工作流重新编辑
如果已经上线,需要先“下线”,再“编辑”

4.5 可对定义的工作流进行定时
在“下线”状态下,可点击“定时”按照需求给工作流定时。
定时完成后,需要点击“定时管理”,把定时上线。
然后再将工作流“上线”,执行工作流,此时是定时执行工作流。
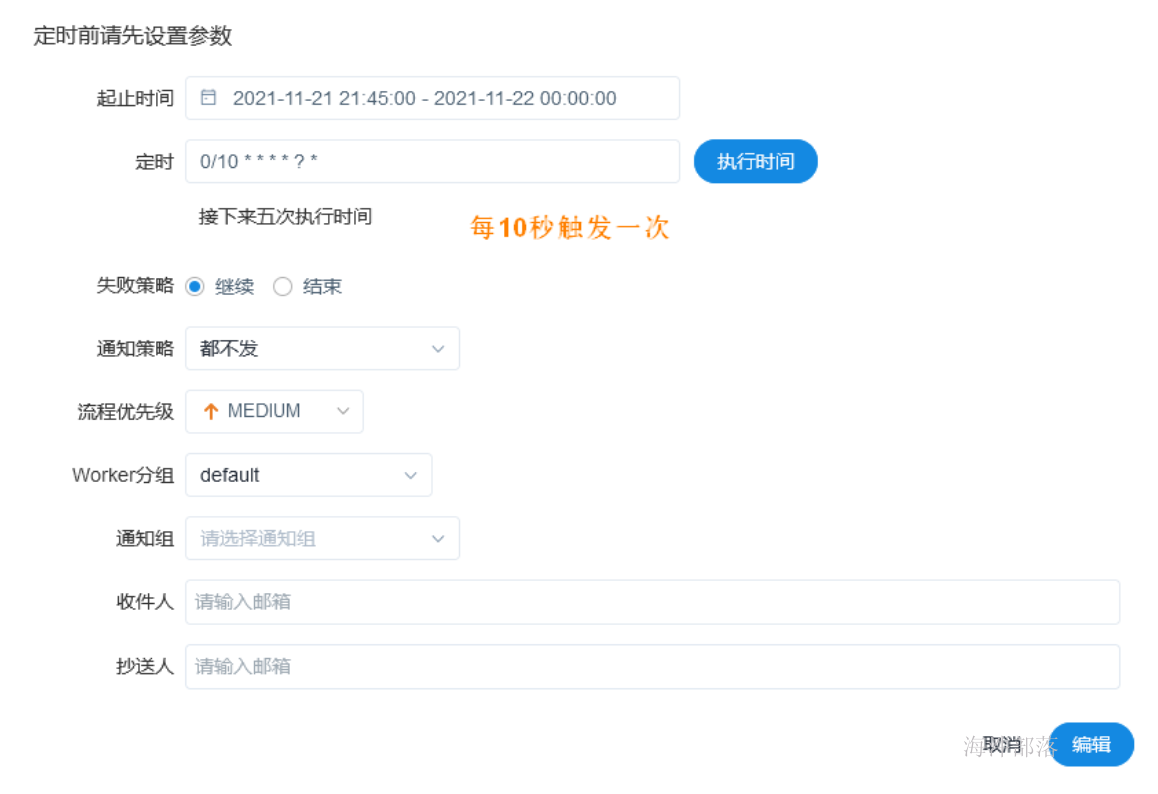
定时上线后:

5 调度器调度sqoop的shell脚本
5.1 sqoop的shell脚本
vim area_op.sh
# 获取batch_date,比如:今天20211010, 那batch_date是20211009
batch_date=$1
# hive认证
kinit -kt /data/hive.keytab hive
# 用sqoop,查询表数据导入到hdfs上
# -Dorg.apache.sqoop.splitter.allow_text_splitter=true: --split-by的是字符串也可以
sqoop import -Dorg.apache.sqoop.splitter.allow_text_splitter=true \
--connect jdbc:mysql://worker-1:3306/sqoop_db \
--username root \
--password 12345678 \
--target-dir /user/hive/comm_area/${batch_date}/ \
--delete-target-dir \
--fields-terminated-by "\t" \
--split-by area_code \
--query 'select comm_area.* from comm_area where $CONDITIONS'
# $?: 返回上个命令的结果, 0:成功, 非0:失败
res=$?
if [ ${res} != 0 ];then
echo 'extract comm_area error! '`date` >> /data/xinniu/extract/comm_area.log
exit 1
else
echo 'extract comm_area successful '`date` >> /data/xinniu/extract/comm_area.log
fi
# impala认证
kinit -kt /data/impala.keytab impala
# 用impala-shell, 创建hive表tmp.comm_area(临时表作用),并指向导入的hdfs目录
impala-shell -k -q "set sync_ddl = true;drop table if exists tmp.comm_area;create external table tmp.comm_area (
area_code string,
area_cname string,
area_ename string
)
row format delimited fields terminated by '\t'
location '/user/hive/comm_area/${batch_date}';
set sync_ddl = false;"
res=$?
if [ ${res} != 0 ];then
echo 'create comm_area tmp table error! '`date` >> /data/xinniu/extract/comm_area.log
exit 1
else
echo 'create comm_area tmp table successful '`date` >> /data/xinniu/extract/comm_area.log
fi
# impala认证
kinit -kt /data/impala.keytab impala
# 用impala-shell,创建hive分区表 itl.comm_area
impala-shell -k -q"set sync_ddl = true;create table if not exists itl.comm_area (
area_code string,
area_cname string,
area_ename string
)
partitioned by (pt string)
stored as parquet
tblproperties ('parquet.compress'='SNAPPY')
;
set sync_ddl = false;"
res=$?
if [ ${res} != 0 ];then
echo 'create comm_area itl table error! '`date` >> /data/xinniu/extract/comm_area.log
exit 1
else
echo 'create comm_area itl table successful '`date` >> /data/xinniu/extract/comm_area.log
fi
# 将临时表中的数据导入到 itl.comm_area 表中
kinit -kt /data/impala.keytab impala
impala-shell -k -q "set sync_ddl = true;alter table itl.comm_area drop if exists partition (pt = '${batch_date}');set sync_ddl = false;"
impala-shell -k -q "set sync_ddl = true;insert into table itl.comm_area partition (pt) select a.*,'${batch_date}' from tmp.comm_area a;set sync_ddl = false;"
res=$?
if [ ${res} != 0 ];then
echo 'load comm_area data to itl table error! '`date` >> /data/xinniu/extract/comm_area.log
exit 1
else
echo 'load comm_area data to itl table successful '`date` >> /data/xinniu/extract/comm_area.log
fi5.2 给脚本加执行权
chmod a+x area_op.sh
5.3 配置调度器关联cdh
当没有配置关联cdh时,调度器日志报找不到 $HADOOP_COMMON_HOME(没配置关联cdh)

配置关联cdh
用 dolphinscheduler 用户
vim /opt/soft/dolphinscheduler/conf/env/dolphinscheduler_env.sh 脚本
export HADOOP_HOME=/opt/cloudera/parcels/CDH/lib/hadoop
export HADOOP_CONF_DIR=/opt/cloudera/parcels/CDH/lib/hadoop/etc/hadoop
5.4 给sqoop 添加 lib jar
由于 sqoop 导入时,会用到json 的jar包, 如果sqoop lib 目录下没有,报如下错误:
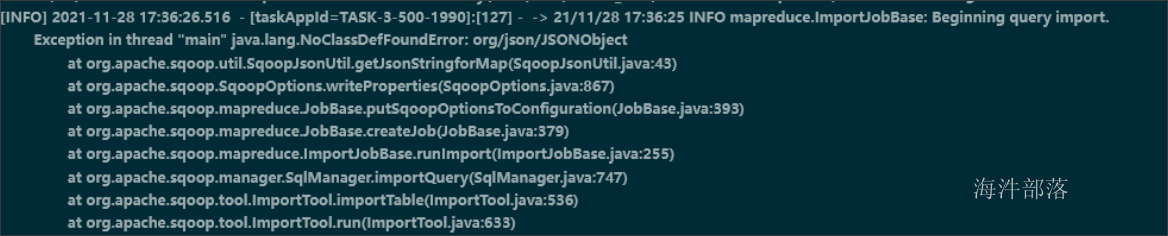
上传一份到 sqoop的lib 目录。



