1 概述

Redis是当前比较热门的NOSQL系统之一,它是一个开源的使用ANSI c语言编写的key-value存储系统(区别于MySQL的二维表格的形式存储)。
Redis 和Memcache类似,但很大程度补偿了Memcache的不足:
- Memcache只能将数据缓存到内存中,无法自动定期写入硬盘,这就表示,一断电或重启,内存清空,数据丢失。所以Memcache的应用场景适用于缓存无需持久化的数据。
- 而Redis不同的是它会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,实现数据的持久化。
Redis支持存储的value类型包括string(字符串)、list(链表)、set(集合)、zset(sorted set --有序集合)和hash(哈希类型)。这些数据类型都支持push/pop、add/remove及取交集并集和差集及更丰富的操作,而且这些操作都是原子性的。在此基础上,redis支持各种不同方式的排序。
与memcached一样,为了保证效率,数据都是缓存在内存中。区别的是redis会周期性的把更新的数据写入磁盘或者把修改操作写入追加的记录文件,并且在此基础上实现了master-slave(主从)同步。而memcached是在内存中,所以是用来弥补memcached的不足。在Redis没出来之前Memcached是被广泛使用,用于与关系型数据库进行补充,存储大量数据的KV结构数据时使用的。而之Redis诞生之后逐渐取代了Memcached。主要是因为4个原因:1、内存缓存 2、数据持久化 3、操作原子性 4、分布式支持
Redis 提供了Java,C/C++,C#,PHP,JavaScript,Perl,Object-C,Python,Ruby,Erlang等客户端,使用很方便。
Redis从第3版本开始支持主从同步和分片(以前的版本需要自己实现,也就是说不是自带的功能)。数据可以从主服务器向任意位置的从服务器上同步,从服务器可以是关联其他从服务器的主服务器。分片机制使Redis可以增加读写性能。由于完全实现了发布/订阅机制,使得从数据库在任何地方同步,可订阅一个频道并接收主服务器完整的消息发布记录。分片机制增加了数据的可扩展性,数据的同步增加了数据冗余和容灾。
redis的官网地址,非常好记,是redis.io
参考 redis 文档翻译页面:http://doc.redisfans.com/index.html
早期 一个网站刚开始开发,先实现
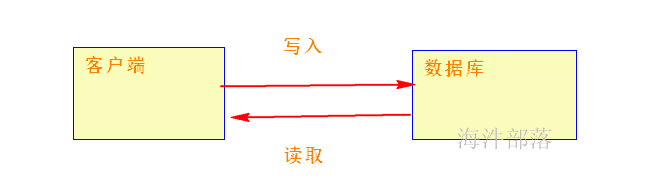
当用户达到一定规模,单个的数据库已经满足不了 请求处理
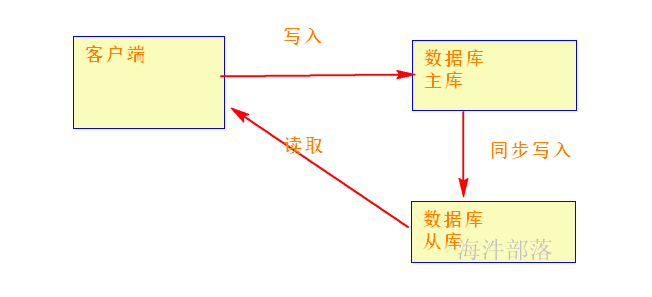
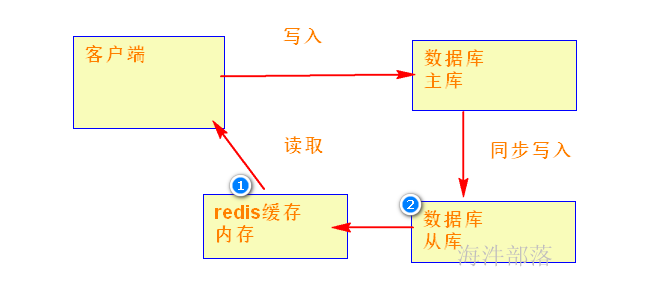
用户规模持续增加,从库的数据也一直在增加,当数据库达到一定规模的时候, 从库里面读取数据就非常慢,这个时候,引入 redis
先从redis读取(redis 内存),如果内存读不到再去 数据库里读取
缓存穿透:指查询一个数据库一定不存在的数据。
解决方法:如果缓存中没有,就写入该key,不过需要设置key的过期时间。在这段时间内,如果key存在,就从redis返回,这样可以防止大量的key命中数据库。
缓存雪崩:指在某一个时间段,缓存集中过期失效。
要保证redis高可用,不能让redis挂了。
缓存击穿:指一个key非常热点,在不停的扛着大并发,大并发集中对这一个点进行访问,当这个key在失效的瞬间,持续的大并发就穿破缓存,直接请求数据库,就像在一个屏障上凿开了一个洞。
防止大量的访问数据库,需要先加锁,然后再更新缓存
2 单机版redis
2.1 安装说明
新克隆出一台单独的虚拟机,用于单机redis安装;本例克隆出来的机器 hostname:rs1.hadoop
1)复制一个虚拟机
2)修改主机名:hostnamectl set-hostname rs1.hadoop
3)修改ip
4)修改host文件
2.2 编译并安装
下载的是源码包需要编译,编译的时候需要gcc依赖,如果没有就自己yum安装(基础环境已经安装过)
make && make install
centos7之前的版本注意:
如果报错的原因是没有安装jemalloc内存分配器,可以安装jemalloc或直接输入
make MALLOC=libc && make install
指定libc的内存分配器,linux的版本不同所以带的内存分配器也不同
#上传到root根目下,直接解压到root用户家目录下
make MALLOC=libc
make && make install安装成功,截图
2.3 redis 配置
1)创建配置文件目录
mkdir /usr/local/redis
2)拷贝配置
cp ~/redis-3.2.12/redis.conf /usr/local/redis/
3)修改配置
设置redis后台运行

设置开启日志

设置绑定host

配置密码永久生效
redis密码设置,默认是临时密码,当重启redis后,临时密码失效。
如果想配置永久密码,可以按照下面的配置;本次不配置永久密码

2.4 启动 redis-server
cd /usr/local/redis
redis-server /usr/local/redis/redis.conf
注意: 第一次在哪启动redis-serser,后面就在哪个目录启动。


2.5 redis 客户端
2.5.1 使用客户连接redis-server
redis-cli -h rs1.hadoop -p 6379
2.5.2 客户端常用命令
set key value EX 5 NX #设置key
get key #得到key的值
mset key1 value1 key2 value2 #批量设置并且是原子的,可以用来减少网络时间消耗
mget key1 key2 #批量获取并且是原子的,可以用来减少网络时间消耗
incr key #相应的key增加1
decr key #相应的key减1
incrby key value #对应的key加指定的值
decrby key value #对应的key减指定的值
del key #删除指定的key
FLUSHALL #删除全部key(清空redis)
ttl key #检查key的剩余时间
[hadoop@rs1 ~]$ redis-cli -h rs1.hadoop -p 6379
rs1.hadoop:6379> set a 1
OK
rs1.hadoop:6379> set b 2
OK
rs1.hadoop:6379> set c 3
OK
rs1.hadoop:6379> get a
"1"
rs1.hadoop:6379> get b
"2"
# 批量set
rs1.hadoop:6379> mset a1 1 a2 2 a3 3
OK
# 批量get
rs1.hadoop:6379> mget a1 a2 a3
1) "1"
2) "2"
3) "3"
# 获取当前库的所有key
rs1.hadoop:6379> keys *
1) "c"
2) "a1"
3) "a"
4) "a2"
5) "a3"
6) "b"
rs1.hadoop:6379> get a
"1"
rs1.hadoop:6379> set a 2
OK
rs1.hadoop:6379> get a
"2"
# 单机redis一共有16个库,0号到15号,可通过select index 切换
rs1.hadoop:6379> select 15
OK
rs1.hadoop:6379[15]> select 16
(error) ERR invalid DB index
rs1.hadoop:6379[15]> keys *
(empty list or set)
rs1.hadoop:6379[15]> select 0
OK
rs1.hadoop:6379> keys *
1) "c"
2) "a1"
3) "a"
4) "a2"
5) "a3"
6) "b"
rs1.hadoop:6379> keys a*
1) "a1"
2) "a"
3) "a2"
4) "a3"
rs1.hadoop:6379> select 1
OK
rs1.hadoop:6379[1]> mset a1 1 a2 2 a3 3 a4 4 a5 5 a6 6 a7 7 a8 8 a9 9
OK
rs1.hadoop:6379[1]> set b 1
OK
rs1.hadoop:6379[1]> keys *
1) "a9"
2) "a5"
3) "a8"
4) "b"
5) "a3"
6) "a4"
7) "a7"
8) "a1"
9) "a2"
10) "a6"
# 分页遍历时, 刚开始游标是0, 随着查询出新游标,再通过新游标继续查询,直到新游标为0,代表已经遍历完一遍
# 注意:count 后面的数值只是个参考
rs1.hadoop:6379[1]> scan 0 match * count 4
1) "9"
2) 1) "a5"
2) "a1"
3) "a2"
4) "a9"
rs1.hadoop:6379[1]> scan 9 match * count 4
1) "15"
2) 1) "a4"
2) "a7"
3) "a8"
4) "b"
5) "a3"
rs1.hadoop:6379> scan 15 match * count 4
1) "0"
2) 1) "a6"
rs1.hadoop:6379[1]> incr button_volume
(integer) 1
rs1.hadoop:6379[1]> incr button_volume
(integer) 2
rs1.hadoop:6379[1]> incr button_volume
(integer) 3
rs1.hadoop:6379[1]> incr button_volume
(integer) 4
rs1.hadoop:6379[1]> incr button_volume
(integer) 5
rs1.hadoop:6379[1]> incr button_volume
(integer) 6
rs1.hadoop:6379[1]> incr button_volume
(integer) 7
rs1.hadoop:6379[1]> incr button_volume
(integer) 8
rs1.hadoop:6379[1]> incrby button_volume 100
(integer) 108
rs1.hadoop:6379[1]> incrby button_volume 100
(integer) 208
rs1.hadoop:6379[1]> incrby button_volume 100
(integer) 308
rs1.hadoop:6379[1]> incrby button_volume 100
(integer) 408
rs1.hadoop:6379[1]> incrby button_volume 100
(integer) 508
rs1.hadoop:6379[1]> incrby button_volume 100
(integer) 608
rs1.hadoop:6379[1]> incrby button_volume 100
(integer) 708
rs1.hadoop:6379[1]> incrby button_volume 100
(integer) 808
rs1.hadoop:6379[1]> decr button_volume
(integer) 807
rs1.hadoop:6379[1]> decr button_volume
(integer) 806
rs1.hadoop:6379[1]> decr button_volume
(integer) 805
rs1.hadoop:6379[1]> decr button_volume
(integer) 804
rs1.hadoop:6379[1]> decr button_volume
(integer) 803
rs1.hadoop:6379[1]> decrby button_volume 100
(integer) 703
rs1.hadoop:6379[1]> decr button_volume
(integer) 702
rs1.hadoop:6379[1]> decr button_volume
(integer) 701
rs1.hadoop:6379[1]> decr button_volume
(integer) 700
rs1.hadoop:6379[1]> decr button_volume
(integer) 699
rs1.hadoop:6379[1]> decrby button_volume 100
(integer) 599
rs1.hadoop:6379[1]> decrby button_volume 100
(integer) 499
rs1.hadoop:6379[1]> decrby button_volume 100
(integer) 399
rs1.hadoop:6379[1]> decrby button_volume 100
(integer) 299
rs1.hadoop:6379[1]> keys *
1) "a9"
2) "a5"
3) "a8"
4) "button_volume"
5) "b"
6) "a3"
7) "a4"
8) "a7"
9) "a1"
10) "a2"
11) "a6"
# 删除某个库的key
rs1.hadoop:6379[1]> del b
(integer) 1
rs1.hadoop:6379[1]> keys *
1) "a9"
2) "a5"
3) "a8"
4) "button_volume"
5) "a3"
6) "a4"
7) "a7"
8) "a1"
9) "a2"
10) "a6"
# 注意: flushall是把所有库的数据删除, 自己测试时不要操作,尤其是在教室集群不要操作
rs1.hadoop:6379[1]> flushall
OK
rs1.hadoop:6379[1]> keys *
(empty list or set)
rs1.hadoop:6379[1]> select 0
OK
rs1.hadoop:6379> keys *
(empty list or set)这些操作都具有原子性
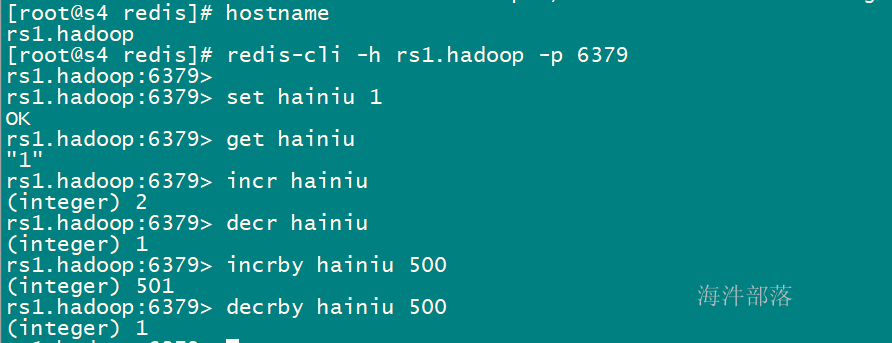
遍历redis 所有key命令: keys *
但是如果redis数据非常大,并且key也非常多的情况下,查询的时候很可能会很慢,造成整个redis阻塞,那么有什么办法解决呢?
通过 scan 命令
SCAN命令是一个基于游标的迭代器, 这意味着命令每次被调用都需要使用上一次这个调用返回的游标作为该次调用的游标参数,以此来延续之前的迭代过程, 当SCAN命令的游标参数被设置为 0 时, 服务器将开始一次新的迭代, 而当服务器向用户返回值为 0 的游标时, 表示迭代已结束。
命令格式
SCAN cursor [MATCH pattern] [COUNT count]命令说明:
如果想对 redis 数据进行遍历,首先cousor 从0开始, 然后 查找指定 匹配的模式,返回指定 count(返回的数据不一定返回count条) 的数据;
再从返回来的游标开始继续查询,直到返回值为 0 的游标时, 表示迭代已结束。
通过 scan num1 match* count num2 来做redis 的分页查询,但不能保证每次都能查询num2个数据出来;
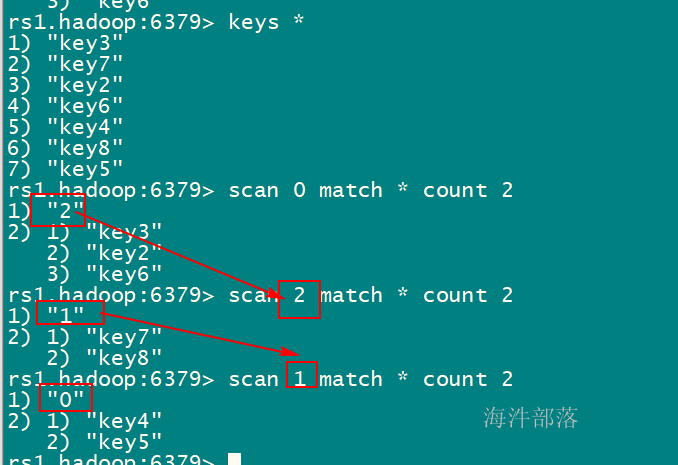
配置redis密码,这个是临时的,如果重启redis将失效
设置密码:12345678
config set requirepass 12345678
get key 报错

重新登录客户端,通过auth 输入密码后,可以get
① redis-cli -h rs1.hadoop -p 6379 -a 12345678

② redis-cli -h rs1.hadoop -p 6379
auth 12345678

2.5.3 通过客户端关闭redis-server
redis-cli -h rs1.hadoop -p 6379 shutdown
接着上面例子,因为设置了密码所以得输入密码才能操作
redis-cli -h rs1.hadoop -p 6379 -a 12345678 shutdown

3 redis3.0 之前,多个redis 节点怎么组成集群?
在redis3.0之前,只有单机版redis,那多个单机redis怎么组成redis集群?redis集群需要考虑哪些问题?
3.1 redis集群需要考虑的问题?
1)数据落到哪台机器上?
target = hash(key)%N (哈希取余的方式会将不同的 key 分发到不同的服务器上)
其中 target 为目标节点,key 为键,N 为 Redis 节点的个数。
2)如果数据倾斜,导致某个节点数据过多问题?
3)节点扩容问题?
target = hash(key)%N+1,导致数据丢失
4)节点丢失问题?

一致性hash 算法
一致性哈希算法在1997年由麻省理工学院提出的一种分布式哈希(DHT)实现算法,设计目标是为了解决因特网中的热点(Hot spot)问题。
一致性hash 算法的设计
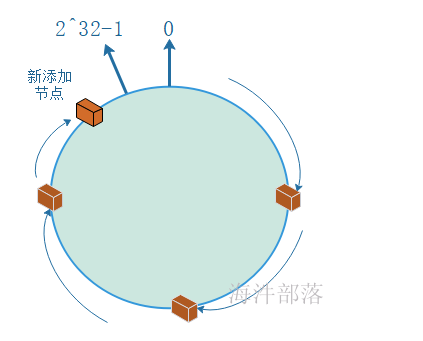
环形Hash空间
按照常用的hash算法来将对应的key哈希到一个具有2^32次方个桶的空间中,即0~(2^32)-1的数字空间中。现在我们可以将这些数字头尾相连,想象成一个闭合的环形。如下图
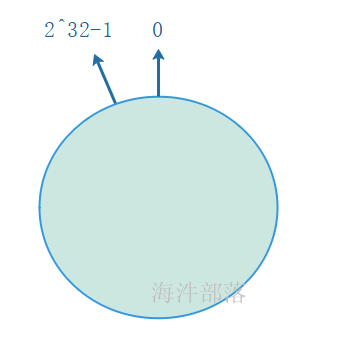
把数据通过一定的hash算法处理后映射到环上
在采用一致性哈希算法的分布式集群中将新的机器加入,其原理是通过使用与对象存储一样的Hash算法将机器也映射到环中(一般情况下对机器的hash计算是采用机器的IP或者机器唯一的别名作为输入值),然后以顺时针的方向计算,将所有对象存储到离自己最近的机器中。
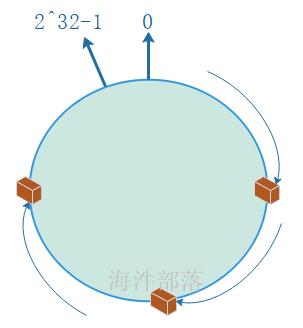
机器节点添加
机器节点删除
如果节点因为故障需要删除,按照顺时针,故障节点数据移动到下一个节点。
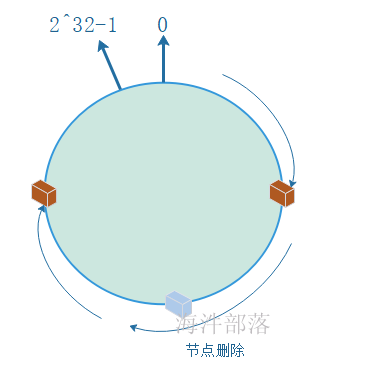
但这样有可能导致下一个节点数据增多,容易产生数据倾斜。怎么解决?
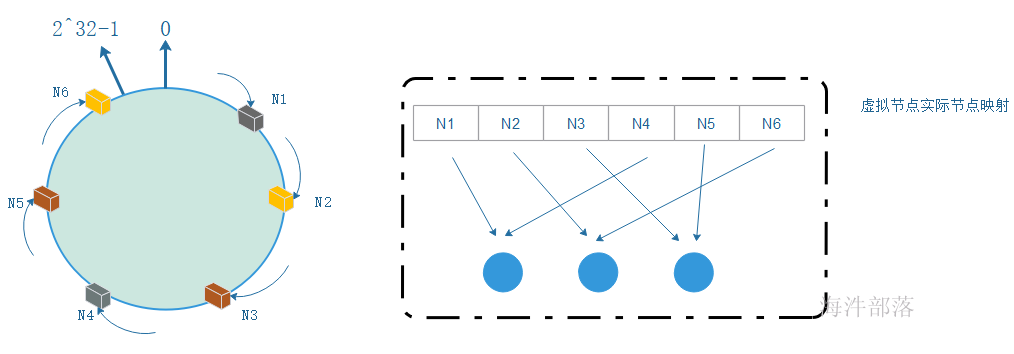
在一致性哈希算法中,为了尽可能的满足各个节点数据均衡,引入了虚拟节点。
虚拟节点( virtual node )是实际节点(机器)在 hash 空间的复制品( replica ),一实际个节点(机器)对应了若干个“虚拟节点”,这个对应个数也成为“复制个数”,“虚拟节点”在 hash 空间中以hash值排列。
比如有3台机器,每台机器映射2个虚拟节点,共把6个虚拟节点映射到环上。如下图:
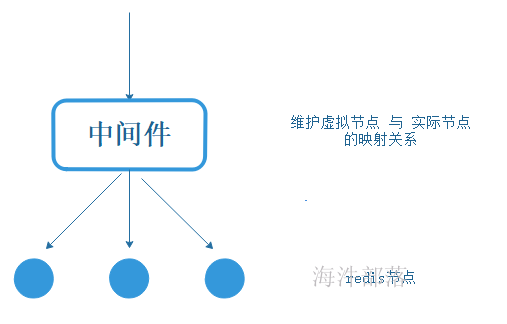
在redis3.0 之前版本,redis 集群搭建需要借助外力,通过中间件实现 一致性hash算法,维护虚拟节点 与 实际节点的映射表。
4 redis cluster 模式
redis 集群模式需要redis3.0及以上版本。
为了在大流量访问下提供稳定的业务,集群化是存储的必然形态,redis从3.0版本开始致力于分布式redis集群;
4.1 redis cluster 原理
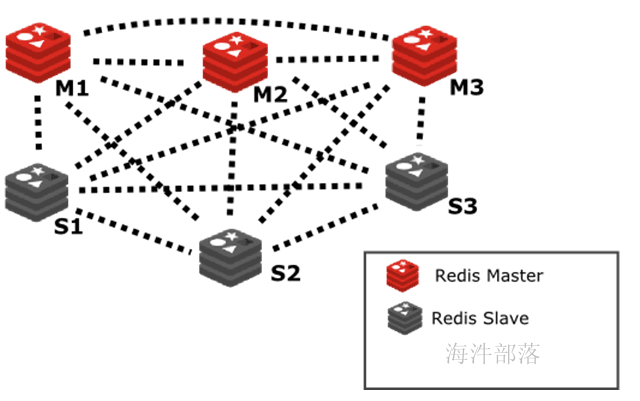
Redis 集群是一个分布式(distributed)、容错(fault-tolerant)的 Redis 实现, 集群可以使用的功能是普通单机 Redis 所能使用的功能的一个子集,Redis 集群不像单机 Redis 那样支持多数据库功能, 集群只使用默认的 0 号数据库, 并且不能使用 SELECT index 命令。
Redis 集群中不存在中心(central)节点或者代理(proxy)节点, 集群的其中一个主要设计目标是达到线性可扩展性(linear scalability)。
redis cluster 架构设计由两部分组成: 主从节点 和 hash slot(槽)。
下面分别介绍:
4.1.1 主从节点
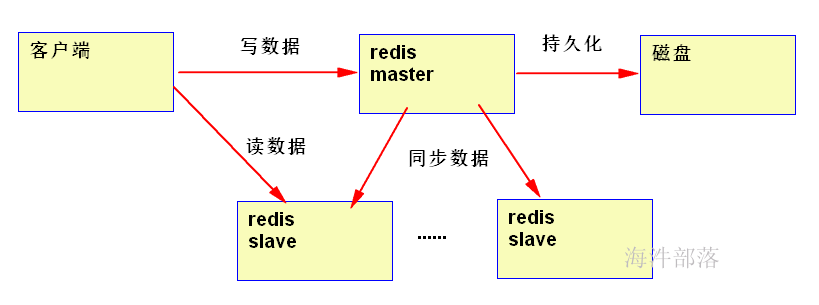
类似HDFS系统,redis也有主从节点,随着数据量的增加,redis为了能提高读性能,将从redis节点处理读请求,将主redis节点作为写请求。
主从模式的设计优缺点:
优点:读写分离,通过增加Slaver可以提高并发读的能力。
缺点:1)Master写能力是瓶颈。
2)虽然理论上对Slaver没有限制但是维护Slaver开销总将会变成瓶颈。
3)Master的磁盘大小也将会成为整个Redis集群存储容量的瓶颈。
4.1.2 hash slot(槽)
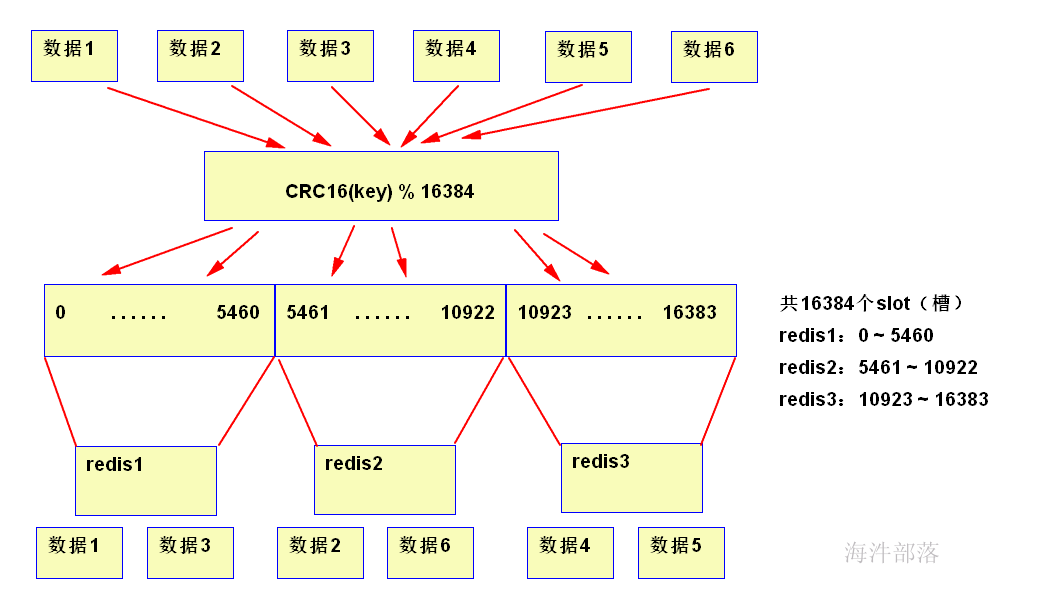
由上图可知:
1)数据对象保存到Redis之前先经过CRC16哈希到一个指定的redis节点上,例如 数据1 最终Hash到了redis1 节点上。
2) 每个Node被平均分配了一个Slot段,对应着0-16384,Slot不能重复也不能缺失,否则会导致对象重复存储或无法存储。
3)Node之间也互相监听,一旦有Node退出或者加入,会按照Slot为单位做数据的迁移。例如redis1 节点如果掉线了,0-5640这些Slot将会平均分摊到redis2 和redis3 上,由于redis2 和 redis3 本身维护的Slot还会在自己身上不会被重新分配,所以迁移过程中不会影响到5641-16384Slot段的使用。
哈希Slot的优缺点:
缺点:每个redis 节点无备用节点,一旦某个节点挂掉了,redis集群会停止运作;
优点:将Redis的写操作分摊到了多个节点上,提高写的并发能力,扩容简单。
4.1.3 主从节点 和 hash slot(槽)结合
在hash slot 基础上,在redis服务节点上,增加master 和 slave 节点。
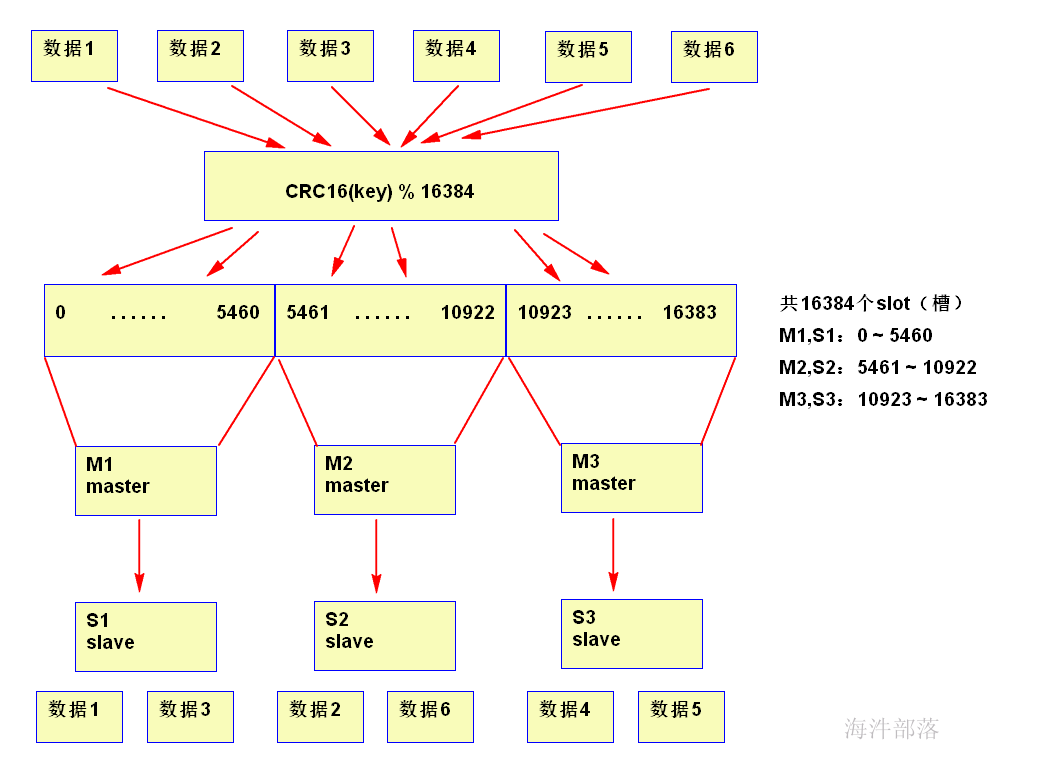
redis-cluster架构中,被设计成共有16384个hash slot。每个master分得一部分slot,其算法为:hash_slot = crc16(key) mod 16384 ,这就找到对应slot。采用hash slot的算法,实际上是解决了redis-cluster架构下,有多个master节点的时候,数据如何分布到这些节点上去。key是可用key,如果有{}则取{}内的作为可用key,否则整个可以是可用key。
redis-cluster 架构至少需要3主3从,且每个实例可使用不同的配置文件。
在cluster架构下,默认的,redis-master节点一般用于接收读写,而redis-slave节点则一般只用于备份(高可用),其与对应的master拥有相同的slot集合;若某个redis-master意外失效,则再将其对应的slave进行升级为临时redis-master。
但如果不介意读取的是redis-cluster中有可能过期的数据并且对写请求不感兴趣时,则亦可通过readonly命令,将slave设置成可读,然后通过slave获取相关的key,达到读写分离。
在cluster架构下,你如果要支撑更大的读吞吐量,或者写吞吐量,或者数据量,都可以直接对master进行横向扩展就可以了。
详细参考翻译的官方文档:
Redis 集群指南(中文翻译,供参考):http://redisdoc.com/topic/cluster-tutorial.html
Redis 集群规范(中文翻译,供参考): http://redisdoc.com/topic/cluster-spec.html
4.2 redis的集群安装和使用
4.2.1 安装规划
要让 Redis3.0 集群正常工作至少需要 3 个 Master 节点,要想实现高可用,每个 Master 节点要配备至少 1 个 Slave 节点。根据以上特点和要求,进行如下的集群实施规划:
使用 6台服务器(物理机或虚拟机)部署 3 个 Master + 3 个 Slave;
| 主机名 | ip | 服务端口 | 集群端口(服务端口+10000) | 主/从 |
|---|---|---|---|---|
| nn1.hadoop | 192.168.142.160 | 6379 | 16379 | Master |
| nn2.hadoop | 192.168.142.161 | 6379 | 16379 | Master |
| s1.hadoop | 192.168.142.162 | 6379 | 16379 | Master |
| s2.hadoop | 192.168.142.163 | 6379 | 16379 | Slave |
| s3.hadoop | 192.168.142.164 | 6379 | 16379 | Slave |
| s4.hadoop | 192.168.142.165 | 6379 | 16379 | Slave |
4.2.2 在原来集群基础上增加s4.hadoop
1)复制一个虚拟机
2)修改主机名:hostnamectl set-hostname s4.hadoop
3)修改ip
4)修改每个机器的host文件
cat “192.168.142.165 s4.hadoop” >> /etc/hosts
cat /etc/hosts
4.2.3 集群每台机器redis 编译并安装
1)将redis 源码包上传到集群,并分发到6台机器上
分发结果:
批量解压
批量编译
make && make install
4.2.4 redis 集群配置
修改配置文件并分发配置文件
在原有单机版的基础上修改配置
开启集群模式

开启超时时间

创建目录: /usr/local/redis
复制配置到/usr/local/redis 目录
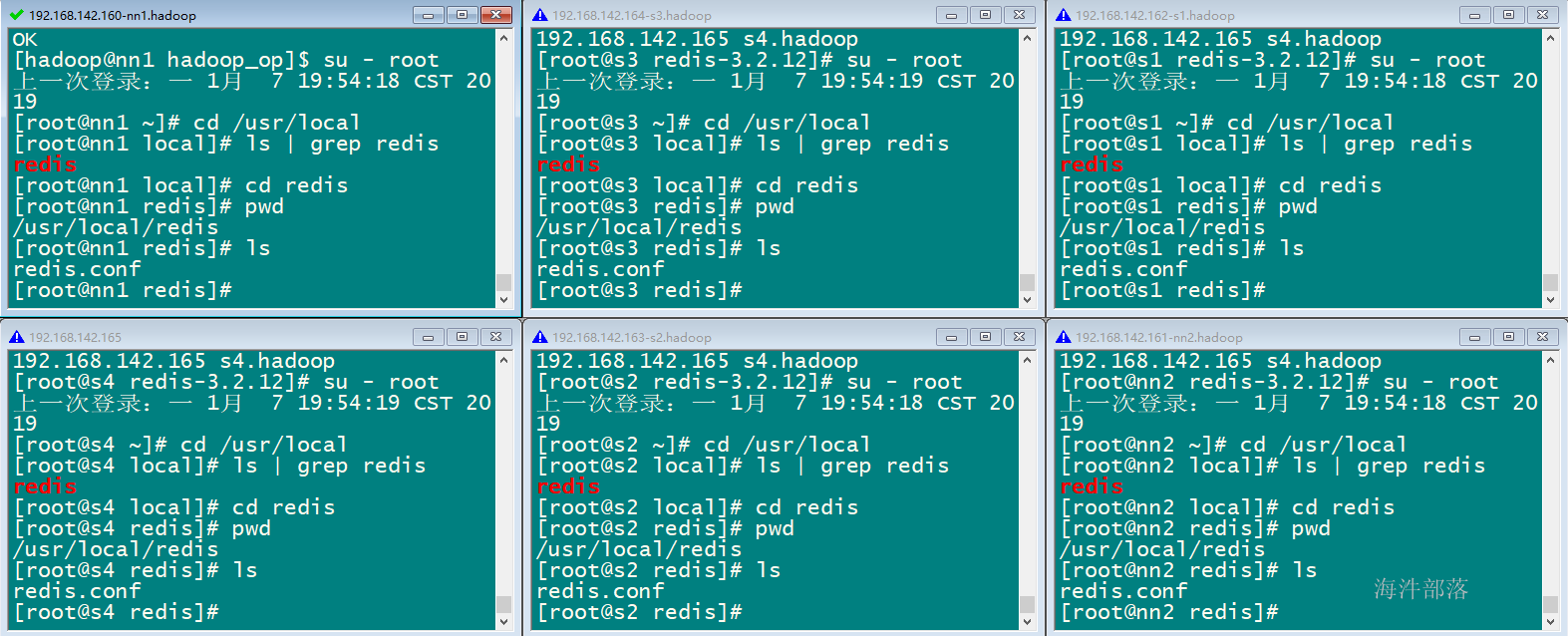
修改每个机器bind的ip
export H=hostname
echo $H
执行命令批量替换每个机器的bind的IP
sed -i "s/bind rs1.hadoop/bind $H/" /usr/local/redis/redis.conf
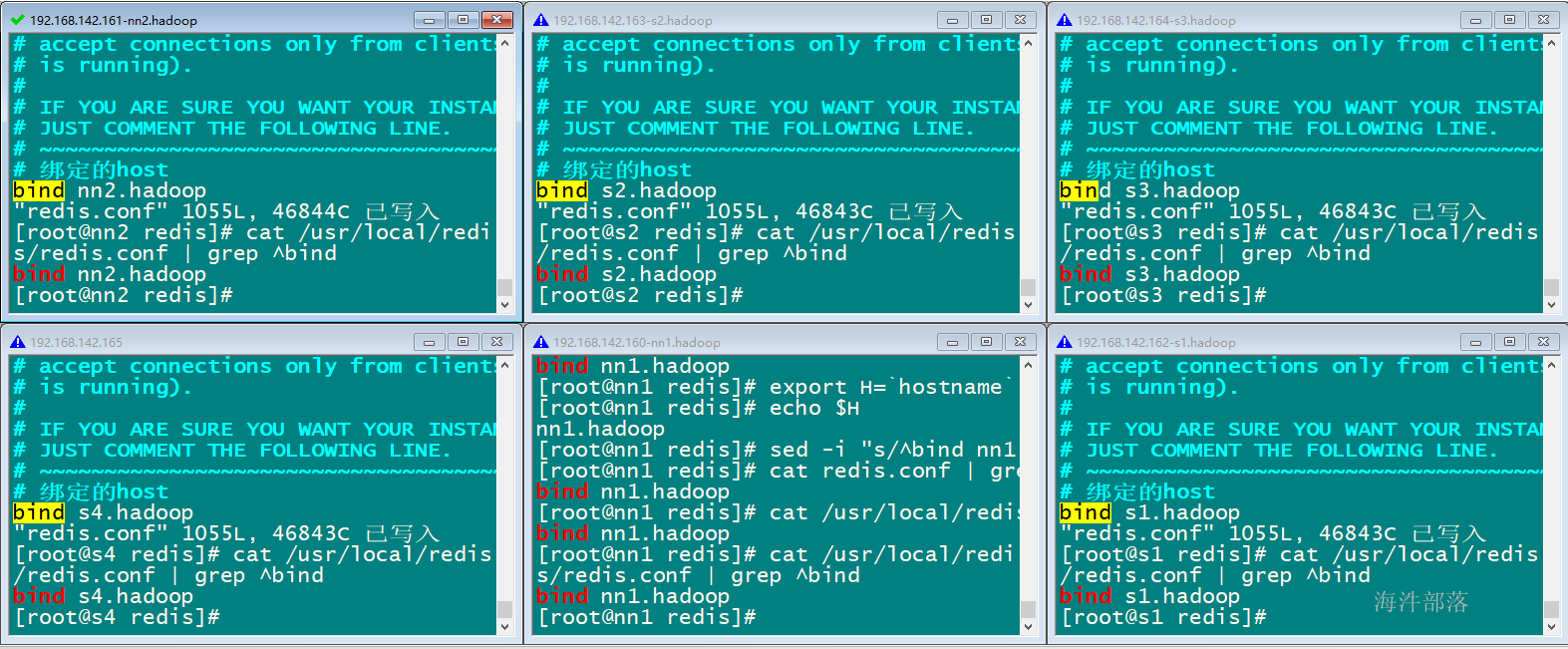
4.2.5 启动redis服务
进入/usr/local/redis 目录启动
cd /usr/local/redis
redis-server /usr/local/redis/redis.conf
当执行启动完成,6台redis-server 进程正在运行
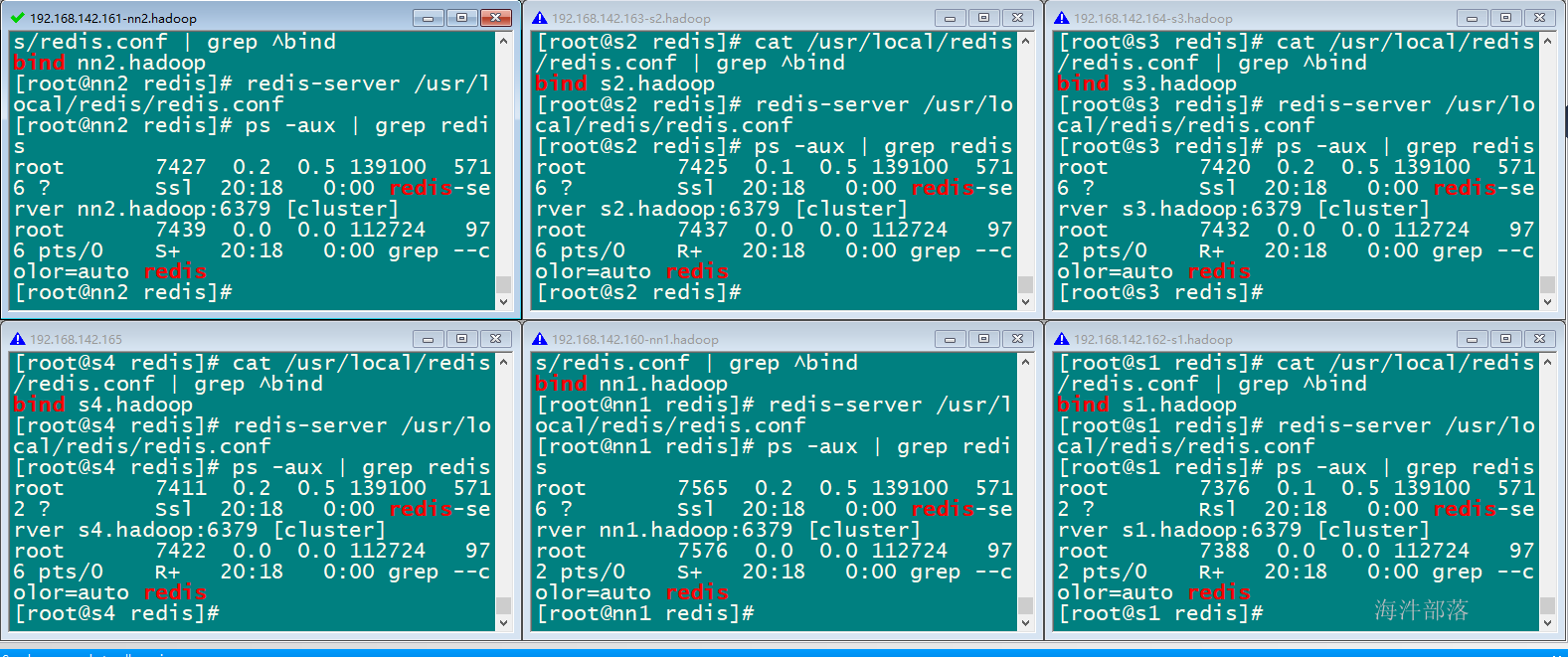
启动完成,在每台机器的 /usr/local/redies 目录下会生成相关文件

注意:启动完毕后,6 个Redis 实例尚未构成集群。
4.2.6 创建redis集群
redis官方提供了redis-trib.rb工具,redis的集群配置程序是用ruby写的,执行这个rb程序得需要先安装rb的环境。但是在使用之前 需要安装ruby;安装ruby,首先安装ruby的包依赖管理工具rvm;
本例在nn1.hadoop上安装ruby。
redis-trib.rb工具所在目录

本小节的安装,都要用自己手机流量,否则安装容易失败,如果失败,就多试几次
安装rvm
离线安装rvm: https://rvm.io/rvm/offline
# 下载rvm离线安装包,如果下载不下来可以用提供的安装包
cd /root
curl -sSL https://github.com/rvm/rvm/tarball/stable -o rvm-stable.tar.gz
mkdir rvm && cd rvm
# 解压安装包
tar -xzf ../rvm-stable.tar.gz -C ./
# 进入源码目录,执行安装rvm
./install --auto-dotfiles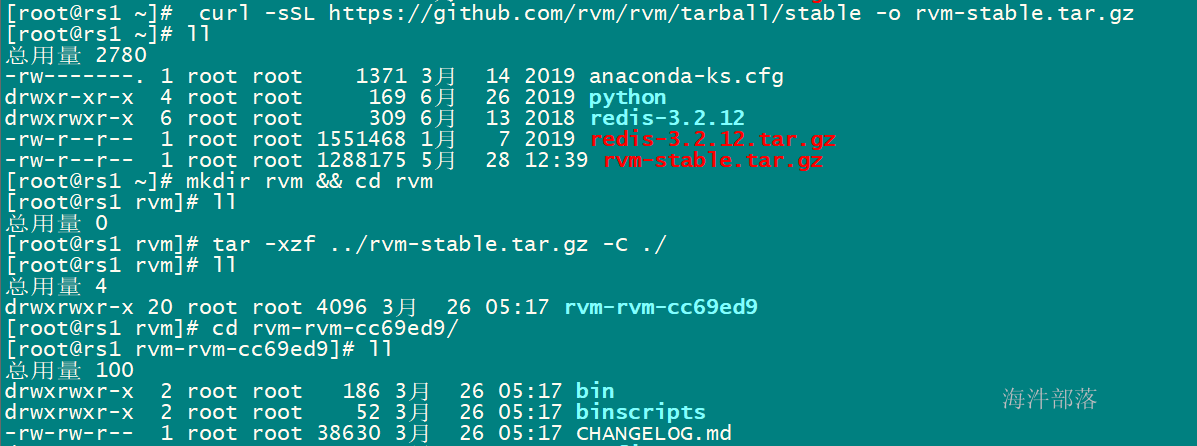
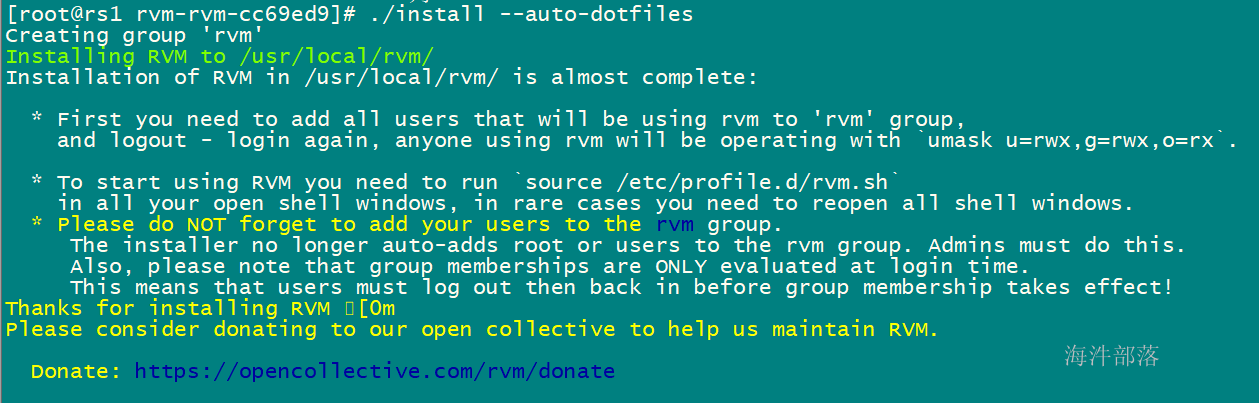
发现rvm已经安装成功了,为了让配置立即生效,我们需要用source命令导入rvm的配置文件。
source /usr/local/rvm/scripts/rvmrvm list known #查看可用版本
rvm install 2.3.4 #这步比较慢
gem install redis -v 4.4.0 # 安装ruby的redis 接口
安装完成之后进入源码目录找到redis-trib.rb脚本,执行下面的命令,创建集群这里要把host换成ip
创建redis 集群命令
/root/redis-3.2.12/src/redis-trib.rb create --replicas 1 192.168.142.160:6379 192.168.142.161:6379 192.168.142.162:6379 192.168.142.163:6379 192.168.142.164:6379 192.168.142.165:6379其中:
数字1:是副本数为1;
前三个是 master 的 redis 地址,后三个是 slave 的 redis 地址;
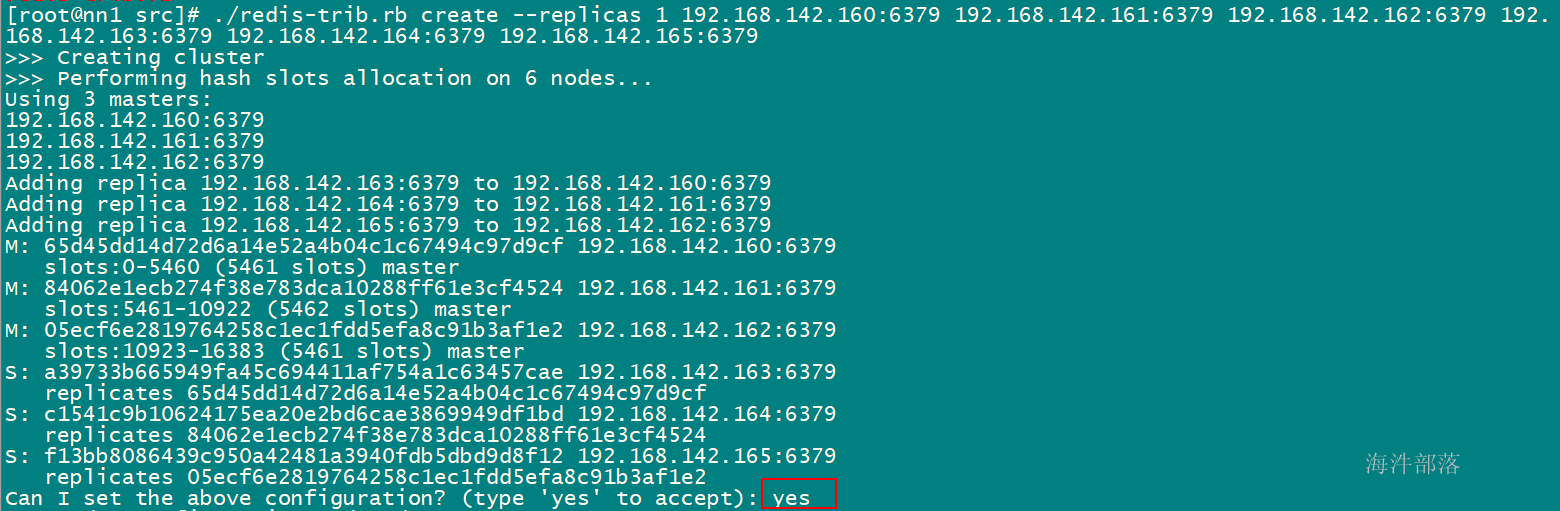
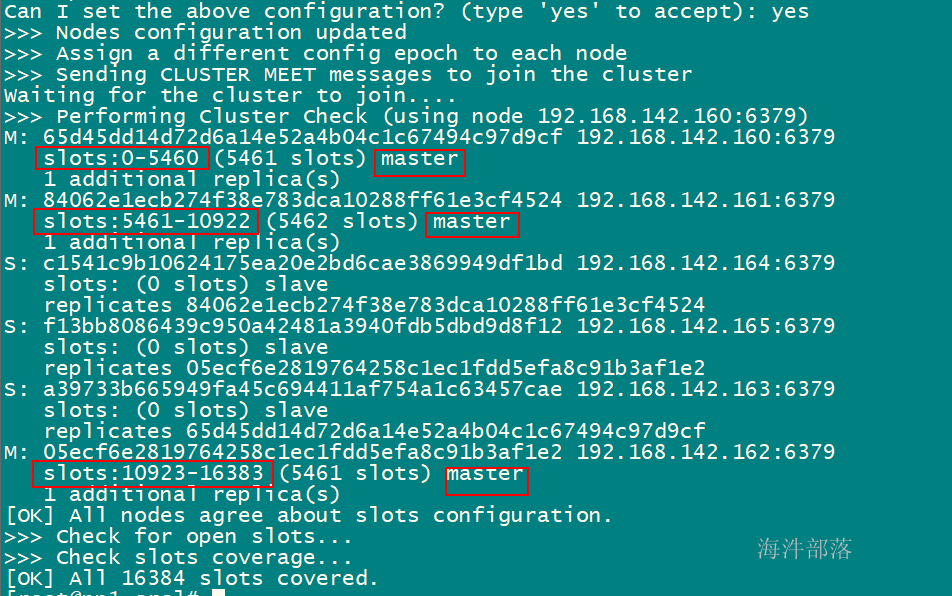
4.2.7 测试集群
redis-cli -c -h nn1.hadoop -p 6379
-c 是指定使用集群模式的客户端
测试读写
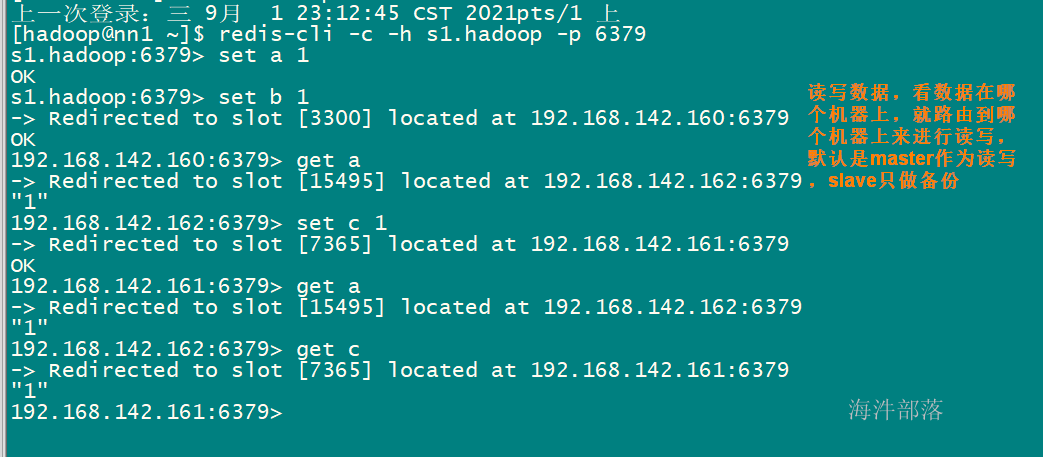
cluster nodes : 查看当前集群节点信息


测试redis高可用
kill掉 nn1的redis服务

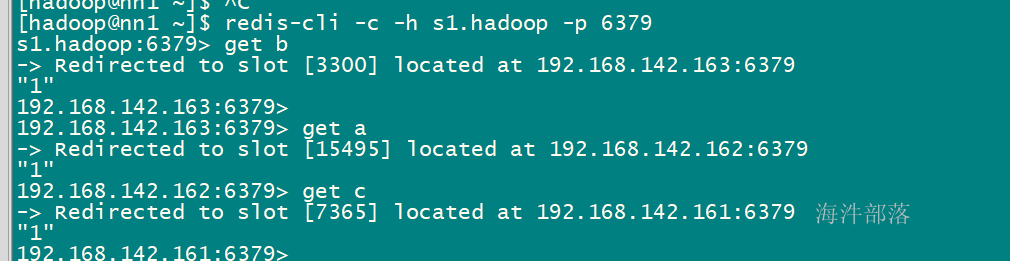
扩展知识:如果想对redis集群操作有更多了解,可以研究它的命令参数
[root@nn1 src]# ./redis-trib.rb
Usage: redis-trib <command> <options> <arguments ...>
create host1:port1 ... hostN:portN
--replicas <arg>
check host:port
info host:port
fix host:port
--timeout <arg>
reshard host:port
--from <arg>
--to <arg>
--slots <arg>
--yes
--timeout <arg>
--pipeline <arg>
rebalance host:port
--weight <arg>
--auto-weights
--use-empty-masters
--timeout <arg>
--simulate
--pipeline <arg>
--threshold <arg>
add-node new_host:new_port existing_host:existing_port
--slave
--master-id <arg>
del-node host:port node_id
set-timeout host:port milliseconds
call host:port command arg arg .. arg
import host:port
--from <arg>
--copy
--replace
help (show this help)4.2.8 创建redis集群后,开启和关闭redis-server服务的方式
关闭方式
在每台机器上执行下面的关闭命令
redis-cli -h nn1.hadoop -p 6379 shutdown
redis-cli -h nn2.hadoop -p 6379 shutdown
redis-cli -h s1.hadoop -p 6379 shutdown
redis-cli -h s2.hadoop -p 6379 shutdown
redis-cli -h s3.hadoop -p 6379 shutdown
redis-cli -h s4.hadoop -p 6379 shutdown
优雅的关闭方式:
H=hostname
redis-cli -c -h $H shutdown
重启方式
在每台机器上执行下面的开启命令
cd /usr/local/redis
redis-server /usr/local/redis/redis.conf
注意: 集群只创建一次,创建完重启后直接用即可。
redis 可视化客户端
https://github.com/caoxinyu/RedisClient
单机的 redis 可以使用select index命令切换数据库,默认有16个数据库,index为0到15

集群redis, 就1个库:

5.2 jedis 获取连接的方式
jedis 获取redis连接的3种方式:
1)jedis 操作单机redis获取redis连接
2)jedis 操作单机redis获取redis连接池,在连接池获取连接
3)jedis 操作 redis 集群 获取 redis 连接
直接获取连接 vs 从连接池获取连接
如果只是获取一次连接,这种方式适合直接获取连接方式。
如果要多次获取连接,这种方式适合先创建连接池,然后再从连接池获取连接。
5.2.1 jedis 操作单机redis获取redis连接
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>2.9.0</version>
</dependency>
public static void main(String[] args) {
// 获取连接 提供ip 和 端口
Jedis jedis = new Jedis("192.168.142.160",6379);
// 切换到10好库
jedis.select(10);
}5.2.2 jedis 操作单机redis获取redis连接池,在连接池获取连接
private static JedisPool getJedisPool() {
JedisPoolConfig config = new JedisPoolConfig();
// 设置最大连接数
config.setMaxTotal(100);
// 最大空闲连接数
config.setMaxIdle(5);
// 最少空闲连接数(初始化连接数)
config.setMinIdle(1);
// 连接等待超时时长60秒
config.setMaxWaitMillis(60 * 1000);
// 在获取redis连接时,自动测试连接是否可用,保证返回可用的连接
config.setTestOnBorrow(true);
// 连接回收到连接池时,自动测试连接是否可用(ping()),如果连接不可用,则不会放回连接池
config.setTestOnReturn(true);
// 自动检测空闲连接是否可用
config.setTestWhileIdle(true);
// 检测空闲连接是否可用的间隔时间
config.setTimeBetweenEvictionRunsMillis(60* 1000);
// 提供ip 和 端口
JedisPool jedisPool = new JedisPool(config,"192.168.142.160",6379);
return jedisPool;
}
public static void main(String[] args) {
// 获取连接池
JedisPool jedisPool = getJedisPool();
// 获取连接
Jedis jedis = jedisPool.getResource();
}5.2.3 jedis 操作 redis 集群 获取 redis 连接
// 提供redis集群节点 ip 和端口
Set<HostAndPort> hostSet = new HashSet<HostAndPort>();
hostSet.add(new HostAndPort("192.168.142.160", 6379));
hostSet.add(new HostAndPort("192.168.142.161", 6379));
hostSet.add(new HostAndPort("192.168.142.162", 6379));
hostSet.add(new HostAndPort("192.168.142.163", 6379));
hostSet.add(new HostAndPort("192.168.142.164", 6379));
hostSet.add(new HostAndPort("192.168.142.165", 6379));
// 创建redis集群的连接
JedisCluster jc = new JedisCluster(hostSet);5.3 操作redis
5.3.1 字符串常规操作
// 添加一条数据
jedis.set("key1", "1");
// 添加多条数据
jedis.mset("key2", "2", "key3", "3", "key4", "5");
// 获取key对应的值
String value1 = jedis.get("key1");
System.out.println(value1);
// 获取keys对应的values
String[] keys = {"key1","key2","key3"};
List<String> list1 = jedis.mget(keys);
// [1, 2, 3]
System.out.println(list1);
// key重命名
jedis.rename("key4", "key5");
String v = jedis.get("key5");
System.out.println("key5: " + v );
// 如果获取了不存在的key,会返回null
String[] keys2 = {"key1","key2","key4"};
// 获取keys对应的values
List<String> list2 = jedis.mget(keys2);
// [1, 2, null]
System.out.println(list2);
// 思考:如何对要写入redis的key去重?(redis有的key不写入redis, 没有key写入redis)
// 自增1,等价于click_volume++。默认为0
jedis.incr("click_volume");
// 在原有值的基础增加指定的值,等价于click_volume+=10;
jedis.incrBy("click_volume",10);
// 自减1,等价于click_volume--
jedis.decr("click_volume");
// 减指定数量的值,等价于click_volume-=10
jedis.decrBy("click_volume",10);
// 如果写入的key已经存在,返回0;如果不存在,写入key对应的值并返回1
long res = jedis.setnx("click_volume","200");
System.out.println("setnx result: " + (res == 0 ? false : true));
// 保存带有效期的key,单位为秒
jedis.setex("expir_key", 5, "5秒后消失");
// 遍历当前库的以"key"字符串开头的 key
Set<String> keys3 = jedis.keys("key*");
System.out.println(keys3);
// 删除对应key的数据
jedis.del("key1");
jedis.del("key2", "key3");5.3.2 用冒号作为分割来设计key
用冒号作为分割是设计key的一种不成文的原则,遵循这种格式设计出的key在某些redis客户端下可以有效的识别;
// 用:间隔的key,在可视化客户端上会分成目录结构
String k1 = "hainiu:key1";
String v1 = "海牛大数据";
jedis.set(k1, v1);
String v1rs = jedis.get(k1);
System.out.println(v1rs);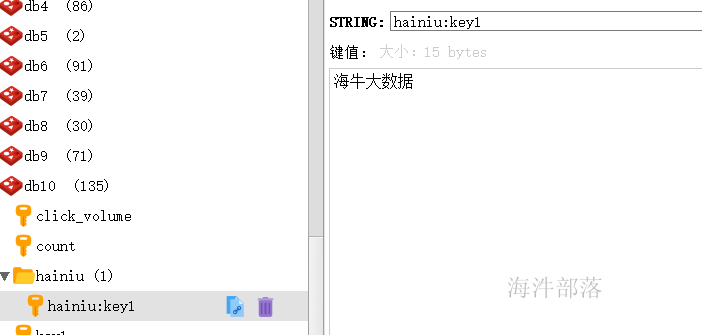
5.3.3 redis key的设计
对比着关系型数据库,我们对redis key的设计原则:
user 表 : id name sex age
第一段把表名转换为key前缀, 比如:user:
第二段放置用于区分key的字段--对应mysql中的主键的列名,比如:id
第三段放置主键值,比如:uid0001
第四段写列名,比如:name
那 user表 id 为 uid0001 用户的name 值 haha
set user:id:uid0001:name haha
set user:id:uid0001:name xiaohua
set user:id:uid0001:age 10
set user:id:uid0001:sex girl
set user:id:uid0002:name haha
set user:id:uid0002:age 10
set user:id:uid0002:sex boy客户端看到的目录结构

如何查询数据?
String[] keys4 = jedis.keys("user:id:uid0001:*").toArray(new String[]{});
System.out.println(Arrays.toString(keys4));
List<String> values4 = jedis.mget(keys4);
System.out.println(values4);5.3.4 redis 支持事务操作
// 开启redis事务
Transaction transaction = jedis.multi();
transaction.set("t1", "1");
transaction.set("t2", "2");
// 抛异常
int t = 1 / 0;
transaction.set("t3", "3");
// 提交事务
List<Object> exec = transaction.exec();
// [OK, OK, OK]
System.out.println(exec);结果:
由于 事务内抛异常, 导致 t1、t2 没添加成功。


