概述
Spark为结构化数据处理引入了一个称为Spark SQL的编程模块。它提供了一个称为DataFrame(数据框)的编程抽象,DF的底层仍然是RDD,并且可以充当分布式SQL查询引擎。
SparkSQL的由来
SparkSQL的前身是Shark。在Hadoop发展过程中,为了给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,Hive应运而生,是当时唯一运行在hadoop上的SQL-on-Hadoop工具。但是,MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,运行效率较低。
后来,为了提高SQL-on-Hadoop的效率,大量的SQL-on-Hadoop工具开始产生,其中表现较为突出的是:
1)MapR的Drill
2)Cloudera的Impala
3)Shark
其中Shark是伯克利实验室Spark生态环境的组件之一,它基于Hive实施了一些改进,比如引入缓存管理,改进和优化执行器等,并使之能运行在Spark引擎上,从而使得SQL查询的速度得到10-100倍的提升。
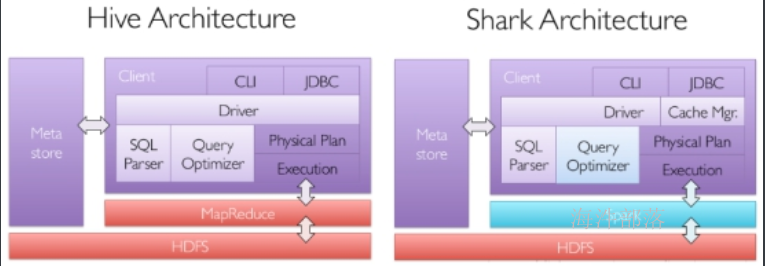
但是,随着Spark的发展,对于野心勃勃的Spark团队来说,Shark对于hive的太多依赖(如采用hive的语法解析器、查询优化器等等),制约了Spark的One Stack rule them all的既定方针,制约了spark各个组件的相互集成,所以提出了sparkSQL项目。
SparkSQL抛弃原有Shark的代码,汲取了Shark的一些优点,如内存列存储(In-Memory Columnar Storage)、Hive兼容性等,重新开发了SparkSQL代码。
由于摆脱了对hive的依赖性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便。
2014年6月1日,Shark项目和SparkSQL项目的主持人Reynold Xin宣布:停止对Shark的开发,团队将所有资源放SparkSQL项目上,至此,Shark的发展画上了句号。


