众所周知,CDH为了推自家的Impala,阉割掉了Spark的spark-sql工具,虽然很多时候我们并不需要spark-sql,但是架不住特殊情况下有使用它的时候,这个根据项目或者团队(个人)情况而异。我这边就是因为项目原因,需要使用spark-sql,因此从网上各种查资料,折腾了好几天,最终在CDH集群上集成了spark-sql,以下操作并不能保证百分百适配你的环境,但思路可供借鉴。
集成步骤
下载Apache-spark2.4.0
因为CDH6.3.2使用的Spark版本是2.4.0,为了避免使用过程中出现某些版本不匹配的隐患,因此需要从官网下载spark2.4.0,下载地址:
https://archive.apache.org/dist/spark/spark-2.4.0/
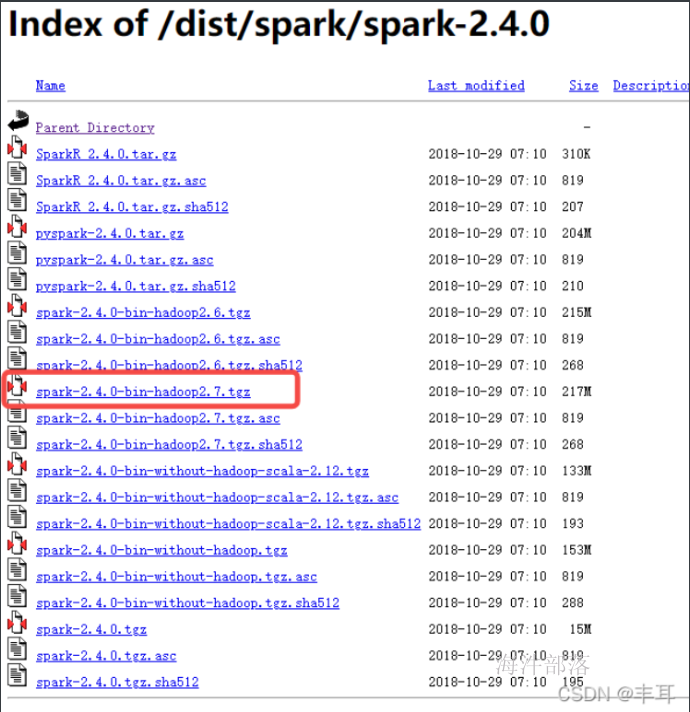
将下载好的压缩包解压到CDH集群服务器的合适目录下
此处我将其放到/opt/cloudera/parcels/CDH/lib/下并起名为spark2
tar -zxvf spark-2.4.0-bin-hadoop2.7.tgz
mv spark-2.4.0-bin-hadoop2.7 /opt/cloudera/parcels/CDH/lib/spark2修改配置文件
将spark2/conf下的所有配置全部删除,并将集群spark的conf文件复制到此处
cd /opt/cloudera/parcels/CDH/lib/spark2/conf
rm -rf *
cp -r /etc/spark/conf/* ./
mv spark-env.sh spark-env说明:
将spark-env.sh改名是为了不让spark-sql走spark环境,二是走hive源数据库。
添加hive-site.xml
将gateway节点的hive-site.xml复制到spark2/conf目录下,不需要做变动
cp /etc/hive/conf/hive-site.xml /opt/cloudera/parcels/CDH/lib/spark2/conf/ 配置yarn.resourcemanager
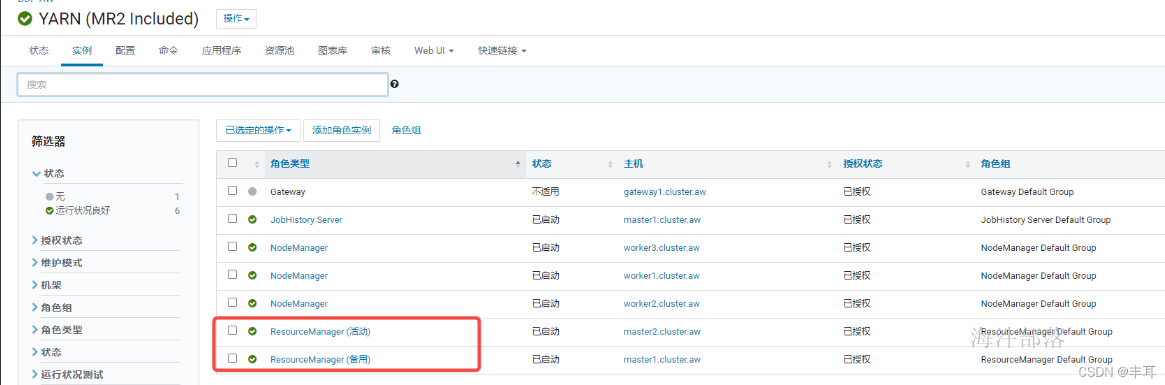
查看你CDH的yarn配置里是否有如下配置,需要开启
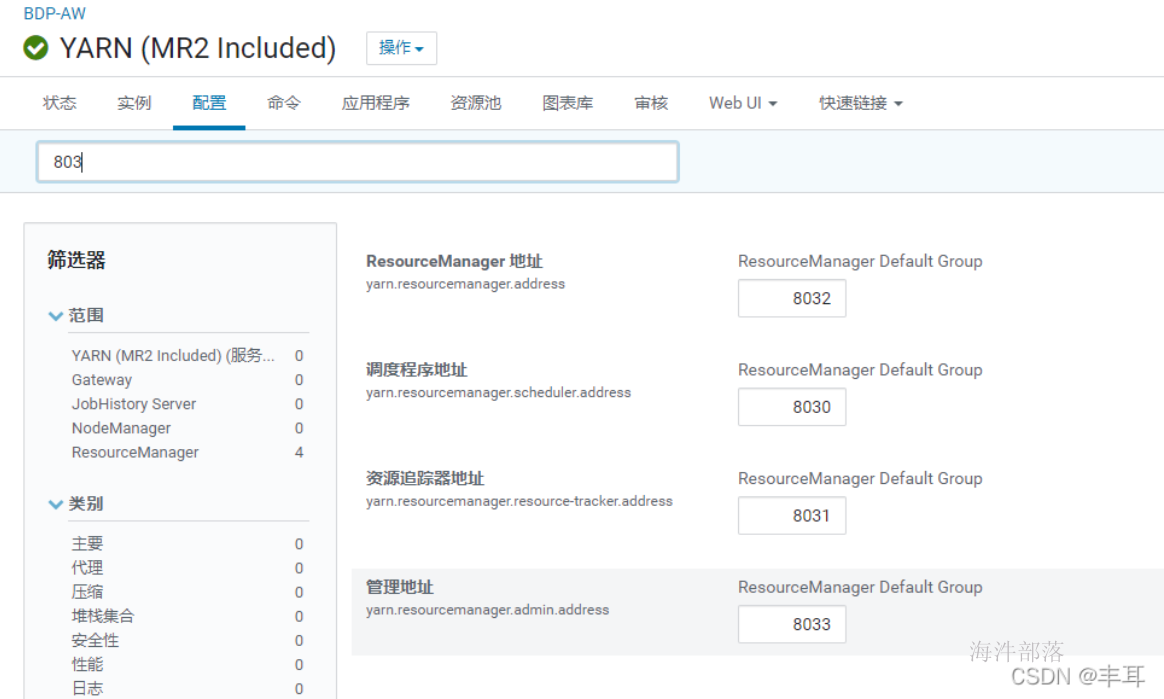
正常情况下,resourcemanager应该会默认启用以上配置的
创建spark-sql
touch /opt/cloudera/parcels/CDH/bin/spark-sql
#!/bin/bash
# Reference: http://stackoverflow.com/questions/59895/can-a-bash-script-tell-what-directory-its-stored-in
export HADOOP_CONF_DIR=/etc/hadoop/conf
export YARN_CONF_DIR=/etc/hadoop/conf
SOURCE="${BASH_SOURCE[0]}"
BIN_DIR="$( dirname "$SOURCE" )"
while [ -h "$SOURCE" ]
do
SOURCE="$(readlink "$SOURCE")"
[[ $SOURCE != /* ]] && SOURCE="$BIN_DIR/$SOURCE"
BIN_DIR="$( cd -P "$( dirname "$SOURCE" )" && pwd )"
done
BIN_DIR="$( cd -P "$( dirname "$SOURCE" )" && pwd )"
LIB_DIR=$BIN_DIR/../lib
export HADOOP_HOME=$LIB_DIR/hadoop
# Autodetect JAVA_HOME if not defined
. $LIB_DIR/bigtop-utils/bigtop-detect-javahome
exec $LIB_DIR/spark2/bin/spark-submit --class org.apache.spark.sql.hive.thriftserver.SparkSQLCLIDriver "$@" 配置快捷方式
alternatives --install /usr/bin/spark-sql spark-sql /opt/cloudera/parcels/CDH/bin/spark-sql 1 

