1 数据仓库概念
数据仓库(dataware house),一般简称DW或DWH,是⼀个很⼤的数据存储集合,出于企业的分析性报告和决策⽀持⽬的⽽创建,对多样的业务数据进⾏筛选与整合。它能为企业提供⼀定的BI(商业智能:例如数据挖掘、数据分析和数据报表)能⼒。
1990年由比尔.恩门首次提出,数据仓库建设特征四大特点面向主题、集成性、稳定性、时变性。
面向主题:
将上游数据(结构化、非结构化)通过数据抽取加载至数据仓库,根据各种业务场景划分不同业务主题,按照主题摆放进行数据存储。
比如:“销售分析”主题就是分析销售情况。
集成性:
将上游分散的数据进行抽取,进行加工与集成,汇总存储汇总层。
比如:数据汇总、统一格式等。
稳定性:
要分析的数据,基本不改动。
时变性:
数据仓库是随时间变化入仓的,传统数据加载方式为T+1的方式加载(今天计算昨天的数据),提供历史某阶段数据查询功能。
分析的数据,一般是历史数据,根据历史数据挖掘出有价值的数据。
2 数据仓库常见术语
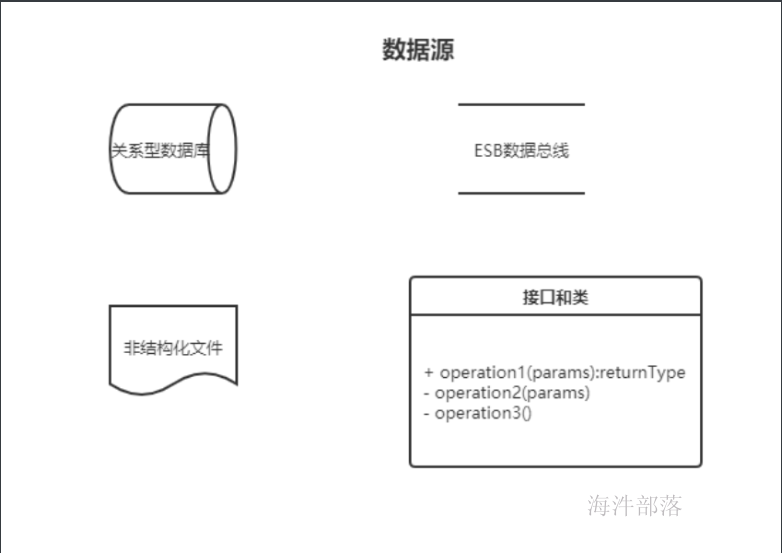
2.1 数据源
上游数据,可以是结构化数据也可以是非结构化数据。
2.2 数据加载(ETL)
通过ETL程序或者ETL脚本将上游数据抽取至数据仓库,抽取方式有对库直抽(sqoop)或上游系统卸数至大数据平台(NAS)。
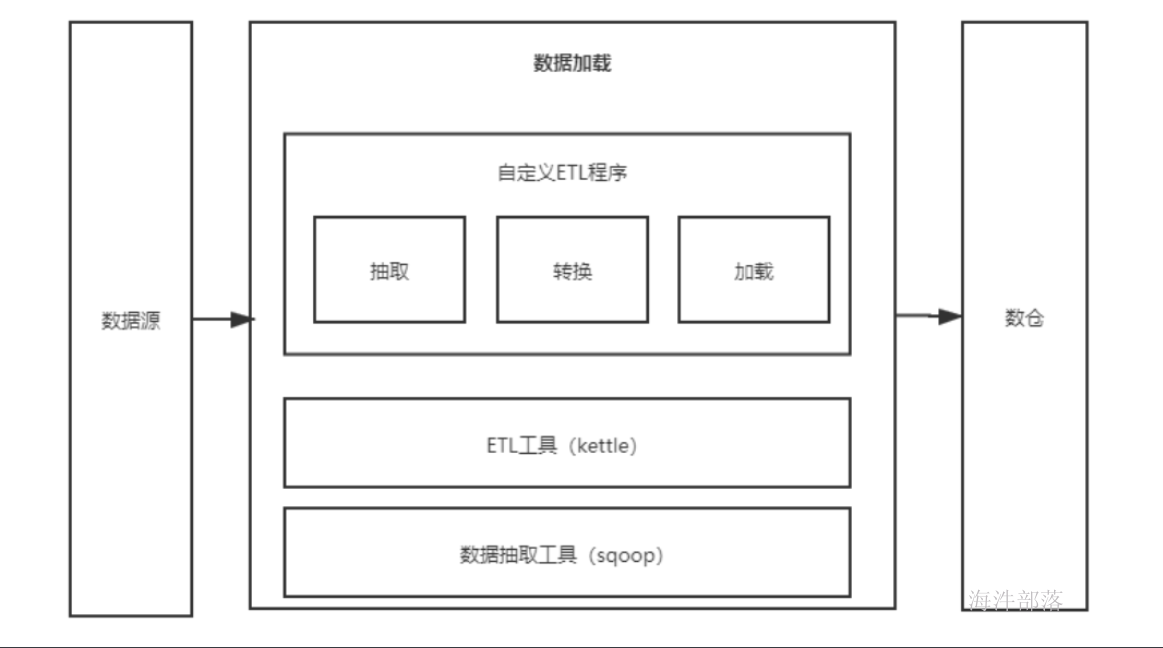
ETL概念:
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据。
ETL分为三个部分:数据抽取、数据的清洗转换、数据的加载。
->数据抽取(Extract):
将各个不同的数据源抽取到一个中间层中。
->数据清洗转换(Cleaning、Transform):
数据清洗是指将不符合要求的数据除掉,包括错误数据、不完整数据、重复数据。
数据转换要做的工作是把所有数据的模板、标准、计算规则等进行统一,如存储结构、数据编码等。
->数据的加载(Load):
是把处理好的数据加载到数据仓库,比如hive。
2.3 数据仓库
用于数据存储与加工处理
2.4 元数据管理
描述数据的数据称为元数据。
元数据主要是记录数据仓库中模型的定义、各层级间的映射关系(例如我们架构的这五层,层与层之间的映射关系要靠元数据来保存),监控数据仓库的数据状态以及ETL任务的运行。
一般会通过元数据质量库来统一地存储和管理元数据,其主要目的就是使数据仓库的设计、部署、操作和管理达成协同和一致,保证数据质量。
数据仓库的元数据:
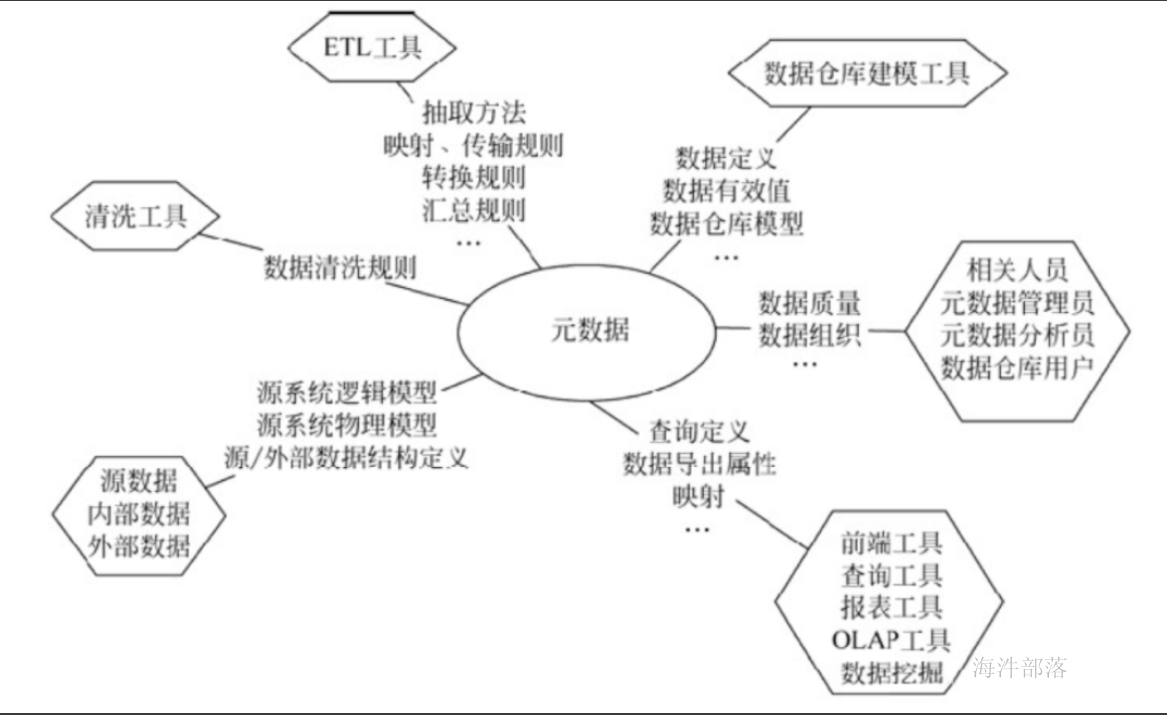
元数据功能:
数据血缘分析:向上追溯元数据对象的数据来源。
影响分析:向下追溯元数据对象对下游的影响。
同步检查:检查源表到目标表的数据结构是否发生变更。
指标一致性分析:定期分析指标定义是否和实际情况一致。
实体关联查询:事实表与维度表的代理键自动关联。
2.5 数据质量
数据质量可以根据以下维度进行测量:
1)完整性:是否有丢失或无法使用的数据?
2)标准性:数据是否符合标准格式?
3)一致性:数据值是提供一致的信息还是提供冲突的信息?
4)准确性:数据是准确的,还是过时的?
5)重复:数据记录或属性在不应该重复的地方是重复的吗?
对数仓数据质量进行管理,通常在数据入仓阶段进行数据入仓有效性检核。
根据业务抽取合理字段入仓。
不允许有脏数据,如:将非结构化数据不经过清洗直接入仓。
检核字段数据的合理性,如:年龄的有效范围。
按照入仓标准进行筛选,在主题加工或汇总加工时进行数据合理性筛选,如字段合理性管理。
数据条数检核,如:从上一层到下一层表数据条数是否正确。
某个字段数据的种类数量检核,如:上层country字段的count(distinct) 和 下一层的count(distinct) 数量是否一致。
检核字段数据的合理性,如:年龄的有效范围。
2.6 存储策略
是指数据存储的策略,如增量、全量存储。
增量存储:适合业务数据,这个数据不会update。
全量存储:适合字典数据,这个数据可能会update。
数据格式,如orc、parquet,压缩方式,如snappy。
2.7 向下供数
数据仓库对下游系统供数,常见供数方式分为:
1)下游系统通过接口访问数仓
2)数仓按照下游系统需求将数据卸载成数据文件供给下游系统。
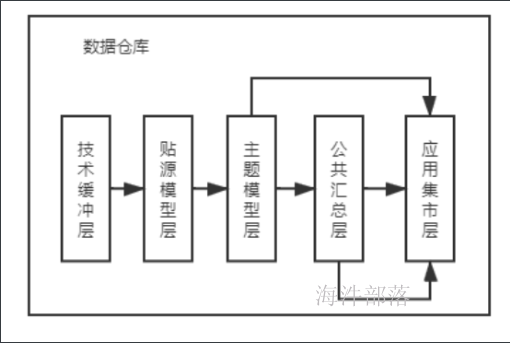
3 数据仓库整体架构
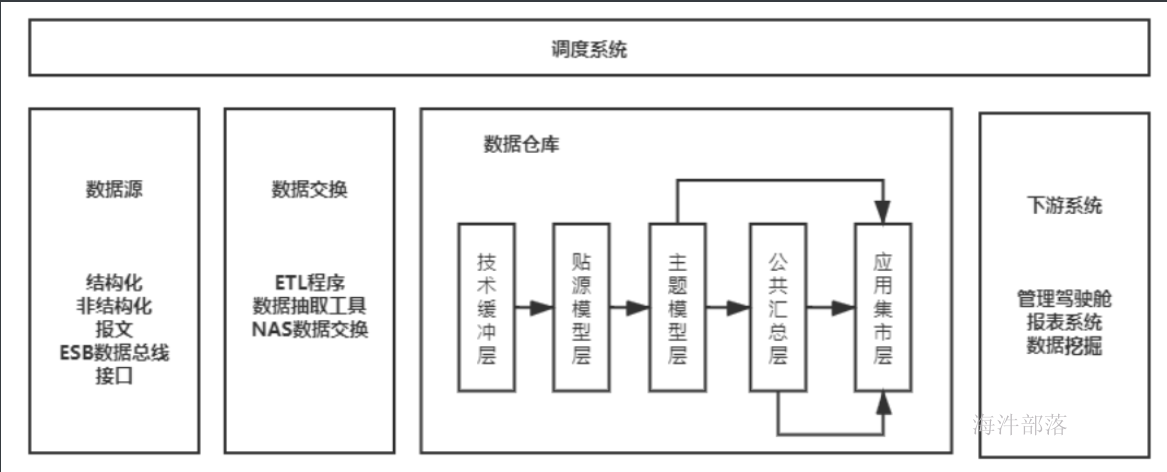
4 数据仓库发展
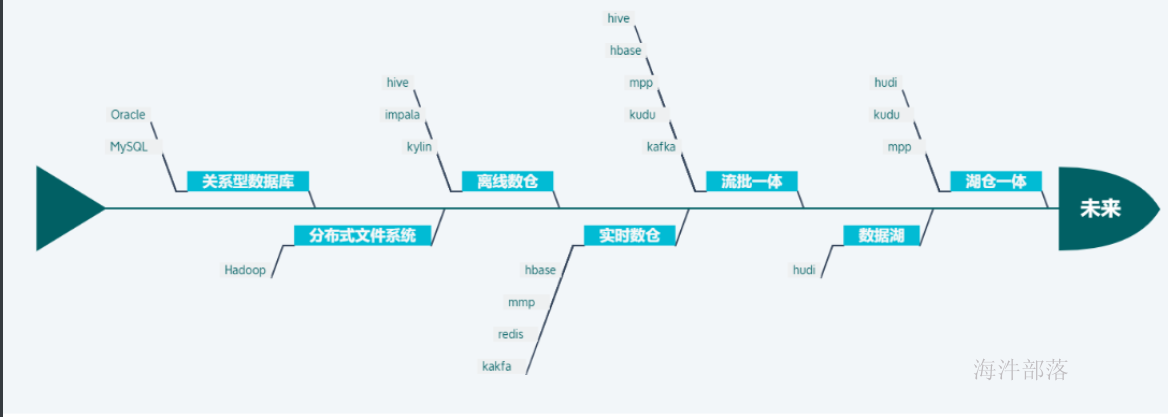
数据湖(Data Lake):
是一个以原始格式存储数据的存储库或系统。它按原样存储数据,而无需事先对数据进行结构化处理。一个数据湖可以存储结构化数据(如关系型数据库中的表),半结构化数据(如CSV、日志、XML、JSON),非结构化数据(如电子邮件、文档、PDF)和二进制数据(如图形、音频、视频)。
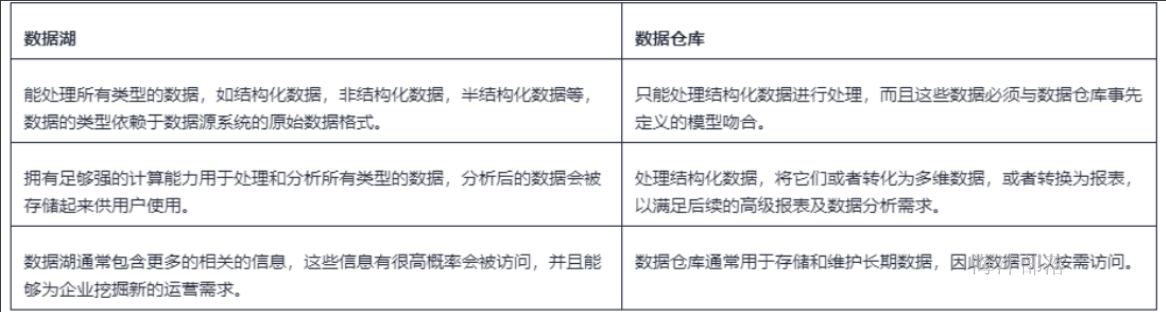
数据湖 与 数据仓库的区别