flinksql课件
table api和sql介绍
Apache Flink 具有两个关系 API——Table API 和 SQL——用于统一流和批处理。Table API 是用于 Scala 和 Java 的语言集成查询 API,它允许以非常直观的方式组合来自关系运算符(例如选择、过滤和联接)的查询。Flink 的 SQL 支持基于实现 SQL 标准的Apache Calcite。无论输入是批输入 (DataSet) 还是流输入 (DataStream),在任一接口中指定的查询都具有相同的语义并指定相同的结果。
Table API 和 SQL 接口以及 Flink 的 DataStream 和 DataSet API 彼此紧密集成。您可以轻松地在所有 API 和基于 API 的库之间切换。例如,您可以使用CEP 库从 DataStream 中提取模式,然后使用 Table API 来分析这些模式,或者在对预处理过的数据运行Gelly 图算法之前,您可以使用 SQL 查询扫描、过滤和聚合批处理表。数据。
请注意,Table API 和 SQL 的功能尚未完成,正在积极开发中。[Table API, SQL] 和 [stream, batch] 输入的每种组合都支持并非所有操作。表程序依赖
根据目标编程语言,您需要将 Java 或 Scala API 添加到项目中,以便使用 Table API 和 SQL 来定义管道:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-java-bridge_2.11</artifactId>
<version>1.10.2</version>
<scope>provided</scope>
</dependency>
<!-- or... -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-api-scala-bridge_2.11</artifactId>
<version>1.10.2</version>
<scope>provided</scope>
</dependency>此外,如果要在 IDE 中本地运行 Table API 和 SQL 程序,则必须添加以下一组模块之一,具体取决于要使用的规划器:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner_2.11</artifactId>
<version>1.10.2</version>
<scope>provided</scope>
</dependency>
<!-- or.. (for the new Blink planner) -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.11</artifactId>
<version>1.10.2</version>
<scope>provided</scope>
</dependency>在内部,部分表生态系统是在 Scala 中实现的。因此,请确保为批处理和流应用程序添加以下依赖项:
```
org.apache.flinkflink-streaming-scala_2.111.10.2provided
**扩展依赖**
如果要实现自定义格式与Kafka交互或者一组用户自定义函数,下面的依赖就足够了,可以用于SQL Client的JAR文件:
```xml
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-common</artifactId>
<version>1.10.2</version>
<scope>provided</scope>
</dependency>目前,该模块包括以下扩展点:
SerializationSchemaFactory
DeserializationSchemaFactory
ScalarFunction
TableFunction
AggregateFunction
Concepts & Common API 通用API
计划器之间的区别
- Blink 将批处理作业视为流的特殊情况。因此,也不支持Table和DataSet之间的转换,批处理作业不会被翻译成DateSet程序,而是被翻译成DataStream程序,与流式作业相同。
- Blink planner 不支持BatchTableSource,使用 boundedStreamTableSource代替它。
- Blink planner 只支持全新的Catalog,不支持ExternalCatalog弃用的。
- FilterableTableSource为老的planner和blink是不相容的。旧规划器会将PlannerExpressions下推到FilterableTableSource,而 Blink 规划器会将Expressions下推。
- 基于字符串的键值配置选项仅用于 Blink 规划器。
- 两个规划器中的实现( CalciteConfig)PlannerConfig是不同的。
- Blink planner 会将多个接收器优化为一个 DAG(仅在TableEnvironment支持,在StreamTableEnvironment上不支持)。旧的规划器总是将每个接收器优化为一个新的 DAG,其中所有 DAG 彼此独立。
- 旧计划器现在不支持目录统计,而 Blink 计划器支持。
Table API and SQL 使用
程序结构
// create a TableEnvironment for specific planner batch or streaming
TableEnvironment tableEnv = ...; // see "Create a TableEnvironment" section
// create a Table
tableEnv.connect(...).createTemporaryTable("table1");
// register an output Table
tableEnv.connect(...).createTemporaryTable("outputTable");
// create a Table object from a Table API query
Table tapiResult = tableEnv.from("table1").select(...);
// create a Table object from a SQL query
Table sqlResult = tableEnv.sqlQuery("SELECT ... FROM table1 ... ");
// emit a Table API result Table to a TableSink, same for SQL result
tapiResult.insertInto("outputTable");
// execute
tableEnv.execute("java_job");创建表环境
表和视图
TableEnvironment 可以注册目录 Catalog,并可以基于 Catalog 注册表
表(Table)是由一个“标识符”(identifier)来指定的,由3部分组成:
Catalog名、数据库(database)名和对象名
表可以是常规的,也可以是虚拟的(视图,View)
常规表(Table)一般可以用来描述外部数据,比如文件、数据库表或消息队 列的数据,也可以直接从 DataStream转换而来
视图(View)可以从现有的表中创建,通常是 table API 或者 SQL 查询的一 个结果集步骤
TableEnvironment 是 flink 中集成 Table API 和 SQL 的核心概念,所有对表 的操作都基于 TableEnvironment
注册 Catalog
在 Catalog 中注册表
执行 SQL 查询
注册用户自定义函数(UDF)
转换DataStream,Dataset和表tableEnv.createTemporaryView("exampleView", table);可以转换为视图,其中如果是关键字使用`符号转义
创建代码
// **********************
// FLINK STREAMING QUERY
// **********************
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.java.StreamTableEnvironment;
EnvironmentSettings fsSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build();
StreamExecutionEnvironment fsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment fsTableEnv = StreamTableEnvironment.create(fsEnv, fsSettings);
// or TableEnvironment fsTableEnv = TableEnvironment.create(fsSettings);
// ******************
// FLINK BATCH QUERY
// ******************
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.table.api.java.BatchTableEnvironment;
ExecutionEnvironment fbEnv = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment fbTableEnv = BatchTableEnvironment.create(fbEnv);
// **********************
// BLINK STREAMING QUERY
// **********************
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.java.StreamTableEnvironment;
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment bsTableEnv = StreamTableEnvironment.create(bsEnv, bsSettings);
// or TableEnvironment bsTableEnv = TableEnvironment.create(bsSettings);
// ******************
// BLINK BATCH QUERY
// ******************
import org.apache.flink.table.api.EnvironmentSettings;
import org.apache.flink.table.api.TableEnvironment;
EnvironmentSettings bbSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build();
TableEnvironment bbTableEnv = TableEnvironment.create(bbSettings);创建表的方式:转换
ExecutionEnvironment fbEnv = ExecutionEnvironment.getExecutionEnvironment();
BatchTableEnvironment fbTableEnv = BatchTableEnvironment.create(fbEnv);
DataSource<String> stringDataSource = fbEnv.readTextFile("table_data/a.txt");
MapOperator<String, Tuple3<String, String, String>> tp3Ds = stringDataSource.map(new MapFunction<String, Tuple3<String, String, String>>() {
@Override
public Tuple3<String, String, String> map(String value) throws Exception {
String[] split = value.split(" ");
return Tuple3.of(split[0], split[1], split[2]);
}
});
Table table = fbTableEnv.fromDataSet(tp3Ds, "id,name,age");
fbTableEnv.toDataSet(table,Row.class).print();blink batch env不支持输出
EnvironmentSettings bbSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inBatchMode().build();
TableEnvironment bbTableEnv = TableEnvironment.create(bbSettings);
BasicTypeInfo [] types ={BasicTypeInfo.STRING_TYPE_INFO,BasicTypeInfo.STRING_TYPE_INFO,BasicTypeInfo.STRING_TYPE_INFO};
String [] fields = {"id","name","age"};
Table table1 = bbTableEnv.fromTableSource(new CsvTableSource("table_data", fields, types));blink streaming env
StreamExecutionEnvironment bsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
EnvironmentSettings bsSettings = EnvironmentSettings.newInstance().useBlinkPlanner().inStreamingMode().build();
StreamTableEnvironment bsTableEnv = StreamTableEnvironment.create(bsEnv, bsSettings);
DataStreamSource<String> ds = bsEnv.socketTextStream("localhost", 6666);
Table table = bsTableEnv.fromDataStream(ds);
bsTableEnv.toAppendStream(table,Row.class).print();
bsEnv.execute();streaming table env
EnvironmentSettings fsSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build();
StreamExecutionEnvironment fsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
StreamTableEnvironment fsTableEnv = StreamTableEnvironment.create(fsEnv, fsSettings);
DataStreamSource<String> ds = fsEnv.socketTextStream("localhost", 6666);
Table table = fsTableEnv.fromDataStream(ds);
fsTableEnv.toAppendStream(table,String.class).print();
fsTableEnv.execute("");基于dataStream转换成表或者视图
public class TestEnvCreate {
public static void main(String[] args) throws Exception {
EnvironmentSettings fsSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build();
StreamExecutionEnvironment fsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
fsEnv.setParallelism(1);
StreamTableEnvironment fsTableEnv = StreamTableEnvironment.create(fsEnv, fsSettings);
DataStreamSource<String> ds = fsEnv.socketTextStream("localhost", 6666);
// SingleOutputStreamOperator<Tuple3<Integer,String,Double>> ds1 = ds.map(new MapFunction<String, Tuple3<Integer,String,Double>>() {
// @Override
// public Tuple3<Integer,String,Double> map(String value) throws Exception {
// String[] split = value.split(" ");
// return Tuple3.of(Integer.valueOf(split[0]), split[1], Double.valueOf(split[2]));
// }
// });
// SingleOutputStreamOperator<MyBean> ds1 = ds.map(new MapFunction<String, MyBean>() {
// @Override
// public MyBean map(String value) throws Exception {
// String[] split = value.split(" ");
// return new MyBean(Integer.valueOf(split[0]), split[1], Double.valueOf(split[2]));
// }
// });
SingleOutputStreamOperator<Row> ds1 = ds.map(new MapFunction<String, Row>() {
@Override
public Row map(String value) throws Exception {
String[] split = value.split(" ");
return Row.of(Integer.valueOf(split[0]), split[1], Double.valueOf(split[2]));
}
}).returns(new RowTypeInfo(Types.INT,Types.STRING,Types.DOUBLE));
// Table table = fsTableEnv.fromDataStream(ds1,"id,name,score");
// Table table = fsTableEnv.fromDataStream(ds1,"f1 as name,f0 as id,f2 as score");
// Table table = fsTableEnv.fromDataStream(ds1,"id,name,score");
fsTableEnv.createTemporaryView("person",ds1,"id,name,score");
Table table1 = fsTableEnv.from("person").select("id,name");
fsTableEnv.toAppendStream(table1,Row.class).print();
// fsTableEnv.toAppendStream(table1,Row.class).print();
fsTableEnv.execute("");
}
public static class MyBean{
private int id;
private String name;
private double score;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public double getScore() {
return score;
}
public void setScore(double score) {
this.score = score;
}
public MyBean(int id, String name, double score) {
this.id = id;
this.name = name;
this.score = score;
}
public MyBean() {
}
}
}
以上可以将Tuple类 ,POJO类的DataStream转换为一个Table对象,同样可以按照列的顺序或者名称进行适配,创建表
同样可以创建View视图
基于表创建视图
tableEnv.createTemporaryView("sensorView", sensorTable)以上所有的env都支持将dataset或datastream进行对象的转换,但是更多的是直接通过tableEnv读取内容形成table
tableEnvironment
.connect(...)
.withFormat(...)
.withSchema(...)
.inAppendMode()
.createTemporaryTable("MyTable")当前版本支持的连接器和格式化方式
Filesystem Built-in Built-in Elasticsearch 6 flink-connector-elasticsearch6Download Elasticsearch 7 flink-connector-elasticsearch7Download Apache Kafka 0.8 flink-connector-kafka-0.8Not available Apache Kafka 0.9 flink-connector-kafka-0.9Download Apache Kafka 0.10 flink-connector-kafka-0.10Download Apache Kafka 0.11 flink-connector-kafka-0.11Download Apache Kafka 0.11+ ( universal)flink-connector-kafkaDownload HBase 1.4.3 flink-hbaseDownload JDBC flink-jdbcDownload Formats
Name Maven dependency SQL Client JAR Old CSV (for files) Built-in Built-in CSV (for Kafka) flink-csvDownload JSON flink-jsonDownload Apache Avro flink-avroDownload
Schema指定
.withSchema(
new Schema()
.field("MyField1", DataTypes.INT()) // required: specify the fields of the table (in this order)
.field("MyField2", DataTypes.STRING())
.field("MyField3", DataTypes.BOOLEAN())
)Connector的指定
FileSystem java版本
.connect(
new FileSystem()
.path("file:///path/to/whatever") // required: path to a file or directory
)
.withFormat( // required: file system connector requires to specify a format,
... // currently only OldCsv format is supported.
) // Please refer to old CSV format part of Table Formats section for more details.FileSystem DDL版本
CREATE TABLE MyUserTable (
...
) WITH (
'connector.type' = 'filesystem', -- required: specify to connector type
'connector.path' = 'file:///path/to/whatever', -- required: path to a file or directory
'format.type' = '...', -- required: file system connector requires to specify a format,
... -- currently only 'csv' format is supported.
-- Please refer to old CSV format part of Table Formats section for more details.
) kafka java版本
.connect(
new Kafka()
.version("0.11") // required: valid connector versions are
// "0.8", "0.9", "0.10", "0.11", and "universal"
.topic("...") // required: topic name from which the table is read
// optional: connector specific properties
.property("zookeeper.connect", "localhost:2181")
.property("bootstrap.servers", "localhost:9092")
.property("group.id", "testGroup")
// optional: select a startup mode for Kafka offsets
.startFromEarliest()
.startFromLatest()
.startFromSpecificOffsets(...)
// optional: output partitioning from Flink's partitions into Kafka's partitions
.sinkPartitionerFixed() // each Flink partition ends up in at-most one Kafka partition (default)
.sinkPartitionerRoundRobin() // a Flink partition is distributed to Kafka partitions round-robin
.sinkPartitionerCustom(MyCustom.class) // use a custom FlinkKafkaPartitioner subclass
)
.withFormat( // required: Kafka connector requires to specify a format,
... // the supported formats are Csv, Json and Avro.
) // Please refer to Table Formats section for more details.kafka DDL版本
CREATE TABLE MyUserTable (
...
) WITH (
'connector.type' = 'kafka',
'connector.version' = '0.11', -- required: valid connector versions are
-- "0.8", "0.9", "0.10", "0.11", and "universal"
'connector.topic' = 'topic_name', -- required: topic name from which the table is read
'connector.properties.zookeeper.connect' = 'localhost:2181', -- required: specify the ZooKeeper connection string
'connector.properties.bootstrap.servers' = 'localhost:9092', -- required: specify the Kafka server connection string
'connector.properties.group.id' = 'testGroup', --optional: required in Kafka consumer, specify consumer group
'connector.startup-mode' = 'earliest-offset', -- optional: valid modes are "earliest-offset",
-- "latest-offset", "group-offsets",
-- or "specific-offsets"
-- optional: used in case of startup mode with specific offsets
'connector.specific-offsets' = 'partition:0,offset:42;partition:1,offset:300',
'connector.sink-partitioner' = '...', -- optional: output partitioning from Flink's partitions
-- into Kafka's partitions valid are "fixed"
-- (each Flink partition ends up in at most one Kafka partition),
-- "round-robin" (a Flink partition is distributed to
-- Kafka partitions round-robin)
-- "custom" (use a custom FlinkKafkaPartitioner subclass)
-- optional: used in case of sink partitioner custom
'connector.sink-partitioner-class' = 'org.mycompany.MyPartitioner',
'format.type' = '...', -- required: Kafka connector requires to specify a format,
... -- the supported formats are 'csv', 'json' and 'avro'.
-- Please refer to Table Formats section for more details.
)同样支持ES和HBASE的链接器,请参考官网
format部分常用代码
WITH (
'format.type' = 'csv', -- required: specify the schema type
'format.fields.0.name' = 'lon', -- optional: define the schema explicitly using type information.
'format.fields.0.data-type' = 'FLOAT', -- This overrides default behavior that uses table's schema as format schema.
'format.fields.1.name' = 'rideTime',
'format.fields.1.data-type' = 'TIMESTAMP(3)',
'format.field-delimiter' = ';', -- optional: field delimiter character (',' by default)
'format.line-delimiter' = U&'\000D\000A'https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/connect.html#table-formats
filesystem链接代码
EnvironmentSettings fsSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build();
StreamExecutionEnvironment fsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
fsEnv.setParallelism(1);
StreamTableEnvironment fsTableEnv = StreamTableEnvironment.create(fsEnv, fsSettings);
DataStreamSource<String> ds = fsEnv.socketTextStream("localhost", 6666);
Table table = fsTableEnv.fromDataStream(ds);
fsTableEnv.sqlUpdate("create table test_sink(id string)with ('connector.type'='filesystem', " +
"'connector.path' = 'file:///E:\\ideaWorkSpace\\flink_32\\table_data\\sql_res'," +
"'format.type' = 'csv')");
table.insertInto("test_sink"); EnvironmentSettings fsSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build();
StreamExecutionEnvironment fsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
fsEnv.setParallelism(1);
StreamTableEnvironment fsTableEnv = StreamTableEnvironment.create(fsEnv, fsSettings);
fsTableEnv.connect(new FileSystem()
.path("file:///E:\\ideaWorkSpace\\flink_32\\table_data/a.txt"))
.withFormat(new OldCsv().fieldDelimiter(" "))
.withSchema(new Schema().field("line", DataTypes.STRING())
.field("line1", DataTypes.STRING())
)
.inAppendMode()
.createTemporaryTable("file_table");
Table table = fsTableEnv.sqlQuery("select * from file_table");
fsTableEnv.toAppendStream(table,Row.class).print();
fsTableEnv.execute("");kafka链接代码
首先引入依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_2.12</artifactId>
<version>1.10.3</version>
</dependency>EnvironmentSettings fsSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build();
StreamExecutionEnvironment fsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
fsEnv.setParallelism(1);
StreamTableEnvironment fsTableEnv = StreamTableEnvironment.create(fsEnv, fsSettings);
fsTableEnv.connect(
new Kafka()
.version("0.10")
.topic("topic_32") // required: topic name from which the table is read
.property("zookeeper.connect", "nn1.hadoop:2181")
.property("bootstrap.servers", "s1.hadoop:9092")
.property("group.id", "testGroup")
.startFromLatest()
)
.withFormat( // required: Kafka connector requires to specify a format,
new Csv().fieldDelimiter(' ')
).withSchema(new Schema().field("line",DataTypes.STRING())
.field("line1",DataTypes.STRING())
.field("line2",DataTypes.STRING())
)
.createTemporaryTable("kafka");
;
Table table = fsTableEnv.sqlQuery("select line,line1,line2 from kafka");
fsTableEnv.toAppendStream(table,Row.class).print();
fsTableEnv.execute("");EnvironmentSettings fsSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build();
StreamExecutionEnvironment fsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
fsEnv.setParallelism(1);
StreamTableEnvironment fsTableEnv = StreamTableEnvironment.create(fsEnv, fsSettings);
String sql = "CREATE TABLE MyUserTable (\n" +
" col1 VARCHAR,\n" +
" col2 VARCHAR,\n" +
" col3 VARCHAR\n" +
") WITH (\n" +
" 'connector.type' = 'kafka', \n" +
" 'connector.version' = '0.10', \n" +
" 'connector.topic' = 'topic_32',\n" +
" 'connector.properties.zookeeper.connect' = 'nn1.hadoop:2181', \n" +
" 'connector.properties.bootstrap.servers' = 's1.hadoop:9092', \n" +
" 'connector.properties.group.id' = 'testGroup',\n" +
" 'connector.startup-mode' = 'latest-offset',\n" +
" 'format.type' = 'csv' , \n" +
" 'format.field-delimiter' = ' ' \n" +
")";
fsTableEnv.sqlUpdate(sql);
Table table = fsTableEnv.from("MyUserTable").select("col1,col2");
fsTableEnv.toAppendStream(table,Row.class).print();
fsTableEnv.execute("");必须使用新版Csv
格式化部分还支持Avro和JSON格式https://ci.apache.org/projects/flink/flink-docs-release-1.10/dev/table/connect.html
Mysql链接代码
flink链接mysql必须使用DDL方式
EnvironmentSettings fsSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build();
StreamExecutionEnvironment fsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
fsEnv.setParallelism(1);
StreamTableEnvironment fsTableEnv = StreamTableEnvironment.create(fsEnv, fsSettings);
String sql = "create table category(cid int,cname string)" +
"WITH(" +
"'connector.type' = 'jdbc'," +
"'connector.url' = 'jdbc:mysql://localhost:3306/hainiu_36'," +
"'connector.table' = 'category',"+
"'connector.driver' = 'com.mysql.jdbc.Driver',"+
" 'connector.username' = 'root',"+
" 'connector.password' = '123456',"+
"'connector.read.fetch-size' = '100'"+
")";
System.out.println(sql);
fsTableEnv.sqlUpdate(sql);
Table table = fsTableEnv.from("category");
fsTableEnv.toAppendStream(table,Row.class).print();
fsTableEnv.execute("");表的查寻
Table API
Table API 是集成在 Scala 和 Java 语言内的查询 API
Table API 基于代表“表”的 Table 类,并提供一整套操作处理的方法 API;这 些方法会返回一个新的 Table 对象,表示对输入表应用转换操作的结果一些关系操作由多个方法调用组成,例如
table.groupBy(...).select(),其中groupBy(...)指定对 的分组table,以及select(...)对分组的投影table。
Table revenue = orders
.filter("cCountry === 'FRANCE'")
.groupBy("cID, cName")
.select("cID, cName, revenue.sum AS revSum");SQL API
Flink 的 SQL 集成基于Apache Calcite,它实现了 SQL 标准。SQL 查询被指定为常规字符串。
Table revenue = tableEnv.sqlQuery(
"SELECT cID, cName, SUM(revenue) AS revSum " +
"FROM Orders " +
"WHERE cCountry = 'FRANCE' " +
"GROUP BY cID, cName"
);混合表 API 和 SQL
Table API 和 SQL 查询可以很容易地混合使用,因为它们都返回
Table对象:
EnvironmentSettings fsSettings = EnvironmentSettings.newInstance().useOldPlanner().inStreamingMode().build();
StreamExecutionEnvironment fsEnv = StreamExecutionEnvironment.getExecutionEnvironment();
fsEnv.setParallelism(1);
StreamTableEnvironment fsTableEnv = StreamTableEnvironment.create(fsEnv, fsSettings);
String sql = "create table product(pid int,pname string,price double,cid int)" +
"WITH(" +
"'connector.type' = 'jdbc'," +
"'connector.url' = 'jdbc:mysql://localhost:3306/hainiu_36'," +
"'connector.table' = 'product',"+
"'connector.driver' = 'com.mysql.jdbc.Driver',"+
" 'connector.username' = 'root',"+
" 'connector.password' = '123456',"+
"'connector.read.fetch-size' = '100'"+
")";
fsTableEnv.sqlUpdate(sql);
Table table = fsTableEnv.sqlQuery("select count(*) as cnt,cid from `product` group by cid");
fsTableEnv.toRetractStream(table,Row.class).print();
fsTableEnv.execute("");
//sql形式代码 Table table = fsTableEnv.from("product").groupBy("cid").aggregate("count(pid) as cnt").select("cid,cnt")
.where("cnt>7");
//API形式代码 Table table1 = fsTableEnv.sqlQuery("select id,name,score from " + table);
//sql和对象混合使用tableApi的方式查寻完毕的数据,继续使用tableAPI方式查寻是可以的,但是不能使用sqlAPI的方式进行查寻
表的更新模式
对于流式查询,需要声明如何执行动态表和外部连接器之间的转换。的更新模式指定哪些类型的消息应与外部系统进行交换:
append:在附加模式下,动态表和外部连接器仅交换 INSERT 消息。
RETRACT:在撤回模式下,动态表和外部连接器交换 ADD 和 RETRACT 消息。INSERT 更改编码为 ADD 消息,DELETE 更改编码为 RETRACT 消息,UPDATE 更改编码为更新(前一个)行的 RETRACT 消息和更新(新)行的 ADD 消息。在此模式下,与 upsert 模式相反,不得定义键。但是,每次更新都包含两条效率较低的消息。
Upsert 模式:在 upsert 模式下,动态表和外部连接器交换 UPSERT 和 DELETE 消息。此模式需要一个(可能是复合的)唯一键,通过该键可以传播更新。外部连接器需要知道唯一键属性才能正确应用消息。INSERT 和 UPDATE 更改被编码为 UPSERT 消息。DELETE 更改为 DELETE 消息。与收回流的主要区别在于,UPDATE 更改使用单个消息进行编码,因此效率更高。表的数据sink插入
文件系统
SingleOutputStreamOperator<Tuple3<Integer,String,Integer>> ds = fsEnv.readTextFile("data/b.txt").map(new MapFunction<String, Tuple3<Integer,String,Integer>>() {
@Override
public Tuple3<Integer, String, Integer> map(String value) throws Exception {
String[] split = value.split(" ");
return Tuple3.of(Integer.valueOf(split[0]),split[1],Integer.valueOf(split[2]));
}
});
Table table = fsTableEnv.fromDataStream(ds, "id,name,age");
Table table1 = table.groupBy("age").aggregate("count(id) as cnt").select("age,cnt");
fsTableEnv.connect(new FileSystem().path("data/sink_res"))
.withFormat(new Csv().fieldDelimiter(','))
.withSchema(new Schema()
.field("age",Types.INT)
// .field("name",Types.STRING)
.field("cnt",Types.LONG)).createTemporaryTable("test_sink");
table1.insertInto("test_sink");注意文本数据文件系统只支持append模式,不支持撤回和upsert模式
SingleOutputStreamOperator<Tuple3<Integer,String,Integer>> ds = fsEnv.readTextFile("data/b.txt").map(new MapFunction<String, Tuple3<Integer,String,Integer>>() {
@Override
public Tuple3<Integer, String, Integer> map(String value) throws Exception {
String[] split = value.split(" ");
return Tuple3.of(Integer.valueOf(split[0]),split[1],Integer.valueOf(split[2]));
}
});
Table table = fsTableEnv.fromDataStream(ds, "id,name,age");
fsTableEnv.connect(new FileSystem().path("data/sink_res"))
.withFormat(new Csv().fieldDelimiter(','))
.withSchema(new Schema()
.field("id",Types.INT)
.field("name",Types.STRING)
.field("age",Types.INT)).createTemporaryTable("test_sink");
table.insertInto("test_sink");
fsTableEnv.execute("");在flinksql中table分为两种SourceTable 和SinkTable,但是现在不会使用这个两种进行描述table对象,都统一用表进行表示,然后底层还是使用TableSink进行表示,所以Csv其实就是CsvTableSink,打开以后我们可以看到它只能Append模式进行操作
kafka sink
同样只支持append模式
Table age = fsTableEnv.fromDataStream(ds, "id,name,age");
fsTableEnv.connect(
new Kafka()
.version("0.10")
.topic("topic_32")
.property("zookeeper.connect", "nn1.hadoop:2181")
.property("bootstrap.servers", "s1.hadoop:9092")
)
.withFormat( new Csv() )
.withSchema( new Schema()
.field("id", DataTypes.INT())
.field("name", DataTypes.STRING())
.field("age", DataTypes.INT())
)
.createTemporaryTable("kafkaOutputTable");
age.insertInto("kafkaOutputTable");ES插入数据
需要引入以下支持,可以向下兼容es5
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch6_2.12</artifactId>
<version>1.10.3</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-json</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency> Table age = fsTableEnv.fromDataStream(ds, "id,name,age");
fsTableEnv.connect(
new Elasticsearch()
.version("6")
.host("s1.hadoop", 9200, "http")
.index("test_sink")
.documentType("person")
)
.inUpsertMode()
.withFormat(new Json())
.withSchema( new Schema()
// .field("id", DataTypes.INT())
// .field("name", DataTypes.STRING())
.field("age", DataTypes.INT())
.field("cnt", DataTypes.BIGINT())
)
.createTemporaryTable("esOutputTable");
// age.groupBy("age").select("age,count(id) as cnt")
age.groupBy("age").select("age,count(id) as cnt")
.insertInto("esOutputTable");
//----------------------------------------------------------------------
sqlEnv.sqlUpdate("create table es(id string,name string,age int,primary key(id)) with(" +
"'connector.type' = 'elasticsearch'," +
"'connector.index' = 'index_37'," +
"'connector.version' = '6'," +
"'connector.hosts' = 'http://s1.hadoop:9200'," +
"'connector.document-type' = 'student'," +
"'update-mode' = 'upsert'," +
"'format.type' = 'json'" +
")");支持upsert模式,但是必须使用count等聚合函数,不能直接插入,没有办法设置唯一主键
mysql表插入数据
Table age = fsTableEnv.fromDataStream(ds, "id,name,age");
String sql = "create table test_sink(age int,cnt bigint)" +
"WITH(" +
"'connector.type' = 'jdbc'," +
"'connector.url' = 'jdbc:mysql://localhost:3306/hainiu_36'," +
"'connector.table' = 'test_sink',"+
"'connector.driver' = 'com.mysql.jdbc.Driver',"+
" 'connector.username' = 'root',"+
" 'connector.password' = '123456',"+
"'connector.read.fetch-size' = '100'"+
")";
fsTableEnv.sqlUpdate(sql);
age.groupBy("age").select("age,count(id) as cnt").insertInto("test_sink");支持upsert,但是不能直接插入数据,会报主键重复错误
插入数据到hbase中
Table age = fsTableEnv.fromDataStream(ds, "id,name,age");
String sql = "create table hbase_sink(rowkey string,info ROW<id string,name string,age string> )" +
"with(" +
"'connector.type' = 'hbase', " +
"'connector.version' = '1.4.3',"+
"'connector.table-name' = 'hbase_sink',"+
"'connector.zookeeper.quorum' = 'nn1.hadoop:2181',"+
"'connector.zookeeper.znode.parent' = '/hbase1'"+
")";
fsTableEnv.sqlUpdate(sql);
// age.groupBy("age").select("age,count(id) as cnt").insertInto("test_sink");
//age.select("id as rowkey,ROW(id,name,age)").insertInto("hbase_sink");表的数据转换为DataSet和dataStream
append模式
这种模式中数据只会追加到流数据的后面
DataStream<Class<?>> ds = tableEnv.toAppendStream(table,Class)retract模式
支持insert和delete两种模式,数据在流中转换为一个元组形式,f0位置是Boolean的数据标识位,表示这个数据是插入的还是撤回的,f1位置则是数据的本身
DataStream<Class<?>> ds = tableEnv.toRetractStream(Table,class)Table age = fsTableEnv.fromDataStream(ds, "id,name,age");
fsTableEnv.createTemporaryView("table1",age);
Table table = fsTableEnv.sqlQuery("select sum(age),avg(age) from table1 group by id");
System.out.println(fsTableEnv.explain(table));在执行计划中会将整个执行过程分为三个部分,分别是逻辑执行计划,优化执行计划和物理执行计划
流处理
关系型查寻和流查寻的比较
| 关系代数 / SQL | 流处理 |
|---|---|
| 关系(或表)是有界(多)元组集。 | 流是无限的元组序列。 |
| 对批处理数据(例如,关系数据库中的表)执行的查询可以访问完整的输入数据。 | 流式查询在启动时无法访问所有数据,并且必须“等待”数据流入。 |
| 批处理查询在生成固定大小的结果后终止。 | 流查询根据接收到的记录不断更新其结果,并且永远不会完成。 |
动态表和连续查询
动态表是 Flink 的 Table API 和 SQL 支持流式数据的核心概念。与表示批处理数据的静态表相比,动态表会随着时间的推移而变化。它们可以像静态批处理表一样进行查询。查询动态表会产生一个连续查询。连续查询永远不会终止并生成动态表作为结果。查询不断更新其(动态)结果表以反映其(动态)输入表上的更改
需要注意的是,连续查询的结果在语义上始终等同于在输入表的快照上以批处理模式执行的同一查询的结果。
下图形象化了流、动态表、连续查询的关系:

- 流被转换为动态表。
- 在动态表上评估连续查询,产生一个新的动态表。
- 生成的动态表被转换回流。
追加流模式
为了使用关系查询处理流,必须将其转换为
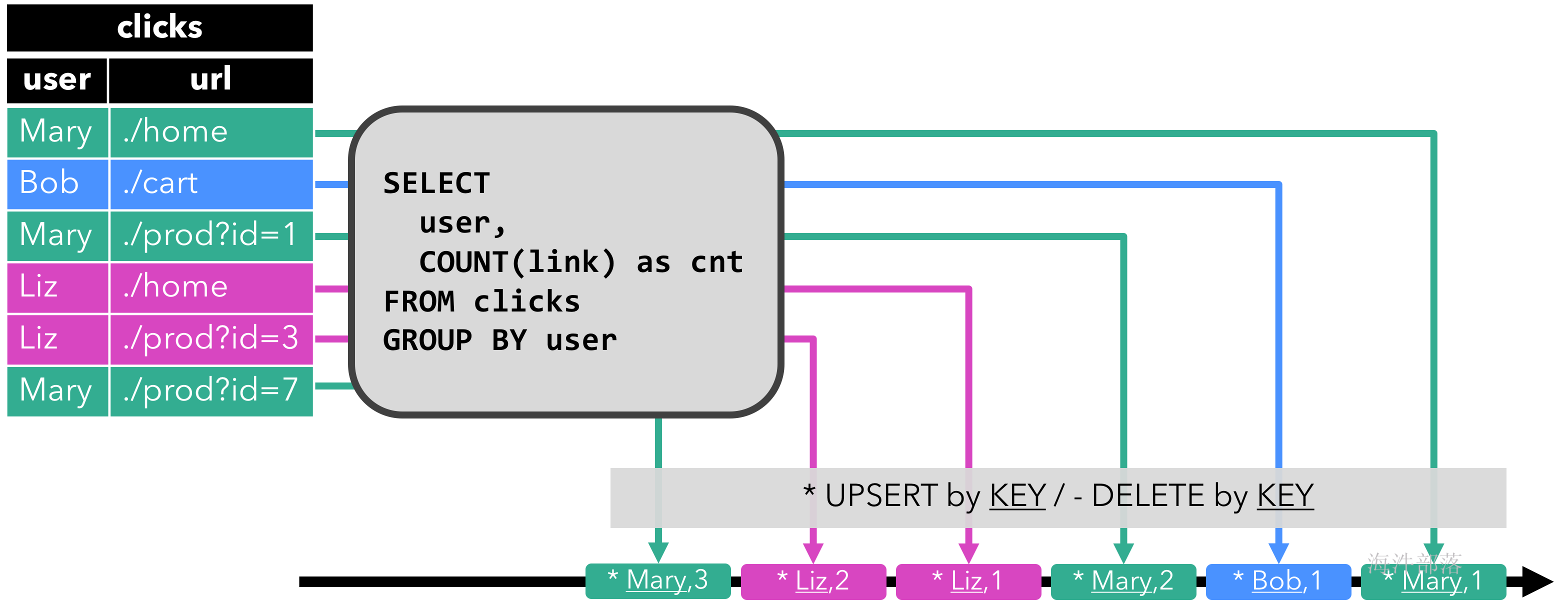
Table. 从概念上讲,流的每条记录都被解释为INSERT对结果表的修改。本质上,我们正在从一个INSERT仅更改日志流构建一个表。下图可视化了点击事件流(左侧)如何转换为表格(右侧)。随着点击流的更多记录被插入,结果表不断增长
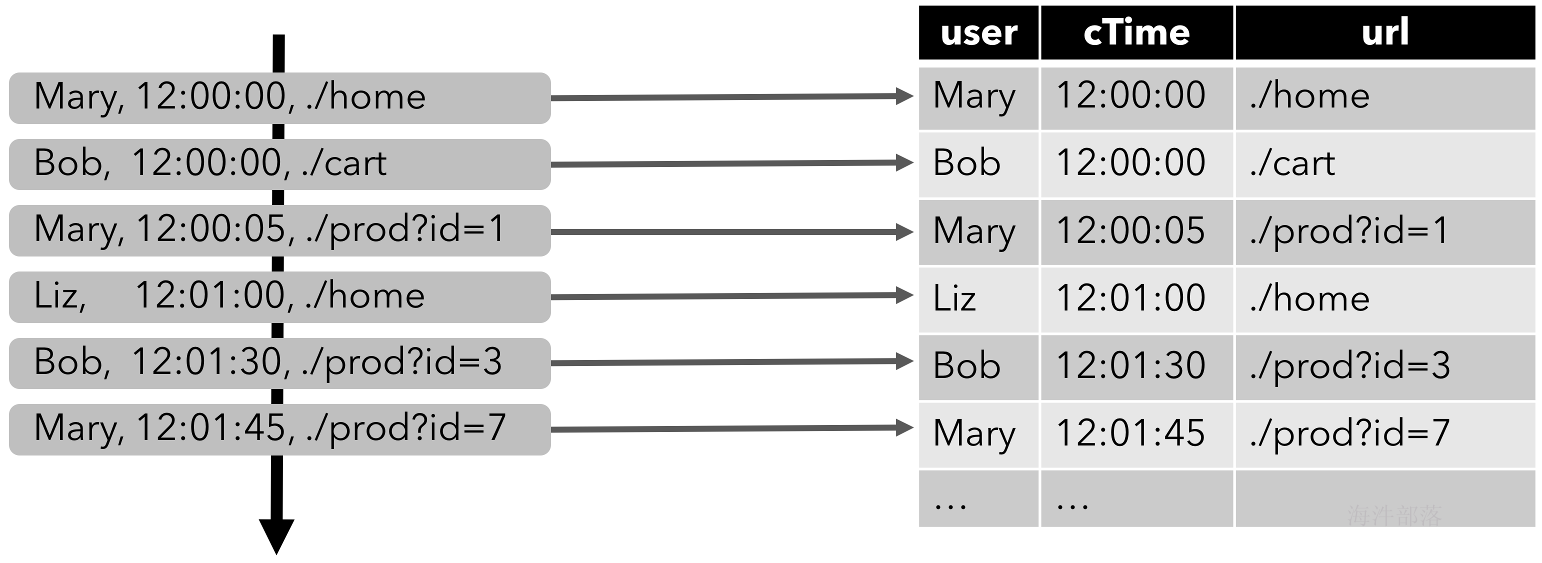
连续查寻
在动态表上评估连续查询并生成一个新的动态表作为结果。与批处理查询相反,连续查询永远不会终止并根据其输入表的更新更新其结果表。在任何时候,连续查询的结果在语义上等同于在输入表的快照上以批处理模式执行的同一查询的结果。
在下面,我们展示了clicks对在点击事件流上定义的表的两个示例查询。
第一个查询是一个简单的GROUP-BY COUNT聚合查询。它将字段clicks上的表分组user并计算访问过的 URL 的数量。下图显示了如何随着时间的推移评估查询,因为clicks表更新了附加行。
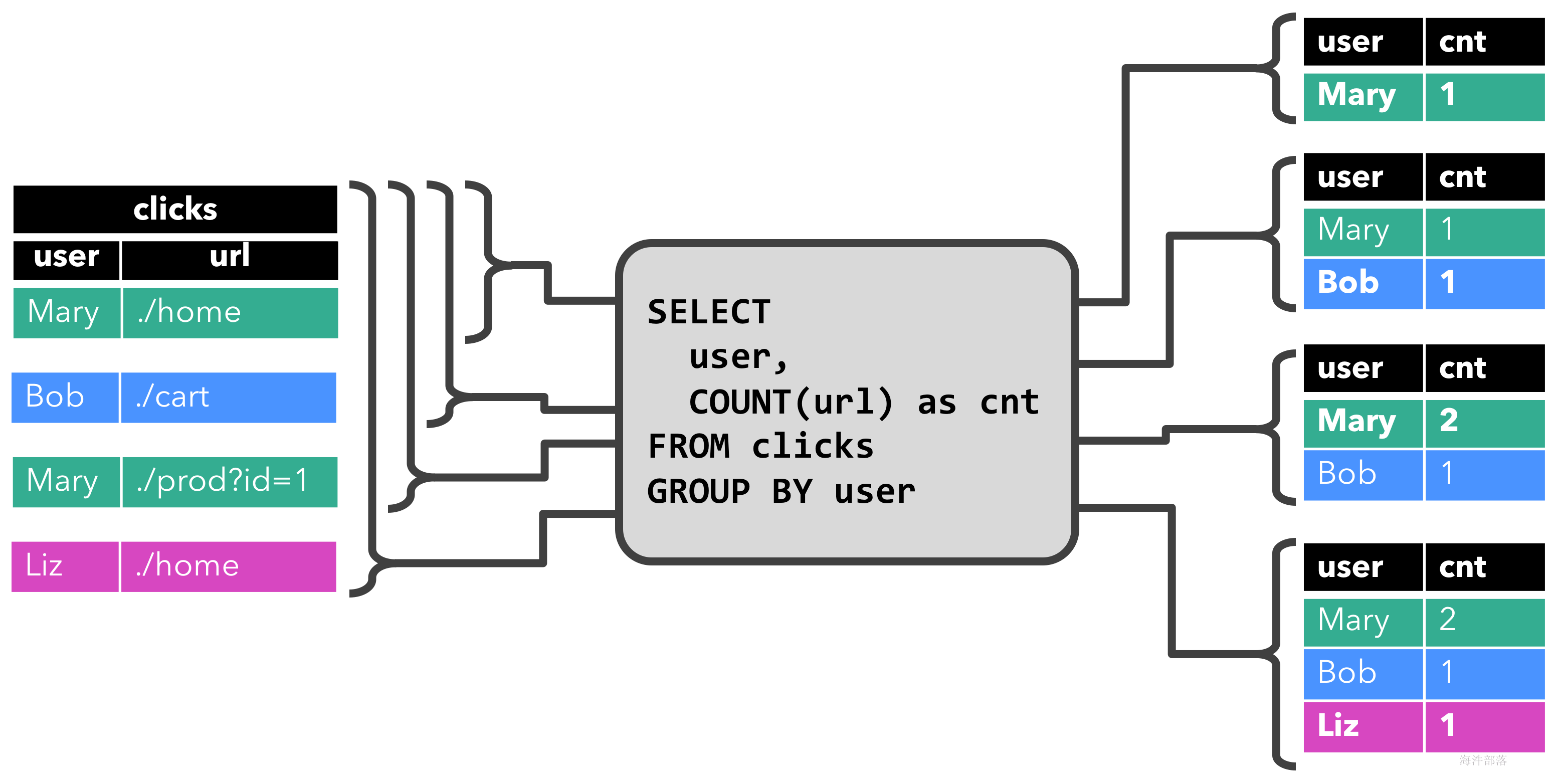
查询开始时,clicks表(左侧)为空。当第一行插入到表中时,查询开始计算结果clicks表。[Mary, ./home]插入第一行后,结果表(右侧,顶部)由单行组成[Mary, 1]。当第二行[Bob, ./cart]插入clicks表中时,查询更新结果表并插入新行[Bob, 1]。第三行[Mary, ./prod?id=1]生成已计算结果行的[Mary, 1]更新,从而更新为[Mary, 2]。最后,[Liz, 1]当第四行被追加到表中时,查询将第三行插入到结果表clicks中。
带有窗口的连续查寻
第二个查询与第一个查询类似,但在计算 URL 数量之前clicks,除了user属性之外,还在每小时滚动窗口上对表进行分组(基于时间的计算,例如窗口基于特殊的时间属性,稍后将讨论) .) 同样,该图显示了不同时间点的输入和输出,以可视化动态表的变化性质。
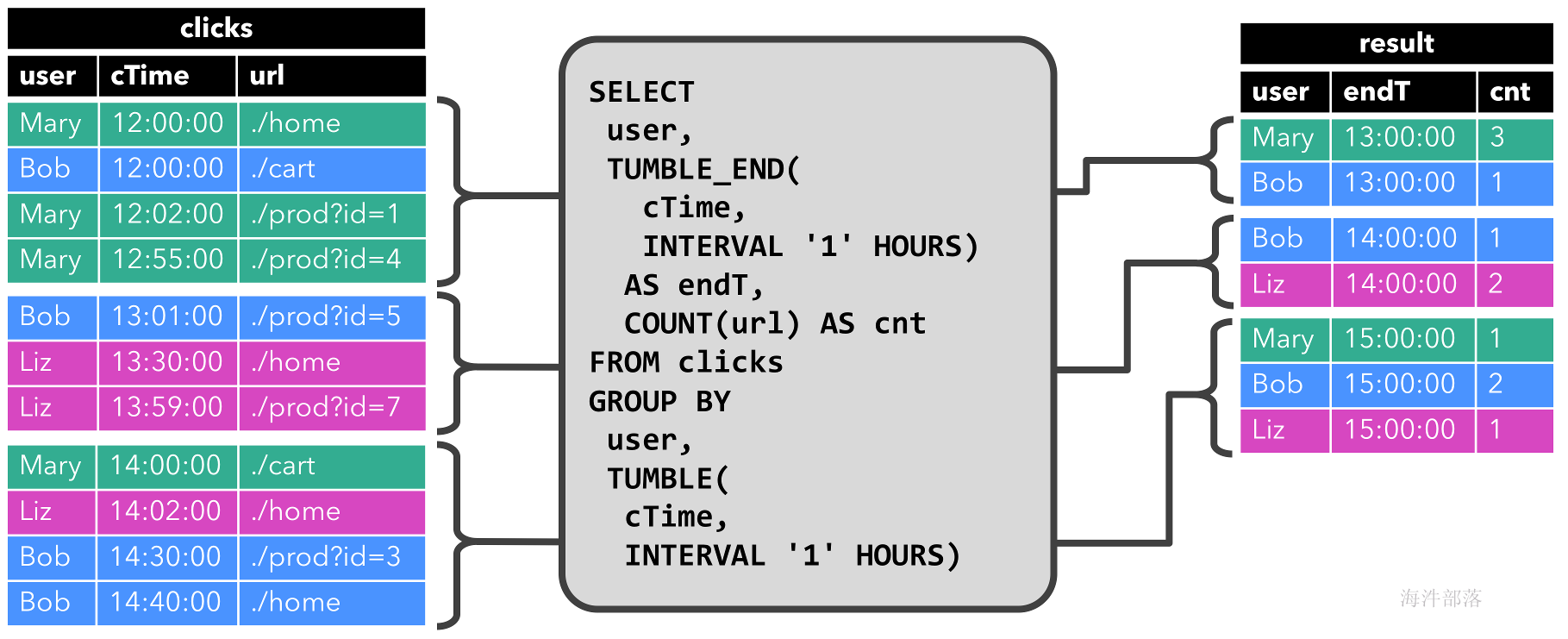
和以前一样,输入表clicks显示在左侧。查询每小时持续计算结果并更新结果表。clicks 表包含四行,时间戳 ( cTime) 位于12:00:00和之间12:59:59。查询从此输入计算两个结果行(每个行一个user)并将它们附加到结果表中。对于13:00:00和之间的下一个窗口13:59:59,该clicks表包含三行,这导致另外两行被附加到结果表中。结果表会更新,因为clicks随着时间的推移添加了更多行。
更新和追加查询
尽管这两个示例查询看起来非常相似(都计算分组计数聚合),但它们在一个重要方面有所不同:
- 第一个查询更新先前发出的结果,即定义结果表包含
INSERT和UPDATE更改的更改日志流。 - 第二个查询只追加到结果表,即结果表的
INSERT变更日志流只包含变更。
查询限制
许多(但不是全部)语义上有效的查询可以评估为对流的连续查询。某些查询的计算成本太高,要么是因为它们需要维护的状态大小,要么是因为计算更新太昂贵。
- 状态大小:连续查询在无界流上进行评估,并且通常应该运行数周或数月。因此,连续查询处理的数据总量可能非常大。必须更新先前发出的结果的查询需要维护所有发出的行以便能够更新它们。例如,第一个示例查询需要存储每个用户的 URL 计数,以便能够在输入表接收到新行时增加计数并发送新结果。如果只跟踪注册用户,则要维护的计数可能不会太高。但是,如果非注册用户获得分配的唯一用户名,则要维护的计数会随着时间的推移而增加,并可能最终导致查询失败。
SELECT user, COUNT(url)
FROM clicks
GROUP BY user;- 计算更新:一些查询需要重新计算和更新大部分发出的结果行,即使只添加或更新了单个输入记录。显然,这样的查询不太适合作为连续查询执行。一个示例是以下查询,它根据
RANK最后一次点击的时间为每个用户计算 a 。一旦clicks表接收到一个新行时,lastAction用户的更新和新的等级必须计算。但是,由于两行不能具有相同的排名,因此所有排名较低的行也需要更新。
SELECT user, RANK() OVER (ORDER BY lastLogin)
FROM (
SELECT user, MAX(cTime) AS lastLogin FROM clicks GROUP BY user
);表到流转换
动态表可以通过不断修改INSERT,UPDATE以及DELETE改变就像一个普通的数据库表。它可能是一个单行的表,它不断更新,一个没有UPDATE和DELETE修改的仅插入表,或介于两者之间的任何表。
将动态表转换为流或将其写入外部系统时,需要对这些更改进行编码。Flink 的 Table API 和 SQL 支持三种方式对动态表的变化进行编码:
- Append-only 流:仅被
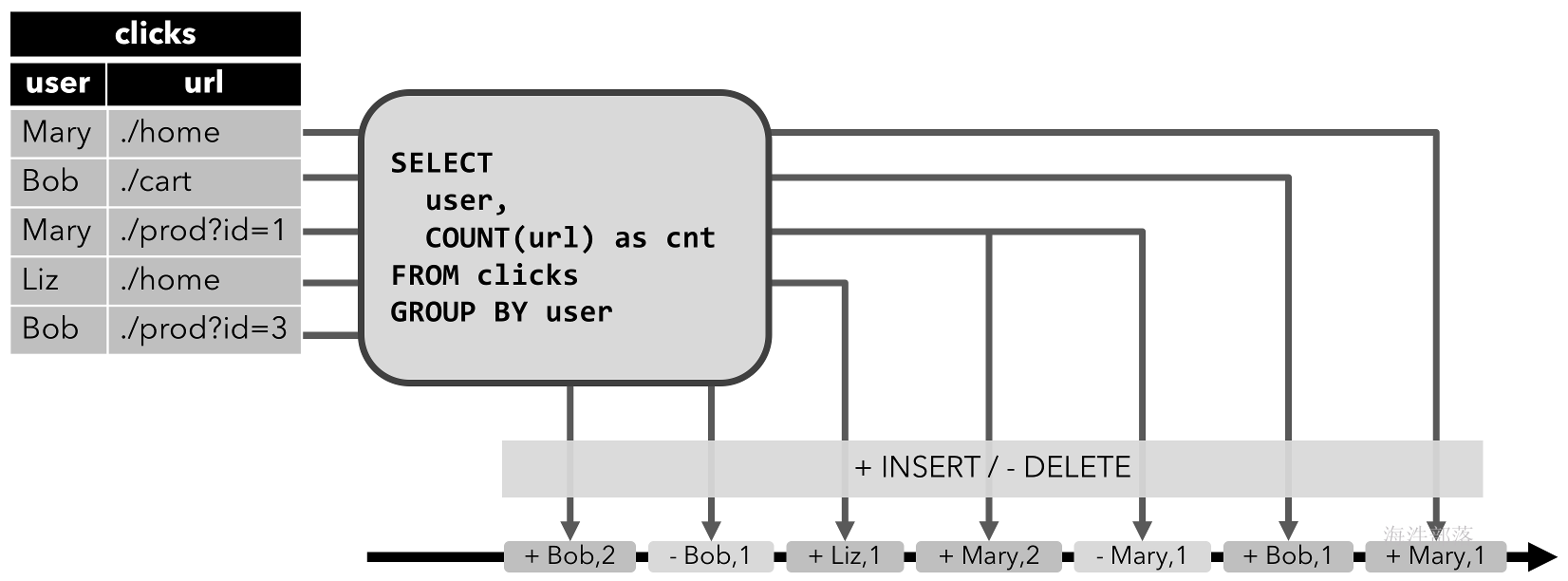
INSERT更改修改的动态表可以通过发出插入的行转换为流。 - 撤回流:撤回流是具有两种类型消息的流,添加消息和撤回消息。通过将
INSERT更改编码为添加消息、将DELETE更改编码为撤回消息以及将UPDATE更改编码为更新(前一)行的撤回消息和更新(新)行的添加消息,将动态表转换为撤回流。下图可视化了动态表到收回流的转换。
- Upsert 流: upsert 流是一种包含两种类型消息的流,upsert 消息和delete 消息。转换为 upsert 流的动态表需要(可能是复合的)唯一键。具有唯一键的动态表通过编码
INSERT和UPDATE更改为 upsert 消息和DELETE更改为删除消息被转换为流。流消费操作符需要知道唯一键属性才能正确应用消息。与收回流的主要区别在于,UPDATE更改使用单个消息进行编码,因此效率更高。下图可视化了动态表到 upsert 流的转换。
时间属性
基于时间的操作(例如Table API和SQL 中的窗口)需要有关时间概念及其来源的信息。因此,表可以提供逻辑时间属性,用于指示时间和访问表程序中的相应时间戳。
时间属性可以是每个表模式的一部分。它们是在从 CREATE TABLE DDL 或 a 创建表DataStream时定义的,或者在使用TableSource. 一旦在开始时定义了时间属性,就可以将其作为字段引用,并可用于基于时间的操作。
只要时间属性未被修改并且只是从查询的一部分转发到另一部分,它就仍然是有效的时间属性。时间属性的行为类似于常规时间戳,可以访问以进行计算。
表程序要求已经为流环境指定了相应的时间特征:
final StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime); // default转换数据流成表的时候指定时间语义字段
处理时间属性是.proctime在模式定义期间使用属性定义的。时间属性只能通过附加的逻辑字段扩展物理模式。因此,它只能在模式定义的末尾进行定义。
Table table = tEnv.fromDataStream(stream, "user_name, data, user_action_time.proctime|rowTime");使用DataStream上面所存在的时间戳进行时间语义设定
SingleOutputStreamOperator<String> ds = fsEnv.addSource(new SourceFunction<String>() {
boolean flag = true;
@Override
public void run(SourceContext<String> ctx) throws Exception {
int i = 0;
while (flag) {
ctx.collect(1 + " hainiu " + (System.currentTimeMillis()-1000));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
flag = false;
}
}).assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<String>(Time.seconds(2)) {
@Override
public long extractTimestamp(String element) {
return Long.valueOf(element.split(" ")[2]);
}
});
SingleOutputStreamOperator<Tuple3<String, String, Long>> ds1 = ds.map(new MapFunction<String, Tuple3<String, String, Long>>() {
@Override
public Tuple3<String, String, Long> map(String value) throws Exception {
String[] split = value.split(" ");
return Tuple3.of(split[0], split[1], Long.valueOf(split[2]));
}
});
Table table = fsTableEnv.fromDataStream(ds1, "id,name,time,ps.proctime,pe.rowtime");
fsTableEnv.toAppendStream(table,Row.class).print();通过连接器和DDL的方式指定时间语义字段
bsTableEnv.connect(
new Kafka()
.version("0.10")
.topic("topic_32") // required: topic name from which the table is read
.property("zookeeper.connect", "nn1.hadoop:2181")
.property("bootstrap.servers", "s1.hadoop:9092")
.property("group.id", "testGroup")
.startFromLatest()
)
.withFormat( // required: Kafka connector requires to specify a format,
new Csv().fieldDelimiter(',')
).withSchema(new Schema().field("id",DataTypes.STRING())
.field("name",DataTypes.STRING())
.field("pt",DataTypes.TIMESTAMP(3))
.proctime()
.field("et",DataTypes.TIMESTAMP(3))
.rowtime(new Rowtime().timestampsFromField("time11").watermarksPeriodicBounded(1000))
//time1这个字段压根不存在,但是必须要写
)
.createTemporaryTable("kafka");
//
Table table = bsTableEnv.from("kafka");
table.printSchema();
bsTableEnv.toAppendStream(table,Row.class).print();
bsTableEnv.execute(""); String sql ="create table test(" +
"id int," +
"name string," +
"time1 bigint," +
"pt as PROCTIME()," +
"et as TO_TIMESTAMP(FROM_UNIXTIME(time1/1000)), " +
"watermark for et as et - interval '1' second " +
") WITH (\n" +
" 'connector.type' = 'filesystem', \n" +
" 'connector.path' = 'data/c.txt', \n" +
" 'format.type' = 'csv' \n" +
")";
fsTableEnv.sqlUpdate(sql);
Table table = fsTableEnv.from("test");窗口操作
group窗口
组窗口根据时间或行计数间隔将行分组为有限组,并为每组评估一次聚合函数。对于批处理表,窗口是按时间间隔对记录进行分组的便捷快捷方式。
Windows 是使用该window(w: GroupWindow)子句定义的,并且需要使用该as子句指定的别名。为了按窗口对表进行分组,必须groupBy(...)像常规分组属性一样在子句中引用窗口别名。以下示例显示如何在表上定义窗口聚合。
Table table = input
.window([GroupWindow w].as("w")) // define window with alias w
.groupBy("w, a") // group the table by attribute a and window w
.select("a, w.start, w.end, w.rowtime, b.count"); // aggregate and add window start, end, and rowtime timestampswindow的全部使用规则
滚动窗口(Tumbling windows)
滚动窗口将行分配给固定长度的非重叠连续窗口。例如,一个 5 分钟的滚动窗口以 5 分钟的间隔对行进行分组。翻转窗口可以定义在事件时间、处理时间或行数上。
Tumbling windows 使用Tumble类定义如下:
| 方法 | 描述 |
|---|---|
over |
将窗口的长度定义为时间或行计数间隔。 |
on |
要对其进行分组(时间间隔)或排序(行计数)的时间属性。对于批处理查询,这可能是任何 Long 或 Timestamp 属性。对于流查询,这必须是声明的事件时间或处理时间时间属性。 |
as |
为窗口分配别名。别名用于在以下groupBy()子句中引用窗口,并可选择在子句中选择窗口属性,例如窗口开始、结束或行时间时间戳select()。 |
// Tumbling Event-time Window
.window(Tumble.over("10.minutes").on("rowtime").as("w"));
// Tumbling Processing-time Window (assuming a processing-time attribute "proctime")
.window(Tumble.over("10.minutes").on("proctime").as("w"));
// Tumbling Row-count Window (assuming a processing-time attribute "proctime")
.window(Tumble.over("10.rows").on("proctime").as("w"));滑动(滑动窗口sliding)
滑动窗口具有固定大小并按指定的滑动间隔滑动。如果滑动间隔小于窗口大小,则滑动窗口重叠。因此,可以将行分配给多个窗口。例如,15 分钟大小和 5 分钟滑动间隔的滑动窗口将每一行分配给 3 个不同的 15 分钟大小的窗口,以 5 分钟的间隔进行评估。滑动窗口可以在事件时间、处理时间或行数上定义。
滑动窗口使用Slide类定义如下:
| 方法 | 描述 |
|---|---|
over |
将窗口的长度定义为时间或行计数间隔。 |
every |
将滑动间隔定义为时间或行计数间隔。滑动间隔的类型必须与大小间隔的类型相同。 |
on |
要对其进行分组(时间间隔)或排序(行计数)的时间属性。对于批处理查询,这可能是任何 Long 或 Timestamp 属性。对于流查询,这必须是声明的事件时间或处理时间时间属性。 |
as |
为窗口分配别名。别名用于在以下groupBy()子句中引用窗口,并可选择在子句中选择窗口属性,例如窗口开始、结束或行时间时间戳select()。 |
// Sliding Event-time Window
.window(Slide.over("10.minutes").every("5.minutes").on("rowtime").as("w"));
// Sliding Processing-time window (assuming a processing-time attribute "proctime")
.window(Slide.over("10.minutes").every("5.minutes").on("proctime").as("w"));
// Sliding Row-count window (assuming a processing-time attribute "proctime")
.window(Slide.over("10.rows").every("5.rows").on("proctime").as("w"));会话(会话窗口)
会话窗口没有固定的大小,但它们的边界由不活动的间隔定义,即,如果在定义的间隙期间没有事件出现,则会话窗口将关闭。例如,当在 30 分钟不活动后观察到一行时,会有 30 分钟间隔的会话窗口开始(否则该行将被添加到现有窗口中),如果在 30 分钟内没有添加行,则关闭。会话窗口可以在事件时间或处理时间工作。
会话窗口是通过使用Session类定义的,如下所示:
| 方法 | 描述 |
|---|---|
withGap |
将两个窗口之间的间隙定义为时间间隔。 |
on |
要对其进行分组(时间间隔)或排序(行计数)的时间属性。对于批处理查询,这可能是任何 Long 或 Timestamp 属性。对于流查询,这必须是声明的事件时间或处理时间时间属性。 |
as |
为窗口分配别名。别名用于在以下groupBy()子句中引用窗口,并可选择在子句中选择窗口属性,例如窗口开始、结束或行时间时间戳select()。 |
// Session Event-time Window
.window(Session.withGap("10.minutes").on("rowtime").as("w"));
// Session Processing-time Window (assuming a processing-time attribute "proctime")
.window(Session.withGap("10.minutes").on("proctime").as("w"));滚动窗口代码
DataStreamSource<String> ds = fsEnv.readTextFile("data/c.txt");
SingleOutputStreamOperator<Tuple3<String, String, Long>> ds1 = ds.map(new MapFunction<String, Tuple3<String, String, Long>>() {
@Override
public Tuple3<String, String, Long> map(String value) throws Exception {
String[] split = value.split(",");
return Tuple3.of(split[0], split[1], Long.valueOf(split[2]));
}
}).assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple3<String, String, Long>>() {
@Override
public long extractAscendingTimestamp(Tuple3<String, String, Long> element) {
return element.f2;
}
});
Table table = fsTableEnv.fromDataStream(ds1, "id,name,time,pt.proctime,et.rowtime");
Table table1 = table.window(Tumble.over("2.seconds").on("et").as("tw"))
.groupBy("name,tw")
.select("name,id.count,tw.start,tw.end");滑动窗口代码
Table table = fsTableEnv.fromDataStream(ds1, "id,name,time,pt.proctime,et.rowtime");
Table table1 = table.window(Slide.over("4.seconds").every("2.seconds").on("et").as("tw"))
.groupBy("name,tw")
.select("name,id.count,tw.start,tw.end");条数滑动窗口
Table table = fsTableEnv.fromDataStream(ds1, "id,name,time,pt.proctime,et.rowtime");
Table table1 = table.window(Slide.over("4.rows").every("2.rows").on("pt").as("tw"))
.groupBy("name,tw")
.select("name,id.count");session会话窗口
Table table = fsTableEnv.fromDataStream(ds1, "id,name,time,pt.proctime,et.rowtime");
Table table1 = table.window(Session.withGap("2.seconds").on("et").as("tw"))
.groupBy("name,tw")
.select("name,id.count");over窗口
跨窗口聚合可从标准 SQL(OVER子句)中SELECT获知,并在查询的子句中定义。与GROUP BY子句中指定的组窗口不同,窗口上方不会折叠行。相反,在窗口聚合上为每个输入行在其相邻行的范围内计算聚合。
Table table = input
.window([OverWindow w].as("w")) // define over window with alias w
.select("a, b.sum over w, c.min over w"); // aggregate over the over window w无界window
// Unbounded Event-time over window (assuming an event-time attribute "rowtime")
.window(Over.partitionBy("a").orderBy("rowtime").preceding("unbounded_range").as("w"));
// Unbounded Processing-time over window (assuming a processing-time attribute "proctime")
.window(Over.partitionBy("a").orderBy("proctime").preceding("unbounded_range").as("w"));
// Unbounded Event-time Row-count over window (assuming an event-time attribute "rowtime")
.window(Over.partitionBy("a").orderBy("rowtime").preceding("unbounded_row").as("w"));
// Unbounded Processing-time Row-count over window (assuming a processing-time attribute "proctime")
.window(Over.partitionBy("a").orderBy("proctime").preceding("unbounded_row").as("w"));有界window
// Bounded Event-time over window (assuming an event-time attribute "rowtime")
.window(Over.partitionBy("a").orderBy("rowtime").preceding("1.minutes").as("w"))
// Bounded Processing-time over window (assuming a processing-time attribute "proctime")
.window(Over.partitionBy("a").orderBy("proctime").preceding("1.minutes").as("w"))
// Bounded Event-time Row-count over window (assuming an event-time attribute "rowtime")
.window(Over.partitionBy("a").orderBy("rowtime").preceding("10.rows").as("w"))
// Bounded Processing-time Row-count over window (assuming a processing-time attribute "proctime")
.window(Over.partitionBy("a").orderBy("proctime").preceding("10.rows").as("w"))over条数窗口
Table table = fsTableEnv.fromDataStream(ds1, "id,name,time,pt.proctime,et.rowtime");
Table table1 = table.window(Over.partitionBy("name").orderBy("et").preceding("2.rows").as("tw"))
.select("name,id.count over tw,time.sum over tw");注意:统计数量是和当前行的差别个数,也就是如果是2row,其实统计的是当前行和之前的两行内容,总共三行
sql查询窗口
组窗口在GROUP BYSQL 查询的子句中定义。就像带有常规GROUP BY子句的查询一样,带有GROUP BY包含组窗口函数的子句的查询会计算每个组的单个结果行。批处理表和流表上的 SQL 支持以下组窗口函数。
| 组窗函数 | 描述 |
|---|---|
TUMBLE(time_attr, interval) |
定义翻滚时间窗口。滚动时间窗口将行分配给具有固定持续时间 ( interval) 的非重叠、连续窗口。例如,一个 5 分钟的滚动窗口以 5 分钟的间隔对行进行分组。滚动窗口可以在事件时间(流 + 批处理)或处理时间(流)上定义。 |
HOP(time_attr, interval, interval) |
定义一个跳跃时间窗口(在 Table API 中称为滑动窗口)。跳跃时间窗口具有固定的持续时间(第二个interval参数),并按指定的跳跃间隔(第一个interval参数)跳跃。如果跳跃间隔小于窗口大小,则跳跃窗口重叠。因此,可以将行分配给多个窗口。例如,15 分钟大小和 5 分钟跳跃间隔的跳跃窗口将每一行分配给 3 个不同的 15 分钟大小的窗口,这些窗口在 5 分钟的间隔内进行评估。可以在事件时间(流 + 批处理)或处理时间(流)上定义跳跃窗口。 |

