1.flink介绍、反压原理、内存管理、对比spark、flink的生态和应用场景以及未来
1.为什么要学习Flink
这几年大数据的飞速发展,出现了很多热门的开源社区,其中著名的有 Hadoop、Storm,以及后来的 Spark,他们都有着各自专注的应用场景。Spark 掀开了内存计算的先河,也以内存为赌注,赢得了内存计算的飞速发展。Spark 的火热或多或少的掩盖了其他分布式计算的系统身影。就像 Flink,也就在这个时候默默的发展着。
在国外一些社区,有很多人将大数据的计算引擎分成了 4 代,当然,也有很多人不会认同。我们先姑且这么认为和讨论。
首先第一代的计算引擎,无疑就是 Hadoop 承载的 MapReduce。这里大家应该都不会对 MapReduce 陌生,它将计算分为两个阶段,分别为 Map 和 Reduce。对于上层应用来说,就不得不想方设法去拆分算法,甚至于不得不在上层应用实现多个 Job 的串联,以完成一个完整的算法,例如迭代计算。
由于这样的弊端,催生了支持 DAG 框架的产生。因此,支持 DAG 的框架被划分为第二代计算引擎。如 Tez 以及更上层的 Oozie。这里我们不去细究各种 DAG 实现之间的区别,不过对于当时的 Tez 和 Oozie 来说,大多还是批处理的任务。
接下来就是以 Spark 为代表的第三代的计算引擎。第三代计算引擎的特点主要是 Job 内部的 DAG 支持(不跨越 Job),以及强调的实时计算。在这里,很多人也会认为第三代计算引擎也能够很好的运行批处理的 Job。
随着第三代计算引擎的出现,促进了上层应用快速发展,例如各种迭代计算的性能以及对流计算和 SQL 等的支持。Flink 的诞生就被归在了第四代。这应该主要表现在 Flink 对流计算的支持,以及更一步的实时性。当然 Flink 也可以支持 Batch 的任务,以及 DAG 的运算。
2.什么是Flink
Apache Flink是一个分布式大数据处理引擎,可对有界数据流和无界数据流进行有状态计算。 可部署在各种集群环境,对各种大小的数据规模进行快速计算。
什么是有界数据流和无界数据流?
- 无界流有一个开始但没有定义的结束。它们不会在生成时终止并提供数据。必须持续处理无界流,即必须在摄取事件后立即处理事件。无法等待所有输入数据到达,因为输入是无界的,并且在任何时间点都不会完成。处理无界数据通常要求以特定顺序(例如事件发生的顺序)摄取事件。
- 有界流具有定义的开始和结束。可以在执行任何计算之前通过摄取所有数据来处理有界流。处理有界流不需要有序摄取,因为可以始终对有界数据集进行排序。有界流的处理也称为批处理。

Apache Flink擅长处理无界和有界数据集。精确控制时间和状态使Flink的运行时能够在无界流上运行任何类型的应用程序。有界流由算法和数据结构内部处理,这些算法和数据结构专门针对固定大小的数据集而设计,从而产生出色的性能。
3.Flink历史
Flink诞生于欧洲的一个大数据研究项目,原名 StratoSphere。该项目是柏林工业大学的一个研究性项目,早期专注于批计算。2014 年,StratoSphere 项目中的核心成员孵化出 Flink,并在同年将 Flink 捐赠 Apache,后来 Flink 顺利成为 Apache 的顶级大数据项目。同时 Flink 计算的主流方向被定位为流计算,即用流式计算来做所有大数据 的计算工作,这就是 Flink 技术诞生的背景。

Apache Flink起了个大早,赶了个晚集,在 2015 年突然出现在大数据舞台,然后似乎在一夜之间从一个无人所知的系统迅速转变为人人皆知的流式处理引擎。
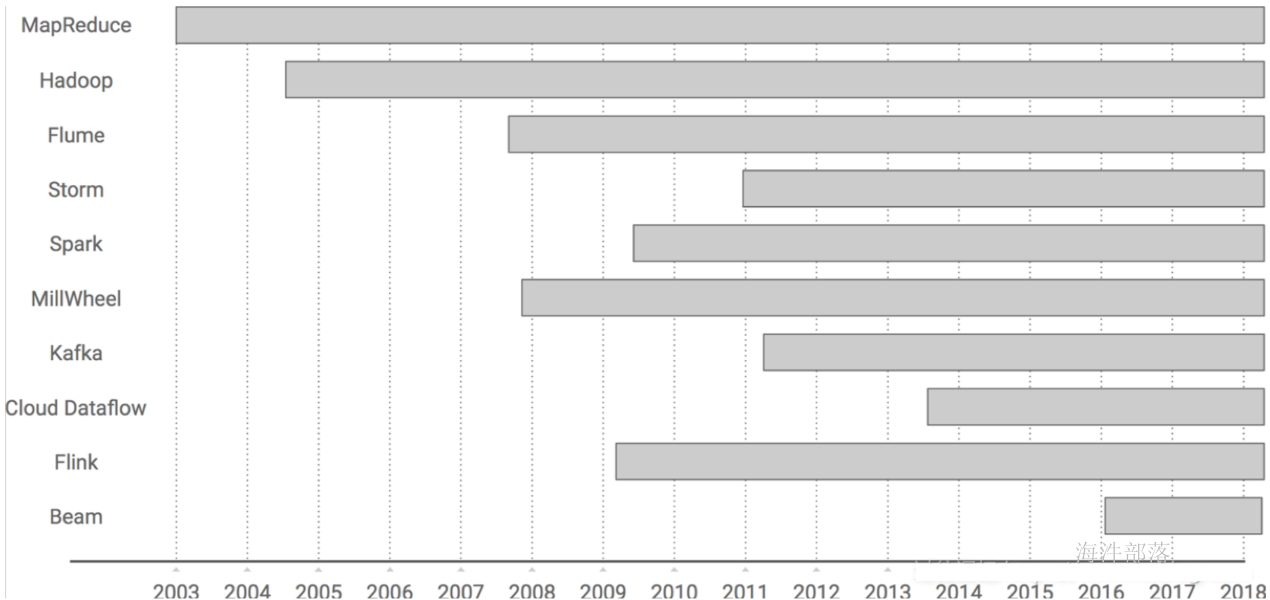
2014 年 Flink 作为主攻流计算的大数据引擎开始在开源大数据行业内崭露头角。区别于 Storm、Spark Streaming 以及其他流式计算引擎的是:它不仅是一个高吞吐、低延迟的 计算引擎,同时还提供很多高级功能。比如它提供有状态的计算,支持状态管理,支持强一致性的数据语义以及支持 Event Time,WaterMark 对消息乱序的处理等
2015 年是流计算百花齐放的时代,各个流计算框架层出不穷。Storm, JStorm, Heron, Flink, Spark Streaming, Google Dataflow (后来的 Beam) 等等。其中 Flink 的一致性语义和最接近 Dataflow 模型的开源实现,使其成为流计算框架中最耀眼的一颗。也许这也 是阿里看中 Flink的原因,并决心投入重金去研究基于 Flink的 Blink框架。
然后就有了阿里爸爸买买买

4.Flink的特点
- 支持java(主)和 scala api(真香)
- 流(dataStream)批(dataSet)一体化
- 支持事件处理和无序处理通过DataStream API,基于DataFlow数据流模型
- 在不同的时间语义(事件时间,摄取时间、处理时间)下支持灵活的窗口(时间,滑动、翻滚,会话,自定义触发器)
- 支持有状态计算的Exactly-once(仅处理一次)容错保证
- 支持基于轻量级分布式快照checkpoint机制实现的容错
- 支持savepoints 机制,一般手动触发,在升级应用或者处理历史数据是能够做到无状态丢失和最小停机时间
- 兼容hadoop的mapreduce,集成YARN,HDFS,Hbase 和其它hadoop生态系统的组件
- 支持大规模的集群模式,支持yarn、Mesos。可运行在成千上万的节点上
- 在dataSet(批处理)API中内置支持迭代程序
- 图处理(批) 机器学习(批) 复杂事件处理(流)
- 自动反压机制
- 高效的自定义内存管理
- 健壮的切换能力在in-memory和out-of-core中
5.flink的反压原理
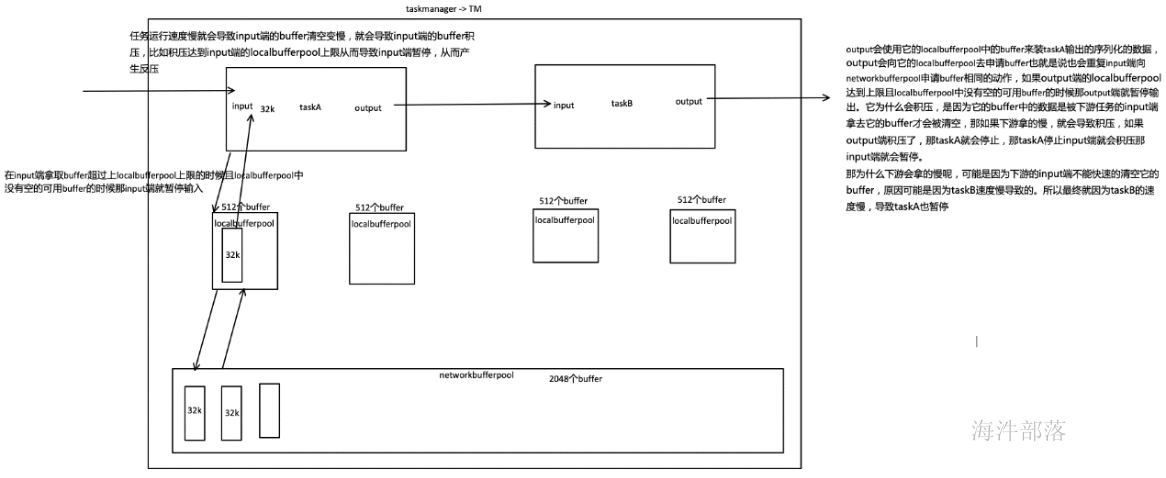
如下图所示展示了 Flink 在网络传输场景下的内存管理。网络上传输的数据会写到 Task 的 InputGate(IG) 中,经过 Task 的处理后,再由 Task 写到 ResultPartition(RS) 中。每个 Task 都包括了输入和输入,输入和输出的数据存在 Buffer 中(都是字节数据)。Buffer 是 MemorySegment 的包装类。

- 根据配置,Flink 会在 NetworkBufferPool 中生成一定数量(默认2048)的内存块 MemorySegment,内存块的总数量就代表了网络传输中所有可用的内存。NetworkEnvironment 和 NetworkBufferPool 是 Task 之间共享的,每个节点(TaskManager)只会实例化一个。
- Task 线程启动时,会向 NetworkEnvironment 注册,NetworkEnvironment 会为 Task 的 InputGate(IG)和 ResultPartition(RP) 分别创建一个 LocalBufferPool(缓冲池)并设置可申请的 MemorySegment(内存块)数量。IG 对应的缓冲池初始的内存块数量与 IG 中 InputChannel 数量一致,RP 对应的缓冲池初始的内存块数量与 RP 中的 ResultSubpartition 数量一致。不过,每当创建或销毁缓冲池时,NetworkBufferPool 会计算剩余空闲的内存块数量,并平均分配给已创建的缓冲池。注意,这个过程只是指定了缓冲池所能使用的内存块数量,并没有真正分配内存块,只有当需要时才分配。为什么要动态地为缓冲池扩容呢?因为内存越多,意味着系统可以更轻松地应对瞬时压力(如GC),不会频繁地进入反压状态,所以我们要利用起那部分闲置的内存块。
- 在 Task 线程执行过程中,当 Netty 接收端收到数据时,为了将 Netty 中的数据拷贝到 Task 中,InputChannel(实际是 RemoteInputChannel)会向其对应的缓冲池申请内存块(上图中的①)。如果缓冲池中也没有可用的内存块且已申请的数量还没到池子上限,则会向 NetworkBufferPool 申请内存块(上图中的②)并交给 InputChannel 填上数据(上图中的③和④)。如果缓冲池已申请的数量达到上限了呢?或者 NetworkBufferPool 也没有可用内存块了呢?这时候,Task 的 Netty Channel 会暂停读取,上游的发送端会立即响应停止发送,拓扑会进入反压状态。当 Task 线程写数据到 ResultPartition 时,也会向缓冲池请求内存块,如果没有可用内存块时,会阻塞在请求内存块的地方,达到暂停写入的目的。
- 当一个内存块被消费完成之后(在输入端是指内存块中的字节被反序列化成对象了,在输出端是指内存块中的字节写入到 Netty Channel 了),会调用 Buffer.recycle() 方法,会将内存块还给 LocalBufferPool (上图中的⑤)。如果LocalBufferPool中当前申请的数量超过了池子容量(由于上文提到的动态容量,由于新注册的 Task 导致该池子容量变小),则LocalBufferPool会将该内存块回收给 NetworkBufferPool(上图中的⑥)。如果没超过池子容量,则会继续留在池子中,减少反复申请的开销。
反压的过程
下面这张图简单展示了两个 Task 之间的数据传输以及 Flink 如何感知到反压的:

- 记录“A”进入了 Flink 并且被 Task 1 处理。(这里省略了 Netty 接收、反序列化等过程)
- 记录被序列化到 buffer 中。
- 该 buffer 被发送到 Task 2,然后 Task 2 从这个 buffer 中读出记录。
不要忘了:记录能被 Flink 处理的前提是,必须有空闲可用的 Buffer
结合上面两张图看:Task 1 在输出端有一个相关联的 LocalBufferPool(称缓冲池1),Task 2 在输入端也有一个相关联的 LocalBufferPool(称缓冲池2)。如果缓冲池1中有空闲可用的 buffer 来序列化记录 “A”,我们就序列化并发送该 buffer。
这里我们需要注意两个场景:
- 本地传输:如果 Task 1 和 Task 2 运行在同一个 worker 节点(TaskManager),该 buffer 可以直接交给下一个 Task。一旦 Task 2 消费了该 buffer,则该 buffer 会被缓冲池1回收。如果 Task 2 的速度比 1 慢,那么 buffer 回收的速度就会赶不上 Task 1 取 buffer 的速度,导致缓冲池1无可用的 buffer,Task 1 等待在可用的 buffer 上。最终形成 Task 1 的降速。
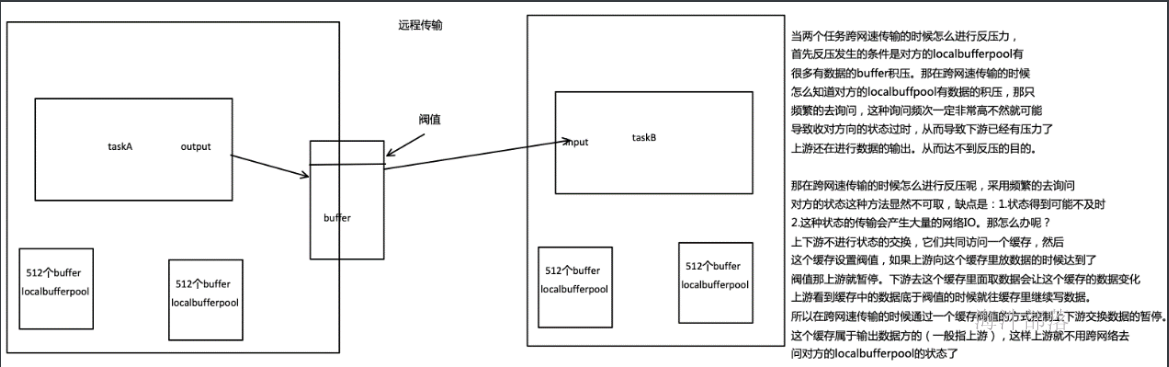
- 远程传输:如果 Task 1 和 Task 2 运行在不同的 worker 节点上,那么 buffer 会在发送到网络(TCP Channel)后被回收。在接收端,会从 LocalBufferPool 中申请 buffer,然后拷贝网络中的数据到 buffer 中。如果没有可用的 buffer,会停止从 TCP 连接中读取数据。在输出端,通过 Netty 的水位值机制(可配置)来保证不往网络中写入太多数据。如果网络中的数据(Netty输出缓冲中的字节数)超过了高水位值,我们会等到其降到低水位值以下才继续写入数据。这保证了网络中不会有太多的数据。如果接收端停止消费网络中的数据(由于接收端缓冲池没有可用 buffer),网络中的缓冲数据就会堆积,那么发送端也会暂停发送。另外,这会使得发送端的缓冲池得不到回收,writer 阻塞在向 LocalBufferPool 请求 buffer,阻塞了 writer 往 ResultSubPartition 写数据。
这种固定大小缓冲池就像阻塞队列一样,保证了 Flink 有一套健壮的反压机制,使得 Task 生产数据的速度不会快于消费的速度。我们上面描述的这个方案可以从两个 Task 之间的数据传输自然地扩展到更复杂的 pipeline 中,保证反压机制可以扩散到整个 pipeline。
反压监控
Flink 的实现中,只有当 Web 页面切换到某个 Job 的 Backpressure 页面,才会对这个 Job 触发反压检测,因为反压检测还是挺昂贵的。JobManager 会通过 Akka 给每个 TaskManager 发送TriggerStackTraceSample消息。默认情况下,TaskManager 会触发100次 stack trace 采样,每次间隔 50ms(也就是说一次反压检测至少要等待5秒钟)。并将这 100 次采样的结果返回给 JobManager,由 JobManager 来计算反压比率(反压出现的次数/采样的次数),最终展现在 UI 上。UI 刷新的默认周期是一分钟,目的是不对 TaskManager 造成太大的负担。

6.flink的内存管理
基于 JVM 的数据分析引擎都需要面对将大量数据存到内存中,这就不得不面对 JVM 存在的几个问题:(java对象对其的方式是8byte为一个单位hotspot虚拟机,32为系统的对象头为8byte 64位系统为16byte)
boolean 1 byte 1 short 2 char 2 int 4 float 4 long 8 double 8
- Java 对象存储密度低。一个只包含 boolean 属性的对象占用了16个字节内存:对象头占了8个,boolean 属性占了1个,对齐填充占了7个。而实际上只需要一个bit(1/8字节)就够了。
- Full GC 会极大地影响性能,尤其是为了处理更大数据而开了很大内存空间的JVM来说,GC 会达到秒级甚至分钟级。
- OOM 问题影响稳定性。OutOfMemoryError是分布式计算框架经常会遇到的问题,当JVM中所有对象大小超过分配给JVM的内存大小时,就会发生OutOfMemoryError错误,导致JVM崩溃,分布式框架的健壮性和性能都会受到影响。
所以目前,越来越多的大数据项目开始自己管理JVM内存了,为的就是获得像 C 一样的性能以及避免 OOM 的发生,Flink 是如何解决上面的问题的,主要内容包括内存管理、定制的序列化工具、缓存友好的数据结构和算法、堆外内存、JIT编译优化等。
积极的内存管理
Flink 并不是将大量对象存在堆上,而是将对象都序列化到一个预分配的内存块上,这个内存块叫做 MemorySegment,它代表了一段固定长度的内存(默认大小为 32KB),也是 Flink 中最小的内存分配单元,并且提供了非常高效的读写方法。你可以把 MemorySegment 想象成是为 Flink 定制的 java.nio.ByteBuffer。它的底层可以是一个普通的 Java 字节数组(byte[]),也可以是一个申请在堆外的 ByteBuffer。每条记录都会以序列化的形式存储在一个或多个MemorySegment中。
Flink 中的 Worker 名叫 TaskManager,是用来运行用户代码的 JVM 进程。TaskManager 的堆内存主要被分成了三个部分
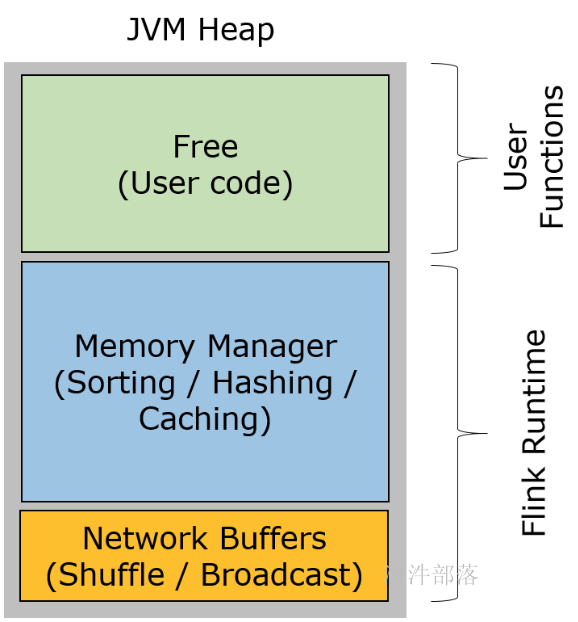
- Network Buffers: 一定数量的32KB大小的 buffer,主要用于数据的网络传输。在 TaskManager 启动的时候就会分配。默认数量是 2048 个,可以通过 taskmanager.network.numberOfBuffers 来配置。
- Memory Manager Pool: 这是一个由 MemoryManager 管理的,由众多MemorySegment组成的超大集合。Flink 中的算法(如 sort/shuffle/join)会向这个内存池申请 MemorySegment,将序列化后的数据存于其中,使用完后释放回内存池。默认情况下,池子占了堆内存的 70% 的大小。
- Remaining (Free) Heap: 这部分的内存是留给用户代码以及 TaskManager 的数据结构使用的。因为这些数据结构一般都很小,所以基本上这些内存都是给用户代码使用的。从GC的角度来看,可以把这里看成的新生代,也就是说这里主要都是由用户代码生成的短期对象。
注意:Memory Manager Pool 主要在Batch模式下使用。在Steaming模式下,该池子不会预分配内存,也不会向该池子请求内存块。也就是说该部分的内存都是可以给用户代码使用的。不过社区是打算在 Streaming 模式下也能将该池子利用起来。
序列化方法
Flink 采用类似 DBMS 的 sort 和 join 算法,直接操作二进制数据,从而使序列化/反序列化带来的开销达到最小。如果需要处理的数据超出了内存限制,则会将部分数据存储到硬盘上。下图描述了 Flink 如何存储序列化后的数据到内存块中,以及在需要的时候如何将数据存储到磁盘上。
从上面我们能够得出 Flink 积极的内存管理以及直接操作二进制数据有以下几点好处:
- 减少GC压力。显而易见,因为所有常驻型数据都以二进制的形式存在 Flink 的MemoryManager中,这些MemorySegment一直呆在老年代而不会被GC回收。其他的数据对象基本上是由用户代码生成的短生命周期对象,这部分对象可以被 Minor GC 快速回收。只要用户不去创建大量类似缓存的常驻型对象,那么老年代的大小是不会变的,Major GC也就永远不会发生。从而有效地降低了垃圾回收的压力。另外,这里的内存块还可以是堆外内存,这可以使得 JVM 内存更小,从而加速垃圾回收。
- 避免了OOM。所有的运行时数据结构和算法只能通过内存池申请内存,保证了其使用的内存大小是固定的,不会因为运行时数据结构和算法而发生OOM。在内存吃紧的情况下,算法(sort/join等)会高效地将一大批内存块写到磁盘,之后再读回来。因此,OutOfMemoryErrors可以有效地被避免。
- 节省内存空间。Java 对象在存储上有很多额外的消耗(如上一节所谈)。如果只存储实际数据的二进制内容,就可以避免这部分消耗。
- 高效的二进制操作 & 缓存友好的计算。二进制数据以定义好的格式存储,可以高效地比较与操作。另外,该二进制形式可以把相关的值,以及hash值,键值和指针等相邻地放进内存中。这使得数据结构可以对高速缓存更友好,可以从 L1/L2/L3 缓存获得性能的提升。
为 Flink 量身定制的序列化框架
目前 Java 生态圈提供了众多的序列化框架:Java serialization, Kryo, Apache Avro 等等。但是 Flink 实现了自己的序列化框架。因为在 Flink 中处理的数据流通常是同一类型,由于数据集对象的类型固定,对于数据集可以只保存一份对象Schema信息,节省大量的存储空间。同时,对于固定大小的类型,也可通过固定的偏移位置存取。当我们需要访问某个对象成员变量的时候,通过定制的序列化工具,并不需要反序列化整个Java对象,而是可以直接通过偏移量,只是反序列化特定的对象成员变量。如果对象的成员变量较多时,能够大大减少Java对象的创建开销,以及内存数据的拷贝大小。
Flink支持的数据类型
Flink支持任意的Java或是Scala类型。Flink 在数据类型上有很大的进步,不需要实现一个特定的接口(像Hadoop中的org.apache.hadoop.io.Writable),Flink 能够自动识别数据类型。Flink 通过 Java Reflection 框架分析。基于 Java 的 Flink 程序 UDF (User Define Function)的返回类型的类型信息,通过 Scala Compiler 分析基于 Scala 的 Flink 程序 UDF 的返回类型的类型信息。类型信息由 TypeInformation 类表示,TypeInformation 支持以下几种类型:
- BasicTypeInfo: 任意Java 基本类型(装箱的)或 String 类型。
- BasicArrayTypeInfo: 任意Java基本类型数组(装箱的)或 String 数组。
- WritableTypeInfo: 任意 Hadoop Writable 接口的实现类。
- TupleTypeInfo: 任意的 Flink Tuple 类型(支持Tuple1 to Tuple25)。Flink tuples 是固定长度固定类型的Java Tuple实现。
- CaseClassTypeInfo: 任意的 Scala CaseClass(包括 Scala tuples)。
- PojoTypeInfo: 任意的 POJO (Java or Scala),例如,Java对象的所有成员变量,要么是 public 修饰符定义,要么有 getter/setter 方法。
- GenericTypeInfo: 任意无法匹配之前几种类型的类。
前六种数据类型基本上可以满足绝大部分的Flink程序,针对前六种类型数据集,Flink皆可以自动生成对应的TypeSerializer,能非常高效地对数据集进行序列化和反序列化。对于最后一种数据类型,Flink会使用Kryo进行序列化和反序列化。每个TypeInformation中,都包含了serializer,类型会自动通过serializer进行序列化,然后用Java Unsafe接口写入MemorySegments。对于可以用作key的数据类型,Flink还同时自动生成TypeComparator,用来辅助直接对序列化后的二进制数据进行compare、hash等操作。对于 Tuple、CaseClass、POJO 等组合类型,其TypeSerializer和TypeComparator也是组合的,序列化和比较时会委托给对应的serializers和comparators。如下图展示 一个内嵌型的Tuple3\<Integer,Double,Person> 对象的序列化过程。
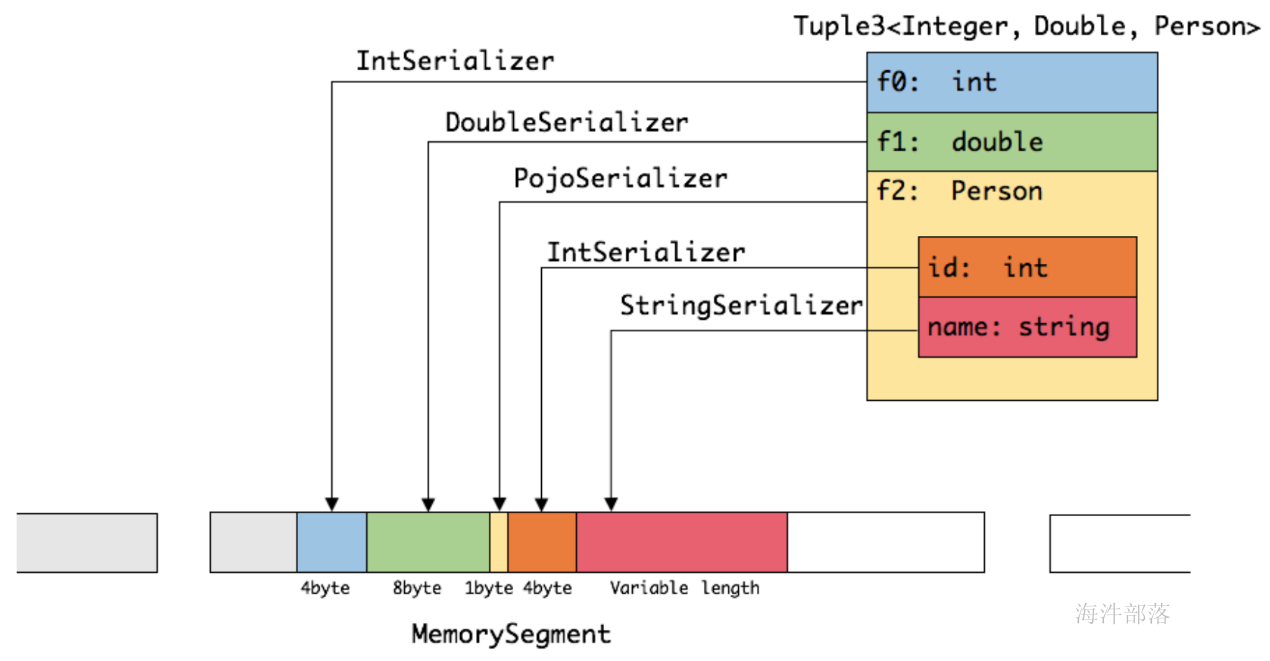
可以看出这种序列化方式存储密度是相当紧凑的。其中 int 占4字节,double 占8字节,POJO多个一个字节的header,PojoSerializer只负责将header序列化进去,并委托每个字段对应的serializer对字段进行序列化。
Flink 的类型系统可以很轻松地扩展出自定义的TypeInformation、Serializer以及Comparator,来提升数据类型在序列化和比较时的性能。
排序
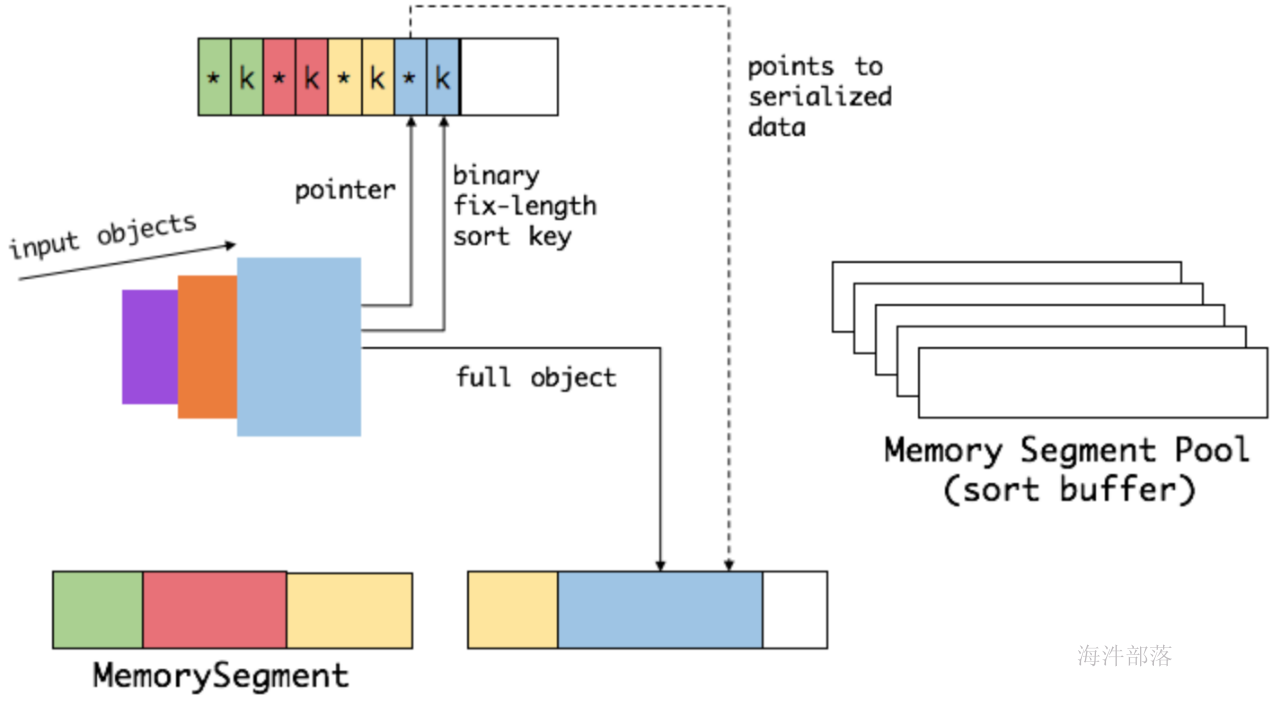
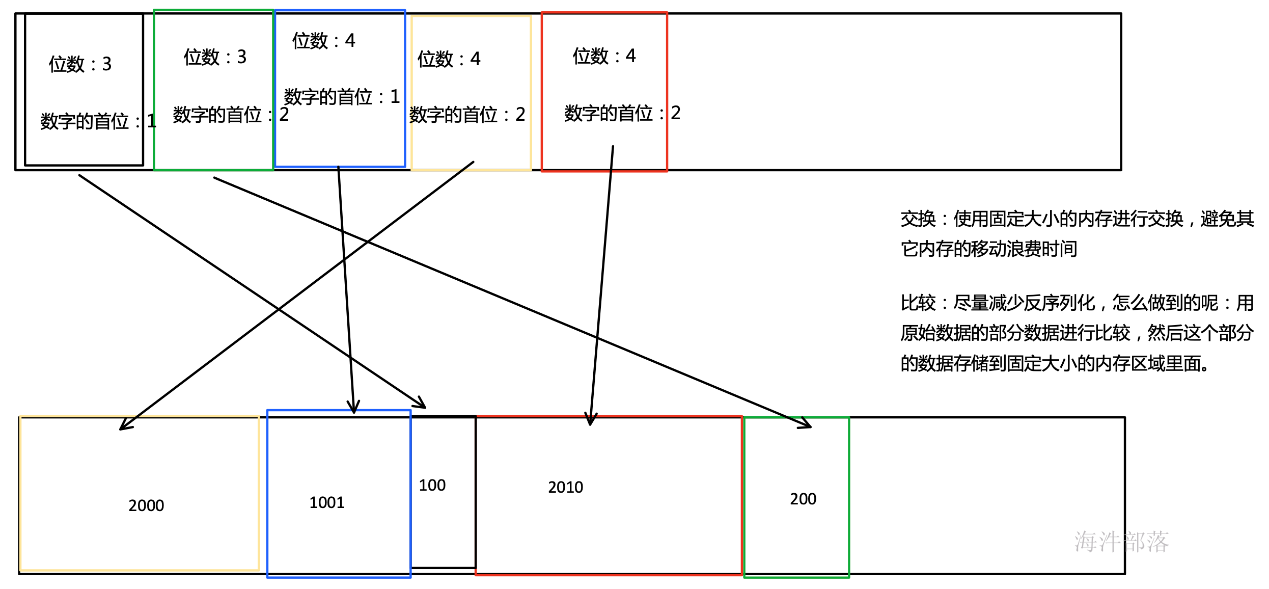
我们会把 sort buffer 分成两块区域。一个区域是用来存放所有对象完整的二进制数据。另一个区域用来存放指向完整二进制数据的指针以及定长的序列化后的key(key+pointer)。如果需要序列化的key是个变长类型,如String,则会取其前缀序列化。当一个对象要加到 sort buffer 中时,它的二进制数据会被加到第一个区域,指针(可能还有key)会被加到第二个区域。
将实际的数据和指针加定长key分开存放有两个目的。第一,交换定长块(key+pointer)更高效,不用交换真实的数据也不用移动其他key和pointer。第二,这样做是缓存友好的,因为key都是连续存储在内存中的,这大大提高了缓存命中率。
排序的关键是比大小和交换。Flink 中,会先用 key 比大小,这样就可以直接用二进制的key比较而不需要反序列化出整个对象。因为key是定长的,所以如果key相同(或者没有提供二进制key),那就必须将真实的二进制数据反序列化出来,然后再做比较。之后,只需要交换key+pointer就可以达到排序的效果,真实的数据不用移动。
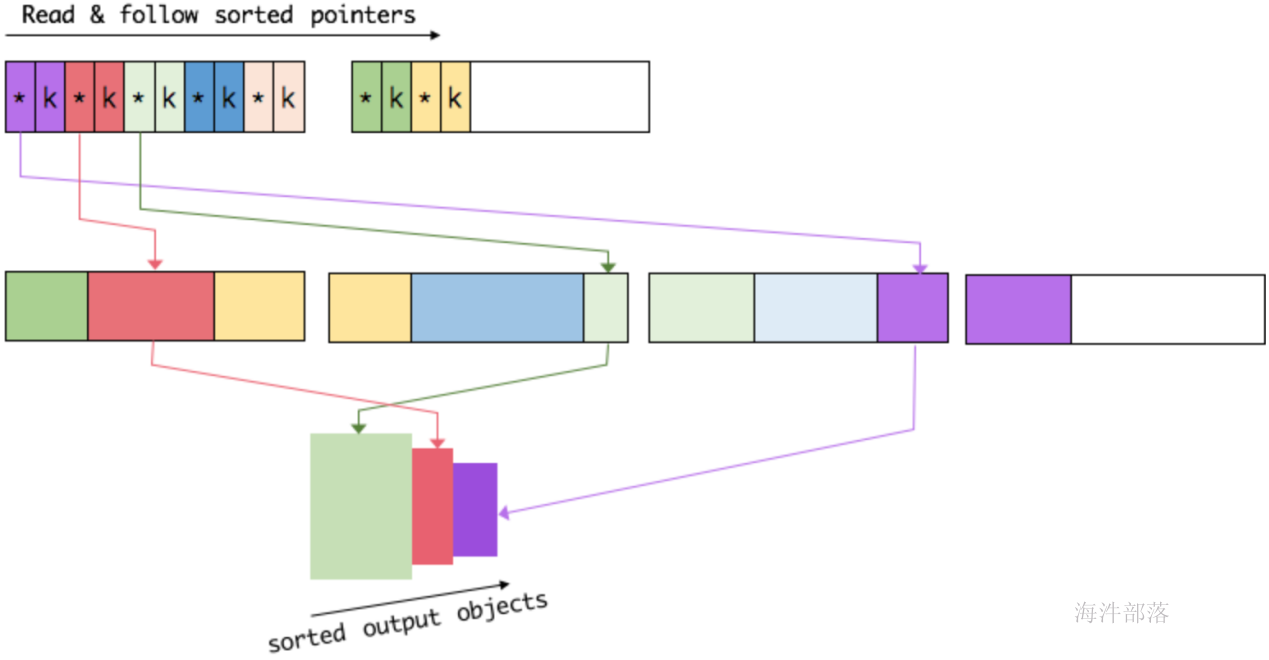
最后,访问排序后的数据,可以沿着排好序的key+pointer区域顺序访问,通过pointer找到对应的真实数据,并写到内存或外部
缓存友好的数据结构和算法
随着磁盘IO和网络IO越来越快,CPU逐渐成为了大数据领域的瓶颈。从 L1/L2/L3 缓存读取数据的速度比从主内存读取数据的速度快好几个量级。通过性能分析可以发现,CPU时间中的很大一部分都是浪费在等待数据从主内存过来上。如果这些数据可以从 L1/L2/L3 缓存过来,那么这些等待时间可以极大地降低,并且所有的算法会因此而受益。
在上面讨论中我们谈到的,Flink 通过定制的序列化框架将算法中需要操作的数据(如sort中的key)连续存储,而完整数据存储在其他地方。因为对于完整的数据来说,key+pointer更容易装进缓存,从而提高了基础算法的效率。这对于上层应用是完全透明的,可以充分享受缓存友好带来的性能提升。
走向堆外内存
Flink 基于堆内存的内存管理机制已经可以解决很多JVM现存问题了,为什么还要引入堆外内存?
- 启动超大内存(上百GB)的JVM需要很长时间,GC停留时间也会很长(分钟级)。使用堆外内存的话,可以极大地减小堆内存(只需要分配Remaining Heap那一块),使得 TaskManager 扩展到上百GB内存不是问题。
- 高效的 IO 操作。堆外内存在写磁盘或网络传输时是 zero-copy,而堆内存的话,至少需要 copy 一次。
- 堆外内存是进程间共享的。也就是说,即使JVM进程崩溃也不会丢失数据。这可以用来做故障恢复(Flink暂时没有利用起这个,不过未来很可能会去做)。
但是强大的东西总是会有其负面的一面,不然为何大家不都用堆外内存呢。
- 堆内存的使用、监控、调试都要简单很多。堆外内存意味着更复杂更麻烦。
- Flink 有时需要分配短生命周期的 MemorySegment,这个申请在堆上会更廉价。
- 有些操作在堆内存上会快一点点。
Flink用通过ByteBuffer.allocateDirect(numBytes)来申请堆外内存,用 sun.misc.Unsafe 来操作堆外内存。在flink的源码中大量的 getXXX/putXXX 方法都是调用了 unsafe 方法去操作内存(这个内存包括堆外内存与堆内内存)。
另外,Flink的源码中,许多方法都被标记成了 final,两个子类也是 final 类型,为的也是优化JIT 编译器(java及时编译器),会提醒 JIT 这个方法是可以被去虚化和内联的。
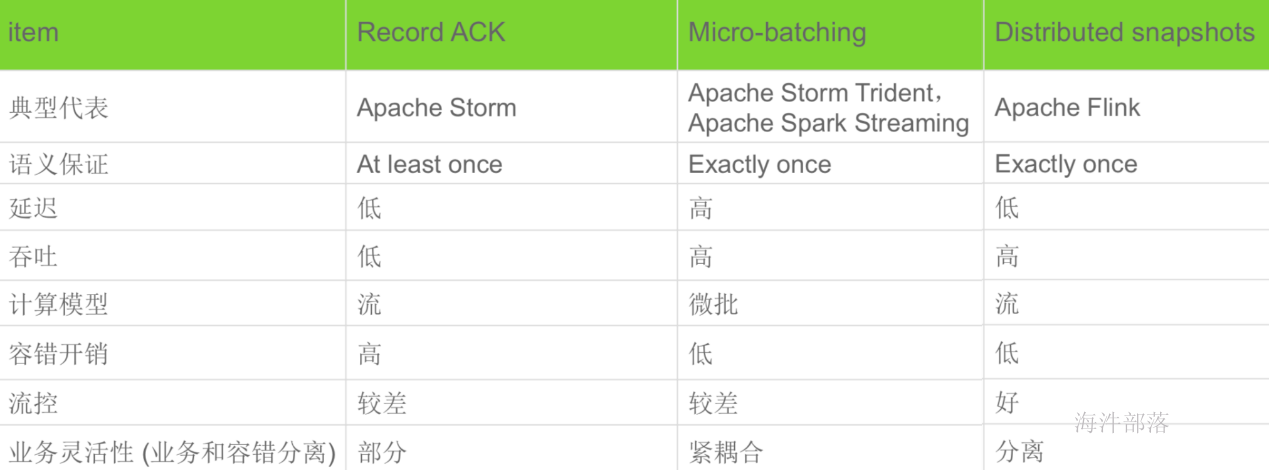
7.对比Spark
流式计算框架对比
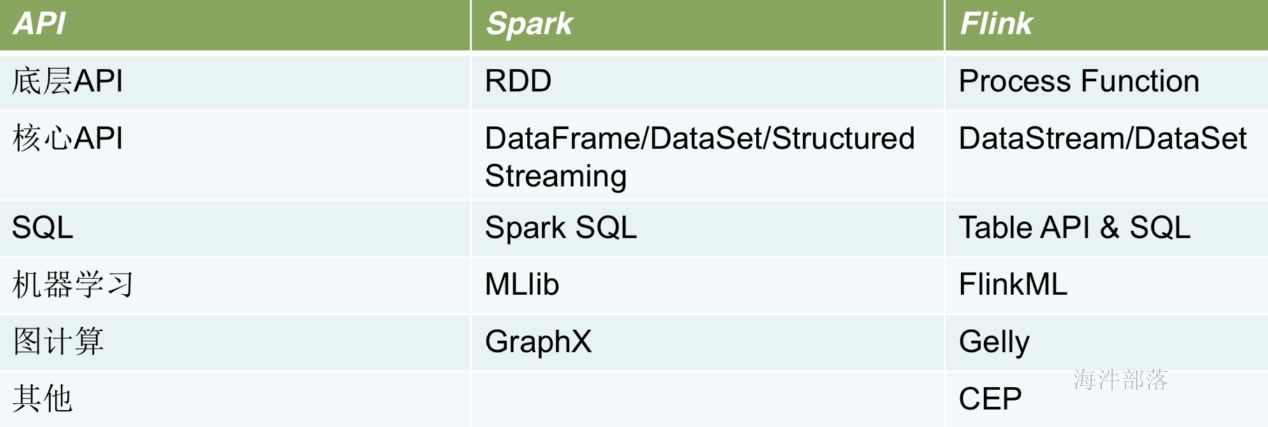
API对比
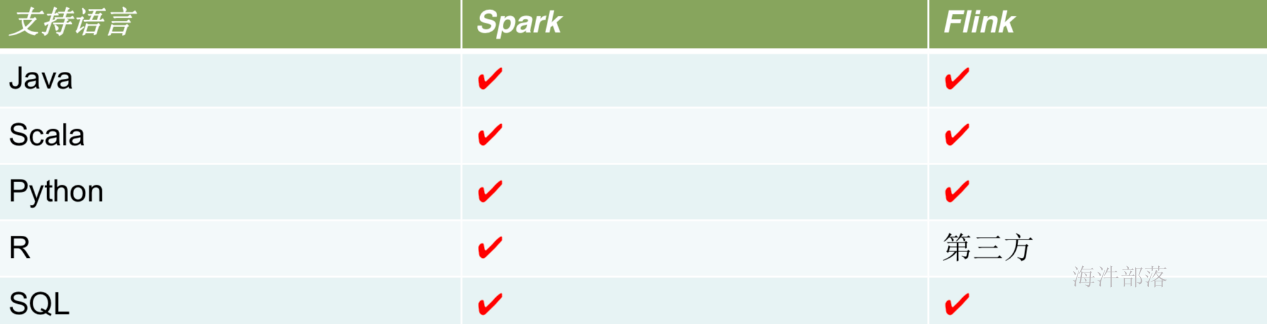
数据源对比
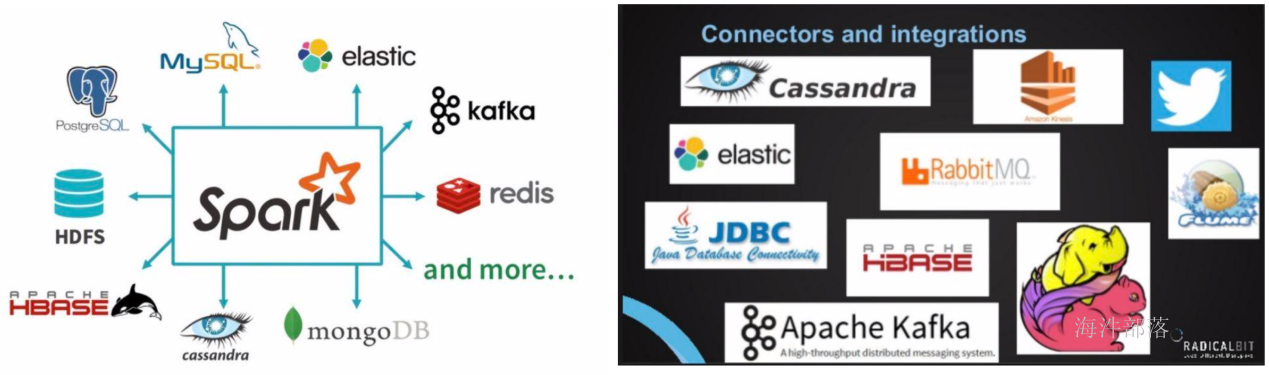
运行环境对比
社区对比
Spark 社区在规模和活跃程度上都是领先的,毕竟多了几年发展时间,同时背后的商业公司Databricks 由于本土优势使得Spark在美国的影响力明显优于Flink
而且作为一个德国公司,Data Artisans 想在美国扩大影响力要更难一些。不过 Flink 社区也有一批 稳定的支持者,达到了可持续发展的规模。
Spark社区活跃度比Flink高很多。
Flink 的中文社区在
目前spark和flink各有所长,spark基于内存的批量运算,flink高可靠的exactly-once的流式运算
还是那句话看你的应用场景是什么,从而选择哪个更适合
8.Flink生态
9.Flink应用场景
10.Flink的未来
- 批计算的突破、流处理和批处理无缝切换、界限越来越模糊、甚至混合
- Flink-SQL
- 完善Machine Learning 算法库,同时 Flink 也会向更成熟的机器学习、深度学习去集成(比如Tensorflow On Flink)
2.Flink的Standalone和YARN模式安装、Standalone和YARN模式的HA
1.Flink生态之核心组件

2.flink的主要运行方式有
- Local:适用于开发
- Standalone:分布式,适用于生产环境
- On YARN:分布式,适用于生产环境(推荐)
3.Standalone集群模式安装
Linux,CentOS 6/7
安装JDK
下载 flink 安装包
https://flink.apache.org/downloads.html
非高可用安装:
1.上传压缩包

2.分发到每个机器上
./scp_all.sh ./up/flink-1.9.3-bin-scala_2.11.tgz /tmp/
3.解压到/usr/local目录下
./ssh_root.sh tar -xzf /tmp/flink-1.9.3-bin-scala_2.11.tgz -C /usr/local/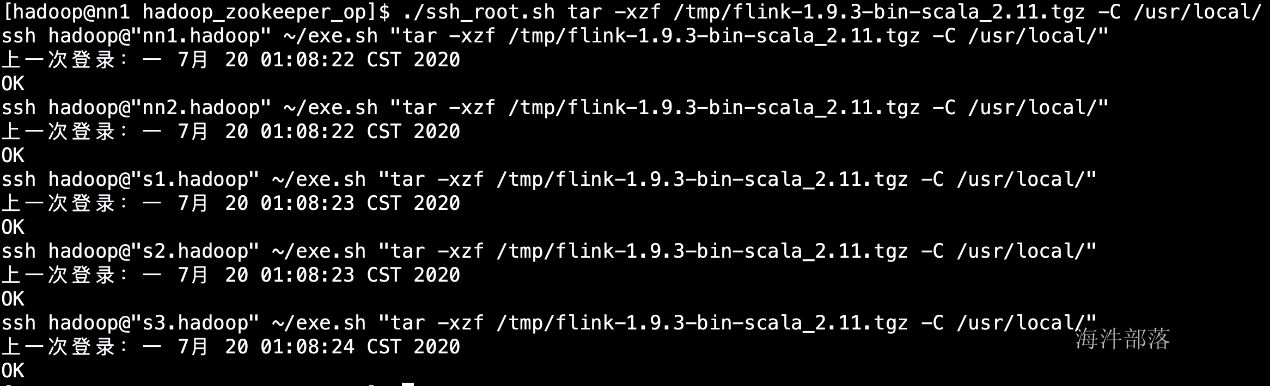
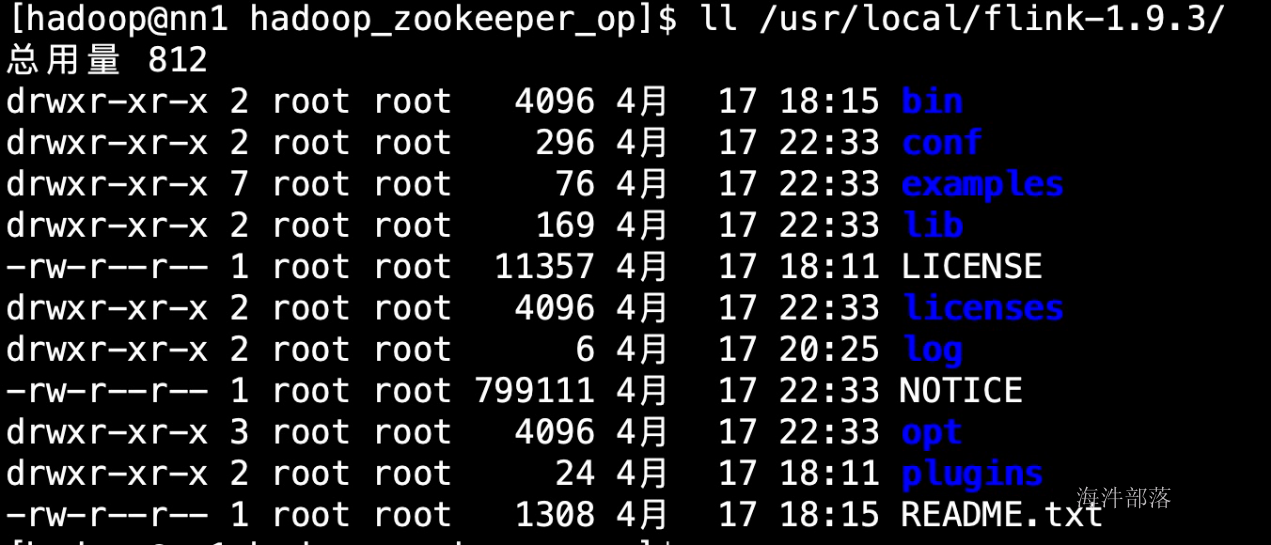
目录说明:
- bin:可执行脚本
- conf:配置文件目录
- examples:测试样例
- lib:依赖jar
- opt:扩展依赖jar
- log:日志
4.修改权限为hadoop
./ssh_root.sh chown -R hadoop:hadoop /usr/local/flink-1.9.3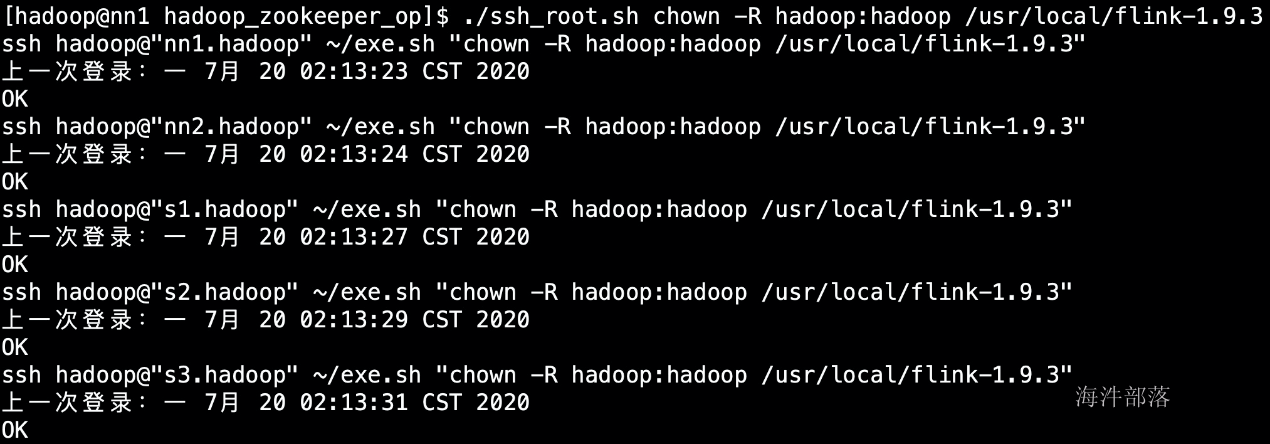
5.创建软件链接
./ssh_root.sh ln -s /usr/local/flink-1.9.3 /usr/local/flink
6.备份原有配置
./ssh_all.sh cp -r /usr/local/flink/conf /usr/local/flink/conf_back
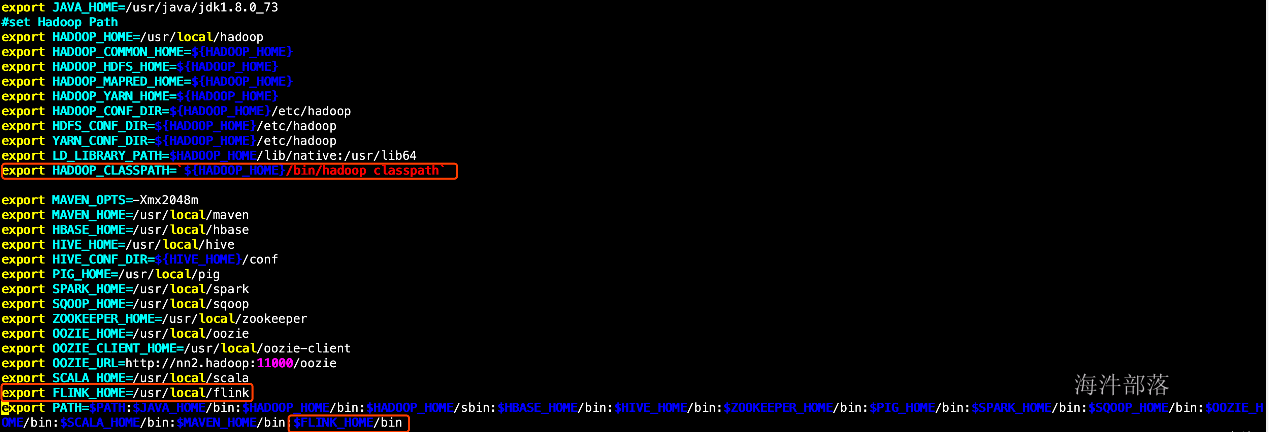
7.在每个机器上增加FLINK_HOME环境变量,之后source一下
8.修改配置(conf目录下)
修改flink-conf.yaml
vim /usr/local/flink/conf/flink-conf.yaml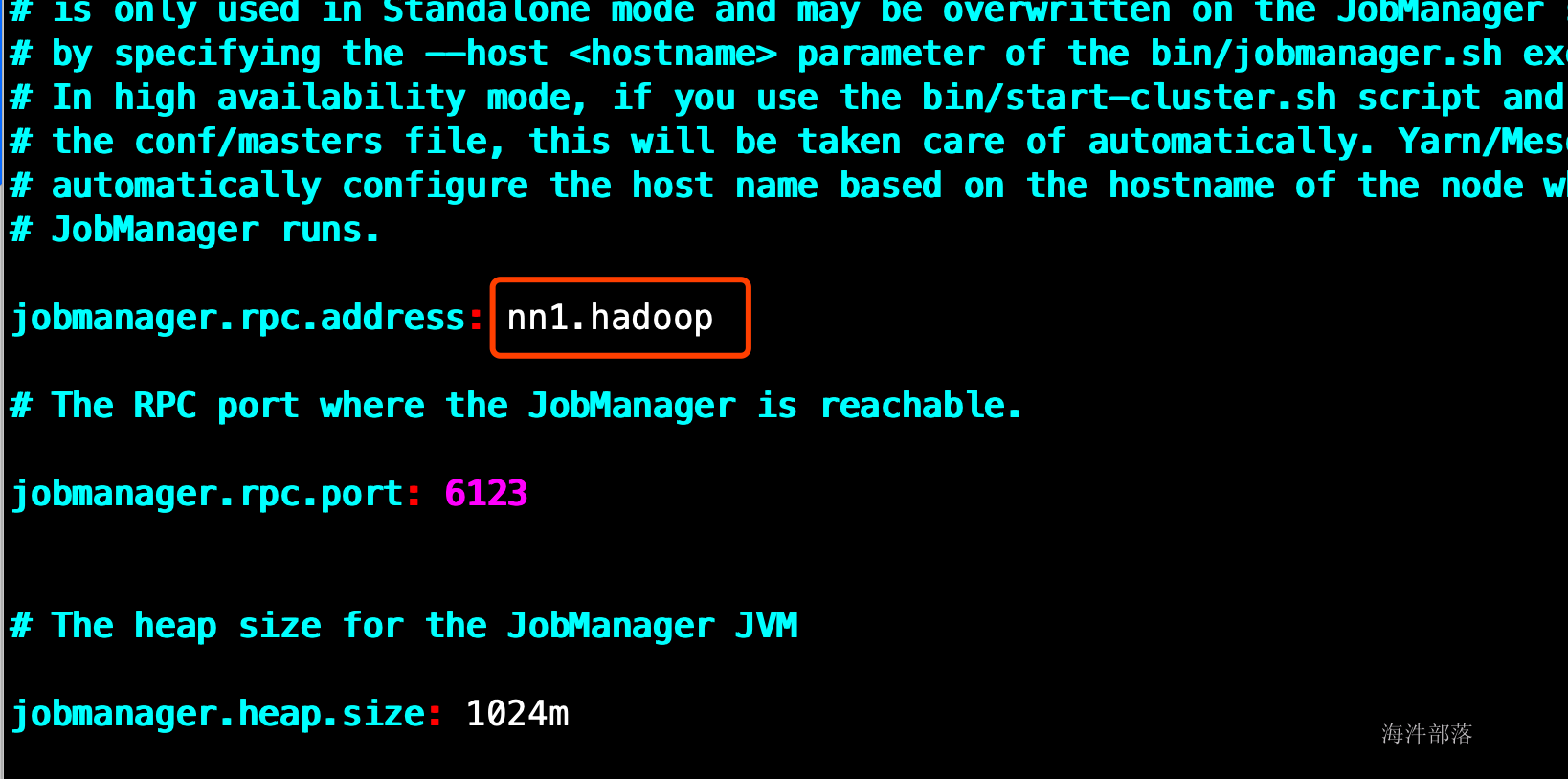
修改master
vim /usr/local/flink/conf/masters
修改slaves
vim /usr/local/flink/conf/slaves
分发修改配置
./scp_all.sh /usr/local/flink/conf/flink-conf.yaml /usr/local/flink/conf/
./scp_all.sh /usr/local/flink/conf/slaves /usr/local/flink/conf/
./scp_all.sh /usr/local/flink/conf/masters /usr/local/flink/conf/
9.启动
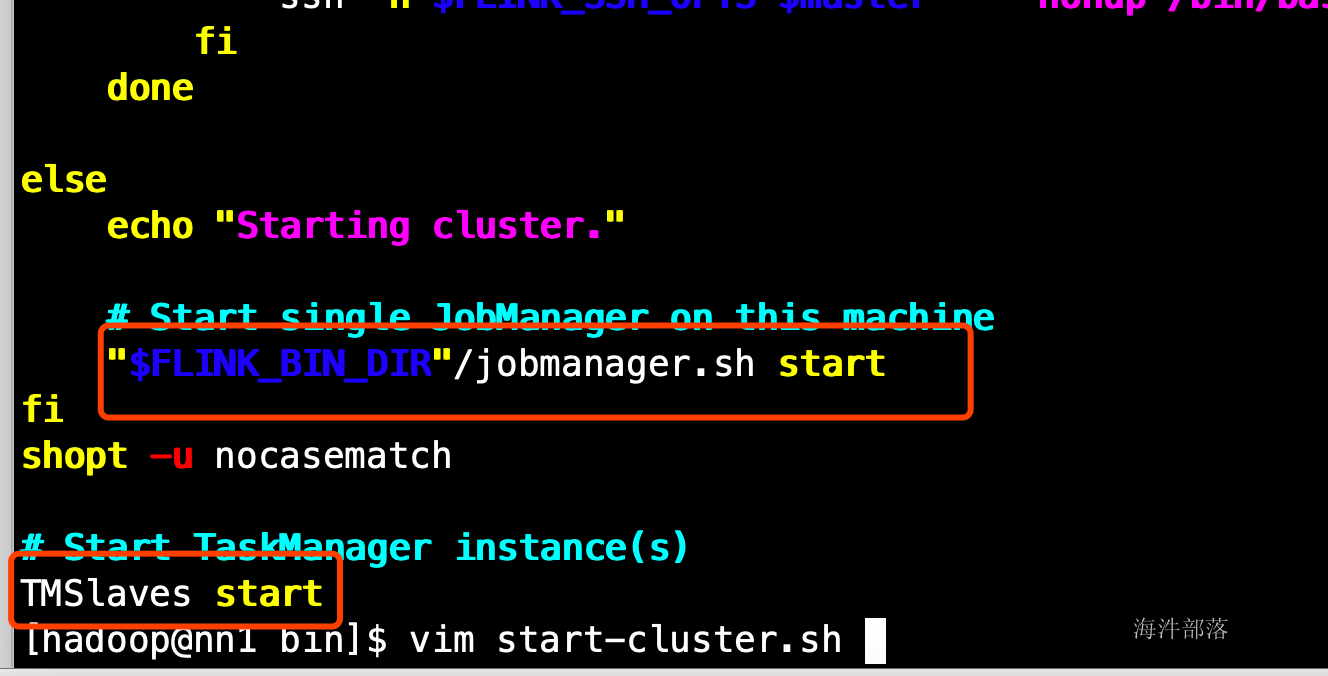
/usr/local/flink/bin/start-cluster.sh
启动日志
vim /usr/local/flink/log/flink-hadoop-standalonesession-0-nn1.hadoop.log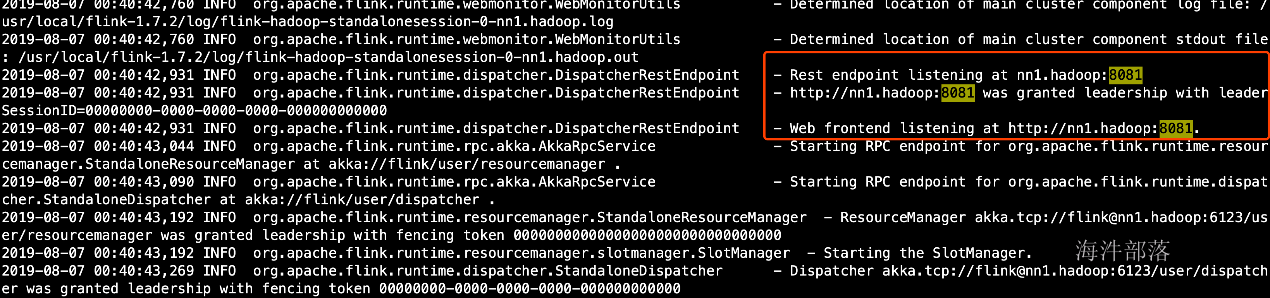
启动flink之后各机器上的进程
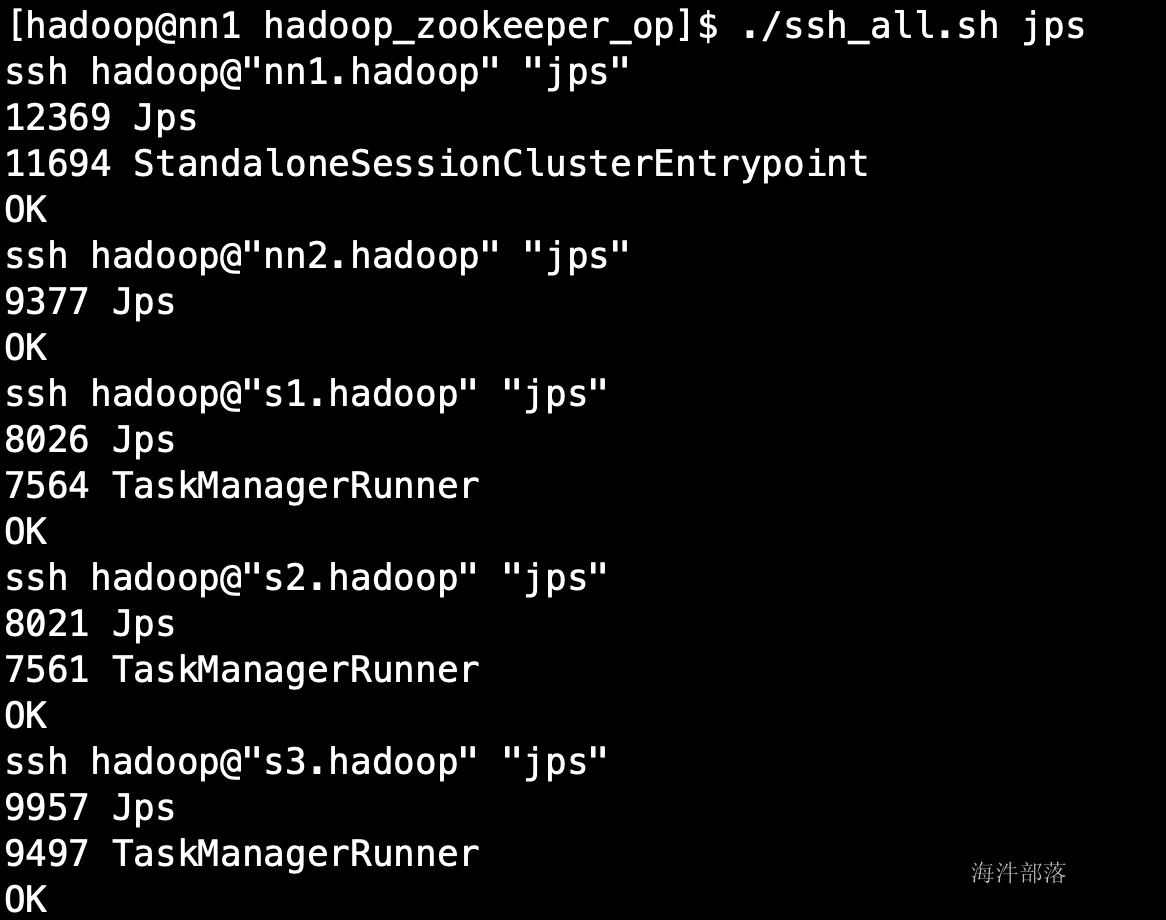
jobManager界面
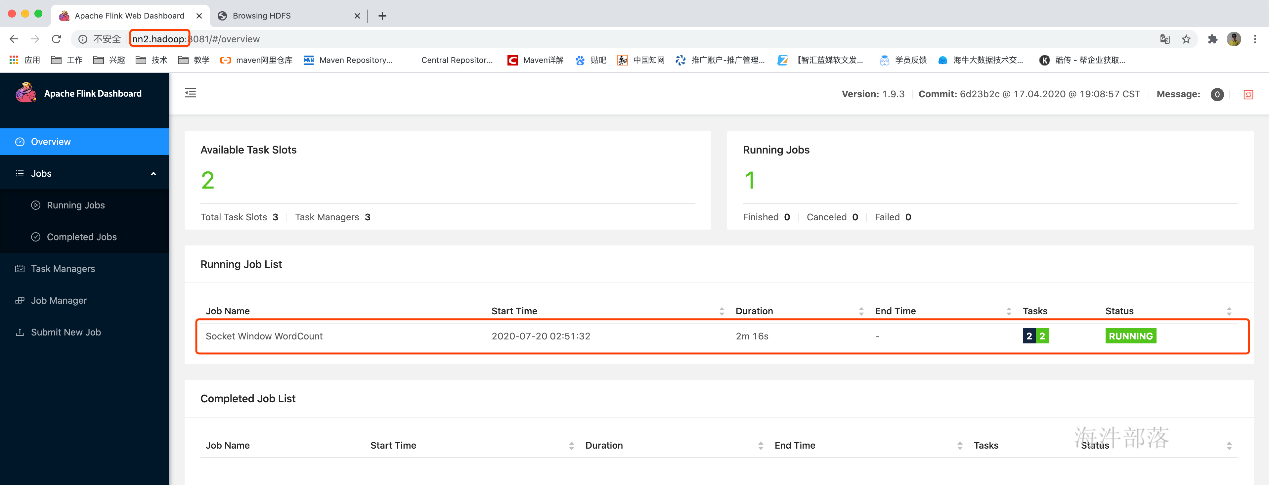
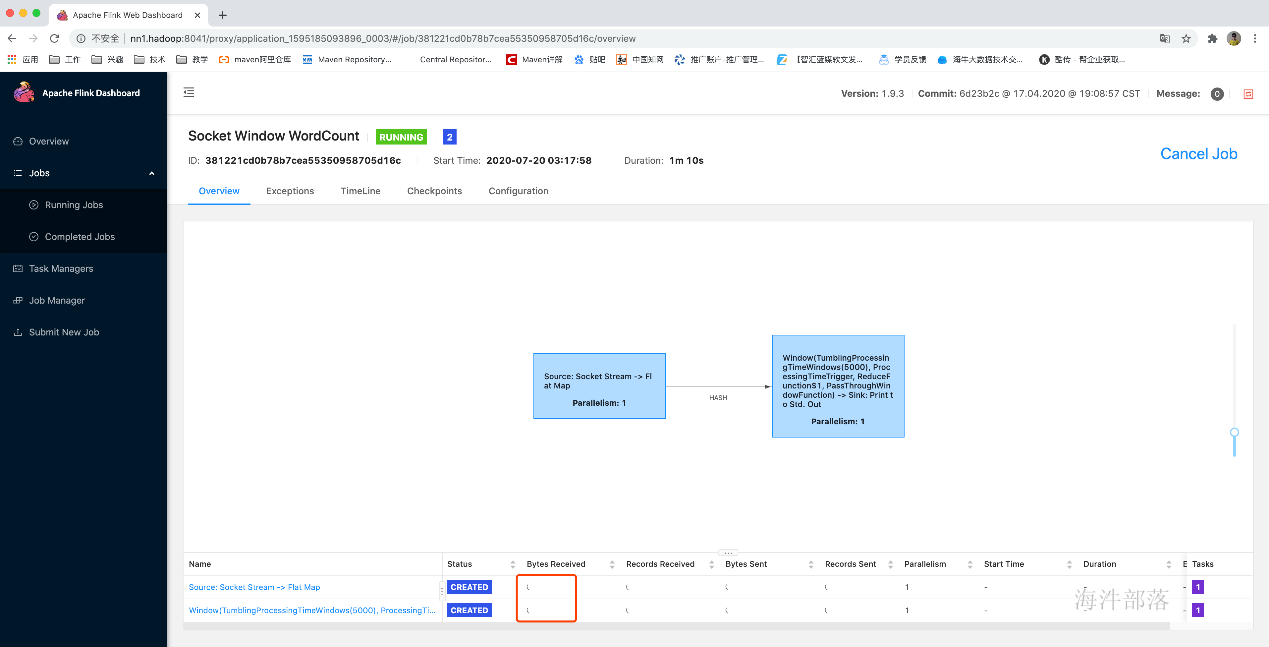
10.测试一下
功能是一个streaming版的WordCount
首先在nn1启动socketServer
nc -l -k -p 6666
提交任务
flink run -d /usr/local/flink/examples/streaming/SocketWindowWordCount.jar --hostname
在nc中输入数据:
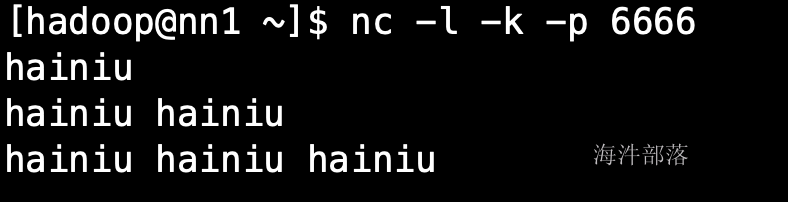
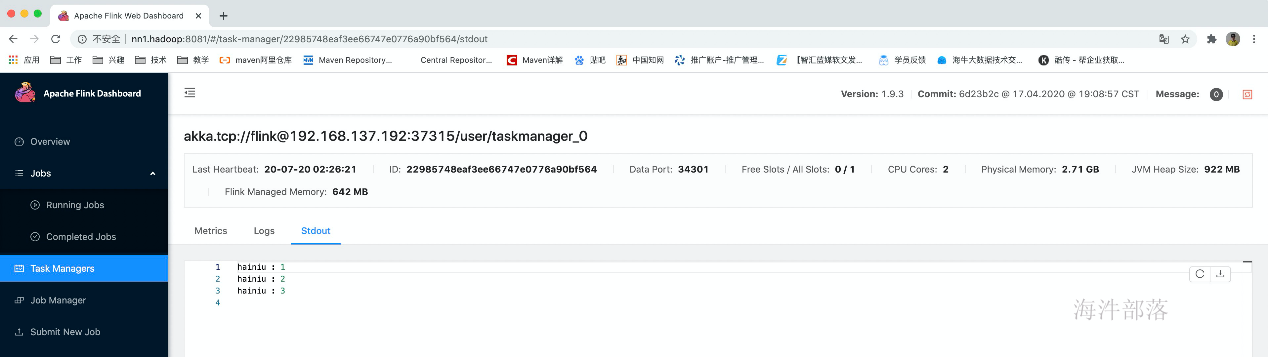
由于任务是在tm中运行,所以数据被打印到tm中
终止任务运行
11.关闭集群
stop-cluster.sh高可用安装:
1.修改配置(conf目录下)
修改flink-conf.yaml
vim /usr/local/flink/conf/flink-conf.yaml高可用相关参数解释:
#指定高可用模式(必须)
high-availability: zookeeper
#ZooKeeper提供分布式协调服务(必须)
high-availability.zookeeper.quorum: nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181
#根ZooKeeper节点,在该节点下放置所有集群节点(推荐)
high-availability.zookeeper.path.root: /flink
#JobManager元数据保存在文件系统storageDir中,只有指向此状态的指针存储在ZooKeeper中(必须)
high-availability.storageDir: hdfs://ns1/flink/ha/
#自定义集群(推荐)
high-availability.cluster-id: /hainiuFlinkCluster
#state checkpoints模式
state.backend: filesystem
#检查点(checkpoint)生成的分布式快照的保存地点,默认是jobmanager的memory,但是HA模式必须配置在hdfs上
state.checkpoints.dir: hdfs://ns1/flink/checkpoints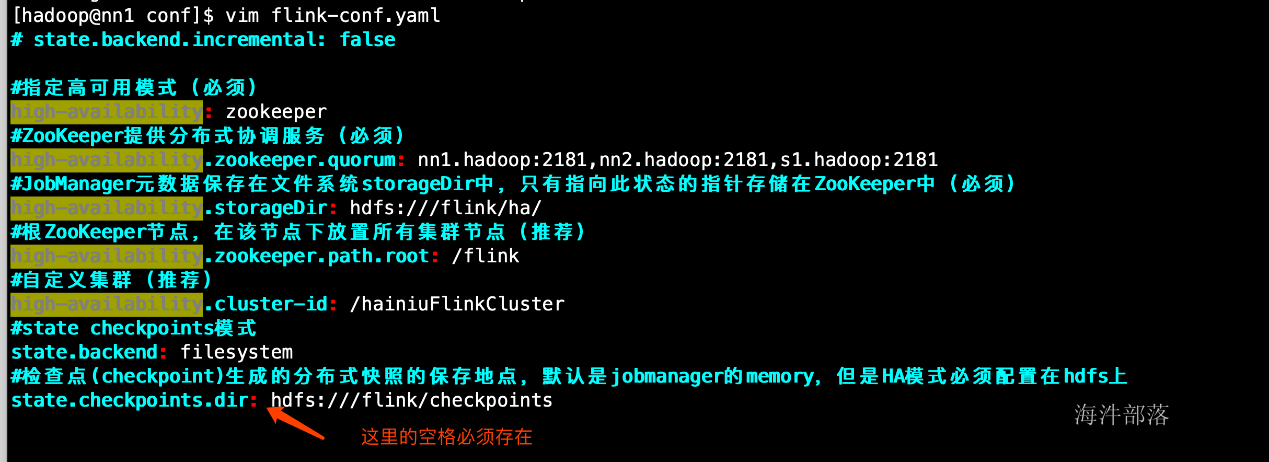
修改master
vim /usr/local/flink/conf/masters
分发修改配置
./scp_all.sh /usr/local/flink/conf/flink-conf.yaml /usr/local/flink/conf/
./scp_all.sh /usr/local/flink/conf/masters /usr/local/flink/conf/
2.启动HA
先启动zookeeper
./ssh_all_zookeeper.sh /usr/local/zookeeper/bin/zkServer.sh start
3.再启动hdfs
start-dfs.sh
4.创建hdfs目录
hadoop fs -mkdir -p hdfs:///flink/ha/
hadoop fs -mkdir -p hdfs:///flink/checkpoints
5.启动flink
/usr/local/flink/bin/start-cluster.sh
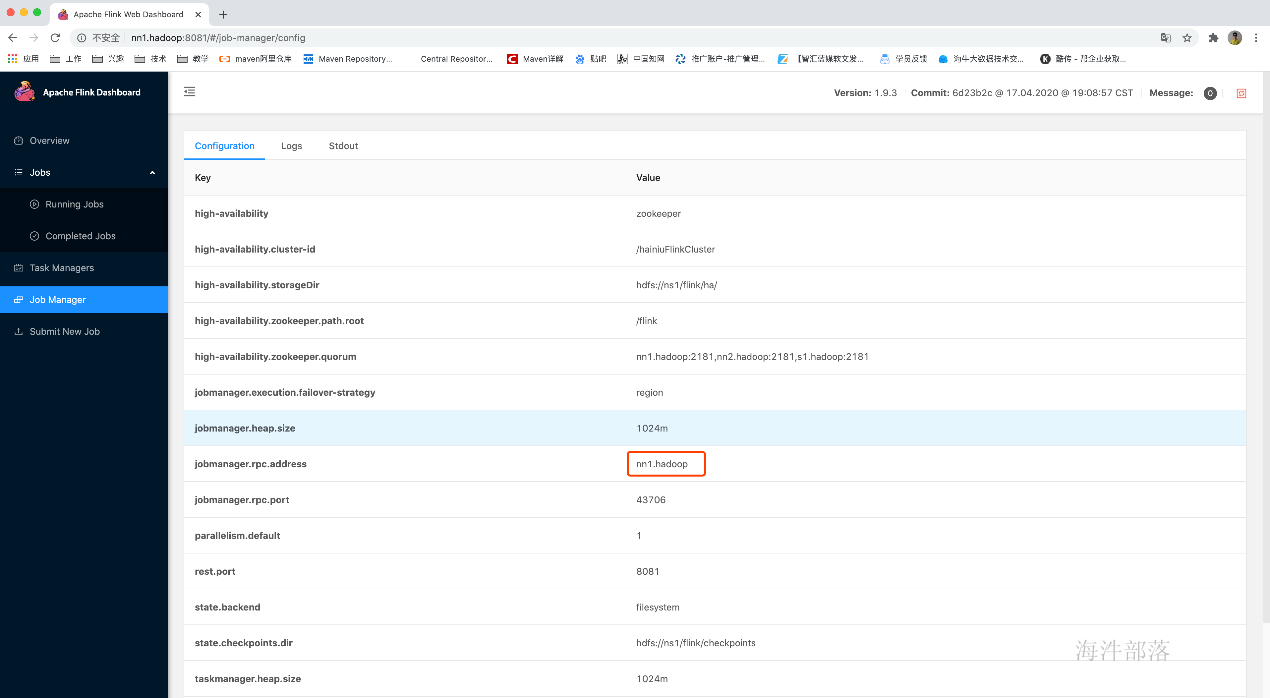
6.验证HA是否生效
查看主master的webUI
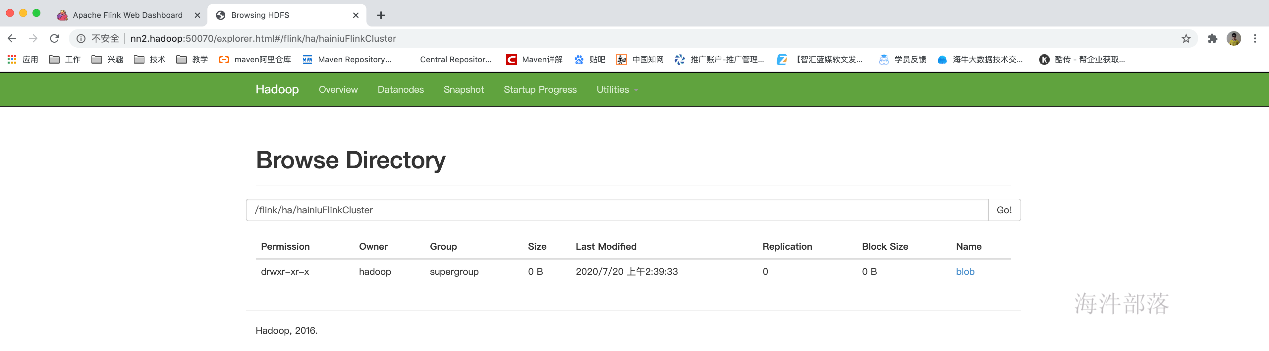
查看hdfs上的master元数据目录
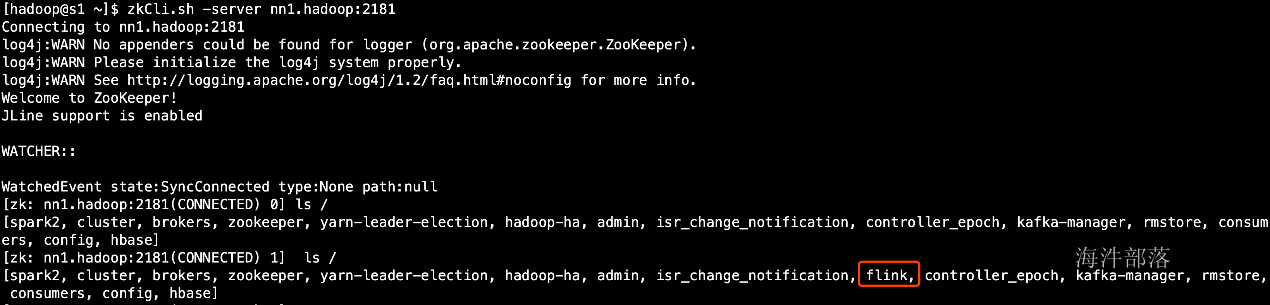
查看zk中的是否新建/flink数据目录
各机器上的进程
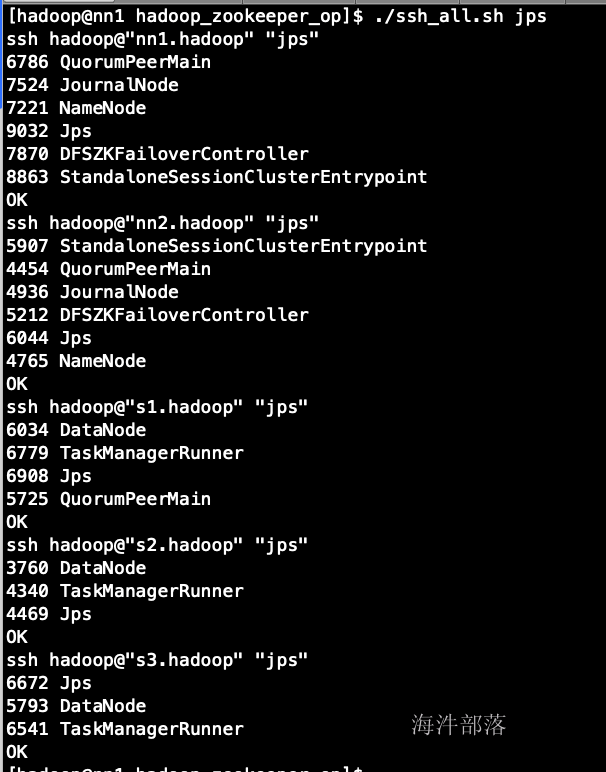
7.高可用演示:
提交任务
flink run -d /usr/local/flink/examples/streaming/SocketWindowWordCount.jar --hostna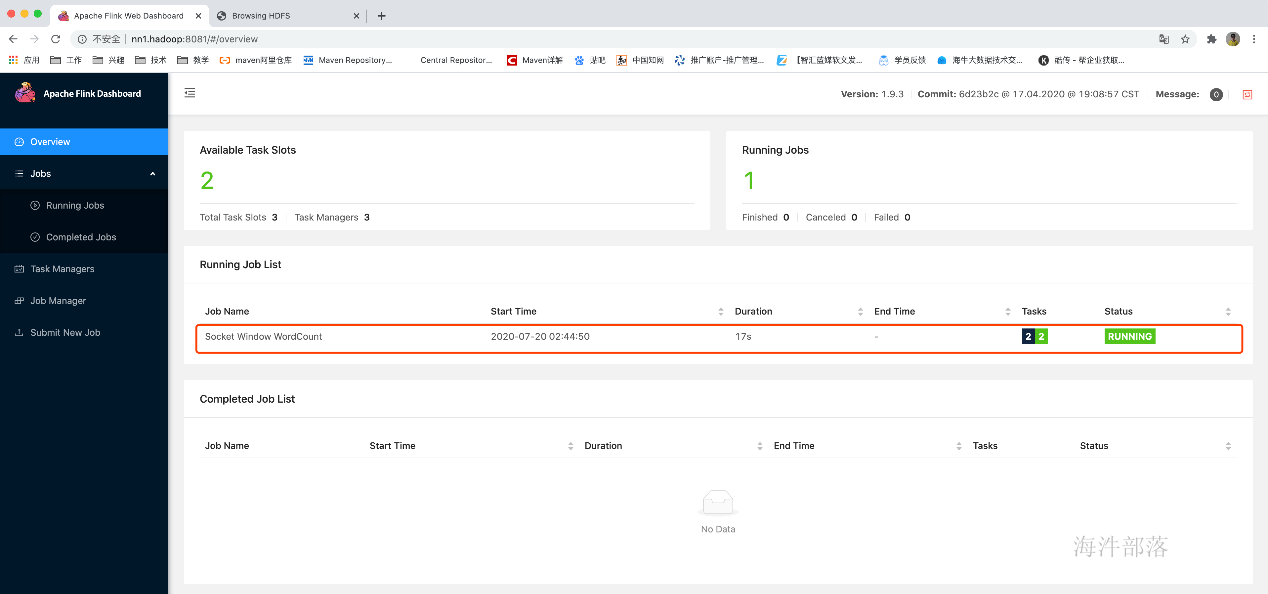
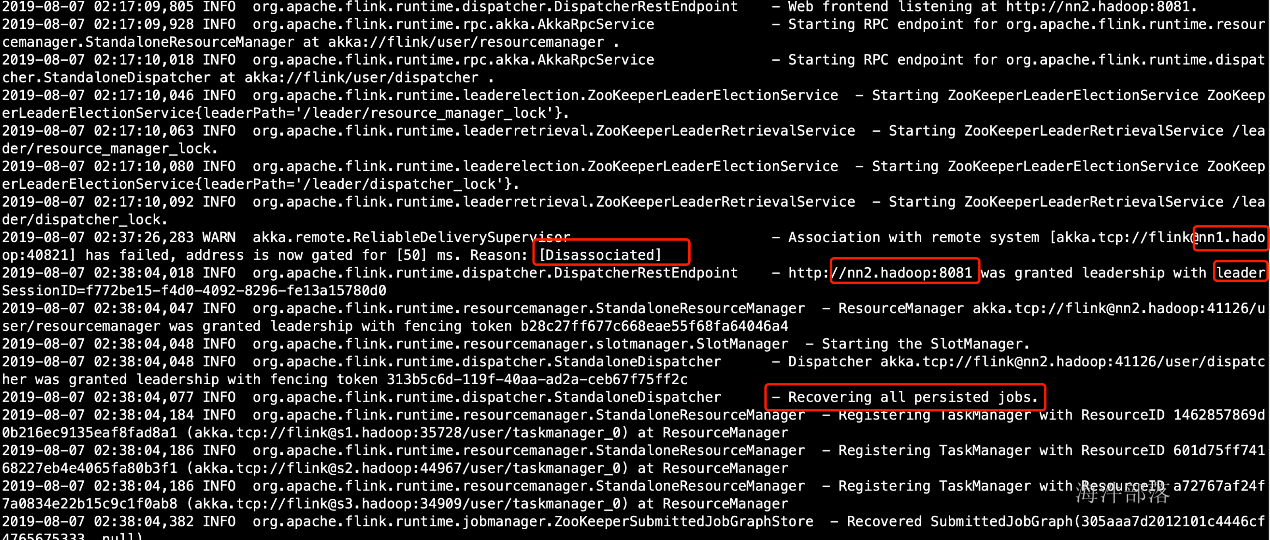
kill掉主master看看从master是否启用,以及运行中的任务是否还在

此时查看 从master 的日志,发现已经进入恢复模式
查看原来的从master的webUI,发现此时已经变成了主master
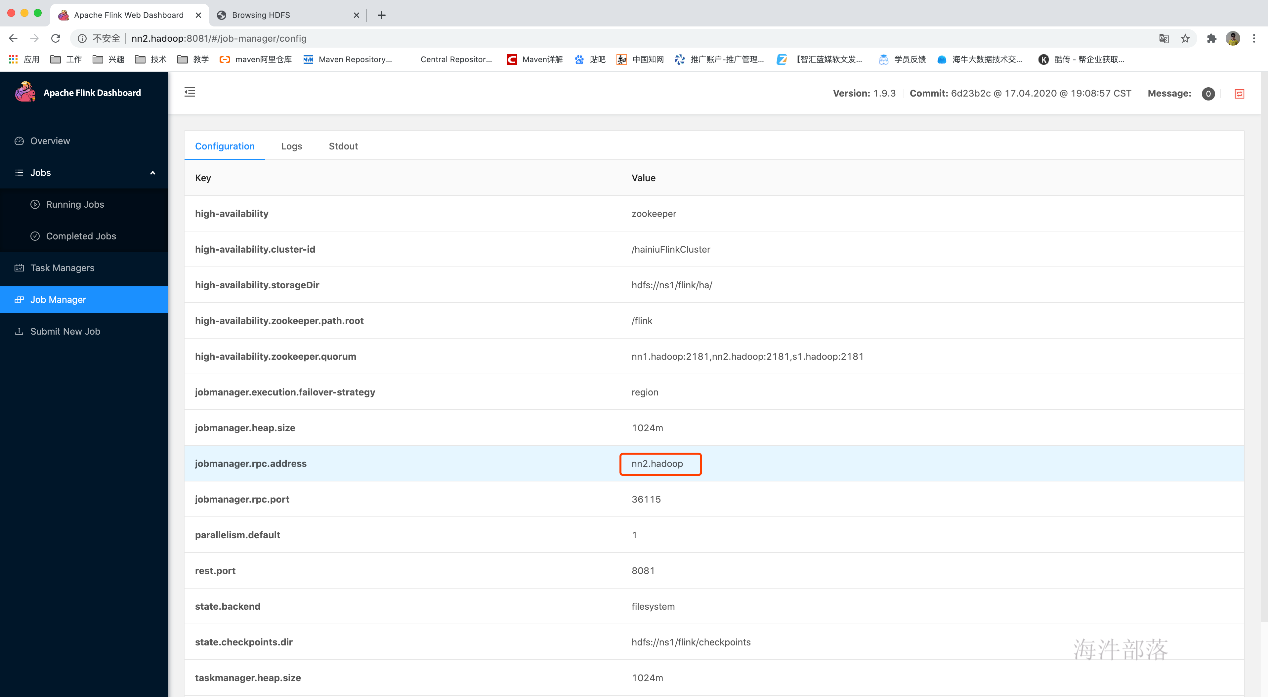
发现任务已恢复并正在运行
8.关闭集群,自动关闭HA
stop-cluster.sh
4.Flink On YARN模式
1.前言
在一个企业中,为了最大化的利用集群资源,一般都会在一个集群中同时运行多种类型的 Workload。因此 Flink 也支持在 Yarn 上面运行。首先,让我们通过下图了解下 Yarn 和 Flink 的关系。
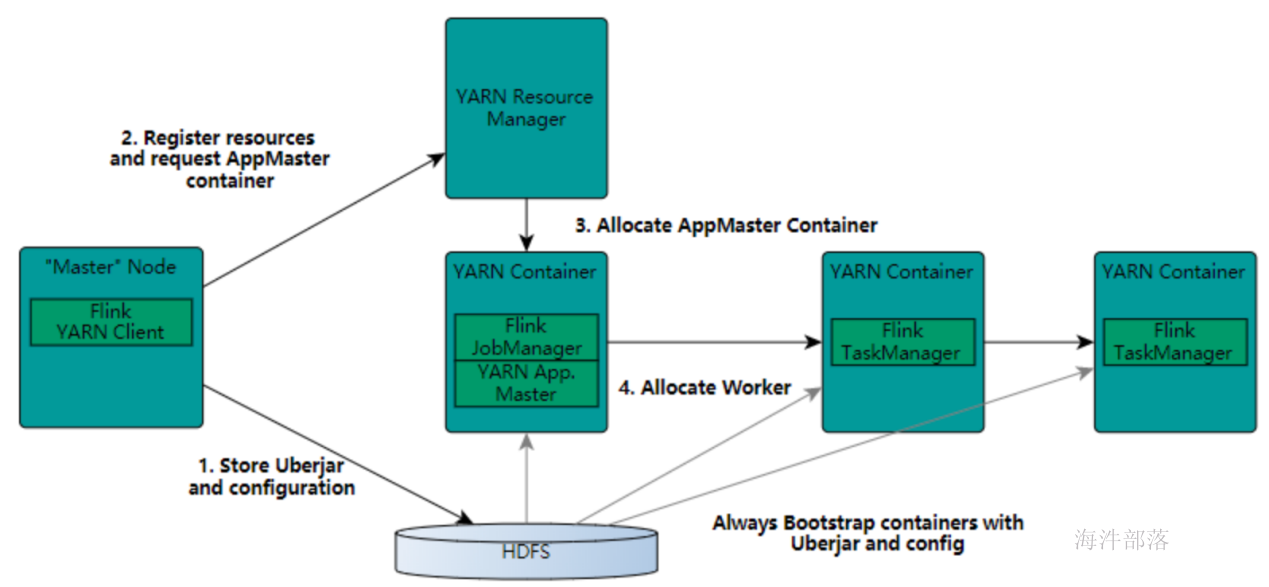
- 在图中可以看出,Flink 与 Yarn 的关系与 MapReduce 和 Yarn 的关系是一样的。Flink 通过 Yarn 的接口实现了自己的 App Master。当在 Yarn 中部署了 Flink,Yarn 就会用自己的 Container 来启动 Flink 的 JobManager(也就是 App Master)和 TaskManager。
- 启动新的Flink YARN会话时,客户端首先检查所请求的资源(容器和内存)是否可用。之后,它将包含Flink和配置的jar上传到HDFS(步骤1)。
- 客户端的下一步是请求(步骤2)YARN容器以启动ApplicationMaster(步骤3)。由于客户端将配置和jar文件注册为容器的资源,因此在该特定机器上运行的YARN的NodeManager将负责准备容器(例如,下载文件)。完成后,将启动ApplicationMaster(AM)。
- 该JobManager和AM在同一容器中运行。一旦它们成功启动,AM就知道JobManager(它自己的主机)的地址。它正在为TaskManagers生成一个新的Flink配置文件(以便它们可以连接到JobManager)。该文件也上传到HDFS。此外,AM容器还提供Flink的Web界面。YARN代码分配的所有端口都是临时端口。这允许用户并行执行多个Flink YARN会话。
- 之后,AM开始为Flink的TaskManagers分配容器,这将从HDFS下载jar文件和修改后的配置。完成这些步骤后,即可建立Flink并准备接受作业。
2.修改配置
配置环境变量
配置日志级别
vim /usr/local/flink/conf/log4j-yarn-session.properties
然后启动yarn
start-yarn.sh
yarn-daemon.sh start proxyserver
#并删除原来的HA信息,不然会恢复以前的任务
#HDFS
hadoop fs -rmr /flink/checkpoints/*
hadoop fs -rmr /flink/ha/*
#ZK
zkCli.sh -server nn1.hadoop:2181
rmr /flink3.在yarn上启动jobManager
yarn-session.sh -s 3 -tm 1024 -n 2 -jm 1024 -qu root.hainiu参数解释:
-s : 每个TaskManager的slot的数量,executor-cores。建议将slot的数量设置每台机器的处理器数量
-tm : 每个TaskManager的内存大小,executor-memory
-n : TaskManager的数量,相当于executor的数量
-jm : JobManager的内存大小,driver-memory
-qu : yarn的资源队列
#可以通过 yarn-session.sh -h 命令来查看其它参数的使用
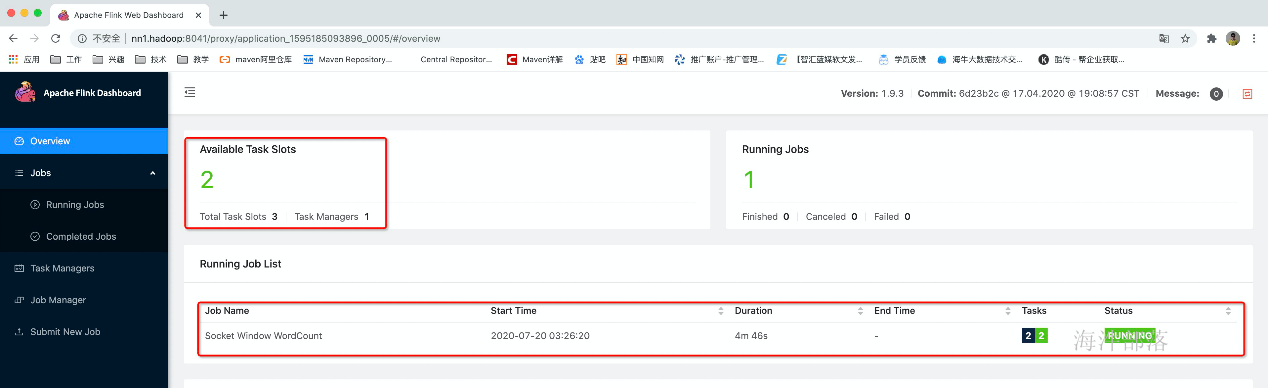
此时只是启动了一个jobManager
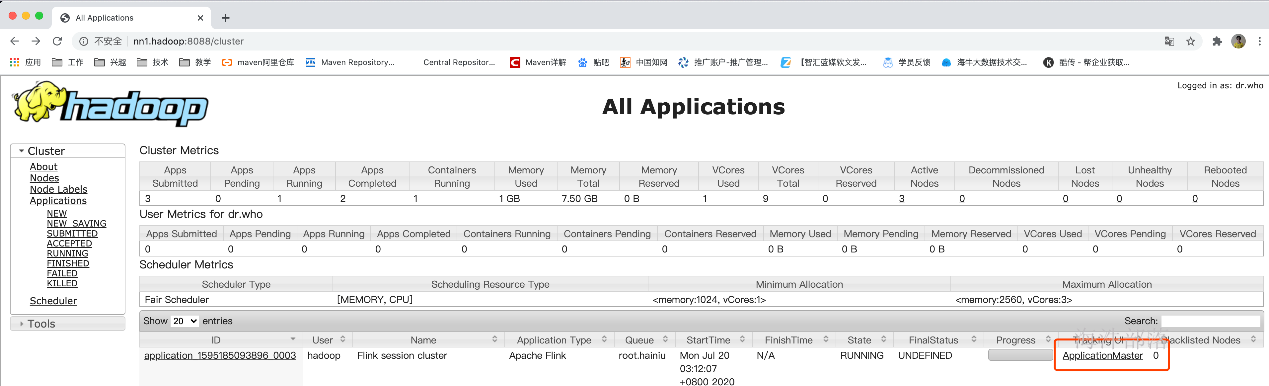
由于没有启动taskManager所以可用资源为0
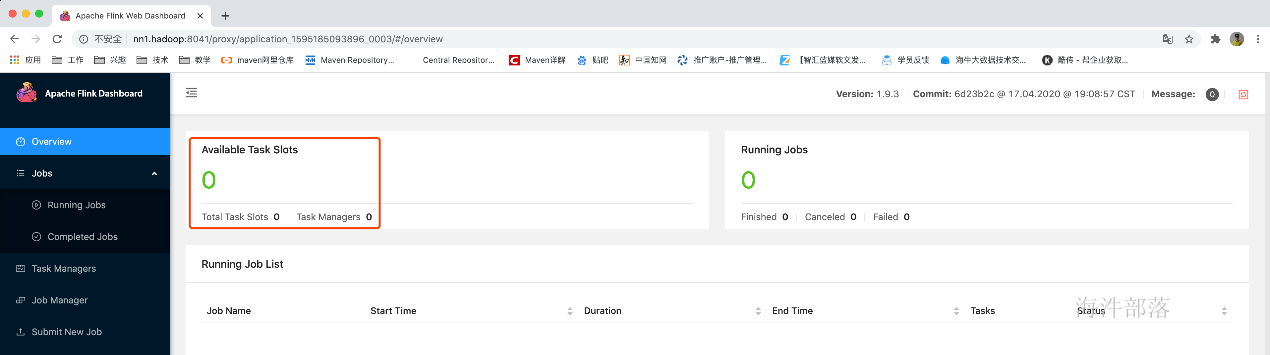
4.此时提交任务,使用刚才的jobManager的address
先启动nc
nc -l -k -p 6666
flink run -m s3.hadoop:45036 -yd /usr/local/flink/examples/streaming/SocketWindowWordCount.jar --hostname nn1.hadoop --port 6666参数解释:
-m jobManager的地址
-yd yarn模式下后台运行
#可以通过直接输入 flink 命令来查看其它参数的使用
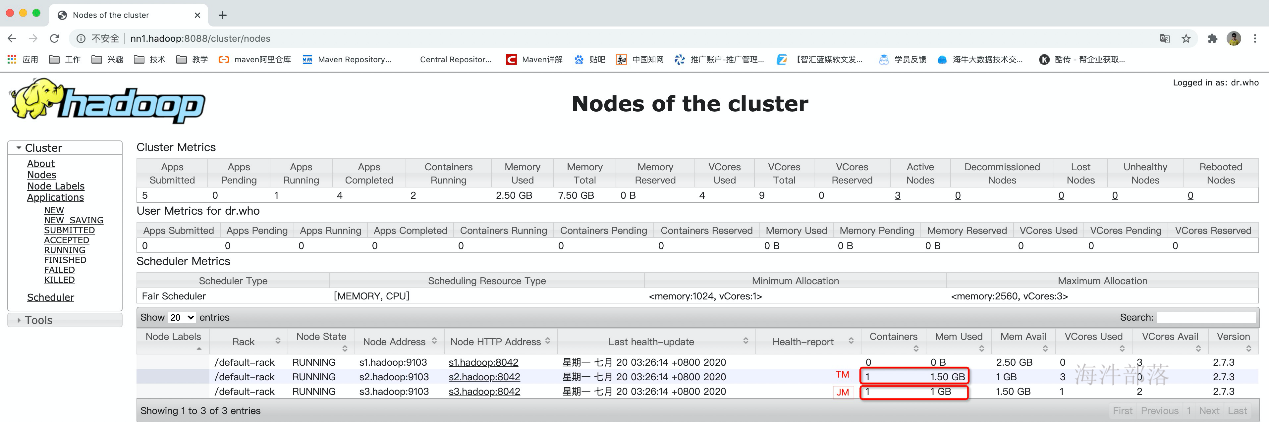
任务提交成功后,根据任务配置的最小资源模式启动相应的taskManager来运行这个任务,由于刚才配置的是2个taskManager每个有3个slot,而这个任务只需要一个slot,所以启动一个taskManager就够用了
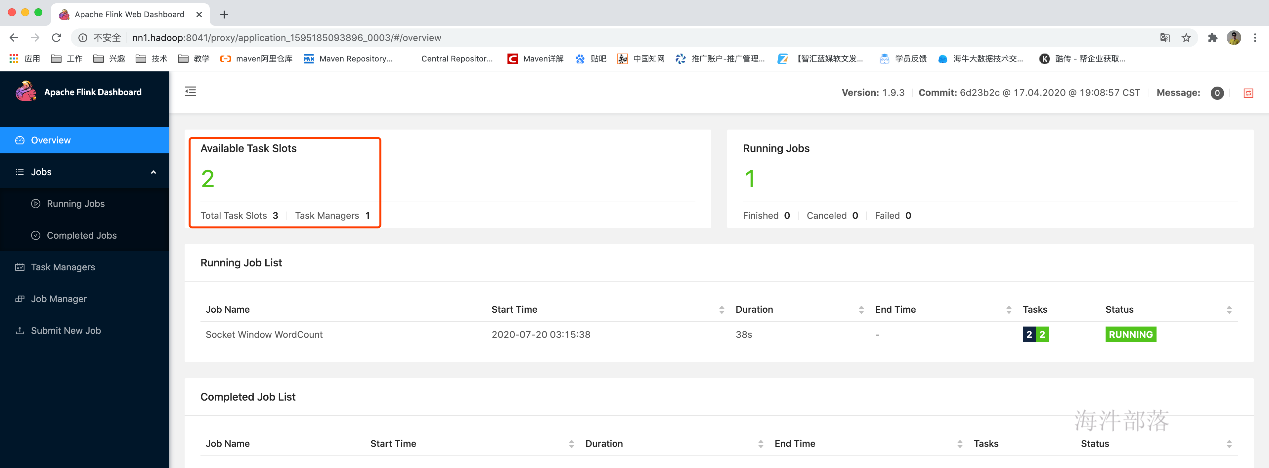
此时启动了5个任务,需要5个slot,而已启动的一个taskManager只有3个slot,所以无法满足已有任务的资源需求,所以就另外再启动了一个taskManager,那整个应用的slot就多出来了3个slot,变成了6个
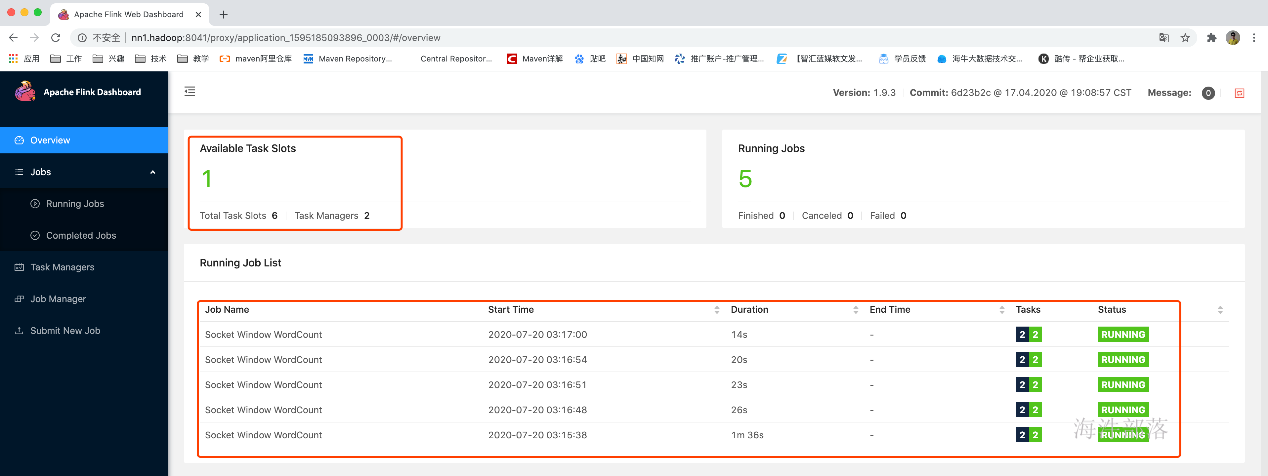
那如果是7个任务怎么办呢?还会再继续启动一个taskManager。如果yarn队列资源不够了才不会继续启动。
如果资源不够用了,那任务会是等待状态,长时间等待任务就会退出。
任务的等待状态
5.yarn模式的HA演示
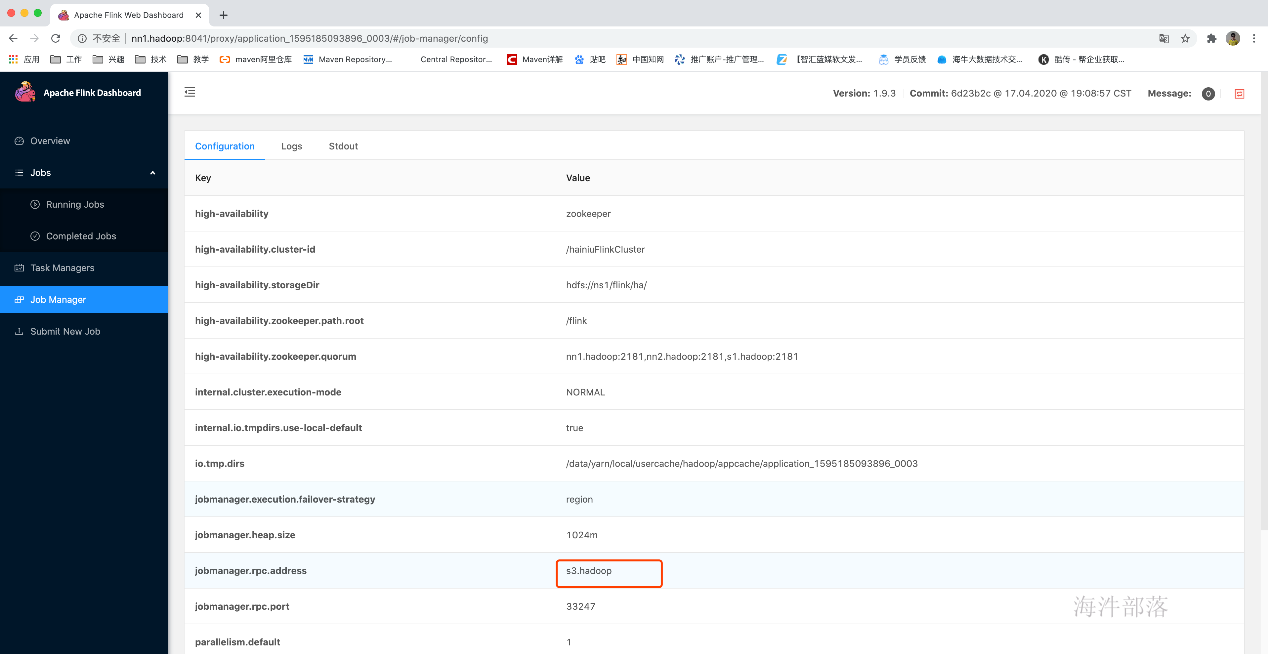
然后去所在机器上kill掉这个jobManager的yarn模式进程
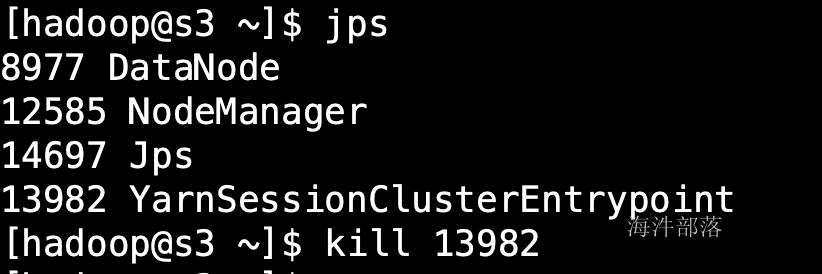
此时yarn会马上尝试重新再次启动这个jobManager
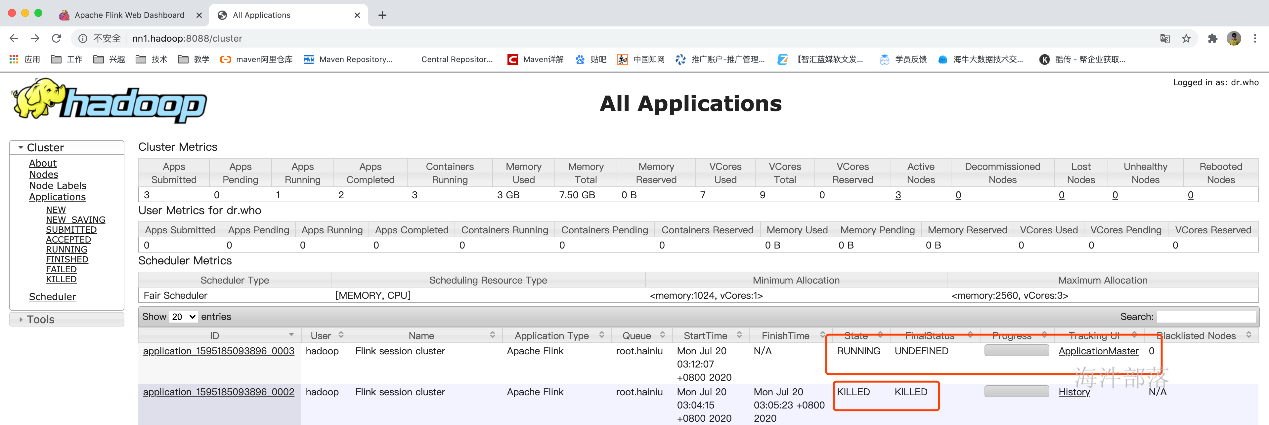
然后jobManager会去恢复,以前重新运行的任务
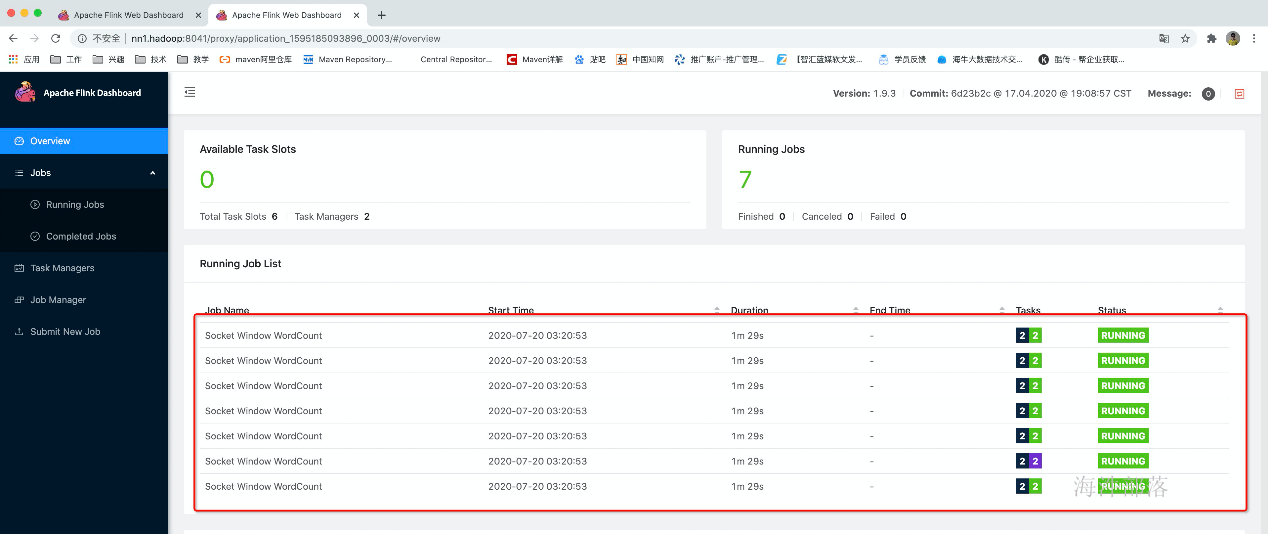
总结:说明flink在yarn模式下也是具备HA功能的,前提是你得在flink-conf.yaml配置HA相关的信息
以上是使用yarn-session.sh先启动了一个jobManager,然后再使用flink run -m jobManamger address来把任务提交到使用yarn-session.sh脚本启动的jobManager上
也可以不使用yarn-session.sh预先启动一个jobManager,而是直接使用flink run来运行一个自带jobManager的flink任务
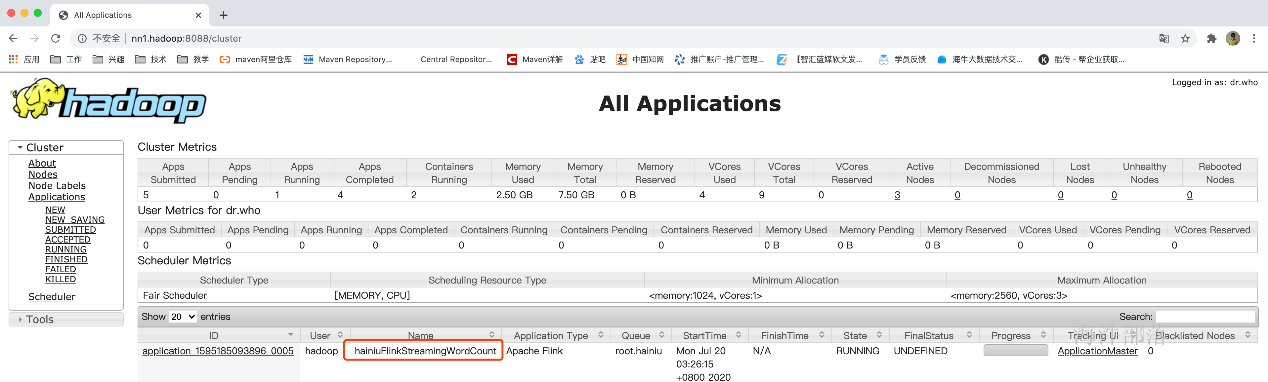
比如下面这个命令,可以启动自带一个内存为1024MB的jobManager,最多2个内存为1536MB的taskManager,并且每个taskManager的taskSlots为3的flink应用,然后在这个flink应用直接运行了一个SocketWindowWordCount的任务
通过此命令运行的flink程序启动临时的jobManager和临时的taskManager,如果结果这个job,那临时的jobManager和taskManager也会直接退出
flink run -m yarn-cluster -yjm 1024 -ytm 1536 -yn 2 -ys 3 -yqu root.hainiu -ynm hainiuFlinkStreamingWordCount \
/usr/local/flink/examples/streaming/SocketWindowWordCount.jar --hostname nn1.hadoop --port 6666参数解释:
-yjm jobManager的内存
-ytm taskManager的内存
-yn tm的数量
-ys 每个tm的任务槽
-yqu yarn资源队列名称
-ynm yarn application nameyarn application name已修改:
6.怎么在yarn模式上使用thinjar
1.怎么让你的tm找到依赖的jar包
flink run -m yarn-cluster -yt /home/hadoop/spark_news_jars -yjm 1024 -ytm 1536 -yn 2 -ys 3 -yqu root.hainiu \
-ynm hainiuFlinkStreamingWordCount /usr/local/flink/examples/streaming/SocketWindowWordCount.jar --hostname nn1.hadoop --port 6666
#yt命令是上传指定目录到flink任务的hdfs目录,然后flink在yarn上中的程序先从这个HDFS把目录下的所有文件(包换刚才yt命令指定的本地目录)下载过来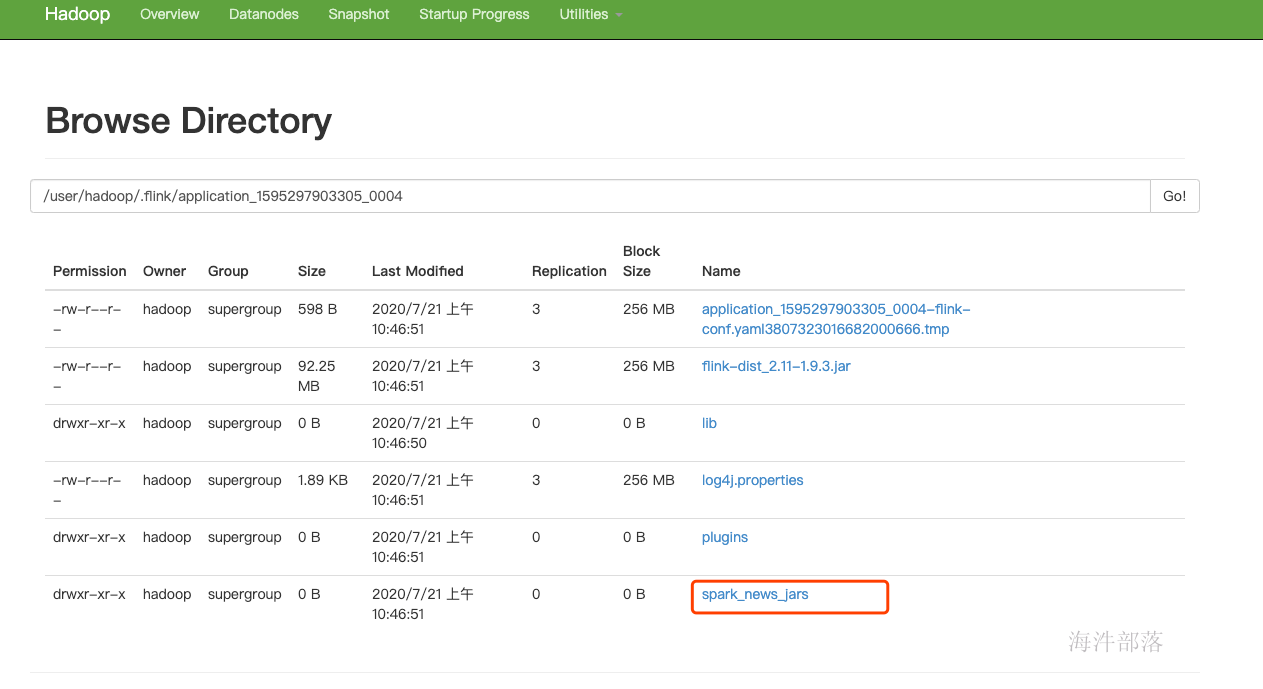
跑任务那个机器的tm的进程信息
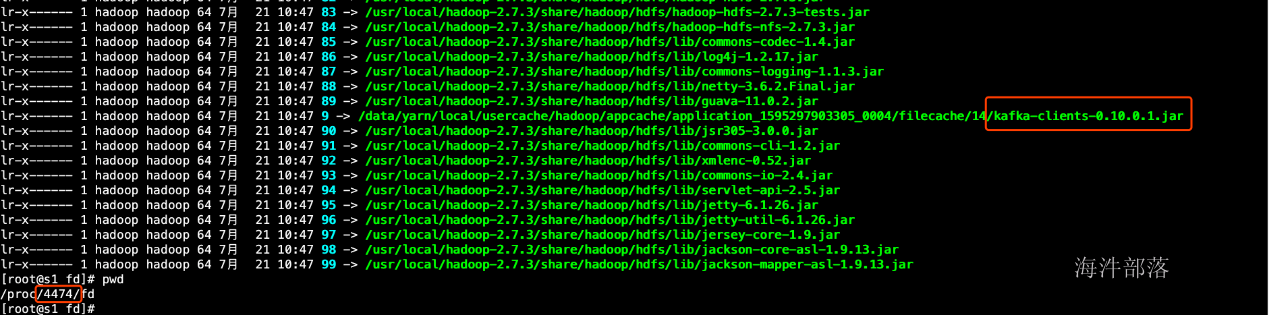
2.怎么让你的driver找到依赖的jar包
跑任务那
flink run -m yarn-cluster -yt /home/hadoop/spark_news_jars -yjm 1024 -ytm 1536 -yn 2 -ys 3 -yqu root.hainiu -ynm hainiuFlinkStreamingWordCount \
-C file:///home/hadoop/spark_news_jars/kafka_2.11-0.10.0.1.jar /usr/local/flink/examples/streaming/SocketWindowWordCount.jar --hostname nn1.hadoop --port 6666
#-C 命令是同时指定driver和taskManager运行的java程序的classpath。这里用这个命令只为了让driver找到jar包,taskmanager是通过yt命令找到jar包的,所以tm上有没有-C命令指定的文件是无所谓的。
#-C 命令指定的文件路径必须URI格式的,那本地文件就以file:///开头,注意不能使用文件通配符"*"个机器的driver的进程信息

怎么指定dirver端找到多个依赖的jar包
结合shell脚本:
$(ll /home/hadoop/spark_news_jars/ |awk 'NR>1{print "-C file:///home/hadoop/spark_news_jars/"$9}'|tr '\n' ' ')最终的命令如下:
flink run -m yarn-cluster -yt /home/hadoop/spark_news_jars -yjm 1024 -ytm 1536 -yn 2 -ys 3 -yqu root.hainiu -ynm hainiuFlinkStreamingWordCount \
$(ll /home/hadoop/spark_news_jars/ |awk 'NR>1{print "-C file:///home/hadoop/spark_news_jars/"$9}'|tr '\n' ' ') \
/usr/local/flink/examples/streaming/SocketWindowWordCount.jar --hostname nn1.hadoop --port 6666跑任务那个机器的driver的进程信息

3.Flink的API分层、开发环境搭建、基本开发流、架构与组件原理、并行度、任务执行计划、chains、SlotGroup与Slot共享
1.Flink的API分层
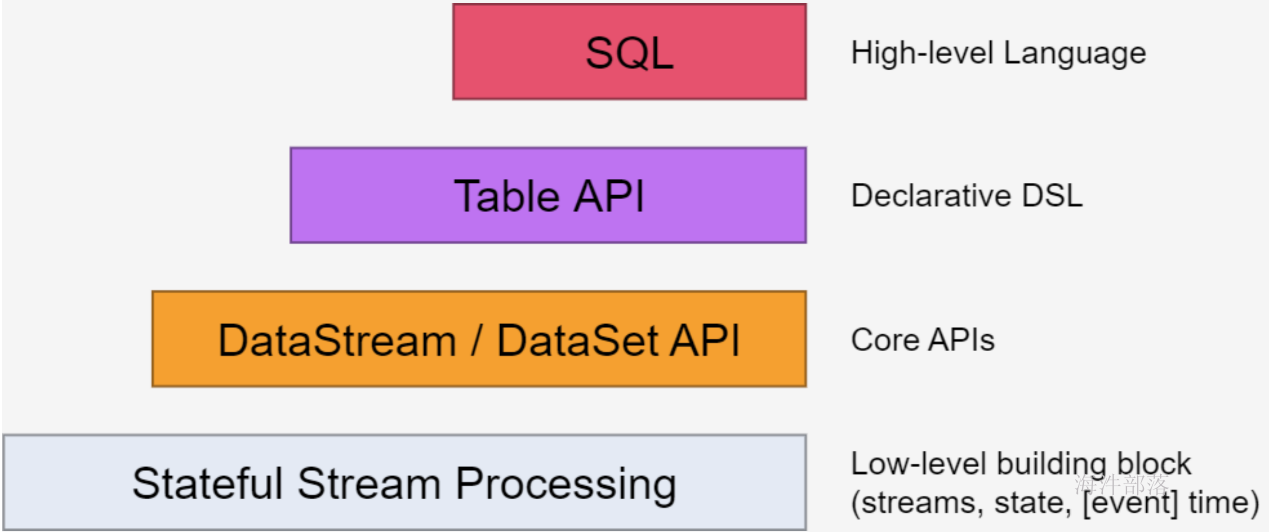
注:越底层API越灵活,越上层的API越轻便
Stateful Stream Processing
- 位于最底层, 是core API 的底层实现
- processFunction
- 利用低阶,构建一些新的组件或者算子
- 灵活性高,但开发比较复杂
Core API
- DataSet - 批处理 API
- DataStream –流处理 API
Table API & SQL
- SQL 构建在Table 之上,都需要构建Table 环境
- 不同的类型的Table 构建不同的Table 环境
- Table 可以与DataStream或者DataSet进行相互转换
- Streaming SQL不同于存储的SQL,最终会转化为流式执行计划
2.flink开发环境搭建
使用maven搭建开发环境
pom:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xmlns="http://maven.apache.org/POM/4.0.0"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.hainiu</groupId>
<artifactId>hainiuflink</artifactId>
<version>1.0</version>
<properties>
<java.version>1.8</java.version>
<scala.version>2.11</scala.version>
<flink.version>1.9.3</flink.version>
<parquet.version>1.10.0</parquet.version>
<hadoop.version>2.7.3</hadoop.version>
<fastjson.version>1.2.72</fastjson.version>
<redis.version>2.9.0</redis.version>
<mysql.version>5.1.35</mysql.version>
<log4j.version>1.2.17</log4j.version>
<slf4j.version>1.7.7</slf4j.version>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
<maven.compiler.compilerVersion>1.8</maven.compiler.compilerVersion>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.build.scope>compile</project.build.scope>
<!-- <project.build.scope>provided</project.build.scope>-->
<mainClass>com.hainiu.Driver</mainClass>
</properties>
<dependencies>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>${slf4j.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>${log4j.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink的hadoop兼容 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink的hadoop兼容 -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hadoop-compatibility_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink的java的api -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink streaming的java的api -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink的scala的api -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink streaming的scala的api -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink运行时的webUI -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-runtime-web_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- 使用rocksdb保存flink的state -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink操作hbase -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-hbase_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink操作es -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-elasticsearch5_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink 的kafka -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink 写文件到HDFS -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-filesystem_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- mysql连接驱动 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- redis连接 -->
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>${redis.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- flink操作parquet文件格式 -->
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-avro</artifactId>
<version>${parquet.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.parquet</groupId>
<artifactId>parquet-hadoop</artifactId>
<version>${parquet.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-parquet_${scala.version}</artifactId>
<version>${flink.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- json操作 -->
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>${fastjson.version}</version>
<scope>${project.build.scope}</scope>
</dependency>
</dependencies>
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptors>
<descriptor>src/assembly/assembly.xml</descriptor>
</descriptors>
<archive>
<manifest>
<mainClass>${mainClass}</mainClass>
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.12</version>
<configuration>
<skip>true</skip>
<forkMode>once</forkMode>
<excludes>
<exclude>**/**</exclude>
</excludes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.1</version>
<configuration>
<source>${java.version}</source>
<target>${java.version}</target>
<encoding>${project.build.sourceEncoding}</encoding>
</configuration>
</plugin>
</plugins>
</build>
</project>
3.flink开发基本流程
1).DataStreamContext
- getExecutionEnvironment 适合jar包与命令
- Jar
- cmd
- createLocalEnvironment 适合本地测试开发
2).DataSet 与 DataStream
- 表示Flink app中的分布式数据集
- 包含重复的、不可变数据集
- DataSet有界、DataStream可以是无界
- 可以从数据源、也可以通过各种转换操作创建
3).flink编程套路
- 获取执行环境(execution environment)
- 加载/创建初始数据集
- 对数据集进行各种转换操作(生成新的数据集)
- 指定将计算的结果放到何处去
- 触发APP执行
4).flink的app计算方式和spark一样都是惰性的
- Flink APP都是延迟执行的
- 只有当execute()被显示调用时才会真正执行
- 本地执行还是在集群上执行取决于执行环境的类型
- 好处:用户可以根据业务构建复杂的应用,Flink可以整体进优化并生成执行计划
5).与sparkstreaming执行任务的不同之处:
- sparkstreaming是生成每小批的task放到executor放起来,任务跑完之后就退出,然后再生成新的task,executor再跑新的task,循环往复执行此动作。
- flink是生成task放到taskManager的taskSlot里面,然后这个task一直不退出,直到这个application整个退出它才退出。
计算模型:
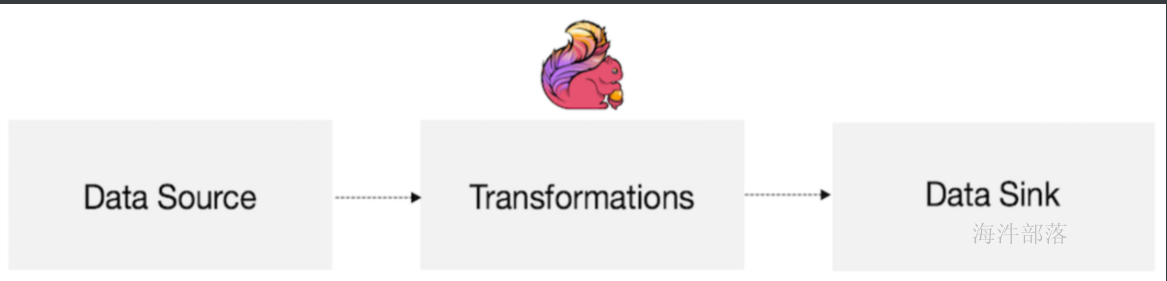
- 定义源
- 写Transformations,就是写operators
- 定义输出
示例代码:
scala版:
package com.hainiu.flink.operator
import org.apache.flink.api.common.functions.FlatMapFunction
import org.apache.flink.configuration.Configuration
import org.apache.flink.streaming.api.scala.{DataStream, StreamExecutionEnvironment}
import org.apache.flink.util.Collector
object SocketWordCount {
def main(args: Array[String]): Unit = {
//获得local运行环境
val env: StreamExecutionEnvironment = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration())
//定义socket的source源
val text: DataStream[String] = env.socketTextStream("localhost", 6666)
//scala开发需要加一行隐式转换,否则在调用operator的时候会报错,作用是找到scala类型的TypeInformation
import org.apache.flink.api.scala._
//写Transformations进行数据的转换
//定义operators,作用是解析数据,分组,并且求wordCount
// val wordCount: DataStream[(String, Int)] = text.flatMap(_.split(" ")).map((_, 1)).keyBy(_._1).sum(1)
//使用FlatMapFunction自定义函数来完成flatMap和map的组合功能
val wordCount: DataStream[(String, Int)] = text.flatMap(new FlatMapFunction[String, (String, Int)] {
override def flatMap(value: String, out: Collector[(String, Int)]) = {
val strings: Array[String] = value.split(" ")
for (s <- strings) {
out.collect((s, 1))
}
}
}).keyBy(_._1).sum(1)
//定义sink,打印数据到控制台
wordCount.print()
//定义任务的名称并运行
//注意:operator是惰性的,只有遇到execute才执行
env.execute("SocketWordCount")
}
}java版:
package com.hainiu.operator;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.KeyedProcessFunction;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.util.Collector;
public class SocketWordCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
DataStreamSource<String> socket = env.socketTextStream("localhost", 6666);
//1.lambda写法
// SingleOutputStreamOperator<String> flatMap = socket.flatMap((String value, Collector<String> out) -> {
// Arrays.stream(value.split(" ")).forEach(word -> {
// out.collect(word);
// });
// }).returns(Types.STRING);
//
// SingleOutputStreamOperator<Tuple2<String, Integer>> map = flatMap.map(f -> Tuple2.of(f, 1)).returns(Types.TUPLE(Types.STRING, Types.INT));
//
// SingleOutputStreamOperator<Tuple2<String, Integer>> sum = map.keyBy(0).sum(1);
//
// sum.print();
//2.function写法
// SingleOutputStreamOperator<String> flatMap = socket.flatMap(new FlatMapFunction<String, String>() {
// @Override
// public void flatMap(String value, Collector<String> out) throws Exception {
// String[] s = value.split(" ");
// for (String ss : s) {
// out.collect(ss);
// }
// }
// });
//
// SingleOutputStreamOperator<Tuple2<String, Integer>> map = flatMap.map(new MapFunction<String, Tuple2<String, Integer>>() {
// @Override
// public Tuple2<String, Integer> map(String value) throws Exception {
// return Tuple2.of(value, 1);
// }
// });
//
// SingleOutputStreamOperator<Tuple2<String, Integer>> sum = map.keyBy("f0").sum(1);
//
// sum.print();
//3.function组合写法
// SingleOutputStreamOperator<Tuple2<String,Integer>> flatMap = socket.flatMap(new FlatMapFunction<String, Tuple2<String,Integer>>() {
// @Override
// public void flatMap(String value, Collector<Tuple2<String,Integer>> out) throws Exception {
// String[] s = value.split(" ");
// for (String ss : s) {
// out.collect(Tuple2.of(ss,1));
// }
// }
// });
//
// SingleOutputStreamOperator<Tuple2<String, Integer>> sum = flatMap.keyBy(f -> f.f0).sum(1);
//
// sum.print();
//4.richfunction组合写法
// SingleOutputStreamOperator<Tuple2<String, Integer>> flatMap = socket.flatMap(new RichFlatMapFunction<String, Tuple2<String, Integer>>() {
//
// private String name = null;
//
// @Override
// public void open(Configuration parameters) throws Exception {
// name = "hainiu_";
// }
//
// @Override
// public void close() throws Exception {
// name = null;
// }
//
// @Override
// public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
// String[] s = value.split(" ");
// for (String ss : s) {
// System.out.println(getRuntimeContext().getIndexOfThisSubtask());
// out.collect(Tuple2.of(name + ss, 1));
// }
// }
// });
//
// SingleOutputStreamOperator<Tuple2<String, Integer>> sum = flatMap.keyBy(new KeySelector<Tuple2<String, Integer>, String>() {
// @Override
// public String getKey(Tuple2<String, Integer> value) throws Exception {
// return value.f0;
// }
// }).sum(1);
//
// sum.print();
//5.processfunction组合写法
SingleOutputStreamOperator<Tuple2<String, Integer>> sum = socket.process(new ProcessFunction<String, Tuple2<String, Integer>>() {
private String name = null;
@Override
public void open(Configuration parameters) throws Exception {
name = "hainiu_";
}
@Override
public void close() throws Exception {
name = null;
}
@Override
public void processElement(String value, Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception {
// getRuntimeContext()
String[] s = value.split(" ");
for (String ss : s) {
System.out.println(getRuntimeContext().getIndexOfThisSubtask());
out.collect(Tuple2.of(name + ss, 1));
}
}
}).keyBy(0).process(new KeyedProcessFunction<Tuple, Tuple2<String, Integer>, Tuple2<String, Integer>>() {
private Integer num = 0;
@Override
public void processElement(Tuple2<String, Integer> value, Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception {
num += value.f1;
out.collect(Tuple2.of(value.f0,num));
}
});
sum.print();
env.execute();
}
}4.Flink架构
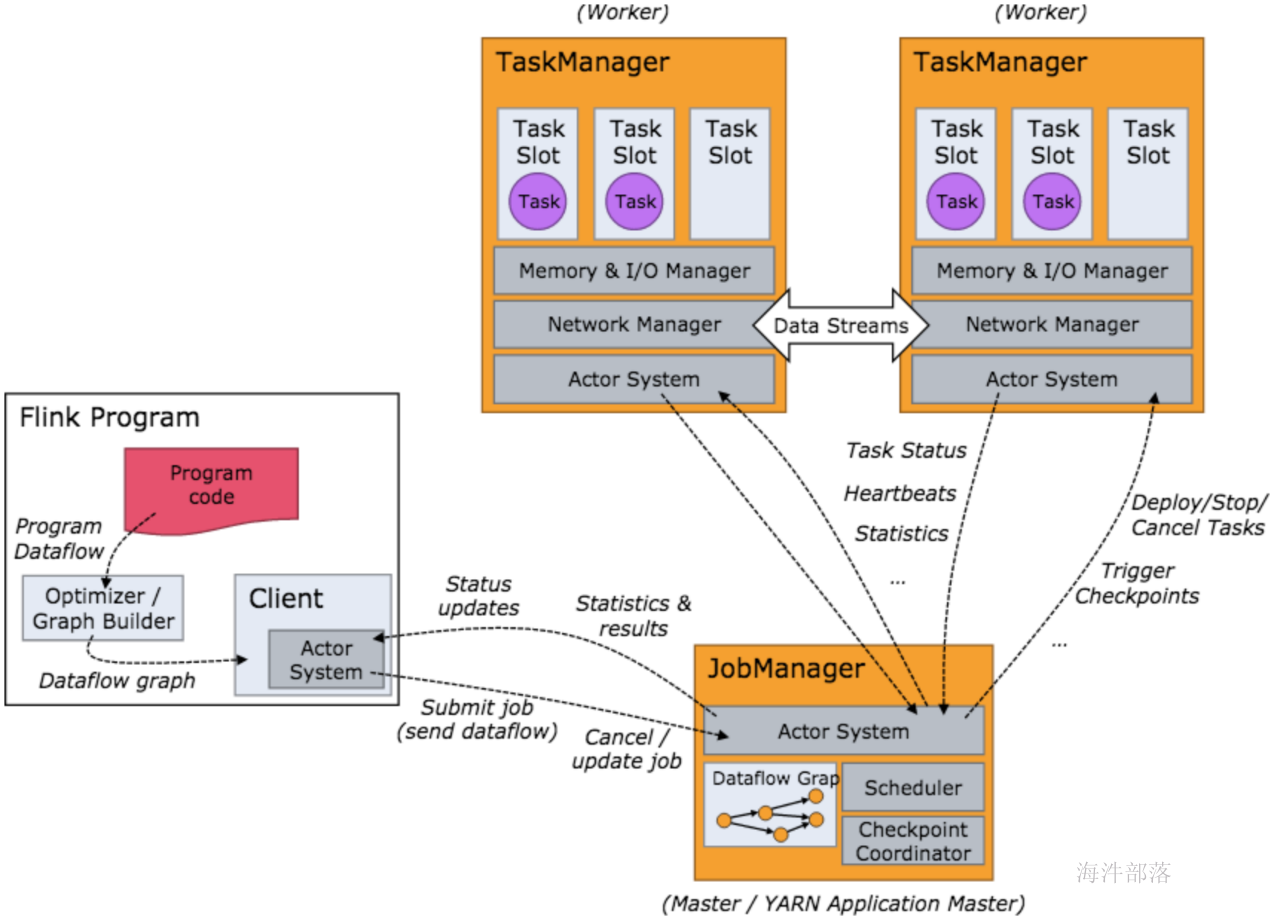
当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager。由 Client 提交任务给 JobManager,JobManager 再调度任务到各个 TaskManager 去执行,然后 TaskManager 将心跳和统计信息汇报给 JobManager。TaskManager 之间以流的形式进行数据的传输。上述三者均为独立的 JVM 进程。
- Client 为提交 Job 的客户端,可以是运行在任何机器上(与 JobManager 环境连通即可)。提交 Job 后,Client 可以结束进程(Streaming的任务),也可以不结束并等待结果返回。
- JobManager 主要负责从 Client 处接收到 Job 和 JAR 包等资源后,会生成优化后的执行计划,并以 Task 的单元调度到各个 TaskManager 去执行。
- TaskManager 在启动的时候就设置好了槽位数(Slot),每个 slot 能启动一个 Task,Task 为线程。从 JobManager 处接收需要部署的 Task,部署启动后,与自己的上游建立 Netty 连接,接收数据并处理。
- flnik架构中的角色间的通信使用Akka,数据的传输使用Netty
5.Task Slot
在上图中我们介绍了 TaskManager 是一个 JVM 进程,并会以独立的线程来执行一个task或多个subtask。为了控制一个 TaskManager 能接受多少个 task,Flink 提出了 Task Slot 的概念。
Flink 中的计算资源通过 Task Slot 来定义。每个 task slot 代表了 TaskManager 的一个固定大小的资源子集。例如,一个拥有3个slot的 TaskManager,会将其管理的内存平均分成三分分给各个 slot。将资源 slot 化意味着来自不同job的task不会为了内存而竞争,而是每个task都拥有一定数量的内存储备。需要注意的是,这里不会涉及到CPU的隔离,slot目前仅仅用来隔离task的内存。
通过调整 task slot 的数量,用户可以定义task之间是如何相互隔离的。每个 TaskManager 有一个slot,也就意味着每个task运行在独立的 JVM 中。每个 TaskManager 有多个slot的话,也就是说多个task运行在同一个JVM中。而在同一个JVM进程中的task,可以共享TCP连接(基于多路复用)和心跳消息,可以减少数据的网络传输。也能共享一些数据结构,一定程度上减少了每个task的消耗。
6.task的并行度
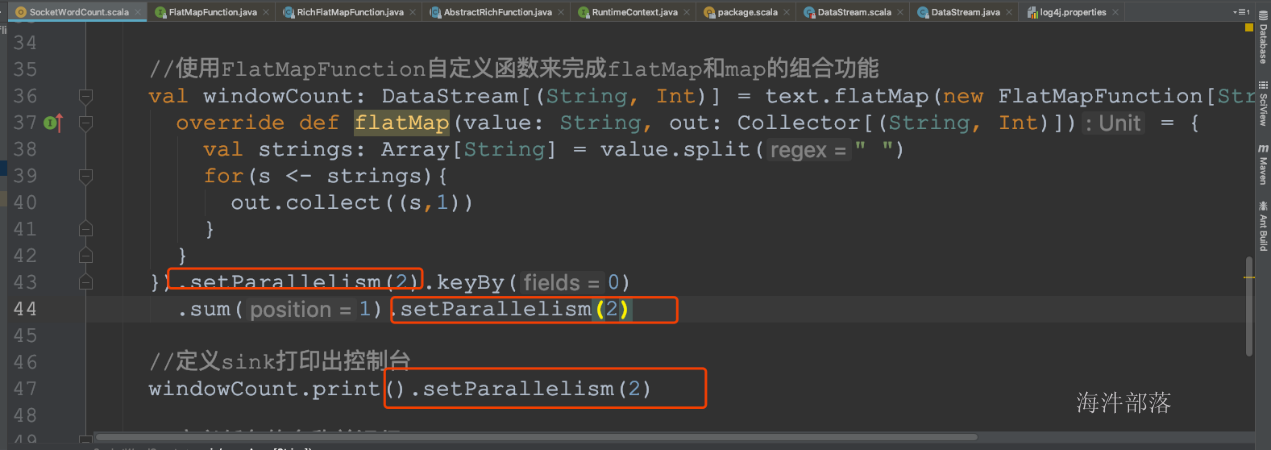
通过job的webUI界面查看任务的并行度
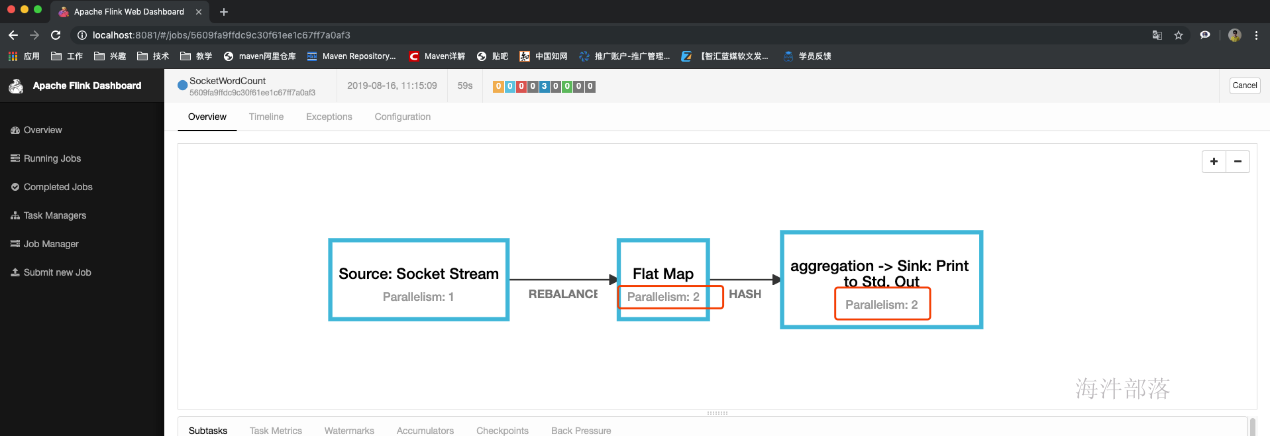
7.任务执行计划
生成个json字符串然后粘贴在这里https://flink.apache.org/visualizer/会看到任务执行图

但这并不是最终在 Flink 中运行的执行图,只是一个表示拓扑节点关系的计划图,在 Flink 中对应了 SteramGraph。另外,提交拓扑后(并发度设为2)还能在 UI 中看到另一张执行计划图,如下所示,该图对应了 Flink 中的 JobGraph。

其实Flink 中的执行图可以分成四层:StreamGraph -> JobGraph -> ExecutionGraph -> 物理执行图
- StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来表示程序的拓扑结构。
- JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager 的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点,这样可以减少数据在节点之间流动所需要的序列化/反序列化/传输消耗。
- ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
- 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
例如上文中的2个并发度(Source为1个并发度)的 SocketTextStreamWordCount 四层执行图的演变过程如下图所示:
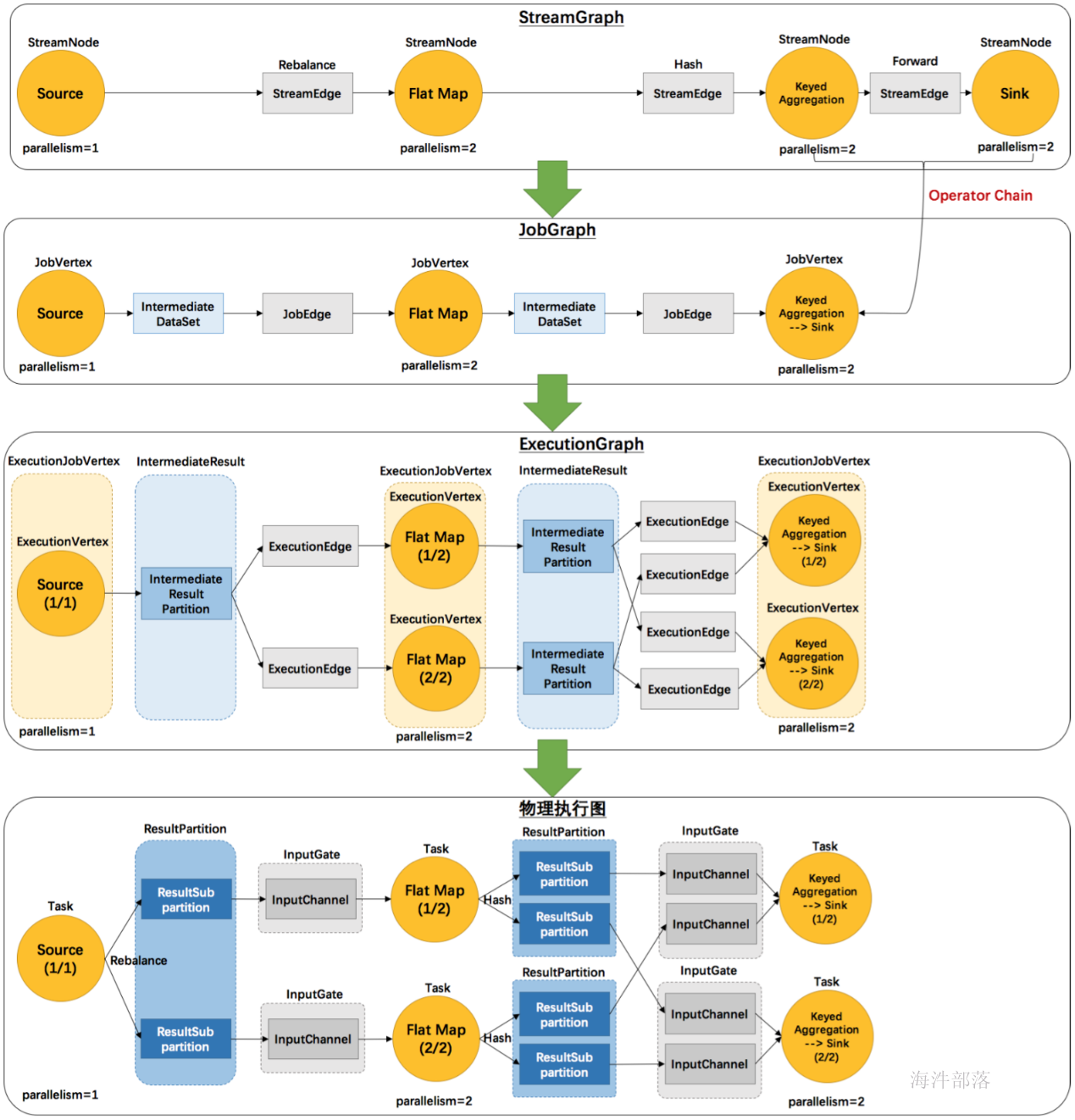
那么 Flink 为什么要设计这4张图呢,其目的是什么呢?Spark 中也有多张图,数据依赖图以及物理执行的DAG。其目的都是一样的,就是解耦,每张图各司其职,每张图对应了 Job 不同的阶段,更方便做该阶段的事情。我们给出更完整的 Flink Graph 的层次图。
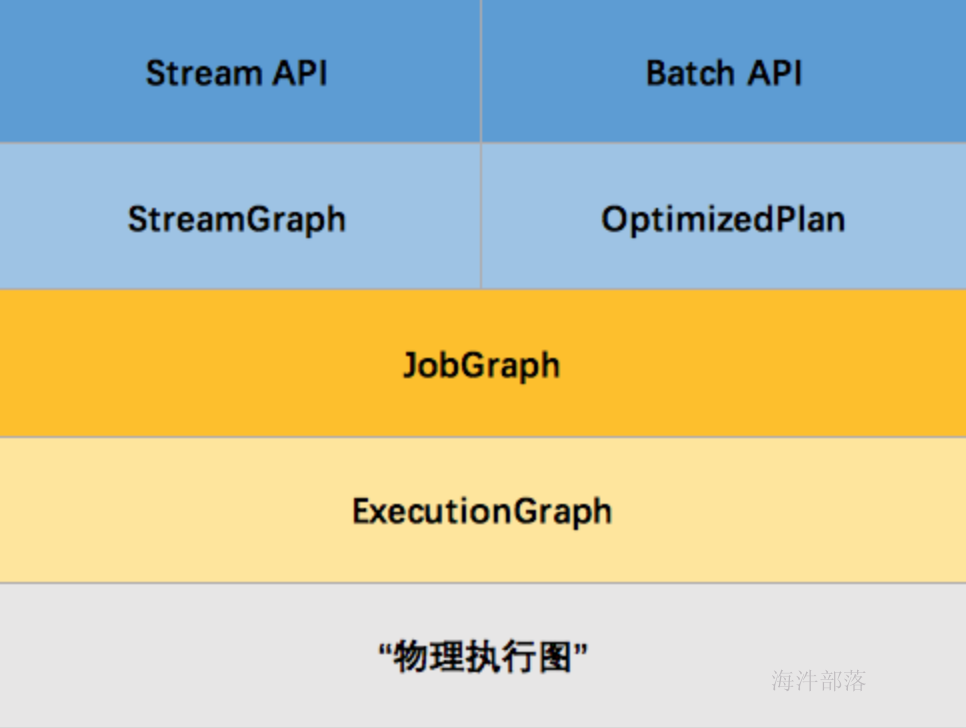
首先我们看到,JobGraph 之上除了 StreamGraph 还有 OptimizedPlan。OptimizedPlan 是由 Batch API 转换而来的。StreamGraph 是由 Stream API 转换而来的。为什么 API 不直接转换成 JobGraph?因为,Batch 和 Stream 的图结构和优化方法有很大的区别,比如 Batch 有很多执行前的预分析用来优化图的执行,而这种优化并不普适于 Stream,所以通过 OptimizedPlan 来做 Batch 的优化会更方便和清晰,也不会影响 Stream。JobGraph 的责任就是统一 Batch 和 Stream 的图,用来描述清楚一个拓扑图的结构,并且做了 chaining 的优化,chaining 是普适于 Batch 和 Stream 的,所以在这一层做掉。ExecutionGraph 的责任是方便调度和各个 tasks 状态的监控和跟踪,所以 ExecutionGraph 是并行化的 JobGraph。而“物理执行图”就是最终分布式在各个机器上运行着的tasks了。所以可以看到,这种解耦方式极大地方便了我们在各个层所做的工作,各个层之间是相互隔离的。
8.Operator Chains
为了更高效地分布式执行,Flink会尽可能地将operator的subtask链接(chain)在一起形成task。每个task在一个线程中执行。将operators链接成task是非常有效的优化:它能减少线程之间的切换,减少消息的序列化/反序列化,减少数据在缓冲区的交换,减少了延迟的同时提高整体的吞吐量。
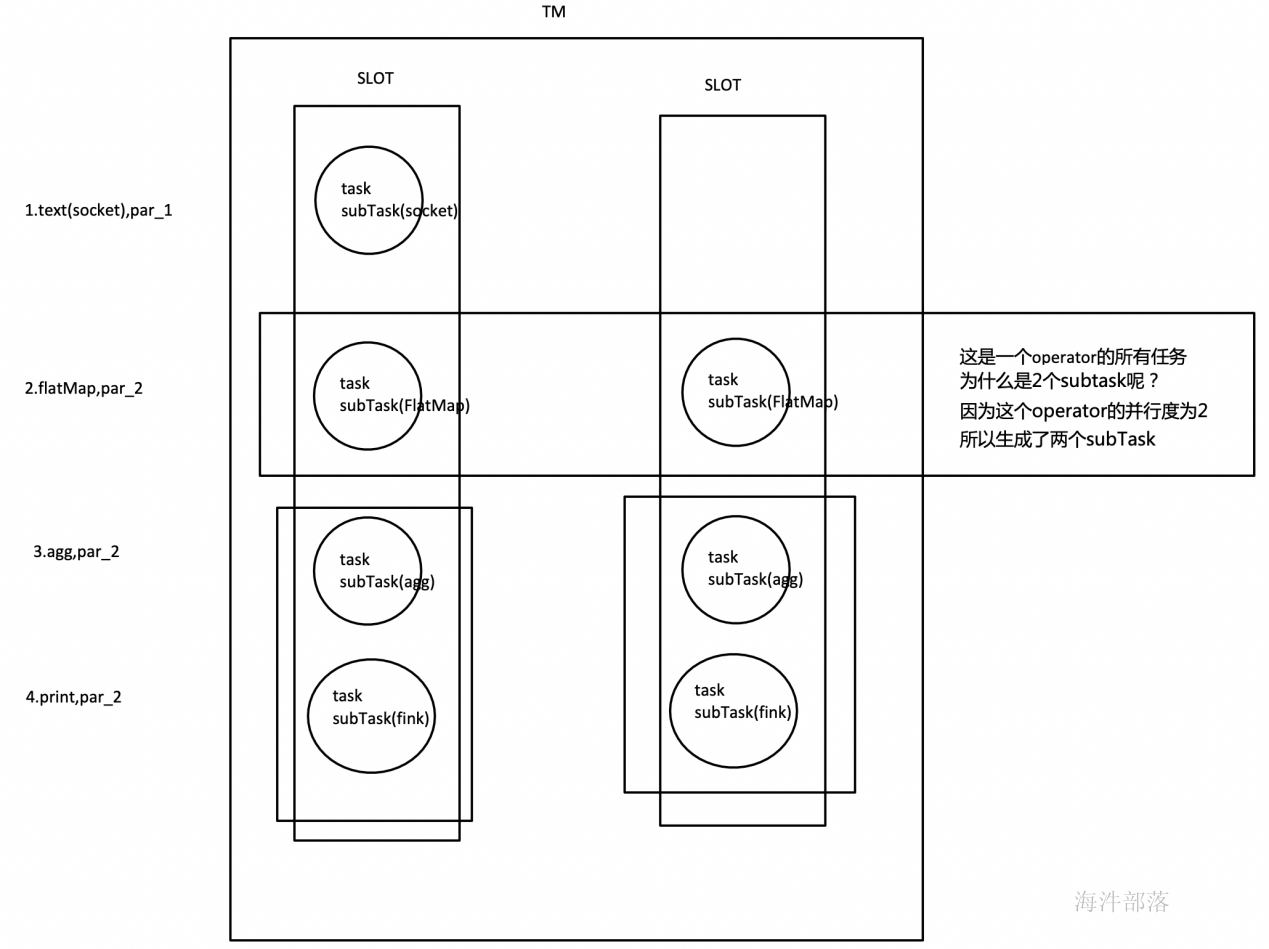
我们仍以上面的 WordCount 为例,下面这幅图,展示了Source并行度为1,FlatMap、KeyAggregation、Sink并行度均为2,最终以5个并行的线程来执行的优化过程。
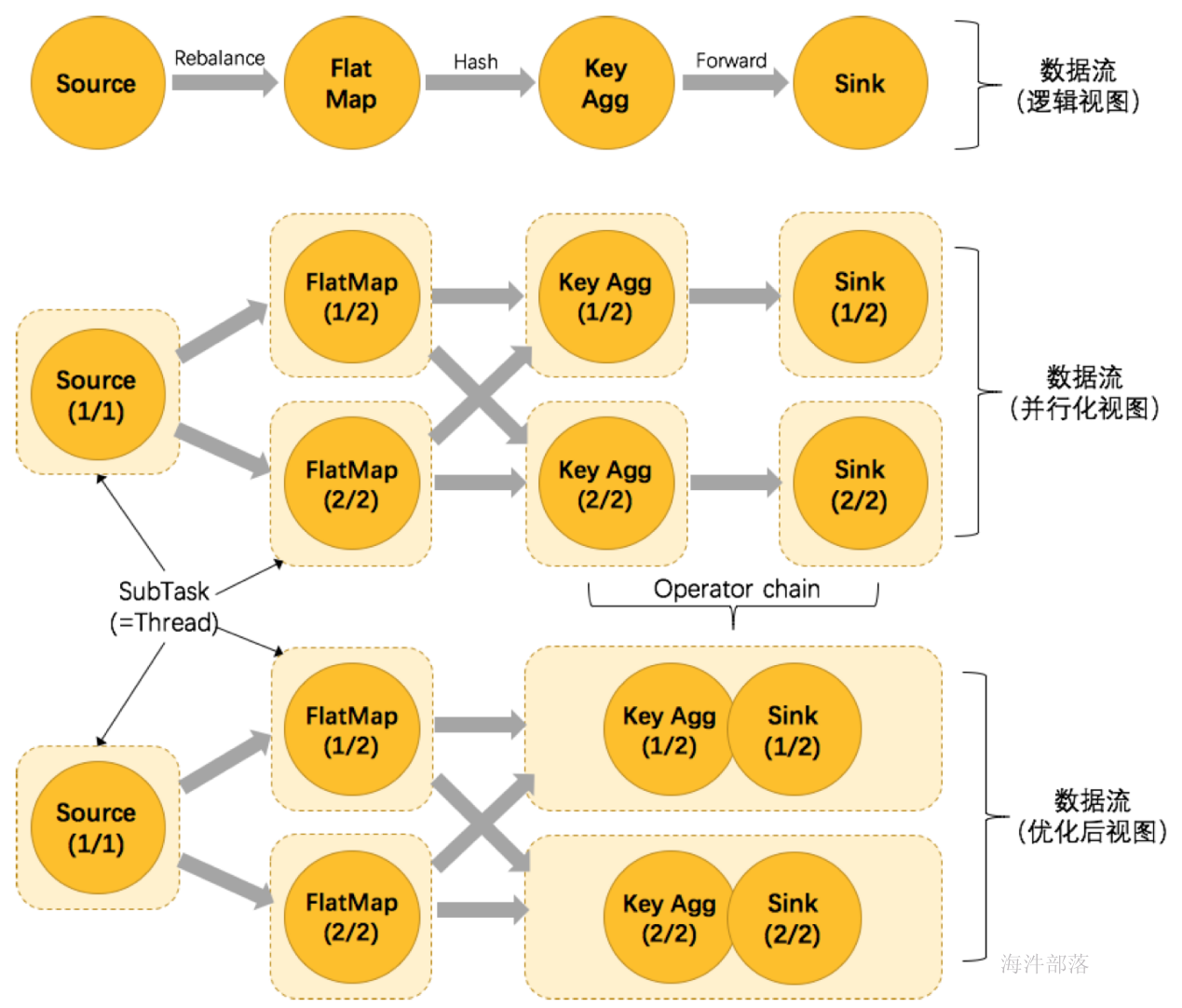
上图中将KeyAggregation和Sink两个operator进行了合并,因为这两个合并后并不会改变整体的拓扑结构。但是,并不是任意两个 operator 就能 chain 一起的。其条件还是很苛刻的:
- 上下游的并行度一致
- 下游节点的入度为1 (也就是说下游节点没有来自其他节点的输入)
- 上下游节点都在同一个 slot group 中(下面会解释 slot group)
- 下游节点的 chain 策略为 ALWAYS(可以与上下游链接,map、flatmap、filter等默认是ALWAYS)
- 上游节点的 chain 策略为 ALWAYS 或 HEAD(只能与下游链接,不能与上游链接,Source默认是HEAD)
- 上下游算子之间没有数据shuffle (数据分区方式是 forward)
- 用户没有禁用 chain
Operator chain的行为可以通过编程API中进行指定。可以通过在DataStream的operator后面(如someStream.map(..))调用startNewChain()来指示从该operator开始一个新的chain(与前面截断,不会被chain到前面)。或者调用disableChaining()来指示该operator不参与chaining(不会与前后的operator chain一起)。在底层,这两个方法都是通过调整operator的 chain 策略(HEAD、NEVER)来实现的。另外,也可以通过调用StreamExecutionEnvironment.disableOperatorChaining()来全局禁用chaining。
代码验证:
- operator禁用chaining
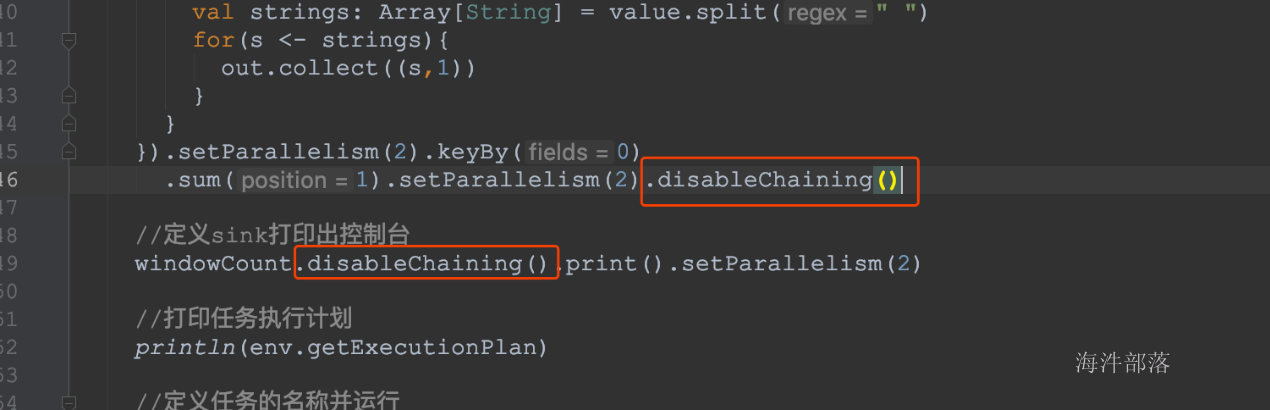
- 全局禁用chaining
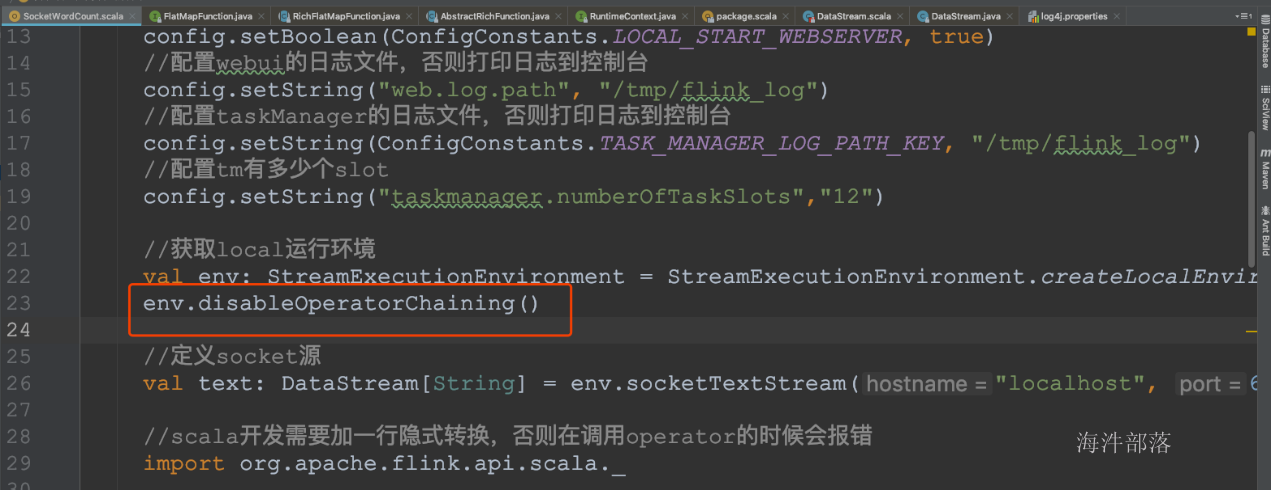
查看job的graph图
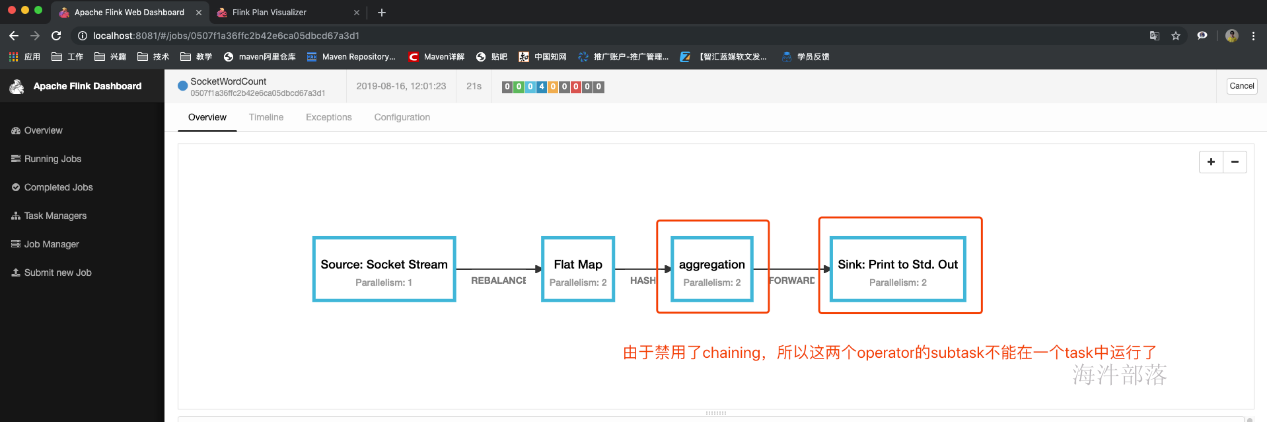
OperatorChain的优缺点:
那么 Flink 是如何将多个 operators chain在一起的呢?chain在一起的operators是如何作为一个整体被执行的呢?它们之间的数据流又是如何避免了序列化/反序列化以及网络传输的呢?下图展示了operators chain的内部实现:
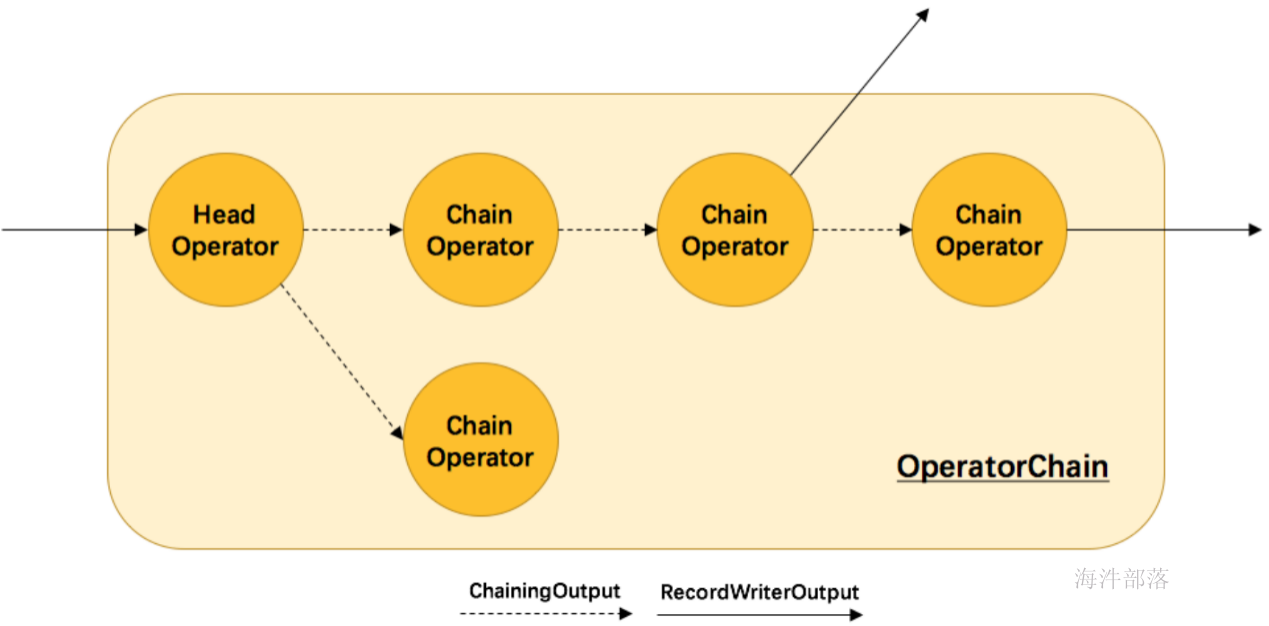
如上图所示,Flink内部是通过OperatorChain这个类来将多个operator链在一起形成一个新的operator。OperatorChain形成的框框就像一个黑盒,Flink 无需知道黑盒中有多少个ChainOperator、数据在chain内部是怎么流动的,只需要将input数据交给 HeadOperator 就可以了,这就使得OperatorChain在行为上与普通的operator无差别,上面的OperaotrChain就可以看做是一个入度为1,出度为2的operator。所以在实现中,对外可见的只有HeadOperator,以及与外部连通的实线输出,这些输出对应了JobGraph中的JobEdge,在底层通过RecordWriterOutput来实现。另外,框中的虚线是operator chain内部的数据流,这个流内的数据不会经过序列化/反序列化、网络传输,而是直接将消息对象传递给下游的 ChainOperator 处理,这是性能提升的关键点,在底层是通过 ChainingOutput 实现的
OperatorChain的优点总结:
- 减少线程切换
- 减少序列化与反序列化
- 减少数据在缓冲区的交换
- 减少延迟并且提高吞吐能力
OperatorChain的缺点总结:
- 可能会让N个比较复杂的业务跑在一个slot中,本来一个业务就慢,这发生这种情况就更慢了,所以可以通过startNewChain()/disableChaining()或全局禁用disableOperatorChaining()给分开
9.SlotSharingGroup 与 CoLocationGroup
每一个 TaskManager 会拥有一个或多个的 task slot,每个 slot 都能跑由多个连续 task 组成的一个 pipeline,比如 MapFunction 的第n个并行实例和 ReduceFunction 的第n个并行实例可以组成一个 pipeline。
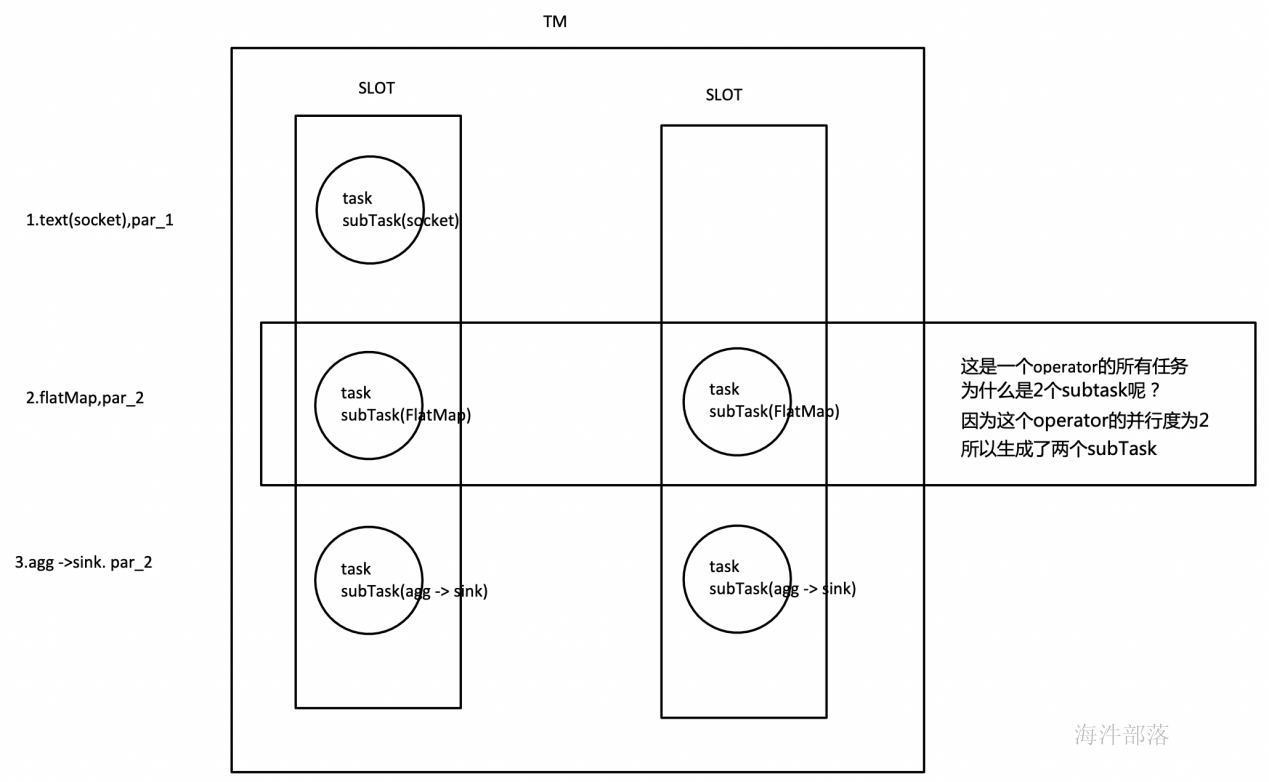
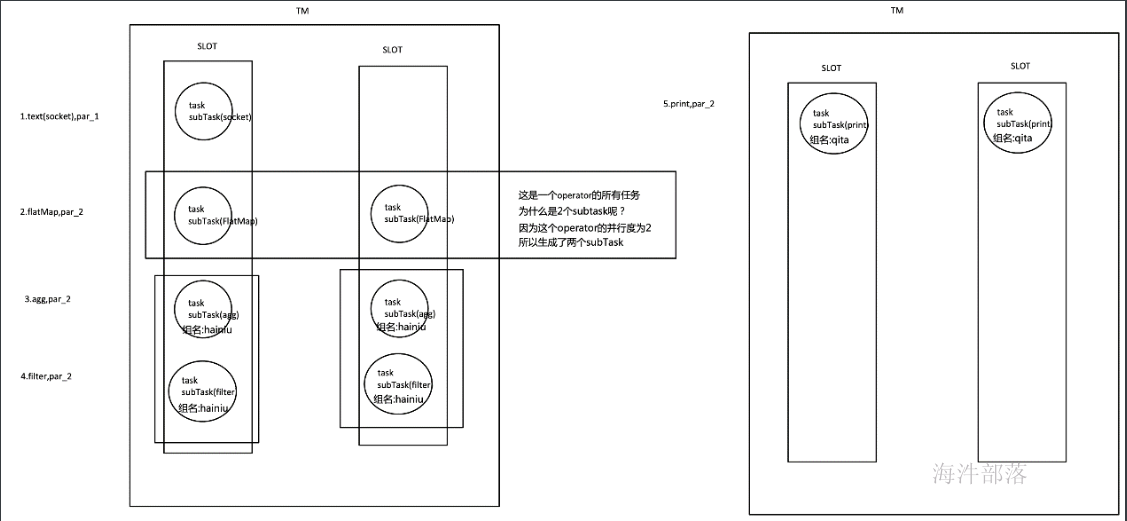
如上文所述的 WordCount 例子,5个Task没有solt共享的时候在TaskManager的slots中如下图分布,2个TaskManager,每个有3个slot:
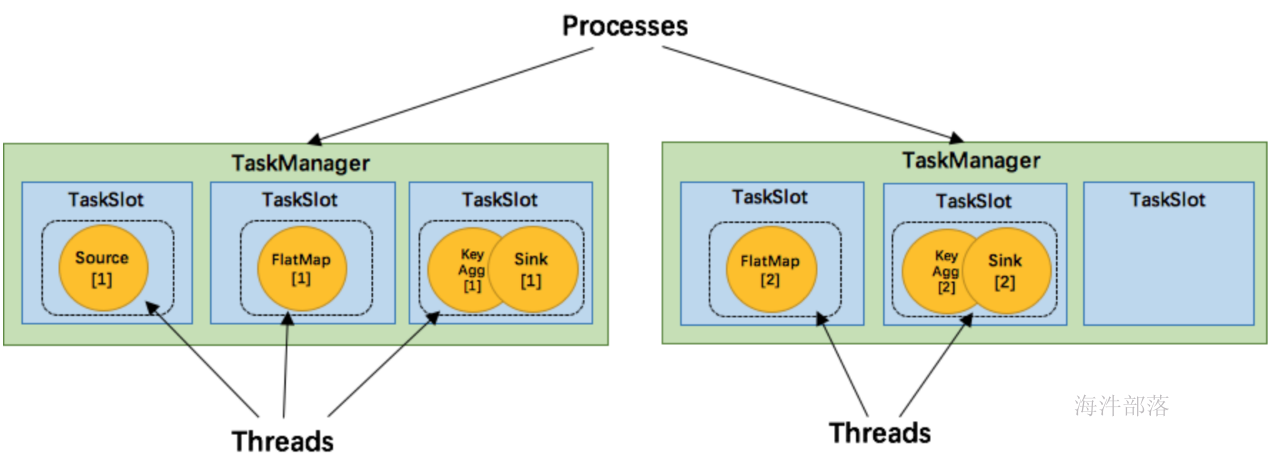
默认情况下,Flink 允许subtasks共享slot,条件是它们都来自同一个Job的不同task的subtask。结果可能一个slot持有该job的整个pipeline。允许slot共享有以下两点好处:
- Flink 集群所需的task slots数与job中最高的并行度一致。
- 更容易获得更充分的资源利用。如果没有slot共享,那么非密集型操作source/flatmap就会占用同密集型操作 keyAggregation/sink 一样多的资源。如果有slot共享,将基线的2个并行度增加到6个,能充分利用slot资源,同时保证每个TaskManager能平均分配到相同数量的subtasks。
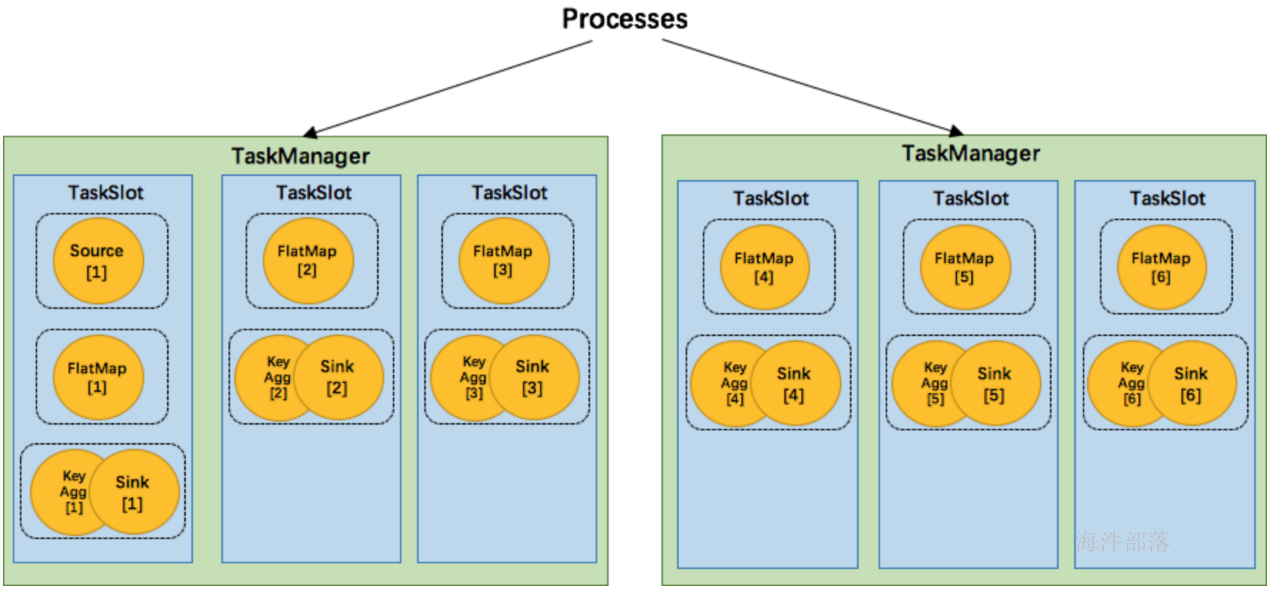
我们将 WordCount 的并行度从之前的2个增加到6个(Source并行度仍为1),并开启slot共享(所有operator都在default共享组),将得到如上图所示的slot分布图。该任务最终会占用6个slots(最高并行度为6)。其次,我们可以看到密集型操作 keyAggregation/sink 被平均地分配到各个 TaskManager。
SlotSharingGroup:
- SlotSharingGroup是Flink中用来实现slot共享的类,它尽可能地让subtasks共享一个slot。
- 保证同一个group的并行度相同的sub-tasks 共享同一个slots
- 算子的默认group为default(即默认一个job下的subtask都可以共享一个slot)
- 为了防止不合理的共享,用户也能通过API来强制指定operator的共享组,比如:someStream.filter(...).slotSharingGroup("group1");就强制指定了filter的slot共享组为group1。
- 怎么确定一个未做SlotSharingGroup设置的算子的Group是什么呢(根据上游算子的 group和自身是否设置group共同确定)
- 适当设置可以减少每个slot运行的线程数,从而整体上减少机器的负载
CoLocationGroup(强制):
- 保证所有的并行度相同的sub-tasks运行在同一个slot
- 主要用于迭代流(训练机器学习模型)
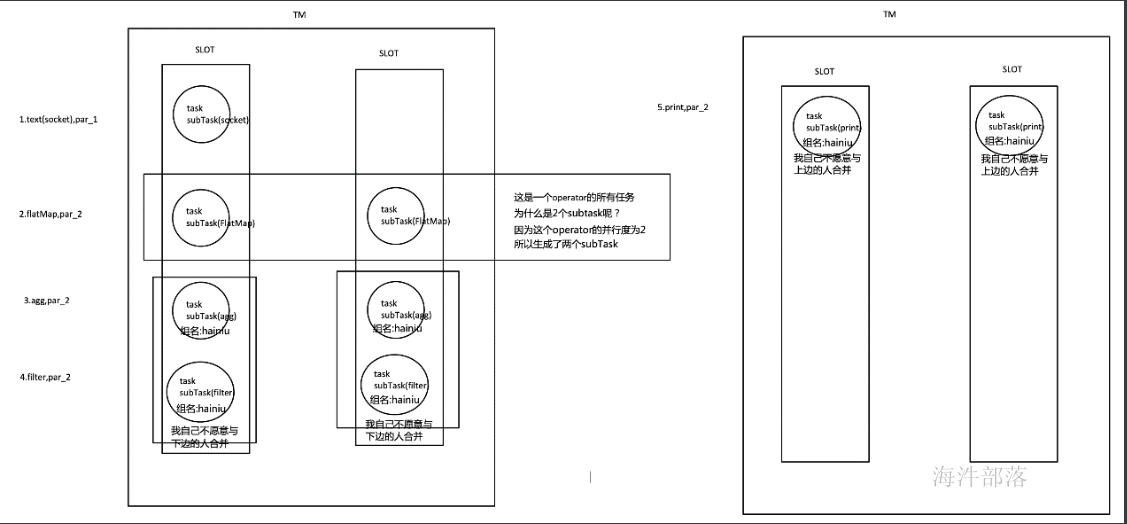
代码验证:
- 设置本地开发环境tm的slot数量
- 设置最后的operator使用新的group
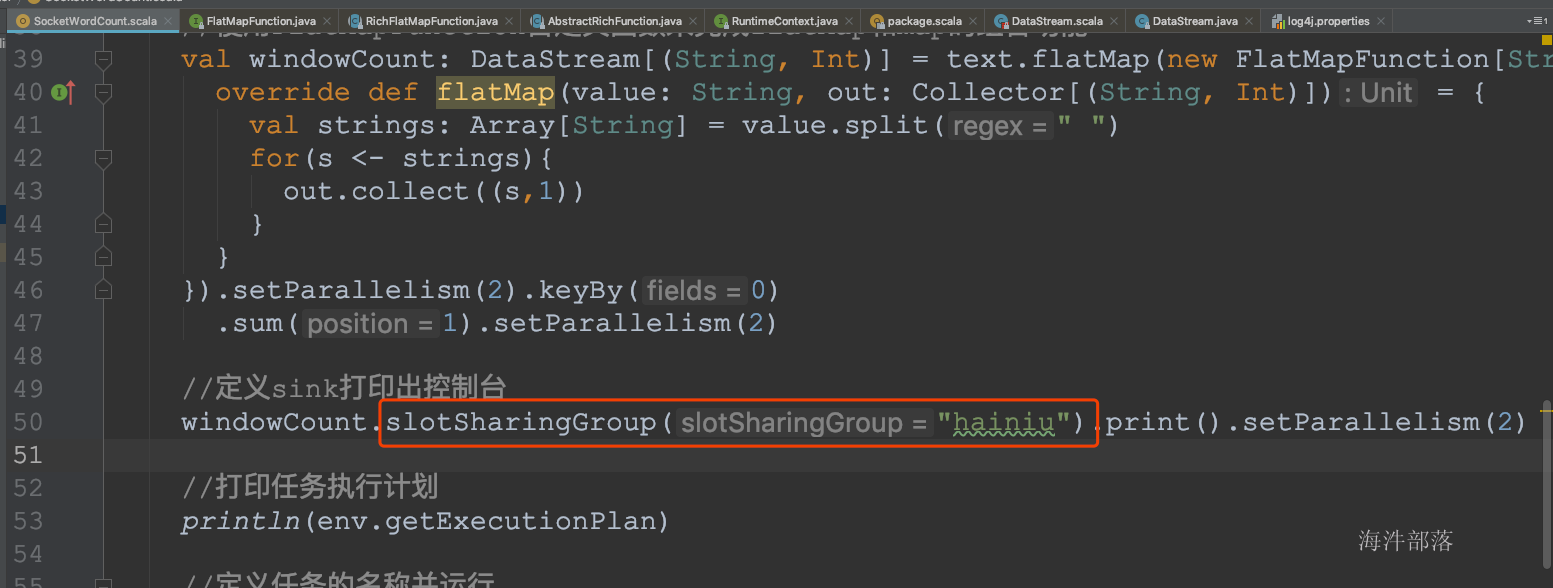
- 由于不和前面的operator在一个group,无法进行slot的共享,所以最后的operator占用了其它slot
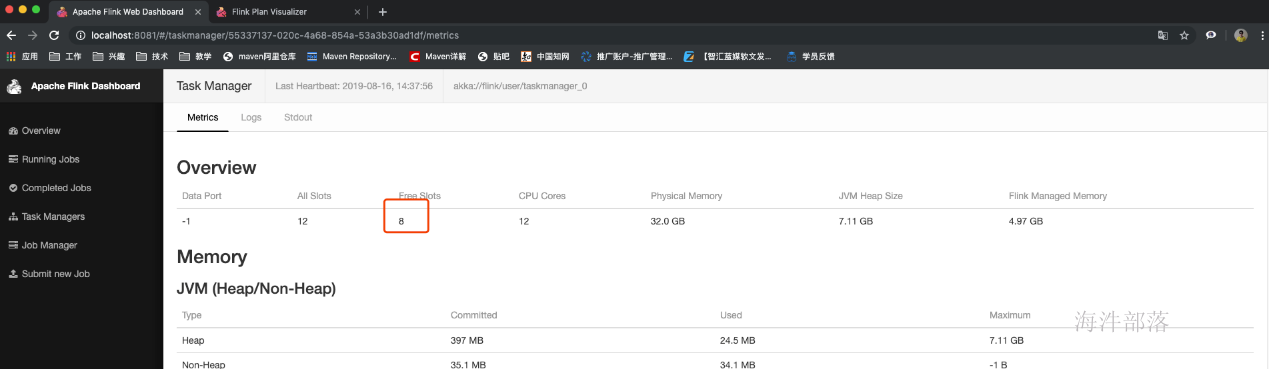
- 为什么占用了两个呢?
- 因为不同组,与上面的default不能共享slot,组间互斥
- 同组中的同一个operator的subtask不能在一个slot中,由于operator的并行度是2,所以占用了两个槽位,subtask组内互斥
原理与实现
那么多个tasks(或者说operators)是如何共享slot的呢?
关于Flink调度,有两个非常重要的原则我们必须知道:
- 同一个operator的各个subtask是不能呆在同一个SharedSlot中的,例如FlatMap[1]和FlatMap[2]是不能在同一个SharedSlot中的。
- Flink是按照拓扑顺序从Source一个个调度到Sink的。例如WordCount(Source并行度为1,其他并行度为2),那么调度的顺序依次是:Source -> FlatMap[1] -> FlatMap[2] -> KeyAgg->Sink[1] -> KeyAgg->Sink[2]。假设现在有2个TaskManager,每个只有1个slot(为简化问题),那么分配slot的过程如图所示:
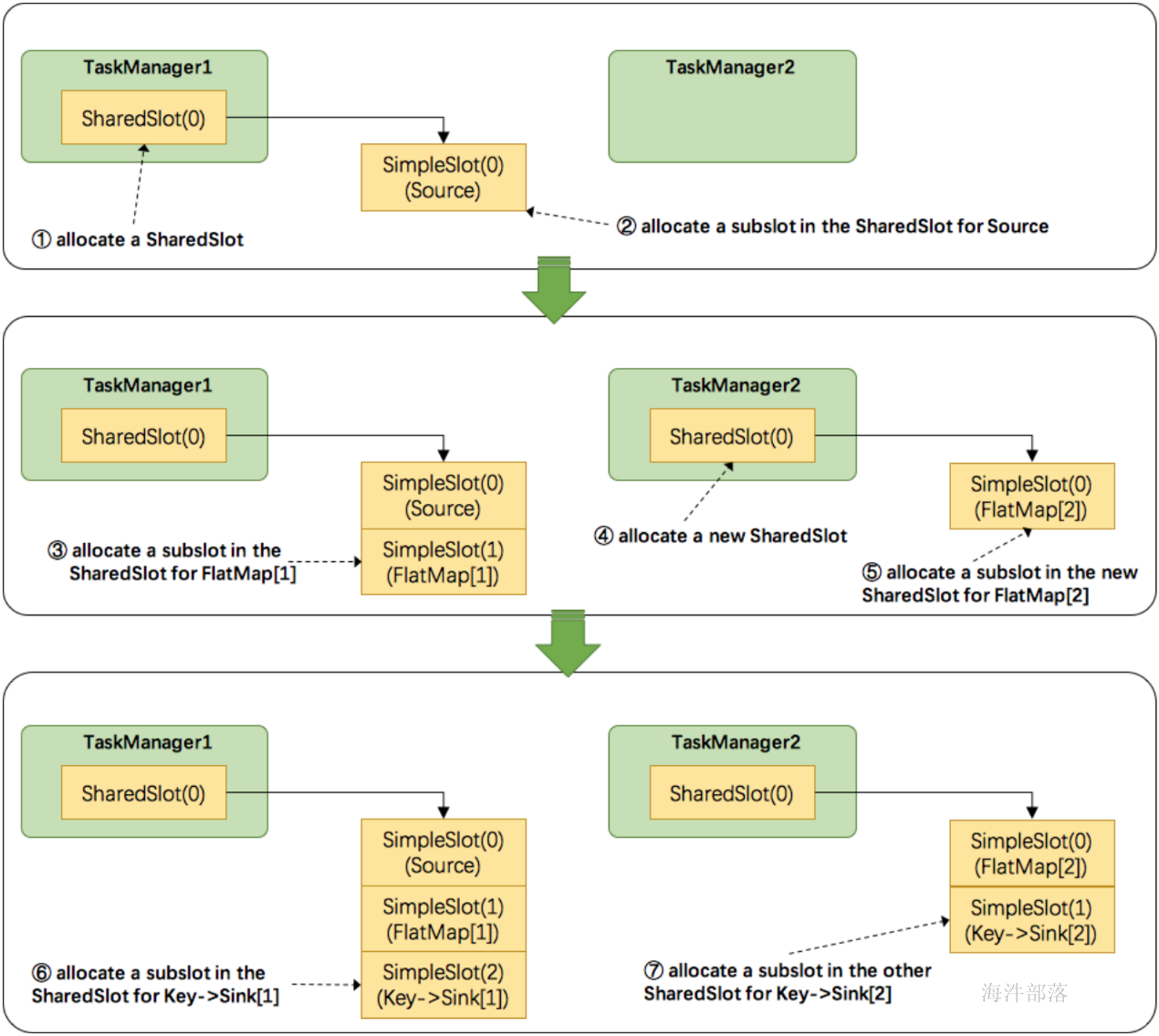
注:图中 SharedSlot 与 SimpleSlot 后带的括号中的数字代表槽位号(slotNumber)
- 为Source分配slot。首先,我们从TaskManager1中分配出一个SharedSlot。并从SharedSlot中为Source分配出一个SimpleSlot。如上图中的①和②。
- 为FlatMap[1]分配slot。目前已经有一个SharedSlot,则从该SharedSlot中分配出一个SimpleSlot用来部署FlatMap[1]。如上图中的③。
- 为FlatMap[2]分配slot。由于TaskManager1的SharedSlot中已经有同operator的FlatMap[1]了,我们只能分配到其他SharedSlot中去。从TaskManager2中分配出一个SharedSlot,并从该SharedSlot中为FlatMap[2]分配出一个SimpleSlot。如上图的④和⑤。
- 为Key->Sink[1]分配slot。目前两个SharedSlot都符合条件,从TaskManager1的SharedSlot中分配出一个SimpleSlot用来部署Key->Sink[1]。如上图中的⑥。
- 为Key->Sink[2]分配slot。TaskManager1的SharedSlot中已经有同operator的Key->Sink[1]了,则只能选择另一个SharedSlot中分配出一个SimpleSlot用来部署Key->Sink[2]。如上图中的⑦。
最后Source、FlatMap[1]、Key->Sink[1]这些subtask都会部署到TaskManager1的唯一一个slot中,并启动对应的线程。FlatMap[2]、Key->Sink[2]这些subtask都会被部署到TaskManager2的唯一一个slot中,并启动对应的线程。从而实现了slot共享。
Flink中计算资源的相关概念以及原理实现。最核心的是 Task Slot,每个slot能运行一个或多个task。为了拓扑更高效地运行,Flink提出了Chaining,尽可能地将operators chain在一起作为一个task来处理。为了资源更充分的利用,Flink又提出了SlotSharingGroup,尽可能地让多个task共享一个slot。
10.如何计算一个应用需要多少slot
- 不设置SlotSharingGroup,就是不设置新的组大家都为default组。(应用的最大并行度)
- 设置SlotSharingGroup ,就是设置了新的组,比如下图有两个组default和test组(所有SlotSharingGroup中的最大并行度之和)
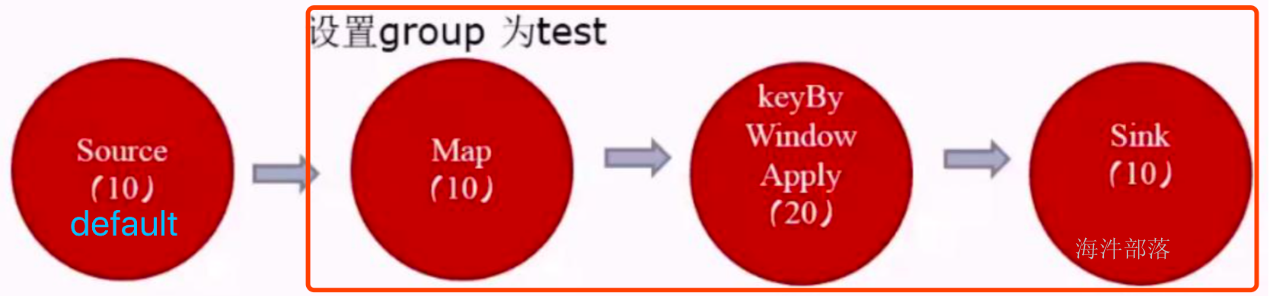
由于source和map之后的operator不属于同一个group,所以source和它们不能在一个solt中运行,而这里的source的default组的并行度是10,test组的并行度是20,所以所需槽位一共是30
11.运行时概念总结
- Job
- Operator
- Parallelism
- Task 与 subtask(线程)
- Chain
- SlotSharingGroup
- CoLocationGroup
- Jobmanger
- TaskManger
- TaskManager Slots
4.flink开发source、operator、sink
1.计算模型

2.DataSource
输入Controlling Latency(控制延迟)
默认情况下,流中的元素并不会一个一个的在网络中传输(这会导致不必要的网络流量消耗) ,而是缓存起来,缓存的大小可以在Flink的配置文件、 ExecutionEnvironment、在某个算子上进行配置(默认100ms)
- 好处:提高吞吐
- 坏处:增加了延迟
- 如何把握平衡
- 为了最大吞吐量,可以设置setBufferTimeout(-1),这会移除timeout机制,缓存中的数据一满就会被发送
- 为了最小的延迟,可以将超时设置为接近0的数(例如5或者10ms)
- 缓存的超时不要设置为0,因为设置为0会带来一些性能的损耗
内置数据源
- 基于文件
env.readTextFile("file:///path")
env.readFile(inputFormat, "file:///path");- 基于Socket
env.socketTextStream("localhost", 6666, '\n')- 基于Collection
env.socketTextStream("localhost", 6666, '\n')import org.apache.flink.api.scala._
env.fromCollection(List(1,2,3))
env.fromElements(1,2,3)
env.generateSequence(0, 1000) #不需要隐式转换自定义数据源
1.实现SourceFunction(非并行的)
示例代码:
function:
package com.hainiu.source;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileChecksum;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.BufferedReader;
import java.io.InputStreamReader;
public class FileCountryDictSourceFunction implements SourceFunction<String> {
private String md5 = null;
private Boolean isCancel = true;
private Integer interval = 10000;
@Override
public void run(SourceContext<String> ctx) throws Exception {
Path pathString = new Path("hdfs://ns1/user/qingniu/country_data");
Configuration hadoopConf = new Configuration();
FileSystem fs = FileSystem.get(hadoopConf);
while (isCancel) {
if(!fs.exists(pathString)){
Thread.sleep(interval);
continue;
}
FileChecksum fileChecksum = fs.getFileChecksum(pathString);
String md5Str = fileChecksum.toString();
String currentMd5 = md5Str.substring(md5Str.indexOf(":") + 1);
if (!currentMd5.equals(md5)) {
FSDataInputStream open = fs.open(pathString);
BufferedReader reader = new BufferedReader(new InputStreamReader(open));
String line = reader.readLine();
while (line != null) {
ctx.collect(line);
line = reader.readLine();
}
reader.close();
md5 = currentMd5;
}
Thread.sleep(interval);
}
}
@Override
public void cancel() {
isCancel = false;
}
}运行类:
package com.hainiu.source;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class FileSource {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> stringDataStreamSource = env.addSource(new FileCountryDictSourceFunction());
stringDataStreamSource.print();
env.execute();
}
}2.实现ParallelSourceFunction与RichParallelSourceFunction(并行的)
以Kafka-connector-source为代表
- 基于Kafka 的partition 机制,Flink实现了并行化数据切分
- Flink 可以消费Kafka的topic,和sink数据到Kafka
- 出现失败时,flink通过checkpoint机制来协调Kafka来恢复应用(通过设置kafka的offset)
引入依赖:
flink支持的kafka版本对比:
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka-0.10_2.11</artifactId>
<version>1.9.3</version>
<scope>compile</scope>
</dependency>flink支持的kafka版本对比:
| Maven Dependency | 支持自 | Class name | Kafka版本 | 说明 |
|---|---|---|---|---|
| flink-connector-kafka- 0.8_2.11 | 1.0.0 | FlinkKafkaConsumer08 FlinkKafkaProducer08 | 0.8.x | 内部使用kakfa的 SimpleConsumer API 。 Flink把Offset提交给Zookeeper |
| flink-connector-kafka- 0.9_2.11 | 1.0.0 | FlinkKafkaConsumer09 FlinkKafkaProducer09 | 0.9.x | 使用kafka的new Consumer API Kafka. |
| flink-connector-kafka- 0.10_2.11 | 1.2.0 | FlinkKafkaConsumer010 FlinkKafkaProducer010 | 0.10.x | 生产和消费支持 Kafka messages with timestamps |
1).Flink KafkaConsumer 的Source API
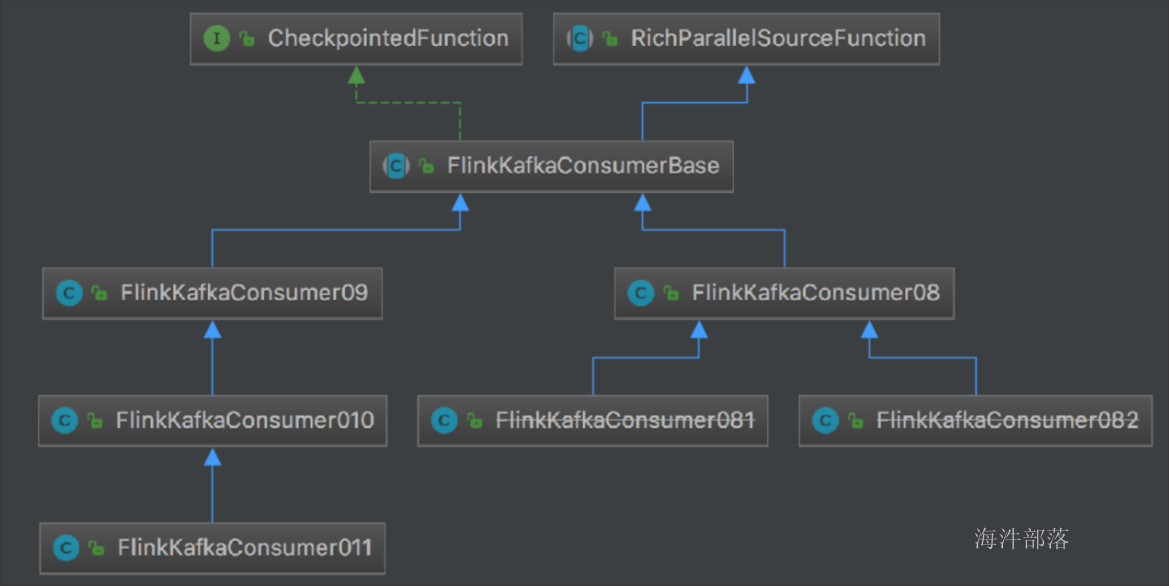
1.FlinkKafkaConsumer010创建方式:
FlinkKafkaConsumer010(String topic, KeyedDeserializationSchema<T> deserializer, Properties props)
FlinkKafkaConsumer010(List<String> topics, DeserializationSchema<T> deserializer, Properties props)
FlinkKafkaConsumer010(List<String> topics, KeyedDeserializationSchema<T> deserializer, Properties props)
FlinkKafkaConsumer010(Pattern subscriptionPattern, KeyedDeserializationSchema<T> deserializer, Properties props)- 三个构造参数:
- 要消费的topic(topic name / topic names/正表达式)
- DeserializationSchema / KeyedDeserializationSchema(反序列化Kafka中的数据))
- Kafka consumer的属性,其中三个属性必须提供:
- bootstrap.servers(逗号分隔的Kafka broker列表)
- zookeeper.connect(逗号分隔的Zookeeper server列表,仅Kafka 0.8需要))
- group.id(consumer group id)
2.反序列化Schema类型
- 作用:对kafka里获取的二进制数据进行反序列化
- FlinkKafkaConsumer需要知道如何将Kafka中的二进制数据转换成Java/Scala对象,DeserializationSchema定义了该转换模式,通过T deserialize(byte[] message)
- FlinkKafkaConsumer从kafka获取的每条消息都会通过DeserializationSchema的T deserialize(byte[] message)反序列化处理
- 反序列化Schema类型(接口):
- DeserializationSchema(只反序列化value)
- KeyedDeserializationSchema
3.常见反序列化Schema
- SimpleStringSchema
- JSONDeserializationSchema / JSONKeyValueDeserializationSchema
- TypeInformationSerializationSchema / TypeInformationKeyValueSerializationSchema
- AvroDeserializationSchema
4.自定义反序列化Schema:
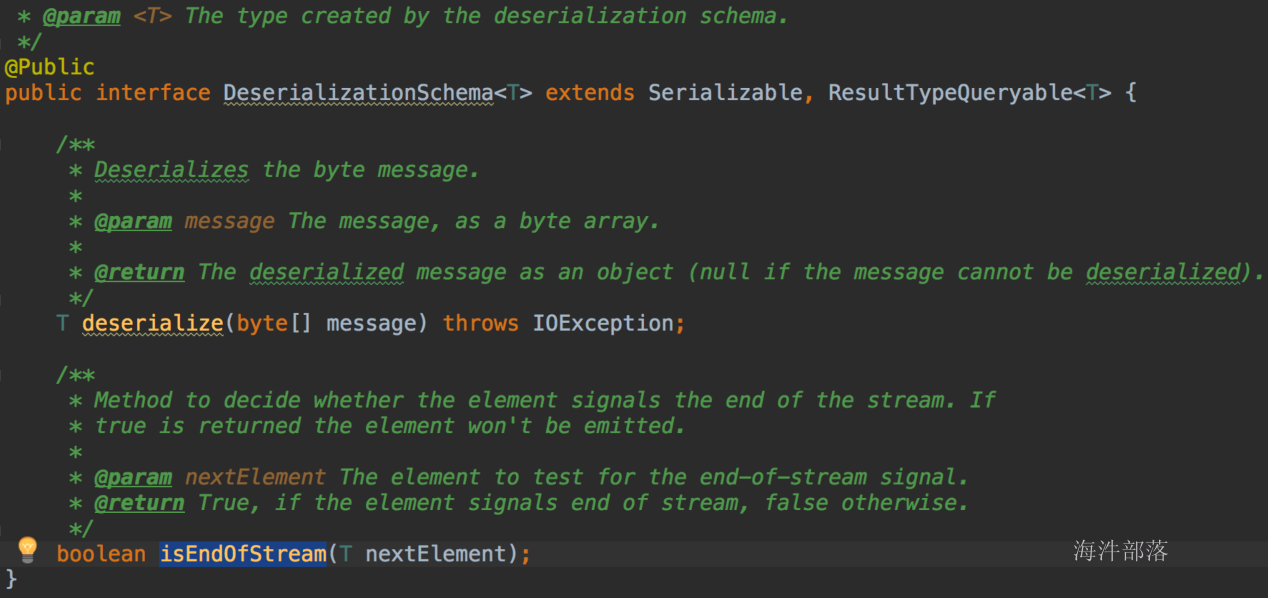
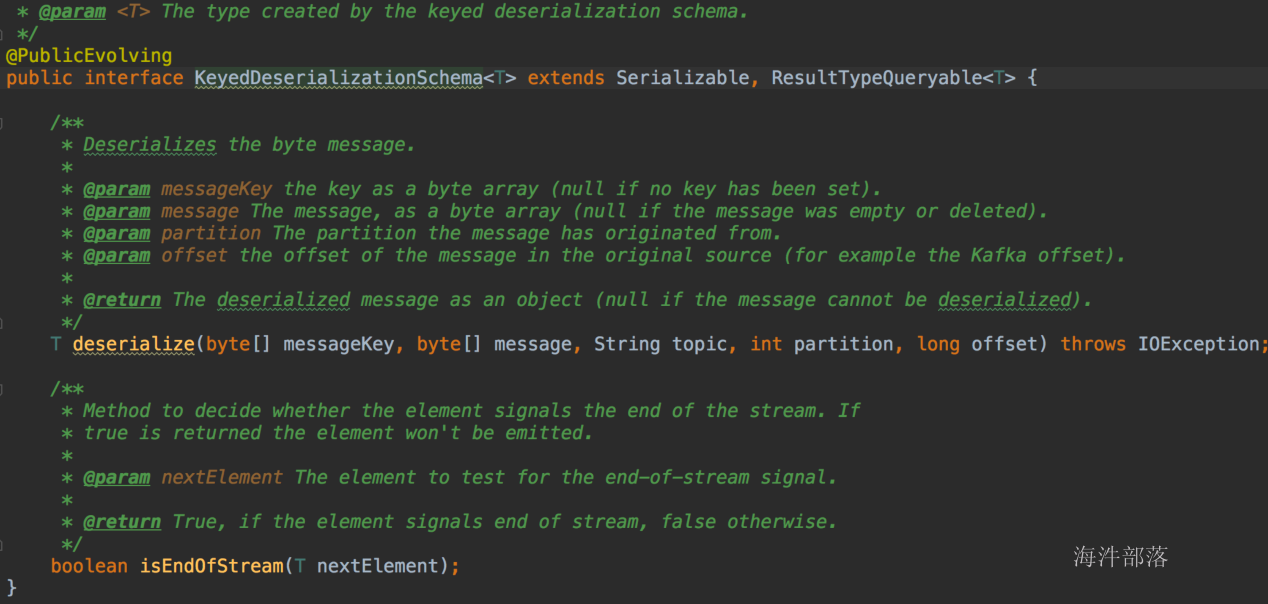
- 实现DeserializationSchema与KeyedDeserializationSchema接口
DeserializationSchema:
KeyedDeserializationSchema:
bean:
package com.hainiu.source;
public class HainiuKafkaRecord {
private String record;
public HainiuKafkaRecord(String record) {
this.record = record;
}
public String getRecord() {
return record;
}
public void setRecord(String record) {
this.record = record;
}
}schema:
package com.hainiu.source;
import org.apache.flink.api.common.serialization.DeserializationSchema;
import org.apache.flink.api.common.typeinfo.TypeInformation;
import java.io.IOException;
public class HainiuKafkaRecordSchema implements DeserializationSchema<HainiuKafkaRecord> {
@Override
public HainiuKafkaRecord deserialize(byte[] message) throws IOException {
HainiuKafkaRecord hainiuKafkaRecord = new HainiuKafkaRecord(new String(message));
return hainiuKafkaRecord;
}
@Override
public boolean isEndOfStream(HainiuKafkaRecord nextElement) {
return false;
}
@Override
public TypeInformation<HainiuKafkaRecord> getProducedType() {
return TypeInformation.of(HainiuKafkaRecord.class);
}
}5.FlinkKafkaConsumer010最简样版代码

6.FlinkKafkaConsumer消费

| 消费模式 | 说明 | |
|---|---|---|
| setStartFromEarliest | 从队头开始,最早的记录 | 内部的Consumer提交到Kafka/zk中的偏移量将被忽略 |
| setStartFromLatest | 从队尾开始,最新的记录 | |
| setStartFromGroupOffsets() | 默认值,从当前消费组记录的偏移量开始,接着上次的偏移量消费 | 以Consumer提交到Kafka/zk中的偏移量最为起始位置开始消费, group.id设置在consumer的properties里; 如果没找到记录的偏移量,则使用consumer的properties的 auto.offset.reset设置的策略 |
| setStartFromSpecificOffsets(Map\<TopicPa rtition, Long>的参数) | 从指定的具体位置开始消费 | |
| setStartFromTimestamp(long) | 从指定的时间戳开始消费 | 对于每个分区,时间戳大于或等于指定时间戳的记录将用作起始位 置。如果一个分区的最新记录早于时间戳,那么只需要从最新记录 中读取该分区。在此模式下,Kafka/zk中提交的偏移量将被忽略 |
注意
- kafka 0.8版本, consumer提交偏移量到zookeeper,后续版本提交到kafka(一个特殊的topic: __consumer_offsets)
7.动态Partition discovery
- Flink Kafka Consumer支持动态发现Kafka分区,且能保证exactly-once
- 默认禁止动态发现分区,把flink.partition-discovery.interval-millis设置大于0即可启用:
properties.setProperty("flink.partition-discovery.interval-millis", "30000")
8.动态Topic discovery
- Flink Kafka Consumer支持动态发现Kafka Topic,仅限通过正则表达式指定topic的方式
- 默认禁止动态发现topic,把flink.partition-discovery.interval-millis设置大于0即可启用
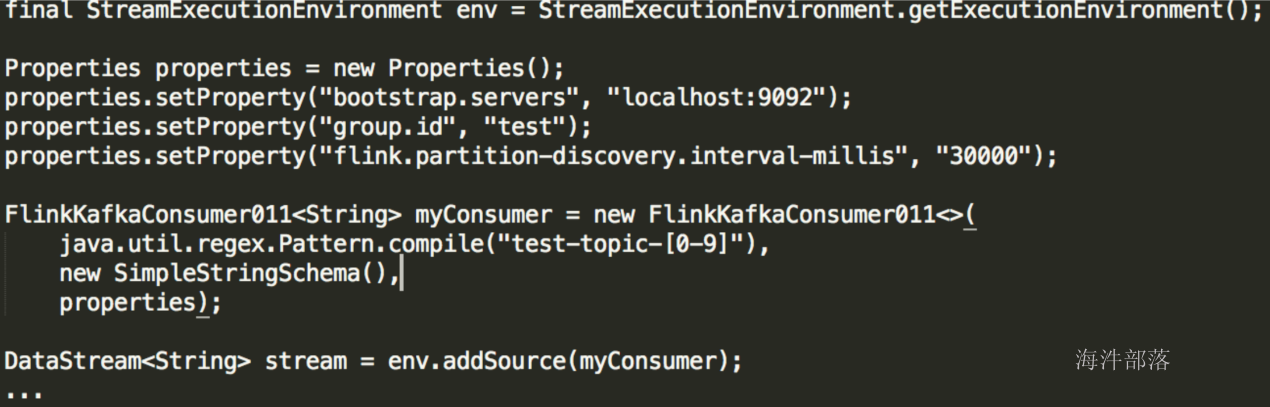
示例代码:
package com.hainiu.source;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import java.util.Properties;
import java.util.regex.Pattern;
public class KafkaRichParallelSource {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
Properties kafkaConsumerProps = new Properties();
kafkaConsumerProps.setProperty("bootstrap.servers", "s1.hadoop:9092,s2.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092");
kafkaConsumerProps.setProperty("group.id", "qingniuflink");
kafkaConsumerProps.setProperty("flink.partition-discovery.interval-millis", "30000");
FlinkKafkaConsumer010<String> kafkaSource = new FlinkKafkaConsumer010<>("flink_event", new SimpleStringSchema(), kafkaConsumerProps);
// FlinkKafkaConsumer010<String> kafkaSource = new FlinkKafkaConsumer010<>(Pattern.compile("flink_event_[0-9]"), new SimpleStringSchema(), kafkaConsumerProps);
// kafkaSource.setStartFromEarliest()
// kafkaSource.setStartFromGroupOffsets()
kafkaSource.setStartFromLatest();
DataStreamSource<String> kafkaInput = env.addSource(kafkaSource);
kafkaInput.print();
FlinkKafkaConsumer010<HainiuKafkaRecord> kafkaBeanSource = new FlinkKafkaConsumer010<>("flink_event", new HainiuKafkaRecordSchema(), kafkaConsumerProps);
DataStreamSource<HainiuKafkaRecord> kafkaBeanInput = env.addSource(kafkaBeanSource);
kafkaBeanInput.print();
env.execute();
}
}3.transformations
下图展示了 Flink 中目前支持的主要几种流的类型,以及它们之间的转换关系。
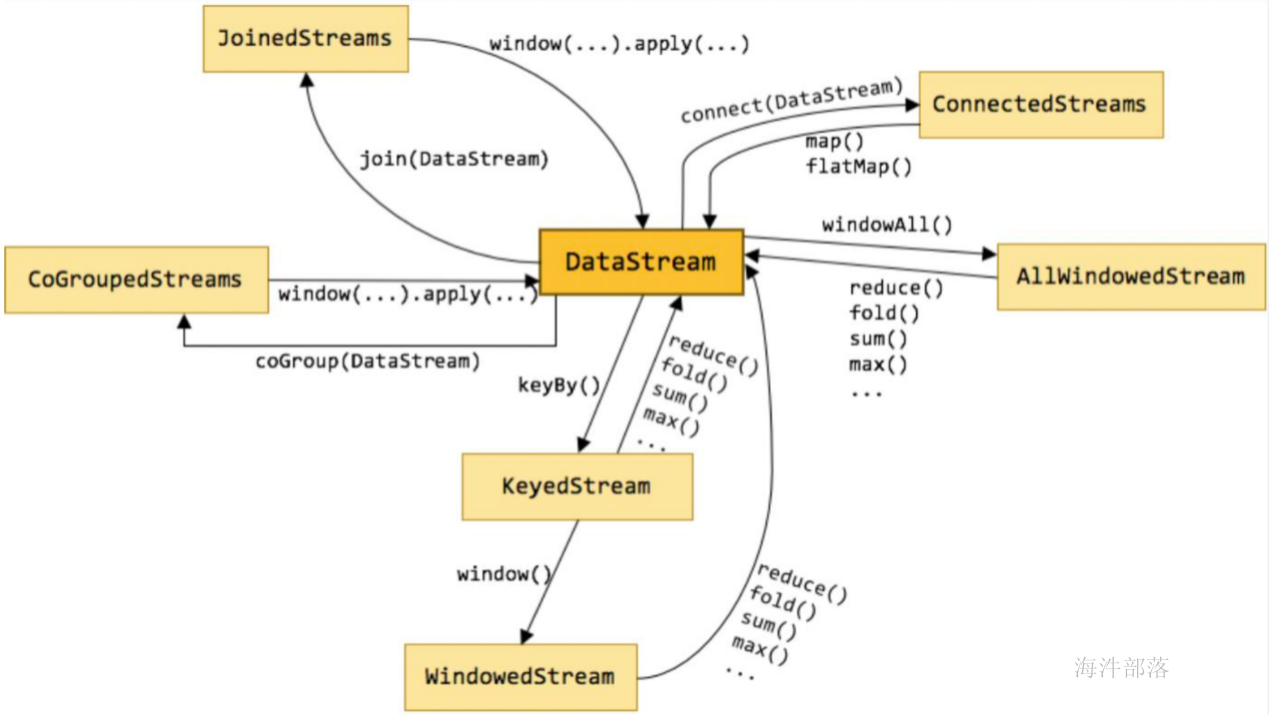
DataStream
DataStream 是 Flink 流处理 API 中最核心的数据结构。它代表了一个运行在多个分区上的并行流。一个 DataStream 可以从 StreamExecutionEnvironment 通过env.addSource(SourceFunction) 获得。
DataStream 上的转换操作都是逐条的,比如 map(),flatMap(),filter()
自定义转换函数
1.函数
scala函数
data.flatMap(f => f.split(" "))java的lambda
data.flatMap(f -> f.split(" "));- 实现接口
text.flatMap(new FlatMapFunction[String,String] {
override def flatMap(value: String, out: Collector[String]) = {
val strings: Array[String] = value.split(" ")
for(s <- strings){
out.collect(s)
}
}
})data.flatMap(f -> f.split(" "));3.Rich Functions
Rich Function中有非常有用的四个方法:open,close,getRuntimeContext和setRuntimecontext 这些功能在创建本地状态、获取广播变量、获取运行时信息(例如累加器和计数器)和迭代信息时非常有帮助。
示例代码:
import java.util.Properties
import org.apache.flink.api.common.functions.RichFlatMapFunction
import org.apache.flink.configuration.Configuration
import org.apache.flink.util.Collector
import org.apache.kafka.clients.producer.{KafkaProducer, Producer, ProducerRecord}
class HainiuRichFlatMapFunction(topic:String,props:Properties) extends RichFlatMapFunction[String,Int]{
var producer:Producer[String,String] = _
override def open(parameters: Configuration): Unit = {
//创建kafka生产者
producer = new KafkaProducer[String,String](props)
}
override def close(): Unit = {
//关闭kafka生产者
producer.close()
}
override def flatMap(value: String, out: Collector[Int]): Unit = {
//使用RuntimeContext得到子线程ID,比如可以用于多线程写文件
println(getRuntimeContext.getIndexOfThisSubtask)
//发送数据到kafka
producer.send(new ProducerRecord[String,String](topic,value))
}
}operators
1.connect 与 union (合并流)
- connect之后生成ConnectedStreams,会对两个流的数据应用不同的处理方法,并且双流之间可以共享状态(比如计数)。这在第一个流的输入会影响第二个流时, 会非常有用。union 合并多个流,新的流包含所有流的数据。
- union是DataStream → DataStream
- connect只能连接两个流,而union可以连接多于两个流
- connect连接的两个流类型可以不一致,而union连接的流的类型必须一致
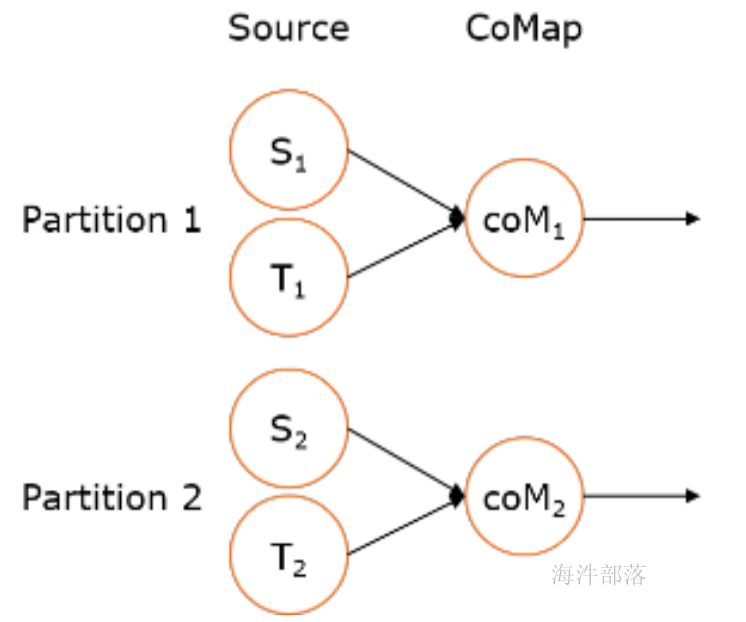
示例代码:
union:
package com.hainiu.operator;
import com.hainiu.source.FileCountryDictSourceFunction;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.ProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.apache.flink.util.Collector;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
public class CountryCodeUnion {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<String> countryDictSource = env.addSource(new FileCountryDictSourceFunction());
Properties kafkaConsumerProps = new Properties();
kafkaConsumerProps.setProperty("bootstrap.servers", "s1.hadoop:9092,s2.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092");
kafkaConsumerProps.setProperty("group.id", "qingniuflink");
kafkaConsumerProps.setProperty("flink.partition-discovery.interval-millis", "30000");
FlinkKafkaConsumer010<String> kafkaSource = new FlinkKafkaConsumer010<>("flink_event", new SimpleStringSchema(), kafkaConsumerProps);
// kafkaSource.setStartFromEarliest()
// kafkaSource.setStartFromGroupOffsets()
kafkaSource.setStartFromLatest();
DataStreamSource<String> kafkainput = env.addSource(kafkaSource);
DataStream<String> union = countryDictSource.union(kafkainput);
SingleOutputStreamOperator<String> process = union.process(new ProcessFunction<String, String>() {
private Map<String, String> map = new HashMap<>();
@Override
public void processElement(String value, Context ctx, Collector<String> out) throws Exception {
String[] split = value.split("\t");
if (split.length > 1) {
map.put(split[0], split[1]);
out.collect(value);
} else {
String countryName = map.get(value);
String outStr = countryName == null ? "no match" : countryName;
out.collect(outStr);
}
}
});
process.print();
env.execute();
}
}connect:
package com.hainiu.operator;
import com.hainiu.source.FileCountryDictSourceFunction;
import com.hainiu.source.HainiuKafkaRecord;
import com.hainiu.source.HainiuKafkaRecordSchema;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.apache.flink.util.Collector;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
public class CountryCodeConnect {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<String> countryDictSource = env.addSource(new FileCountryDictSourceFunction());
Properties kafkaConsumerProps = new Properties();
kafkaConsumerProps.setProperty("bootstrap.servers", "s1.hadoop:9092,s2.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092");
kafkaConsumerProps.setProperty("group.id", "qingniuflink");
kafkaConsumerProps.setProperty("flink.partition-discovery.interval-millis", "30000");
FlinkKafkaConsumer010<HainiuKafkaRecord> kafkaSource = new FlinkKafkaConsumer010<>("flink_event", new HainiuKafkaRecordSchema(), kafkaConsumerProps);
// kafkaSource.setStartFromEarliest()
// kafkaSource.setStartFromGroupOffsets()
kafkaSource.setStartFromLatest();
DataStreamSource<HainiuKafkaRecord> kafkainput = env.addSource(kafkaSource);
ConnectedStreams<String, HainiuKafkaRecord> connect = countryDictSource.connect(kafkainput);
SingleOutputStreamOperator<String> connectInput = connect.process(new CoProcessFunction<String, HainiuKafkaRecord, String>() {
private Map<String, String> map = new HashMap<String, String>();
@Override
public void processElement1(String value, Context ctx, Collector<String> out) throws Exception {
String[] split = value.split("\t");
map.put(split[0], split[1]);
out.collect(value);
}
@Override
public void processElement2(HainiuKafkaRecord value, Context ctx, Collector<String> out) throws Exception {
String countryCode = value.getRecord();
String countryName = map.get(countryCode);
String outStr = countryName == null ? "no match" : countryName;
out.collect(outStr);
}
});
connectInput.print();
env.execute();
}
}2.keyBy
- 含义: 根据指定的key进行分组(逻辑上把DataStream分成若干不相交的分区,key一样的event会 被划分到相同的partition,内部采用类似于hash分区来实现)
- 转换关系: DataStream → KeyedStream
- 使用场景: 分组(类比SQL中的分组)比如join,coGroup,keyBy,groupBy,Reduce,GroupReduce,Aggregate,Windows
KeyedStream
- KeyedStream用来表示根据指定的key进行分组的数据流。
- 一个KeyedStream可以通过调用DataStream.keyBy()来获得。
- 在KeyedStream上进行任何transformation都将转变回DataStream。
- 在实现中,KeyedStream会把key的信息传入到算子的函数中。
示例代码:
package com.hainiu.operator;
import com.hainiu.source.FileCountryDictSourceFunction;
import com.hainiu.source.HainiuKafkaRecord;
import com.hainiu.source.HainiuKafkaRecordSchema;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.apache.flink.util.Collector;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
public class CountryCodeConnect {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
DataStreamSource<String> countryDictSource = env.addSource(new FileCountryDictSourceFunction());
Properties kafkaConsumerProps = new Properties();
kafkaConsumerProps.setProperty("bootstrap.servers", "s1.hadoop:9092,s2.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092");
kafkaConsumerProps.setProperty("group.id", "qingniuflink");
kafkaConsumerProps.setProperty("flink.partition-discovery.interval-millis", "30000");
FlinkKafkaConsumer010<HainiuKafkaRecord> kafkaSource = new FlinkKafkaConsumer010<>("flink_event", new HainiuKafkaRecordSchema(), kafkaConsumerProps);
// kafkaSource.setStartFromEarliest()
// kafkaSource.setStartFromGroupOffsets()
kafkaSource.setStartFromLatest();
DataStreamSource<HainiuKafkaRecord> kafkainput = env.addSource(kafkaSource);
ConnectedStreams<String, HainiuKafkaRecord> connect = countryDictSource.connect(kafkainput);
SingleOutputStreamOperator<String> connectInput = connect.process(new CoProcessFunction<String, HainiuKafkaRecord, String>() {
private Map<String, String> map = new HashMap<String, String>();
@Override
public void processElement1(String value, Context ctx, Collector<String> out) throws Exception {
String[] split = value.split("\t");
map.put(split[0], split[1]);
out.collect(value);
}
@Override
public void processElement2(HainiuKafkaRecord value, Context ctx, Collector<String> out) throws Exception {
String countryCode = value.getRecord();
String countryName = map.get(countryCode);
String outStr = countryName == null ? "no match" : countryName;
out.collect(outStr);
}
});
connectInput.print();
env.execute();
}
}Key的类型限制:
- 不能是没有覆盖hashCode方法的POJO(也就是bean)
- 不能是数组
POJO:
package com.hainiu.source;
public class HainiuKafkaRecord {
private String record;
public HainiuKafkaRecord(String record) {
this.record = record;
}
public String getRecord() {
return record;
}
public void setRecord(String record) {
this.record = record;
}
@Override
public int hashCode() {
final int prime = 31;
int result = 1;
result = prime * result + ((record == null) ? 0 : record.hashCode());
return result;
}
}示例代码:
package com.hainiu.operator;
import com.hainiu.source.FileCountryDictSourceFunction;
import com.hainiu.source.HainiuKafkaRecord;
import com.hainiu.source.HainiuKafkaRecordSchema;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.KeyedCoProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.apache.flink.util.Collector;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
public class CountryCodeConnectKeyByObject {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> countryDictSource = env.addSource(new FileCountryDictSourceFunction());
Properties kafkaConsumerProps = new Properties();
kafkaConsumerProps.setProperty("bootstrap.servers", "s1.hadoop:9092,s2.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092");
kafkaConsumerProps.setProperty("group.id", "qingniuflink");
kafkaConsumerProps.setProperty("flink.partition-discovery.interval-millis", "30000");
FlinkKafkaConsumer010<HainiuKafkaRecord> kafkaSource = new FlinkKafkaConsumer010<>("flink_event", new HainiuKafkaRecordSchema(), kafkaConsumerProps);
// kafkaSource.setStartFromEarliest()
// kafkaSource.setStartFromGroupOffsets()
kafkaSource.setStartFromLatest();
DataStreamSource<HainiuKafkaRecord> kafkainput = env.addSource(kafkaSource);
KeyedStream<Tuple2<HainiuKafkaRecord, String>, HainiuKafkaRecord> countryDictKeyBy = countryDictSource.map(new MapFunction<String, Tuple2<HainiuKafkaRecord, String>>() {
@Override
public Tuple2<HainiuKafkaRecord, String> map(String value) throws Exception {
String[] split = value.split("\t");
return Tuple2.of(new HainiuKafkaRecord(new String(split[0])), split[1]);
}
}).keyBy(new KeySelector<Tuple2<HainiuKafkaRecord, String>, HainiuKafkaRecord>() {
@Override
public HainiuKafkaRecord getKey(Tuple2<HainiuKafkaRecord, String> value) throws Exception {
return value.f0;
}
});
KeyedStream<HainiuKafkaRecord, HainiuKafkaRecord> record = kafkainput.keyBy(new KeySelector<HainiuKafkaRecord, HainiuKafkaRecord>() {
@Override
public HainiuKafkaRecord getKey(HainiuKafkaRecord value) throws Exception {
return value;
}
});
ConnectedStreams<Tuple2<HainiuKafkaRecord, String>, HainiuKafkaRecord> connect = countryDictKeyBy.connect(record);
SingleOutputStreamOperator<String> connectInput = connect.process(new KeyedCoProcessFunction<HainiuKafkaRecord, Tuple2<HainiuKafkaRecord, String>, HainiuKafkaRecord, String>() {
private Map<String, String> map = new HashMap<String, String>();
@Override
public void processElement1(Tuple2<HainiuKafkaRecord, String> value, Context ctx, Collector<String> out) throws Exception {
String currentKey = ctx.getCurrentKey().getRecord();
map.put(currentKey, value.f1);
out.collect(value.toString());
}
@Override
public void processElement2(HainiuKafkaRecord value, Context ctx, Collector<String> out) throws Exception {
HainiuKafkaRecord currentKey = ctx.getCurrentKey();
String countryName = map.get(currentKey.getRecord());
String outStr = countryName == null ? "no match" : countryName;
out.collect(currentKey.toString() + "--" + outStr);
}
});
connectInput.print();
env.execute();
}
}*可能会出现数据倾斜,可根据实际情况结合物理分区来解决
3.物理分区
算子间数据传递模式
- One-to-one streams 保持元素的分区和顺序
- Redistributing streams
改变流的分区策略取决于使用的算子
- keyBy()(re-partitions by hashing the key)
- broadcast()
- rebalance()(which re-partitions randomly)
都是Transformation,都可以改变分区
| 分区Transformation | 说明 |
|---|---|
| Random partitioning | 按均匀分布随机划分元素,网络开销往往比较大 dataStream.shuffle() |
| Round-robin partitioning | 循环对元素进行分区,为每一个分区创建相等的负载,这在数据倾斜时非常有用的: dataStream.rebalance() |
| Rescaling | 跟rebalance有点类似,但不是全局的,通过轮询调度将元素从上游的task一个子 集发送到下游task的一个子集: dataStream.rescale(); |
| Broadcasting | 将元素广播到每个分区上 dataStream.broadcast(); |
| Custom partitioning | dataStream.partitionCustom(partitioner, "someKey") 或 dataStream.partitionCustom(partitioner, 0) |
4.解决数据倾斜
1).One-to-one streams 解决数据倾斜的方法:
rebalance
- 含义:再平衡,用来减轻数据倾斜
- 转换关系: DataStream → DataStream
- 使用场景:处理数据倾斜,比如某个kafka的partition的数据比较多
示例代码:
val stream: DataStream[MyType] = env.addSource(new FlinkKafkaConsumer08[String](...))
val str1: DataStream[(String, MyType)] = stream.flatMap { ... }
val str2: DataStream[(String, MyType)] = str1.rebalance()
val str3: DataStream[AnotherType] = str2.map { ... }上述 DataStream 上的转换在运行时会转换成如下的执行图:
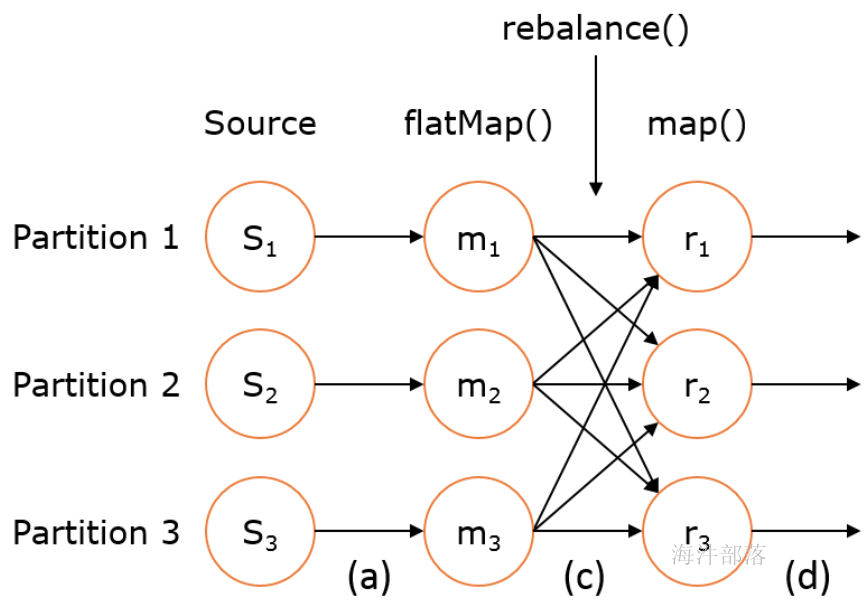
如上图的执行图所示,DataStream 各个算子会并行运行,算子之间是数据流分区。如 Source 的第一个并行实例(S1)和 flatMap() 的第一个并行实例(m1)之间就是一个数据流分区。而在 flatMap() 和 map() 之间由于加了 rebalance(),它们之间的数据流分区就有3个子分区(m1的数据流向3个map()实例)。
rescale
- 原理:通过轮询调度将元素从上游的task一个子集发送到下游task的一个子集
- 转换关系:DataStream → DataStream
- 使用场景:数据传输都在一个TaskManager内,不需要通过网络。
原理:
第一个task并行度为2,第二个task并行度为6,第三个task并行度为2。从第一个task到第二个task,Src的 子集Src1 和 Map的子集Map1,2,3对应起来,Src1会以轮询调度的方式分别向Map1,2,3发送记录。 从第二个task到第三个task,Map的子集1,2,3对应Sink的子集1,这三个流的元素只会发送到Sink1。 假设我们每个TaskManager有三个Slot,并且我们开了SlotSharingGroup,那么通过rescale,所有的数据传输都在一个TaskManager内,不需要通过网络。
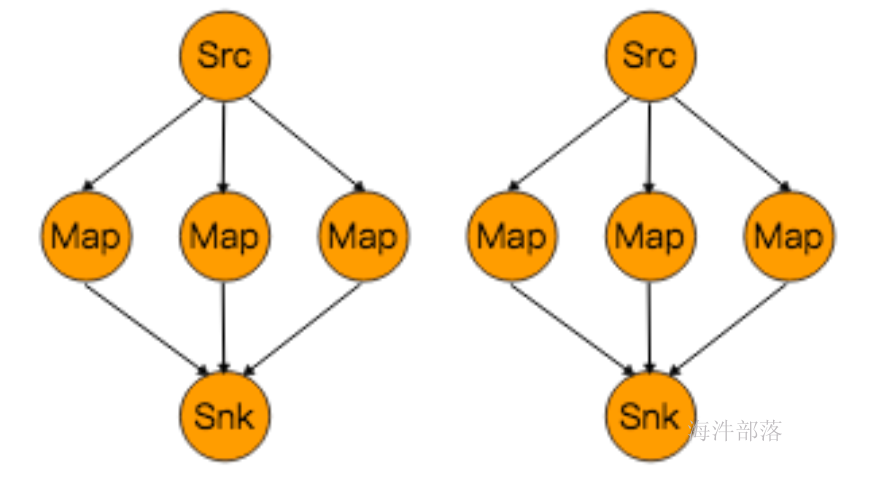
2).Redistributing streams 解决数据倾斜的方法:
自定义partitioner
- 转换关系:DataStream → DataStream
- 使用场景:自定义数据处理负载
- 实现方法:
- 实现org.apache.flink.api.common.functions.Partitioner接口
- 覆盖partition方法
- 设计算法返回partitionId
示例代码:
package com.hainiu.operator;
import com.hainiu.source.FileCountryDictSourceFunction;
import com.hainiu.source.HainiuKafkaRecord;
import com.hainiu.source.HainiuKafkaRecordSchema;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.apache.flink.util.Collector;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
public class CountryCodeConnectCustomPartitioner {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> countryDictSource = env.addSource(new FileCountryDictSourceFunction());
Properties kafkaConsumerProps = new Properties();
kafkaConsumerProps.setProperty("bootstrap.servers", "s1.hadoop:9092,s2.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092");
kafkaConsumerProps.setProperty("group.id", "qingniuflink");
kafkaConsumerProps.setProperty("flink.partition-discovery.interval-millis", "30000");
FlinkKafkaConsumer010<HainiuKafkaRecord> kafkaSource = new FlinkKafkaConsumer010<>("flink_event", new HainiuKafkaRecordSchema(), kafkaConsumerProps);
// kafkaSource.setStartFromEarliest()
// kafkaSource.setStartFromGroupOffsets()
kafkaSource.setStartFromLatest();
DataStreamSource<HainiuKafkaRecord> kafkainput = env.addSource(kafkaSource);
DataStream<Tuple2<String, String>> countryDictPartition = countryDictSource.map(new MapFunction<String, Tuple2<String, String>>() {
@Override
public Tuple2<String, String> map(String value) throws Exception {
String[] split = value.split("\t");
return Tuple2.of(split[0], split[1]);
}
}).partitionCustom(new Partitioner<String>() {
@Override
public int partition(String key, int numPartitions) {
if (key.contains("CN")) {
return 0;
} else {
return 1;
}
}
}, new KeySelector<Tuple2<String, String>, String>() {
@Override
public String getKey(Tuple2<String, String> value) throws Exception {
return value.f0;
}
});
DataStream<HainiuKafkaRecord> recordPartition = kafkainput.partitionCustom(new Partitioner<String>() {
@Override
public int partition(String key, int numPartitions) {
if (key.contains("CN")) {
return 0;
} else {
return 1;
}
}
}, new KeySelector<HainiuKafkaRecord, String>() {
@Override
public String getKey(HainiuKafkaRecord value) throws Exception {
return value.getRecord();
}
});
ConnectedStreams<Tuple2<String, String>, HainiuKafkaRecord> connect = countryDictPartition.connect(recordPartition);
SingleOutputStreamOperator<String> connectInput = connect.process(new CoProcessFunction<Tuple2<String, String>, HainiuKafkaRecord, String>() {
private Map<String, String> map = new HashMap<String, String>();
@Override
public void processElement1(Tuple2<String, String> value, Context ctx, Collector<String> out) throws Exception {
map.put(value.f0, value.f1);
out.collect(value.toString());
}
@Override
public void processElement2(HainiuKafkaRecord value, Context ctx, Collector<String> out) throws Exception {
String countryCode = value.getRecord();
String countryName = map.get(countryCode);
String outStr = countryName == null ? "no match" : countryName;
out.collect(outStr);
}
});
connectInput.print();
env.execute();
}
}使用parititoner解决数据倾斜
package com.hainiu.flink.operator;
import com.hainiu.flink.source.FileCountryDictSourceFunction;
import com.hainiu.flink.source.HainiuKafkaRecord;
import com.hainiu.flink.source.HainiuKafkaRecordSchema;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.Partitioner;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.apache.flink.util.Collector;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
import java.util.Random;
public class CountryCodeConnectCustomPartitioner {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
Properties kafkaConsumerProps = new Properties();
kafkaConsumerProps.setProperty("bootstrap.servers", "s1.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092");
kafkaConsumerProps.setProperty("group.id", "qingniuflink");
kafkaConsumerProps.setProperty("flink.partition-discovery.interval-millis", "30000");
FlinkKafkaConsumer010<HainiuKafkaRecord> kafkaSource = new FlinkKafkaConsumer010<>("flink_event", new HainiuKafkaRecordSchema(), kafkaConsumerProps);
kafkaSource.setStartFromLatest();
DataStreamSource<HainiuKafkaRecord> kafkaInput = env.addSource(kafkaSource);
DataStream<HainiuKafkaRecord> kafka = kafkaInput.map(new MapFunction<HainiuKafkaRecord, HainiuKafkaRecord>() {
@Override
public HainiuKafkaRecord map(HainiuKafkaRecord value) throws Exception {
String record = value.getRecord();
Random random = new Random();
int i = random.nextInt(10);
return new HainiuKafkaRecord(i + "_" + record);
}
}).partitionCustom(new Partitioner<HainiuKafkaRecord>() {
@Override
public int partition(HainiuKafkaRecord key, int numPartitions) {
String[] s = key.getRecord().split("_");
String randomId = s[0];
return new Integer(randomId);
}
},
new KeySelector<HainiuKafkaRecord, HainiuKafkaRecord>() {
@Override
public HainiuKafkaRecord getKey(HainiuKafkaRecord value) throws Exception {
return value;
}
});
DataStreamSource<String> countryDictSource = env.addSource(new FileCountryDictSourceFunction());
DataStream<Tuple2<HainiuKafkaRecord, String>> countryDict = countryDictSource.flatMap(new FlatMapFunction<String, Tuple2<HainiuKafkaRecord, String>>() {
@Override
public void flatMap(String value, Collector<Tuple2<HainiuKafkaRecord, String>> out) throws Exception {
String[] split = value.split("\t");
String key = split[0];
String values = split[1];
for (int i = 0; i < 10; i++) {
String randomKey = i + "_" + key;
Tuple2<HainiuKafkaRecord, String> t2 = Tuple2.of(new HainiuKafkaRecord(randomKey), values);
out.collect(t2);
}
}
}).partitionCustom(new Partitioner<HainiuKafkaRecord>() {
@Override
public int partition(HainiuKafkaRecord key, int numPartitions) {
String[] s = key.getRecord().split("_");
String randomId = s[0];
return new Integer(randomId);
}
}, new KeySelector<Tuple2<HainiuKafkaRecord, String>, HainiuKafkaRecord>() {
@Override
public HainiuKafkaRecord getKey(Tuple2<HainiuKafkaRecord, String> value) throws Exception {
return value.f0;
}
});
ConnectedStreams<Tuple2<HainiuKafkaRecord, String>, HainiuKafkaRecord> connect = countryDict.connect(kafka);
SingleOutputStreamOperator<String> connectInput = connect.process(new CoProcessFunction<Tuple2<HainiuKafkaRecord, String>, HainiuKafkaRecord, String>() {
private Map<String, String> map = new HashMap<String, String>();
@Override
public void processElement1(Tuple2<HainiuKafkaRecord, String> value, Context ctx, Collector<String> out) throws Exception {
map.put(value.f0.getRecord(), value.f1);
out.collect(value.toString());
}
@Override
public void processElement2(HainiuKafkaRecord value, Context ctx, Collector<String> out) throws Exception {
String countryName = map.get(value.getRecord());
String outStr = countryName == null ? "no match" : countryName;
out.collect(outStr);
}
});
connectInput.print();
env.execute();
}
}5.reduce 与 fold
- 分组之后当然要对分组之后的数据也就是KeyedStream进行各种聚合操作啦
- KeyedStream → DataStream
- 对于KeyedStream的聚合操作都是滚动的(rolling,在前面的状态基础上继续聚合),千万不要理解为批处理时的聚合操作(DataSet,其实也是滚动聚合,只不过他只把最后的结果给了我们)
| 聚合操作 | 意义 |
|---|---|
| reduce | KeyedStream流上,将上一次reduce的结果和本次的进行操作 |
| fold | 对keyedStream流上的event进行连接操作 |
| sum/min/minBy/max/maxBy | reduce的特例,min和minBy的区别是min返回的是一个最小值,而minBy返回的是其字段中包含最小值的元素(同样原理适用于max和maxBy) |
| process | 底层的聚合操作 |
示例代码:
package com.hainiu.operator;
import com.hainiu.source.FileCountryDictSourceFunction;
import com.hainiu.source.HainiuKafkaRecord;
import com.hainiu.source.HainiuKafkaRecordSchema;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.KeyedCoProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
public class CountryCodeConnectKeyByCountryCount {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> countryDictSource = env.addSource(new FileCountryDictSourceFunction());
Properties kafkaConsumerProps = new Properties();
kafkaConsumerProps.setProperty("bootstrap.servers", "s1.hadoop:9092,s2.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092");
kafkaConsumerProps.setProperty("group.id", "qingniuflink");
kafkaConsumerProps.setProperty("flink.partition-discovery.interval-millis", "30000");
FlinkKafkaConsumer010<HainiuKafkaRecord> kafkaSource = new FlinkKafkaConsumer010<>("flink_event", new HainiuKafkaRecordSchema(), kafkaConsumerProps);
// kafkaSource.setStartFromEarliest()
// kafkaSource.setStartFromGroupOffsets()
kafkaSource.setStartFromLatest();
DataStreamSource<HainiuKafkaRecord> kafkainput = env.addSource(kafkaSource);
KeyedStream<Tuple2<String, String>, String> countryDictKeyBy = countryDictSource.map(new MapFunction<String, Tuple2<String, String>>() {
@Override
public Tuple2<String, String> map(String value) throws Exception {
String[] split = value.split("\t");
return Tuple2.of(split[0], split[1]);
}
}).keyBy(new KeySelector<Tuple2<String, String>, String>() {
@Override
public String getKey(Tuple2<String, String> value) throws Exception {
return value.f0;
}
});
KeyedStream<HainiuKafkaRecord, String> record = kafkainput.keyBy(new KeySelector<HainiuKafkaRecord, String>() {
@Override
public String getKey(HainiuKafkaRecord value) throws Exception {
return value.getRecord();
}
});
ConnectedStreams<Tuple2<String, String>, HainiuKafkaRecord> connect = countryDictKeyBy.connect(record);
SingleOutputStreamOperator<Tuple2<String, Integer>> connectInput = connect.process(new KeyedCoProcessFunction<String, Tuple2<String, String>, HainiuKafkaRecord, Tuple2<String, Integer>>() {
private Map<String, String> map = new HashMap<String, String>();
@Override
public void processElement1(Tuple2<String, String> value, Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception {
map.put(ctx.getCurrentKey(), value.f1);
out.collect(Tuple2.of(value.f0, 1));
}
@Override
public void processElement2(HainiuKafkaRecord value, Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception {
String countryCode = ctx.getCurrentKey();
String countryName = map.get(countryCode);
String outStr = countryName == null ? "no match" : countryName;
out.collect(Tuple2.of(countryName.substring(0, countryName.indexOf(" ")), 1));
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> reduce = connectInput.keyBy(0).reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
});
reduce.print();
env.execute();
}
}6.OutputTab(拆分流)
- 只能在processFunction中使用
- 根据条件输出不同类型的数据
示例代码:
package com.hainiu.operator;
import com.hainiu.source.FileCountryDictSourceFunction;
import com.hainiu.source.HainiuKafkaRecord;
import com.hainiu.source.HainiuKafkaRecordSchema;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.KeyedCoProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
public class CountryCodeConnectKeyByCountryCountOutputTag {
private static final OutputTag<String> ot = new OutputTag<String>("china") {
};
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> countryDictSource = env.addSource(new FileCountryDictSourceFunction());
Properties kafkaConsumerProps = new Properties();
kafkaConsumerProps.setProperty("bootstrap.servers", "s1.hadoop:9092,s2.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092");
kafkaConsumerProps.setProperty("group.id", "qingniuflink");
kafkaConsumerProps.setProperty("flink.partition-discovery.interval-millis", "30000");
FlinkKafkaConsumer010<HainiuKafkaRecord> kafkaSource = new FlinkKafkaConsumer010<>("flink_event", new HainiuKafkaRecordSchema(), kafkaConsumerProps);
// kafkaSource.setStartFromEarliest()
// kafkaSource.setStartFromGroupOffsets()
kafkaSource.setStartFromLatest();
DataStreamSource<HainiuKafkaRecord> kafkainput = env.addSource(kafkaSource);
KeyedStream<Tuple2<String, String>, String> countryDictKeyBy = countryDictSource.map(new MapFunction<String, Tuple2<String, String>>() {
@Override
public Tuple2<String, String> map(String value) throws Exception {
String[] split = value.split("\t");
return Tuple2.of(split[0], split[1]);
}
}).keyBy(new KeySelector<Tuple2<String, String>, String>() {
@Override
public String getKey(Tuple2<String, String> value) throws Exception {
return value.f0;
}
});
KeyedStream<HainiuKafkaRecord, String> record = kafkainput.keyBy(new KeySelector<HainiuKafkaRecord, String>() {
@Override
public String getKey(HainiuKafkaRecord value) throws Exception {
return value.getRecord();
}
});
ConnectedStreams<Tuple2<String, String>, HainiuKafkaRecord> connect = countryDictKeyBy.connect(record);
SingleOutputStreamOperator<Tuple2<String, Integer>> connectInput = connect.process(new KeyedCoProcessFunction<String, Tuple2<String, String>, HainiuKafkaRecord, Tuple2<String, Integer>>() {
private Map<String, String> map = new HashMap<String, String>();
@Override
public void processElement1(Tuple2<String, String> value, Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception {
map.put(ctx.getCurrentKey(), value.f1);
out.collect(Tuple2.of(value.f0, 1));
}
@Override
public void processElement2(HainiuKafkaRecord value, Context ctx, Collector<Tuple2<String, Integer>> out) throws Exception {
String countryCode = ctx.getCurrentKey();
String countryName = map.get(countryCode);
String outStr = countryName == null ? "no match" : countryName;
if (outStr.contains("中国")) {
ctx.output(ot, outStr);
}
out.collect(Tuple2.of(countryName.substring(0, countryName.indexOf(" ")), 1));
}
});
SingleOutputStreamOperator<Tuple2<String, Integer>> reduce = connectInput.keyBy(1).reduce(new ReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
});
reduce.print();
connectInput.getSideOutput(ot).print();
env.execute();
}
}4.sink
内置数据输出
- 基于文件
#使用TextOutputFormat
stream.writeAsText("/path/to/file")
#使用CsvOutputFormat
stream.writeAsCsv("/path/to/file")2.基于Socket
stream.writeToSocket(host, port, SerializationSchema)3.基于标准/错误输出
stream.writeToSocket(host, port, SerializationSchema)#注: 线上应用杜绝使用,采用抽样打印或者日志的方式
stream.print()
stream.printToErr()自定义数据输出
- 实现SinkFunction 或 继承RichSinkFunction(在没有自行改变并行度的情况下,是否并行取决其父operator)
1.实现RichSinkFunction
- 实现写入文件写入文件到HDFS
示例代码:
function:
package com.hainiu.sink;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.sink.RichSinkFunction;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.text.SimpleDateFormat;
import java.util.Date;
public class HDFSSinkFunction extends RichSinkFunction<String> {
private FileSystem fs = null;
private SimpleDateFormat sf = null;
private String pathStr = null;
@Override
public void open(Configuration parameters) throws Exception {
org.apache.hadoop.conf.Configuration conf = new org.apache.hadoop.conf.Configuration();
fs = FileSystem.get(conf);
sf = new SimpleDateFormat("yyyyMMddHH");
pathStr = "hdfs://ns1/user/qingniu/flinkstreaminghdfs";
}
@Override
public void close() throws Exception {
fs.close();
}
@Override
public void invoke(String value, Context context) throws Exception {
if (null != value) {
String format = sf.format(new Date());
int indexOfThisSubtask = getRuntimeContext().getIndexOfThisSubtask();
StringBuilder sb = new StringBuilder();
sb.append(pathStr).append("/").append(indexOfThisSubtask).append("_").append(format);
Path path = new Path(sb.toString());
FSDataOutputStream fsd = null;
if (fs.exists(path)) {
fsd = fs.append(path);
} else {
fsd = fs.create(path);
}
fsd.write((value + "\n").getBytes("UTF-8"));
fsd.close();
}
}
}运行类:
package com.hainiu.sink;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class HDFSFile {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = env.socketTextStream("localhost", 6666);
source.addSink(new HDFSSinkFunction());
env.execute();
}
}2.以Kafka-connector-sink
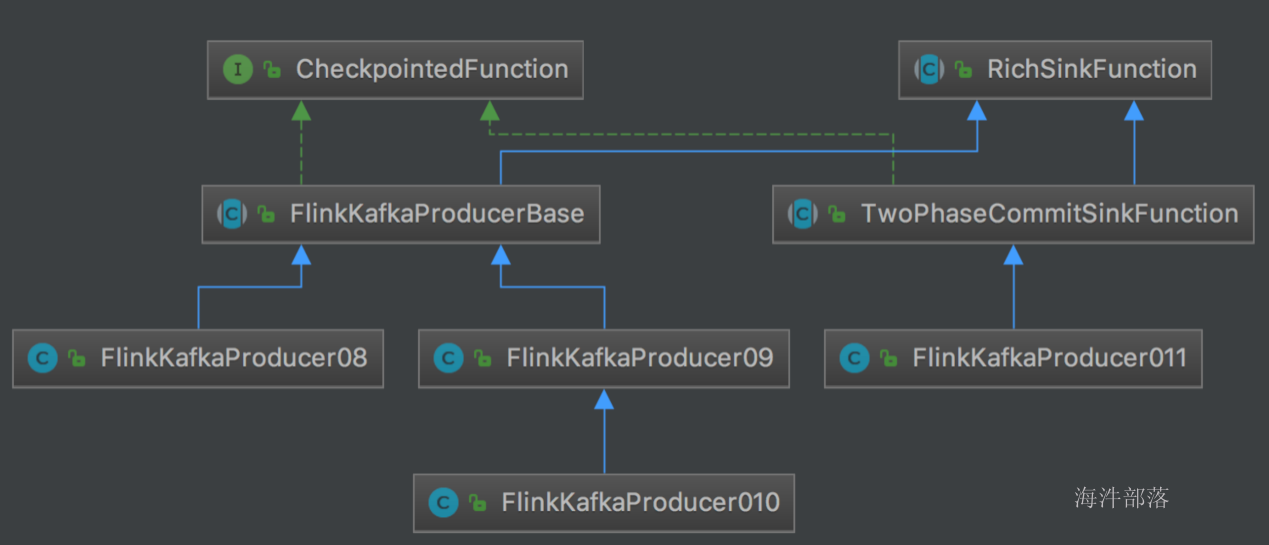
1.FlinkFlinkKafkaProducer创建方式:
FlinkKafkaProducer010(String brokerList, String topicId, SerializationSchema<T> serializationSchema)
FlinkKafkaProducer010(String topicId, SerializationSchema<T> serializationSchema, Properties producerConfig)
FlinkKafkaProducer010(String brokerList, String topicId, KeyedSerializationSchema<T> serializationSchema)
FlinkKafkaProducer010(String topicId, KeyedSerializationSchema<T> serializationSchema, Properties producerConfig)
FlinkKafkaProducer010(String topicId,SerializationSchema<T> serializationSchema,Properties producerConfig,@Nullable FlinkKafkaPartitioner<T> customPartitioner)
FlinkKafkaProducer010(String topicId,KeyedSerializationSchema<T> serializationSchema,Properties producerConfig,@Nullable FlinkKafkaPartitioner<T> customPartitioner)2.常见序列化Schema
- TypeInformationKeyValueSerializationSchema
- SimpleStringSchema
4.自定义序列化Schema:
- 实现KeyedSerializationSchema接口
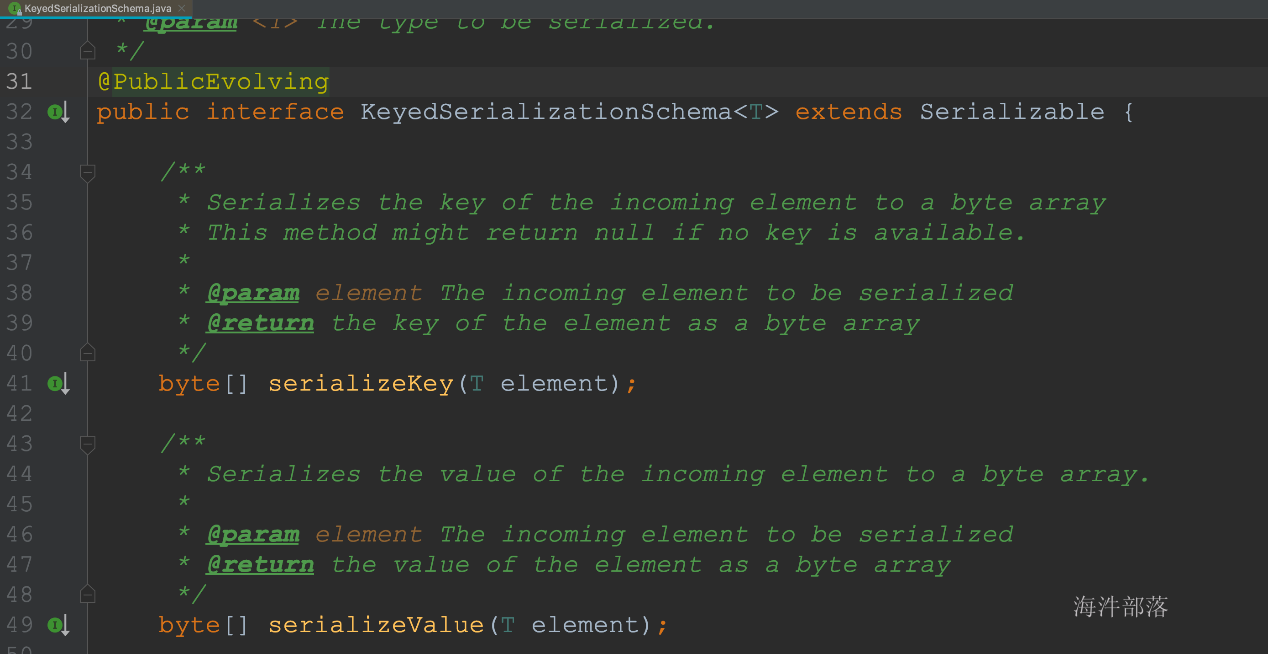
示例代码:
case class KafkaEventP(message: String, eventTime: Long)
//自定义Serializer用来进行对象序列化到kafka中
class KafkaEventPKeyedSerializationSchema extends KeyedSerializationSchema[KafkaEventP] {
//序列化到kafka的key
override def serializeKey(element: KafkaEventP): Array[Byte] = {
element.message.getBytes()
}
//序列化到kafka的value
override def serializeValue(element: KafkaEventP): Array[Byte] = {
s"hainiu_processed_${element.message}".getBytes()
}
//得到目标topic可以不指定,因为在创建sink的时候已经指定
override def getTargetTopic(element: KafkaEventP): String = {
null
}
}4.producerConfig
FlinkKafkaProducer内部KafkaProducer的配置
https://kafka.apache.org/documentation.html
示例代码:
Properties producerPropsSns = new Properties();
producerPropsSns.setProperty("bootstrap.servers", "s1.hadoop:9092,s2.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092");
producerPropsSns.setProperty("retries", "3");5.FlinkKafkaPartitioner
- 默认使用FlinkFixedPartitioner,即每个subtask的数据写到同一个Kafka partition中
- 自定义分区器:继承FlinkKafkaPartitioner
示例代码:
Partitioner:
package com.hainiu.sink;
import org.apache.flink.streaming.connectors.kafka.partitioner.FlinkKafkaPartitioner;
public class HainiuFlinkPartitioner extends FlinkKafkaPartitioner {
@Override
public int partition(Object record, byte[] key, byte[] value, String targetTopic, int[] partitions) {
return 1;
}
}运行类:
package com.hainiu.sink;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaProducer010;
import java.util.Properties;
public class KafkaRichParallelSink {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = env.socketTextStream("localhost", 6666);
Properties producerPropsSns = new Properties();
producerPropsSns.setProperty("bootstrap.servers", "s1.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092");
producerPropsSns.setProperty("retries", "3");
//FlinkKafkaProducer010类的构造函数支持自定义kafka的partitioner,
FlinkKafkaProducer010 kafkaOut = new FlinkKafkaProducer010<String>("flink_event_result",
new SimpleStringSchema(),
producerPropsSns,new HainiuFlinkPartitioner());
source.addSink(kafkaOut);
env.execute();
}
}5.状态与容错
1.Flink恢复机制
1.通过配置重生策略进行容错
- Flink支持不同的重启策略,这些策略控制在出现故障时如何重新启动job
| Restart Strategy | 配置项 | 默认值 | 说明 |
|---|---|---|---|
| 固定延迟(Fixed delay) | restart-strategy:fixed-delay | 如果超过最大尝试次数,作业最终会失败。在连续两次重启尝试之间等待固定的时间。 | |
| restart-strategy.fixed-delay.attempts:3 | 1或者Integer.MAX_VALUE(启用checkpoint但未指定重启策略时) | ||
| restart-strategy.fixed-delay.delay:10s | akka.ask.timeout或者10s(启用checkpoint但未指定重启策略时) | ||
| 失败率(Failure rate) | restart-strategy:failure-rate | 在失败后重新启动作业,但是当超过故障率(每个时间间隔的故障)时,作业最终会失败。在连续两次重启尝试之间等待固定的时间。 | |
| restart-strategy:failure-rate.max-failures-per-interval:3 | 1 | ||
| restart-strategy.failure-rate.failure-rateinterval:5min | 1 minute | ||
| restart-strategy:failure-rate.delay:10s | akka.ask.timeout | ||
| 不恢复(No restart) | restart-strategy:none | 如果没有启用checkpointing,则使用无重启(no restart)策略。 |
- 重启策略可以在flink-conf.yaml中配置,表示全局的配置。也可以在应用代码中动态指定,会覆盖全局配置
固定延迟的代码
env.setRestartStrategy(
RestartStrategies.fixedDelayRestart(
3,
Time.of(0,TimeUnit.SECONDS)
)
)示例代码:
package com.hainiu.state;
import com.hainiu.source.FileCountryDictSourceFunction;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.concurrent.TimeUnit;
public class FileSourceRestart {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//恢复策略
env.setRestartStrategy(
RestartStrategies.fixedDelayRestart(
3, // number of restart attempts
Time.of(0, TimeUnit.SECONDS) // delay
)
);
DataStreamSource<String> stringDataStreamSource = env.addSource(new FileCountryDictSourceFunction());
stringDataStreamSource.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
System.out.println(value);
if(value.contains("中国")){
int a = 1/0;
}
return value;
}
}).print();
env.execute();
}
}通过以上配置可以给你的程序增加生命条数,但是有个问题?能不能不仅增加生命条件,还能帮我存档?通过checkpoint加上state进行数据存档
2.Flink的state
1.什么是状态(State)
- Flink中的状态:一般指一个具体的task/operator某时刻在内存中的状态(例如某属性的值)
2.状态的作用
- 增量计算
- 聚合操作
- 机器学习训练模式
- 等等
- 容错
- Job故障重启
- 升级
3.没有状态的日子如何度过
- Storm+Hbase,把这状态数据存放在Hbase中,计算的时候再次从Hbase读取状态数据,做更新在写入进去。这样就会有如下几个问题:
- 流计算任务和Hbase的数据存储有可能不在同一台机器上,导致性能会很差。这样经常会做远端的访问,走网络和存储
- 备份和恢复是比较困难,因为Hbase是没有回滚的,要做到Exactly onces很困难。在分布式环境下,如果程序出现故障,只能重启Storm,那么Hbase的数据也就无法回滚到之前的状态。比如广告计费的这种场景,Storm+Hbase是行不通的,出现的问题是钱可能就会多算,解决以上的办法是Storm+mysql,通过mysql的回滚解决一致性的问题。但是架构会变得非常复杂。性能也会很差,要commit确保数据的一致
- 对于storm而言状态数据的划分和动态扩容也是非常难做的,一个很严重的问题是所有用户都会strom上重复的做这些工作,比如搜索,广告都要在做一遍,由此限制了部门的业务发展
4.Flink有状态的计算
5.Flink丰富的状态访问和高效的容错机制
6.状态分类
- Operator State
- Keyed State
- 特殊的:Broadcast State(1.5开始)
1).Operator State
- 绑定到特定operator并行实例,每个operator的并行实例维护一个状态
- 与key无关
- 思考:一个并行度为3的source有几个状态(只考虑一个算子需要一个逻辑状态的情形)
- 支持的数据类型
- ListState\<T>
- 例子:FlinkKafkaConsumer
- 每个Kafka Consumer实例都维护一个topic分区和偏移量的映射作为其操作状态。
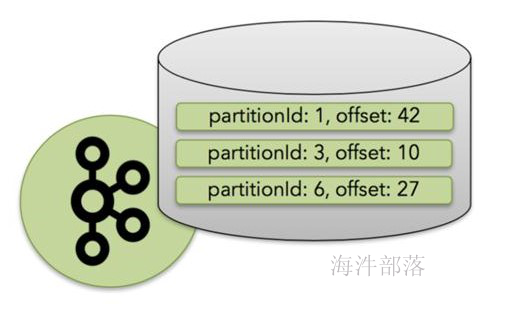
2).Keyed State
- 基于KeyedStream之上的状态,dataStream.keyBy(),只能在作用于KeyedStrem上的function/Operator里使用
- KeyBy之后的Operator State,可理解为分区过的Operator State
- 每个并行keyed Operator的每个实例的每个key有一个Keyed State:即\<parallel-operator-instance,key>就是一个唯一的状态,由于每个key属于一个keyed operator的并行实例,因此我们可以将其简单地理解为\<operator,key>
- 思考:一个并行度为2的keyed Operator有多少个状态(只考虑一个算子需要一个逻辑状态的情形)
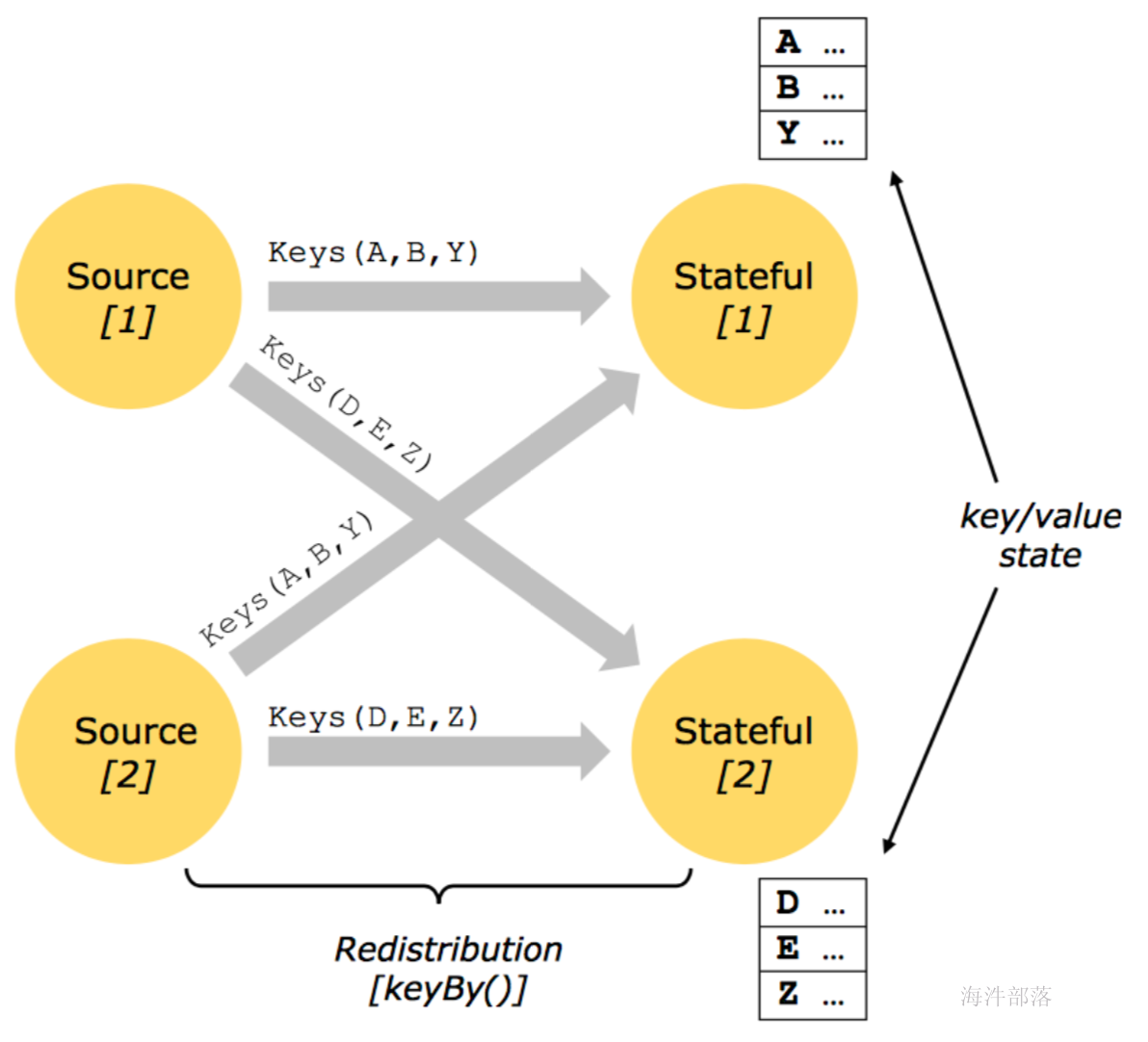
- 支持的数据结构
- ValueState\<T>:保留一个可以更新和检索的值
- update(T)
- value()
- ListState\<T>:保存一个元素列表
- add(T)
- addAll(List\<T>)
- get(T)
- clear()
- ReducingState\<T>:保存一个值,该值表示添加到该状态所有值的聚合。
- add(T)
- AggregatingState\<IN,OUT>:保存一个值,该值表示添加到该状态的所有值的聚合。(与ReducingState相反,聚合类型添加到该状态的元素可以有不同类型)
- add(T)
- FoldingState\<T,ACC>:不推荐使用
- add(T)
- MapState\<UK,UV>:保存一个映射列表
- put(UK,UV)
- putAll(Map\<UK,UV>)
- get(UK)
- ValueState\<T>:保留一个可以更新和检索的值
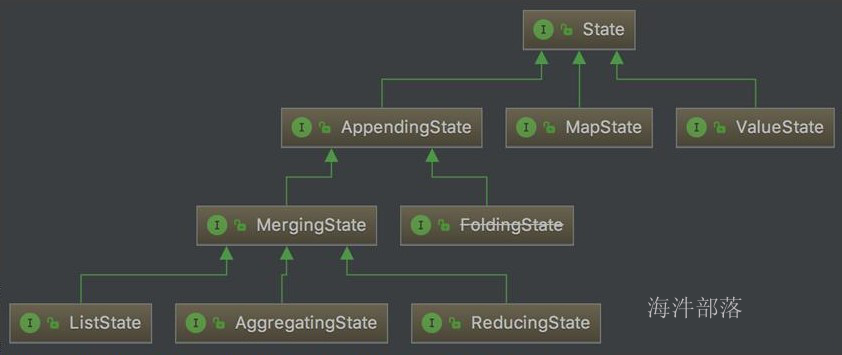
3).注意:
- 状态不一定存储在内存,可能驻留在磁盘或其他地方
- 状态是使用RuntimeContext访问的,因此只能在Rich函数或process函数中访问
4).状态的表现形式
- Keyed State和Operator State,可以以两种形式存在:原始状态和托管状态。
- managed(托管状态):
- 托管状态是指Flink框架管理的状态,如ValueState,ListState,MapState等。
- 通过框架提供的接口来更新和管理状态的值
- 不需要序列化
- raw(原始状态)
- 原始状态是由用户自行管理的具体的数据结构,Flink在做checkpoint的时候,使用byte[]来读写状态内容,对其内部数据结构一无所知
- 需要序列化
- 通常在DataStream上的状态推荐使用托管的状态,当用户自定义operator时,会使用到原始状态。
- 大多数都是托管状态,除非自定义实现。
3.Flink的checkpoint
1).状态容错
- 有了状态自然需要状态容错,否则状态就失去意义了
- Flink状态容错的机制就是checkpoint
2).状态容错示意图
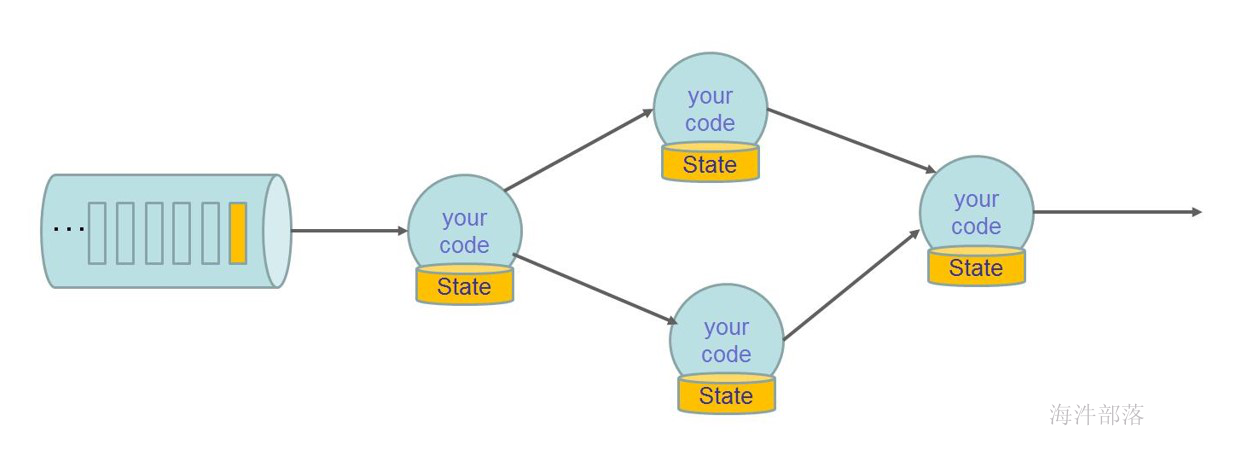
3).状态容错示意图(checkpoint)
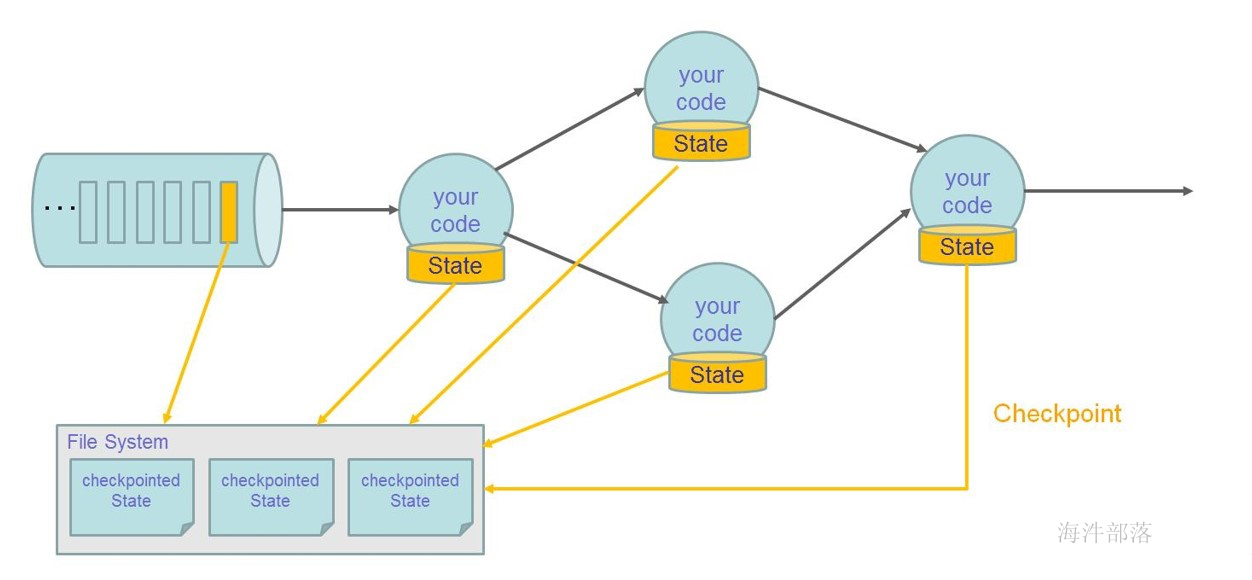
4).状态容错示意图(Restore)
- 恢复所有状态
- 设置source的位置(例如:Kafka的offset)
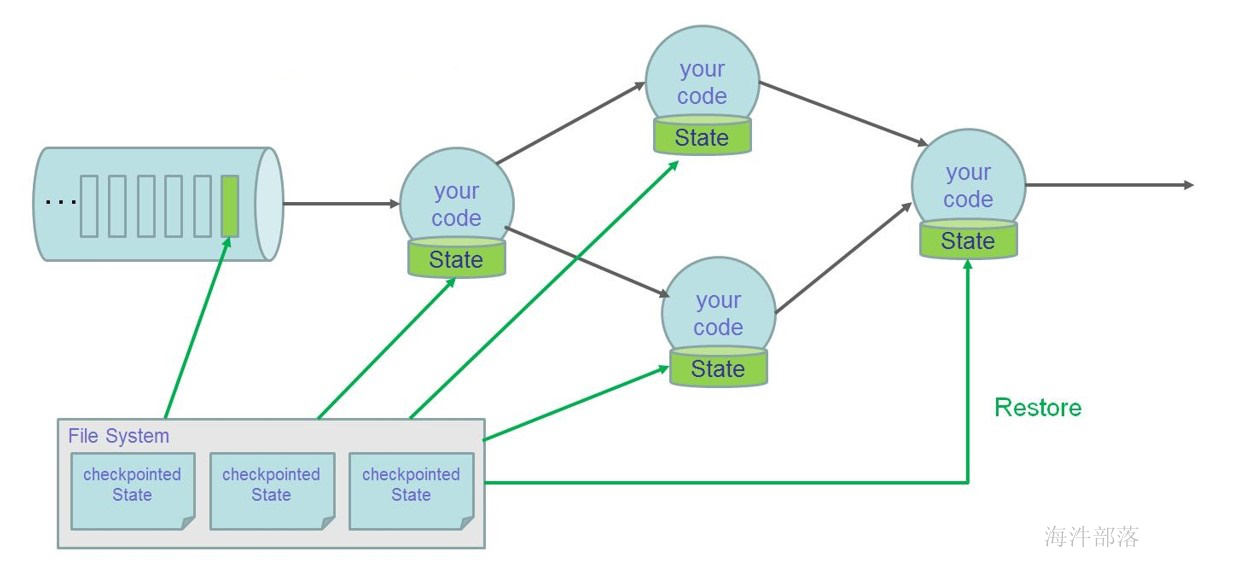
5).Checkpointing是什么
- 概念
- 所谓checkpoint,就是在某一时刻,将所有task的状态做一个快照(snapshot),然后存储到State Backend
- 一种连续性绘制数据流状态的机制(周期性的),该机制确保即使出现故障,程序的状态最终也将为数据流中的每一条记录提供exactly once的语意保证(只能保证flink系统内,对于sink和source需要依赖的外部的组件一同保证)
- 全局快照,持久化保存所有的task / operator的State
- 序列化数据集合
- 注意:可以通过开关使用at least once语意保证
- 注意:Checkpoint是通过分布式snapshot实现的,没有特殊说明时snapshot和checkpoint和back-up是一个意思
- 注意:State和Checkpointing不要搞混
- 特点:
- 轻量级容错机制
- 可异步
- 全量 vs 增量
- 失败情况可回滚至最近一次成功的checkpoint(自动)
- 周期性(无需人工干预)
4.Checkpointing与State的使用
启用Checkpointing
1).如何开启Checkpointing
- Checkpointing默认是禁用的
- 注意:迭代job目前不支持Checkpoint
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//start a checkpoint every 1000 ms
env.enableCheckpointing(1000);
//advanced options:
//set mode to exactly-once (this is the default)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//make sure 500 ms of progress happen between checkpoints
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);
//checkpoints have to complete within one minute,or are discarded
env.getCheckpointConfig().setCheckpointTimeout(60000);
//allow only one checkpoint to be in progress at the same time
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);
//enable externalized checkpoints which are retained after job cancellation
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
env.getCheckpointConfig().setFailOnCheckpointingErrors(true);2).Checkpointing高级选项之checkpointMode
- CheckpointingMode.EXACTLY_ONCE
- CheckpointingMode.AT_LEAST_ONCE
- 如何选择:一般情况下选择EXACTLY_ONCE,除非场景要求极低的延迟(几毫秒)
- 注意:要想整个EXACTLY_ONCE,source和sink也要同时保证EXACTLY_ONCE
//set mode to exactly-once (this is the default)
env.getCheckpointConfig().setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);3).Checkpointing高级选项之保留策略
- 默认情况下,检查点不被保留,仅用于从故障中恢复作业。可以启用外部持久化检查点,同时指定保留策略
- ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION:在作业取消时保留检查点。注意,在这种情况系,必须在取消后手动清理检查点状态。
- ExternalizedCheckpointCleanup.DELETE_ON_CANCELLATION当作业被cancel时,删除检查点。检查点状态仅在作业失败时可用。
//enable externalized checkpoints which are retained after cancellation
env.getCheckpointConfig().enableExternalizedCheckpoints(ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);4).Checkpointing其他高级选项
- checkpointing的超时时间:超过时间没有完成则会被终止
//checkpoints have to complete within one minute, or are discarded
env.getCheckpointConfig().setCheckpointTimeout(60000);- checkpointing最小间隔:用于指定上一个checkpoint完成之后最小等多久可以出发另一个checkpoint,当指定这个参数时,maxConcurrentCheckpoints的值为1
//make sure 500 ms of progress happen between checkpoints
env.getCheckpointConfig().setMinPauseBetweenCheckpoints(500);- maxConcurrentCheckpoints:指定运行中的checkpoint最多可以有多少个(设定checkpointing最小间隔时本参数即为1)
//allow only one checkpoint to be in progress at the same time
env.getCheckpointConfig().setMaxConcurrentCheckpoints(1);- failOnCheckpointingErrors用于指定在checkpoint发生异常的时候,是否应该fail该task,默认为true,如果设置为false,则task会拒绝checkpoint然后继续运行
env.getCheckpointConfig().setFailOnCheckpointingErrors(true);注意,当开启checkpointing对重启(no restart)策略的影响:
- 如果没有启用checkpointing,就是不恢复数据。
- 如果启用了checkpointing,但没有配置重启策略,则使用固定延迟(fixed-delay)策略,其中尝试重启次数是Integer>MAX_VALUE
1.使用Operator State方式1:实现CheckpointedFunction
- Stateful function(RichFunction)实现CheckpointedFunction接口,必须实现两个方法:
- Void snapshotState(FunctionSnapshotContext context) throws Exception
Checkpoint执行时调用
一般用于原始状态与托管状态进行交换
- Void initializeState(FunctionlnitializationContext context) throws Exception;(初始化以及恢复逻辑)
Stateful function第一次初始化时调用
Stateful function从较早的checkpoint恢复时调用
示例代码:
checkpointFunction:
package com.hainiu.state;
import org.apache.flink.api.common.state.ListState;
import org.apache.flink.api.common.state.ListStateDescriptor;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.runtime.state.FunctionInitializationContext;
import org.apache.flink.runtime.state.FunctionSnapshotContext;
import org.apache.flink.streaming.api.checkpoint.CheckpointedFunction;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileChecksum;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.List;
public class FileCountryDictSourceOperatorStateCheckpointedFunction implements SourceFunction<String>,CheckpointedFunction {
private String md5 = null;
private ListState<String> ls = null;
private Boolean isCancel = true;
private Integer interval = 1000;
@Override
public void run(SourceContext<String> ctx) throws Exception {
Path pathString = new Path("hdfs://ns1/user/qingniu/country_data");
Configuration hadoopConf = new Configuration();
FileSystem fs = FileSystem.get(hadoopConf);
while (isCancel) {
if(!fs.exists(pathString)){
Thread.sleep(interval);
continue;
}
System.out.println(md5);
FileChecksum fileChecksum = fs.getFileChecksum(pathString);
String md5Str = fileChecksum.toString();
String currentMd5 = md5Str.substring(md5Str.indexOf(":") + 1);
if (!currentMd5.equals(md5)) {
FSDataInputStream open = fs.open(pathString);
BufferedReader reader = new BufferedReader(new InputStreamReader(open));
String line = reader.readLine();
while (line != null) {
ctx.collect(line);
line = reader.readLine();
}
reader.close();
md5 = currentMd5;
}
Thread.sleep(interval);
}
}
@Override
public void cancel() {
isCancel = false;
}
@Override
public void snapshotState(FunctionSnapshotContext context) throws Exception {
ls.clear();
ls.add(md5);
System.out.println("snapshotState");
}
@Override
public void initializeState(FunctionInitializationContext context) throws Exception {
ListStateDescriptor<String> lsd = new ListStateDescriptor<String>("md5",String.class);
ls = context.getOperatorStateStore().getListState(lsd);
if (context.isRestored()){
Iterable<String> strings = ls.get();
String next = strings.iterator().next();
md5 = next;
}
}
}运行程序:
package com.hainiu.state;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.concurrent.TimeUnit;
public class FileSourceOperatorStateCheckpointed {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(1000);
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
//保存EXACTLY_ONCE
checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//每次ck之间的间隔,不会重叠
checkpointConfig.setMinPauseBetweenCheckpoints(2000L);
//每次ck的超时时间
checkpointConfig.setCheckpointTimeout(20000L);
//如果ck执行失败,程序是否停止
checkpointConfig.setFailOnCheckpointingErrors(true);
//job在执行CANCE的时候是否删除ck数据
checkpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//恢复策略
env.setRestartStrategy(
RestartStrategies.fixedDelayRestart(
3, // number of restart attempts
Time.of(0, TimeUnit.SECONDS) // delay
)
);
DataStreamSource<String> stringDataStreamSource = env.addSource(new FileCountryDictSourceOperatorStateCheckpointedFunction());
stringDataStreamSource.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
if(value.contains("中国")){
int a = 1/0;
}
return value;
}
}).print();
env.execute();
}
}2.使用Operator State方式2:实现ListCheckpointed(这个接口自己本身就带了一个ListState)
- Stateful function(RichFunction)实现ListCheckpointed接口,只用ListState的重分配方式
- 必须实现两个方法
- List\<T>snapshotState(long checkpointld,long timestamp) throws Exception;
Checkpoint执行时调用
这个方法的返回值,会被当成一个listState ,util.List->listState
- void restoreState(List\<T>state) throws Exception;
这个方法的传入参数,实际上snapshotState返回的listState -> util.List,所以在这个方法面能直接得到listState恢复的数据。
Stateful function从较早的checkpoint恢复时调用
示例代码:
ListCheckpointed:
package com.hainiu.state;
import org.apache.flink.streaming.api.checkpoint.ListCheckpointed;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileChecksum;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.ArrayList;
import java.util.List;
public class FileCountryDictSourceOperatorStateListCheckpointedFunction implements SourceFunction<String>, ListCheckpointed<String> {
private String md5 = null;
private Boolean isCancel = true;
private Integer interval = 1000;
@Override
public void run(SourceContext<String> ctx) throws Exception {
Path pathString = new Path("hdfs://ns1/user/qingniu/country_data");
Configuration hadoopConf = new Configuration();
FileSystem fs = FileSystem.get(hadoopConf);
while (isCancel) {
if (!fs.exists(pathString)) {
Thread.sleep(interval);
continue;
}
System.out.println(md5);
FileChecksum fileChecksum = fs.getFileChecksum(pathString);
String md5Str = fileChecksum.toString();
String currentMd5 = md5Str.substring(md5Str.indexOf(":") + 1);
if (!currentMd5.equals(md5)) {
FSDataInputStream open = fs.open(pathString);
BufferedReader reader = new BufferedReader(new InputStreamReader(open));
String line = reader.readLine();
while (line != null) {
ctx.collect(line);
line = reader.readLine();
}
reader.close();
md5 = currentMd5;
}
Thread.sleep(interval);
}
}
@Override
public void cancel() {
isCancel = false;
}
@Override
public List<String> snapshotState(long checkpointId, long timestamp) throws Exception {
List<String> list = new ArrayList<>();
list.add(md5);
System.out.println("snapshotState");
return list;
}
@Override
public void restoreState(List<String> state) throws Exception {
md5 = state.get(0);
}
}运行程序:
package com.hainiu.state;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.concurrent.TimeUnit;
public class FileSourceOperatorStateListCheckpointed {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(1000);
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
//保存EXACTLY_ONCE
checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//每次ck之间的间隔,不会重叠
checkpointConfig.setMinPauseBetweenCheckpoints(2000L);
//每次ck的超时时间
checkpointConfig.setCheckpointTimeout(20000L);
//如果ck执行失败,程序是否停止
checkpointConfig.setFailOnCheckpointingErrors(true);
//job在执行CANCE的时候是否删除ck数据
checkpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
// //恢复策略
env.setRestartStrategy(
RestartStrategies.fixedDelayRestart(
3, // number of restart attempts
Time.of(0, TimeUnit.SECONDS) // delay
)
);
DataStreamSource<String> stringDataStreamSource = env.addSource(new FileCountryDictSourceOperatorStateListCheckpointedFunction());
stringDataStreamSource.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
if(value.contains("中国")){
int a = 1/0;
}
return value;
}
}).print();
env.execute();
}
}2.使用KeyedState:
1.Keyed State之过期超时策略
- 由于Keyed State太多,所以flink提供了针对Keyed State TTL的设置
- 任何类型的keyed State都可以设置TTL。如果TTL已配置,且状态已过期,则将以最佳方式处理
- 所有State collection都支持条目级别的TTL,即list、map中的条目独立expire
- 用法:
StateTtlConfig ttlConfig = StateTtlConfig
.newBuilder(Time.seconds(1))
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
.build();
ValueStateDescriptor<String> stateDescriptor = new ValueStateDescriptor<>("text state", String.class);
stateDescriptor.enableTimeToLive(ttlConfig);- Refresh策略(默认是OnCreateAndWrite):设置如何更新keyedState的最后访问时间
- StateTtlConfig.UpdateType.Disabled - 禁用TTL,永不过期
- StateTtlConfig.UpdateType.OnCreateAndWrite - 每次写操作均更新State的最后访问时间(Create、Update)
- StateTtlConfig.UpdateType.OnReadAndWrite - 每次读写操作均更新State的最后访问时间
- 状态可见性(默认是NeverReturnExpired):设置是否返回过期的值(过期尚未清理,此时正好被访问)
- StateTtlConfig.StateVisibility.NeverReturnExpired - 永不返回过期状态
- StateTtlConfig.StateVisibility.ReturnExpiredlfNotCleanedUp - 可以返回过期但尚未清理的状态值
- TTL time等级
- setTimeCharacteristic(TimeCharacteristic timeCharacteristic)
- 目前只支持ProcessingTime
2.Keyed State之过期状态清理
- 清理策略
- 默认:已经过期的数据被显示读取时才会清理(可能会导致状态越来越大,后续版本会改进)
- FULL_STATE_SCAN_SNAPSHOT:在checkpoint时清理full snapshot中的expired state
- CleanupFullSnapshot()
- 不适用于在RocksDB state backend上的incremental checkpointing
3.Keyed State TTL的注意事项
- 启用TTL增加后端状态存储的消耗
- 原来没启用TTL,后来启用TTL做恢复会将导致兼容性失败和StatmigrationException(反之也一样)
- TTL配置不是检查或保存点的一部分
示例代码:
package com.hainiu.state;
import com.hainiu.source.FileCountryDictSourceFunction;
import com.hainiu.source.HainiuKafkaRecord;
import com.hainiu.source.HainiuKafkaRecordSchema;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.state.MapState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.StateTtlConfig;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.KeyedCoProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.apache.flink.util.Collector;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
public class CountryCodeConnectKeyByKeyedState {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(1000);
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
//保存EXACTLY_ONCE
checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//每次ck之间的间隔,不会重叠
checkpointConfig.setMinPauseBetweenCheckpoints(2000L);
//每次ck的超时时间
checkpointConfig.setCheckpointTimeout(20000L);
//如果ck执行失败,程序是否停止
checkpointConfig.setFailOnCheckpointingErrors(true);
//job在执行CANCE的时候是否删除ck数据
checkpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//恢复策略
env.setRestartStrategy(
RestartStrategies.fixedDelayRestart(
3, // number of restart attempts
Time.of(0, TimeUnit.SECONDS) // delay
)
);
DataStreamSource<String> countryDictSource = env.addSource(new FileCountryDictSourceFunction());
Properties kafkaConsumerProps = new Properties();
kafkaConsumerProps.setProperty("bootstrap.servers", "s1.hadoop:9092,s2.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092");
kafkaConsumerProps.setProperty("group.id", "qingniuflink");
kafkaConsumerProps.setProperty("flink.partition-discovery.interval-millis", "30000");
FlinkKafkaConsumer010<HainiuKafkaRecord> kafkaSource = new FlinkKafkaConsumer010<>("flink_event", new HainiuKafkaRecordSchema(), kafkaConsumerProps);
// kafkaSource.setStartFromEarliest()
// kafkaSource.setStartFromGroupOffsets()
kafkaSource.setStartFromLatest();
DataStreamSource<HainiuKafkaRecord> kafkainput = env.addSource(kafkaSource);
KeyedStream<Tuple2<String, String>, String> countryDictKeyBy = countryDictSource.map(new MapFunction<String, Tuple2<String, String>>() {
@Override
public Tuple2<String, String> map(String value) throws Exception {
String[] split = value.split("\t");
return Tuple2.of(split[0], split[1]);
}
}).keyBy(new KeySelector<Tuple2<String, String>, String>() {
@Override
public String getKey(Tuple2<String, String> value) throws Exception {
return value.f0;
}
});
KeyedStream<HainiuKafkaRecord, String> record = kafkainput.keyBy(new KeySelector<HainiuKafkaRecord, String>() {
@Override
public String getKey(HainiuKafkaRecord value) throws Exception {
return value.getRecord();
}
});
ConnectedStreams<Tuple2<String, String>, HainiuKafkaRecord> connect = countryDictKeyBy.connect(record);
SingleOutputStreamOperator<String> connectInput = connect.process(new KeyedCoProcessFunction<String, Tuple2<String, String>, HainiuKafkaRecord, String>() {
private MapState<String,String> map = null;
@Override
public void open(Configuration parameters) throws Exception {
//keyState的TTL策略
StateTtlConfig ttlConfig = StateTtlConfig
//keyState的超时时间为100秒
.newBuilder(Time.seconds(100))
//当创建和更新时,重新计时超时时间
.setUpdateType(StateTtlConfig.UpdateType.OnCreateAndWrite)
//失败时不返回keyState的值
//.setStateVisibility(StateTtlConfig.StateVisibility.NeverReturnExpired)
//失败时返回keyState的值
.setStateVisibility(StateTtlConfig.StateVisibility.ReturnExpiredIfNotCleanedUp)
//ttl的时间处理等级目前只支持ProcessingTime
.setTimeCharacteristic(StateTtlConfig.TimeCharacteristic.ProcessingTime)
.build();
//从runtimeContext中获得ck时保存的状态
MapStateDescriptor<String,String> msd = new MapStateDescriptor<String, String>("map",String.class,String.class);
msd.enableTimeToLive(ttlConfig);
map = getRuntimeContext().getMapState(msd);
}
@Override
public void processElement1(Tuple2<String, String> value, Context ctx, Collector<String> out) throws Exception {
map.put(ctx.getCurrentKey(), value.f1);
out.collect(value.toString());
}
@Override
public void processElement2(HainiuKafkaRecord value, Context ctx, Collector<String> out) throws Exception {
for(Map.Entry<String,String> m:map.entries()){
System.out.println(m.getKey());
System.out.println(m.getValue());
}
if(value.getRecord().equals("CN")){
int a = 1/0;
}
String countryCode = ctx.getCurrentKey();
String countryName = map.get(countryCode);
String outStr = countryName == null ? "no match" : countryName;
out.collect(outStr);
}
});
connectInput.print();
env.execute();
}
}3.使用BroadcastState:
之前的程序是使用Distribute(keyBy)的方式让数据进行shuffle完成数据的join的,那shuffle可能会带来数据倾斜的问题,那怎么能不shuffle完成数据的join呢?使用广播状态,相当于spark的广播变量的作用。
1).为特殊场景而生
- 特殊场景:来自一个流的一些数据需要广播到所有下游任务,在这些任务中,这些数据被本地存储并用于处理另一个流上的所有传入元素。例如:一个低吞吐量流,其中包含一组规则,我们希望对来自另一个流的所有元素按规则进行计算。
- 典型应用:
- 常规事件流.connect(事件流)
- 常规配置流.connect(配置流)
2).Broadcast State使用套路(三步)
- 创建常规事件流DataStream / KeyedDataStream
- 创建BroadcastedStream:创建规则流 / 配置流(低吞吐)并广播
- 连接两个Stream,生成BroadcastConnectedStream并实现计算处理
- proccess(BroadcastProcessFunction and KeyedBroadcastProcessFunction)
3).BroadcastProcessFunction
public abstract class BroadcastProcessFunction<IN1,IN2,OUT> extends BaseBroadcastProcessFunction {
public abstract void processElement(IN1 value,ReadOnlyContext ctx,Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(IN2 value,Context ctx,Collector<OUT> out) throws Exception;
}- processElement(...):负责处理非广播流中的传入元素,他可以使用与广播状态进行匹配
- processBroadcastElement(...):负责处理广播流中的传入元素(例如规则),一般把广播流的元素添加到状态(MapState)里去备用,processElement处理业务数据时就可以使用(规则)
- ReadOnlyContext和Context的不同
- ReadOnlyContext对Broadcast State有只读权限
- Context有读写权限
首先来个badCase
示例代码:
发射map类型的sourceFunction
package com.hainiu.source;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FileChecksum;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
public class FileCountryDictSourceMapFunction implements SourceFunction<Map<String,String>> {
private String md5 = null;
private Boolean isCancel = true;
private Integer interval = 10000;
@Override
public void run(SourceContext<Map<String,String>> ctx) throws Exception {
Path pathString = new Path("hdfs://ns1/user/qingniu/country_data");
Configuration hadoopConf = new Configuration();
FileSystem fs = FileSystem.get(hadoopConf);
while (isCancel) {
if(!fs.exists(pathString)){
Thread.sleep(interval);
continue;
}
FileChecksum fileChecksum = fs.getFileChecksum(pathString);
String md5Str = fileChecksum.toString();
String currentMd5 = md5Str.substring(md5Str.indexOf(":") + 1);
if (!currentMd5.equals(md5)) {
FSDataInputStream open = fs.open(pathString);
BufferedReader reader = new BufferedReader(new InputStreamReader(open));
String line = reader.readLine();
Map<String,String> map = new HashMap<>();
while (line != null) {
String[] split = line.split("\t");
map.put(split[0],split[1]);
line = reader.readLine();
}
ctx.collect(map);
reader.close();
md5 = currentMd5;
}
Thread.sleep(interval);
}
}
@Override
public void cancel() {
isCancel = false;
}
}运行类:
package com.hainiu.operator;
import com.hainiu.source.FileCountryDictSourceMapFunction;
import com.hainiu.source.HainiuKafkaRecord;
import com.hainiu.source.HainiuKafkaRecordSchema;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.CoProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.apache.flink.util.Collector;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
public class CountryCodeConnectMap {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
//必须设置不然匹配不上
env.setParallelism(1);
DataStreamSource<Map<String, String>> countryDictSource = env.addSource(new FileCountryDictSourceMapFunction());
Properties kafkaConsumerProps = new Properties();
kafkaConsumerProps.setProperty("bootstrap.servers", "s1.hadoop:9092,s2.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092");
kafkaConsumerProps.setProperty("group.id", "qingniuflink");
kafkaConsumerProps.setProperty("flink.partition-discovery.interval-millis", "30000");
FlinkKafkaConsumer010<HainiuKafkaRecord> kafkaSource = new FlinkKafkaConsumer010<>("flink_event", new HainiuKafkaRecordSchema(), kafkaConsumerProps);
// kafkaSource.setStartFromEarliest()
// kafkaSource.setStartFromGroupOffsets()
kafkaSource.setStartFromLatest();
DataStreamSource<HainiuKafkaRecord> kafkainput = env.addSource(kafkaSource);
ConnectedStreams<Map<String, String>, HainiuKafkaRecord> connect = countryDictSource.connect(kafkainput);
SingleOutputStreamOperator<String> connectInput = connect.process(new CoProcessFunction<Map<String, String>, HainiuKafkaRecord, String>() {
private Map<String, String> map = new HashMap<String, String>();
@Override
public void processElement1(Map<String, String> value, Context ctx, Collector<String> out) throws Exception {
for (Map.Entry<String, String> entry : value.entrySet()) {
map.put(entry.getKey(), entry.getValue());
}
out.collect(value.toString());
}
@Override
public void processElement2(HainiuKafkaRecord value, Context ctx, Collector<String> out) throws Exception {
String countryCode = value.getRecord();
String countryName = map.get(countryCode);
String outStr = countryName == null ? "no match" : countryName;
out.collect(outStr);
}
});
connectInput.print();
env.execute();
}
}使用广播状态进行优化:
public abstract class BroadcastProcessFunction<IN1,IN2,OUT> extends BaseBroadcastProcessFunction {
public abstract void processElement(IN1 value,ReadOnlyContext ctx,Collector<OUT> out) throws Exception;
public abstract void processBroadcastElement(IN2 value,Context ctx,Collector<OUT> out) throws Exception;
}- processElement(...):负责处理非广播流中的传入元素,他可以使用与广播状态进行匹配
- processBroadcastElement(...):负责处理广播流中的传入元素(例如规则),一般把广播流的元素添加到状态(MapState)里去备用,processElement处理业务数据时就可以使用(规则)
- ReadOnlyContext和Context的不同
- ReadOnlyContext对Broadcast State有只读权限
- Context有读写权限
示例代码:
package com.hainiu.state;
import com.hainiu.source.FileCountryDictSourceMapFunction;
import com.hainiu.source.HainiuKafkaRecord;
import com.hainiu.source.HainiuKafkaRecordSchema;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.runtime.state.memory.MemoryStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.BroadcastConnectedStream;
import org.apache.flink.streaming.api.datastream.BroadcastStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.apache.flink.util.Collector;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
public class CountryCodeConnectMapBroadCast {
private static final MapStateDescriptor<String, String> msd = new MapStateDescriptor<>("countryCodeMap", String.class, String.class);
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(1000);
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
//保存EXACTLY_ONCE
checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//每次ck之间的间隔,不会重叠
checkpointConfig.setMinPauseBetweenCheckpoints(2000L);
//每次ck的超时时间
checkpointConfig.setCheckpointTimeout(20000L);
//如果ck执行失败,程序是否停止
checkpointConfig.setFailOnCheckpointingErrors(true);
//job在执行CANCE的时候是否删除ck数据
checkpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//指定保存ck的存储模式,这个是默认的
MemoryStateBackend stateBackend = new MemoryStateBackend(10 * 1024 * 1024, false);
//指定保存ck的存储模式
// FsStateBackend stateBackend = new FsStateBackend("file:///Users/leohe/Data/output/flink/checkpoints", true);
// RocksDBStateBackend stateBackend = new RocksDBStateBackend("file:///Users/leohe/Data/output/flink/checkpoints", true);
env.setStateBackend(stateBackend);
//恢复策略
env.setRestartStrategy(
RestartStrategies.fixedDelayRestart(
3, // number of restart attempts
Time.of(0, TimeUnit.SECONDS) // delay
)
);
DataStreamSource<Map<String, String>> countryDictSource = env.addSource(new FileCountryDictSourceMapFunction());
Properties kafkaConsumerProps = new Properties();
kafkaConsumerProps.setProperty("bootstrap.servers", "s1.hadoop:9092,s2.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092");
kafkaConsumerProps.setProperty("group.id", "qingniuflink");
kafkaConsumerProps.setProperty("flink.partition-discovery.interval-millis", "30000");
FlinkKafkaConsumer010<HainiuKafkaRecord> kafkaSource = new FlinkKafkaConsumer010<>("flink_event", new HainiuKafkaRecordSchema(), kafkaConsumerProps);
// kafkaSource.setStartFromEarliest()
// kafkaSource.setStartFromGroupOffsets()
kafkaSource.setStartFromLatest();
DataStreamSource<HainiuKafkaRecord> kafkainput = env.addSource(kafkaSource);
BroadcastStream<Map<String, String>> broadcastinput = countryDictSource.broadcast(msd);
BroadcastConnectedStream<HainiuKafkaRecord, Map<String, String>> broadcastConnect = kafkainput.connect(broadcastinput);
SingleOutputStreamOperator<String> broadcastConnectInput = broadcastConnect.process(new BroadcastProcessFunction<HainiuKafkaRecord, Map<String, String>, String>() {
//private Map<String, String> map = new HashMap<String, String>();
@Override
public void processElement(HainiuKafkaRecord value, ReadOnlyContext ctx, Collector<String> out) throws Exception {
String countryCode = value.getRecord();
ReadOnlyBroadcastState<String, String> broadcastState = ctx.getBroadcastState(msd);
String countryName = broadcastState.get(countryCode);
// String countryName = map.get(countryCode);
String outStr = countryName == null ? "no match" : countryName;
out.collect(outStr);
}
@Override
public void processBroadcastElement(Map<String, String> value, Context ctx, Collector<String> out) throws Exception {
BroadcastState<String, String> broadcastState = ctx.getBroadcastState(msd);
for (Map.Entry<String, String> entry : value.entrySet()) {
broadcastState.put(entry.getKey(), entry.getValue());
}
// for (Map.Entry<String, String> entry : value.entrySet()) {
// map.put(entry.getKey(), entry.getValue());
// }
out.collect(value.toString());
}
});
broadcastConnectInput.print();
env.execute();
}
}广播状态的别一种使用方法,keyBy之后的:
KeyedBroadcastProcessFunction
- processElement(...):负责处理非广播流中的传入元素
- processBroadcastElement(...):负责处理广播流中的传入元素(例如规则),一般把广播流的元素添加到状态里去备用,processElement处理业务数据时就可以使用(规则)
- ReadOnlyContext和Context的不同
- ReadOnlyContext对Broadcast State有只读权限
- Context有读写权限
示例代码:
package com.hainiu.state;
import com.hainiu.source.FileCountryDictSourceMapFunction;
import com.hainiu.source.HainiuKafkaRecord;
import com.hainiu.source.HainiuKafkaRecordSchema;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.state.BroadcastState;
import org.apache.flink.api.common.state.MapStateDescriptor;
import org.apache.flink.api.common.state.ReadOnlyBroadcastState;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.runtime.state.memory.MemoryStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.*;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunction;
import org.apache.flink.streaming.api.functions.co.KeyedBroadcastProcessFunction;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer010;
import org.apache.flink.util.Collector;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
import java.util.concurrent.TimeUnit;
public class CountryCodeConnectMapKeyedBroadCast {
private static final MapStateDescriptor<String, String> msd = new MapStateDescriptor<>("countryCodeMap", String.class, String.class);
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(1000);
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
//保存EXACTLY_ONCE
checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//每次ck之间的间隔,不会重叠
checkpointConfig.setMinPauseBetweenCheckpoints(2000L);
//每次ck的超时时间
checkpointConfig.setCheckpointTimeout(20000L);
//如果ck执行失败,程序是否停止
checkpointConfig.setFailOnCheckpointingErrors(true);
//job在执行CANCE的时候是否删除ck数据
checkpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//指定保存ck的存储模式,这个是默认的
MemoryStateBackend stateBackend = new MemoryStateBackend(10 * 1024 * 1024, false);
//指定保存ck的存储模式
// FsStateBackend stateBackend = new FsStateBackend("file:///Users/leohe/Data/output/flink/checkpoints", true);
// RocksDBStateBackend stateBackend = new RocksDBStateBackend("file:///Users/leohe/Data/output/flink/checkpoints", true);
env.setStateBackend(stateBackend);
//恢复策略
env.setRestartStrategy(
RestartStrategies.fixedDelayRestart(
3, // number of restart attempts
Time.of(0, TimeUnit.SECONDS) // delay
)
);
DataStreamSource<Map<String, String>> countryDictSource = env.addSource(new FileCountryDictSourceMapFunction());
Properties kafkaConsumerProps = new Properties();
kafkaConsumerProps.setProperty("bootstrap.servers", "s1.hadoop:9092,s2.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092");
kafkaConsumerProps.setProperty("group.id", "qingniuflink");
kafkaConsumerProps.setProperty("flink.partition-discovery.interval-millis", "30000");
FlinkKafkaConsumer010<HainiuKafkaRecord> kafkaSource = new FlinkKafkaConsumer010<>("flink_event", new HainiuKafkaRecordSchema(), kafkaConsumerProps);
// kafkaSource.setStartFromEarliest()
// kafkaSource.setStartFromGroupOffsets()
kafkaSource.setStartFromLatest();
DataStreamSource<HainiuKafkaRecord> kafkainput = env.addSource(kafkaSource);
KeyedStream<HainiuKafkaRecord, String> record = kafkainput.keyBy(new KeySelector<HainiuKafkaRecord, String>() {
@Override
public String getKey(HainiuKafkaRecord value) throws Exception {
return value.getRecord();
}
});
BroadcastStream<Map<String, String>> broadcastinput = countryDictSource.broadcast(msd);
BroadcastConnectedStream<HainiuKafkaRecord, Map<String, String>> broadcastConnect = record.connect(broadcastinput);
SingleOutputStreamOperator<String> broadcastConnectInput = broadcastConnect.process(new KeyedBroadcastProcessFunction<String, HainiuKafkaRecord, Map<String, String>, String>(){
//private Map<String, String> map = new HashMap<String, String>();
@Override
public void processElement(HainiuKafkaRecord value, ReadOnlyContext ctx, Collector<String> out) throws Exception {
String countryCode = ctx.getCurrentKey();
ReadOnlyBroadcastState<String, String> broadcastState = ctx.getBroadcastState(msd);
String countryName = broadcastState.get(countryCode);
// String countryName = map.get(countryCode);
String outStr = countryName == null ? "no match" : countryName;
out.collect(outStr);
}
@Override
public void processBroadcastElement(Map<String, String> value, Context ctx, Collector<String> out) throws Exception {
BroadcastState<String, String> broadcastState = ctx.getBroadcastState(msd);
for (Map.Entry<String, String> entry : value.entrySet()) {
broadcastState.put(entry.getKey(), entry.getValue());
}
// for (Map.Entry<String, String> entry : value.entrySet()) {
// map.put(entry.getKey(), entry.getValue());
// }
out.collect(value.toString());
}
});
broadcastConnectInput.print();
env.execute();
}
}4).注意事项
- 每个任务的广播状态的元素顺序有可能不一样
- Broadcast State保存在内存中(并不在RocksDB)
5.CheckPoint原理(面试经常问)
- 通过往source 注入barrier
- barrier作为checkpoint的标志
1.Barrier
- 全局异步化是snapshot的核心机制
- Flink分布式快照的核心概念之一就是数据栅栏(barrier)。这些barrier被插入到数据流中,作为数据流的一部分和数据一起向下流动。Barrier不会干扰正常数据,数据严格有序。一个barrier把数据流分割成两部分:一部分进入到当前快照,另一部分进入下一个快照。每一个barrier都带有快照ID,并且barrier之前的数据都进入了此快照。Barrier不会干扰数据流处理,所以非常轻量。多个不同快照的多个barrier会在流中同时出现,即多个快照可能同时创建。
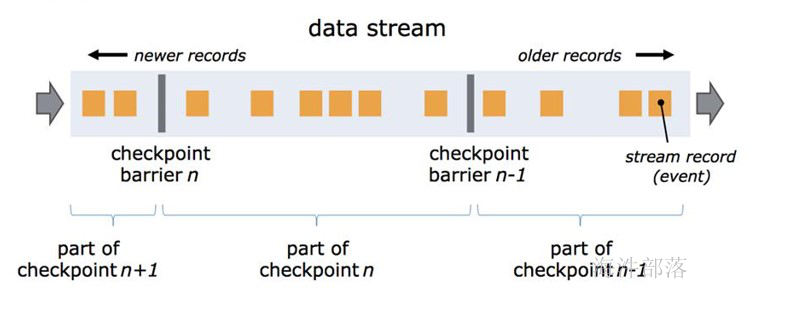
- Barrier在数据源端插入,当snapshot n的barrier插入后,系统会记录当前snapshot位置值 n(用Sn表示)。
- 例如,在Apache Kafka中,这个变量表示某个分区中最后一条数据的偏移量。这个位置值 Sn 会被发送到一个称为checkpoint cordinator的模块。(即Flink 的 JobManager)
2.分布式环境下的ck原理:
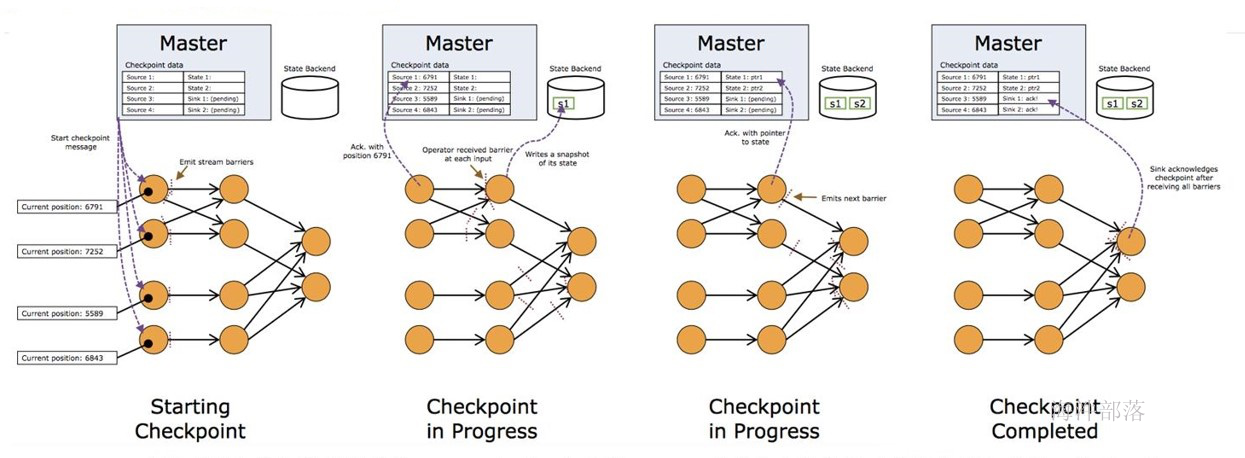
在分布式情况下:
- operator在收到所有输入数据流中的barrier之后,在发射barrier到其输出流之前对其状态进行快照。此时,在barrier之前的数据对状态的更新已经完成,不会再依赖barrier之前数据。
- 然后它会向其所有输出流插入一个标识 snapshot n 的barrier。当sink operator (DAG流的终点)从其输入流接收到所有barrier n时,它向checkpoint coordinator 确认 snapshot n 已完成当,所有sink 都确认了这个快照,代表快照在分布式的情况被标识为整体完成。
由于快照可能非常大,所以后端存储系统可配置。默认是存储到JobManager的内存中,但是对于生产系统,需要配置成一个可靠的分布式存储系统(例如HDFS)。状态存储完成后,operator会确认其checkpoint完成,发射出barrier到后续输出流。
快照现在包含了:
- 对于并行输入数据源:快照创建时数据流中的位置偏移
- 对于operator:存储在快照中的状态指针
3.Barrier多并行度(对齐),flink怎么保证Exactly Once
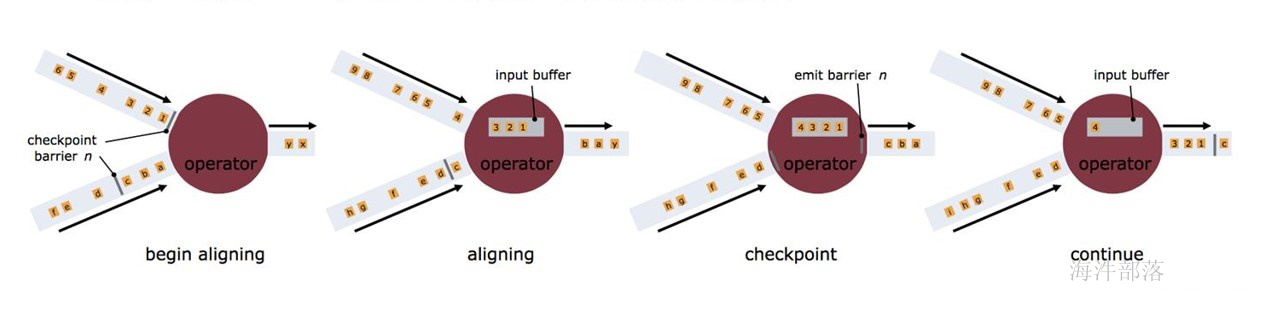
接收超过一个输入流的operator需要基于barrier对齐(align)输入。参见上图:
- operator 只要一接收到某个输入流的barrier n,它就不能继续处理此数据流后续的数据,直到operator接收到其余流的barrier n。否则会将属于snapshot n 的数据和snapshot n+1的搞混
- barrier n 所属的数据流先不处理,从这些数据流中接收到数据被放入接收缓存里(input buffer)
- 当从最后一个流中提取到barrier n 时,operator 会发射出所有等待向后发送的数据,然后发射snapshot n 所属的barrier
- 经过以上步骤,operator 恢复所有输入流数据的处理,优先处理输入缓存中的数据
4.Exactly Once vs. At Least Once
- 对齐就Exactly Once(两个Barrier之间的数据就像在一个事务里一样,sink收到所有barrier n 时提交任务),不对齐就At Least Once
- Flink提供了在 checkpoint 时关闭对齐的方法,当 operator 接收到一个 barrier 时,就会打一个快照,而不会等待其他 barrier。
- 跳过对齐操作使得即使在 barrier 到达时,Operator 依然继续处理输入。这就是说:operator 在 checkpoint n 创建之前,继续处理属于 checkpoint n+1 的数据。所以当异常恢复时,这部分数据就会重复,因为它们被包含在了 checkpoint n 中,同时也会在之后再次被处理。
- 注意:对齐操作只会发生在拥有多输入运算(join)或者多个输出的 operator(重分区、分流)的场景下。所以,对于 map(), flatmap(), fliter() 等的并行操作即使在至少一次的模式中仍然会保证严格一次。
5.使用Checkpointing的前提条件
- 在一定时间内可回溯的datasource(故障时可以回溯数据),常见的:
- 一般是可持久化的消息队列:例如Kafka、RabbitMQ、Amazon Kinesis、Google PubSub
- 也可以是文件系统:HDFS、S3、、NFS、Ceph
- 可持久化存储State的存储系统,通常使用分GFS布式文件系统(Checkpointing就是把job的所有状态都周期性持久化到存储里)
- 一般是HDFS、S3、GFS、NFS、Ceph
- 注意:如果想保存checkpointing的时候是exactly-once的,那也需要你的存储端支持幂特性/事务
- 一般是hbase的rowkey,redies的key或者mysql的事务
帮我把档存到那里?
6.State Backend
选择合适的State Backend
1.什么是State Backend
- State Backend就是用来保存快照的地方
- 用来在Checkpointing机制中持久化所有状态的一致性快照,这些状态包括:
- 非用户定义的状态:例如,timers、非用户自定义的stateful operators(connectors,windows)
- 用户定义的状态:就是前面讲的用户自定义的stateful operato所使用的Keyed State and Operator State
2.目前Flink自带三个开箱即用State Backend:
1).MemoryStateBackend(默认)
- MemoryStateBackend在Java堆上维护状态。Key/value状态和窗口运算符使用哈希表存储值和计时器等
- Checkpoint时,MemoryStateBackend对State做一次快照,并在向JobManager发送Checkpoint确认完成的消息中带上此快照数据,然后快照就会存储在JobManager的堆内存中
- MemoryStateBackend可以使用异步的方式进行快照(默认开启),推荐使用异步的方式避免阻塞。如果不希望异步,可以在构造的时候传入false(也可以通过全局配置文件指定),如下
StateBackend backend = new MemoryStateBackend(10*1024*1024,false);
env.setStateBackend(backend);- 限制
- 单个State的大小默认限制为5MB,可以在MemoryStateBackend的构造函数中增加
- 不论如何配置,State大小都无法大于akka.framesize(JobManager和TaskManager之间发送的最大消息的大小默认是10MB)
- JobManager必须有足够的内存大小
- 适用场景
- 本地开发和调试
- 小状态job,如只使用Map、FlatMap、Filter...或Kafka Consumer
2).FsStateBackend
- FsStateBackend需要配置一个文件系统的URL,如"hdfs://namenode:40010/flink/checkpoint"或"file:///data/flink/checkpoints"。
- FsStateBackend在TaskManager的内存中持有正在处理的数据。Checkpoint时将state snapshot 写入文件系统目录下的文件中。文件的路径等元数据会传递给JobManager,存在其内存中 (或者在HA模式下,存储在元数据checkpoint中)。
- FsStateBackend可以使用异步的方式进行快照(默认开启),推荐使用异步的方式避免阻塞。如果不希望异步可以在构造的时候传入false(也可以通过全局配置文件指定),如下:
StateBackend backend = new FsStateBackend("hdfs://namenode:40010/flink/checkpoints",false);
env.setStateBackend(backend);- 适用场景
- 大状态、长窗口、大键/值状态的job
- 所有高可用性的情况
3).RocksDBStateBackend
- RocksDBStateBackend需要配置一个文件系统的URL来,如"hdfs://namenode:40010/flink/checkpoint"或"file:///data/flink/checkpoints"
- RocksDBStateBackend将运行中的数据保存在RocksDB数据库中,(默认情况下)存储在TaskManager数据目录中,在Checkpoint时,整个RocksDB数据库将被Checkpointed到配置的文件系统和目录中。文件的路径等元数据会传递给JobManager,存在其内存中(或者在HA模式下,存储在元数据checkpoint中)。
- RocksDBStateBackend总是执行异步快照
StateBackend backend = new RocksDBStateBackend("hdfs://namenode:40010/flink/checkpoints");
env.setStateBackend(backend);- 限制
- RocksDB JNI API是基于byte[],因此key和value最大支持大小为2\^31个字节(2GB)。RocksDB自身在支持较大value时候有问题(merge operations in RocksDB(e.g.ListState))
- 适用场景
- 超大状态,超长窗口、大键/值状态的job
- 所有高可用性的情况
- 与前两种状态后端对比:
- 目前只有RocksDBStateBackend支持增量checkpoint(默认全量)
- 状态保存在数据库中,即使用RockDB可以保存的状态量仅受可用磁盘空间量的限制,相比其他的状态后端可保存更大的状态,但开销更大(读/写需要反序列化/序列化去检索/存储状态),吞吐受到限制
使用RocksDBStateBackend特有配置
| 配置项 | 默认值 | 说明 |
|---|---|---|
| state.backend.rocksdb.localdir | (none) | |
| state.backend.rocksdb.timer-service.factory | “HEAP” | 指定timer service状态存储在哪里, HEAP/ROCKSDB |
- 代码中配置RocksDBStateBackend(可覆盖全局配置)
StateBackend backend = new RocksDBStateBackend("hdfs://namenode:40010/flink/checkpoints",true);
env.setStateBackend(backend);- 需要单独引入POM依赖
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-statebackend-rocksdb_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>- 默认情况下(MemoryStateBackend):State保存在taskmanager的内存中,checkpoint存储在JobManager的内存中
4).StateBackend总结

1).配置StateBackend
- 全局配置(配置文件conf/flink-conf.yaml)
# The backend that will be used to store operator state checkpoints
state.backend: filesystem
#Directory.for storing checkpoints
state.checkpoints.dir: hdfs:namenode:40010/flink/checkpoints- 每个job单独配置State Backend(可覆盖全局配置)
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStateBackend(new FsStateBackend("hdfs://namenode:40010/flink/checkpoints"));示例代码:
package com.hainiu.state;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.runtime.state.memory.MemoryStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.concurrent.TimeUnit;
public class FileSourceOperatorStateListCheckpointedStateBackend {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.enableCheckpointing(1000);
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
//保存EXACTLY_ONCE
checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//每次ck之间的间隔,不会重叠
checkpointConfig.setMinPauseBetweenCheckpoints(2000L);
//每次ck的超时时间
checkpointConfig.setCheckpointTimeout(20000L);
//如果ck执行失败,程序是否停止
checkpointConfig.setFailOnCheckpointingErrors(true);
//job在执行CANCE的时候是否删除ck数据
checkpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//指定保存ck的存储模式,这个是默认的
MemoryStateBackend stateBackend = new MemoryStateBackend(10 * 1024 * 1024, false);
//指定保存ck的存储模式
// FsStateBackend stateBackend = new FsStateBackend("file:///Users/leohe/Data/output/flink/checkpoints", true);
// RocksDBStateBackend stateBackend = new RocksDBStateBackend("file:///Users/leohe/Data/output/flink/checkpoints", true);
env.setStateBackend(stateBackend);
//恢复策略
env.setRestartStrategy(
RestartStrategies.fixedDelayRestart(
3, // number of restart attempts
Time.of(0, TimeUnit.SECONDS) // delay
)
);
DataStreamSource<String> stringDataStreamSource = env.addSource(new FileCountryDictSourceOperatorStateListCheckpointedFunction());
stringDataStreamSource.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
if (value.contains("中国")) {
int a = 1 / 0;
}
return value;
}
}).print();
env.execute();
}
}Checkpointing的默认全局配置(conf/flink-conf.yaml)
7.Savepoint
| 配置项 | 默认值 | 说明 |
|---|---|---|
| state.backend | (none) | • 用于指定checkpoint state存储的backend, 默认为none; • 目前支持的backends是'jobmanager','filesystem','rocksdb' • 也可以使用它们的工厂类的全限定名: 例如org.apache.flink.runtime.state.filesystem. FsStateBackendFactory • 如果没指定, 默认使用jobmanager, 即MemoryStateBackend |
| state.backend.async | true | 用于指定backend是否使用异步, 有些不支持async或者只支持async的state backend可能会忽略这个参数 |
| state.backend.fs.memory-threshold | 1024 | 用于指定存储state的files大小阈值, 如果小于该值则会存储在root checkpoint metadata file |
| state.backend.incremental | false | 用于指定是否采用增量checkpoint, 有些不支持增量checkpoint的backend会忽略该配置; 目前只有rocksdb支持 |
| state.backend.local-recovery | false | |
| state.checkpoints.dir | (none) | • 用于指定checkpoint的data files和meta data存储的目录, 该目录必须对所有参与的TaskManagers及JobManagers可见(有读写权限) • 例如: hdfs://namenode-host:port/flink-checkpoints |
| state.checkpoints.num-retained | 1 | 用于指定保留的已完成的checkpoints最大个数 |
| state.savepoints.dir | (none) | • 用于指定savepoints的默认目录 • 例如: hdfs://namenode-host:port/flink-checkpoints |
| taskmanager.state.local.root-dirs | (none) |
1).Savepoint概念
- 概念
- savepoint可以理解为是一种特殊的checkpoint,savepoint就是指向checkpoint的一个指针,实际上也是使用通过checkpointing机制创建的streaming job的一致性快照,可以保存数据源的offset、并行操作状态也就是流处理过程中的状态历史版本。需要手动触发,而且不会过期,不会被覆盖,除非手动删除。正常情况下的线上环境是不需要设置savepoint的。除非对job或集群做出重大改动的时候, 需要进行测试运行。
- 可以从应用在过去的任意做了savepoint的时刻开始继续消费,具有可以replay的功能
- Savepoint由两部分组成:
- 数据目录:稳定存储上的目录,里面的二进制文件是streaming job状态的快照
- 元数据文件:指向数据目录中属于当前Savepoint的数据文件的指针(绝对路径)
- 与Checkpoint的区别:Savepoint相当于备份(类比数据库备份)、Checkpoint相当于recovery log
- Checkpoint是Flink自动创建的"recovery log"用于故障自动恢复,由Flink创建,不需要用户交互。用户cancel作业时就删除,除非启动了保留机制(External Checkpoint)
- Savepoint由用户创建,拥有和删除,保存点在作业终止后仍然存在。
- 作用
- job开发新版本(更改job graph、更改并行度等等),应用重新发布
- Flink版本的更新
- 业务迁移,集群需要迁移,不容许数据丢失
2).区分Checkpoint、External Checkpoint、Savepoint
| 概念 | 描述 | 使用场景 |
|---|---|---|
| Checkpoint | 定期、自动的对job下的所有状态多快照并存储,会过期,仅用于从故障中恢复(重启策略)。当job cancel之后会被删除。 | 应用内部restarting时使用 |
| External Checkpoint | 一旦Flink处理程序被cancel后,会保留Checkpoint数据,以便根据实际需要恢复到指定的Checkpoint处理;属于checkpoint的范畴 | |
| Savepoint | 用于创建的job state的“备份”,是一种特殊的checkpoint,只不过不像checkpoint定期的从系统中去触发的,它是用户通过命令触发,存储格式和checkpoint一样(代码都一样); 注意:当Checkpoint使用RocksDBStateBackend并使用增量Checkpoint时会使用RocksDB内部格式,就跟Savepoint格式不一样了 | job开发新版本(更改job graph、更改并行度等等),应用重新发布 Flink版本的更新 业务迁移,集群需要迁移,不容许数据丢失 |
3).assigning Operator ID
- 为了便于未来升级job程序,建议为operator分配ID,例如:
DataStream<String> stream = env.
//Stateful source(e.g. Kafka) with ID
.addSource(new StatefulSource())
.uid("source-id") //ID for the source operator
.shuffle()
// Stateful mapper with ID
.map(new StatefulMapper())
.name("mapper-id") //ID for the mapper
//Stateless printing sink
.print(); // Auto-generated ID- 如果不指定ID会自动生成,只要ID不变就能从指定的Savepoint恢复。自动生成ID依赖于结构,代码会变更会导致ID改变,所以手工分配ID是推荐的做法
- 设置ID之后,Savepoint可以想象为一个map映射(Operator ID -> State)
4).触发Savepoint
- 直接触发Savepoint(想象你要为数据库做个备份)
$ bin/flink savepoint :jobId [:targetDirectory]- 直接触发Savepoint(Flink on yarn):
$ bin/flink savepoint :jobId [:targetDirectory] -yid :yarnAppId- Cancel Job with Savepoint:
$ bin/flink cancel -s [:targetDirectory] :jobId5).从Savepoint恢复job
- 从指定Savepoint恢复job
$ bin/flink run -s :savepointPath [:runArgs]- 从指定Savepoint恢复job(允许跳过不能映射的状态,例如删除了一个operator)
$ bin/flink run -s :savepointPath -n [:runArgs]6).删除Savepoint
- 删除Savepoint
$ bin/flink savepoint -d :savepointPath- 注意:还可以通过常规的文件系统操作手动删除Savepoint(不影响其他Savepoint或Checkpoint)
8.状态的重新分配
Operator State与Keyed State的Redistribute(重新分配)
1).Operator State Redistribute
- Redistribute:当Operator改变并发度的时候(Rescale),会触发状态的Redistribute,即Operator State里的数据会重新分配到Operator的Task实例
- 举例:某Operator的并行度由3改为2
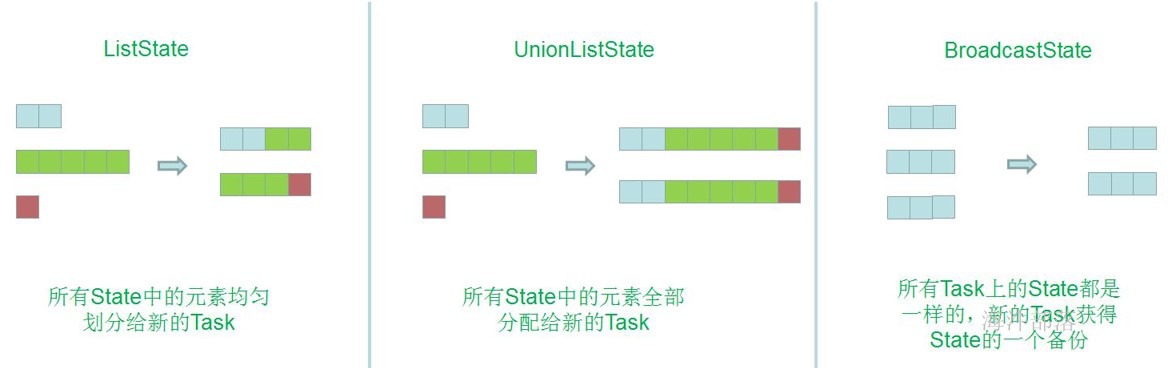
- 不同数据结构的动态扩展方式不一样:
- ListState:并发度在改变的时候,会将并发上的每个List都取出,然后把这些List合并到一个新的List,然后根据元素的个数在均匀分配给新的Task
- UnionListState:相比于ListState更加灵活,把划分的方式交给用户去做,当改变并发的时候,会将原来的List拼接起来。然后不做划分,直接交给用户(每个Task给全量的状态,用户自己划分)
- BroadcastState:如大表和小表做Join时,小表可以直接广播给大表的分区,在每个并发上的数据都是完全一致的。做的更新也相同,当改变并发的时候,把这些数据COPY到新的Task即可,以上是Flink Operator States提供的3种扩展方式,用户可以根据自己的需求做选择。
2).Keyed State的Redistribute(重新分配)
- Keyed State Redistribute
- Key被Redistribute哪个task,他对应的Keyed State就被Redistribute到哪个Task
- Keyed State Redistribute是基于Key Group来做分配的:
- 将key分为group
- 每个key分配到唯一的group
- 将group分配给task实例
- Keyed State最终分配到哪个Task:group ID和taskID是从0开始算的
- hash=hash(key)
- KG=hash % numOfKeyGroups
- Subtask=KG* taskNum / numOfKeyGroups
numOfKeyGroups是有多少个组,taskNum有多少个任务,KG是组ID从0开始算,Subtask是任务ID从0开始算
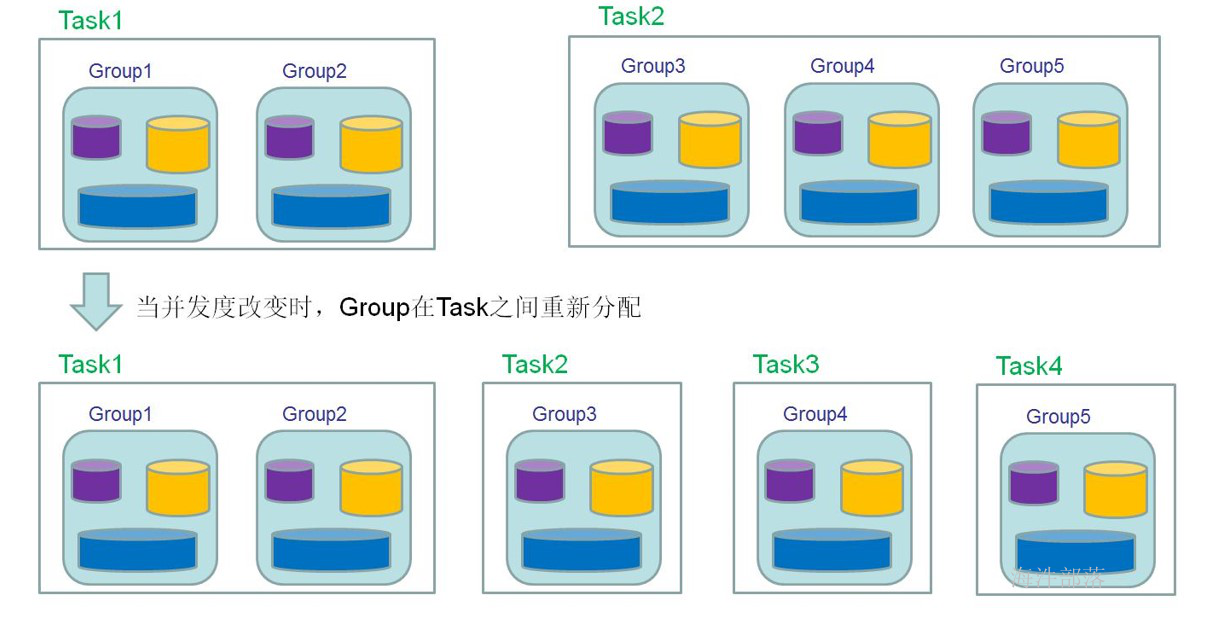
CheckpointedFunction如何选择重分配策略
CheckpointedFunction接口通过不同的Redistribute方案提供对Operator State的访问
获取状态时指定:getListState/getUnionListState(注意:ListState的不同分配策略,自己要根据不同的分配策略写对应拿取数据的逻辑)
9.kafka的source与sink的容错
1.FlinkKafkaConsumer容错
1).理解FlinkKafkaSource的容错性 (影响出错时数据消费的位置)

- 如果Flink启用了检查点,Flink Kafka Consumer将会周期性的checkpoint其Kafka偏移量到快照。
- 通过实现CheckpointedFunction
- ListState\<Tuple2\<KafkaTopicPartition, Long>>
- 保证仅一次消费
- 如果作业失败,Flink将流程序恢复到最新检查点的状态,并从检查点中存储的偏移量开始重新消费Kafka中的记录。(此时前面所讲的消费策略就不能决定消费起始位置了,因为出故障了)
2).Flink Kafka Consumer Offset提交行为
| 情形 | 谁决定消费起始位置 |
|---|---|
| 禁用Checkpoint | Flink Kafka Consumer依赖于内部使用的Kafka客户端的自动定期偏移提交功能。因此,要禁用或启用偏移量提交,只需将enable.auto.commit(或auto.commit.enable for Kafka 0.8) / auto.commit.interval.ms设置设置到Kafka客户端的Properties |
| 启用Checkpoint | Checkpoint时会保存Offset到snapshot 当一次Checkpoint完成时,Flink Kafka Consumer将snapshot中的偏移量提交给 kafka/zookeeper。这确保Kafka Consumer中提交的偏移量与检查点状态中的偏移量一致。 用户可以通过调用Flink Kafka Consumer的setCommitOffsetsOnCheckpoints(boolean) ,方法来禁用或启用偏移提交到kafka/zookeeper (默认情况下,行为为true)。 在此场景中,Properties中的自动定期偏移量提交设置将被完全忽略。 |
3).不同情况下消费起始位置的分析
| 情形 | 谁决定消费起始位置 |
|---|---|
| 第一次启动, 无savepoint(常规情况) | 由消费模式决定 |
| 通过savepoint启动(应用升级,比如加 大并行度) | 由savepoint记录的offset决定 |
| 有checkpoint,失败后,job恢复的情况 | 由checkpoint的snapshoot中记录的offset决定 |
| 无checkpoint,失败后,job恢复的情况 | 由消费模式决定 |
2.FlinkKafkaProducer容错
| 版本 | 容错性保证 |
|---|---|
| Kafka 0.8 | at most once(有可能丢数据) |
| Kafka 0.9/0.10 | 启动checkpoint时默认保证at-least-once(有可能重复) setLogFailuresOnly(boolean) 默认是false(false保证at-least-once)往kafka发送数据失败了是否打日志: False:不打日志,直接抛异常,导致应用重启(at-least-once) True:打日志(丢数据) setFlushOnCheckpoint(boolean) 默认是true(true保证at_least_once)Flink checkpoint时是否等待正在写往kafka的数据返回ack |
| Kafka 0.11 | 必须启动checkpoint 可以通过构造参数选择容错性语意: Semantic.NONE:可能丢失也可能重复 Semantic.AT_LEAST_ONCE:不会丢失,但可能重复(默认) Semantic.EXACTLY_ONCE:使用Kafka事务提供exactly-once语义 |
Properties producerPropsSns = new Properties();
producerPropsSns.setProperty("bootstrap.servers", "s1.hadoop:9092,s3.hadoop:9092,s4.hadoop:9092,s5.hadoop:9092,s6.hadoop:9092,s7.hadoop:9092,s8.hadoop:9092");
producerPropsSns.setProperty("retries", "3");
//FlinkKafkaProducer010类的构造函数支持自定义kafka的partitioner,
FlinkKafkaProducer010 kafkaOut = new FlinkKafkaProducer010<String>("flink_event_result",new SimpleStringSchema(),producerPropsSns,new HainiuFlinkPartitioner());
kafkaOut.setLogFailuresOnly(false);
kafkaOut.setFlushOnCheckpoint(true);6.time、Watermarks、windows、windows的operator
1.time
DataStream支持的三种time
- DataStream有大量基于time的operator
- Flink支持三种time:
- EventTime
- IngestTime
- ProcessingTime
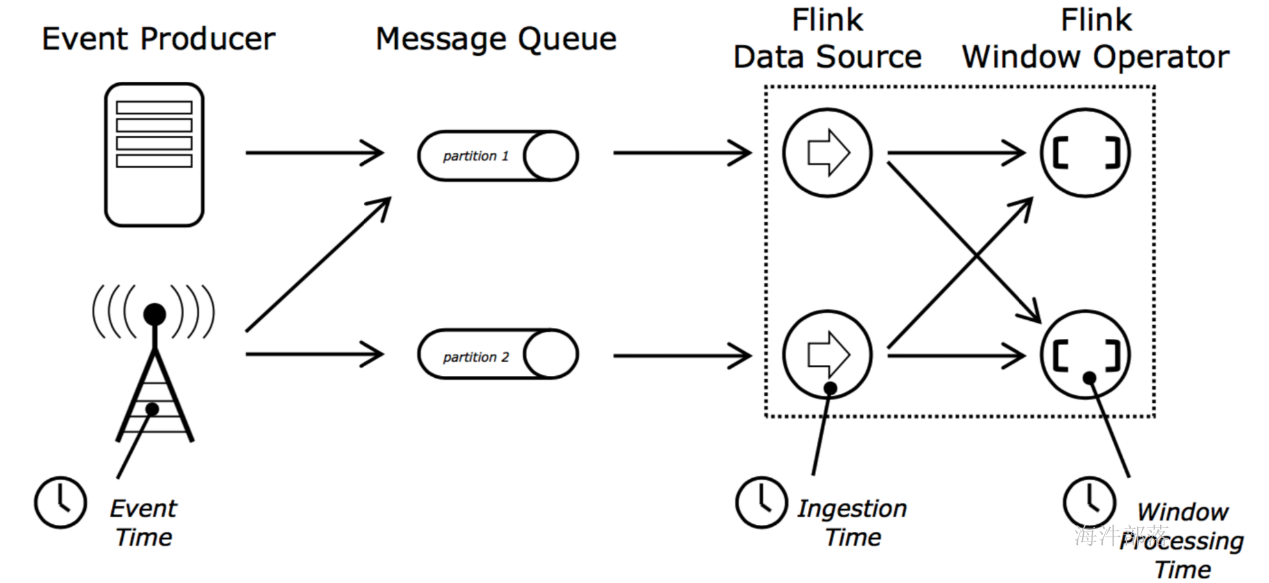
三个时间的比较
- EventTime
- 事件生成时的时间,在进入Flink之前就已经存在,可以从event的字段中抽取
- 必须指定watermarks的生成方式
- 优势:确定性:乱序、延时、或者数据重复等情况,都能给出正确的结果
- 弱点:处理无序事件时性能和延迟受到影响
- IngestTime
- 事件进入flink的时间,即在source里获取的当前系统的时间,后续操作统一使用该时间
- 不需要指定watermarks的生成方式(自动生成)
- 弱点:不能处理无序事件和延迟数据
- ProcessingTime
- 执行操作的机器的当前系统时间(每个算子都不一样)
- 不需要流和机器之间的协调
- 优势:最佳的性能和最低的延迟
- 弱点:不确定性 ,容易受到各种因素影像(event产生的速度、到达flink的速度、在算子之间传输速度等),压根就不管顺序和延迟
- 比较
- 性能: ProcessingTime> IngestTime> EventTime
- 延迟: ProcessingTime\< IngestTime\< EventTime
- 确定性: EventTime> IngestTime> ProcessingTime
根据业务选择最合适的时间

这个是hadoop的yarn日志,图中标注的是event time,同时也是yarn服务产生真正动作的时间,在进入操作时那台机器的系统时间是2019-04-07 21:10:55,666,
需求是要统计每隔5分钟内的日志error个数。
这时要使用event time才是是正确的。
注意:一般都需要使用event time,除非由于特殊情况只能用另外两种时间来代替
设置time类型
• 设置时间特性
val env = StreamExecutionEnvironment.getExecutionEnvironment()
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime)- 不设置Time 类型,默认是processingTime
- 如果使用EventTime则需要在source之后明确指定Timestamp Assigner & Watermark Generator
2.Timestamp and Watermarks 时间戳和水位线
Watermarks
- out-of-order/late element
- 实时系统中,由于各种原因造成的延时,造成某些消息发到flink的时间延时于事件产生的时间。如果 基于event time构建window,但是对于late element,我们又不能无限期的等下去,必须要有个机制来保证一个特定的时间后,必须触发window去进行计算了。这个特别的机制,就是watermark 。
- Watermarks(水位线)就是来处理这种问题的机制
- 是event time处理进度的标志
- 表示比watermark更早(更老)的事件都已经到达(没有比水位线更低的数据 )
- 基于watermark来进行窗口触发计算的判断
有序流中Watermarks
- 在某些情况下,基于Event Time的数据流是有续的
- 在有序流中,watermark就是一个简单的周期性标记。
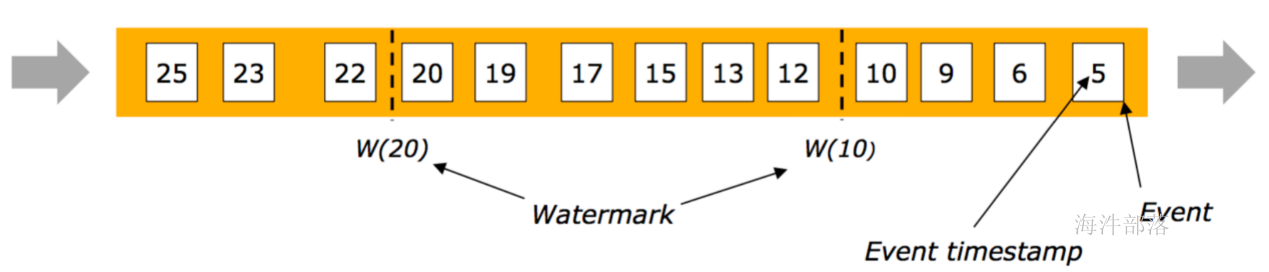
乱序流中Watermarks
- 在更多场景下,基于Event Time的数据流是无续的
- 在无序流中,watermark至关重要,它告诉operator比watermark更早(更老/时间戳更小)的事件已经到达, operator可以将内部事件时间提前到watermark的时间戳(可以触发window计算啦)

并行流中的Watermarks
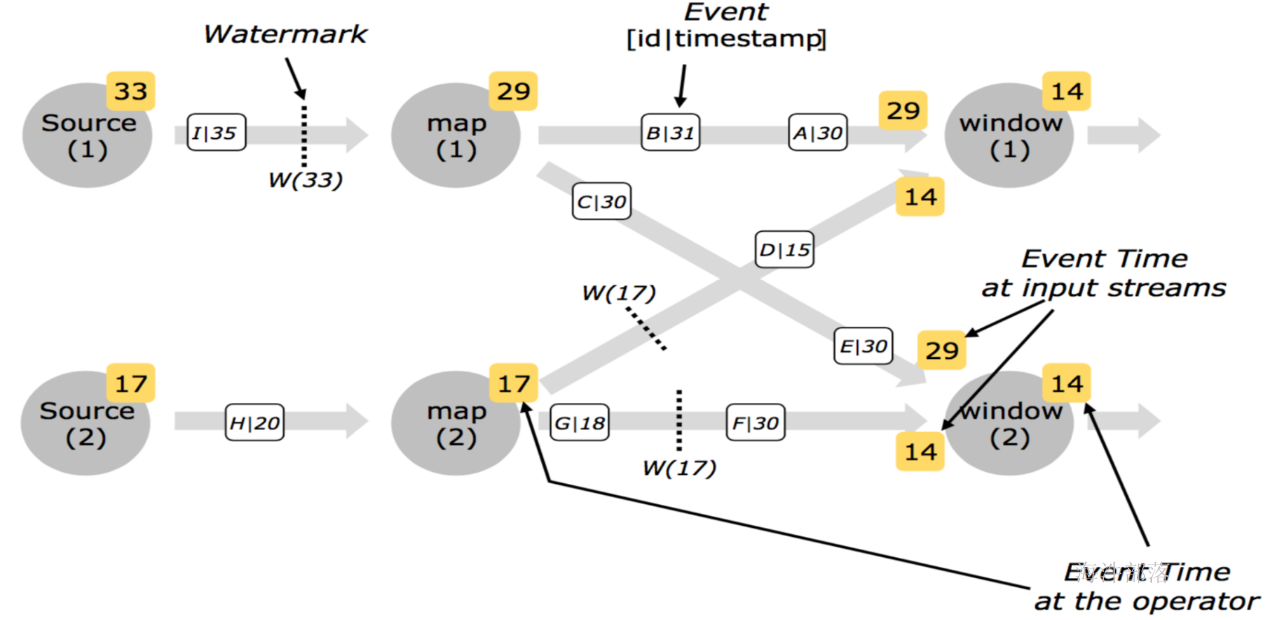
- 通常情况下, watermark在source函数中生成,但是也可以在source后任何阶段,如果指定多次后面会覆盖前面的值。 source的每个sub task独立生成水印
- watermark通过operator时会推进operators处的当前event time,同时operators会为下游生成一个新的watermark
- 多输入operator(union、 keyBy)的当前watermark是其输入流watermark的最小值
生成Timestamp和Watermark
- 需要设置 Timestamp / Watermark 的地方
- 只有基于EventTime的流处理程序需要指定Timestamp和Watermarks的生成方式
- 指定时间特性为Event Time
val env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
#声明时间特性为Event Time后,Flink需要知道每个event的timestamp(一般从event的某个字段去抽取)
#Flink还需要知道目前event time的进度也就是Watermarks(一般伴随着Event Time一起指定生成的,二者息息相关)- 注意事项
- timestamp和watermark都是采用毫秒
- 代码中的event、element、record都是一个意思
生成Timestamp和Watermark有两种方式
1.直接在source function中生成
- 自定义source实现SourceFunction接口或者继承RichParallelSourceFunction
示例代码:
package com.hainiu.windows;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.watermark.Watermark;
public class TimestampWatermarkMethod1 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStreamSource<String> dss = env.addSource(new SourceFunction<String>() {
private Boolean isCancel = true;
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (isCancel) {
long currentTime = System.currentTimeMillis();
String testStr = currentTime + "\thainiu\t" + (currentTime - 1000);
String[] split = testStr.split("\t");
Long timestamp = Long.valueOf(split[0]);
String data = split[1];
Long waterMarkTime = Long.valueOf(split[2]);
ctx.collectWithTimestamp(data,timestamp);
ctx.emitWatermark(new Watermark(waterMarkTime));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isCancel = false;
}
});
dss.print();
env.execute();
}
}2.timestamp assigner / watermark generator
- 通过assignTimestampsAndWatermarks方法指定timestamp assigner / watermark generator
- 一般在datasource后调用assignTimestampsAndWatermarks方法,也可以在第一个基于event time的operator之前指定(例如window operator)
- 特例:使用Kafka Connector作为source时,在source内部assignTimestampsAndWatermarks
- assignTimestampsAndWatermarks
- 含义:提取记录中的时间戳作为Event time,主要在window操作中发挥作用,不设置默认就是ProcessingTime
- 限制:只有基于event time构建window时才起作用
- 使用场景:当你需要使用event time来创建window时,用来指定如何获取event的时间戳
两种Watermark
- Periodic Watermarks
- 基于Timer
- ExecutionConfig.setAutoWatermarkInterval(msec) (默认是 200ms, 设置watermarker发送的周期)
- 实现AssignerWithPeriodicWatermarks 接口
- Puncuated WaterMarks
- 基于某些事件触发watermark 的生成和发送(由用户代码实现,例如遇到特殊元素)
- 实现AssignerWithPuncuatedWatermarks 接口
1.Periodic Watermark
- 周期性调用getCurrentWatermark,如果获取的Watermark不等于null且比上一个最新的Watermark大 就向下游发射
示例代码:
package com.hainiu.windows;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.watermark.Watermark;
import javax.annotation.Nullable;
public class TimestampWatermarkMethod2 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStreamSource<String> dss = env.addSource(new SourceFunction<String>() {
private Boolean isCancel = true;
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (isCancel) {
long currentTime = System.currentTimeMillis();
String testStr = currentTime + "\thainiu";
ctx.collect(testStr);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isCancel = false;
}
});
dss.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<String>() {
private long maxOutOfOrderness = 1000;
private long waterMarkTime;
@Nullable
@Override
public Watermark getCurrentWatermark() {
//要比上一个最新的Watermark大
//减去就是允许延时的时间
return new Watermark(waterMarkTime - maxOutOfOrderness);
}
@Override
public long extractTimestamp(String element, long previousElementTimestamp) {
String[] split = element.split("\t");
Long timestamp = Long.valueOf(split[0]);
waterMarkTime = timestamp;
return timestamp;
}
}).print();
env.execute();
}
}2.Puncuated Watermark
- 根据自定义条件生成Watermark
示例代码:
package com.hainiu.windows;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.AssignerWithPunctuatedWatermarks;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.watermark.Watermark;
import javax.annotation.Nullable;
public class TimestampWatermarkMethod3 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStreamSource<String> dss = env.addSource(new SourceFunction<String>() {
private Boolean isCancel = true;
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (isCancel) {
long currentTime = System.currentTimeMillis();
String testStr = currentTime + "\thainiu";
ctx.collect(testStr);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isCancel = false;
}
});
dss.assignTimestampsAndWatermarks(new AssignerWithPunctuatedWatermarks<String>() {
private long maxOutOfOrderness = 1000;
@Override
public Watermark checkAndGetNextWatermark(String lastElement, long extractedTimestamp) {
String[] split = lastElement.split("\t");
String data= split[1];
if(data.equals("hainiu")){
return new Watermark(extractedTimestamp - maxOutOfOrderness);
}else {
return null;
}
}
@Override
public long extractTimestamp(String element, long previousElementTimestamp) {
String[] split = element.split("\t");
Long timestamp = Long.valueOf(split[0]);
return timestamp;
}
}).print();
env.execute();
}
}以上是使用接口实现自定义WaterMarker和Timestamp的生成方法。
当然也可以使用Flink提供好的方法:
1).AscendingTimestampExtractor
- 适用于event时间戳单调递增的场景,用于有序数据流
示例代码:
package com.hainiu.windows;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
public class TimestampWatermarkMethod4 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStreamSource<String> dss = env.addSource(new SourceFunction<String>() {
private Boolean isCancel = true;
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (isCancel) {
long currentTime = System.currentTimeMillis();
String testStr = currentTime + "\thainiu";
ctx.collect(testStr);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isCancel = false;
}
});
dss.assignTimestampsAndWatermarks(new AscendingTimestampExtractor<String>() {
@Override
public long extractAscendingTimestamp(String element) {
String[] split = element.split("\t");
Long timestamp = Long.valueOf(split[0]);
return timestamp;
}
}).print();
env.execute();
}
}2).BoundedOutOfOrdernessTimestampExtractor
- 允许固定延迟的Assigner,适用于预先知道最大延迟的场景(例如最多比之前的元素延迟1000ms),用于乱序数据流在windows中处理延时数据。
示例代码:
package com.hainiu.windows;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.timestamps.BoundedOutOfOrdernessTimestampExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
public class TimestampWatermarkMethod5 {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStreamSource<String> dss = env.addSource(new SourceFunction<String>() {
private Boolean isCancel = true;
@Override
public void run(SourceContext<String> ctx) throws Exception {
while (isCancel) {
long currentTime = System.currentTimeMillis();
String testStr = currentTime + "\thainiu";
ctx.collect(testStr);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isCancel = false;
}
});
dss.assignTimestampsAndWatermarks(new BoundedOutOfOrdernessTimestampExtractor<String>(Time.seconds(10)) {
@Override
public long extractTimestamp(String element) {
String[] split = element.split("\t");
Long timestamp = Long.valueOf(split[0]);
return timestamp;
}
}).print();
env.execute();
}
}- 延迟数据处理,用于乱序数据流不在windows中,在别一个地方处理延时数据。
- allowedLateness(),设定最大延迟时间,触发被延迟,不宜设置太长
- sideOutputTag,设置侧输出标记,侧输出是可用于给延迟数据设置标记,然后根据标记再获取延迟的数据 ,这样就不会丢弃数据了
示例代码:
package com.hainiu.flink.windows;
import org.apache.flink.api.common.functions.MapFunction;
import org.apache.flink.api.common.typeinfo.BasicTypeInfo;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import org.apache.flink.util.OutputTag;
import java.util.Iterator;
public class TimestampWatermarkMethod6 {
private static final OutputTag<String> late = new OutputTag<String>("late", BasicTypeInfo.STRING_TYPE_INFO){};
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
env.setParallelism(1);
SingleOutputStreamOperator<String> stringSingleOutputStreamOperator = env.addSource(new SourceFunction<String>() {
private Boolean isCancel = true;
@Override
public void run(SourceContext<String> ctx) throws Exception {
int num = 1;
while (isCancel) {
long currentTime = System.currentTimeMillis();
if (num % 2 == 0) {
//这里的4000可能超时也可能不超时
currentTime -= 4000;
}
String testStr = currentTime + "\thainiu\t" + num;
System.out.println("source:" + testStr);
num++;
ctx.collect(testStr);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isCancel = false;
}
}).assignTimestampsAndWatermarks(new AscendingTimestampExtractor<String>() {
@Override
public long extractAscendingTimestamp(String element) {
String[] split = element.split("\t");
String s = split[0];
Long eventTime = Long.valueOf(s);
return eventTime;
}
});
SingleOutputStreamOperator<String> process = stringSingleOutputStreamOperator.keyBy(new KeySelector<String, String>() {
@Override
public String getKey(String value) throws Exception {
String[] split = value.split("\t");
return split[1];
}
}).timeWindow(Time.seconds(2))
.allowedLateness(Time.seconds(2))
.sideOutputLateData(late)
.process(new ProcessWindowFunction<String, String, String, TimeWindow>() {
@Override
public void process(String s, Context context, Iterable<String> elements, Collector<String> out) throws Exception {
System.out.println("subtask:" + getRuntimeContext().getIndexOfThisSubtask() +
",start:" + context.window().getStart() +
",end:" + context.window().getEnd() +
",waterMarks:" + context.currentWatermark() +
",currentTime:" + System.currentTimeMillis());
Iterator<String> iterator = elements.iterator();
for (; iterator.hasNext(); ) {
String next = iterator.next();
System.out.println("windows-->" + next);
out.collect("on time:" + next);
}
}
});
//处理准时的数据
process.print();
//处理延时的数据
DataStream<String> lateOutPut = process.getSideOutput(late);
lateOutPut.map(new MapFunction<String, String>() {
@Override
public String map(String value) throws Exception {
return "late:" + value;
}
}).print();
env.execute();
}
} 3.Window
什么是windows,以及windows的作用,可以参考spark的windows
- Flink 认为 Batch 是 Streaming 的一个特例,所以 Flink 底层引擎是一个流式引擎,在上面实现了流 处理和批处理。而窗口(window)就是从 Streaming 到 Batch 的一个桥梁。Flink 提供了非常完善的窗口机制,这是Flink最大的亮点之一(其他的亮点包括消息乱序处理,和 checkpoint 机制)。
- Window是一种切割无限数据集为有限块并进行相应计算的处理手段(跟keyBy一样,也是一种分组 手段)
- 在流处理应用中,数据是连续不断的,因此我们不可能等到所有数据都到了才开始处理。当然我们可以每来一个消息就处理一次,但是有时我们需要做一些聚合类的处理,例如:在过去的1分钟内有多少用户点击了我们的网页。在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的 数据,并对这个窗口内的数据进行计算。
Window Assingers(Window分类器),分为Keyed Windows和Non-Keyed Windows
- Window Assinger是干啥的
- 当你决定stream是否keyby之后,window是没有构建的,你还需要指定一个window Assinger 用于定义元素如何分配到窗口中
- window Assinger如何指定?
- Keyedstream:window(WindowAssigner)
- non-keyed streams:windowAll(WindowAssigner)
- window Assinger的作用:负责将每个传入的元素分配给一个或多个窗口
Windows分类器API示例:
- Keyed Windows(在已经按照key分组的基础上(KeyedStream),再构建多任务并行window)

- Non-Keyed Windows(在未分组的DataStream上构建单任务window,并行度是1,API都带All后缀)

取决于是否使用了keyBy
WindowedStream & AllWindowedStream
- WindowedStream代表了根据key分组,并且基于WindowAssigner切分窗口的数据流。所以WindowedStream都是从KeyedStream衍生而来的。而在WindowedStream上进行任何transformation也都将转变回DataStream。
val stream: DataStream[MyType] = ...
val windowed: WindowedDataStream[MyType] = stream
.keyBy("userId")
.window(TumblingEventTimeWindows.of(Time.seconds(5))) // Last 5 seconds of data
val result: DataStream[ResultType] = windowed.reduce(myReducer)- 上述 WindowedStream 的样例代码在运行时会转换成如下的执行图:
- Flink 的窗口实现中会将到达的数据缓存在对应的窗口buffer中。当到达窗口发送的条件时,Flink 会对整个窗口中的数据进行处理(由Trigger控制)。Flink 在聚合类窗口有一定的优化,即不会保存窗口中的所有值,而是每到一个元素执行一次聚合函数,最终只保存一份数据即可。
- 在key分组的流上进行窗口切分是比较常用的场景,也能够很好地并行化(不同的key上的窗口聚合可以分配到不同的task去处理)。不过有时候我们也需要在普通流上进行窗口的操作,这就是 AllWindowedStream。AllWindowedStream是直接在DataStream上进行windowAll(...)操作。AllWindowedStream 的实现是基于 WindowedStream 的(Flink 1.1.x 开始)。Flink 不推荐使用AllWindowedStream,因为在普通流上进行窗口操作,就势必需要将所有分区的流都汇集到单个的Task中,而这个单个的Task很显然就会成为整个Job的瓶颈。
Keyed Windows 对比 Non-Keyed Windows(以基于time的window为例)
Window分类(Window Assinger类型)
- 有了window Assinger,才会创建出各种形式的window来覆盖我们所需的各种场景,所以不用 过多关注window本身的分类,关注window Assinger的分类即可
- Count-based window:根据元素个数对数据流进行分组切片
- Tumbling CountWindow
- Sliding CountWindow
- Time-based window :根据时间对数据流进行分组切片,设置方式window(start,end)
- Tumbling Window
- Sliding Window
- Session Window

所有类型窗口对比:
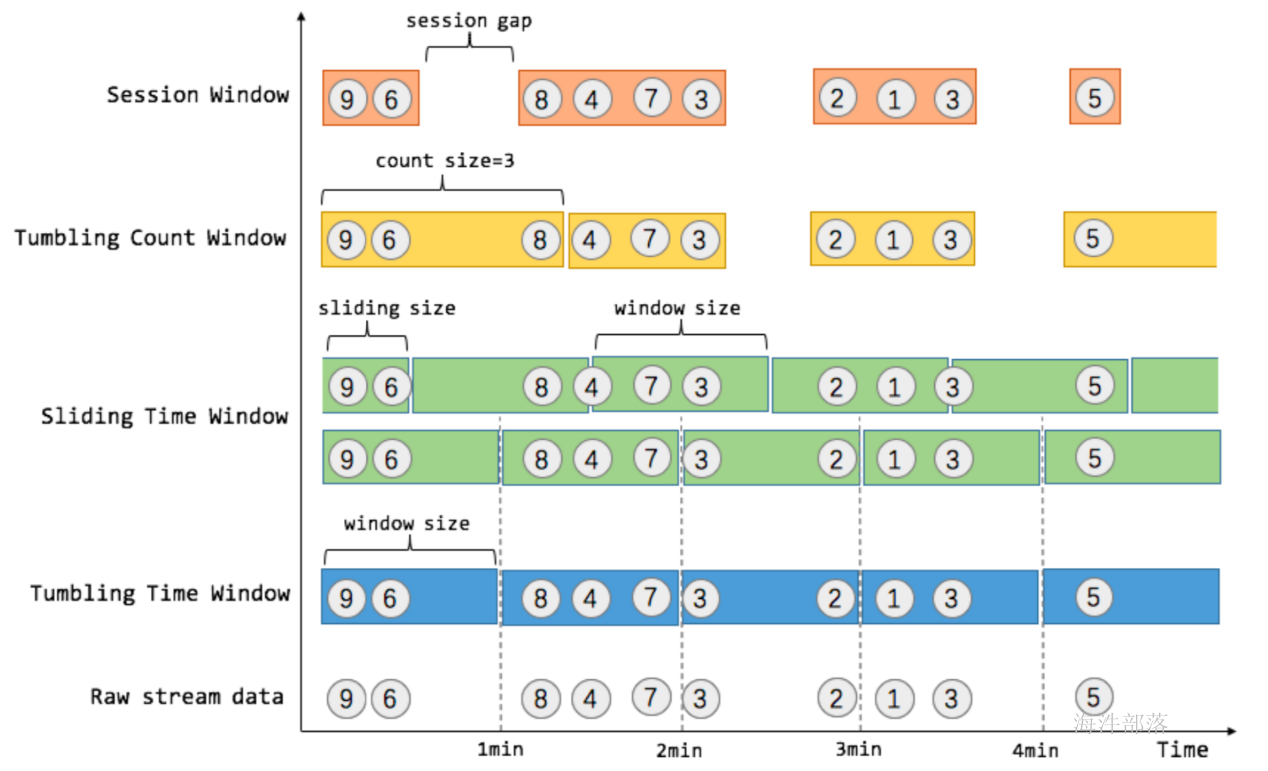
| 大类 | 小类 | 按照key切分 | Time-base/按时间切 分 | Count-base/按count 切分 |
|---|---|---|---|---|
| Keyed-Window | Tumbling Window | 是 | 是 | 是 |
| Sliding Window | 是 | 是 | 是 | |
| Session Window | 是 | 是(不固定) | 否 | |
| Global Windows | 是 | 是/否 | 是/否 | |
| Tumbling count Window | 是 | 否 | 是 | |
| Sliding count Window | 是 | 否 | 是 | |
| Non-keyed Window | Tumbling Window | 否 | 是 | 是 |
| Sliding Window | 否 | 是 | 是 | |
| Session Window | 否 | 是(不固定) | 否 | |
| Tumbling count Window | 否 | 否 | 是 | |
| Sliding count Window | 否 | 否 | 是 |
Window的生命周期
- 创建:当属于该窗口的第一个元素到达时就会创建该窗口
- 销毁:当时间(event/process time)超过窗口的结束时间戳+用户指定的延迟时
- (allowedLateness(\<time>)),窗口将被移除(仅限time-based window)
- 例如:对于一个每5分钟创建Tumbling Windows(即翻滚窗口)窗口,允许1分钟的时延,Flink将会在12:00到12:05这段时间内第一个元素到达时创建窗口,当watermark超过12:06时,该窗口将被移除
- Trigger(触发器):指定了窗口函数在什么条件下可被触发,触发器还可以决定在创建和删除窗口之间的任何时间清除窗口的内容。在这种情况下,清除仅限于窗口中的元素,而不是窗口元数据。这意味着新数据仍然可以添加到该窗口中。
- 例如:当窗口中的元素个数超过4个时“ 或者 ”当水印达到窗口的边界时“触发计算
- Evictor(驱逐者):将在触发器触发之后或者在函数被应用前后,过滤(filter)窗口中的元素
- Window 的函数:函数里定义了应用于窗口(Window)生命周期内的计算逻辑
总结
- Window Assigner:分配器,解决数据分到那个窗口的问题。
- Trigger:触发器,解决什么时候开始算的问题。
- Evictor:“驱逐者”,类似filter作用,解决窗口运算前后数据过滤的问题。
窗口练习:
Tumbling Windows(翻滚窗口)
- 定义:将数据依据固定的窗口长度对数据进行切片
- 特点:
- 时间对齐
- 窗口长度固定
- event无重叠
- 适用场景:计算各个时间段的指标
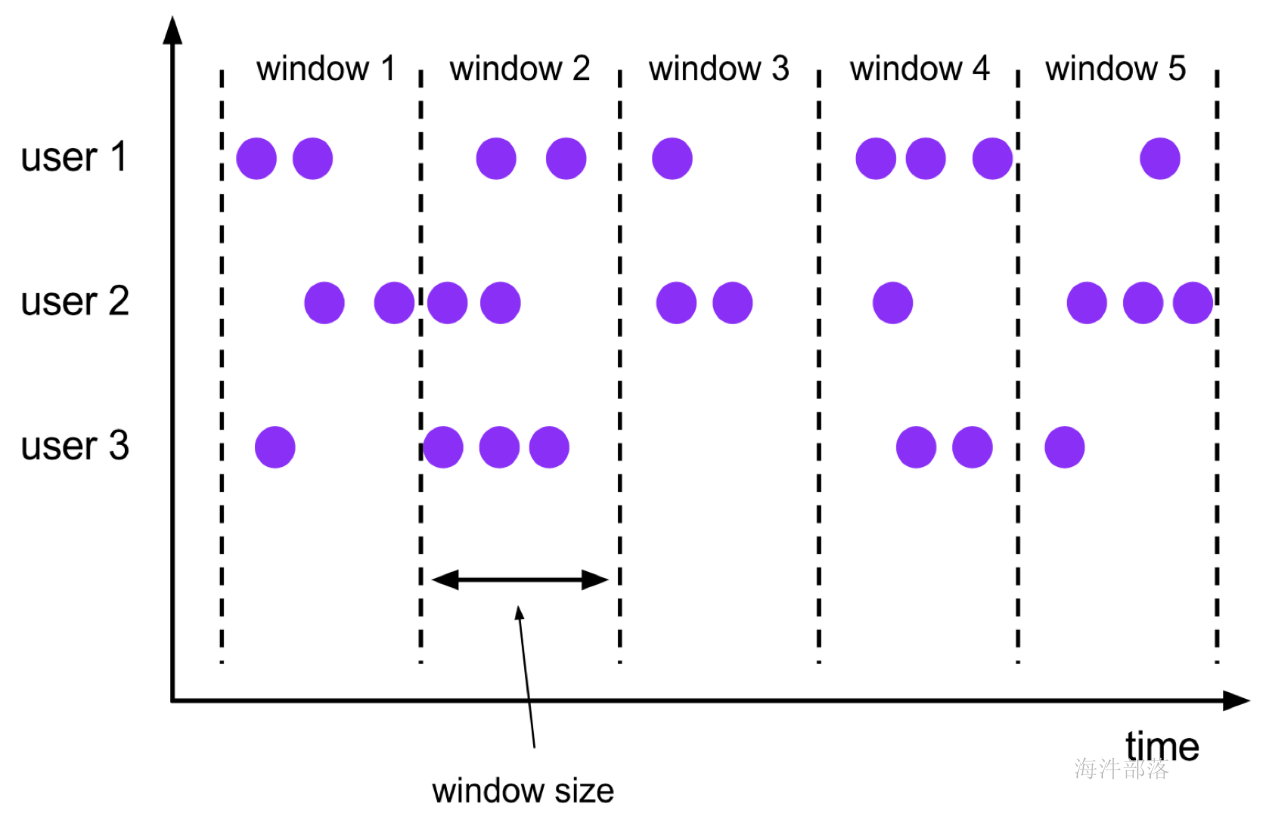
Tumbling Windows的使用
- 对齐方式:默认是aligned with epoch(整点、整分、整秒等)。
示例代码:
package com.hainiu.flink.windows;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.util.Iterator;
public class TumblingWindows {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
SingleOutputStreamOperator<String> stringSingleOutputStreamOperator = env.addSource(new SourceFunction<String>() {
private Boolean isCancel = true;
@Override
public void run(SourceContext<String> ctx) throws Exception {
int num = 1;
while (isCancel) {
long currentTime = System.currentTimeMillis();
String testStr = currentTime + "\thainiu\t" + num;
num++;
ctx.collect(testStr);
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isCancel = false;
}
}).assignTimestampsAndWatermarks(new AscendingTimestampExtractor<String>() {
@Override
public long extractAscendingTimestamp(String element) {
String[] split = element.split("\t");
String s = split[0];
Long eventTime = Long.valueOf(s);
return eventTime;
}
});
KeyedStream<String, String> keyedStream = stringSingleOutputStreamOperator.keyBy(new KeySelector<String, String>() {
@Override
public String getKey(String value) throws Exception {
String[] split = value.split("\t");
return split[1];
}
});
keyedStream.window(TumblingEventTimeWindows.of(Time.seconds(10),Time.seconds(9)))
.process(new ProcessWindowFunction<String, String, String, TimeWindow>() {
@Override
public void process(String s, Context context, Iterable<String> elements, Collector<String> out) throws Exception {
System.out.println("subtask:" + getRuntimeContext().getIndexOfThisSubtask() +
",start:" + context.window().getStart() +
",end:" + context.window().getEnd() +
",waterMarks:" + context.currentWatermark() +
",currentTime:" + System.currentTimeMillis());
Iterator<String> iterator = elements.iterator();
Integer sum = 0;
for (; iterator.hasNext(); ) {
String next = iterator.next();
System.out.println(next);
String[] split = next.split("\t");
String s1 = split[2];
Integer integer = Integer.valueOf(s1);
sum += integer;
}
out.collect("sum:" + sum);
}
}).print();
keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(5)));
keyedStream.window(TumblingProcessingTimeWindows.of(Time.seconds(5),Time.seconds(2)));
env.execute();
}
}Sliding Windows(滑动窗口)
- 定义:是固定窗口的更广义的一种形式。滑动窗口由固定的窗口长度和滑动间隔组成
- 特点:
- 时间对齐
- 窗口长度固定
- event有重叠(如果滑动间隔大于窗口是允许的,但是会造成数据丢失)
- 适用场景:每5分钟求统计一小时的数据,那就应该5分钟是窗口的滑动间隔,1小时为窗口的大小
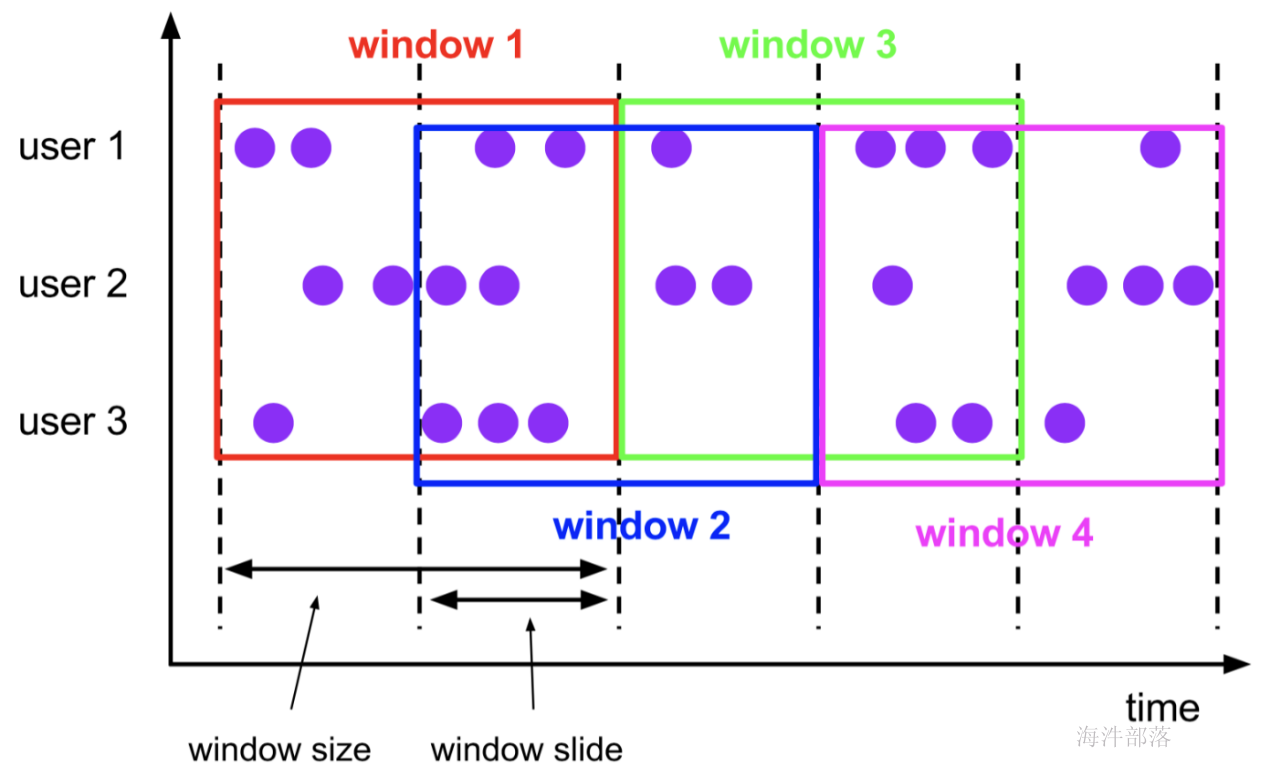
Sliding Windows的使用
- 对齐方式:默认是aligned with epoch(整点、整分、整秒等)。
示例代码:
package com.hainiu.windows;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.windowing.assigners.SlidingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.assigners.SlidingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
public class SlidingWindows {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
SingleOutputStreamOperator<Tuple3<String, Long, Long>> hainiu = env.addSource(new SourceFunction<Tuple3<String, Long, Long>>() {
private Boolean isCancel = true;
@Override
public void run(SourceContext<Tuple3<String, Long, Long>> ctx) throws Exception {
while (isCancel) {
ctx.collect(new Tuple3<>("hainiu", 1L, System.currentTimeMillis()));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isCancel = false;
}
}).assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple3<String, Long, Long>>() {
@Override
public long extractAscendingTimestamp(Tuple3<String, Long, Long> element) {
return element.f2;
}
});
KeyedStream<Tuple3<String, Long, Long>, String> keyBy = hainiu.keyBy(new KeySelector<Tuple3<String, Long, Long>, String>() {
@Override
public String getKey(Tuple3<String, Long, Long> value) throws Exception {
return value.f0;
}
});
SingleOutputStreamOperator<Tuple3<String, Long, Long>> sum = keyBy.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5)))
.reduce(new ReduceFunction<Tuple3<String, Long, Long>>() {
@Override
public Tuple3<String, Long, Long> reduce(Tuple3<String, Long, Long> value1, Tuple3<String, Long, Long> value2) throws Exception {
return Tuple3.of(value1.f0, value1.f1 + value2.f1, value2.f2);
}
});
// SingleOutputStreamOperator<Tuple3<String, Long, Long>> sum = keyBy.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5)))
// .reduce(new ReduceFunction<Tuple3<String, Long, Long>>() {
// @Override
// public Tuple3<String, Long, Long> reduce(Tuple3<String, Long, Long> value1, Tuple3<String, Long, Long> value2) throws Exception {
// return Tuple3.of(value1.f0, value1.f1 + value2.f1, value2.f2);
// }
// });
// SingleOutputStreamOperator<Tuple3<String, Long, Long>> sum = keyBy.window(SlidingProcessingTimeWindows.of(Time.seconds(10), Time.seconds(5), Time.seconds(2)))
// .reduce(new ReduceFunction<Tuple3<String, Long, Long>>() {
// @Override
// public Tuple3<String, Long, Long> reduce(Tuple3<String, Long, Long> value1, Tuple3<String, Long, Long> value2) throws Exception {
// return Tuple3.of(value1.f0, value1.f1 + value2.f1, value2.f2);
// }
// });
sum.print();
env.execute();
}
}Session Windows(事件窗口)
- 定义:类似于web应用 的session,即一段时间没有接受到新数据就会生成新的窗口(固定gap/gap fun)
- 特点:
- 时间无对齐
- event不重叠
- 没有固定开始和结束时间
- 适用场景:基于用户行为进行统计分析

Session Windows的使用
- Gap
- 固定gap
- 动态gap:实现SessionWindowTimeGapExtractor
- 特殊处理方式
- session window operator为每个到达的event创建一个新窗口,如果它们之间的距离比定义的间隔更近,则将窗口合并在一起
- 为了能够合并, session window operator需要合并触发器和合并窗口函数,例如ReduceFunction、 AggregateFunction或ProcessWindowFunction (FoldFunction不能合并)
示例代码:
package com.hainiu.windows;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.windowing.assigners.EventTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.assigners.SessionWindowTimeGapExtractor;
import org.apache.flink.streaming.api.windowing.time.Time;
public class SessionWindows {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
SingleOutputStreamOperator<Tuple3<String, Long, Long>> hainiu = env.addSource(new SourceFunction<Tuple3<String, Long, Long>>() {
private Boolean isCancel = true;
@Override
public void run(SourceContext<Tuple3<String, Long, Long>> ctx) throws Exception {
long num = 0;
while (isCancel) {
num += 1;
ctx.collect(new Tuple3<>("hainiu", num, System.currentTimeMillis()));
if (num % 5 == 0) {
Thread.sleep(3000);
} else {
Thread.sleep(1000);
}
}
}
@Override
public void cancel() {
isCancel = false;
}
}).assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple3<String, Long, Long>>() {
@Override
public long extractAscendingTimestamp(Tuple3<String, Long, Long> element) {
return element.f2;
}
});
KeyedStream<Tuple3<String, Long, Long>, String> keyBy = hainiu.keyBy(new KeySelector<Tuple3<String, Long, Long>, String>() {
@Override
public String getKey(Tuple3<String, Long, Long> value) throws Exception {
return value.f0;
}
});
SingleOutputStreamOperator<Tuple3<String, Long, Long>> sum = keyBy.window(EventTimeSessionWindows.withGap(Time.seconds(2)))
.reduce(new ReduceFunction<Tuple3<String, Long, Long>>() {
@Override
public Tuple3<String, Long, Long> reduce(Tuple3<String, Long, Long> value1, Tuple3<String, Long, Long> value2) throws Exception {
return Tuple3.of(value1.f0, value1.f1 + value2.f1, value2.f2);
}
});
// SingleOutputStreamOperator<Tuple3<String, Long, Long>> sum = keyBy.window(EventTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor<Tuple3<String, Long, Long>>() {
// @Override
// public long extract(Tuple3<String, Long, Long> element) {
// if (element.f1 % 5 == 0) {
// return 2500L;
// } else {
// return 2000L;
// }
// }
// })).reduce(new ReduceFunction<Tuple3<String, Long, Long>>() {
// @Override
// public Tuple3<String, Long, Long> reduce(Tuple3<String, Long, Long> value1, Tuple3<String, Long, Long> value2) throws Exception {
// return Tuple3.of(value1.f0, value1.f1 + value2.f1, value2.f2);
// }
// });
// SingleOutputStreamOperator<Tuple3<String, Long, Long>> sum = keyBy.window(ProcessingTimeSessionWindows.withGap(Time.seconds(2)))
// .reduce(new ReduceFunction<Tuple3<String, Long, Long>>() {
// @Override
// public Tuple3<String, Long, Long> reduce(Tuple3<String, Long, Long> value1, Tuple3<String, Long, Long> value2) throws Exception {
// return Tuple3.of(value1.f0, value1.f1 + value2.f1, value2.f2);
// }
// });
// SingleOutputStreamOperator<Tuple3<String, Long, Long>> sum = keyBy.window(ProcessingTimeSessionWindows.withDynamicGap(new SessionWindowTimeGapExtractor<Tuple3<String, Long, Long>>() {
// @Override
// public long extract(Tuple3<String, Long, Long> element) {
// if (element.f1 % 5 == 0) {
// return 2500L;
// } else {
// return 2000L;
// }
// }
// })).reduce(new ReduceFunction<Tuple3<String, Long, Long>>() {
// @Override
// public Tuple3<String, Long, Long> reduce(Tuple3<String, Long, Long> value1, Tuple3<String, Long, Long> value2) throws Exception {
// return Tuple3.of(value1.f0, value1.f1 + value2.f1, value2.f2);
// }
// });
sum.print();
env.execute();
}
}Global Windows
- 定义:有相同key的所有元素分配给相同的单个全局窗口
- 必须指定自定义触发器否则没有任何意义
- 注意:不要跟Non-keyed Window搞混,两个不同的角度
Global Windows的使用
- Trigger :触发器,触发窗口的计算或数据清除,每个Window Assigner有一个默认的Trigger。解决什么时候开始算的问题
- Evictor :“驱逐者”,类似filter作用。在Trigger触发之后,window被处理前或者后,Evictor用来删除窗口中无用的元素,可以进一步解决窗口输入输出数据的问题,默认是没有驱逐器的,所以也不常用。
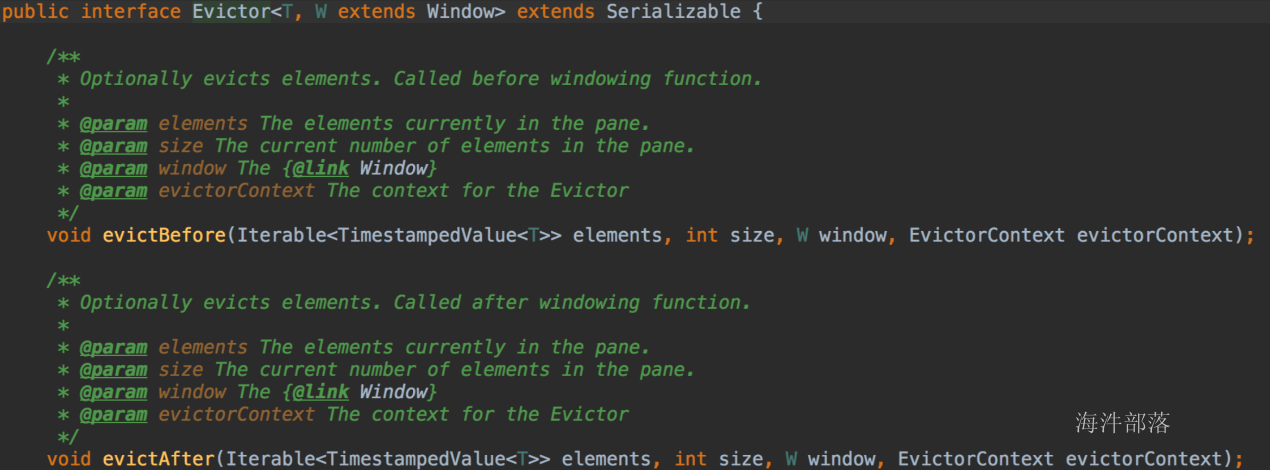
示例代码:
package com.hainiu.windows;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.windowing.assigners.GlobalWindows;
import org.apache.flink.streaming.api.windowing.evictors.Evictor;
import org.apache.flink.streaming.api.windowing.triggers.CountTrigger;
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow;
import org.apache.flink.streaming.runtime.operators.windowing.TimestampedValue;
import java.util.Iterator;
public class GlobalWindowsH {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
SingleOutputStreamOperator<Tuple3<String, Long, Long>> hainiu = env.addSource(new SourceFunction<Tuple3<String, Long, Long>>() {
private Boolean isCancel = true;
@Override
public void run(SourceContext<Tuple3<String, Long, Long>> ctx) throws Exception {
long num = 0;
while (isCancel) {
num += 1;
ctx.collect(new Tuple3<>("hainiu", num, System.currentTimeMillis()));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isCancel = false;
}
}).assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple3<String, Long, Long>>() {
@Override
public long extractAscendingTimestamp(Tuple3<String, Long, Long> element) {
return element.f2;
}
});
KeyedStream<Tuple3<String, Long, Long>, String> keyBy = hainiu.keyBy(new KeySelector<Tuple3<String, Long, Long>, String>() {
@Override
public String getKey(Tuple3<String, Long, Long> value) throws Exception {
return value.f0;
}
});
SingleOutputStreamOperator<Tuple3<String, Long, Long>> sum = keyBy.window(GlobalWindows.create())
.trigger(CountTrigger.of(5))
.evictor(new Evictor<Tuple3<String, Long, Long>, GlobalWindow>() {
@Override
public void evictBefore(Iterable<TimestampedValue<Tuple3<String, Long, Long>>> elements, int size, GlobalWindow window, EvictorContext evictorContext) {
for (Iterator<TimestampedValue<Tuple3<String, Long, Long>>> iterator = elements.iterator(); iterator.hasNext(); ) {
TimestampedValue<Tuple3<String, Long, Long>> next = iterator.next();
System.out.println("before:" + next.getValue());
if (next.getValue().f1 % 5 == 0) {
iterator.remove();
}
}
}
@Override
public void evictAfter(Iterable<TimestampedValue<Tuple3<String, Long, Long>>> elements, int size, GlobalWindow window, EvictorContext evictorContext) {
for (Iterator<TimestampedValue<Tuple3<String, Long, Long>>> iterator = elements.iterator(); iterator.hasNext(); ) {
TimestampedValue<Tuple3<String, Long, Long>> next = iterator.next();
System.out.println("after:" + next.getValue());
}
}
})
.reduce(new ReduceFunction<Tuple3<String, Long, Long>>() {
@Override
public Tuple3<String, Long, Long> reduce(Tuple3<String, Long, Long> value1, Tuple3<String, Long, Long> value2) throws Exception {
return Tuple3.of(value1.f0, value1.f1 + value2.f1, value2.f2);
}
});
sum.print();
env.execute();
}
}窗口函数(作用在window上的Operator)
- 在定义了窗口分配器之后,我们需要为每一个窗口明确的指定计算逻辑,这个就是窗口函数要做的事情,当系统决定一个窗口已经准备好执行之后,这个窗口函数将被用来处理窗口中的每一个元素(可能是分组的)。
- 窗口函数有那些:
| function | 优点 | 缺点 |
|---|---|---|
| ReduceFunction | 更高效,因为在每个窗口中增量地对每一个到达的元素执行聚合操作(增量 聚合) | 场景覆盖不全,无法获取窗口的元数据 |
| AggregateFunction(max/maxBy...) | ||
| FoldFunction(不推荐) | ||
| WindowFunction/AllWindowFunction | 场景覆盖全面,可以拿到窗口的元数据: | • 相对低效一些,先把属于窗口的 所有元素都缓存,等到该计算了, 全部拿出来再计算; • 都可跟reducefun、aggfun、 foldfun组合使用 |
| ProcessWindowFunction/Process AllWindowFunction | ||
| ProcessWindowFunction与前三者 之一组合(混搭) | 兼具高效和场景的覆盖 |
- 特别提示:在没有专门说明的情况下,凡是带All的API就是给Non-keyed window使用的
WindowFunction用法:
示例代码:
package com.hainiu.windows;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.functions.windowing.WindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.GlobalWindows;
import org.apache.flink.streaming.api.windowing.evictors.Evictor;
import org.apache.flink.streaming.api.windowing.triggers.CountTrigger;
import org.apache.flink.streaming.api.windowing.windows.GlobalWindow;
import org.apache.flink.streaming.runtime.operators.windowing.TimestampedValue;
import org.apache.flink.util.Collector;
import java.util.Iterator;
public class WindowsFunctionOnCountWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
SingleOutputStreamOperator<Tuple3<String, Long, Long>> hainiu = env.addSource(new SourceFunction<Tuple3<String, Long, Long>>() {
private Boolean isCancel = true;
@Override
public void run(SourceContext<Tuple3<String, Long, Long>> ctx) throws Exception {
long num = 0;
while (isCancel) {
num += 1;
ctx.collect(new Tuple3<>("hainiu", num, System.currentTimeMillis()));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isCancel = false;
}
}).assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple3<String, Long, Long>>() {
@Override
public long extractAscendingTimestamp(Tuple3<String, Long, Long> element) {
return element.f2;
}
});
KeyedStream<Tuple3<String, Long, Long>, String> keyBy = hainiu.keyBy(new KeySelector<Tuple3<String, Long, Long>, String>() {
@Override
public String getKey(Tuple3<String, Long, Long> value) throws Exception {
return value.f0;
}
});
keyBy.window(GlobalWindows.create())
.trigger(CountTrigger.of(5))
.evictor(new Evictor<Tuple3<String, Long, Long>, GlobalWindow>() {
@Override
public void evictBefore(Iterable<TimestampedValue<Tuple3<String, Long, Long>>> elements, int size, GlobalWindow window, EvictorContext evictorContext) {
for (Iterator<TimestampedValue<Tuple3<String, Long, Long>>> iterator = elements.iterator(); iterator.hasNext(); ) {
TimestampedValue<Tuple3<String, Long, Long>> next = iterator.next();
System.out.println("before:" + next.getValue());
}
}
@Override
public void evictAfter(Iterable<TimestampedValue<Tuple3<String, Long, Long>>> elements, int size, GlobalWindow window, EvictorContext evictorContext) {
for (Iterator<TimestampedValue<Tuple3<String, Long, Long>>> iterator = elements.iterator(); iterator.hasNext(); ) {
TimestampedValue<Tuple3<String, Long, Long>> next = iterator.next();
iterator.remove();
}
}
})
.apply(new WindowFunction<Tuple3<String, Long, Long>, Tuple2<String, Long>, String, GlobalWindow>() {
@Override
public void apply(String s, GlobalWindow window, Iterable<Tuple3<String, Long, Long>> input, Collector<Tuple2<String, Long>> out) throws Exception {
long sum = 0;
Iterator<Tuple3<String, Long, Long>> iterator = input.iterator();
for (input.iterator(); iterator.hasNext(); ) {
Tuple3<String, Long, Long> next = iterator.next();
System.out.println(next);
sum += next.f1;
}
System.out.println(sum);
out.collect(Tuple2.of(s, sum));
}
}).print();
env.execute();
}
}ProcessWindowFunction/ProcessAllWindowFunction与ReduceFunction混搭用法
- 含义: ProcessWindowFunction可以与ReduceFunction、AggregateFunction或FoldFunction组合,以便在元素到达窗口时增量地聚合它们。当窗口关闭时,ProcessWindowFunction将提供聚合结果。ProcessWindowFunction可以在访问附加窗口元信息的同时进行增量计算。
示例代码:
package com.hainiu.windows;
import org.apache.flink.api.common.functions.AggregateFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.api.java.tuple.Tuple4;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import org.apache.flink.streaming.api.functions.timestamps.AscendingTimestampExtractor;
import org.apache.flink.streaming.api.functions.windowing.ProcessWindowFunction;
import org.apache.flink.streaming.api.windowing.assigners.TumblingEventTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.windows.TimeWindow;
import org.apache.flink.util.Collector;
import java.util.Iterator;
public class ProcessAggregateFunctionOnCountWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
SingleOutputStreamOperator<Tuple3<String, Long, Long>> hainiu = env.addSource(new SourceFunction<Tuple3<String, Long, Long>>() {
private Boolean isCancel = true;
@Override
public void run(SourceContext<Tuple3<String, Long, Long>> ctx) throws Exception {
long num = 0;
while (isCancel) {
num += 1;
ctx.collect(new Tuple3<>("hainiu", num, System.currentTimeMillis()));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
isCancel = false;
}
}).assignTimestampsAndWatermarks(new AscendingTimestampExtractor<Tuple3<String, Long, Long>>() {
@Override
public long extractAscendingTimestamp(Tuple3<String, Long, Long> element) {
return element.f2;
}
});
KeyedStream<Tuple3<String, Long, Long>, String> keyBy = hainiu.keyBy(new KeySelector<Tuple3<String, Long, Long>, String>() {
@Override
public String getKey(Tuple3<String, Long, Long> value) throws Exception {
return value.f0;
}
});
SingleOutputStreamOperator<Tuple4<String, Long, Long, Long>> sum = keyBy.window(TumblingEventTimeWindows.of(Time.seconds(5)))
.aggregate(new AggregateFunction<Tuple3<String, Long, Long>, Tuple2<String, Long>, Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> createAccumulator() {
return Tuple2.of("", 0L);
}
@Override
public Tuple2<String, Long> add(Tuple3<String, Long, Long> value, Tuple2<String, Long> accumulator) {
System.out.println("aggregate:" + value);
return Tuple2.of(value.f0, value.f1 + accumulator.f1);
}
@Override
public Tuple2<String, Long> getResult(Tuple2<String, Long> accumulator) {
return accumulator;
}
@Override
public Tuple2<String, Long> merge(Tuple2<String, Long> a, Tuple2<String, Long> b) {
return Tuple2.of(a.f0, a.f1 + b.f1);
}
}, new ProcessWindowFunction<Tuple2<String, Long>, Tuple4<String, Long, Long, Long>, String, TimeWindow>() {
@Override
public void process(String s, Context context, Iterable<Tuple2<String, Long>> elements, Collector<Tuple4<String, Long, Long, Long>> out) throws Exception {
for (Iterator<Tuple2<String, Long>> iterator = elements.iterator(); iterator.hasNext(); ) {
Tuple2<String, Long> next = iterator.next();
System.out.println("process:" + next);
}
Tuple2<String, Long> next = elements.iterator().next();
TimeWindow window = context.window();
out.collect(Tuple4.of(next.f0, next.f1, window.getStart(), window.getEnd()));
}
});
sum.print();
env.execute();
}
}4.windows的operator练习:
1.WindowsAll基础使用
示例代码:
package com.hainiu.windows;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import java.util.ArrayList;
import java.util.List;
public class ReduceFunctionOnCountWindowAll {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
List<Tuple2<String,Long>> list = new ArrayList<>();
list.add(Tuple2.of("hainiu",1L));
list.add(Tuple2.of("hainiu2",2L));
list.add(Tuple2.of("hainiu",3L));
list.add(Tuple2.of("hainiu2",4L));
list.add(Tuple2.of("hainiu3",100L));
DataStreamSource<Tuple2<String, Long>> input = env.fromCollection(list);
KeyedStream<Tuple2<String, Long>, String> keyBy = input.keyBy(new KeySelector<Tuple2<String, Long>, String>() {
@Override
public String getKey(Tuple2<String, Long> value) throws Exception {
return value.f0;
}
});
SingleOutputStreamOperator<Tuple2<String, Long>> reduce = keyBy.countWindowAll(2).reduce(new ReduceFunction<Tuple2<String, Long>>() {
@Override
public Tuple2<String, Long> reduce(Tuple2<String, Long> value1, Tuple2<String, Long> value2) throws Exception {
return Tuple2.of(value1.f0, value1.f1 + value2.f1);
}
});
reduce.print();
env.execute();
}
}2.windows join
| operator | 说明 |
|---|---|
| cogroup | • 侧重于group,是对同一个key上的两组集合进行操作 • CoGroup的作用和join基本相同,但有一点不一样的是,如果未能找 到新到来的数据与另一个流在window中存在的匹配数据,仍会可将其 输出 • 只能在window中用 |
| join | 而 join 侧重的是pair,是对同一个key上的每对元素进行操作 类似inner join 按照一定条件分别取出两个流中匹配的元素,返回给下游处理 Join是cogroup 的特例 只能在window中用 |
1).cogroup与join
示例代码:
package com.hainiu.windows;
import org.apache.flink.api.common.functions.CoGroupFunction;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.functions.KeySelector;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.ProcessingTimeSessionWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.api.windowing.triggers.CountTrigger;
import org.apache.flink.util.Collector;
import java.util.Iterator;
public class CoGroupOnAndJoinSessionWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> s1 = env.socketTextStream("localhost", 6666);
DataStreamSource<String> s2 = env.socketTextStream("localhost", 7777);
SingleOutputStreamOperator<Tuple2<String, Integer>> input1 = s1.map(f -> Tuple2.of(f, 1)).returns(Types.TUPLE(Types.STRING, Types.INT));
SingleOutputStreamOperator<Tuple2<String, Integer>> input2 = s2.map(f -> Tuple2.of(f, 1)).returns(Types.TUPLE(Types.STRING, Types.INT));
/**
* 1、创建两个socket stream。然后转成元素组成(String, Integer)类型的tuple。
* 2、join条件为两个流中的数据((String, Integer)类型)第一个元素相同。
* 3、为测试方便,这里使用session window。只有两个元素到来时间前后相差不大于10秒之时才会被匹配。
* Session window的特点为,没有固定的开始和结束时间,只要两个元素之间的时间间隔不大于设定值,就会分配到同一个window中,否则后来的元素会进入新的window。
* 4、将window默认的trigger修改为count trigger。这里的含义为每到来一个元素,都会立刻触发计算。
* 5、由于设置的并行度为12,所以有12个task
* 6、所以两边相同的key会跑到其中一个task中,这样才能达到join的目的
* 但是由于使用的是cogroup所以两边流跑到一个task中的key无论能不能匹配,都会以执行打印
* 不能匹配的原因可能其中一个流相同的那个key还没有发送过来
*/
input1.coGroup(input2)
.where(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
})
.equalTo(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
})
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
.trigger(CountTrigger.of(1))
.apply(new CoGroupFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, String>() {
@Override
public void coGroup(Iterable<Tuple2<String, Integer>> first, Iterable<Tuple2<String, Integer>> second, Collector<String> out) throws Exception {
StringBuilder sb = new StringBuilder();
sb.append("Data in stream1: \n");
for (Iterator<Tuple2<String, Integer>> iterator = first.iterator(); iterator.hasNext(); ) {
Tuple2<String, Integer> next = iterator.next();
sb.append(next.f0).append("<->").append(next.f1).append("\n");
}
sb.append("Data in stream2: \n");
for (Iterator<Tuple2<String, Integer>> iterator = second.iterator(); iterator.hasNext(); ) {
Tuple2<String, Integer> next = iterator.next();
sb.append(next.f0).append("<->").append(next.f1).append("\n");
}
out.collect(sb.toString());
}
}).print();
/**
* 1、创建两个socket stream。然后转成元素组成(String, Integer)类型的tuple。
* 2、join条件为两个流中的数据((String, Integer)类型)第一个元素相同。
* 3、为测试方便,这里使用session window。只有两个元素到来时间前后相差不大于10秒之时才会被匹配。
* Session window的特点为,没有固定的开始和结束时间,只要两个元素之间的时间间隔不大于设定值,就会分配到同一个window中,否则后来的元素会进入新的window。
* 4、将window默认的trigger修改为count trigger。这里的含义为每到来一个元素,都会立刻触发计算。
* 5、处理匹配到的两个数据,例如到来的数据为("hainiu",1)和("hainiu",1),输出到下游则为"hainiu == hainiu"
* 6、结论:
* a、join只返回匹配到的数据对。若在window中没有能够与之匹配的数据,则不会有输出。
* b、join会输出window中所有的匹配数据对。
* c、不在window内的数据不会被匹配到。
* */
input1.join(input2)
.where(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
})
.equalTo(new KeySelector<Tuple2<String, Integer>, String>() {
@Override
public String getKey(Tuple2<String, Integer> value) throws Exception {
return value.f0;
}
})
.window(ProcessingTimeSessionWindows.withGap(Time.seconds(10)))
.trigger(CountTrigger.of(1))
.apply(new JoinFunction<Tuple2<String, Integer>, Tuple2<String, Integer>, String>() {
@Override
public String join(Tuple2<String, Integer> first, Tuple2<String, Integer> second) throws Exception {
return first.f0 + " == " + second.f0;
}
}).print();
env.execute();
}
}原理图:
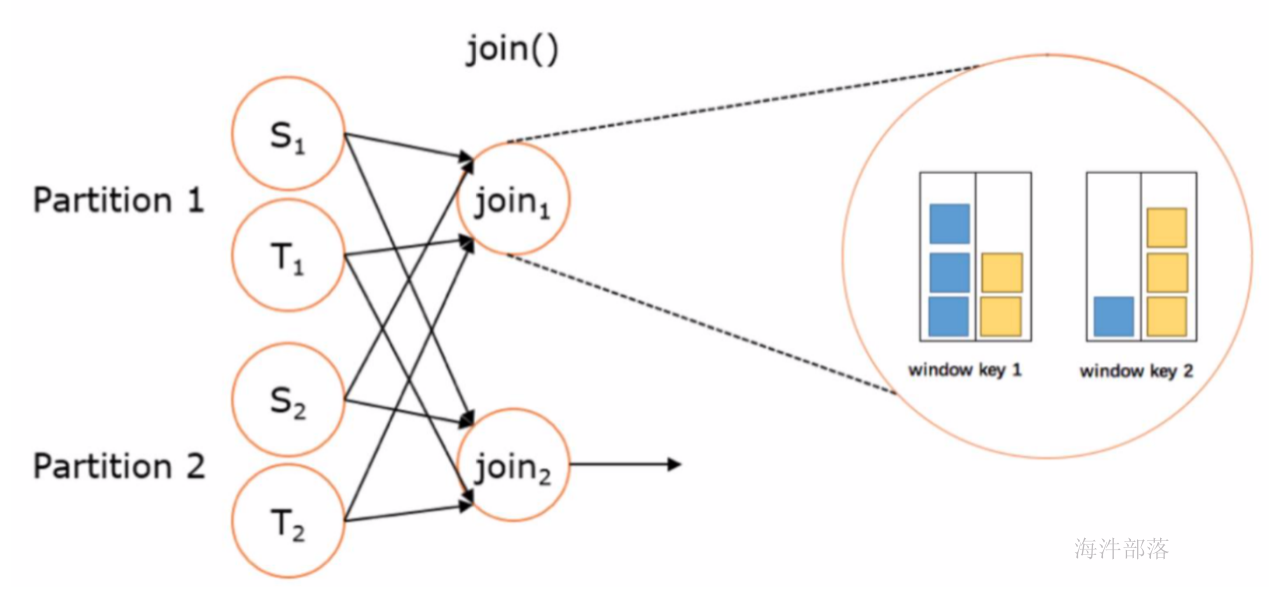
不同的windows的join场景:
- Tumbling Window Join
- Sliding Window Join
- Session Window Join
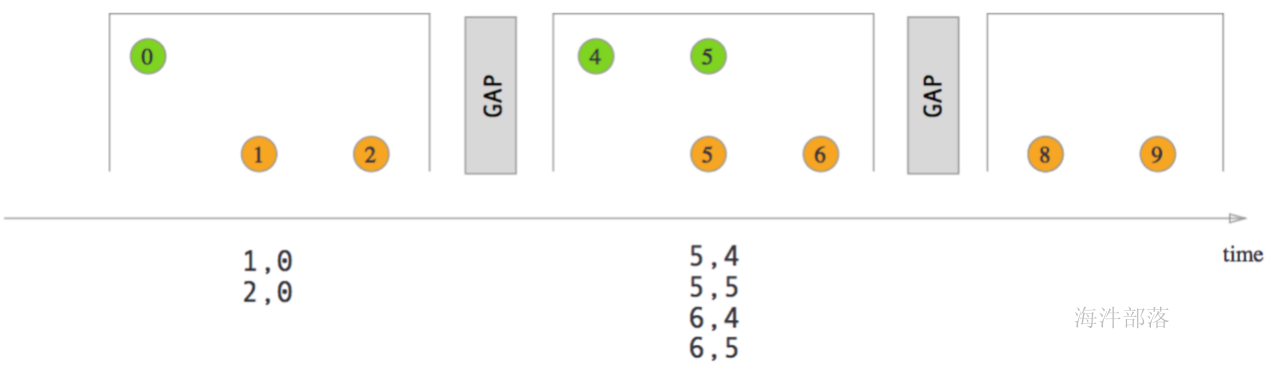
7.TimerService、累加器、parquet格式、flink行存储与列存储操作
1.ProcessFunction
- 不要跟ProcessWindowFunction混为一谈
- ProcessFunction是一个低阶的流处理操作,它可以访问流处理程序的基础构建模块
- 事件是一条一条处理的
- 对状态的处理,比如容错性,一致性,仅在keyed stream中
- 提供定时器,基于event time和processing time, 仅在keyed stream中
- ProcessFunction可以看作是一个具有keyed state 和 timers访问权的FlatMapFunction
- 通过RuntimeContext访问keyed state
- 计时器允许应用程序对处理时间和事件时间中的更改作出响应。对processElement(...)函数的每次调用都获得一个Context对象,该对象可以访问元素的event time timestamp和TimerService
2.TimerService
- TimerService可用于为将来的event/process time瞬间注册回调。当到达计时器的特定时间时,将调用onTimer(...)方法。在该调用期间,所有状态都再次限定在创建计时器时使用的键的范围内,从而允许计时器操作键控状态
- processing-time/event-time timer都由TimerService在内部维护并排队等待执行。
- 仅在keyed stream中有效
- 由于Flink对(每个key+timestamp)只维护一个计时器。如果为相同的timestamp注册了多个timer , 则只调用onTimer()方法一次。
- Flink保证同步调用onTimer()和processElement() 。因此用户不必担心状态的并发修改。
- 容错
- Timer具有容错和checkpoint能力(基于flink app的状态)。从故障恢复或从savepoint启动应用程序时,Timer将被恢复。
- 大量计时器会增加检查点存储空间,因为计时器是检查点状态的一部分
1).TimerService的使用
需求:使用processFunction的TimeService实现两个流的Join功能并实现sessionWindows
示例代码:
package com.hainiu.windows;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.KeyedCoProcessFunction;
import org.apache.flink.util.Collector;
public class ConnectJoinTimeServerSessionWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> s1 = env.socketTextStream("localhost", 6666);
DataStreamSource<String> s2 = env.socketTextStream("localhost", 7777);
KeyedStream<Tuple3<String, Integer, Long>, Tuple> input1 = s1.map(f -> Tuple3.of(f, 1, System.currentTimeMillis())).returns(Types.TUPLE(Types.STRING, Types.INT, Types.LONG)).keyBy("f0");
KeyedStream<Tuple3<String, Integer, Long>, Tuple> input2 = s2.map(f -> Tuple3.of(f, 1, System.currentTimeMillis())).returns(Types.TUPLE(Types.STRING, Types.INT, Types.LONG)).keyBy("f0");
/**
* 使用timerService实现SessionWindows的Join功能
* 注意:这个join因为没有使用state,所以只要不同的key跑在一个subTask里面也能Join在一起
* 因为Operator中的变量是共用的
*/
ConnectedStreams<Tuple3<String, Integer, Long>, Tuple3<String, Integer, Long>> connect = input1.connect(input2);
SingleOutputStreamOperator<String> process = connect.process(new KeyedCoProcessFunction<String, Tuple3<String, Integer, Long>, Tuple3<String, Integer, Long>, String>() {
private Long datatime = null;
private String outString = "";
private int intervalTime = 3000;
@Override
public void processElement1(Tuple3<String, Integer, Long> value, Context ctx, Collector<String> out) throws Exception {
outString += value.f0 + "\t";
datatime = value.f2;
ctx.timerService().registerProcessingTimeTimer(datatime + intervalTime);
System.out.println("subTaskId:" + getRuntimeContext().getIndexOfThisSubtask() + ",value:" + value.f0);
}
@Override
public void processElement2(Tuple3<String, Integer, Long> value, Context ctx, Collector<String> out) throws Exception {
outString += value.f0 + "\t";
datatime = value.f2;
ctx.timerService().registerProcessingTimeTimer(datatime + intervalTime);
System.out.println("subTaskId:" + getRuntimeContext().getIndexOfThisSubtask() + ",value:" + value.f0);
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
System.out.println("timerService start");
if (timestamp == datatime + intervalTime) {
out.collect(outString);
outString = "";
}
}
});
process.print();
env.execute();
}
}升级版示例代码:
package com.hainiu.windows;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.state.ReducingState;
import org.apache.flink.api.common.state.ReducingStateDescriptor;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.co.KeyedCoProcessFunction;
import org.apache.flink.util.Collector;
public class ConnectJoinTimeServerStateSessionWindow {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> s1 = env.socketTextStream("localhost", 6666);
DataStreamSource<String> s2 = env.socketTextStream("localhost", 7777);
KeyedStream<Tuple3<String, Integer, Long>, Tuple> input1 = s1.map(f -> Tuple3.of(f, 1, System.currentTimeMillis())).returns(Types.TUPLE(Types.STRING, Types.INT, Types.LONG)).keyBy("f0");
KeyedStream<Tuple3<String, Integer, Long>, Tuple> input2 = s2.map(f -> Tuple3.of(f, 1, System.currentTimeMillis())).returns(Types.TUPLE(Types.STRING, Types.INT, Types.LONG)).keyBy("f0");
/**
* 使用timerService实现SessionWindows的Join功能
* 注意:这个join因为使用keyedState,所以即使不同的key跑在一个subTask里面也是每个key join自己的
* 因为keyedState是属于每个key的
*/
ConnectedStreams<Tuple3<String, Integer, Long>, Tuple3<String, Integer, Long>> connect = input1.connect(input2);
SingleOutputStreamOperator<String> process = connect.process(new KeyedCoProcessFunction<String, Tuple3<String, Integer, Long>, Tuple3<String, Integer, Long>, String>() {
private int intervalTime = 3000;
private ReducingState<String> rs = null;
private ValueState<Long> vs = null;
@Override
public void open(Configuration parameters) throws Exception {
ReducingStateDescriptor<String> rsd = new ReducingStateDescriptor<String>("rsd", new ReduceFunction<String>() {
@Override
public String reduce(String value1, String value2) throws Exception {
return value1 + "\t" + value2;
}
}, String.class);
rs = getRuntimeContext().getReducingState(rsd);
ValueStateDescriptor<Long> vsd = new ValueStateDescriptor<>("vsd", Long.class);
vs = getRuntimeContext().getState(vsd);
}
@Override
public void processElement1(Tuple3<String, Integer, Long> value, Context ctx, Collector<String> out) throws Exception {
rs.add(value.f0);
vs.update(value.f2);
ctx.timerService().registerProcessingTimeTimer(vs.value() + intervalTime);
System.out.println("subTaskId:" + getRuntimeContext().getIndexOfThisSubtask() + ",value:" + value.f0);
}
@Override
public void processElement2(Tuple3<String, Integer, Long> value, Context ctx, Collector<String> out) throws Exception {
rs.add(value.f0);
vs.update(value.f2);
ctx.timerService().registerProcessingTimeTimer(vs.value() + intervalTime);
System.out.println("subTaskId:" + getRuntimeContext().getIndexOfThisSubtask() + ",value:" + value.f0);
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
System.out.println("timerService start");
Long dataTime = vs.value();
if (timestamp == dataTime + intervalTime) {
out.collect(rs.get());
rs.clear();
}
}
});
process.print();
env.execute();
}
}2).计时器合并
- 由于Flink对每个键和时间戳只维护一个计时器,因此可以通过降低计时器频率来合并计时器,从而减少计时器的数量。
- event-time timer只会在watermarks到来时触发
- 使用ctx.timerService().deleteEventTimeTimer删除过期Timer
示例代码:
package com.hainiu.windows;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.state.ReducingState;
import org.apache.flink.api.common.state.ReducingStateDescriptor;
import org.apache.flink.api.common.state.ValueState;
import org.apache.flink.api.common.state.ValueStateDescriptor;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple;
import org.apache.flink.api.java.tuple.Tuple3;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.TimeCharacteristic;
import org.apache.flink.streaming.api.datastream.ConnectedStreams;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.AssignerWithPeriodicWatermarks;
import org.apache.flink.streaming.api.functions.co.KeyedCoProcessFunction;
import org.apache.flink.streaming.api.watermark.Watermark;
import org.apache.flink.util.Collector;
import javax.annotation.Nullable;
public class ConnectJoinTimeServerStateSessionWindowEventTimeMerge {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
env.setStreamTimeCharacteristic(TimeCharacteristic.EventTime);
DataStreamSource<String> s1 = env.socketTextStream("localhost", 6666);
DataStreamSource<String> s2 = env.socketTextStream("localhost", 7777);
KeyedStream<Tuple3<String, Integer, Long>, Tuple> input1 = s1.map(f -> Tuple3.of(f, 1, System.currentTimeMillis())).returns(Types.TUPLE(Types.STRING, Types.INT, Types.LONG))
.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<Tuple3<String, Integer, Long>>() {
@Nullable
@Override
public Watermark getCurrentWatermark() {
return new Watermark(System.currentTimeMillis());
}
@Override
public long extractTimestamp(Tuple3<String, Integer, Long> element, long previousElementTimestamp) {
return element.f2;
}
}).keyBy("f0");
KeyedStream<Tuple3<String, Integer, Long>, Tuple> input2 = s2.map(f -> Tuple3.of(f, 1, System.currentTimeMillis())).returns(Types.TUPLE(Types.STRING, Types.INT, Types.LONG))
.assignTimestampsAndWatermarks(new AssignerWithPeriodicWatermarks<Tuple3<String, Integer, Long>>() {
@Nullable
@Override
public Watermark getCurrentWatermark() {
return new Watermark(System.currentTimeMillis());
}
@Override
public long extractTimestamp(Tuple3<String, Integer, Long> element, long previousElementTimestamp) {
return element.f2;
}
}).keyBy("f0");
/**
* 使用timerService实现SessionWindows的Join功能
* 注意:这个join因为使用keyedState,所以即使不同的key跑在一个subTask里面也是每个key join自己的
* 因为keyedState是属于每个key的
*/
ConnectedStreams<Tuple3<String, Integer, Long>, Tuple3<String, Integer, Long>> connect = input1.connect(input2);
SingleOutputStreamOperator<String> process = connect.process(new KeyedCoProcessFunction<String, Tuple3<String, Integer, Long>, Tuple3<String, Integer, Long>, String>() {
private int intervalTime = 3000;
private ReducingState<String> rs = null;
private ValueState<Long> currentTime = null;
private ValueState<Long> currentTimeService = null;
@Override
public void open(Configuration parameters) throws Exception {
ReducingStateDescriptor<String> rsd = new ReducingStateDescriptor<String>("rsd", new ReduceFunction<String>() {
@Override
public String reduce(String value1, String value2) throws Exception {
return value1 + "\t" + value2;
}
}, String.class);
rs = getRuntimeContext().getReducingState(rsd);
ValueStateDescriptor<Long> currentTimeSD = new ValueStateDescriptor<>("currentTime", Long.class);
currentTime = getRuntimeContext().getState(currentTimeSD);
ValueStateDescriptor<Long> lastTimeServiceSD = new ValueStateDescriptor<>("lastTimeService", Long.class);
currentTimeService = getRuntimeContext().getState(lastTimeServiceSD);
}
@Override
public void processElement1(Tuple3<String, Integer, Long> value, Context ctx, Collector<String> out) throws Exception {
doWork(value, ctx);
}
@Override
public void processElement2(Tuple3<String, Integer, Long> value, Context ctx, Collector<String> out) throws Exception {
doWork(value, ctx);
}
private void doWork(Tuple3<String, Integer, Long> value, KeyedCoProcessFunction<String, Tuple3<String, Integer, Long>, Tuple3<String, Integer, Long>, String>.Context ctx) throws Exception {
rs.add(value.f0);
if (currentTimeService.value() != null) {
ctx.timerService().deleteEventTimeTimer(currentTimeService.value());
}
long timestamp = ctx.timestamp();
currentTime.update(timestamp);
currentTimeService.update(timestamp + intervalTime);
ctx.timerService().registerEventTimeTimer(currentTimeService.value());
System.out.println("subTaskId:" + getRuntimeContext().getIndexOfThisSubtask() + ",value:" + value.f0);
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector<String> out) throws Exception {
System.out.println("timerService start");
Long dataTime = currentTime.value();
if (timestamp == dataTime + intervalTime) {
out.collect(rs.get());
rs.clear();
}
}
});
process.print();
env.execute();
}
}3.累加器和计数器
- 用于在flink程序运行过程中进行计数,类似于spark的Accumulator或mr的counter
1).内置累加器:
- IntCounter
- LongCounter
- DoubleCounter
- Histogram
2).自定义累加器
- 实现Accumulator或者SimpleAccumulator
3).如何使用累加器
- 第一步:在自定义的转换操作里创建累加器对象: private IntCounter numLines = new IntCounter();
- 第二步:注册累加器对象,通常是在rich function的open()方法中。这里你还需要定义累加器的名字 getRuntimeContext().addAccumulator("num-lines", this.numLines);
- 第三步:在operator函数的任何地方使用累加器,包括在open()和close()方法中this.numLines.add(1);
- 第四步:结果存储在JobExecutionResult里
JobExecutionResult myJobExecutionResult = env.execute("Flink Batch Java API Skeleton");
myJobExecutionResult.getAccumulatorResult("num-lines")
示例代码:
package com.hainiu.windows;
import org.apache.flink.api.common.JobExecutionResult;
import org.apache.flink.api.common.accumulators.IntCounter;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class IntCounterBounded {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.createLocalEnvironmentWithWebUI(new Configuration());
// DataStreamSource<String> input1 = env.socketTextStream("localhost", 6666);
DataStreamSource<String> input1 = env.fromElements("a a a", "b b b");
input1.flatMap(new RichFlatMapFunction<String, Tuple2<String, Integer>>() {
private IntCounter inc = null;
@Override
public void open(Configuration parameters) throws Exception {
inc = new IntCounter();
getRuntimeContext().addAccumulator("hainiu", this.inc);
}
@Override
public void flatMap(String value, Collector<Tuple2<String, Integer>> out) throws Exception {
String[] strs = value.split(" ");
for (String s : strs) {
this.inc.add(1);
out.collect(Tuple2.of(s, 1));
}
}
}).print();
JobExecutionResult res = env.execute("intCount");
Integer num = (Integer) res.getAccumulatorResult("hainiu");
System.out.println(num);
}
}升级版示例代码:
package com.hainiu.windows;
import org.apache.flink.api.common.accumulators.IntCounter;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class IntCounterUnbounded {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> input1 = env.socketTextStream("localhost", 6666);
input1.flatMap(new RichFlatMapFunction<String, IntCounter>() {
private IntCounter inc = null;
@Override
public void open(Configuration parameters) throws Exception {
inc = new IntCounter();
getRuntimeContext().addAccumulator("hainiu", this.inc);
}
@Override
public void flatMap(String value, Collector<IntCounter> out) throws Exception {
String[] strs = value.split(" ");
for (String s : strs) {
this.inc.add(1);
}
out.collect(this.inc);
}
}).print();
env.execute("intCount");
}
}再升级版示例代码:
package com.hainiu.windows;
import org.apache.flink.api.common.functions.ReduceFunction;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.DataStreamUtils;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.util.Collector;
import java.util.Iterator;
public class IntCounterUnboundedWindows {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> input1 = env.socketTextStream("localhost", 6666);
SingleOutputStreamOperator<Integer> reduce = input1.flatMap(new RichFlatMapFunction<String, Integer>() {
@Override
public void flatMap(String value, Collector<Integer> out) throws Exception {
String[] strs = value.split(" ");
for (String s : strs) {
out.collect(1);
}
}
}).timeWindowAll(Time.seconds(5))
.reduce(new ReduceFunction<Integer>() {
@Override
public Integer reduce(Integer value1, Integer value2) throws Exception {
return value1 + value2;
}
});
Iterator<Integer> collect = DataStreamUtils.collect(reduce);
for (; collect.hasNext(); ) {
Integer next = collect.next();
//插入mysql
System.out.println("count:" + next);
}
env.execute("intCount");
}
}4.parquet格式
1).文件的列式存储与行式存储对比
行式存储比如Avro或者文本
2).列式存储代表
Apache Parquet,Apache ORC,适合离线分析,不支持单条纪录级别的update操作
1.ORC文件格式:
- ORC原生是不支持嵌套数据格式的,而是通过对复杂数据类型特殊处理的方式实现嵌套格式的支持,例如对于如下的hive表:
CREATE TABLE `orcStructTable`(
`name` string,
`course` struct<course:string,score:int>,
`score` map<string,int>,
`work_locations` array<string>)- ORC文件:保存在文件系统上的普通二进制文件,一个ORC文件中可以包含多个stripe,每一个stripe包含多条记录,这些记录按照列进行独立存储,对应到Parquet中的row group的概念。
- 文件级元数据:包括文件的描述信息PostScript、文件meta信息(包括整个文件的统计信息)、所有stripe的信息和文件schema信息。
- stripe:一组行形成一个stripe,每次读取文件是以行组为单位的,一般为HDFS的块大小,保存了每一列的索引和数据。
- stripe元数据:保存stripe的位置、每一个列的在该stripe的统计信息以及所有的stream类型和位置。
- row group:索引的最小单位,一个stripe中包含多个row group,默认为10000个值组成。
- stream:一个stream表示文件中一段有效的数据,包括索引和数据两类。索引stream保存每一个row group的位置和统计信息,数据stream包括多种类型的数据,具体需要哪几种是由该列类型和编码方式决定。
- 文件结构:
2.parquet文件格式:
- Apache Parquet是一种能够有效存储嵌套数据的列式存储格式。
- 和Avro一样支持可变字段,不存在的字段不抛出异常,返回"NULL"
- Parquet文件由一个文件头(header),一个或多个紧随其后的文件块(block),以及一个用于结尾的文件尾(footer)构成。
- 文件头仅包含Parquet文件的每个文件块负责存储一个行组,行组由列块组成,且一个列块负责存储一列数据。每个列块中的的数据以页为单位。
- 文件结构:
参考文献:
https://www.jianshu.com/p/76b7776ed567
https://blog.csdn.net/yu616568/article/details/51868447
3).使用flink进行文件存储,并按时间切割文件
文件有三种状态:
- in-progress:正在写入
- pending:写入完成,由in-progress转为pending状态
- finished:当checkpoint后,由pengding转为finished状态
1).行式文件(文本)存储
示例代码:
package com.hainiu.file;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.connectors.fs.bucketing.BucketingSink;
import org.apache.flink.streaming.connectors.fs.bucketing.DateTimeBucketer;
import java.time.ZoneId;
public class Streaming2RowFormatFile {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
DataStreamSource<String> input = env.socketTextStream("localhost", 6666);
// 方式1:将数据导入Hadoop的文件夹
//recordData.writeAsText("file:///Users/leohe/Data/output/flinkout/rowformat/");
// 方式2:将数据导入Hadoop的文件夹
BucketingSink<String> hadoopSink = new BucketingSink<>("file:///Users/leohe/Data/output/flinkout/rowformat/");
// 使用东八区时间格式"yyyy-MM-dd--HH"命名存储区
hadoopSink.setBucketer(new DateTimeBucketer<>("yyyy-MM-dd-HH", ZoneId.of("Asia/Shanghai")));
// 下述两种条件满足其一时,创建新的块文件
// 条件1.设置块大小为100MB
hadoopSink.setBatchSize(1024 * 1024 * 100);
// 条件2.设置时间间隔10秒
hadoopSink.setBatchRolloverInterval(10000);
// 设置块文件前缀
hadoopSink.setPendingPrefix("");
// 设置块文件后缀
hadoopSink.setPendingSuffix("");
// 设置运行中的文件前缀
hadoopSink.setInProgressPrefix(".");
// 添加Hadoop-Sink,处理相应逻辑
input.addSink(hadoopSink);
env.execute();
}
}2).列式文件(parquet)存储
1.POJO类,示例代码:
package com.hainiu.file;
public class HainiuParquetPojo {
private String word;
private Long count;
public HainiuParquetPojo(){
}
public HainiuParquetPojo(String word, Long count) {
this.word = word;
this.count = count;
}
public String getWord() {
return word;
}
public void setWord(String word) {
this.word = word;
}
public Long getCount() {
return count;
}
public void setCount(Long count) {
this.count = count;
}
}2.写入文件,示例代码:
package com.hainiu.file;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.core.fs.Path;
import org.apache.flink.formats.parquet.avro.ParquetAvroWriters;
import org.apache.flink.runtime.state.memory.MemoryStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner;
import java.time.ZoneId;
import java.util.concurrent.TimeUnit;
public class Streaming2ColumnFormatFile {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
env.enableCheckpointing(1000);
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
//保存EXACTLY_ONCE
checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//每次ck之间的间隔,不会重叠
checkpointConfig.setMinPauseBetweenCheckpoints(2000L);
//每次ck的超时时间
checkpointConfig.setCheckpointTimeout(20000L);
//如果ck执行失败,程序是否停止
checkpointConfig.setFailOnCheckpointingErrors(true);
//job在执行CANCE的时候是否删除ck数据
checkpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//指定保存ck的存储模式,这个是默认的
MemoryStateBackend stateBackend = new MemoryStateBackend(10 * 1024 * 1024, false);
env.setStateBackend(stateBackend);
//恢复策略
env.setRestartStrategy(
RestartStrategies.fixedDelayRestart(
3, // number of restart attempts
Time.of(0, TimeUnit.SECONDS) // delay
)
);
DataStreamSource<String> socket = env.socketTextStream("localhost", 6666);
SingleOutputStreamOperator<HainiuParquetPojo> input = socket.map(f -> Tuple2.of(f, 1L)).returns(Types.TUPLE(Types.STRING, Types.LONG))
.keyBy(0).sum(1)
.map(f -> new HainiuParquetPojo(f.f0, f.f1));
DateTimeBucketAssigner bucketAssigner = new DateTimeBucketAssigner("yyyy/MMdd/HH", ZoneId.of("Asia/Shanghai"));
StreamingFileSink streamingFileSink = StreamingFileSink.
forBulkFormat(new Path("file:///Users/leohe/Data/output/flinkout/columnformat/"),
ParquetAvroWriters.forReflectRecord(HainiuParquetPojo.class))
.withBucketCheckInterval(1000 * 60)
.withBucketAssigner(bucketAssigner)
.build();
input.addSink(streamingFileSink);
env.execute();
}
}3.压缩写入:
1).由于官方api不支持parquet文件压缩,所以自定义压缩工具类:
示例代码:
package com.hainiu.file;
import org.apache.avro.Schema;
import org.apache.avro.generic.GenericData;
import org.apache.avro.generic.GenericRecord;
import org.apache.avro.reflect.ReflectData;
import org.apache.avro.specific.SpecificData;
import org.apache.avro.specific.SpecificRecordBase;
import org.apache.flink.formats.parquet.ParquetBuilder;
import org.apache.flink.formats.parquet.ParquetWriterFactory;
import org.apache.parquet.avro.AvroParquetWriter;
import org.apache.parquet.hadoop.ParquetWriter;
import org.apache.parquet.hadoop.metadata.CompressionCodecName;
import org.apache.parquet.io.OutputFile;
import java.io.IOException;
public class CompressionParquetAvroWriter {
private CompressionParquetAvroWriter() {
}
public static <T extends SpecificRecordBase> ParquetWriterFactory<T> forSpecificRecord(Class<T> type, CompressionCodecName compressionCodecName) {
final String schemaString = SpecificData.get().getSchema(type).toString();
final ParquetBuilder<T> builder = (out) -> createAvroParquetWriter(schemaString, SpecificData.get(), out, compressionCodecName);
return new ParquetWriterFactory<>(builder);
}
//compressionCodecName 压缩算法
public static ParquetWriterFactory<GenericRecord> forGenericRecord(Schema schema, CompressionCodecName compressionCodecName) {
final String schemaString = schema.toString();
final ParquetBuilder<GenericRecord> builder = (out) -> createAvroParquetWriter(schemaString, GenericData.get(), out, compressionCodecName);
return new ParquetWriterFactory<>(builder);
}
//compressionCodecName 压缩算法
public static <T> ParquetWriterFactory<T> forReflectRecord(Class<T> type, CompressionCodecName compressionCodecName) {
final String schemaString = ReflectData.get().getSchema(type).toString();
final ParquetBuilder<T> builder = (out) -> createAvroParquetWriter(schemaString, ReflectData.get(), out, compressionCodecName);
return new ParquetWriterFactory<>(builder);
}
//compressionCodecName 压缩算法
private static <T> ParquetWriter<T> createAvroParquetWriter(
String schemaString,
GenericData dataModel,
OutputFile out,
CompressionCodecName compressionCodecName) throws IOException {
final Schema schema = new Schema.Parser().parse(schemaString);
return AvroParquetWriter.<T>builder(out)
.withSchema(schema)
.withDataModel(dataModel)
.withCompressionCodec(compressionCodecName)//压缩算法
.build();
}
}2).以SNAPPY格式压缩写入文件,示例代码:
package com.hainiu.file;
import org.apache.flink.api.common.restartstrategy.RestartStrategies;
import org.apache.flink.api.common.time.Time;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.core.fs.Path;
import org.apache.flink.runtime.state.memory.MemoryStateBackend;
import org.apache.flink.streaming.api.CheckpointingMode;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.CheckpointConfig;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.functions.sink.filesystem.StreamingFileSink;
import org.apache.flink.streaming.api.functions.sink.filesystem.bucketassigners.DateTimeBucketAssigner;
import org.apache.parquet.hadoop.metadata.CompressionCodecName;
import java.time.ZoneId;
import java.util.concurrent.TimeUnit;
public class Streaming2ColumnFormatFileCompression {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(2);
env.enableCheckpointing(1000);
CheckpointConfig checkpointConfig = env.getCheckpointConfig();
//保存EXACTLY_ONCE
checkpointConfig.setCheckpointingMode(CheckpointingMode.EXACTLY_ONCE);
//每次ck之间的间隔,不会重叠
checkpointConfig.setMinPauseBetweenCheckpoints(2000L);
//每次ck的超时时间
checkpointConfig.setCheckpointTimeout(20000L);
//如果ck执行失败,程序是否停止
checkpointConfig.setFailOnCheckpointingErrors(true);
//job在执行CANCE的时候是否删除ck数据
checkpointConfig.enableExternalizedCheckpoints(CheckpointConfig.ExternalizedCheckpointCleanup.RETAIN_ON_CANCELLATION);
//指定保存ck的存储模式,这个是默认的
MemoryStateBackend stateBackend = new MemoryStateBackend(10 * 1024 * 1024, false);
env.setStateBackend(stateBackend);
//恢复策略
env.setRestartStrategy(
RestartStrategies.fixedDelayRestart(
3, // number of restart attempts
Time.of(0, TimeUnit.SECONDS) // delay
)
);
DataStreamSource<String> socket = env.socketTextStream("localhost", 6666);
SingleOutputStreamOperator<HainiuParquetPojo> input = socket.map(f -> Tuple2.of(f, 1L)).returns(Types.TUPLE(Types.STRING, Types.LONG))
.keyBy(0).sum(1)
.map(f -> new HainiuParquetPojo(f.f0, f.f1));
DateTimeBucketAssigner bucketAssigner = new DateTimeBucketAssigner("yyyy/MMdd/HH", ZoneId.of("Asia/Shanghai"));
StreamingFileSink streamingFileSink = StreamingFileSink.
forBulkFormat(new Path("file:///Users/leohe/Data/output/flinkout/columnformat/"),
CompressionParquetAvroWriter.forReflectRecord(HainiuParquetPojo.class, CompressionCodecName.SNAPPY))
.withBucketCheckInterval(1000 * 60)
.withBucketAssigner(bucketAssigner)
.build();
input.addSink(streamingFileSink);
env.execute();
}
}3).使用hive进行验证:
表的schema:
CREATE EXTERNAL TABLE IF NOT EXISTS `hainiu_parquet_pojo`(
`word` string,
`count` bigint
)
PARTITIONED BY (`year` string, `day` string, `hour` string)
ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe'
STORED AS INPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetInputFormat'
OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat'
LOCATION 'file:///Users/leohe/Data/output/flinkout/columnformat';
alter table hainiu_parquet_pojo add IF NOT EXISTS partition(year='2020',day='0728',hour='19') location '2020/0728/19';也就是说只能按照每个checkpoint来压缩,这样的话如果ck间隔太短,会产生许多小文件,间隔太长就失去了实时性
4).小文件处理
不管是Flink还是SparkStreaming写hdfs不可避免需要关注的一个点就是如何处理小文件,众多的小文件会带来两个影响:
- Hdfs NameNode维护元数据成本增加
- 下游hive/spark任务执行的数据读取成本增加
理想状态下是按照设置的文件大小滚动,那为什么会产生小文件呢?这与文件滚动周期、checkpoint时间间隔设置相关,如果滚动周期较短、checkpoint时间也比较短或者数据流量有低峰期达到文件不活跃的时间间隔,很容易产生小文件,接下来介绍几种处理小文件的方式:
1).减少并行度
- 回顾一下文件生成格式:part + subtaskIndex + connter,其中subtaskIndex代表着任务并行度的序号,也就是代表着当前的一个写task,越大的并行度代表着越多的subtaskIndex,数据就越分散,如果我们减小并行度,数据写入由更少的task来执行,写入就相对集中,这个在一定程度上减少的文件的个数,但是在减少并行的同时意味着任务的并发能力下降;
2).增大checkpoint周期或者文件滚动周期
- 以parquet写分析为例,parquet写文件由processing状态变为pending状态发生在checkpoint的snapshotState阶段中,如果checkpoint周期时间较短,就会更快发生文件滚动,增大checkpoint周期,那么文件就能积累更多数据之后发生滚动,但是这种增加时间的方式带来的是数据的一定延时;
3).下游任务合并处理
- 待Flink将数据写入hdfs后,下游开启一个hive或者spark定时任务,通过改变分区的方式,将文件写入新的目录中,后续任务处理读取这个新的目录数据即可,同时还需要定时清理产生的小文件,这种方式虽然增加了后续的任务处理成本,但是其即合并了小文件提升了后续任务分析速度,也将小文件清理了减小了对NameNode的压力,相对于上面两种方式更加稳定,因此也比较推荐这种方式。
对于小文件合并比较推荐使用下游任务合并处理方式。
8.presto安装与使用
1.Presto介绍
1).什么是Presto
- Presto是可以访问HDFS,替代使用MapReduce作业(例如Hive或Pig)进行TB或PB级数据处理。
- Presto用于处理数据仓库并进行数据分析,汇总大量数据生成报告。这些工作负载通常被归类为在线分析处理(OLAP)。
- Presto是一个在Facebook的主持下运作的开源项目。它是在Facebook上发明的,并且该项目继续由Facebook内部开发人员和社区中的许多第三方开发人员开发。
2).Presto支持从以下Hadoop版本读取Hive数据:
- Apache Hadoop 1.x
- Apache Hadoop 2.x版
- Cloudera CDH 4
- Cloudera CDH 5
支持以下文件格式:文本,SequenceFile,RCFile,ORC和Parquet。
此外,需要远程Hive Metastore。不支持本地或嵌入式模式。Presto不使用MapReduce,因此仅需要HDFS。
3).架构:
Presto服务器有两种类型:协调器和工作器。以下部分说明了两者之间的区别。
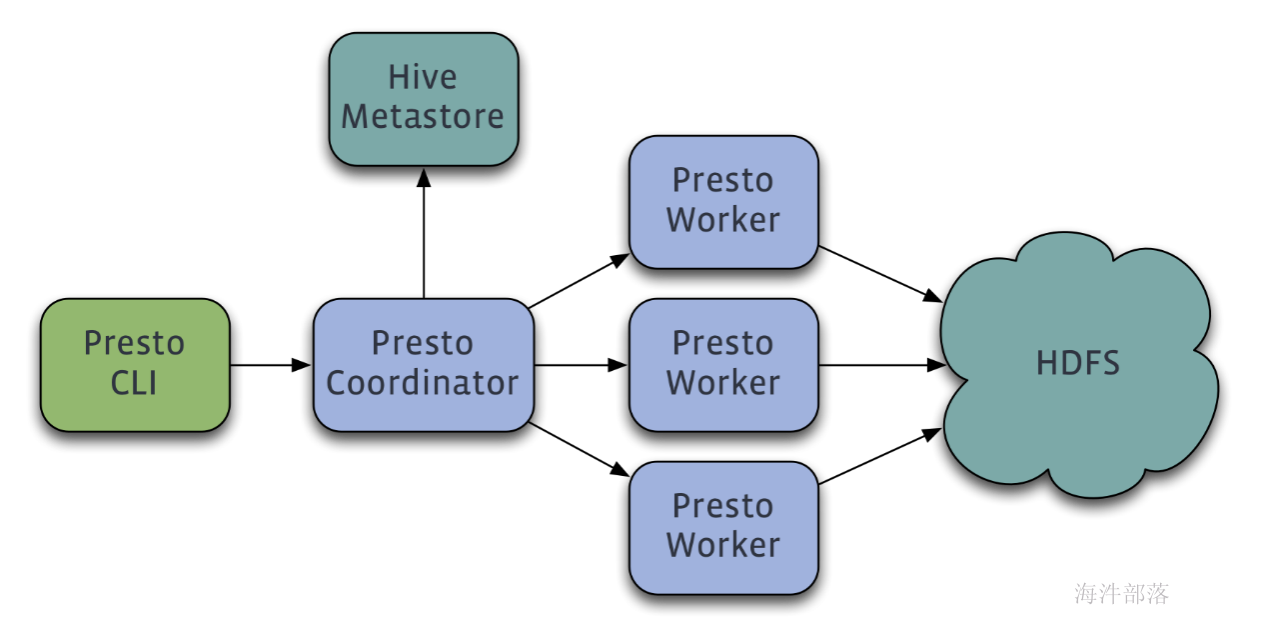
- Coordinator(协调器)
- Presto Coordinator是负责解析语句,计划查询和管理Presto工作程序节点的服务器。
- 它是Presto安装的“大脑”,也是客户端连接以提交执行语句的节点。
- Coordinator跟踪每个Worker上的活动并协调查询的执行。
- Coordinator创建涉及一系列阶段的查询的逻辑模型,然后将其转换为在Presto Worker群集上运行的一系列关联任务。
- Coordinator使用REST API与Worker进行通信。
- Worker(工作节点)
- Presto worker是Presto安装中的服务器,负责执行任务和处理数据。
- Coordinator负责从Worker那里获取结果,并将最终结果返回给Cli。
- 当Presto worker进程启动时,它将自己注册给Coordinator,这样Coordinator可以用它来执行任务。
- 出于开发或测试目的,可以将Presto的单个实例配置为执行这两个角色。
4).文档
- 官方帮助文档:https://prestodb.io/docs/0.195/index.html
- 常用语句:https://blog.csdn.net/Lnho2015/article/details/51428782?utm_medium=distribute.pc_aggpage_search_result.none-task-blog-2\~all\~first_rank_v2\~rank_v25-4-51428782.nonecase
- 与hive有一些不同的地方:https://blog.csdn.net/qq_37833410/article/details/103270386
2.Presto整合hive安装
1.上传压缩包

2.分发到每个机器上
./scp_all.sh ./up/presto-server-0.195.tar.gz /tmp/
3.解压到/usr/local目录下
./ssh_root.sh "tar -xzf /tmp/presto-server-0.195.tar.gz -C /usr/local/"
目录说明:
- bin:可执行脚本
- lib:依赖jar
- plugin:扩展连接jar包
4.修改权限为hadoop
./ssh_root.sh "chown -R hadoop:hadoop /usr/local/presto-server-0.195"
5.创建软件链接
./ssh_root.sh "ln -s /usr/local/presto-server-0.195 /usr/local/presto"
6.手动创建放配置文件的目录
./ssh_all.sh "mkdir /usr/local/presto/etc"
./ssh_all.sh "mkdir /usr/local/presto/etc/catalog"
7.上传配置文件
8.分发修改配置
./scp_all.sh ./up/config.properties /usr/local/presto/etc/
./scp_all.sh ./up/jvm.config /usr/local/presto/etc/
./scp_all.sh ./up/log.properties /usr/local/presto/etc/
./scp_all.sh ./up/node.properties /usr/local/presto/etc/
./scp_all.sh ./up/jmx.properties /usr/local/presto/etc/catalog/
./scp_all.sh ./up/hive.properties /usr/local/presto/etc/catalog/9.修改配置
export H=`hostname|awk -F "." '{print $1}'`
sed -i "s/node.id=nn1/node.id=$H/" /usr/local/presto/etc/node.properties
把nn1,s1,s2,s3改成worker
sed -i "s/coordinator=true/coordinator=false/" /usr/local/presto/etc/config.properties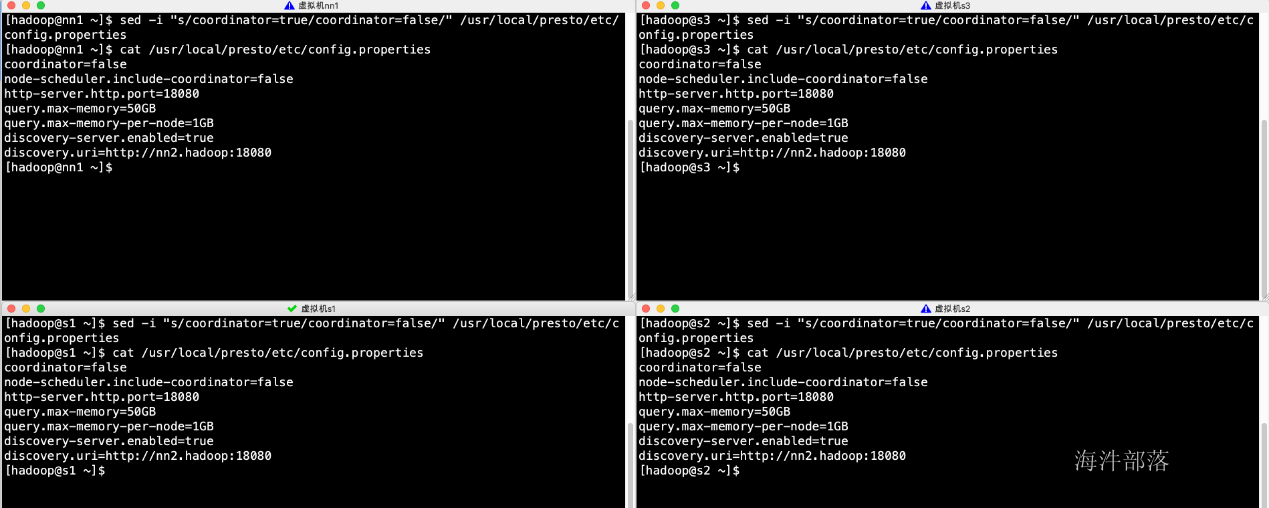
发送presto自己专用JDK到每个机器
./scp_all.sh ./up/jdk.tar /tmp/
并presto自己专用JDK到每个机器的/usr/local/presto/ 目录下
./ssh_all.sh tar -xzf /tmp/jdk.tar -C /usr/local/presto/
修改启动脚本,vim /usr/local/presto/bin/launcher,在里面配置上自己专有的虚拟机
PATH=/usr/local/presto/jdk1.8.0_101/bin/:$PATH
java -version
把修改好的启动脚本分发到每台机器:
./scp_all.sh /usr/local/presto/bin/launcher /usr/local/presto/bin/
10.启动presto服务
./ssh_all.sh /usr/local/presto/bin/launcher start启动presto之后各机器上的进程:
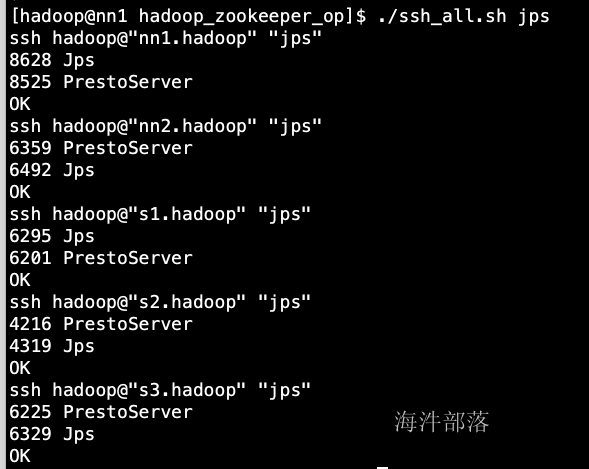
打开nn2机器的Coordinator界面
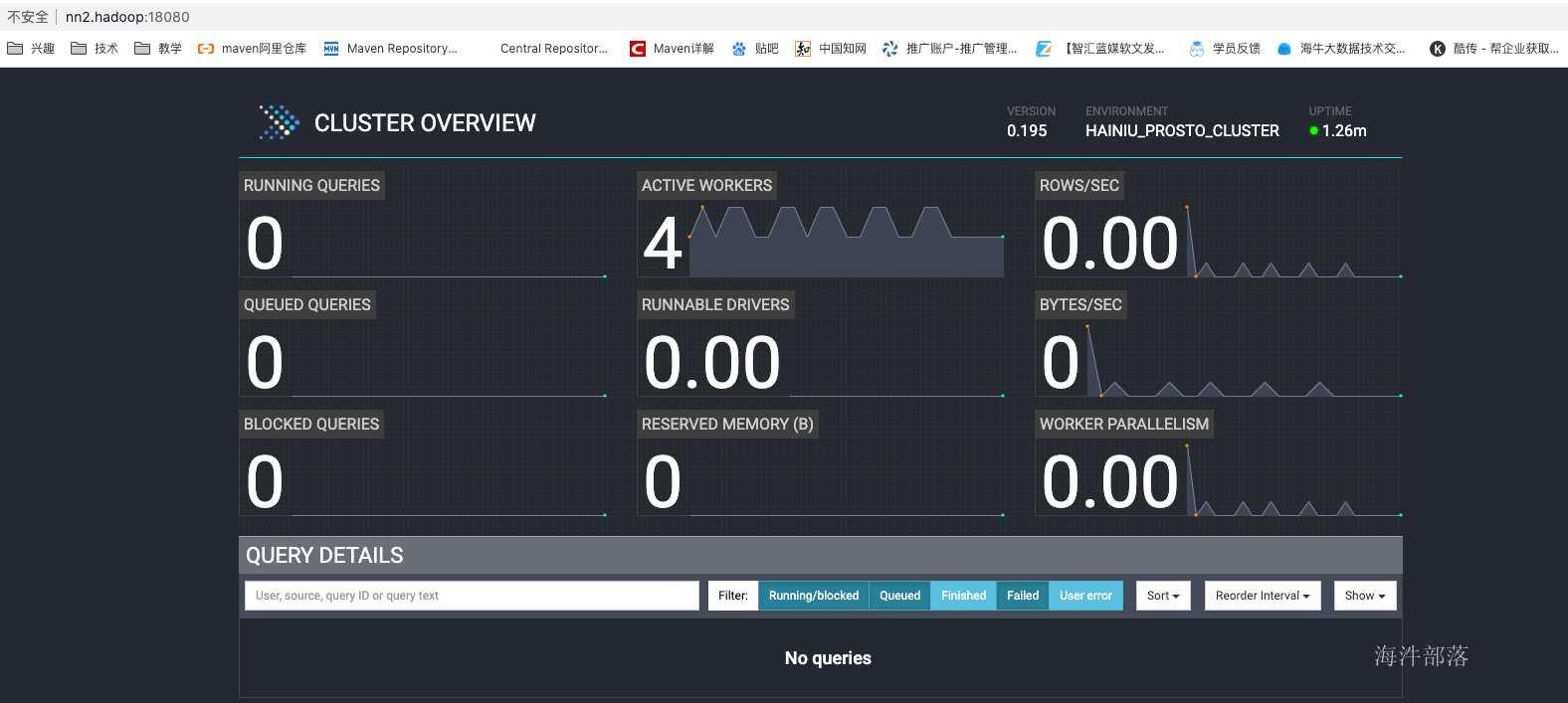
此时presto的集群服务已经安装完成:
11.安装客户端
mv ./up/presto-cli-0.195-executable.jar /usr/local/presto/bin/presto
chmod +x /usr/local/presto/bin/presto
然后修改环境变量:

12.测试一下连接hive
1).首先启动HDFS
./ssh_all_zookeeper.sh /usr/local/zookeeper/bin/zkServer.sh start
start-dfs.sh2).启动hive的元库:
nohup hive --service metastore > /dev/null 2>&1 &3).presto客户端连接hive元库
presto --server nn2.hadoop:18080 --catalog hive
到这里就说明成功了。
4).停止presto集群
./ssh_all.sh /usr/local/presto/bin/launcher stop
海牛集群的presto访问地址:
9.CoolNiu商城Flink实时数仓-ETL部分
1.数仓架构演变
1).离线数仓流程
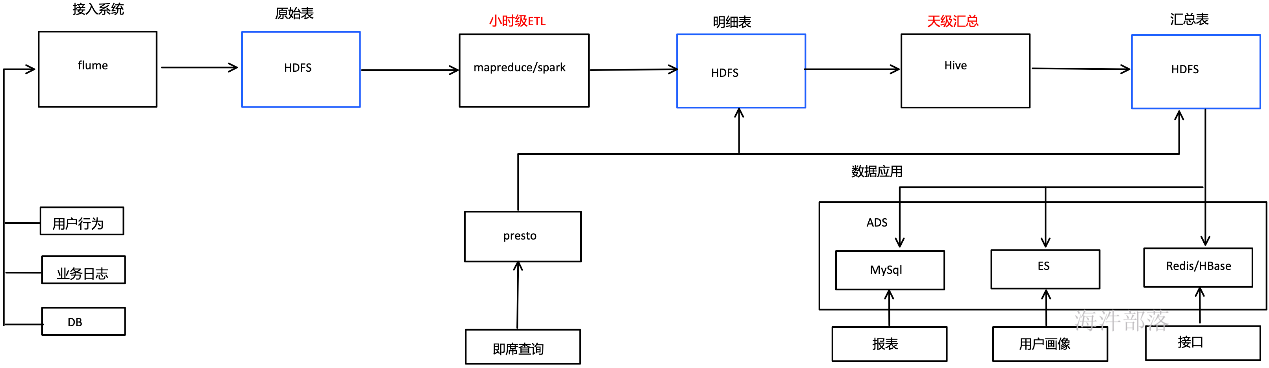
2).实时数仓流程
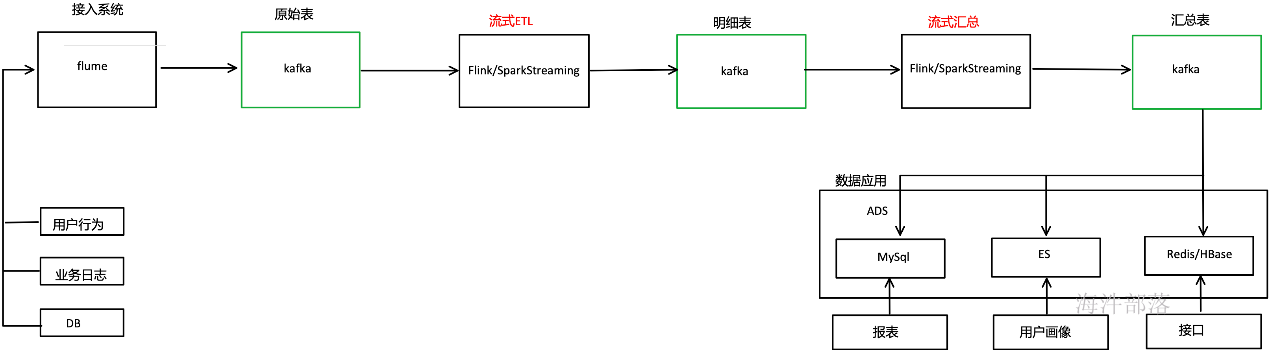
3).离线实时合并
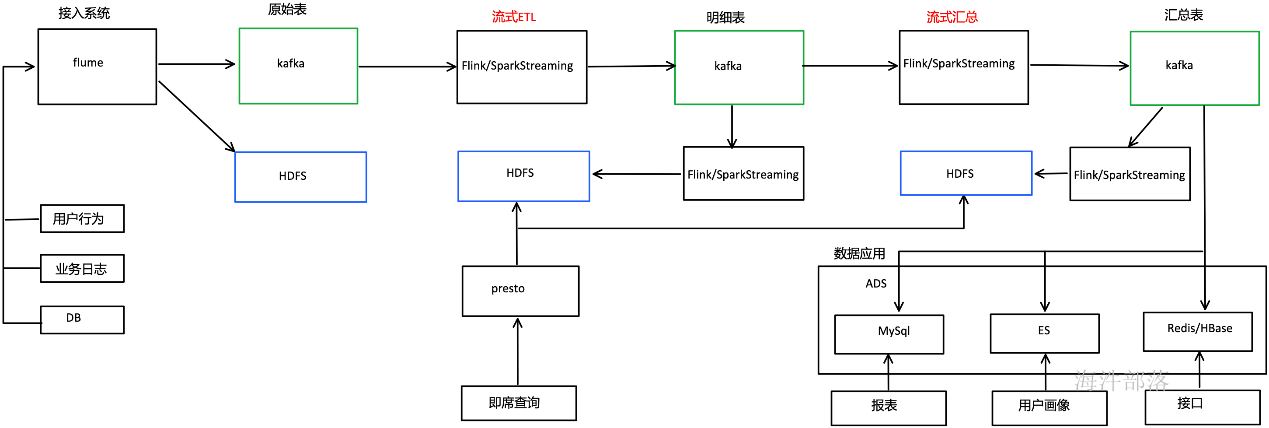
2.CoolNiu商城架构
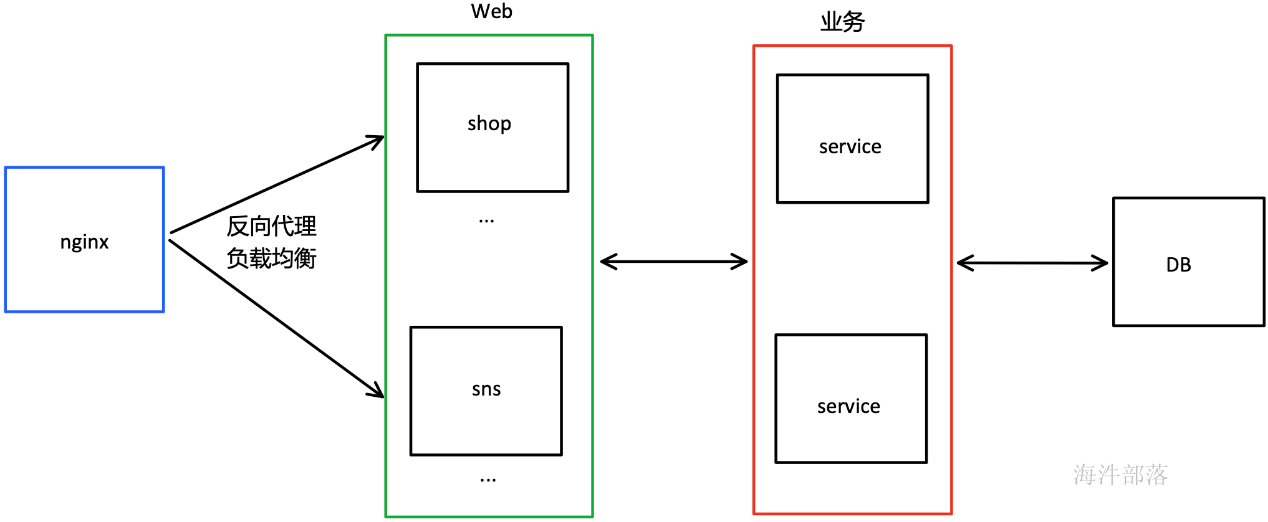
3.CoolNiu商城部署
1).nginx安装在nn1
(1).上传nginx源包并解压

tar -xzf ./tengine-2.2.0.tar.gz -C /root/
(2).检查系统编译环境并生成makefile文件
(3).configure成功结果
(4).编译并安装
make && make install
(5).安装完成会在/usr/local/目录下生成nginx目录,其中的conf目录是配置文件目录
(6).进入配置文件目录并创建sites-enabled目录
mkdir /usr/local/nginx/conf/sites-enabled
(7).反向代理与负载均衡配置
删除原来的nginx配置
rm -rf /usr/local/nginx/conf/nginx.conf将 nginx.conf 上传到/usr/local/nginx/conf/目录
mkdir -p /usr/local/nginx/conf/sites-enabled将 hainiushop.com 上传到/usr/local/nginx/conf/sites-enabled目录
修改hainiushop.com配置文件,将ip修改成安装tomcat的机器IP
vim /usr/local/nginx/conf/sites-enabled/hainiushop.com
(8).检查配置文件是否合法
/usr/local/nginx/sbin/nginx -t
(9).启动nginx
/usr/local/nginx/sbin/nginx
2).tomcat安装在nn2
上传3个tomcat到nn2

并解压到/usr/local目录下
tar -xzf ./tomcat.tar -C /usr/local/将tomcat修改成hadoop用户
chown -R hadoop:hadoop /usr/local/apache-tomcat-image-8.0.20/
chown -R hadoop:hadoop /usr/local/apache-tomcat-service-8.0.20/
chown -R hadoop:hadoop /usr/local/apache-tomcat-shop-8.0.20/
3).数据库初始化
1).修改mysql配置
#修改 /etc/my.cnf 文件
#在[mysqld]下添加
sql_mode=STRICT_TRANS_TABLES,NO_ZERO_IN_DATE,NO_ZERO_DATE,ERROR_FOR_DIVISION_BY_ZERO,NO_AUTO_CREATE_USER,NO_ENGINE_SUBSTITUTION2).重启mysql
systemctl restart mysqld3).创建数据库和用户并给用户赋权
CREATE USER 'hainiushop'@'%' IDENTIFIED BY '12345678';
create database hainiu_shop default charset utf8 collate utf8_bin;
grant all privileges on hainiu_shop.* to 'hainiushop'@'%' identified by '12345678';
flush privileges; 
4).给hainiu_shop库创建表并导入数据
1.上传sql文件

2.执行导入命令
#数据库备份命令 不用执行
mysqldump -hlocalhost -uhainiushop -P3306 -p12345678 hainiu_shop > /tmp/hainiu_shop.sql
#执行这个导入命令就行
mysql -uhainiushop -P3306 -p12345678 hainiu_shop < /tmp/hainiu_shop.sql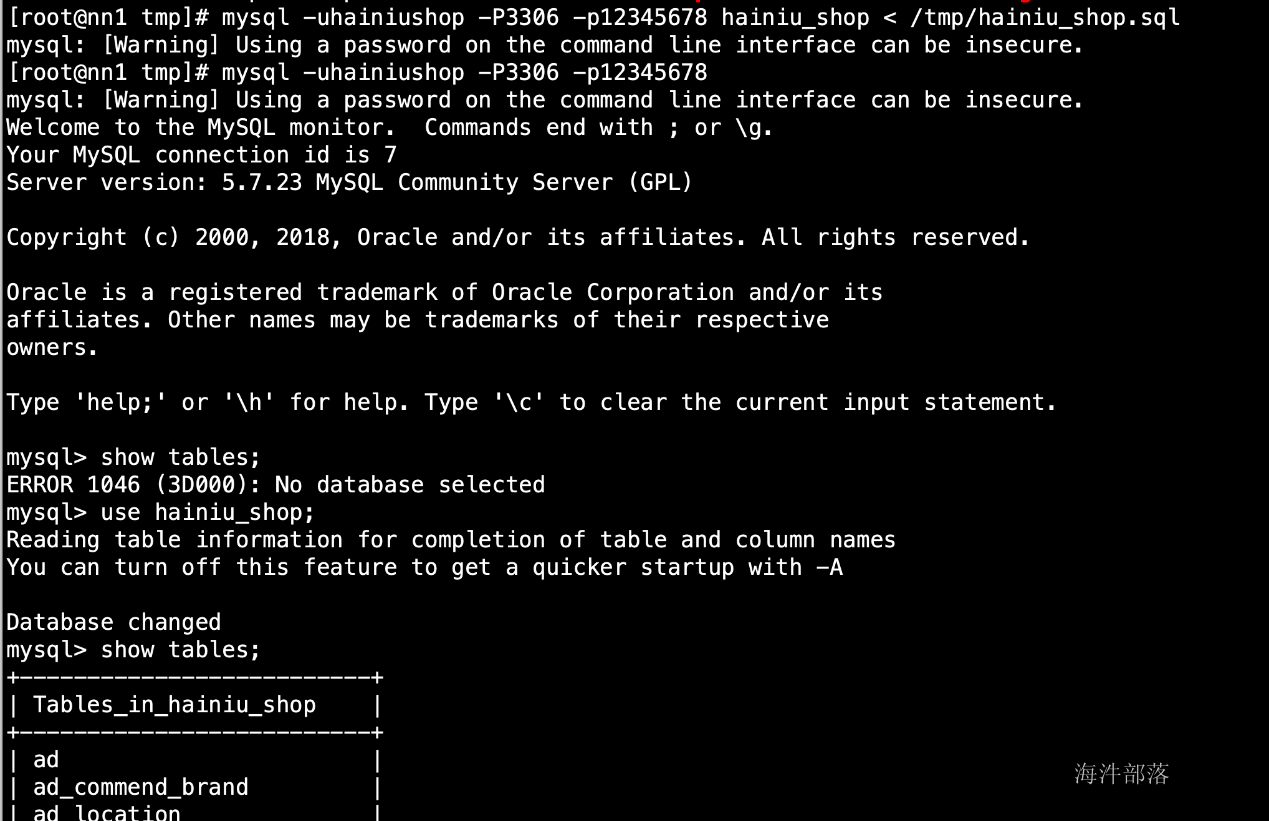

一共有91张表
4).项目部署在nn2
1.上传项目代码
2.解压每个项目到指定的tomcat目录下
tar -xzf ./hainiushop_shop.tar -C /usr/local/apache-tomcat-shop-8.0.20/webapps/
tar -xzf ./hainiushop_sns.tar -C /usr/local/apache-tomcat-shop-8.0.20/webapps/
tar -xzf ./hainiushop_sso.tar -C /usr/local/apache-tomcat-shop-8.0.20/webapps/
tar -xzf ./hainiushop_service.tar -C /usr/local/apache-tomcat-service-8.0.20/webapps/3.修改项目配置
修改hainiushop_service项目和hainiushop_sso项目的mysql连接,改为你自己的数据库地址
vim /usr/local/apache-tomcat-service-8.0.20/webapps/hainiushop_service/WEB-INF/proxool.xml
vim /usr/local/apache-tomcat-shop-8.0.20/webapps/hainiushop_sso/WEB-INF/proxool.xml
5).配置本机和nn2机器的hosts,域名映射nginx的IP
192.168.137.190 www.hainiushop.com
192.168.137.190 sns.hainiushop.com
192.168.137.190 sso.hainiushop.com
192.168.137.190 image.hainiushop.com6).启动tomcat
/usr/local/apache-tomcat-image-8.0.20/bin/startup.sh
/usr/local/apache-tomcat-service-8.0.20/bin/startup.sh
/usr/local/apache-tomcat-shop-8.0.20/bin/startup.sh1.验证service到数据库是否访问成功
http://nn2.hadoop:8082/hainiushop_service/ucenter/address/list.action?json={%27uid%27:1}
2.打开首页看图片是否加载成功
自行验证注册和登录
4.CoolNiu商城数据产出
1).用户行为日志
nginx配置,nn1机器
vim /usr/local/nginx/conf/sites-enabled/hainiushop.com
#重新加载nginx配置
/usr/local/nginx/sbin/nginx -s reload
#分别输出shop和sns的两个用户行为日志到不同的文件里面2).业务日志
service的log4j配置,nn2机器
vim /usr/local/apache-tomcat-service-8.0.20/webapps/hainiushop_service/WEB-INF/classes/log4j.properties
#创建数据目标
mkdir -p /data/hainiu_shop_service_log/
#重新启动service的tomcat服务
/usr/local/apache-tomcat-service-8.0.20/bin/shutdown.sh
/usr/local/apache-tomcat-service-8.0.20/bin/startup.sh 3).访问首页验证日志是否正常产出
#nn1用户行为日志
tail -f /data/hainiu_shop_access_log/access_shop.log
#nn2业务日志
tail -f /data/hainiu_shop_service_log/service.log
4).日志格式详解
1.access日志
使用nginx的map策略进行资源文件的请求过滤,让其不打日志,减少下游任务没用的数据过滤
map $request $loggable {
default 1;
"~*\.jsp" 1;
"~*\.(gif|jpg|jpeg|png|bmp|swf|css|ico)" 0;
"~*\.js" 0;
}要日志中的这些数据?

用户行为日志,字段含义:
1:IP
2:打日志的时间
3:请求的类型GET/POST
4:请求的地址
5:请求状态码
6:POST提交的数据
7:refer,来源
8:浏览器的Agent信息
9:用户浏览器的唯一标识,这个是自己的程序产生的,不是nginx生成的
10:用户登陆的用户名,如果用户不登陆就没有
主要使用那些数据能产生咱们数仓中用户行为数据明细表的字段呢?

1.图中第4个字段,就是nginx的access中的request字段,记录get请求的,截取get请求带过来的参数做为表的字段。
2.图中第6个字段,就是nginx的access中的request_body字段,记录post请求的,截取post请求带过来的参数做为表的字段。
这些可变的字段咱们在hive表中可以使用map类型进行存储,比如这个样子
model.memberName=hainiushopTest&model.memberPwd=12345678&x=66&y=23
returnURL=http://www.hainiushop.com/index.jsp
Map<String,String> map = new HashMap<>();
map.put(returnURL,http://www.hainiushop.com/index.jsp)
map.put(model.memberName,hainiushopTest)
map.put(model.memberPwd,12345678)另外需要remote_addr和time_local转换成long型
2.service日志

service日志,字段含义:
1.时间:service端打日志的时间
2.IP,用户的IP
3.用户浏览器的唯一标识,这个是自己的程序产生的,不是nginx生成的
4.用户登陆的用户名,如果用户不登陆就没有
5.web项目的请求地址:可以确实用户点了那个网址发送的请求,用于以后区别业务
6.返回的Json数据:请求查的数据,可以理解为某个页面的展示数据
7.web项目请求的Action的包地址:web项目发送请求的Action类,用于区别是那个项目
8.返回的Json数据所对应的数据Bean包地址:用于描述Json数据是那个数据类型,另外还能描述返回的数据是多条记录(java.util.ArrayList),还是一条记录(Bean.class.gatName()),如果是多条记录且是空的集合(java.util.ArrayList\<>)那这条数据就过滤掉。另外如果包地址不是以com.hainiu开头也都过滤掉。
5.ODS层数据存储
ODS层使用flume完成数据上传到HFDS与KAFKA
flume的配置
1.service的日志flume配置:
[{"inode":7602217,"pos":217596,"file":"/data/hainiu_shop_service_log/service.log"}]# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# sources类型
a1.sources.r1.type = TAILDIR
#存储读取文件数据最后位置
a1.sources.r1.positionFile = /home/hadoop/flume_conf/taildir_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /data/hainiu_shop_service_log/service.log
# hdfs sink-k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://ns1/data/hainiu/hainiu_shop_service_all_log/%Y/%m%d/%H
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 300
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = service_%Y%m%d%H
a1.sinks.k1.hdfs.fileSuffix = .log.snappy
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = snappy
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.callTimeout = 40000
# kafka sink-k2
a1.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k2.kafka.bootstrap.servers = nn1.hadoop:9092,nn2.hadoop:9092,s1.hadoop:9092
a1.sinks.k2.kafka.topic = hainiu_shop_service_all
a1.sinks.k2.kafka.producer.acks = -1
# channals-c1 memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 10000
# channals-c2 memory
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000000
a1.channels.c2.transactionCapacity = 10000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c22.nginx的日志flume配置:
shop:
[{"inode":4718595,"pos":20368420,"file":"/data/hainiu_shop_access_log/access_shop.log"}]# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# sources类型
a1.sources.r1.type = TAILDIR
#存储读取文件数据最后位置
a1.sources.r1.positionFile = /home/hadoop/flume_conf/taildir_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /data/hainiu_shop_access_log/access_shop.log
# hdfs sink-k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://ns1/data/hainiu/hainiu_shop_access_shop_log/%Y/%m%d/%H
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 300
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = access_%Y%m%d%H
a1.sinks.k1.hdfs.fileSuffix = .log.snappy
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = snappy
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.callTimeout = 40000
# kafka sink-k2
a1.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k2.kafka.bootstrap.servers = nn1.hadoop:9092,nn2.hadoop:9092,s1.hadoop:9092
a1.sinks.k2.kafka.topic = hainiu_shop_access_shop
a1.sinks.k2.kafka.producer.acks = -1
# channals-c1 memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 10000
# channals-c2 memory
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000000
a1.channels.c2.transactionCapacity = 10000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2sns:
[{"inode":4718595,"pos":20368420,"file":"/data/hainiu_shop_access_log/access_sns.log"}]# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# sources类型
a1.sources.r1.type = TAILDIR
#存储读取文件数据最后位置
a1.sources.r1.positionFile = /home/hadoop/flume_conf/taildir_position.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /data/hainiu_shop_access_log/access_sns.log
# hdfs sink-k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs://ns1/data/hainiu/hainiu_shop_access_sns_log/%Y/%m%d/%H
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.rollInterval = 300
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = access_%Y%m%d%H
a1.sinks.k1.hdfs.fileSuffix = .log.snappy
a1.sinks.k1.hdfs.fileType = CompressedStream
a1.sinks.k1.hdfs.codeC = snappy
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.callTimeout = 40000
# kafka sink-k2
a1.sinks.k2.type = org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k2.kafka.bootstrap.servers = nn1.hadoop:9092,nn2.hadoop:9092,s1.hadoop:9092
a1.sinks.k2.kafka.topic = hainiu_shop_access_sns
a1.sinks.k2.kafka.producer.acks = -1
# channals-c1 memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 1000000
a1.channels.c1.transactionCapacity = 10000
# channals-c2 memory
a1.channels.c2.type = memory
a1.channels.c2.capacity = 1000000
a1.channels.c2.transactionCapacity = 10000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c23.然后启动hdfs与kafka集群
4.在kafka-manager创建topic
5.启动flume-agent
1).在nn1上启动flume-agent
#shop
nohup flume-ng agent -n a1 -c /home/hadoop/flume_conf_shop -f /home/hadoop/flume_conf_shop/taildir-access.conf \
-Dflume.root.logger=DEBUG,console >> /dev/null 2>&1 &
#sns
nohup flume-ng agent -n a1 -c /home/hadoop/flume_conf_sns -f /home/hadoop/flume_conf_sns/taildir-access.conf \
-Dflume.root.logger=DEBUG,console >> /dev/null 2>&1 &2).在nn2上启动flume-agent
nohup flume-ng agent -n a1 -c /home/hadoop/flume_conf -f /home/hadoop/flume_conf/taildir-service.conf \
-Dflume.root.logger=DEBUG,console >> /dev/null 2>&1 &6.启动一个consumer看一下topic里面有没有数据
/usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 --topic hainiu_shop_access_shop
/usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 --topic hainiu_shop_access_sns
/usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 --topic hainiu_shop_service_all6.DWD层数据清洗(ETL)
1).Flink实时ETL
1.服务端业务日志ETL
/usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 --topic hainiu_shop_service_all
->
/usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 --topic hainiu_shop_service_shop_dwd
/usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 --topic hainiu_shop_service_sns_dwd2.用户行为日志ETL
/usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 --topic hainiu_shop_access_shop
->
/usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 --topic hainiu_shop_access_shop_dwd
/usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 --topic hainiu_shop_access_sns
->
/usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 --topic hainiu_shop_access_sns_dwd3.创建DWD层使用的topic,做为Flink实时ETL之后的数据中转
2).数据实时存储
1.shop_access:
/usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 --topic hainiu_shop_access_shop_dwd
->
HDFS2.shop_service:
/usr/local/kafka/bin/kafka-console-consumer.sh --zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 --topic hainiu_shop_service_shop_dwd
->HDFS3).任务的集群运行
集群涉及的服务
zk
hdfs
yarn
kafka
kafkamanager
hivemetaservice
presto
CoolNiu商城
nn1 nginx mysql
nn2 service shop image
flume ods
nn1 access_shop access_sns
nn2 service1.etl实时任务
#etl任务--->用户行为数据:
flink run -m yarn-cluster -yd -yjm 1024 -ytm 1024 -yn 1 -ys 1 -yqu root.hainiu -ynm access_all_etl_dwd_kafka \
-yt /home/hadoop/flink_hainiu_shop $(ll /home/hadoop/flink_hainiu_shop/ |awk 'NR>1{print "-C file:///home/hadoop/flink_hainiu_shop/"$9}'|tr '\n' ' ') \
/home/hadoop/hainiushopflink-1.0-shop.jar access_all_etl_dwd_kafka
#etl任务--->服务端业务数据:
flink run -m yarn-cluster -yd -yjm 1024 -ytm 1024 -yn 1 -ys 1 -yqu root.hainiu -ynm service_all_etl_dwd_kafka \
-yt /home/hadoop/flink_hainiu_shop $(ll /home/hadoop/flink_hainiu_shop/ |awk 'NR>1{print "-C file:///home/hadoop/flink_hainiu_shop/"$9}'|tr '\n' ' ') \
/home/hadoop/hainiushopflink-1.0-shop.jar service_all_etl_dwd_kafka2.实时存储任务
#商城项目--->数据落地任务,用户行为数据:
flink run -m yarn-cluster -yd -yjm 1024 -ytm 1024 -yn 1 -ys 1 -yqu root.hainiu -ynm access_shop_dwd_hdfs \
-yt /home/hadoop/flink_hainiu_shop $(ll /home/hadoop/flink_hainiu_shop/ |awk 'NR>1{print "-C file:///home/hadoop/flink_hainiu_shop/"$9}'|tr '\n' ' ') \
/home/hadoop/hainiushopflink-1.0-shop.jar access_shop_dwd_hdfs
#商城项目--->数据落地任务,服务端业务数据:
flink run -m yarn-cluster -yd -yjm 1024 -ytm 1024 -yn 1 -ys 1 -yqu root.hainiu -ynm service_shop_dwd_hdfs \
-yt /home/hadoop/flink_hainiu_shop $(ll /home/hadoop/flink_hainiu_shop/ |awk 'NR>1{print "-C file:///home/hadoop/flink_hainiu_shop/"$9}'|tr '\n' ' ') \
/home/hadoop/hainiushopflink-1.0-shop.jar service_shop_dwd_hdfs
4).表的Schema管理
1.根据HDFS上这个存储的文件地址:
2.使用TableGenerateUtil获取表的create语句:

3.再使用HDFSUtil获得这个表的partition语句:

这时就获得了create table语句与add partitions语句
然后打开hive的client执行SQL
5).即席查询
1.启动presto进行查询
#启动presto集群
./ssh_all.sh /usr/local/presto/bin/launcher start
#启动presto客户端连接
presto --server nn2.hadoop:18080 --catalog hive2.点击hainiushop.com的页面就可以使用presto进行实时查询: