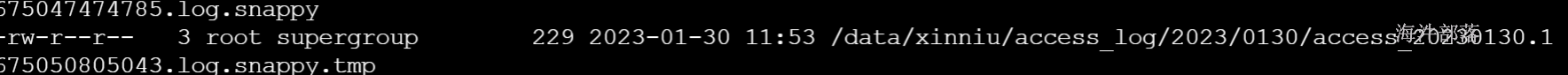1 flume归集access.log日志到HDFS
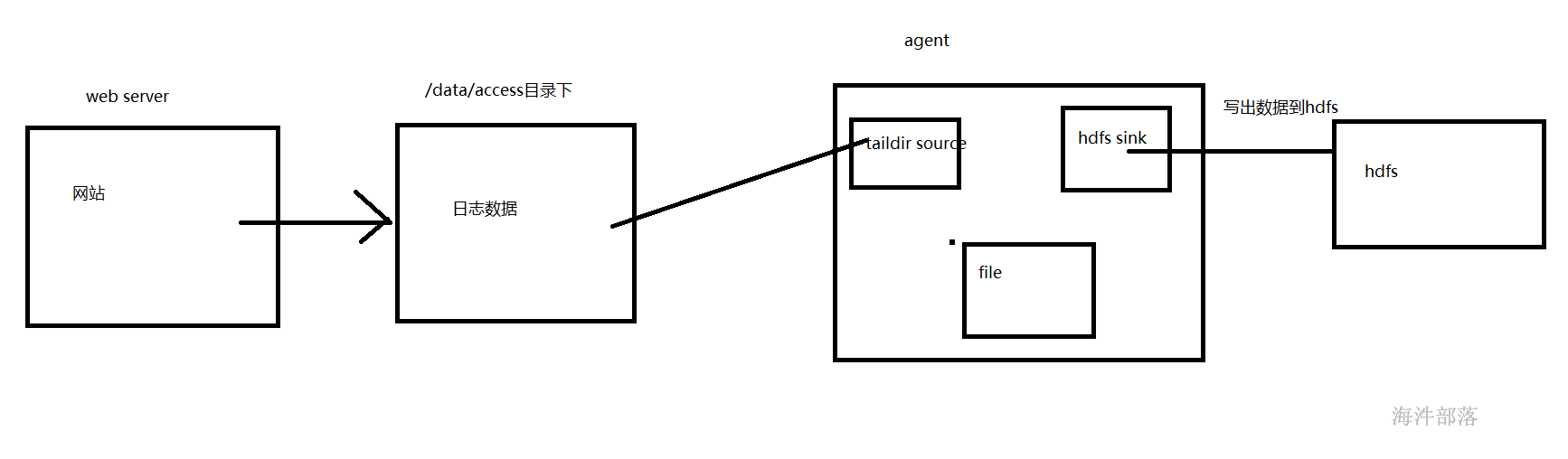
1.1 安装nginx用于模拟生成点击日志
解压nginx并编译安装
# 解压
tar -xzf ./tengine-2.2.0.tar.gz -C /usr/local
# 检查系统编译环境并生成makefile文件
cd /usr/local/tengine-2.2.0
./configure
#编译并安装
make && make install安装完成会在/usr/local/目录下生成nginx目录
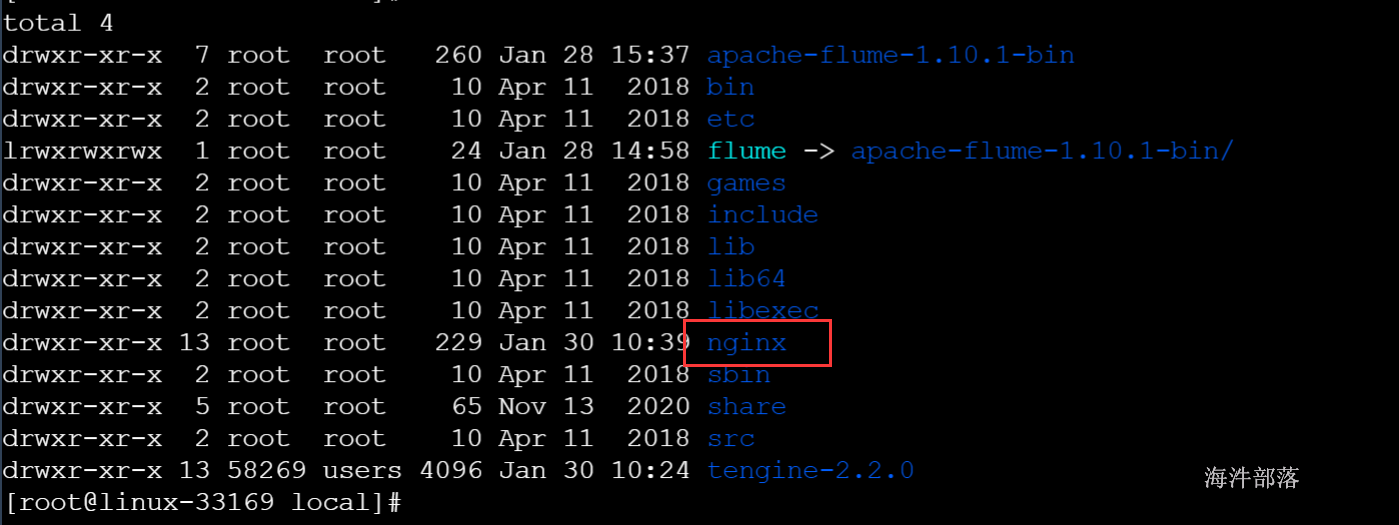
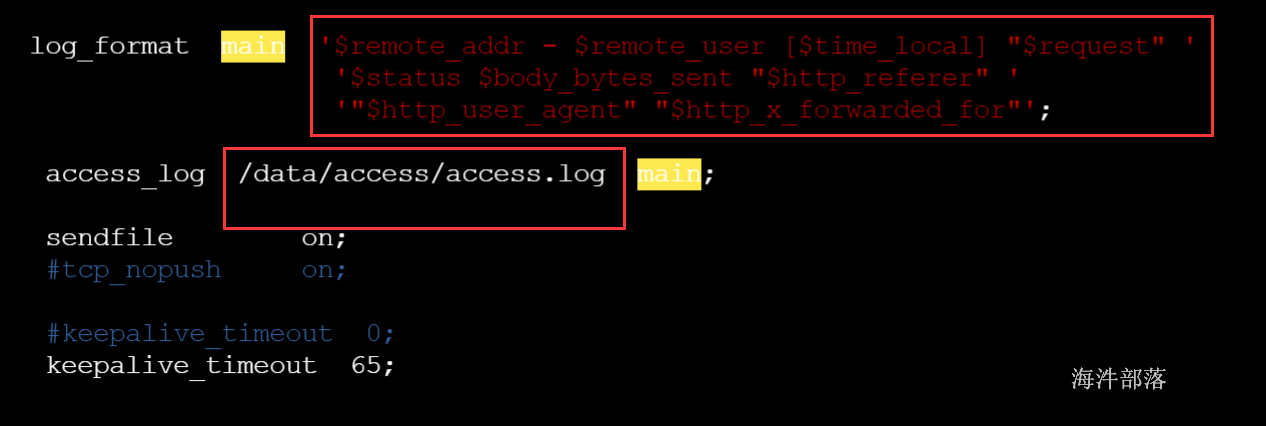
进入nginx安装目录下的conf目录编辑nginx.conf配置文件用于产生日志
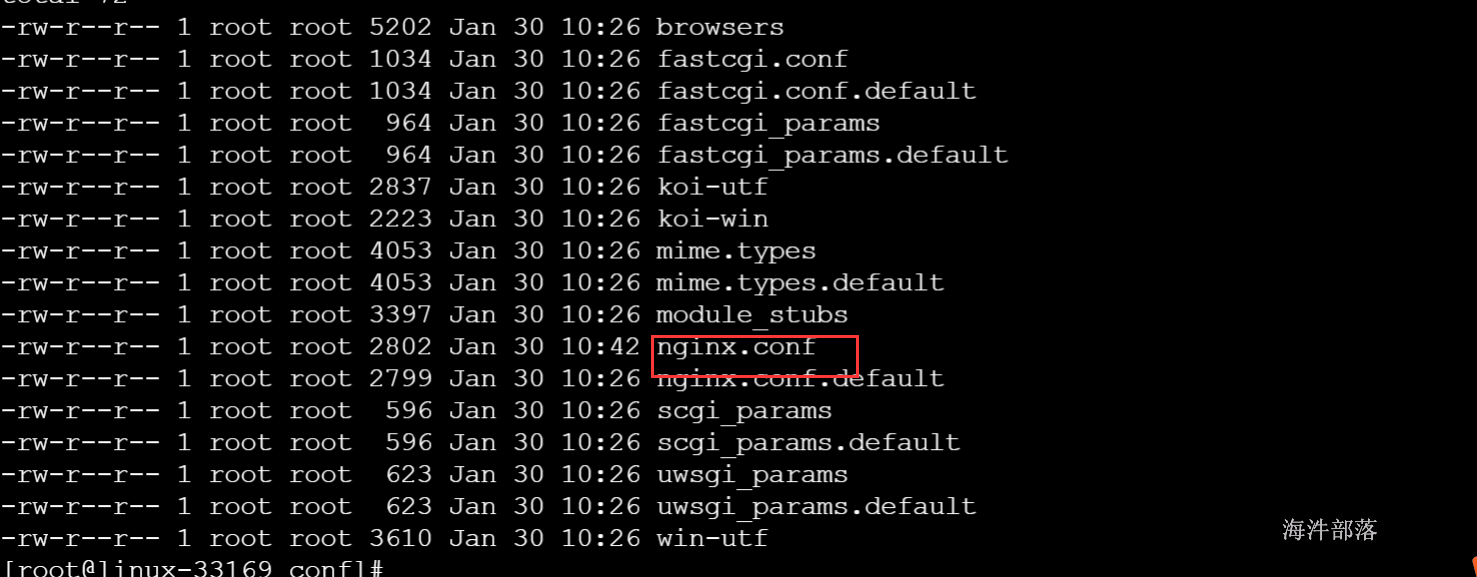
指定产生的日志格式以及输出目录
2 启动nginx
/usr/local/nginx/sbin/nginx
远程桌面访问nginx默认端口80
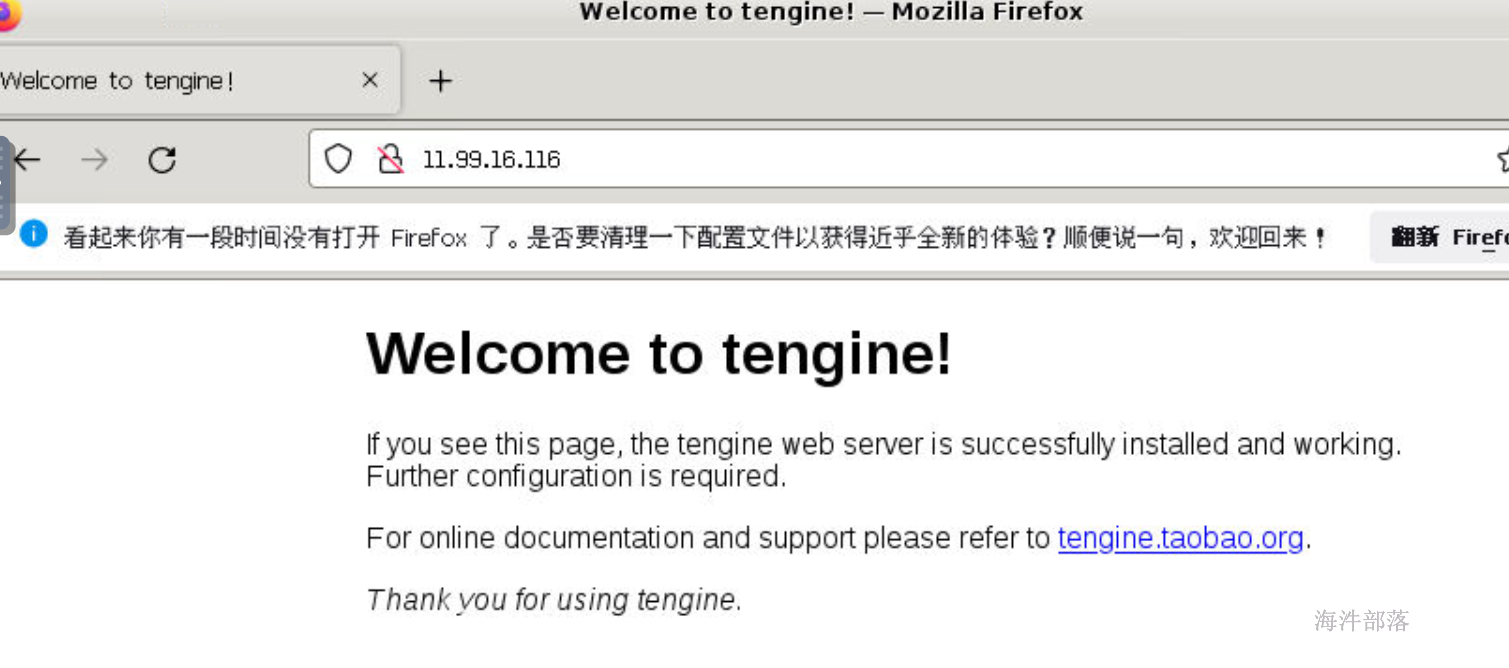
观察日志是否产生

3 flume收集日志数据到hdfs
过flume归集实现将日志写入hdfs用于离线处理
sources:taildir
channel:file
sink:hdfs
hdfs归集: 每5分钟生成一个文件,并且带有snappy压缩;
1)配置
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# sources类型
a1.sources.r1.type = TAILDIR
#存储读取文件数据最后位置
a1.sources.r1.positionFile = /data/flume/taildir_position_access.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /data/access/access.log
# hdfs sink-k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs:///data/xinniu/access_log/%Y/%m%d
a1.sinks.k1.hdfs.rollInterval = 300
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = access_%Y%m%d
a1.sinks.k1.hdfs.fileSuffix = .log.snappy
# 设置输出压缩
a1.sinks.k1.hdfs.fileType = CompressedStream
# 设置snappy压缩
a1.sinks.k1.hdfs.codeC = snappy
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.callTimeout = 0
# channals file
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /data/flume/data/checkpoint_access
a1.channels.c1.dataDirs = /data/flume/data/data_access
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1启动agent
flume-ng agent -n a1 -c /usr/local/flume/conf/ -f ./access.agent -Dflume.root.logger=INFO,console测试:
数据收集到hdfs指定的位置

2 flume归集access.log日志到kafka
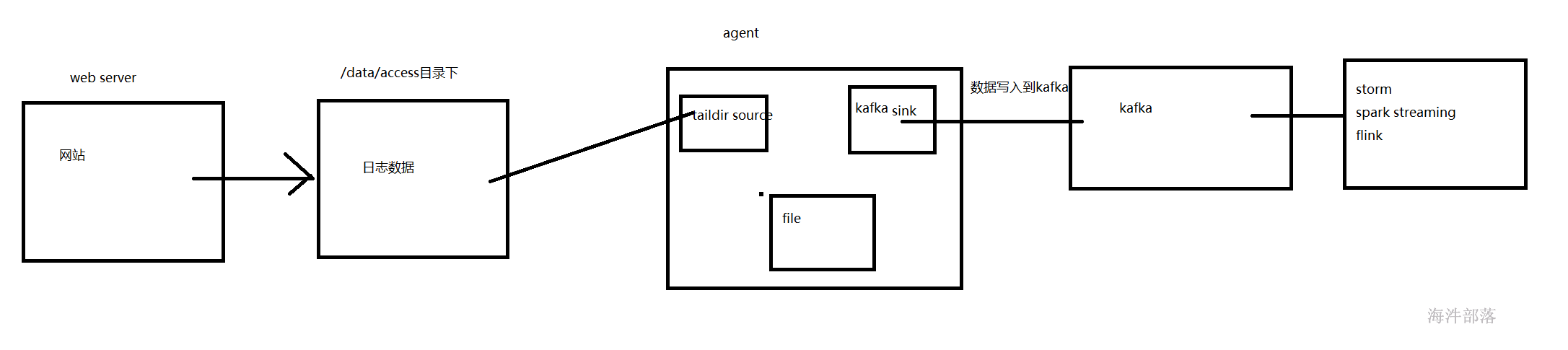
过flume归集实现将日志写入kafka用于实时处理
sources:taildir
channel:file
sink:kafka
1)配置
# Name the components on this agent
a1.sources = r1
a1.sinks = k1
a1.channels = c1
# sources类型
a1.sources.r1.type = TAILDIR
#存储读取文件数据最后位置
a1.sources.r1.positionFile = /data/flume/data/taildir_position_access.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /data/access/access.log
# hdfs sink-k1
a1.sinks.k1.type= org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.kafka.bootstrap.servers = localhost:9092
a1.sinks.k1.kafka.topic = access
# channals file
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /data/xinniu/flume/data/checkpoint_access
a1.channels.c1.dataDirs = /data/xinniu/flume/data/data_access
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1删除之前产生的日志,并重新加载nginx
rm -rf access.log
/usr/local/nginx/sbin/nginx -s reload启动kafka消费者,消费access topic主题的数据
kafka-console-consumer.sh --bootstrap-server 11.99.173.7:9092 --topic access启动agent
flume-ng agent -n a1 -c /usr/local/flume/conf/ -f ./access.agent -Dflume.root.logger=INFO,console测试:
kafka消费者消费到数据
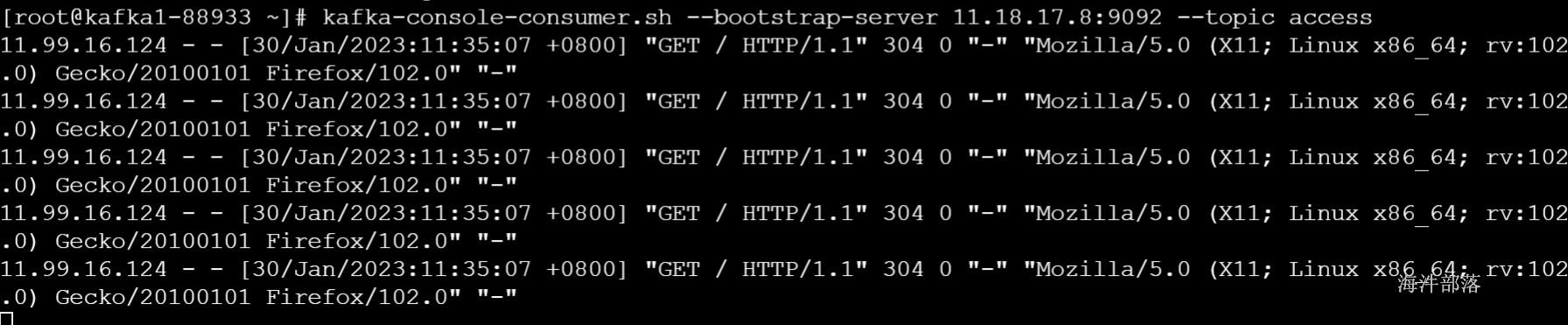
3 flume归集access.log日志到hdfs和kafka
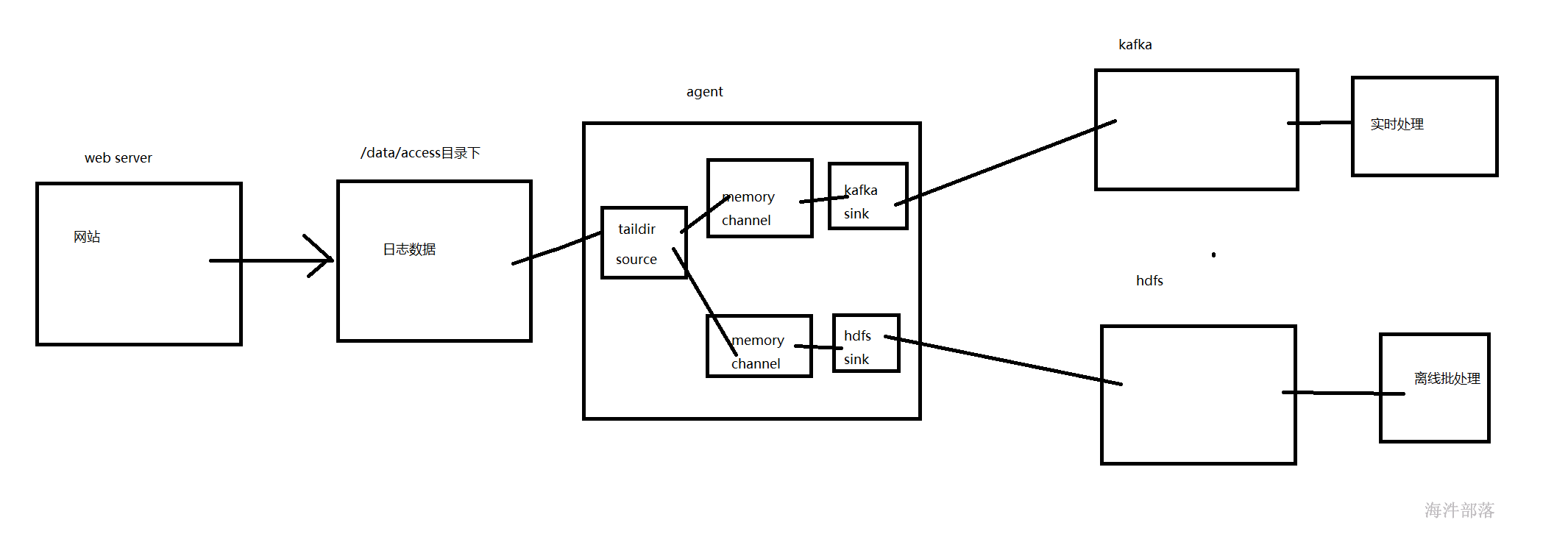
过flume归集实现将日志写入hdfs用于离线处理,同时归集到kafka用于实时处理
sources:taildir
channel:file
sink:kafka,hdfs
1)配置
# Name the components on this agent
a1.sources = r1
a1.sinks = k1 k2
a1.channels = c1 c2
# sources类型
a1.sources.r1.type = TAILDIR
#存储读取文件数据最后位置
a1.sources.r1.positionFile = /data/flume/data/taildir_position_access.json
a1.sources.r1.filegroups = f1
a1.sources.r1.filegroups.f1 = /data/access/access.log
# hdfs sink-k1
a1.sinks.k2.type= org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k2.kafka.bootstrap.servers = localhost:9092
a1.sinks.k2.kafka.topic = access
# kafka sink-k2
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path = hdfs:///data/xinniu/access_log/%Y/%m%d
a1.sinks.k1.hdfs.writeFormat = Text
a1.sinks.k1.hdfs.rollInterval = 300
a1.sinks.k1.hdfs.rollSize = 0
a1.sinks.k1.hdfs.rollCount = 0
a1.sinks.k1.hdfs.filePrefix = access_%Y%m%d
a1.sinks.k1.hdfs.fileSuffix = .log.snappy
# 设置输出压缩
a1.sinks.k1.hdfs.fileType = CompressedStream
# 设置snappy压缩
a1.sinks.k1.hdfs.codeC = snappy
a1.sinks.k1.hdfs.useLocalTimeStamp = true
a1.sinks.k1.hdfs.callTimeout = 0
# channals file
a1.channels.c1.type = file
a1.channels.c1.checkpointDir = /data/xinniu/flume/data/checkpoint_access
a1.channels.c1.dataDirs = /data/xinniu/flume/data/data_access
a1.channels.c2.type = file
a1.channels.c2.checkpointDir = /data/xinniu/flume/data/checkpoint_access1
a1.channels.c2.dataDirs = /data/xinniu/flume/data/data_access1
# Bind the source and sink to the channel
a1.sources.r1.channels = c1 c2
a1.sinks.k1.channel = c1
a1.sinks.k2.channel = c2删除之前产生的日志,并重新加载nginx
rm -rf access.log
/usr/local/nginx/sbin/nginx -s reload启动kafka消费者,消费access topic主题的数据
kafka-console-consumer.sh --bootstrap-server 11.99.173.7:9092 --topic access启动agent
flume-ng agent -n a1 -c /usr/local/flume/conf/ -f ./access_kafka_hdfs.agent -Dflume.root.logger=INFO,console测试:
kafka消费者消费到数据
hdfs新导入的数据