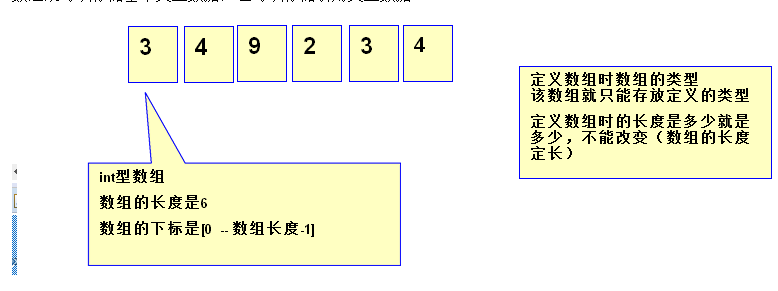
1 数组
数组是编程语言中最常见的的数据结构,其本身是个引用类型数据。
java数组要求所有的数组元素具有相同的数据类型。
一旦数组的初始化完成,数组在内存中所占的空间将被固定下来,数组的长度将不可变
数组既可以存储基本类型数据,也可以存储引用类型数据

1.2 数组初始化
数组初始化有两种方式:
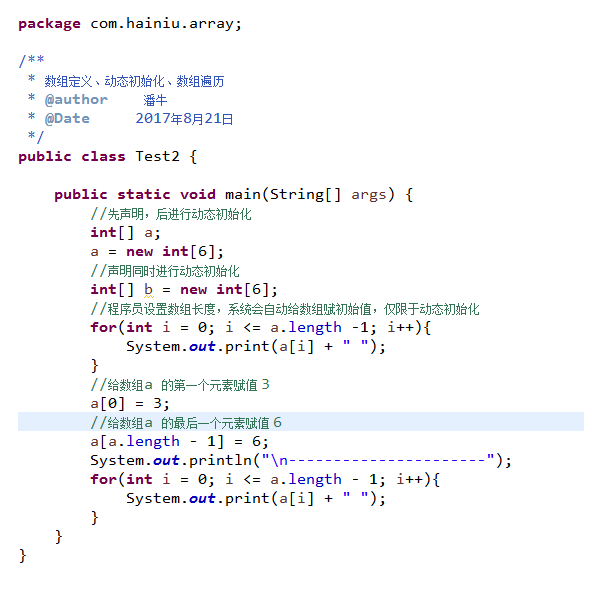
静态初始化:初始化时由程序员显示指定每个数组元素的初始值,由系统决定数组长度
动态初始化:初始化时程序员只指定数组长度,由系统为数组分配初始值
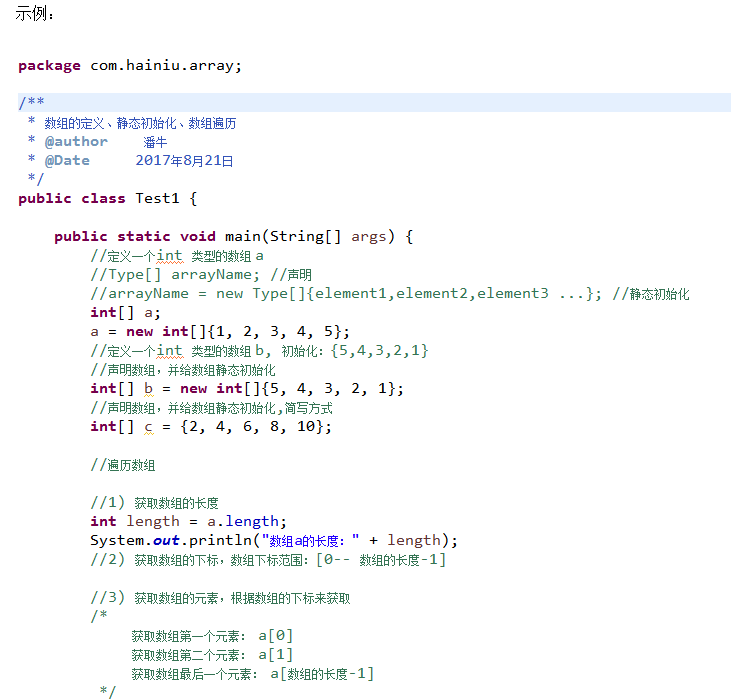
1.2.1 静态初始化
语法格式:





1.3 堆内存、栈内存、引用变量
Java把内存划分成两种:一种是栈内存,一种是堆内存。
栈内存:
在方法中定义的一些基本类型的变量和对象的引用变量都是在方法的栈内存中分配。
当在一段代码块中定义一个变量时,java就在栈中为这个变量分配内存空间,当超过变量的作用域后,java会自动释放掉为该变量分配的内存空间,该内存空间可以立刻被另作他用。
运行速度快,主要用来执行程序。
堆内存:
堆内存用于存放由new创建的对象和数组。
在堆中分配的内存,由java虚拟机自动垃圾回收器来管理。
运行速度慢,主要用于创建数组、对象。
引用变量与栈内存、堆内存的关系:
在堆中产生了一个数组或者对象后,还可以在栈中定义一个特殊的变量,这个变量的取值等于数组或者对象在堆内存中的首地址,在栈中的这个特殊的变量就变成了数组或者对象的引用变量。
引用变量就相当于是为数组或对象起的一个名称,以后就可以在程序中使用栈中的引用变量来访问堆中的数组或对象。
引用变量是普通变量,定义时在栈中分配内存,引用变量在程序运行到作用域外释放。而数组和对象本身在堆中分配,即使程序运行到使用new产生数组和对象的语句所在地代码块之外,数组和对象本身占用的堆内存也不会被释放,数组和对象在没有引用变量指向它的时候,才变成垃圾,不能再被使用,但是仍然占着内存,在随后的一个不确定的时间被垃圾回收器释放掉。这个也是java比较占内存的主要原因,实际上,栈中的引用变量指向堆内存中的变量(数组或对象本身),这就是 Java 中的指针!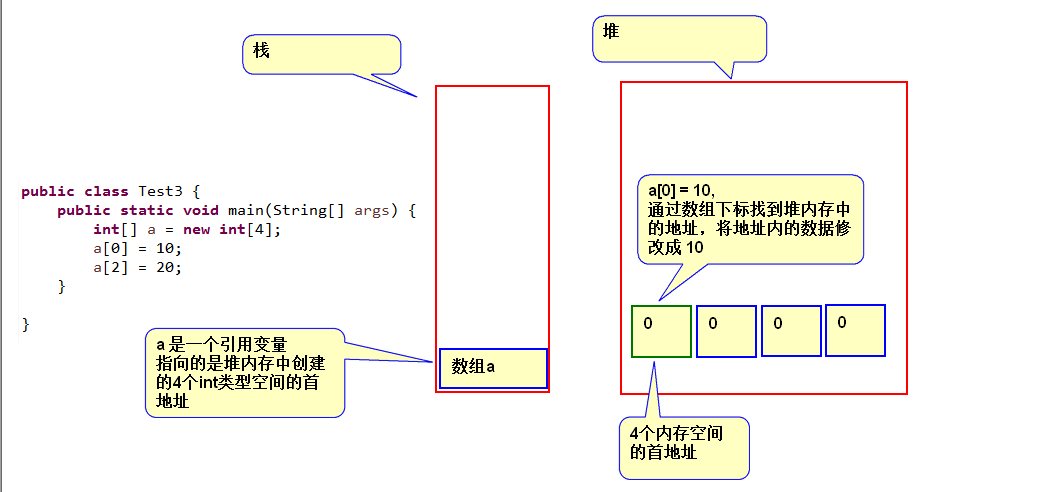
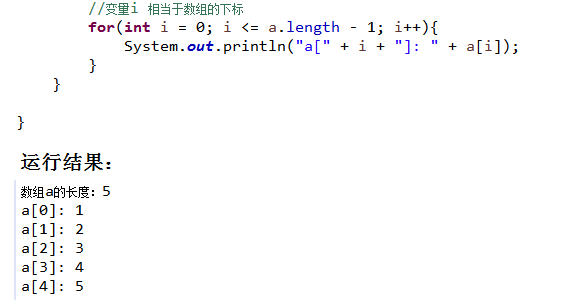
1.4 数组遍历
数组通过下标访问,下标范围【0 ~ 数组长度-1】
如果数组下标越界,编译时不会出现异常,运行时会报
java.lang.ArrayIndexOutOfBoundsException:N(数组索引越界异常)
1.5 foreach循环
java5之后,java提供foreach 循环遍历数组和集合更加简洁
使用foreach 循环遍历数组和集合元素时,无须获得数组和集合长度,无须用下标来访问数组元素和集合元素
语法格式:


2 数组变量内存分析
数组引用变量只是一个引用,这个引用变量可以指向任何有效的内存,只有当该引用指向有效内存后,才可以通过该数组变量来访问数组元素。
实际的数组对象被存储在堆(heap)内存中
如果引用该数组对象的数组引用变量时一个局部变量,那么他被存储在栈(stack)内存中。
栈内存:所有在方法中定义的局部变量都是放到栈内存中,随着方法的执行结束,这个方法的内存栈也将自然销毁。
堆内存:当在程序中创建对象,这个对象将保存堆内存中,堆内存不随着方法执行结束而销毁,只有当对象没有任何引用变量引用它时,系统的垃圾回收器才会在合适的时候回收它。
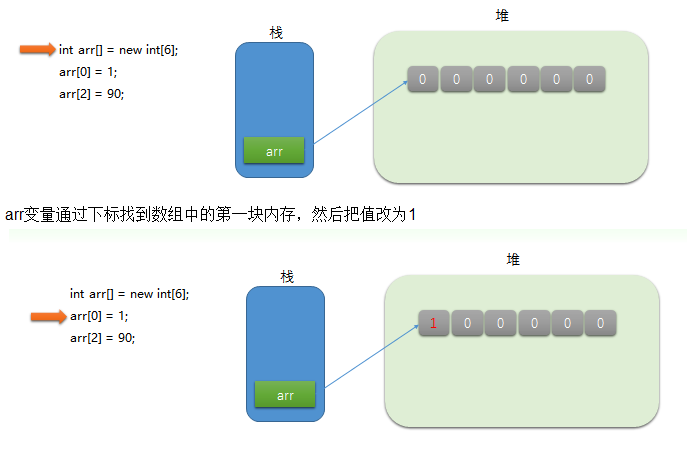
示例:
动态初始化后,系统内存中实际产生了6块内存区(堆内存),分配默认值0
arr变量引用指向数组本身
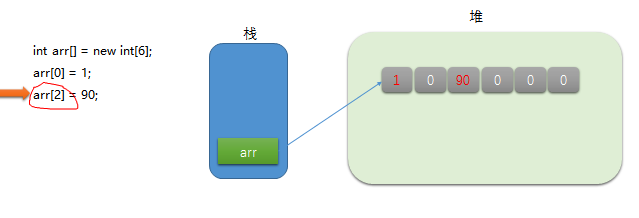
arr变量通过下标找到数组中的第三块内存,然后把值改为90
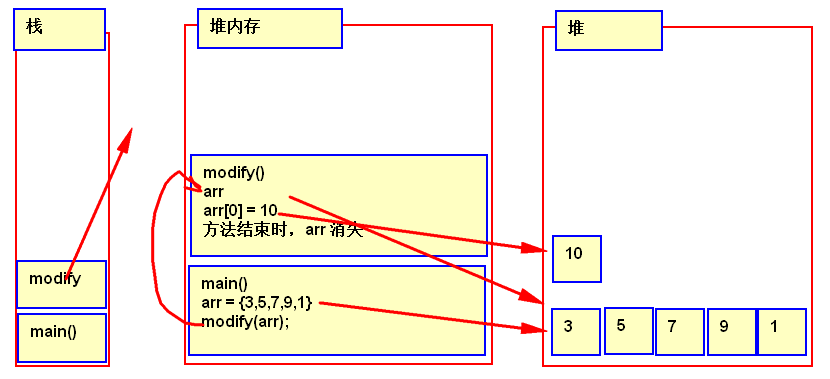
3 方法参数传递之数组
数组类型传入方法的参数是个数组的首地址。
如果在方法内对数组的元素改变,当方法执行完,方法外该数组的元素也随着改变。

4 数组的应用
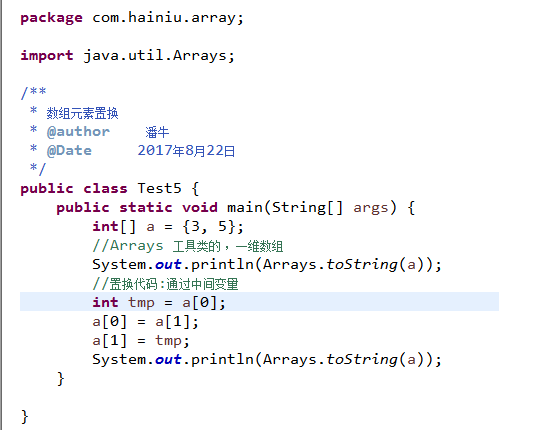
4.1 数组的拷贝
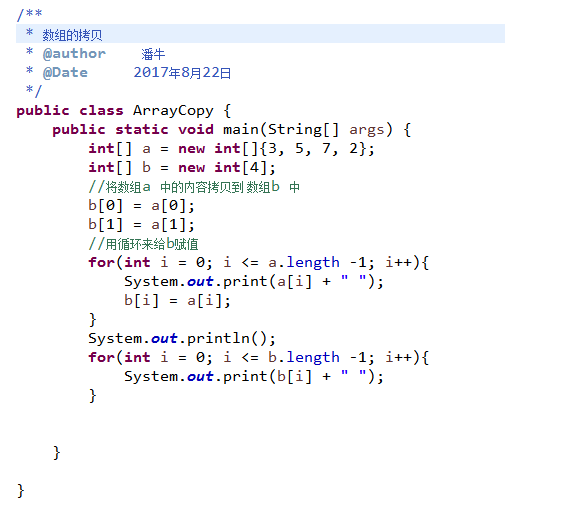

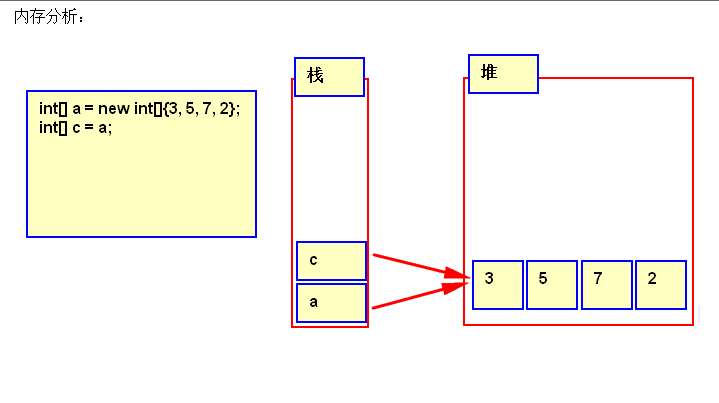
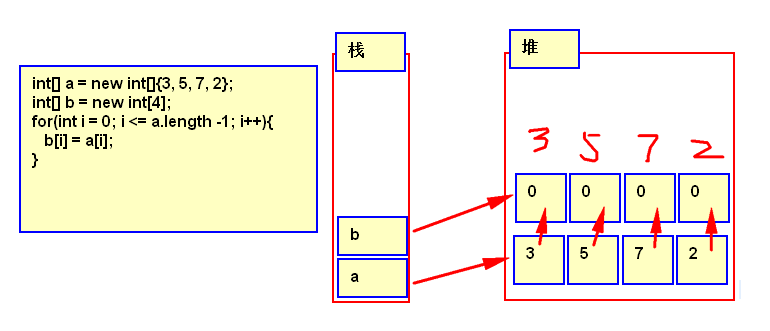
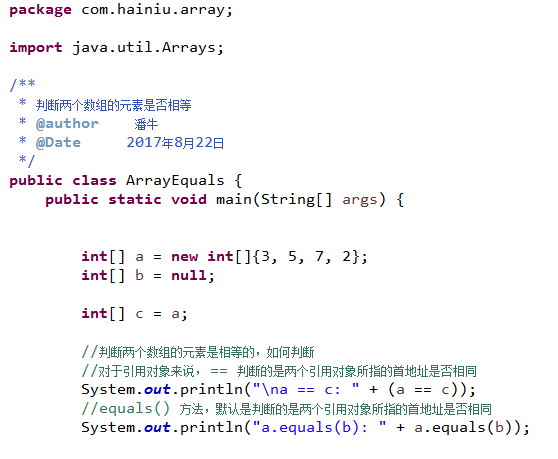
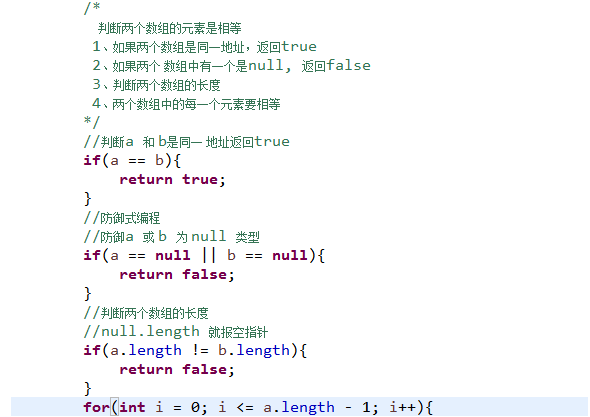
判断两个数组元素是否相等





4.3 数组排序
排序的目的是为了能快速的查找
排序分类可以分为两种:内排序和外排序。在排序过程中,全部记录存放在内存,则称为内排序;如果排序过程中需要使用外存(硬盘、软盘、光盘、U盘等),则称为外排序。
内排序可以分为以下几类:
(1)、插入排序:直接插入排序、二分法插入排序、希尔排序。
(2)、选择排序:简单选择排序、堆排序。
(3)、交换排序:冒泡排序、快速排序。
(4)、归并排序
(5)、基数排序
由于时间的关系,只讲具有代表性的冒泡排序、选择排序和快速排序。
下面各种排序算法,以升序为例,讲解
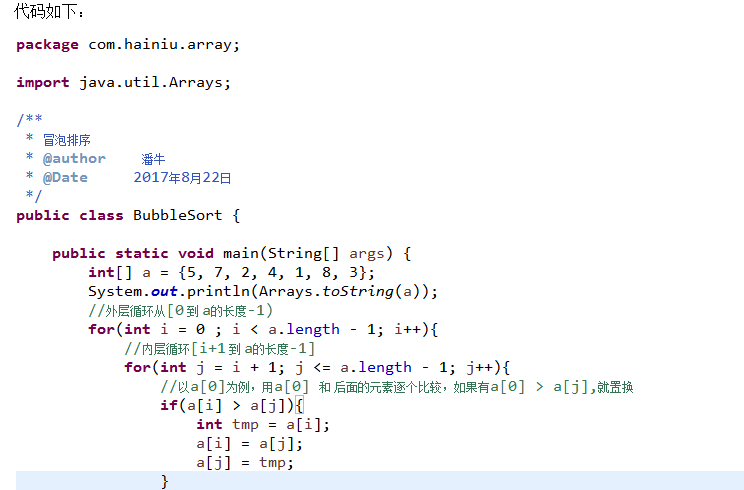
4.3.1 冒泡排序
交换排序的一种
思想:
先拿数组下标0 的元素 与 数组内下标>0的元素进行比较,只要其他元素比下标0元素小,则进行元素交换,直到下标0 元素与其他都比较完。
然后再拿下标1的元素 与 数组内下标 >1 的元素进行比较,只要比下标1的小,则进行元素交换,直到下标1 元素与 >1的元素都比较完。
以此类推
直到length-1元素都比较完成 。


分析:
•若文件初状为正序,则一趟起泡就可完成排序,排序码的比较次数为n-1,且没有记录移动,时间复杂度是O(n)
•若文件初态为逆序,则需要n-1趟起泡,每趟进行n-i次排序码的比较,且每次比较都移动n-1次,比较和移动次数均达到最大值∶O(n2)
•起泡排序平均时间复杂度为O(n2)
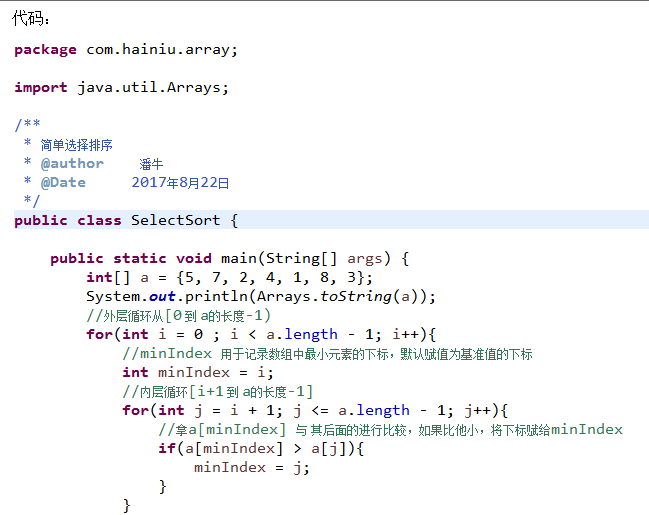
4.3.2 简单选择排序
选择排序的一种
思想:
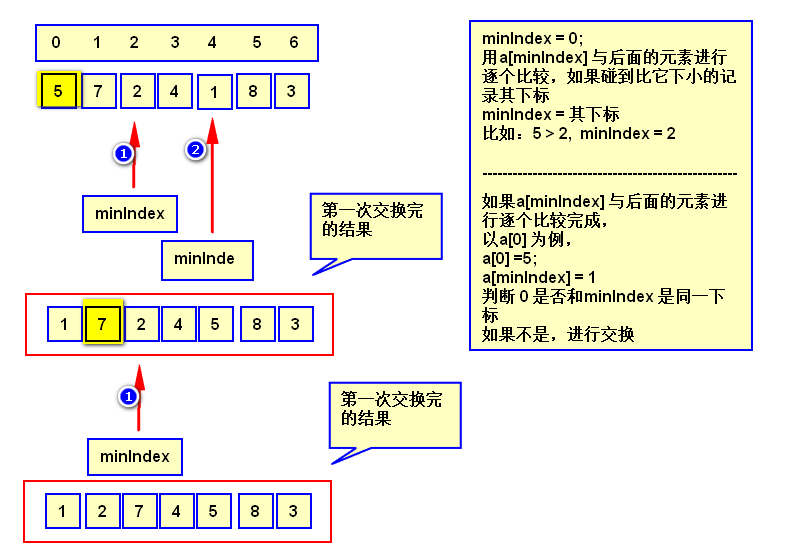
给定数组:int[] arr={里面n个数据};
第1趟排序,在待排序数据arr[0]~arr[n-1]中选出最小的数据,将它与arrr[0]交换;
第2趟,在待排序数据arr[1]~arr[n-1]中选出最小的数据,将它与arr[1]交换;
以此类推
第i趟在待排序数据arr[i]~arr[n-1]中选出最小的数据,将它与arr[i-1]交换,直到全部排序完成。
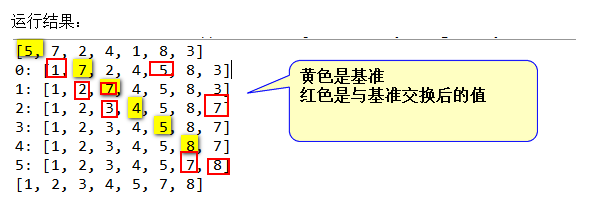
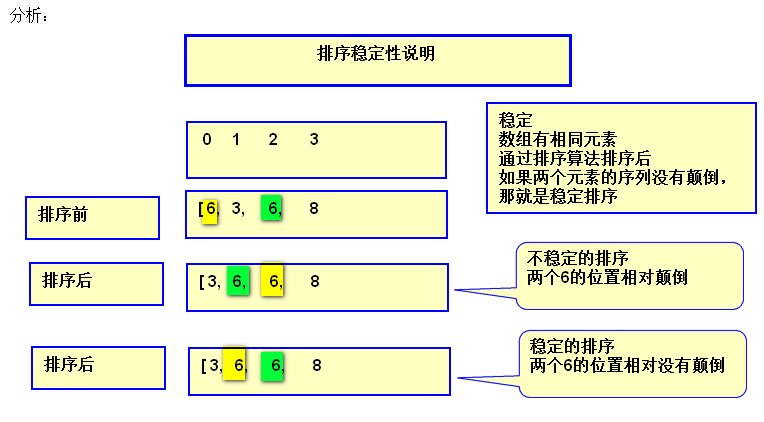
简单选择排序是不稳定的排序。
时间复杂度:T(n)=O(n2)。
4.3.3 快速排序
交换排序的一种
采用分治法的思想 :
首先,说说分治的思想。分治, “分而治之”,就是把一个复杂的问题分成两个或更多的相同或相似的子问题,再把子问题分成更小的子问题……直到最后子问题可以简单的直接求解,原问题的解即子问题的解的合并。
分治通过减小问题规模,对问题各个击破,其策略是:对于一个规模为n的问题,若该问题可以容易地解决(比如说规模n较小)则直接解决,否则将其分解为k个规模较小的子问题,这些子问题互相独立且与原问题形式相同,递归地解这些子问题,然后将各子问题的解合并得到原问题的解。
分治法的基本步骤
分治法在每一层递归上都有三个步骤:
step1 分解:将原问题分解为若干个规模较小,相互独立,与原问题形式相同的子问题;
step2 解决:若子问题规模较小而容易被解决则直接解,否则递归地解各个子问题
step3 合并:将各个子问题的解合并为原问题的解。
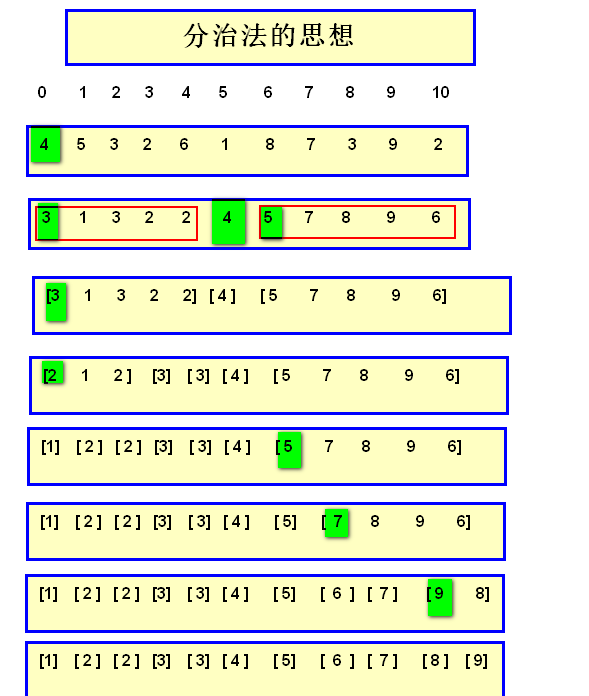
快速排序思想:
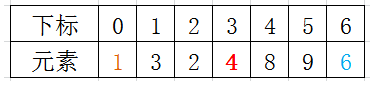
下面有个a数组,有7个元素,取下标0的元素为基准数
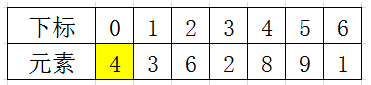
初始时,low = 0; high = 6; tmp = a[0] = 4;
先用挖坑填数法,直至 low >= high ,找到要分割的基准依据,基准数左面是小于等于基准数的元素,基准数右面是大于等于基准数的元素。
由于已经将 a[0] 中的数保存到 tmp 中,可以理解成在数组 a[0] 上挖了个坑,可以将其它数据填充到这来。
从 high 开始向前找一个 小于tmp 的数。当 high=6 时,符合条件,将 a[6] 挖出再填到上一个坑 a[0] 中。a[0]=a[6];这样一个坑a[0]就被搞定了。
但又形成了一个新坑a[6],这怎么办了?简单,再找数字来填 a[6]这个坑。
从 low 开始向后找一个大于tmp的数,当i=2,符合条件,将 a[2] 挖出再填到上一个坑中,a[6] = a[2];
此时,又形成了一个新坑a[2]
经过第一轮后,结果如下:
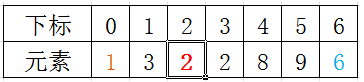
现在 low = 2; high = 6; tmp =4; 然后继续用挖坑填数法
从 high 开始向前找一个 小于tmp 的数。当 high=3 时,符合条件,将 a[3] 挖出再填到上一个坑 a[2] 中
形成新坑a[3],
从 low 开始向后找一个大于tmp的数,当 low = 3 时,low >= high, 此次循环结束。(循环结束的前提是 low >= high)
然后把新坑a[3] 用 tmp填上,a[3] = tmp 。所有坑都已填满。
经过上面的过程,已经找到基准位置
此时,数组内容如下:
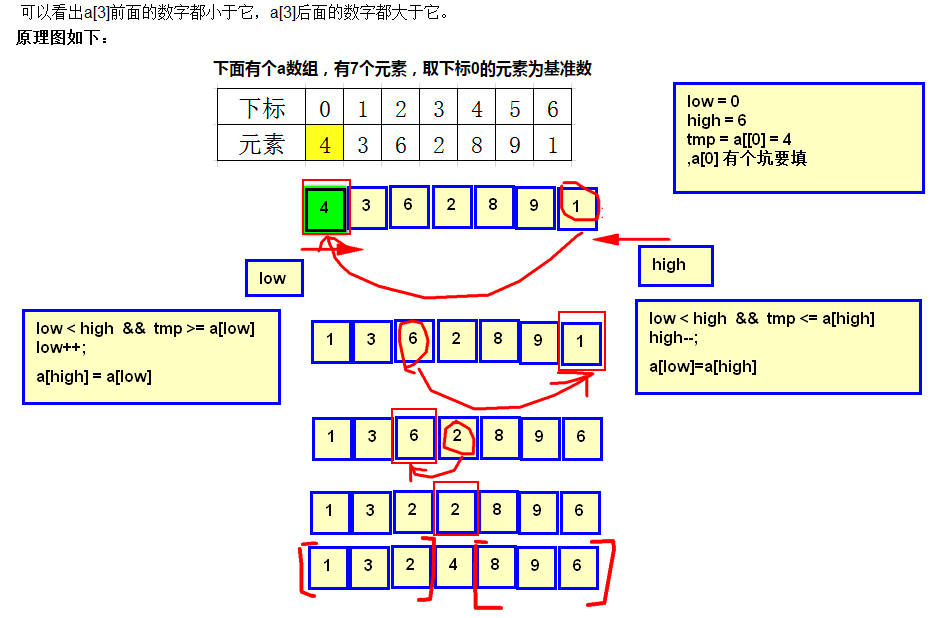

因此再根据分治法对a[0…2]和a[4…6]这二个子区间重复上述步骤,直到将数组分割成一个一个的元素为止。
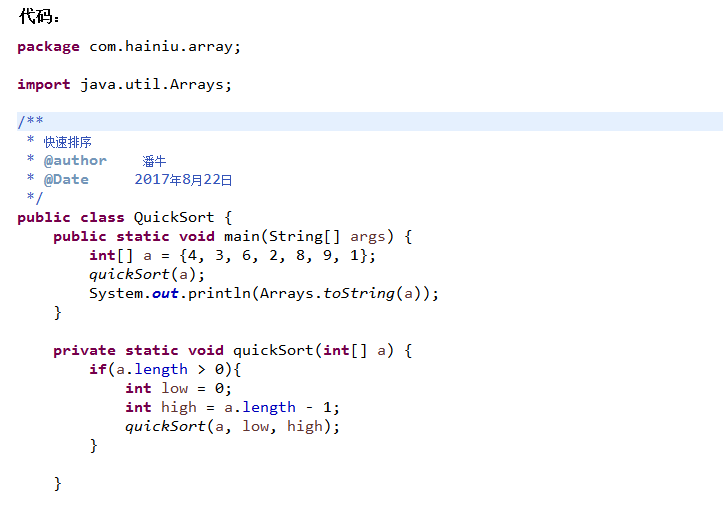


分析:
快速排序是不稳定的排序。
快速排序的时间复杂度为O(nlogn)。
当n较大时使用快排比较好,当序列基本有序时用快排反而不好。
时间复杂度是度量算法执行的时间长短,时间复杂度常用大O符号表述
空间复杂度是度量算法执行时运用空间的大小,空间复杂度常用大O符号表述
三种排序的对比:
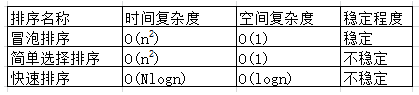
排序算法选择
数据规模较小
对稳定性不作要求宜用简单选择排序
对稳定性有要求宜用冒泡
数据规模不是很大
完全可以用内存空间,序列杂乱无序,对稳定性没有要求,快速排序,此时要付出log(N)的额外空间。
序列初始基本有序(正序),宜用冒泡
4.4 数组的查找
4.4.1 一般查找
数组可有序,也可无序。
key = 10;
查这个key在数组中的位置,如果找到返回数组下标
如果没找到,返回-1
search方法:
版权声明:原创作品,允许转载,转载时务必以超链接的形式表明出处和作者信息。否则将追究法律责任。来自海汼部落-青牛,http://hainiubl.com/topics/183


