1.hbase bulk load
pom:

代码:
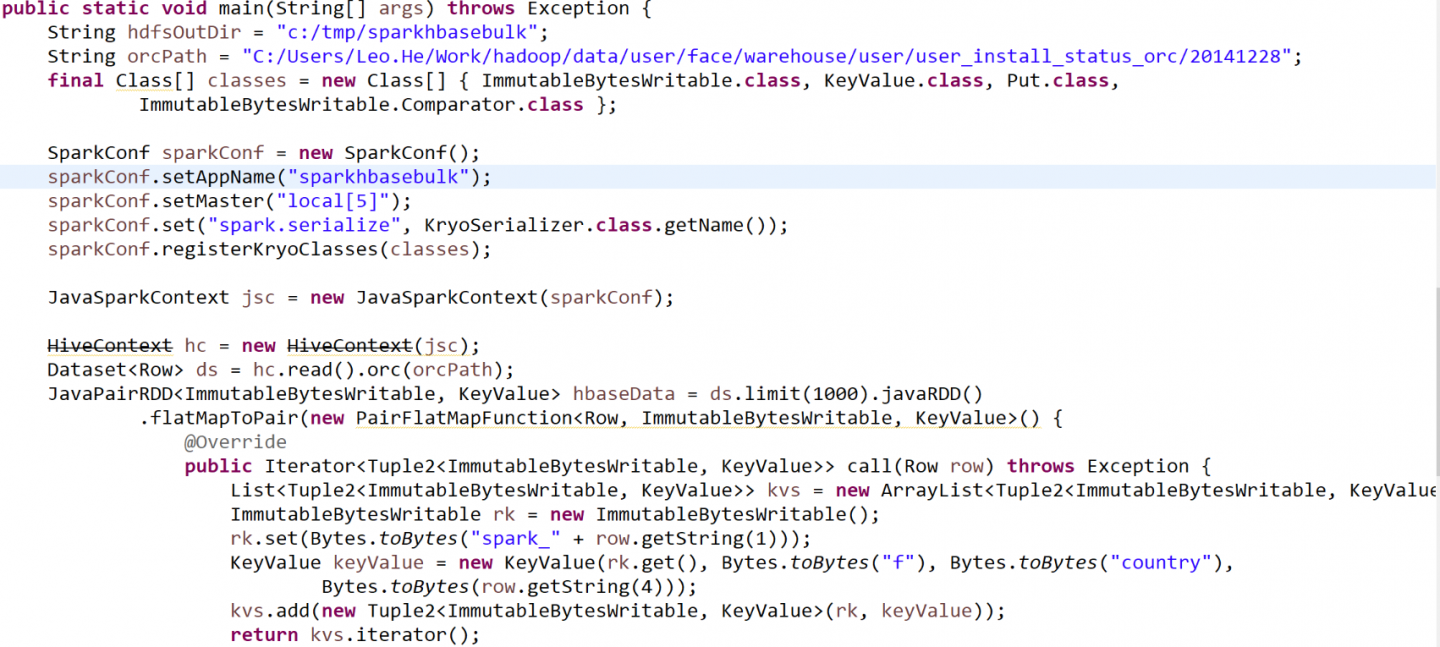
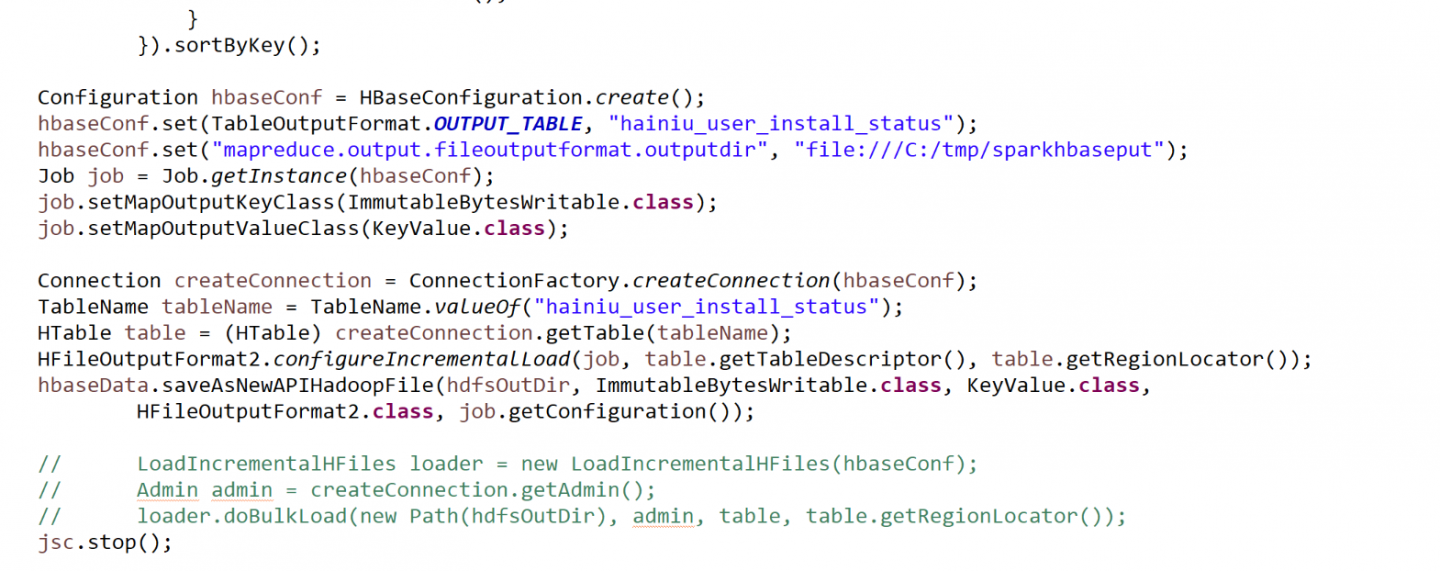
结果:

2.spark on yarn
修改如下代码



用assembly打成jar包
常规方法
spark-submit --jars $(echo /usr/local/hbase/lib/*.jar | tr ' ' ',') --class com.hainiu.spark.hbase.SparkHbaseBulk --master yarn --queue hainiu ~/spark-1.0-hainiu.jar /data/hainiu/user_install_status/20141228/part-r-00001 /user/qingniu/task/user_install_status

加driver工具
spark-submit --jars $(echo /usr/local/hbase/lib/*.jar | tr ' ' ',') --master yarn --queue hainiu ~/spark-1.0-hainiu.jar sparkhbaseload /data/hainiu/user_install_status/20141228/part-r-00001 /user/qingniu/task/user_install_status


配置环境变量,跳过上传hbase的jar包,好加快启动速度
spark-submit --master yarn --queue hainiu ~/spark-1.0-hainiu.jar sparkhbaseload /data/hainiu/user_install_status/20141228/part-r-00001 /user/qingniu/task/user_install_status
spark-env.sh

把每个机器上的hbase lib下的yarn相关的移除
yarn 包冲突
mv /usr/local/hbase/lib/hadoop-yarn-api-2.5.1.jar /usr/local/hbase/lib/hadoop-yarn-api-2.5.1.jar_back
mv /usr/local/hbase/lib/hadoop-yarn-client-2.5.1.jar /usr/local/hbase/lib/hadoop-yarn-client-2.5.1.jar_back
mv /usr/local/hbase/lib/hadoop-yarn-common-2.5.1.jar /usr/local/hbase/lib/hadoop-yarn-common-2.5.1.jar_back
mv /usr/local/hbase/lib/hadoop-yarn-server-common-2.5.1.jar /usr/local/hbase/lib/hadoop-yarn-server-common-2.5.1.jar_back

3.spark streaming
概述
随着大数据技术的不断发展,人们对于大数据的实时性处理要求也在不断提高,传统的 MapReduce 等批处理框架在某些特定领域,例如实时用户推荐、用户行为分析这些应用场景上逐渐不能满足人们对实时性的需求,因此诞生了一批如 S3、Storm 这样的流式分析、实时计算框架。Spark 由于其内部优秀的调度机制、快速的分布式计算能力,所以能够以极快的速度进行迭代计算。正是由于具有这样的优势,Spark 能够在某些程度上进行实时处理,Spark Streaming 正是构建在此之上的流式框架。
Spark Streaming可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafka、ZeroMQ等消息队列以及TCP sockets或者目录文件从数据源获取数据之后,可以使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统,数据库

Spark Streaming接收这些实时输入数据流,会将它们按批次划分,然后交给Spark引擎处理,生成按照批次划分的结果流。
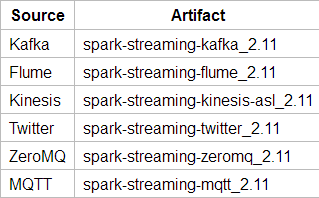
Spark的各个子框架,都是基于核心Spark的,Spark Streaming在内部的处理机制是,接收实时流的数据,并根据一定的时间间隔拆分成一批批的数据,然后通过Spark Engine处理这些批数据,最终得到处理后的一批批结果数据。
对应的批数据,在Spark内核对应一个RDD实例,因此,对应流数据的DStream可以看成是一组RDDs,即RDD的一个序列。通俗点理解的话,在流数据分成一批一批后,通过一个先进先出的队列,然后 Spark Engine从该队列中依次取出一个个批数据,把批数据封装成一个RDD,然后进行处理,这是一个典型的生产者消费者模型,对应的就有生产者消费者模型的问题,即如何协调生产速率和消费速率。
Storm与Spark Streming比较
1.处理模型以及延迟
虽然两框架都提供了可扩展性(scalability)和可容错性(fault tolerance),但是它们的处理模型从根本上说是不一样的。Storm可以实现亚秒级时延的处理,而每次只处理一条event,而Spark Streaming可以在一个短暂的时间窗口里面处理多条(batches)Event。所以说Storm可以实现亚秒级时延的处理,而Spark Streaming则有一定的时延。
2.容错和数据保证
然而两者的代价都是容错时候的数据保证,Spark Streaming的容错为有状态的计算提供了更好的支持。在Storm中,每条记录在系统的移动过程中都需要被标记跟踪,所以Storm只能保证每条记录最少被处理一次,但是允许从错误状态恢复时被处理多次。这就意味着可变更的状态可能被更新两次从而导致结果不正确。
任一方面,Spark Streaming仅仅需要在批处理级别对记录进行追踪,所以他能保证每个批处理记录仅仅被处理一次,即使是node节点挂掉。
3.批处理框架集成
Spark Streaming的一个很棒的特性就是它是在Spark框架上运行的。这样你就可以想使用其他批处理代码一样来写Spark Streaming程序,或者是在Spark中交互查询。这就减少了单独编写流批量处理程序和历史数据处理程序。
4.生产支持
两者都可以在各自的集群框架中运行,但是Storm可以在Mesos上运行, 而Spark Streaming可以在YARN和Mesos上运行。
Storm已经出现好多年了,而且自从2011年开始就在Twitter内部生产环境中使用,还有其他一些公司。而据twitter跳槽过来的同事说,现在他们内部已经不使用storm了,转而使用Spark Streaming,可现Spark Streaming正渐渐成为主流
Spark Streaming优缺点
优点:
版权声明:原创作品,允许转载,转载时务必以超链接的形式表明出处和作者信息。否则将追究法律责任。来自海汼部落-青牛,http://hainiubl.com/topics/196


