scala介绍
hadoop(java)
hive(java)
hbase(java)
kafka(scala)
spark(scala)
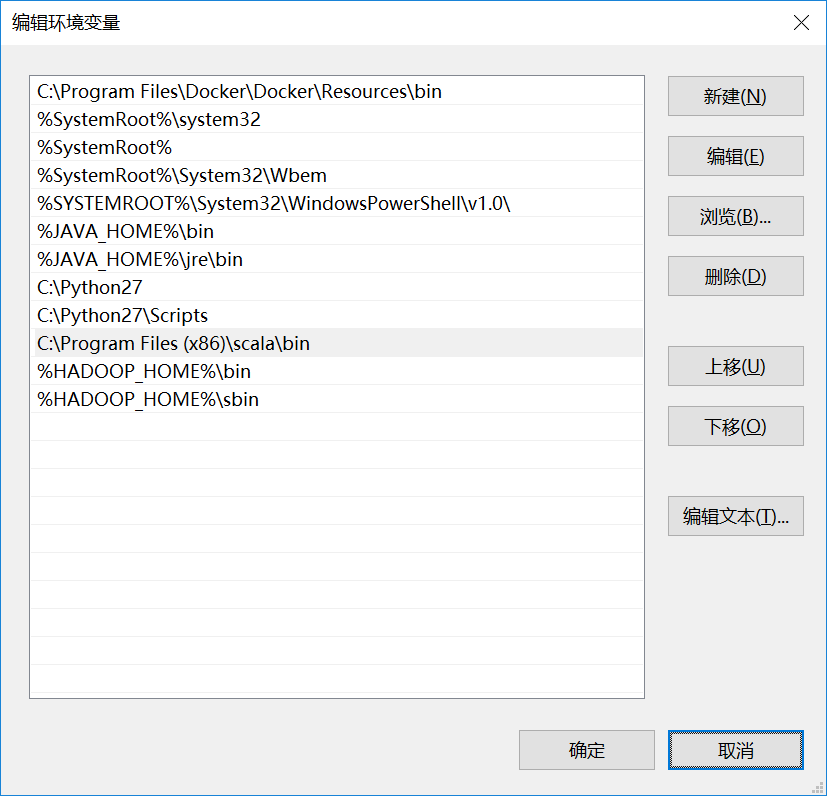
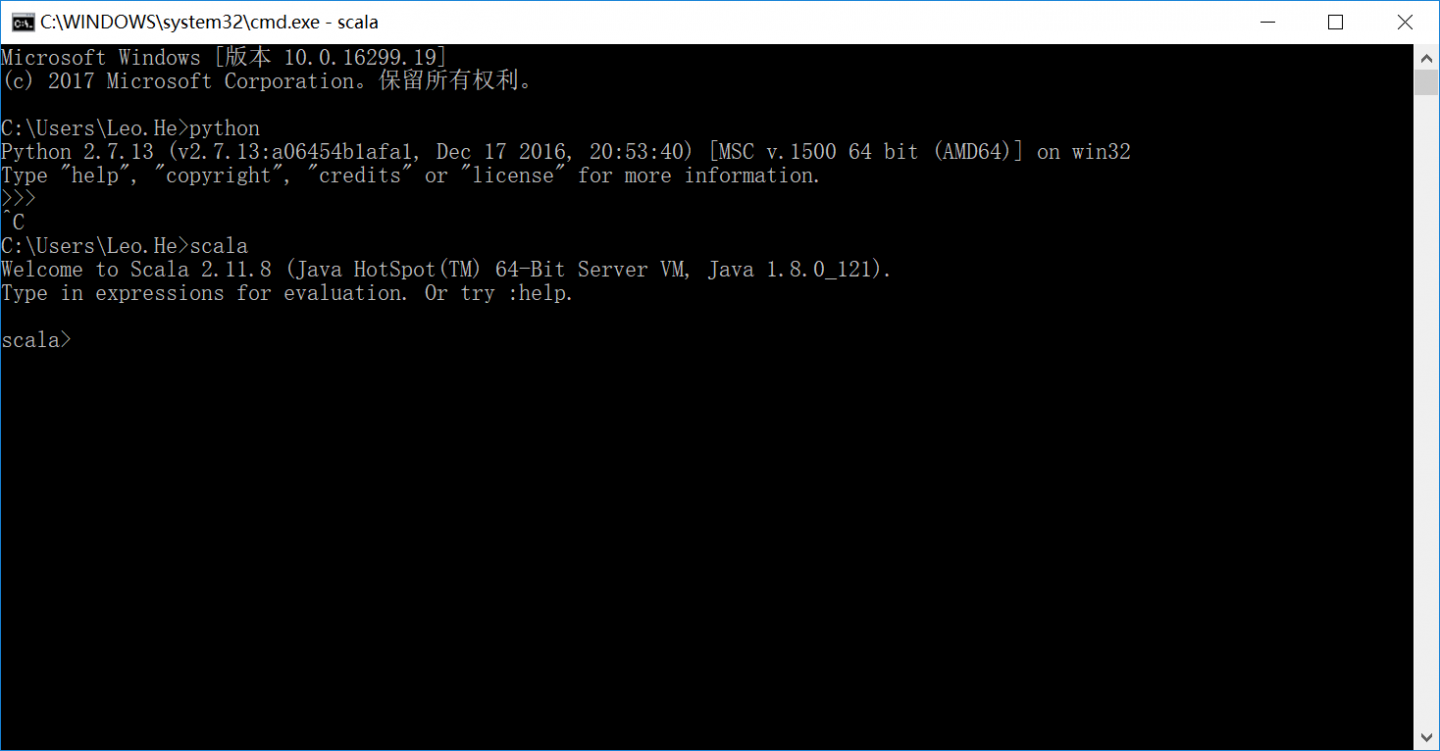
scala安装
开发工具idea安装与使用
插件:maven,scala

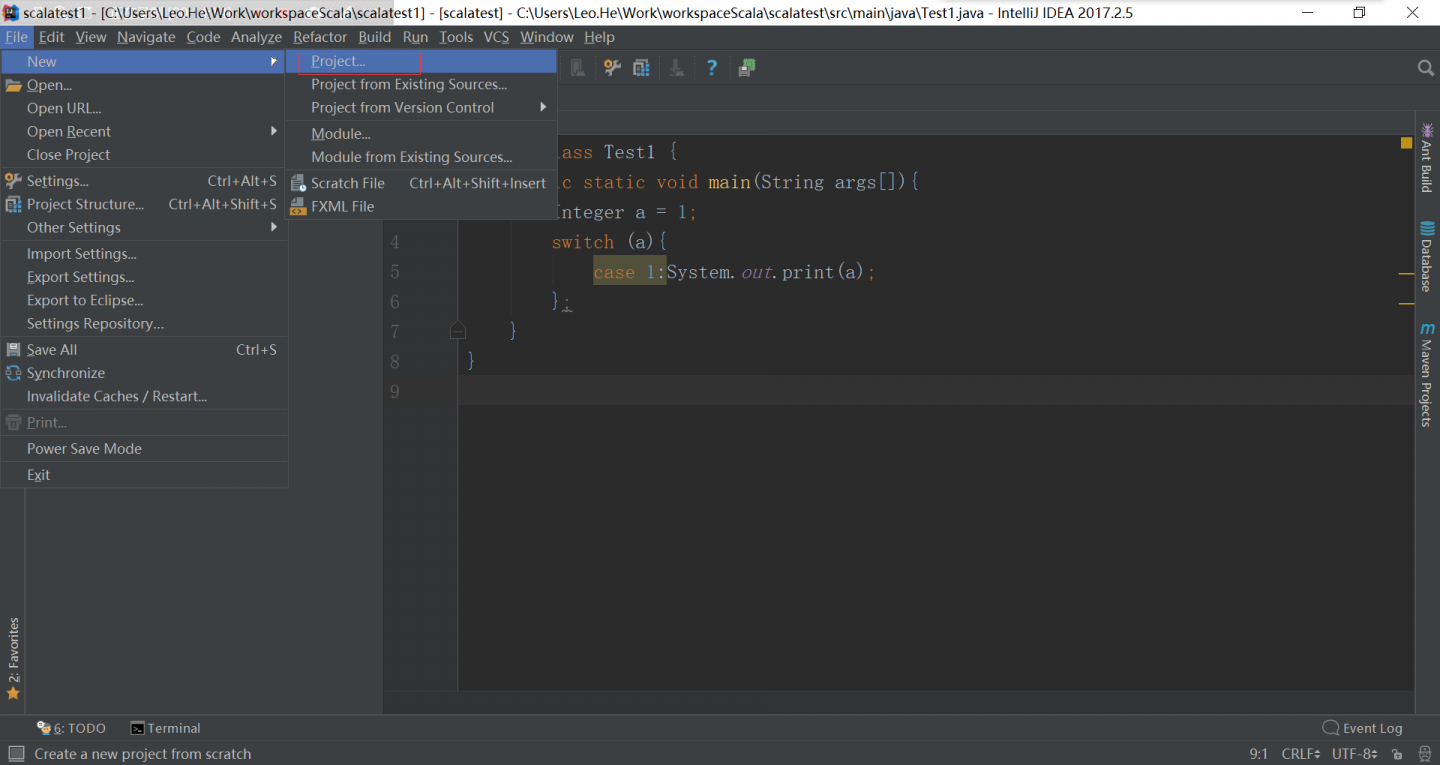
创建maven项目
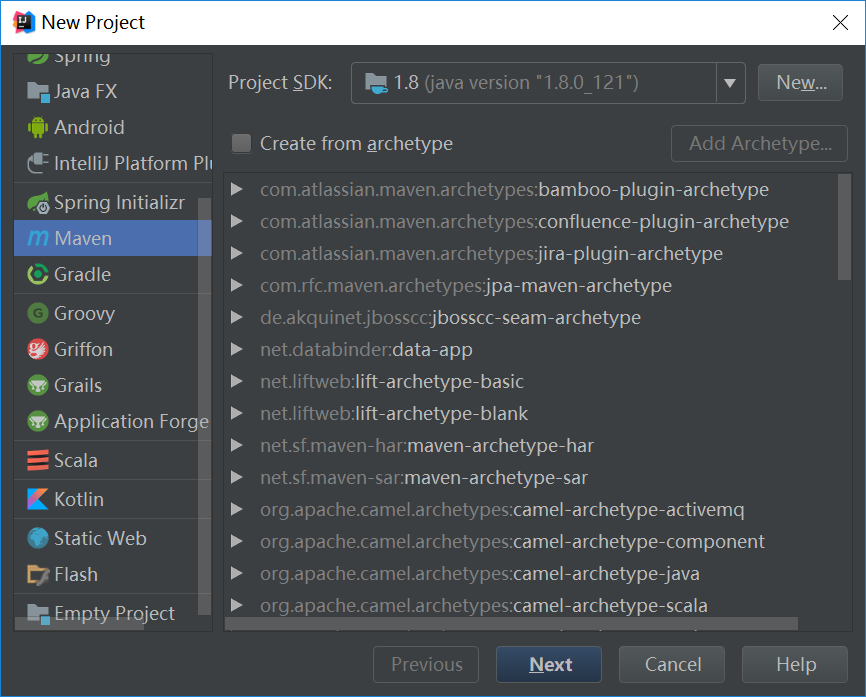
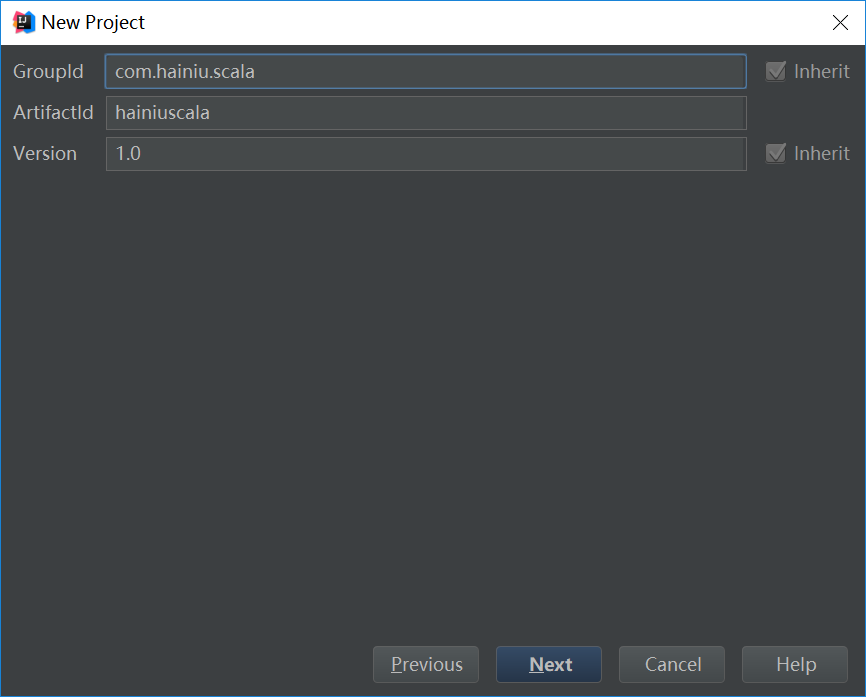
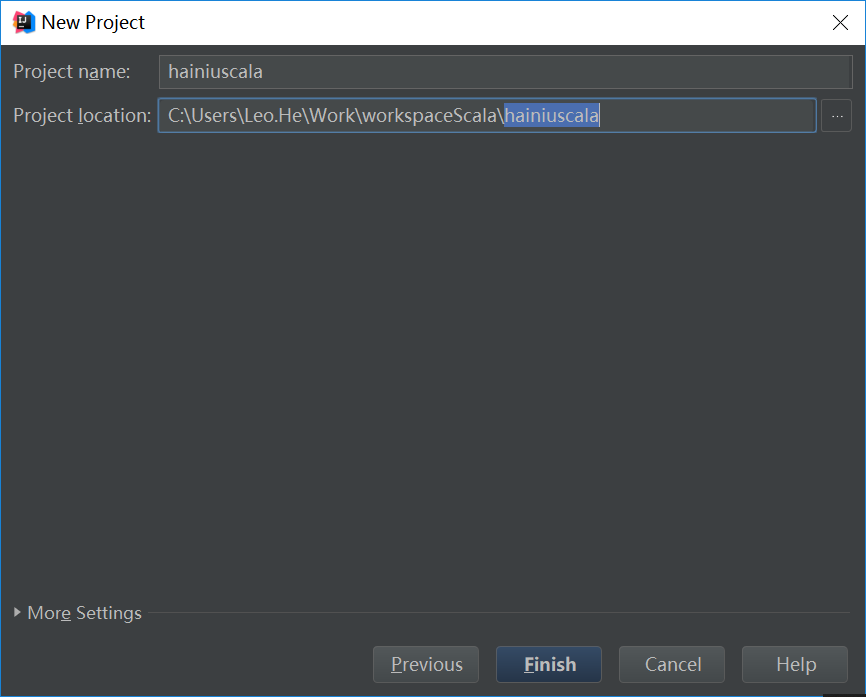
创建scala代码目录
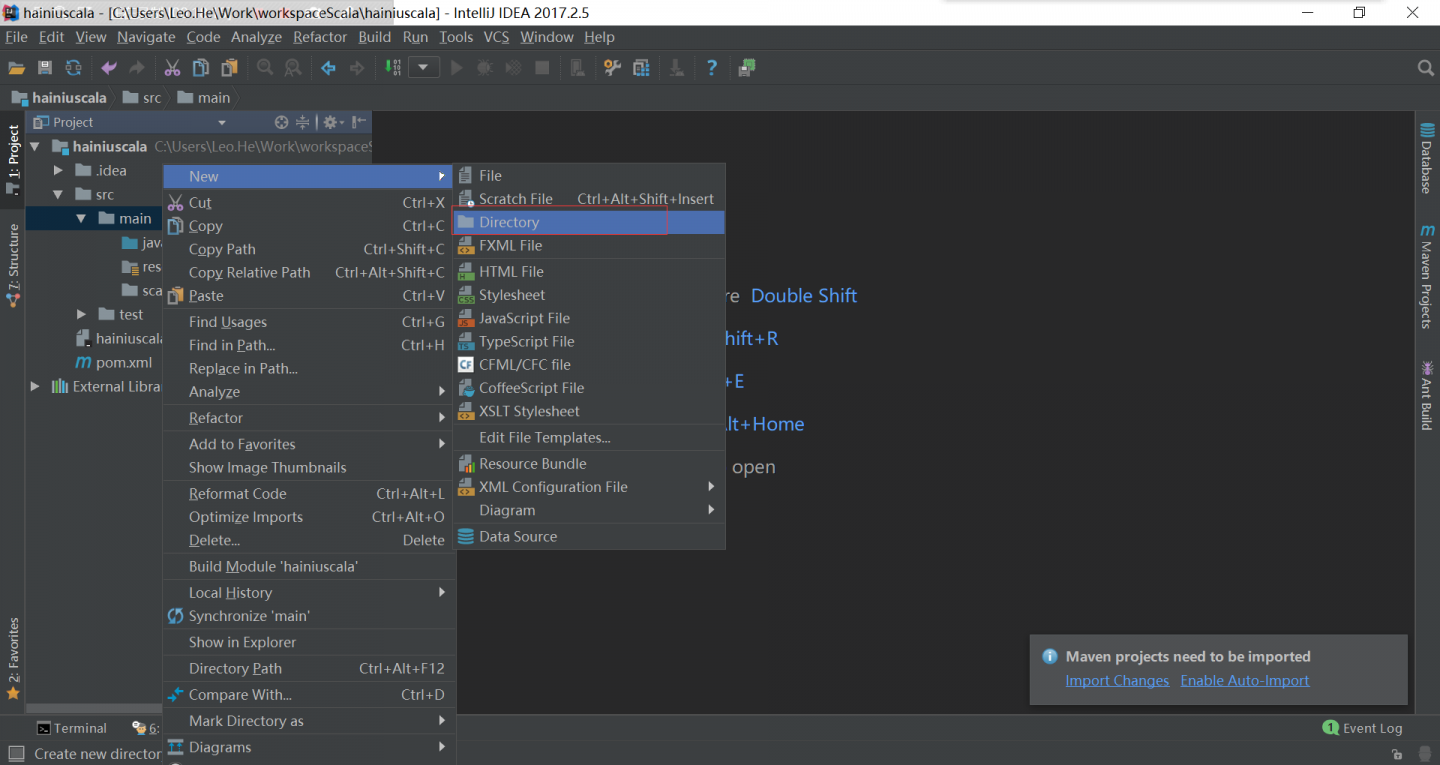
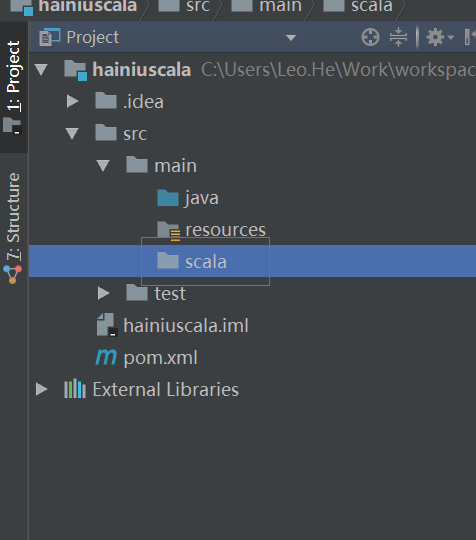
配置项目
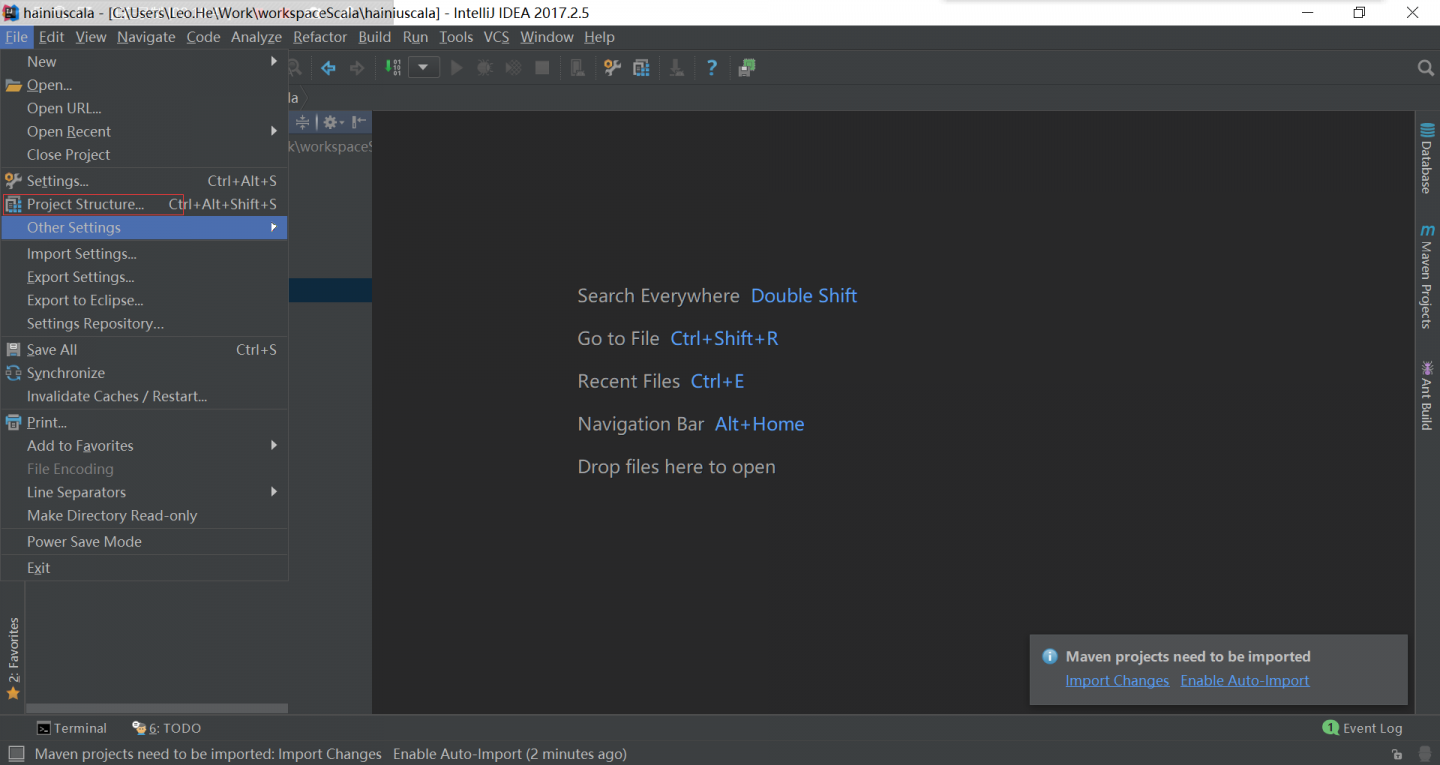

把新建的目录变成source目录
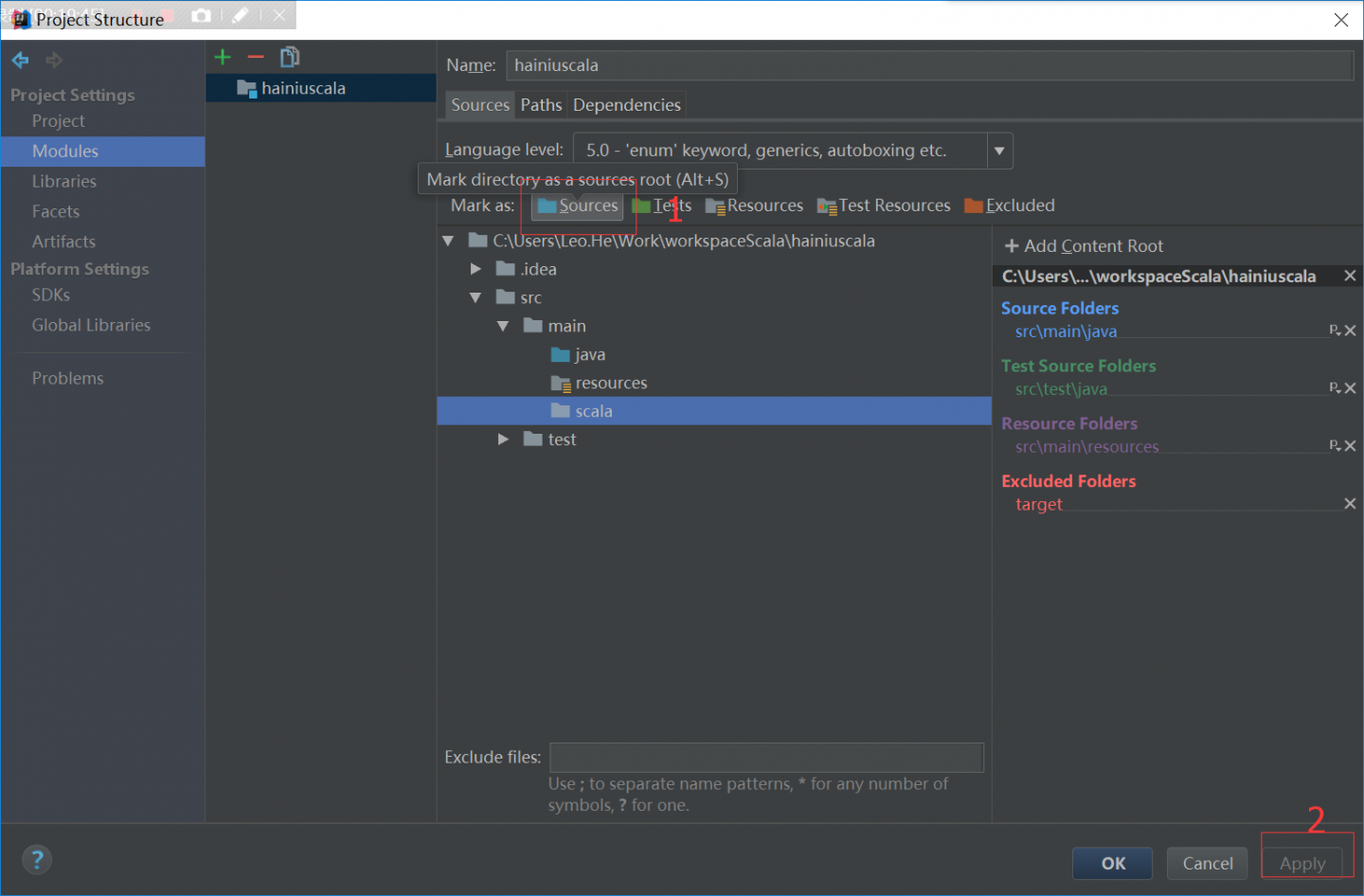
加scala SDK否则就不能创建scala的类
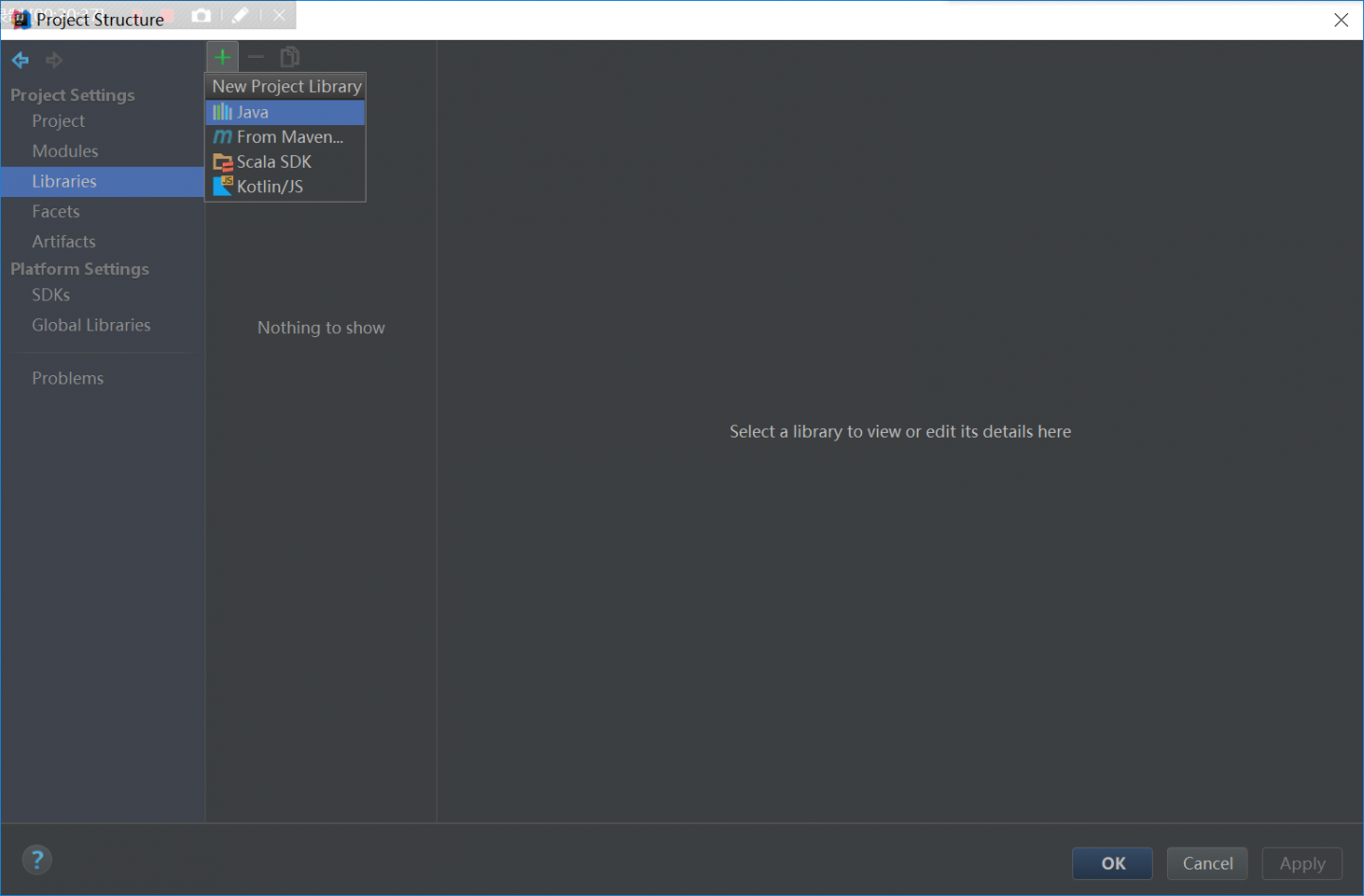
scala版的helloword
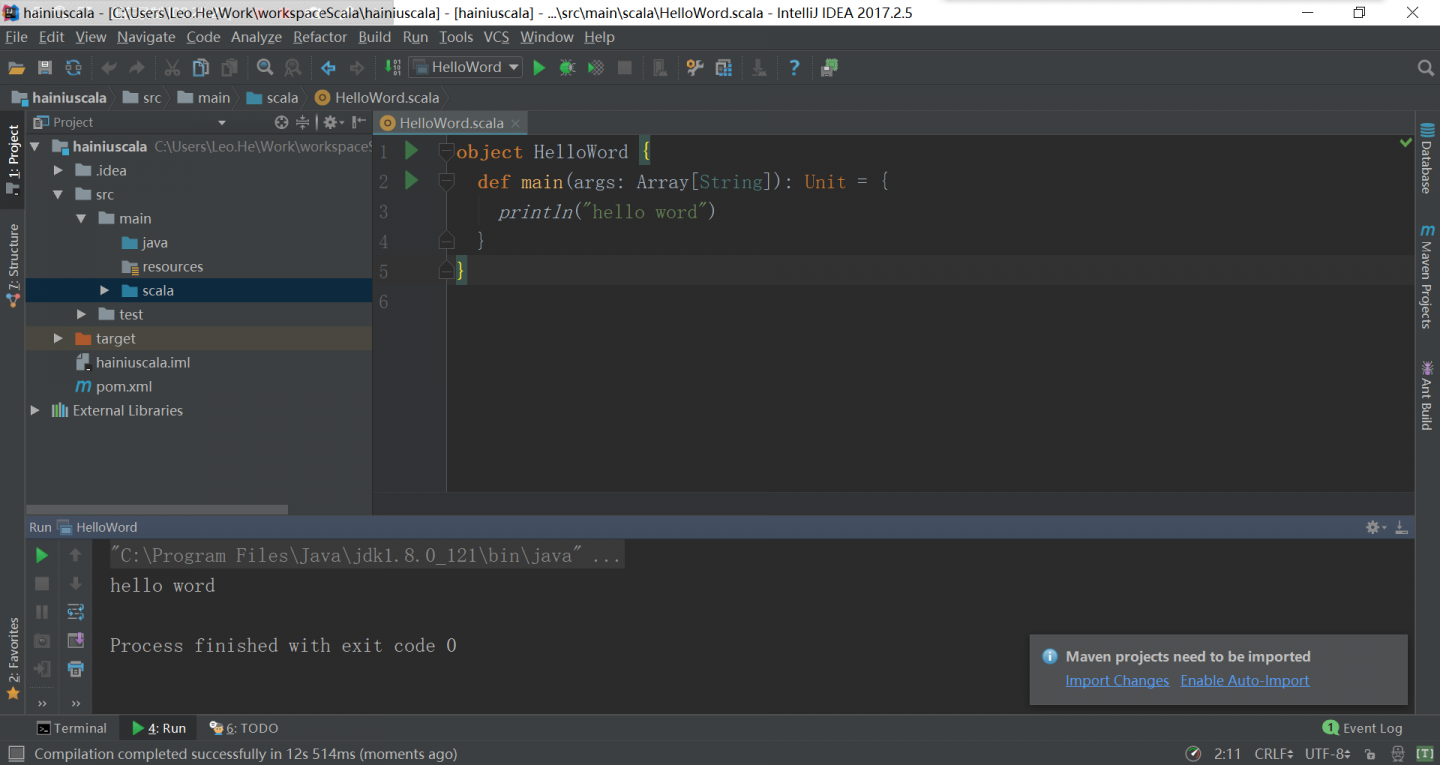
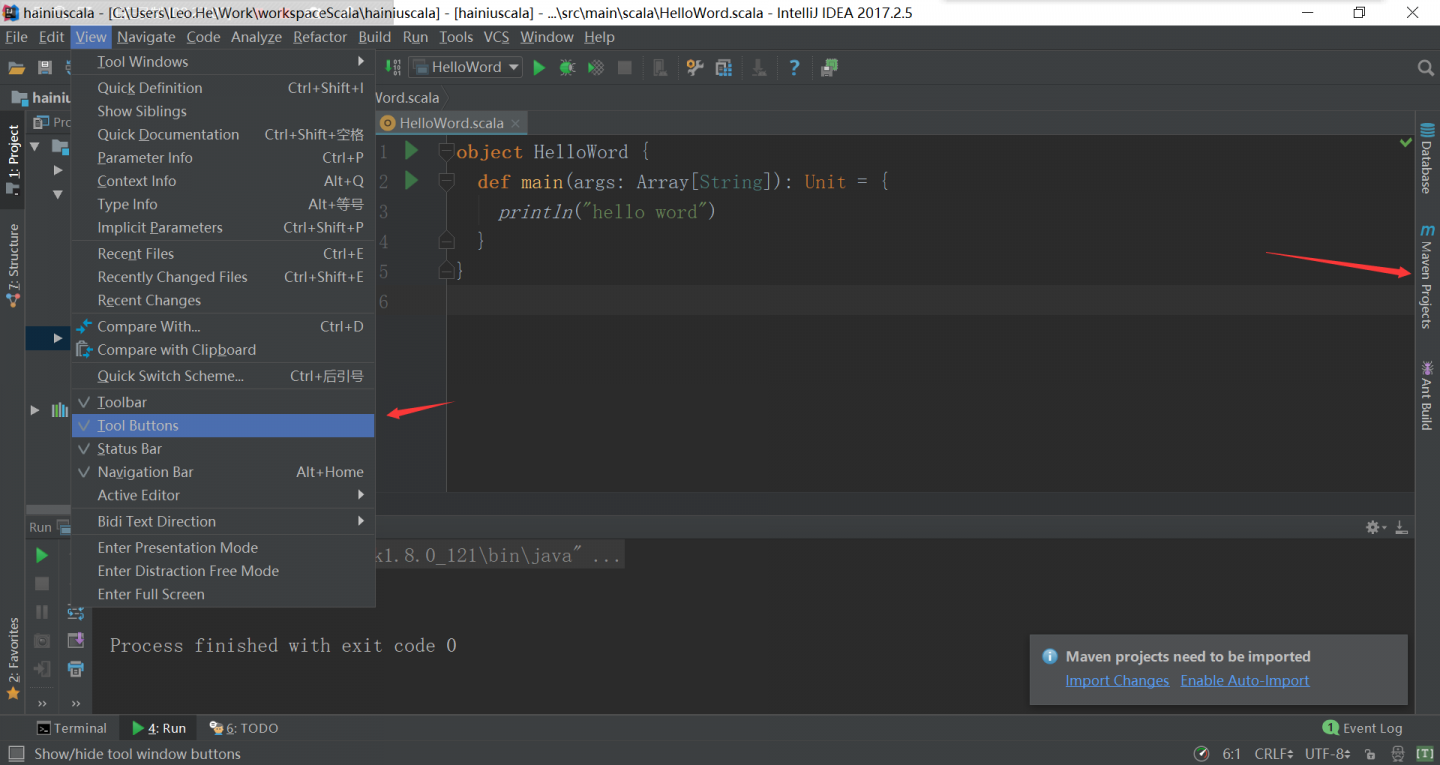
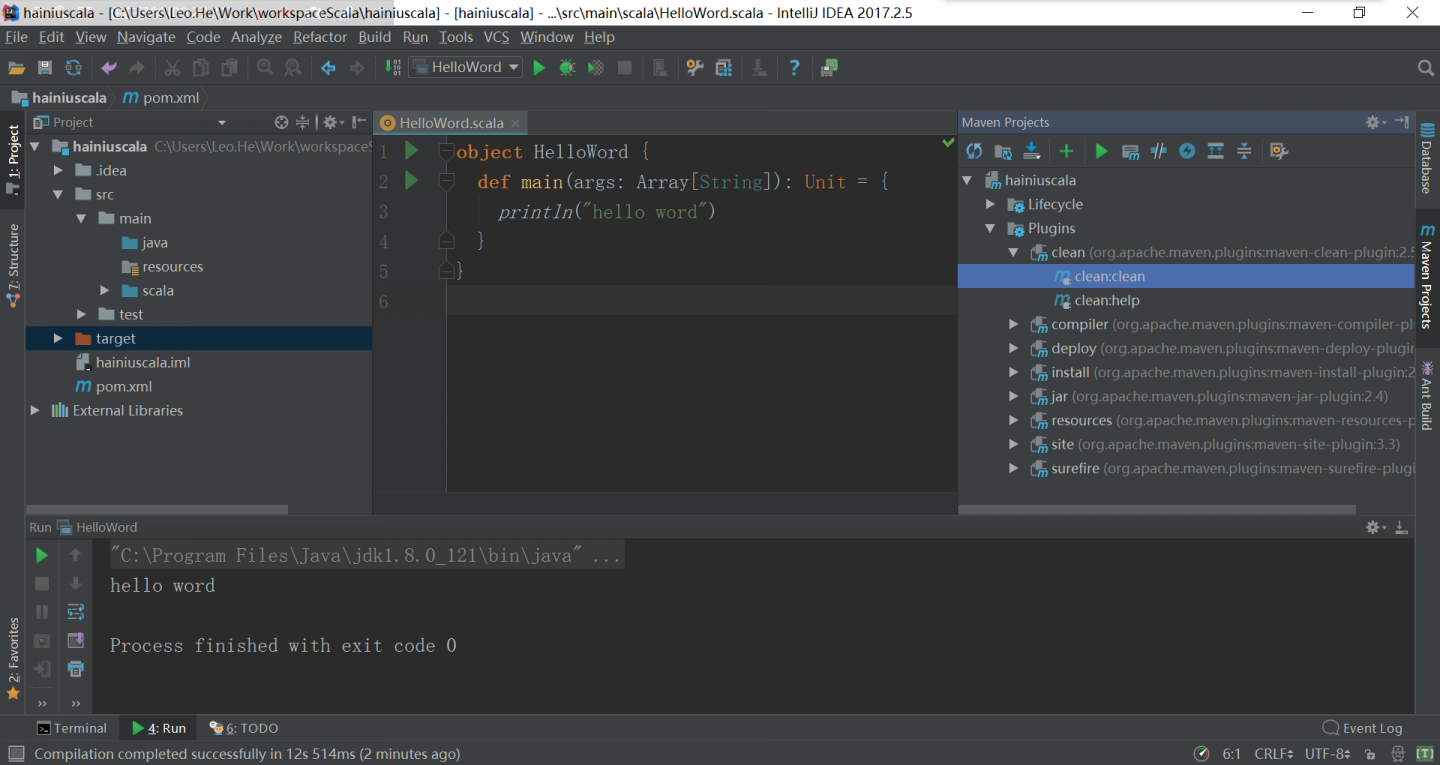
idea上maven的使用
清理target
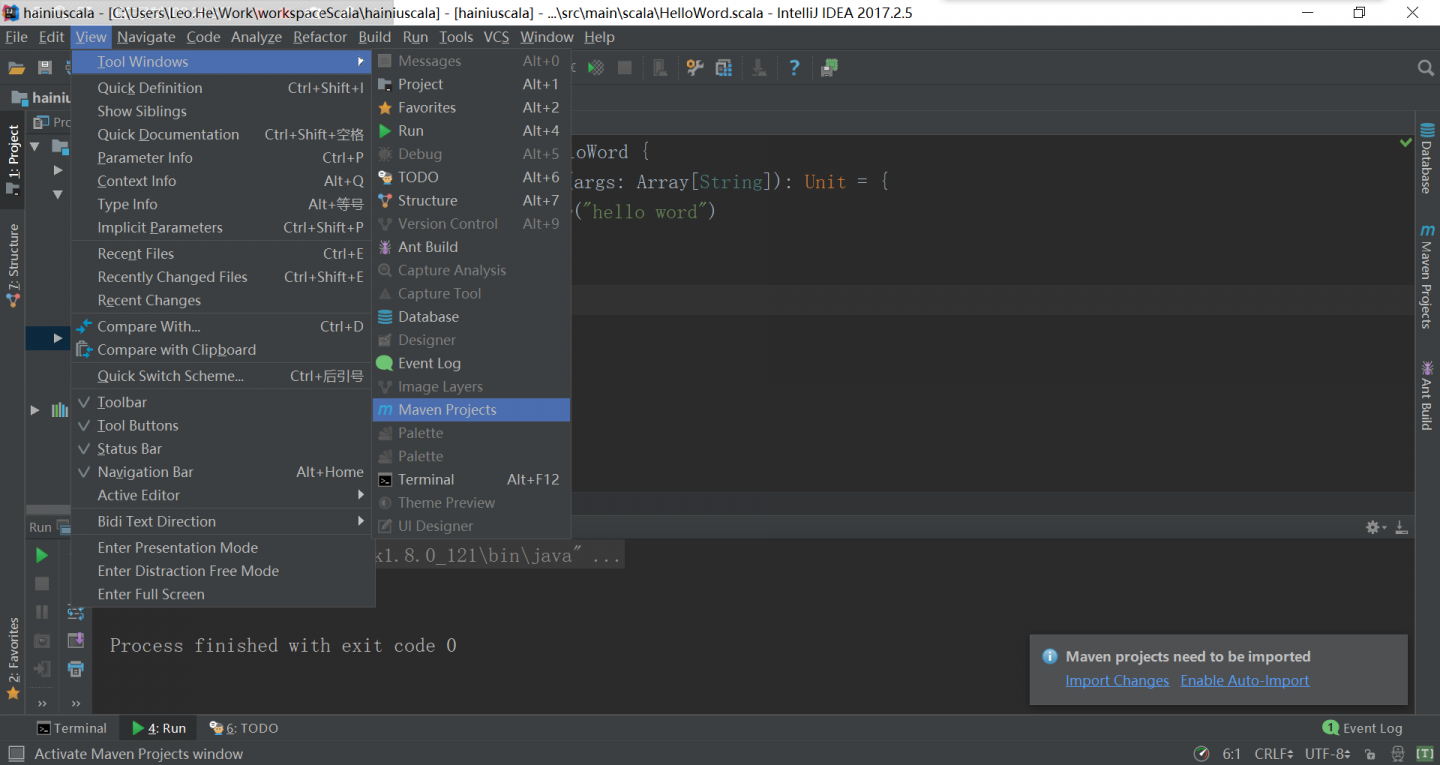
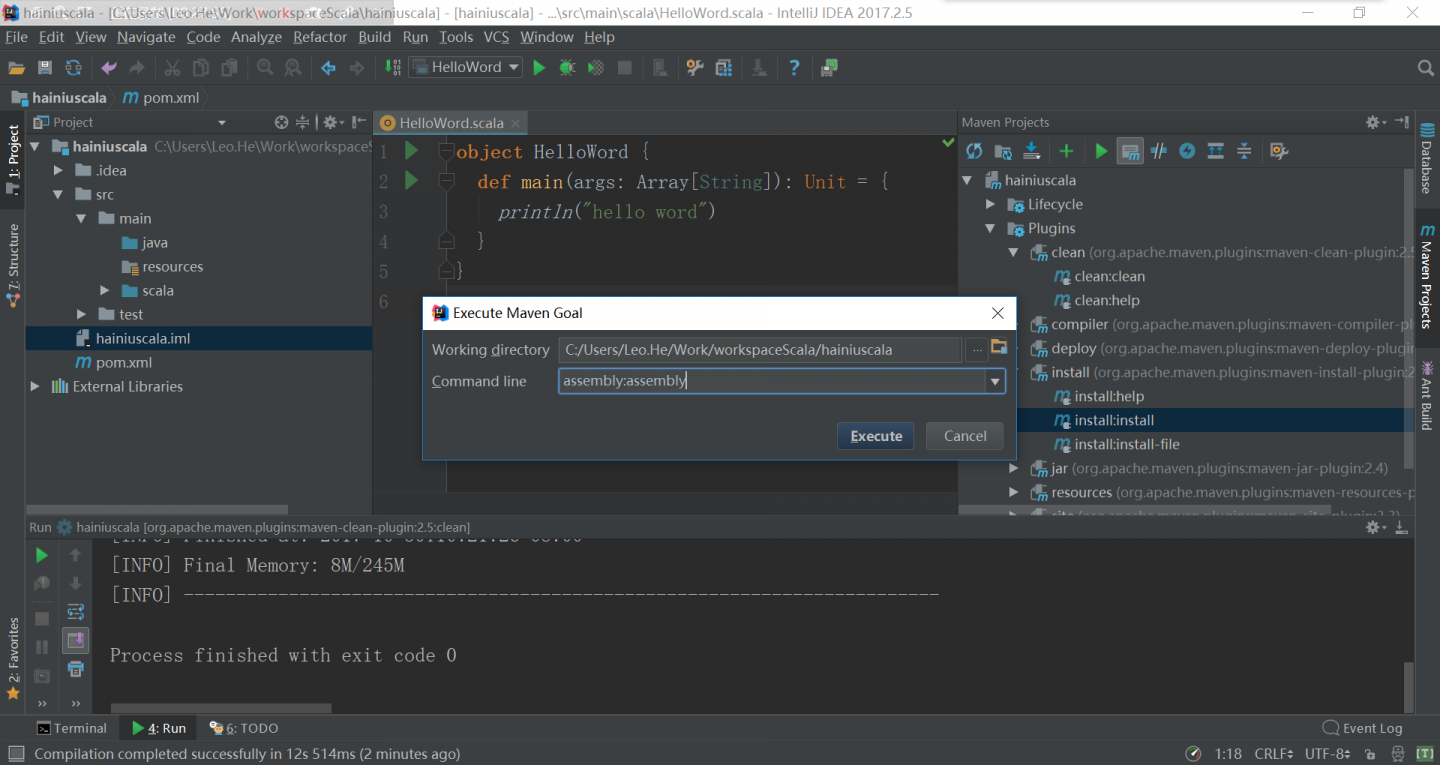
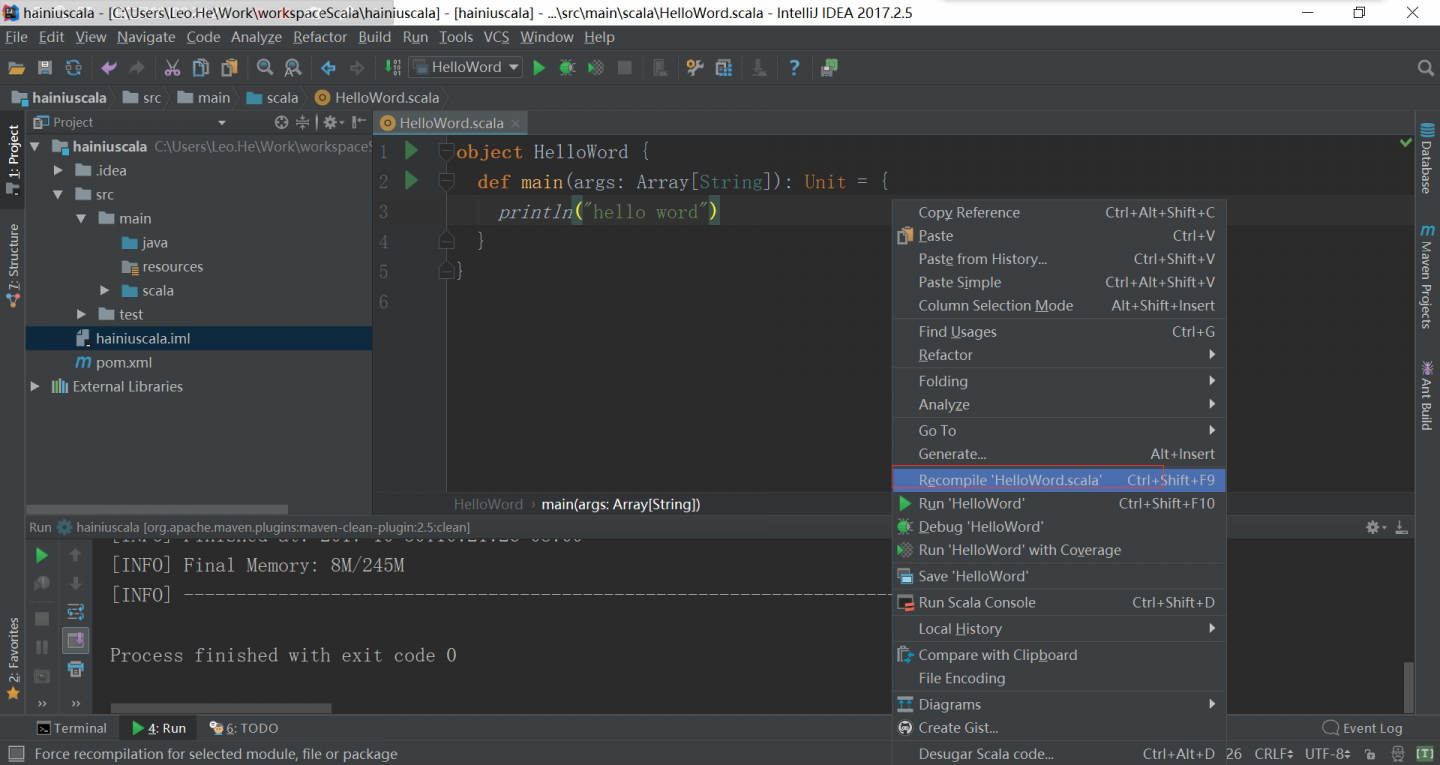
重新编译
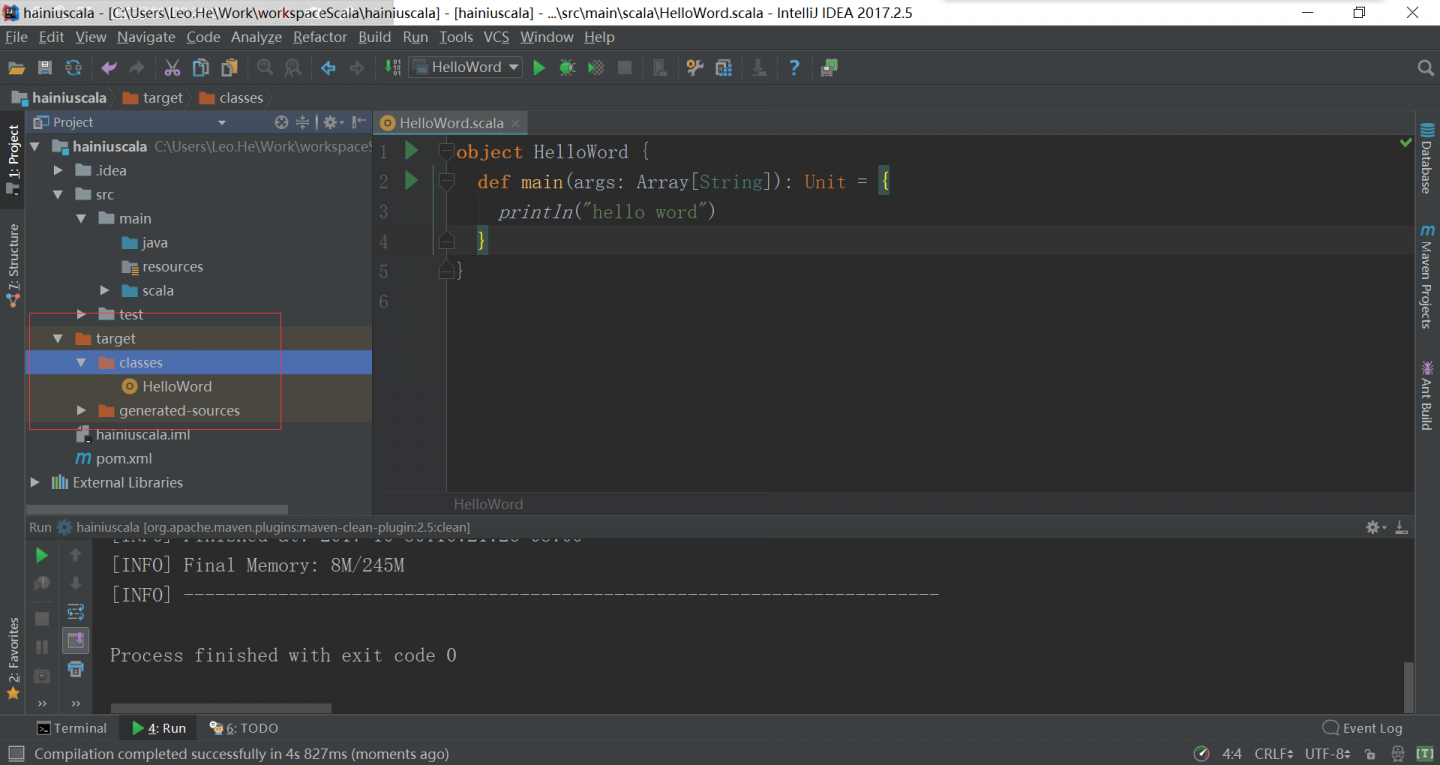
修改maven的配置
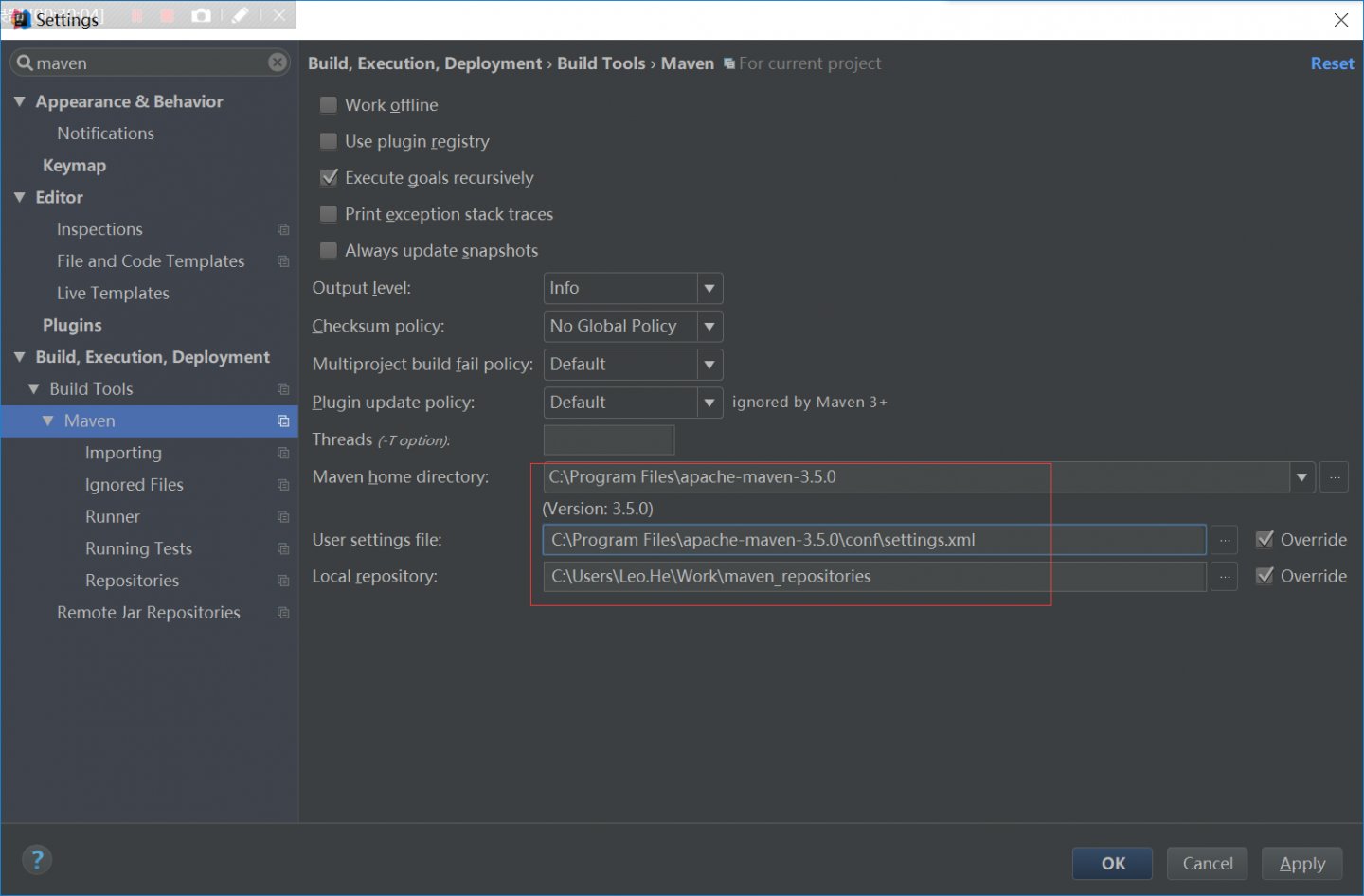
修改字体
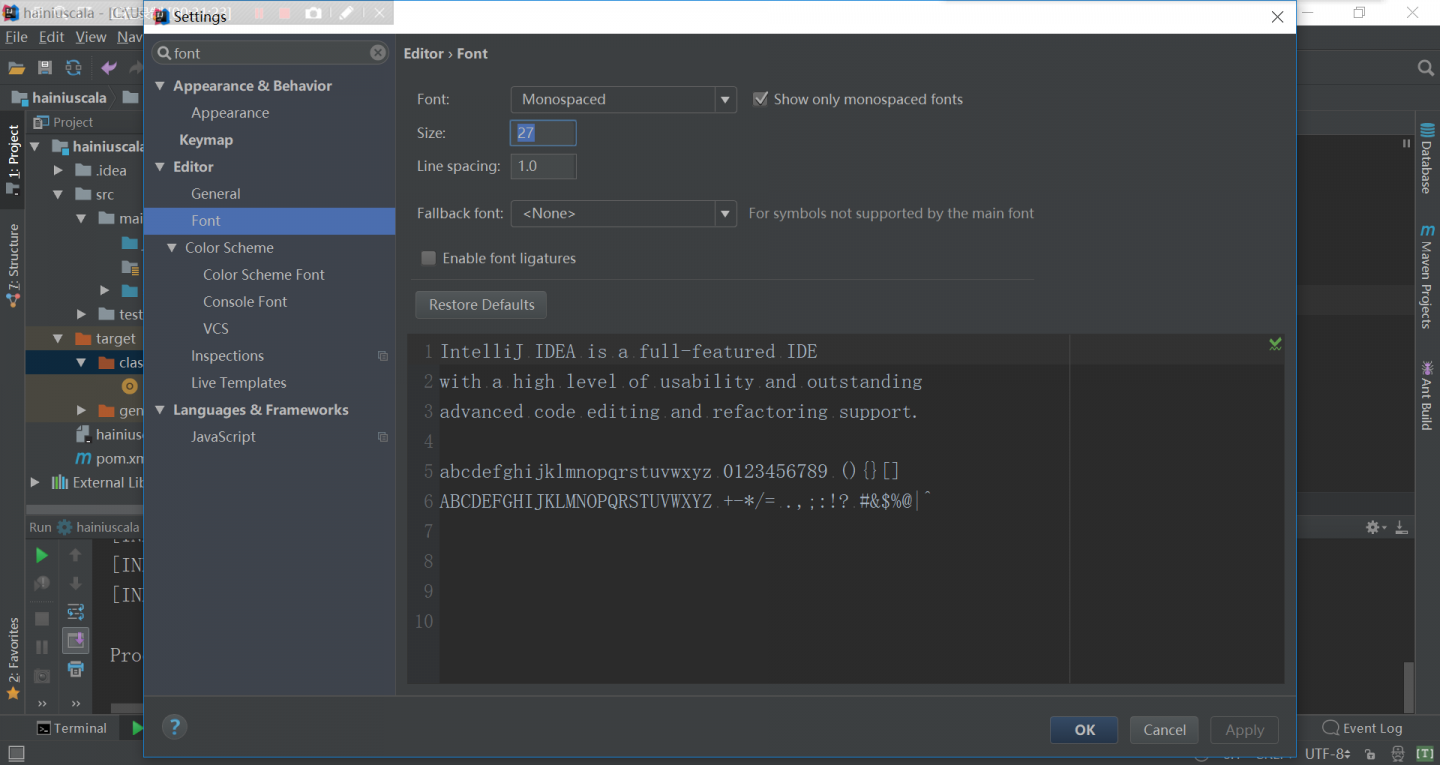
import其他项目

怎么在idea查看源码
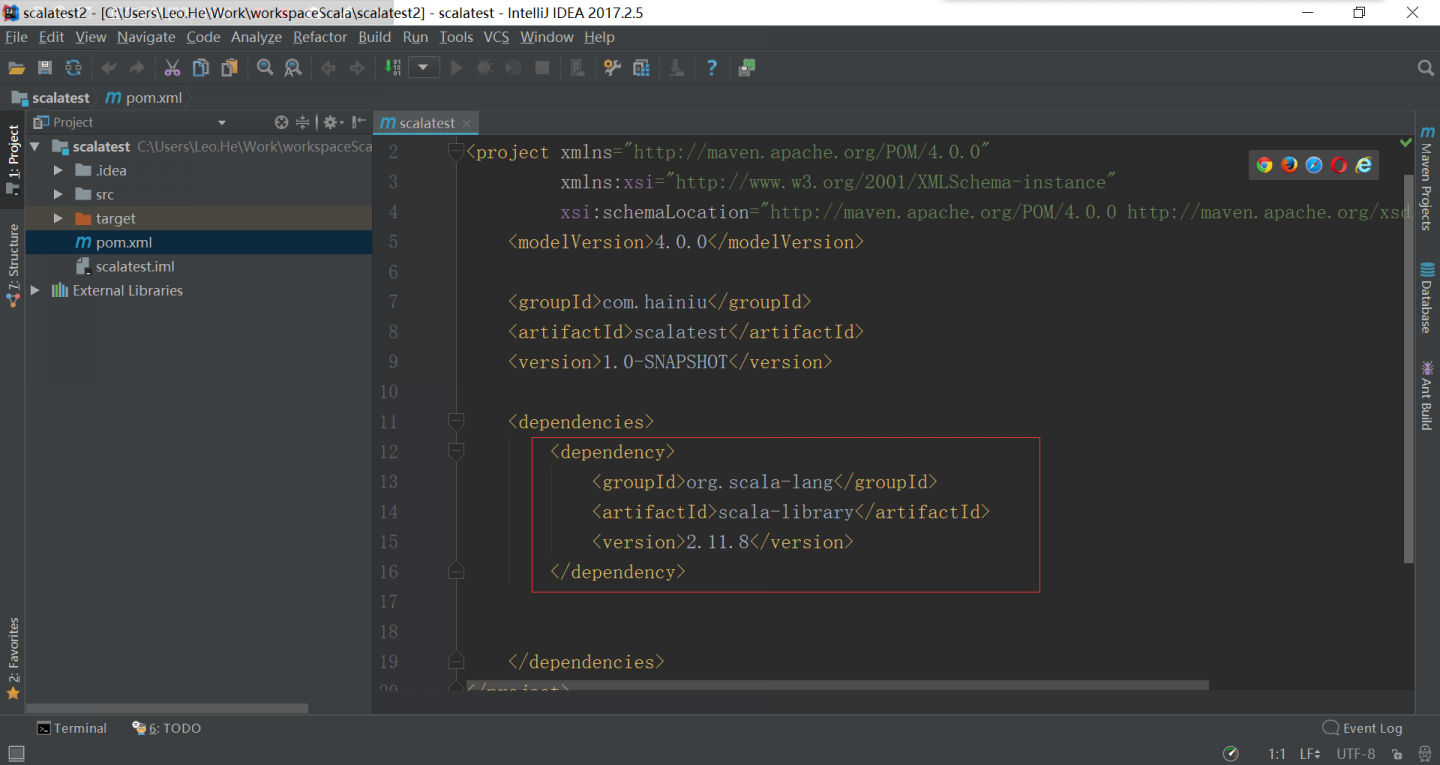
修改快捷键
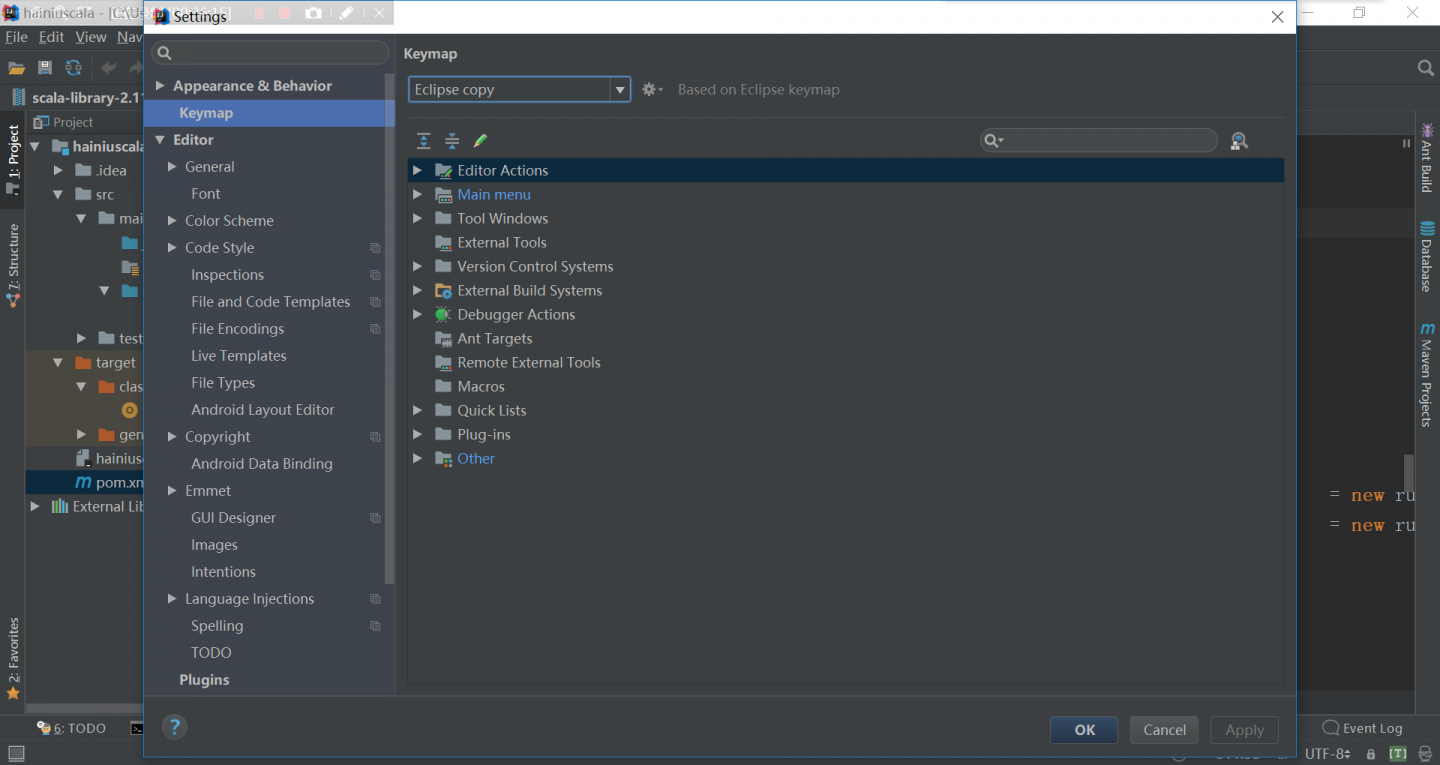
scala语法
val:变量的引用不过变
var:变量的引用可变
scala推荐用val,val就是value的缩写
scala语言结尾不用分号和Python语言比较相似
scala不指定变量类型是会根据值进行自动推断,当然也可以在初始化的时候明确指定变量的类型
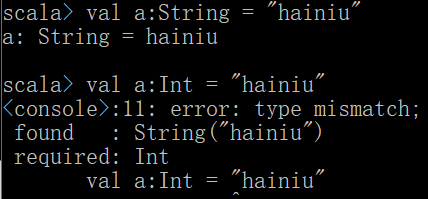
scala的值类型有7种:
Byte、Char、Short、Int、Long、Float、Double
与Java相比值类型无引用类型,比如java中int对应的Integer
引用类型有那些比如Integer类型或者自己定义的类
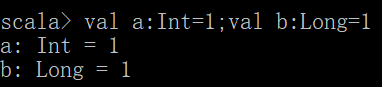
条件表达式:
val x = 3
val y = if(x > 1) 1 else -1
val是不可变变量,但是在赋值之前if(x > 1) 1 else -1语句已经有结果了
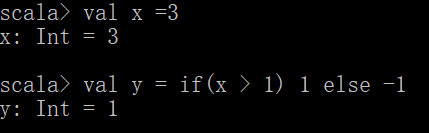
混合类型表达式,支持返回多种类型(前提是在不确定类型的情况下,val y:String或val y:Int这样都不行)
val y = if(x > 1) 1 else "hello"
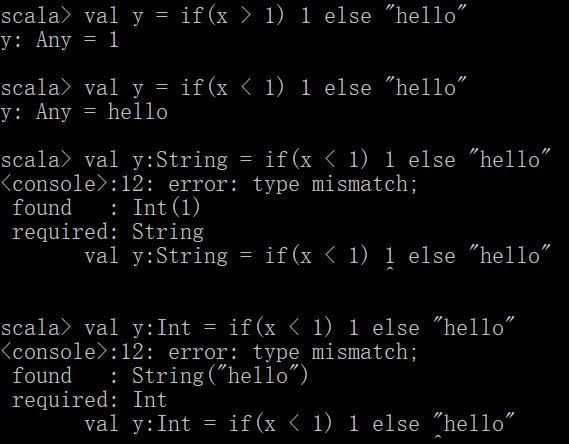
val b = if(x < 1) 1
注意这个后面没有else返回的是AnyVal类型,这个AnyVal是所有类型的基类,就跟Object是Java里面所有类的基类一样
这个语句和 val b = if(x<1) 1 else () 一个意思,这个语句里的()是Unit类型就相当于Java里面的void
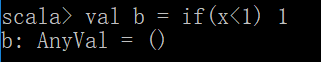
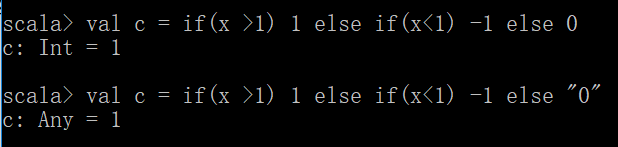
else if用法
val c = if(x > 1) 1 else if (x < 1) -1 else 0 这个和java里面一样的
for循环
1 to 10
返回1到10的所有值

1 until 10 等于Range(1,10),和Python里的range一样的用法
返回1到9的所有值,也就是不包括10
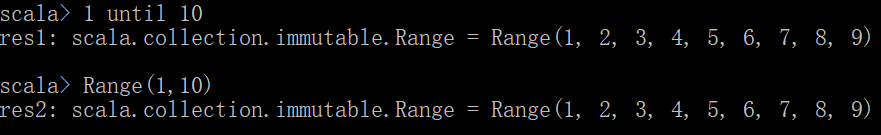
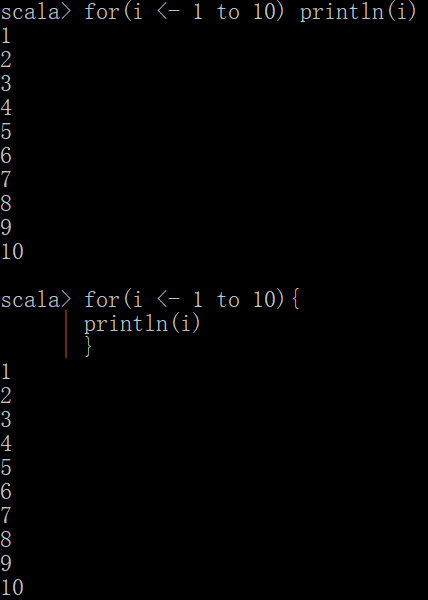
for(i <- 1 to 10){
println(i)
}
for(i <- 1 to 10) println(i)
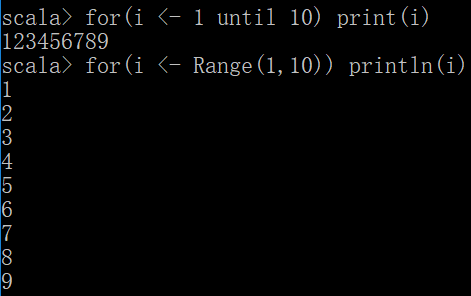
or(i <- 1 until 10) println(i)
for(i <- Range(1,10)) println(i)
结合数组使用
val arr = Array("a","b","c")
for(i <- arr) println(i)
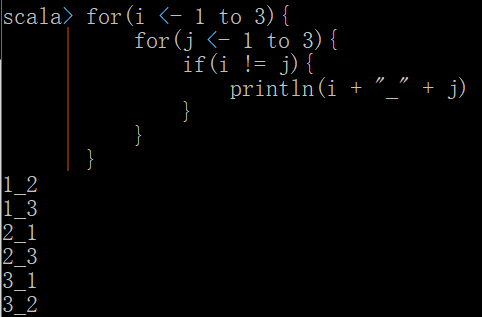
嵌套for循环
for(i <- 1 to 3){
for(j <- 1 to 3){
if(i != j){
println(i + "_" + j)
}
}
}
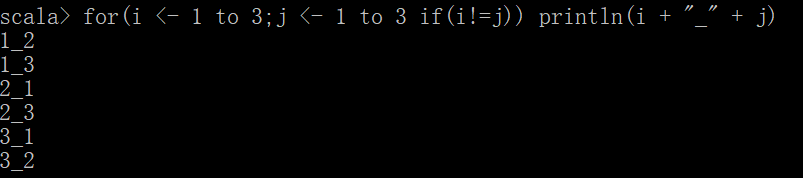
简便写法
for(i <- 1 to 3;j <- 1 to 3 if(i != j)) println(i + "_" + j)
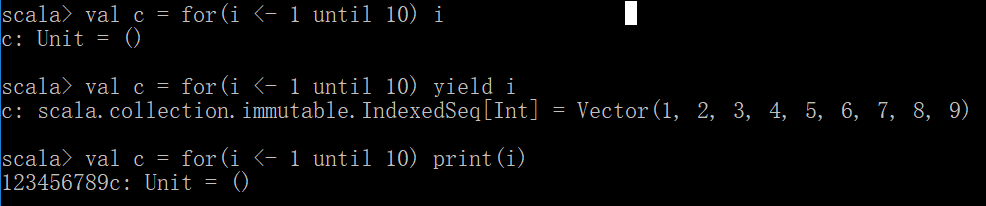
yield关键字结合for循环使用
val c = for(i <- 1 until 10) yield i
结果会生成一个集合,也就是yield的作用是把每次迭代生成的值封装到一个集合中,当然也可以理解成yield会自动创建一个集合
如果把yield去掉那返回给C的值就为Unit
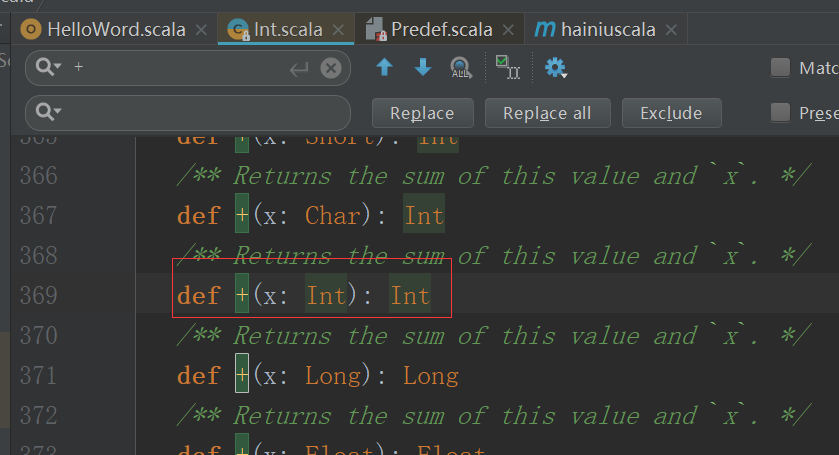
方法:
在scala中的操作符都被当成方法存在,比如说+、-、*、/
1+2就是1.+(2)的调用,
如果2被当成doule类型的了
强调用Int类型的写法为1.+(2:Int)
可以在idea中搜索Int类查看支持的方法

方法声明:
def 方法名([变量:变量类型,变量:变量类型]):返回值={方法体}
示例:
def bb(a:Int):Unit={
println(a)
}

方法的简写

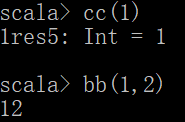
def cc(a:Int):Int = return a

调用方法
bb(1)
cc(2)
函数声明:
在java中方法和函数是一个意思,在scala中方法和函数是两种含义
[val 变量名 = ] ([变量:变量类型,变量:变量类型]) => 函数体
示例:
var c = (a:Int) => a+1
var c = (a:Int,b:Int) => a+1
(a:Int,b:Int) => a+1,这里没有[val 变量名 = ]称为匿名函数
函数体中有多个语句用分号隔开
var c = (a:Int,b:Int) => {val d=a+b;d}

函数可以做为方法的参数使用,这也是scala比较灵活的地方
示例:
def bb(a:Int):Unit={
println(a)
}
var c = (a:Int,b:Int) => {val d=a+b;d}
bb(c(1,2))

方法的参数直接是函数
def method(func:(Int,Int) => Int) = func(5,6)
val f1 = (a:Int,b:Int) => a + b
method(f1)
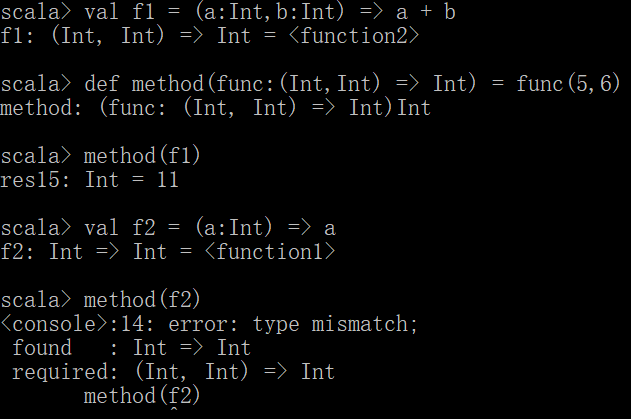

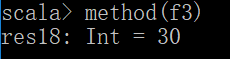
方法转换成函数
def method1(x:Int,y:Int):Int = x+y
val f2 = method1<空格>_

也可以把方法当参数使用,这也因为scala会隐式的把方法转换成函数,但并不是直接支持方法当参数的模式,只是做了隐式的转换,这种函数的转换分两种显示用<空格>_和隐式的,这也提现了scala灵活的地方。

数组:
分为定长和变长的,也就是可以改变长度和固定长度的(同样 集合、映射、元组也分为定长和变长)
定长不用引用第3方的包,变长需要引用
定长数组:
val arr1 = new ArrayInt
val arr1 = new ArrayString

print(arr1)
直接打印是没有值的
print(arr1.toBuffer)
要打印有值的需要转换成数组缓冲

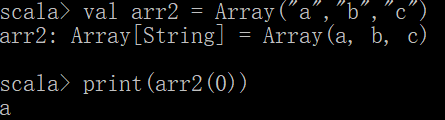
val arr2 = Array("a","b","c")
注意设置带初始值的定长数组不能用new,因为是调用Array的静态对象,这个静态对象可以传递多个参数,而new的是调用类的构造方法只能接受一个参数就是数组的长度

数组下标也是从0开始的,和java对比不同的是java用的[],而scala用的是()
print(arr2(0))
变长数组
不能直接使用需要引用ArrayBuffer这个类
不引入就找不到这个类

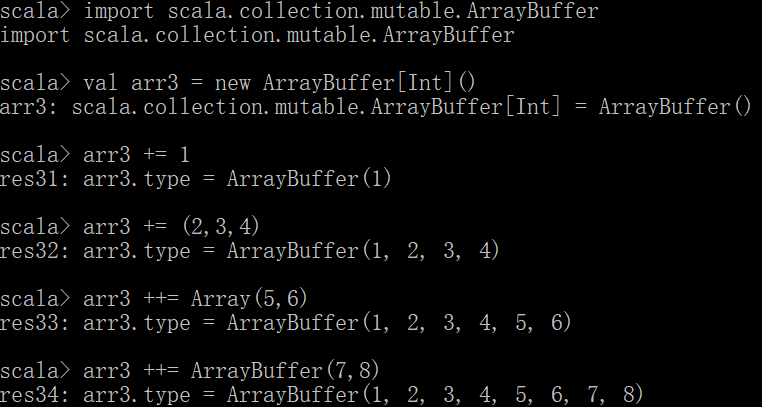
import scala.collection.mutable.ArrayBuffer
val arr3 = ArrayBuffer[Int]()
变长数组操作:
追加操作
arr3+=1 单追加
arr3 += (2,3,4) 元组进行多个追加
arr3 ++= Array(5,6) 定长数组进行多个追加
arr3 ++= ArrayBuffer(7,8) 变长数组进行多个追加
插入操作
arr3.insert(0,-1,0) 在下标为0的位置插入多个元素,在下标为0的位置插入-1和0两个元素
删除操作
arr3.remove(1,3) 从下标为1开始删除3个元素

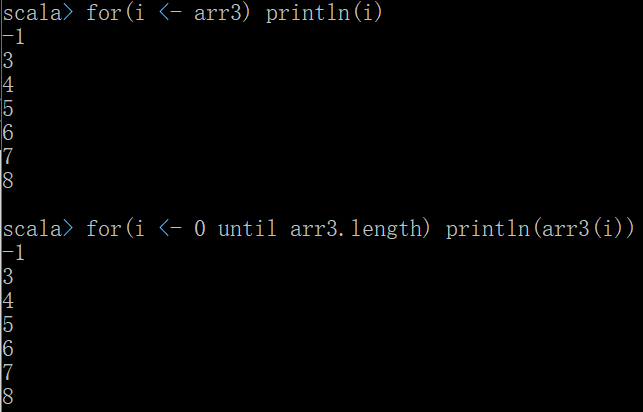
数组遍例用for
for(i <- arr3) println(i)
下标方式
for(i <- 0 until arr3.length) println(arr3(i))
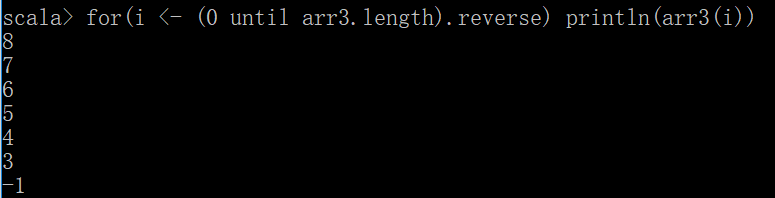
数组反转
for(i <- (0 until arr3.length).reverse) println(arr3(i))
可以集合yield产生别一个新的数组
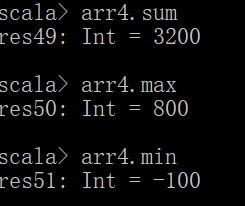
val arr4 = for(i <- (0 until arr3.length).reverse) yield arr3(i)*100

数组求合
arr4.sum
数组求最大值
arr4.max
数组求最小值
arr4.min
数组升序排序
arr.sorted
数组降序排序
arr.sorted.reverse

映射:
映射也就是一个hash表,相当于java里的map
val map1 = Map("a" -> 1,"b" -> 2,"c" -> 3) scala中通常用->来表示键值对
val map2 = Map(("a",1),("b",2),("c",3)) 使用元组的方式来声明一个映射
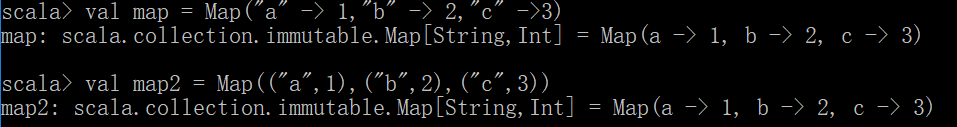
取值
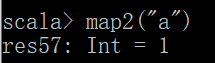
map2("a")
修改得需要引用可变的map,默认的Map是不可变的所以不能修改
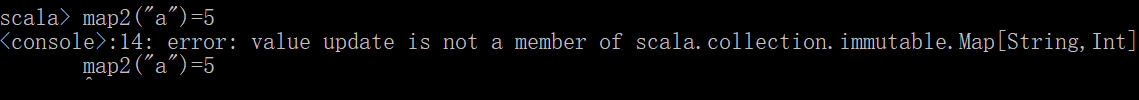
可变的map
import scala.collection.mutable.Map import scala.collection.mutable._ 多引用的方法,就是不止引用map,和python里的*类似
val map2 = Map(("a",1),("b",2),("c",3))
map2("a")=5
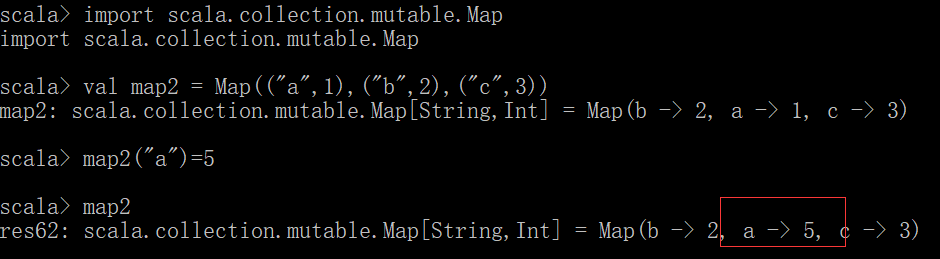
取不包含值的方法
map2("d") 直接取的话和python一样不包含这个key会报错
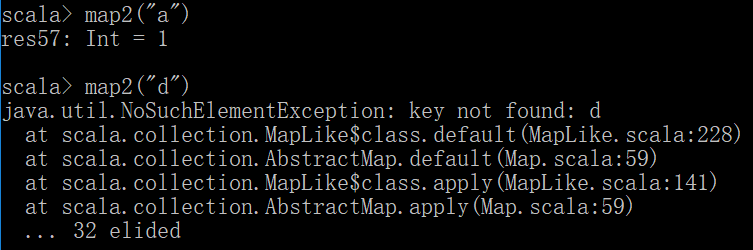
map2.getOrElse("d","4") getOrElse是如果有值会返回键对应的值,没有值就返回一个默认的,这里是字符串“4”,在开发中常用这种方式,因为可以避免报错

注意:这里的map2是用val修饰的,但用val修饰的变量不可变,那为什么map2可变,是因为val修饰的变量对应的引用不可变,就是引用自身的操作与变量无关

元组:
用小括号包含的多个值或多个键值对
(1,2,3,4)
("a",1)
(("a",1),("b",2),("c",3),("d",4))

元组可以放多种不同类型的数据
val re = ("a",1,1L,1.0,Array(1,2),Map(("a",1)),"b" -> 2)

取值
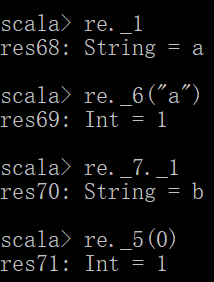
re._1 元组的下标是从1开始的,而数组的下标是从0开始的,要注意区别
re._6("a") 取元组中的映射对应的key值
re._7._1 取元组中的元组
re._5(0) 取元组中的数组下标为0的值
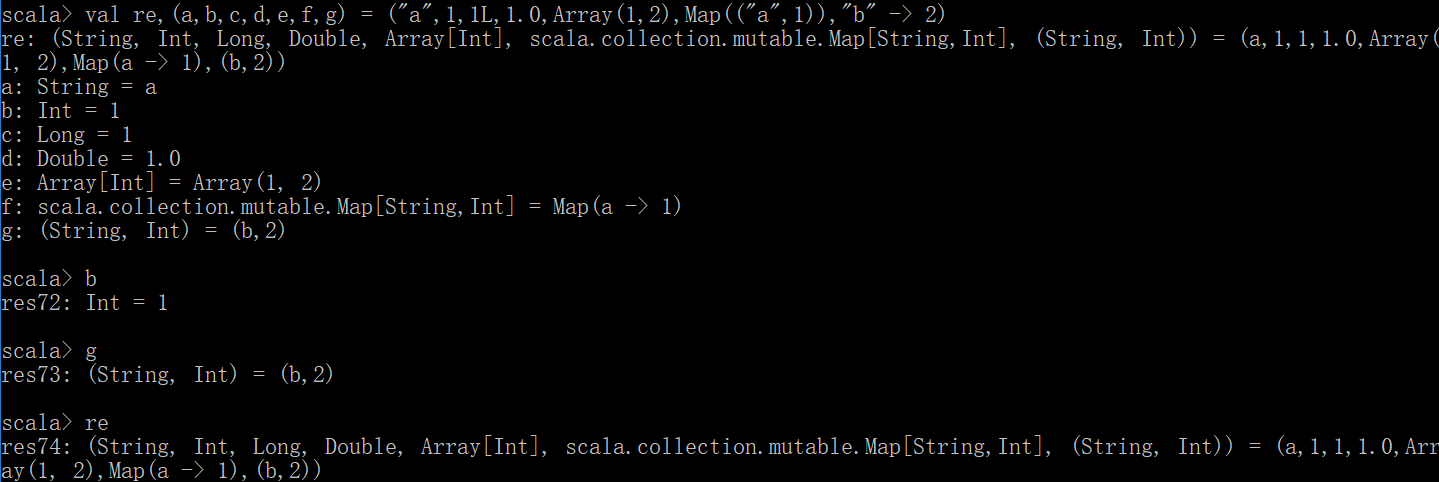
利用元组进行组合赋值
val re,(a,b,c,d,e,f,g) = ("a",1,1L,1.0,Array(1,2),Map(("a",1)),"b" -> 2)
数组转换成映射(map)
toMap操作
val arr = Array(("a",1),("b",2))
arr.toMap

zip操作(拉链操作)
val arr1 = Array("a","b")
var arr2 = Array(1,2)
arr1 zip arr2


zip操作也可以两个数组长度不对应,如果不对应时进行截取
var arr3 = Array("a","b","c")
arr3.zip(arr2)

集合:
scala的集合有三种:Seq(序列)、Set(集合,排重)、Map(映射)
序列List
不可变序列
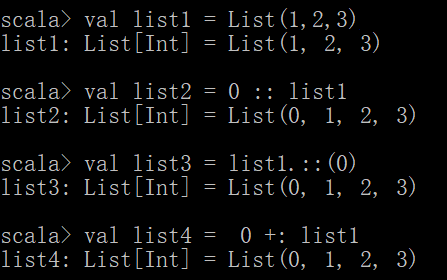
val list1 = List(1,2,3)
在list前面添加
val list2 = 0 :: list1 在原有的list1前面加一个0并赋值给list2
以下3种和上面这种结果一样的,只是写法不一样
val list3 =list1.::(0)
val list4 = 0 +: list1
val list5 = list.+:(0)

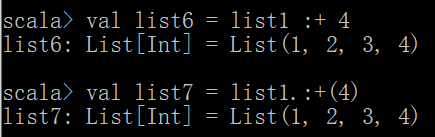
在list后面添加
val list6 = list1 :+ 4
val list7 = list1.:+(4)
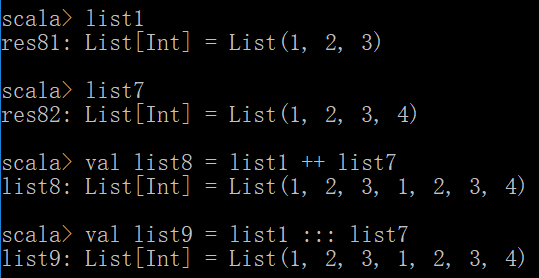
合并两个list并生成新的list
val list8 = list1 ++ list7
val list9 = list1 ::: list7
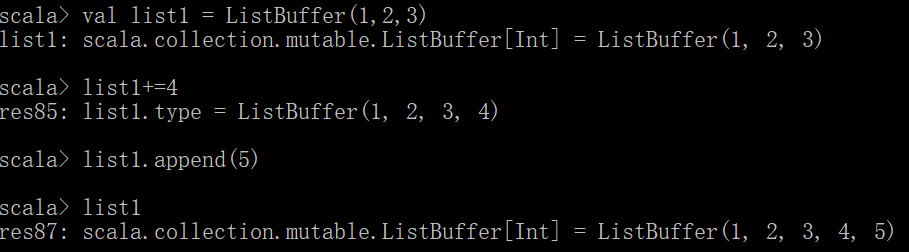
可变序列
import scala.collection.mutable.ListBuffer
或者
import scala.collection.mutable._
val list1 = ListBuffer(1,2,3)
list1 += 4
list1.append(5)
合并list
val list2 = ListBuffer(6,7,8)
list1 ++= list2
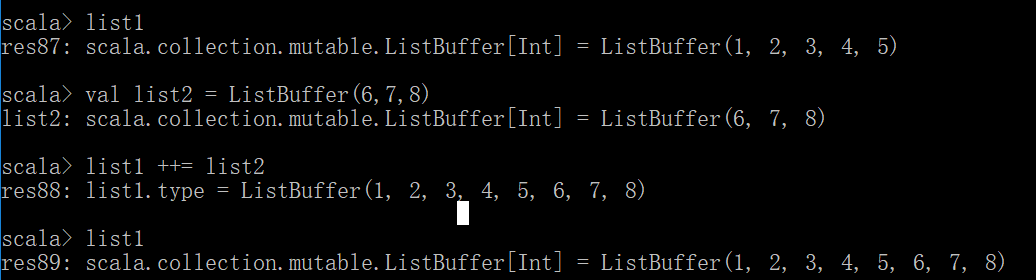
++=是生成了新list并赋值
++是生成了新list但没有赋值,除非自己指定比如val list3 = list1 ++ list2
注意:在可变list上也可以调用不可变list的"::","+:",":+","++",":::",区别是可变list返回的是新的ListBuffer,不可变list返回的是List
:: 在list前面添加
+: 在list前面添加
:+ 在list后面添加
++ 两个list拼接
::: 两个list拼接
版权声明:原创作品,允许转载,转载时务必以超链接的形式表明出处和作者信息。否则将追究法律责任。来自海汼部落-青牛,http://hainiubl.com/topics/207


