第5章 SQL语句(DQL)
1) DDL 数据定义语言 表=java类 每一条数据 都是 这个表的一个对象
2) DML语句 数据操作语言 添加 修改 删除
数据的查询 = 数据分析
5.1DQL准备工作和语法
5.1.1准备工作
创建商品表:
商品表 product
商品编号 主键 自增
商品名称 字符
商品价格 浮点型
商品类别ID > 在某些时刻 一个表的一个数据的id就能代表这个表的这条数据的全部
代码 :
添加测试数据:
5.1.2 DQL语法:
select [distinct] * | 列名,列名 from 表 where 条件;
5.2 简单查询
-
查询所有的商品

- 查询商品名和商品价格.

3.1 表别名:
3.2 列别名:
- 去掉重复值

5.查询结果是表达式(运算查询):将所有商品的价格+10元进行显示.
5.3 条件查询 java if结构其实是一样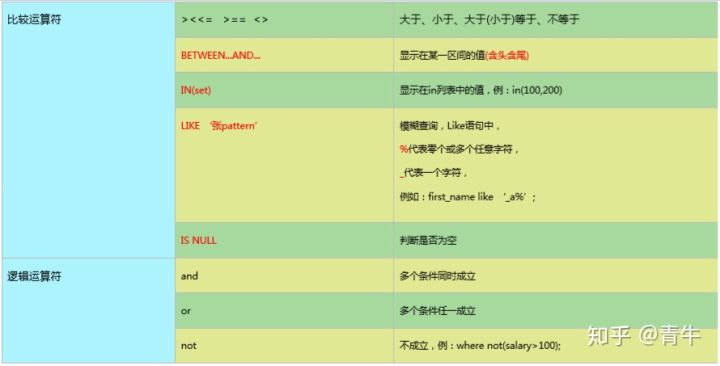
查询商品名称为“三只松鼠坚果炒货零食特产每日坚果开心果100g/袋”的商品所有:

查询价格为299商品
查询价格不是800的所有商品
查询商品价格大于60元的所有商品
查询商品价格在2000到10000之间所有商品
查询商品价格小于2000或大于10000的所有商品
查询商品价格等于 306830 28512 的商品
查询含有 '霸' 字的所有商品

查询以'三'开头的所有商品
查询第二个字为'想'的所有商品
商品没有分类的商品
查询有分类的商品
5.4 排序查询
通过order by语句,可以将查询出的结果进行排序。暂时放置在select语句的后。
格式:
SELECT * FROM 表名 ORDER BY 排序字段 ASC|DESC;
ASC 升序 (默认)
DESC 降
1.使用价格排序(降序)
2.在价格排序(降序)的基础上,以分类排序(降序)
3.显示商品的价格(去重复),并排序(降序)
5.5 聚合查询
之前我们做的查询都是横向查询,它们都是根据条件一行一行的进行判断,而使用聚合函数查询是纵向查询,它是对一列的值进行计算,然后返回一 个单一的值;另外聚合函数会忽略空值。
说白了,聚合查询就是先把表的数据聚在一起,统一进行计算后,再得出一个结果的查询方式;
我们学习如下五个聚合函数:
count:统计指定列不为NULL的记录行数;
sum:计算指定列的数值和,如果指定列类型不是数值类型,那么计算结果为0;
max:计算指定列的大值,如果指定列是字符串类型,那么使用字符串排序运算;
min:计算指定列的小值,如果指定列是字符串类型,那么使用字符串排序运算;
avg:计算指定列的平均值,如果指定列类型不是数值类型,那么计算结果为0;
1 查询商品的总条数
2 查询价格大于2000商品的总条数
3 查询分类为 1 的所有商品的总和

4 查询分类为2所有商品的平均价格
5 查询商品的大价格和小价格
5.6 分组查询
分组查询是指使用group by字句对查询进行分组。
格式:
SELECT 字段1,字段2… FROM 表名GROUP BY分组字段 HAVING 分组条件;
分组操作中的having子语句,是用于在分组后对数据进行过滤的,作用类似于where条件。
having与where的区别:
having是在分组后对数据进行过滤
where是在分组前对数据进行过滤
having后面可以使用分组函数(统计函数)
where后面不可以使用分组函数
1 统计各个分类商品的个数

第6章 SQL导出与导入
6.1 SQL导出
数据库的备份是指将数据库转换成对应的sql文件
6.1.1 可视化工具导出
双击打开要备份的数据库,右键选择 "转存储SQL文件" ,然后选择SQL文件的存放位置即可;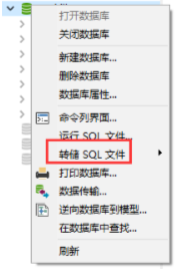
此处需要注意的是我们打开SQL后需要关注以下: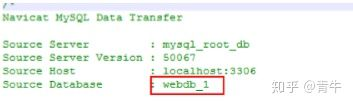
此处显示了备份数据库的名称
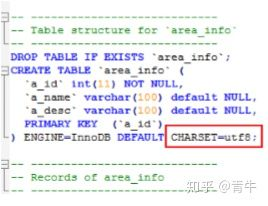
此处显示了编码规则
6.2 SQL导入
SQL导入的前提是你必须先创建一个一模一样的数据库才可以导入SQL语句,所以此处就用上了我们上面的那些
6.2.1可视化工具导入SQL
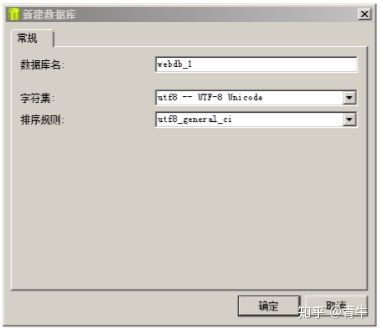
-
创建数据库
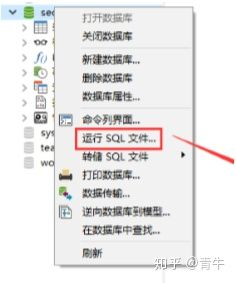
- 在创建好的数据库上右键运行SQL文件
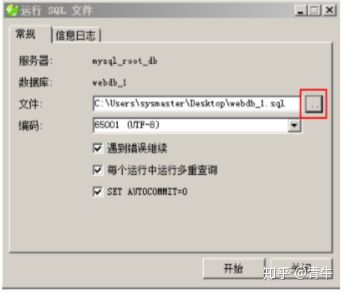
点击 "开始" 按钮 进行数据的导入;
第7章 多表操作(多表的查询)
7.1 前情回顾
回顾 : mysql 安装 基本语法
SQL语言 :
DDL语句 : 对表 数据库 等存储结构的操作 创建一个结构 create xxx 修改一个结构 alter xxxx 摧毁一个结构 drop xxx 查询某个结构 show xxxx desc table
DML语句 : 对数据本身的操作
数据存储 insert 插入 inert into 表 (列) values (值)
更新数据 update update 表 set 列(字段) = 值 where 限定条件
删除数据 delete from 表 where 限定条件
拓展 : 删除表的所有数据的时候
1) delete from 表 查一条 删一条 记录一个受影响行数
2) truncate table 表 摧毁表结构 重新创建表结构
总结 : 当删除表的所有数据的时候 如果数据量非常大的时候(1亿条以上) truncate table
DQL语句
select 列 from 表
拓展 :
按条件查询
排序 order by
聚合(count sum avg max min) + 分组 group by > 以后的数据分析行业来说是非常重要的
但是不得不说 对数据分组 永远都是查询成本非常高的活 数据量越大 分组消耗的性能也越大
问题 :
数据库是干什么的?
存储数据
mysql 大数据库管理系统 ORACLE DB2
根据业务创建自己的小数据库
我们把同类的数据放在一起 然后起一个类型名称 (表)
person
dog
同类型的数据 可以放在一个表里 不同类型的数据应该分别存储在不同的表里
怎么区分是同类型的数据呢?
看数据的属性(表的字段)
1 孙建国 男 24 北京市
2 赵文明 男 24 河北省
id name sex age from
哈士奇 赵铁柱
create table dog id name type color mastername
7.2 多表查询
实际开发中,一个项目通常需要很多张表才能完成。
例如:京东在展示商品的时候就需要很多表,比如
分类表(category)、
商品表(products)、
那么如果我们做一个业务需要多张表提供数据的话,那么这些表之间肯定是有联系的,所以我们就来探讨一下表与表的联系;
7.2.1 表与表之间的关系
7.2.1.1 一对多关系:
常见实例:客户和订单,分类和商品,部门和员工 学生和班级.
一对多建表原则:在从表(多方)创建一个字段,字段作为外键指向主表(一方)的主键.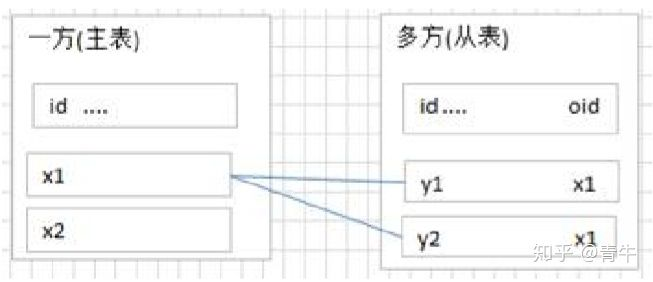
举个例子:
班级与学生
原始 : 19xx年
数据库开发出来 : 所有的数据都保存在一起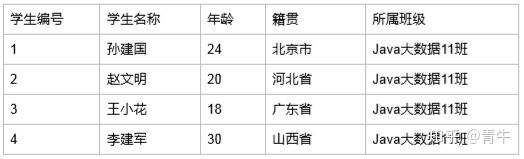
这种数据存储方法我们可以看出 所属班级这一列的数据随着学生的增多会大量重复,这时候大家就要像一个问题,这种重复的数据会占用很大的存储空 间,那么有没有解决办法呢?
后来 :
- 创建一个班级表(主表)

班级表中 Java大数据11班的编号是1 也就是说在某些场合下 班级编号为1的班级 = Java大数据11班 所以在保存学生的时候我们只保存班级编号就可以了
- 保存学生
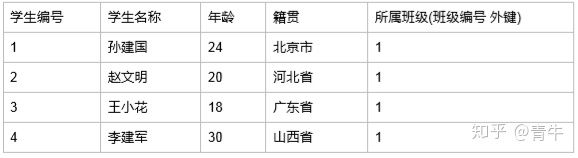
此时我们用一个数组代替了具体的名称,这样的好处就是 数字占用的字节数比汉子要小了很多,所以浪费的空间也小了很多
但是大家要注意一个问题,就是此时学生表中有一列专门存储的班级表的主键值,那么这一列对于学生表来说叫做外键列
包含外键的表 叫做外键表 外键对应的表的主键所在的表我们叫做主键表
外键表的外键列的值与主键表的主键值是对应的,那么这种对应关系我们就叫他 多对一 关系
在多对一关系中 多的一方(包含外键)叫做从表 一的一方叫做 主表
我们了解了多对一关系,那么在实际应用中我们该如何应用这种设计方案呢?
1) 确定好你要设计实体
2) 确定好 实体之间关系
3) 做好主外键关联
举个例子 员工 与 部门 表结构
1) 抽取实体设计 员工(实体) 部门(实体) --> 外键一定是存在于从表中
2) 分清关系 一个员工 只能属于一个部门 但是 一个部门下有多个员工
3) 一定是先写主键表 部门表 再创建 外键表 员工表
部门表
主键 deptID
员工表
N列 外键 deptID
7.2.2.2 一对一关系:(特殊的多对一)
如果在一对多关系中 多的一方 也变成了一 那么两个实体之间就是一对一关系了
现实生活中 一对一设计其实并不太多,因为一对一关系是没有必要分表设计的,举个例子:
我们知道一个人有一个身份证,有一份档案,拿身份证举例,我们会这么设计人员表
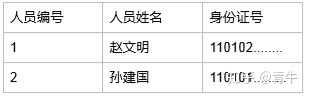
如果一对一设计成两张表就很尴尬了
首先创建身份证号表
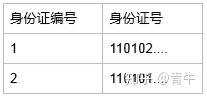
在创建人员表
通过观察大家就可以很明显的发现 在实际的开发中应用不多.因为一对一可以创建成一张表.
7.2.2.3 多对多关系: 当 多对一关系中 一的一方变成 多 那么这个时候就会出现一种新关系 多对多关系
举个例子 : 数据库设计经常会应用到两个实体 叫做 用户 和 角色
什么是用户 : 就是身处某个环境中的人
什么是 角色 : 就是身处某个环境中你扮演的那个身份,比如
同样是你,在学校这个环境你就是学生,这里面 你是用户 你的角色是学生
再比如说你在家这个环境中你就是子女,这里面 你是用户 你的角色是子女
那么此处有一个问题,从上面的例子我们可以看出一个用户可以由多个角色,反过来一个角色有可以被多个用户所拥有,那么这时候我们该怎么表示这种 关系呢?
假如 现在给大家这么几个角色
角色表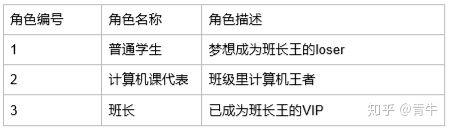
用户表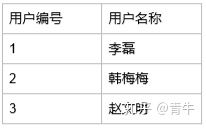
表示关系 : 李磊 韩梅梅 赵文明 都是学生 韩梅梅计算机课代表 赵文明是班长
关系设计
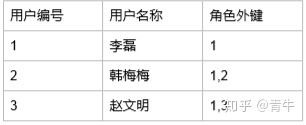
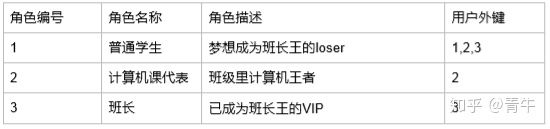
上述的关系设计已经违反了列的存值特性,一行记录肯定保存不了多个值!所以此时这种设计就不行了
那么如果想正确的表示角色和用户的关系怎么办呢?这时你需要再创建一张表,叫中间表
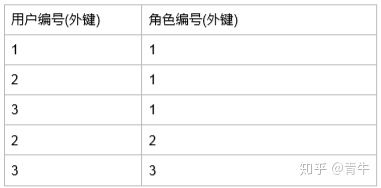
多对多关系:
常见实例:学生和老师、用户和角色
多对多关系建表原则:需要创建第三张表,中间表中至少两个字段,这两个字段分别作为外键指向各自一方的主键.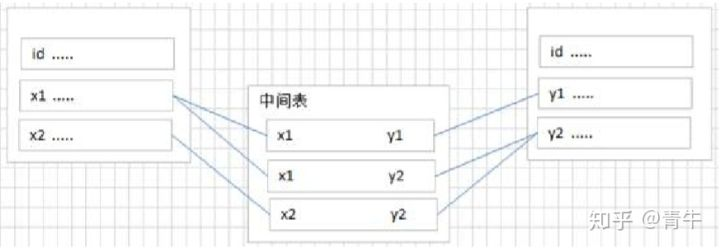
7.3 外键约束
现在我们有两张表“分类表”和“商品表”,为了表明商品属于哪个分类,通常情况下,我们将在商品表上添加一列,用于存放分类c_id的,此 列称为:外键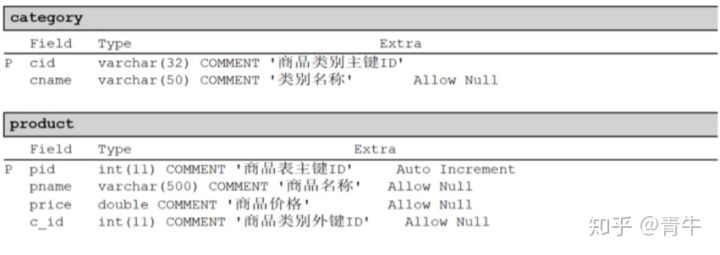
此时“分类表category”称为:主表,“cid”我们称为主键。“商品表products”称为:从表,c_id称为外键。
我们通过主表的主键和从表的外键来描述主外键关系,呈现就是一对多关系。
外键特点:
从表外键的值是对主表主键的引用。
从表外键类型,必须与主表主键类型一致。
声明外键约束
语法:alter table 从表 add [constraint] [外键名称] foreign key (从表外键字段名) references 主表 (主表的主键);
[外键名称] 用于删除外键约束的,一般建议“_fk”结尾
alter table 从表 drop foreign key 外键名称
使用外键目的:保证数据完整性
7.4 一对多操作
7.4.1 分析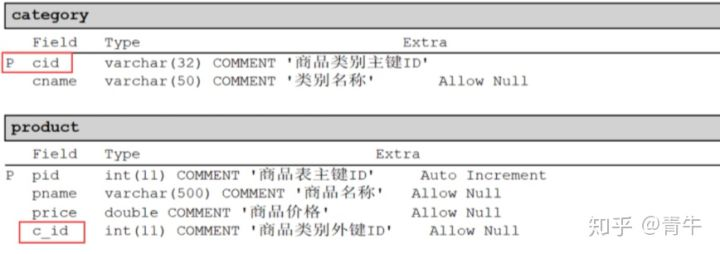
category分类表,为一方,也就是主表,必须提供主键cid
products商品表,为多方,也就是从表,必须提供外键c_id
7.4.2 实现:分类和商品
清空商品类别表和商品表(不清空的话是创建不了外键约束的)
设置商品表的外键cid 不为null
修改商品分类表的主键(商品分类表主键是varchar的不能和晚间匹配,必须修改)

添加约束
7.4.3 验证外键约束
1 向分类表中添加数据
2 向商品表中添加已经存在的商品类别的商品
3 向商品表中添加不存在的商品类别的商品 (报错,违反了主外键约束)


4 删除指定分类(分类被商品使用) -- 执行异常(因为要删除的商品分类被外检表引用,所以会报错)

7.5 多对多
7.5.1 分析
多对多我们可以拆分成两个一对多去做,根据我们之前的分析如果创建多对多关系的话必须有两个实体表和一个中间表 中间表和两个实体表之前保持多对一关联;
7.5.2 实现:用户与角色
创建用户表
创建角色表
创建中间表
创建中间表与用户表外键
创建中间表与角色表外键
创建中间表的联合主键(可省略)
7.5.3 测试多对多关系
1 向用户表中添加数据
2 向角色表中添加数据
3 向中间表添加数据(数据存在)
4 删除中间表的数据
5 向中间表添加数据(数据不存在) -- 执行异常

6 删除用户表或者角色表数据 -- 执行异常
7.6 注意
主外键约束除了可以帮助我们保证数据的完整性,同时也限制了数据操作的灵活性,此处大家要注意自己公司的具体要求,如果要求数据完整那就必须创 建主外键约束如果要求保证操作灵活那么除了主键约束外不可以创建外键约束,大家要根据具体需求自己把控;



