数据完整性及其采用的技术
保证数据在传输过程中不损坏 ,常见的保证数据完整性采用的技术
奇偶校验技术
根据被传输的一组二进制代码的数位中"1"的个数是奇数或偶数来进行校验。采用奇数的称为奇校验,反之,称为偶校验。采用何种校验是事先规定好的。通常专门设置一个奇偶校验位,用它使这组代码中“1”的个数为奇数或偶数。若用奇校验,则当接收端收到这组代码时,校验"1"的个数是否为奇数,从而确定传输代码的正确性。又分单向奇偶校验和双向奇偶校验(方块校验)。
ECC校验纠错技术
ECC的英文全称是Error Checking and Correcting(错误检查和纠正),从这个名称就可以看出它的主要功能就是"发现并纠正错误"。
CRC-32循环冗余校验技术
循环冗余校验(英语:Cyclic redundancy check,通称“CRC”)是一种根据网络数据数据包或电脑文件等数据产生简短固定位数校验码的一种散列函數,主要用来检测或校验数据传输或者保存后可能出现的错误。生成的数字在传输或者存储之前计算出来并且附加到数据后面,然后接收方进行检验确定数据是否发生变化。一般来说,循环冗余校验的值都是32位的整数。
其根本思想就是先在要发送的帧后面附加一个数,生成一个新帧发送给接收端。当然,这个附加的数不是随意的,它要使所生成的新帧能与发送端和接收端共同选定的某个特定数整除(注意,这里不是直接采用二进制除法,而是采用一种称之为"模2除法")。到达接收端后,再把接收到的新帧除以(同样采用"模2除法")这个选定的除数。因为在发送端发送数据帧之前就已通过附加一个数,做了“去余”处理(也就已经能整除了),所以结果应该是没有余数。如果有余数,则表明该帧在传输过程中出现了差错。
CRC32 crc32 = new CRC32();
crc32.update("hello".getBytes());
long result = crc32.getValue();
System.out.println(Long.toHexString(result));HDFS的数据完整性
HDFS以透明方式校验所有写入它的数据,并在默认设置下,会在读取数据时验证校验和。针对数据的每个io.bytes.per.checksum(默认512字节)字节,都会创建一个单独的校验和。数据节点负责在存储数据及其校验和之前验证它们收到的数据。从客户端和其它数据节点复制过来的数据。客户端写入数据并且将它发送到一个数据节点管线中,在管线的最后一个数据节点验证校验和。客户端读取数据节点上的数据时,会验证校验和,将其与数据节点上存储的校验和进行对比。每个数据节点维护一个连续的校验和验证日志,因此它知道每个数据块最后验证的时间。每个数据节点还会在后台线程运行一个DataBlockScanner(数据块检测程序),定期验证存储在数据节点上的所有块,为了防止物理存储介质中位衰减锁造成的数据损坏。
HDFS通过复制完整的副本来产生一个新的,无错的副本来“治愈”哪些出错的数据块。工作方式:如果客户端读取数据块时检测到错误,抛出Checksum Exception前报告该坏块以及它试图从名称节点中药读取的数据节点。名称节点将这个块标记为损坏的,不会直接复制给客户端或复制该副本到另一个数据 节点。它会从其他副本复制一个新的副本。
压缩
文件压缩主要有两个好处,一是减少了存储文件所占空间,另一个就是为数据传输提速。在hadoop大数据的背景下,这两点尤为重要,那么我现在就先来了解下hadoop中的文件压缩。
Hadoop里支持很多种压缩格式:
| 格式 | 工具 | 算法 | 扩展名 | splitable | codec |
|---|---|---|---|---|---|
| DEFLATE | 无 | DEFLATE | .deflate | 不 | org.apache.hadoop.io.compress.DefaultCodec |
| gzip | gzip | DEFLATE | .gz | 不 | org.apache.hadoop.io.compress.GzipCodec |
| bzip2 | bzip2 | bzip2 | .bz2 | 是 | org.apache.hadoop.io.compress.BZip2Codec |
| lzo | lzop | LZO | .lzo | 不 | com.hadoop.compression.lzo.LzopCodec |
| snappy | 无 | snappy | .snappy | 否 | org.apache.hadoop.io.compress.SnappyCodec |
| LZ4 | 无 | LZ4 | .lz4 | 否 | org.apache.hadoop.io.compress.Lz4Codec |
DEFLATE是同时使用了LZ77算法与哈夫曼编码(Huffman Coding)的一个无损数据压缩算法,源代码可以在zlib库中找到。gzip是以DEFLATE算法为基础扩展出来的一种算法。
压缩算法选择
一般准则
您需要平衡压缩和解压缩数据所需的能力、读写数据所需的磁盘 IO,以及在网络中发送数据所需的网络带宽。正确平衡这些因素有赖于集群和数据的特征,以及您的使用模式。
如果数据已压缩(例如 JPEG 格式的图像),则不建议进行压缩。事实上,结果文件实际上可能大于原文件。
GZIP 压缩使用的 CPU 资源比 Snappy 或 LZO 更多,但可提供更高的压缩比。GZIP 通常是不常访问的冷数据的不错选择。而 Snappy 或 LZO 则更加适合经常访问的热数据。
BZip2 还可以为某些文件类型生成比 GZip 更多的压缩,但是压缩和解压缩时会在一定程度上影响速度。HBase 不支持 BZip2 压缩。
Snappy 的表现通常比 LZO 好。应该运行测试以查看您是否检测到明显区别。
对于 MapReduce,如果您需要已压缩数据可拆分,BZip2、LZO 和 Snappy 格式都可拆分,但是 GZip 不可以。可拆分性与 HBase 数据无关。
对于 MapReduce,您可压缩中间数据、输出或二者。相应地调整您为 MapReduce 作业提供的参数。以下示例压缩中间数据和输出。
hadoop jar hadoop-examples-.jar sort -Dmapreduce.compress.map.output=true \
-Dmapreduce.map.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec \
-Dmapreduce.output.compress=true \
-Dmapreduce.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec -outKey \
org.apache.hadoop.io.Text -outValue org.apache.hadoop.io.Text input output \序列化
序列化(serialization)是指将结构化的对象转化为字节流,以便在网络上传输或者写入到硬盘进行永久存储;相对的反序列化(deserialization)是指将字节流转回到结构化对象的过程。
在分布式系统中进程将对象序列化为字节流,通过网络传输到另一进程,另一进程接收到字节流,通过反序列化转回到结构化对象,以达到进程间通信。在Hadoop中,Mapper,Combiner,Reducer等阶段之间的通信都需要使用序列化与反序列化技术。举例来说,Mapper产生的中间结果(<key: value1, value2...>)需要写入到本地硬盘,这是序列化过程(将结构化对象转化为字节流,并写入硬盘),而Reducer阶段读取Mapper的中间结果的过程则是一个反序列化过程(读取硬盘上存储的字节流文件,并转回为结构化对象),需要注意的是,能够在网络上传输的只能是字节流,Mapper的中间结果在不同主机间洗牌时,对象将经历序列化和反序列化两个过程。
序列化是Hadoop核心的一部分,在Hadoop中,位于org.apache.hadoop.io包中的Writable接口是Hadoop序列化格式的实现。
Hadoop Writable接口是基于DataInput和DataOutput实现的序列化协议,紧凑(高效使用存储空间),快速(读写数据、序列化与反序列化的开销小)。Hadoop中的键(key)和值(value)必须是实现了Writable接口的对象(键还必须实现WritableComparable,以便进行排序)。
Hadoop自身提供了多种具体的Writable类,包含了常见的Java基本类型(boolean、byte、short、int、float、long和double等)和集合类型(BytesWritable、ArrayWritable和MapWritable等)。这些类型都位于org.apache.hadoop.io包中。

下面的表格显示的是Hadoop对Java基本类型包装后相应的Writable类占用的字节长度:
| Java基本类型 | Writable实现 | 序列化后字节数 (bytes) |
|---|---|---|
| boolean | BooleanWritable | 1 |
| byte | ByteWritable | 1 |
| short | ShortWritable | 2 |
| int | IntWritable | 4 |
| VIntWritable | 1-5 | |
| float | FloatWritable | 4 |
| long | LongWritable | 8 |
| VLongWritable | 1-9 | |
| double | DoubleWritable | 8 |
不同的Writable类序列化后占用的字数长度是不一样的,需要综合考虑应用中数据特征选择合适的类型。对于整数类型有两种Writable类型可以选择,一种是定长(fixed-length)Writable类型,IntWritable和LongWritable;另一种是变长(variable-length)Writable类型,VIntWritable和VLongWritable。定长类型顾名思义使用固定长度的字节数表示,比如一个IntWritable类型使用4个长度的字节表示一个int;变长类型则根据数值的大小使用相应的字节长度表示,当数值在-112~127之间时使用1个字节表示,在-112~127范围之外的数值使用头一个字节表示该数值的正负符号以及字节长度(zero-compressed encoded integer)。
定长的Writable类型适合数值均匀分布的情形,而变长的Writable类型适合数值分布不均匀的情形,一般情况下变长的Writable类型更节省空间,因为大多数情况下数值是不均匀的。
Text类的字节序列表示为一个VIntWritable + UTF-8字节流,VIntWritable为整个Text的字符长度,UTF-8字节数组为真正的Text字节流。
虽然Hadoop内建了多种Writable类提供用户选择,Hadoop对Java基本类型的包装Writable类实现的RawComparable接口,使得这些对象不需要反序列化过程,便可以在字节流层面进行排序,从而大大缩短了比较的时间开销,但是当我们需要更加复杂的对象时,Hadoop的内建Writable类就不能满足我们的需求了(需要注意的是Hadoop提供的Writable集合类型并没有实现RawComparable接口,因此也不满足我们的需要),这时我们就需要定制自己的Writable类,特别将其作为键(key)的时候更应该如此,以求达到更高效的存储和快速的比较。
下面的实例展示了如何定制一个Writable类,一个定制的Writable类首先必须实现Writable或者WritableComparable接口,然后为定制的Writable类编写write(DataOutput out)和readFields(DataInput in)方法,来控制定制的Writable类如何转化为字节流(write方法)和如何从字节流转回为Writable对象。
Hadoop 中的文件格式
SequenceFile
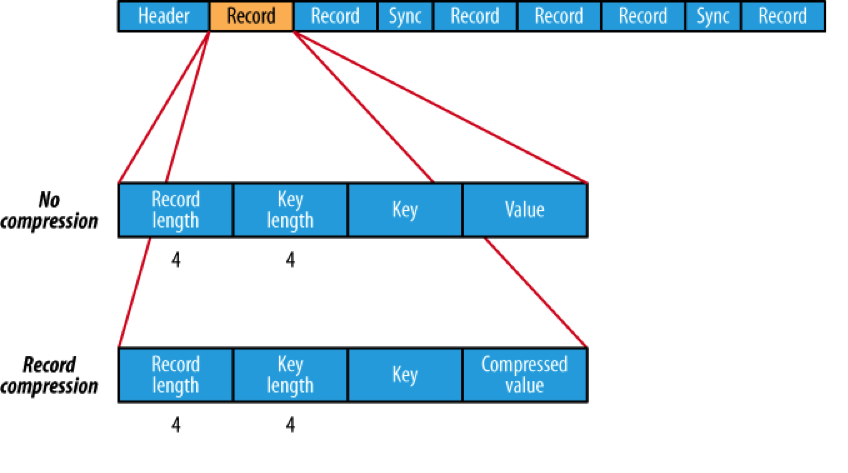
SequenceFile是Hadoop API 提供的一种二进制文件,它将数据以<key,value>的形式序列化到文件中。这种二进制文件内部使用Hadoop 的标准的Writable 接口实现序列化和反序列化。它与Hadoop API中的MapFile 是互相兼容的。Hive 中的SequenceFile 继承自Hadoop API 的SequenceFile,不过它的key为空,使用value 存放实际的值, 这样是为了避免MR 在运行map 阶段的排序过程。如果你用Java API 编写SequenceFile,并让Hive 读取的话,请确保使用value字段存放数据,否则你需要自定义读取这种SequenceFile 的InputFormat class 和OutputFormat class。
RCFile
RCFile(Record Columnar File)存储结构遵循的是“先水平划分,再垂直划分”的设计理念,这个想法来源于PAX。它结合了行存储和列存储的优点:首先,RCFile保证同一行的数据位于同一节点,因此元组重构的开销很低;其次,像列存储一样,RCFile能够利用列维度的数据压缩,并且能跳过不必要的列读取。下图一个HDFS块内RCFile方式存储的例子。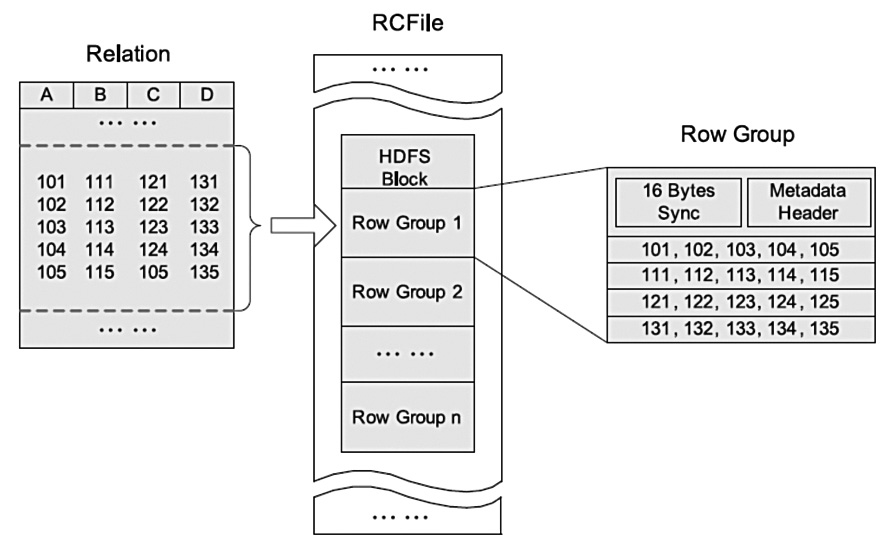
Orcfile
Orcfile(Optimized Row Columnar)是hive 0.11版里引入的新的存储格式,是对之前的RCFile存储格式的优化。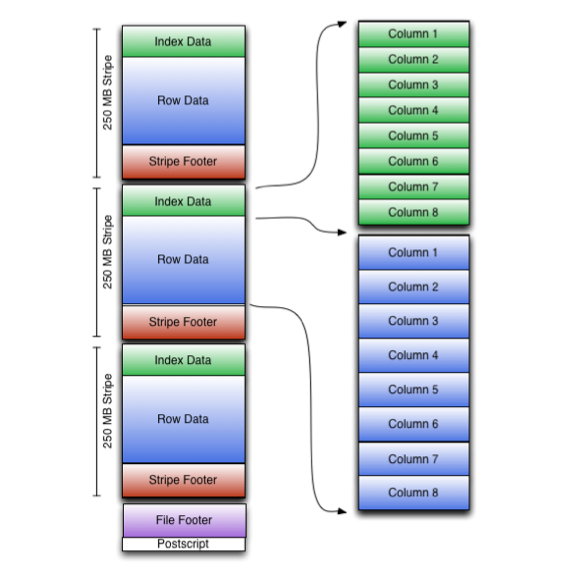
可以看到每个Orc文件由1个或多个stripe组成,每个stripe250MB大小,这个Stripe实际相当于之前的rcfile里的RowGroup概念,不过大小由4MB->250MB,这样应该能提升顺序读的吞吐率。每个Stripe里有三部分组成,分别是Index Data,Row Data,Stripe Footer:
- Index Data:一个轻量级的index,默认是每隔1W行做一个索引。这里做的索引应该只是记录某行的各字段在Row Data中的offset.
- Row Data:存的是具体的数据,和RCfile一样,先取部分行,然后对这些行按列进行存储。与RCfile不同的地方在于每个列进行了编码,分成多个Stream来存储,具体如何编码在下一篇解析里会讲。
- Stripe Footer:存的是各个Stream的类型,长度等信息。
每个文件有一个File Footer,这里面存的是每个Stripe的行数,每个Column的数据类型信息等;每个文件的尾部是一个PostScript,这里面记录了整个文件的压缩类型以及FileFooter的长度信息等。在读取文件时,会seek到文件尾部读PostScript,从里面解析到File Footer长度,再读FileFooter,从里面解析到各个Stripe信息,再读各个Stripe,即从后往前读。
ORC有如下优势:
- 单个Hive Task输出单个文件,减小文件系统负载。
- 支持datetime、decimal和其他复杂类型(struct、list、map和union)。
- 文件内含轻量级索引。减少不必要的扫描,高效定位记录。
- 基于数据类型的块模式压缩。例如String和Integer可以采用不同的压缩方式。
- 同一文件可以利用多个RecordReader并发读取。
- 支持免扫描进行文件分块。
- 读写文件时,绑定I/O所需的最大内存空间。
- 文件的metadata采取Protocol Buffers格式,允许灵活的属性增删。
Avro
Avro是一种用于支持数据密集型的二进制文件格式。它的文件格式更为紧凑,若要读取大量数据时,Avro能够提供更好的序列化和反序列化性能。并且Avro数据文件天生是带Schema定义的,所以它不需要开发者在API 级别实现自己的Writable对象。最近多个Hadoop 子项目都支持Avro 数据格式,如Pig 、Hive、Flume、Sqoop和Hcatalog。
Parquet
Parquet的灵感来自于2010年Google发表的Dremel论文,文中介绍了一种支持嵌套结构的存储格式,并且使用了列式存储的方式提升查询性能.
Parquet文件是以二进制方式存储的,所以是不可以直接读取的,文件中包括该文件的数据和元数据,因此Parquet格式文件是自解析的。在HDFS文件系统和Parquet文件中存在如下几个概念。
HDFS块(Block):它是HDFS上的最小的副本单位,HDFS会把一个Block存储在本地的一个文件并且维护分散在不同的机器上的多个副本。HDFS文件(File):一个HDFS的文件,包括数据和元数据,数据分散存储在多个Block中。
行组(Row Group):按照行将数据物理上划分为多个单元,每一个行组包含一定的行数,在一个HDFS文件中至少存储一个行组,Parquet读写的时候会将整个行组缓存在内存中,所以如果每一个行组的大小是由内存大的小决定的,例如记录占用空间比较小的Schema可以在每一个行组中存储更多的行。
列块(Column Chunk):在一个行组中每一列保存在一个列块中,行组中的所有列连续的存储在这个行组文件中。一个列块中的值都是相同类型的,不同的列块可能使用不同的算法进行压缩。
页(Page):每一个列块划分为多个页,一个页是最小的编码的单位,在同一个列块的不同页可能使用不同的编码方式。

比较
存储空间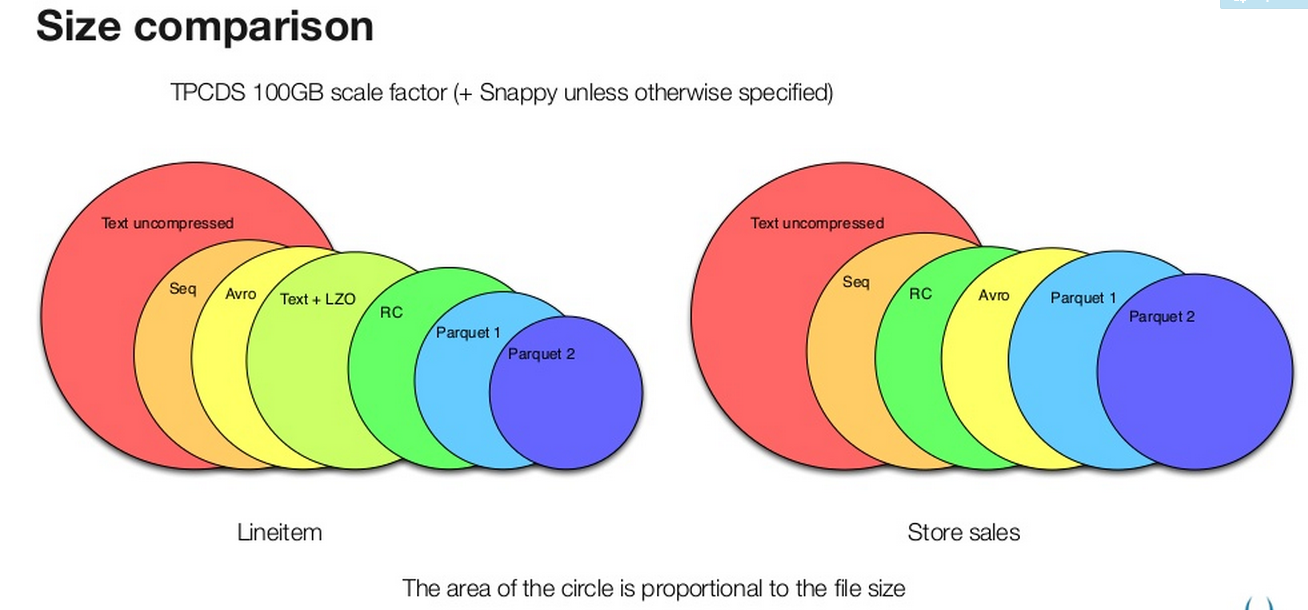
可以看出Parquet较之于其他的二进制文件存储格式能够更有效的利用存储空间,而新版本的Parquet(2.0版本)使用了更加高效的页存储方式,进一步的提升存储空间。
参考文献
RCFile: A Fast and Space-efficient Data Placement Structure in MapReduce-based Warehouse System



