数据仓库前置知识
数据仓库分层
使用数据分层目的,减少重复开发,隔离原始数据,按照业务需求设计层次。较为常见的为早期的四层架构(贴源层ods、明细层dwd、汇总层dws、集市层ads),如果是复杂数仓使用传统的四层架构不能满足需求,多采用五层架构(技术缓冲层ITL、贴源模型层IOL、主题模型层IML、共性加工层ICL、应用集市层IDL),针对每层功能在下面章节详细介绍。
数据存储策略
存储策略分类
数据存储方式分为增量与全量两大类。
增量存储,即每天新增的,这类数据存储方式为每天只抽取增量部分,抽取新增的数据进行存储,一般增量存储都采用分片的方式进行存储,即使用分区的方式进行存储,每天一个分区。
全量存储,即每天存储最新一天全量数据,每天在源系统全量提取最新数据,进行存储,全量存储又分为保存历史与不保存历史,保存历史的通常叫做全量快照表,每天全量保存到一个分区中,另外一种不保存历史的方式则为在数据仓库中只保存一份最新的表,没有分区,不能查询历史某个时间节点的数据。
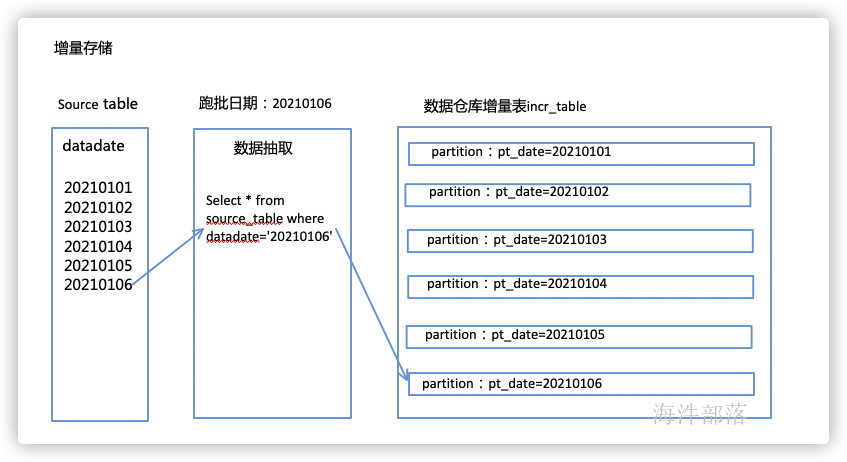
如上,每天只从源系统抽取跑批日期当天的数据,插入到数仓中跑批日期当天的分区中。
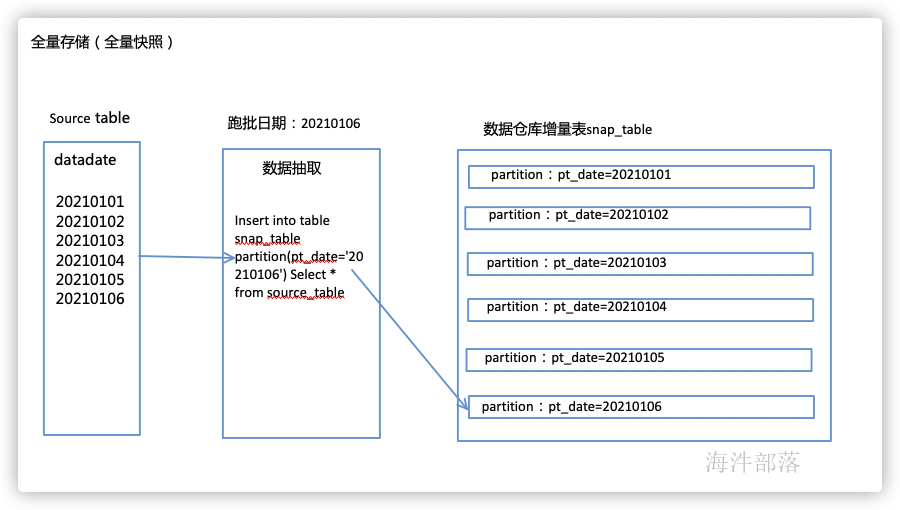
如上,每天从源系统全量抽取,没有where条件,然后插入到数仓的快照表的指定跑批日期的分区中,每天保存一份。
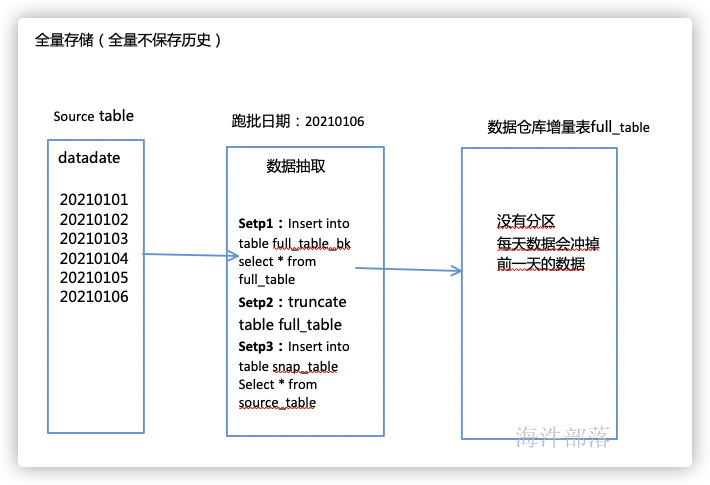
如上,每天从源系统全量抽取数据,覆盖到数仓中的全量表里,但是在覆盖前一定要做数据备份,避免数据丢失,可以在数据插入完成之后,将备份表再删除。
拉链表
拉链表概述
拉链表核心思想,像个拉链,有开链与闭链,我们通常将最新的数据称为开链数据,历史数据称为闭链数据,拉链表支持历史数据查询,且空间占用较小,但是数据加工处理较为繁琐,属于时间换空间的设计方式,拉链表一个时间维度中同一个用户只保存一条用户状态。拉链表通常会增加三个技术字段“开始日期startdate、结束日期enddate、状态标识mark”。
通过主键(PK)与历史数据进行对比,判断拉链表中最新的数据与历史数据是否一致,如果发生变化或者新增则进行相应的开链、闭链操作。
开链:是一个开放的区间,一条数据从一个开始时间(startdate)开始一直持续到了现在仍然没有变化,我们也不知道他在未来哪一天才会变化,所以我们通常将enddate设置成一个较大的时间29991231或者30000101。
闭链:是一个闭合的区间,指数据在一个时间区间内的状态,有开始时间与结束时间。
拉链表示例


拉链表查询某个时间节点(2021年01月06日)最新状态:
Select * from zip_table where startdate<=20210106 and enddate>20210106;
此时在拉链表中命中了一条数据,即:{xxxname:xxx,gfname:002,startdate:20210105,enddate:20210201}
如上查询方式通常叫做"卡拉链",startdate<=querydate and enddate>querydate
拉链表形态示例:
| Xxxname | Gfname | Startdate | Enddate |
|---|---|---|---|
| Xxx | 001 | 20210101 | 20210105 |
| Xxx | 002 | 20210105 | 20210201 |
| Xxx | 003 | 20210201 | 29991231 |
如上示例拉链表供记录了三个id的历史变化情况,支持任何时间段历史数据的查询。
拉链表适用场景
有历史某个时间节点查询需求、数据量较大、变化比较缓慢的数据。
如用户基本信息表,数据量非常庞大,手机号这类基本字段不经常变化,但是有变化的可能性,为了满足支持历史某个时间节点的状态查询,有两种实现方式,可以使用全量快照的方式进行存储,但是由于数据量比较大,并且变化的数据较少,每天重复的保存了未变化的数据,造成磁盘空间的严重浪费,第二种方式则为拉链表存储,在数仓中只保存一份数据,某个时间段内只保存一份数据,不重复存储,并且支持历史查询。
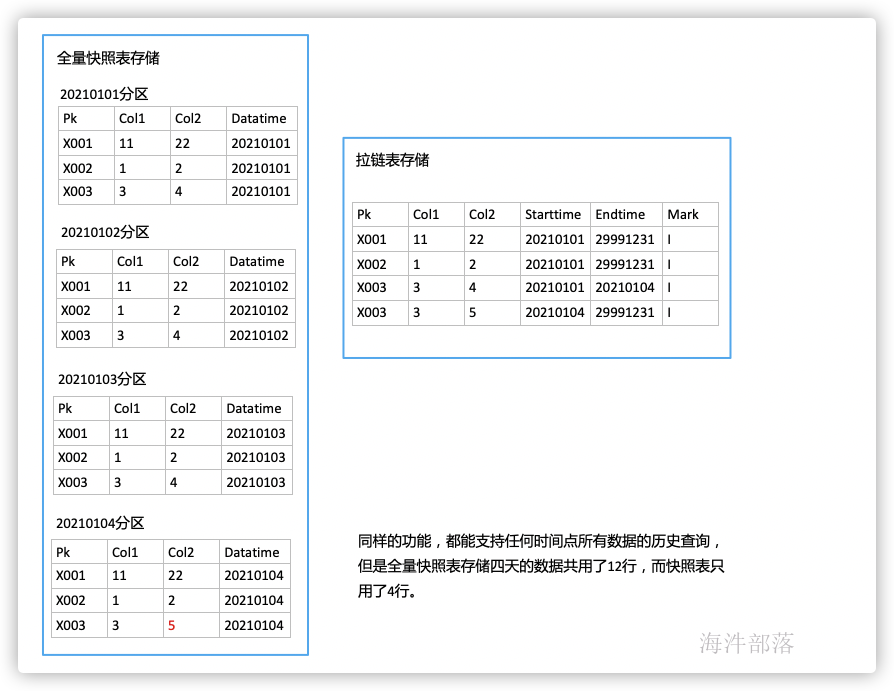
类似应用场景还有一些字典表、码表、规则表等。
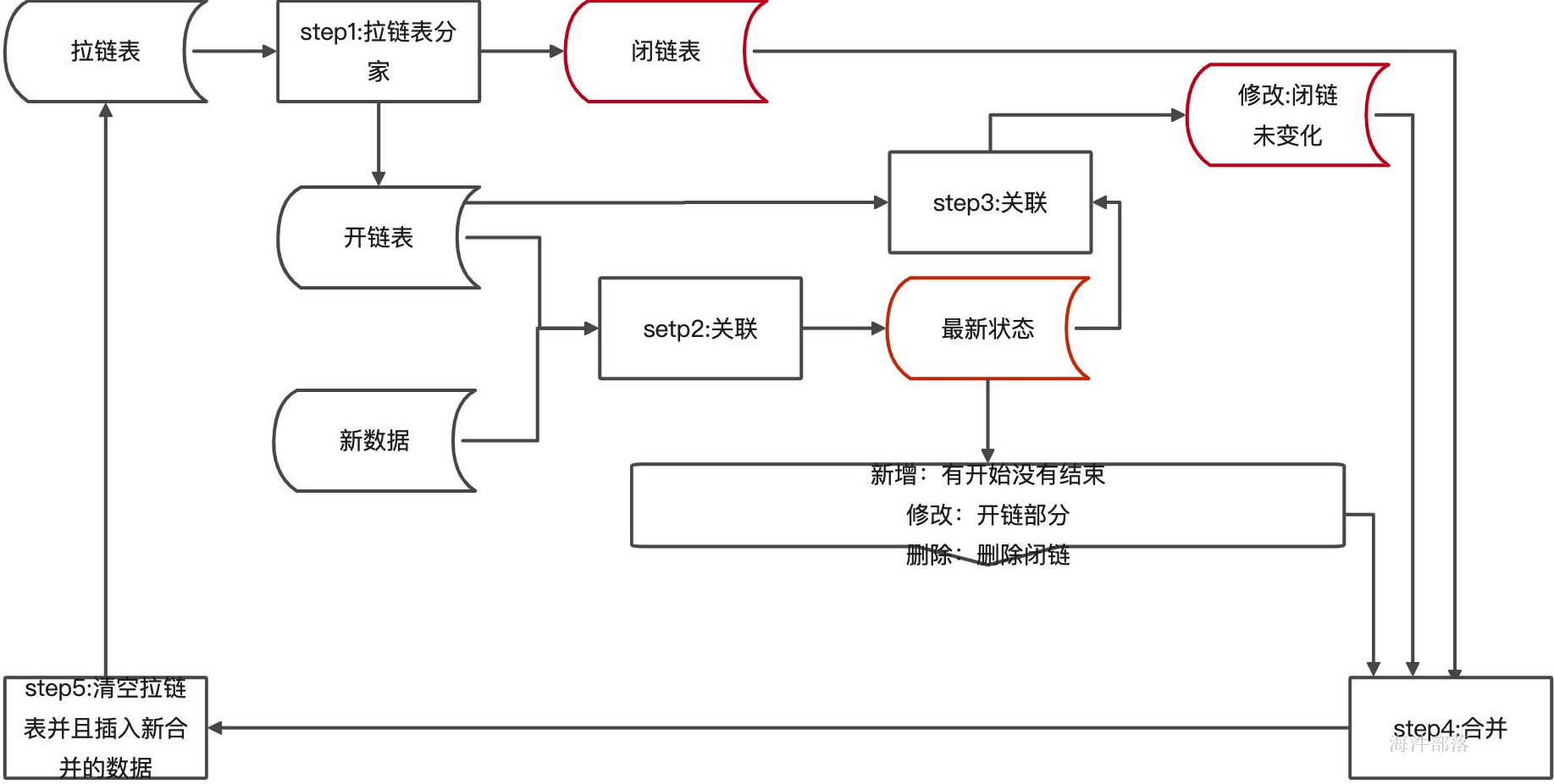
拉链表算法设计
设计思想,每天从上游抽取全量数据,与拉链表中最新的数据进行对比,针对不同情况处理方式如下:
*修改类:通过对比发现上游系统最新数据与拉链表中的数据不一致,在拉链表中闭链该条数据,同时开启一条新的开链数据,状态标识为"I";
* 新增类:通过对比发现上游系统有,但是拉链表中没有,在拉链表中新增一条新的开链数据,状态标识为"I";
* 删除类:通过对比发现上游系统没有,但是拉链表中有,在拉链表中闭链该条数据,状态标识为"D";
* 未变化:通过对比发现上游系统数据与拉链表中的数据一致,则保持拉链表中现有状态不变;
拉链表SQL分析
数据准备
-- 拉链表建表语句
CREATE TABLE xinniu.zip_table(
pk string,
col1 string,
col2 string,
starttime string,
endtime string,
mark string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
STORED AS TEXTFILE
;
-- 拉链表初始化数据加载
load data local inpath '/tmp/xinniu/zipinitdata' into table zip_table;
-- 上游系统建表语句
CREATE TABLE xinniu.source_table(
pk string,
col1 string,
col2 string)
PARTITIONED BY (datatime string)
ROW FORMAT DELIMITED FIELDS TERMINATED BY '|'
STORED AS TEXTFILE;
-- 上游系统数据加载
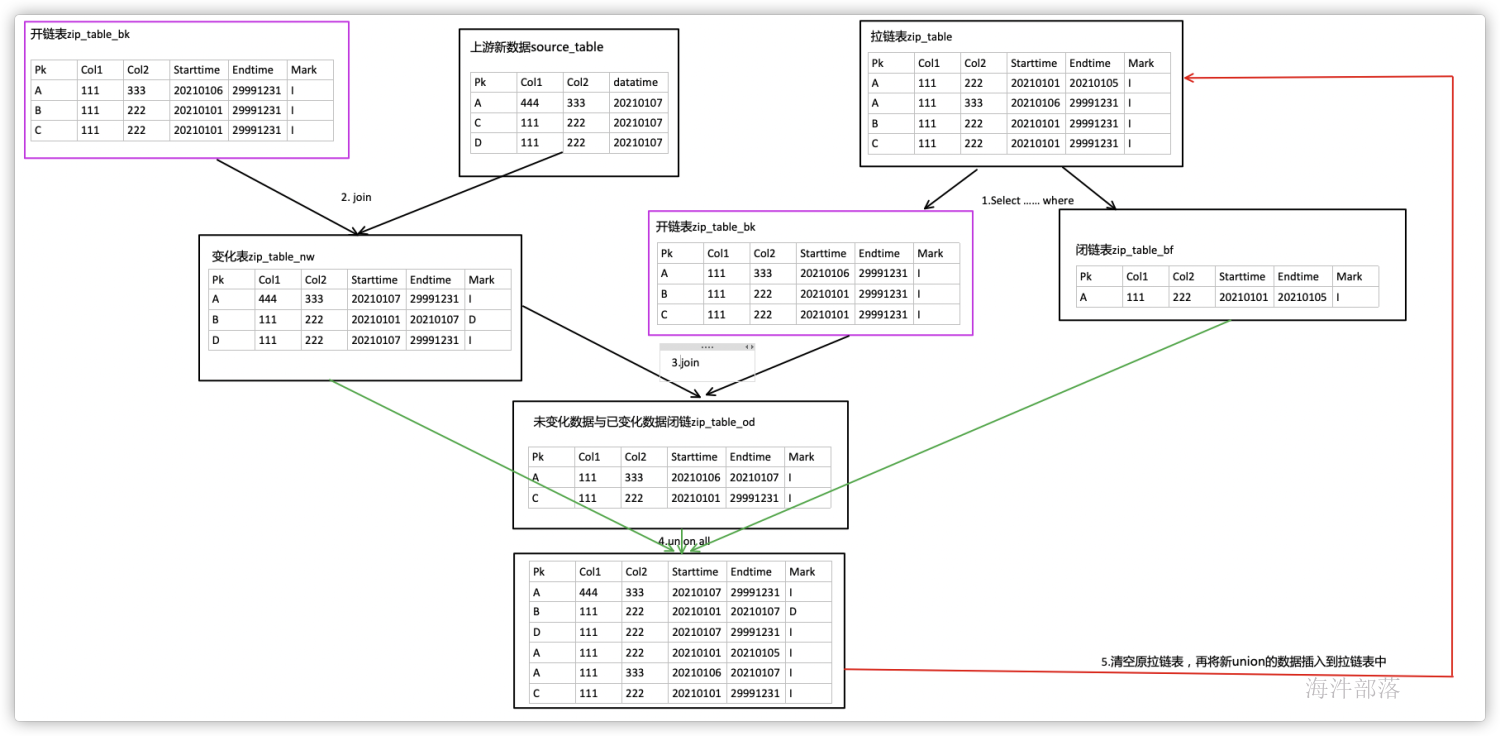
load data local inpath '/tmp/xinniu/sourcedata-20210107' into table xinniu.source_table partition (datatime='20210107');- step1:拆分开链数据与闭链数据
- 创建开链表zip_table_bk、闭链表zip_table_bf;
- 查询拉链表中开链数据与闭链数据分别插入开链表与闭链表中,在插入数据前需要判断备份表是否为空,如果不为空则不进行插入,避免数据异常;
-- 创建开链表
CREATE TABLE IF NOT EXISTS xinniu.zip_table_bk stored AS orc tblproperties ("orc.compress" = "SNAPPY") AS
SELECT
pk,
col1,
col2,
startTime ,
endTime ,
mark
FROM
xinniu.zip_table
WHERE
1 = 0 ;
-- 抽取开链数据到开链表
INSERT
INTO
xinniu.zip_table_bk
SELECT
pk,
col1,
col2,
startTime ,
endTime ,
mark
FROM
xinniu.zip_table
join (select count(1) cnt from xinniu.zip_table_bk limit 1) b
WHERE
startTime < '${hiveconf:batch_date}'
AND endTime >= '${hiveconf:batch_date}'
AND b.cnt = 0
;
-- 创建闭链表
CREATE TABLE IF NOT EXISTS xinniu.zip_table_bf stored AS orc tblproperties ("orc.compress" = "SNAPPY") AS
SELECT
pk,
col1,
col2,
startTime ,
endTime ,
mark
FROM
xinniu.zip_table
WHERE
1 = 0 ;
--抽取闭链数据到闭链表
INSERT
INTO
xinniu.zip_table_bf
SELECT
pk,
col1,
col2,
startTime ,
endTime ,
mark
FROM
xinniu.zip_table
join
(
SELECT
count(1) cnt
FROM
xinniu.zip_table_bf
LIMIT 1) b
WHERE
endTime < '${hiveconf:batch_date}'
AND b.cnt = 0 ;- step2:开链表与上游系统新数据关联,提取出发生变化(新增、修改、删除)的数据插入到zip_table_nw变化表中。
-- 中间加工表清空
DROP TABLE IF EXISTS xinniu.zip_table_nw;
-- 创建中间表 新增变化修改中间表
CREATE TABLE IF NOT EXISTS xinniu.zip_table_nw stored AS orc tblproperties ("orc.compress" = "SNAPPY") AS
SELECT
pk,
col1,
col2,
startTime ,
endTime ,
mark
FROM
xinniu.zip_table
WHERE
0 = 1;
-- 与上游数据对比,将变化数据插入到变化表中
INSERT
INTO
TABLE xinniu.zip_table_nw
SELECT
nvl(n.pk,o.pk),
nvl(n.col1,o.col1) ,
nvl(n.col2,o.col2) ,
CASE
WHEN n.pk IS NULL THEN o.startTime
ELSE '${hiveconf:batch_date}'
END AS startTime ,
CASE
WHEN n.pk IS NULL THEN '${hiveconf:batch_date}'
ELSE '29991231'
END AS endTime ,
CASE
WHEN ( n.pk is null ) THEN 'D'
ELSE 'I'
END AS mark
FROM
(
SELECT
pk,
col1,
col2
FROM
xinniu.source_table
WHERE
dataTime = '${hiveconf:batch_date}' ) n
FULL JOIN xinniu.zip_table_bk o ON o.pk = n.pk
WHERE
(
o.pk IS NULL )
OR (
n.pk IS NULL )
OR (
nvl( CAST(o.col1 AS string) , '' ) <> nvl( CAST(n.col1 AS string) , '' )
OR nvl( CAST(o.col2 AS string) , '' ) <> nvl( CAST(n.col2 AS string) , '' )
)
;- step3:开链表与变化表关联对比,生成未变化数据,已变化数据闭链,插入到zip_table_od表。
-- 清空中间表
DROP TABLE IF EXISTS xinniu.zip_table_od;
-- 创建中间表 未变化中间表
CREATE TABLE IF NOT EXISTS xinniu.zip_table_od stored AS orc tblproperties ("orc.compress" = "SNAPPY") AS
SELECT
pk,
col1,
col2,
startTime ,
endTime ,
mark
FROM
xinniu.zip_table
WHERE
0 = 1;
-- 对比开链表与变化表,闭环已变化数据,生成未变化数据,插入到zip_table_od表
INSERT
INTO
TABLE xinniu.zip_table_od
SELECT
o.pk,
o.col1,
o.col2,
o.startTime ,
CASE
WHEN n.startTime IS NOT NULL THEN '${hiveconf:batch_date}'
WHEN o.endTime >= '${hiveconf:batch_date}' THEN '29991231' ELSE o.endTime
END AS endTime ,
'I' AS mark
FROM
xinniu.zip_table_bk o
LEFT JOIN xinniu.zip_table_nw n ON o.pk = n.pk
WHERE
nvl(n.endTime,'29991231') <> '${hiveconf:batch_date}'
;step4:清空拉链表,合并变化表nw、闭链表bf、未变化与已变化闭链表od。
-- 清空拉链表
TRUNCATE TABLE xinniu.zip_table;
-- 插入数据到拉链表
INSERT
INTO
TABLE xinniu.zip_table
SELECT
*
FROM
xinniu.zip_table_nw
UNION ALL
SELECT
*
FROM
xinniu.zip_table_od
UNION ALL
SELECT
*
FROM
xinniu.zip_table_bf ;- 最后清空所有临时表
DROP TABLE xinniu.zip_table_bk;
DROP TABLE xinniu.zip_table_bf;
DROP TABLE xinniu.zip_table_nw;
DROP TABLE xinniu.zip_table_od;可以将上面的所有步骤分装到一个文件中,使用hive -f的方式调用sql文件,使用-hiveconf的方式传入跑批日期,实现调度系统自动调用。
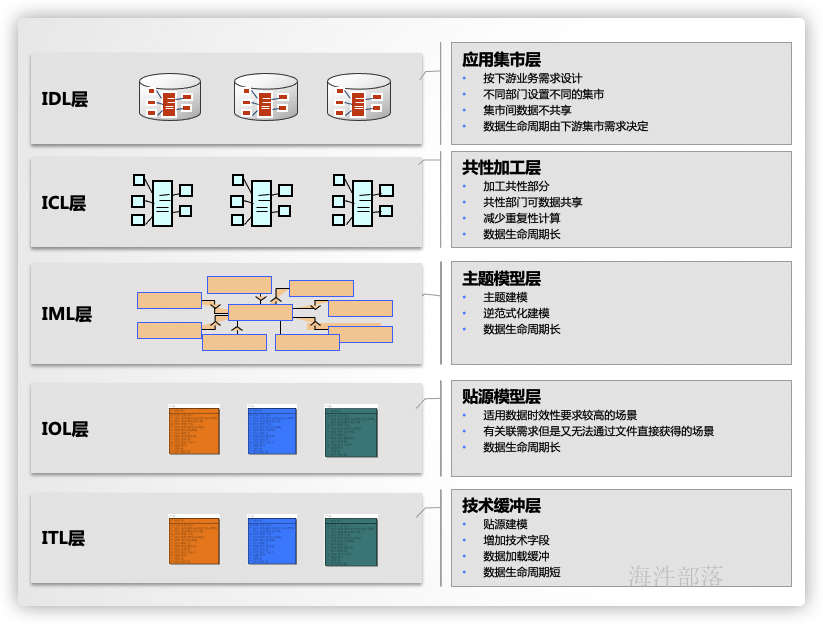
数据架构设计
本次课程采用五层的架构模式,即技术缓冲层ITL、贴源模型层IOL、主题模型层IML、共性加工层ICL、应用集市层IDL,如下图
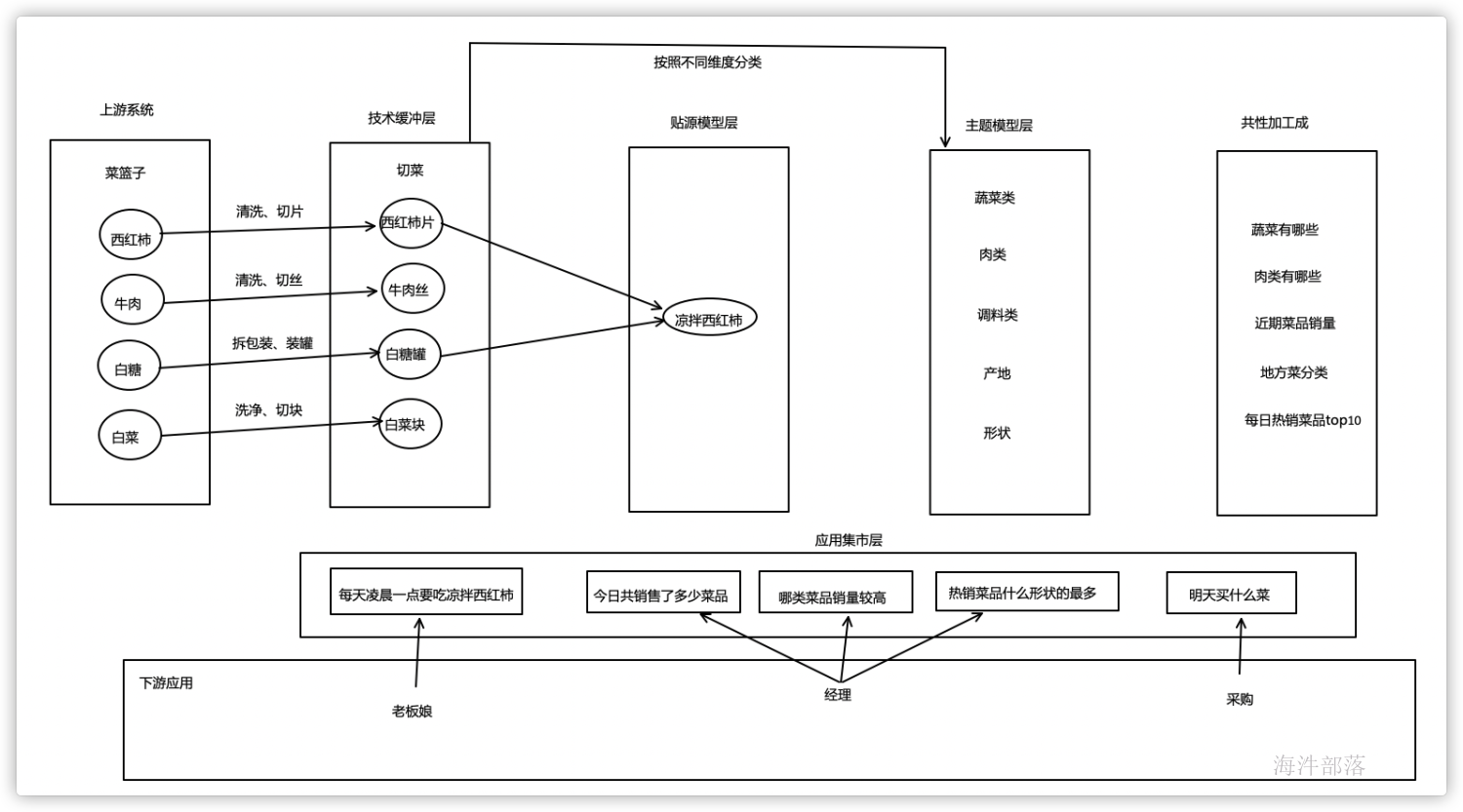
通俗理解数仓
技术缓冲层
技术缓冲层概述
技术缓冲层(ITL),贴源抽取,只增加需要的技术字段(ETL date),其他字段保持与源系统一致,该层数据用于给贴源模型层供数,增加缓冲层的目的是为了实现贴源模型层数据处理缓冲,避免计算过程积压在ETL过程。
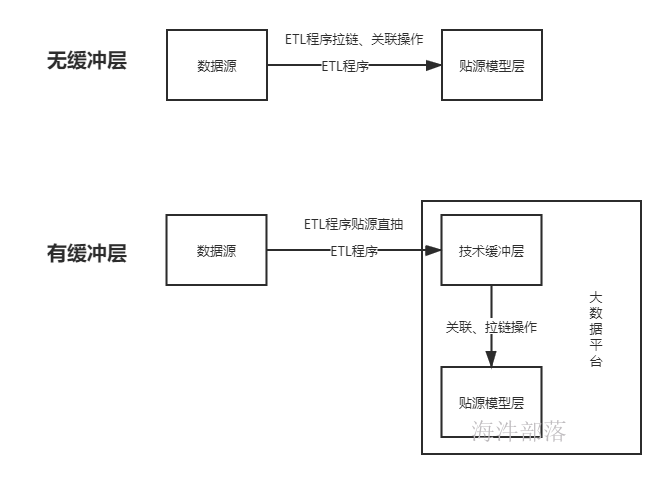
如上图,如果没有增加缓冲层,贴源模型层如果做拉链表,那么就只能在ETL阶段实现,这样对ETL步骤压力较大,因为ETL服务器性能远不如大数据集群,甚至有些ETL服务器还是单点部署。如果采用了技术缓冲层,那么ETL阶段只需要直抽上游数据到大数据平台即可,不需要在ETL阶段做复杂计算,向贴源模型层的装数动作在大数据平台完成。
同时技术缓冲层可以避免数据加载错误,在数据抽取有误时,在技术缓冲层及时检核发现,进行数据重新抽取,避免数据直接接入贴源层。
本层特点
数据完全贴源抽取,中间不做逻辑计算,只增加技术字段;
在本层需要严格把控数据检核;
数据保存周期一般为一周,采用分区方式保存;
贴源模型层
贴源模型层概述
贴源模型层(IOL),采用贴源建模的方式加载,数据加工场景通常适合于数据整合度低、时效性要求较高且需要进行加工但又无法直接通过文件加工获得的应用,可以以开放数据库直连的方式对外提供服务,也可以导出数据文件给下游系统的方式对外供数。就应用而言,贴源模型层主要是满足数据的快速接入,建设时效性要求比较高、跨系统的数据分析,从而减轻业务系统的压力,同时支持数据检查和监管类的应用。数据保存周期一般为永久保留,提供多部门任意历史数据查询。
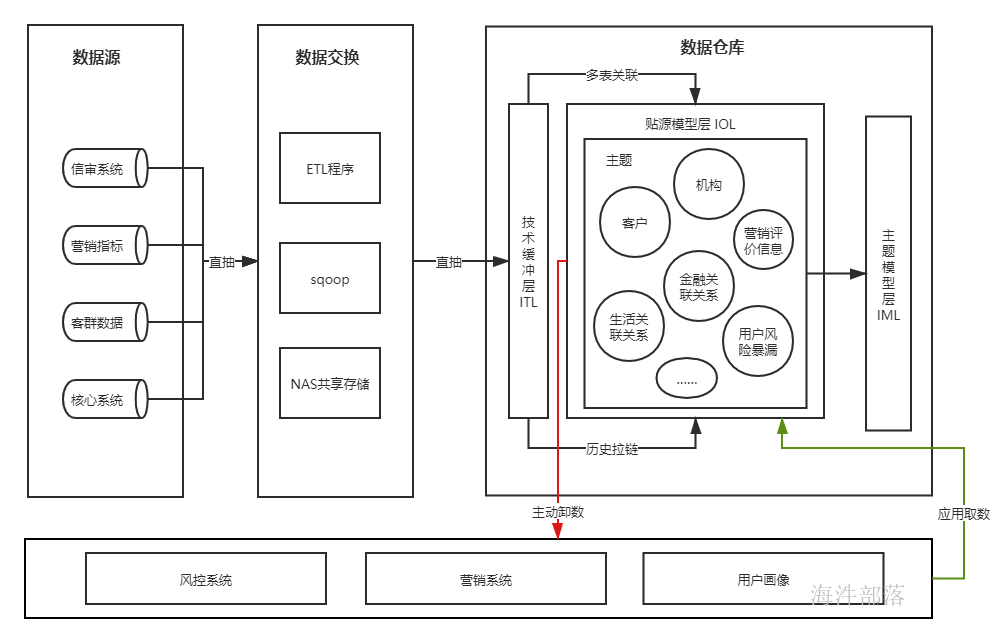
针对多种源系统数据,通过技术缓冲层将数据进行表级关联或历史拉链等算法,将数据存入贴源模型层中,本层中主题设计不会设计特别多,只是针对下游系统对时效性要求较高的场景进行建设,当下游系统有简单模型划分时在本层划分主题,否则交由主题模型层进行主题详细划分。
本层特点
整合度低且不能通过文件加工获得,对建设时效性要求较高,则通过简单处理及模型拆分的方式对下供数;
跨系统数据分析需求,则关联后,使用宽表落地,否则数据保留在技术缓冲层;
数据存储周期一般为永久存储;
主题模型层
主题模型层概述
主题模型层(IML),作为数据仓库中最重要的基础存储区,此数据区将按照分析型业务的特点对所有进入大数据平台的源数据按照主题进行分类存储,主题的划分是对分析型应用系统对数据需求的分类归纳,如金融行业较为权威的九大主题模型,主题模型层数据来源于技术缓冲层和贴源模型层,主题模型层采用弱三范式进行数据组织。
主题模型层会对历史数据进行累积和保存,与技术缓冲层和贴源模型层相比,主题模型层的数据涉及范围更广、存储周期更长。
主题模型层表类型分为以下几类:
-
第一类、带有时间戳且不会更新的事件表或者几乎每天都会发生变化的流水表;
- 第二类、会增删改的状态表,数据体量大但是变化频率低,即缓慢变化维SCD(Slowly Changing Dimensions);
对于第一类表,需要从技术缓冲层获取增量信息,并根据数据映射加载到主题模型层的目标表中,而对于第二类表,在从技术缓冲层获取到数据后,需要使用时间拉链算法进行数据加载和转换,在目标表中以开始日期和结束日期以及标识状态来保留历史数据。
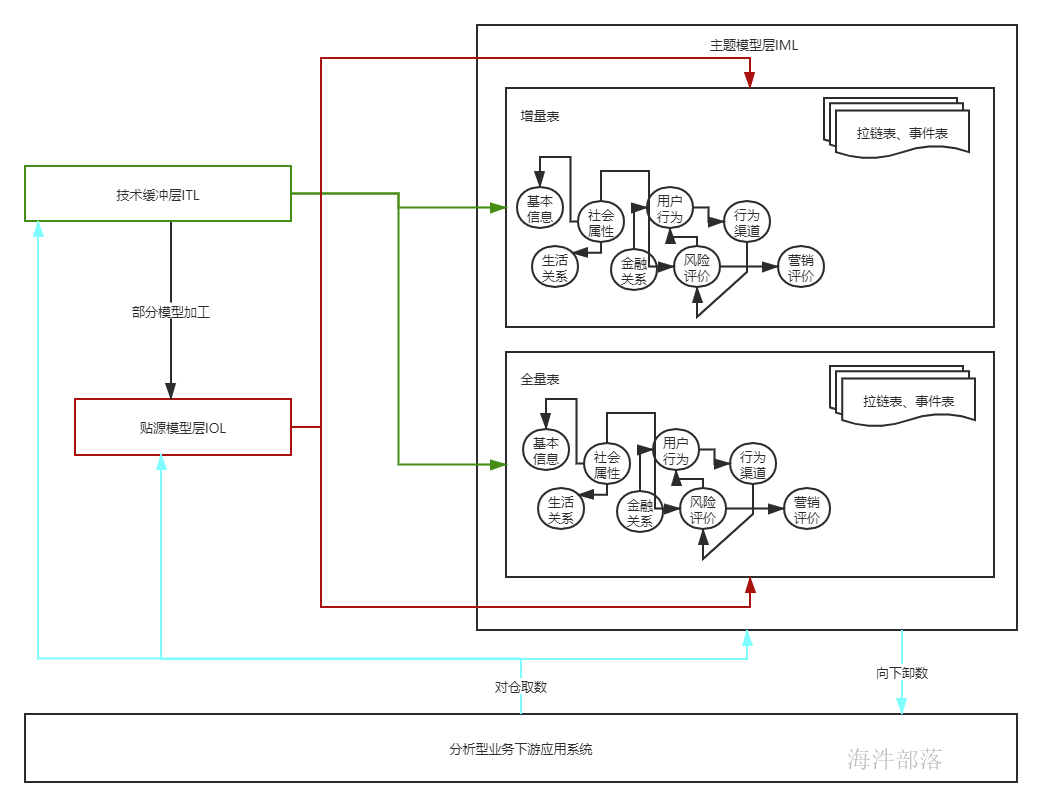
本层特点
偏重于历史和整合;
建设周期较长;
适合实现较长历史周期的数据需求;
适合实现一些站在全局角度的高端分析应用及随机查询需求;
实现多种业务整合的应用需求;
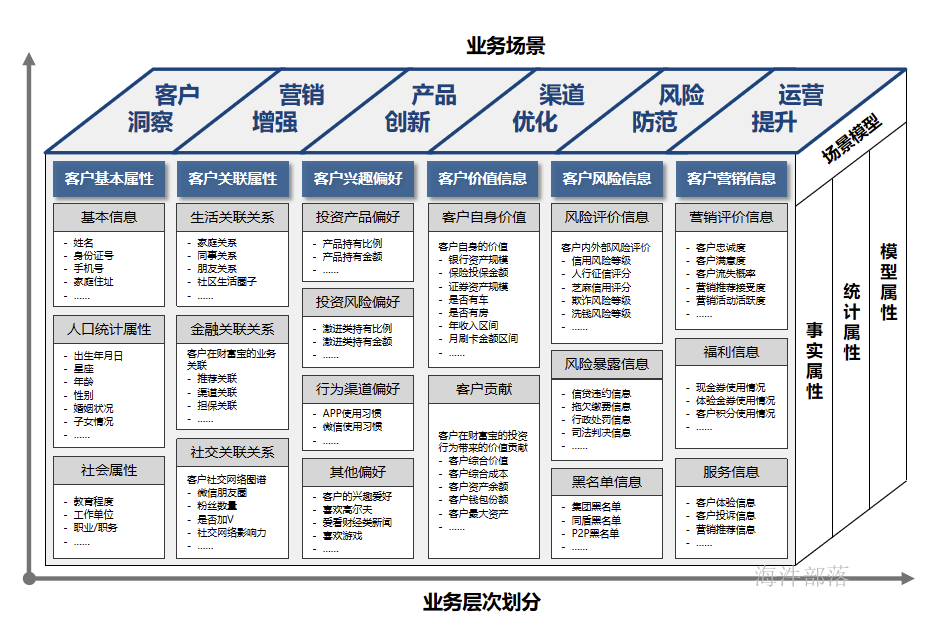
金融主题模型示例
共性加工层
共性加工层概述
共性加工层(ICL),是从业务视角出发,提炼出对数据平台具有共性的数据访问和统计需求,从而构建一个面向支持应用的、提供共享的数据访问服务的公共数据。
共性加工层的数据来源于贴源模型层或主题模型层,数据组织形式采用逆三范式的方式,所以该层的表都是一些较大的宽表,涉及维度较多,这样才能从应用的角度出发设计,基于这种设计初衷,针对多种应用系统进行业务调研,设计出共性部分以及汇总部分,构建共性加工层。
共性加工层的构建主要完成对基础数据的预连接、预计算、预汇总,主要实现目标如下:
-
同时服务于多个不同应用,实现数据加工结果的共享,减少系统重复加工的开销;
-
提高用数查询效率;
-
降低应用开发和数据查询的复杂程度;
- 实现对常用业务统计口径的定义和维护,避免不同的应用系统加工出来不同口径的结果,如码表、计算规则、营销策略等;
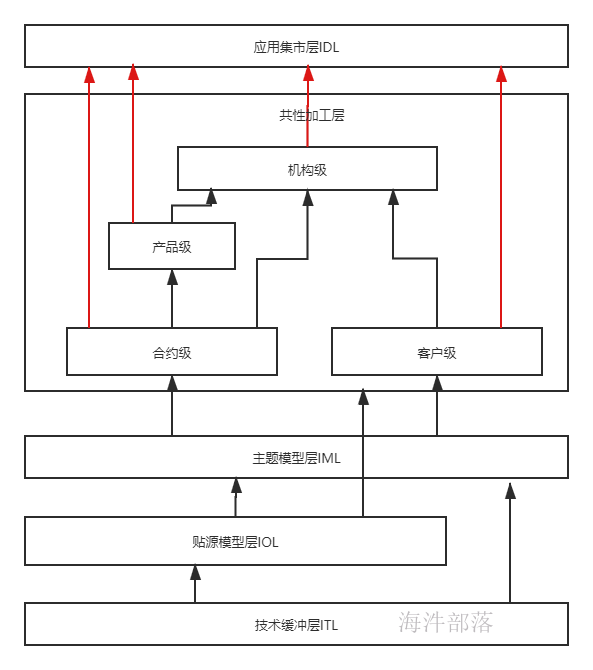
由于不同业务各有特点,所以不同业务的维度和指标将不尽相同,所以共性加工层也需要按照业务适当的划分成不同主题域,如金融领域可划分为:合约级、客户级、产品级、机构级,列举主题域如下:
-
合约级:合约级是银行账户、合同、借据、行用卡等数据的分类汇总,银行账户包括存款账户、贷款账户、内部账户、信用卡账户等,合同包括个人贷款合同、对公贷款合同等,借据包括贷款借据、贴现借据等。
-
客户级:客户级数据汇总主要是针对客户账务数据和基本信息汇总 ,以及客户整合、客户贡献的方案等,一般客户级可以划分为个人客户汇总、个人客户存款汇总、个人客户贷款汇总、个人客户额度汇总、个人客户理财汇总、个人客户其他资产汇总、对公客户汇总、对公客户存款汇总、对公客户贷款汇总、对公客户贴现汇总。
-
产品级:产品级数据汇总主要是按照不同业务产品口径进行的汇总,如贷款业务条线余额统计、中间业务产品收益统计。
- 机构级:机构级主要是对存贷款账户、信用卡、客户主题数据按机构属性的汇总,机构级数据汇总可以由合约级汇总得到,按照机构维度划分,如内部机构信息表、机构对公贷款汇总、机构个人存款汇总、机构对公存款汇总、机构拆借汇总、机构内部账户汇总、机构授信汇总、机构贴现汇总。
应用集市层
应用集市层(IDL),用于支持各种分析型的应用,除了高级分析人员可以对大数据平台进行灵活查询以外,大数据大数据平台上的应用均以数据集市的方式对外提供数据服务,应用集市层不同于共性加工层,其数据仅面向于特定的应用,在应用间不做数据共享,如果应用间使用存在数据共享需求,那么在共性加工层实现共性加工,应用集市层可以构建在大数据平台内,也可以构建在大数据平台以外(应用子系统平台内),其数据组织形式没有固定限制,按照实际应用子系统决定数据组织形式,其数据来源于上层基础数据区与共性加工层。
各种应用集市的建设都依赖于业务实现的需求,所以设计侧重点和设计方法都不同。


