1 通过 scan 读取 hbase 表
应用场景:
当想读取hbase表数据,做进一步数据处理或数据分析时,需要用scan 读取 HBASE 表。
读取方法:
直到读取数据的inputformat是 TableInputFormat,

keyin: ImmutableBytesWritable rowkey
valuein:Result 一行(rowkey)的数据
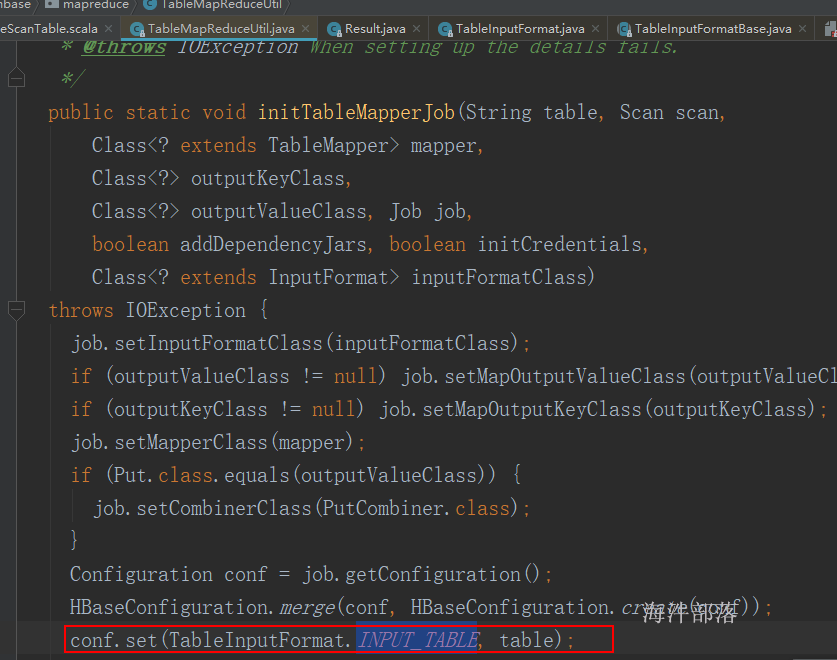
1.1 scan 全表
package day05.hbase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkHbaseScanTable {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkHbaseScanTable")
val sc = new SparkContext(conf)
// conf: Configuration = hadoopConfiguration,
// fClass: Class[F], inputformatclass
// kClass: Class[K], keyin
// vClass: Class[V] valuein
val hbaseConf: Configuration = HBaseConfiguration.create()
// 设置表名称
hbaseConf.set(TableInputFormat.INPUT_TABLE, "panniu:spark_user")
val rdd: RDD[(ImmutableBytesWritable, Result)] = sc.newAPIHadoopRDD(hbaseConf, classOf[TableInputFormat],classOf[ImmutableBytesWritable],classOf[Result])
// rdd 的分区数是由 hbase表查询结果数据的region数量决定。
// 因为只有一个region,所以只有一个分区
println(s"rdd.size:${rdd.getNumPartitions}")
rdd.foreach(f =>{
val rowkey: String = Bytes.toString(f._1.get())
val result: Result = f._2
val value: String = Bytes.toString(result.getValue(Bytes.toBytes("cf"), Bytes.toBytes("count")))
// spark_write_p_84 column=cf:count, timestamp=1578988887742, value=84
println(s"${rowkey}\tcolumn=cf:count,value=${value}")
})
}
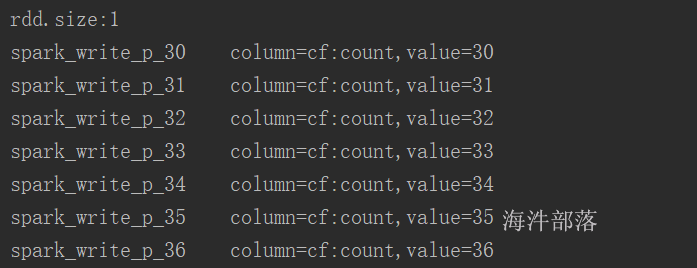
}结果:
1.2 scan 指定范围
package day05.hbase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.client._
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableMapReduceUtil}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkHbaseScanTable {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkHbaseScanTable")
val sc = new SparkContext(conf)
// conf: Configuration = hadoopConfiguration,
// fClass: Class[F], inputformatclass
// kClass: Class[K], keyin
// vClass: Class[V] valuein
val scan = new Scan()
// 设置范围
scan.setStartRow(Bytes.toBytes("spark_write_p_40"))
scan.setStopRow(Bytes.toBytes("spark_write_p_500"))
val hbaseConf: Configuration = HBaseConfiguration.create()
// 设置表名称
hbaseConf.set(TableInputFormat.INPUT_TABLE, "panniu:spark_user")
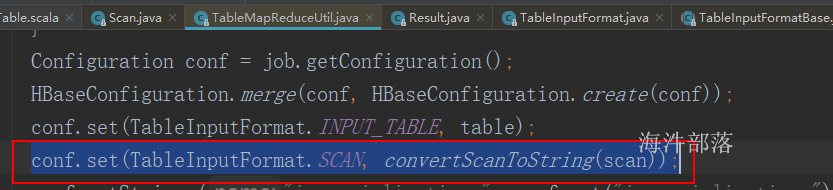
// 通过将scan对象转成对应的字符串,来设置查询范围
hbaseConf.set(TableInputFormat.SCAN, TableMapReduceUtil.convertScanToString(scan))
val rdd: RDD[(ImmutableBytesWritable, Result)] = sc.newAPIHadoopRDD(hbaseConf, classOf[TableInputFormat],classOf[ImmutableBytesWritable],classOf[Result])
// rdd 的分区数是由 hbase表查询结果数据的region数量决定。
// 因为只有一个region,所以只有一个分区
println(s"rdd.size:${rdd.getNumPartitions}")
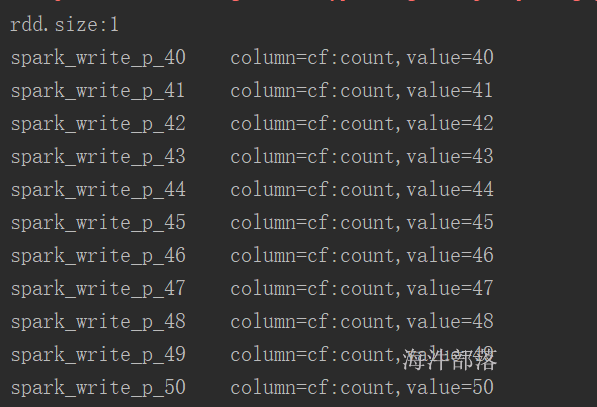
rdd.foreach(f =>{
val rowkey: String = Bytes.toString(f._1.get())
val result: Result = f._2
val value: String = Bytes.toString(result.getValue(Bytes.toBytes("cf"), Bytes.toBytes("count")))
// spark_write_p_84 column=cf:count, timestamp=1578988887742, value=84
println(s"${rowkey}\tcolumn=cf:count,value=${value}")
})
}
}结果:
1.3 总结
此种方式,会根据scan的范围来确定数据是在哪几个region中,有几个region,spark 任务就有几个分区。
读取region数据时,需要不断地请求RegionServer。如果读取的数据量大,那会频繁的请求RegionServer,这样会影响 RegionServer的性能。
2 通过读取 Hbase Snapshot
2.1 Hbase Snapshot 概述
2.1.1 概念
Snapshot即是快照,代表某个时刻数据库中表的状态,就像是照片一样,记录了该时刻所有的数据。
HBase可以对某个时刻的表建立snapshot,过后可以恢复到该snapshot的状态,也可以用snapshot建立一个新的表等等。
hbase Snapshot 的创建并不复制数据,而是元数据的复制,也就是说快照有个文件记录了每个region的hfile文件位置。
2.1.2 操作
1)创建 Snapshot
为表’sourceTable’打一个快照’snapshotName’。
快照时,先flush;而且快照并不涉及数据移动,可以在线完成。
snapshot 'sourceTable', 'snapshotName'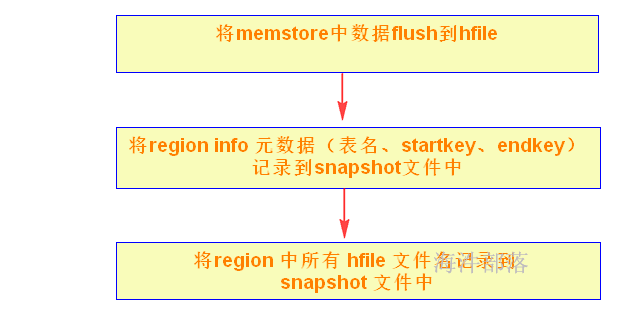
例如:
snapshot 'panniu:spark_user', 'spark_user_snapshot1'
当执行上面的命令时,会生成下面的快照目录和文件:

其中:
.snapshotinfo 为 snapshot 基本信息,包含待 snapshot 的表名称以及 snapshot 名;
data.manifest 为 snapshot 执行后生成的元数据信息,即 snapshot 结果信息。
2)通过 Snapshot 恢复表
恢复指定快照,恢复过程会替代原有数据,将表还原到快照点,快照点之后的所有更新将会丢失。需要注意的是原表需要先disable掉,才能执行restore_snapshot操作。
restore_snapshot 'snapshotName'3) 通过 Snapshot clone 新表
根据快照恢复出一个新表,恢复过程不涉及数据移动,可以在秒级完成。
clone_snapshot 'snapshotName', 'tableName'4)需要注意的问题
我们知道snapshot实际上是一系列原始表的元数据,主要包括表schema信息、原始表所有region的region info信息,region包含的列族信息以及region下所有的hfile文件名以及文件大小等。那如果原始表发生了compaction导致hfile文件名发生了变化或者region发生了分裂,甚至删除了原始表,之前所做的snapshot是否就失效了?
这你大可不必担心,hbase 给你想好了应对策略。它是在原始表发生compact的操作前会将原始表复制到archive目录下再执行compact(对于表删除操作,正常情况也会将删除表数据移动到archive目录下),这样snapshot对应的元数据就不会失去意义,只不过原始数据不再存在于数据目录下,而是移动到了archive目录下。
例如:
当对快照后的表执行 major_compact,此时会进行版本合并并删除老版本。在删除之前,会把要删除的文件复制到 archive 目录下,如下图:

当要执行恢复或克隆时,通过快照记录的元数据,很快会定位到 archive目录,完成快照恢复。
2.1.3 应用场景
1)数据备份
通常情况下,对重要的业务数据,建议至少每天执行一次snapshot来保存数据的快照记录,并且定期清理过期快照,这样如果业务发生重要错误需要回滚的话是可以回滚到之前的一个快照点的。
如果要对集群做重大的升级的话,建议升级前对重要的表执行一次snapshot,一旦升级有任何异常可以快速回滚到升级前。
2)数据迁移
使用snapshot将表数据导出到HDFS,再使用Hive\Spark等进行离线数据分析,比如审计报表、月度报表等。
2.2 读取 Hbase Snapshot
步骤:
先创建快照,再通过快照读取 hfile 文件。
创建快照:snapshot 'panniu:user_install_status', 'user_install_status_snapshot'
读取方法:
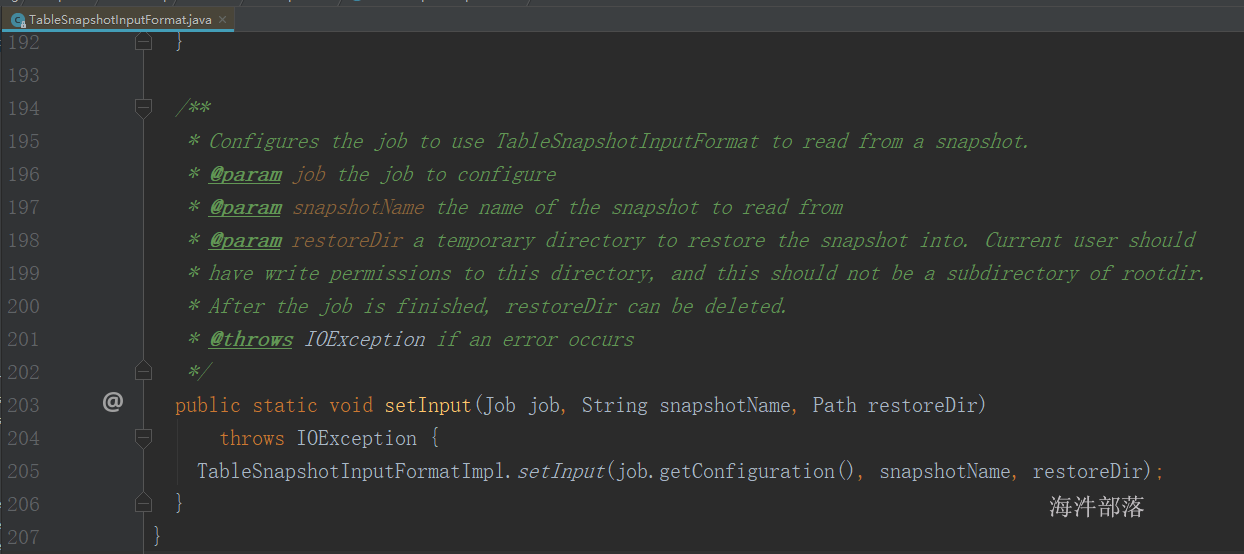
代码:
package hbase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.Path
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.{Result, Scan}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
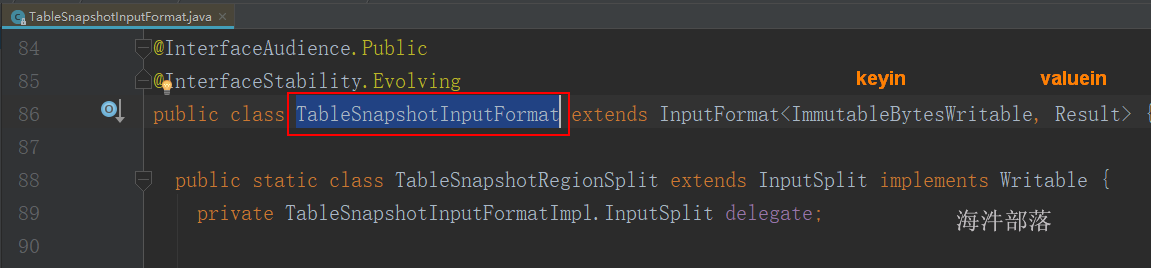
import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableMapReduceUtil, TableSnapshotInputFormat}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.mapreduce.Job
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkHbaseReadSnapShot {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkHbaseReadSnapShot")
val sc = new SparkContext(conf)
val hbaseConf: Configuration = HBaseConfiguration.create()
val job: Job = Job.getInstance(hbaseConf)
val snapshotName:String = "user_install_status_snapshot"
val restoreDir:Path = new Path("hdfs://ns1/user/panniu/spark/restore")
val scan = new Scan()
// scan.setStartRow(Bytes.toBytes("wspark_write_10"))
// 设置 scan 范围,必须要有scan
job.getConfiguration.set(TableInputFormat.SCAN, TableMapReduceUtil.convertScanToString(scan))
// 配置读取快照相关参数
TableSnapshotInputFormat.setInput(job, snapshotName, restoreDir)
val rdd: RDD[(ImmutableBytesWritable, Result)] = sc.newAPIHadoopRDD(job.getConfiguration,
classOf[TableSnapshotInputFormat], classOf[ImmutableBytesWritable], classOf[Result])
println(s"rdd.size:${rdd.getNumPartitions}")
rdd.foreach(f =>{
val rowkey: String = Bytes.toString(f._1.get())
val result: Result = f._2
val aid: String = rowkey.split("_")(0)
val pkgname: String = Bytes.toString(result.getValue(Bytes.toBytes("cf"), Bytes.toBytes("pkgname")))
val uptime: String = Bytes.toString(result.getValue(Bytes.toBytes("cf"), Bytes.toBytes("uptime")))
val typestr: String = Bytes.toString(result.getValue(Bytes.toBytes("cf"), Bytes.toBytes("type")))
val country: String = Bytes.toString(result.getValue(Bytes.toBytes("cf"), Bytes.toBytes("country")))
val gpcategory: String = Bytes.toString(result.getValue(Bytes.toBytes("cf"), Bytes.toBytes("gpcategory")))
// spark_write_p_84 column=cf:count, timestamp=1578988887742, value=84
println(s"${aid}\t${pkgname}\t${uptime}\t${typestr}\t${country}\t${gpcategory}")
})
}
}运行代码前环境配置:
本例是 采用本地运行spark任务,读取教室集群快照。
1)将 教室集群的 core-site.xml 和 hdfs-site.xml 放到 工程资源目录下
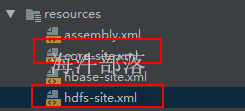
2)给 hbase-site.xml 增加 如下配置
<!-- 当读取集群hbase 快照时打开 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns1/hbase</value>
<description>region server的共享目录,用来持久化HBase</description>
</property>3)手动创建restoreDir,并设置 restoreDir 的权限是 777

运行代码结果:
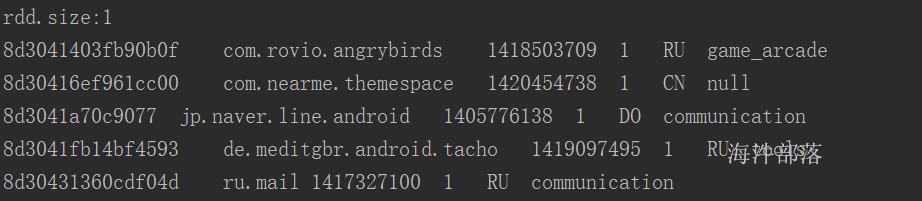
运行代码后:
因为本例是读取教室集群hdfs,所以在执行完后需要把下面的配置还原,否则其他程序将不能执行。
1)将 教室集群的 core-site.xml 和 hdfs-site.xml 从工程资源目录删除。
2)给 hbase-site.xml 添加的 hbase.rootdir 注释掉,因为本地执行,默认找当前机器的目录,而不是hdfs。
2.3 总结
此种方式,会根据scan的范围来确定数据是在哪几个region中,有几个region,spark 任务就有几个分区。
但此种方式是直接读取对应region的hfile文件,不需要频繁请求RegionServer,减小对RegionServer的影响。而且读取快照扫描,会自动对数据做版本合并,获取最新的数据。


