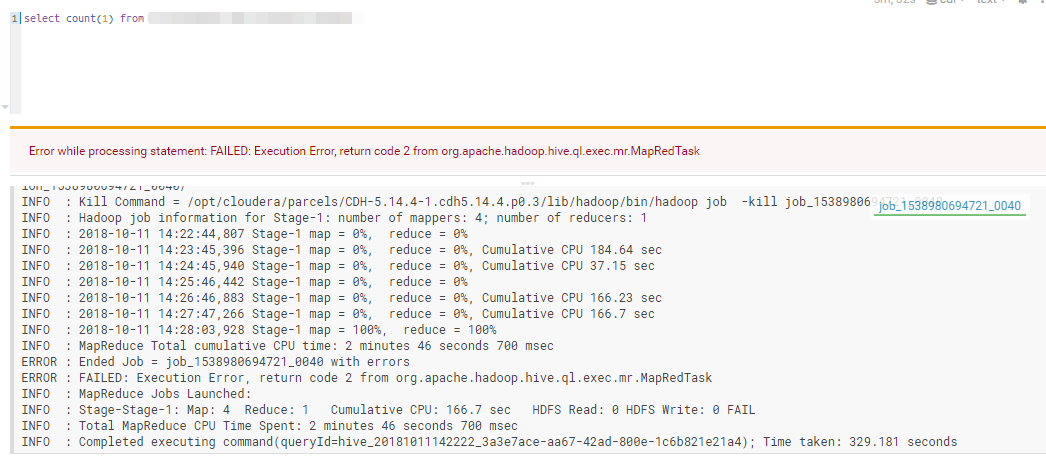
老师您好,我在生产上遇到一个这样一个情况,我们有46亿的数据,有1TB的大小,占用hdfs就是3个多TB了,我们采用gz格式将数据进行压缩,建立hive表,将数据load into到hive表了。表数据能够使用select * from table能查询出数据,但是在对表进行计算时(select count(1))出现1个小时了但是map=0%,这个表完全没用办法进行计算。集群性能为(4core/28GB)x9datanode.
请问老师,hive对压缩的数据进行计算不是在逻辑上将数据进行解压吗?我该如何设置才能计算这个表?
尝试过建立一张分区表将,想这个gz格式的hive数据查询出来再插入到建好的分区表中,但是也遇到相同的情况map任务跑了17小时还是0%?请问我该如何将数据插入到hive分区表?
insert into dist_tablename PARTITION(yearmonth)
select *,substr(inventory_date,0,7) yearmonth
from src_tablename