@青牛 不一样是没问题的
最近话题
- 在 storm 如何保证每个 worker(jvm)只保存一份静态数据?
- jstorm ui 中 sendtps 和 secvtps ,TupleLifeCycle ProcessLatency 分别什么含义?
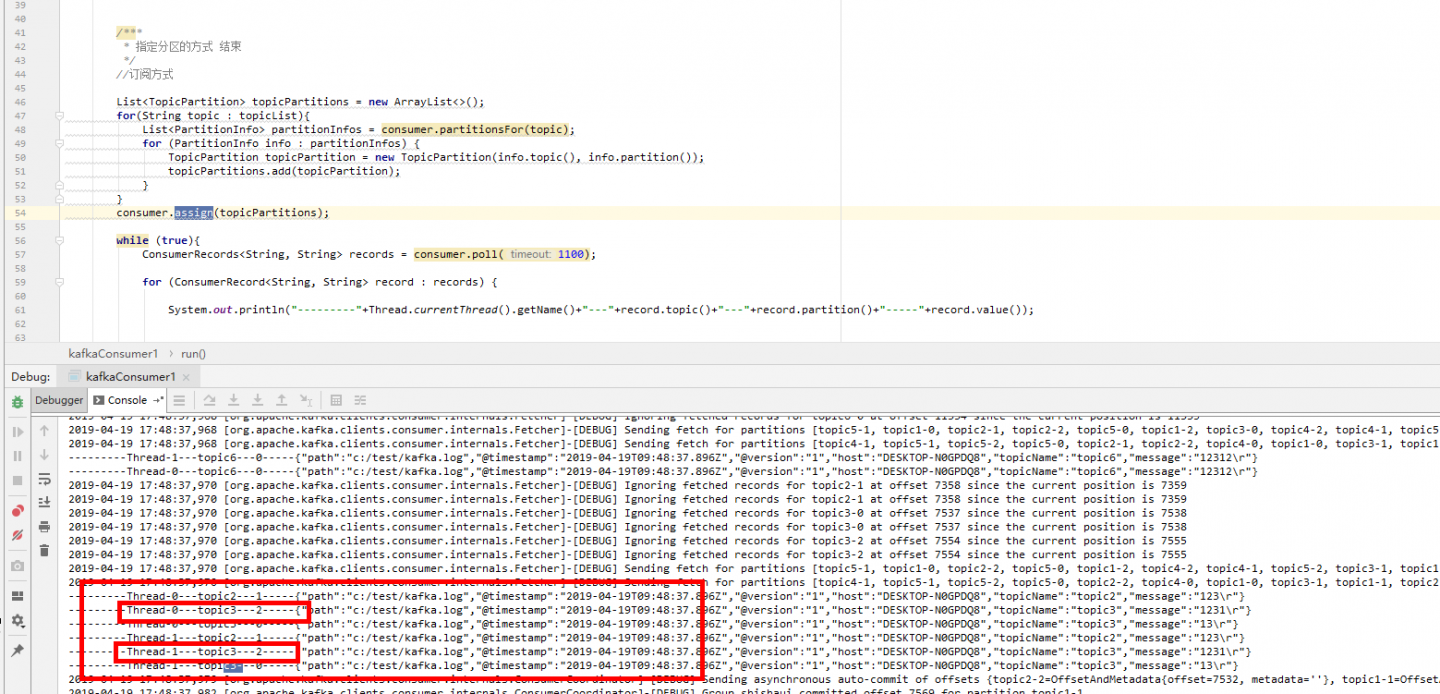
- kafka 同一个消费组里 多个消费者 使用 consumer.assign (topicPartitions);会造成数据重复吗?
- kafka 消费者怎样每次只消费 30 条?
- storm 怎样均衡的处理 kafka 数据?
- flink apply 方法中为什么不能使用 lambda?
- flink f DataStream 怎样做到每隔 30 秒入一次库?
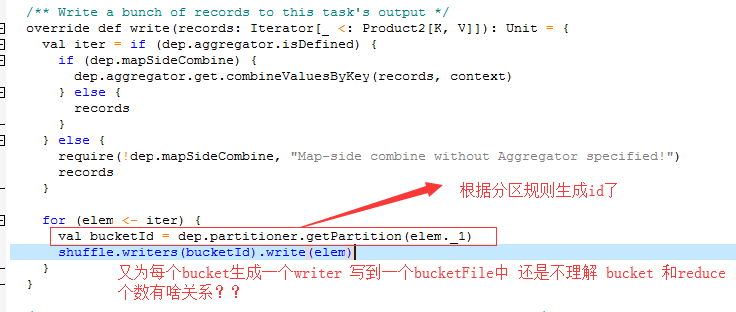
- spark shuffle 在原始的 Hash Shuffle 机制中怎么生存 bucket?
- hive 怎样批量创建表?
- 使用 jdbc 连接 hive 出错 hadoop is not allowed to impersonate hadoop????
- spark Dataset.createTempView 作用是什么?
- 急求 spark 视频教程?
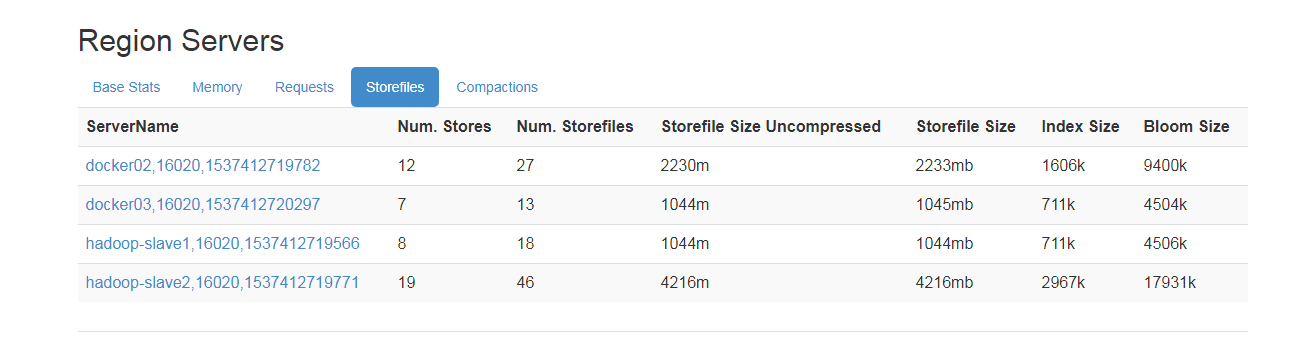
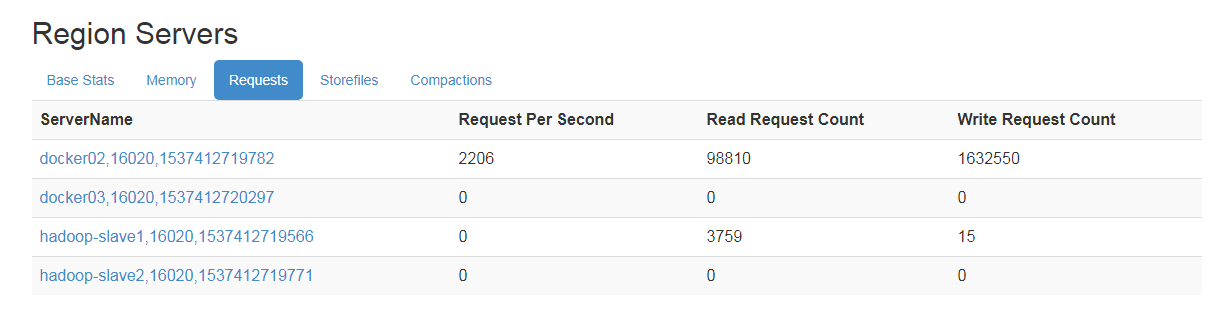
- hbase 分布式集群 所有的请求都集中在一个 regionserver 节点上是怎么回事?
- hadoop lzo 如何安装 ?最好有个文档谢谢
- hadoop2.x 中的 mapreduce.map.memory.mb 和 mapred.child.java.opts 应该设置多大才合适?应遵循什么设置...
- MapReduce 应该优化哪些配置?
最新评论
-
信息被删除或无权限查看
-
信息被删除或无权限查看
- kafka 同一个消费组里 多个消费者 使用 consumer.assign (topicPartitions);会造成数据重复吗?
- kafka 同一个消费组里 多个消费者 使用 consumer.assign (topicPartitions);会造成数据重复吗?
- kafka 同一个消费组里 多个消费者 使用 consumer.assign (topicPartitions);会造成数据重复吗?
- kafka 同一个消费组里 多个消费者 使用 consumer.assign (topicPartitions);会造成数据重复吗?
- kafka 同一个消费组里 多个消费者 使用 consumer.assign (topicPartitions);会造成数据重复吗?
- storm 怎样均衡的处理 kafka 数据?
- spark shuffle 在原始的 Hash Shuffle 机制中怎么生存 bucket?
- hive 怎样批量创建表?
- hive 怎样批量创建表?
- 使用 jdbc 连接 hive 出错 hadoop is not allowed to impersonate hadoop????
- 海牛部落 spark 系列教程(四十六):kafka 介绍与安装、kafka-java-API、spark-streaming-kafka、cogroup
- spark 基于内存的分布式计算框架
- 急求 spark 视频教程?
- spark 基于内存的分布式计算框架
-
信息被删除或无权限查看
- hbase 分布式集群 所有的请求都集中在一个 regionserver 节点上是怎么回事?
- hbase 分布式集群 所有的请求都集中在一个 regionserver 节点上是怎么回事?
- hbase 分布式集群 所有的请求都集中在一个 regionserver 节点上是怎么回事?
 还是这样
还是这样