关于 “” 的搜索结果, 共 2411 条
Python 中多线程无法结束线程怎么办?
by
 冰雹
冰雹
https://hainiubl.com/topics/36808?
2019-06-28
⋅
2623
⋅
0
⋅
1
我在爬接口 几百万次 我在用线程的时候 每一次的线程都在积累 导致内存越来越大,我换用线程池 虽然解决了线程不增长 手动gc。但是发现线程池执行的很慢50个大小的线程池并发就9个左右 越来越少,而且还不如自己扔进去的线程跑得快,这是什么情况?自己写的线程怎么结束...
大家好,请问 python 中如何修改列表中的字典?
by
 不忘初心
不忘初心
https://hainiubl.com/topics/36809?
2019-06-28
⋅
2589
⋅
0
⋅
1
刚才做了个购物车,想要完善一下,将物品(由列表包围的字典)添加到自己的shopping_car空字典中
自己又试了下,新建了列表,对列表中的键的值进行更新,还是报错,我想问题可能就出现在这里
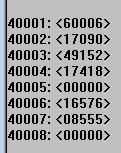
python 怎么把读取寄存器的 16 位无符号整数(十进制)转换为浮点? 浮点数应该占用两个寄存器?
by
 晓儒
晓儒
https://hainiubl.com/topics/36810?
2019-06-28
⋅
3305
⋅
0
⋅
1
我有三个属性的数据集,分别是时间,用户,数量,如何根据这三个属性利用 python 构建对应的三维张量?
by
 MindHacker
MindHacker
https://hainiubl.com/topics/36811?
2019-06-28
⋅
2263
⋅
0
⋅
1
张量分解
如何在 webStorm 的 configurations 中使用 yarn?
by
 张小果
张小果
https://hainiubl.com/topics/36812?
2019-06-28
⋅
7073
⋅
0
⋅
1
如何在webStorm的Configurations中使用yarn
为什么 MapReduce 中 context.write () 有时候不执行或者没有数据?
by
 肖海艳
肖海艳
https://hainiubl.com/topics/36813?
2019-06-28
⋅
3107
⋅
0
⋅
1
为什么MapReduce中context.write()有时候不执行或者没有数据?
jdbc setSting 插入记录后是空的?
by
 Perry
Perry
https://hainiubl.com/topics/36814?
2019-06-28
⋅
2979
⋅
0
⋅
1
public static boolean addUser(String username,String password){
PreparedStatement pst=null;
conn=getConnection();
try {
conn.setAutoCommit(true);
pst=conn.prepareStatement("select * from person where username=?");//这里也不成功
pst....
SQL 预编译中有 null 的情况怎么办?
by
 BOBO
BOBO
https://hainiubl.com/topics/36815?
2019-06-28
⋅
2484
⋅
0
⋅
1
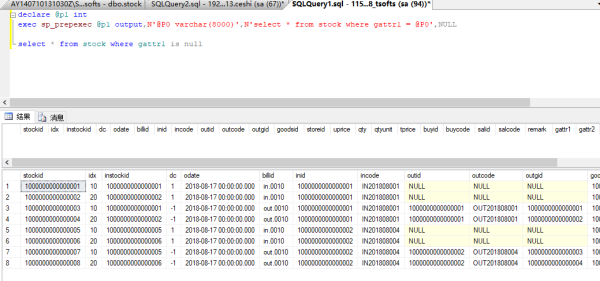
select语句使用预编译,某个参数为null时怎么处理?例如:
select * from tbl where fld=?
要查询fld为null的情况,使用了null查询不到数据
 Sunmer
Sunmer
https://hainiubl.com/topics/36816?
2019-06-28
⋅
2547
⋅
0
⋅
1
MySQL 索引文件的上限是多少?
MySQL inner join 关联 没有走索引?
by
 李伟
李伟
https://hainiubl.com/topics/36817?
2019-06-28
⋅
4005
⋅
0
⋅
1
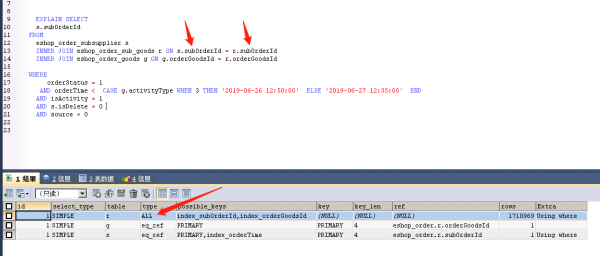
表的subOrderId是主键int类型
r表的subOrderId是int类型,是索引,为什么这里join查询不走索引呢?好奇怪哦,直接全表扫描了。
Java 线程池中的任务是否能算作是轻量级线程?
by
 蓝天
蓝天
https://hainiubl.com/topics/36818?
2019-07-01
⋅
2405
⋅
0
⋅
1
Java线程池中的任务是否能算作是轻量级线程?又能否称之为协程呢?
基于这个问题我的思考是,首先任何执行指令都需要争抢到CPU资源才能执行,这是一切的前提,协程也不例外。
Java线程池中的任务和 goroutine 和内核线程都是 M:N 的,Java 线程池中的任务相对于...
如何在 Mac 系统中的 anaconda3 中的 vscode 里运行第一个 Python 程序?
by
 Shihw丶疙瘩
Shihw丶疙瘩
https://hainiubl.com/topics/36819?
2019-07-01
⋅
3114
⋅
0
⋅
1
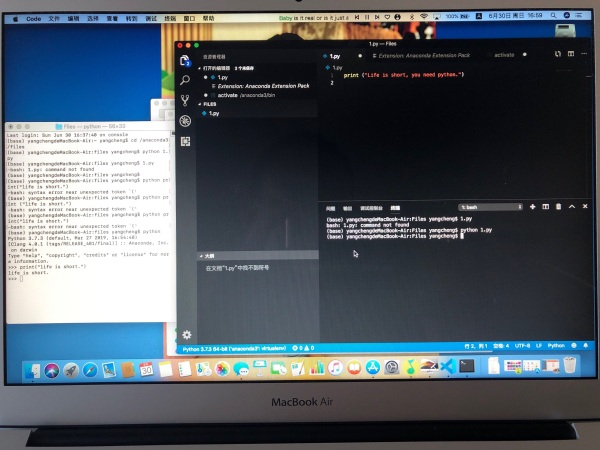
纯新新手提问,希望不会被人鄙视,不过我相信有内涵的大佬是不会鄙视我的!
我挺无奈的,望大家指点一二!是不是路径不对?
字符串拼接的 sql 不能在 MySQL 中直接执行,有什么好的工具能自动格式化吗?
by
 陪你去看海
陪你去看海
https://hainiubl.com/topics/36820?
2019-07-01
⋅
2619
⋅
0
⋅
1
idea里面写的sql有一大堆 +号 “”号的,粘出来不能执行,还得替换,有没有什么好用的工具直接替换的?
先问问有没有工具,没有再自己写么
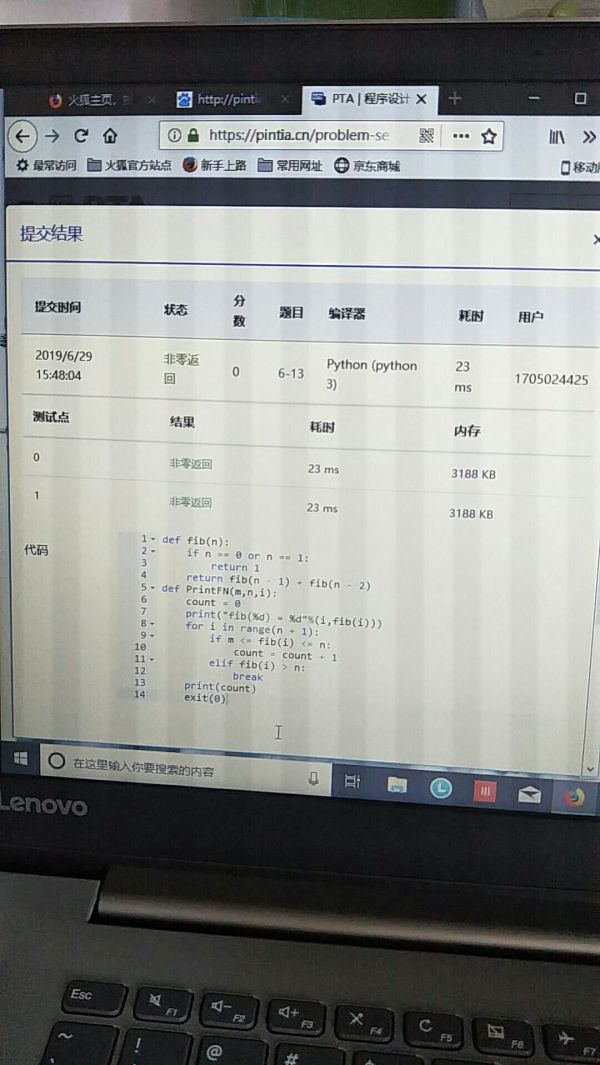
Pta 非零返回怎么办?
by
 Best
Best
https://hainiubl.com/topics/36821?
2019-07-01
⋅
5312
⋅
0
⋅
1
如图 这个非零返回怎么改 网上说加exit(0)也试了
flink 如何让每一条数据进来后延迟一段时间再被处理?
by
 neo
neo
https://hainiubl.com/topics/36822?
2019-07-01
⋅
3860
⋅
0
⋅
1
现在有这么一个需求,mq每次推一条数据进来以后都需要查一次数据库拿到相关数据做一些业务处理,但是由于其他原因入库是有一定延迟的,所以当从mq拿到消息直接查数据库可能会查不到,用flink之后怎么让每一条消息进来后不被立刻处理,而是延迟一段时间再被处理?而且这...
MySQL inner join 关联 没有走索引?
by
 雾走黄昏
雾走黄昏
https://hainiubl.com/topics/36824?
2019-07-02
⋅
4505
⋅
0
⋅
1
s表的subOrderId是主键int类型
r表的subOrderId是int类型,是索引,为什么这里join查询不走索引呢?好奇怪哦,直接全表扫描了。

SQL 预编译中有 null 的情况怎么办?
by
 天灬空
天灬空
https://hainiubl.com/topics/36825?
2019-07-02
⋅
2625
⋅
0
⋅
1
select语句使用预编译,某个参数为null时怎么处理?例如:
select * from tbl where fld=?
要查询fld为null的情况,使用了null查询不到数据
Python 中怎样用列表表示 0 到无穷大整数?
by
 矢量
矢量
https://hainiubl.com/topics/36826?
2019-07-03
⋅
3657
⋅
0
⋅
1
threshold=[0,]这样可以吗?
python 怎么删除文件前面的一段内容?
by
 慧有未来
慧有未来
https://hainiubl.com/topics/36827?
2019-07-03
⋅
2629
⋅
0
⋅
1
python怎么删除文件前0h——19h的内容
Python dataframe 多列数据过滤,如何优化代码?
by
 mhcnsk
mhcnsk
https://hainiubl.com/topics/36828?
2019-07-03
⋅
2530
⋅
0
⋅
1
代码如下,可以运行也可以得到需要的结果,但是我觉得函数不漂亮,想学习一下高手是如何优化,写出简介的代码。在STACKOVERFLOW上也发了帖子,目前没有收到答案,听说知乎有很多大神,特来求助,有好的答案可以搭讪10元(第一次用知乎提问,不知道怎么打赏)
import...
请问 python 中 image [...] 和 image [:,:,:] 有什么区别?
by
 Colen
Colen
https://hainiubl.com/topics/36829?
2019-07-03
⋅
2959
⋅
0
⋅
1
请问python中image[...]和image[:,:,:]有什么区别?
如何使用 Python,把经纬度映射成 x,y?
by
 风口浪尖
风口浪尖
https://hainiubl.com/topics/36830?
2019-07-03
⋅
2649
⋅
0
⋅
1
求助啊,找好了好久没找到相关办法,或者如何使用excel转换也行。经纬度是在数据集中的两列,怎么转换呢?
Java 怎么加密.class 文件?
by
 妞妞
妞妞
https://hainiubl.com/topics/36831?
2019-07-04
⋅
2341
⋅
0
⋅
1
Java怎么加密.class文件?
现在有什么好的方案替换 zookeeper+ dubbo 吗?
by
 Wiley
Wiley
https://hainiubl.com/topics/36832?
2019-07-04
⋅
3057
⋅
0
⋅
1
dubbo为什么被阿里弃用?zookeeper的瓶颈对zookeeper有多大影响?zookeeper和其他服务注册中心对比有什么优缺点?
为什么传统的 rdbms 不给每个表提供一个 counter 来计算每个表的行数呢?
by
 Phyllis2016
Phyllis2016
https://hainiubl.com/topics/36833?
2019-07-04
⋅
2435
⋅
0
⋅
1
感觉这是一个比较基础的功能。但是为什么大部分db都需要用 count这个函数来计算行数而不是直接把行数存在某个变量 需要的时候直接拿呢?
for 循环与 while 循环可以相互转换,为什么要有多种循环?
by
 高文超
高文超
https://hainiubl.com/topics/36834?
2019-07-04
⋅
2751
⋅
0
⋅
1
好像各种语言中,for循环都可以与其它循环进行转换,那为什么要有多种循环语句?直接用for循环写不就好了?
如何把 CloudWatch 上的 logs 传输到 MySQL 或 DynamoDB 数据库上进行分析?
by
 y514637059
y514637059
https://hainiubl.com/topics/36835?
2019-07-04
⋅
2602
⋅
0
⋅
1
具体的问题是这样的,现在我有一些已经上传到amazon cloudwatch的logs文件,但是cloudwatch并不是一个适合分析数据的平台,因此我想有没有办法将cloudwatch上的日志能够流式传输到MySql或者Amazon DynamoDB这样的数据库中进行分析,并在未来将结果可视化出来?
CQRS 架构中的 eventsource 有啥好的数据库可以实现?
by
 那些年后会有期
那些年后会有期
https://hainiubl.com/topics/36836?
2019-07-04
⋅
2323
⋅
0
⋅
1
首先需要满足超高的写入性能,因为事件是非常频繁的东西,其次要能保证时序性。最后还要有一定的条件查询能力,比如我要看某个订单的所有事件。我目前想到的选型有这几种:cassandra kudu mongodb ignite
Hadoop 到底是干什么用的?
by
 夜莺
夜莺
https://hainiubl.com/topics/36837?
2019-07-05
⋅
2533
⋅
0
⋅
1
Hadoop到底是干什么用的,主要的应用场景和应用领域是什么,主要解决的核心问题又是什么,在编写代码方面他是一种api规范吗?为什么我们要用他呢?
程序在本地运行和在 hadoop 集群上运行的区别?
by
 秋意浓
秋意浓
https://hainiubl.com/topics/36838?
2019-07-05
⋅
2982
⋅
0
⋅
1
请问程序在本地运行和在hadoop集群上运行有什么区别吗?既然本地可以运行,为什么还要在集群上运行?