关于 “” 的搜索结果, 共 2411 条
从小白到大数据技术专家的学习历程
by
 青牛
青牛
https://hainiubl.com/topics/44?
2017-01-11
⋅
48433
⋅
577
⋅
34
>最近有很多人问我,大数据是怎么学?需要学什么技术以及这些技术的学习顺序是什么?今天有时间我把个问题总结成文章分享给大家。
####不知道大数据是干什么的同学看这里:http://hainiubl.com/topics/48
***
####那大数据处理技术怎么学习呢?首先我们要学习J...
写给 java 程序员的 scala 快速入门
by
青牛
https://hainiubl.com/topics/45?
2017-01-13
⋅
6148
⋅
3
⋅
0
如果你之前是一名 Java 程序员,并了解 Java 语言的基础知识,那么你能很快学会 Scala 的基础语法。
## 安装Scala
到Scala官方下载地址下载:http://scala-lang.org/download/:
Linux下面下载安装:
```
wget http://downloads.lightbend.com/scala/2.11.8/s...
Eclipse 下将 MR 任务远程提交到 Hadoop 集群
by
 Anonymous
Anonymous
https://hainiubl.com/topics/46?
2017-01-18
⋅
5315
⋅
3
⋅
0
<p>
一、介绍
</p>
<p>
以前写完MapReduce任务以后总是打包上传到Hadoop集群,然后通过shell命令去启动任务,然后在各个节点上去查看Log日志文件,后来为了提高开发效率,需要找到通过Ecplise直接将MaprReduce任务直接提交到Hadoop集群中。该章节讲述用户如何从Ec...
Hadoopd 的 Configuration 对象与参数设置
by
Anonymous
https://hainiubl.com/topics/47?
2017-01-21
⋅
7603
⋅
2
⋅
1
<p>
一、介绍
</p>
<p>
我们在使用MapReduce框架进行开发时,总会使用到Configuration类的一个实例对象去初始化一个人任务,然后进行任务提交,而在整个任务执行过程中,客户点实例化的Configuration的对象,将作为整个任务过程中参数版本,任务执行过程中所需要...
[新手必读] 大数据到底是干什么用的?
by
青牛
https://hainiubl.com/topics/48?
2017-01-22
⋅
19259
⋅
18
⋅
2
大数据这个词已经被炒的满天飞,还有的人说它是泡沫,现在什么东西即使没用大数据技术也要加个大数据概念,要不都觉得落伍了,当然这是迎合宣传的手段,不过搞虚假宣传还是不太好的。那真正使用大数据技术的地方且比较有代表性的产品有那些:
* 云存储:中国比较好的有...
java 反射机制总结
by
青牛
https://hainiubl.com/topics/49?
2017-01-30
⋅
3554
⋅
1
⋅
0
## 什么是Java反射
Java反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
Java反射(放射)机制:“程...
很迷茫,求大神指引?
by
 null
null
https://hainiubl.com/topics/53?
2017-02-06
⋅
5804
⋅
3
⋅
5
工作java后台大半年了,公司是一个创业型公司,工作也比较空闲,有时候有事做有时候没事做,领导偶尔会布置一些简单的任务,基本都是出于无任务状态,个人觉得是由于领导认为自己工作能力不足,所以安排任务也时比较轻的,无聊的时候在想,自己一直都是这样的状态感觉没...
为什么要关闭 SELinux
by
 Mrv1
Mrv1
https://hainiubl.com/topics/54?
2017-02-08
⋅
8338
⋅
0
⋅
5
今天在看青牛大神发布的视频时,配置Hadoop开发环境,需要关闭SELinux,本着更深入学习的心态,去网上搜索了一下,为什么要关闭SELinux,以及它是什么,有什么作用?
SELinux是一个安全子系统,在这种访问控制体系的限制下,进程只能访问那些在他的任务中所需要文件。...
Hadoop 集群启动问题
by
Mrv1
https://hainiubl.com/topics/55?
2017-02-08
⋅
5747
⋅
0
⋅
5
###因为计算机内存有限,部署了3台虚拟机,一台master.hadoop,剩下两台slave1.hadoop和slave2.hadoop。
<p>按照视频上的步骤来,配置成功后,输入命令start-dfs.sh启动集群服务。从网页打开ip:50070,切换到Datanodes菜单栏下,Node这一栏在某一时刻只有一个节点,而...
cloudera manager 无法正常访问
by
 瑬氓
瑬氓
https://hainiubl.com/topics/56?
2017-02-09
⋅
7770
⋅
0
⋅
1
我启动了Manager: /opt/cloudera-manager/cm-5.4.3/etc/init.d/cloudera-scm-server start
Agents: /opt/cloudera-manager/cm-5.4.3/etc/init.d/cloudera-scm-agent start
这两条命令之后,我查看agent状态是正在运行的,但是我去访问7180端口的时候无法连接到服务...
websocket
by
 刘先森
刘先森
https://hainiubl.com/topics/57?
2017-02-13
⋅
3964
⋅
0
⋅
0
为什么我的websocket连接不上,
我的服务器的地址注册:
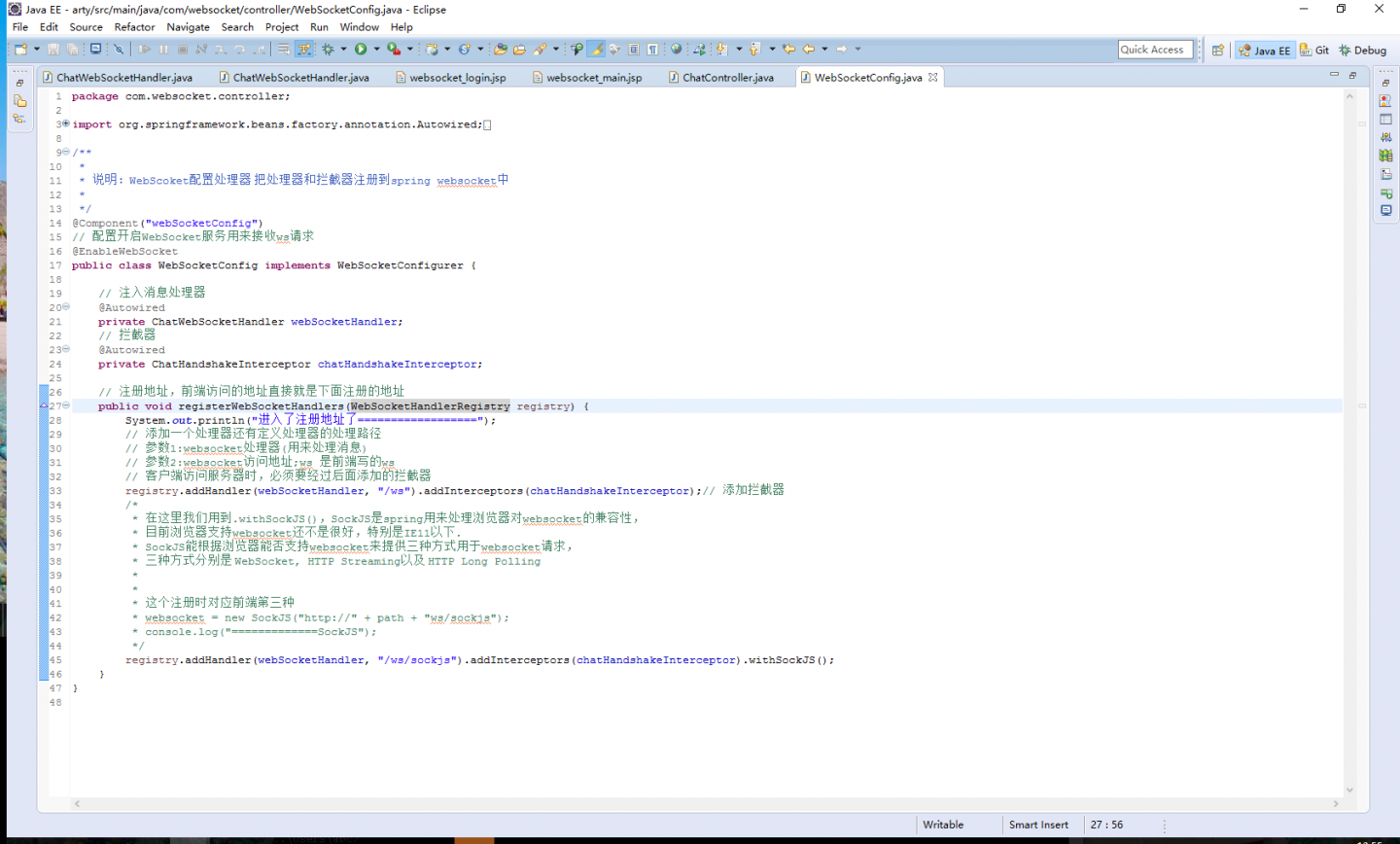
客户端连接:
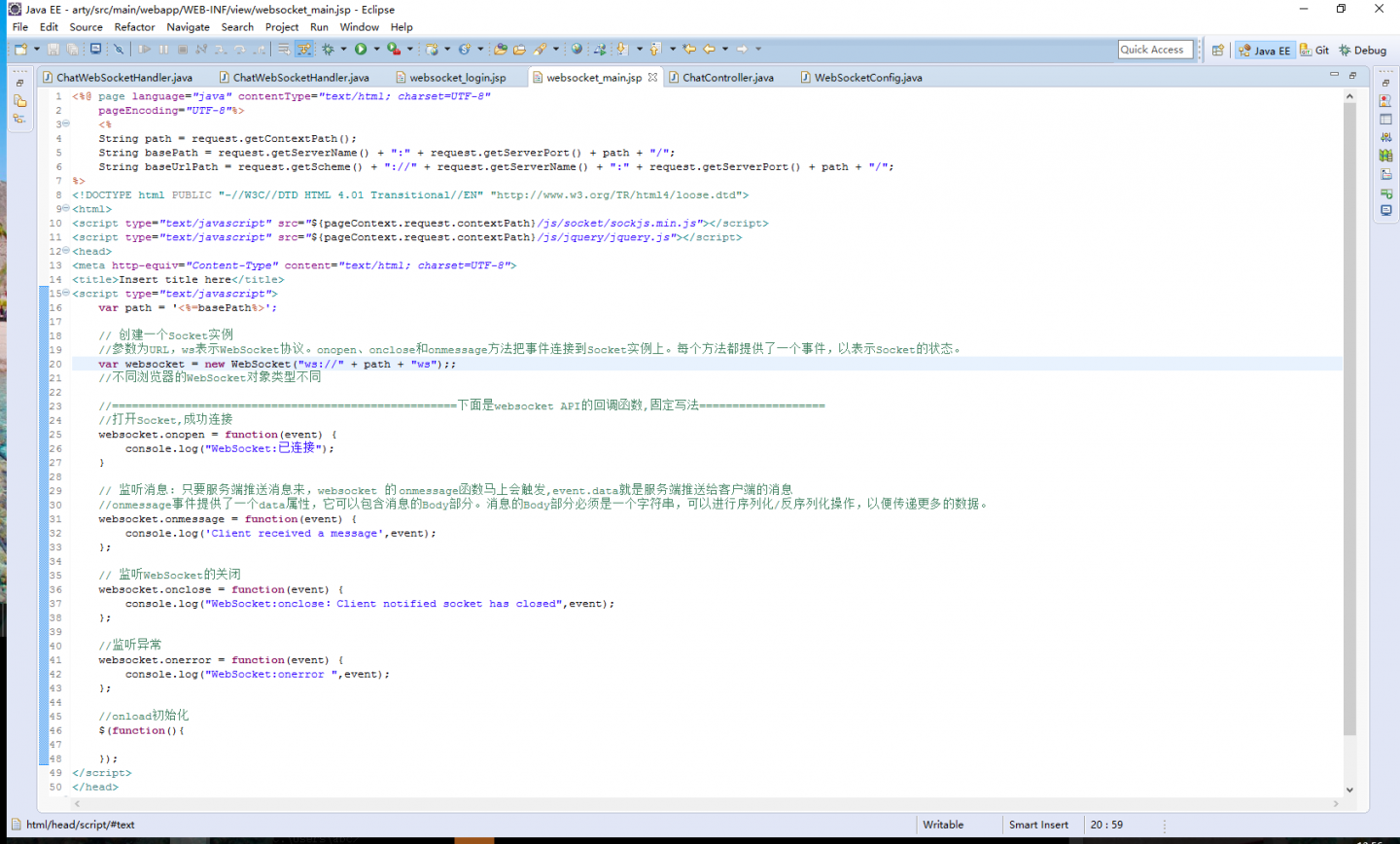
spring 已经扫描了服务器...
eclipse 编写 wordcount 出现代码小问题
by
 鲁西黄牛
鲁西黄牛
https://hainiubl.com/topics/59?
2017-02-14
⋅
4829
⋅
0
⋅
1
我的ToolRunner出了点问题
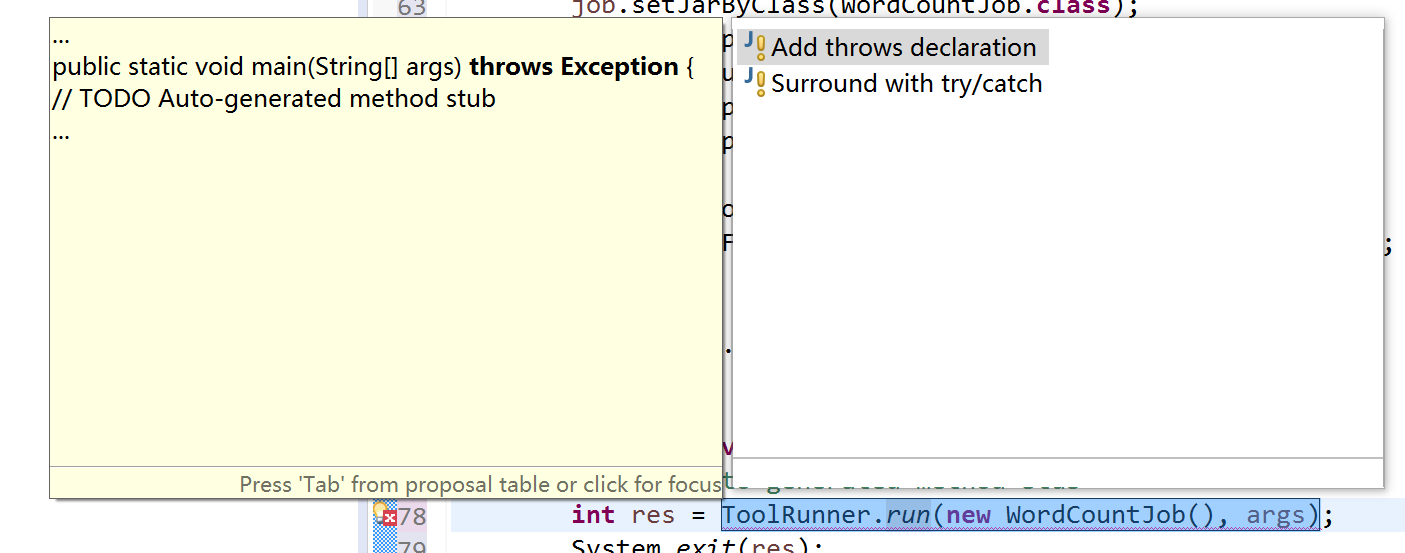
还有这个setOutputPath,提示我需要改成别的
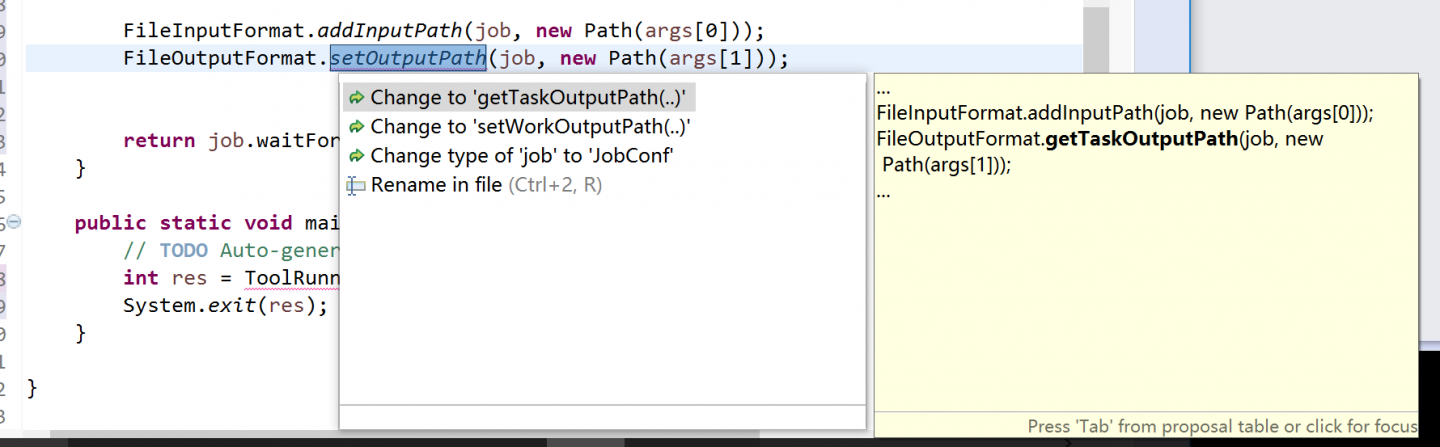
这是我引用的包
![file]...
shell 编程 CentOS6.7
by
 夏广伟
夏广伟
https://hainiubl.com/topics/60?
2017-02-14
⋅
4263
⋅
1
⋅
1
centos6.7下yum和wget命令不能用
yum install lrzsz -y 后报错
by
 Jackluolovedata
Jackluolovedata
https://hainiubl.com/topics/61?
2017-02-14
⋅
10441
⋅
1
⋅
1
[root@localhost ~]# yum install lrzsz -y
已加载插件:fastestmirror
One of the configured repositories failed (未知),
and yum doesn't have enough cached data to continue. At this point the only
safe thing yum can do is fail. There are a few w...
Eclipse 编编译 WordCount 程序报错
by
鲁西黄牛
https://hainiubl.com/topics/62?
2017-02-15
⋅
4789
⋅
0
⋅
1
编写之后,输入目录和输出目录都写好了,但是当运行的时候,显示
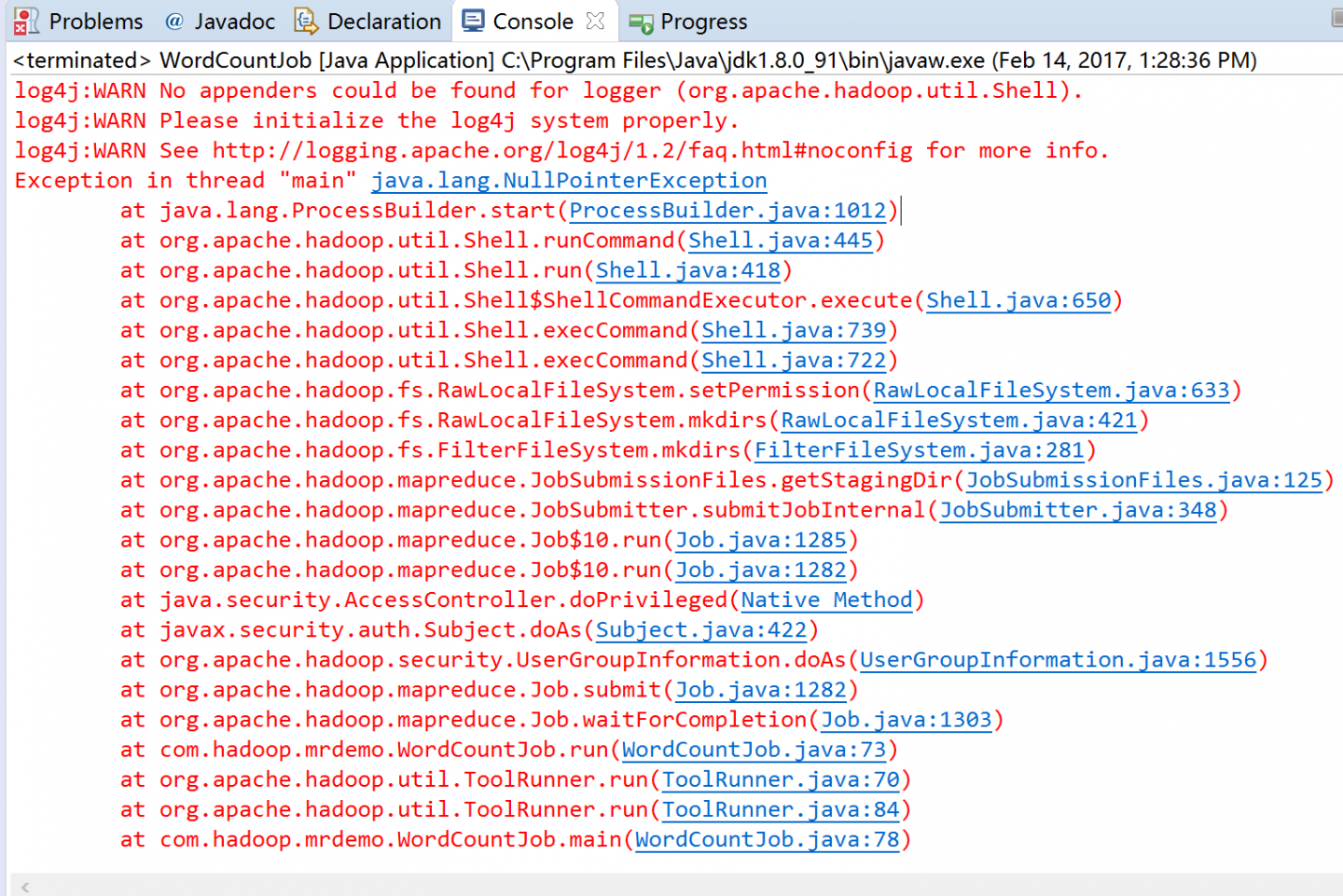
这是我路径的配置
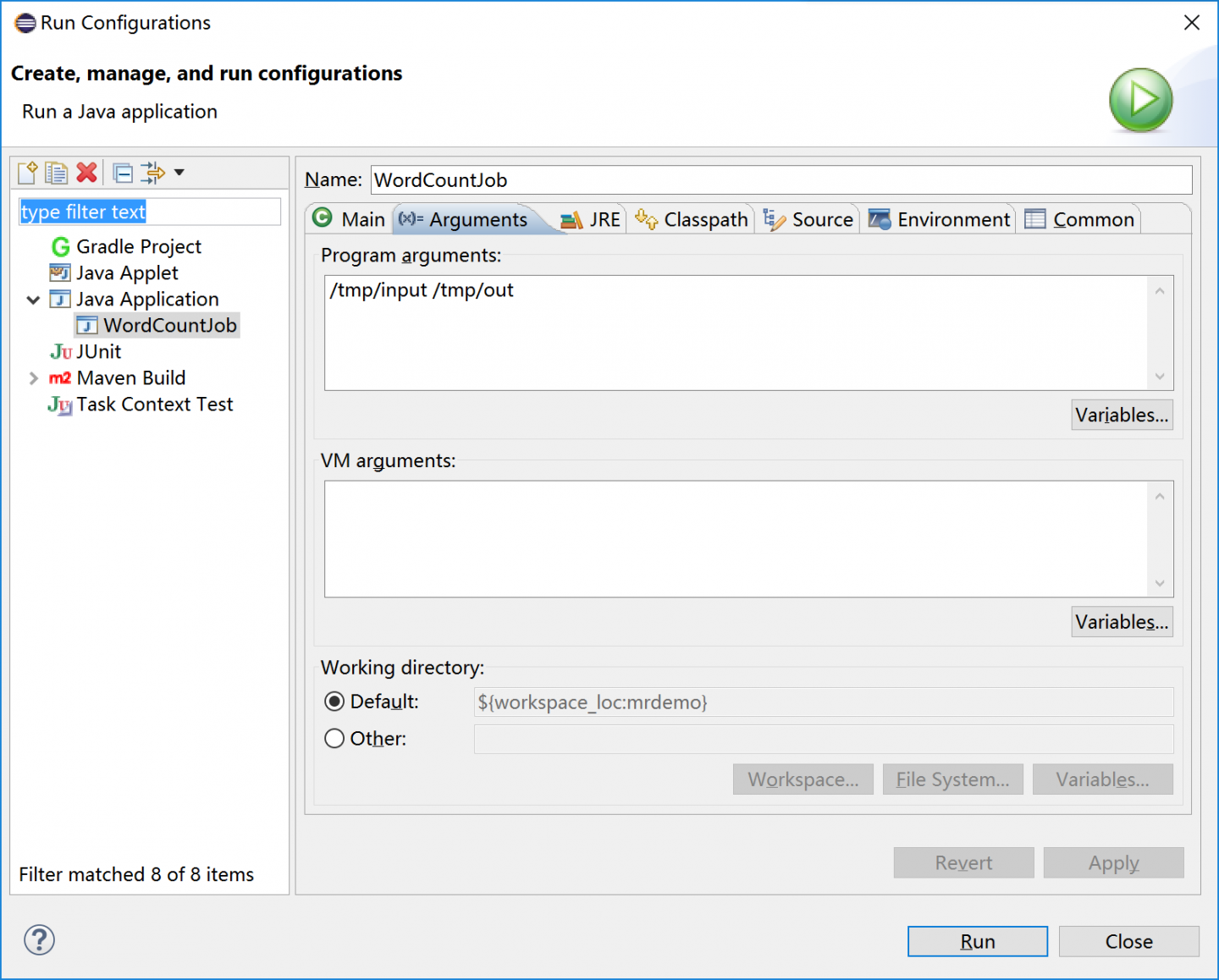
运行后,tmp文...
问题代码(wordcount)
by
鲁西黄牛
https://hainiubl.com/topics/63?
2017-02-15
⋅
3818
⋅
0
⋅
0
package com.hadoop.mrdemo;
import java.io.IOException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.LongWritable;
import org.apache.hado...
/usr/java/default 找不到不知该如何写?
by
 泰特hp5583
泰特hp5583
https://hainiubl.com/topics/65?
2017-02-17
⋅
5008
⋅
1
⋅
2
##修改hadoop运行脚本时
##/usr/java/default文件找不到,该文件应该怎么写?
本地模式运行 storm 的 wordCount 出错
by
瑬氓
https://hainiubl.com/topics/67?
2017-02-19
⋅
5575
⋅
0
⋅
0

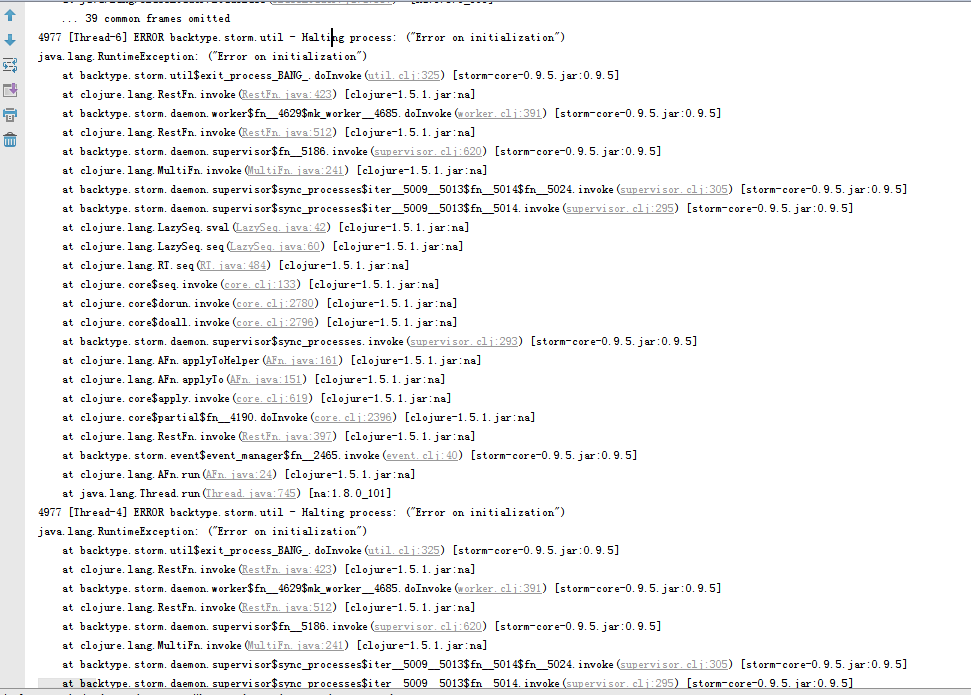
报错就是上面的截图,但是我看了依赖里面,有这个包的!!然后不知道如何解决这个storm的错误
pom.xml的添...
Hadoop DistributedCache 在 Windows 使用失败
by
青牛
https://hainiubl.com/topics/68?
2017-02-23
⋅
6181
⋅
0
⋅
0
最近有同学反馈,在windows下使用 Hadoop DistributedCache 失败.
```
17/02/23 12:13:12 INFO mapred.LocalDistributedCacheManager: Creating symlink: \tmp\hadoop-Administrator\mapred\local\1487823192632\student.dat <- D:\workspace\projects\mrdemo/stude...
分布式实时系统 STORM 的运行时模型
by
 开元
开元
https://hainiubl.com/topics/69?
2017-03-02
⋅
5565
⋅
1
⋅
0
**一 storm的静态模型**
>storm的静态模型比较好理解,弄清楚Topology,Spout,Bolt,Stream的含义大概就明白了,不清楚的可以看看strom文档中的Concepts部分。
但是storm是个并行执行的框架,运行状态下的模型是怎么样的呢?
**二 storm运行时基本模型**
>s...
mapreduce 编译出现错误,请问一下,该如何解决
by
 闭关修炼中
闭关修炼中
https://hainiubl.com/topics/70?
2017-03-10
⋅
5131
⋅
0
⋅
1
[hadoop@mini3 ~]$ hadooop jar wordcount.jar cn.itcast.bigdata.mr.flCount.FlowCount /flowsum/input /flowsum/output
-bash: hadooop: command not found
[hadoop@mini3 ~]$ hadoop jar wordcount.jar cn.itcast.bigdata.mr.flCount.FlowCount /flowsum/input /fl...
hbase 遇到的问题解决
by
 shengda
shengda
https://hainiubl.com/topics/71?
2017-03-14
⋅
10738
⋅
2
⋅
1
近两天学习Hbase的全分布式搭建,因为好几个地方疏忽,几个问题同时出现,着实费了好些时间才理清,为了方便理解,问题解决后每次只重现一个错误,分别记录。
##一、防火墙未关闭
之前记得在学Hadoop的时候所有节点的防火墙就已经关好了,所以这个问题刚开始的时候...
hadoop 集群部署
by
 水墨之风
水墨之风
https://hainiubl.com/topics/72?
2017-03-16
⋅
4629
⋅
0
⋅
1
照着视频做时出现如下问题:
slave1的ip是192.168.11.200,希望老师指导一下

Eclipse + scala 报错 missing or invalid dependency detected while loading class file 'XXX.class'...
by
shengda
https://hainiubl.com/topics/73?
2017-03-18
⋅
6795
⋅
2
⋅
1
近两天学习spark,根据官网文档http://spark.apache.org/docs/2.1.0/quick-start.html 做Self-contains App的实验时需要加载spark-core_2.11-2.1.0.jar, 因为maven的插件m2eclipse-scala(见scala ide官网http://scala-ide.org/docs/current-user-doc/gettingstarted/in...
spark streaming 没有统计结果
by
shengda
https://hainiubl.com/topics/75?
2017-03-28
⋅
5077
⋅
1
⋅
1
<pre><code>
# bin/spark-submit --class org.apache.spark.examples.streaming.HdfsWordCount examples/jars/spark-examples_2.11-2.1.0.jar hdfs://hadoop.lsd1.com:9000/wordcount/input
Using Spark's default log4j profile: org/apache/spark/log4j-defaults.pr...
大数据与商业的完美融合
by
 咚咚牛
咚咚牛
https://hainiubl.com/topics/78?
2017-05-05
⋅
4932
⋅
2
⋅
0
对于大数据,这无疑是一个前所未有的黄金时代。现在,几乎每个人的口袋里都有一部可以随时联网的智能手机,更强大的平板电脑则安静的躺在数亿人的手提包里,加之久久没有退出历史舞台的个人电脑和方兴未艾的物联网中的电子设备,这个世界,每时每刻有数以百亿计的电子精...
海牛 Hadoop 系列教程(一):服务器基础环境
by
青牛
https://hainiubl.com/topics/79?
2017-05-07
⋅
80911
⋅
115
⋅
333
###虚拟机linux使用的是centos7操作系统
###1. 安装sz rz工具,用于以后用rz sz上传下载文件
yum install -y lrzsz
###2. 将原来的yum源配置进行备份
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base_repo_bak
:批量操作多台服务器
by
青牛
https://hainiubl.com/topics/80?
2017-05-07
⋅
44098
⋅
72
⋅
199
###1. 每个虚拟机设置静态IP
cd /etc/sysconfig/network-scripts/
ifconfig/ip add 查看网卡的硬件名称和基本信息
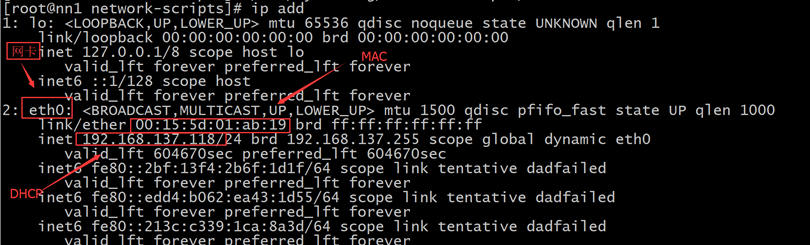
记下这个UUID
:zookeeper
by
青牛
https://hainiubl.com/topics/81?
2017-05-08
⋅
38914
⋅
66
⋅
155
###1. 复制一个nn2虚拟机并设置好主机名,静态IP,HOST
修改crt上的配置文件把当前连接名称改成好识别的,并把登录用户修改成hadoop,尽量少用root操作,这样以后登录都使用hadoop用户
验证是否当前为root用户可以用vim打开某个文件查看比如/etc/hosts
:编译 hadoop 源码
by
青牛
https://hainiubl.com/topics/82?
2017-05-08
⋅
33367
⋅
140
⋅
135
需要的软件
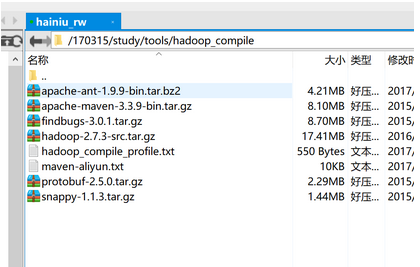
###1. 切换到su用户
mkdir hadoop_c

上传所使用的包
![file](http://hainiubl.com/uploads/...