关于 “” 的搜索结果, 共 2411 条
海牛部落 Hadoop 系列教程(五):高可用(HA)HDFS 安装
by
 青牛
青牛
https://hainiubl.com/topics/83?
2017-05-08
⋅
32382
⋅
85
⋅
125
###1. 把hadoop的tar包分发到每个机器上
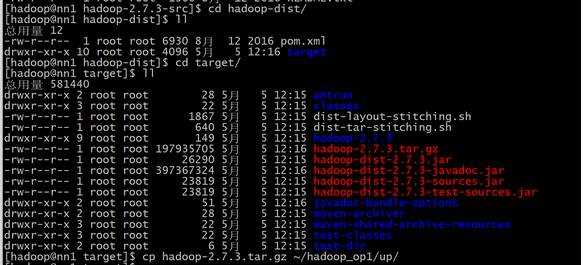
./scp_all.sh ./up/hadoop-2.7.3.tar.gz /tmp/ 拷贝到每个机器的tmp目录下
:HDFS 原理以及常用命令
by
青牛
https://hainiubl.com/topics/84?
2017-05-09
⋅
31168
⋅
68
⋅
118
###1. HDFS(Hadoop Distributed File System)有什么动机和目的
(1)提供较高的容错率,因为数据有备份,通过机架感知策略namenode会尽量将数据的复本放到不同的机架上,所以小规模的宕机不影响数据的存储。
(2)可以使用底成本的硬件搭建一个分布式文件系统,但对于一般...
大数据的神奇之处
by
 咚咚牛
咚咚牛
https://hainiubl.com/topics/85?
2017-05-10
⋅
4367
⋅
2
⋅
1
进入2012年以来,大数据(Big Date)一词越来越多地被提及与使用,它已经出现过在《纽约时报》、《华尔街时报》的专栏封面,人们用他来描述和定义信息爆炸时代产生的海量数据,进入美国白宫网的新闻,在国内一些网络主题的讲座沙龙中,被嗅觉灵敏的银河证券、国军证券、...
海牛部落 Hadoop 系列教程(七):yarn 原理以及日常使用
by
青牛
https://hainiubl.com/topics/86?
2017-05-11
⋅
30273
⋅
43
⋅
110
###1. yarn(Yet Another Resource Negotiator)的优点
(1).提高集群资源的利用率。
(2).对更多大数据处理工具的支持,从而使hadoop更像一个平台。
(3).在yarn上使用的数据处理工具是安装在客户端,而不是安装在整个集群上,所以数据处理工具更容易升级。
###2. y...
海牛部落 Hadoop 系列教程(八):mapreducer 原理
by
青牛
https://hainiubl.com/topics/87?
2017-05-12
⋅
35817
⋅
58
⋅
145
###1. mapreduce的主要目的
分而治之,化大为小。
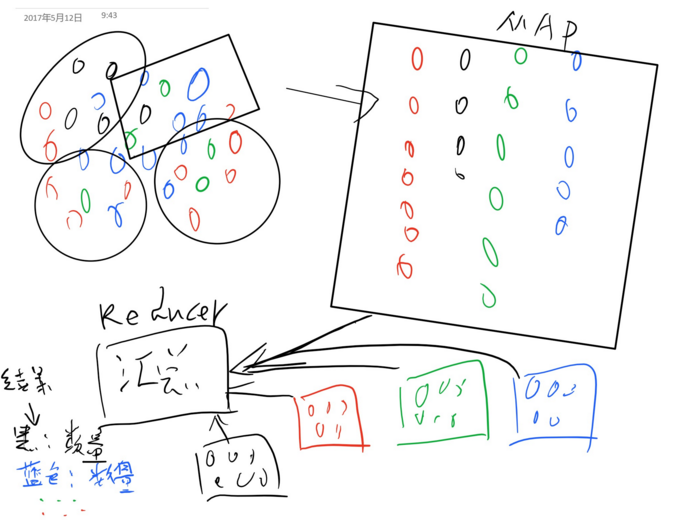
###2. map和reducer阶段分别解决什么样的问题
map阶段解决的问题,就是把输入变成KV结果用于reducer的输入
##以下内容回帖刷新可见…...
海牛部落 Hadoop 系列教程(九):hadoop 的 Windows 伪分布式环境部署
by
青牛
https://hainiubl.com/topics/88?
2017-05-15
⋅
24007
⋅
29
⋅
77
###1. mapreducer shuffle过程回顾
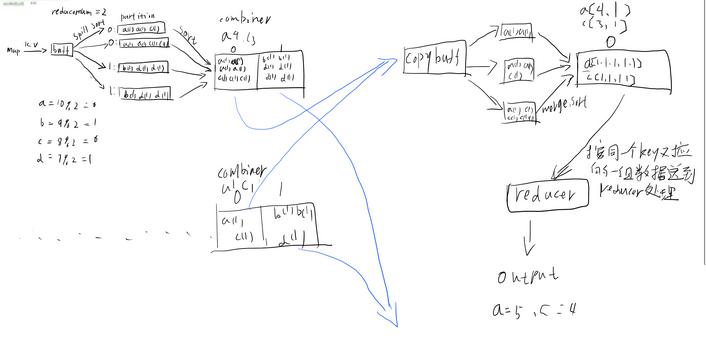
###2. 需要的软件
https://github.com/steveloughran/winutils
winutils-master
:Windows 开发 wordcount
by
青牛
https://hainiubl.com/topics/89?
2017-05-15
⋅
24198
⋅
39
⋅
70
###1. 需要的软件
###2. 解压eclipse
##以下内容回帖刷新可见………………
海牛部落 Hadoop 系列教程(十一):mapreducer 编程 counter、combiner、压缩、任务配置、MR JOB 配置文件的加载机制
by
青牛
https://hainiubl.com/topics/90?
2017-05-16
⋅
21498
⋅
72
⋅
63
###1. counter使用
mapper里设置count
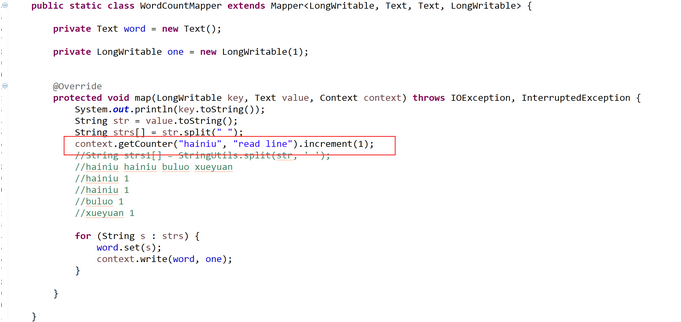
reducer里设置count

##以下内容回帖刷新可见………………
海牛部落 Hadoop 系列教程(十二):mapper 本地模式执行过程源码分析
by
青牛
https://hainiubl.com/topics/91?
2017-05-18
⋅
19617
⋅
43
⋅
44
###1. 得到jobsubmitter用于提交任务,使用的是LocalJobRunner
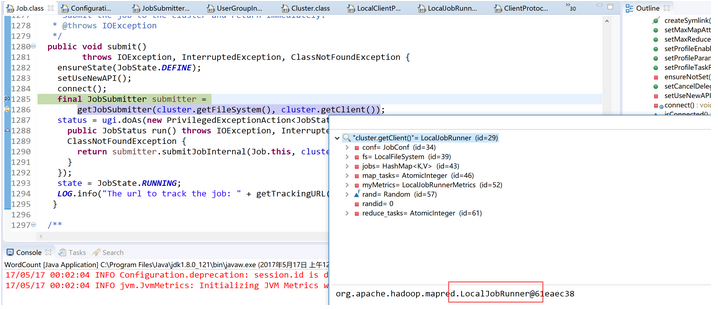
###2. 执行提交工作的提交任务方法
##以下内容回帖刷新可见………………
海牛部落 Hadoop 系列教程(十三):mapreducer 编程,排重、全局与分组的最大值最小值词计算、自定义序列化类
by
青牛
https://hainiubl.com/topics/92?
2017-05-19
⋅
19638
⋅
37
⋅
48
###1. 排重
利用reducer的输入key是已经是排重过的先天特性进行数据的排重
mapper和reducer实现

job配置
##以下内容回帖刷新可见………………
我的 VirtualBox 的安装虚拟机时版本里没有六十四位怎么办
by
 总有逗比挑衅本尊xxxxxx
总有逗比挑衅本尊xxxxxx
https://hainiubl.com/topics/93?
2017-05-19
⋅
4540
⋅
1
⋅
2
 我的电脑支持虚拟模式,但是在BIOS里找不到设置虚拟模式的 ,求大神解答
我的虚拟机都设置好了,可是启动的时候出了问题。
by
总有逗比挑衅本尊xxxxxx
https://hainiubl.com/topics/94?
2017-05-22
⋅
4264
⋅
2
⋅
1
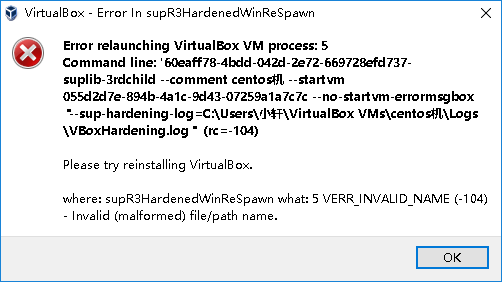
海牛部落 Hadoop 系列教程(十四):mapreducer 编程,多目录输出、innerjoin 实现、多目录输入并指定所用 mapper
by
青牛
https://hainiubl.com/topics/95?
2017-05-22
⋅
15857
⋅
85
⋅
42
###1. 多目录输出
maxout/max
maxout在输出目录下新建的文件夹
max输出文件的前缀
结果
##以下内容...
海牛部落 Hadoop 系列教程(十五):mapreducer 編程,semijoin,distributedcache 使用,排序,writableComparator 使用
by
青牛
https://hainiubl.com/topics/96?
2017-05-22
⋅
16847
⋅
69
⋅
44
###1. semijoin,distributedcache使用
semijoin的意思是在mapper端进行连接适合数据集小(一般为比较小的字典文件)与数据集大的连接。因为数据已经在maper端join了所以不需要运行reducer
使用时在客户端用-Dmapreduce.job.cache.files或者-files通过命令行指定本地...
海牛部落 hadoop 系列教程(十六):mapreducer 编程,自定义 partition 实现整体排序、自定义组合 key 实现二次排序、assembly 打包方式、集群运行 mr 程序
by
青牛
https://hainiubl.com/topics/97?
2017-05-23
⋅
16712
⋅
42
⋅
37
###1. 多个reducer实现整体排序
先观察数据情况,根据数据的分布去设计partitioner
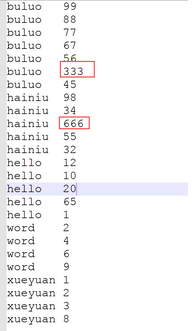
这组数据中大于100的只有2个,大部分数据还是在小于100的区间,所以就拿100当个分界点
去算0到10...
海牛部落 hadoop 系列教程(十七):mapreducer 编程,任务工作链、生产项目打包方式
by
青牛
https://hainiubl.com/topics/98?
2017-05-25
⋅
15487
⋅
99
⋅
43
###1. MR任务工作链设置流程
配置好任务依赖关系并把任务加到工作链中
使用run方法运行
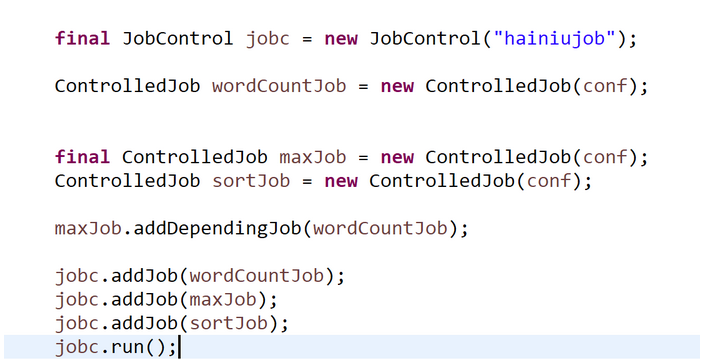
###2. 任务工作链退出方式
由于job.run是个阻塞方法,所以需要在线程中监控任务的执行结果并调用...
海牛部落 hadoop 系列教程(十八):mapreducer 编程,任务工作链高级运行方法
by
青牛
https://hainiubl.com/topics/99?
2017-05-26
⋅
20514
⋅
43
⋅
47
###1. 项目工具类
项目的工具类要统一放到util中,命名方式要以Util结尾,这样别人看到类名就知道这是一个通用的工具类
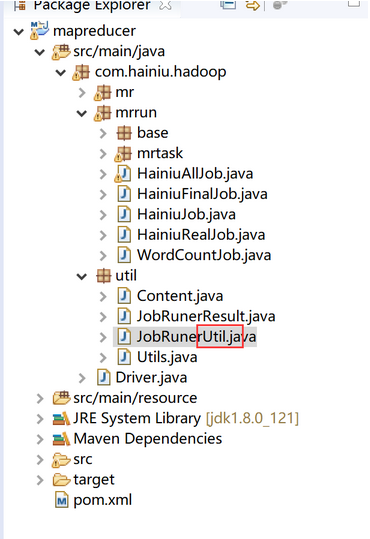
编写通用判断为空工具类
:hive 介绍与安装
by
青牛
https://hainiubl.com/topics/103?
2017-05-31
⋅
44641
⋅
14
⋅
200
###1. hive介绍
Hive是一个基于Hadoop的开源数据仓库工具,用于存储和处理海量结构化数据。它是Facebook 2008年8月开源的一个数据仓库框架,提供了类似于SQL语法的HQL语句作为数据访问接口
###2. hive的优缺点
优点:
Hive 使用类SQL 查询语法, 最大限度的实...
海牛部落 hive 系列教程(二十):hive 数据类型、运算符、建库、建表
by
青牛
https://hainiubl.com/topics/112?
2017-06-01
⋅
26351
⋅
3
⋅
86
1.hive的数据组织
基本概念和关系型数据库类似,如:库,表,列,分区。按照数据组织粒度由大到小说明:
数据库 Databases Database起到命名空间的功能,避免表,视图等定义的混乱,同时也为权限的定义及分配提供良好的隔离。
表 Tables 每个表包含一个主题信息,有...
大数据是多设备营销的未来关键因素
by
咚咚牛
https://hainiubl.com/topics/113?
2017-06-02
⋅
3813
⋅
0
⋅
0

数字营销人员肯定会接触到采用多个设备的客户。根据Criteo Mobile电子商务报告,40%的在线交易涉及多个设备。未能在不同平台上吸引客户的厂商正在使其数字化战略成为市场机会。
传统...
大数据技术在商业银行中的应用研究:场景、对策、模式
by
咚咚牛
https://hainiubl.com/topics/114?
2017-06-02
⋅
4793
⋅
2
⋅
0
###一、 大数据技术在银行业中应用的前景
20世纪以来,信息技术在金融业中的大量广泛使用,使其累积了体量庞大的数据和信息,金融机构当中存储着数以万计的数据,这种情况迫使金融机构必须要考虑如何将这些数据转换为可以创造实际价值的内容,为企业尽可能多的创造...
大数据驱动制造业迈向智能化
by
咚咚牛
https://hainiubl.com/topics/115?
2017-06-02
⋅
4597
⋅
0
⋅
0
“人类正从IT时代走向DT时代,”阿里巴巴集团创始人马云在各种场合都不遗余力地推销自己的观点,信息社会已经进入了大数据(Big Data)时代。大数据的涌现改变着人们的生活与工作方式,也改变着制造业企业的运作模式。
###一、 制造业也处于一个数据爆炸的时代
近年...
海牛部落 hive 系列教程(二十一):hive 的 orc 文件、bucket 使用、表操作、关联查询
by
青牛
https://hainiubl.com/topics/116?
2017-06-02
⋅
23967
⋅
5
⋅
77
###1. ORC文件
一、定义
ORC File,它的全名是Optimized Row Columnar (ORC) file,其实就是对RCFile做了一些优化。据官方文档介绍,这种文件格式可以提供一种高效的方法来存储Hive数据。它的设计目标是来克服Hive其他格式的缺陷。运用ORC File可以提高Hive的读、...
海牛部落 hive 系列教程(二十二):hive 的 select、union、SQL 依赖并发执行、mapsidejoin、fulljoin、GROUPINGSETS、ifcase
by
青牛
https://hainiubl.com/topics/117?
2017-06-05
⋅
20176
⋅
47
⋅
58
###1. HIVE SELECT 语法
SELECT [ALL | DISTINCT] select_expr, select_expr, ...
FROM table_reference
[WHERE where_condition]
[GROUP BY col_list]
[ORDER BY col_list]
[CLUSTER BY col_list | [DISTRIBUTE BY col_list] [SORT BY col_list] ]
[...
海牛部落 hive 系列教程(二十三):hive 的 grouping sets、排序、窗口函数用法
by
青牛
https://hainiubl.com/topics/118?
2017-06-05
⋅
19905
⋅
1
⋅
47
###1. GROUPING SETS
语法
SELECT a, b, SUM( c ) FROM tab1 GROUP BY a, b GROUPING SETS ( (a, b), a, b, () )
等于
SELECT a, b, SUM( c ) FROM tab1 GROUP BY a, b
UNION ALL
SELECT a, null, SUM( c ) FROM tab1 GROUP BY a
UNION ALL
SELECT null, b, SU...
Hive SQL 执行计划深度解析
by
青牛
https://hainiubl.com/topics/119?
2017-06-06
⋅
6973
⋅
2
⋅
0
Hive是基于Hadoop的一个数据仓库系统,在各大公司都有广泛的应用。我们公司的数据仓库也是基于Hive搭建,每天执行近万次的Hive ETL计算流程,负责每天数百GB的数据存储和分析。Hive的稳定性和性能对我们的数据分析非常关键。
在几次升级Hive的过程中,我们遇到了一些大...
海牛部落 hive 系列教程(二十四):在 eclipse 上运行 hive、自定义 UDF 和 UDAF、在集群运行自定义函数
by
青牛
https://hainiubl.com/topics/120?
2017-06-06
⋅
25012
⋅
5
⋅
79
###1. 在eclipse上运行hive
通过sh -x /usr/local/hive/bin/hive查看执行了那个类

发现是执行的hive的cli,在阿里云上搜索hive-cli
:hive 自定义 UDTF
by
青牛
https://hainiubl.com/topics/121?
2017-06-08
⋅
18774
⋅
17
⋅
58
###1. UDTF
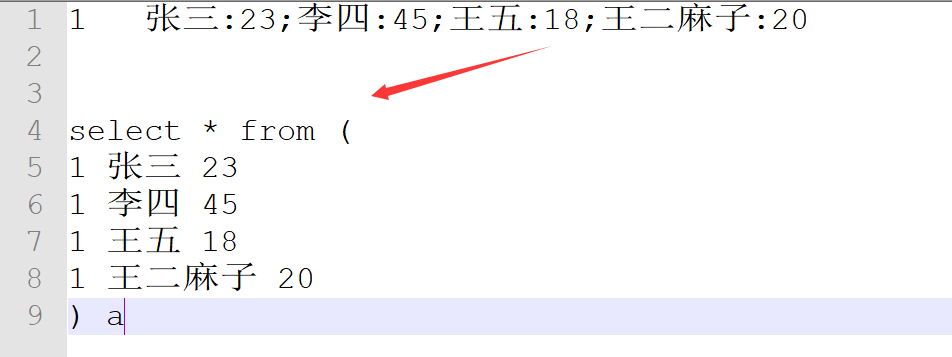
继承org.apache.hadoop.hive.ql.udf.generic.GenericUDTF,实现initialize, process, close三个方法。
:Hbase 概述与安装、Hbase 原理和简单的 shell 操作
by
青牛
https://hainiubl.com/topics/122?
2017-06-09
⋅
25114
⋅
59
⋅
82
###1. HBASE安装:
HMaster regionserver
(1).上传hbase的压缩包
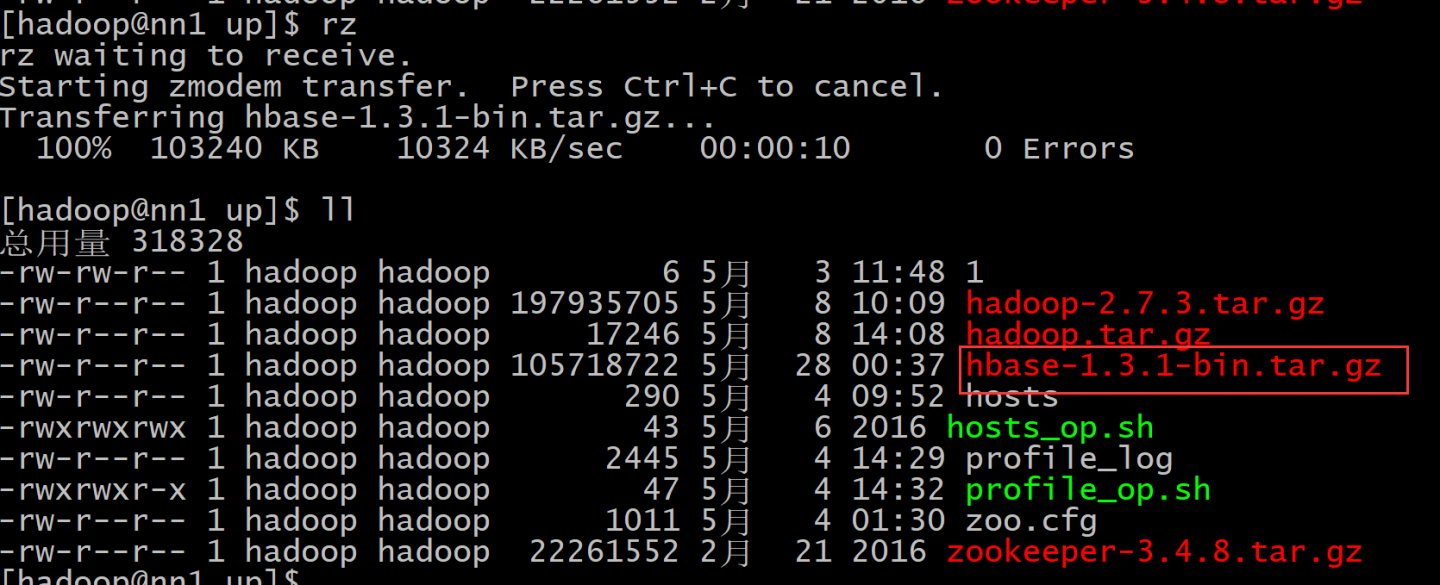
(2).分发压缩包
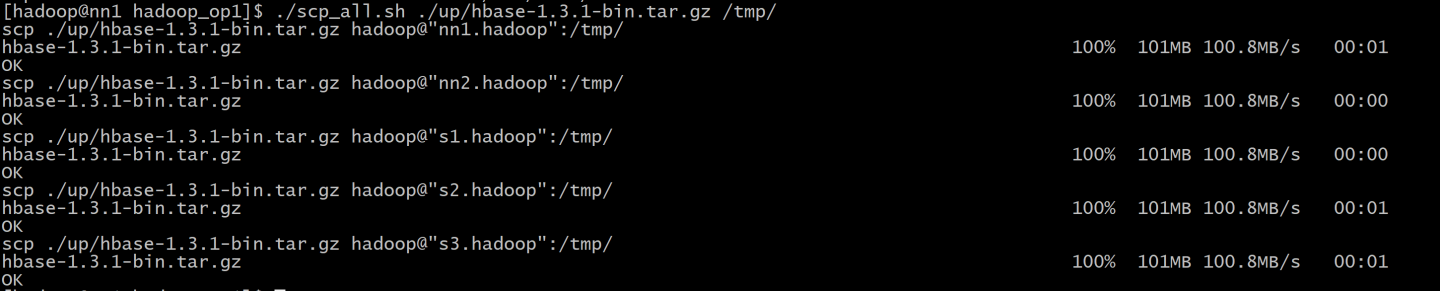
(3).解压hbase...
海牛部落 java 系列教程(二十七):Hbase 的 Java 操作
by
青牛
https://hainiubl.com/topics/123?
2017-06-12
⋅
23829
⋅
49
⋅
80
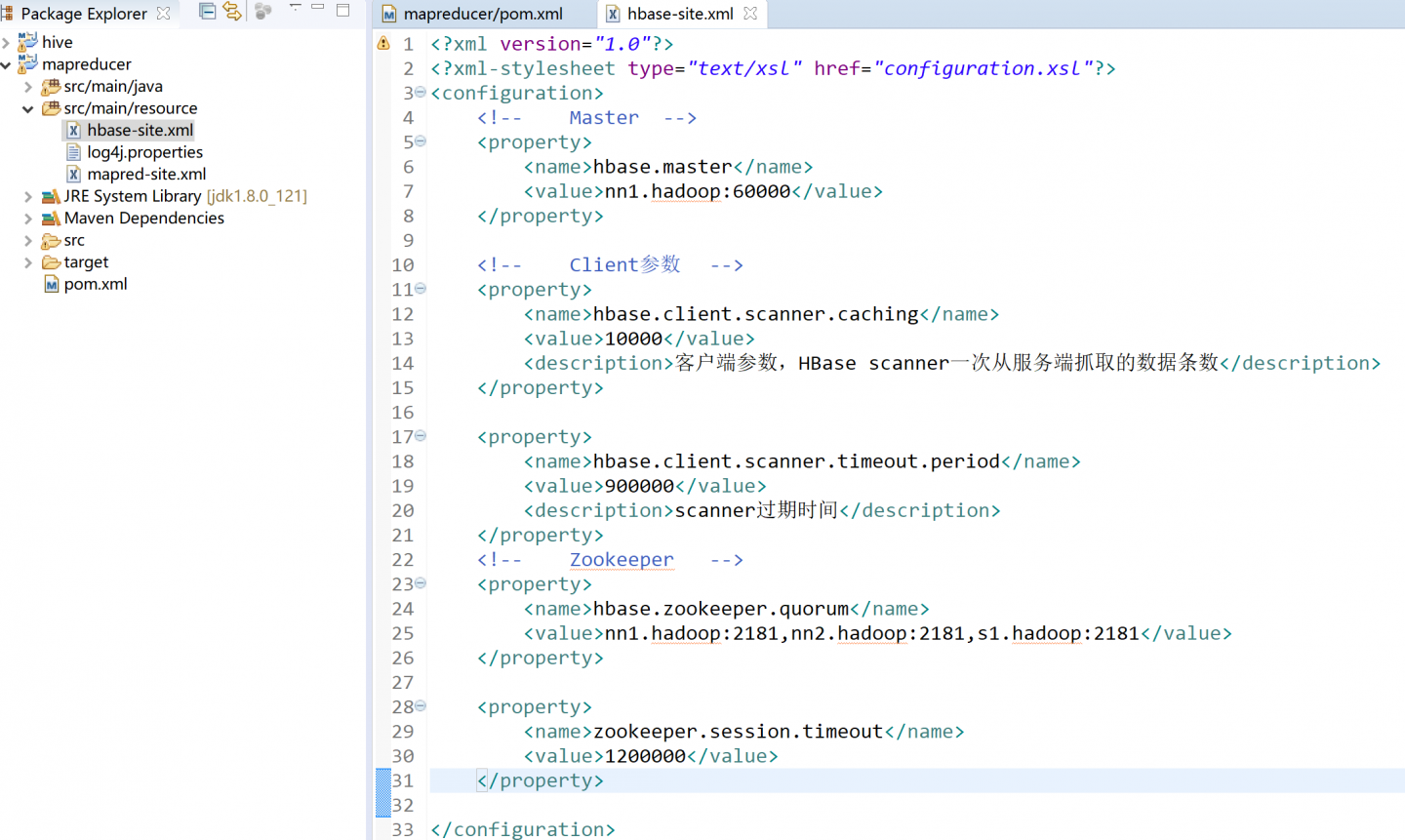
###1. eclipse上安装hbase开发环境
修改pom添加hbase-client
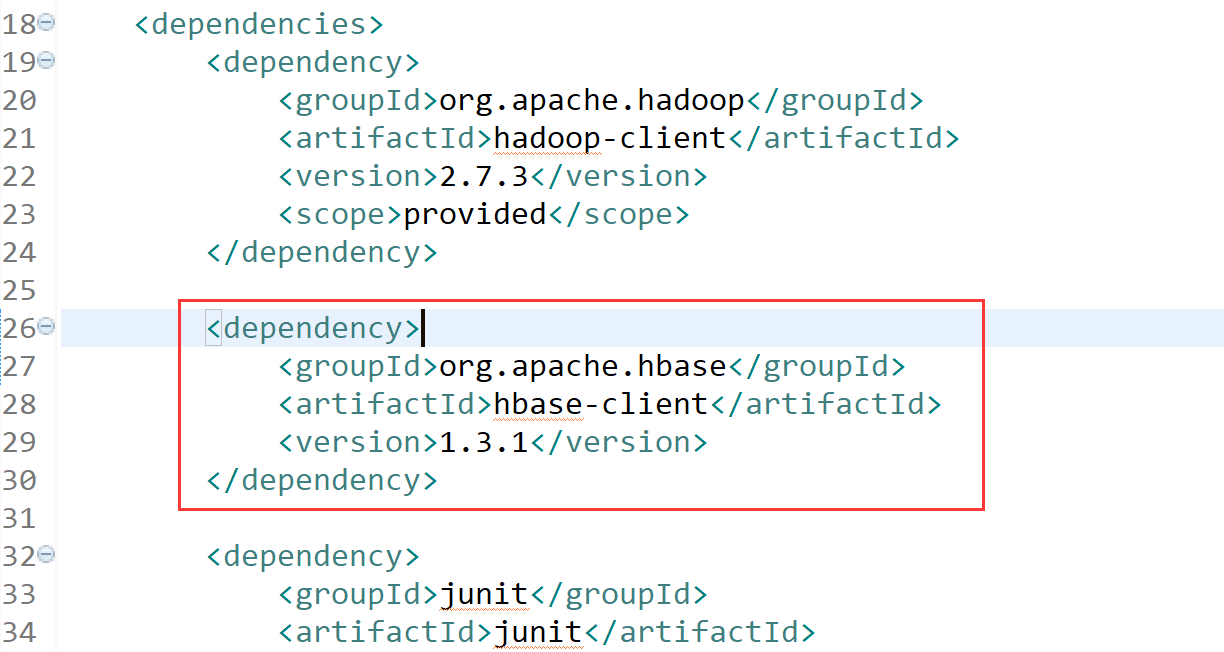
把hbase-site.xml放到resource目录下
包...