关于 “” 的搜索结果, 共 2411 条
Ubuntu 下 LNMP 开发环境源码安装
by
 紫云互联
紫云互联
https://hainiubl.com/topics/205?
2017-11-03
⋅
4395
⋅
1
⋅
0
安装Nginx
# wget http://nginx.org/download/nginx-1.8.0.tar.gz
# wget http://prdownloads.sourceforge.net/libpng/zlib-1.2.8.tar.gz
# wget ftp://ftp.csx.cam.ac.uk/pub/software/programming/pcre/pcre-8.37.tar.gz
# tar zxvf zlib-1.2.8.tar.gz
# tar zxv...
Dubbo 与 Zookeeper、SpringMVC 整合和使用
by
紫云互联
https://hainiubl.com/topics/206?
2017-11-03
⋅
4786
⋅
1
⋅
0
**windows环境介绍:**
myeclipse 10
jdk1.6
tomcat 6.0.35
一、安装Zookeeper
1.通过链接下载对应的包 http://www.apache.org/dist/zookeeper/
2.Zookeeper下载后解压即可,见下图
3.进入到conf里面,会看到zoo_sample.cfg...
scala 环境安装与基本语法
by
 青牛
青牛
https://hainiubl.com/topics/207?
2017-11-27
⋅
14209
⋅
3
⋅
18
scala介绍
hadoop(java)
hive(java)
hbase(java)
kafka(scala)
spark(scala)
scala安装
:Unit = {
println("init")
}
def main(args: Array[String]): Unit = {
val property = init()...
scala 基础 3
by
青牛
https://hainiubl.com/topics/209?
2017-11-28
⋅
9373
⋅
0
⋅
16
apply 和 unapply 方法
apply方法一般被称为注入方法一般用于伴生对象初始化的操作,apply方法的参数列表不需要和构造函数的参数列表统一
unapply方法常被称为提取方法可以用unapply方法提取相同操作的对象,unapply方法会返回一个Option,其内部生成一个Some对象...
scala 基础 4
by
青牛
https://hainiubl.com/topics/210?
2017-11-28
⋅
9790
⋅
1
⋅
11
隐式转换
作用:能够丰富现有类库的功能,对类的方法进行增强
隐式转换函数
以implicit关键字声明并带有单个参数的函数
比如1 to 10其实是调用的1.to(10)这个方法
但是在Int类中并没有to这个方法
 刘百会
刘百会
https://hainiubl.com/topics/212?
2017-12-05
⋅
4461
⋅
0
⋅
1

官方提供的restful接口
但是总是报错
根据提供的接口,我传递的参数有jobid和时间,
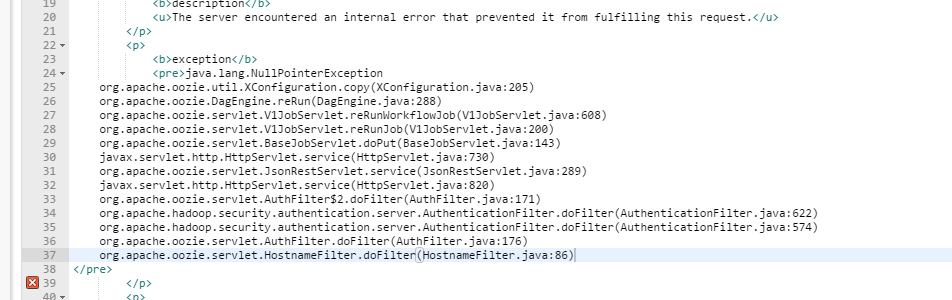
在线等,有人遇到...
请青牛老师帮忙看一下
by
 sunshine
sunshine
https://hainiubl.com/topics/213?
2017-12-06
⋅
4885
⋅
0
⋅
3


hadoop block missing
by
 竹马吃了青梅
竹马吃了青梅
https://hainiubl.com/topics/214?
2017-12-07
⋅
3673
⋅
0
⋅
1
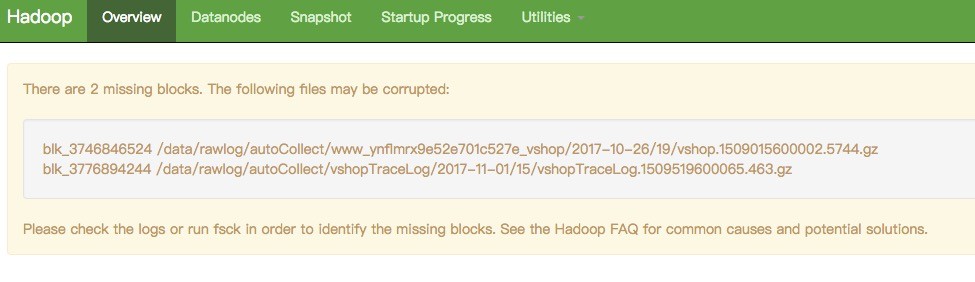
像这种有问题的block块大家一般是怎么处理的,有办法可以修复吗?
hadoop 如何统计每日提交的任务总数,map,reduce 数量
by
竹马吃了青梅
https://hainiubl.com/topics/215?
2017-12-07
⋅
4211
⋅
1
⋅
1
Hadoop如何统计每日提交的任务总数,map,reduce数量
MapReduce 编程系列
by
 HiHadoop
HiHadoop
https://hainiubl.com/topics/216?
2017-12-14
⋅
12269
⋅
1
⋅
35
Hadoop经典的wordcount, 如何只输入单词频率出现最高的单词呢? 能否给个思路呀
[公告] 海牛部落发帖及问答提问教程
by
青牛
https://hainiubl.com/topics/217?
2017-12-15
⋅
14305
⋅
3
⋅
2
一、打开海牛部落(https://www.hainiubl.com), 点击右上角“登录”按钮进入(图1)页面。点击(图1)页面中的“使用微信登录”按钮进入微信二维码登录页面(图2),手机微信扫描登录。扫描后进入(图3)填写新用户注册信息,注册成功后可直接登录。
 陳二狗
陳二狗
https://hainiubl.com/topics/218?
2017-12-15
⋅
3840
⋅
1
⋅
2
sparkstreaming 如何处理上一时刻数据,并跟当前时刻数据整合做计算
例如:
某一时刻数据为 201712152013 + id= 500
下一个处理时间片段为 201712152014 + id=1000
需要将当前id 减去上个时间段id 计算出结果
我用 python 写个计算 +docker+k8/swarm+ 分布式文件系统 达到的效果和 hadoop 系列有什么区别?
by
 海牛龙龙
海牛龙龙
https://hainiubl.com/topics/220?
2017-12-18
⋅
4418
⋅
1
⋅
1
大数据架构开发中,hadoop系列,spark系列和go,docker系列,是什么关系?
我用python写个计算+docker+k8/swarm+分布式文件系统 达到的效果和hadoop系列有什么区别?
排序、分组 的问题看不懂
by
 漂泊
漂泊
https://hainiubl.com/topics/221?
2017-12-18
⋅
4606
⋅
1
⋅
2
```
package sort;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import java.net.URI;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;...
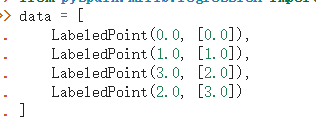
如何将 pyspark.sql.dataframe.DataFrame 类型 转换为 list () list [LabelePoint ()] 用的 python
by
 healcool
healcool
https://hainiubl.com/topics/222?
2017-12-19
⋅
13322
⋅
2
⋅
4
pyspark 用的 1.63 pyhton 3.5
如何 将查到的 表数据 自己添加 标签 转换为 带标签的 数据 自定义标签 ,随便自己怎么定

[scala基础2](http://hainiubl.com/topics/208)
[scala基础3](http://hainiubl.com/topics/209)
[scala基础4](http://hainiubl.com/topics/210)
[scala基础5](http://hainiubl.com/topics/211)
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema version.
by
 姚明臣
姚明臣
https://hainiubl.com/topics/224?
2017-12-20
⋅
15122
⋅
1
⋅
12
org.apache.hadoop.hive.metastore.HiveMetaException: Failed to get schema version.
Underlying cause: java.sql.SQLException : Access denied for user 'root'@'H001' (using password: YES)
SQL Error code: 1045
Use --verbose for detailed stacktrace.
***...
> load data local inpath '/opt/hive/student.txt' into table db_hivetest.student; 报错是为什么?
by
姚明臣
https://hainiubl.com/topics/225?
2017-12-20
⋅
6060
⋅
0
⋅
5
> load data local inpath '/opt/hive/student.txt' into table db_hivetest.student;
Loading data to table db_hivetest.student
Failed with exception org.apache.hadoop.ipc.RemoteException(java.io.IOException): File /root/hive/warehouse/db_hivetest.db/...
字段变化的表在大数据中如何存储 ?
by
 xiexie
xiexie
https://hainiubl.com/topics/227?
2017-12-22
⋅
4776
⋅
0
⋅
7
现在有个需求就是 有张表,表的字段 有时候会增加 或者减少, 用大数据的话 采用什么方式合理。我想过用HBASE,但是考虑到后续需要对这些数据进行数据分析,HBASE在数据分析这块儿 又没有什么优势。所以有些顾虑,不知道朋友有什么好的方法没 。有知道的朋友还请指点下...
用 java 写 spark 的聚合函数格式是什么
by
 陌二狗
陌二狗
https://hainiubl.com/topics/228?
2017-12-23
⋅
4291
⋅
1
⋅
9
用java写spark的聚合函数格式是什么啊,scala中这样写没错,java就不行了

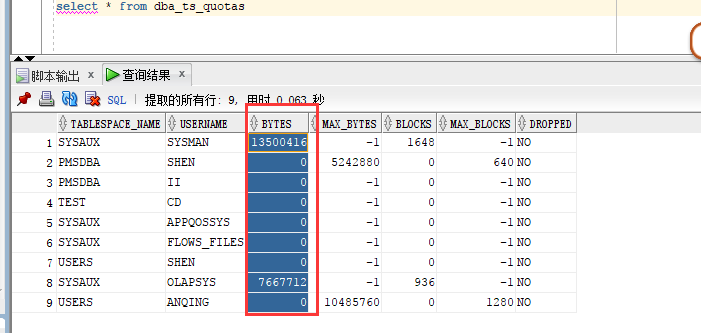
oracle 空间配额问题。求大神指教。
by
 奔跑的红烧肉
奔跑的红烧肉
https://hainiubl.com/topics/230?
2017-12-25
⋅
3387
⋅
0
⋅
1
标注的地方是已使用过配额空间的大小?
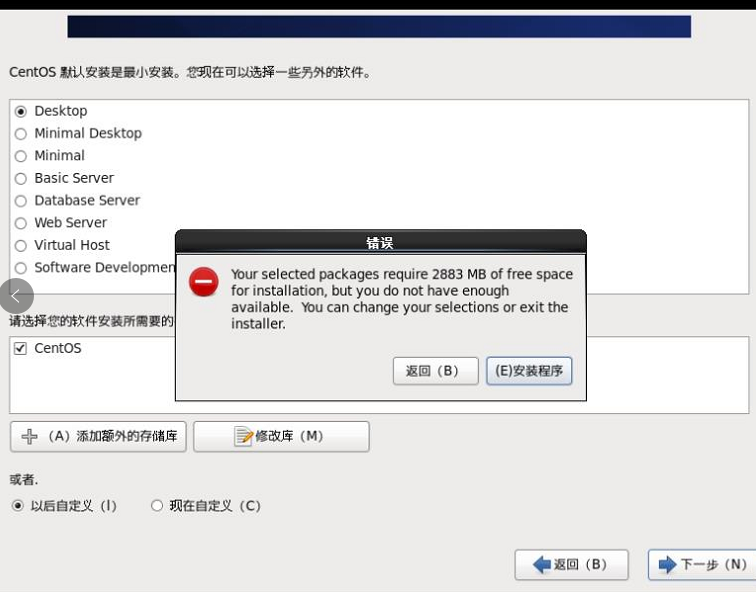
虚拟机安装总是出这个问题
by
 牛牛
牛牛
https://hainiubl.com/topics/231?
2017-12-25
⋅
2813
⋅
1
⋅
1
Spark 在 yarn 集群中提交任务失败
by
 Xibaibai
Xibaibai
https://hainiubl.com/topics/232?
2017-12-25
⋅
4249
⋅
0
⋅
1
日志如下:
```
17/12/25 09:09:15 INFO Client: Requesting a new application from cluster with 8 NodeManagers
17/12/25 09:09:15 INFO Client: Verifying our application has not requested more than the maximum memory capability of the cluster (192512 M...
数据开发与 ETL 的区别
by
 慧爱万泽
慧爱万泽
https://hainiubl.com/topics/233?
2017-12-25
⋅
7967
⋅
1
⋅
5
最近与朋友(ETL从业)聊天,发现个小白问题:发现他们做的数据清洗和存储 和数据开发的流程一样, 而数据开发后面 涉及到的分析挖掘和数据应用 理解的是应用层, 不理解的是数据开发与ETL的区别和联系, ETL工程师如果转,转开发还是转应用好。
oracle 11G 冷热备份 / 恢复的详情流程是什么?请大神详情解答。
by
奔跑的红烧肉
https://hainiubl.com/topics/234?
2017-12-26
⋅
3206
⋅
0
⋅
0
冷热备份的具体操作流程是什么。
备份、恢复的操作流程。越详细越好。求大神指教。小白再次谢过。
spark2.2 查询 MySQL 的问题
by
 maxy
maxy
https://hainiubl.com/topics/235?
2017-12-26
⋅
4952
⋅
1
⋅
7
Dataset<Row> data = spark.read().format("jdbc")
.option("driver", "com.mysql.jdbc.Driver")
.option("url", url)
.option("dbtable", table)
.option("user", "root")
.option("password", "root").load();
data.createOrRepla...
spark lambda 表达式传参
by
maxy
https://hainiubl.com/topics/236?
2017-12-27
⋅
3799
⋅
0
⋅
2
JavaPairRDD<String, Integer> pairdd=maprdd.mapToPair(line->{
String arr[] = line.split(",");
return new Tuple2<String,Integer>(arr[0],Integer.parseInt(arr[1]));
}).reduceByKey((x,y)->{
return x+y;
}).filter(我要过滤...