看到一篇文章说,直接kafka到spark到mysql出现了数据重复的问题,然后在spark后再加一个kafka,解决了数据重复问题,为什么呢??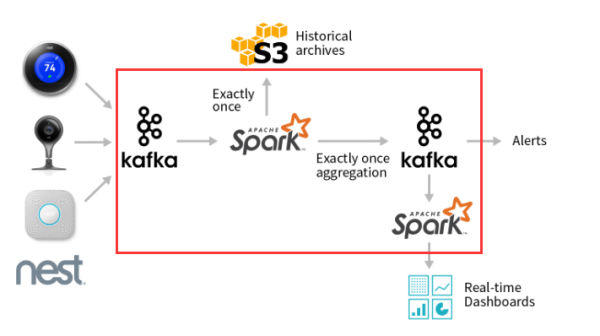
Kafka-spark-kafka-spark 架构有什么优势吗,为何两次使用 kafka?
成为第一个点赞的人吧 
回复数量: 1
-

那篇文章?什么场景?解决什么问题?
作者:七里芬芳

春风亭老朝。
- GitHub
- 公司
- 城市
七里芬芳 的其他话题
- Hive 为什么每次启动都需要初始化元数据,不然会报错如下,怎么解决?
- spark collect (),当数据量比较大时,卡死怎么解决?
- kafka spring 如何发送的消息,他自己管理 zookeeper 吗?
- Kafka-spark-kafka-spark 架构有什么优势吗,为何两次使用 kafka?
- SparkStreaming 消费 kafka 数据,怎样解决大量初始化数据的问题?
- 如何解决 Spark 大规模数据运行情况下,速度越来越慢的情况?
- spark 如何实现一个快速的 RDD 中所有的元素相互计算?
- Spark 是一种内存计算引擎,为什么他还要依赖 HDFS 这种文件系统呢?
分类下其他主题
关注海汼部落
