val spark = SparkSession
.builder()
.master("local")
.appName("testtt")
.getOrCreate()
val path ="C:/1/a.txt"
val sc = spark.sparkContext
val c: Array[(String, Int)] = sc.textFile(path)
.flatMap(.split(" "))
.map(x=>(x,1))
.reduceByKey( + _)
.collect()
这个程序为什么stage的划分跟书上的不一样,reduceByKey前面的不应该跟reduceByKey划分在一起吗?原理上说最后一个rdd划分一个stage,然后如果遇到宽依赖划分新的stage吗,但是看起来不一样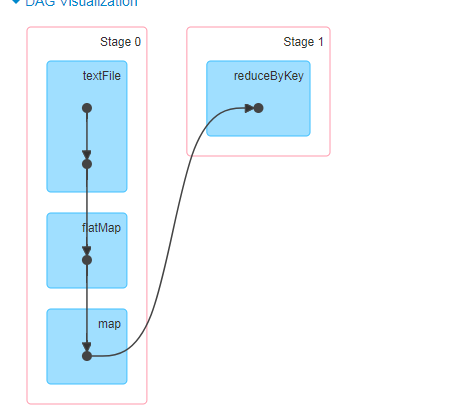
wordcount 之 stage 划分?
回复数量: 2
-

你map之前不都是没有产生宽依赖吗,你的textFile->flatMap->map在一个节点上就可以完成,reduceByKey是聚合操作,也就是说所有前置节点的数据都会shuffle到一个节点上做聚合操作。最后一个rdd产不产生stage要看是不是像reduceByKey产生宽依赖的聚合操作,如果不是聚合操作就不重新划分stage。
你看的那个书啊,不会是骗子王家林的吧 -

@青牛 能不能帮忙看看这个连接里面的案例为什么跟您解释的不一样
https://www.cnblogs.com/bonelee/p/6039469.html
作者:xiaolin93
xiaolin93 的其他话题
分类下其他主题
关注海汼部落
