
根据理解 这个 在shuffle过程中,会把相应数据划分到相应的分区中。
但是这个shuffle的时候,还不知道整个数据的全貌,如何能确认有几个partitions,又如何放置到第几个partiition中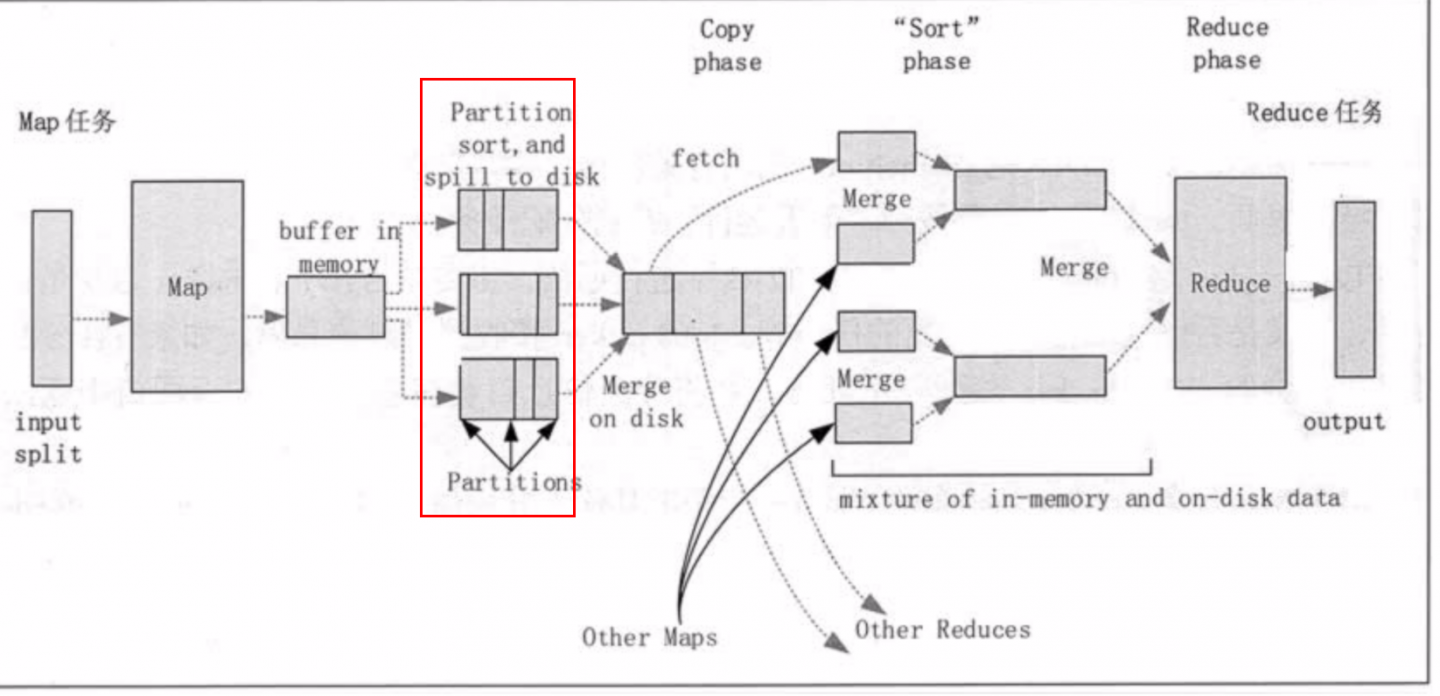
比如数据刚开始的时候 只有3个partitions,随着数据的增长整个partition的数据量会增加的
原来放到第3个partition的数据,可能就变为第4个了,且是否每个parition中包含的key值内容也发生了改变?
MR 的 shuffle 阶段 是如何确认 数据相应的分区的?
成为第一个点赞的人吧 
回复数量: 1
-

有几个reduce就有几个partition,放到那个partition中根据key的hashCode % numReduceTask去算的。一个任务跑起来那reduce的任务数就固定下来了,所以partition的数量就固定下来了,并不会因为数据变多动态调整partition。
作者:羽翔

- 公司
- 城市
羽翔 的其他话题
- 在工作中遇到一个 hive 表用到了自定义的一个类,无法查询对应表,如何将这个类部署到 hadoop 集群不同 ip 的 agent 上?
- 如何在 join 的 mapper 阶段 不同表来自多个输入时,如何指定对应的输入文件?
- 如何解决 在 mapreduce 程序进行优化的时候,使用了 snappy 和 gz 压缩格式 运行报错缺失压缩类?
- eclipse 添加 dbutils 依赖的时候 搜索不到对应的结果?
- 为什么说现在 大数据平台 存算分离 是一种更好的方案?
- MR 的 shuffle 阶段 是如何确认 数据相应的分区的?
- 运行 Word count 报错 Exception in thread "main" java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows.access0 (Ljava/lang/String;I) Z ?
- nn1.hadoop:8088 页面中的 user metrics for dr.who 的作用是什么?
分类下其他主题
关注海汼部落
