问两个问题:
1.MyAvgUDAF这个例子中,那个自定义缓冲区不擦写好像也没有问题,我们这个算平均值的例子是不是可以不擦除?
2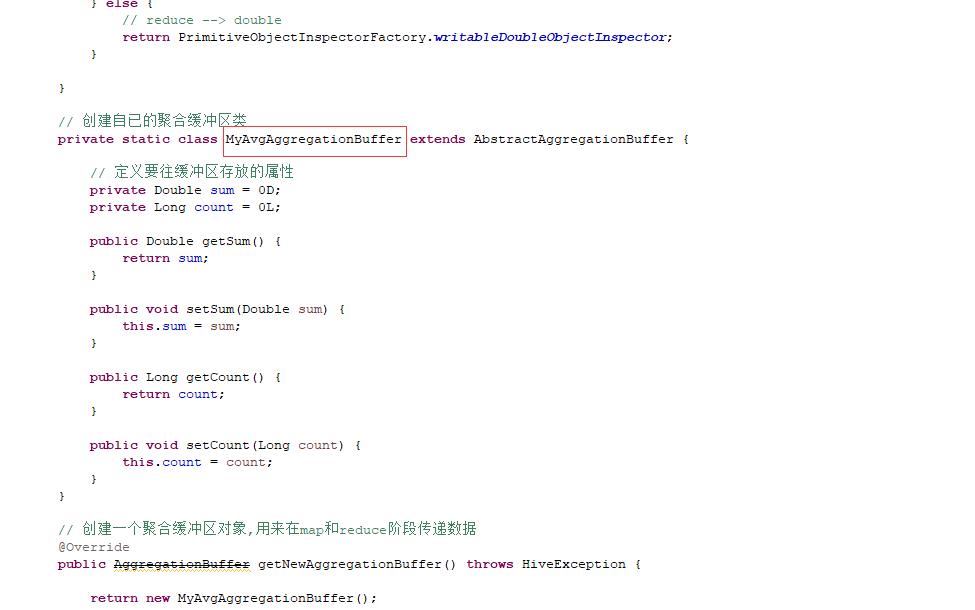 这个自定义缓冲区在分布式环境下运行时,是怎么个原理,是每一个node上都会有一个独立的MyAvgAggregationBuffer对象,这个node的map的任务共享这个缓冲区吗?最后的结果值是怎么汇总到一起的?
这个自定义缓冲区在分布式环境下运行时,是怎么个原理,是每一个node上都会有一个独立的MyAvgAggregationBuffer对象,这个node的map的任务共享这个缓冲区吗?最后的结果值是怎么汇总到一起的?
hive 自定义 udaf 的缓冲区集群工作原理是什么?
成为第一个点赞的人吧 
回复数量: 3
-

MyAvgAggregationBuffer就是数据的bean,每map用自己的,然后在reduce进行汇总,merge方法就相当于reducer中的reduce方法,UDAF那几个方法就是个mr的过程。
-

@青牛 红框中的获取缓冲区是获取这个map自已的缓冲区还是其他map的?
下面又进行了聚合,我没懂它是和缓冲区中谁的值进行聚合了?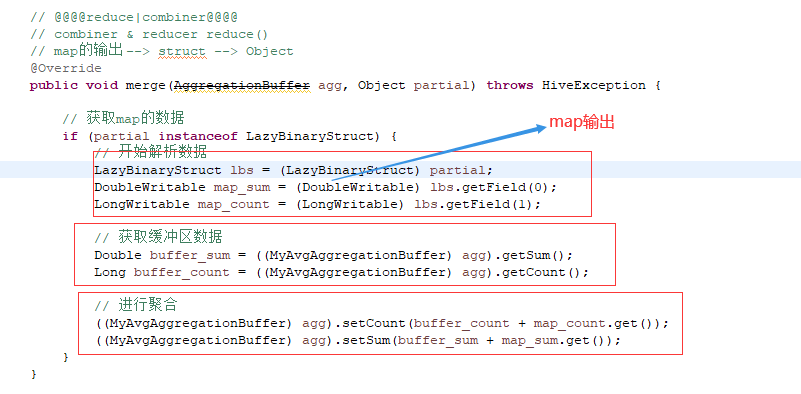
-
@Balder-Chang 不要把它理解成缓冲区,就理解成数据的bean,过去的是自己的,底层是mr都是自己跑自己的。
如果觉得我的文章对您有用,请随意打赏。你的支持将鼓励我继续创作!

请使用微信扫描二维码。
Balder-Chang 的其他话题
分类下其他主题
关注海汼部落
