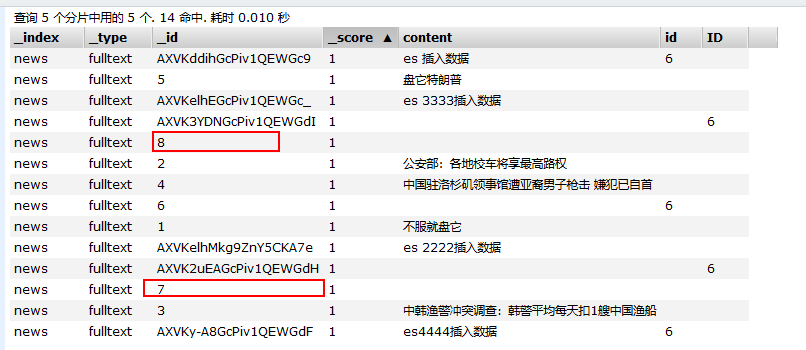
我在用Spark插入Es时,不想用Es自己生成的ID,但自己插入ID报错。代码如下图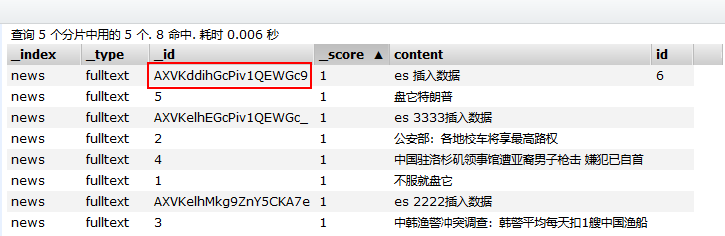
val conf: SparkConf = new SparkConf().setAppName("SparkElasticsearch").setMaster("local[*]")
conf.set("es.index.auto.create", "true")
conf.set("es.nodes", "s1.hadoop")
conf.set("es.port", "9200")
conf.set("es.index.auto.create", "false")
val sc: SparkContext = new SparkContext(conf)
//插入数据, "_id" -> 6
val saveRdd: RDD[Map[String, Any]] = sc.parallelize(Array(Map("_id" -> 6, "content" -> "es4444插入数据")))
saveRdd.saveToEs("news/fulltext")错误如下图:
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/F:/apache-maven-3.5.0/repository/org/slf4j/slf4j-log4j12/1.7.16/slf4j-log4j12-1.7.16.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/F:/apache-maven-3.5.0/repository/org/apache/logging/log4j/log4j-slf4j-impl/2.4.1/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
[Stage 0:> (0 + 0) / 12]20/10/21 17:42:52 ERROR spark.TaskContextImpl: Error in TaskCompletionListener
org.elasticsearch.hadoop.rest.EsHadoopInvalidRequest: Found unrecoverable error [192.168.17.83:9200] returned Bad Request(400) - Field [_id] is a metadata field and cannot be added inside a document. Use the index API request parameters.; Bailing out..
at org.elasticsearch.hadoop.rest.RestClient.processBulkResponse(RestClient.java:251)
at org.elasticsearch.hadoop.rest.RestClient.bulk(RestClient.java:203)
at org.elasticsearch.hadoop.rest.RestRepository.tryFlush(RestRepository.java:222)
at org.elasticsearch.hadoop.rest.RestRepository.flush(RestRepository.java:244)
at org.elasticsearch.hadoop.rest.RestRepository.close(RestRepository.java:269)
at org.elasticsearch.hadoop.rest.RestService$PartitionWriter.close(RestService.java:121)
at org.elasticsearch.spark.rdd.EsRDDWriter$$anonfun$write$1.apply(EsRDDWriter.scala:60)
at org.elasticsearch.spark.rdd.EsRDDWriter$$anonfun$write$1.apply(EsRDDWriter.scala:60)
at org.apache.spark.TaskContext$$anon$1.onTaskCompletion(TaskContext.scala:123)
at org.apache.spark.TaskContextImpl$$anonfun$markTaskCompleted$1.apply(TaskContextImpl.scala:97)
at org.apache.spark.TaskContextImpl$$anonfun$markTaskCompleted$1.apply(TaskContextImpl.scala:95)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:48)
at org.apache.spark.TaskContextImpl.markTaskCompleted(TaskContextImpl.scala:95)
at org.apache.spark.scheduler.Task.run(Task.scala:112)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:322)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
20/10/21 17:42:52 ERROR executor.Executor: Exception in task 11.0 in stage 0.0 (TID 11)
org.apache.spark.util.TaskCompletionListenerException: Found unrecoverable error [192.168.17.83:9200] returned Bad Request(400) - Field [_id] is a metadata field and cannot be added inside a document. Use the index API request parameters.; Bailing out..
at org.apache.spark.TaskContextImpl.markTaskCompleted(TaskContextImpl.scala:105)
at org.apache.spark.scheduler.Task.run(Task.scala:112)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:322)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
20/10/21 17:42:52 WARN scheduler.TaskSetManager: Lost task 11.0 in stage 0.0 (TID 11, localhost, executor driver): org.apache.spark.util.TaskCompletionListenerException: Found unrecoverable error [192.168.17.83:9200] returned Bad Request(400) - Field [_id] is a metadata field and cannot be added inside a document. Use the index API request parameters.; Bailing out..
at org.apache.spark.TaskContextImpl.markTaskCompleted(TaskContextImpl.scala:105)
at org.apache.spark.scheduler.Task.run(Task.scala:112)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:322)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)
20/10/21 17:42:52 ERROR scheduler.TaskSetManager: Task 11 in stage 0.0 failed 1 times; aborting job
Exception in thread "main" org.apache.spark.SparkException: Job aborted due to stage failure: Task 11 in stage 0.0 failed 1 times, most recent failure: Lost task 11.0 in stage 0.0 (TID 11, localhost, executor driver): org.apache.spark.util.TaskCompletionListenerException: Found unrecoverable error [192.168.17.83:9200] returned Bad Request(400) - Field [_id] is a metadata field and cannot be added inside a document. Use the index API request parameters.; Bailing out..
at org.apache.spark.TaskContextImpl.markTaskCompleted(TaskContextImpl.scala:105)
at org.apache.spark.scheduler.Task.run(Task.scala:112)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:322)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1142)
at java.util.concurrent.ThreadPoolExecutor$Worker.run(ThreadPoolExecutor.java:617)
at java.lang.Thread.run(Thread.java:745)