设计规范选择
在实际生产过程中,尤其是在模型设计的过程中经常会涉及到范式化问题,我们分为范式化和逆范式化两种。
| 模型 | 数据冗余 | 性能 |
|---|---|---|
| 范式化 | 数据没有冗余,更新容易。 | 当表的数量比较多,查询设计需要很多关联模型(join)时,会导致查询性能低下。 |
| 逆范式化 | 数据冗余将带来很好的读取性能 (因为不需要join很多表,而且通常反范式模型很少做更新操作)。 | 需要维护冗余数据,从目前NoSQL的发展可以看到,对磁盘空间的消耗是可以接受的。 |
范式化跟逆范式化所要求的正好相反,在逆范式的设计模式中允许适当的数据的冗余,用这个冗余去换取操作数据时间的缩短,用空间来换取时间,把数据冗余在多个表中,当查询时,可以减少或者是避免表之间的关联,从而提高sql执行效率,在GaussDB 200数据库中,数据均匀分布在每个节点上,数据处理(扫描、关联、分组等)负载被分摊到每个节点,利用了集群的优势,从而极大提升了业务查询性能。
行、列存储选择
各自适用场景
- 行存储
- 点查询,返回数据较少,基于索引的查询
- 增删改较多的场景
- 列存储
- 统计分析类查询,group、join较多的场景
- 即席查询场景,查询条件列不确定,使用行存无法确定索引
数据分布方式
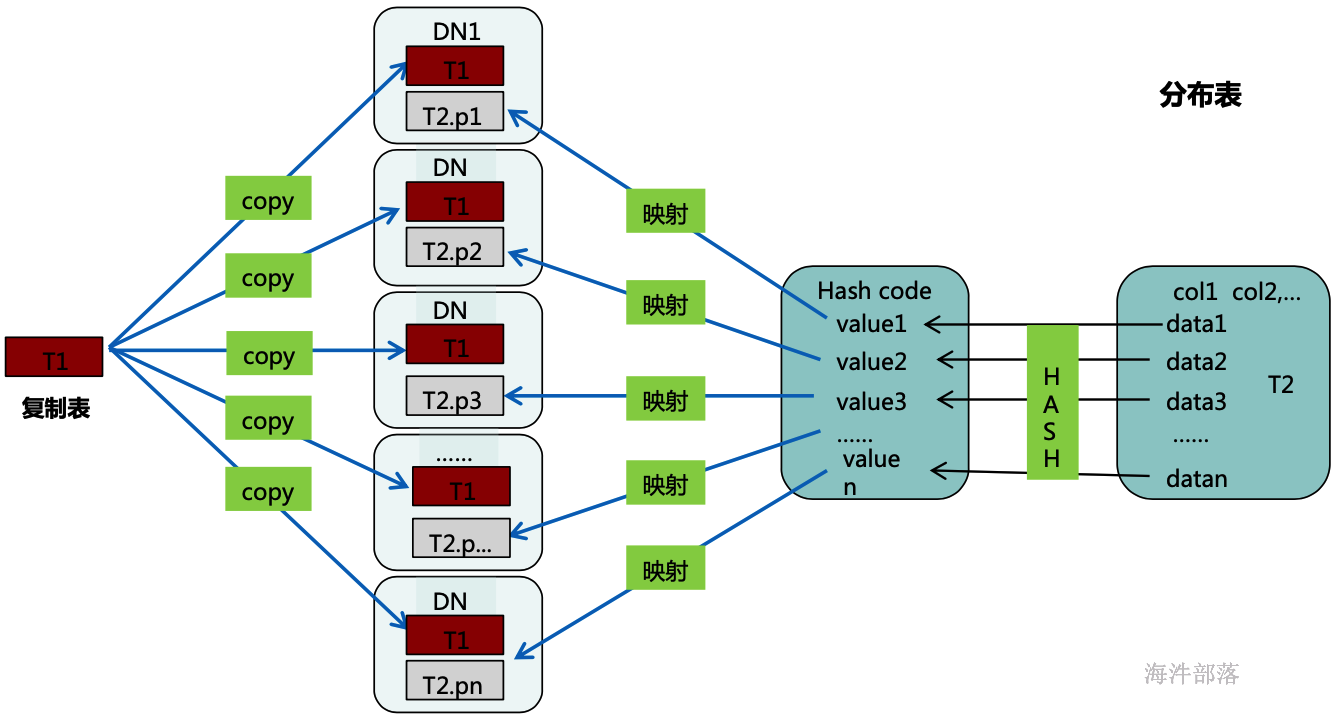
数据分布方式如上图分为复制表与分布表两种。
-
复制表(replication)
将表中的所有数据复制到每一dn节点上,适用于一些常用且较小的表
-
分布表(hash散列)
将表中指定字段(col2)进行hash运算后,生成对应的hash值,根据DN实例与哈希值的映射关系获得该元组的目标存储位置,适用于数据量较大的表(如图中T2) ,在实际生产过程中,合理选择分布键尤为重要。
分布存储和并发查询是MPP架构数据库的主要优势所在。将一个大数据量表中的数据, 按合适分布策略分散存储在多个DN实例内,可极大提升数据库性能。
GaussDB 200支持如下表所示的数据分布策略:
| 策略 | 描述 | 适用场景 |
|---|---|---|
| 散列(Hash) | 将表中的数据通过hash方式散列到集群中的所有DN实例上。 | 数据量较大的表。 |
| 复制(Replication) | 将表中的数据复制到所有DN实例 上,每个DN实例都拥有全量数据。 | 数据量较小的表(10W行记录以下),根据集群数量酌情处理。 |
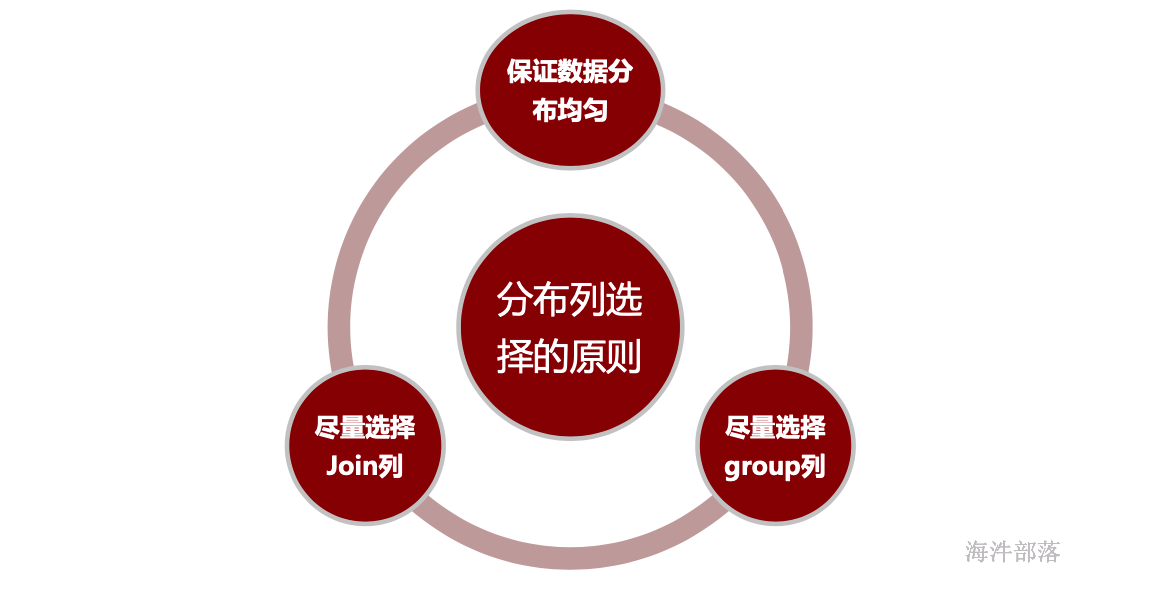
分布列选择策略:
-
尽量选择distinct值比较多的列,保证数据均匀分布,分布均匀是为了避免木桶效应,各个主机对等执行。
- 尽量选择Join列或group 列做分布列,尽量选择Join列或group列是为了避免数据节点之间数据流动, 提高性能。
当不指定表分布策略的时候,默认为分布表。

