gaussdb200存储过程
-
声明部分:声明PL/SQL用到的变量,类型及游标,以及局部的存储过程和函数。
DECLARE -
执行部分:过程及SQL语句,程序的主要部分。必选。
BEGIN -
执行异常部分:错误处理。可选。
EXCEPTION -
结束
END; / -
存储过程简单示例
DECLARE var varchar(20); num1 integer; BEGIN var := 'xiniu'; dbms_output.put_line('hello '||var); num1 := 1/0; EXCEPTION WHEN division_by_zero THEN RAISE NOTICE 'caught division_by_zero'; END; /
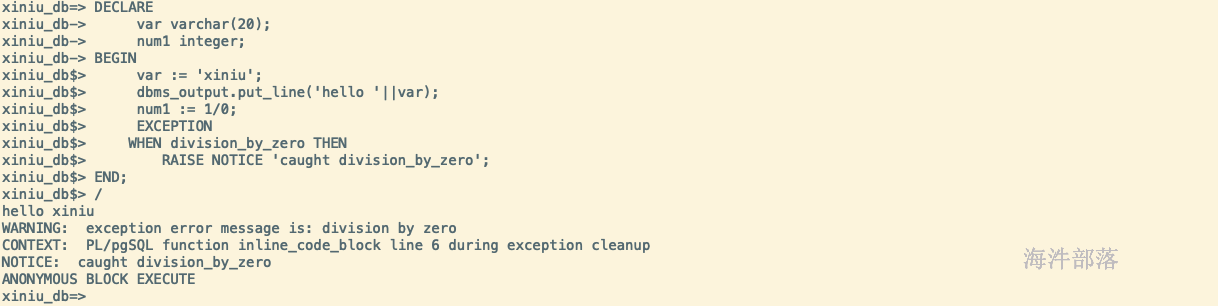
-
存储过程变量声明与赋值
DECLARE -- 变量声明并赋值 VAR1 integer := 1; -- 变量声明 VAR2 varchar(20); BEGIN -- dbms_output.put_line为打印到控制台语句,|| 为字符串拼接 dbms_output.put_line('变量var1声明时的初始值:'||VAR1); -- 为变量赋值 VAR1 := 2; VAR2 := VAR1 * 100; dbms_output.put_line('变量var1重新赋值后的值:'||VAR1); dbms_output.put_line('变量var2的值:'||VAR2); END; /

-
调用语句
-- 创建存储过程customer_address_procedure CREATE OR REPLACE PROCEDURE customer_address_procedure ( -- 没有带输入输出关键字的字段是输入字段 ca_address_sk_in NUMBER(6), -- out 关键字代表是输出字段 sk_sum out NUMBER(8,2), sk_cnt out INTEGER ) IS BEGIN -- 使用into关键字为后面的变量赋值 SELECT sum(ca_address_id), count(*) INTO sk_sum, sk_cnt FROM myschema.customer_address where ca_address_sk = ca_address_sk_in; END; / -- 创建存储过程customer_address_procedure2 CREATE OR REPLACE PROCEDURE customer_address_procedure2 AS -- 声明变量 v_num NUMBER(8,2); v_sum INTEGER; BEGIN -- 调用语句 并且给两个变量赋值 customer_address_procedure(1, v_sum, v_num); -- 打印输出 dbms_output.put_line(v_sum||'#'||v_num); -- 返回语句 RETURN; END; / -- 调用存储过程customer_address_procedure2. CALL customer_address_procedure2(); -- 清除存储过程 DROP PROCEDURE customer_address_procedure2; DROP PROCEDURE customer_address_procedure; -- 创建函数func_return. CREATE OR REPLACE FUNCTION func_return returns void language plpgsql AS $$ DECLARE v_num INTEGER := 1; BEGIN dbms_output.put_line(v_num); -- 返回语句 RETURN; END $$; -- 调用函数func_return CALL func_return(); -- 清除函数 DROP FUNCTION func_return;


gaussdb200函数与返回值
-
无参函数声明,指定类型返回
-- 无参函数 返回类型为integer CREATE OR REPLACE FUNCTION void_func() RETURNS integer -- 必须指定过程语言(PL/PGSQL) language plpgsql AS $$ DECLARE -- 声明一个int类型变量并赋初始值为0 res integer := 0; BEGIN -- 循环1到10 FOR i IN 1 .. 10 LOOP -- 给res赋值 res:=res + i; dbms_output.put_line('i:'||i); dbms_output.put_line('当前res值:'||res); END LOOP; -- 返回res RETURN res; END $$; -- 调用函数 call void_func(); -- 删除函数 drop function void_func();

-
有参函数构建
-- 创建一张临时表并插入数据 CREATE TABLE t1(a int); INSERT INTO t1 VALUES(1),(10),(100),(1000),(10000); -- 创建有参函数 create or replace function func(insert_data int) returns void language plpgsql as $$ begin -- 插入数据 insert into t1 values (insert_data); end $$; -- 调用函数 call func(100000); -- 查询表 select * from t1; -- 删除函数 drop function func; -- 清除表 drop table t1;
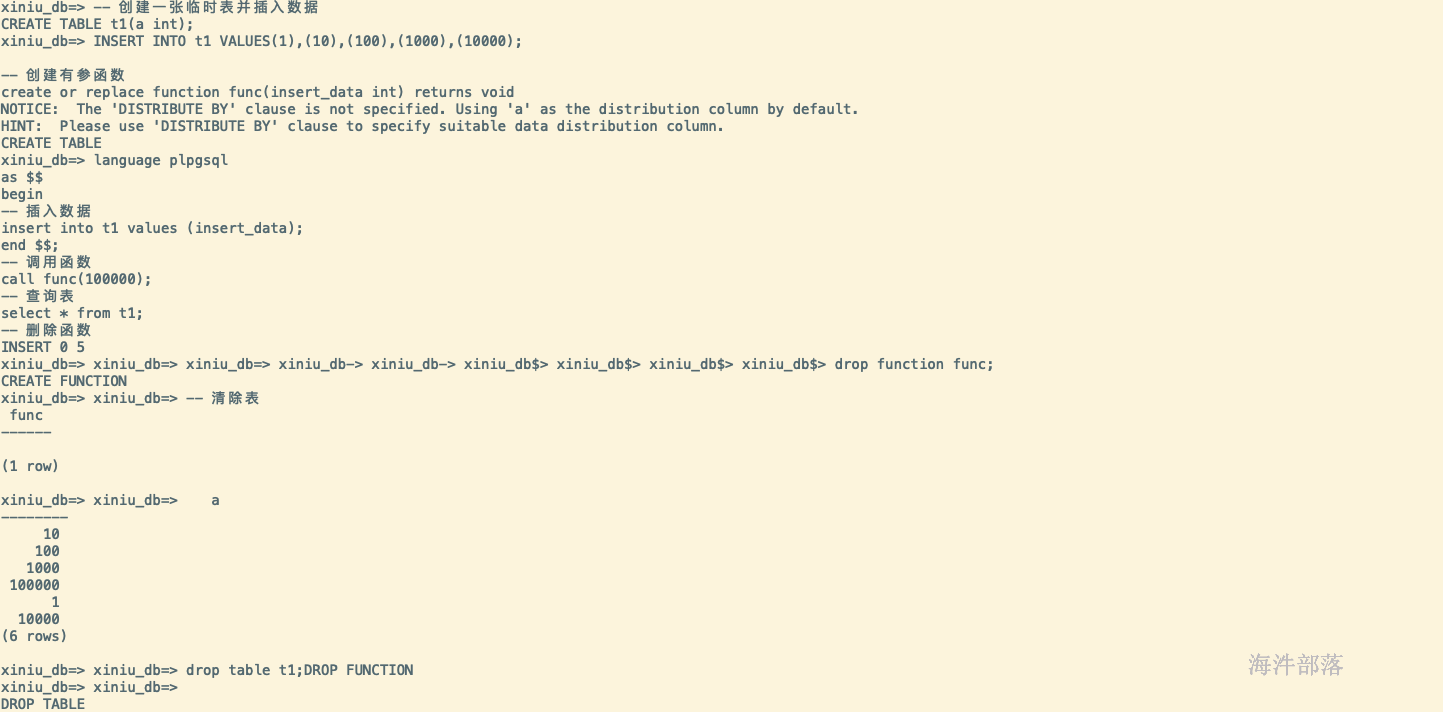
存储过程操作分区
- 创建分区
-- 创建测试表
CREATE TABLE myschema.procedure_opt_partition
(
pk integer NOT NULL ,
datadate date NOT NULL ,
col1 character(10) ,
col2 character varying(60) ,
col3 character(15)
)
TABLESPACE xiniu
DISTRIBUTE BY HASH (pk)
PARTITION BY RANGE (datadate)
(
PARTITION p_10000101 VALUES LESS THAN('10000101')
)
ENABLE ROW MOVEMENT;
-- 需求说明:
-- 如上表每天有一个分区,使用datadate作为分区字段,如果一次性创建好未来若干年的分区,对索引影响较大,所以我们每天创建分区,此时就使用存储过程来创建。
DROP FUNCTION IF EXISTS add_partition(varchar(10),varchar(100),varchar(10),varchar(10));
CREATE OR REPLACE FUNCTION add_partition(schema_name varchar(10),table_name varchar(100),partition_name varchar(10), batch_date varchar(10))
RETURNS void AS $$
DECLARE
V_SQL1 TEXT;
V_SQL2 TEXT;
V_RETURN TEXT;
V_RETURN2 TEXT;
BEGIN
raise notice 'jedge partiton exists or no !';
V_SQL1 = '
select count(1) from DBA_TAB_PARTITIONS where lower(table_name)='''||table_name||''' and lower(schema)='''||schema_name||''' and partition_name='''||partition_name||'''
';
raise notice 'jedge partition sql:%',V_SQL1;
EXECUTE V_SQL1 INTO V_RETURN;
raise notice 'jedge table result:%',V_RETURN;
if V_RETURN = 0 then
V_SQL2 = 'alter table '||schema_name||'.'||table_name||' add partition '||partition_name||' values less than (date'''||batch_date||''')';
raise notice 'add partition sql:%',V_SQL2;
EXECUTE V_SQL2;
end if;
END
$$ LANGUAGE plpgsql;
-- 调用
call add_partition('myschema','procedure_opt_partition','p_20210609','20210609');
-- 查询分区
select * from DBA_TAB_PARTITIONS where lower(table_name)= 'procedure_opt_partition' and lower(schema)= 'myschema';
-- 清除表
drop table myschema.procedure_opt_partition;


