#!/bin/bash
/usr/lib/spark/bin/spark-submit --master yarn \
--deploy-mode client \
--principal self_Research@WZJDH \
--keytab /home/wzjd_verify/szmt/auth/self_Research.keytab \
--conf "spark.executor.extraJavaOptions=-XX:+UseConcMarkSweepGC" \
--conf spark.hadoop.fs.hdfs.impl.disable.cache=true \
--files /home/wzjd_verify/szmt/auth/spark_jaas.conf,/home/wzjd_verify/szmt/auth/spark_kafka.keytab,config/SparkStreamingKafka.properties,config/beijing_kafka.properties \
--conf "spark.driver.extraJavaOptions=-Djava.security.auth.login.config=/home/wzjd_verify/szmt/auth/kafka_client_jaas.conf" \
--conf "spark.executor.extraJavaOptions=-Djava.security.auth.login.config=./spark_jaas.conf" \
--conf spark.default.parallelism=1104 \
--conf spark.network.timeout=360s \
--conf spark.executor.heartbeatInterval=300s \
--conf spark.yarn.executor.memoryOverhead=4096 \
--conf spark.ui.port=0 \
--conf "spark.ui.filters=" \
--queue root.bdoc.self_Research \
--num-executors 184 \
--executor-memory 4G \
--executor-cores 3 \
--driver-memory 10G \
--name KafkaDataCount_JT_mme \
array_topic=("AH_mme" "BJ_mme" "CQ_mme" "FJ_mme" "GD_mme" "GS_mme" "GX_mme" "GZ_mme" "HA_mme" "HB_mme" "HE_mme" "HI_mme" "HL_mme" "HN_mme" "JL_mme" "JS_mme" "JX_mme" "LN_mme" "NM_mme" "NX_mme" "QH_mme" "SC_mme" "SD_mme" "SH_mme" "SN_mme" "SX_mme" "TJ_mme" "XJ_mme" "XZ_mme" "YN_mme" "ZJ_mme")
for((i=0;i<${#array_topic[*]};i++));do
--class cn.chinamobile.cmit.dsjptb.KafkaDataCount /home/wzjd_verify/szmt/zhaozhen/KafkaDataCount.jar "${array_topic[i]}" "3" >/data02/szmt/KafkaDataCount/KafkaDataCount_JT_mme$(date "+%Y%m%d%H%M%S").log 2>&1 &
sleep 4m
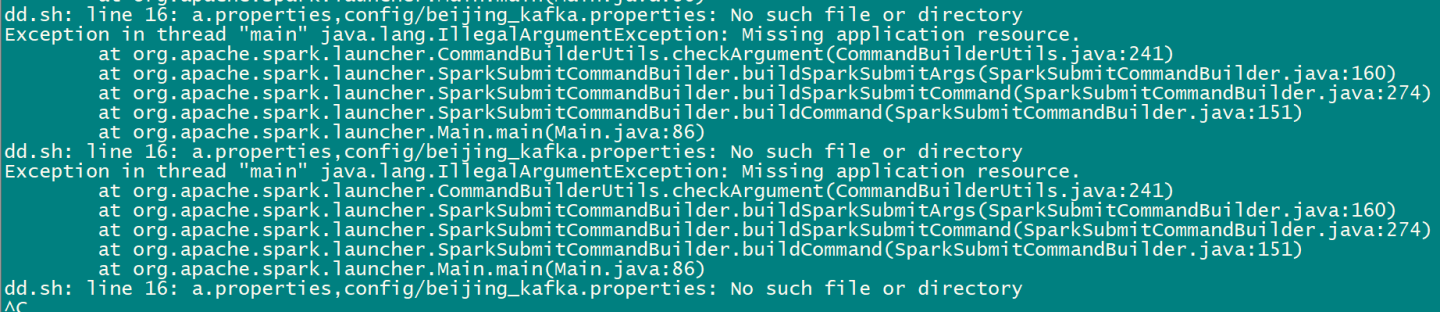
done;然后报错了
求大神指教