MySQL - day02
1. 表关系
表与表之间一般存在三种关系,即一对一,一对多,多对多关系。
1.1 一对一
一对一关系是建立在两张表之间的关系。一个表中的一条数据可以对应另一个表中的一条数据。
例如:一个人对应一张身份证,一张身份证对应一个人。
实现方式:
在任意一个表建立外键,去关联另外一个表的主键。
示例:
-- 创建person表
CREATE TABLE person(
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键id
NAME VARCHAR(20) -- 姓名
);
-- 添加数据
INSERT INTO person VALUES (NULL,'张三'),(NULL,'李四');
-- 创建card表
CREATE TABLE card(
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键id
number VARCHAR(20) UNIQUE NOT NULL, -- 身份证号
pid INT UNIQUE, -- 外键列
CONSTRAINT cp_fk1 FOREIGN KEY (pid) REFERENCES person(id)
);
-- 添加数据
INSERT INTO card VALUES (NULL,'12345',1),(NULL,'56789',2);注:一对一关系使用场景较少,因为在该案例的场景中,我们可以把身份证号码作为person表的一个字段。
2.2 一对多
一对多关系是建立在两张表之间的关系。一个表中的一条数据可以对应另一个表中的多条数据,但另一个表中的一条数据只能对应第一张表的一条数据。
例如:
一个班级拥有多个学生,一个学生只能够属于某个班级。
一个用户可以有多个订单,一个订单只能属于某个用户。
实现方式:
在多的一方,建立外键约束,来关联一的一方主键。注意:外键永远在多方。外键允许重复,允许含有空值。
示例:
-- 上一节讲解外键约束时,采用的用户和订单表即为一对多的关系
-- 班级和学生示例
-- 创建班级表
CREATE TABLE class (
c_id INT PRIMARY KEY AUTO_INCREMENT, -- 主键id
c_name VARCHAR(100) NOT NULL, -- 班级名称
c_capacity INT -- 班级容量
);
-- 班级表插入数据
INSERT INTO class
VALUES
(NULL, "大数据01", 80),
(NULL, "大数据02", 80),
(NULL, "大数据03", 60);
SELECT * FROM class;
-- 创建学生表
CREATE TABLE student (
s_id INT PRIMARY KEY AUTO_INCREMENT, -- 主键id
s_name VARCHAR(100) NOT NULL, -- 学生姓名
cid INT, -- 外键列 学生所属班级
CONSTRAINT sc_fk1 FOREIGN KEY (cid) REFERENCES class (c_id) -- 外键约束
);
DESC student;
-- 学生表插入数据(如果外键列所表示的班级id在班级表不存在,则数据插入失败)
INSERT INTO student
VALUES
(NULL, "张三", 1),
(NULL, "李四", 1),
(NULL, "王五", 2);
SELECT * FROM student;2.3 多对多
多对多关系是关系数据库中两个表之间的一种关系, 该关系中第一个表中的一个行可以与第二个表中的一个或多个行相关。第二个表中的一个行也可以与第一个表中的一个或多个行相关。
例如:
学生表和课程表:一个学生可以选修多门课程,一个课程可以被多个学生选修。
产品表和订单表:一个订单中可以包含多个产品,一个产品可能出现在多个订单中。
实现方式:
创建第三个表,该表通常称为联接表,它将多对多关系划分为两个一对多关系。在该表中建立两个列,每个列作为外键参照各自的表的主键。
示例:
-- 创建student表
CREATE TABLE student(
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键id
NAME VARCHAR(20) -- 学生姓名
);
-- 添加数据
INSERT INTO student VALUES (NULL,'张三'),(NULL,'李四');
-- 创建course表
CREATE TABLE course(
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键id
NAME VARCHAR(10) -- 课程名称
);
-- 添加数据
INSERT INTO course VALUES (NULL,'语文'),(NULL,'数学');
-- 创建中间表
CREATE TABLE stu_course(
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键id
sid INT, -- 用于和student表中的id进行外键关联
cid INT, -- 用于和course表中的id进行外键关联
CONSTRAINT sc_fk1 FOREIGN KEY (sid) REFERENCES student(id), -- 添加外键约束
CONSTRAINT sc_fk2 FOREIGN KEY (cid) REFERENCES course(id) -- 添加外键约束
);
-- 添加数据
INSERT INTO stu_course VALUES (NULL,1,1),(NULL,1,2),(NULL,2,1),(NULL,2,2);
-- 上面的关系表示id为1的学生选择了id为1和2的课程,而id为1的课程也被id为1和2的两个学生选择,多对多的关系
-- 练习 订单表和商品表
-- 创建订单表
CREATE TABLE t_order (
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键id
order_number VARCHAR(20) NOT NULL, -- 订单编号
order_time TIMESTAMP -- 下单时间
);
-- 创建商品表
CREATE TABLE t_product (
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键id
product_name VARCHAR(100), -- 商品名称
product_price DOUBLE -- 商品价格
);
-- 创建中间表(连接表表名一般情况下,取两张表的名字用下划线连接,方便管理)
CREATE TABLE t_order_product (
id INT PRIMARY KEY AUTO_INCREMENT, -- 主键id
order_id INT, -- 引用订单表id
product_id INT, -- 引用商品表id
CONSTRAINT order_product_fk1 FOREIGN KEY (order_id) REFERENCES t_order (id),
CONSTRAINT order_product_fk2 FOREIGN KEY (product_id) REFERENCES t_product (id)
);
-- 插入数据
INSERT INTO t_product
VALUES (NULL, "西游记", 88), (NULL, "三国演义", 77), (NULL, "水浒传", 99);
SELECT * FROM t_product;
INSERT INTO t_order
VALUES (NULL, "hn001", NULL), (NULL, "hn002", NULL), (NULL, "hn003", NULL);
SELECT * FROM t_order;
-- 插入中间表数据
INSERT INTO t_order_product
VALUES
(NULL, 1, 1),(NULL, 1, 3),(NULL, 2, 2),(NULL, 2, 3);
-- 表示:id为1的订单买了西游记和水浒传两本书;id为2的订单买了三国演义和水浒传两本书
SELECT * FROM t_order_product;
注意:在多对多关系中,插入数据时,先两侧再中间表;而删除数据时,要先中间后两侧。
2. 多表查询
2.1 笛卡尔积
笛卡尔积在SQL中的实现方式是交叉连接(Cross Join)。所有连接方式都会先生成临时笛卡尔积表,笛卡尔积是关系代数里的一个概念,表示两个表中的每一行数据任意组合。
在实际应用中,笛卡尔积本身大多没有什么实际用处,只有在两个表连接时加上限制条件,才会有实际意义。
例如:
学生student表
| stu_id | name | cla_id |
|---|---|---|
| 1 | 张三 | 1002 |
| 2 | 李四 | 1002 |
| 3 | 王五 | 1003 |
班级classes表
| cla_id | name | gra_id |
|---|---|---|
| 1002 | 2班 | 1 |
| 1003 | 3班 | 2 |
年级grade表
| gra_id | name |
|---|---|
| 1 | 1年级 |
| 2 | 2年级 |
两个表笛卡尔积结果:
SELECT * FROM student, classes;
/*
student和classes两个表笛卡尔积结果(将两个表的数据全部组合,3*2共计6条):
id name cla_id id NAME gra_id
1 张三 1002 1002 2班 1
1 张三 1002 1003 3班 2
2 李四 1002 1002 2班 1
2 李四 1002 1003 3班 2
3 王五 1003 1002 2班 1
3 王五 1003 1003 3班 2
*/再加第三张表:
SELECT * FROM student, classes, grade;
-- 将产生 6 * 2 = 12条数据
/*
id name cla_id id NAME gra_id id NAME
1 张三 1002 1002 2班 1 1 1年级
1 张三 1002 1003 3班 2 1 1年级
1 张三 1002 1002 2班 1 2 2年级
1 张三 1002 1003 3班 2 2 2年级
2 李四 1002 1002 2班 1 1 1年级
2 李四 1002 1003 3班 2 1 1年级
2 李四 1002 1002 2班 1 2 2年级
2 李四 1002 1003 3班 2 2 2年级
3 王五 1003 1002 2班 1 1 1年级
3 王五 1003 1003 3班 2 1 1年级
3 王五 1003 1002 2班 1 2 2年级
3 王五 1003 1003 3班 2 2 2年级
*/SQL的多表查询(笛卡尔积原理):
- 先确定数据要用到哪些表。
- 将多个表先通过笛卡尔积变成一个表。
- 然后去除不符合逻辑的数据(根据两个表的关系去掉)。
- 最后当做是一个虚拟表一样来加上条件即可。
准备数据:
-- 创建category分类表
CREATE TABLE category (
cid int comment '主键id',
cname varchar(50) DEFAULT NULL comment '分类名称',
PRIMARY KEY (cid)
);
-- 创建product 表,并声明 category 表的cid字段作为外键
CREATE TABLE product (
pid int(11) NOT NULL AUTO_INCREMENT comment '主键id',
pname varchar(500) DEFAULT NULL comment '产品名称',
price DECIMAL(10,2) DEFAULT NULL comment '产品价格',
cid int(11) DEFAULT NULL comment '产品所属类别',
PRIMARY KEY (pid),
KEY `produce_cid_fk` (`cid`),
CONSTRAINT `produce_cid_fk` FOREIGN KEY (`cid`) REFERENCES `category` (`cid`)
);
-- 分类表中添加数据
insert into category (cid,cname) values
(1,'家用电器/电脑'),
(2,'男装/女装/童装/内衣'),
(3,'女鞋/箱包/珠宝/钟表'),
(4,'食品/酒类/生鲜/特产'),
(5,'美妆/个护清洁/宠物');
-- 向商品表中添加数据
INSERT INTO product VALUES(null,' 联想(Lenovo)威6 14英寸商务轻薄笔记本电脑(i7-8550U 8G 256G PCIe SSD FHD MX150 Win10 两年上门)鲨鱼灰',5999,1);
INSERT INTO product VALUES(null,'联想(Lenovo)拯救者Y7000 15.6英寸游戏笔记本电脑(英特尔八代酷睿i5-8300H 8G 512G GTX1050 黑)',5999,1);
INSERT INTO product VALUES(null,'三洋(SANYO)9公斤智能变频滚筒洗衣机 臭氧除菌 空气洗 WiFi智能 中途添衣 Magic9魔力净',2499,1);
INSERT INTO product VALUES(null,'海尔(Haier) 滚筒洗衣机全自动 10公斤变频 99%防霉抗菌窗垫EG10014B39GU1',2499,1);
INSERT INTO product VALUES(null,'雷神(ThundeRobot)911SE炫彩版 15.6英寸游戏笔记本电脑(I7-8750H 8G 128SSD+1T GTX1050Ti Win10 RGB IPS)',6599,1);
INSERT INTO product VALUES(null,'七匹狼休闲裤男2018秋装新款纯棉男士直筒商务休闲长裤子男装 2775 黑色 32/80A',299,2);
INSERT INTO product VALUES(null,'真维斯JEANSWEST t恤男 纯棉圆领男士净色修身青年打底衫长袖体恤上衣 浅花灰 M',35,2);
INSERT INTO product VALUES(null,'PLAYBOY/花花公子休闲裤男弹力修身 秋季适中款商务男士直筒休闲长裤 黑色适中款 31(2.4尺)',128,2);
INSERT INTO product VALUES(null,'劲霸男装K-Boxing 短版茄克男士2018新款休闲舒适棒球领拼接青年夹克|FKDY3114 黑色 185',362,2);
INSERT INTO product VALUES(null,'Chanel 香奈儿 女包 2018全球购 新款蓝色鳄鱼皮小牛皮单肩斜挎包A 蓝色',306830,3);
INSERT INTO product VALUES(null,'皮尔卡丹(pierre cardin)钱包真皮新款横竖款男士短款头层牛皮钱夹欧美商务潮礼盒 黑色横款(款式一)',269,3);
INSERT INTO product VALUES(null,'PRADA 普拉达 女士黑色皮质单肩斜挎包 1BD094 PEO V SCH F0OK0',28512,3);
INSERT INTO product VALUES(null,'好想你 干果零食 新疆特产 阿克苏灰枣 免洗红枣子 玛瑙红500g/袋',21.9,4);
INSERT INTO product VALUES(null,'三只松鼠坚果大礼包1588g每日坚果礼盒干果组合送礼火红A网红零食坚果礼盒8袋装',128,4);
INSERT INTO product VALUES(null,'三只松鼠坚果炒货零食特产每日坚果开心果100g/袋',32.8,4);
INSERT INTO product VALUES(null,'洽洽坚果炒货孕妇坚果零食恰恰送礼每日坚果礼盒(26g*30包) 780g/盒(新老包装随机发货)',149,4);
INSERT INTO product VALUES(null,'今之逸品【拍3免1】今之逸品双眼皮贴双面胶美目舒适隐形立显大眼男女通用 中号160贴',9.9,5);
INSERT INTO product VALUES(null,'自然共和国 原自然乐园 芦荟舒缓保湿凝胶300ml*2(约600g)进口补水保湿舒缓晒后修复面膜',72,5);
2.2 内连接查询
内连接可以看做先对两个表进行了交叉连接后,再通过加上限制条件(SQL中通过关键字on)剔除不符合条件的行的子集。INNER JOIN 关键字在表中存在至少一个匹配时返回行。
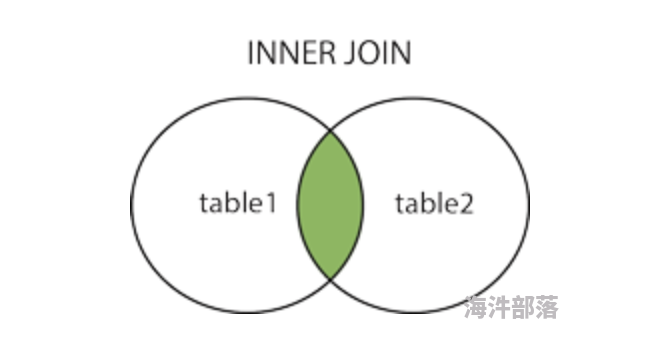
显示内连接
标准语法:
SELECT 列名 FROM 表名1 [INNER] JOIN 表名2 ON 关联条件;示例:
-- 查看所有的商品信息,并且展示其所属分类信息
SELECT * FROM product p INNER JOIN category c ON p.cid = c.cid;
-- 加条件,查询名称中包含 坚果 信息的商品及所属分类信息
SELECT * FROM product p INNER JOIN category c ON p.cid = c.cid WHERE p.pname like '%坚果%';隐式内连接
标准语法:
SELECT 列名 FROM 表名1,表名2 where 关联条件;示例:
-- 查看所有的商品信息,并且展示其所属分类信息
select * from product p, category c where p.cid = c.cid;
-- 加条件
select * from product p, category c where p.cid = c.cid and p.pname like '%坚果%';推荐使用显示内连接。
2.3 左外连接查询
左外连接查询从左表(table1)返回所有的行,即使右表(table2)中没有匹配。如果右表中没有匹配,则结果为 NULL。
语法:
SELECT column_name(s)
FROM table1
LEFT [OUTER] JOIN table2
ON table1.column_name = table2.column_name;
-- 注:其中的OUTER关键字可以省略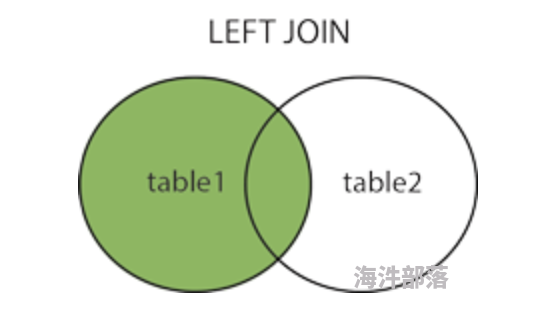
示例:
-- 查询所有的商品分类信息,并将该分类下所有的商品展示
SELECT * FROM category c LEFT OUTER JOIN product p on c.cid = p.cid;
-- 可以看到即使商品表中没有该分类的商品,也会展示分类表中的信息数据库在通过连接两张或多张表来返回记录时,都会生成一张中间的临时表,然后再将这张临时表返回给用户。
2.4 右外连接查询
RIGHT JOIN 关键字从右表(table2)返回所有的行,即使左表(table1)中没有匹配。如果左表中没有匹配,则结果为 NULL。
语法:
SELECT column_name(s)
FROM table1
RIGHT OUTER JOIN table2
ON table1.column_name=table2.column_name;
示例:
-- 用右连接实现上面的查询结果
select * from product p right join category c on c.cid = p.cid;练习:
-- 查询各分类产品的平均价格
SELECT
c.cid, c.cname, avg(p.price)
FROM
product p
LEFT OUTER JOIN category c
on p.cid = c.cid
group by c.cid2.5 子查询
子查询指一个查询语句嵌套在另一个查询语句内部的查询,这个特性从MySQL4.1 开始引入,在 SELECT 子句中先计算子查询,子查询结果作为外层另一个查询的过滤条件,查询可以基于一个表或者多个表。
对于一个普通的查询语句,子查询可以出现在两个位置。
2.5.1 出现在 from 语句后当成数据表
语法:
SELECT 列名 FROM 表名 [别名],(SELECT 列名 FROM 表名 [WHERE 条件]) [别名] [WHERE 条件];示例:
-- 通过商品表统计商品共有多少分类
select count(*) from (select DISTINCT cid from product) t1;
select count(*) from (select cid from product group by cid) t1;2.5.2 出现在where 条件后作为过滤条件的值
子查询的结果是单行单列的
语法:
SELECT 列名 FROM 表名 WHERE 列名=(SELECT 列名 FROM 表名 [WHERE 条件]);示例:
-- 类别为 家用电器/电脑的商品名称和价格
select pname, price from product
where cid=(select cid from category where cname='家用电器/电脑');子查询的结果是多行单列的
语法:
SELECT 列名 FROM 表名 WHERE 列名 [NOT] IN (SELECT 列名 FROM 表名 [WHERE 条件]); 示例:
-- 查询商品价格大于5000的类别
select * from category where cid in (select cid from product where price>5000);
-- 获取所有商品中,平均价格大于1000的分类的全部商品
select * from product where cid in (select p.cid FROM product p group by p.cid HAVING avg(price) > 1000);使用子查询要注意如下要点:
1)子查询要用括号括起来。
2)把子查询当成数据表时(出现在from 之后),可以为该子查询起别名,尤其是作为前缀来限定数据列时,必须给子查询起别名。
3)把子查询当成过滤条件时,将子查询放在比较运算符的右边,这样可以增强查询的可读性。
2.6 自关联查询
自连接查询就是当前表与自身的连接查询,表中的某一列,关联了这个表中的另外一列。
此时查询的关键点在于虚拟化出一张表给一个别名。
准备数据:
-- 创建员工表
CREATE TABLE employee (
id INT PRIMARY KEY AUTO_INCREMENT, -- 员工编号
NAME VARCHAR(20), -- 员工姓名
mgr INT, -- 上级编号
salary DOUBLE -- 员工工资
);
-- 添加数据
INSERT INTO employee VALUES
(1001,'孙悟空',1005,9000.00),
(1002,'猪八戒',1005,8000.00),
(1003,'沙和尚',1005,8500.00),
(1004,'小白龙',1005,7900.00),
(1005,'唐僧',NULL,15000.00),
(1006,'武松',1009,7600.00),
(1007,'李逵',1009,7400.00),
(1008,'林冲',1009,8100.00),
(1009,'宋江',NULL,16000.00);
在上述的员工表中,上级编号字段关联本表的员工id,通过该字段可以找到当前员工的上级,为空表示该员工没有上级员工。
查询:
-- 查询所有员工的姓名及其直接上级的姓名,没有上级的员工也需要查询
SELECT
e1.*,
e2.`NAME`,
e2.`salary`
FROM
employee e1
LEFT OUTER JOIN
employee e2
ON
e1.`mgr` = e2.`id`练习:
-- 创建地区表
CREATE TABLE region (
r_id INT PRIMARY KEY AUTO_INCREMENT, -- 主键ID
r_name VARCHAR(50) NOT NULL COMMENT '地区名称',
r_parent_id INT COMMENT '地区父ID'
);
-- 添加数据
INSERT INTO region VALUES
(1001, "北京市", NULL),
(1002, "上海市", NULL),
(1003, "东城区", 1001),
(1004, "西城区", 1001),
(1005, "朝阳区", 1001),
(1006, "丰台区", 1001),
(1007, "海淀区", 1001),
(1008, "黄浦区", 1002),
(1009, "徐汇区", 1002),
(1010, "长宁区", 1002),
(1011, "静安区", 1002),
(1012, "普陀区", 1002);
-- 查询出北京市各区信息
SELECT * FROM region r WHERE r.`r_parent_id` = (SELECT r_id FROM region WHERE r_name = "北京市");
-- 查询出北京市各区信息
SELECT
r1.*,
r2.`r_name`
FROM
region r1
INNER JOIN
region r2
ON
r1.`r_parent_id` = r2.`r_id`
WHERE
r2.`r_name` = "北京市";
2.7 UNION 操作符
UNION 操作符用于合并两个或多个 SELECT 语句的结果集。
语法:
SELECT column_name(s) FROM table1
UNION
SELECT column_name(s) FROM table2;注意:
UNION 内部的每个 SELECT 语句必须拥有相同数量的列。列也必须拥有相似的数据类型。同时,每个 SELECT 语句中的列的顺序必须相同。
UNION 会自动去除多个结果中的重复结果,如果允许重复的值,使用 UNION ALL。
示例:
-- 查询分类为 '家用电器/电脑' 的 价格大于3000的 商品信息
SELECT p.pid, p.pname, p.price, c.cid, c.cname
FROM product p join category c
on p.cid = c.cid
WHERE c.cname = '家用电器/电脑' and p.price > 200
-- 查询分类为 '男装/女装/童装/内衣' 的 价格大于200的 商品信息;
SELECT p.pid, p.pname, p.price, c.cid, c.cname
FROM product p join category c
on p.cid = c.cid
WHERE c.cname = '男装/女装/童装/内衣' and p.price > 200
-- 将上面两条语句的查询结果合并
SELECT p.pid, p.pname, p.price, c.cid, c.cname
FROM product p join category c
ON p.cid = c.cid
WHERE c.cname = '家用电器/电脑' and p.price > 200
UNION
SELECT p.pid, p.pname, p.price, c.cid, c.cname
FROM product p join category c
on p.cid = c.cid
WHERE c.cname = '男装/女装/童装/内衣' and p.price > 200
-- 如果有重复数据,UNION ALL会保留重复2.8 多表查询练习
1) 查询价格在一万以内名字中包含 '想' 的商品
隐式内连接
-- 查询价格在一万以内名字中包含 '想' 的商品
select * from category c,product p where c.cid = p.cid and p.price <= 10000 and p.pname like '%想%';隐式内连接是借助where条件来设定关联关系,所以这样如果一旦where条件变多整体关联关系就很难把控,并且表越多,隐式内连接关联就越乱,多表连接时不建议用。
显式内连接
-- 先通过连接条件生成临时结果,然后再通过where条件筛选出最终结果
select * from category c
inner join product p on c.cid = p.cid -- 此处设置连接条件
where p.price < 10000 and p.pname like '%想%'; -- 此处设置连接后的筛选条件2)查询所有分类商品的个数
左外连接 :
-- 先通过连接条件生成临时结果,然后再通过group by 汇总出最终结果
select c.cname,count(p.cid) num from category c
left join product p on c.cid = p.cid
group by c.cname;3)使用子查询解决大分页
先快速定位需要获取的id段,然后再关联:
SELECT a.* FROM 表1 a, (select id from 表1 where 条件 LIMIT 100000,20) b where a.id=b.id3. 视图
什么是视图
视图是一张虚拟表
表示一张表的部分数据或多张表的综合数据
其结构和数据是建立在对表的查询基础上
视图中不存放数据
数据存放在视图所引用的原始表中
一个原始表,根据不同用户的不同需求,可以创建不同的视图
为什么使用视图
- 重用SQL语句
- 简化复杂的SQL操作。在编写查询后,可以方便地重用它而不必知道其基本查询细节。
- 使用表的一部分而不是整个表。
- 保护数据。可以授予用户访问表的特定部分的权限,而不是整个表的访问权限。
规定及限制
- 因为视图不包含数据,所以每次使用视图时,都必须处理查询执行时需要的所有检索
- 与表一样,视图必须唯一命名(不能给视图取与别的视图或表相同的名字) 名称_view
- 对于可以创建的视图数目没有限制
- 视图大部分情况都不能更新和删除,比如多表导出、groupby、常量字段等等
视图语法
-- 创建视图
create view view_name as
<select 语句>;
-- 查询视图数据
select 字段1,字段2, ... from view_name
-- 删除视图
drop view view_name;示例:
-- 查询 类别为 家用电器/电脑 且 商品价格>5000的商品信息
select pname, price from product
where cid=(select cid from category where cname='家用电器/电脑') and price > 5000;
-- 查询 类别为 家用电器/电脑 且 商品价格<5000的商品信息
select pname, price from product
where cid=(select cid from category where cname='家用电器/电脑') and price < 5000;发现上面的两个查询有公共的部分,那我们就可以把公共部分创建视图,基于这个视图在来查询相应价格的数据
-- 创建视图 (查询 类别为 家用电器/电脑 的 商品信息)
create view cp1_view as
select pname, price from product
where cid=(select cid from category where cname='家用电器/电脑');
-- 在此基础上,用视图直接筛选价格>5000的商品
select * from cp1_view where price > 5000;
-- 在此基础上,用视图直接筛选价格<5000的商品
select * from cp1_view where price < 5000;删除视图:
drop view cp1_view;4. 索引
4.1 索引概述
为什么要学索引
如果新华字典没有汉语拼音、偏旁部首目录,你如何查找某个汉字?
一页一页翻找,效率低
如果带着汉语拼音、偏旁部首目录,你如何查找?
先看汉语拼音目录,找到汉字对应的页数,直接找对应页码即可。利用索引检索,效率高
索引是什么
Mysql官方对索引的定义是:索引(Index)是帮助Mysql高效获取数据的数据结构。
提取句子主干就是:索引是数据结构。
索引的目的
索引的目的在于提高查询或检索效率。(拿空间换时间)
索引的优势
提高数据检索效率,降低数据库IO成本。
降低数据排序的成本,降低CPU的消耗。
索引的劣势
索引也是一张表,保存了主键和索引字段,并指向实体表的记录,所以也需要占用内存。
虽然索引大大提高了查询速度,同时却会降低更新表的速度,如对表进行INSERT、UPDATE和DELETE。因为更新表时,MySQL不仅要保存数据,还要保存一下索引文件每次更新添加了索引列的字段, 都会调整因为更新所带来的键值变化后的索引信息 。
4.2 MySQL的索引存储结构
MySQL默认使用的是B+树存储结构,如下图所示:
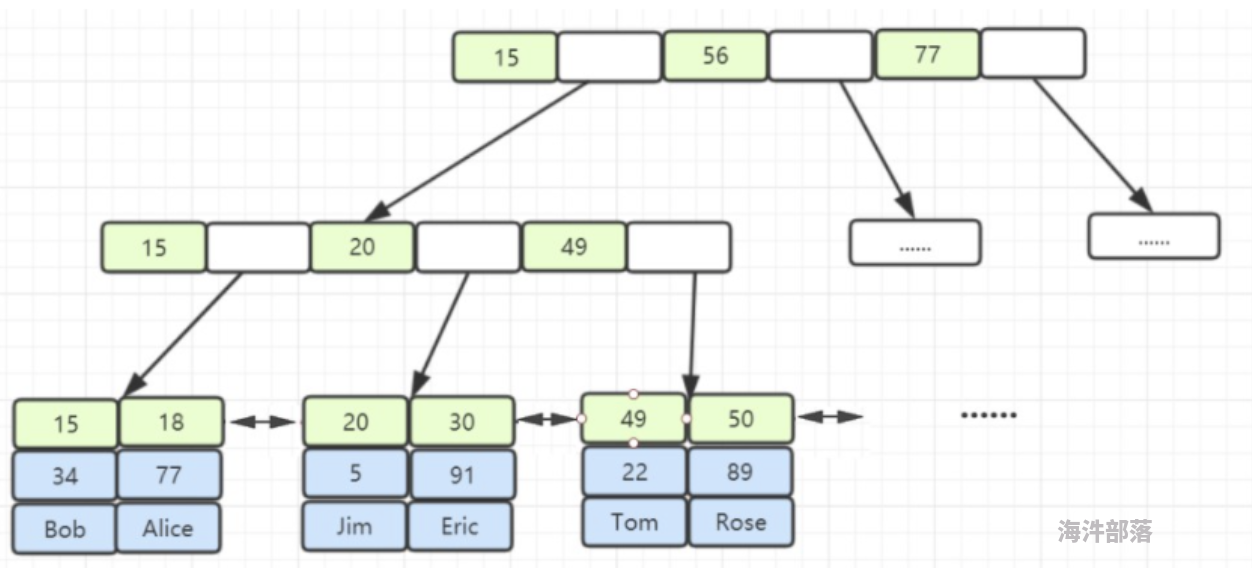
其中:
非叶子节点只存储键值。
只有叶子节点才会存储数据,数据存储的是非主键的数据。
叶子节点之间使用双向指针连接,最底层的叶子节点形成了一个双向有序链表。
优势:
范围查询特别方便,只需要在叶子节点利用有序链表查找范围即可。
4.3 MySQL索引分类
- 普通索引: 最基本的索引,它没有任何限制。
- 唯一索引:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值组合必须唯一。
- 主键索引:一种特殊的唯一索引,不允许有空值。一般在建表时同时创建主键索引。
- 组合索引:顾名思义,就是将单列索引进行组合。
- 外键索引:只有InnoDB引擎支持外键索引,用来保证数据的一致性、完整性和实现级联操作。
- 全文索引:快速匹配全部文档的方式。InnoDB引擎5.6版本后才支持全文索引。MEMORY引擎不支持。
4.4 MySQL 索引使用
索引语法
-- 创建索引
CREATE [UNIQUE|FULLTEXT] INDEX 索引名称
[USING 索引类型] -- 默认是B+TREE
ON 表名(列名...);
-- 查看索引
SHOW INDEX FROM 表名;
-- 删除索引
DROP INDEX 索引名称 ON 表名;alter语句添加索引
-- 普通索引
ALTER TABLE 表名 ADD INDEX 索引名称(列名);
-- 组合索引
ALTER TABLE 表名 ADD INDEX 索引名称(列名1,列名2,...);
-- 主键索引(添加主键约束,就是主键索引)
ALTER TABLE 表名 ADD PRIMARY KEY(主键列名);
-- 外键索引(添加外键约束,就是外键索引)
ALTER TABLE 表名 ADD CONSTRAINT 外键名 FOREIGN KEY (本表外键列名) REFERENCES 主表名(主键列名);
-- 唯一索引
ALTER TABLE 表名 ADD UNIQUE 索引名称(列名);
-- 全文索引(mysql只支持文本类型)
ALTER TABLE 表名 ADD FULLTEXT 索引名称(列名);1)查询时总是要按照商品价格作为查询条件时,可以给商品表的商品价格添加一个索引
create INDEX index_product_price on product(price);2)查看某个表的索引
show index from product;
部分结果说明
Table:创建索引的表
Non_unique:索引是否非唯一
Key_name:索引的名称
Column_name:定义索引的列字段
Seq_in_index:该列在索引中的位置
Null:该列是否能为空值
Index_type:索引类型
3)删除索引
DROP INDEX index_product_price on product;4.5 MySql创建索引的使用技巧
创建索引的指导原则
(一) 按照下列标准选择建立索引的列
- 频繁搜索的列
- 经常用作查询选择的列
- 经常排序、分组的列
- 经常用作连接的列(主键/外键)
(二) 请不要使用下面的列创建索引
- 仅包含几个不同值的列
- 表中仅包含几行
(三) 使用索引时注意事项
- 查询时减少使用*返回全部列,不要返回不需要的列
- 索引应该尽量小,在字节数小的列上建立索引
-
WHERE子句中有多个条件表达式时,包含索引列的表达式应置于其他条件表达式之前
- 避免在ORDER BY子句中使用表达式
4.6 索引失效的场景
1)当在查询条件中出现 <>、NOT、in、not exists 时,查询时更倾向于全表扫描。
2)在查询条件中有or 也不走索引,尽量不使用。
3)查询条件使用LIKE通配符
SQL语句中,使用后置通配符会走索引,例如查询姓张的学生(select * from student where name LIKE '张%'),而前置通配符(select * from student where name LIKE '%牛')会导致索引失效而进行全表扫描。
4)在索引列上使用函数 或 计算。
5)索引列数据类型不匹配。比如:字段类型是string, 但条件值不是string。
5 行列转换
5.1 行转列
即将原本同一列下多行的不同内容作为多个字段,输出对应内容。
准备数据:
-- 创建成绩表
CREATE TABLE row_to_column_score (
id INT(11) NOT NULL auto_increment,
userid VARCHAR(20) NOT NULL COMMENT '用户id',
subject VARCHAR(20) COMMENT '科目',
score DOUBLE COMMENT '成绩',
PRIMARY KEY(id)
)ENGINE = INNODB DEFAULT CHARSET = utf8;
-- 添加数据
INSERT INTO row_to_column_score(userid,subject,score) VALUES ('001','语文',90);
INSERT INTO row_to_column_score(userid,subject,score) VALUES ('001','数学',92);
INSERT INTO row_to_column_score(userid,subject,score) VALUES ('001','英语',80);
INSERT INTO row_to_column_score(userid,subject,score) VALUES ('002','语文',88);
INSERT INTO row_to_column_score(userid,subject,score) VALUES ('002','数学',90);
INSERT INTO row_to_column_score(userid,subject,score) VALUES ('002','英语',75.5);
INSERT INTO row_to_column_score(userid,subject,score) VALUES ('003','语文',70);
INSERT INTO row_to_column_score(userid,subject,score) VALUES ('003','数学',85);
INSERT INTO row_to_column_score(userid,subject,score) VALUES ('003','英语',90);
INSERT INTO row_to_column_score(userid,subject,score) VALUES ('003','政治',82);
-- 查看全部
select * from row_to_column_score;
+----+--------+---------+-------+
| id | userid | subject | score |
+----+--------+---------+-------+
| 1 | 001 | 语文 | 90 |
| 2 | 001 | 数学 | 92 |
| 3 | 001 | 英语 | 80 |
| 4 | 002 | 语文 | 88 |
| 5 | 002 | 数学 | 90 |
| 6 | 002 | 英语 | 75.5 |
| 7 | 003 | 语文 | 70 |
| 8 | 003 | 数学 | 85 |
| 9 | 003 | 英语 | 90 |
| 10 | 003 | 政治 | 82 |
+----+--------+---------+-------+
10 rows in set (0.00 sec)先来查看转换后的结果:
+--------+--------+--------+--------+--------+
| userid | 语文 | 数学 | 英语 | 政治 |
+--------+--------+--------+--------+--------+
| 001 | 90 | 92 | 80 | 0 |
| 002 | 88 | 90 | 75.5 | 0 |
| 003 | 70 | 85 | 90 | 82 |
+--------+--------+--------+--------+--------+可以看出,这里行转列是将原来的subject字段的多行内容选出来,作为结果集中的不同列,并根据userid进行分组显示对应的score。
1、使用case...when....then 进行行转列
select userid,
sum(case subject when '语文' then score else 0 end) as '语文',
sum(case subject when '数学' then score else 0 end) as '数学',
sum(case subject when '英语' then score else 0 end) as '英语',
sum(case subject when '政治' then score else 0 end) as '政治'
from row_to_column_score
group by userid;2、使用IF() 进行行转列:
select userid,
sum(if(subject = '语文',score,0)) as '语文',
sum(if(subject = '数学',score,0)) as '数学',
sum(if(subject = '英语',score,0)) as '英语',
sum(if(subject = '政治',score,0)) as '政治'
from row_to_column_score
group by userid;注意:
SUM() 是为了能够使用GROUP BY根据userid进行分组,因为每一个userid对应的subject="语文"的记录只有一条,所以SUM() 的值就等于对应那一条记录的score的值。
3、合并字段显示:利用group_concat()
select userid, GROUP_CONCAT(subject, ':', score) as 成绩
from row_to_column_score
GROUP BY userid;注意:
group_concat()会计算哪些行属于同一组,将属于同一组的列显示出来。要返回哪些列,由函数参数(就是字段名)决定。分组必须有个标准,就是根据group by指定的列进行分组。
5.2 列转行
准备数据:
-- 创建成绩表
CREATE TABLE column_to_row_score (
id INT(11) NOT NULL auto_increment,
userid VARCHAR(20) NOT NULL COMMENT '用户id',
cn_score DOUBLE COMMENT '语文成绩',
math_score DOUBLE COMMENT '数学成绩',
en_score DOUBLE COMMENT '英语成绩',
po_score DOUBLE COMMENT '政治成绩',
PRIMARY KEY(id)
)ENGINE = INNODB DEFAULT CHARSET = utf8;
-- 插入数据
INSERT INTO column_to_row_score(userid,cn_score,math_score,en_score,po_score) VALUES ('001',90,92,80,0);
INSERT INTO column_to_row_score(userid,cn_score,math_score,en_score,po_score) VALUES ('002',88,90,75.5,0);
INSERT INTO column_to_row_score(userid,cn_score,math_score,en_score,po_score) VALUES ('003',70,85,90,82);
-- 查看全部
select * from column_to_row_score;
+----+--------+----------+------------+----------+----------+
| id | userid | cn_score | math_score | en_score | po_score |
+----+--------+----------+------------+----------+----------+
| 1 | 001 | 90 | 92 | 80 | 0 |
| 2 | 002 | 88 | 90 | 75.5 | 0 |
| 3 | 003 | 70 | 85 | 90 | 82 |
+----+--------+----------+------------+----------+----------+
3 rows in set (0.00 sec)先查看转换后的结果:
+--------+--------+-------+
| userid | course | score |
+--------+--------+-------+
| 001 | 数学 | 92 |
| 001 | 语文 | 90 |
| 001 | 政治 | 0 |
| 001 | 英语 | 80 |
| 002 | 政治 | 0 |
| 002 | 英语 | 75.5 |
| 002 | 数学 | 90 |
| 002 | 语文 | 88 |
| 003 | 政治 | 82 |
| 003 | 英语 | 90 |
| 003 | 数学 | 85 |
| 003 | 语文 | 70 |
+--------+--------+-------+看以看出,转换是将userid的每个科目分数分散成一条记录显示出来。
实现:
select userid, '语文' as course, cn_score as score from column_to_row_score
union all
select userid, '数学' as course, math_score as score from column_to_row_score
union all
select userid, '英语' as course, en_score as score from column_to_row_score
union all
select userid, '政治' as course, po_score as score from column_to_row_score
order by userid;这里其实是将每个userid对应的多个科目的成绩查出来,通过UNION将结果合并起来,达到上面的效果。
6 topN问题
准备数据:
-- 创建学生成绩表
CREATE TABLE `stu_score` (
`id` int(11) NOT NULL AUTO_INCREMENT, -- id
`name` varchar(20) DEFAULT NULL, -- 姓名
`course` varchar(20) DEFAULT NULL, -- 课程名称
`score` int(11) DEFAULT NULL, -- 成绩
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=10 DEFAULT CHARSET=utf8;
-- 插入数据
insert into stu_score(name,course,score) values
('张三','语文',80),
('李四','语文',90),
('王五','语文',93),
('张三','数学',77),
('李四','数学',68),
('王五','数学',99),
('张三','英语',90),
('李四','英语',50),
('王五','英语',89);需求1:查询每门课程分数最高的学生以及成绩
-- 使用自关联查询
select a.*
from stu_score a
join (select course, max(score) max_score from stu_score group by course) b
on a.course = b.course and a.score = max_score;
/*
分析:
上面的查询,是首先按照课程分组,将每门课程的最高分先查询出来,虚拟化成一张表
然后使用原成绩表与该表关联,条件是两张表的课程和成绩相同
即查询出每门课程最高成绩的学生信息
*/
-- 使用子查询
select a.* from stu_score a where score = (select max(score) from stu_score b where a.course = b.course);
/*
分析:
课程相同的条件下,查询最高的成绩
再查询成绩为最高成绩的学生信息
*/
+----+--------+--------+-------+
| id | name | course | score |
+----+--------+--------+-------+
| 12 | 王五 | 语文 | 93 |
| 15 | 王五 | 数学 | 99 |
| 16 | 张三 | 英语 | 90 |
+----+--------+--------+-------+需求2:查询每门课程前两名的学生以及成绩
-- 使用自关联查询
select a.*
from stu_score a
left join stu_score b
on a.course = b.course and a.score < b.score
group by a.id
having count(b.id) < 2
order by a.course, a.score desc;
/*
解释:
左表a + 右表b
首先查询所有课程相同,但是a的成绩小于b的成绩的数据;
然后按照a表中的数据分组;
分组后统计每条数据(即每条学生成绩信息),在b表中对应的数据 < 2 (如果有一个比当前学生成绩高的,就出现1条,所以要求前2名,比当前学生成绩高的应该小于2,这样就取到了top2)
最后按照课程和成绩排序,使结果好看
*/
-- 使用子查询
select a.*
from stu_score a
where (select count(*) from stu_score b where a.course = b.course and a.score < b.score) < 2
order by a.course, a.score desc;
/*
分析:
课程相同的条件下,查询a表成绩比b表小的
判断条件 这样的数据少于2条,那么a表中该记录就是top2
*/
+----+--------+--------+-------+
| id | name | course | score |
+----+--------+--------+-------+
| 15 | 王五 | 数学 | 99 |
| 13 | 张三 | 数学 | 77 |
| 16 | 张三 | 英语 | 90 |
| 18 | 王五 | 英语 | 89 |
| 12 | 王五 | 语文 | 93 |
| 11 | 李四 | 语文 | 90 |
+----+--------+--------+-------+

