1 scala介绍

Scala是一门现代的多范式编程语言,平滑地集成了面向对象和函数式语言的特性,旨在以简练、优雅的方式来表达常用编程模式。
Scala的设计吸收借鉴了许多种编程语言的思想,只有很少量特点是Scala自己独有的。
Scala语言的名称来自于“可伸展的语言”,从写个小脚本到建立个大系统的编程任务均可胜任。
大教堂:几近完美的建筑物,花费很长时间建设,而一旦建成了就长时间保持不变;
集市:每天都会被集市中的人调整和扩展。
Scala就像集市一样,每天都在不断地被使用者扩展。
它没有提供“完美齐全”语言中可能需要的所有东西,而是把制作这些东西的工具交给使用者。
Scala运行于Java平台(JVM,Java 虚拟机)上,并兼容现有的Java程序,Scala代码可以调用Java方法,访问Java字段,继承Java类和实现Java接口。
在面向对象方面,Scala是一门非常纯粹的面向对象编程语言,也就是说,在Scala中,每个值都是对象,每个操作都是方法调用。
什么是函数式编程?
函数式编程中的函数,是指数学中的函数,即自变量的映射。也就是说一个函数的值仅决定于函数参数的值,不依赖其他状态。比如sqrt(x)函数计算x的平方根,只要x不变,不论什么时候调用,调用几次,值都是不变的。
函数式编程有如下特点:
1)函数是头等公民。可以把函数当做参数传给另一个函数。也可以把函数当做返回值返回出来,也可以在一个函数体里定义一个函数。
2)纯函数式编程,没有副作用。即变量一经赋值,就不可变。
3)引用透明性。指的是函数的运行不依赖于外部变量或“状态”,只依赖于输入的参数,任何时候只要参数相同,引用函数所得到的返回值总是相同的。
如:sqrt(2) 永远等于 4。

Scala具有以下突出的优点:
◇ Scala具备强大的并发性,支持函数式编程,可以更好地支持分布式系统;
◇ Scala语法简洁,Scala程序保守估计是同样Java程序的一半左右;并且能提供优雅的API;
◇ Scala兼容Java,运行速度快,现有的很多大数据框架使用Scala开发,比如spark,kafka,flink;
现在大数据生态系统的语言支持:
hadoop(java)
hive(java)
hbase(java)
kafka(scala)
spark(scala)
Flink(java)
2 scala及idea安装与配置

2.1 安装 scala
安装 scala-2.11.8.msi,windows会自动将scala加到path中
查看版本

2.2 安装和配置idea
官方下载地址: https://www.jetbrains.com/zh-cn/idea/download/\#section=windows
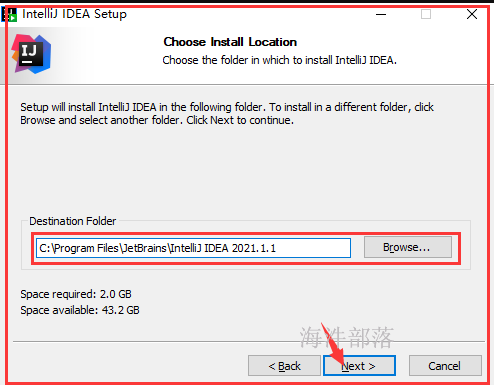
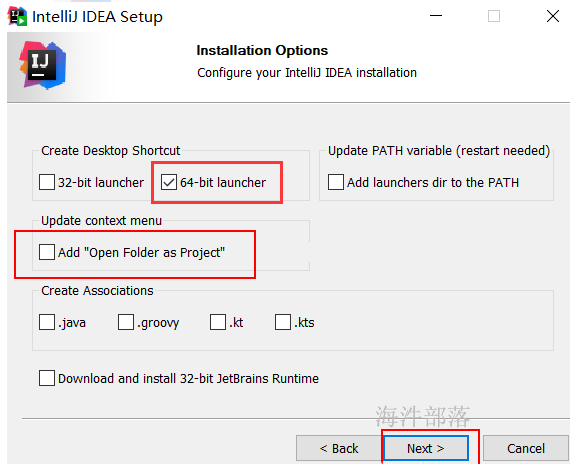
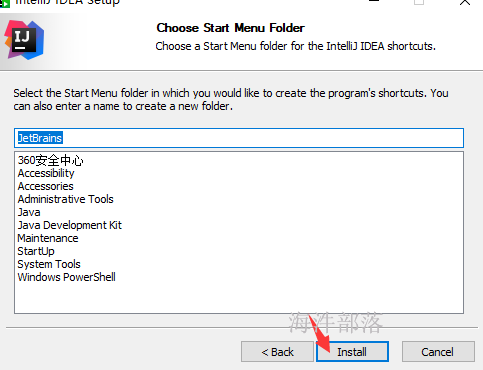
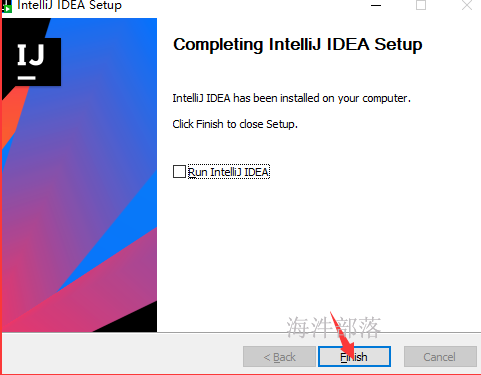
双击 “idea快捷方式”图标

进入主页面
破解idea参考 《idea破解教程.mht》,破解步骤笔记不体现,破解后可无限30重试使用。
2.3 安装scala插件
idea 2021版本,自带scala插件,无需安装。
进入设置界面查看
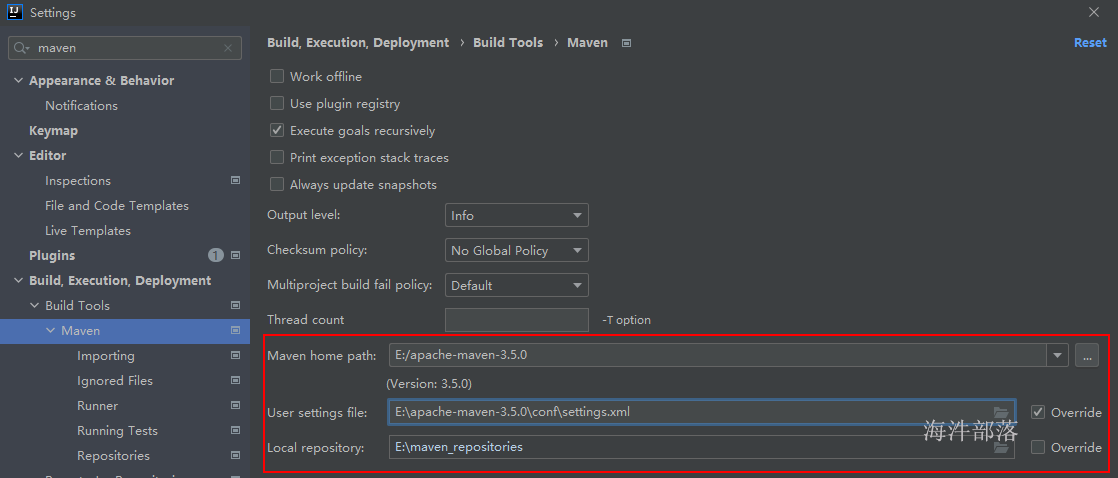
idea 2021版本,自带 maven 插件,无需安装。
2.5 创建maven工程
选择maven工程,配置jdk,点next
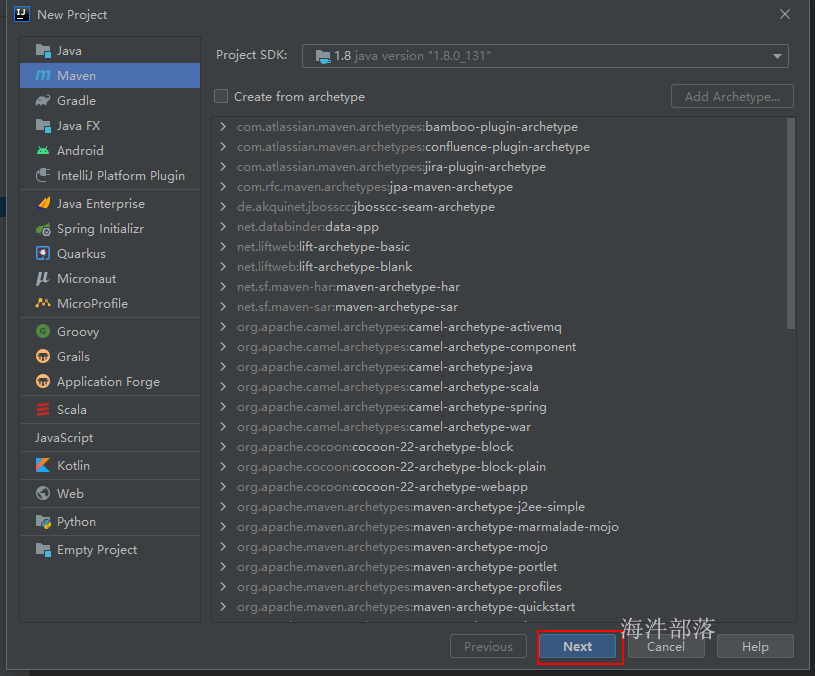
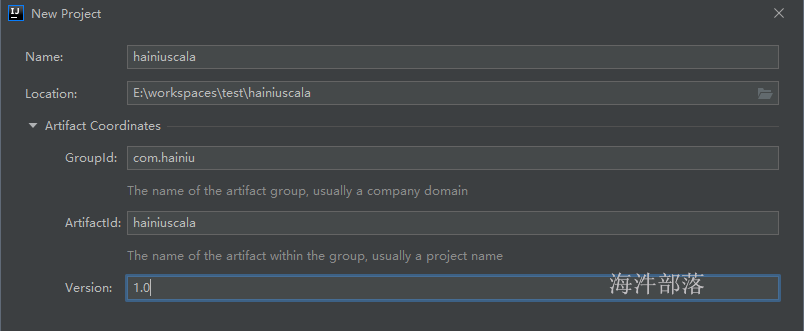
点击 finish 完成工程创建。
2.6 修改idea 主题样式和字体样式
修改idea 主题样式

修改字体样式

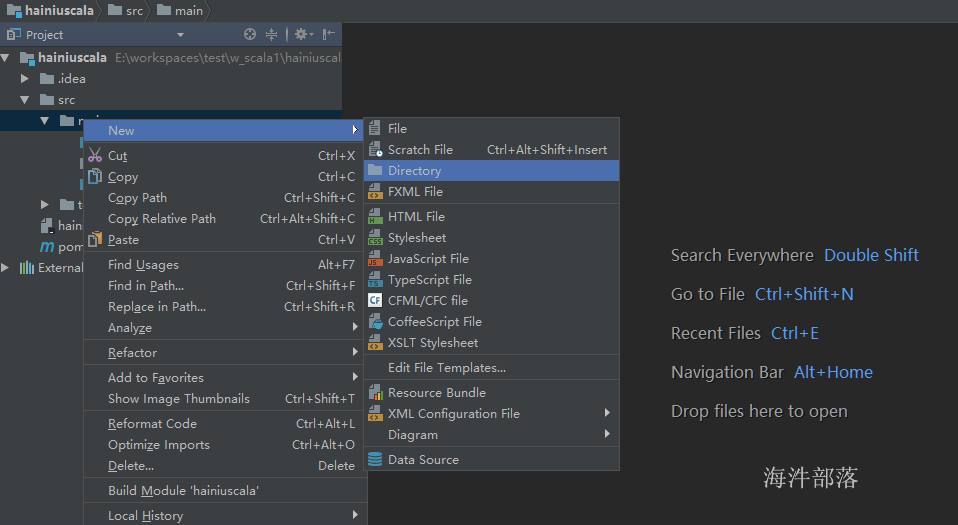
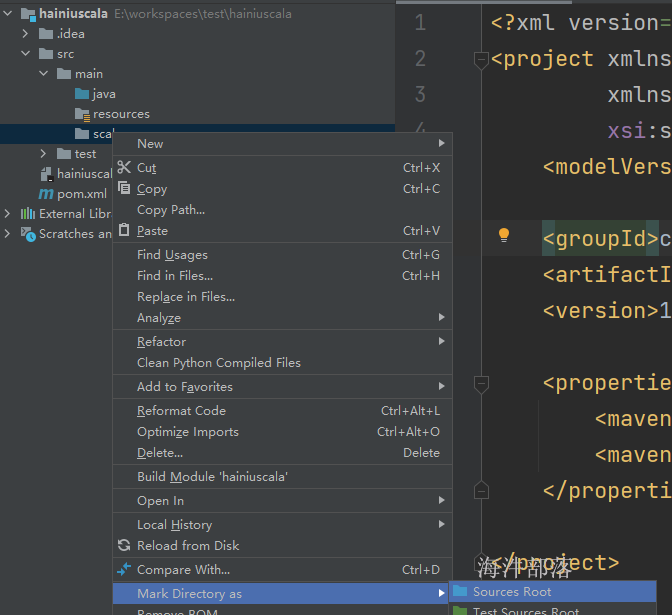
1)右键要修改的目录 → Mark directory as → Sources Root
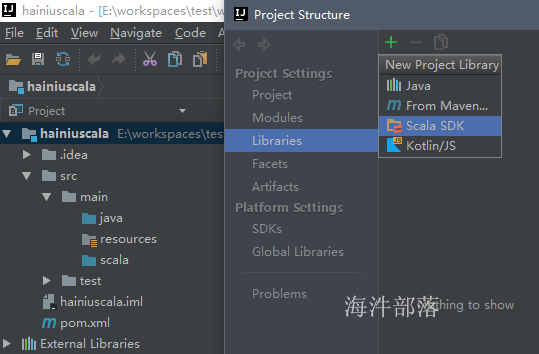
2)File → Project Structure… → Modules
或 右键工程 → Open Module Settings

maven工程默认是java,需要加入 scala SDK。否则工程不能创建scala的类
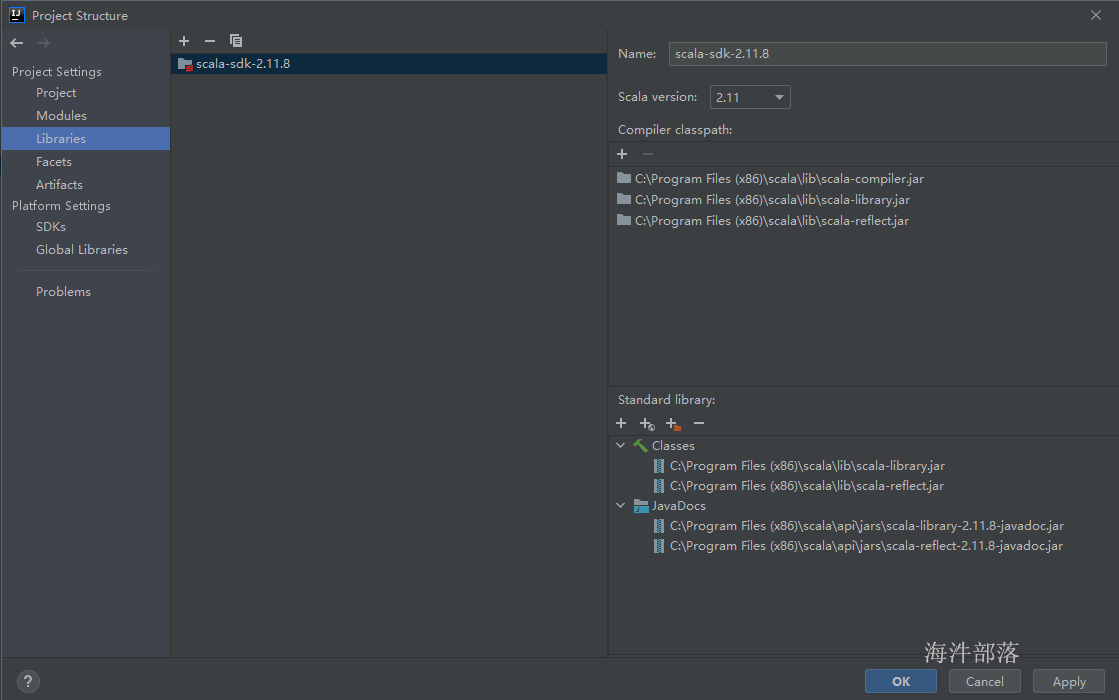
首次时,需要点击 “Browse”选择离线scala sdk。

2.11 idea上maven的使用
打开 maven projects 视图
view → Tool Windows → Maven Projects
或 view → Tool Buttons
清理target
当前没有配置assembly 插件,如果配置了assembly插件,可以点击 “刷新”按钮后,看到assembly插件,后续打包就用这个插件。
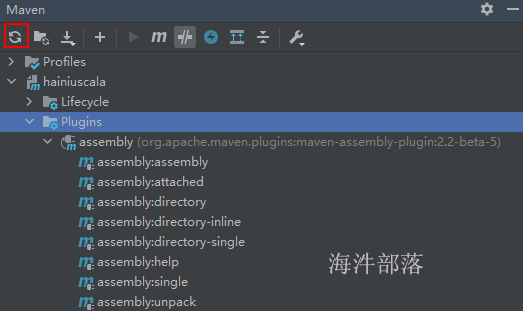
2.12 怎么在idea查看源码
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.11.8</version>
</dependency>
</dependencies>2.13 修改快捷键
可根据自己喜好更改。
3 数据类型、变量、操作符、语句
3.1 基本数据类型
scala 的基本类型有 9种:
Byte、Char、Short、Int、Long、Float、Double、Boolean、Unit
Scala中没有基本数据类型的概念,所有的类型都是对象。

AnyVal:代表所有基本类型。
AnyRef:代表所以引用类型,包括 Scala class 和 Java class。
Any:是所有类的超类。如果不知道表达式的结果是什么类型可以用Any。
Unit:只有一个实例值 (),方法返回Unit 相当于返回了Java中的void。
scala> val a:Int = 10
a: Int = 10
scala> val b:String = "hehe"
b: String = hehe
scala> val c:Any = "hainiu"
c: Any = hainiu
scala> val d:Unit = ()
d: Unit = ()3.2 变量声明
val:变量的引用不可变,底层相当于final 修饰
var:变量的引用可变
scala推荐用val,val就是value的缩写。
scala语言结尾不用分号和Python语言比较相似。
scala不指定变量类型是会根据值进行自动推断,当然也可以在初始化的时候明确指定变量的类型;
// val 修饰的引用不可变
scala> val a:Int = 10
a: Int = 10
// scala不指定变量类型是会根据值进行自动推断
scala> val a = 10
a: Int = 10
scala> a = 11
<console>:12: error: reassignment to val
a = 11
^
// 变量的引用可变
scala> var b:Int = 10
b: Int = 10
scala> b = 20
b: Int = 20
// 如果给变量指定具体类型,会校验数据类型和指定类型是否一致
scala> val c:Int = "hainiu"
<console>:11: error: type mismatch;
found : String("hainiu")
required: Int
val c:Int = "hainiu"
^3.3 操作符
Scala 为它的基本类型提供了丰富的操作符集,包括:
算数运算符:加(+)、减(-) 、乘(*) 、除(/) 、余数(%);
关系运算符:大于(>)、小于(\<)、等于(=)、不等于(!=)、大于等于(>=)、小于等于(\<=);
逻辑运算符:逻辑与(&&)、逻辑或(||)、逻辑非(!);
位运算符:按位与(&)、按位或(|)、按位异或(\^)、按位取反(\~)、左移(\<\<)、右移(>>)、无符号右移(>>>);
赋值运算符:“=” 及其与其他运算符结合的扩展赋值运算符,例如 +=、-=;
注意:
1)与java不同的是这些运算符的操作,都是方法的调用;
2)在 scala中各种赋值表达式的值都是Unit类型;
scala> var b = 1
b: Int = 1
// b = 2 的结果是Unit,所以c的类型是Unit
scala> val c = b = 2
c: Unit = ()
// b 的值改变了
scala> println(b)
23.4 语句
scala 语句行尾的位置建议不加分号;
scala 代码可以自动格式化


4 控制结构
4.1 if 条件表达式
if 语句用来实现两个分支的选择结构,语法如下:
if(表达式1){
语句块1
}else if(表达式2){
语句块2
}else{
语句块3
}运行逻辑和java相同,这块内容省略。
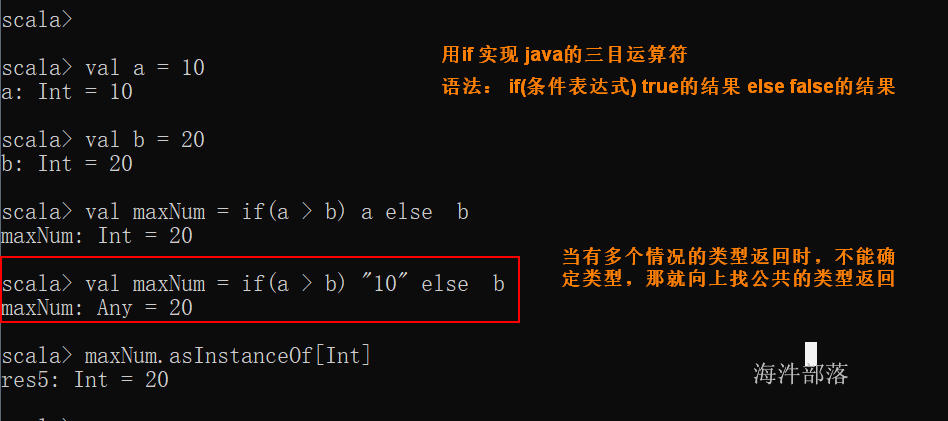
与java 不同的是, scala 可以通过if 语句实现 java 三目运算符的逻辑;
4.2 while 循环
scala 拥有与java相同的while、do while 循环。
x = 1
while(x <= 10){
print(x + " ")
x = x + 1
}
x = 1
do{
print(x + " ")
x = x + 1
}while(x <= 10)4.3 for 循环
但scala没有与java相同的for循环,它的for循环语法
//跟java一样,只不过生成器里面的语法不一样,可以嵌套使用
for(生成器) 循环体
//高级for,for的推导式
for(生成器 [守卫] [;生成器 守卫]...) 循环体其中:
1)生成器:是 变量 \<-表达式 的形式
1 to 3 : 返回 1 到 3 的序列
1 until 3:返回 1 到 2 的序列
scala> 1 to 3
res0: scala.collection.immutable.Range.Inclusive = Range(1, 2, 3)
scala> 1 until 3
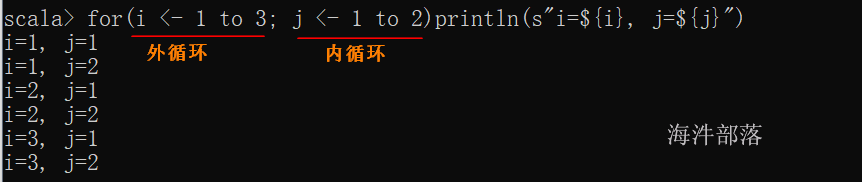
res1: scala.collection.immutable.Range = Range(1, 2)单层循环
scala> for(i <- 1 to 3) println("i=" + i)
i=1
i=2
i=3
// 在字符串中替换变量
scala> for(i <- 1 to 3) println(s"i=${i}")
i=1
i=2
i=3输出双层循环中,外循环1到3, 内循环1到2
一般写法:
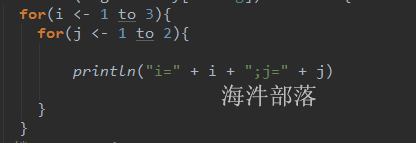
高级写法:
2)守卫:是以if开头的boolean表达式,每个生成器后面都可以跟一个
如:双层循环中,外循环1到3, 内循环1到2,输出外层循环1到2,内层循环1 的值
一般写法:

高级写法:

3)yield关键字结合for循环使用
val c = for(i \<- 1 until 10) yield i
yield 的作用是把每次迭代生成的值封装到一个集合中,当然也可以理解成yield会自动创建一个集合
如果把yield去掉那返回给C的值就为Unit

4.4 循环控制语句
Scala 不支持 break 或 continue 语句,但从 2.8 版本后使用另外一种方式来实现 break 语句。当在循环中使用 break 语句,在执行到该语句时,就会中断循环并执行循环体之后的代码块。
语法格式:
// 导入以下包
import scala.util.control.Breaks
// 创建 Breaks 对象
val loop = new Breaks
// 在 breakable 中循环
loop.breakable(
// 循环
for(...){
....
// 循环中断
loop.break
}
)代码:
import scala.util.control.Breaks
// 单例对象
object HelloWorld {
def main(args: Array[String]): Unit = {
// println("hello world")
// 创建breaks对象
val breaks = new Breaks
println("实现break")
// 实现 i == 3 退出循环
breaks.breakable(
// catch 异常
for(i <- 1 to 5){
// 抛异常
if(i == 3) breaks.break()
println(s"i=${i}")
}
)
println("实现continue")
for(i <- 1 to 5){
breaks.breakable(
if(i == 3){
breaks.break()
} else{
// val n = 1 / 0
println(s"i=${i}")
}
)
}
}
}执行结果:

5 方法与函数
5.1 方法
在scala中的操作符都被当成方法存在,比如说+、-、*、/
1+2就是1.+(2)的调用,
2.0 是doule类型,强调用Int类型的写法为1.+(2:Int)

可以在idea中搜索Int类查看支持的方法
方法声明与使用
定义方法的语法:
def 方法名([变量:变量类型,变量:变量类型]):返回值类型={方法体}其中:
在scala 中,方法里面的最后一个表达式的值就是方法的返回值,不需要return 返回;
示例:
定义无参无返回值的方法:
// 定义无参无返回值的方法
scala> def say():Unit = {println("say hello")}
say: ()Unit
scala> say()
say hello
// 简化过程
scala> def say():Unit = {println("say hello")}
say: ()Unit
// 方法体有一个语句,省略{}
scala> def say():Unit = println("say hello")
say: ()Unit
// 方法返回值可以由方法体返回结果类型推测
scala> def say() = println("say hello")
say: ()Unit
// 方法形参列表是空, 可省略()
scala> def say = println("say hello")
say: Unit
scala> say
say hello
scala> say()
<console>:13: error: Unit does not take parameters
say()
// 带有返回值的方法
def add(a:Int, b:Int):Int={val c = a + b; return c}定义带有有参有返回值方法:
// 定义带有有参有返回值方法
scala> def add(a:Int, b:Int):Int={val c = a + b; return c}
add: (a: Int, b: Int)Int
scala> add(4,5)
res8: Int = 9
// 简化流程
scala> def add(a:Int, b:Int):Int={val c = a + b; return c}
add: (a: Int, b: Int)Int
// scala 不建议用return返回方法结果,默认最后一个就是方法的返回值
scala> def add(a:Int, b:Int):Int={val c = a + b; c}
add: (a: Int, b: Int)Int
// 去掉中间变量c
scala> def add(a:Int, b:Int):Int={a + b}
add: (a: Int, b: Int)Int
// 方法体有一个语句,省略{}
scala> def add(a:Int, b:Int):Int=a + b
add: (a: Int, b: Int)Int
// 方法返回值可以由方法体返回结果类型推测
scala> def add(a:Int, b:Int)=a + b
add: (a: Int, b: Int)Int
scala> add(4,5)
res9: Int = 9方法的调用:
object M1 {
def say(name:String) = {
println(s"say ${name}")
}
def add(a:Int, b:Int) = a + b
def main(args: Array[String]): Unit = {
// 普通调用
M1.say("hainiu")
// 中缀方法调用
M1 say "hainiu"
// 大括号调用,当只有一个入参时才能用
M1 say {"hainiu"}
M1.add(4,5)
// 中缀方法调用
M1 add (4,5)
}
}5.2 函数
在 java 中方法和函数是一个意思,在 scala 中方法和函数是两种含义。
方法:属于类或对象的成员
函数:是对象
在 scala 中,函数是一等公民。可以在任何地方定义,在函数内或函数外,可以作为函数的参数和返回值;函数还可以赋给变量。
函数声明:
val 变量名:[变量类型1,变量类型2 => 函数体返回类型 ] = ([变量:变量类型,变量:变量类型]) => 函数体示例:
// 函数本身是没有名字的--匿名函数
// function2 是 函数有 两个输入参数 和 一个输出, 本例是 两个Int输入,一个Int输出
scala> (a:Int, b:Int) => a + b
res10: (Int, Int) => Int = <function2>
scala> res10(4,5)
res11: Int = 9
// 把匿名函数赋给变量,这个变量名称就成了函数名称
scala> val add:(Int,Int)=>Int = (a:Int, b:Int) => a + b
add: (Int, Int) => Int = <function2>
scala> add(4,5)
res12: Int = 9function中的参数最多有22个
函数的结果做为方法的参数:
示例:
// 定义周长函数
val perimeter = (a:Int,b:Int) => (a+b) *2
// 定义面积函数
val area = (a:Int, b:Int) => a*b
// 定义求和方法
def add(a:Int, b:Int) = a+b
// 计算长方形周长和面积的和
println(add(perimeter(4,5), area(4,5)))函数作为方法的参数:
// 定义js方法,内部有个入参是函数
scala> def js(a:Int, b:Int, func:(Int,Int)=>Int) = func(a,b)
js: (a: Int, b: Int, func: (Int, Int) => Int)Int
// 调用时,只要符合两个Int输入,一个Int输出的函数都可以作为参数
scala> js(4,5, perimeter) // 计算周长
res13: Int = 18
scala> js(4,5, area) // 计算面积
res14: Int = 20方法转换成函数
1)用空格下划线的方式
# 定义方法def add_def(a:Int,b:Int) = a + b# 方法转函数,用空格下划线的方式val add_func = add_def<空格>_2)也可以把方法当参数使用,这也因为scala会隐式的把方法转换成函数,但并不是直接支持方法当参数的模式,只是做了隐式的转换,这种函数的转换分两种显示用空格_和隐式的,这也体现了scala灵活的地方。
// 定义方法add_def
def add_def(a:Int,b:Int) = a + b
// 定义方法js,接收参数是函数
def js(a:Int, b:Int, func:(Int,Int) => Int) = func(a,b)
// 隐式的将方法转换成了函数
println(js(add_def))6 数据结构
在scala 编程中经常需要用到各种数据结构,比如数组(Array)、元组(Tuple)、列表(List)、映射(Map)、集合(Set)等。
Scala同时支持可变集合和不可变集合,不可变集合从不可变,可以安全的并发访问;
不可变集合:scala.collection.immutable
可变集合: scala.collection.mutable
Scala优先采用不可变集合,对于几乎所有的集合类,Scala都同时提供了可变和不可变的版本;
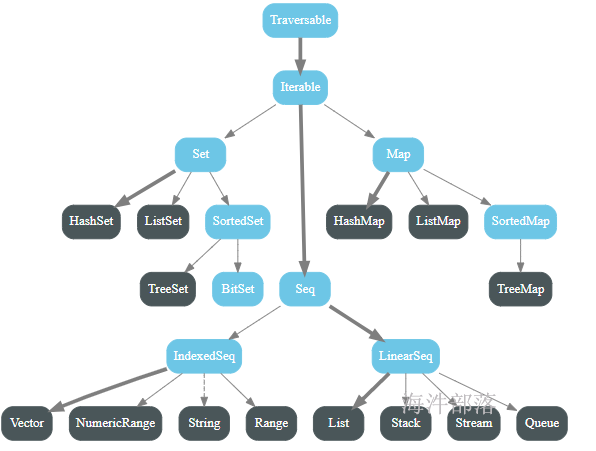
6.1 数组
数组是一种可变的、可索引的、元素具有相同类型的数据集合;
分为定长和变长的,也就是可以改变长度和固定长度的(同样 集合、映射、元组也分为定长和变长);
定长不用引用第3方的包,变长需要引用;
1)定长数组
// 静态初始化
// 在Array的object对象中有apply方法(就是创建对象的),不需要new关键字了
scala> val arr = Array[Int](1,2,3)
arr: Array[Int] = Array(1, 2, 3)
// 动态初始化
scala> val arr1 = new Array[Int](3)
arr1: Array[Int] = Array(0, 0, 0)
// 获取数组长度
scala> arr.size
res32: Int = 3
// 获取数组元素, 下标从0开始,用()括起来
scala> arr(0)
res33: Int = 1
// 不可变数组可以修改元素
scala> arr(0) = 10
scala> println(arr)
[I@49825659
// 通过toBUffer来看到内部数据
scala> println(arr.toBuffer)
ArrayBuffer(10, 2, 3)
// 数组内部存储的类型是一致的,如果不一致,就找公共的类型
scala> val arr = Array(1,"aa",Array[Int](1,2,3))
arr: Array[Any] = Array(1, aa, Array(1, 2, 3))
scala> arr(2)
res37: Any = Array(1, 2, 3)
scala> arr(2)(1)
<console>:13: error: Any does not take parameters
arr(2)(1)
^
// Any类型什么也干不了,需要强转成指定类型
scala> res37.asInstanceOf[Array[Int]]
res39: Array[Int] = Array(1, 2, 3)
scala> res39(1)
res40: Int = 2
scala> val arr = Array[Int](1,4,2,5,6,7)
arr: Array[Int] = Array(1, 4, 2, 5, 6, 7)
// 升序排序
scala> arr.sorted
res41: Array[Int] = Array(1, 2, 4, 5, 6, 7)
// 降序排序
scala> arr.sorted.reverse
res42: Array[Int] = Array(7, 6, 5, 4, 2, 1)
// 聚合函数
scala> arr.sum
res43: Int = 25
scala> arr.max
res45: Int = 7
scala> arr.min
res46: Int = 1
// 数组元素遍历
scala> for(i <- arr) print(s"${i} ")
1 4 2 5 6 7
scala>
// 数组下标方式遍历
scala> for(i <- 0 until arr.size) print(s"${arr(i)} ")
1 4 2 5 6 7
scala> arr.size
res49: Int = 6
scala> arr.length
res50: Int = 6
// 数组和yield产生新数组
scala> for(i <- arr) yield i * 10
res51: Array[Int] = Array(10, 40, 20, 50, 60, 70)注意:
设置带初始值的定长数组不能用new,因为是调用Array的静态对象,这个静态对象可以传递多个参数,而new的是调用类的构造方法只能接受一个参数就是数组的长度
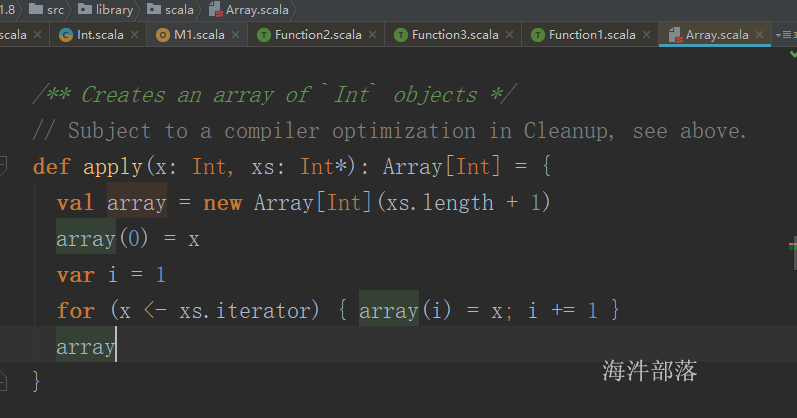
不能直接使用,需要引用ArrayBuffer这个类,不引入就找不到这个类
scala> val arr = new ArrayBuffer[Int]
<console>:11: error: not found: type ArrayBuffer
val arr = new ArrayBuffer[Int]
^
// 变长数组需要手动引入
scala> import scala.collection.mutable.ArrayBuffer
import scala.collection.mutable.ArrayBuffer
scala> val arr = new ArrayBuffer[Int]
arr: scala.collection.mutable.ArrayBuffer[Int] = ArrayBuffer()
// 后面追加
scala> arr.append(-1)
// 指定下标插入
scala> arr.insert(0,-2)
scala> println(arr)
ArrayBuffer(-2, -1)
// + 用来加元素和元组
scala> arr += 1
res55: arr.type = ArrayBuffer(-2, -1, 1)
scala> arr += (2,3)
res56: arr.type = ArrayBuffer(-2, -1, 1, 2, 3)
// ++ 用来++同类(序列)
scala> arr ++= Array[Int](4,5)
res57: arr.type = ArrayBuffer(-2, -1, 1, 2, 3, 4, 5)
scala> arr ++= ArrayBuffer[Int](6,7)
res58: arr.type = ArrayBuffer(-2, -1, 1, 2, 3, 4, 5, 6, 7)
// -- 用来--同类(序列)
scala> arr --= ArrayBuffer[Int](6,7)
res59: arr.type = ArrayBuffer(-2, -1, 1, 2, 3, 4, 5)
scala> arr --= Array[Int](4,5)
res60: arr.type = ArrayBuffer(-2, -1, 1, 2, 3)
// - 用来-元素或元组
scala> arr -= (2,3)
res61: arr.type = ArrayBuffer(-2, -1, 1)
scala> arr -= 1
res62: arr.type = ArrayBuffer(-2, -1)
// remove 减下标并能获取到下标对应的元素
scala> arr.remove(0)
res63: Int = -2
scala> println(arr)
ArrayBuffer(-1)- 定长数组与变长数组的相互转换
to[Byte Short Int Long Double Float String Char] to[Map List Set Array Buffer]
asInstanceOf[类型]
scala> val arr = Array[Int](1,2,3)
arr: Array[Int] = Array(1, 2, 3)
// Array ---> ArrayBuffer
scala> arr.toBuffer
res65: scala.collection.mutable.Buffer[Int] = ArrayBuffer(1, 2, 3)
// ArrayBuffer ---> Array
scala> res65.toArray
res66: Array[Int] = Array(1, 2, 3)6.2 元组
scala 的元组是对多个不同类型对象的一种简单封装。Scala 提供了TupleN 类(N的范围为1 \~ 22),用于创建一个包含N个元素的元组。
构造元组只需把多个元素用逗号隔开并用圆括号括起来。
元组取值时应该按照元祖的属性取值,属性值_N(1-22),而数组的下标是从0开始的,要注意区别;
对偶元祖:只有两个元素的元祖就是对偶元祖
存在一个swap的方法,对偶元祖是一个kv类型的键值对,主要是map中的元素,zip拉链操作会形成对偶元祖
课堂练习:定义一个方法,方法的参数是一个Array(1,2,3,4,5,6,7,8)->得到一个字符串”2 1 4 3 6 5 8 7”
课堂练习:定义一个方法参数是一个Array[Int]第二个参数是number:Int,要求一次性返回和number比较之后,大于number的元素个数,小于number的元素个数和等于number的元素个数
课堂练习:定义一个函数参数是Array[Int]要求一次性返回这个数组中的最大值最小值和平均值(double)类型的
// 元组的每个元素都可以看到具体的类型
scala> val t1 = (1, "hainiu", Array[Int](1,2,3), (4,5))
t1: (Int, String, Array[Int], (Int, Int)) = (1,hainiu,Array(1, 2, 3),(4,5))
// 元组用 t1._N, N从1开始
scala> t1._2
res15: String = hainiu
scala> t1._3(1)
res16: Int = 2
scala> t1._4._2
res17: Int = 5
// 元组元素不可修改
scala> t1._1 = 10
<console>:12: error: reassignment to val
t1._1 = 106.3 列表
1)不可变列表
不可变列表:元素和长度都不可变
// 不可变列表:元素和长度都不可变
scala> val list = List[Int](1,2,3)
list: List[Int] = List(1, 2, 3)
scala> list(1)
res19: Int = 2
// 元素不可变
scala> list(1) = 10
<console>:13: error: value update is not a member of List[Int]
list(1) = 10
^
scala> list.size
res21: Int = 3但可以产生新的列表
scala> val list2 = List(1,2,3)
list2: List[Int] = List(1, 2, 3)
// 在list2 前面加 0 ---> List(0, 1, 2, 3)
scala> list2.::(0)
scala> list2.+:(0)
scala> 0 :: list2
scala> 0 +: list2
// 在list2 后面加 0 ---> List(1, 2, 3, 0)
scala> list2.:+(0)
scala> list2 :+ 0
// 合并两个list并生成新的list
scala> list2 ::: List(2,3,4)
res29: List[Int] = List(1, 2, 3, 2, 3, 4)
scala> list2 ++ List(2,3,4)
res30: List[Int] = List(1, 2, 3, 2, 3, 4)
// Nil 代表空列表
scala> Nil
res31: scala.collection.immutable.Nil.type = List()
scala> 0 :: 1 :: Nil
res32: List[Int] = List(0, 1)2)可变列表
// 需要主动引入可变列表
scala> import scala.collection.mutable.ListBuffer
import scala.collection.mutable.ListBuffer
scala> val list = new ListBuffer[Int]
list: scala.collection.mutable.ListBuffer[Int] = ListBuffer()
// 添加元素
scala> list.append(1)
// 在指定位置插入
scala> list.insert(0, -1)
// + 用来加元素和元组
scala> list += 2
res15: list.type = ListBuffer(-1, 1, 2)
scala> list += (3,4)
res16: list.type = ListBuffer(-1, 1, 2, 3, 4)
// ++ 用来++同类(序列)
scala> list ++= Array(5,6)
res17: list.type = ListBuffer(-1, 1, 2, 3, 4, 5, 6)
scala> list ++= List(7,8)
res18: list.type = ListBuffer(-1, 1, 2, 3, 4, 5, 6, 7, 8)
// 删除元素, 减下标元素
scala> list.remove(0)
res19: Int = -1
scala> list.size
res20: Int = 8
// -- 用来--同类(序列)
scala> list --= List(7,8)
res21: list.type = ListBuffer(1, 2, 3, 4, 5, 6)
scala> list --= Array(5,6)
res22: list.type = ListBuffer(1, 2, 3, 4)
// - 用来减元素和元组
scala> list -= (1,2)
res23: list.type = ListBuffer(3, 4)
scala> list -= 3
res24: list.type = ListBuffer(4)注意:在可变list上也可以调用不可变list的“::”,“+:”,“:+”,“++”,“:::”,区别是可变list返回的是新的ListBuffer,不可变list返回的是新的List。
:: 在列表前面添加 【ListBuffer 不可用】
+: 在列表前面添加
:+ 在列表后面添加
++ 两个列表拼接
::: 两个列表拼接 【ListBuffer 不可用】
scala> val list = ListBuffer(1,2,3)
list: scala.collection.mutable.ListBuffer[Int] = ListBuffer(1, 2, 3)
// :: ::: 在可变列表中用不了
scala> 0 :: list
<console>:14: error: value :: is not a member of scala.collection.mutable.ListBuffer[Int]
0 :: list
^
scala> 0 +: list
res27: scala.collection.mutable.ListBuffer[Int] = ListBuffer(0, 1, 2, 3)
scala> list :+ 0
res28: scala.collection.mutable.ListBuffer[Int] = ListBuffer(1, 2, 3, 0)
scala> list ++ List(4,5)
res29: scala.collection.mutable.ListBuffer[Int] = ListBuffer(1, 2, 3, 4, 5)
scala> list ::: List(4,5)
<console>:14: error: type mismatch;
found : scala.collection.mutable.ListBuffer[Int]
required: List[?]
list ::: List(4,5)
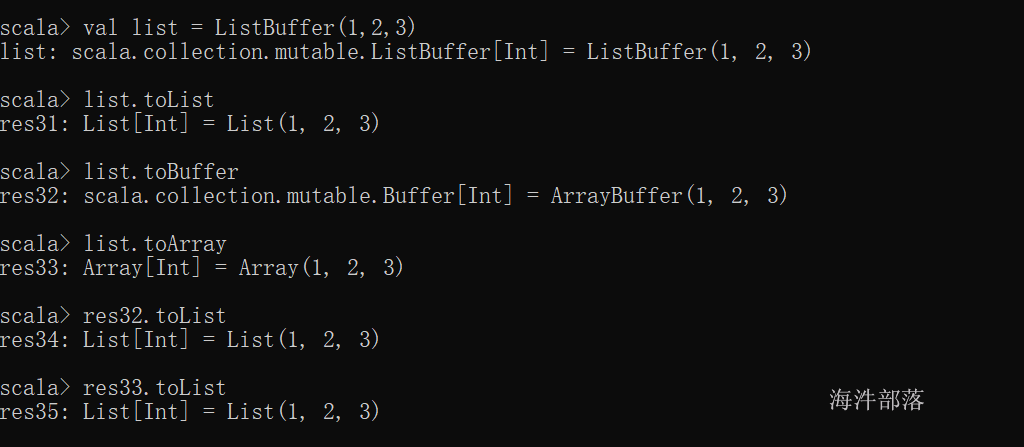
^3)ListBuffer 、 List、ArrayBuffer、Array的转换
6.4 集合
特性:去重
1)不可变set
scala> val set = Set(1,2,3)
set: scala.collection.immutable.Set[Int] = Set(1, 2, 3)
scala> set.size
res36: Int = 3
// 获取第一个元素
scala> set.head
res37: Int = 1
// 获取除了第一个元素以外的其他元素组成的set
scala> set.tail
res38: scala.collection.immutable.Set[Int] = Set(2, 3)
// 判断集合是否为空
scala> set.isEmpty
res40: Boolean = false
// 使用不可变的HashSet,需要引入不可变HashSet
scala> val set = HashSet(1,2,3)
<console>:12: error: not found: value HashSet
val set = HashSet(1,2,3)
^
scala> import scala.collection.immutable.HashSet
import scala.collection.immutable.HashSet
scala> val set = HashSet(1,2,3)
set: scala.collection.immutable.HashSet[Int] = Set(1, 2, 3)
scala> set.size
res41: Int = 3
// 不可变set可以产生新的set集合
scala> set + 1
res42: scala.collection.immutable.HashSet[Int] = Set(1, 2, 3)
scala> set + 4
res43: scala.collection.immutable.HashSet[Int] = Set(1, 2, 3, 4)
scala> set ++ Set(3,5)
res44: scala.collection.immutable.HashSet[Int] = Set(5, 1, 2, 3)2)可变set
// 引入不可变HashSet
scala> import scala.collection.immutable.HashSet
import scala.collection.immutable.HashSet
scala> val set = HashSet(1,2,3)
set: scala.collection.immutable.HashSet[Int] = Set(1, 2, 3)
// 引入可变HashSet
scala> import scala.collection.mutable.HashSet
import scala.collection.mutable.HashSet
// 报错原因是当前有两个HashSet, 创建对象不知道用哪个
scala> val set = new HashSet[Int]
<console>:14: error: reference to HashSet is ambiguous;
it is imported twice in the same scope by
import scala.collection.mutable.HashSet
and import scala.collection.immutable.HashSet
val set = new HashSet[Int]
^
// 冲突了,起别名,用别名来创建对象
scala> import scala.collection.mutable.{HashSet => HashSetMu}
import scala.collection.mutable.{HashSet=>HashSetMu}
scala> val set = new HashSetMu[Int]
set: scala.collection.mutable.HashSet[Int] = Set()
// 可变集合的添加
scala> set.add(1)
res45: Boolean = true
scala> set.add(1)
res46: Boolean = false
scala> set += 2
res47: set.type = Set(1, 2)
scala> set += (3,4)
res48: set.type = Set(1, 2, 3, 4)
scala> set ++= Set(4,5)
res49: set.type = Set(1, 5, 2, 3, 4)
scala> println(set)
Set(1, 5, 2, 3, 4)
// 因为set不按照下标取遍历, remove减的是元素
scala> set.remove(5)
res51: Boolean = true
scala> set -= 1
res52: set.type = Set(2, 3, 4)
scala> set -= (2,3)
res53: set.type = Set(4)
scala> set --= Set(4)
res54: set.type = Set()
scala> set.isEmpty
res55: Boolean = true6.5 映射
映射也就是一个hash表,相当于java里的map。
1)不可变map
// 创建不可变map对象
// kv键值对:可以用 k -> v 表示, 也可以用 (k, v) 表示
scala> val map = Map("a"->1, "b"->(1,2), ("c",3))
map: scala.collection.immutable.Map[String,Any] = Map(a -> 1, b -> (1,2), c -> 3)
scala> map.size
res0: Int = 3
// 获取key对应的value
scala> map("a")
res1: Any = 1
// 强转
scala> res0.asInstanceOf[Int]
res2: Int = 1
// 不可变map不能修改元素
scala> map("a") = 10
<console>:13: error: value update is not a member of scala.collection.immutable.Map[String,Any]
map("a") = 10
^
// 获取时如果key不存在,抛异常
scala> map("d")
java.util.NoSuchElementException: key not found: d
at scala.collection.MapLike$class.default(MapLike.scala:228)
at scala.collection.AbstractMap.default(Map.scala:59)
at scala.collection.MapLike$class.apply(MapLike.scala:141)
at scala.collection.AbstractMap.apply(Map.scala:59)
... 32 elided
// 解决方案1: 通过get方法,获取Option对象
// Option 对象有两个子类:
// None:代表没数据
// Some: 代表有数据, 可通过get() 提取Some对象里的数据
scala> map.get("d")
res5: Option[Any] = None
// 获取对应的Option对象
scala> map.get("a")
res6: Option[Any] = Some(1)
// 提取数据
scala> res6.get
res7: Any = 1
// 解决方案2:通过getOrElse方法,如果key不存在,将设置的默认值返回
scala> map.getOrElse("d", "default value")
res8: Any = default value 不可变 Map 内部元素不可变,但可以产生新的Map
scala> val map = Map("a"->1)
map: scala.collection.immutable.Map[String,Int] = Map(a -> 1)
scala> map + ("b"-> 2)
res9: scala.collection.immutable.Map[String,Int] = Map(a -> 1, b -> 2)
scala> map + (("c", 3))
res10: scala.collection.immutable.Map[String,Int] = Map(a -> 1, c -> 3)
scala> map ++ Map("d"-> 4)
res11: scala.collection.immutable.Map[String,Int] = Map(a -> 1, d -> 4)
scala> res9 - "b"
res12: scala.collection.immutable.Map[String,Int] = Map(a -> 1)
scala> res11 - ("d")
res13: scala.collection.immutable.Map[String,Int] = Map(a -> 1)2)可变map
添加删除数据
// 引入可变的HashMap
scala> import scala.collection.mutable.HashMap
import scala.collection.mutable.HashMap
scala> val map = new HashMap[String,Int]
map: scala.collection.mutable.HashMap[String,Int] = Map()
// 添加数据
scala> map.put("a",1)
res69: Option[Int] = None
scala> println(map)
Map(a -> 1)
scala> map += ("b"-> 2)
res71: map.type = Map(b -> 2, a -> 1)
scala> map += (("c", 3))
res72: map.type = Map(b -> 2, a -> 1, c -> 3)
scala> map ++= Map("d"-> 4)
res73: map.type = Map(b -> 2, d -> 4, a -> 1, c -> 3)
// 删除数据
scala> map.remove("a")
res74: Option[Int] = Some(1)
scala> res74.get
res75: Int = 1
scala> map -= "b"
res76: map.type = Map(d -> 4, c -> 3)
scala> map -= ("c","d")
res77: map.type = Map()
scala> map.isEmpty
res79: Boolean = true遍历map
// 遍历map
scala> val map = HashMap("b" -> 2, "d" -> 4, "a" -> 1, "c" -> 3)
map: scala.collection.mutable.HashMap[String,Int] = Map(b -> 2, d -> 4, a -> 1, c -> 3)
// 以keyset的方式根据key找value
scala> for(k <- map.keySet)println(s"k:${k}, v:${map(k)}")
k:b, v:2
k:d, v:4
k:a, v:1
k:c, v:3
// 直接遍历一组k,v
scala> for((k,v) <- map)println(s"k:${k}, v:${v}")
k:b, v:2
k:d, v:4
k:a, v:1
k:c, v:3
// 遍历value
scala> for(v <- map.values)println(s"v:${v}")
v:2
v:4
v:1
v:3利用元组进行组合赋值
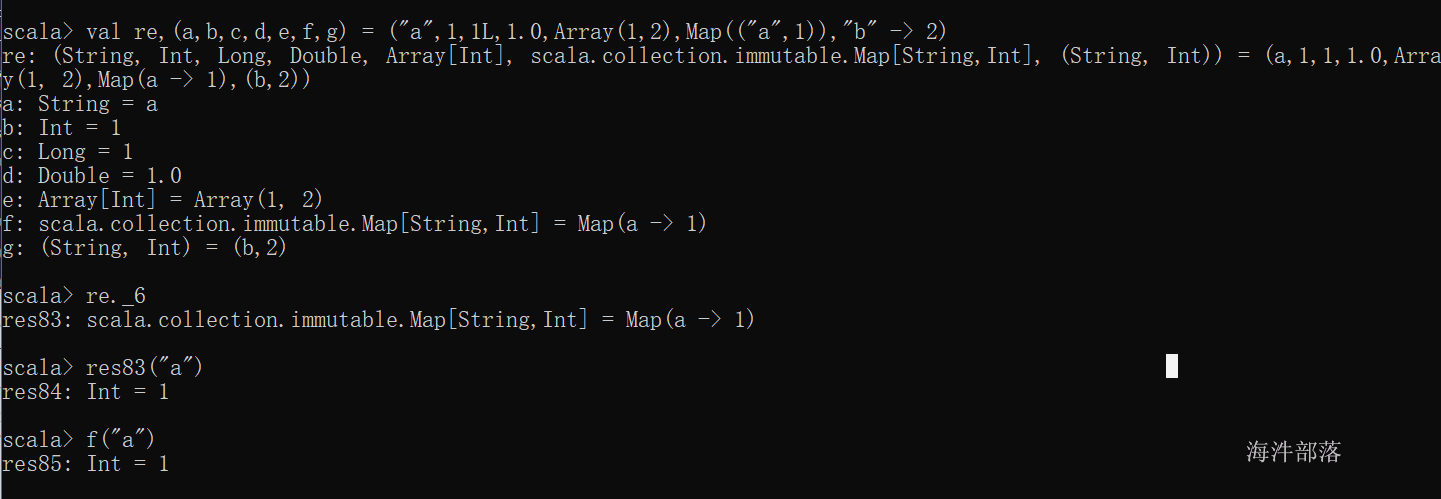
val re,(a,b,c,d,e,f,g) = ("a",1,1L,1.0,Array(1,2),Map(("a",1)),"b" -> 2)
toMap操作——将对偶的数组转换成map
// 对偶数组
scala> val arr1 = Array(("a",1), ("b",2))
arr1: Array[(String, Int)] = Array((a,1), (b,2))
scala> arr1.toMap
res86: scala.collection.immutable.Map[String,Int] = Map(a -> 1, b -> 2)
// 对偶列表
scala> val list = List(("a",1), ("b",2))
list: List[(String, Int)] = List((a,1), (b,2))
scala> list.toMap
res87: scala.collection.immutable.Map[String,Int] = Map(a -> 1, b -> 2)zip操作(拉链操作),通过拉链操作得到对偶数组或列表
ZipWithIndex
scala> val arr1 = Array("a", "b", "c")
arr1: Array[String] = Array(a, b, c)
scala> val arr2 = Array(1,2)
arr2: Array[Int] = Array(1, 2)
// 通过拉链得到对偶数组,如果对不齐就舍去
scala> arr1.zip(arr2)
res88: Array[(String, Int)] = Array((a,1), (b,2))
scala> arr2.zip(arr1)
res89: Array[(Int, String)] = Array((1,a), (2,b))
scala> arr1 zip arr2
res90: Array[(String, Int)] = Array((a,1), (b,2))
scala> res88.toMap
res91: scala.collection.immutable.Map[String,Int] = Map(a -> 1, b -> 2)如何将 List(Array("a",1), Array("b",2)) 转化成 Map("a"->1, "b"-> 2)

7 懒加载 lazy
惰性变量用法放在不可变变量之前;
只有在调用惰性变量时才会去实例化这个变量,类似于java中单例模式的懒汉模式;
作用:是将推迟复杂的计算,直到需要计算的时候才计算,而如果不使用,则完全不会进行计算。
//没有lazy关键字的时候
object LazyDemo {
def init():Unit = {
println("init")
}
def main(args: Array[String]): Unit = {
val p = init()
println("init after")
println(p)
println(p)
}
}
// ---输出结果---
init
init after
()
()
// 带有lazy关键字的变量
object LazyDemo2{
def init():Unit = {
println("init")
}
def main(args: Array[String]): Unit = {
// 只有在使用该变量时,才初始化,而且只初始化一次
lazy val p = init()
println("init after")
println(p)
println(p)
}
}
// ---输出结果---
init after
init
()
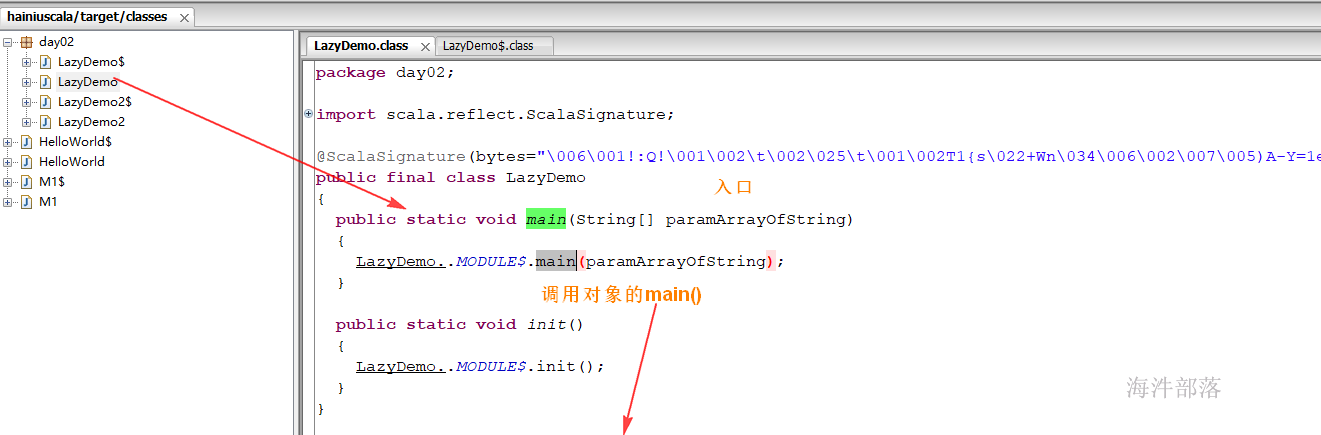
()通过反编译工具查看后发现
不带有 lazy 关键字:
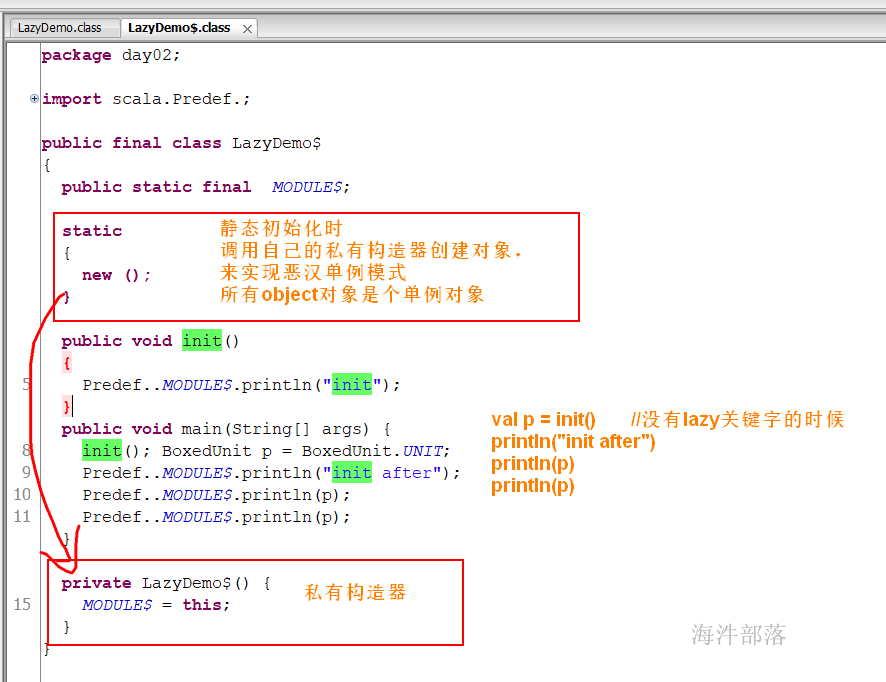
带有lazy关键字
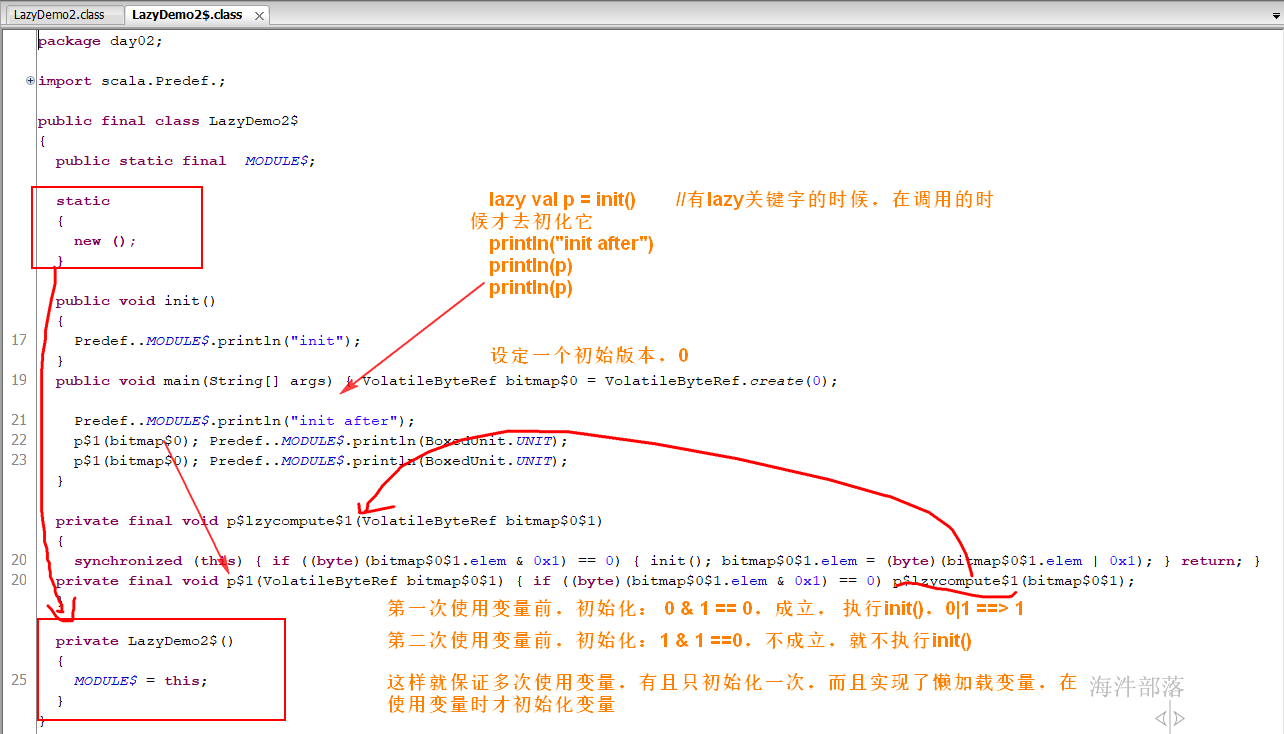
总结:
对于这样一个表达式: lazy val t:T = expr 无论expr是什么东西,字面量也好,方法调用也好。Scala的编译器都会把这个expr包在一个方法中,并且生成一个flag来决定只在它第一次被访问时才调用该方法。
8 集合常用方法和函数操作
foreach
foreach 方法的原型:
// f 返回的类型是Unit, foreach 返回的类型是Unit
def foreach[U](f: Elem => U)该方法接受一个函数 f 作为参数, 函数 f 的类型为Elem => U,即 f 接受一个参数,参数的类型为容器元素的类型Elem,f 返回结果类型为 U。foreach 遍历集合的每个元素,并将f 应用到每个元素上。
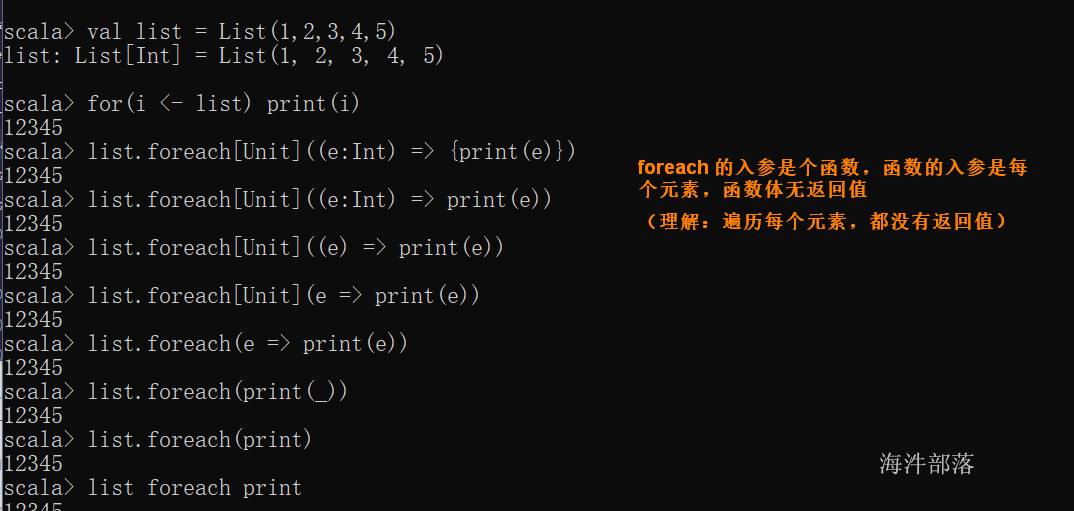
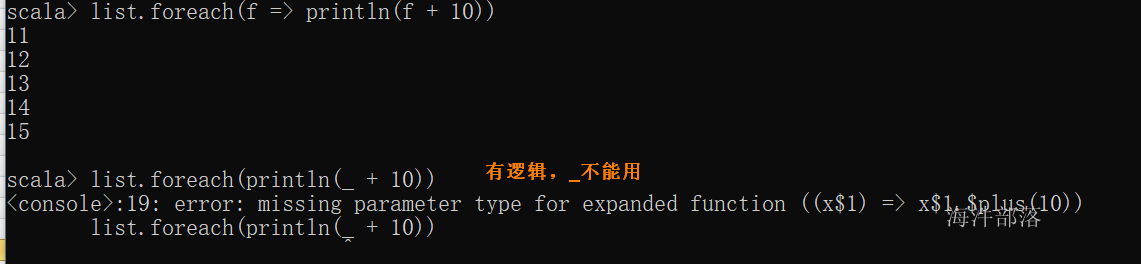
注意:一般在foreach都是用f => xx这种,很少用 _
函数体但凡有点逻辑,_就报错了
- 下滑线通配每一个元素,这个是它的使用方式
- 下划线在代表一个含义的时候只能用一次
- 下划线不能单独使用
sorted、sortBy、sortWith
sorted:按照元素自身进行排序;
sortBy: 按照应用函数 f 之后产生的元素进行排序;
SortWith:传入ab两个值,然后返回比较规则比如a>b
// 按照自身元素排序
val list0 = List(1,4,2,3,5)
list0.sorted
// 按照指定元素排序
val list1 = List(("a",3), ("c",1), ("b",2))
// 按照元组里第一个元素排序
list1.sortBy(_._1)
// 按照元组里第二个元素排序
list1.sortBy(_._2)
// 按照元组里第二个元素降序排序
list1.sortBy(_._2).reverseflatten
当有一个集合的集合,然后你想对这些集合的所有元素进行操作时,就会用到 flatten;
List(List(1,2), List(3,4)) —–> List(1,2,3,4)
List(Array(1,2),Array(3,4)) —–> List(1,2,3,4)
List(Map(“a”->1,“b”->2), Map(“c”->3,“d”->4)) —–> List((a,1), (b,2), (c,3), (d,4))
val list = List(List(1,2), List(3,4))
list.flatten注意:flatten 不支持元组
// 下面的方法报错
val list = List((1,2), (3,4))
list.flattenmap, flatMap
map 操作
map操作是针对集合的典型变换操作,它将某个函数应用到集合中的每个元素,并产生一个结果集合;
map方法返回一个与原集合类型大小都相同的新集合,只不过元素的类型可能不同。
val list = List(1,2,3,4)
// 对list 里面的每个元素加1,并返回新的集合
list.map(x => x+1) // 等效于 list.map(_ + 1)
val list2 = List("a b c", "d e f")
// 新集合和原集合的类型不同
list2.map(x => x.split(" "))flatMap 操作
flatMap的执行过程: map –> flatten
val list = List("a b c", "d e f")
list.map(_.split(" ")).flatten
// flatMap = map + flatten
list.flatMap(_.split(" "))注意:同flatten一样,不支持元组
filter
遍历一个集合并从中获取满足指定条件的元素组成一个新的集合;
val list = List(1,2,3,4,5)
// 筛选偶数组成新集合
list.filter(x => x % 2 == 0)
list.filter(_ % 2 == 0)如何过滤出大于2的奇数?
val list = List(1,2,3,4,5)
list.filter(_ > 2).filter(_ % 2 != 0)
list.filter(f => if(f > 2 && f % 2 != 0) true else false)并行集合
通过list.par 会将集合变成并行集合,可以利用多线程来进行运算。
val list = List(1,2,3,4,5)
println("-----list-----------------")
val s1 = list.foreach(f => println(s"${Thread.currentThread().getName} ==> ${f}"))
println("-----list.par-------------")
val s2 = list.par.foreach(f => println(s"${Thread.currentThread().getName} ==> ${f}"))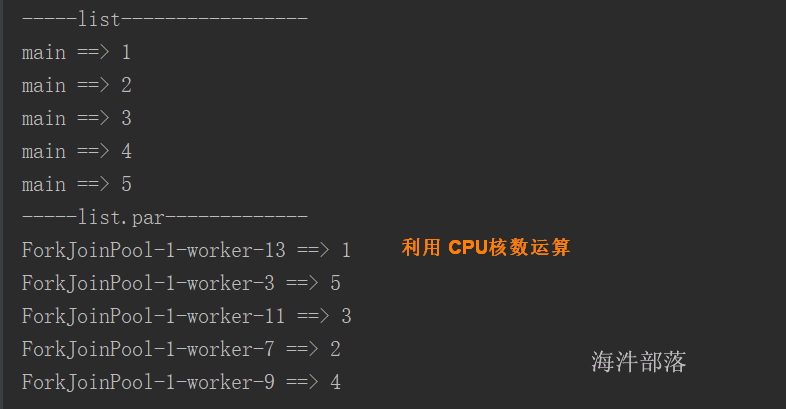
reduce、reduceLeft、reduceRight
reduce:reduce(op: (A1, A1) => A1): A1 。reduce操作是按照从左到右的顺序进行规约。(((1+2)+3)+4)+5
reduceLeft:reduceLeft[B >: A](f: (B, A) => B): B。是按照从左到右的顺序进行规约。 (((1+2)+3)+4)+5
reduceRight:reduceRight[B >: A](op: (A, B) => B): B。是按照从右到左的顺序进行规约。1+(2+(3+(4+5)))
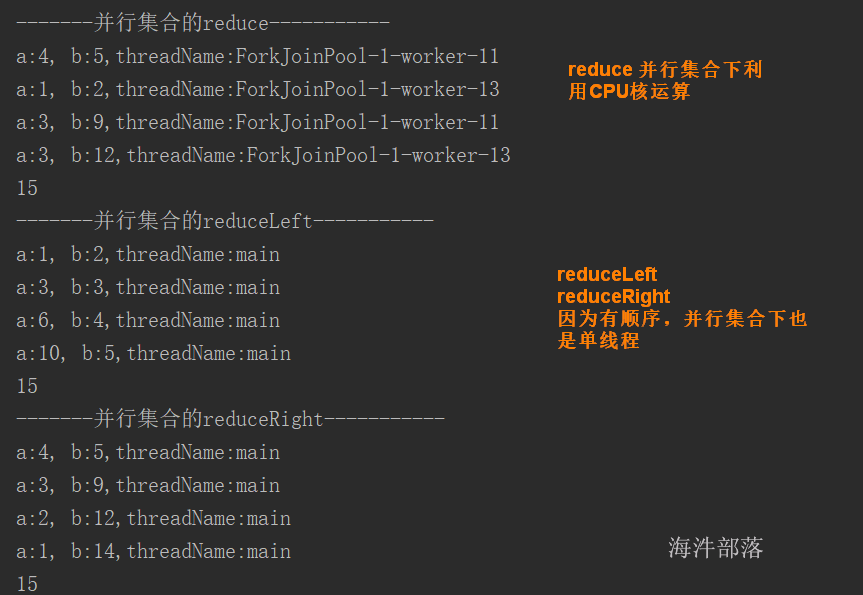
单线程下: reduce 和 reduceLeft一样
并行集合运行下: reduce利用CPU数运行, reduceLeft 有方向,只能单线程运行
val list = List(1,2,3,4,5)
println("-----reduce-------------")
val sum: Int = list.reduce((a: Int, b: Int) => {
println(s"a:${a}, b:${b}")
a + b
})
println(sum)
println("------reduceLeft------------")
val sum1: Int = list.reduceLeft((a: Int, b: Int) => {
println(s"a:${a}, b:${b}")
a + b
})
println(sum1)
println("------reduceRight------------")
val sum2: Int = list.reduceRight((a: Int, b: Int) => {
println(s"a:${a}, b:${b}")
a + b
})
println(sum2)
println("-------并行集合的reduce-----------")
// 利用并行集合多线程运算,没有顺序
val sum3: Int = list.par.reduce((a: Int, b: Int) => {
println(s"a:${a}, b:${b},threadName:${Thread.currentThread().getName}")
a + b
})
println(sum3)
println("-------并行集合的reduceLeft-----------")
// reduceLeft 将并行集合多线程的运算变成了单线程,有顺序
val sum4: Int = list.par.reduceLeft((a: Int, b: Int) => {
println(s"a:${a}, b:${b},threadName:${Thread.currentThread().getName}")
a + b
})
println(sum4)
println("-------并行集合的reduceRight-----------")
// reduceRight 将并行集合多线程的运算变成了单线程,有顺序
val sum5: Int = list.par.reduceRight((a: Int, b: Int) => {
println(s"a:${a}, b:${b},threadName:${Thread.currentThread().getName}")
a + b
})
println(sum5)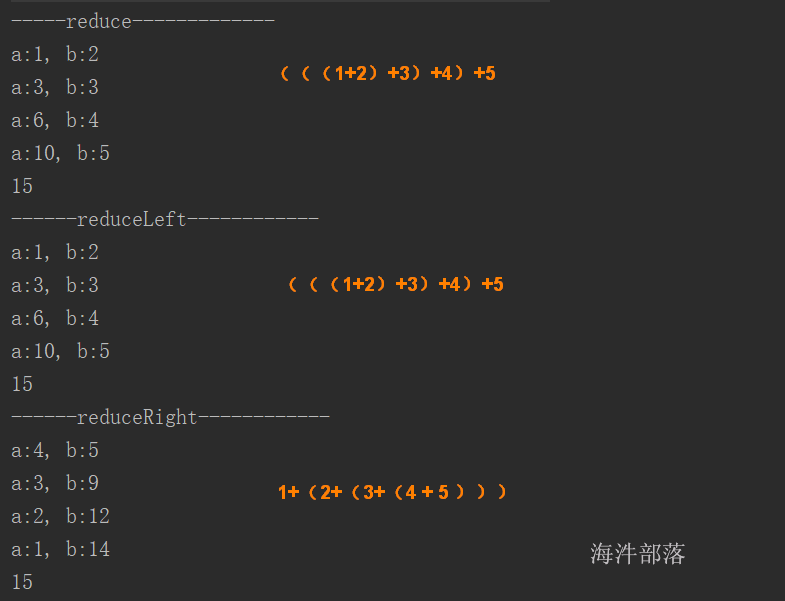
如何简写?
scala> val list = List(1,2,3,4,5)
list: List[Int] = List(1, 2, 3, 4, 5)
scala> list.reduce((a:Int,b:Int) => {a + b})
res18: Int = 15
scala> list.reduce((a:Int,b:Int) => {println(s"${a} + ${b} = ${a + b}");a + b})
1 + 2 = 3
3 + 3 = 6
6 + 4 = 10
10 + 5 = 15
res19: Int = 15
scala> list.sum
res20: Int = 15
// 求最大值
scala> list.max
res21: Int = 5
// 用reduce实现求最大值
scala> list.reduce((a:Int,b:Int) => {println(s"${a} vs ${b}");if(a > b) a else b})
1 vs 2
2 vs 3
3 vs 4
4 vs 5
res22: Int = 5
scala> list.reduce((a:Int,b:Int) => {a + b})
res23: Int = 15
scala> list.reduce(_ + _)
res24: Int = 15
scala> list.par.reduce(_ + _)
res25: Int = 15fold, foldLeft, foldRight
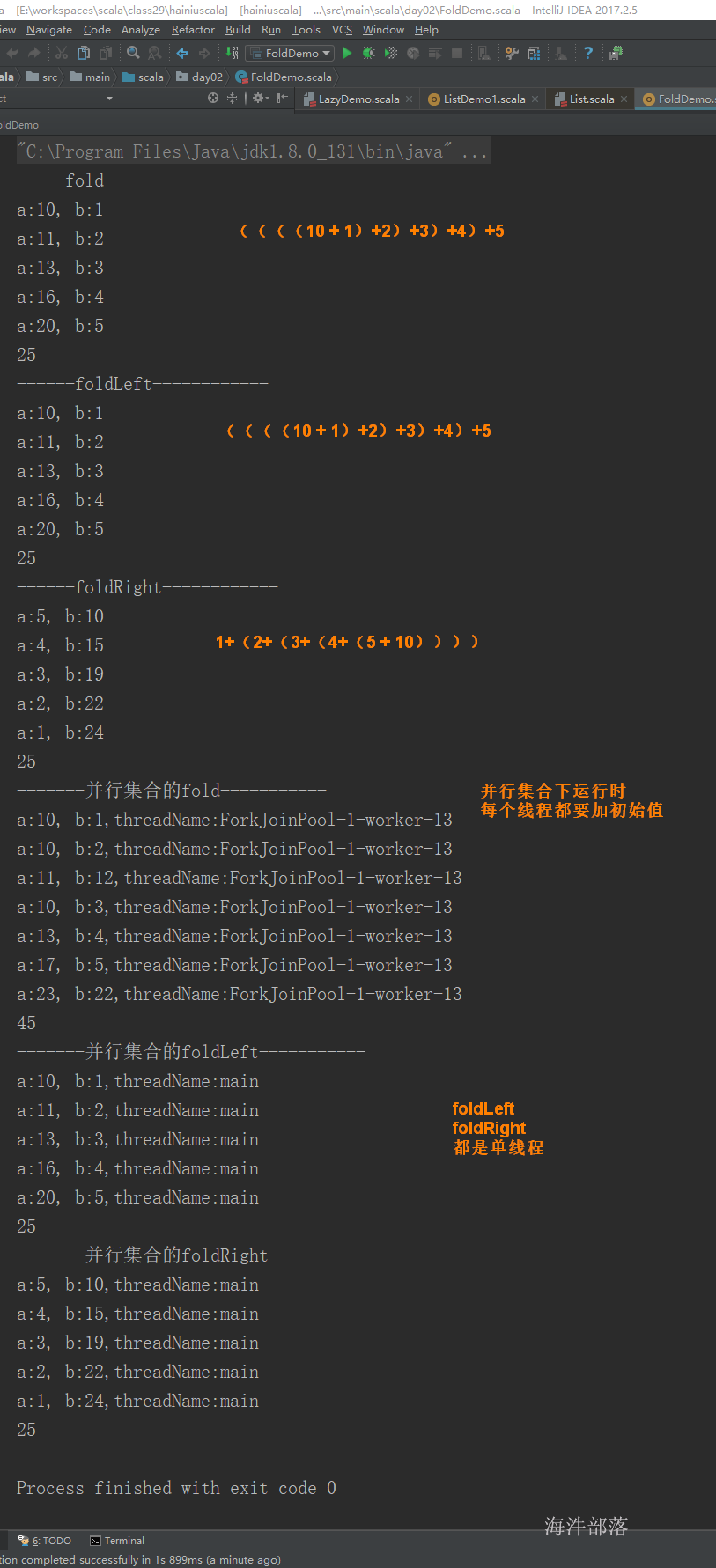
fold:fold[A1 >: A](z: A1)(op: (A1, A1) => A1): A1 。带有初始值的reduce,从一个初始值开始,从左向右将两个元素合并成一个,最终把列表合并成单一元素。((((10+1)+2)+3)+4)+5
foldLeft:foldLeft[B](z: B)(f: (B, A) => B): B 。带有初始值的reduceLeft。((((10+1)+2)+3)+4)+5
foldRight:foldRight[B](z: B)(op: (A, B) => B): B。带有初始值的reduceRight。1+(2+(3+(4+(5+10))))
object FoldDemo {
def main(args: Array[String]): Unit = {
val list = List(1,2,3,4,5)
println("-----fold-------------")
val sum = list.fold(10)((a:Int, b:Int)=> {
println(s"a:${a}, b:${b}")
a+b
})
println(sum)
println("------foldLeft------------")
val sum1: Int = list.foldLeft(10)((a: Int, b: Int) => {
println(s"a:${a}, b:${b}")
a + b
})
println(sum1)
println("------foldRight------------")
val sum2: Int = list.foldRight(10)((a: Int, b: Int) => {
println(s"a:${a}, b:${b}")
a + b
})
println(sum2)
println("-------并行集合的fold-----------")
// 利用并行集合多线程运算,没有顺序
val sum3: Int = list.par.fold(10)((a: Int, b: Int) => {
println(s"a:${a}, b:${b},threadName:${Thread.currentThread().getName}")
a + b
})
println(sum3)
println("-------并行集合的foldLeft-----------")
// foldLeft 将并行集合多线程的运算变成了单线程,有顺序
val sum4: Int = list.par.foldLeft(10)((a: Int, b: Int) => {
println(s"a:${a}, b:${b},threadName:${Thread.currentThread().getName}")
a + b
})
println(sum4)
println("-------并行集合的foldRight-----------")
// foldRight 将并行集合多线程的运算变成了单线程,有顺序
val sum5: Int = list.par.foldRight(10)((a: Int, b: Int) => {
println(s"a:${a}, b:${b},threadName:${Thread.currentThread().getName}")
a + b
})
println(sum5)
}
}
如何简写?
scala> val list = List(1,2,3,4,5)
list: List[Int] = List(1, 2, 3, 4, 5)
scala> list.fold(10)((a,b)=> a + b)
res35: Int = 25
scala> list.fold(10)(_ + _)
res36: Int = 25aggregate
将每个分区里面的元素进行聚合,然后用combine函数将每个分区的结果和初始值进行combine操作;

val list = List(1,2,3,4,5)
// 当集合不是并行集合时,combop函数不执行
val sum: Int = list.aggregate(0)((a: Int, b: Int) => {
println(s"step1:a:${a}, b:${b}")
a + b
},
(a: Int, b: Int) => {
println(s"step2:a:${a}, b:${b}")
a + b
}
)
println(sum)
//-------运行结果-----------------------------
step1:a:0, b:1
step1:a:1, b:2
step1:a:3, b:3
step1:a:6, b:4
step1:a:10, b:5
15
//--------------------------------------------------------------
val list = List(1,2,3,4,5)
// 当集合是并行集合时,combop函数执行
// step1:做基础聚合, step2:在step1 基础上做聚合,相当于combiner
val sum2: Int = list.par.aggregate(0)((a: Int, b: Int) => {
println(s"step1:a:${a}, b:${b}")
a + b
},
(a: Int, b: Int) => {
println(s"step2:a:${a}, b:${b}")
a + b
}
)
println(sum2)
//-------运行结果-----------------------------
15
step1:a:0, b:1
step1:a:0, b:4
step1:a:0, b:5
step1:a:0, b:2
step1:a:0, b:3
step2:a:1, b:2
step2:a:4, b:5
step2:a:3, b:9
step2:a:3, b:12
15总结:
reduce/reduceLeft/reduceRight: 认为每个元素类型一样
fold: 带有初始值的reduce,初始值类型和元素类型一样;并行集合下注意初始值的设定;
foldLeft/foldRight: 初始值类型和元素类型可以不一样,规约结果和初始值类型一致;并行集合下是单线程运算
aggregate:初始值类型和元素类型可以不一样,规约结果和初始值类型一致;并行集合下是利用CPU核数运算
groupBy、grouped
groupBy:将list 按照某个元素内的字段分组,返回map。 List((k,v),(k,v)) –> Map(k, List(k,v))
grouped:按列表按照固定的大小进行分组,返回迭代器。List(1,2,3,4,5) –> Iterator[List[A]]
val list = List(("a",1),("a",2), ("b",3))
// 将list里的按照元素内的第一个进行分组
val map: Map[String, List[(String, Int)]] = list.groupBy(_._1)
println(map)
// -----输出结果-----------------------------
Map(b -> List((b,3)), a -> List((a,1), (a,2)))
val list1 = List("a", 1, "a", 2, "b", 3, 4)
val it: Iterator[List[Any]] = list1.grouped(2)
println(it)
// 调用迭代器toBuffer,会把迭代器里的数据都迭代出来,有且只能迭代一次
println(it.toBuffer)
println(it)
// -----输出结果-----------------------------
non-empty iterator
ArrayBuffer(List(a, 1), List(a, 2), List(b, 3), List(4))
empty iteratormapValues
对map映射里每个key的value 进行操作。
val map = Map("b" -> List(1,2,3), "a" -> List(4,5,6))
// 对每个key的value 求和
val n1 = map.mapValues(_.sum)
println(n1)group by 和 mapValues 组合
scala> val list = List(("a",1), ("a", 1), ("b",1))
list: List[(String, Int)] = List((a,1), (a,1), (b,1))
// 按照单词把元素分到一组,但不运算
scala> list.groupBy(f => f._1)
res49: scala.collection.immutable.Map[String,List[(String, Int)]] = Map(b -> List((b,1)), a -> List((a,1), (a,1)))
// 利用 mapValues 对每个key的value做运算
scala> res49.mapValues(f => f.size)
res51: scala.collection.immutable.Map[String,Int] = Map(b -> 1, a -> 2)
// 按照单词统计数值
scala> val list = List(("a",1), ("a", 2), ("b",1), ("b", 3))
list: List[(String, Int)] = List((a,1), (a,2), (b,1), (b,3))
scala> list.groupBy(_._1)
res52: scala.collection.immutable.Map[String,List[(String, Int)]] = Map(b -> List((b,1), (b,3)), a -> List((a,1), (a,2)))
scala> res52.mapValues(_.map(_._2))
res54: scala.collection.immutable.Map[String,List[Int]] = Map(b -> List(1, 3), a -> List(1, 2))
scala> res52.mapValues(_.map(_._2).sum)
res55: scala.collection.immutable.Map[String,Int] = Map(b -> 4, a -> 3)diff, union, intersect
diff : 两个集合的差集;
union : 两个集合的并集;
intersect: 两个集合的交集;
val nums1 = List(1,2,3)
val nums2 = List(2,3,4)
val diff1 = nums1 diff nums2
println(diff1)
val diff2 = nums2.diff(nums1)
println(diff2)
val union1 = nums1 union nums2
println(union1)
val union2 = nums2 ++ nums1
println(union2)
val intersection = nums1 intersect nums2
println(intersection)
//-------运行结果-----------------------------
List(1)
List(4)
List(1, 2, 3, 2, 3, 4)
List(2, 3, 4, 1, 2, 3)
List(2, 3)实现 wordcount
实现统计 List(“a b c d”,“a d e s”) 单词的个数
scala> val list = List("a b c d","a d e s")
list: List[String] = List(a b c d, a d e s)
scala> list.flatMap(_.split(" "))
res56: List[String] = List(a, b, c, d, a, d, e, s)
scala> res56.map(f => (f, 1))
res57: List[(String, Int)] = List((a,1), (b,1), (c,1), (d,1), (a,1), (d,1), (e,1), (s,1))
scala> res57.groupBy(_._1)
res58: scala.collection.immutable.Map[String,List[(String, Int)]] = Map(e -> List((e,1)), s -> List((s,1)), a -> List((a,1), (a,1)), b -> List((b,1)), c -> List((c,1)), d -> List((d,1), (d,1)))
scala> res58.mapValues(_.size)
res59: scala.collection.immutable.Map[String,Int] = Map(e -> 1, s -> 1, a -> 2, b -> 1, c -> 1, d -> 2)
scala> res59.toList
res60: List[(String, Int)] = List((e,1), (s,1), (a,2), (b,1), (c,1), (d,2))
scala> res60.sortBy(_._2)
res61: List[(String, Int)] = List((e,1), (s,1), (b,1), (c,1), (a,2), (d,2))
scala> res61.reverse
res62: List[(String, Int)] = List((d,2), (a,2), (c,1), (b,1), (s,1), (e,1))
scala>
scala> list.flatMap(_.split(" ")).map((_,1)).groupBy(_._1).mapValues(_.size)
res63: scala.collection.immutable.Map[String,Int] = Map(e -> 1, s -> 1, a -> 2, b -> 1, c -> 1, d -> 2)
scala> res63.toList.sortBy(_._2).reverse
res64: List[(String, Int)] = List((d,2), (a,2), (c,1), (b,1), (s,1), (e,1))9 类
类和对象是Java、C++等面向对象编程的基础概念。类是用来创建对象的蓝图。定义好类以后,就可以使用new关键字来创建对象。
scala 如果不写权限修饰符,默认是public。
一个类文件可以声明多个类;
定义语法:
//模板类
class 类名{
}
//单例对象--使用main(), 来测试
object 类名{
}其中:
类中可以放属性、方法、函数;
类中属性的定义和变量的定义一样,用val 或 var 进行定义,默认权限是public;
类中方法用关键字def 定义;
object对象,也称单例对象,该对象编译后都是静态成员;
如果有同样一个类与该object名字一样,则称该object为该类的伴生对象,相对应,该类为object的伴生类;
类中的属性:
可以分为可变(var)和不可变(val)
访问修饰可以分 private 和 private[this]
示例:
package day02
class ClassDemo1 {
// 定义可变的属性
var name = "hainiu"
// 地址:刚开始没值,后来给的值
// 用_占位,刚开始的初始值和 定义属性类型一致,字符串默认是null
// 当用 _占位,属性类型不可省略
var addr:String = _
// 定义不可变的属性
val sex = "boy"
// 定义方法
def say = println("say hello")
// 定义函数
val printFunc = () => println(s"name:${name}, sex:${sex}")
}
object ClassDemo1Test{
def main(args: Array[String]): Unit = {
// 创建 对象
val demo = new ClassDemo1
println(demo.name)
println(demo.sex)
demo.say
demo.printFunc()
// demo.sex = "girl"
demo.name = "hehe"
demo.printFunc()
// 字符串初始值是null
println(demo.addr)
demo.addr = "北京市昌平区"
println(demo.addr)
}
}private 与 private[this]
用private修饰的属性,该属性属于对象私有变量,只有本类和伴生对象能访问到;
用private[this]修饰后,该属性属于对象私有变量,只有本类才能访问,伴生对象也访问不到;
package day02
class ClassDemo2 {
val name:String = "翠花"
// private 修饰的成员,伴生对象可访问,其他对象不可访问
private val age:Int = 32
// private[this] 修饰的成员,当前对象可用, 伴生对象、其他对象均不可访问
private[this] val money:Double = 8.8
}
// class ClassDemo2 的伴生对象
object ClassDemo2{
def main(args: Array[String]): Unit = {
val demo = new ClassDemo2
println(demo.name)
println(demo.age)
// demo.money
}
}
object ClassDemo2Test{
def main(args: Array[String]): Unit = {
val demo = new ClassDemo2
println(demo.name)
// demo.age
// demo.money
}
}10 构造器
用于对类进行属性的初始化,分为主构造器和辅助构造器;
10.1 主构造器
语法:
//参数可以有默认值
class 类名 [private] (参数列表){
}其中:
1)定义类的时候,就定义了构造器。即:是()内的内容。
2)主构造器会执行类中定义的所有语句。
3)private 加在主构造器前面标识这个主构造器是私有的,外部不能访问这个构造器。
package day02
// 主构造器参数如果是var、val修饰的,那就是public
// var:可变, val:不可变
class ConDemo1(var name:String, val age:Int) {
}
object ConDemo1Demo{
def main(args: Array[String]): Unit = {
// 通过主构造器创建对象
val demo = new ConDemo1("傻强", 10)
println(s"name:${demo.name}, age:${demo.age}")
demo.name = "奀妹"
// demo.age = 10
}
}4)主构造器内的参数可以是默认值;当参数有默认值,且参数在后面时,创建对象时可以不用给参数赋值;
package day02
// 主构造器参数如果是var、val修饰的,那就是public
// var:可变, val:不可变
class ConDemo1(var name:String, val age:Int=10) {
}
object ConDemo1Demo{
def main(args: Array[String]): Unit = {
// 通过主构造器创建对象
// val demo = new ConDemo1("傻强")
val demo = new ConDemo1("傻强", 11)
println(s"name:${demo.name}, age:${demo.age}")
demo.name = "奀妹"
// demo.age = 10
}
}5)主构造器内的参数可以用var、val修饰,也可以不加 var、val 修饰
a)var 修饰的参数,可以在其他类中访问和修改;
b)val 修饰的参数,只可以在其他类中访问,但不能修改;
c)不加 var、val 修饰的参数,就相当于被private [this] val 修饰,不可以在其他类中访问和修改;
// 如果主构造器的参数没有var、val 修饰代表private[this]
class ConDemo2(var name:String, val age:Int=10, addr:String = "四川") {
def printInfo = println(this.addr)
}
object ConDemo2{
def main(args: Array[String]): Unit = {
val demo = new ConDemo2("傻强")
println(s"name:${demo.name}, age:${demo.age}")
// demo.addr
}
}
object ConDemo2Demo{
def main(args: Array[String]): Unit = {
// 通过主构造器创建对象
val demo = new ConDemo2("傻强")
println(s"name:${demo.name}, age:${demo.age}")
// demo.addr
demo.printInfo
}
}10.2 辅助构造器
赋值构造器的名称是 this;
辅助构造器可以理解成java中的构造器重载,且辅助构造器的第一行必须要先调用主构造器(这点和python 的基础调用父类比较相似);
辅助构造器可以没有,如果有要在类中进行定义,辅助构造器可以声明主构造器没有的参数,可以通过辅助构造给属性赋值;
辅助构造器的参数不能用val或者var修饰,因为其参数都是参考主构造器或者类中的;
package day02
class ConDemo3(val name:String) {
var age:Int = _
var addr:String = _
// 通过辅助构造器实现scala的构造器重载
// 辅助构造器的名字:this
// 把this当做方法,传参不能有var、val修饰
// 构造器的第一句需要 调用主构造器
// 给属性赋值,属性的存在
def this(name:String, age:Int) = {
this(name)
this.age = age
}
def this(name:String, age:Int, addr:String) = {
this(name)
this.age = age
this.addr = addr
}
// 辅助构造器不能和主构造器参数类型一致
// def this(name:String) = {
// this(name)
// }
}
object ConDemo3{
def main(args: Array[String]): Unit = {
// 通过主构造器创建对象
val demo = new ConDemo3("hainiu")
println(demo.name)
// 通过辅助构造器创建对象
val demo2 = new ConDemo3("hainiu", 10)
println(s"name:${demo2.name}, age:${demo2.age}")
// 通过辅助构造器创建对象
val demo3 = new ConDemo3("hainiu", 10, "北京")
println(s"name:${demo3.name}, age:${demo3.age},addr:${demo3.addr}")
}
}10.3 总结
主构造器
1)主构造器的参数列表要放到类名的后面,和类名放在一起,val修饰的构造参数具有不可变性,var修饰的构造参数具有可变性;
2)如果参数没有用val或var修饰,那它不可被外面直接访问(可通过相应的get方法访问),只能在本类中使用;
3)如果参数没有用val或var修饰,伴生对象也无法使用(相当于用private[this]),也不可在本类中进行修改,因为它被当成隐藏的val修饰的;
辅助构造器
1)辅助构造器可以没有;如果有,要在类中进行定义。
2)辅助构造器可以声明主构造器没有的参数,如果声明了其它参数那这个参数需要在类中进行定义,否则提示无法找到这个参数;
3)辅助构造器的参数不能用val或者var修饰,因为其参数都是参考主构造器或者类中的;
4)辅助构造器也可以理解成java中的构造器重载,且辅助构造器的第一行必须要先调用主构造器(这点和python的子类调用父类比较相似,而JAVA可以选择是否调用默认构造器)
idea使用:
如果按ctrl+p,提示有两行或多行的时候那就说明有辅助构造器;
快捷键修改
settings → Keymap,在搜索框输入 “parameter info”, 然后双击搜索结果“parameter info”,选择添加快捷键,再点applay → ok。

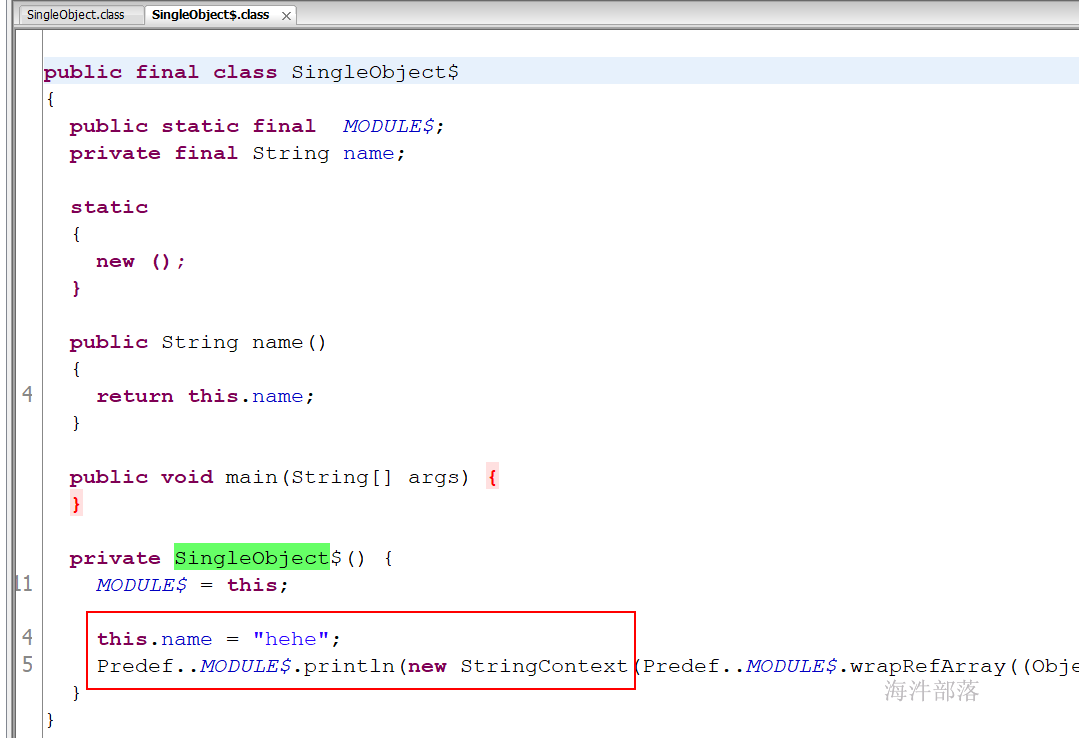
11 单例对象
在scala中没有像java一样的static关键字;
在scala中是没有静态方法和静态字段的,但是可以使用object关键字加类名的语法结构实现同样的功能;
在scala中用object修饰的为单例对象,单例对象中主要存放常量和工具方法;

上面代码通过反编译发现:
定义单例对象,实现连接池的操作, 提供获取可用连接个数、获取连接、释放连接
package day03
import scala.collection.mutable.ArrayBuffer
object ConnFactory {
// 利用初始化代码来初始化连接池里面的连接
// 连接池最大连接3个
private val maxNum:Int = 3
//
private val conns = new ArrayBuffer[Conn]
for(i <- 1 to 3){
conns += new Conn(i)
}
// 获取可用连接个数
def getConnSize = this.conns.size
//获取连接
def getConn:Conn = {
if(this.conns.size == 0){
null
}else{
val conn = this.conns.remove(0)
conn
}
}
// 释放连接
def releaseConn(conn:Conn):Boolean = {
if(conn == null || this.conns.size == this.maxNum){
false
}else{
this.conns += conn
true
}
}
}
object ConnFactoryTest{
def main(args: Array[String]): Unit = {
println(ConnFactory.getConnSize)
val conn1 = ConnFactory.getConn
val conn2 = ConnFactory.getConn
val conn3 = ConnFactory.getConn
val conn4 = ConnFactory.getConn
println(s"${conn1}, ${conn2}, ${conn3}, ${conn4}")
val res4 = ConnFactory.releaseConn(conn4)
val res3 = ConnFactory.releaseConn(conn3)
val res2 = ConnFactory.releaseConn(conn2)
val res1 = ConnFactory.releaseConn(conn1)
val res0 = ConnFactory.releaseConn(conn1)
println(s"${res4}, ${res3}, ${res2}, ${res1}, ${res0}")
}
}
// 连接对象
class Conn(val id:Int){
override def toString: String = s"Conn[${id}]"
}12 伴生对象
在Scala中,单例对象分为两种,一种是并未自动关联到特定类上的单例对象,称为独立对象 ;
另一种是关联到一个类上的单例对象,该单例对象与该类共有相同名字,则这种单例对象称为伴生对象,对应类称为伴生类。
一个单例对象未必是一个伴生对象,但是一个伴生对象一定是一个单例对象;
每个类都可以有伴生对象,伴生类与伴生对象必须写在同一个文件中;

ip.txt
192.168.88.189 op.hadoop
192.168.88.195 nn2.hadoop
利用类和伴生对象,解析ip对应的主机名
package day03
import scala.io.Source
// 伴生类
class Parser(val ip:String) {
def parse = {
// 调用伴生对象的map获取对应ip的主机名
Parser.map.getOrElse(ip, "无该主机")
}
}
// 伴生对象
object Parser{
// 读取文件并转成map
private val list = Source.fromFile("/tmp/scala/ip.txt").getLines().toList
private val list2 = list.map(_.split(" "))
private val list3 = list2.map(f => (f(0), f(1)))
private val map = list3.toMap
println(map)
}
object ParserTest{
def main(args: Array[String]): Unit = {
val parser = new Parser("192.168.88.180")
println(parser.parse)
}
}13 private关键字总结
修饰class
1、在class前面使用private可以被相同包(包含递归子包)访问(能引入类);
2、在class前面使用private[包名]代表是包的访问权限,只能指定的包名和子包(包含递归子包)下才能访问;
private修饰 主构造器、主构造器参数、辅助构造器、属性、方法, 当前类和伴生对象可以访问,其他对象不能访问;
private[this]修饰 主构造器、主构造器参数、辅助构造器、属性、方法, 只有当前类可以访问;
private[包名] 修饰 主构造器、主构造器参数、辅助构造器、属性、方法, 指定包名及子包可访问。
示例:
在class前面使用private可以被相同包(包含递归子包)访问(能引入类);

子包可引入
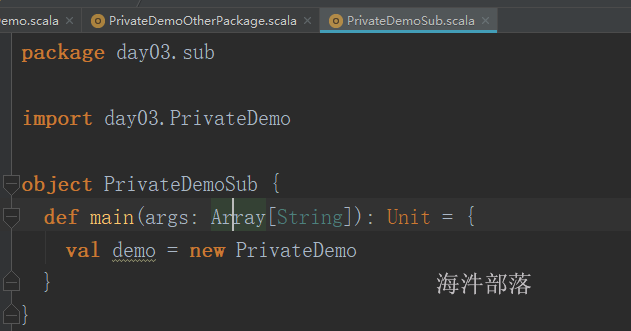
其他包不能引入
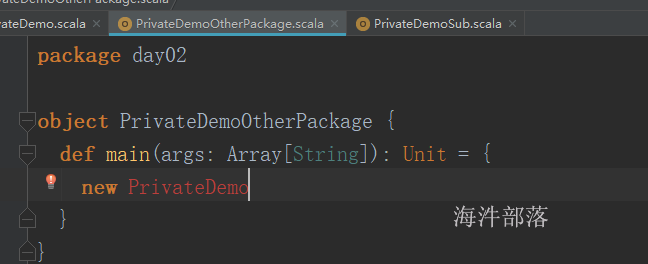
在class前面使用private[包名]代表是包的访问权限,只能指定的包名和子包(包含递归子包)下才能访问;
package day03
// private[this] 修饰的主构造器,伴生对象和其他对象都不可访问
class PrivateDemo2 private[this] (val name:String) {
var age:Int = _
// private[包名] 修饰的辅助构造器,同包名或递归子包都可访问
private[day03] def this(name:String, age:Int ) = {
this(name)
this.age = age
}
}
object PrivateDemo2{
def main(args: Array[String]): Unit = {
// val demo = new PrivateDemo2("hainiu")
val demo = new PrivateDemo2("hainiu", 10)
}
}
object privateDemo2Other{
def main(args: Array[String]): Unit = {
// val demo = new PrivateDemo2("hainiu")
val demo = new PrivateDemo2("hainiu", 10)
}
}14 模式匹配
14.1 match 语句
match 语句用在当需要从多个分支中进行选择的场景,类似于java 中的switch 语句。
语法:
变量 match{
case "值" => 语句块1 // 语句块后不用加break
case "值2" => 语句块2
case _ => 语句块N // 类似于java的default
}其中:
1)case 后面的表达式可以是任何类型的常量,如字段串、类、元组、集合等;
2)与java的switch不同的是,match 结构中不需要break 语句来跳出判断;
3)最后一个case语句用了通配符“_”,相当于java的default;
4)如果匹配不到,就会报错;
14.2 字符串匹配
import scala.util.Random
object MatchDemo {
def main(args: Array[String]): Unit = {
var arr = Array("A","B","C","D")
val a = arr(Random.nextInt(arr.length))
println(a)
a match {
case "A" => println("a")
case "B" => println("b")
case "C" => println("c")
case _ => println("other")
}
}
}14.3 类型匹配
match除了匹配特定的常量,还能匹配某种类型的所有值;
在scala 中倾向于用这样的模式匹配,而不是isInstanceOf 操作符;
package day03
import scala.util.Random
object MatchDemo2 {
def main(args: Array[String]): Unit = {
val arr: Array[Any] = Array(1, 100L, 3.14, "1000", Array[Int](1,2,3))
val data: Any = arr(Random.nextInt(arr.size))
var data2:Int = 0
// 用 match匹配类型
data match {
case x:Int => data2 = x
case x:Long => data2 = x.toInt
case x:Double => data2 = x.toInt
case x:String => data2 = x.toInt
case x:Array[Int] => data2 = x.sum
}
println(s"data:${data}, data2:${data2}")
// 这种多类型匹配不适合用 isInstanceOf, asInstanceOf
// if(data.isInstanceOf[Int]){
// data2 = data.asInstanceOf[Int]
// }else if(data.isInstanceOf[Long]){
// data2 = data.asInstanceOf[Long].toInt
// }
}
}14.4 数组、元组、集合匹配
元组匹配时case后面的值的个数应与被匹配的元组中数据的个数相同,否则报错。
当有多个条件能匹配到时以最先匹配到的条件为准
object MatchDemo3 {
def main(args: Array[String]): Unit = {
val arr = Array(1, 2, 3, 4)
arr match {
case Array(1, x, y) => println(s"x:$x,y:$y")
case Array(_, x, y, d) => println(s"x:$x,y:$y,d:$d")
case _ => println("other")
}
val tuple = (5, 6, 7)
tuple match {
case (1, a, b) => println(s"case1 a:$a,b:$b")
case (3, a, b) => println(s"case2 a:$a,b:$b")
case (_, x, y) => println(s"case3 a:$x,b:$y")
case _ => println("other")
}
val list = List(7,8,9)
list match {
case 7 :: b :: Nil => println(s"case 1 b:$b")
case List(a,b,c) => println(s"case 2 a:$a,b:$b,c:$c")
case 7 :: 8 :: b :: Nil => println(s"case 3 b:$b")
case _ => println("other")
}
}
}
//-----------运行结果-----------------
x:2,y:3,d:4
case3 a:6,b:7
case 2 a:7,b:8,c:914.5 偏函数匹配
1)使用 case 语句构造匿名函数与偏函数。
// 构造匿名函数
val list = List(1,2,3)
// 下面三种方式同等效果
val list1 = list.map((x:Int) => x*2)
// 编译器把case语句翻译成普通函数
val list2 = list.map({case x:Int => x*2})
val list3 = list map {case x:Int => x*2}
// 当把case语句翻译成普通函数时,如果匹配不上会报错
val list4 = List(1,2,3,"aaa",4)
//这句就会报错
val list5 = list4 map {case x:Int => x * 2}
val list = List(1,2,3, "aaa", 4)
// collect 接收偏函数作为参数,此时把case语句作为参数传递,scala编译器会把 case 语句翻译成偏函数
// 当构造偏函数时,值匹配能匹配上的,不能匹配上的放弃并顾虑掉;
list.collect({case x:Int => x*2})
res10: List[Int] = List(2, 4, 6, 8)总结:
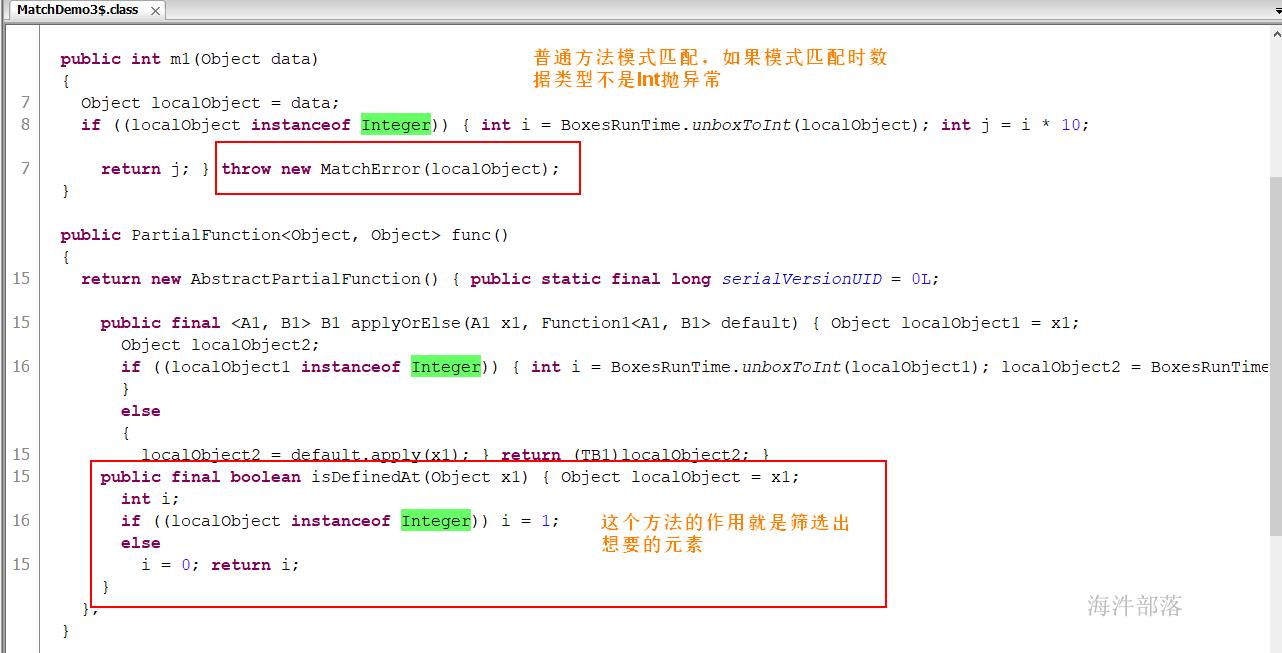
当编译器把case语句翻译成函数时,如果匹配不上会报错;
当编译器把case语句翻译成偏函数时,匹配不上的放弃并过滤掉;
2)偏函数
在Scala中,所有偏函数的类型皆被定义为 PartialFunction[-A, +B] 类型,PartialFunction[-A, +B] 又派生自 Function1 。
PartialFunction[-A, +B] ,其中 A 是方法参数类型,B是方法返回值类型。
PartialFunction(偏函数)内部常与 case 语句搭配,进行模式匹配,函数体里的模式匹配没有match关键字;
当把偏函数作为函数使用时,如果匹配不上会报错;
当把偏函数作为偏函数时,匹配不上的放弃并过滤掉;
package day03
object MatchDemo3 {
// 定义普通方法
def m1(data:Any):Int = {
data match {
case x:Int => x * 10
// case x:String => x.toInt * 10
// case _ => 0
}
}
// 定义偏函数
def func:PartialFunction[Any, Int] = {
case x:Int => x * 10
}
def main(args: Array[String]): Unit = {
println(m1(10))
//println(m1("10"))
println(func(10))
val list = List(1,2,3, "aa", "bb")
// collect接收偏函数,func定义时只要Int
println(list.collect(func))
println(list.map(m1))
}
}
15 apply和unapply方法
apply、unapply方法都被隐式的调用
apply方法:
1)在一个类的伴生对象中定义apply方法,在生成这个类的对象时,就省去了new关键字。
2)apply方法的参数列表不需要和构造函数的参数列表统一,也就是说apply 方法支持重载。
3)apply 方法可以通过主构造器和辅助构造器new对象;
4)apply方法 定义在object 里,是创建对象;如果定义在class 里,是获取对象的数据;
apply方法定义在object对象
package day03
class ApplyDemo(val name:String) {
var age:Int = _
def this(name:String, age:Int) = {
this(name)
this.age = age
}
}
object ApplyDemo{
// 在 object对象上定义apply方法是用来创建对象的
// 调用主构造器创建对象
def apply(name: String): ApplyDemo = {
println("==> apply(name: String)")
new ApplyDemo(name)
}
// 调用辅助构造器创建对象
// apply方法是可以重载的
def apply(name: String, age:Int): ApplyDemo = {
println("==> apply(name: String, age:Int)")
new ApplyDemo(name, age)
}
def main(args: Array[String]): Unit = {
// 直接new对象
val demo = new ApplyDemo("hainiu")
// 通过scala隐式的调用apply方法(主构造器)创建对象,此时不需要new关键字
val demo2 = ApplyDemo("hainiu")
println(demo2.name)
// 通过隐式调用apply方法(调用的辅助构造器)来创建对象
val demo3 = ApplyDemo("hainiu", 10)
println(s"${demo3.name}, ${demo3.age}")
}
}apply方法定义在class上
package day03
class ApplyDemo2 {
private val list = List(1,5,2,3,6,7)
// apply 方法定义在class上是用来提取数据的
// 就相当于数组、列表提取数据一样
def apply(index:Int) = {
this.list(index)
}
}
object ApplyDemo2{
def main(args: Array[String]): Unit = {
val demo = new ApplyDemo2
println(demo.apply(0))
println(demo(0))
}
}unapply方法:
1)可以认为unapply方法是apply方法的反向操作,apply方法接受构造参数变成对象,而unapply方法接受一个对象,从中提取值。
2)unapply方法常被称为提取方法,可以用unapply方法提取相同操作的对象,unapply方法会返回一个Option,其内部生成一个Some对象,这个Some是做相似对象的封装。
3)unapply 不支持重载。
4)unapply常被用于模糊匹配。
Option Option中的泛型个数影响unapply方法返回some参数的个数和模式匹配中的case类型参数的个数。 Option 子类: None:无数据,scala 用None 来表达 无数据, 相当于java 的 null Some:有数据。 用的地方: 1)模式匹配 2)集合
package day03
class UnapplyDemo(val name:String, val age:Int) {
}
object UnapplyDemo{
// unapply方法是用来解构的
// 你给我对象,我把对象里的数据提取出来(通过模式匹配)
def unapply(arg: UnapplyDemo): Option[(String, Int)] = {
println("==> unapply(arg: UnapplyDemo): Option[(String, Int)]")
Some((arg.name, arg.age))
}
// unapply方法不能重载
// def unapply(arg: UnapplyDemo): Option[String] = {
// println("==> unapply(arg: UnapplyDemo): Option[(String, Int)]")
// Some(arg.name)
// }
def main(args: Array[String]): Unit = {
val demo = new UnapplyDemo("hainiu", 10)
demo match{
// type1: 由于是直接匹配对象,所以不需要走unapply方法
// case x : UnapplyDemo => println(s"type1==>${x.name}, ${x.age}")
// 下面的都是提取对象里面数据的,这些都走unapply方法
case UnapplyDemo(x,y) => println(s"type2==>${x}, ${y}")
case UnapplyDemo(x) => println(s"type3==>${x._1}, ${x._2}")
case UnapplyDemo("hainiu", y) => println(s"type4==>hainiu, ${y}")
}
}
}总结:
apply 方法定义 object 中,用于创建对象;
apply方法定义 class 中, 用于提取数据;
unapply 方法 定义在 object 对象中, 用于提取对象数据;
16 样例类和样例对象
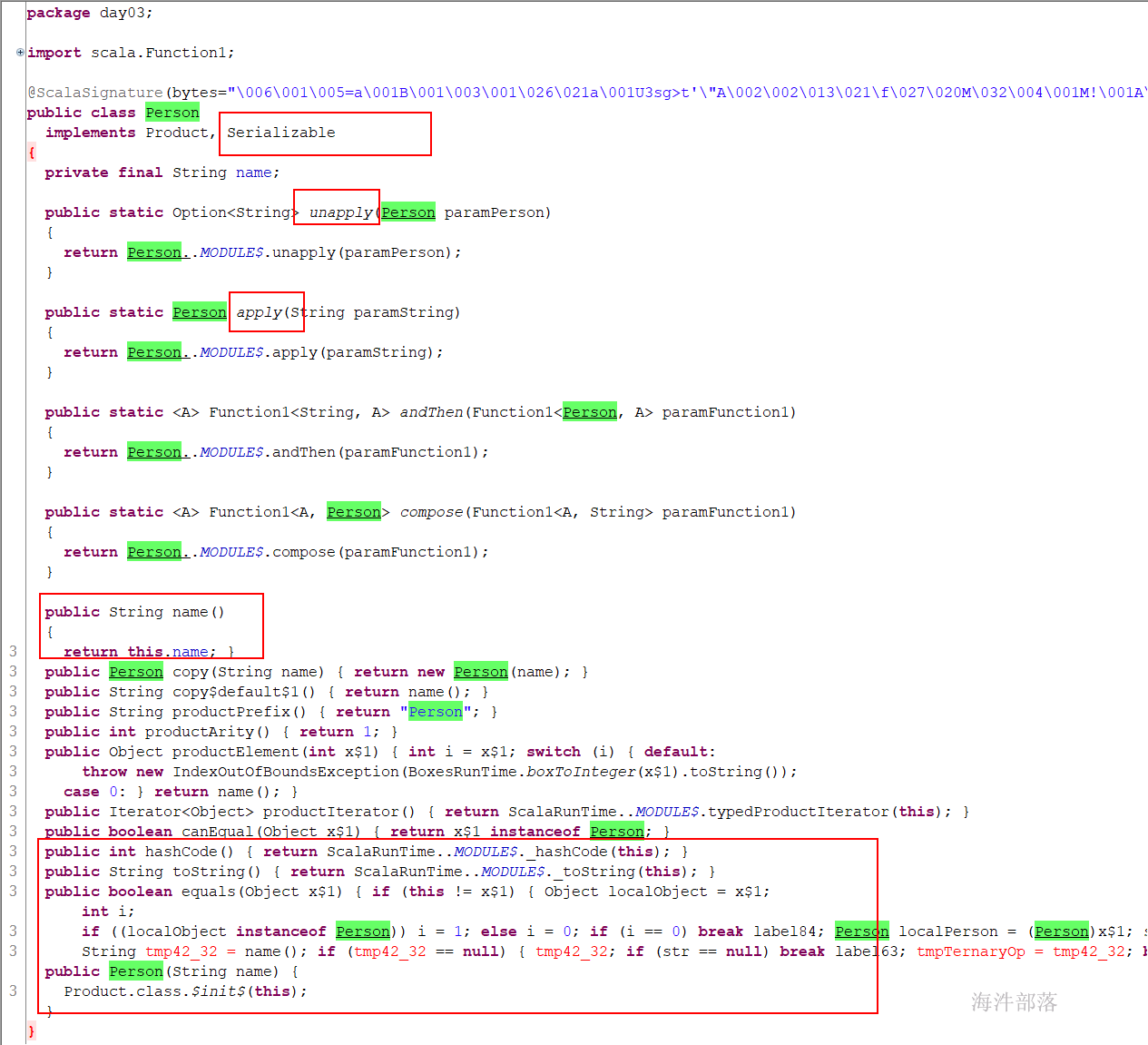
样例类
在class 前加上 case 关键字,这样的类称为样例类。默认实现了Serializable接口,可以封装数据。
scala 为每一个样例类自动生成一个伴生对象,在该伴生对象中自动生成的模板代码包括:
1)一个apply 方法,实例化该类的时候无需使用new 关键字;
2)一个unapply 方法,该方法包含一个类型为伴生类的参数,返回结果是Option 类型;
对应的类型参数是N元组,N是伴生类中主构造参数的个数;
unapply 方法用于对对象的解构操作,在case 类模式匹配中,该方法被自动调用,并将待匹配的对象作为参数传递给它;
如:
// 定义case类
case class Person(name:String, age:Int){}
//编译器自动生成的伴生对象是
object Person{
// apply 方法
def apply(name:String,age:Int) = new Person(name,age)
// unapply 方法
def unapply(p:Person):Option((String,Int)) = Some((p.name,p.age))
}
样例对象
样例对象也是一个对象只是在实现的时候在object前面加上了case用于支持模式匹配,默认实现了Serializable接口,不可以封装数据。
case object 对象名示例:
package day03
import scala.util.Random
// 定义无构造参数样例类
case class CaseClass() {
def say = println("say hello")
}
// 定义有构造参数的样例类
case class CaseClass2(val name:String){
def say = println(s"say ${name}")
}
// 定义样例对象
case object CaseObject{
def say = println("say object")
}
object CaseTest{
def main(args: Array[String]): Unit = {
val arr = Array(CaseClass(), CaseClass2("hainiu"), CaseObject)
val data = arr(Random.nextInt(arr.size))
println(data)
data match {
case x:CaseClass => x.say
// case x:CaseClass2 => x.say
case CaseClass2(x) => println(x)
case x:CaseObject.type => x.say
}
}
}通过样例类实现支持模式匹配的多参
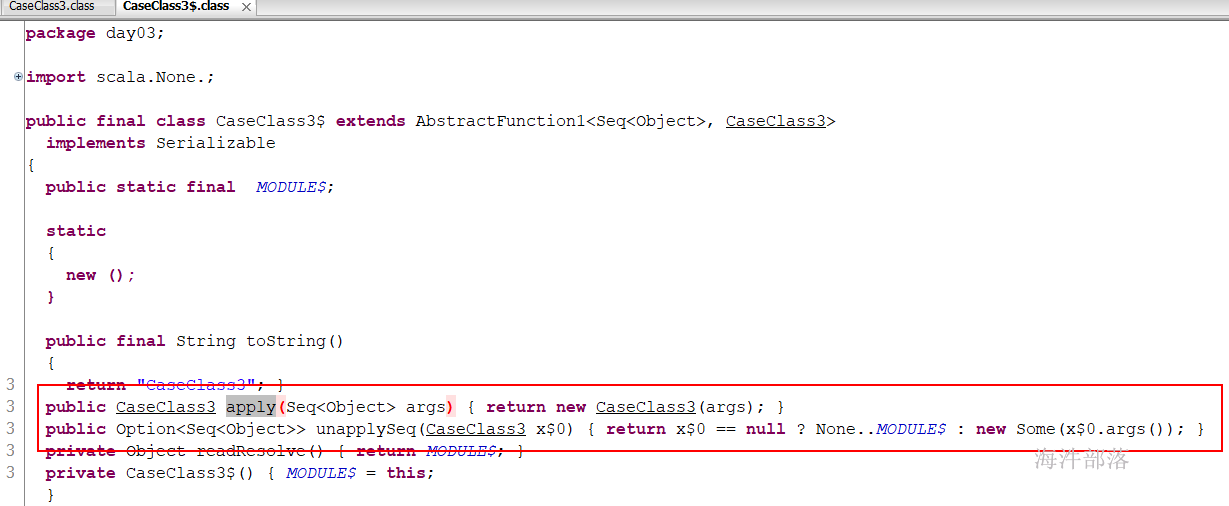
package day03
case class CaseClass3(val args:Any*)
object CaseClass3Test{
def main(args: Array[String]): Unit = {
val demo = CaseClass3(1,2,3,4,5,6,7,8)
demo match{
// unapplySeq方法,模式匹配的时候,可以匹配到序列里的每个元素
case CaseClass3(a,b,c,d,_*) => println(s"${a}, ${b}, ${c}, ${d}")
}
}
}反编译后查看:
17 抽象类(abstract class)与 特质(trait)
抽象类:
抽象类与Java相似,只是Java中没有属性的抽象,scala可以有属性的抽象;
特质:
可以把特质理解成Java中升级版的接口
在Java中接口不能声明没有值的属性和有实现的方法,而Scala可以声明没有值的属性和有实现的方法;
重写:
重写与Java相似,只是Java中没有重写属性的概念,而 scala 可以重写属性;
特质和抽象类的使用区别:
只能继承一个抽象类,但可以实现多个特质。这点和Java一样;
下面分别详细说明
17.1 抽象类
1)重写父类的非抽象成员(包括字段和方法)时,必须加上override 关键字;
package day03
abstract class Car {
// 定义普通属性
val name:String = "车"
// 定义抽象属性(属性不赋值)
val brand:String
// 定义普通方法
def description = {
println("这是抽象类里面的普通方法")
}
// 定义抽象方法(方法没有方法体)
def action():Unit
}
// 定义子类继承父类
class BYDCar extends Car{
// 子类重写父类的抽象成员,可加可不加 override
val brand: String = "比亚迪"
def action(): Unit = {
println("研发的刀片电池,使用更安全")
}
// 子类重写父类的非抽象成员,必须加override
override val name: String = "电车"
override def description: Unit = {
super.description
println(s"${brand} ${name}")
action()
}
}
object CarDemo{
def main(args: Array[String]): Unit = {
val car = new BYDCar
car.description
}
}
2)如果父类有构造器,则子类主构造器必须调用父类的主构造器或辅助构造器。
子类的辅助构造器,不能调用父类的构造器。
package day03
abstract class Car(val color:String) {
var price:Double = _
def this(color:String, price:Double) = {
this(color)
this.price = price
}
// 定义普通属性
val name:String = "车"
// 定义抽象属性(属性不赋值)
val brand:String
// 定义普通方法
def description = {
println("这是抽象类里面的普通方法")
}
// 定义抽象方法(方法没有方法体)
def action():Unit
}
// 定义子类继承父类
// 子类主构造器继承父类的主构造器
class BYDCar(color:String, types:String) extends Car(color:String){
// 子类重写父类的抽象成员,可加可不加 override
val brand: String = "比亚迪"
def action(): Unit = {
println("研发的刀片电池,使用更安全")
}
// 子类重写父类的非抽象成员,必须加override
override val name: String = "电车"
override def description: Unit = {
super.description
println(s"${brand} ${color} ${types} ${name}")
action()
}
}
// 继承父类的辅助构造器
class WULINGCar(color:String,price:Double, types:String) extends Car(color:String, price:Double){
// 子类重写父类的抽象成员,可加可不加 override
val brand: String = "五菱"
def action(): Unit = {
println("大众的选择,销量杠杠滴")
}
// 子类重写父类的非抽象成员,必须加override
override val name: String = "电车"
override def description: Unit = {
super.description
println(s"${brand} ${color} ${types} ${name}")
println(s"亲民价:${price}")
action()
}
}
object CarDemo{
def main(args: Array[String]): Unit = {
val car = new BYDCar("炫彩蓝", "秦DMI油电混")
car.description
println("-----------------")
val car2 = new WULINGCar("各种颜色", 28800,"宏光Mini")
car2.description
}
}
17.2 特质
定义特质需要用 trait 关键字;
特质可以包含抽象成员和非抽象成员,这与scala 的抽象类类似,包含抽象成员时,不需要abstract 关键字;
在Scala中,无论继承类还是继承Trait都是用extends关键字;
在重写特质的方法时,不需要给出override 关键字;
package day03
trait Fly {
// 定义普通属性
val name:String = "飞"
// 定义抽象属性
val maxFlyHigh:Int
// 定义普通方法
def description = {
println("这是特质里面的普通方法")
}
// 定义抽象方法
def action():Unit
}
class Bird extends Fly{
// 重写抽象成员
val maxFlyHigh: Int = 1000
def action(): Unit = {
println("鸟用翅膀飞")
}
// 重写非抽象成员
override val name: String = "火烈鸟"
override def description: Unit = {
super.description
println(s"${name}")
action()
println(s"最大飞行高度:${maxFlyHigh}")
}
}
object TraitTest{
def main(args: Array[String]): Unit = {
val bird = new Bird
bird.description
}
}
当不继承类直接实现一个特质,可以不用with直接用extends,实现多个特质的时候可以用多个with,但是必须先extends第一个
如: class T1 extends T2 with T3 with T4
package day03
trait Fly {
// 定义普通属性
val name:String = "飞"
// 定义抽象属性
val maxFlyHigh:Int
// 定义普通方法
def description = {
println("这是特质里面的普通方法")
}
// 定义抽象方法
def action():Unit
}
trait Run{
def run():Unit
}
class Bird extends Fly{
// 重写抽象成员
val maxFlyHigh: Int = 1000
def action(): Unit = {
println("鸟用翅膀飞")
}
// 重写非抽象成员
override val name: String = "火烈鸟"
override def description: Unit = {
super.description
println(s"${name}")
action()
println(s"最大飞行高度:${maxFlyHigh}")
}
}
// 实现多个特质用with
class AirPlane extends Fly with Run{
override val maxFlyHigh: Int = 10000
override def action(): Unit = {
println("飞机用翅膀飞")
}
override def run(): Unit = {
println("飞机用轱辘跑")
}
override def description: Unit = {
super.description
action()
run()
println(s"最大飞行高度:${maxFlyHigh}")
}
}
object TraitTest{
def main(args: Array[String]): Unit = {
val bird = new Bird
bird.description
println("------------------")
val plane = new AirPlane
plane.description
}
}
特质通过字段的初始化和其他特质体中的语句构成来实现构造的逻辑。
但特质不能 new 实例。
trait T1{
// 特质构造执行
val a:String = "aaa"
println(a)
def t1():Unit
}
trait T2{
// 特质构造执行
val b:String = "bbb"
println(b)
def t2():Unit
}
class T1Sub extends T1 with T2{
//本类构造执行
val c:String = "ccc"
println(c)
def t1():Unit={
println("do t1()")
}
def t2():Unit={
println("do t2()")
}
}
object T1SubTest{
def main(args: Array[String]): Unit = {
// 调用 new T1Sub 时,先执行T1的构造,再执行T2的构造,然后执行本类构造
val t = new T1Sub
t.t1()
t.t2()
}
}
//-----------运行结果-----------------
aaa
bbb
ccc
do t1()
do t2()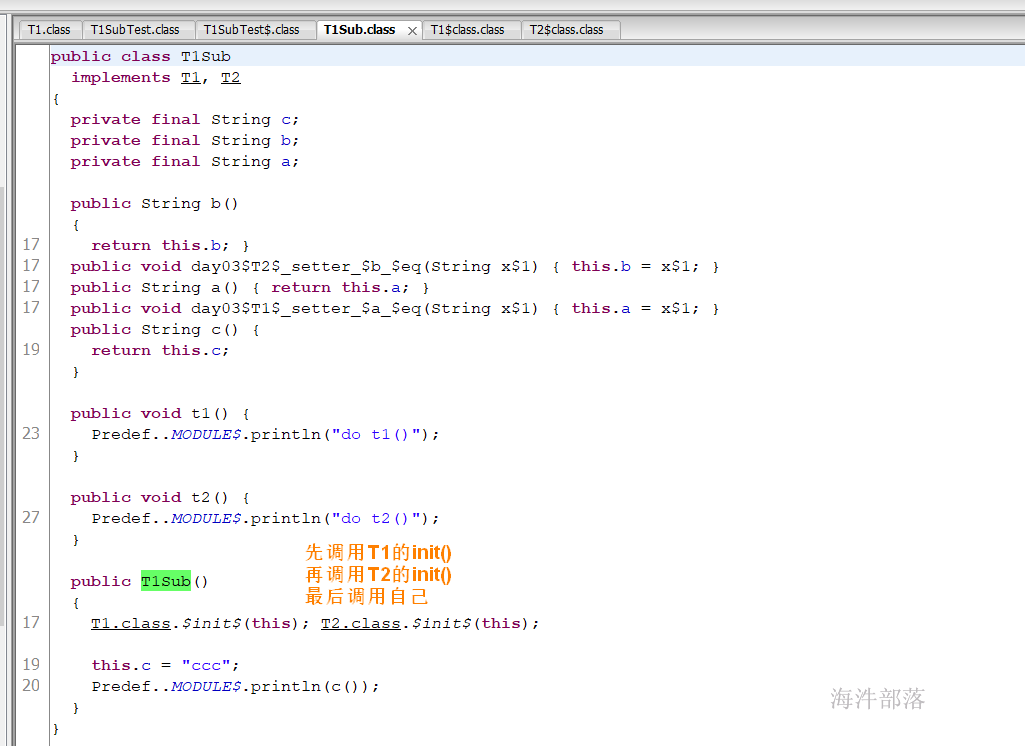
什么时候使用特质和抽象类?
使用角度:
主次关系用抽象类,额外功能用特质,比如蜘蛛侠。
语法角度:
1)优先使用特质。一个类扩展多个特质是很方便的,但却只能扩展一个抽象类。
2)如果你需要构造函数参数,使用抽象类。因为抽象类可以定义带参数的构造函数,而特质不行。
18 高阶函数
在数据和计算中,高阶函数是至少满足下列一个条件的函数:
1)接受一个或多个函数作为输入
2)输出一个函数
输出一个函数
// 输出Int类型
scala> def add(a:Int, b:Int) = a + b
add: (a: Int, b: Int)Int
// 输出函数Int => Int
scala> def add(a:Int, b:Int) = (c:Int) => a + b + c
add: (a: Int, b: Int)Int => Int
// 使用时需要传入多个括号的数据
scala> add(1,2)
res0: Int => Int = <function1>
scala> res0(3)
res1: Int = 6
scala> add(1,2)(3)
res2: Int = 6
// 输出函数 Int => (Int => Int)
scala> def add(a:Int, b:Int) = (c:Int) => (d:Int) => a + b + c + d
add: (a: Int, b: Int)Int => (Int => Int)
scala> add(1,2)(3)(4)
res3: Int = 10传入的是一个函数
传入函数 (Int,Int) => Int
// 输入参数是 函数 (Int,Int)=>Int
scala> def js(func:(Int,Int)=>Int) = func
js: (func: (Int, Int) => Int)(Int, Int) => Int
scala> val func1 = (a:Int, b:Int) => a + b
func1: (Int, Int) => Int = <function2>
scala> val func2 = (a:Int, b:Int) => a * b
func2: (Int, Int) => Int = <function2>
scala> js(func1)
res6: (Int, Int) => Int = <function2>
scala> res6(1,2)
res7: Int = 3
scala> js(func1)(1,2)
res8: Int = 3
scala> js(func2)(1,2)
res9: Int = 2传入函数 Int => Int
scala> def js(func:(Int)=>Int) = func
js: (func: Int => Int)Int => Int
scala> val func1 = (a:Int) => a + 10
func1: Int => Int = <function1>
scala> val func2 = (a:Int) => a * 10
func2: Int => Int = <function1>
scala> js(func1)(1)
res10: Int = 11
scala> js(func2)(1)
res11: Int = 10在上面的基础上,在集合里用函数
scala> val list = List(1,2,3,4,5)
list: List[Int] = List(1, 2, 3, 4, 5)
// 将列表中每个元素+1 产生新元素,并组成新列表
scala> list.map(f => js(func1)(f))
res13: List[Int] = List(11, 12, 13, 14, 15)
scala> list.map(js(func1)(_))
res14: List[Int] = List(11, 12, 13, 14, 15)
scala> list.map(js(func1))
res15: List[Int] = List(11, 12, 13, 14, 15)
scala> list.map(js(func2))
res16: List[Int] = List(10, 20, 30, 40, 50)19 部分参数函数
如果函数传递所有预期的参数, 则表示已完全应用它。 如果只传递几个参数并不是全部参数, 那么将返回部分应用的函数。 这样就可以方便地绑定一些参数, 其余的参数可稍后填写补上;
scala> def add(a:Int, b:Int) = a + b
add: (a: Int, b: Int)Int
scala> add(1,2)
res17: Int = 3
// 部分参数就是 固定一部分参数,传入一部分参数
// 方式1:
// 使用时,用_:Int 做参数占位,用于传入参数
scala> val func1 = add(1, _:Int)
func1: Int => Int = <function1>
scala> func1(2)
res20: Int = 3
// 方式2
// 利用函数,固定一部分参数,传入一部分参数
scala> val func2 = (b:Int) => add(1, b)
func2: Int => Int = <function1>
scala> func2(2)
res21: Int = 320 柯理化(颗粒化)
柯里化(Currying)是把接受多个参数的函数变换成接受一个单一参数(最初函数的第一个参数)的函数,并且返回接受余下的参数且返回结果的新函数的技术。
是把接受多个参数的函数变成接受一个参数的函数;
柯理化的两种表现形式:
以 加法函数为例:
def curring(x:Int)(y:Int) = x + y
def curring(x:Int) = (y:Int) => x + y
在柯理化形式的基础上,固定一个参数,传入一个参数
scala> def curring(x:Int)(y:Int) = x + y
curring: (x: Int)(y: Int)Int
scala> curring(4)(5)
res23: Int = 9
// 第一种方式
scala> val func1 = curring(5)_
func1: Int => Int = <function1>
scala> func1(4)
res25: Int = 9
// 第二种方式
scala> val func2 = (x:Int) => curring(x)(5)
func2: Int => Int = <function1>
scala> func2(4)
res26: Int = 9
scala> def curring(x:Int) = (y:Int) => x + y
curring: (x: Int)Int => Int
// 第三种方式
scala> val func3 = (x:Int) => curring(x)(5)
func3: Int => Int = <function1>
scala> func3(4)
res27: Int = 9柯里化函数,配合implicit关键字使用
// 定义带有隐式参数的add方法
// implicit 修饰参数,代表该参数是隐式参数
scala> def add(a:Int)(implicit b:Int = 5) = a + b
add: (a: Int)(implicit b: Int)Int
// 直接传参
scala> add(4)(5)
res22: Int = 9
scala> add(4)(10)
res24: Int = 14
// 执行时,首先找当前环境是否有和隐式参数类型相同的隐式值,如果找到,用隐式值作为隐式参数
// 如果没找到,看隐式参数是否有默认值,如果有,使用默认值
// 如果还没找到,那就抛异常
// 当前环境没有和隐式参数类型相同的隐式值,隐式参数有默认值,使用默认值
// 4 + 5(默认值)
scala> add(4)
res25: Int = 9
// 定义隐式值
scala> implicit val b1:Int = 20
b1: Int = 20
// 当前环境有和隐式参数类型相同的隐式值,使用隐式值
// 4 + 20(隐式值)
scala> add(4)
res26: Int = 24
// 通过 implicitly[Int] 可提取出当前环境的隐式值并赋给变量
scala> val c:Int = implicitly[Int]
c: Int = 20
// 定义String类型隐式值
scala> implicit val b2:String = "aa"
b2: String = aa
scala> add(4)
res27: Int = 24
// 定义 Int类型隐式值, 当前环境有两个Int类型的隐式值
scala> implicit val b3:Int = 30
b3: Int = 30
// 由于当前环境有两个Int类型的隐式值,调用时不知道找哪个,所以报错
scala> add(4)
<console>:16: error: ambiguous implicit values:
both value b1 of type => Int
and value b3 of type => Int
match expected type Int
add(4)
^
// 由于当前环境已乱套,可通过退出重进解决
scala> :quit
C:\Users\My>scala
Welcome to Scala 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_131).
Type in expressions for evaluation. Or try :help.
scala>在开发环境中使用柯里化和implicit,切记不能在同一个类中使用
package util
// 隐式成员是单独放在一个地方,使用的时候引入
object MyPredef {
// 定义隐式值1
implicit val b1:Int = 10
// 定义隐式值2
implicit val b2:Int = 20
}
package day03
object CurringDemo {
// 定义带有隐式参数的方法
def add(a:Int)(implicit b:Int = 5) = a + b
def main(args: Array[String]): Unit = {
println(add(4)(1))
println(add(4))
// 引入隐式值之后,当前环境就有隐式值了
import util.MyPredef.b1
println(add(4))
// 当前环境有两个Int类型隐式值,报异常
// import util.MyPredef.b2
// println(add(4))
}
}21 隐式转换
作用:能够丰富现有类库的功能,对类的方法进行增强,常用作类型转换也就是把一个类型转赋予另一个类的功能;
隐式转换应用场景
隐式转换函数、隐式值、隐式参数、隐式对象(只能在静态对象中使用);
21.1 隐式转换函数
隐式转换函数 是指 以implicit关键字声明并带有单个参数的函数,这样的函数被自动应用。
// 声明隐式函数,用于将 int类型转成 String 类型
implicit val int2Stringfunc = (a:Int) => a.toString使用示例:
// 定义Int类型
scala> val a = 12345
a: Int = 12345
// Int类型没有 length 方法
scala> a.length
<console>:13: error: value length is not a member of Int
a.length
^
// 定义隐式转换函数 (Int)=>String
scala> implicit def int2string(a:Int) = a.toString
warning: there was one feature warning; re-run with -feature for details
int2string: (a: Int)String
// 当执行时,看Int类型是否有length成员,如果有直接调用
// 如果没有,但当前环境是否有隐式函数,能将Int转成有该length成员的类型,如果有则调用
// 执行过程: Int --> String --> 调用String类型的length方法
scala> a.length
res2: Int = 5scala内部自带了很多隐式转换函数和方法。如1 to 10其实是调用的1.to(10)这个方法
但是在Int类中并没有to这个方法
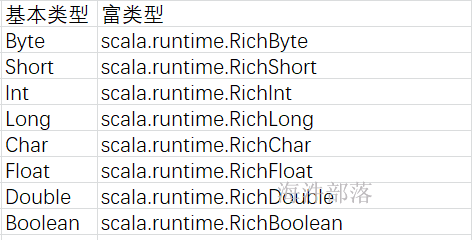
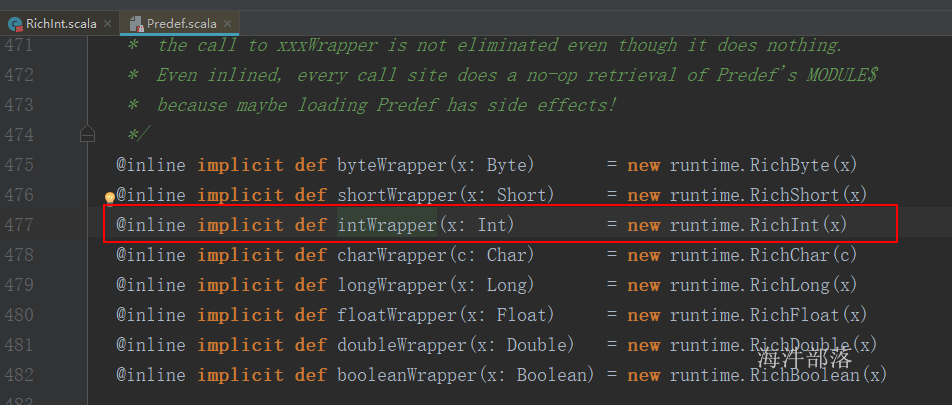
intWrapper就是以implicit关键字声明并带有单个参数的函数,intWrapper就是一个隐式转换方法;
用于scala 和 java 类型互转
scala> val a:Int = 1
a: Int = 1
// 将 scala 的 Int类型 赋给 java 的 Integer 类型
scala> val b:Integer = a
b: Integer = 1
// 将 java 的 Integer 类型 赋给 scala 的 Int类型
scala> val c:Int = b
c: Int = 1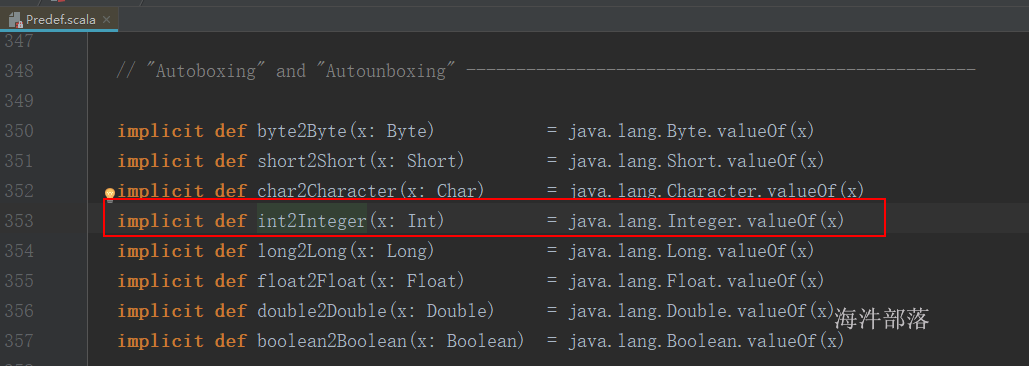
predef这个类就是预定义的predefine的简写
在shell中用:implicit -v来查看,默认有多少个隐式转换函数
在2.11.8中有69个隐式转换,scala升级比较快所以其它版本可能不同
隐式转换函数其实用到了装饰模式(增强)
核心思想:用组合实现嵌套逻辑,每层有自己的个性化动作。在不修改原有类的基础上,给原有类增加功能。
21.2 隐式参数和隐式值
在调用含有隐式参数的函数时,编译器会自动寻找合适的隐式值当做隐式参数,而只有用implict标记过的值、对象、函数才能被找到。
def add(x:Int)(implicit y:Int = 10) = x + y // 参考 柯理化 隐式关键字例子
隐式参数注意:方法的参数如果有多个隐式参数的话,只需要使用一个implicit关键字,隐式参数列表必须放在方法的参数列表后面;
示例:
scala> def demo(a:Int)(implicit b:Int, c:Int) = a + b + c
demo: (a: Int)(implicit b: Int, implicit c: Int)Int
scala> implicit val b1:Int = 10
b1: Int = 10
// 一个隐式值作用在多个隐式参数上
scala> demo(5)
res5: Int = 25隐式函数作为隐式参数:
// 定义隐式函数
implicit val int2stringfunc = (a:Int) => a.toString
def sayLength(implicit str:String) = println(s"${str.length}")
sayLength(1234)21.3 隐式对象
隐式对象只能在别的trait/类/对象内部定义。
package util
object MyPredef {
// 定义隐式值1
implicit val b1:Int = 10
// 定义隐式值2
implicit val b2:Int = 20
// 定义隐式对象(虽然是对象,但必须把它包起来,因为不能作为顶级对象)
implicit object HainiuObj{
def say() = println("say hello")
}
}
package day04
import util.MyPredef
object ImplictObjectDemo {
def main(args: Array[String]): Unit = {
// 先引入隐式对象,当前环境就有这个隐式对象了
import util.MyPredef.HainiuObj
// 通过implicitly 把 隐式对象变成显示的
val obj = implicitly[MyPredef.HainiuObj.type ]
obj.say()
}
}21.4 隐式转换的应用示例
1)类型转换
object ImplicitDemo {
/**
* 定义了一个隐式转换的方法
*/
implicit def double2Int(d:Double) = {
println(s"double:${d} to int:${d.toInt} method")
d.toInt
}
/**
* 定义了一个隐式转换的函数
*/
implicit val double2IntF = (d:Double) => {
println(s"double:${d} to int:${d.toInt} function")
d.toInt
}
def m1(a:Int) = println(a)
def main(args: Array[String]): Unit = {
//当隐式转换方法和隐式转换函数同时存在,也就是入参,返回类型相同的情况下,则先找函数,因为scala是函数式编程,那函数就是老大
//如果函数和方法同时存在,就优先用函数
val d:Int = 6.6
m1(6.6)
}
}2)给代表文件地址的字符串增加一个可以读文件的功能
这是一个显示的调用并不是一个隐式的调用,这是我们平时开发过程中常用的方法
package day04
import scala.io.Source
class Reader(val path:String) {
// 读取文件得到文件内容返回
def read = Source.fromFile(path).mkString
}
object Reader{
def main(args: Array[String]): Unit = {
val path:String = "/tmp/scala/ip.txt"
val reader = new Reader(path)
println(reader.read)
}
}隐式转换函数的实现方法
首先在MyPredef写一个String的隐式转换函数;

package day04
import scala.io.Source
class Reader(val path:String) {
// 读取文件得到文件内容返回
def read = Source.fromFile(path).mkString
}
object Reader{
def main(args: Array[String]): Unit = {
val path:String = "/tmp/scala/ip.txt"
// val reader = new Reader(path)
// 通过隐式转换函数给字符串赋予读文件的功能(String => Reader)
import util.MyPredef.string2Reader
println(path.read)
}
}后面:会用到给字符串赋予删除hdfs目录的功能。
3)隐式转换参数 + 隐式转换对象 + 泛型 + Ordered
示例:
已知类 HainiuStudent,对 HainiuStudent 的两个对象作比较。
class HainiuStudent(val name:String, val age:Int){
override def toString: String = s"name:${name}, age:${age}"
}Ordered使用隐士转换进行比较:代码自行实现
22 泛型
泛型就是不确定的类型,可以在类或方法不确实传入类型时使用,可以提高代码的灵活性和复用性;
scala中泛型的用法和java中差不多,但是会有一些自己独特的语法;
泛型类:指定类可以接受任意类型参数。
泛型方法:指定方法可以接受任意类型参数。
22.1 泛型类基本用法
package day04
import day04.SexEnumObj.SexEnum
// 定义带有泛型的抽象类
abstract class FXDemo[T](val t : T) {
def printInfo():Unit
}
// 子类继承父类,把泛型具体化成Int
class FXIntDemo[Int](t : Int) extends FXDemo[Int](t:Int){
override def printInfo(): Unit = {
println(s"FXIntDemo[Int](${t})")
}
}
// 子类继承父类,把泛型具体化成String
class FXStringDemo[String](t : String) extends FXDemo[String](t:String){
override def printInfo(): Unit = {
println(s"FXIntDemo[String](${t})")
}
}
// 定义带有多泛型的类
class FXABCDemo[A, B, C](val a:A, val b:B, val c:C){
override def toString: String = s"${a}, ${b}, ${c}"
}
// 定义sex的枚举对象
object SexEnumObj extends Enumeration{
// 定义枚举类型(用于泛型)
type SexEnum = Value
// 定义枚举值
val boy, girl = Value
}
object FXDemo{
def main(args: Array[String]): Unit = {
val demo = new FXIntDemo[Int](100)
demo.printInfo()
val demo2 = new FXStringDemo[String]("xiaoming")
demo2.printInfo()
val demo3 = new FXABCDemo[String, Int, String]("xiaoming", 20, "boy")
println(demo3)
val demo4 = new FXABCDemo[String, Int, SexEnum]("xiaoming", 20, SexEnumObj.boy)
println(demo4)
}
}22.2 泛型种类
[B \<: A] UpperBound 上界,B类型的父类是A类型,左侧的B的类型必须是A类型或者A类型的子类。
[B >: A] LowerBound 下界,B类型的子类是A类型,左侧的B的类型必须是A类型或者A类型的父类。
[-A] 逆变,通常作为参数类型,T是A的子类。
[+B] 协变,通常作为返回类型,T是B的父类。
22.2.1 UpperBound
UpperBound 用在泛型类或泛型方法上,用于限制传递的参数必须是 指定类型对象或其子类对象。
如果想实现两个对象的比较,需要该对象实现Comparable接口。然后再配上泛型实现通用比较。
泛型继承,java的用法
package javaday04;
public class UpperBoundDemo<T extends Comparable<T>> {
// psvm
public static void main(String[] args) {
// Integer 实现了 Comparable接口,创建对象时,约束通过
UpperBoundDemo<Integer> demo1 = new UpperBoundDemo<Integer>();
// Hainiu 没实现 Comparable接口,创建对象时,约束不通过
// UpperBoundDemo<Hainiu> demo2 = new UpperBoundDemo<Hainiu>();
// 约束通过
UpperBoundDemo<HainiuComparable> demo3 = new UpperBoundDemo<HainiuComparable>();
}
}
class Hainiu{}
class HainiuComparable implements Comparable<HainiuComparable>{
public int compareTo(HainiuComparable o) {
return 0;
}
}泛型继承,scala用法
package day04
// 在类上定义泛型, new对象时就会约束
class UpperBoundDemo[T <: Comparable[T]](val t:T) {
}
object UpperBoundDemo{
def main(args: Array[String]): Unit = {
// 因为 Integer 是 Comparable 实现类,所以约束通过
val demo = new UpperBoundDemo[Integer](100)
println(demo.t)
// 约束通过
val demo2 = new UpperBoundDemo[HainiuComparable](new HainiuComparable())
}
}
class HainiuComparable implements Comparable<HainiuComparable>{
public int compareTo(HainiuComparable o) {
return 0;
}
}22.2.2 LowerBound
LowerBound 用在泛型类或泛型方法上,用于限制传递的参数必须是 指定类型对象或其父类对象。
package day04
class LowerBoundDemo[T] {
// 将lowerbound约束到方法上
def say[R>:T](r:R) = println(s"say ${r}")
}
object LowerBoundDemo{
def main(args: Hainiurray[String]): Unit = {
// new对象时指定泛型是Hainiu类型
val demo = new LowerBoundDemo[Hainiu]
// say方法是lowerbound约束, 只有Hainiu或Hainiu的父类可以通过约束
demo.say[Hainiu](new Hainiu)
demo.say[HainiuSupper](new HainiuSupper)
// Hainiu的子类是不能通过约束的
// demo.say[HainiuSub](new HainiuSub)
// 如果调用方法时不加泛型,那就约束通过(不约束)
demo.say(new HainiuSub)
}
}
class HainiuSupper
class Hainiu extends HainiuSupper
class HainiuSub extends Hainiu22.2.3 协变与逆变
在声明Scala的泛型类型时,“+”表示协变(covariance),而“-”表示逆变(contravariance)。
C[+T]:如果A是B的子类,那么C[A]是C[B]的子类;通常作为返回值类型。
C[-T]:如果A是B的子类,那么C[B]是C[A]的子类;通常作为参数类型。
C[T]:无论A和B是什么关系,C[A]和C[B]没有从属关系。

scala> class A
defined class A
scala> class B extends A
defined class B
scala> class C extends B
defined class C
scala> def func(f:B=>B)=f
func: (f: B => B)B => B
scala> func((b:B)=>new B)
res0: B => B = <function1>
scala> func((b:A)=>new B)
res1: B => B = <function1>
scala> func((b:C)=>new B)
<console>:16: error: type mismatch;
found : C => B
required: B => B
func((b:C)=>new B)
^
scala> func((b:B)=>new A)
<console>:15: error: type mismatch;
found : A
required: B
func((b:B)=>new A)
^
scala> func((b:B)=>new B)
res4: B => B = <function1>
scala> func((b:B)=>new C)
res5: B => B = <function1>
scala> func((b:A)=>new C)
res6: B => B = <function1>23 Akka
24.1 Akka 概述
Spark的RPC是通过Akka类库实现的,Akka用Scala语言开发,基于Actor并发模型实现;
Akka具有高可靠、高性能、可扩展等特点,使用Akka可以轻松实现分布式RPC功能。
Actor是Akka中最核心的概念,它是一个封装了状态和行为的对象,Actor之间可以通过交换消息的方式进行通信,每个Actor都有自己的收件箱(MailBox)。
通过Actor能够简化锁及线程管理,可以非常容易地开发出正确地并发程序和并行系统。
Akka 具有如下特性:
1)提供了一种高级抽象,能够简化在并发(Concurrency)/并行(Parallelism)应用场景下的编程开发;
2)提供了异步非阻塞的、高性能的事件驱动编程模型;
3)超级轻量级事件处理(每GB堆内存几百万Actor);
24.2 Akka 组成及架构原理
ActorSystem
在Akka中,ActorSystem是一个重量级的结构。
ActorSystem 的职责是 负责创建并管理其创建的Actor,ActorSystem的单例的,一个JVM进程中有一个即可,而Actor是多例的。
Actor
在Akka中,Actor负责通信,在Actor中有一些重要的生命周期方法
1)preStart()方法:该方法在Actor对象构造方法执行后执行,整 个Actor生命周期中仅执行一次, 就像 mapreduce里的 setup()
2)receive()方法:该方法在Actor的preStart方法执行完成后执行,用于接收消息,会被反复执行, 就像mapreduce里的map()
每个actor 对象有对应的外部引用xxxRef,可以通过该 actor 对象的外部引用与actor通信。
img
img
akka的架构原理
mailbox负责存储actor收到的消息,dispatcher负责从mailbox取消息,分配线程给actor执行具体的业务逻辑。
sender引用代表最近收到消息的发送actor,通常用于回消息,比如 sender() !xxxx。
24.3 Akka 的使用
使用Akka需要增加这两个的pom依赖
<!-- 添加 akka 的 actor 依赖 -->
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-actor_2.11</artifactId>
<version>2.4.17</version>
</dependency>
<!-- 多进程之间的 Actor 通信 -->
<dependency>
<groupId>com.typesafe.akka</groupId>
<artifactId>akka-remote_2.11</artifactId>
<version>2.4.17</version>
</dependency>24.3.1 发送给自己
步骤:
1)创建ActorSystem

2)定义处理信息的Actor实现类
class HelleAkka extends Actor{
//接受消息
override def receive: Receive = {
//接受消息的处理逻辑
}
}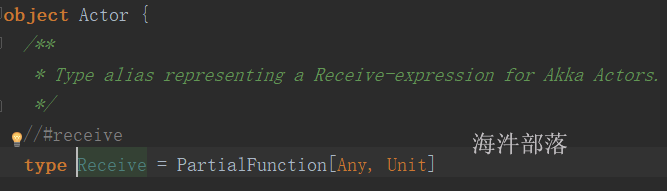
3)创建目标Actor的ActorRef对象

4)往目标Actor的ActorRef对象发送信息
package day05
import akka.actor.{Actor, ActorRef, ActorSystem, Props}
class HelloAkkaActor extends Actor{
override def preStart() ={
println("do preStart()")
}
override def receive: Receive = {
case "start" => println("actor receive==>start ....")
case "id01" => println("actor receive==>id01")
case "stop this" =>{
println("actor receive==> stop this, stop....")
// 关闭它自己,ActorSystem不关闭
context.stop(self)
}
case "stop all" =>{
println("actor receive==> stop all, stop....")
// 关闭ActorSystem
context.system.terminate()
}
}
}
object HelloAkka{
def main(args: Array[String]): Unit = {
// 创建ActorSystem对象
val sys = ActorSystem("hello_sys")
// 创建actor,并返回ActorRef对象
val helloRef: ActorRef = sys.actorOf(Props[HelloAkkaActor], "hello")
helloRef ! "start"
helloRef ! "id01"
// helloRef ! "stop this"
helloRef ! "stop all"
}
}24.3.2 发送给本机的其它线程
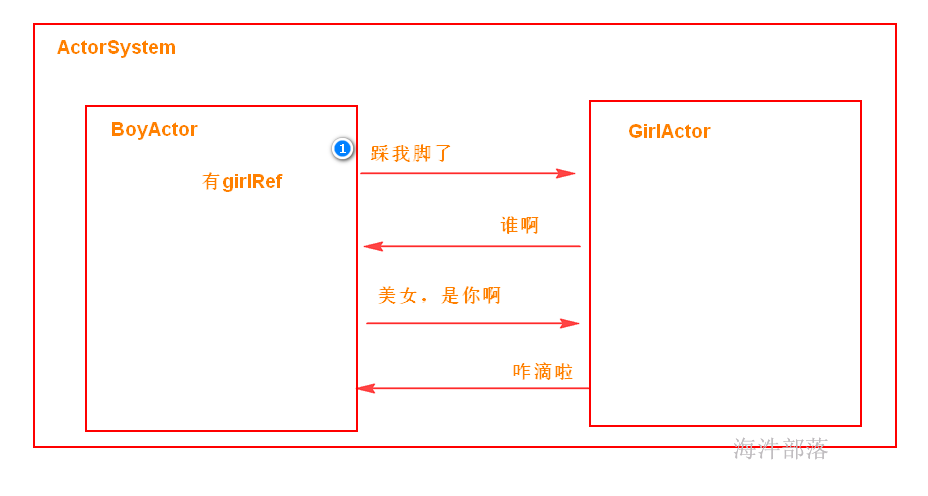
package day05
import akka.actor.{Actor, ActorRef, ActorSystem, Props}
class GirlActor extends Actor{
override def receive: Receive = {
case "踩我脚了" =>{
println("GirlActor receive=> 踩我脚了, 思索片刻,回复 ‘谁啊’")
Thread.sleep(1000)
sender() ! "谁啊"
}
case "美女是你啊" =>{
println("GirlActor receive=> 美女是你啊, 回复 ‘咋滴啦’")
sender() ! "咋滴啦"
}
}
}
class BoyActor(girlRef:ActorRef) extends Actor{
override def receive: Receive = {
case "action" =>{
println("BoyActor receive==> action, dialog start ....")
girlRef ! "踩我脚了"
}
case "谁啊" =>{
println("BoyActor receive==> 谁啊, send '美女是你啊'")
girlRef ! "美女是你啊"
}
case "咋滴啦" =>{
println("BoyActor receive==> 咋滴啦, send ‘踩我脚了’")
girlRef ! "踩我脚了"
}
}
}
object DialogAkka {
def main(args: Array[String]): Unit = {
val sys = ActorSystem("dialog_sys")
// 创建 GirlActor,并返回girl的ActorRef对象
val girlRef: ActorRef = sys.actorOf(Props[GirlActor], "girl")
// 创建 BoyActor , 并返回Boy的ActorRef对象
val boyRef: ActorRef = sys.actorOf(Props[BoyActor](new BoyActor(girlRef)), "boy")
boyRef ! "action"
}
}24.3.3 发送给不同的进程

远端actorRef设置参数:
Id name age
akka.actor.provider = akka.remote.RemoteActorRefProvider
akka.remote.netty.tcp.hostname = \$host
akka.remote.netty.tcp.port = \$port
- 创建一个 Server 端用于回复消息
server
package day05
import akka.actor.{Actor, ActorSystem, Props}
import com.typesafe.config.{Config, ConfigFactory}
class ServerActor extends Actor{
override def receive: Receive = {
case "start" => println("ServerActor receive==> start, start....")
case "马上开始发送计算任务" =>{
println("ServerActor receive==> 马上开始发送计算任务")
}
case Client2ServerMsg(num1, symbol, num2) =>{
println(s"ServerActor receive==> ${num1} ${symbol} ${num2}")
var errCode = "000000"
var errMsg = "成功"
var result:Int = 0
symbol match {
case "+" => result = num1 + num2
case "-" => result = num1 - num2
case "*" => result = num1 * num2
case _ =>{
errCode = "err001"
errMsg = "当前版本只支持+、-、*运算,待版本升级后尝试其他运算"
}
}
val msg = Server2ClientMsg(errCode, errMsg, result)
println(s"ServerActor send==>${msg}")
// 返回数据(errCode, errMsg, result)
sender() ! msg
}
}
}
object ServerActor{
def main(args: Array[String]): Unit = {
val host:String = "127.0.0.1"
val port:Int = 8888
// 解析配置参数
val config:Config = ConfigFactory.parseString(
s"""
|akka.actor.provider = akka.remote.RemoteActorRefProvider
|akka.remote.netty.tcp.hostname = $host
|akka.remote.netty.tcp.port = $port
""".stripMargin
)
val sys = ActorSystem("server_sys", config)
// akka地址:akka.tcp://server_sys@127.0.0.1:8888/user/server
val serverRef = sys.actorOf(Props[ServerActor], "server")
serverRef ! "start"
}
}启动后结果:

- 创建一个 Client 端发送消息
client
package day05
import akka.actor.{Actor, ActorSelection, ActorSystem, Props}
import com.typesafe.config.{Config, ConfigFactory}
import scala.util.Random
class ClientActor(val serverHost:String, val serverPort:Int) extends Actor{
var serverRef: ActorSelection = _
override def preStart(): Unit = {
// 通过akka地址获取到ServerActor的Ref对象,如果这个Actor对象不存在,该方法是不创建对象的
serverRef = context.actorSelection(s"akka.tcp://server_sys@${serverHost}:${serverPort}/user/server")
}
override def receive: Receive = {
case "start" => {
println("ClientActor receive==> start, start....")
println("ClientActor send==> 马上开始发送计算任务")
serverRef ! "马上开始发送计算任务"
}
case SendClientMsg(data) =>{
println(s"ClientActor receive==>${data}")
val arr = data.split(" ")
if(arr.size != 3){
println(s"ClientActor receive data error, info: ${data}")
}else{
val num1 = arr(0).toInt
val num2 = arr(2).toInt
val symbol = arr(1)
val msg = Client2ServerMsg(num1, symbol, num2)
println(s"ClientActor send msg to Server==>${msg}")
serverRef ! msg
}
}
case msg:Server2ClientMsg =>{
println(s"ClientActor from Server receive==>${msg}")
}
}
}
object ClientActor{
def main(args: Array[String]): Unit = {
val serverHost:String = "127.0.0.1"
val serverPort:Int = 8888
val host:String = "127.0.0.1"
val port:Int = 8889
// 解析配置参数
val config:Config = ConfigFactory.parseString(
s"""
|akka.actor.provider = "akka.remote.RemoteActorRefProvider"
|akka.remote.netty.tcp.hostname = $host
|akka.remote.netty.tcp.port = $port
""".stripMargin
)
val sys = ActorSystem("client_sys", config)
// akka地址:akka.tcp://client_sys@127.0.0.1:8889/user/client
val clientRef = sys.actorOf(Props[ClientActor](new ClientActor(serverHost, serverPort)), "client")
clientRef ! "start"
// 随机生成 100 以内的计算
val arr = Array[String]("+", "-", "*", "/")
val random = new Random()
while(true){
val num1 = random.nextInt(100)
val num2 = random.nextInt(100)
val sysbol = arr(random.nextInt(arr.size))
clientRef ! SendClientMsg(s"$num1 ${sysbol} $num2")
Thread.sleep(1000)
}
}
}case class 用于传输消息
// 本地发送给ClientActor消息
case class SendClientMsg(val data:String)
// ClientActor 发送给 ServerActor的消息
case class Client2ServerMsg(val num1:Int, val symbol:String, val num2:Int)
// ServerActor 把计算结果返回给ClientActor
case class Server2ClientMsg(val errCode:String, val errMsg:String, val result:Int)运行效果:
clientActor
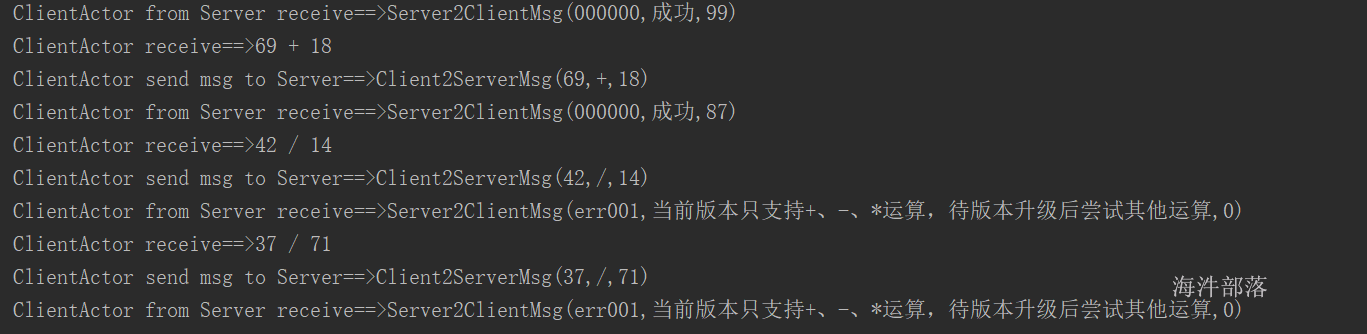

24.4 打包上集群
1)修改代码参数
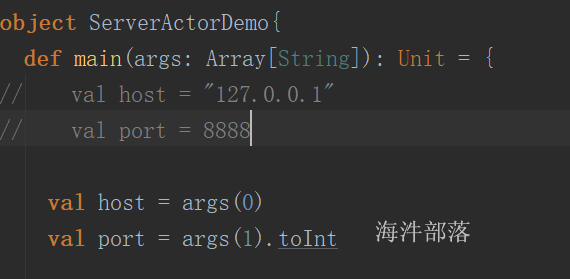
2)添加打包pom,确保资源文件目录配置与实际一致
<build>
<resources>
<resource>
<directory>src/main/resources</directory>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptors>
<descriptor>src/main/resources/assembly.xml</descriptor>
</descriptors>
<!--<archive>-->
<!--<manifest>-->
<!--<mainClass>${package.mainClass}</mainClass>-->
<!--</manifest>-->
<!--</archive>-->
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.12</version>
<configuration>
<skip>true</skip>
<forkMode>once</forkMode>
<excludes>
<exclude>**/**</exclude>
</excludes>
</configuration>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
</plugins>
</build>3)添加 assembly.xml
<assembly xmlns="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/plugins/maven-assembly-plugin/assembly/1.1.0 http://maven.apache.org/xsd/assembly-1.1.0.xsd">
<id>hainiu</id>
<formats>
<format>jar</format>
</formats>
<includeBaseDirectory>false</includeBaseDirectory>
<fileSets>
<fileSet>
<directory>${project.build.directory}/classes</directory>
<outputDirectory>/</outputDirectory>
<excludes>
<exclude>*.xml</exclude>
<exclude>*.properties</exclude>
</excludes>
</fileSet>
</fileSets>
<dependencySets>
<dependencySet>
<outputDirectory>/</outputDirectory>
<useProjectArtifact>false</useProjectArtifact>
<unpack>true</unpack>
<scope>runtime</scope>
</dependencySet>
</dependencySets>
</assembly>注意:
如果网址有红线,Alt+Enter,选择 Ignored Schemas and DTDs(忽略)即可。到时候,运行打包时Maven会在Maven中央仓库中寻找最新版的assembly插件。
4)执行clean,然后执行 工程的rebuild
5)执行 assembly:assembly 打包
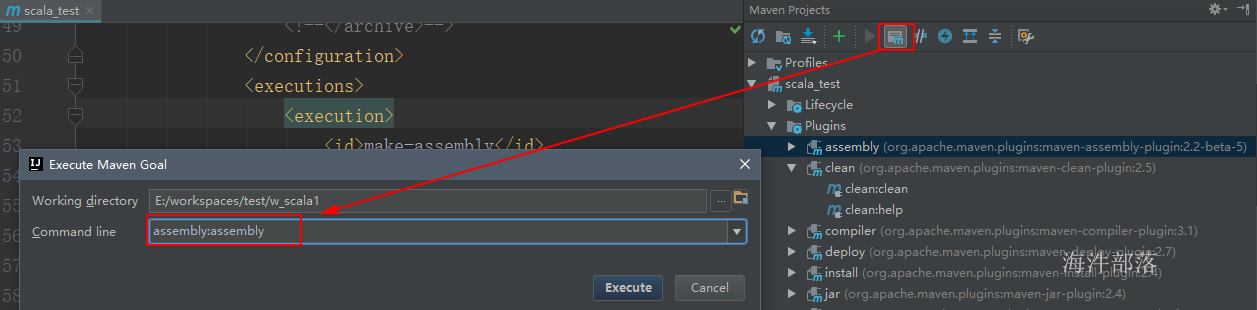
手动合并成一个reference.conf,并添加到导出的jar 包里。
6)集群执行启动server Actor,启动本地client Actor,与集群的ServerActor 通信

服务端信息: