1 spark 概述
1.1 Spark产生的背景
MapReduce的局限性:
1)仅支持Map 和 Reduce 两种操作;
2)MapReduce多个任务的中间结果落地磁盘,不能充分利用内存,任务运行效率低;
3)适合批处理,不适合实时性要求高的场景;
4)程序编写过于复杂;
5)资源不能复用,每次需要重新发分配资源
1.2 什么是Spark
Spark,是一种通用的大数据计算框架,正如传统大数据技术Hadoop的MapReduce、Hive引擎,以及Storm流式实时计算引擎等。
Spark是加州大学伯克利分校AMP实验室(Algorithms, Machines, and People Lab)开发的通用内存并行计算框架,用于构建大型的、低延迟的数据分析应用程序。
Spark使用强大的Scala语言开发,它还提供了对Scala、Python、Java(支持Java 8)和R语言的支持。
Apache顶级项目,项目主页:http://spark.apache.org
1.3 Spark历史
2009年由Berkeley’s AMPLab开始编写最初的源代码
2010年开放源代码
2013年6月进入Apache孵化器项目
2014年2月成为Apache的顶级项目(8个月时间)
2014年5月底Spark1.0.0发布,打破Hadoop保持的基准排序纪录
2014年12月Spark1.2.0发布
2015年11月Spark1.5.2发布
2016年1月Spark1.6发布
2016年12月Spark2.1发布
1.4 为什么要用Spark
运行速度快:
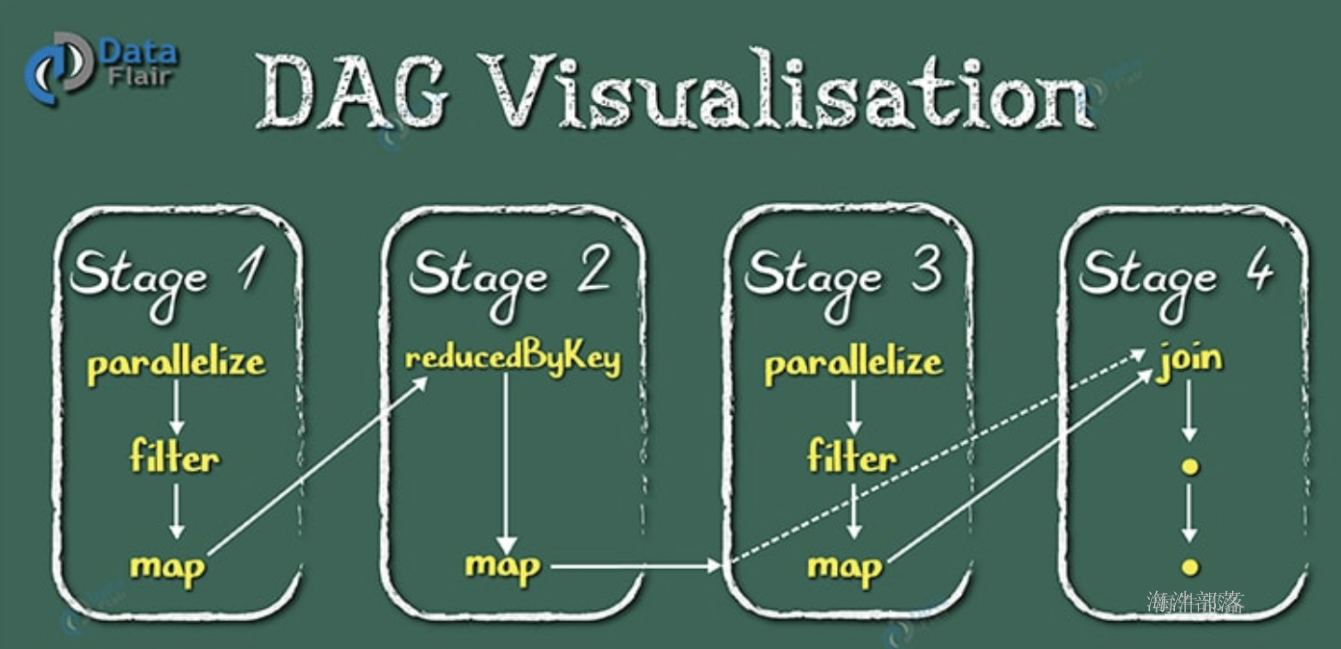
使用DAG(全称 Directed Acyclic Graph, 中文为:有向无环图)执行引擎以支持循环数据流与内存计算(当然也有部分计算基于磁盘,比如shuffle);
易用性好:
支持使用Scala、Java、Python和R语言进行编程,可以通过Spark Shell进行交互式编程 ;
通用性强:
Spark提供了完整而强大的工具,包括SQL查询、流式计算、机器学习和图算法组件;
随处运行:
可运行于独立的集群模式中,可运行于Hadoop中,也可运行于Amazon EC2等云环境中,并且可以访问HDFS、Cassandra、HBase、Hive等多种数据源;
Hadoop:
可以用普通硬件搭建Hadoop集群,用于解决存储和计算问题;
1)解决存储:HDFS
2)解决计算:MapReduce
3)资源管理:YARN
Spark:
Spark是在借鉴了MapReduce之上发展而来的,继承了其分布式并行计算的优点并改进了MapReduce明显的缺陷;
Spark不能代替Hadoop,但可能代替MapReduce。
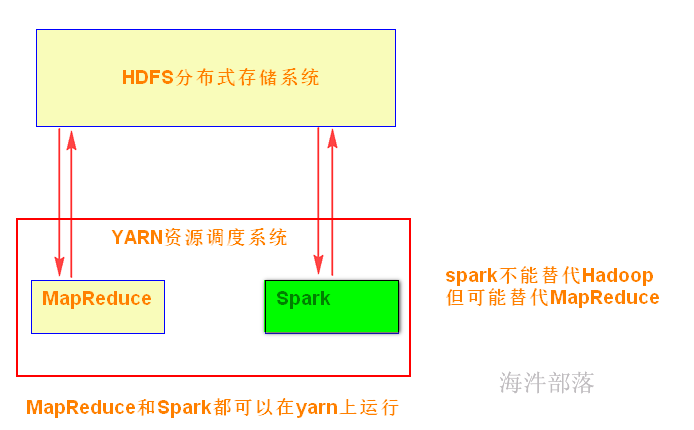
现状:
Spark主要用于大数据的计算,而Hadoop以后主要用于大数据的存储(HDFS),以及资源调度(Yarn)。Spark+Hadoop的组合,是未来大据领域最热门的组合,也是最有前景的组合! 当然spark也有自己的集群模式。
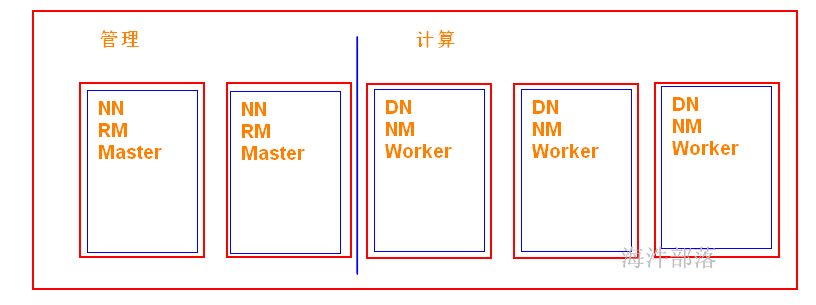
通过yarn队列去管理mr 和 spark任务的资源。
1.6 Spark 对比 MapReduce
1)spark可以把多次使用的数据放到内存中
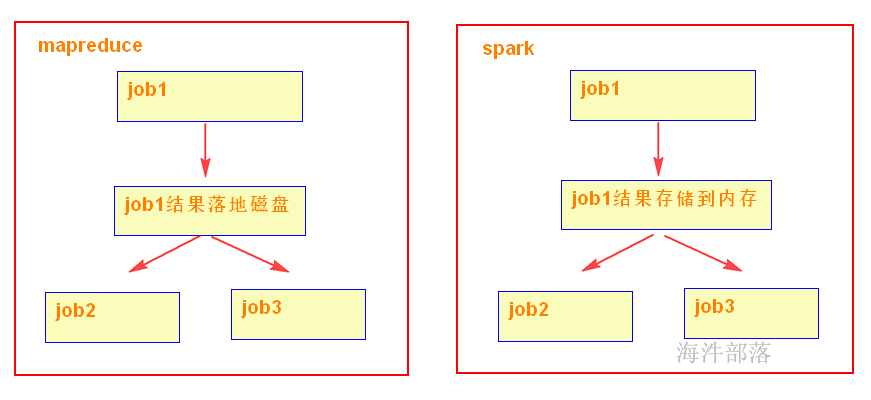
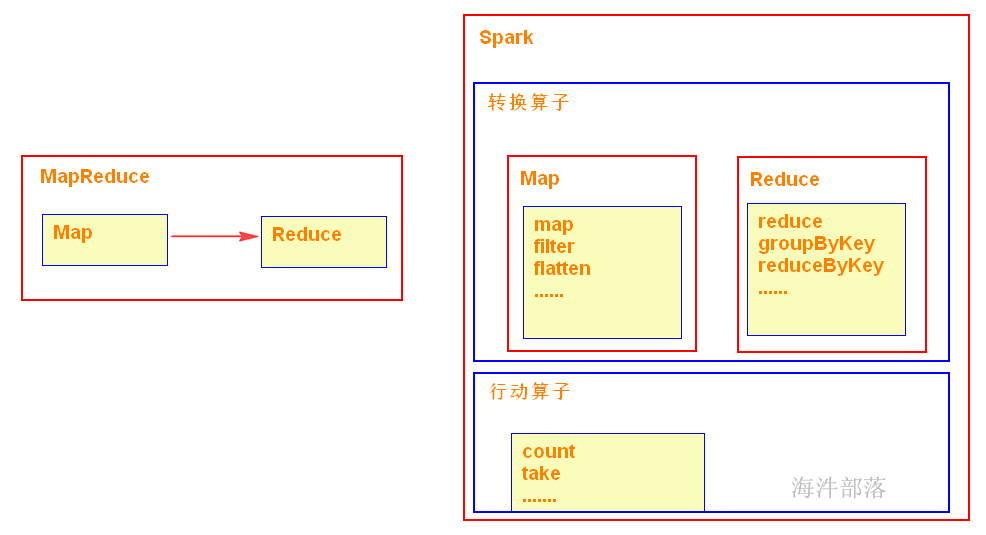
4)在代码编写方面,不需要写那么复杂的MapReduce逻辑。
缺点:
过度依赖内存,内存不够用了就很难堪

2 spark生态
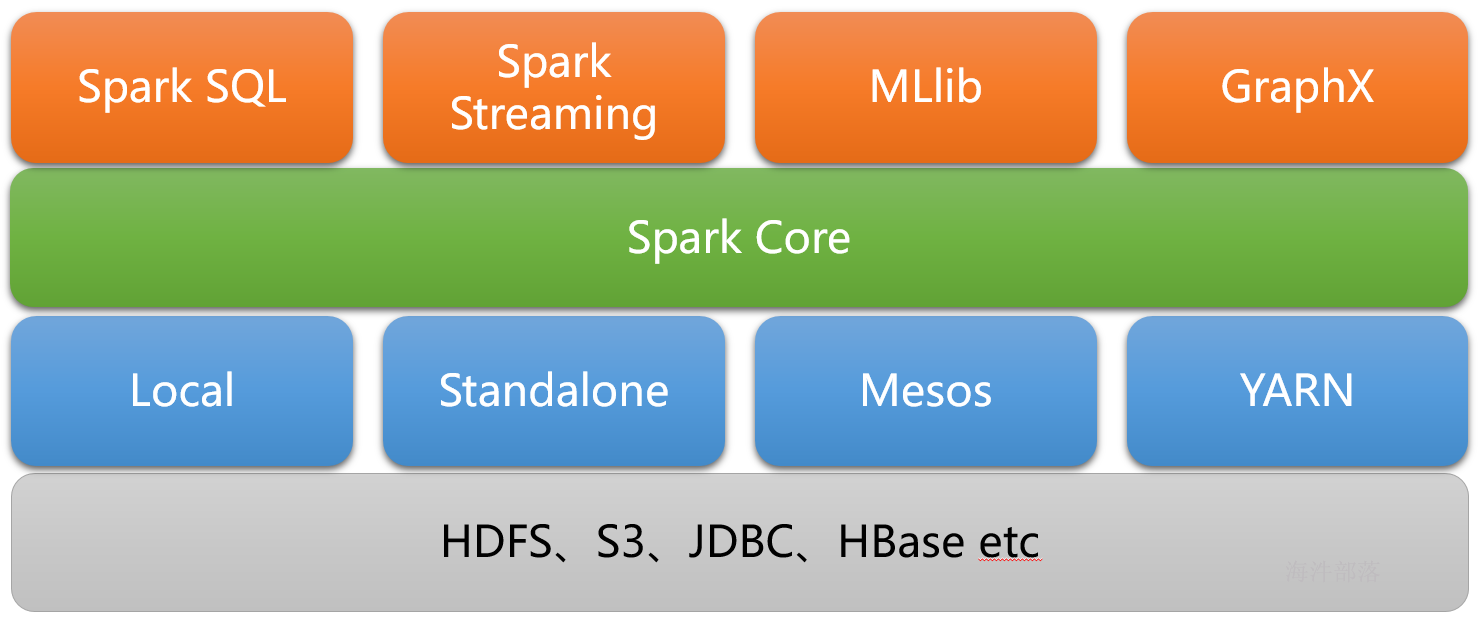
实现了spark的基本功能、包括任务调度、内存管理、错误恢复与存储系统交互等模块。spark core中还包含了对弹性分布式数据集(resileent distributed dataset)的定义;
spark sql:
是spark用来操作结构化数据的程序,通过SPARK SQL,我们可以使用SQL或者HIVE(HQL)来查询数据,支持多种数据源,比如HIVE表就是JSON等,除了提供SQL查询接口,还支持将SQL和传统的RDD结合,开发者可以在一个应用中同时使用SQL和编程的方式(API)进行数据的查询分析,SPARK SQL是在1.0中被引入的;
Spark Streaming:
是Spark提供的对实时数据进行流式计算的组件,比如网页服务器日志,或者是消息队列都是数据流。
MLLib:
是Spark中提供常见的机器学习功能的程序库,包括很多机器学习算法,比如分类、回归、聚类、协同过滤等。
GraphX:
是用于图计算的比如社交网络的朋友关系图。
3 Spark应用场景
Yahoo将Spark用在Audience Expansion中的应用,进行点击预测和及时查询等;
淘宝技术团队使用了Spark来解决多次迭代的机器学习算法、高计算复杂度的算法等。应用于内容推荐、社区发现等;
腾讯大数据精准推荐借助Spark快速迭代的优势,实现了在“数据实时采集、算法实时训练、系统实时预测”的全流程实时并行高维算法,最终成功应用于广点通pCTR投放系统上;
优酷土豆将Spark应用于视频推荐(图计算)、广告业务,主要实现机器学习、图计算等迭代计算;
目前大数据在互联网公司主要应用在广告、报表、推荐系统等业务上。在广告业务方面需要大数据做应用分析、效果分析、定向优化等,在推荐系统方面则需要大数据优化相关排名、个性化推荐以及热点点击分析等。这些应用场景的普遍特点是计算量大、效率要求高。
4 Spark环境部署
主要运行方式
Local
Standalone
On YARN
On Mesos
5 Standalone集群模式安装
Linux,CentOS 6/7
安装JDK
下载 spark 安装包
http://spark.apache.org/downloads.html
5.1 非高可用安装
5.1.1 安装步骤
1)上传压缩包

./scp_all.sh ../up/spark-3.1.2-bin-hadoop2.7.tgz /tmp/
./ssh_root.sh tar -xzf /tmp/spark-3.1.2-bin-hadoop2.7.tgz -C /usr/local
3)修改权限为hadoop
./ssh_root.sh chown -R hadoop:hadoop /usr/local/spark-3.1.2-bin-hadoop2.7
4)创建软件链接
./ssh_root.sh ln -s /usr/local/spark-3.1.2-bin-hadoop2.7 /usr/local/spark
查看/usr/local/目录

bin:可执行脚本
conf:配置文件目录
data:examples里的测试样例的测试数据集
examples:测试样例
jars:lib库
python/R:是python和R
sbin:控制脚本
yarn:yarn支持库
5)备份原有conf 目录
./ssh_all.sh cp -r /usr/local/spark/conf /usr/local/spark/conf_back
6)重命名conf 目录 的配置文件
./ssh_all.sh mv /usr/local/spark/conf/spark-defaults.conf.template /usr/local/spark/conf/spark-defaults.conf
./ssh_all.sh mv /usr/local/spark/conf/spark-env.sh.template /usr/local/spark/conf/spark-env.sh
./ssh_all.sh mv /usr/local/spark/conf/workers.template /usr/local/spark/conf/workers
./ssh_all.sh mv /usr/local/spark/conf/log4j.properties.template /usr/local/spark/conf/log4j.properties
7)在 nn1.hadoop 机器 修改spark-env.sh


./scp_all.sh /usr/local/spark/conf/spark-env.sh /usr/local/spark/conf/
./scp_all.sh /usr/local/spark/conf/workers /usr/local/spark/conf/
10)在/etc/profile 下增加spark的path,并分发到其他机器

1)启动脚本
/usr/local/spark/sbin/start-all.sh
启动spark

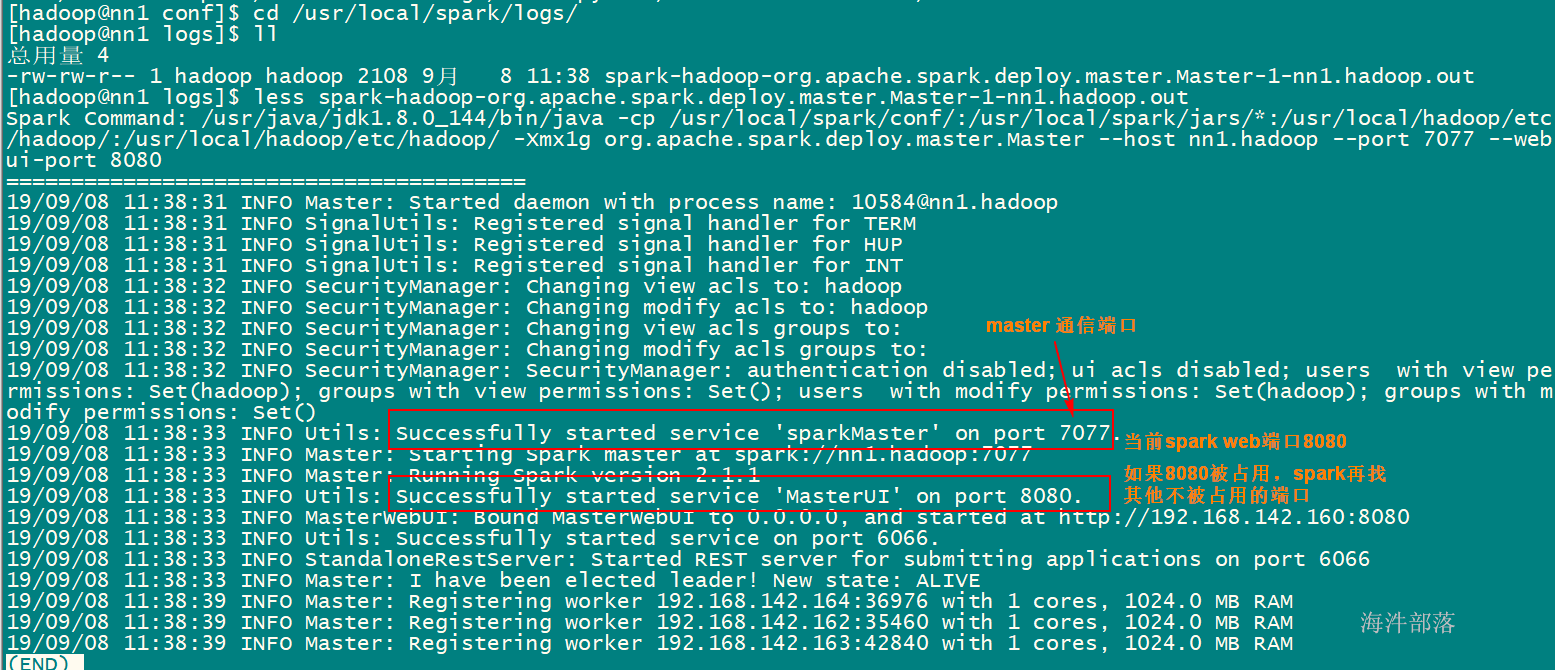

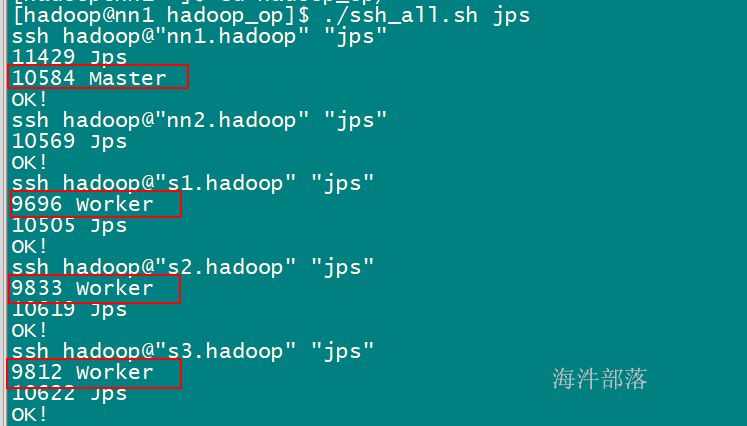
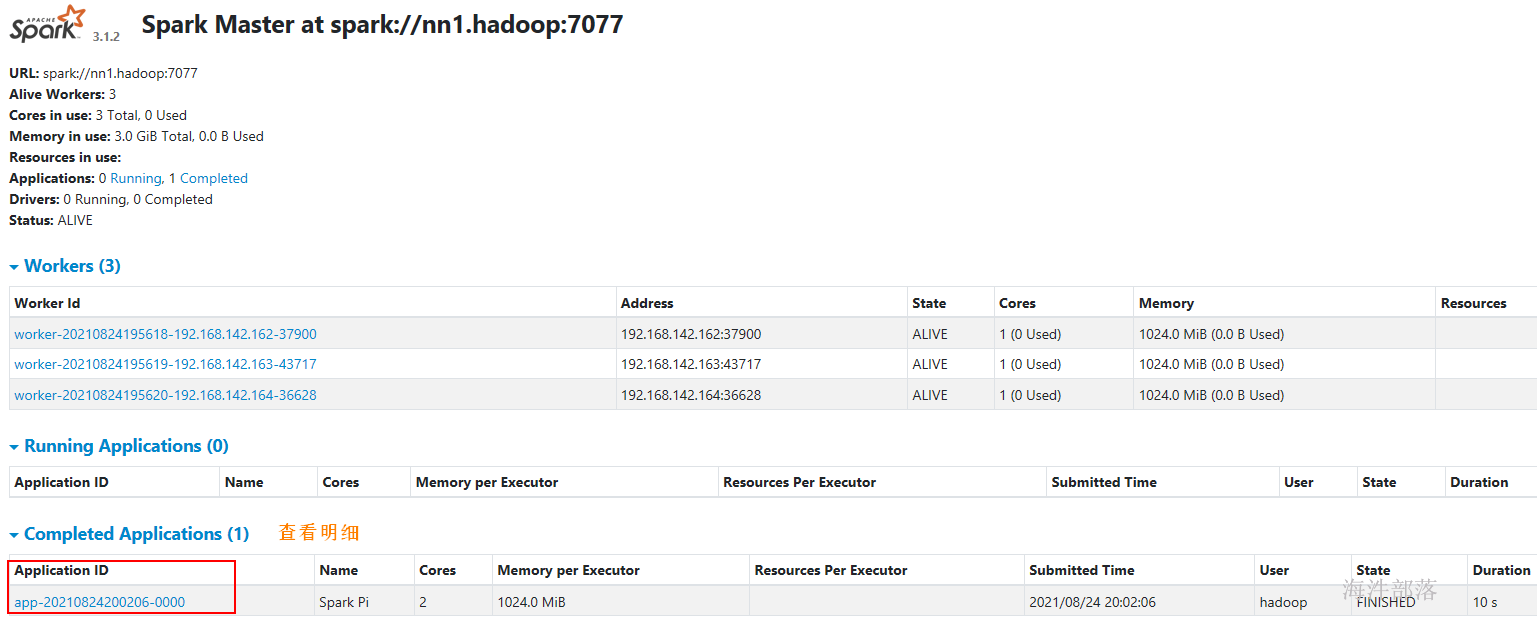
5.1.3 spark测试
用spark-submit提交spark应用程序。
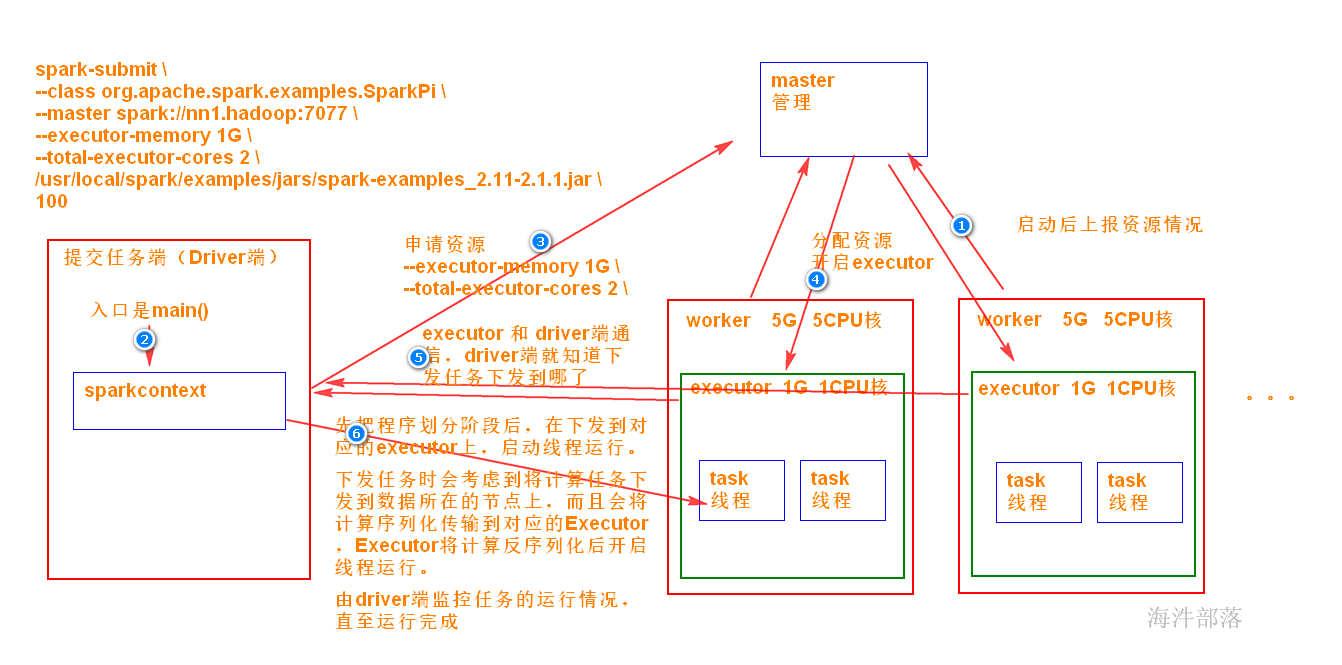
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master spark://nn1.hadoop:7077 \
--executor-memory 1G \
--total-executor-cores 2 \
/usr/local/spark/examples/jars/spark-examples_2.12-3.1.2.jar \
100参考:
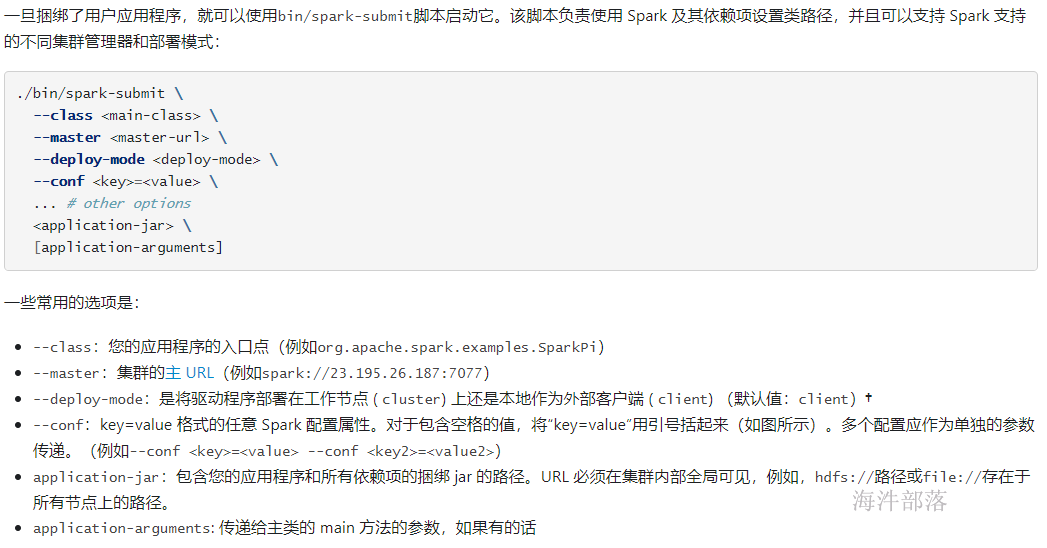
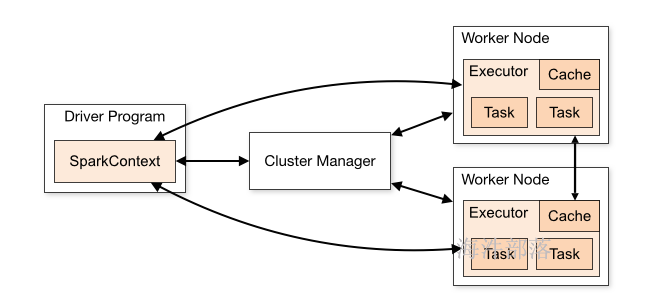
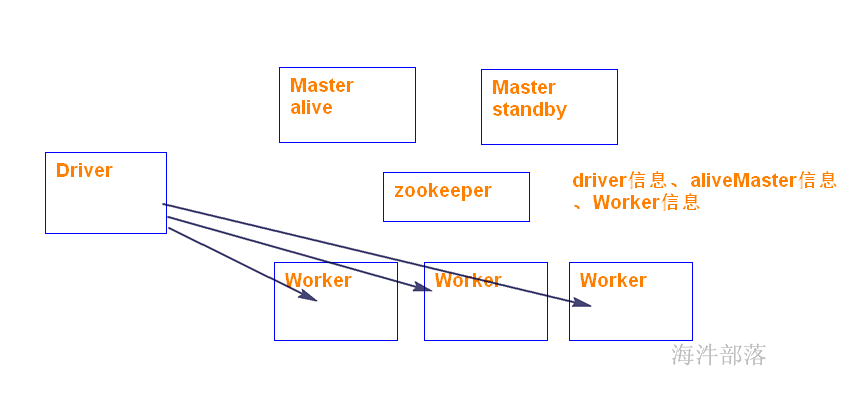
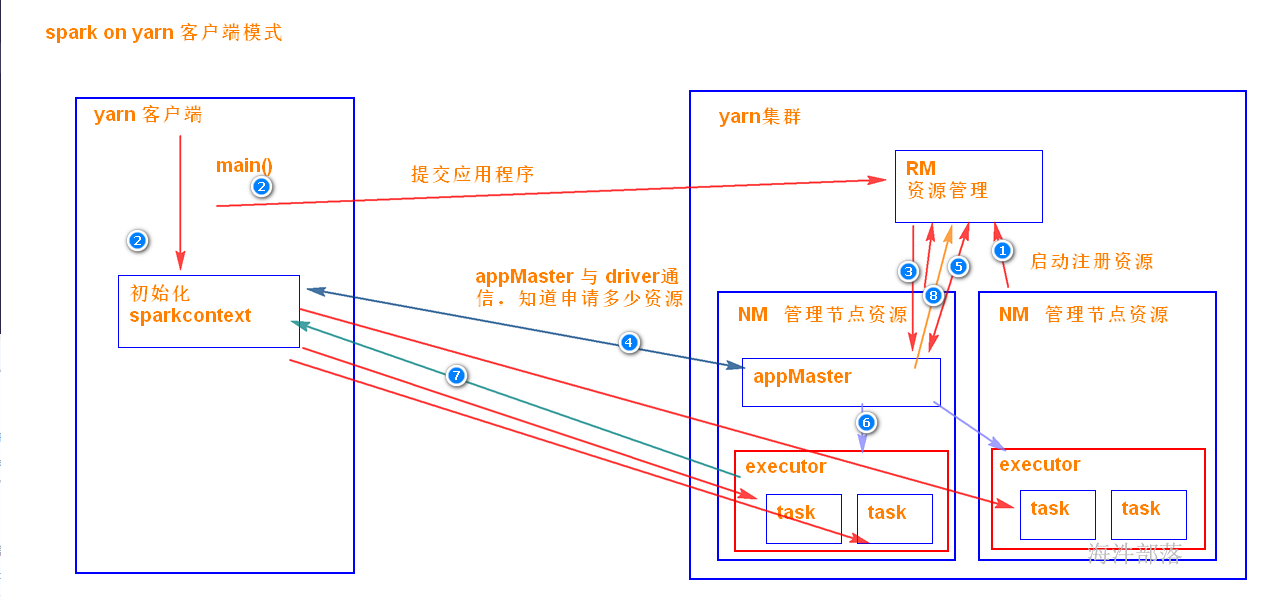
Driver: 运行 Application 的 main() 函数的节点,提交任务,并下发计算任务;
Cluster Manager:在standalone模式中即为Master主节点,负责整个集群节点管理以及资源调度;在YARN模式中为资源管理器;
Worker节点:上报自己节点的资源情况,启动 和 管理 Executor;
Executor:执行器,是为某个Application运行在worker节点上的一个进程;负责执行task任务(线程);
Task:被送到某个Executor上的工作单元,跟MR中的MapTask和ReduceTask概念一样,是运行Application的基本单位。
运行大概流程:
1)driver 端提交应用,并向master申请资源;
2)Master节点通过RPC和Worker节点通信,根据资源情况在相应的worker节点启动Executor 进程;并将资源参数和Driver端的位置传递过来;
3)启动的Executor 进程 会主动与 Driver端通信,Driver 端根据代码的执行情况,产生多个task,发送给Executor;
4)Executor 启动 task 做真正的计算,每个Task 得到资源参数后,对相应的输入分片数据执行计算逻辑;
spark 高可用是通过zookeeper 实现。
5.2.1 修改配置spark-env.sh,并分发到其他机器
export SPARK_DAEMON_JAVA_OPTS=“-Dspark.deploy.recoveryMode=ZOOKEEPER -Dspark.deploy.zookeeper.url=nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 -Dspark.deploy.zookeeper.dir=/spark2”


#step1:启动zookeeper
#step2:启动spark
/usr/local/spark/sbin/start-all.sh
#step3:在nn2.hadoop节点启动spark ha
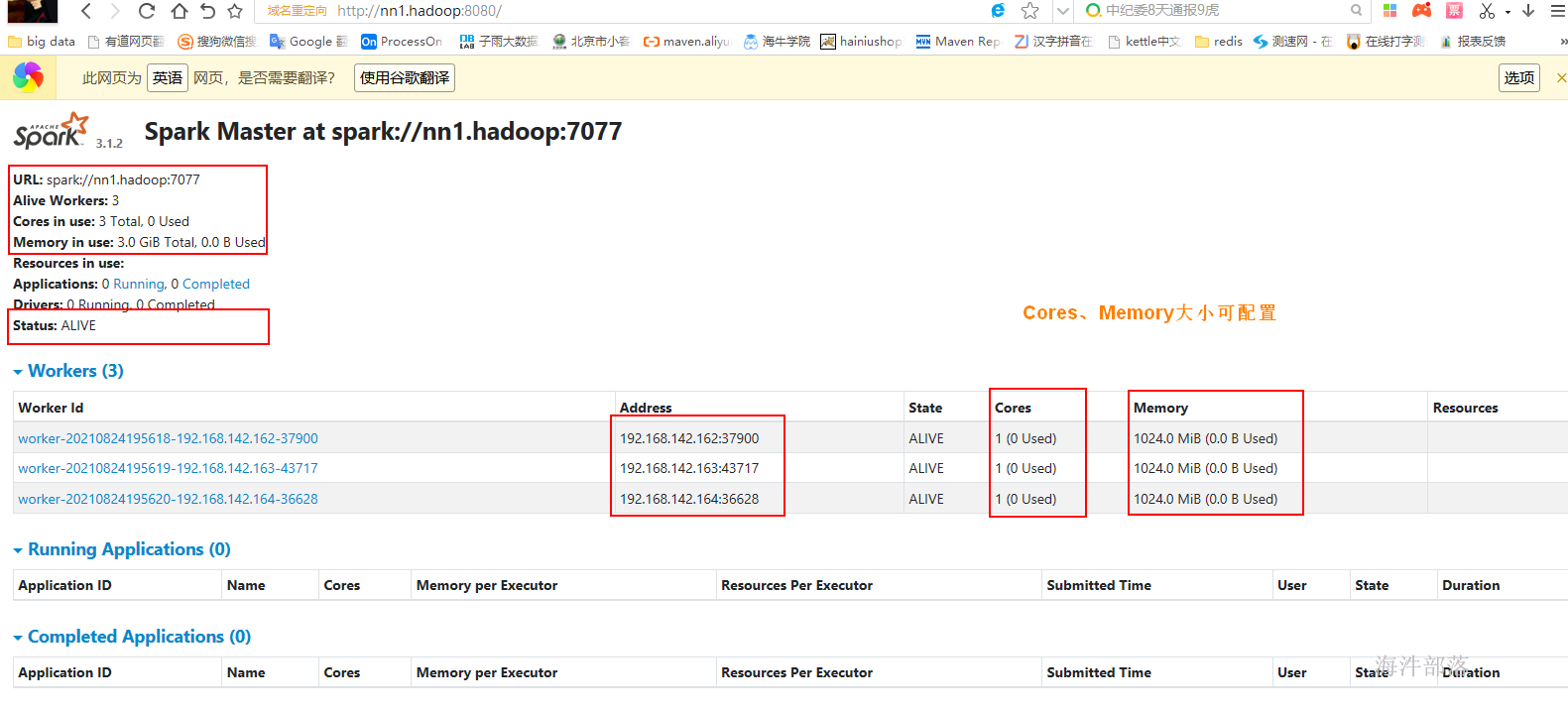
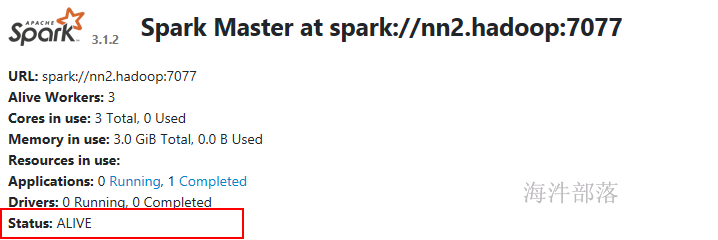
/usr/local/spark/sbin/start-master.sh 启动后查看进程:
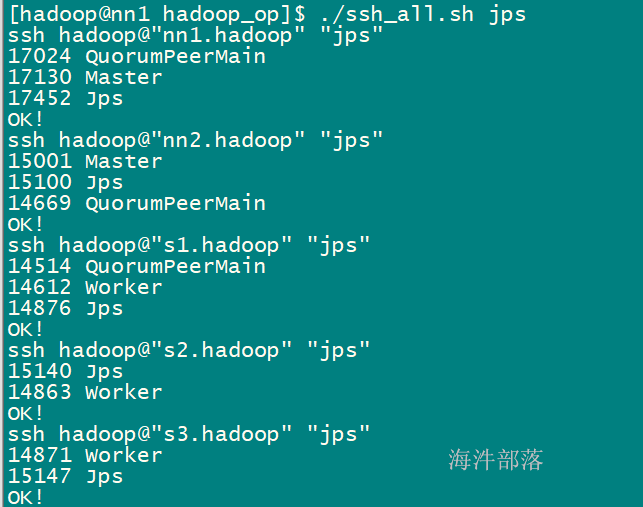
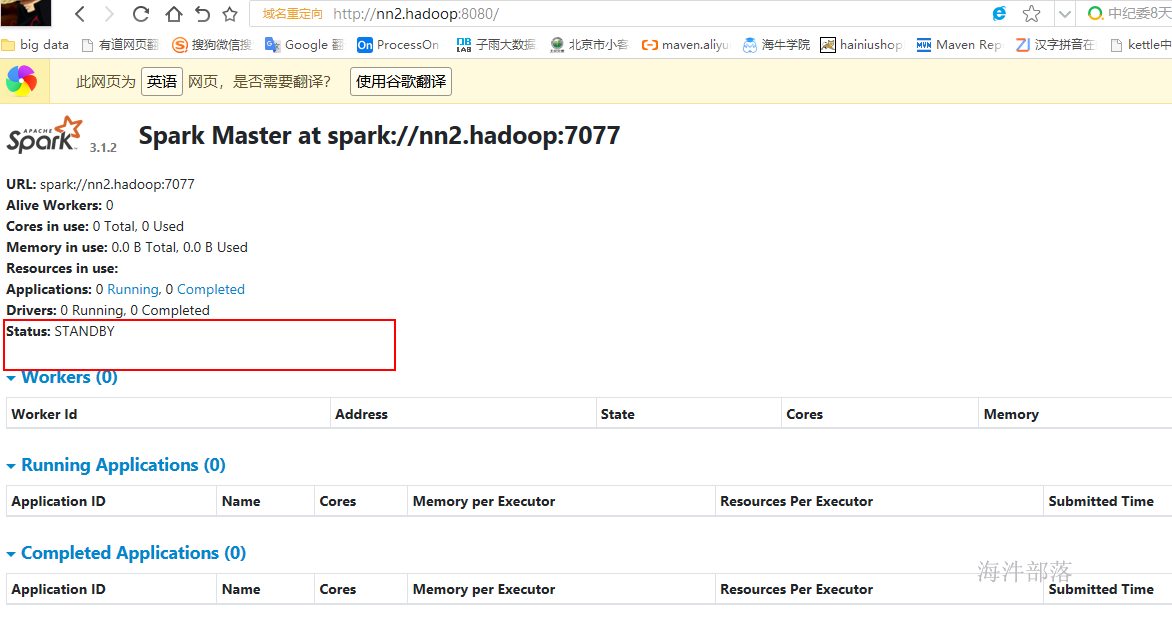
查看nn2.hadoop spark的web页面,当前是standby 状态。
在运行下面的任务的同时,kill 掉 ALIVE 的 master,看会不会切换
spark-submit
–class org.apache.spark.examples.SparkPi
–master spark://nn1.hadoop:7077,nn2.hadoop:7077
–executor-memory 1G
–total-executor-cores 2
/usr/local/spark/examples/jars/spark-examples_2.12-3.1.2.jar
5000
为了不打印太多日志,把log 级别设置成WARN
vim /usr/local/spark/conf/log4j.properties


5.2.4 高可用原理
在应用程序执行过程中,如果进行master 的ha切换会影响应用程序的运行吗?
不会,因为程序运行前已经向master申请过资源了。申请过后就是Driver与Executors之间的通信,这个过程一般不需要Master参与,除非executor有故障。
粗粒度:应用程序需要多少资源,就一次性分配。
好处:是一次性分配资源好后,不需要再关心资源的分配,而在作业运行过程中可以让driver和executors交互,
完成作业或程序运行。
弊端:假设有一百万个任务,如果只有一个任务没有完成,那么其他所有资源都会闲置,其他任务会等待,造成浪费。
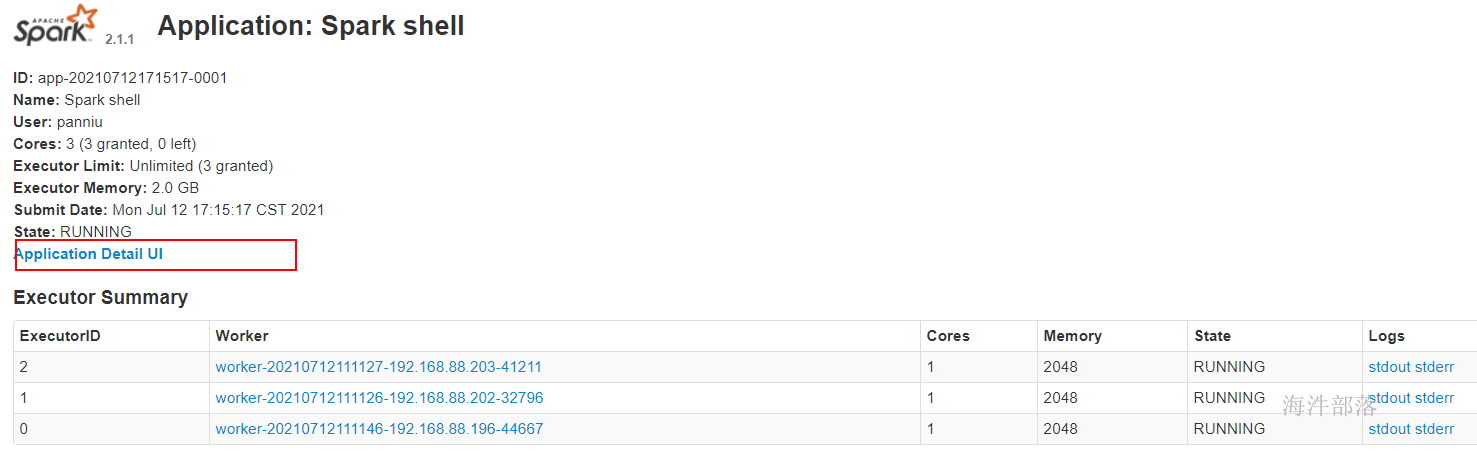
5.3 spark-shell开发wordCount
Spark Shell:
是基础scala的的命令行客户端,是一个spark的driver应用程序,可以写spark程序进行测试,可以本地运行也可以集群运行,取决于是否设置–master
准备数据

spark-shell –master spark://nn1.hadoop:7077 –executor-memory 2G –total-executor-cores 3
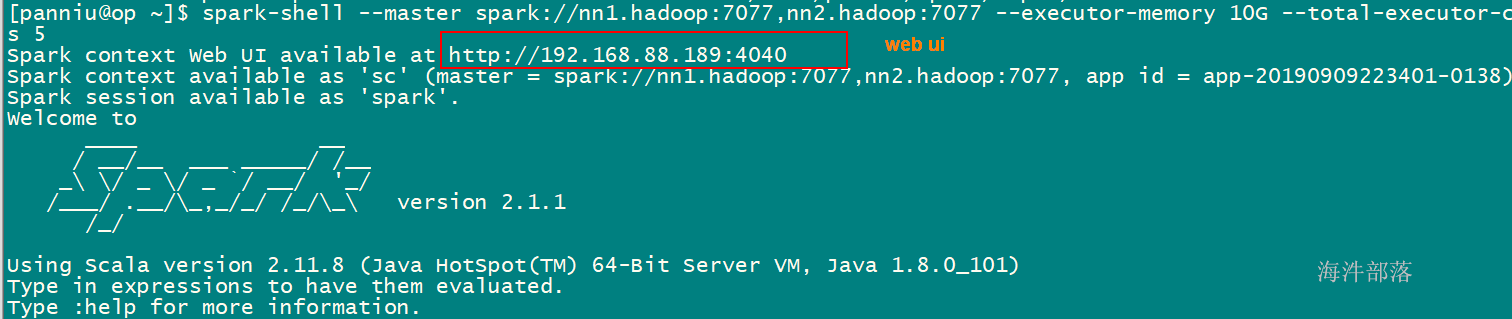
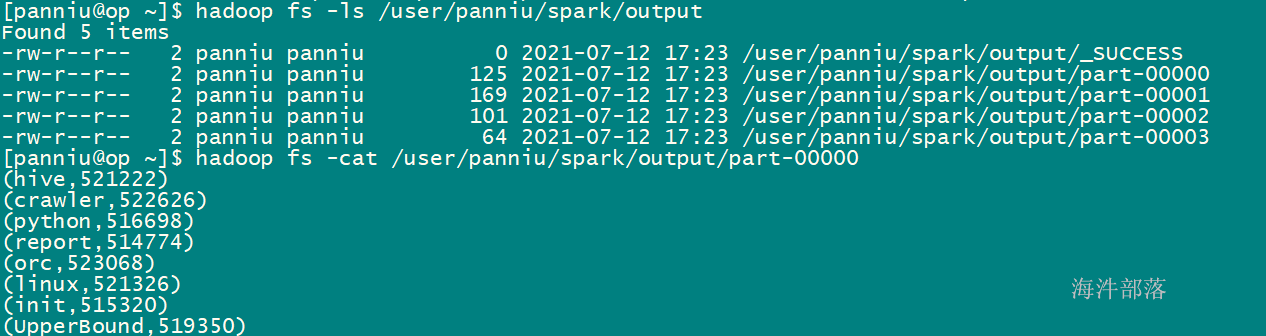
// 计算hdfs目录下的wordcount,并输出到/user/panniu/spark/output
sc.textFile("hdfs://ns1/user/panniu/spark/input").flatMap(_.split("\t")).map((_,1)).reduceByKey(_ + _).saveAsTextFile("hdfs://ns1/user/panniu/spark/output")输出目录不能存在,存在报错



| yarn | spark的standAlone调度模式对比 | spark集群各组件的功能 |
|---|---|---|
| ResourceManager | Master | 管理子节点,调度资源,接受任务请求 |
| NodeManger | Worker | 管理当前节点,并管理子节点 |
| YarnChild | Executor (Task) | 运行真正的计算逻辑(Task) |
| client | driver | driver(Client+AppMaster)提交App,管理该任务的Executor |
| ApplicationMaster |
spark on yarn 的
5.4.1 yarn-client模式
是driver端是独立于 yarn集群的,运算的时候,driver端需要管理executor 中task的运行,所以driver端(客户端)是不能离开的。
driver端在客户端上,所以好调试日志。
当在客户端提交多个spark应用时,它会对客户端造成很大的网络压力,yarn-client模式只适合 交互式环境开发。
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--queue hainiu \
/usr/local/spark/examples/jars/spark-examples_2.12-3.1.2.jar \
20000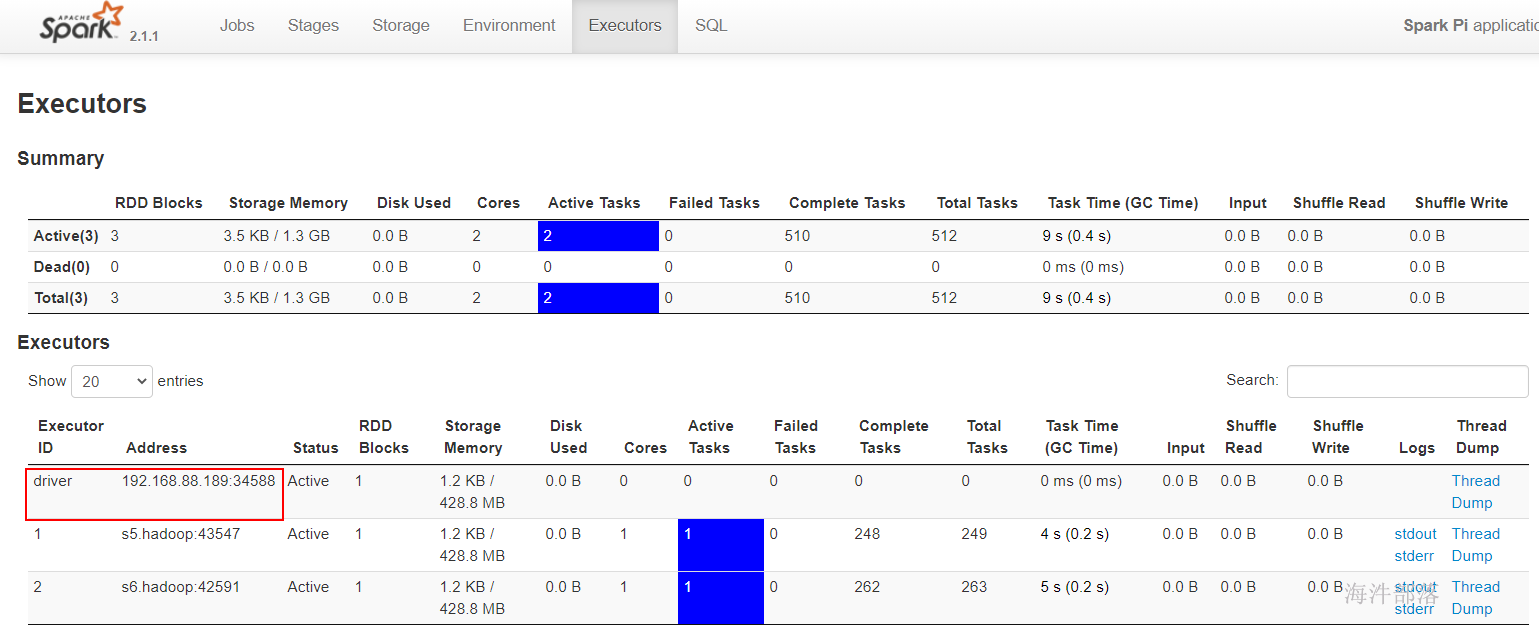
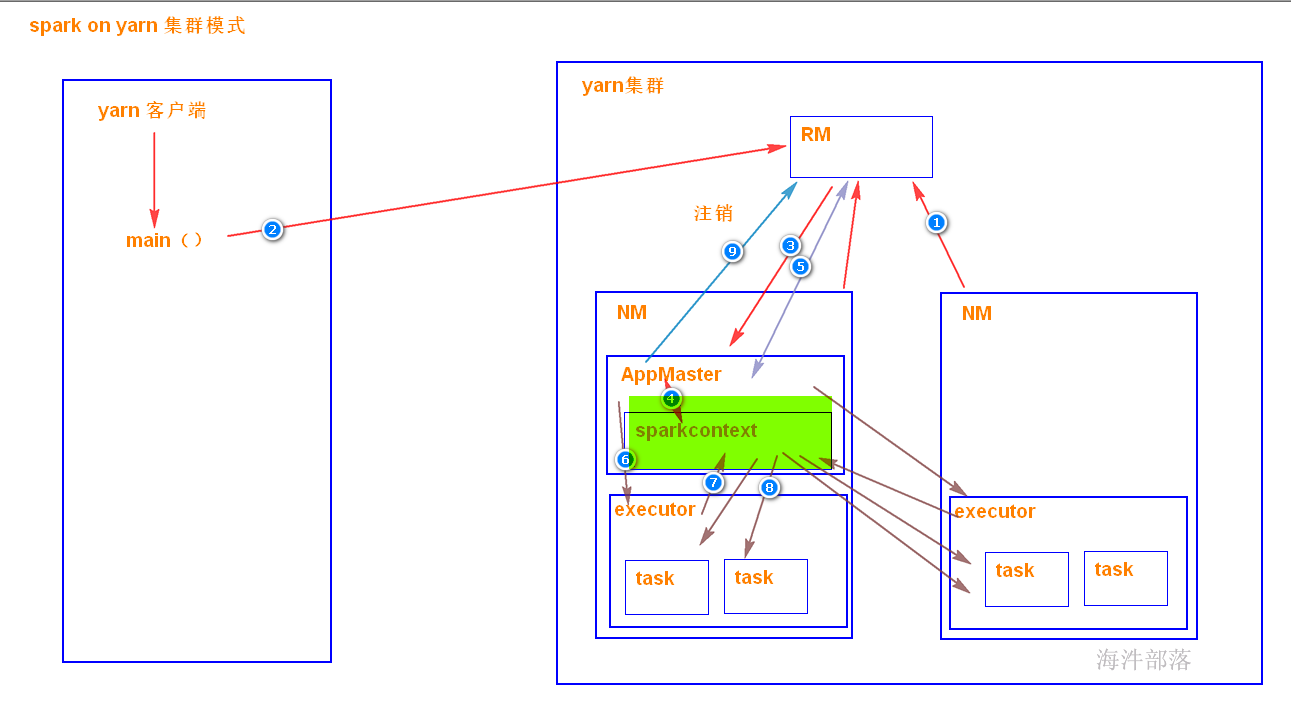
5.4.2 yarn-集群模式
driver端是在APPMater节点,是在yarn集群里面,那运行和监控executor 的任务都是在yarn集群里面。yarn提交任务的客户端是可以离开的。
driver端在yarn集群里面,所以不好调试日志。
客户端一经提交可以离开,常用于正常的提交应用,适合生产环境。
spark-submit \
--class org.apache.spark.examples.SparkPi \
--master yarn \
--queue hainiu \
--deploy-mode cluster \
/usr/local/spark/examples/jars/spark-examples_2.12-3.1.2.jar \
20000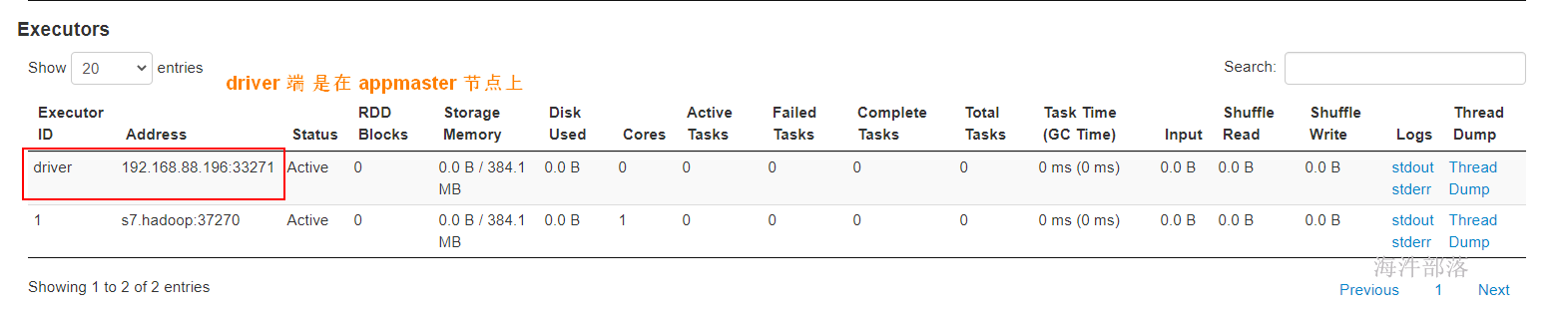
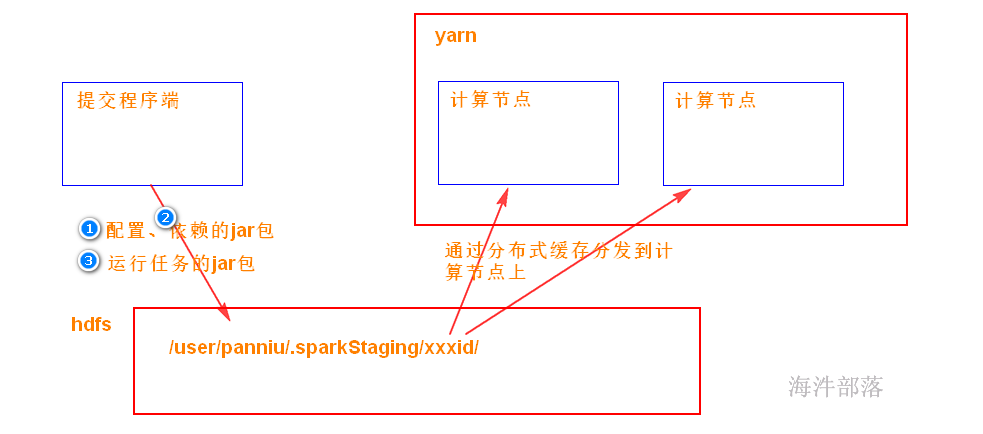
当spark在yarn上运行时,yarn要拿到 3样:
1)运行用的配置
2)运行要依赖的jar包
默认是SPARK_HOME/jars 目录下的jar包打包
如果想加入其它jar包,可通过 –jars 添加
3)运行任务的jar包(带有代码的jar包)
这3样需要从提交程序端 上传到 /user/xxx/.sparkStaging/yarnid/目录下(分布式缓存),然后再分发到运行任务的计算节点。
6.1
JDK 1.8
IDEA + scala2.12的sdk
6.2 开发spark项目的maven依赖
本课程采用spark3.1.2 + scala2.12的sdk
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
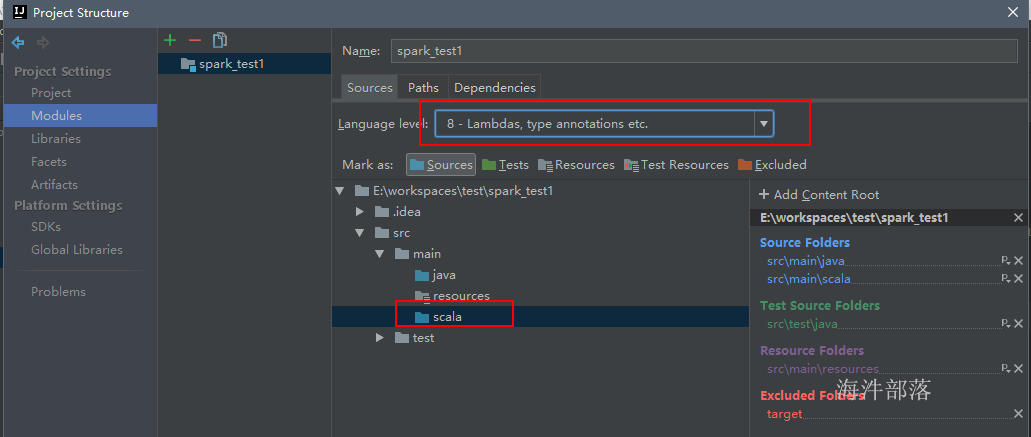
</dependencies>6.3 搭建spark的开发环境
1)在idea创建maven工程
2)创建scala目录,并设置成代码目录 和 jdk级别为8
6)添加 log4j.properties
7 spark wordcount 代码实现
7.1 scala版
第一版wordcount
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[String] = sc.textFile("/tmp/spark/input1")
val mapRdd: RDD[(String, Int)] = rdd.flatMap(_.split("\t")).map((_,1))
// groupBy+mapValues 效率低, groupBy只是按照key把数据集合在一起,并不计算,拉取的数据量特别大
// val resRdd: RDD[(String, Int)] = mapRdd.groupBy(_._1).mapValues(_.size)
// reduceByKey效率高, reduceByKey是按照key把数据聚合在一起并计算出value的结果
// RDD 里没有 reduceByKey, 但是能用, 说明有隐式转换函数将 rdd增强了
val resRdd: RDD[(String, Int)] = mapRdd.reduceByKey(_ + _)
// val arr: Array[(String, Int)] = resRdd.collect()
// println(arr.toBuffer)
val outputDir:String = "/tmp/spark/output"
val outputPath:Path = new Path(outputDir)
// 主动删除输出目录
val hadoopConf: Configuration = new Configuration()
val fs: FileSystem = FileSystem.get(hadoopConf)
if(fs.exists(outputPath)){
fs.delete(outputPath, true)
println(s"delete outputpath: ${outputPath.toString}")
}
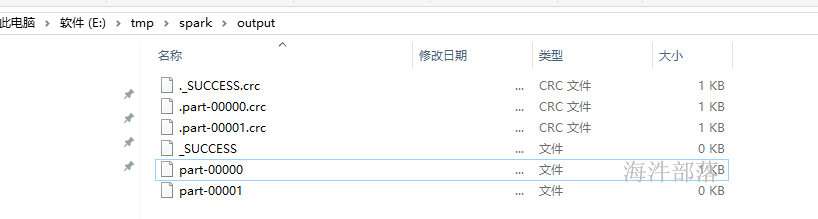
resRdd.saveAsTextFile(outputDir)
}
}第二版:
利用隐式转换函数, 给字符串赋予删除hdfs目录功能
HdfsUtil
package com.hainiu.util
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
class HdfsUtil(val outputDir:String) {
def deleteHdfs = {
val outputPath:Path = new Path(outputDir)
// 主动删除输出目录
val hadoopConf: Configuration = new Configuration()
val fs: FileSystem = FileSystem.get(hadoopConf)
if(fs.exists(outputPath)){
fs.delete(outputPath, true)
println(s"delete outputpath: ${outputPath.toString}")
}
}
}隐式转换
package com.hainiu.util
object MyPredef {
// 定义隐式转换函数实现 将String转HdfsUtil
implicit def string2HdfsUtil(outputDir:String) = new HdfsUtil(outputDir)
}程序
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object WordCount {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[String] = sc.textFile("/tmp/spark/input1")
val mapRdd: RDD[(String, Int)] = rdd.flatMap(_.split("\t")).map((_,1))
// groupBy+mapValues 效率低, groupBy只是按照key把数据集合在一起,并不计算,拉取的数据量特别大
// val resRdd: RDD[(String, Int)] = mapRdd.groupBy(_._1).mapValues(_.size)
// reduceByKey效率高, reduceByKey是按照key把数据聚合在一起并计算出value的结果
// RDD 里没有 reduceByKey, 但是能用, 说明有隐式转换函数将 rdd增强了
val resRdd: RDD[(String, Int)] = mapRdd.reduceByKey(_ + _)
// val arr: Array[(String, Int)] = resRdd.collect()
// println(arr.toBuffer)
val outputDir:String = "/tmp/spark/output"
import com.hainiu.util.MyPredef.string2HdfsUtil
// 给字符串赋予删除hdfs的功能
outputDir.deleteHdfs
resRdd.saveAsTextFile(outputDir)
}
}结果:
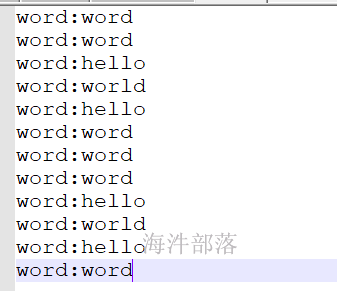
用cache优化,实现复用:
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object CacheDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("CacheDemo")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[String] = sc.textFile("/tmp/spark/input1")
val mapRdd: RDD[(String, Int)] = rdd.flatMap(_.split("\t")).map(f => {
println(s"word:${f}")
(f,1)
})
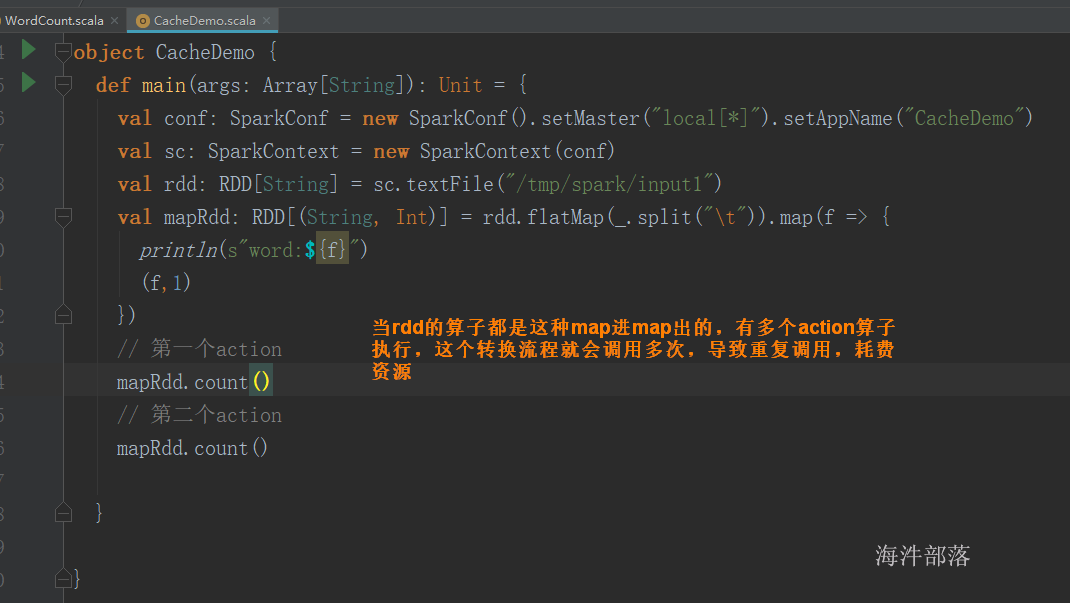
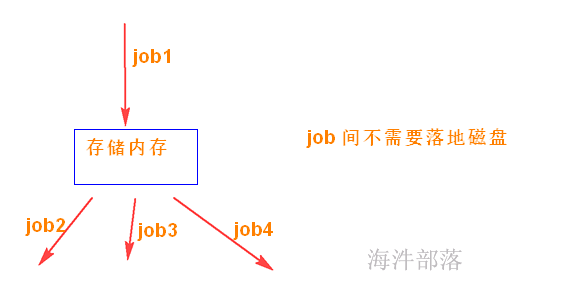
// 当执行cache时,会将mapRdd的数据缓存到存储内存,等下一个action执行时,碰到cache,
// 就不向上追溯,直接从存储内存拿取数据取运算,这样实现复用
// cache的默认缓存级别 :StorageLevel.MEMORY_ONLY
// 缓存到内存,写入存储内存的数据不需要序列化,直接把对象写入即可,使用时也许不要反序列化速度快。
val cache: RDD[(String, Int)] = mapRdd.cache()
// 第一个action
println(cache.count())
// 第二个action
println(cache.count())
}
}
8 .RDD
8.1 RDD设计背景
在实际应用中,存在许多迭代式计算,这些应用场景的共同之处是,不同计算阶段之间会重用中间结果,即一个阶段的输出结果会作为下一个阶段的输入。但是,目前的MapReduce框架都是把中间结果写入到HDFS中,带来了大量的数据复制、磁盘IO和序列化开销。显然,如果能将结果保存在内存当中,就可以大量减少IO。RDD就是为了满足这种需求而出现的,它提供了一个抽象的数据架构,我们不必担心底层数据的分布式特性,只需将具体的应用逻辑表达为一系列转换处理,不同RDD之间的转换操作形成依赖关系,可以实现管道化,从而避免了中间结果的落地存储,大大降低了数据复制、磁盘IO和序列化开销。
8.2 RDD概念
RDD(Resilient Distributed Datasets,弹性分布式数据集)代表可并行操作元素的不可变分区集合。
一个RDD就是一个分布式对象集合,本质上是一个只读的分区记录集合,每个RDD可以分成多个分区,每个分区就是一个数据集片段(HDFS上的块),并且一个RDD的不同分区可以被保存到集群中不同的节点上,从而可以在集群中的不同节点上进行并行计算。
RDD提供了一种高度受限的共享内存模型,即RDD是只读的记录分区的集合,不能直接修改,只能基于稳定的物理存储中的数据集来创建RDD,或者通过在其他RDD上执行确定的转换操作(如map、join和groupBy)而创建得到新的RDD。
RDD提供了一组丰富的操作以支持常见的数据运算,分为“行动”(Action)和“转换”(Transformation)两种类型,前者用于执行计算并指定输出的形式,后者指定RDD之间的相互依赖关系。两类操作的主要区别是,转换操作(比如map、filter、groupBy、join等)接受RDD并返回RDD,而行动操作(比如count、collect等)接受RDD但是返回非RDD(即输出一个值或结果)。
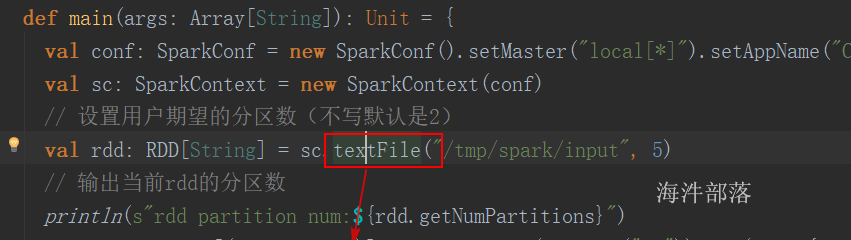
设置期望最小split分区数 和 打印实际split的分区数:

每个分片的大小计算方法如下:
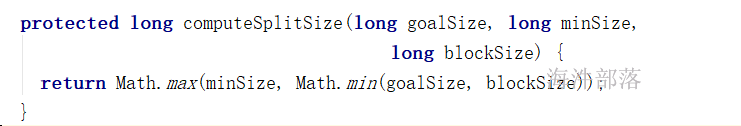
goalSize:是根据用户期望的分区数算出来的,每个分区的大小,总文件大小/用户期望分区数;

minSize :InputSplit的最小值,由配置参数mapred.min.split.size(在/conf/mapred-site.xml文件中配置)确定,默认是1(字节);

blockSize :文件在HDFS中存储的block大小(在/conf/hdfs-site.xml文件中配置),不同文件可能不同,默认是64MB或者128MB。
在windows系统中,一个块是32MB。
每个分片数据的划分过程会考虑机架、host等因素。

有这么个输入数据

如果不设置期望分区数,就是默认的 2
globalSize = (4.104 + 4.104 + 98.491) / 2 = 53.3495MB
blockSize = 32MB
globalSize > blockSize , 按照blockSize来分
word1.txt ——> 1
wrod2.txt ——> 1
word3.txt ——> 3 (2块64M, 剩余的 / 32 \< 1.1,分1个块)
共分5个split。
如果设置期望分区数5
globalSize = (4.104 + 4.104 + 98.491) / 5 = 21.3398
blockSize = 32MB
globalSize \< blockSize , 按照 globalSize 来分
word1.txt ——> 1
wrod2.txt ——> 1
word3.txt ——> 5 (98.491 / 21.3398 = 4.6 —》 5)
共分7个split。
源码:
Spark用Scala语言实现了RDD的API,程序员可以通过调用API实现对RDD的各种操作。RDD典型的执行过程如下:
1)RDD读入外部数据源(或者内存中的集合)进行创建;
2)RDD经过一系列的“转换”操作,每一次都会产生不同的RDD,供给下一个“转换”使用;
3)最后一个RDD经“行动”操作进行处理,并输出到外部数据源(或者变成Scala/JAVA集合或变量)。
需要说明的是,RDD采用了惰性调用,即在RDD的执行过程中,真正的计算发生在RDD的“行动”操作,对于“行动”之前的所有“转换”操作,Spark只是记录下“转换”操作应用的一些基础数据集以及RDD生成的轨迹,即相互之间的依赖关系,而不会触发真正的计算。
java程序示例
JavaSparkContext sc = new JavaSparkContext(conf);
JavaRDD<String> lines = sc.textFile(logFile);
JavaRDD<String> filter = lines.filter(new Function<String, Boolean>() {
@Override
public Boolean call(String v1) throws Exception {
return v1.contains("helle world");
}
});
cache = filter.cache();
long count = cache.count();
System.out.println(count);scala:
val conf = new SparkConf
val sparkContext = new SparkContext(conf)
val lines :RDD = sparkContext.textFile(logFile)
//lines.filter((a:String) => a.contains("hello world"))
val count = lines.filter(_.contains("hello world")).cache().count()
println(count)可以看出,一个Spark应用程序,基本是基于RDD的一系列计算操作。
第1行代码用于创建JavaSparkContext对象;
第2行代码从HDFS文件中读取数据创建一个RDD;
第3行代码对fileRDD进行转换操作得到一个新的RDD,即filterRDD;
filter.cache() 表示对 filter 进行持久化,把它保存在内存或磁盘中(这里采用cache接口把数据集保存在内存中),方便后续重复使用,当数据被反复访问时(比如查询一些热点数据,或者运行迭代算法),这是非常有用的,而且通过cache()可以缓存非常大的数据集,支持跨越几十甚至上百个节点; count()是一个行动操作,用于计算一个RDD集合中包含的元素个数。
这个程序的执行过程如下:
1)创建这个Spark程序的执行上下文,即创建SparkContext对象;
2)从外部数据源(即HDFS文件)中读取数据创建fileRDD对象;
3)构建起fileRDD和filterRDD之间的依赖关系,形成DAG图,这时候并没有发生真正的计算,只是记录转换的轨迹;
4)执行action代码时,count()是一个行动类型的操作,触发真正的计算,开始执行从fileRDD到filterRDD的转换操作,并把结果持久化到内存中,最后计算出filterRDD中包含的元素个数。
8.3 RDD特性
总体而言,Spark采用RDD以后能够实现高效计算的主要原因如下:
1)高效的容错性(血缘关系容错)。现有的分布式共享内存、键值存储、内存数据库等,为了实现容错,必须在集群节点之间进行数据复制或者记录日志,也就是在节点之间会发生大量的数据传输,这对于数据密集型应用而言会带来很大的开销。在RDD的设计中,数据只读,不可修改,如果需要修改数据,必须从父RDD转换到子RDD,由此在不同RDD之间建立了血缘关系。所以,RDD是一种天生具有容错机制的特殊集合,不需要通过数据冗余的方式(比如详细的记录操作的日志)实现容错,而只需通过RDD父子依赖(血缘)关系重新计算得到丢失的分区来实现容错,无需回滚整个系统,这样就避免了数据复制的高开销,而且重算过程可以在不同节点之间并行进行,实现了高效的容错。此外,RDD提供的转换操作都是一些粗粒度的操作(比如map、filter和join),RDD依赖关系只需要记录这种粗粒度的转换操作,而不需要记录具体的数据和各种细粒度操作的日志(比如对哪个数据项进行了修改),这就大大降低了数据密集型应用中的容错开销;
2)中间结果持久化到内存(cache)。数据在内存中的多个RDD操作之间进行传递,不需要“落地”到磁盘上,避免了不必要的读写磁盘开销;
3)存放的数据可以是Java对象,避免了不必要的对象序列化和反序列化开销(但占用内存的空间)。

rdd 弹性体现在哪?
1)自动进行内存和磁盘换;
2)基于血缘关系的高效容错;
3)task如果失败会特定次数的重试,默认重试4次;
4)stage如果失败会自动进行特定次数的重试,默认重试4次
5)通过cache容错和通过持久化来对数据进行复用;
6)数据调度弹性,DAG划分、TASK调度和资源管理无关;
7)数据分片的高度弹性(可重新分区);
8.4 RDD之间的依赖关系
RDD中不同的操作会使得不同RDD中的分区会产生不同的依赖。RDD中的依赖关系分为窄依赖(Narrow Dependency)与宽依赖(Wide Dependency)。
宽依赖与窄依赖
窄依赖表现为一个父RDD的分区对应于一个子RDD的分区,或多个父RDD的分区对应于一个子RDD的分区;
宽依赖则表现为存在一个父RDD的一个分区对应一个子RDD的多个分区;
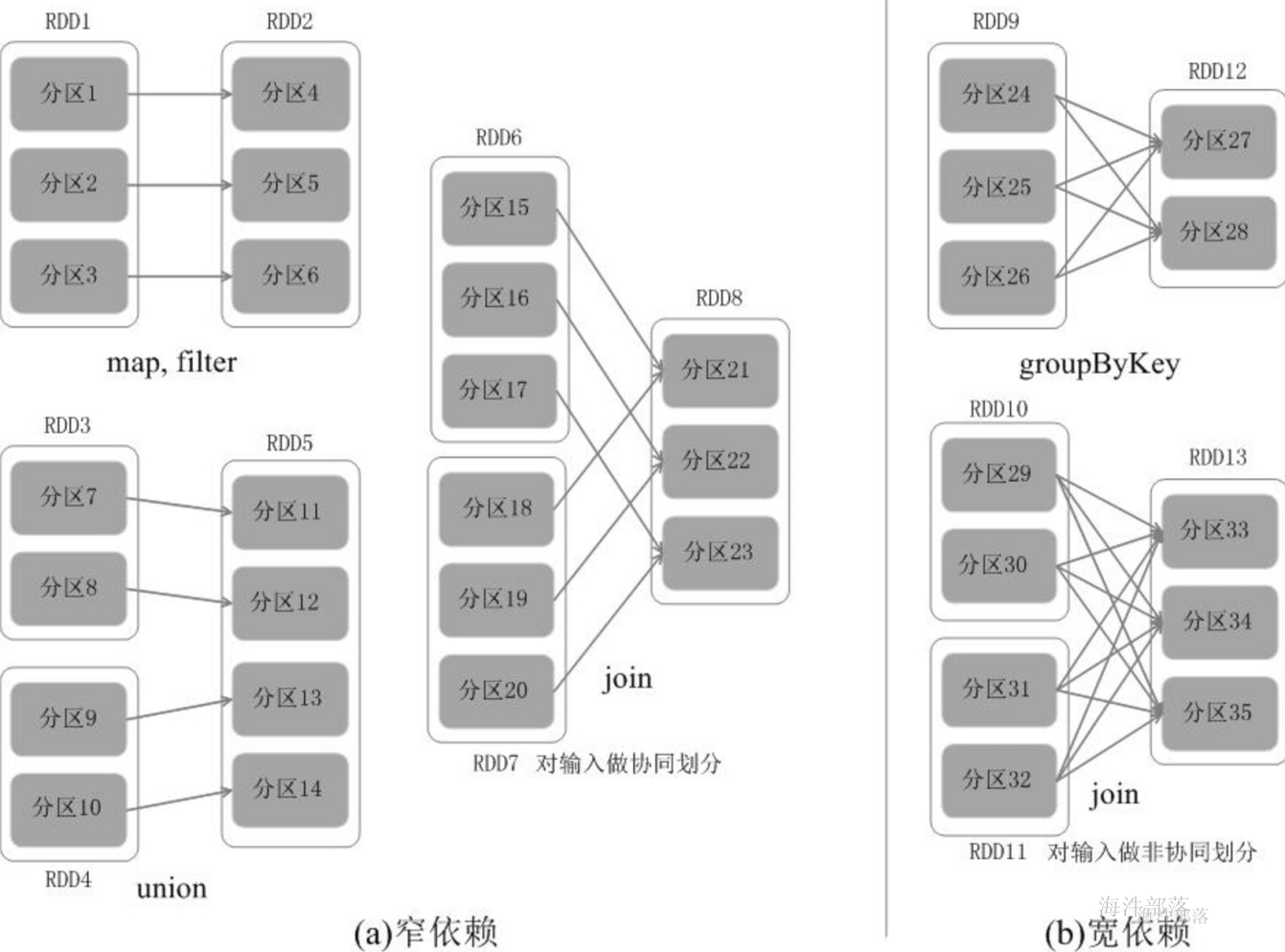
(1)对输入进行协同划分,属于窄依赖。所谓协同划分(co-partitioned)是指多个父RDD的某一分区的所有“键(key)”,落在子RDD的同一个分区内,不会产生同一个父RDD的某一分区,落在子RDD的两个分区的情况。
(2)对输入做非协同划分,属于宽依赖。
对于窄依赖的RDD,可以以流水线的方式计算所有父分区,不会造成网络之间的数据混合。对于宽依赖的RDD,则通常伴随着Shuffle操作,即首先需要计算好所有父分区数据,然后在节点之间进行Shuffle。
窄依赖与宽依赖的区别
Spark的这种依赖关系设计,使其具有了天生的容错性,大大加快了Spark的执行速度。因为,RDD数据集通过“血缘关系”记住了它是如何从其它RDD中演变过来的,血缘关系记录的是粗颗粒度的转换操作行为,当这个RDD的部分分区数据丢失时,它可以通过血缘关系获取足够的信息来重新运算和恢复丢失的数据分区,由此带来了性能的提升。相对而言,在两种依赖关系中,窄依赖的失败恢复更为高效,它只需要根据父RDD分区重新计算丢失的分区即可(不需要重新计算所有分区),而且可以并行地在不同节点进行重新计算。而对于宽依赖而言,单个节点失效通常意味着重新计算过程会涉及多个父RDD分区,开销较大。此外,Spark还提供了数据检查点,用于持久化中间RDD,从而使得在进行失败恢复时不需要追溯到最开始的阶段。在进行故障恢复时,Spark会对数据检查点开销和重新计算RDD分区的开销进行比较,从而自动选择最优的恢复策略。
8.5 阶段的划分
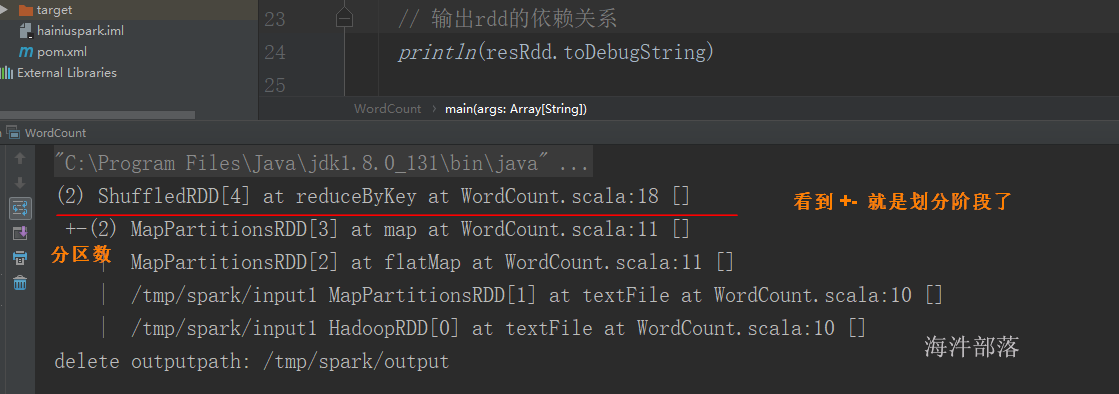
Spark通过分析各个RDD的依赖关系生成了DAG,再通过分析各个RDD中的分区之间的依赖关系来决定如何划分阶段,具体划分方法是:在DAG中进行反向解析,遇到宽依赖就断开,遇到窄依赖就把当前的RDD加入到当前的阶段中;将窄依赖尽量划分在同一个阶段中,可以实现流水线计算。例如,假设从HDFS中读入数据生成3个不同的RDD(即A、C和E),通过一系列转换操作后再将计算结果保存回HDFS。对DAG进行解析时,在依赖图中进行反向解析,由于从RDD A到RDD B的转换以及从RDD B和F到RDD G的转换,都属于宽依赖,因此,在宽依赖处断开后可以得到三个阶段,即阶段1、阶段2和阶段3。可以看出,在阶段2中,从map到union都是窄依赖,这两步操作可以形成一个流水线操作,比如,分区7通过map操作生成的分区9,可以不用等待分区8到分区10这个转换操作的计算结束,而是继续进行union操作,转换得到分区13,这样流水线执行大大提高了计算的效率。
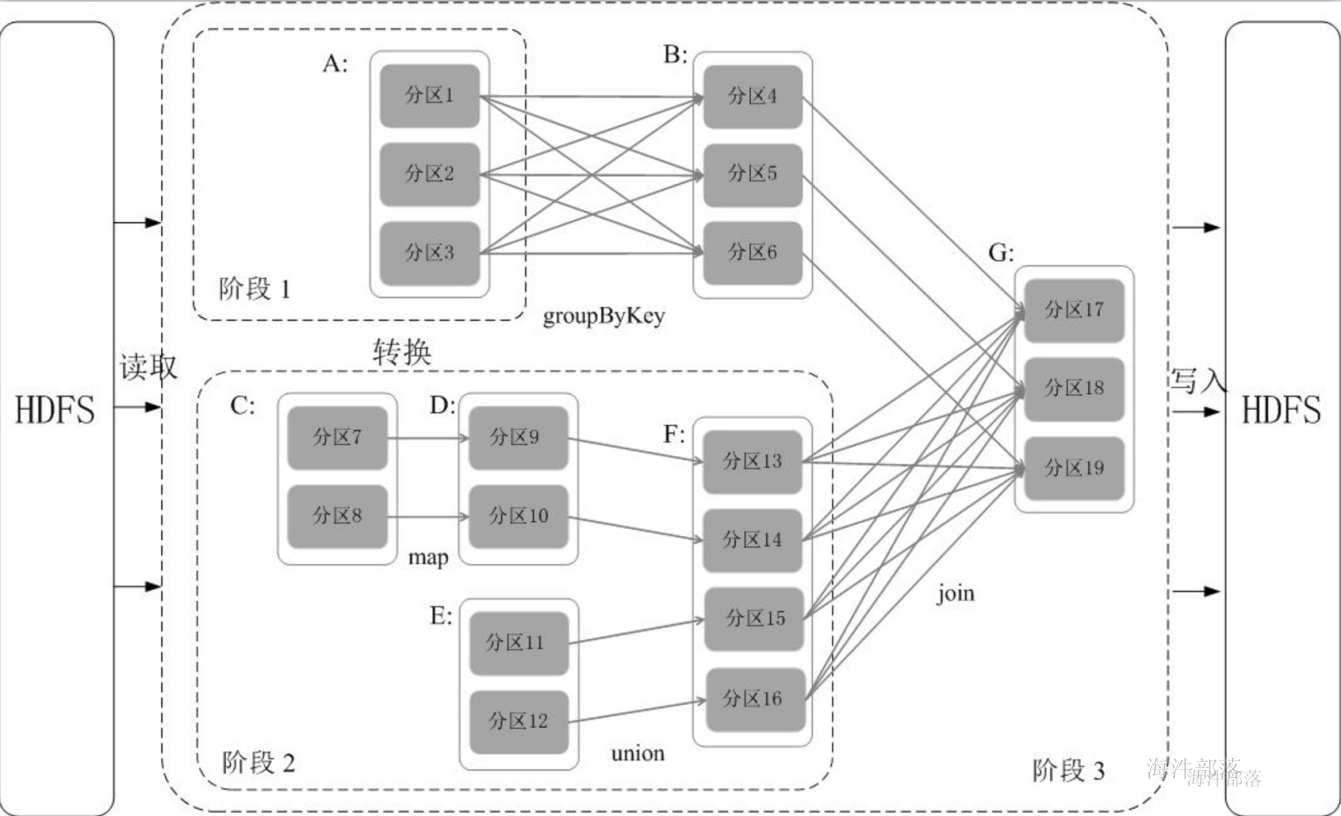
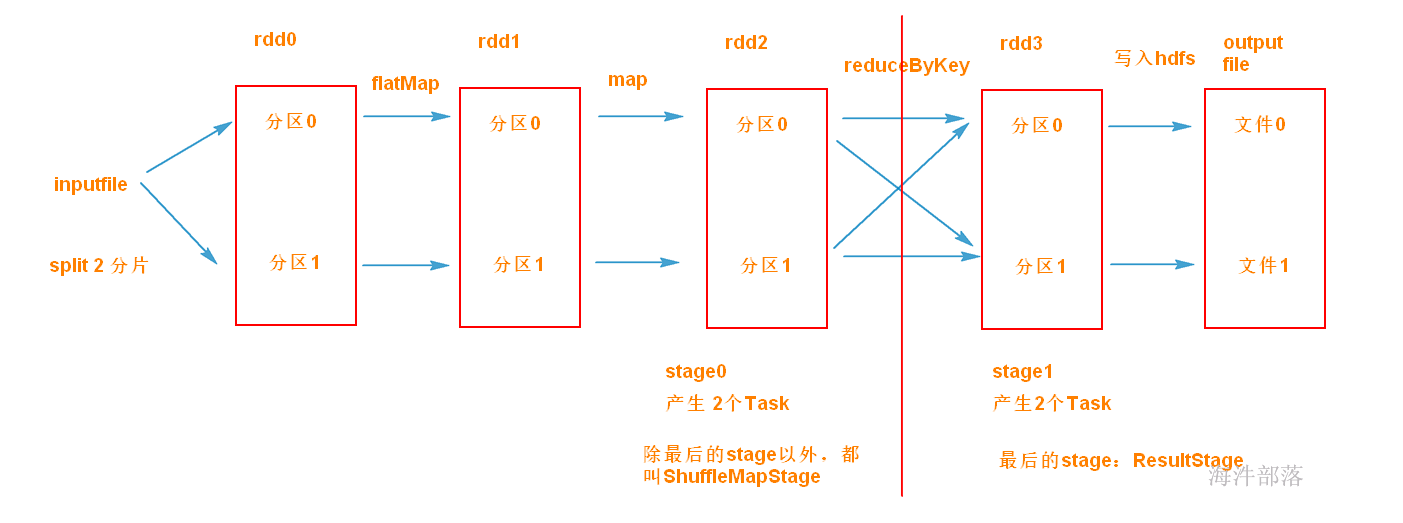
当RDD 执行action 动作时,会触发DAG划分阶段。
调用栈如下:
rdd.count
SparkContext.runJob
DAGScheduler.runJob
DAGScheduler.submitJob (向事件监听器提交任务)
DAGSchedulerEventProcessLoop.doOnReceive (监听器接收到任务,执行doOnReceive)
DAGScheduler.handleJobSubmitted
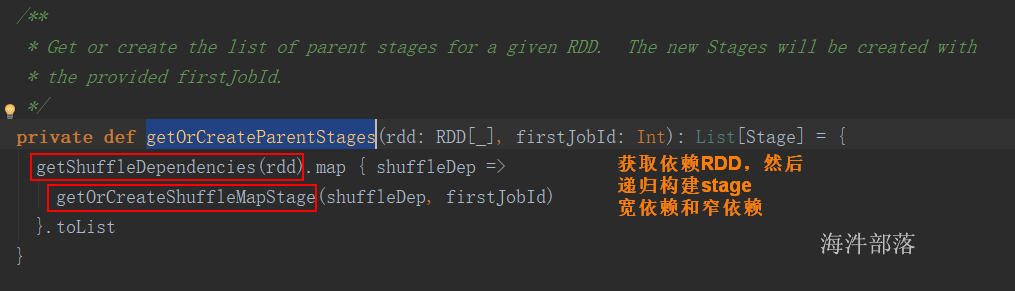
DAGScheduler.createResultStage
DAGScheduler.getOrCreateParentStages (递归构建stage)
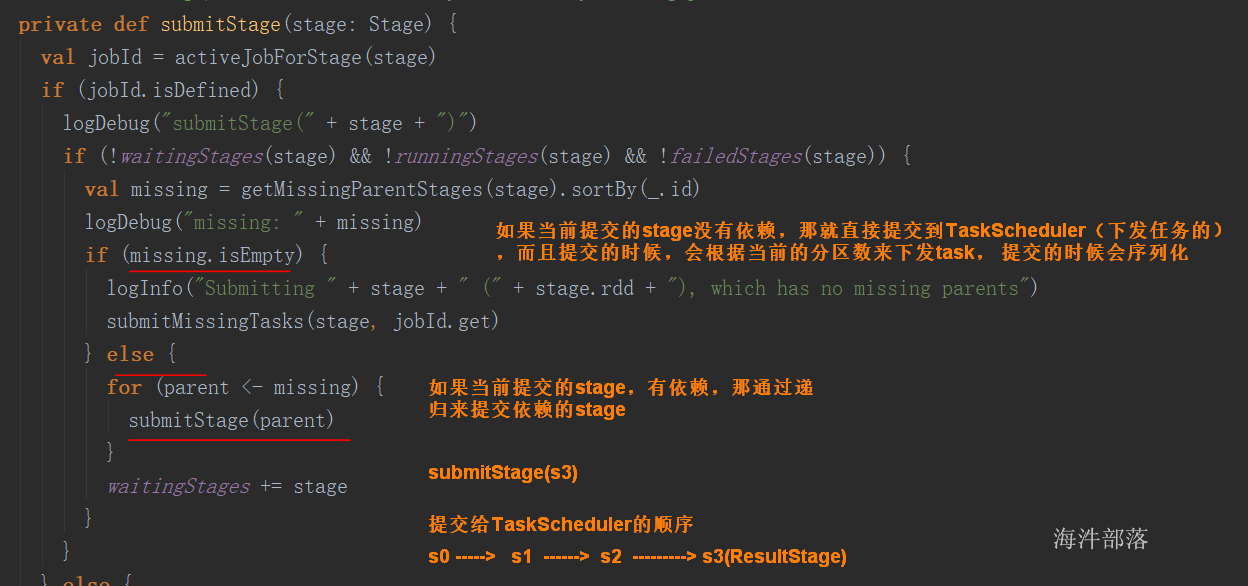
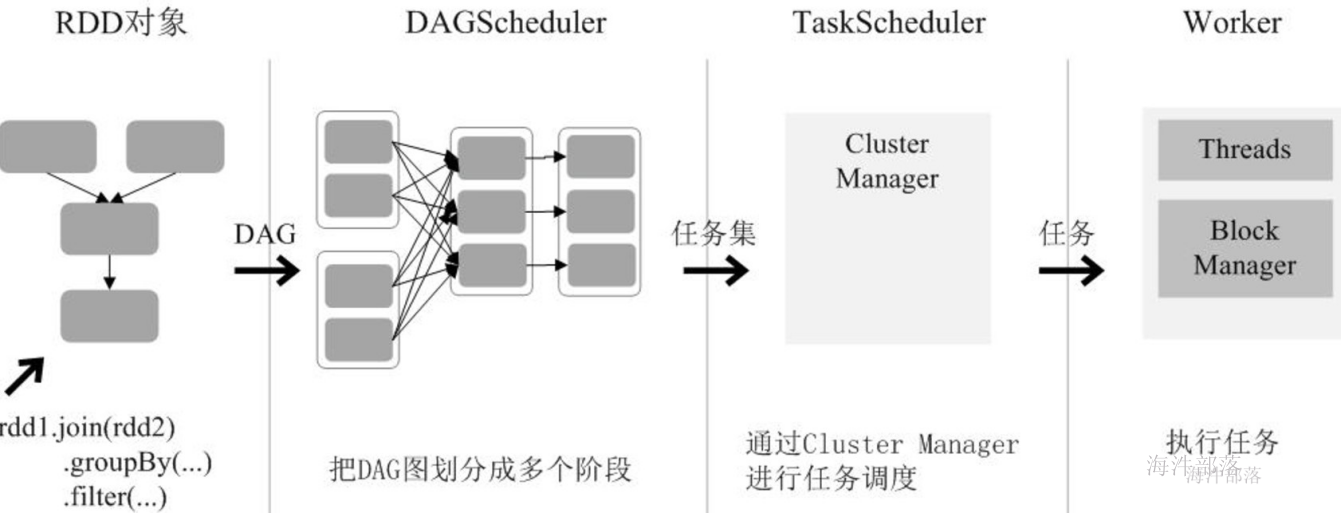
通过上述对RDD概念、依赖关系和阶段划分的介绍,结合之前介绍的Spark运行基本流程,这里再总结一下RDD在Spark架构中的运行过程:
(1)创建RDD对象;
(2)SparkContext负责计算RDD之间的依赖关系,构建DAG;
(3)DAGScheduler负责把DAG图分解成多个阶段,每个阶段中包含了多个算子,每个算子包含多个task,每个task会被任务调度器分发给各个工作节点(Worker Node)上的Executor去执行。
调度阶段(Stage):每个作业会因为RDD之间的依赖关系拆分成多组任务集合,称为调度阶段,也叫任务集(TaskSet)。调度阶段的划分是由DAGScheduler来划分的,调度阶段有ShuffleMapStage 和 ResultStage(最终Stage) 两种。
任务(Task):分发到Executor 上的工作任务,是 Spark 实际执行应用的最小单元。
DAGScheduler:是调度阶段的任务调度器,负责接收Spark应用提交的作业,根据RDD的依赖关系划分阶段,并提交给TaskScheduler。
TaskScheduler:它接受DAGScheduler提交过来的Stage,然后把任务分发到指定的Worker节点的Executor来运行该任务。
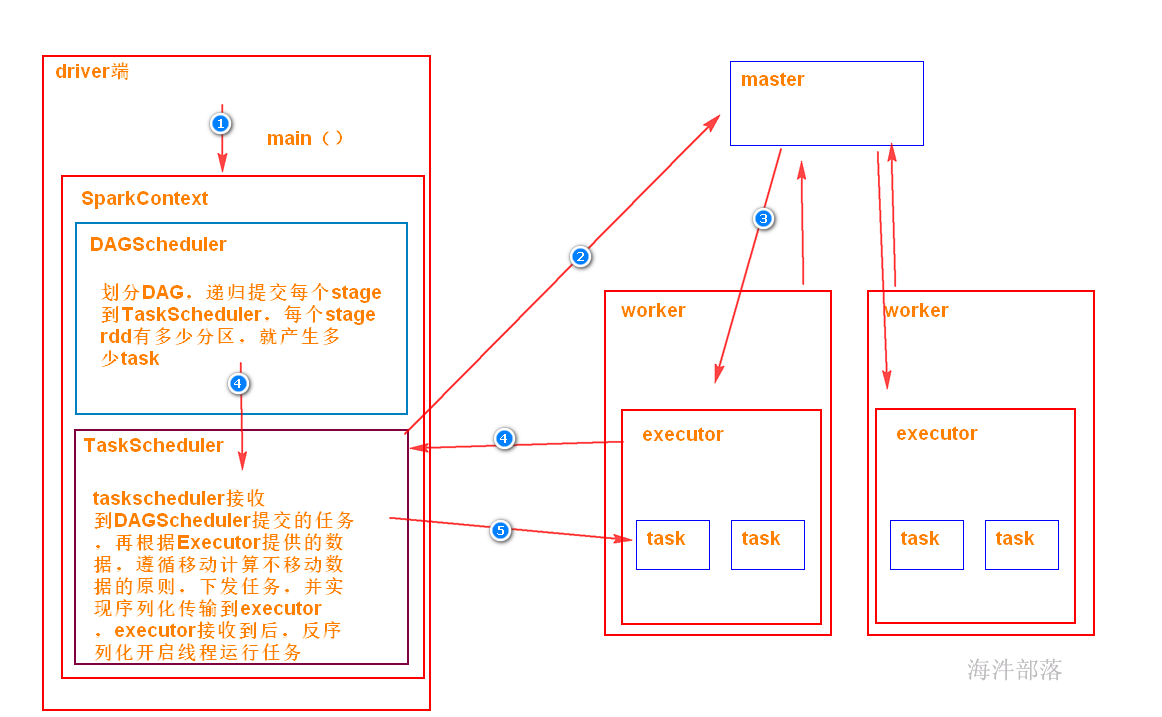
2)初始化TaskScheduler时,会向master申请资源;
3)master用资源在worker端开启executor;
4)executor 与 TaskScheduler通信;于此同时DAGscheduler划分DAG,提交给TaskScheduler;
5)TaskScheduler接收到提交的任务,下发并管理任务;
Task被执行的并发度 = Executor数目 * 每个Executor核数(=core总个数)
就是一次能同时执行多少个task。
官方给的建议:1个CPU核数对应2–3个task。
当 executor数=2, 每个executor核数=1, task被执行的并行度= 2 * 1 = 2, 8个task就需要迭代4次。
当 executor数=2, 每个executor核数=2, task被执行的并行度= 2 * 2 = 4, 8个task就需要迭代2次。
因为一个job会划分很多个阶段,所以没必要把所有阶段的task都占有一个CPU核,这样会极大的浪费资源。
分配资源时,尽量task数能整除开 task被执行的并行度,这样不会有CPU核空转。
比如 6 executor数=2, 每个executor核数=3, task被执行的并行度= 2 * 3 = 6, 那执行一次后,就有4个核空转,浪费资源。
回顾spark-shell中执行的spark任务。会更能体会数据分片、阶段划分。
9 RDD编程
开启spark-shell
本地模式:spark-shell
集群模式:spark-shell –master spark://nn1.hadoop:7077, nn2.hadoop:7077 –executor-memory 1G –total-executor-cores 2
9.1 RDD创建
1)textFile():从文件系统加载数据创建RDD
val conf = new SparkConf().setAppName("rddtest").setMaster("lcoal")
val sc: SparkContext = new SparkContext(conf)
val data: RDD[String] = sc.textFile("E:\\tmp\\spark\\input\\f1.txt")2)parallelize():集合并行化,从一个已经存在的集合上创建RDD
val arr = Array(1,2,3,4,5)
val data: RDD[Int] = sc.parallelize(arr)
println(data.count()) // 统计RDD元素个数
9.2 RDD操作
RDD操作包括两种类型,即转换(Transformation)操作和行动(Action)操作。
9.2.1 转换操作
对于RDD而言,每一次转换操作都会产生不同的RDD,供给下一个操作使用。RDD的转换过程是惰性求值的,也就是说,整个转换过程只是记录了转换的轨迹,并不会发生真正的计算,值遇到行动操作时,才会触发“从头到尾”的真正的计算。
9.2.1.1 常用转换操作
| 函数 | 说明 | 示例 |
|---|---|---|
| map(func) | 将函数应用于RDD中的每个元素,将返回值构成新的RDD | 假设RDD的元素是{“1 2 3”,“4 5 6”} val rdd1 = rdd.map(s => s.split("“)) rdd1的元素是 {Array(”1“,”2“,”3“),Array(”4“,”5“,”6")} |
| flatMap(func) | 将函数应用于RDD中的每个元素,将返回的迭代器的所有内容构成新的RDD 执行过程:map—> flat(拍扁) | 假设RDD的元素是{“1 2 3”,“4 5 6”} val rdd1 = rdd.flatMap(s => s.split("“)) rdd1的元素是 {”1“,”2“,”3“,”4“,”5“,”6"} |
| filter(func) | 返回一个由通过func函数测试(返回true)的元素组成的RDD | 假设RDD的元素是 {1,2,3,4} val rdd1 = rdd.filter(s => s\<3) rdd1的元素是 {1,2} |
| distinct() | 排重 | |
| mapPartitions() | 先partition,再把每个partition进行map函数 | |
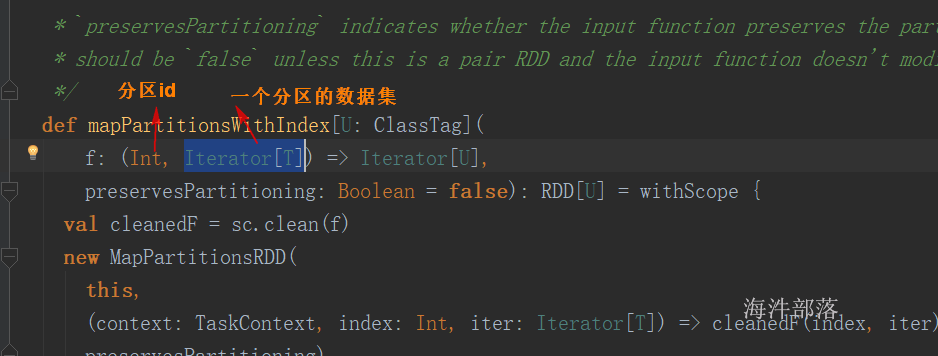
| mapPartitionsWithIndex() | 先partition,再把每个partition进行map函数,并传入partitionid |
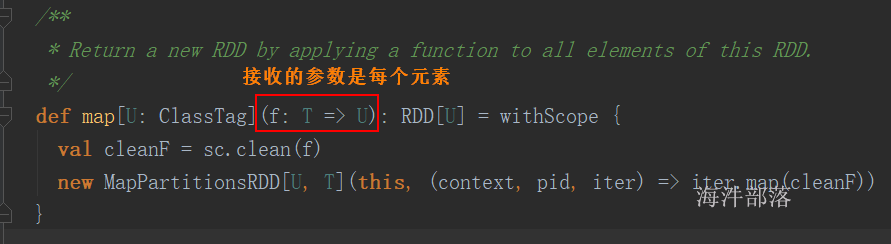
map(func)
val rdd = sc.parallelize(List(“1 2 3”, “4 5 6”))
val rdd1 = rdd.map(s => s.split(" ")).collect

val rdd1 = rdd.map(s => s+1).collect

val rdd = sc.parallelize(List(“1 2 3”, “4 5 6”))
val rdd1 = rdd.flatMap(s => s.split(" ")).collect

val rdd = sc.parallelize(List(1,2,3,4))
val rdd1 = rdd.filter(s => s \< 3).collect


val rdd = sc.parallelize(List(1,2,3,4,1,2,2))
val rdd1 = rdd.distinct().collect

map
mapPartitionsWithIndex
先partition,再把每个partition进行map函数,并传入partitionid
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object RddDemo2 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[6]").setAppName("CacheDemo")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(1 to 4, 2)
// 对rdd的每个元素进行转换
// val rdd2: RDD[Int] = rdd.map(f => {
// println(s"f:${f}")
// f + 1
// })
// val arr: Array[Int] = rdd2.collect()
// println(arr.toBuffer)
// 先按照分区得到每个分区的数据集合(it)
// 然后通过转换得到新的数据集合(it2)
// index: 代表当前分区id
val rdd2: RDD[Int] = rdd.mapPartitionsWithIndex((index, it) => {
val list: List[Int] = it.toList
println(s"index:${index}, it:${list}")
val list2: List[Int] = list.map(_ + 1)
list2.iterator
})
val arr: Array[Int] = rdd2.collect()
println(arr.toBuffer)
}
}应用场景:
1)mapPartitionsWithIndex:比如当需要一个分区创建一个连接,写入一个分区的数据时,可以使用,这样可以减少创建不必要的连接对象。
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object RddDemo2 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[6]").setAppName("CacheDemo")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(1 to 10, 2)
// 一个元素创建一个连接,写入元素,效率低
// rdd.map(f =>{
// println(s"创建连接, 写入:${f}")
//
// }).count()
// 一个分区创建一个连接,写入一个分区的元素,效率高
rdd.mapPartitionsWithIndex((index, it) =>{
println(s"创建连接:${index}")
val list: List[Int] = it.toList
for(i <- list){
println(s"连接${index}, 写入:${i}")
}
println(s"关闭连接${index}")
list.iterator
}).count()
}
}9.2.1.2 键值对RDD操作
键值对RDD(pair RDD)是指每个RDD元素都是(key, value)键值对类型;
| 函数 | 目的 |
|---|---|
| reduceByKey(func) | 合并具有相同键的值,RDD[(K,V)] => RDD[(K,V)]按照key进行分组,并通过func 进行合并计算 |
| groupByKey() | 对具有相同键的值进行分组,RDD[(K,V)] => RDD[(K, Iterable)]只按照key进行分组,不对value合并计算 |
| mapValues(func) | 对 PairRDD中的每个值应用一个函数,但不改变键不会对值进行合并计算 |
| flatMapValues(func) | 对PairRDD 中的每个值应用一个返回迭代器的函数,然后对返回的每个元素都生成一个对应原键的键值对记录 |
| keys() | 返回一个仅包含键的 RDD,RDD[(K,V)] => RDD[K]返回键不去重 |
| values() | 返回一个仅包含值的 RDD,RDD[(K,V)] => RDD[V] |
| sortByKey() | 返回一个根据键排序的 RDD,默认是升序false:降序 |
| Intersection union subtract | |
| subtractByKey(other) | 删掉RDD中键与other RDD中的键相同的元素 |
| cogroup | 将两个RDD中拥有相同键的数据分组到一起,RDD[(K,V)],RDD[(K, W)] => RDD[(K, (Iterable,Iterable))] |
| join(other) | 对两个RDD进行内连接,RDD[(K,V)],RDD[(K, W)] => RDD[(K, (V, W))]相当于MySQL 的 innerjoin |
| rightOuterJoin | 对两个RDD进行右连接,RDD[(K,V)],RDD[(K, W)] => RDD[(K, (Option[V], W))]相当于MySQL 的 rightjoin |
| leftOuterJoin | 对两个RDD进行左连接,RDD[(K,V)],RDD[(K, W)] => RDD[(K, (V, Option[W]))]相当于MySQL 的 leftjoin |
groupByKey() vs reduceByKey()
公共调用的底层方法

groupByKey()
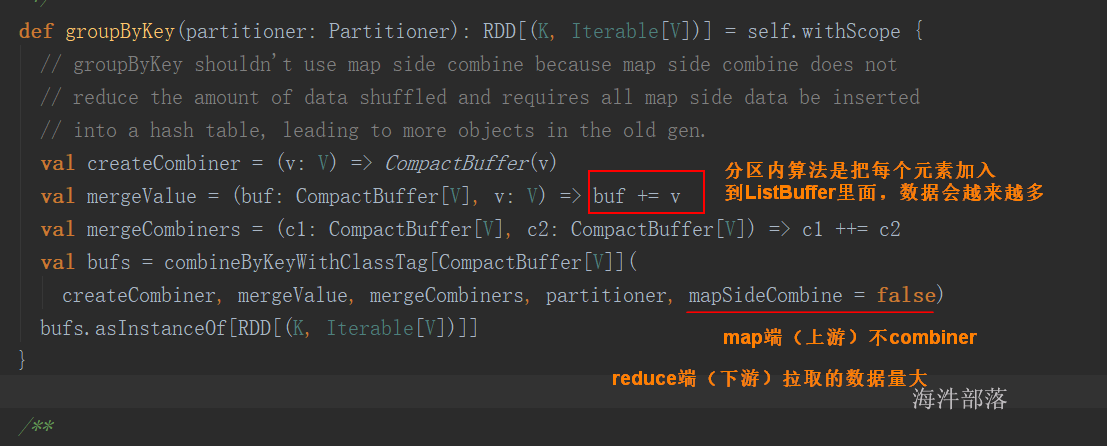
val rdd=sc.parallelize(List((“hainiu”,1),(“hainiu”,2),(“niu”,1)))
rdd.groupByKey().collect

reduceByKey(func)

val rdd=sc.parallelize(List((“hainiu”,1),(“hainiu”,2),(“niu”,1)))
rdd.reduceByKey(_ + _ ).collect // _ + _ 等价于 (a,b) => a+b

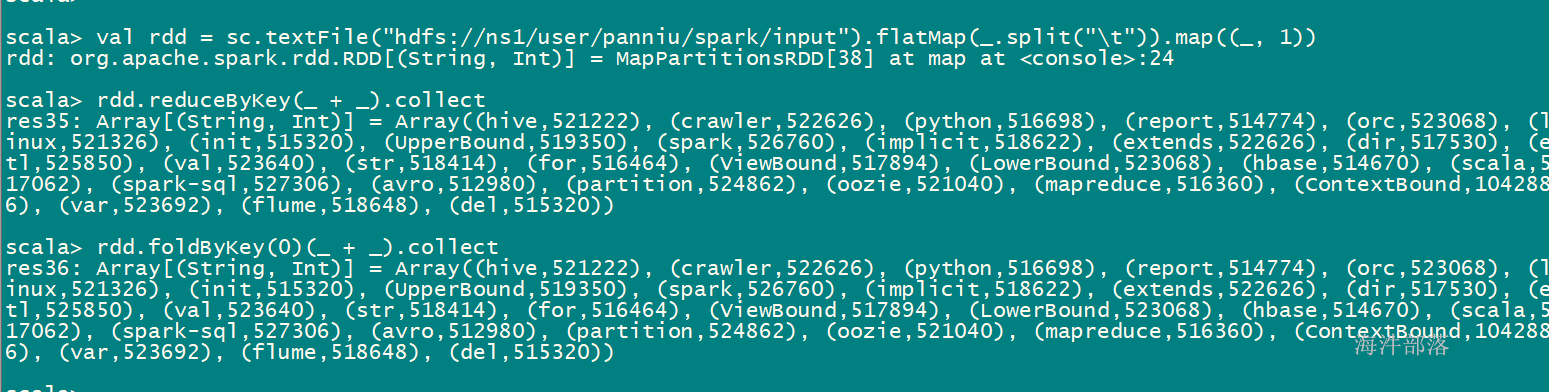
val rdd=sc.parallelize(List((“hainiu”,1),(“hainiu”,2),(“niu”,1)))
rdd.groupByKey.map(x => (x._1, x._2.sum)).collect

sc.textFile(“hdfs://ns1/user/panniu/spark/input”).flatMap(.split(")).map((,1)).groupByKey.map(kv=>(kv._1,kv._2.sum)).collect

val rdd=sc.parallelize(List((“hainiu”,1),(“hainiu”,2),(“niu”,1)))
rdd.keys.collect

val rdd=sc.parallelize(List((“hainiu”,1),(“hainiu”,2),(“niu”,1)))
rdd.values.collect

val rdd=sc.parallelize(List((“hainiu”,1),(“hainiu”,2),(“niu”,1)))
rdd.mapValues(s => s +1).collect

val rdd=sc.parallelize(List((“hainiu”, “a b”),(“hainiu”,“c d”),(“niu”,“e”)))
rdd.flatMapValues(s => s.split(" ")).collect

sortByKey()
val rdd=sc.parallelize(List((“a”, 1),(“c”,3),(“b”,2)))
rdd.sortByKey().collect //按key升序
rdd.sortByKey(false).collect // 按key降序

根据抽样水塘算法,可以将大的数据集,按照要分区的数量,将数据分到对应的分区里。分区间的数据是有序的,分区内是无序的。
val conf: SparkConf = new SparkConf().setMaster("local[5]").setAppName("SparkDemo2")
val sc = new SparkContext(conf)
val rdd: RDD[(Int,Int)] = sc.parallelize(List((1,1),(4,4),(3,3),(7,7),(6,6),(2,2)),2)
// 通过RangePartitioner实现,分区间有序,分区内无序
val partitioner = new RangePartitioner(2,rdd)
val rdd2: RDD[(Int, Int)] = rdd.partitionBy(partitioner)
rdd2.mapPartitionsWithIndex((index,it) =>{
println(s"rangepartition后rdd:${index}, ${it.toList}")
it
}).count()
sortBy()
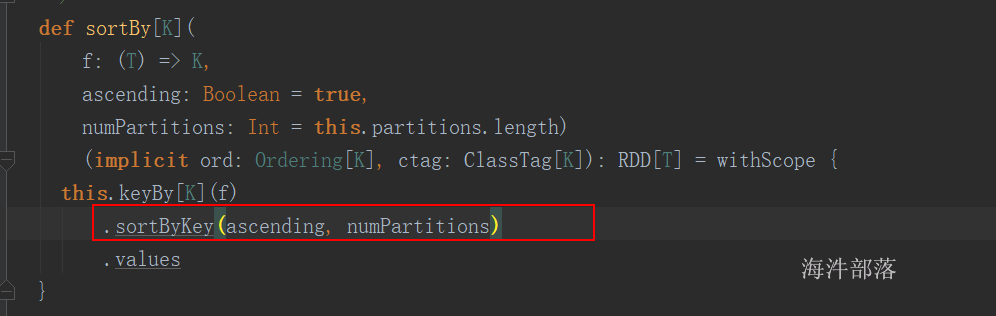
val rdd=sc.parallelize(List((“a”, 1),(“b”,3),(“c”,2)))
rdd.sortBy(_._2).collect //按value升序
rdd.sortBy(_._2,false).collect // 按value降序

cogroup()
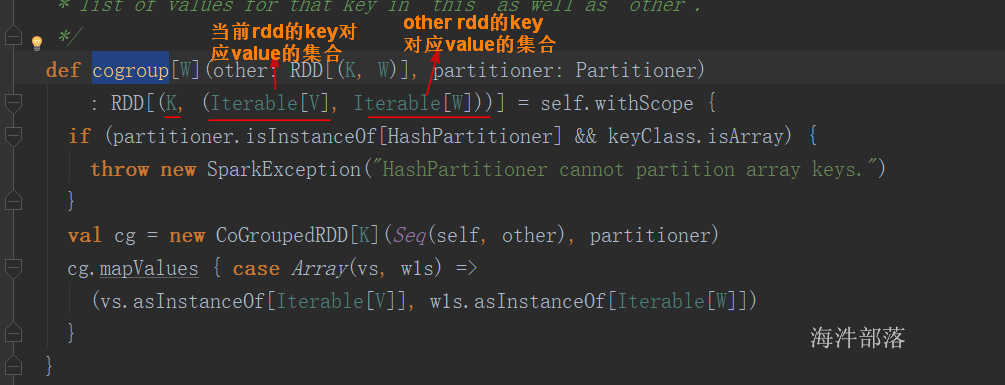
val rdd1=sc.parallelize(List((“id01”, “aa”),(“id02”,“bb”),(“id03”,“cc”)))
val rdd2=sc.parallelize(List((“id01”, 10),(“id03”,13),(“id04”,14)))
rdd1.cogroup(rdd2).collect

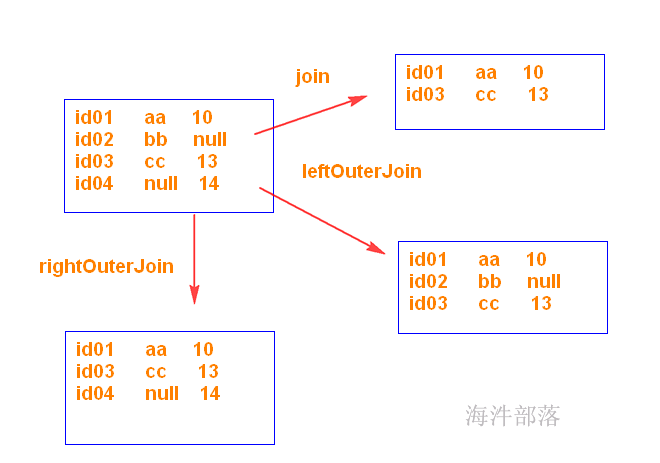
join()——innerjoin
val rdd1=sc.parallelize(List((“id01”, “aa”),(“id02”,“bb”),(“id03”,“cc”)))
val rdd2=sc.parallelize(List((“id01”, 10),(“id03”,13),(“id04”,14)))
rdd1.join(rdd2).collect

val rdd1=sc.parallelize(List((“id01”, “aa”),(“id02”,“bb”),(“id03”,“cc”)))
val rdd2=sc.parallelize(List((“id01”, 10),(“id03”,13),(“id04”,14)))
rdd1.leftOuterJoin(rdd2).collect

val rdd1=sc.parallelize(List((“id01”, “aa”),(“id02”,“bb”),(“id03”,“cc”)))
val rdd2=sc.parallelize(List((“id01”, 10),(“id03”,13),(“id04”,14)))
rdd1.rightOuterJoin(rdd2).collect

9.2.1.3 RDD 间操作
假设rdd的元素是:{1, 2, 3},other元素是:{3, 4, 5}
| 函数 | 目的 | 示例 | 结果 |
|---|---|---|---|
| union(other) | 生成一个包含两个RDD中所有元素的RDD | rdd.union(other) | {1,2,3,3,4,5} |
| intersection(other) | 求两个RDD交集的RDD | rdd.intersection(other) | {3} |
| subtract(other) | 移除一个RDD中的内容,差集 | rdd.subtract(other) | {1,2} |
| cartesian(other) | 与另一个RDD的笛卡儿积 | rdd.cartesian(other) | {(1,3),(1,4)….} |
注意:类型要一致
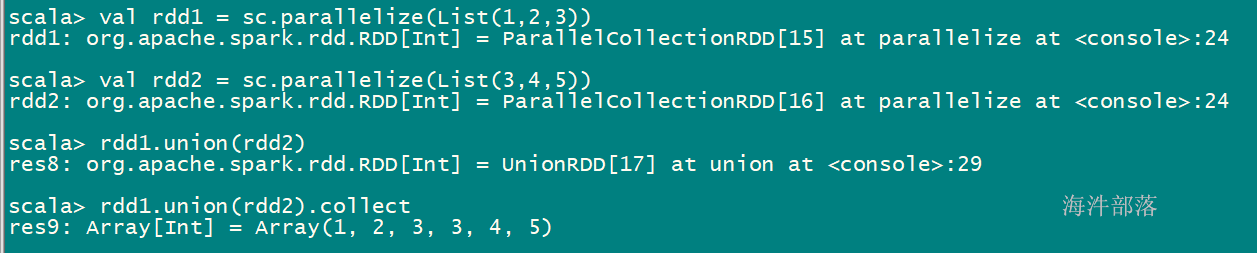
union(other) 并集
val rdd1 = sc.parallelize(List(1,2,3))
val rdd2 = sc.parallelize(List(3,4,5))
rdd1.union(rdd2).collect
val rdd1 = sc.parallelize(List(1,2,3))
val rdd2 = sc.parallelize(List(3,4,5))
rdd1.intersection(rdd2).collect

val rdd1 = sc.parallelize(List(1,2,3))
val rdd2 = sc.parallelize(List(3,4,5))
rdd1.subtract(rdd2).collect

val rdd1 = sc.parallelize(List(1,2,3))
val rdd2 = sc.parallelize(List(3,4,5))
rdd1.cartesian(rdd2).collect

9.2.1.4 checkpoint
执行在action之后,checkpoint 会忘记血缘关系。并且把数据放到hdfs上。 cache 不会忘记血缘关系,把数据放到内存。sc.setCheckpointDir.png)
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object CheckPointDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("CacheDemo")
val sc: SparkContext = new SparkContext(conf)
// 设置checkpoint目录
sc.setCheckpointDir("/tmp/spark/check")
val rdd: RDD[Int] = sc.parallelize(1 to 6, 2)
val rdd2: RDD[Int] = rdd.map(f => {
println(s"f:${f}")
f * 10
})
val cache: RDD[Int] = rdd2.cache()
// 设置checkpoint
// 当action执行触发checkpoint操作,它会向上追溯,如果是像map, flatMap这类的窄依赖,它会一直向上追溯
// 这就导致重复运算,所以需要在checkpoint前面加个cache,不让重复运算
// 当执行完checkpoint后,之前的血缘关系都会忘记
cache.checkpoint()
cache.count()
println(cache.getCheckpointFile)
}
}
Cache和chkpt的比对
- cache一次性 容易丢失数据 不能数据共享
- Ckpt将数据保存到hdfs中稳定,永久,共享,但是需要触发两次运算,cache和ckpt连用,cache不需要进行计算,但是DAG依旧存在,ckpt需要截断DAG
9.2.1.5 coalesce 与 repartition

当分区由多变少时,不需要shuffle,也就是父RDD与子RDD之间是窄依赖。 但极端情况下(1000个分区变成1个分区),这时如果将shuffle设置为false,父子RDD是窄依赖关系,他们同处在一个Stage中,就可能造成spark程序的并行度不够,从而影响性能,如果1000个分区变成1个分区,为了使coalesce之前的操作有更好的并行度,可以将shuffle设置为true。
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object RePartitionDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("wordcount")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[String] = sc.textFile("/tmp/spark/input1")
val mapRdd: RDD[(String, Int)] = rdd.flatMap(_.split("\t")).map((_,1))
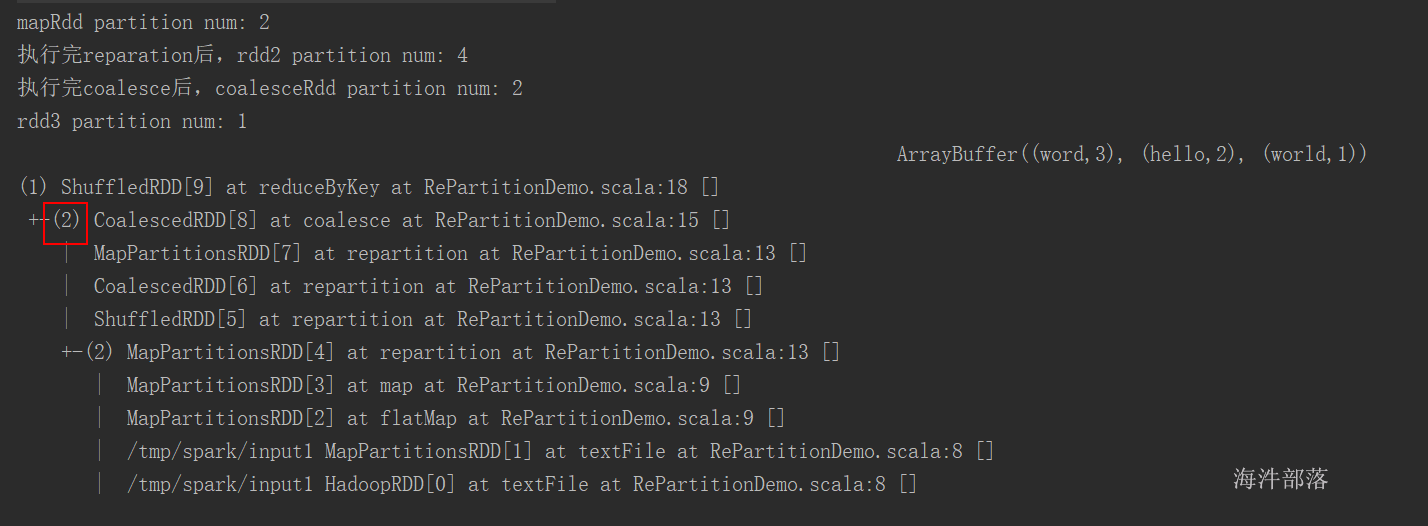
println(s"mapRdd partition num: ${mapRdd.getNumPartitions}")
// 先执行 reparation
// reparation会产生shuffle,宽依赖
val rdd2: RDD[(String, Int)] = mapRdd.repartition(4)
println(s"执行完reparation后,rdd2 partition num: ${rdd2.getNumPartitions}")
// coalesce产生shuffle,是窄依赖
// 当一个阶段内有多个rdd,每个rdd可能分区数不同,那提交这个阶段的task时,
// task数是按照最后的rdd分区数
val coalesceRdd: RDD[(String, Int)] = rdd2.coalesce(2)
println(s"执行完coalesce后,coalesceRdd partition num: ${coalesceRdd.getNumPartitions}")
// 执行reduceByKey
// 算子本身带着 重新分区的个数
val rdd3: RDD[(String, Int)] = coalesceRdd.reduceByKey(_ + _, 1)
println(s"rdd3 partition num: ${rdd3.getNumPartitions}")
val arr: Array[(String, Int)] = rdd3.collect()
println(arr.toBuffer)
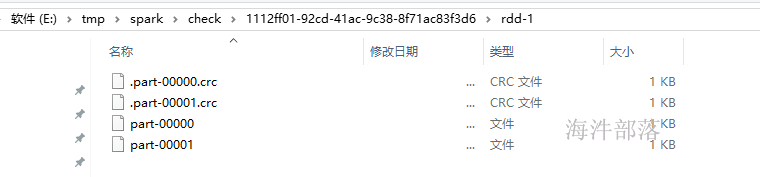
println(rdd3.toDebugString)
}
}
9.2.1.6 其他转换操作
foldByKey


aggregateByKey
带有初始值的reduceByKey,
分区内的算法和分区间的算法可以不一样

对PairRDD中相同的Key值进行聚合操作,在聚合过程中同样使用了一个中立的初始值。和aggregate函数类似,aggregateByKey返回值的类型不需要和
RDD中value的类型一致。因为aggregateByKey是对相同Key中的值进行聚合操作,所以aggregateByKey函数最终返回的类型还是PairRDD,对应的结果
是Key和聚合后的值。
执行大概逻辑是:
(zeroValue+分区1的value数据) 得到分区1中间结果
(zeroValue+分区2的value数据) 得到分区2中间结果
(zeroValue+分区1的value数据)+ (zeroValue+分区2的value数据)
对PairRDD进行运算,在运算过程中如果分区中没有该key,就不计算该分区的key的值。
跟aggregate 不同的是,在combiner计算时,不再加初始值。
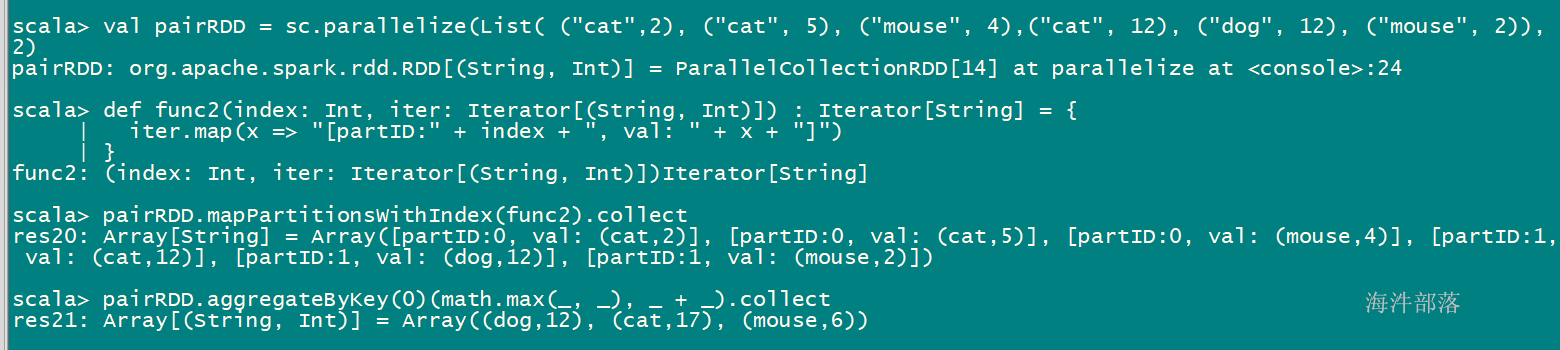
val pairRDD = sc.parallelize(List( (“cat”,2), (“cat”, 5), (“mouse”, 4),(“cat”, 12), (“dog”, 12), (“mouse”, 2)), 2)
def func2(index: Int, iter: Iterator[(String, Int)]) : Iterator[String] = {
iter.map(x => “[partID:" + index + ", val: " + x + "]”)
}
pairRDD.mapPartitionsWithIndex(func2).collect
pairRDD.aggregateByKey(0)(math.max(, ), _ + _).collect
分区0:
cat: 5
mouse: 4
分区1:
cat: 12
dog: 12
mouse: 2
分区间汇总:
cat: 5+12=17
dog: 0 + 12 =12
mouse: 4 + 2 = 6
pairRDD.aggregateByKey(100)(math.max(, ), _ + _).collect
分区0:
cat: 100
mouse: 100
分区1:
cat: 100
dog: 100
mouse: 100
分区间汇总:
cat: 100+100=200
dog: 0 + 100 =100
mouse: 100 + 100 = 200

combineByKey
spark的reduceByKey、aggregateByKey、foldByKey函数底层调用的都是 combinerByKey(现在换成了 combineByKeyWithClassTag);他们都可以实现局部聚合再全局聚合;语法:
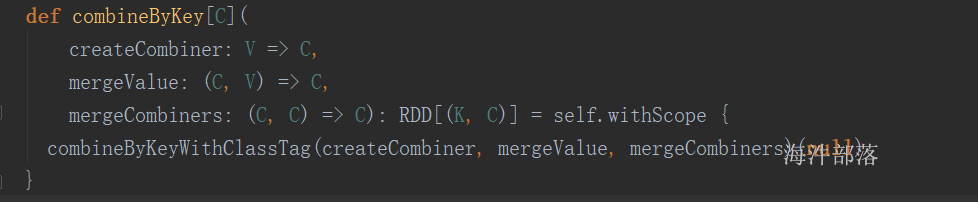
mergeValue: (C, V) => C,该函数把元素V合并到之前的元素C(createCombiner)上 (这个操作在每个分区内进行)
mergeCombiners: (C, C) => C,该函数把2个元素C合并 (这个操作在不同分区间进行)
val rdd1 = sc.parallelize(List((“aa”,1), (“aa”,2),(“bb”,2),(“aa”,3), (“bb”,3),(“cc”,4)), 2)
val rdd2 = rdd1.combineByKey(x => x, (a: Int, b: Int) => a + b, (m: Int, n: Int) => m + n)
rdd2.collect

rdd3.collect

reduceByKey:无初始值、接收的函数的输入和输出类型一致、分区内和分区间的算法是一样的; foldByKey:有初始值、接收的初始值与函数的输入和输出类型一致、分区内和分区间的算法是一样的; aggregateByKey:分区内和分区间的算法可以不一样、初始值类型可以和rdd元素类型不一致; combineByKey :完全定制,想怎么完怎么玩。
val rdd1 = sc.parallelize(List((“e”, 5), (“c”, 3), (“d”, 4), (“c”, 2), (“a”, 1)))

9.2.2 行动操作
假设rdd 的元素是:{1, 2, 3, 3}
假设rdd2 的元素是:{(“a”, 1), (“b”, 2)}
| 函数 | 目的 | 示例 | 结果 |
|---|---|---|---|
| collect() | 以数组的形式返回RDD中的所有元素 | rdd.collect() | {1, 2, 3, 3} |
| collectAsMap() | 该函数用于Pair RDD 最终返回Map类型的结果 | rdd2.collectAsMap() | Map(“a”->1,“b”->2) |
| count() | RDD中的元素个数 | rdd.count() | 4 |
| countByValue() | 各元素在RDD中出现的次数 | rdd.countByValue() | {(1, 1), (2, 1), (3, 2)} |
| take(n) 在scala中是截取集合take slice 在spark中也是截取rdd变成本地集合,在截取数据的时候是按照分区截取的,存在的数据在几个分区中就会存在几个job任务 | 从RDD中返回 n 个元素 | rdd.take(1) | {1} |
| first() | 从RDD中返回第一个元素 | rdd.first() | 1 |
| top(num) | 返回最大的 num 个元素 | rdd.top(2) | {3,3} |
| takeOrdered(num)(ordering) | 按照指定顺序返回前面num个元素 | rdd.takeOrdered(2) | {1,2} |
| reduce(func) | 通过函数func(输入两个参数并返回一个值)聚合数据集中的元素,比如求和 | rdd.reduce((a,b)=>a+b) | ((1+2) + 3) + 3) = 9 |
| fold(zero)(func) | 和reduce一样,给定初值,每个分区计算时都会使用此初值 | rdd.fold(1)((a,b)=>a+b) | 2个分区时结果:1+ ((1+1) + 2) + ((1 +3) +3) |
| aggregate(zeroValue)(seqOp,combOp) | 和reduce类似,但可以返回类型不同的结果 | rdd.aggregate(0)((x,y) => x + y, (x,y) => x + y) | 9 |
| foreach(func) | 对每个元素使用func函数 | rdd.foreach(println(_)) | 在executor端打印输出所有元素 |
| ForeachPartition |
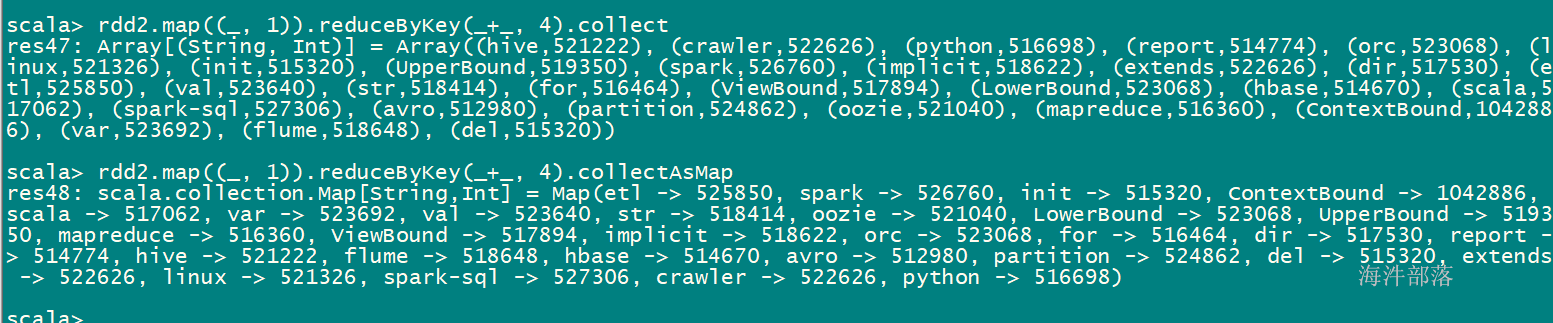
collect vs collectAsMap
collect: 以数组的形式返回RDD中的所有元素
collectAsMap: 以map方式返回,作用在键值对rdd上,如果你想的返回的数据是排序好的,那就用collect
foreach vs foreachPartition
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.rdd.RDD
object ForeachDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("CacheDemo")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(1 to 6, 2)
// foreach 和 foreachPartition 内的函数都是在executor端运行
// windows 是利用多线程运行,所以能看见,但如果在集群运行,看不见输出结果
// 是分区内的每个元素一个一个的迭代。
// rdd.foreach(f =>{
// println(s"f:${f}")
// })
// 先分区,分区里的数据组成的迭代器,拿着迭代器去迭代每个元素
rdd.foreachPartition(it =>{
// scala的foreach
it.foreach(f =>{
println(s"f:${f}")
})
})
}
}foreach是每个partition的数据,该函数内需要传入一个函数。
val rdd1 = sc.parallelize(List(1, 2, 3, 4, 5, 6, 7, 8, 9), 3)
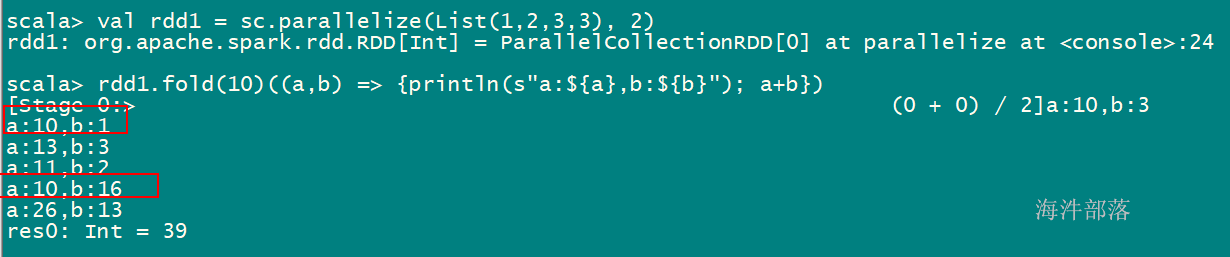
fold val rdd1 = sc.parallelize(List(1,2,3,3), 2)
rdd1.fold(10)((a,b) => {println(s“a:{b}”); a+b})
10 + (10+1+2) + (10 + 3 + 3)
val func = (index: Int, iter: Iterator[Int]) => {
iter.map(x => s“[partID:{x}]”)
}
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)
rdd1.mapPartitionsWithIndex(func).collect

aggregate(zeroValue)(seqOp,combOp)
执行aggregate,大概逻辑是:
(zeroValue+分区1的数据) 得到分区1中间结果
(zeroValue+分区2的数据) 得到分区2中间结果
zeroValue + (zeroValue+分区1的数据)+ (zeroValue+分区2的数据)
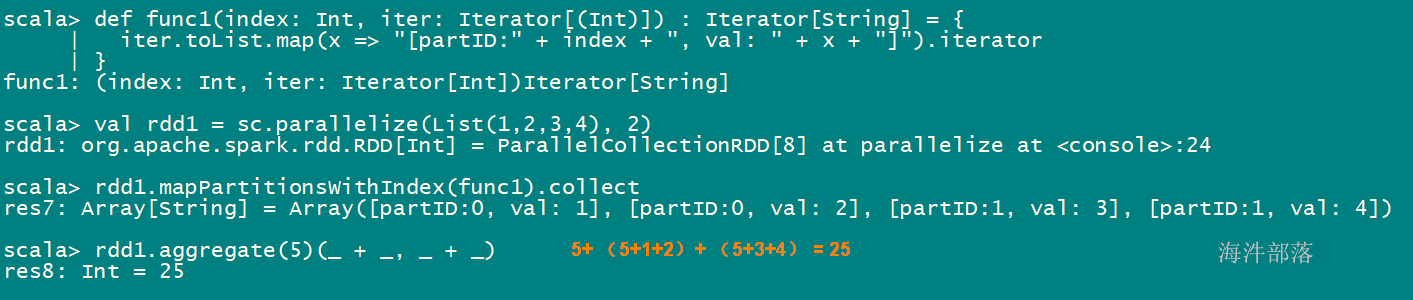
def func1(index: Int, iter: Iterator[(Int)]) : Iterator[String] = {
iter.toList.map(x => “[partID:" + index + ", val: " + x + "]”).iterator
}
val rdd1 = sc.parallelize(List(1,2,3,4), 2)
rdd1.mapPartitionsWithIndex(func1).collect
rdd1.aggregate(5)(_ + , + _)
5+(5+1+2) + (4+3+4)
iter.toList.map(x => “[partID:" + index + ", val: " + x + "]”).iterator
}
val rdd1 = sc.parallelize(List(1,2,3,4,5,6,7,8,9), 2)
rdd1.mapPartitionsWithIndex(func1).collect
rdd1.aggregate(0)(math.max(, ), _ + _)
0 +4 + 9 = 13
rdd1.aggregate(5)(math.max(, ), _ + _)
5 + 5 + 9 = 19

10 rdd的存储级别
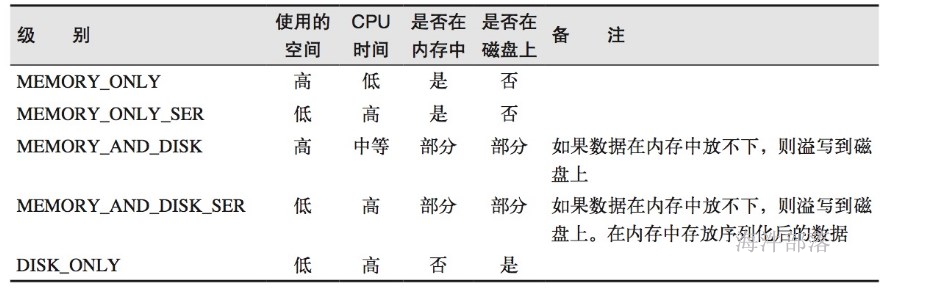
cache() 调用 persist(),且默认存储级别是 MEMORY_ONLY。
persist() 用来设置RDD的存储级别
| 存储级别 | 意义 |
|---|---|
| MEMORY_ONLY | 使用未序列化的Java对象格式,将数据保存在内存中。如果内存不够存放所有的数据,则数据可能就不会进行持久化。那么下次对这个RDD执行算子操作时,那些没有被持久化的数据,需要从源头处重新计算一遍。这是默认的持久化策略,使用cache()方法时,实际就是使用的这种持久化策略 |
| MEMORY_AND_DISK | 使用未序列化的Java对象格式,优先尝试将数据保存在内存中。如果内存不够存放所有的数据,会将数据写入磁盘文件中,下次对这个RDD执行算子时,持久化在磁盘文件中的数据会被读取出来使用 |
| MEMORY_ONLY_SER | 基本含义同MEMORY_ONLY。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC |
| MEMORY_AND_DISK_SER | 基本含义同MEMORY_AND_DISK。唯一的区别是,会将RDD中的数据进行序列化,RDD的每个partition会被序列化成一个字节数组。这种方式更加节省内存,从而可以避免持久化的数据占用过多内存导致频繁GC |
| DISK_ONLY | 使用未序列化的Java对象格式,将数据全部写入磁盘文件中 |
| MEMORY_ONLY_2, MEMORY_AND_DISK_2, etc. | 对于上述任意一种持久化策略,如果加上后缀_2,代表的是将每个持久化的数据,都复制一份副本,并将副本保存到其他节点上。这种基于副本的持久化机制主要用于进行容错 |
JAVA对象 = 对象头 + 实例数据 + 对象填充(补余用的,用于保证对象所占空间是8个字节的整数倍)
// MEMORY_ONLY 存储
import org.apache.spark.storage.StorageLevel
val rdd1 = sc.textFile(“hdfs://ns1/user/panniu/spark/input”).flatMap(.split(")).map((,1))
val rdd2 = rdd1.persist(StorageLevel.MEMORY_ONLY)
rdd2.count()

import org.apache.spark.storage.StorageLevel
val rdd1 = sc.textFile(“hdfs://ns1/user/panniu/spark/input”).flatMap(.split(")).map((,1))
val rdd2 = rdd1.persist(StorageLevel.MEMORY_ONLY_SER)
rdd2.count()


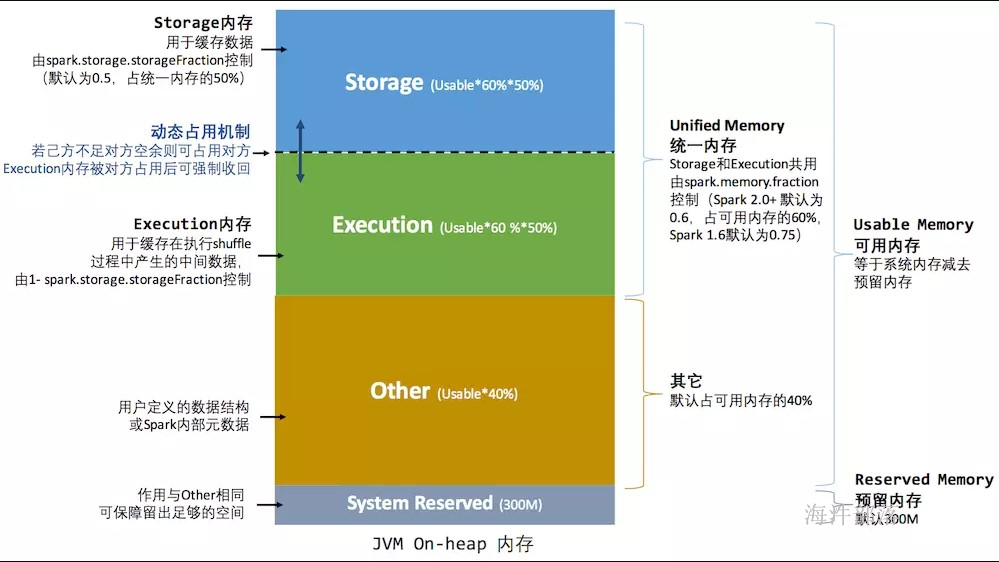
Spark 作为一个以擅长内存计算为优势的计算引擎,内存管理方案是其非常重要的模块; Spark的内存可以大体归为两类:execution(运行内存)和storage(存储内存),前者包括shuffles、joins、sorts和aggregations所需内存,后者包括cache和节点间数据传输所需内存;
在Spark 1.5和之前版本里,运行内存和存储内存是静态配置的,不支持借用;Spark 1.6之后引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域,提供更好的性能。
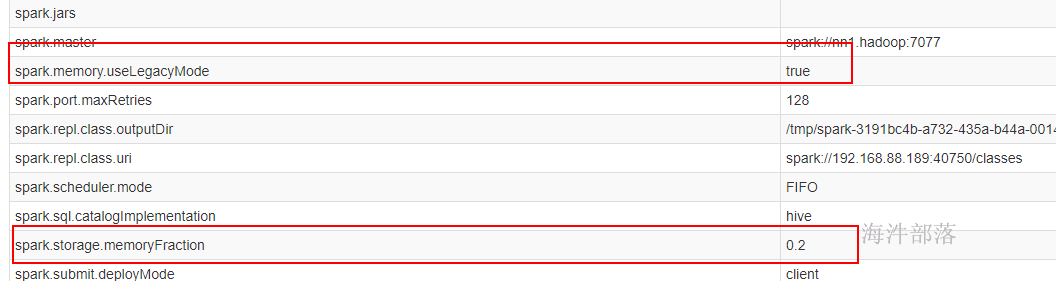
11.1 静态内存管理——spark1.5
spark1.6 及以后兼容了 spark1.5 的内存管理。当配置 spark.memory.useLegacyMode=true 时,采用spark1.5的内存管理;当spark.memory.useLegacyMode=false时,采用spark1.6 及以后的内存管理。
spark1.5 的内存管理实现类: StaticMemoryManager
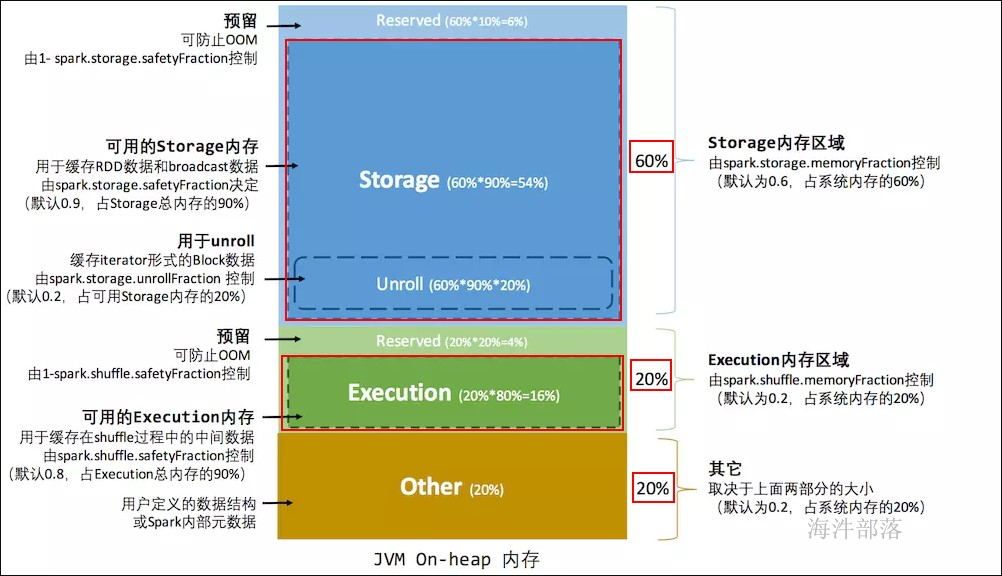
spark.storage.memoryFraction:
spark 存储总内存占 系统内存的百分比,默认是 0.6。
spark.shuffle.memoryFraction:
spark shuffle 执行用到的内存 占系统内存的百分比,默认是0.2。
spark.storage.safetyFraction:
可用的存储内存占总存储内存的百分比,默认是 0.9。
spark.shuffle.safetyFraction:
可用的shuffle操作执行内存占总执行内存的百分比, 默认是 0.8。
private def getMaxExecutionMemory(conf: SparkConf): Long = {
val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
// 如果拿到的最大内存 < 32M
if (systemMaxMemory < MIN_MEMORY_BYTES) {
throw new IllegalArgumentException(s"System memory $systemMaxMemory must " +
s"be at least $MIN_MEMORY_BYTES. Please increase heap size using the --driver-memory " +
s"option or spark.driver.memory in Spark configuration.")
}
if (conf.contains("spark.executor.memory")) {
val executorMemory = conf.getSizeAsBytes("spark.executor.memory")
if (executorMemory < MIN_MEMORY_BYTES) {
throw new IllegalArgumentException(s"Executor memory $executorMemory must be at least " +
s"$MIN_MEMORY_BYTES. Please increase executor memory using the " +
s"--executor-memory option or spark.executor.memory in Spark configuration.")
}
}
val memoryFraction = conf.getDouble("spark.shuffle.memoryFraction", 0.2)
val safetyFraction = conf.getDouble("spark.shuffle.safetyFraction", 0.8)
(systemMaxMemory * memoryFraction * safetyFraction).toLong
}
private def getMaxStorageMemory(conf: SparkConf): Long = {
val systemMaxMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
val memoryFraction = conf.getDouble("spark.storage.memoryFraction", 0.6)
val safetyFraction = conf.getDouble("spark.storage.safetyFraction", 0.9)
(systemMaxMemory * memoryFraction * safetyFraction).toLong
}举例:executor 的最大可用内存1000M
存储总内存 = 1000M * 0.6 = 600M
运行总内存 = 1000M * 0.2 = 200M
other = 1000M - 600M - 200M = 200M
存储总内存 = 安全存储内存 + 预留内存(防止OOM)
安全存储内存 = 存储总内存 * 0.9 = 600 * 0.9 = 540M
预留内存 = 存储总内存 * (1-0.9) = 60M
运行总内存 = 安全运行内存 + 预留内存(防止OOM)
安全运行内存 = 运行总内存 * 0.8 = 200M * 0.8 = 160M
预留内存 = 运行总内存 * (1-0.8) = 40M
缺点:
这种内存管理方式的缺陷,即 execution 和 storage 内存分配,即使在一方内存不够用而另一方内存空闲的情况下也不能共享,造成内存浪费。
11.2 统一内存管理——spark1.6以后
当spark.memory.useLegacyMode=false时,采用spark1.6 及以后的内存管理。
spark1.6及以后 的内存管理实现类: UnifiedMemoryManager
当前spark版本是 spark2.1.1 ,参数配置部分与spark1.6 不同,下面讲解按照spark2.1.1 版本进行参数讲解。
spark.memory.fraction:
spark内存占可用内存(系统内存 - 300)的百分比,默认是0.6。
spark.memory.storageFraction:
spark的存储内存占spark内存的百分比,默认是0.5。
spark的统一内存管理,可以通过配置 spark.memory.storageFraction ,来调整 存储内存和执行内存的比例,进而实现内存共享。
private def getMaxMemory(conf: SparkConf): Long = {
val systemMemory = conf.getLong("spark.testing.memory", Runtime.getRuntime.maxMemory)
val reservedMemory = conf.getLong("spark.testing.reservedMemory",
// 300M
if (conf.contains("spark.testing")) 0 else RESERVED_SYSTEM_MEMORY_BYTES)
// 最小内存大小:450M
val minSystemMemory = (reservedMemory * 1.5).ceil.toLong
if (systemMemory < minSystemMemory) {
throw new IllegalArgumentException(s"System memory $systemMemory must " +
s"be at least $minSystemMemory. Please increase heap size using the --driver-memory " +
s"option or spark.driver.memory in Spark configuration.")
}
// SPARK-12759 Check executor memory to fail fast if memory is insufficient
if (conf.contains("spark.executor.memory")) {
val executorMemory = conf.getSizeAsBytes("spark.executor.memory")
if (executorMemory < minSystemMemory) {
throw new IllegalArgumentException(s"Executor memory $executorMemory must be at least " +
s"$minSystemMemory. Please increase executor memory using the " +
s"--executor-memory option or spark.executor.memory in Spark configuration.")
}
}
val usableMemory = systemMemory - reservedMemory
val memoryFraction = conf.getDouble("spark.memory.fraction", 0.6)
(usableMemory * memoryFraction).toLong
}
def apply(conf: SparkConf, numCores: Int): UnifiedMemoryManager = {
// 获取最大可用内存
val maxMemory = getMaxMemory(conf)
new UnifiedMemoryManager(
conf,
maxHeapMemory = maxMemory,
// 存储内存 = 获取最大可用内存 * 0.5
onHeapStorageRegionSize =
(maxMemory * conf.getDouble("spark.memory.storageFraction", 0.5)).toLong,
numCores = numCores)
}举例:系统内存1000M
系统预留内存 = 300M
可用内存 = 系统内存 - 系统预留内存 = 1000 - 300 = 700M
spark内存 = 可用内存 * 0.6 = 700 * 0.6 = 420M
存储内存 和 执行内存 均占一半, 210M
为了提高内存利用率,spark针对Storage Memory 和 Execution Memory有如下策略:
1)一方空闲,一方内存不足情况下,内存不足一方可以向空闲一方借用内存;
2)只有Execution Memory可以强制拿回Storage Memory在Execution Memory空闲时,借用的Execution Memory的部分内存(如果因强制取回,而Storage Memory数据丢失,重新计算即可);
3)Storage Memory只能等待Execution Memory主动释放占用的Storage Memory空闲时的内存。(这里不强制取回,因为如果task执行,数据丢失就会导致task 失败);
用spark1.5的方式提交,
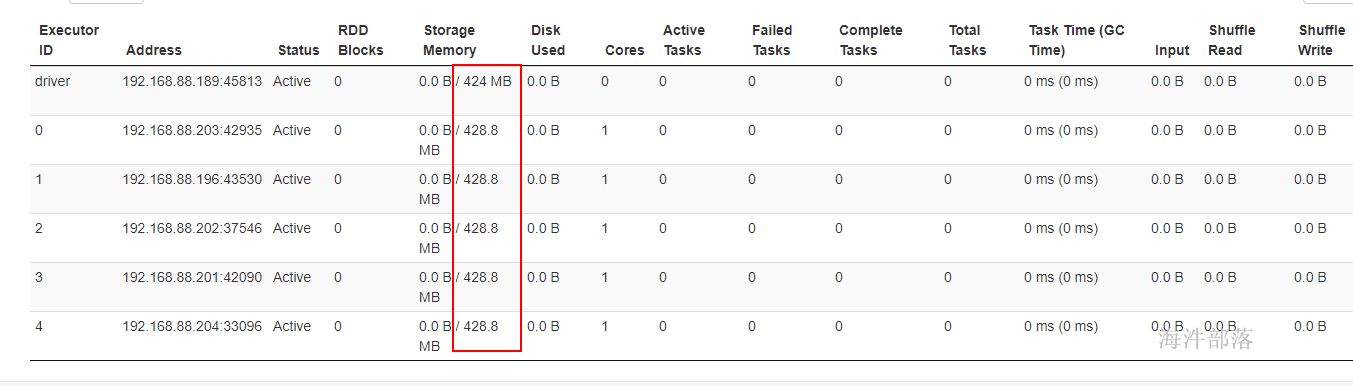
spark-shell –master spark://nn1.hadoop:7077 –executor-memory 1G –total-executor-cores 5 –conf spark.memory.useLegacyMode=true

spark-shell –master spark://nn1.hadoop:7077 –executor-memory 1G –total-executor-cores 5
存储内存是可用内存的一半。可用内存分配比:60%
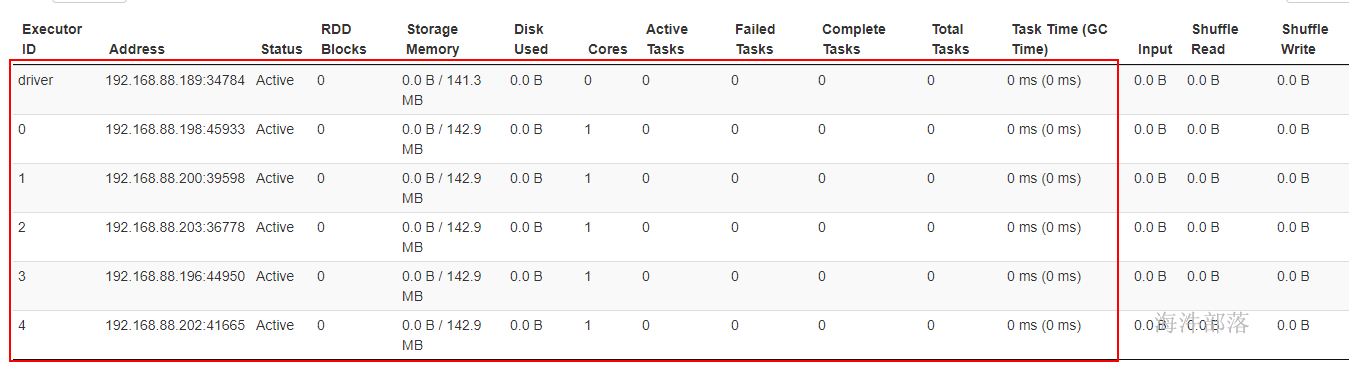
存储内存是可用内存的一半。可用内存分配比:20%
BlockManager是Spark的分布式存储系统,与我们平常说的分布式存储系统是有区别的,区别就是这个分布式存储系统只会管理Block块数据,它运行在所有节点上。
BlockManager的结构是Maser-Slave架构,Master就是Driver上的BlockManagerMaster,Slave就是每个Executor上的BlockManager。BlockManagerMaster负责接受Executor上的BlockManager的注册以及管理BlockManager的元数据信息。
运行图:
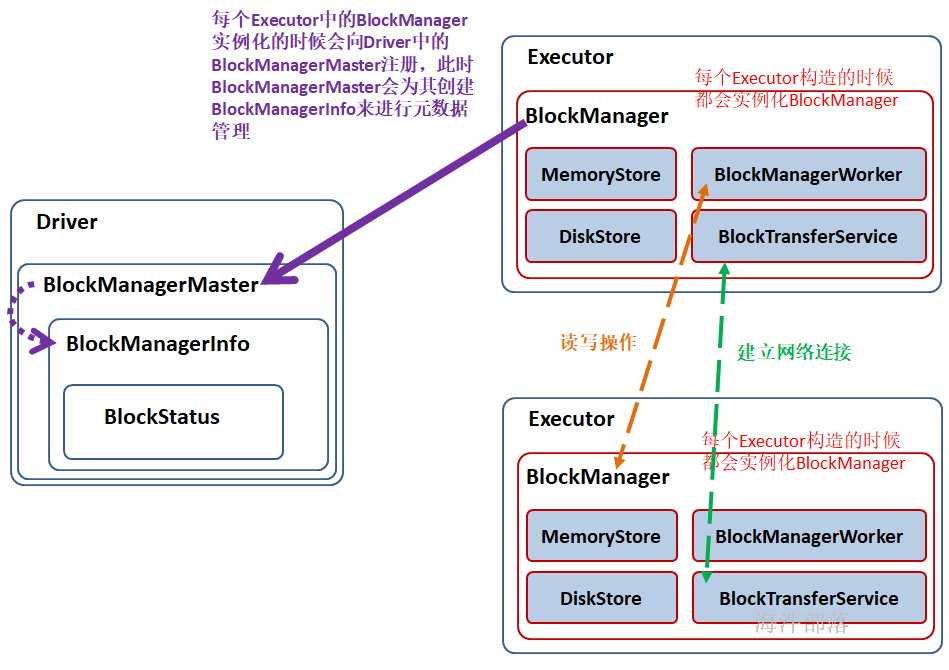
1)在 Application 启动的时候会在 SparkEnv 中注册 BlockMangerMaster。
BlockManagerMaster:对整个集群的 Block 数据进行管理;
2)每个启动一个 Executor 都会实例化 BlockManagerSlave 并通过远程通信的方式注册给 BlockMangerMaster;
3)BlockManagerSlave由 4部分组成:
MemoryStore:负责对内存上的数据进行存储和读写;
DiskStore:负责对磁盘上的数据进行存储和读写;
BlockTransferService:负责与远程其他Executor 的BlockManager建立网络连接;
BlockManagerWorker:负责对远程其他Executor的BlockManager的数据进行读写;
4)当Executor 的BlockManager 执行了增删改操作,那就必须将 block 的 blockStatus 上报给Driver端的BlockManagerMaster,BlockManagerMaster 内部的BlockManagerMasterEndPoint 内维护了 元数据信息的映射。通过Map、Set结构,很容易维护 增加、更新、删除元数据,进而达到维护元数据的功能。
// 维护 BlockManagerId 与 BlockManagerInfo 的关系
// 而BlockManagerInfo内部维护 JHashMap[BlockId, BlockStatus] 的映射关系
private val blockManagerInfo = new mutable.HashMap[BlockManagerId, BlockManagerInfo]
// 维护 executorID 与 BlockManagerId 的关系
private val blockManagerIdByExecutor = new mutable.HashMap[String, BlockManagerId]
// 维护 BlockId 与 HashSet[BlockManagerId] 的关系, 因为数据块可能有副本
private val blockLocations = new JHashMap[BlockId, mutable.HashSet[BlockManagerId]]JHashMap[BlockId, mutable.HashSet[BlockManagerId]]
HashMap[executorID, BlockManagerId]
HashMap[BlockManagerId, BlockManagerInfo]
JHashMap[BlockId, BlockStatus]
13 共享变量
Spark两种共享变量:广播变量(broadcast variable)与累加器(accumulator)。
累加器用来对信息进行聚合,相当于mapreduce中的counter;而广播变量用来高效分发较大的对象,相当于semijoin中的DistributedCache 。
共享变量出现的原因:
我们传递给Spark的函数,如map(),或者filter()的判断条件函数,能够利用定义在函数之外的变量,但是集群中的每一个task都会得到变量的一个副本,并且task在对变量进行的更新不会被返回给driver。
object SharedVarTest {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sharedvartest")
val sc = new SparkContext(conf)
//driver端定义外部变量list
val list = List(1,5,8)
// driver端定义外部变量count用于计数
var count:Int = 0
val rdd: RDD[Int] = sc.parallelize(List(1,2,3,4,5,6,7,8), 2)
val filter: RDD[Int] = rdd.filter( x => {
// executor 端用于计算和统计
if(list.contains(x)) {
count = count + 1
println(s"-->count:${count}")
true
}else{
false
}
})
val rs: Array[Int] = filter.collect()
// 发现executor端修改了,但driver端并没有修改
println(s"count:${count}")
println(rs.toBuffer)
}
}原因总结:
对于executor端,driver端的变量是外部变量。
excutor端修改了变量count,根本不会让driver端跟着修改。如果想在driver端得到executor端修改的变量,需要用累加器实现。
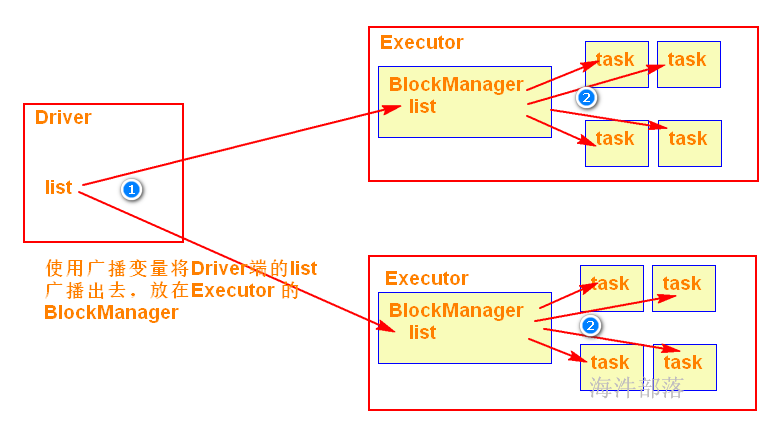
当在Executor端用到了Driver变量,不使用广播变量,在每个Executor中有多少个task就有多少个Driver端变量副本。如果这个变量中的数据很大的话,会产生很高的传输负载,导致执行效率降低,也可能会造成内存溢出。需要广播变量提高运行效率。
累加器
累加器可以很简便地对各个worker返回给driver的值进行聚合。累加器最常见的用途之一就是对一个job执行期间发生的事件进行计数。
用法:
var acc: LongAccumulator = sc.longAccumulator // 创建累加器
acc.add(1) // 累加器累加
acc.value // 获取累加器的值
广播变量
使用广播变量可以使程序高效地将一个很大的只读数据发送到executor节点,会将广播变量放到executor的BlockManager中,而且对每个executor节点只需要传输一次,该executor节点的多个task可以共用这一个。
用法:
val broad: Broadcast[List[Int]] = sc.broadcast(list) // 把driver端的变量用广播变量包装
broad.value // 从广播变量获取包装的数据,用于计算
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
object SharedVarTest {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("sharedvartest")
val sc = new SparkContext(conf)
// 定义list
val list = List(1,5,8)
// driver端用广播变量包装
val broad: Broadcast[List[Int]] = sc.broadcast(list)
// driver端定义累加器
val countAcc: LongAccumulator = sc.longAccumulator
val rdd: RDD[Int] = sc.parallelize(List(1,2,3,4,5,6,7,8), 2)
val filter: RDD[Int] = rdd.filter( x => {
// 在executor提取广播变量里的数据,用提起的数据计算即可
val list2: List[Int] = broad.value
if(list2.contains(x)) {
// executor 使用累加器汇总
countAcc.add(1L)
true
}else{
false
}
})
val cache: RDD[Int] = filter.cache()
// action1
val rs: Array[Int] = cache.collect()
// action2
cache.count()
// 执行完成后,获取累加器的结果
// 累加器在累积的时候,不会管是否重复累积,这个由程序员自己控制
println(s"count:${countAcc.value}")
println(rs.toBuffer)
}
}
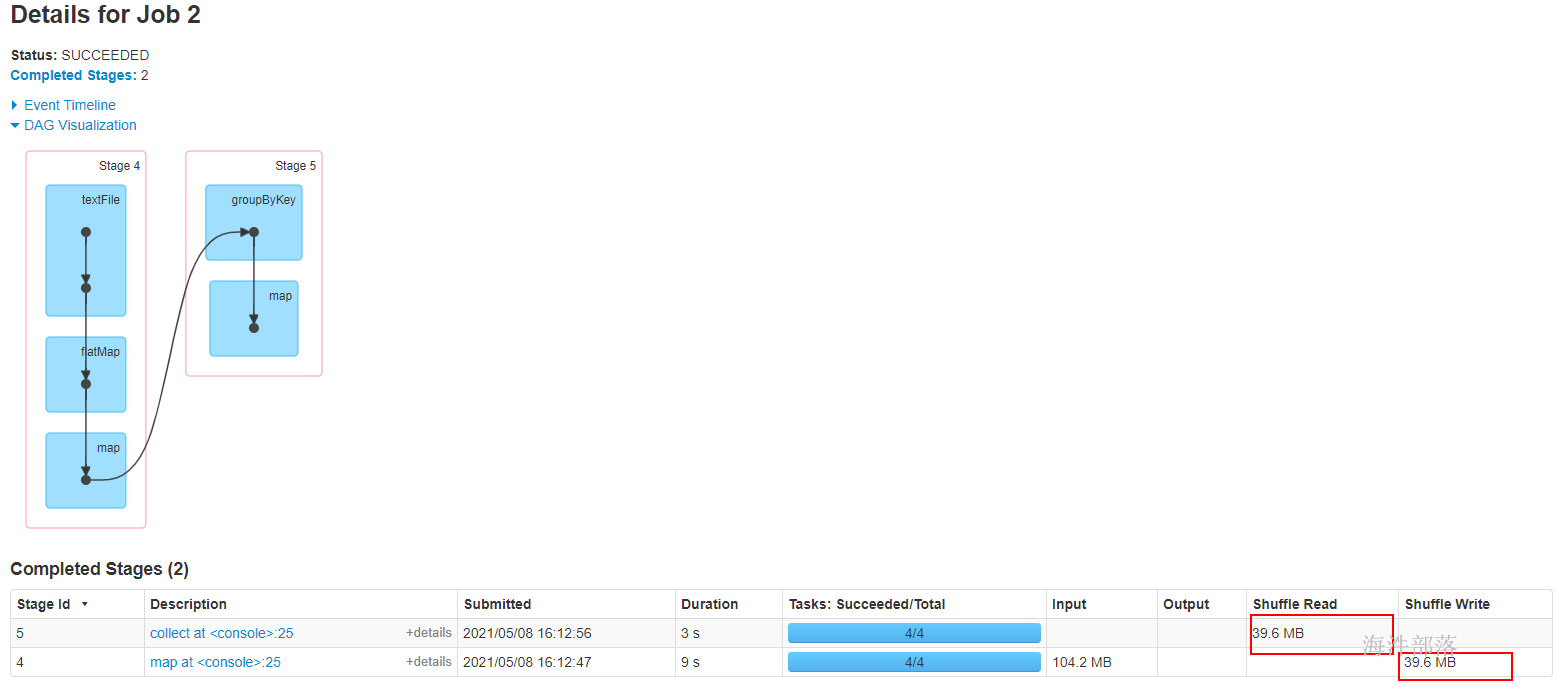
14 spark 的 sort 和 shuffle
14.2 shuffle
对spark任务划分阶段,遇到宽依赖会断开,所以在stage 与 stage 之间会产生shuffle,大多数Spark作业的性能主要就是消耗在了shuffle环节,因为该环节包含了大量的磁盘IO、序列化、网络数据传输等操作。
负责shuffle过程的执行、计算和处理的组件主要就是ShuffleManager,也即shuffle管理器。而随着Spark的版本的发展,ShuffleManager也在不断迭代。
ShuffleManager 大概有两个: HashShuffleManager 和 SortShuffleManager。
历史:
在spark 1.2以前,默认的shuffle计算引擎是HashShuffleManager;
在spark 1.2以后的版本中,默认的ShuffleManager改成了SortShuffleManager;
在spark 2.0以后,抛弃了 HashShuffleManager。
14.2.1 HashShuffleManager
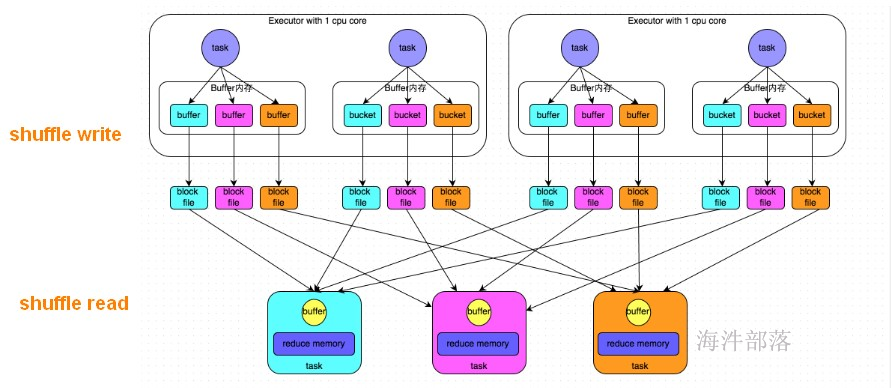
上游 stage 有 2个 Executor,每个Executor 有 2 个 task。
下游 stage 有 3个task。
shuffle write阶段:
将相当于mapreduce的shuffle write,按照key的hash 分桶,写出中间文件。上游的每个task写自己的文件。
写出中间文件个数 = maptask的个数 * reducetask的个数
上图写出的中间文件个数 = 4 * 3 = 12
假设上游 stage 有 10 个Executor,每个 Executor有 5 个task,下游stage 有 4 个task,写出的中间文件数 = (10 * 5) * 4 = 200 个,由此可见,shuffle write操作所产生的磁盘文件的数量是极其惊人的。
shuffle read 阶段:
就相当于mapreduce 的 shuffle read, 每个reducetask 拉取自己的数据。
由于shuffle write的过程中,task给下游stage的每个task都创建了一个磁盘文件,因此shuffle read的过程中,每个task只要从上游stage的所有task所在节点上,拉取属于自己的那一个磁盘文件即可。
弊端:
shuffle write阶段占用大量的内存空间,会导致频繁的GC,容易导致OOM;也会产生大量的小文件,写入过程中会产生大量的磁盘IO,性能受到影响。适合小数据集的处理。
14.2.2 HashShuffleManager 优化
开启consolidate机制。
设置参数:spark.shuffle.consolidateFiles。该参数默认值为false,将其设置为true即可开启优化机制。
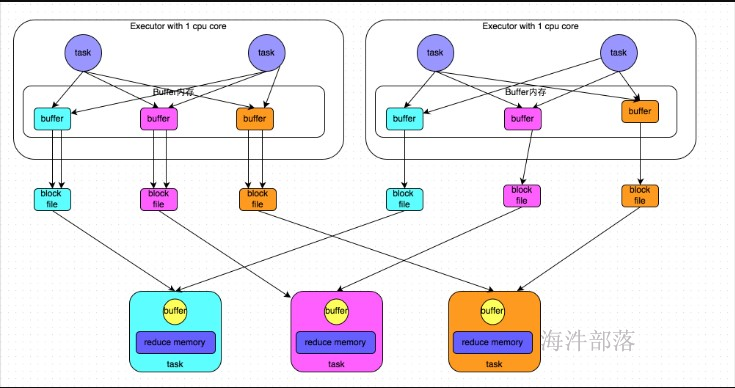
假设:每个Executor只有1个CPU core,也就是说,无论这个Executor上分配多少个task线程,同一时间都只能执行一个task线程。
上游 stage 有 2个 Executor,每个Executor 有 2 个 task,每个Executor只有1个CPU core。
下游 stage 有 3个task。
shuffle write阶段:
开启consolidate机制后,允许上游的多个task写入同一个文件,这样就可以有效将多个task的磁盘文件进行一定程度上的合并,从而大幅度减少磁盘文件的数量,进而提升shuffle write的性能。
写出中间文件个数 = 上游的CPU核数 * 下游task的个数
上图写出的中间文件个数 = 2 * 3 = 6
假设上游 stage 有 10 个Executor,每个Executor只有1个CPU core,每个 Executor有 5 个task,下游stage 有 4 个task,写出的中间文件数 = 10 * 4 = 40个
shuffle read 阶段:
就相当于mapreduce 的 shuffle read, 每个reducetask 拉取自己的数据。
由每个reducetask只要从上游stage的所在节点上,拉取属于自己的那一个磁盘文件即可。
弊端:
优化后的HashShuffleManager,虽然比优化前减少了很多小文件,但在处理大量数据时,还是会产生很多的小文件。
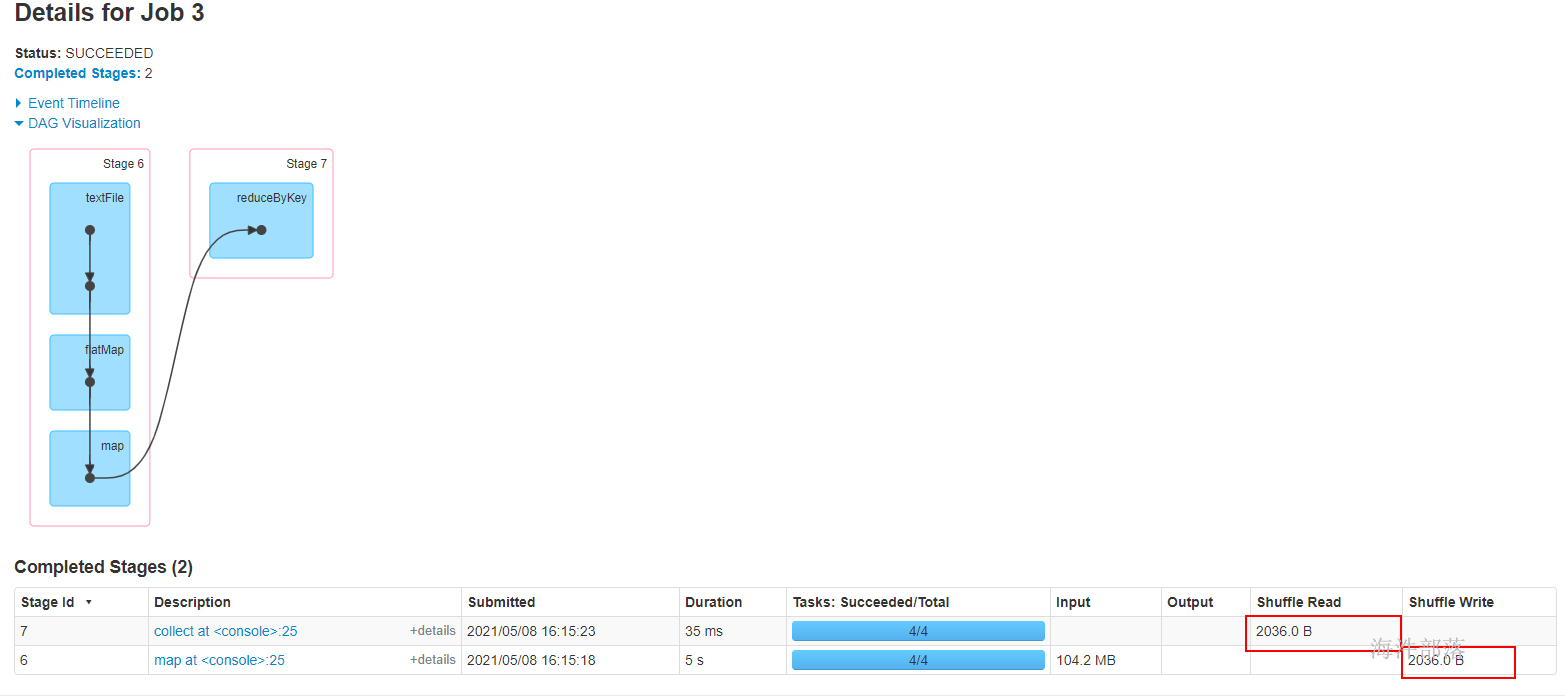
14.2.3 SortShuffleManager
Spark在引入Sort-Based Shuffle以前,比较适用于中小规模的大数据处理。为了让Spark在更大规模的集群上更高性能处理更大规模的数据,于是就引入了SortShuffleManager。
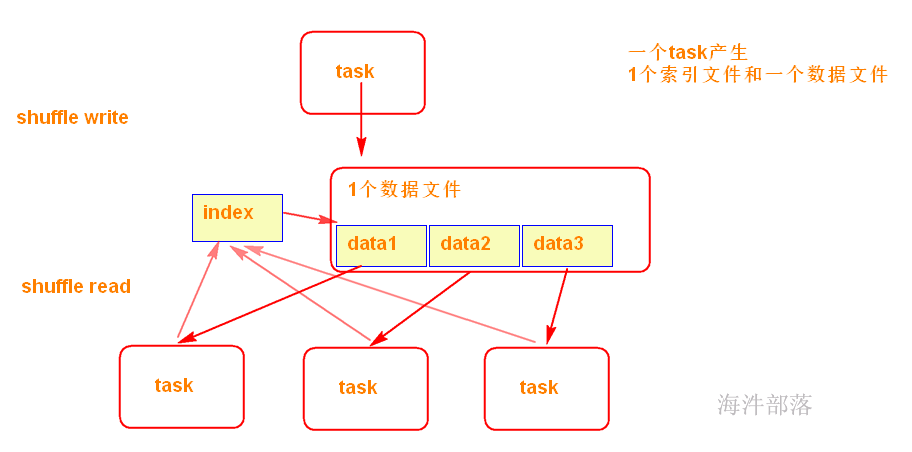
SortShuffleManager不会为每个Reducer中的Task生成一个单独的文件,相反,会把上游中每个mapTask所有的输出数据Data只写到一个文件中。并使用了Index文件存储具体 mapTask 输出数据在该文件的位置。
因此 上游 中的每一个mapTask中产生两个文件:Data文件 和 Index 文件,其中Data文件是存储当前Task的Shuffle输出的,而Index文件中存储了data文件中的数据通过partitioner的分类索引。
写出文件数 = maptask的个数 * 2 (index 和 data )
可见,SortShuffle 的产生的中间文件的多少与 上个stage 的 maptask 数量有关。
shuffle read 阶段:
下游的Stage中的Task就是根据这个Index文件获取自己所要抓取的上游Stage中的mapShuffleMapTask产生的数据的;
14.2.5 shuffle 总结
回顾整个Shuffle的历史,Shuffle产生的临时文件的数量的变化以此为:
Hash Shuffle:M*R;
Consolidate 方式的Hash Shuffle:C*R;
Sort Shuffle:2*M;
其中:M:上游stage的task数量,R:下游stage的task数量,C:上游stage运行task的CPU核数
14.2.6 验证理论
由于spark2.0以后 HashShuffle已经不存在,要验证HashShuffle 需要spark1.5的 环境。
<dependencies>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.11</artifactId>
<version>1.5.2</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
</dependency>
</dependencies>在spark1.5环境下,运行HashShuffle 需要在代码中设置SparkConf 的参数
spark.shuffle.manager ,值设置成hash。
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object HashShuffleTest {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("HashShuffleTest").setMaster("local[2]")
conf.set("spark.shuffle.manager", "hash")
conf.set("spark.shuffle.consolidateFiles", "true")
val sc = new SparkContext(conf)
// sc.setLogLevel("DEBUG")
val outPath = "/tmp/spark/output/wordcount"
val hadoopConf = new Configuration()
val fs: FileSystem = FileSystem.get(hadoopConf)
val path = new Path(outPath)
if (fs.exists(path)) {
fs.delete(path, true)
}
val line: RDD[String] = sc.textFile("/tmp/spark/input",2)
println(line.partitions.length)
val sort: RDD[(String, Int)] = line.flatMap(_.split(" ")).map((_,1)).reduceByKey((a,b) => a+b,4)
sort.saveAsTextFile(outPath)
//打印rdd的debug信息可以方便的查看rdd的依赖,从而可以看到那一步产生shuffle
println(sort.toDebugString)
}
}CPU核数 = 2
上游task数 = 5
下游task数 = 4
产生中间文件数 = 5 * 4 = 20
增加Consolidate后的HashShuffle,需要增加参数
spark.shuffle.consolidateFiles,设置成true

上游task数 = 5
下游task数 = 4
产生中间文件数 = 2 * 4 = 8
SortShuffle 测试,在spark1.5环境下,默认用SortShuffle
只需要把之前的两个参数注释掉即可
CPU核数 = 2
上游task数 = 5
下游task数 = 4
产生中间文件数 = 2 * 5 = 10
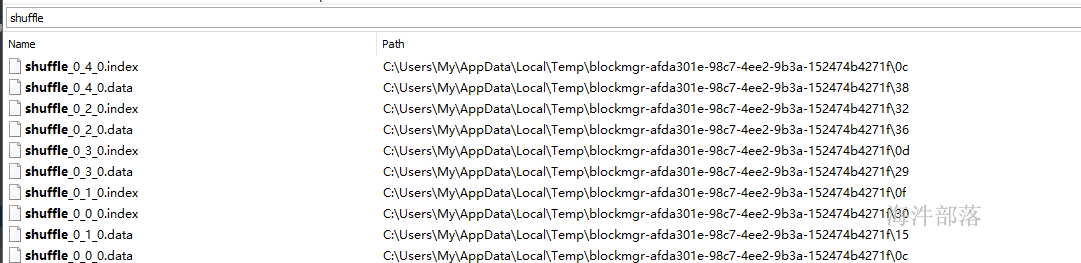
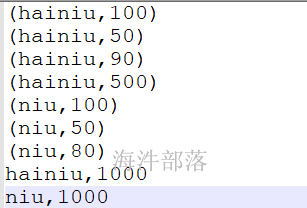
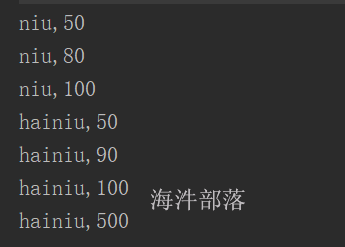
筛选带有()的数据,实现先按照单词降序排序,单词相同再按照数值升序排序

import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
// 定义二次排序比较key,在内部实现二次排序比较逻辑 同时要实现序列化接口
// spark 序列化支持java的序列化框架,默认使用java序列化框架
class SecondarySortKey(val word:String, val num:Int) extends Ordered[SecondarySortKey] with Serializable{
override def compare(that: SecondarySortKey): Int = {
// 实现先按照单词降序排序,单词相同再按照数值升序排序
if(this.word.compareTo(that.word) == 0){
// 按照数值升序排序
this.num - that.num
}else{
// 按照单词降序排序
that.word.compareTo(this.word)
}
}
}
object ScondarySort {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("ScondarySort")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[String] = sc.textFile("/tmp/spark/secondary_sort/input")
val rdd2: RDD[(SecondarySortKey, String)] = rdd.filter(f => {
if (f.contains("(") && f.contains(")")) {
true
} else {
false
}
}).map(f => {
// "(hainiu,100)" --> "hainiu,100"
val str: String = f.substring(1, f.length - 1)
val arr: Array[String] = str.split(",")
(new SecondarySortKey(arr(0), arr(1).toInt), str)
})
// val arr: Array[(SecondarySortKey, String)] = rdd2.sortByKey().collect()
// sortBy 、 sortByKey 都有shuffle,SecondarySortKey 必须实现序列化
val arr: Array[(SecondarySortKey, String)] = rdd2.sortBy(_._1).collect()
for(t <- arr){
println(t._2)
}
}
}输入数据
eq、equals、sameElements的使用
eq:是比较内存地址。
比较样例类的数据用 equals。
比较集合内的数据用 sameElements
scala> case class Hainiu(val id:Int, val name:String)
defined class Hainiu
scala> val h1 = Hainiu(1, "hehe")
h1: Hainiu = Hainiu(1,hehe)
scala> val h2 = Hainiu(1, "hehe")
h2: Hainiu = Hainiu(1,hehe)
// 比较内存地址
scala> h1.eq(h2)
res0: Boolean = false
// 比较样例类对象数据
scala> h1.equals(h2)
res1: Boolean = true
scala> val list1 = List(1,2,3)
list1: List[Int] = List(1, 2, 3)
scala> val list2 = List(1,2,3)
list2: List[Int] = List(1, 2, 3)
// 比较list内存地址
scala> list1.eq(list2)
res2: Boolean = false
// 比较 list数据
scala> list1.sameElements(list2)
res3: Boolean = true16 spark mapjoin
16.1 spark使用的pom
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.hainiu</groupId>
<artifactId>hainiuspark</artifactId>
<version>1.0</version>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.scope>compile</project.build.scope>
<!-- <project.build.scope>provided</project.build.scope>-->
</properties>
<dependencies>
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>2.12.12</version>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_2.12</artifactId>
<version>3.1.2</version>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.3</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- spark 操作 hbase用到的-->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>1.3.1</version>
<exclusions>
<exclusion>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
</exclusion>
</exclusions>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>1.3.1</version>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-cli</artifactId>
<version>3.1.2</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- sparkSQL编程-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_2.12</artifactId>
<version>3.1.2</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- sparkSQL-hive -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_2.12</artifactId>
<version>3.1.2</version>
<scope>${project.build.scope}</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.35</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- 访问spark thriftserver 用的-->
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-jdbc</artifactId>
<version>3.1.2</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- sparkStreaming直连kafka操作-->
<!-- https://mvnrepository.com/artifact/org.apache.kafka/kafka -->
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka_2.12</artifactId>
<version>0.10.2.2</version>
<scope>${project.build.scope}</scope>
<exclusions>
<exclusion>
<artifactId>kafka-clients</artifactId>
<groupId>org.apache.kafka</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming-kafka-0-10_2.12</artifactId>
<version>3.1.2</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- sparkStreaming操作-->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-streaming_2.12</artifactId>
<version>3.1.2</version>
<scope>${project.build.scope}</scope>
</dependency>
<!-- spark3 读写 es -->
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-spark-30_2.12</artifactId>
<version>7.12.1</version>
<scope>${project.build.scope}</scope>
</dependency>
</dependencies>
<build>
<resources>
<resource>
<directory>src/resources</directory>
</resource>
</resources>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptors>
<descriptor>src/resources/assembly.xml</descriptor>
</descriptors>
<!-- <archive>
<manifest>
<mainClass>${package.mainClass}</mainClass>
</manifest>
</archive>-->
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.12</version>
<configuration>
<skip>true</skip>
<forkMode>once</forkMode>
<excludes>
<exclude>**/**</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
</project>16.2 mapjoin所用工具及数据
使用之前封装的orc工具读取hive的orc格式文件;

读取 user_install_status_orc 表的部分数据(orc格式)

使用广播变量向各RDD分发字典数据集;
使用累加类统计数据的join情况
输出10条join之后的数据结果,并将数据输出到ORC文件中
16.3 用spark读取orc文件,并与字典文件join,输出10条的join结果
package java;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hive.ql.io.orc.OrcNewInputFormat;
import org.apache.hadoop.hive.ql.io.orc.OrcStruct;
import org.apache.hadoop.io.NullWritable;
import org.apache.spark.Accumulator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.broadcast.Broadcast;
import scala.Tuple2;
import util.OrcFormat;
import util.OrcUtil;
import util.Utils;
import java.io.*;
import java.util.HashMap;
import java.util.Map;
public class MapJoin {
public static void main(String[] args) throws IOException {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local[*]");
sparkConf.setAppName("mapjoin");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
Configuration conf = new Configuration();
String path = "/tmp/spark/mapjoin_input";
// 读取hdfs上的orc文件,并转换成相应的pairRDD
JavaPairRDD<NullWritable, OrcStruct> orcPairRdd = sc.newAPIHadoopFile(path,
OrcNewInputFormat.class, NullWritable.class, OrcStruct.class, conf);
// 加载字典文件到内存
String dictPath = "/tmp/spark/country_dict.dat";
Map<String,String> countryMap = new HashMap<String,String>();
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(dictPath), "utf-8"));
String line = null;
while((line = reader.readLine()) != null){
String tmp[] = line.split("\t");
String code = tmp[0];
String countryName = tmp[1];
countryMap.put(code, countryName);
}
// 定义广播变量
final Broadcast<Map<String,String>> broadcast = sc.broadcast(countryMap);
// 定义累加器
final Accumulator<Integer> hasCountryAcc = sc.accumulator(0);
final Accumulator<Integer> notHasCountryAcc = sc.accumulator(0);
// 读取PairRDD的每个数据,并与字典map进行join
JavaRDD<String> stringRdd = orcPairRdd.map(new Function<Tuple2<NullWritable, OrcStruct>, String>() {
public String call(Tuple2<NullWritable, OrcStruct> v1) throws Exception {
// 创建orcUtil对象
OrcUtil orcUtil = new OrcUtil();
// 设置读取orc文件, 传入指定的schema
orcUtil.setOrcTypeReadSchema(OrcFormat.SCHEMA);
// 读取country简称
String countryCode = orcUtil.getOrcData(v1._2, "country");
Map<String, String> map = broadcast.getValue();
String countryName = map.get(countryCode);
if (!Utils.isEmpty(countryName)) {
// 统计匹配上的个数
hasCountryAcc.add(1);
} else {
// 统计没匹配上的个数
notHasCountryAcc.add(1);
}
return countryCode + "\t" + countryName;
}
});
// 从计算节点拉取10条数据,并打印
for(String s: stringRdd.take(10)){
System.out.println(s);
}
System.out.println(notHasCountryAcc.value());
System.out.println(hasCountryAcc.value());
}
}程序运行结果:

16.4 利用 OrcUtil 将 join 的结果 以 ORC 文件格式保存到hdfs上
注意输出hadoop格式时要将rdd转成 pairrdd
package java;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hive.ql.io.orc.OrcNewInputFormat;
import org.apache.hadoop.hive.ql.io.orc.OrcNewOutputFormat;
import org.apache.hadoop.hive.ql.io.orc.OrcStruct;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Writable;
import org.apache.hadoop.io.compress.SnappyCodec;
import org.apache.spark.Accumulator;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.JavaSparkContext;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.broadcast.Broadcast;
import scala.Tuple2;
import util.OrcFormat;
import util.OrcUtil;
import util.Utils;
import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.util.HashMap;
import java.util.Map;
public class MapJoinSaveFile {
public static void main(String[] args) throws IOException {
SparkConf sparkConf = new SparkConf();
sparkConf.setMaster("local[*]");
sparkConf.setAppName("mapjoin");
JavaSparkContext sc = new JavaSparkContext(sparkConf);
Configuration conf = new Configuration();
String path = "/tmp/spark/mapjoin_input";
// 读取hdfs上的orc文件,并转换成相应的pairRDD
JavaPairRDD<NullWritable, OrcStruct> orcPairRdd = sc.newAPIHadoopFile(path,
OrcNewInputFormat.class, NullWritable.class, OrcStruct.class, conf);
// 加载字典文件到内存
String dictPath = "/tmp/spark/country_dict.dat";
Map<String,String> countryMap = new HashMap<String,String>();
BufferedReader reader = new BufferedReader(new InputStreamReader(new FileInputStream(dictPath), "utf-8"));
String line = null;
while((line = reader.readLine()) != null){
String tmp[] = line.split("\t");
String code = tmp[0];
String countryName = tmp[1];
countryMap.put(code, countryName);
}
// 定义广播变量
final Broadcast<Map<String,String>> broadcast = sc.broadcast(countryMap);
// 定义累加器
final Accumulator<Integer> hasCountryAcc = sc.accumulator(0);
final Accumulator<Integer> notHasCountryAcc = sc.accumulator(0);
// 读取PairRDD的每个数据,并与字典map进行join,返回序列化的对象
JavaPairRDD<NullWritable, Writable> orcPairRddW = orcPairRdd.mapToPair(new PairFunction<Tuple2<NullWritable, OrcStruct>, NullWritable, Writable>() {
@Override
public Tuple2<NullWritable, Writable> call(Tuple2<NullWritable, OrcStruct> v1) throws Exception {
// 创建orcUtil对象
OrcUtil orcUtil = new OrcUtil();
// 设置读取orc文件, 传入指定的schema
orcUtil.setOrcTypeReadSchema(OrcFormat.SCHEMA);
// 读取country简称
String countryCode = orcUtil.getOrcData(v1._2, "country");
Map<String, String> map = broadcast.getValue();
String countryName = map.get(countryCode);
if (!Utils.isEmpty(countryName)) {
// 统计匹配上的个数
hasCountryAcc.add(1);
} else {
// 统计没匹配上的个数
notHasCountryAcc.add(1);
}
// 将数据序列化成orc格式
orcUtil.setOrcTypeWriteSchema("struct<code:string,name:string>");
orcUtil.addAttr(countryCode, countryName);
Writable w = orcUtil.serialize();
return new Tuple2<NullWritable, Writable>(v1._1, w);
}
});
// 设置输出orc文件采用snappy压缩
conf.set("orc.compress", SnappyCodec.class.getName());
String outPath = "/tmp/spark/mapjoin_output";
// 将序列化对象写入hdfs
orcPairRddW.saveAsNewAPIHadoopFile(outPath,NullWritable.class, Writable.class, OrcNewOutputFormat.class,conf);
System.out.println(hasCountryAcc.value());
System.out.println(notHasCountryAcc.value());
}
}程序运行结果
16.5 scala 版本实现上面的功能
package com.hainiu.sparkcore
import com.hainiu.util.{OrcFormat, OrcUtil}
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hive.ql.io.orc.{CompressionKind, OrcNewInputFormat, OrcNewOutputFormat, OrcStruct}
import org.apache.hadoop.io.compress.SnappyCodec
import org.apache.hadoop.io.{NullWritable, Writable}
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ListBuffer
import scala.io.Source
object MapJoin {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("mapjoin")
val sc: SparkContext = new SparkContext(conf)
// 读取hdfs上的orc文件,并转换成相应的pairRDD
val inputPath:String = "/tmp/spark/mapjoin_input"
// path: String,
// fClass: Class[F],
// kClass: Class[K],
// vClass: Class[V],
// conf: Configuration = hadoopConfiguration
val orcPairRdd: RDD[(NullWritable, OrcStruct)] = sc.newAPIHadoopFile(inputPath,
classOf[OrcNewInputFormat],
classOf[NullWritable],
classOf[OrcStruct])
// 加载字典文件到内存,并加载到广播变量里
val dictPath:String = "/tmp/spark/country_dict.dat"
// "CN\t中国"
val list: List[String] = Source.fromFile(dictPath).getLines().toList
val tuples: List[(String, String)] = list.map(f => {
val arr: Array[String] = f.split("\t")
(arr(0), arr(1))
})
val map: Map[String, String] = tuples.toMap
val broad: Broadcast[Map[String, String]] = sc.broadcast(map)
// 定义累加器统计join上的
val matchAcc: LongAccumulator = sc.longAccumulator
// 定义累加器统计join不上的
val notMatchAcc: LongAccumulator = sc.longAccumulator
// (NullWritable, OrcStruct) --> (NullWritable, Writable)
val orcWriteRdd: RDD[(NullWritable, Writable)] = orcPairRdd.mapPartitionsWithIndex((index, it) => {
// 创建 OrcUtil对象
val orcUtil: OrcUtil = new OrcUtil
// 根据schema获取读的inspector
orcUtil.setOrcTypeReadSchema(OrcFormat.SCHEMA)
// 根据schema获取写的inspector
orcUtil.setOrcTypeWriteSchema("struct<code:string,name:string>")
// 提取广播变量里的数据
val map2: Map[String, String] = broad.value
val orcList = new ListBuffer[(NullWritable, Writable)]
it.foreach(f => {
val countryCode: String = orcUtil.getOrcData(f._2, "country")
val option: Option[String] = map2.get(countryCode)
if (option == None) {
notMatchAcc.add(1L)
} else {
matchAcc.add(1L)
// 获取join的国家名称
val countryName: String = option.get
// 将国家码和国家名称添加到 orcList
orcUtil.addAttr(countryCode, countryName)
val w: Writable = orcUtil.serialize()
orcList += ((NullWritable.get(), w))
}
})
orcList.iterator
})
// 写入orc文件
val outputPath:String = "/tmp/spark/mapjoin_output"
import com.hainiu.util.MyPredef.string2HdfsUtil
outputPath.deleteHdfs
val hadoopConf: Configuration = new Configuration()
hadoopConf.set(CompressionKind.SNAPPY.name(), classOf[SnappyCodec].getName);
// 执行 saveAsNewAPIHadoopFile的rdd必须符合能写入该文件类型的rdd
// path: String,
// keyClass: Class[_],
// valueClass: Class[_],
// outputFormatClass: Class[_ <: NewOutputFormat[_, _]],
// conf: Configuration = self.context.hadoopConfiguration
orcWriteRdd.saveAsNewAPIHadoopFile(outputPath,
classOf[NullWritable],
classOf[Writable],
classOf[OrcNewOutputFormat])
println(s"matchAcc:${matchAcc.value}")
println(s"notMatchAcc:${notMatchAcc.value}")
}
}
源码:
def saveAsNewAPIHadoopDataset(conf: Configuration): Unit = self.withScope {
// Rename this as hadoopConf internally to avoid shadowing (see SPARK-2038).
val hadoopConf = conf
val job = NewAPIHadoopJob.getInstance(hadoopConf)
val formatter = new SimpleDateFormat("yyyyMMddHHmmss", Locale.US)
val jobtrackerID = formatter.format(new Date())
val stageId = self.id
val jobConfiguration = job.getConfiguration
val wrappedConf = new SerializableConfiguration(jobConfiguration)
// OutputFOrmatClass
val outfmt = job.getOutputFormatClass
val jobFormat = outfmt.newInstance
if (isOutputSpecValidationEnabled) {
// FileOutputFormat ignores the filesystem parameter
jobFormat.checkOutputSpecs(job)
}
val writeShard = (context: TaskContext, iter: Iterator[(K, V)]) => {
// iter: 一个分区的数据
val config = wrappedConf.value
/* "reduce task" <split #> <attempt # = spark task #> */
val attemptId = new TaskAttemptID(jobtrackerID, stageId, TaskType.REDUCE, context.partitionId,
context.attemptNumber)
val hadoopContext = new TaskAttemptContextImpl(config, attemptId)
// 创建outputFormat实例,本次具体实例就是OrcNewOutputFormat对象
val format = outfmt.newInstance
format match {
case c: Configurable => c.setConf(config)
case _ => ()
}
val committer = format.getOutputCommitter(hadoopContext)
committer.setupTask(hadoopContext)
val outputMetricsAndBytesWrittenCallback: Option[(OutputMetrics, () => Long)] =
initHadoopOutputMetrics(context)
// 获取到能写入orc文件的具体RecordWriter, 本例是 OrcRecordWriter
// 一个分区创建一个RecordWriter对象
val writer = format.getRecordWriter(hadoopContext).asInstanceOf[NewRecordWriter[K, V]]
require(writer != null, "Unable to obtain RecordWriter")
var recordsWritten = 0L
Utils.tryWithSafeFinallyAndFailureCallbacks {
while (iter.hasNext) {
val pair = iter.next()
// 写入式一行一行写入
// 调用对应RecordWriter对象的write方法
writer.write(pair._1, pair._2)
// Update bytes written metric every few records
maybeUpdateOutputMetrics(outputMetricsAndBytesWrittenCallback, recordsWritten)
recordsWritten += 1
}
}(finallyBlock = writer.close(hadoopContext))
committer.commitTask(hadoopContext)
outputMetricsAndBytesWrittenCallback.foreach { case (om, callback) =>
om.setBytesWritten(callback())
om.setRecordsWritten(recordsWritten)
}
1
} : Int
val jobAttemptId = new TaskAttemptID(jobtrackerID, stageId, TaskType.MAP, 0, 0)
val jobTaskContext = new TaskAttemptContextImpl(wrappedConf.value, jobAttemptId)
val jobCommitter = jobFormat.getOutputCommitter(jobTaskContext)
// When speculation is on and output committer class name contains "Direct", we should warn
// users that they may loss data if they are using a direct output committer.
val speculationEnabled = self.conf.getBoolean("spark.speculation", false)
val outputCommitterClass = jobCommitter.getClass.getSimpleName
if (speculationEnabled && outputCommitterClass.contains("Direct")) {
val warningMessage =
s"$outputCommitterClass may be an output committer that writes data directly to " +
"the final location. Because speculation is enabled, this output committer may " +
"cause data loss (see the case in SPARK-10063). If possible, please use an output " +
"committer that does not have this behavior (e.g. FileOutputCommitter)."
logWarning(warningMessage)
}
jobCommitter.setupJob(jobTaskContext)
// runJob 提交action操作,执行 writeShard 函数写入数据
self.context.runJob(self, writeShard)
jobCommitter.commitJob(jobTaskContext)
}16.6 定义Driver并运行mapjoin
可以像mapreduce那样 封装个 Driver,在启动参数中配置

package util
import rdd.MapJoin
import org.apache.hadoop.util.ProgramDriver
object Driver {
def main(args: Array[String]): Unit = {
val driver = new ProgramDriver
// MapJoin 需要有伴生类,classOf找的是伴生类
driver.addClass("mapjoin", classOf[MapJoin], "mapJoin任务")
driver.run(args)
}
}
17 spark序列化使用
由于大多数Spark计算的内存性质,Spark程序可能会受到集群中任何资源(CPU,网络带宽或内存)的瓶颈。通常,如果内存资源足够,则瓶颈是网络带宽。
数据序列化,这对于良好的网络性能至关重要。
在Spark的架构中,在网络中传递的或者缓存在内存、硬盘中的对象需要进行序列化操作。比如:
1)分发给Executor上的Task
2)广播变量
3)Shuffle过程中的数据缓存
等操作,序列化起到了重要的作用,将对象序列化为慢速格式或占用大量字节的格式将大大减慢计算速度。通常,这是优化Spark应用程序的第一件事。
spark 序列化分两种:一种是Java 序列化; 另一种是 Kryo 序列化。
17.1 Java序列化
定义UserInfo类
public class UserInfo{
private String name = "hainiu"; // java实现了序列化
private int age = 10; // java实现了序列化
private Text addr = new Text("beijing"); // 没有实现java的 Serializable接口
public UserInfo() {
}
@Override
public String toString() {
return "UserInfo{" +
"name='" + name + '\'' +
", age=" + age +
", addr=" + addr +
'}';
}
}java实现序列化的一般方法:
1)让类实现Serializable接口
当使用Serializable方案的时候,你的对象必须继承Serializable接口,类中的属性如果有实例那也必须是继承Serializable 可序列化的;
package com.hainiu.sparkcore
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SerDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SerDemo")
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.parallelize(List("aa","aa","bb","aa"),2)
val broad: Broadcast[UserInfo] = sc.broadcast(new UserInfo)
val pairRdd: RDD[(String, UserInfo)] = rdd.map(f => {
val userInfo: UserInfo = broad.value
(f, userInfo)
})
// 因为groupByKey有shuffle,需要序列化
val groupRdd: RDD[(String, Iterable[UserInfo])] = pairRdd.groupByKey()
val arr: Array[(String, Iterable[UserInfo])] = groupRdd.collect()
for(t <- arr){
println(t)
}
}
}
2)static和transient修饰的属性不会被序列化,可以通过在属性上加 static 或 transient 修饰来解决序列化问题。
static修饰的是类的状态,而不是对象状态,所以不存在序列化问题;

这样导致数据丢失。
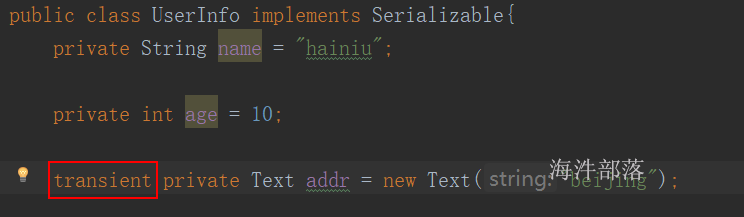
给addr 属性用 transient 修饰,导致反序列化后数据丢失

java 序列化弊端:
1)如果引入第三方类对象作为属性,如果对象没有实现序列化,那这个类也不能序列化;
2)用 transient 修饰 的属性,反序列化后数据丢失;
3)Java序列化很灵活(支持所有对象的序列化)但性能较差,同时序列化后占用的字节数也较多(包含了序列化版本号、类名等信息);

17.2 Kryo 序列化
由于java序列化性能问题,spark 引入了Kryo序列化机制。
Spark 也推荐用 Kryo序列化机制。Kryo序列化机制比Java序列化机制性能提高10倍左右,Spark之所以没有默认使用Kryo作为序列化类库,是因为它不支持所有对象的序列化,同时Kryo需要用户在使用前注册需要序列化的类型,不够方便。
1)开启序列化
spark 默认序列化方式 是 用java序列化

conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer") // classOf[KryoSerializer].getName 一样效果2)配置序列化参数
当开启序列化后,需要配置 【spark.kryo.registrationRequired】属性为true,默认是false,如果是false,Kryo序列化时性能有所下降。

注册有两种方式:
第一种:
// 开启Kryo序列化
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 要求主动注册
conf.set("spark.kryo.registrationRequired", "true")
// 方案1:
val classes: Array[Class[_]] = Array[Class[_]](
classOf[UserInfo],
classOf[Text],
Class.forName("scala.reflect.ClassTag$GenericClassTag"),
classOf[Array[UserInfo]]
)
//将上面的类注册
conf.registerKryoClasses(classes)第二种:
封装一个自定义注册类,然后把自定义注册类注册给Kryo。
a)自定义注册类:
class MyRegistrator extends KryoRegistrator {
override def registerClasses(kryo: Kryo): Unit = {
kryo.register(classOf[UserInfo])
kryo.register(classOf[Text])
kryo.register(Class.forName("scala.reflect.ClassTag$GenericClassTag"))
kryo.register(classOf[Array[UserInfo]])
}
}b)配置自定义注册类
// 开启Kryo序列化
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 要求主动注册
conf.set("spark.kryo.registrationRequired", "true")
// 设置注册类
conf.set("spark.kryo.registrator",classOf[MyRegistrator].getName)代码:
package spark05
import com.esotericsoftware.kryo.Kryo
import java05.UserInfo
import org.apache.hadoop.io.Text
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.serializer.KryoRegistrator
import org.apache.spark.{SparkConf, SparkContext}
object SerDemo {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SerDemo")
// 开启Kryo序列化
conf.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// 要求主动注册
conf.set("spark.kryo.registrationRequired", "true")
// 方案1:
// val classes: Array[Class[_]] = Array[Class[_]](
// classOf[UserInfo],
// classOf[Text],
// Class.forName("scala.reflect.ClassTag$GenericClassTag"),
// classOf[Array[UserInfo]]
// )
//将上面的类注册
// conf.registerKryoClasses(classes)
// 方案2
conf.set("spark.kryo.registrator",classOf[MyRegistrator].getName)
val sc = new SparkContext(conf)
val rdd: RDD[String] = sc.parallelize(List("aa","aa","bb","aa"),2)
val user = new UserInfo
val broad: Broadcast[UserInfo] = sc.broadcast(user)
val rdd2: RDD[(String, UserInfo)] = rdd.map(f => {
val user2: UserInfo = broad.value
(f, user2)
})
// 目的是让rdd产生shuffle
val arr: Array[(String, Iterable[UserInfo])] = rdd2.groupByKey().collect()
arr.foreach(println)
}
}
class MyRegistrator extends KryoRegistrator {
override def registerClasses(kryo: Kryo): Unit = {
kryo.register(classOf[UserInfo])
kryo.register(classOf[Text])
kryo.register(Class.forName("scala.reflect.ClassTag$GenericClassTag"))
kryo.register(classOf[Array[UserInfo]])
}
}运行结果:

18 GC对spark性能的影响分析
18.1 什么是GC
垃圾收集 Garbage Collection 通常被称为“GC”,回收没用的对象以释放空间。
GC 主要回收的是虚拟机堆内存的空间,因为new 的对象主要是在堆内存。
18.2 垃圾收集的算法
1)标记 -清除算法
“标记-清除”(Mark-Sweep)算法,如它的名字一样,算法分为“标记”和“清除”两个阶段:首先标记出所有需要回收的对象,在标记完成后统一回收掉所有被标记的对象。之所以说它是最基础的收集算法,是因为后续的收集算法都是基于这种思路并对其缺点进行改进而得到的。
它的主要缺点有两个:一个是效率问题,标记和清除过程的效率都不高;另外一个是空间问题,标记清除之后会产生大量不连续的内存碎片,空间碎片太多可能会导致,当程序在以后的运行过程中需要分配较大对象时无法找到足够的连续内存而不得不提前触发另一次垃圾收集动作。
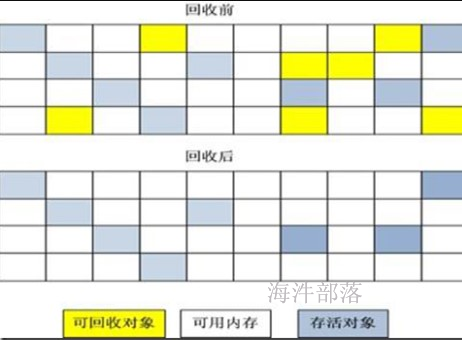
2)复制算法
“复制”(Copying)的收集算法,它将可用内存按容量划分为大小相等的两块,每次只使用其中的一块。当这一块的内存用完了,就将还存活着的对象复制到另外一块上面,然后再把已使用过的内存空间一次清理掉。
这样使得每次都是对其中的一块进行内存回收,内存分配时也就不用考虑内存碎片等复杂情况,缺点:这种算法持续复制长生存期的对象则导致效率降低。
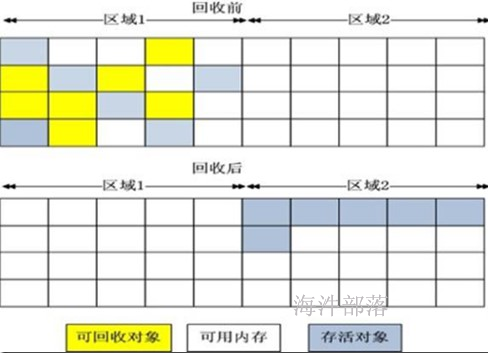
3)标记-整理算法
复制收集算法在对象存活率较高时就要执行较多的复制操作,效率将会变低。更关键的是,如果不想浪费50%的空间,就需要有额外的空间进行分配担保,以应对被使用的内存中所有对象都100%存活的极端情况,所以在老年代一般不能直接选用这种算法。
根据老年代的特点,有人提出了另外一种“标记-整理”(Mark-Compact)算法,标记过程仍然与“标记-清除”算法一样,但后续步骤不是直接对可回收对象进行清理,而是让所有存活的对象都向一端移动,然后直接清理掉端边界以外的内存;
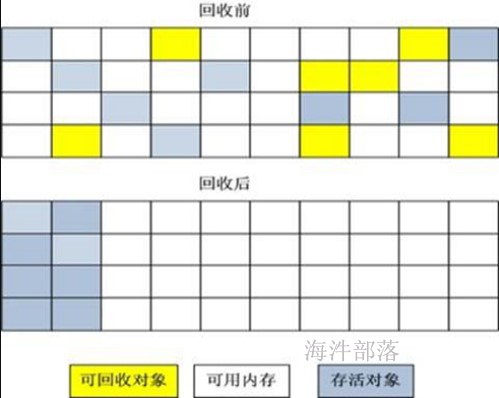
4)分代收集算法
GC分代的基本假设:绝大部分对象的生命周期都非常短暂,存活时间短。
“分代收集”(Generational Collection)算法,把Java堆分为新生代和老年代,这样就可以根据各个年代的特点采用最适当的收集算法。在新生代中,每次垃圾收集时都发现有大批对象死去,只有少量存活,那就选用复制算法,只需要付出少量存活对象的复制成本就可以完成收集。而老年代中因为对象存活率高、没有额外空间对它进行分配担保,就必须使用“标记-清理”或“标记-整理”算法来进行回收。

18.3 JVM的minor gc与full gc
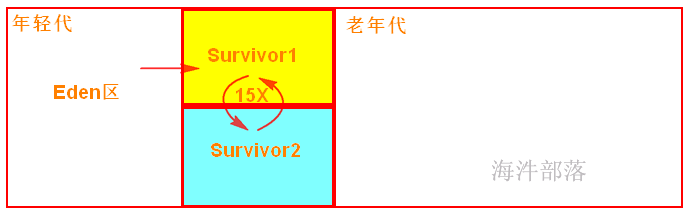
其中:
年轻代:存放岁数比较年轻的对象。分为 Eden区 和 Survivor区。
Eden区:开始对象分配的地方;
Survivor区:是经过minor gc 后存活对象的存储区域,一般这个区域要比Eden区小。分为两个区:from 和 to。
老年代:存放存活时间长的对象和年轻代存不下的对象,这个区域要比年轻代大的多。
1)对象分配
一般对象分配:当有新对象产生时,JVM会把对象分配到Eden区,Survivor区作为备用;
大对象分配:大对象是指需要连续空间的java对象,如很长的数组、字符串。这样的大对象不会分配在年轻代,直接进入老年代。
2)minor gc(年轻代 gc)
minor gc 是指 年轻代的垃圾收集动作。因为年轻代中的对象基本都是朝生夕死的(80%以上),所以Minor gc 会非常频繁,回收速度也比较快。
触发条件:Eden区满了。
操作方法:
1)第一次minor gc,通过复制算法,将Eden区存活的对象复制到 Survivor from 区,对象年龄设为1;
2)以后的minor gc,通过复制算法,将Eden区 和 Survivor from 区 存活的对象 复制到 Survivor to 区,然后 再将 to 区 变成新的 from 区,同时对象的年龄+1,一旦某个对象达到了指定的次数,就会把该对象移到老年代。
3)full gc(老年代 gc)
full gc 是指 老年代的垃圾收集动作。因为老年代中的对象大多是存活时间长的对象,老年代回收要用 标记整理或标记清除算法,回收速度很慢。
触发条件:老年代满了。
操作方法:
通过标记整理或标记清除算法,扫描老年代的每个对象,并回收不可达的对象。
18.4 频繁GC的影响及优化方法
1)频繁GC的影响
task运行期间动态创建的对象使用的Jvm堆内存的情况

当给spark任务分配的内存少了,会频繁发生minor gc,如果存活时间长的对象特别多,就会发生full gc。
当频繁的new对象时,导致很快进入老年代,这样也可能发生full gc。
频繁gc 会影响 工作任务线程的正常执行,从而降低spark 应用程序的性能。
2)优化方案
a)优化代码,避免频繁new 同一个对象,导致的频繁gc。
b)调节可用存储内存和执行内存的比例,以减少gc 发生的频率。
c)对应存储内存,可以考虑存储序列化后的对象,调节序列化级别为MEMORY_DISK_SER或MEMORY_ONLY_SER,这样占用内存空间小。
d)还可以使用Kryo序列化类库,进行序列化,因为kryo序列化方法可以进一步的降低RDD的parition的内存占用量。
19 spark 操作 hbase
spark没有读写hbase的api,如果想用spark操作hbase表,需要参考java和MapReduce操作hbase的api。
19.1 hbase配置
1)pom
之前已经配置过,不需要配置
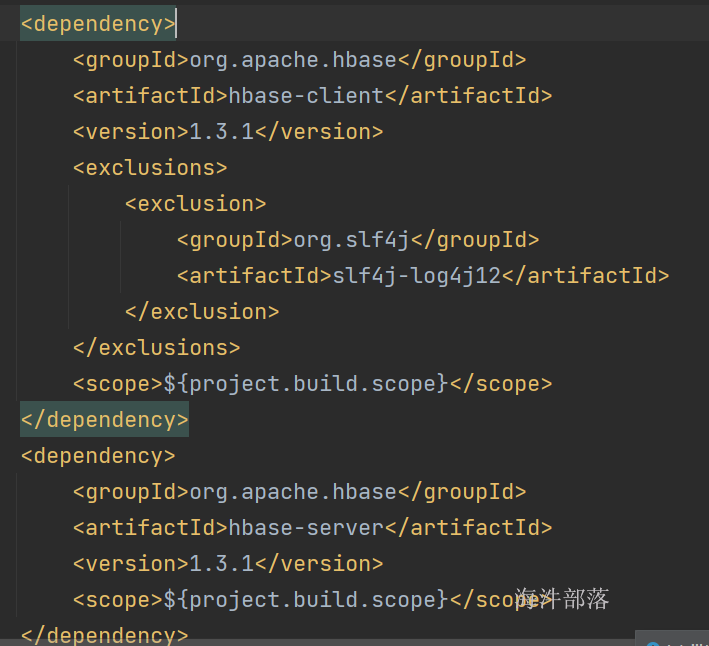
2)hbase-site.xml
<?xml version="1.0"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<!-- Client参数 -->
<property>
<name>hbase.client.scanner.caching</name>
<value>10000</value>
<description>客户端参数,HBase scanner一次从服务端抓取的数据条数</description>
</property>
<property>
<name>hbase.client.scanner.timeout.period</name>
<value>900000</value>
<description>scanner过期时间</description>
</property>
<!-- Zookeeper -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181</value>
</property>
<property>
<name>zookeeper.session.timeout</name>
<value>1200000</value>
</property>
<!-- 如果连接教室集群,配置这个 -->
<property>
<name>zookeeper.znode.parent</name>
<value>/hbase1</value>
</property>
</configuration>创建 hbase表

19.2 table put
用表操作对象的put() 插入数据
程序:
package com.hainiu.sparkhbase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.hbase.client.{Connection, ConnectionFactory, HTable, Put}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkHbaseTablePut {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkHbaseTablePut")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(10 until 20, 2)
// 一个元素创建一个hbase连接,一条一条写入,效率低
rdd.foreach(f =>{
val hbaseConf: Configuration = HBaseConfiguration.create()
var conn: Connection = null
var table: HTable = null
try{
// 创建hbase连接
conn = ConnectionFactory.createConnection(hbaseConf)
// 创建表操作对象
table = conn.getTable(TableName.valueOf("panniu:spark_user")).asInstanceOf[HTable]
// 创建Put对象
val put: Put = new Put(Bytes.toBytes(s"spark_put_${f}"))
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("count"),Bytes.toBytes(s"${f}") )
// 写入
table.put(put)
}catch {
case e:Exception => e.printStackTrace()
}finally {
table.close()
conn.close()
}
})
}
}
用表操作对象的put(list) 批量插入数据
package com.hainiu.sparkhbase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.client.{Connection, ConnectionFactory, HTable, Put}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkHbaseTablePuts {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkHbaseTablePuts")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(20 until 30, 2)
// 一个分区创建一个hbase连接,批量写入,效率高
rdd.foreachPartition(it =>{
// 把每个Int 转成 Put对象
val puts: Iterator[Put] = it.map(f => {
// 创建Put对象
val put: Put = new Put(Bytes.toBytes(s"spark_puts_${f}"))
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("count"), Bytes.toBytes(s"${f}"))
put
})
println("--创建hbase连接--")
val hbaseConf: Configuration = HBaseConfiguration.create()
var conn: Connection = null
var table: HTable = null
try{
// 创建hbase连接
conn = ConnectionFactory.createConnection(hbaseConf)
// 创建表操作对象
table = conn.getTable(TableName.valueOf("panniu:spark_user")).asInstanceOf[HTable]
// 通过隐式转换,将scala的List转成javaList
import scala.collection.convert.wrapAsJava.seqAsJavaList
// 一个分区的数据批量写入
table.put(puts.toList)
}catch {
case e:Exception => e.printStackTrace()
}finally {
table.close()
conn.close()
}
})
}
}
19.4 tableoutputformat put
用TableOutputFormat 来实现写入数据
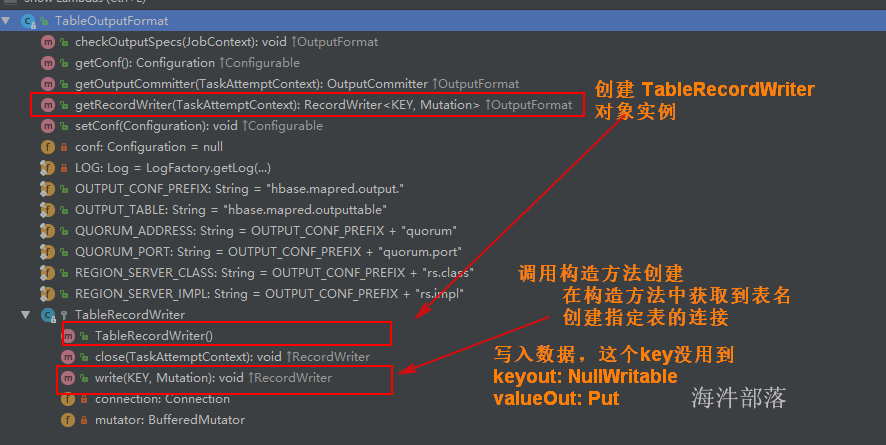
package com.hainiu.sparkhbase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.client.{Connection, ConnectionFactory, HTable, Put}
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.hbase.{HBaseConfiguration, TableName}
import org.apache.hadoop.io.NullWritable
import org.apache.hadoop.mapreduce.Job
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkHbaseTableWrite {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkHbaseTableWrite")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(30 until 40, 2)
// Int --> (NullWritable, Put)
val hbaseWriteRdd: RDD[(NullWritable, Put)] = rdd.map(f => {
// 创建Put对象
val put: Put = new Put(Bytes.toBytes(s"spark_write_${f}"))
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("count"), Bytes.toBytes(s"${f}"))
(NullWritable.get(), put)
})
// 创建带有hbase连接的Hadoop Configuration对象
val hbaseConf: Configuration = HBaseConfiguration.create()
// 设置写入hbase的表名
hbaseConf.set(TableOutputFormat.OUTPUT_TABLE, "panniu:spark_user")
// 借助于mapreduce的Job对象添加参数配置
val job: Job = Job.getInstance(hbaseConf)
job.setOutputFormatClass(classOf[TableOutputFormat[NullWritable]])
job.setOutputKeyClass(classOf[NullWritable])
job.setOutputValueClass(classOf[Put])
// 当输出数据没有输出目录时,用这个api
hbaseWriteRdd.saveAsNewAPIHadoopDataset(job.getConfiguration)
}
}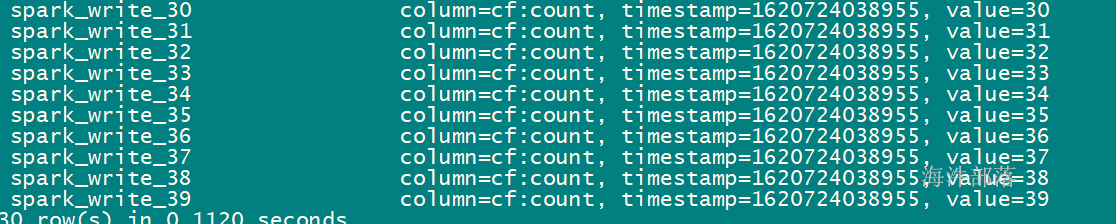
put: 一个元素创建一个连接,一条一条写入
puts: 一个分区创建一个连接,一个分区数据批量写入
write: 一个分区创建一个连接, 一个分区数据一条一条写入
效率高–> 低: puts —> write —-> put
19.5 tableoutputformat put partitions
package com.hainiu.sparkhbase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.Put
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.hadoop.io.NullWritable
import org.apache.hadoop.mapreduce.Job
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkHbaseTableWriteWithPartiton {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkHbaseTableWriteWithPartiton")
val sc: SparkContext = new SparkContext(conf)
val rdd: RDD[Int] = sc.parallelize(40 until 100, 20)
// Int --> (NullWritable, Put)
val hbaseWriteRdd: RDD[(NullWritable, Put)] = rdd.map(f => {
// 创建Put对象
val put: Put = new Put(Bytes.toBytes(s"spark_write_${f}"))
put.addColumn(Bytes.toBytes("cf"), Bytes.toBytes("count"), Bytes.toBytes(s"${f}"))
(NullWritable.get(), put)
})
// 创建带有hbase连接的Hadoop Configuration对象
val hbaseConf: Configuration = HBaseConfiguration.create()
// 设置写入hbase的表名
hbaseConf.set(TableOutputFormat.OUTPUT_TABLE, "panniu:spark_user")
// 借助于mapreduce的Job对象添加参数配置
val job: Job = Job.getInstance(hbaseConf)
job.setOutputFormatClass(classOf[TableOutputFormat[NullWritable]])
job.setOutputKeyClass(classOf[NullWritable])
job.setOutputValueClass(classOf[Put])
println("rdd分区:" + hbaseWriteRdd.getNumPartitions)
// 可以通过coalsese 来减少分区数
val hbaseWriteRdd2: RDD[(NullWritable, Put)] = hbaseWriteRdd.coalesce(2)
println("重分区后rdd分区:" + hbaseWriteRdd2.getNumPartitions)
// 当输出数据没有输出目录时,用这个api
hbaseWriteRdd2.saveAsNewAPIHadoopDataset(job.getConfiguration)
println(hbaseWriteRdd2.toDebugString)
}
}
19.6 通过scan读取hbase表
参考 TableMapReduceUtil.initTableMapperJob() 中参数的配置
package com.hainiu.sparkhbase
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.{Result, Scan}
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.{TableInputFormat, TableMapReduceUtil}
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object SparkHbaseTableScan {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkHbaseTableScan")
val sc: SparkContext = new SparkContext(conf)
val scan:Scan = new Scan
scan.setStartRow(Bytes.toBytes("spark_puts_20"))
scan.setStopRow(Bytes.toBytes("spark_puts_z"))
// 带有hbase连接的配置
val hbaseConf: Configuration = HBaseConfiguration.create()
// 设置hbase表名
hbaseConf.set(TableInputFormat.INPUT_TABLE, "panniu:spark_user")
// 设置查询范围
hbaseConf.set(TableInputFormat.SCAN, TableMapReduceUtil.convertScanToString(scan))
// 读取hbase生产rdd
// conf: Configuration = hadoopConfiguration,
// fClass: Class[F],
// kClass: Class[K],
// vClass: Class[V]
val rdd: RDD[(ImmutableBytesWritable, Result)] = sc.newAPIHadoopRDD(hbaseConf,
classOf[TableInputFormat],
classOf[ImmutableBytesWritable],
classOf[Result])
// rdd的分区数取决于读取hbase数据的region数
println(s"rdd分区数:${rdd.getNumPartitions}")
val rdd2: RDD[String] = rdd.map(f => {
val rowkey: String = Bytes.toString(f._1.get())
val result: Result = f._2
val count: String = Bytes.toString(result.getValue(Bytes.toBytes("cf"), Bytes.toBytes("count")))
s"${rowkey}\t${count}"
})
val arr: Array[String] = rdd2.collect()
for(s <- arr){
println(s)
}
}
}结果:
19.8 spark on yarn 运行spark任务
19.8.1 在教室集群yarn上跑上面的任务
1)在教室集群yarn上跑任务,需要修改如下代码:
注释掉本地执行模式

输出目录、表名改成参数传递

2)增加导入hbase功能
3)加入driver的执行方式创建 要执行任务的class类在driver类中增加任务配置
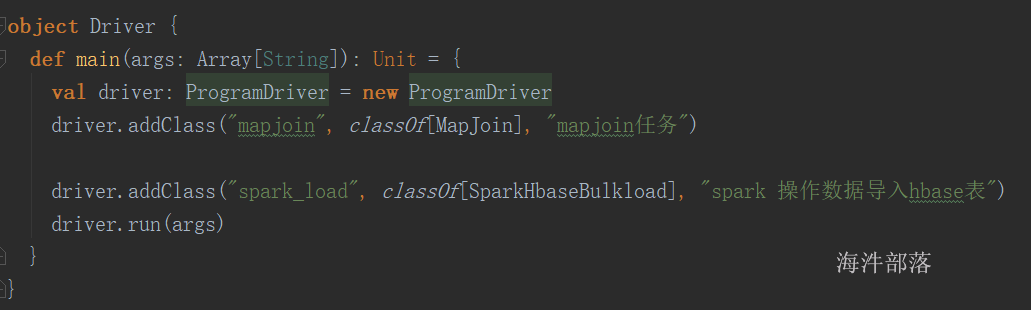
修改pom,配置jar包运行主类
4)修改pom 的scope 为provided
5)打成jar包
clean —-> rebuild工程 —-> 用assembly打成jar包
idea配置assembly
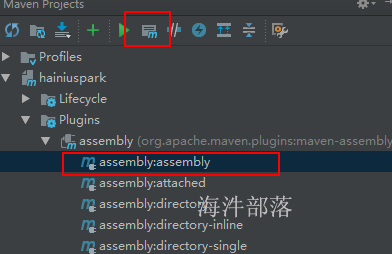
7)执行任务
spark-submit –jars \$(echo /usr/local/hbase/lib/*.jar | tr ’ ’ ‘,’) –master yarn –queue hainiu hainiuspark-1.0-hainiu.jar spark_load /user/panniu/spark/hbase_bulk_output panniu:spark_load
其中:echo /usr/local/hbase/lib/*.jar | tr ’ ’ ‘,’ 是把lib目录下的jar包名称用“ , ” 分隔。
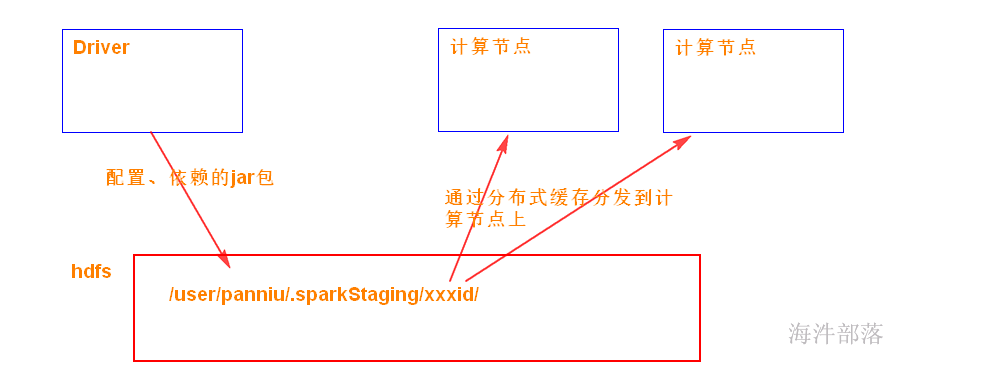
只要sparkclasspath下没有的jar包,都需要 从driver端分发,启动任务时,得需要将当driver端的jar上传到hdfs上,启动时耗费时间比较长。需要优化。
19.8.2 运行优化
由于上面的运行方式,每次运行时会将spark driver端的hbase lib 目录下的 jar 包上传到hdfs上的 /user/xxx/.sparkStaging 目录下,启动速度变慢。
如何省略上传的步骤?
19.8.2.1 方案1:(过渡版)
由于每个节点都部署了hbase服务,所以可以在spark-env.sh 文件里,把hbase 的相关jar包配置到 spark_classpath 目录下,这样就省略了上传到hdfs的步骤。

spark-submit –master yarn –queue hainiu hainiuspark-1.0-hainiu.jar spark_hbase_bulk /user/hadoop/spark/spark_user
弊端:
但这么做会强制其它任务spark任务driver端和executo都加载了hbase的Jar,比如会引起spark-sql的冲突。
19.8.2.2 方案2:(最终版)
*推荐使用*
–driver-class-path参数和 spark-defaults.conf 的设置代替 spark-env.sh 中 spark_classpath 的设置

当提交任务时,executor 根据配置去hdfs 目录下去拉取jar包
如果driver端需要jar 包 可以通过配置 –driver-class-path /usr/local/spark/jars/:/usr/local/hbase/lib/ 的方式实现
执行命令:
spark-submit –driver-class-path /usr/local/spark/jars/:/usr/local/hbase/lib/ –master yarn –queue hainiu hainiuspark-1.0-hainiu.jar spark_load /user/panniu/spark/hbase_bulk_output panniu:spark_load

spark-submit –driver-class-path /usr/local/spark/jars/:/usr/local/hbase/lib/ –master yarn –deploy-mode cluster –queue hainiu hainiuspark-1.0-hainiu.jar spark_load /user/panniu/spark/hbase_bulk_output panniu:spark_load
需要Hadoop权限才能运行
20 spark-sql
20.1 SparkSQL的发展历程
20.1.1 Hive and Shark
SparkSQL的前身是Shark,是给熟悉RDBMS但又不理解MapReduce的技术人员提供快速上手的工具,hive应运而生,它是运行在Hadoop上的SQL-on-hadoop工具。但是MapReduce计算过程中大量的中间磁盘落地过程消耗了大量的I/O,运行效率低。为了提高SQL-on-Hadoop的效率,shark 应运而生。它修改了下图所示的右下角的内存管理、物理计划、执行三个模块,并使之能运行在Spark引擎上,从而使得SQL查询的速度得到10-100倍的提升。
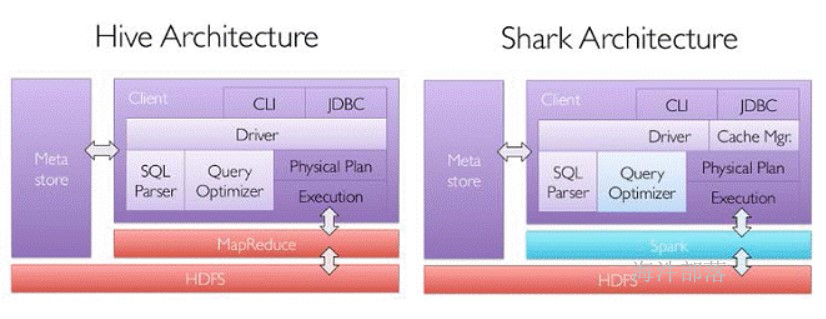
随着Spark的发展,对于野心勃勃的Spark团队来说,Shark对于Hive的太多依赖(如采用Hive的语法解析器、查询优化器等等),制约了Spark各个组件的相互集成,所以提出了SparkSQL项目。
SparkSQL抛弃原有Shark的代码,摆脱了对Hive的依赖性,SparkSQL无论在数据兼容、性能优化、组件扩展方面都得到了极大的方便。
hive与spark-sql的对比
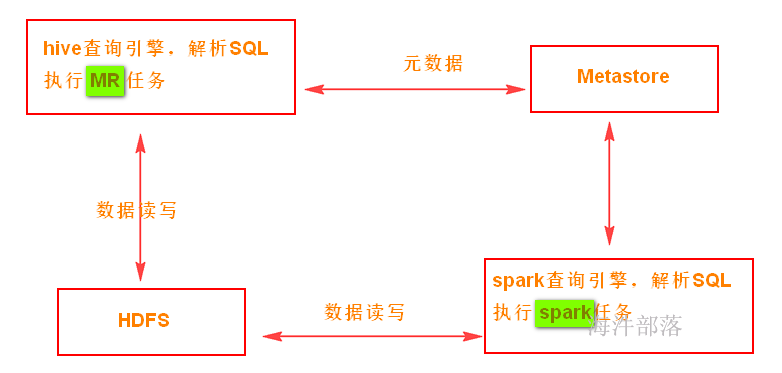
20.2 教室集群配置
1)拷贝hive的 hive-site.xml 配置文件到spark conf的目录下,并删除不必要的信息
<configuration>
<!-- HDFS start -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/hive/warehouse</value>
<description>hive使用的HDFS目录</description>
</property>
<!-- HDFS end -->
<!-- metastore start 在客户端使用时,mysql连接和metastore同时出现在配置文件中,客户端会选择使用metastore -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>校验metastore版本信息是否与sparkjar 版本一致;true:校验;false:不校验</description>
</property>
<property>
<name>hive.metastore.uris</name>
<value>thrift://nn2.hadoop:9083</value>
</property>
<!-- metastore end -->
<!-- hiveserver start -->
<property>
<name>hive.server2.thrift.min.worker.threads</name>
<value>5</value>
<description>Minimum number of Thrift worker threads</description>
</property>
<property>
<name>hive.server2.thrift.max.worker.threads</name>
<value>500</value>
<description>Maximum number of Thrift worker threads</description>
</property>
<property>
<name>hive.server2.thrift.bind.host</name>
<value>op.hadoop</value>
<description>hive开启的thriftServer地址</description>
</property>
<property>
<name>hive.server2.thrift.port</name>
<value>20000</value>
<description>开启spark的thriftServer端口</description>
</property>
<!-- hiveserver end -->
</configuration>其中:
hive.metastore.schema.verification,用于校验 metastore版本信息是否与spark jar 版本一致;true:校验;false:不校验;
hive 有个hiveserver2服务,端口是10000;而spark 用的hiveserver2服务,配置的端口是20000,不冲突。
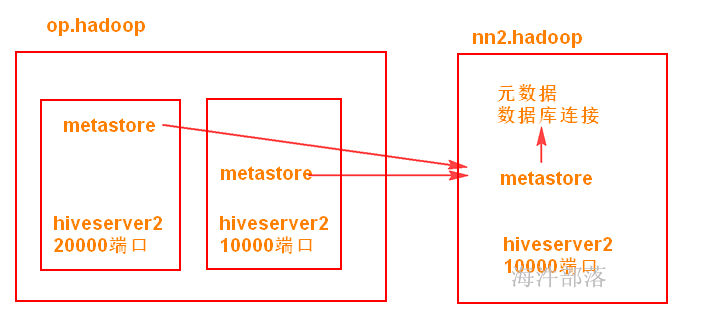
2)spark-env.sh
使得spark 能与hadoop关联。

上传/usr/local/spark/jars下的所有jar包到hdfs上的/user/hadoop/spark/lib_jars目录

4)减少spark sql 日志输出,修改spark conf 目录下的 log4j.properties
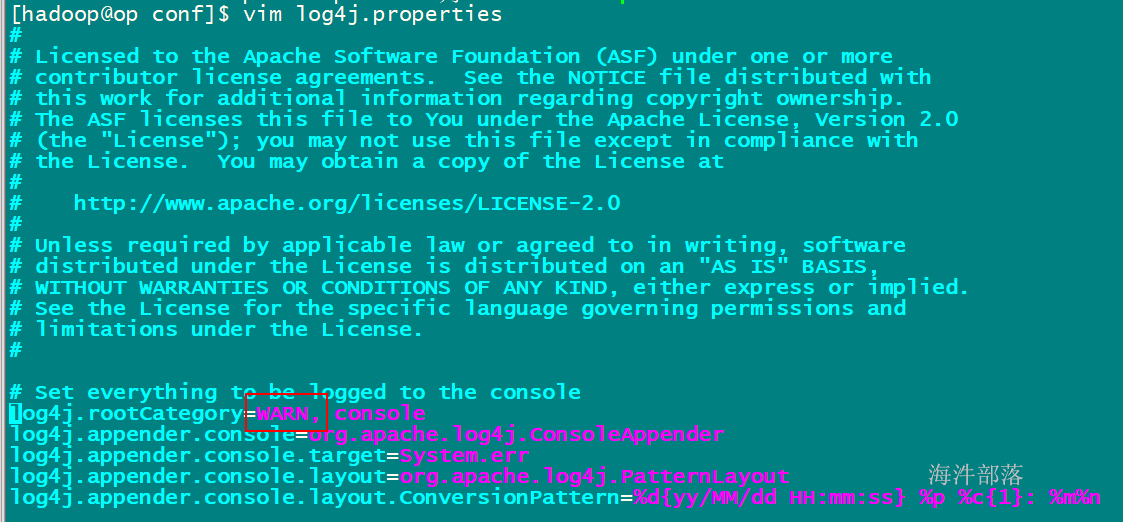
20.3 spark-sql shell(自己玩)
20.3.1 启动spark-SQL shell 步骤
# 启动yarn集群
#启动hive服务
nohup hive --service metastore > /dev/null 2>&1 &
#执行sparkSQLspark-sql –master yarn –queue hainiu –num-executors 12 –executor-memory 5G
这种方式每个人一个driver彼此之间的数据无法共享;
启动任务后,发现还没跑 任务,就已经占用了 资源,因为现在还没有机制能计算出跑SQL任务会用多少内存。而hive是只有跑任务才去算占用多少资源。
20.3.2 运行sparkSQL
写hive命令即可。
-- 查看数据库
show databases;
-- 进入数据库
use panniu; 1)查询统计user_install_status表记录数

执行带有shuffle 的SQL,会产生200 partition。
select count(1) from (select count(1) from user_install_status group by aid) a;
可以通过 set spark.sql.shuffle.partitions=20; 进行设置partition的个数,这样可以减少shuffle的次数。
set spark.sql.shuffle.partitions=20;
select sum(num) from (select count(*) as num from user_install_status group by country) a;
20.3.3 通过bin/spark-sql –help可以查看CLI命令参数
spark-sql –help
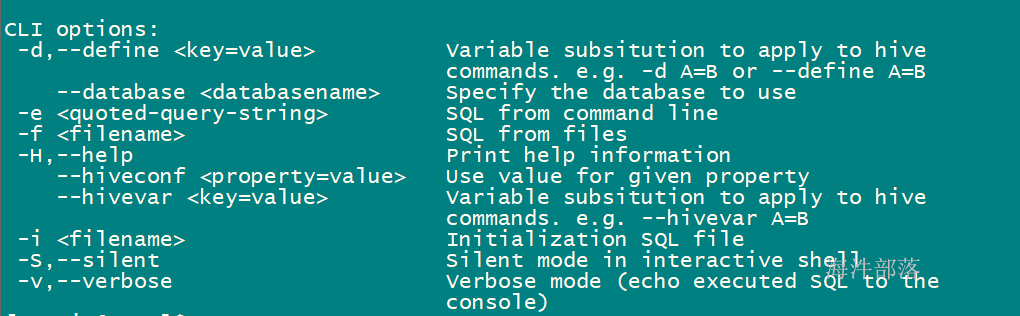
spark-shell -h 查看帮助
20.4 spark thriftserver(共享玩)
ThriftServer是一个JDBC/ODBC接口,用户可以通过JDBC/ODBC连接ThriftServer来访问SparkSQL的数据。ThriftServer在启动的时候,会启动了一个SparkSQL的应用程序,而通过JDBC/ODBC连接进来的客户端共同分享这个SparkSQL应用程序的资源,也就是说不同的用户之间可以共享数据;ThriftServer启动时还开启一个侦听器,等待JDBC客户端的连接和提交查询。所以,在配置ThriftServer的时候,至少要配置ThriftServer的主机名和端口,如果要使用Hive数据的话,还要提供Hive Metastore的uris。
这种方式所有人可以通过driver连接,彼此之间的数据可以共享。
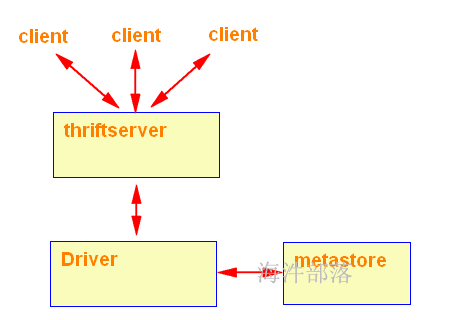
20.4.1 启动spark thriftserver
#启动yarn集群
#启动hive服务
nohup hive --service metastore > /dev/null 2>&1 &
#启动thriftserver服务
/usr/local/spark/sbin/start-thriftserver.sh --master yarn --queue hainiu在 op.hadoop 机器启动thriftserver 服务
集群只要启动一个即可,如果报端口被占用,说明有人已经启动过。
20.4.2 使用spark的beeline 连接 thriftserver
beeline 分为hive 和 spark的。
hive 的 beeline :/usr/local/hive/bin/beeline
spark 的 beeline : /usr/local/spark/bin/beeline
在op.hadoop上启动beelie, 连接 op.hadoop 的thriftserver 服务
/usr/local/spark/bin/beeline
!connect jdbc:hive2://op.hadoop:20000
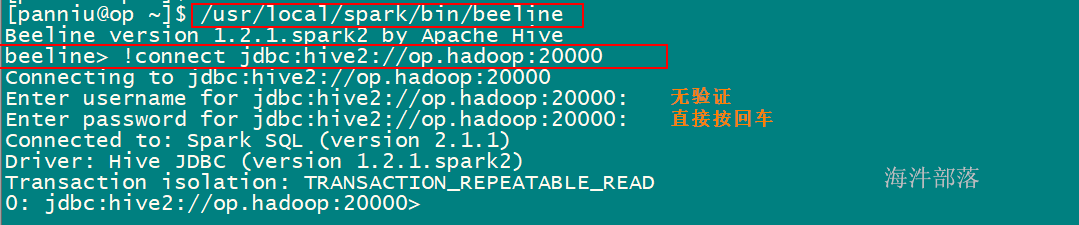



20.4.3 在thriftsever 上跑 sparkSQL
select count(*) from user_install_status;

cache table 表名;
cache table 数据集别名 as 查询SQL内存不够就刷到硬盘
cache table user_install_status_other;


/usr/local/spark/sbin/start-thriftserver.sh –master yarn –queue hainiu –num-executors 5 –executor-memory 4g


select sum(num) from (select count(*) as num from user_install_status_other group by country) a;
– 先缓存SQL
cache table groupbydata as select count(*) as num from user_install_status_other group by country;
– 利用数据集查询
select sum(num) from groupbydata;
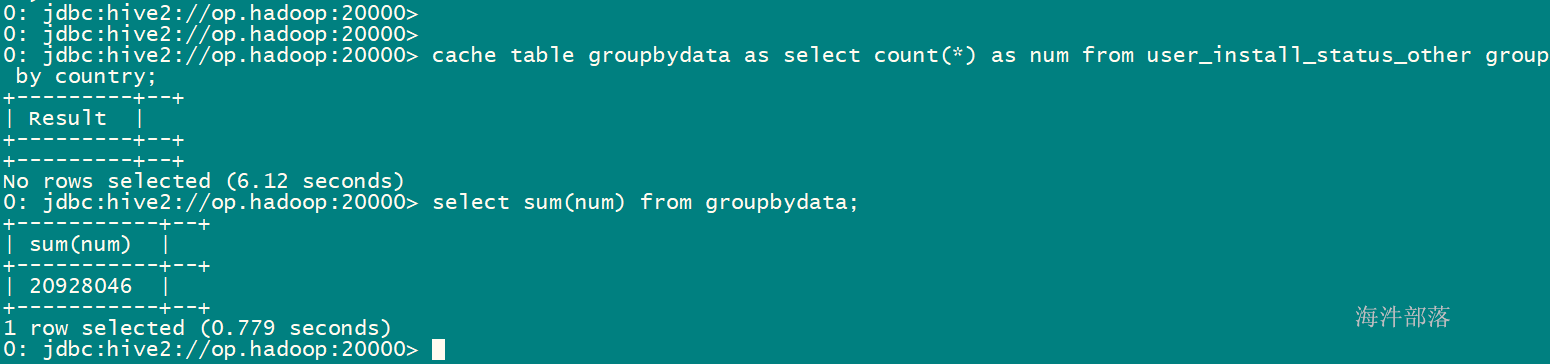
20.5 spark-webUI
怎么合理的运用并行化,比如要处理的数据最终生成的parttion是30个,那你的job设置的资源就应该是10到15个cores。为什么呢?因为官方推荐的设置是(2\~3)*cores = parttions,这样设置的主要原因是executor不会太闲置或者太繁忙。
select count(*) from user_txt;

先看你的RDD会有多少个task,也就是有多少个parttion
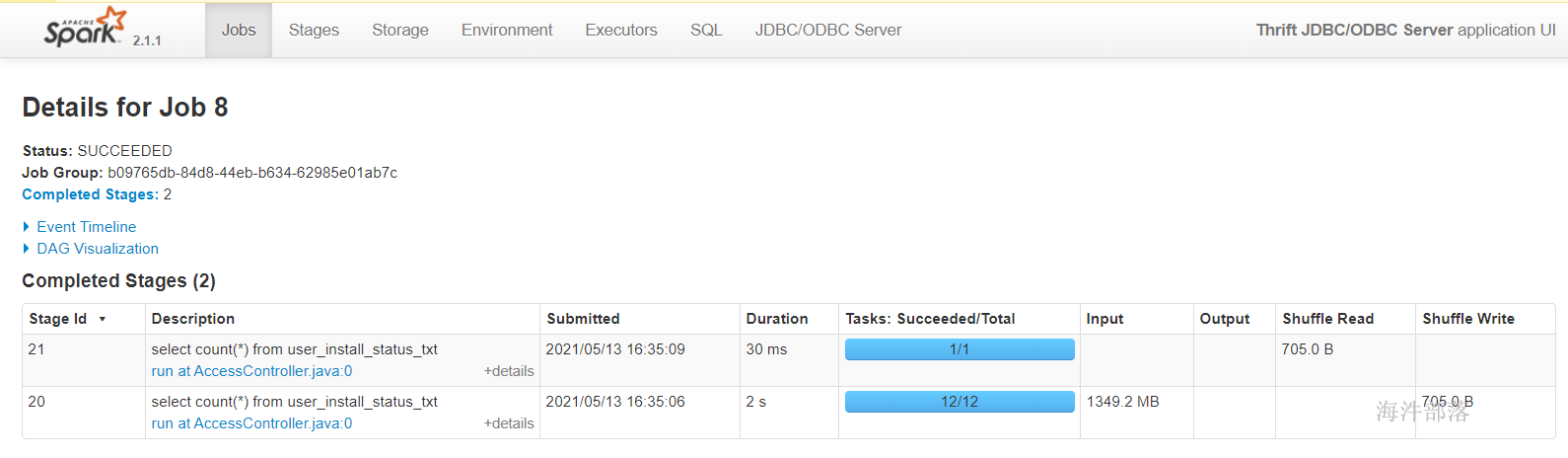
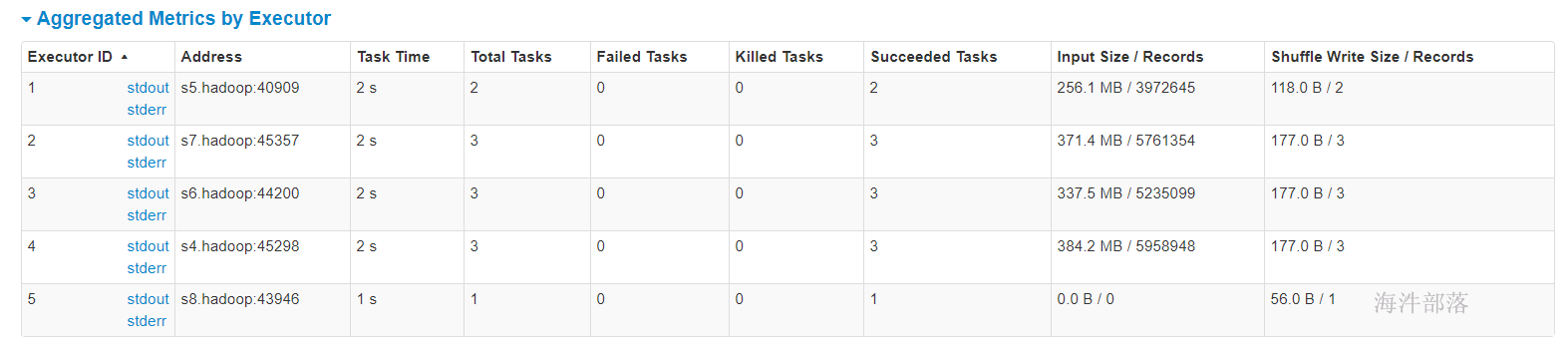
job运行13个task,提供的CPU核数5个, 相对比较合理,但CPU核有空转的。
如何知道自己使用的RDD到底会使用多大的存储空间?
直接缓存表方式:
如果表数据是txt格式,可以根据表对应hdfs的大小来设定。
如果表数据是orc格式文件,那缓存的大小 = 对应hdfs的大小 * 3。



20.6 spark-sql执行过程
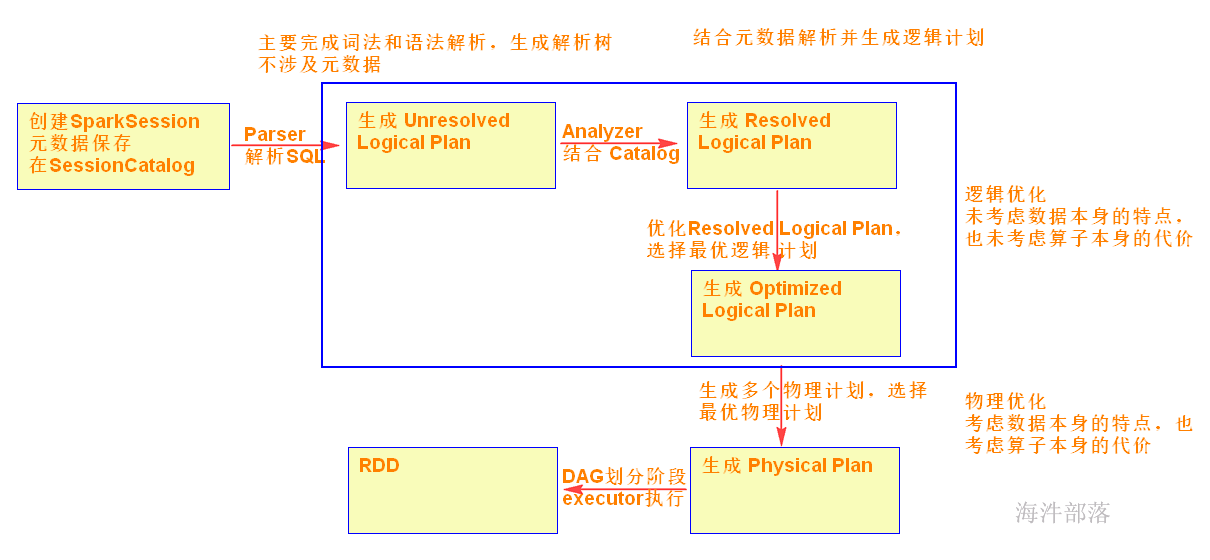
20.7 通过JDBC连接thriftserver
pom里添加spark的hive-jdbc,之前已经添加过
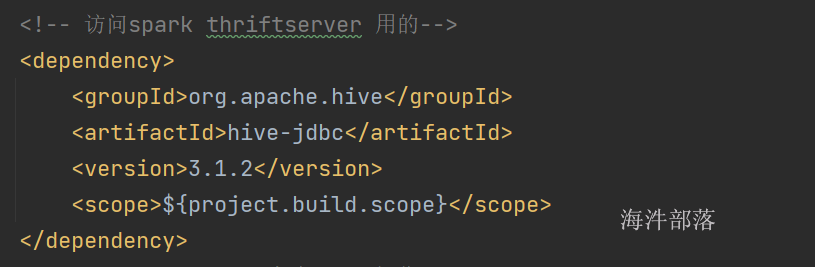
使用JDBC访问spark-sql server 程序:
package com.hainiu.sparksql
import java.sql.{Connection, DriverManager, ResultSet, Statement}
import org.apache.hive.jdbc.HiveDriver
object ThriftServerClient {
def main(args: Array[String]): Unit = {
// 加载hivedriver
classOf[HiveDriver]
var conn: Connection = null
var stmt: Statement = null
try{
// 创建连接
conn = DriverManager.getConnection("jdbc:hive2://op.hadoop:20000/c30pan", "","")
// 创建statement对象
stmt = conn.createStatement()
// 为了防止group by 产生过多分区,设置的
stmt.execute("set spark.sql.shuffle.partitions=2")
val sql:String =
"""
|select sum(num) from (select count(*) as num
|from user_install_status_other group by country) a
""".stripMargin
// 执行查询
val rs: ResultSet = stmt.executeQuery(sql)
while(rs.next()) {
val num: Long = rs.getLong(1)
println(s"num:${num}")
}
}catch {
case e:Exception => e.printStackTrace()
}finally {
stmt.close()
conn.close()
}
}
}结果:
20.8 spark-sql 编程
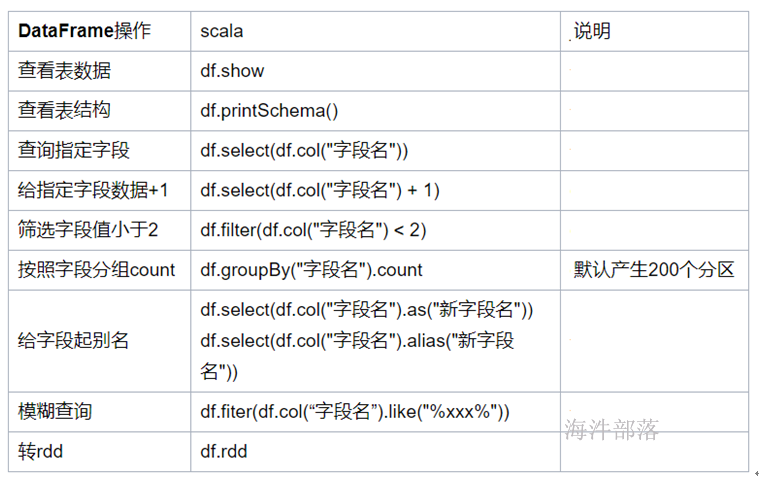
20.8.1 spark-sql的json
添加pom依赖,之前已经添加过
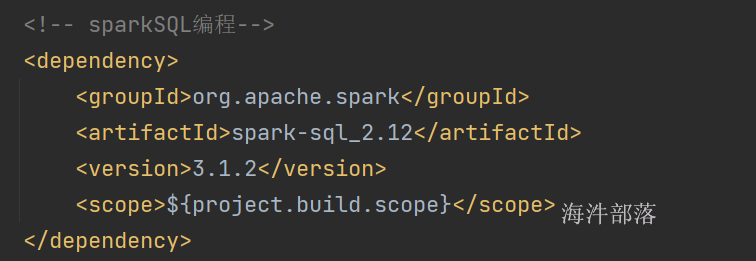
json文件内容
{"country":"CN", "gpcategory":"game", "pkgname":"cn.gameloft.aa", "num":1}
{"country":"CN", "gpcategory":"game", "pkgname":"cn.gameloft.bb", "num":2}
{"country":"RU", "gpcategory":"social", "pkgname":"com.wechat", "num":2}程序:
package com.hainiu.sparksql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
// 读json文件
object SparkSQL01 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkSQL01").setMaster("local[*]")
// conf.set("spark.sql.shuffle.partitions", "2")
val sc: SparkContext = new SparkContext(conf)
// 创建SQLContext对象
val sqlc: SQLContext = new SQLContext(sc)
// 读取json文件创建DataFrame对象
val df: DataFrame = sqlc.read.json("/tmp/sparksql/input_json/data_json.txt")
df.printSchema()
// 查询前20条
df.show()
// 查看country列中的内容
// df.select(df.apply("country")).show()
// df.select(df("country")).show()
// df.select("country","num").show()
// 查询所有country和num,并把num+1
// df.select(df("country"), (df("num") + 1).as("num1")).show()
// 查询num < 2 的数据
// df.filter(df("num") < 2).show()
// 按照country 统计相同country的数量
// select country, count(*) from xxx group by country;
val groupByDF: DataFrame = df.groupBy(df("country")).count()
groupByDF.printSchema()
groupByDF.show()
// 将统计后的结果保存到hdfs上
// 将dataframe 转rdd, 直接转即可
val rdd: RDD[Row] = groupByDF.rdd
val rdd2: RDD[String] = rdd.map(row => {
// rdd[Row] 提取数据用下面的方式
val countryName: String = row.getString(0)
val num: Long = row.getLong(1)
s"${countryName}\t${num}"
})
val coalesceRdd: RDD[String] = rdd2.coalesce(2)
val outputPath:String = "/tmp/sparksql/output_text"
import com.hainiu.util.MyPredef.string2HdfsUtil
outputPath.deleteHdfs
coalesceRdd.saveAsTextFile(outputPath)
}
}SQLContext、HiveContext、SparkSession区别
SQLContext、HiveContext 是spark1.X 使用,HiveContext extends SQLContext,如果读取hive配置使用hive功能,用HiveContext;否则用SQLContext;
SparkSession 是 spark 2.X 使用,在 spark2.X 版本中 SQLContext 和 HiveContext 都被SparkSession替代;
20.8.2 spark-sql自定义schema
数据集
CN game cn.gameloft.aa 1
CN game cn.gameloft.bb 2
RU social com.wechat 1把这个数据集映射成4个字段的表结构,然后筛选这个表中带有CN的数据,并统计记录数
程序:
package com.hainiu.sparksql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{DataType, DataTypes, StructField, StructType}
import org.apache.spark.{SparkConf, SparkContext}
import org.apache.spark.sql.{DataFrame, Row, SQLContext}
import scala.collection.mutable.ArrayBuffer
// 根据Rdd[Row] 构建 DataFrame
object SparkSQL02 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkSQL02").setMaster("local[*]")
// conf.set("spark.sql.shuffle.partitions", "2")
val sc: SparkContext = new SparkContext(conf)
// 创建SQLContext对象
val sqlc: SQLContext = new SQLContext(sc)
val rdd: RDD[String] = sc.textFile("/tmp/sparksql/input_text")
// RDD[String] --> RDD[Row]
val rowRdd: RDD[Row] = rdd.map(f => {
// CN game cn.gameloft.aa 1
val arr: Array[String] = f.split("\t")
val country: String = arr(0)
val gpcategory: String = arr(1)
val pkgname: String = arr(2)
val num: Long = arr(3).toLong
// 提供了apply方法
Row(country, gpcategory, pkgname, num)
})
// 设置row里面每个字段的具体类型
val fields: ArrayBuffer[StructField] = new ArrayBuffer[StructField]
fields += new StructField("country", DataTypes.StringType,true)
fields += new StructField("gpcategory", DataTypes.StringType,true)
fields += new StructField("pkgname", DataTypes.StringType,true)
fields += new StructField("num", DataTypes.LongType,true)
val structType: StructType = StructType(fields)
// 根据rowrdd 构建dataframe
val df: DataFrame = sqlc.createDataFrame(rowRdd, structType)
df.printSchema()
df.show()
// select country, count(*) from xxx group by country
df.groupBy(df("country")).count().show()
}
}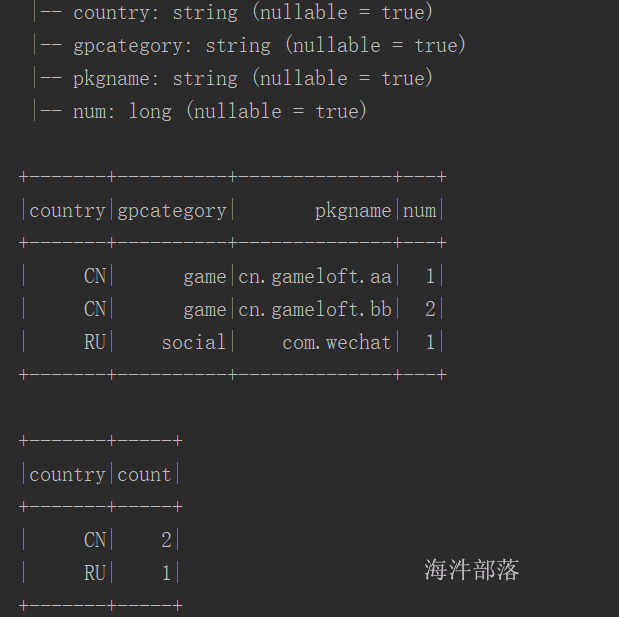
20.8.3 spark-sql用对象自定义schema
首先定义一个数据bean,作用是可以根据这个数据bean通过反射的方式映射出表的结构和生成ds数据集
代码: 用sql语句代替df的api
以text 方式读取text数据, 并将一行的数据封装成一个Bean对象,根据Bean对象创建一个临时视图,通过筛选临时视图得到例子2的结果,并将结果转成rdd打印输出
程序:
package com.hainiu.sparksql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{DataTypes, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Row, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ArrayBuffer
class DFBean(val country:String, val gpcategory:String, val pkgname:String, val num:Long){
// 通过反射拿到字段名country, 拼接getCountry方法来获取数据
def getCountry = this.country
def getGpcategory = this.gpcategory
def getPkgname = this.pkgname
def getNum = this.num
}
// 根据Rdd[Bean] 构建 DataFrame
object SparkSQL03 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkSQL03").setMaster("local[*]")
// conf.set("spark.sql.shuffle.partitions", "2")
val sc: SparkContext = new SparkContext(conf)
// 创建SQLContext对象
val sqlc: SQLContext = new SQLContext(sc)
val rdd: RDD[String] = sc.textFile("/tmp/sparksql/input_text")
// RDD[String] --> RDD[DFBean]
val beanRdd: RDD[DFBean] = rdd.map(f => {
// CN game cn.gameloft.aa 1
val arr: Array[String] = f.split("\t")
val country: String = arr(0)
val gpcategory: String = arr(1)
val pkgname: String = arr(2)
val num: Long = arr(3).toLong
// 提供了apply方法
new DFBean(country, gpcategory, pkgname, num)
})
val df: DataFrame = sqlc.createDataFrame(beanRdd, classOf[DFBean])
df.printSchema()
df.show()
// select country, count(*) from xxx group by country
// 通过这个方法给DataFrame数据集创建临时视图,并设置视图名称
df.createOrReplaceTempView("dftable")
// 用视图直接写sql
val groupByDF: DataFrame = sqlc.sql("select country, count(*) as num1 from dftable group by country")
groupByDF.printSchema()
groupByDF.show()
}
}20.8.4 spark-sql支持hive的ORC格式文件
添加POM依赖,之前已经添加过
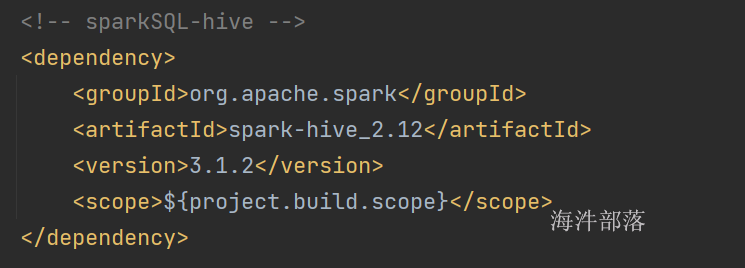
读取orc文件,写入orc和json文件。
程序:
package com.hainiu.sparksql
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{DataTypes, StructField, StructType}
import org.apache.spark.sql._
import org.apache.spark.{SparkConf, SparkContext}
import scala.collection.mutable.ArrayBuffer
//以读orc的方式读取orc文件构建DF
//用DF的api方式查询筛选结果写入orc文件和json文件
object SparkSQL04 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkSQL04").setMaster("local[*]")
conf.set("spark.sql.shuffle.partitions", "1")
val sc: SparkContext = new SparkContext(conf)
// 创建SQLContext对象
val sqlc: SQLContext = new SQLContext(sc)
// 读取orc文件生成DataFrame
val df: DataFrame = sqlc.read.orc("/tmp/sparksql/input_orc")
// df.printSchema()
// df.show()
// select country, num from
// (select country, count(*) as num from xxx group by country) t
// where t.num > 5
// 通过Dataframe api 拼接SQL
val groupByDF: DataFrame = df.groupBy(df("country")).count()
val filterDF: Dataset[Row] = groupByDF.filter(groupByDF("count") > 5)
// filterDF.printSchema()
// filterDF.show()
// sparksql cache 的默认缓存级别:storageLevel: StorageLevel = MEMORY_AND_DISK
val cacheDS: Dataset[Row] = filterDF.cache()
// 把结果写入orc和json文件
// 以 覆盖写入方式, 写入到orc文件, 文件输出到 /tmp/sparksql/output_orc
cacheDS.write.mode(SaveMode.Overwrite).format("orc").save("/tmp/sparksql/output_orc")
cacheDS.write.mode(SaveMode.Overwrite).format("json").save("/tmp/sparksql/output_json")
}
}结果:
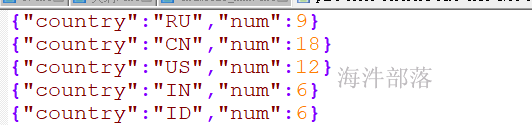
20.8.5 使用SQL形式实现第4点的功能
读取orc文件,将查询结果写入text文件
程序:
package com.hainiu.sparksql
import org.apache.spark.sql._
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext}
//以读orc的方式读取orc文件构建DF
//通过DF构建临时视图,用SQL查询的方式筛选结果写入text文件
object SparkSQL05 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkSQL05").setMaster("local[*]")
conf.set("spark.sql.shuffle.partitions", "1")
val sc: SparkContext = new SparkContext(conf)
// 创建HiveContext对象
val hqlc: HiveContext = new HiveContext(sc)
// 读取orc文件生成DataFrame
val df: DataFrame = hqlc.read.orc("/tmp/sparksql/input_orc")
// df.printSchema()
// df.show()
// select country, num from
// (select country, count(*) as num from xxx group by country) t
// where t.num > 5
// 创建临时视图
df.createOrReplaceTempView("dftable")
val sql:String =
"""
|select concat(country, '\t',num) as country_num from
|(select country, count(*) as num from dftable group by country) t where t.num>5
""".stripMargin
val df2: DataFrame = hqlc.sql(sql)
// df2.printSchema()
// df2.show()
// 如果想把dataframe的数据写入text文件,那这个数据集必须只有一个字段,否则写入失败
df2.write.mode(SaveMode.Overwrite).format("text").save("/tmp/sparksql/output_text")
}
}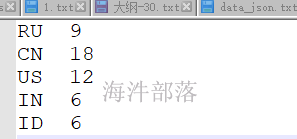
20.8.6 使用HQL形式实现第4点的功能
通过hiveSQL 创建数据库,创建表,查询表,导出text文件
程序:
package com.hainiu.sparksql
import org.apache.spark.sql._
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext}
//以读orc的方式读取orc文件构建DF
//通过DF构建hive库、hive表
//通过hive查询的方式筛选结果
object SparkSQL06 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkSQL06").setMaster("local[*]")
conf.set("spark.sql.shuffle.partitions", "1")
val sc: SparkContext = new SparkContext(conf)
// 创建HiveContext对象
val hqlc: HiveContext = new HiveContext(sc)
// 建数据库
hqlc.sql("create database if not exists c30pan")
// 进入数据库
hqlc.sql("use c30pan")
// 建表
hqlc.sql(
"""
|CREATE TABLE if not exists `spark_user_orc`(
| `aid` string COMMENT 'from deserializer',
| `pkgname` string COMMENT 'from deserializer',
| `uptime` bigint COMMENT 'from deserializer',
| `type` int COMMENT 'from deserializer',
| `country` string COMMENT 'from deserializer')
|ROW FORMAT SERDE
| 'org.apache.hadoop.hive.ql.io.orc.OrcSerde'
|STORED AS INPUTFORMAT
| 'org.apache.hadoop.hive.ql.io.orc.OrcInputFormat'
|OUTPUTFORMAT
| 'org.apache.hadoop.hive.ql.io.orc.OrcOutputFormat'
""".stripMargin)
// 导入数据
hqlc.sql("load data local inpath '/tmp/sparksql/input_orc' overwrite into table spark_user_orc")
// 通过SQL视图的方式查询结果
val df: DataFrame = hqlc.sql("select * from spark_user_orc")
df.printSchema()
df.show()
}
}元数据和数据库位置:
如果没有hive-site.xml配置,会用derby数据库当元数据,derby数据库会在当前项目目录下;
如果没有配置warehouse的地址,warehouse的生成目录也会在当前项目目录下,你创建的数据库和表的目录都在这个生成的warehouse目录;
来个加载hive-site.xml 配置
执行代码后:
结论:
加入hive-site.xml 配置后, 初始化HiveContext时会加载hive-site.xml 的配置,使配置生效。
这时所使用的元数据是MySQL里的, 数据是hive库里的。
20.8.7 使用spark-sql的JDBC访问MYSQL
添加POM依赖,之前已经添加过:
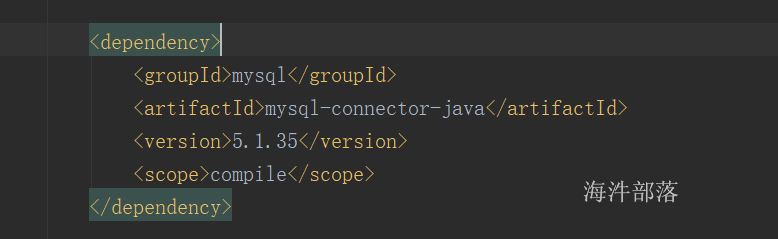
程序:
package com.hainiu.sparksql
import java.util.Properties
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Row, SQLContext}
import org.apache.spark.{SparkConf, SparkContext}
//使用spark-sql的JDBC访问MYSQL
object SparkSQL07 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkSQL07").setMaster("local[*]")
// conf.set("spark.sql.shuffle.partitions", "2")
val sc: SparkContext = new SparkContext(conf)
// 创建SQLContext对象
val sqlc: SQLContext = new SQLContext(sc)
// 设置数据库用户名和密码
val prop: Properties = new Properties()
prop.setProperty("user", "root")
prop.setProperty("password", "111111")
// jdbc连接MySQL生成DataFrame
val df1: DataFrame = sqlc.read.jdbc("jdbc:mysql://localhost:3306/hainiu_test","student",prop)
val df2: DataFrame = sqlc.read.jdbc("jdbc:mysql://localhost:3306/hainiu_test","student_course",prop)
df1.createOrReplaceTempView("s")
df2.createOrReplaceTempView("sc")
// 将 student表和 student_course表 inner join
val joinDF: DataFrame = sqlc.sql("select * from s, sc where s.S_ID=sc.SC_S_ID")
joinDF.printSchema()
joinDF.show()
}
}
20.8.8 sparkSession使用
程序:
package com.hainiu.sparksql
import java.util.Properties
import com.mysql.jdbc.Driver
import org.apache.spark.sql.{DataFrame, SQLContext, SparkSession}
import org.apache.spark.{SparkConf, SparkContext}
//使用spark-sql的JDBC访问MYSQL
// 用SparkSession
object SparkSQL08 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkSQL08").setMaster("local[*]")
// conf.set("spark.sql.shuffle.partitions", "2")
// 创建sparksession对象
val sparkSession: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// sparkSession.sparkContext.xxx
// 设置数据库用户名和密码
val prop: Properties = new Properties()
prop.setProperty("user", "root")
prop.setProperty("password", "111111")
// jdbc连接MySQL生成DataFrame
val df1: DataFrame = sparkSession.read.jdbc("jdbc:mysql://localhost:3306/hainiu_test", "student", prop)
// val df2: DataFrame = sparkSession.read.jdbc("jdbc:mysql://localhost:3306/hainiu_test", "student_course", prop)
val df2: DataFrame = sparkSession.read.format("jdbc")
.option("driver", classOf[Driver].getName)
.option("url", "jdbc:mysql://localhost:3306/hainiu_test")
.option("dbtable", "student_course")
.option("user", "root")
.option("password", "111111").load()
df1.createOrReplaceTempView("s")
df2.createOrReplaceTempView("sc")
// 将 student表和 student_course表 inner join
val joinDF: DataFrame = sparkSession.sql("select * from s, sc where s.S_ID=sc.SC_S_ID")
joinDF.printSchema()
joinDF.show()
}
}20.9 RDD、DataFrame、Dataset
20.9.1 概念
RDD:
弹性分布式数据集;
DataFrame:
DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。这样的数据集可以用SQL查询。
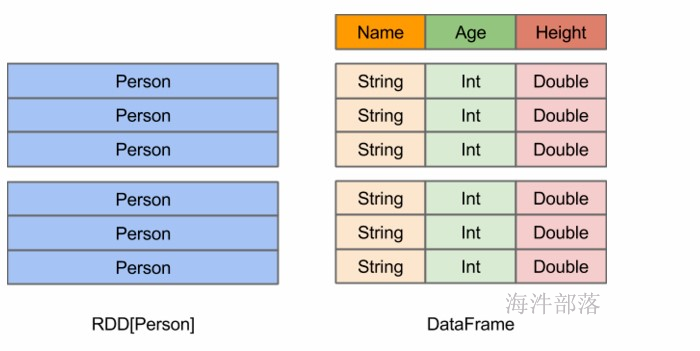
DataFrame 是 DataSet[Row]
DataSet:
Dataset是一个强类型的特定领域的对象,Dataset也被称为DataFrame的类型化视图,这种DataFrame是Row类型的Dataset,即Dataset[Row]。

20.9.2 三者共性
1)RDD、DataFrame、Dataset全都是spark平台下的弹性分布式数据集,为处理超大型数据提供便利;
2)三者都有惰性机制,在进行创建、转换,如map方法时,不会立即执行,只有在遇到Action,如foreach时,三者才会开始遍历运算,极端情况下,如果代码里面有创建、转换,但是后面没有在Action中使用对应的结果,在执行时会被直接跳过,如
val sparkconf = new SparkConf().setMaster("local").setAppName("test")
val spark = SparkSession.builder().config(sparkconf).getOrCreate()
val rdd=spark.sparkContext.parallelize(Seq(("a", 1), ("b", 1), ("a", 1)))
// rdd df ds 三者不遇到action不执行
rdd map {line=> {
println("运行")
line._1
}
}map中的println(“运行”)并不会运行
3)三者都可以缓存运算;
4)三者都有partition;
5)三者有许多共同的函数,如filter,排序等;
20.9.3 DataFrame、Dataset 的共性
1)在对DataFrame和Dataset进行操作,许多操作都需要这个包进行支持;
import sparkSession.implicits._
// 其中:sparkSession 是 SparkSession的变量名2)DataFrame和Dataset均可使用模式匹配获取各个字段的值和类型;
// DataFrame:
df map {
case Row(col1:String,col2:Int)=>
println(s"${col1}, ${col2}")
s"${col1}\t${col2}"
}
//等效于
df.map(row => {
val col1: String = row.getString(0)
val col2: Int = row.getInt(1)
println(s"${col1}, ${col2}")
s"${col1}\t${col2}"
}).show()
// DataSet:
// DataSet 可以通过样例类构建
case class ColClass(col1:String,col2:Int) //定义字段名和类型
ds.map{
case f:ColClass => s"${f.col1}\t${f.col2}"
}.show()
// 等效于
ds.map{
case ColClass(col1, col2) => s"${col1}\t${col2}"
}.show()
// 等效于
ds.map(f =>{
s"${f.col1}\t${f.col2}"
}).show()20.9.4 区别
1)RDD不支持sparksql操作,可用于处理非结构化数据和结构化数据;而DataFrame和DataSet用于处理结构化数据;
2)与RDD和Dataset不同,DataFrame每一行的类型固定为Row,只有通过解析才能获取各个字段的值,如
testDF.foreach{
line =>
val col1=line.getString("col1")
val col2=line.getAs[String]("col2")
}每一列的值没法直接访问;
3)DataFrame与Dataset均支持sparksql的操作,比如select,groupby之类,还能注册临时表/视窗,进行sql语句操作,如
dataDF.createOrReplaceTempView("tmp")
spark.sql("select ROW,DATE from tmp where DATE is not null order by DATE").show(100,false)4)DataFrame与Dataset支持一些特别方便的保存方式,比如保存成csv,可以带上表头,这样每一列的字段名一目了然
//保存
val saveoptions = Map("header" -> "true", "delimiter" -> ",", "path" -> "/tmp/sparksql/output_csv")
ds.write.format("com.databricks.spark.csv").mode(SaveMode.Overwrite).options(saveoptions).save()
//读取
val options = Map("header" -> "true", "delimiter" -> ",", "path" -> "/tmp/sparksql/output_csv")
val datarDF= spark.read.options(options).format("com.databricks.spark.csv").load()利用这样的保存方式,可以方便的获得字段名和列的对应,而且分隔符(delimiter)可以自由指定;

用excel打开后,看到单元格
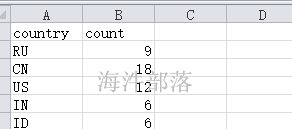
5)Dataset中,每一行是什么类型是固定的,在自定义了case class之后可以很自由的获得每一行的信息
case class Coltest(name:String,col2:Int) //定义字段名和类型
/**
rdd
("a", 1)
("b", 1)
("a", 1)
* */
val test: Dataset[Coltest]=rdd map {line=>
Coltest(line._1,line._2)
}.toDS
test map {
line=>
println(line.name)
println(line.col2)
}可以看出,Dataset在需要访问列中的某个字段时是非常方便的,然而,如果要写一些适配性很强的函数时,如果使用Dataset,行的类型又不确定,可能是各种case class,无法实现适配,这时候用DataFrame即Dataset[Row]就能比较好的解决问题
20.9.5 三者之间的转换
RDD、DataFrame、Dataset三者有许多共性,有各自适用的场景常常需要在三者之间转换;
// DataFrame/Dataset 转 RDD:
val rdd1:RDD[ROW]=testDF.rdd
val rdd2:RDD[ROW/其它]=testDS.rdd
//RDD 转 DataFrame:
// 通过隐式转换函数 rddToDatasetHolder 将 rdd --> DatasetHolder[DateSet]
// 再通过 toDF 函数,得到 DateFrame
import sparkSession.implicits._
val testDF = rdd map {line=>
(line._1,line._2)
}.toDF("col1","col2")
// 一般用元组把一行的数据写在一起,然后在toDF中指定字段名
// RDD转Dataset
// 通过隐式转换函数 rddToDatasetHolder 将 rdd --> DatasetHolder[DateSet]
// 再通过 toDS 函数,得到 DateSet
import spark.implicits._
val testDS = rdd map {line=>
(line._1,line._2)
}.toDS() 代码示例:
package sparksql
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql._
object SparkSql09 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("SparkSql09")
// 设置shuffle产生1个分区
conf.set("spark.sql.shuffle.partitions", "1")
// 构建SparkSession对象
val sparkSession: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// 引入隐式转换
import sparkSession.implicits._
val rdd: RDD[String] = sparkSession.sparkContext.parallelize(List("a 1", "a 2", "b 2"), 2)
val rdd2: RDD[(String, Int)] = rdd.map(f => {
val arr: Array[String] = f.split(" ")
(arr(0), arr(1).toInt)
})
// ------rdd转 dataframe------
// 通过隐式转换函数 rddToDatasetHolder, 将rdd转成DatasetHolder对象,并调用其toDF方法实现
val df: DataFrame = rdd2.toDF("word", "num")
// df.printSchema()
// df.show()
// df.map(f =>{
// val word: String = f.getString(0)
// val num: Int = f.getInt(1)
// s"${word}\t${num}"
// }).show()
df.map{
case Row(word:String, num:Int) => s"${word}\t${num}"
}.show()
// ------rdd转DataSet------
// 通过隐式转换函数 rddToDatasetHolder, 将rdd转成DatasetHolder对象,并调用其toDS方法实现
val rdd3: RDD[CaseBean] = rdd2.map(f => CaseBean(f._1, f._2))
val ds: Dataset[CaseBean] = rdd3.toDS()
ds.printSchema()
ds.show()
ds.map{
// 匹配对象类型
case x:CaseBean => s"${x.word}\t${x.num}"
}.show()
ds.map{
// 匹配对象的数据
case CaseBean(word, num) => s"${word}\t${num}"
}.show()
ds.map(f =>{
s"${f.word}\t${f.num}"
}).show()
// ------df 转 rdd 可直接转,不需要隐式转换------------
val dfRdd: RDD[Row] = df.rdd
dfRdd.map(f =>{
val word: String = f.getString(0)
val num: Int = f.getInt(1)
s"${word}\t${num}"
}).foreach(f =>println(s"dfrdd_${f}"))
// ------ds 转 rdd 可直接转,不需要隐式转换------------
val dsRdd: RDD[CaseBean] = ds.rdd
dsRdd.map(f =>{
s"${f.word}\t${f.num}"
}).foreach(f => println(s"dsrdd_${f}"))
}
}
case class CaseBean(val word:String, val num:Int)20.10 spark-sql的UDF
程序:
package com.hainiu.sparksql
import java.util.Properties
import com.mysql.jdbc.Driver
import org.apache.spark.SparkConf
import org.apache.spark.sql.{DataFrame, SparkSession}
//使用spark-sql的JDBC访问MYSQL
// 用SparkSession
// 自定义udf函数,并使用
object SparkSQL10 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkSQL10").setMaster("local[*]")
// conf.set("spark.sql.shuffle.partitions", "2")
// 创建sparksession对象
val sparkSession: SparkSession = SparkSession.builder().config(conf).getOrCreate()
// sparkSession.sparkContext.xxx
//注册函数 输入字符串 ==> 计算字符串长度
sparkSession.udf.register("len", (name:String)=> name.length)
// 设置数据库用户名和密码
val prop: Properties = new Properties()
prop.setProperty("user", "root")
prop.setProperty("password", "111111")
// jdbc连接MySQL生成DataFrame
val df1: DataFrame = sparkSession.read.jdbc("jdbc:mysql://localhost:3306/hainiu_test", "student", prop)
df1.createOrReplaceTempView("s")
// 使用函数
val df2: DataFrame = sparkSession.sql("select s_name, len(s_name) as namelen from s")
df2.printSchema()
df2.show()
}
}
21 spark Streaming
21.1 spark streaming介绍
21.1.1 背景
随着大数据技术的不断发展,人们对于大数据的实时性处理要求也在不断提高,传统的 MapReduce 等批处理框架在某些特定领域,例如实时用户推荐、用户行为分析这些应用场景上逐渐不能满足人们对实时性的需求,因此诞生了一批如 S3、Storm 这样的流式分析、实时计算框架。Spark 由于其内部优秀的调度机制、快速的分布式计算能力,所以能够以极快的速度进行迭代计算。正是由于具有这样的优势,Spark 能够在某些程度上进行实时处理,Spark Streaming 正是构建在此之上的流式框架。
21.1.2 Spark Streaming 设计
支持输入输出的数据源:
Spark Streaming 是 Spark 的核心组件之一,它可以实现高吞吐量的、具备容错机制的实时流数据的处理。支持从多种数据源获取数据,包括Kafka、ZeroMQ等消息队列以及TCP sockets或者目录文件从数据源获取数据之后,可以使用诸如map、reduce、join和window等高级函数进行复杂算法的处理。最后还可以将处理结果存储到文件系统,数据库或显示在仪表盘里。

Spark Streaming 的基本原理是将实时输入数据流以时间片(通常在0.5\~2秒之间)为单位进行拆分,然后采用 Spark 引擎以类似批处理的方式处理每个时间片数据,执行流程如下图所示:

Spark Streaming 最主要的抽象是离散化数据流(DStream),DStream 表示连续不断的数据流。在内部实现上,Spark Streaming 的输入数据按照时间片分成一段一段,每一段数据转换为 Spark 中的 RDD,并且对 DStream 的操作都最终被转变为相应的 RDD 操作。如下图所示:

以 wordcount 为例,一个又一个句子会像流水一样源源不断到达,Spark Streaming 会把数据流按照时间片切分成一段一段,每段形成一个 RDD,这些 RDD 构成了一个 DStream。对这个 DStream 执行 flatMap 操作时,实际上会被转换成针对每个 RDD 的 flatMap 操作,转换得到的每个新的 RDD 又构成了一个新的DStream。如下图所示:
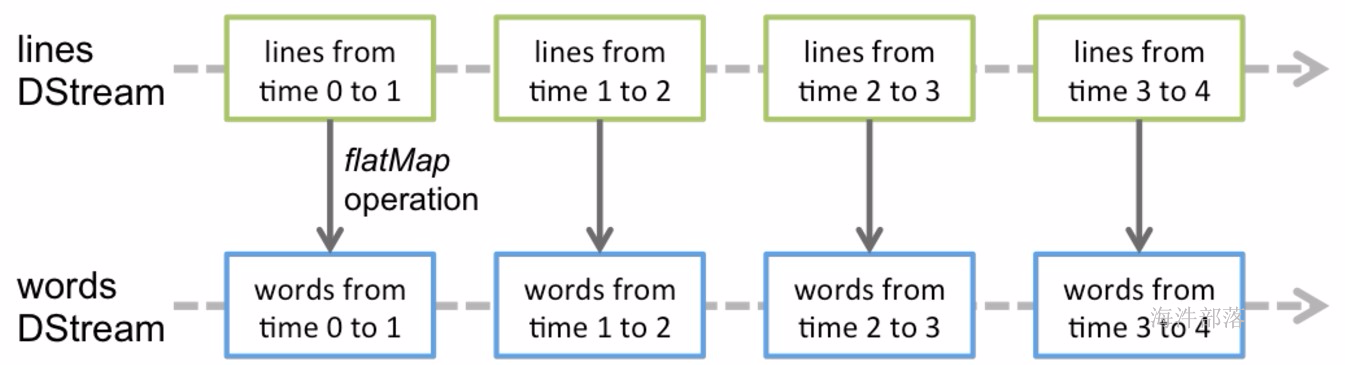
21.1.3 Spark Streaming 与 flink的对比
对比
| 对比点 | Flink | Spark Streaming |
|---|---|---|
| 实时计算模型 | 纯实时,来一条数据,处理一条数据 | 准实时,对一个时间段内的数据收集起来,作为一个RDD,再处理 |
| 实时计算延迟度 | 毫秒级 | 秒级 |
| 吞吐量 | 低(移动数据不移动计算) | 高(移动计算不移动数据) |
1)处理模型以及延迟
SparkStreaming 无法实现毫秒级的流计算。Spark Streaming可以在一个短暂的时间窗口里面处理多条(batches)Event,并且 SparkStreaming 将流数据分解为一系列批处理作业,在这个过程中会产生多个spark 作业,每段数据的处理都会经过DAG图分解、任务调度等过程,需要一定的额开销。
2)容错和数据保证
然而两者的都有容错时候的数据保证,Spark Streaming的容错为有状态的计算提供了更好的支持。在Storm中,每条记录在系统的移动过程中都需要被标记跟踪,所以Storm只能保证每条记录最少被处理一次,但是允许从错误状态恢复时被处理多次。这就意味着可变更的状态可能被更新两次从而导致结果不正确。
另一方面,Spark Streaming仅仅需要在批处理级别对记录进行追踪,所以他能保证每个批处理记录仅仅被处理一次,即使是node节点挂掉。
3)批处理框架集成
Spark Streaming的一个很棒的特性就是它是在Spark框架上运行的。这样你就可以使用spark的批处理代码一样来写Spark Streaming程序,或者是在Spark中交互查询比如spark-sql。这就减少了单独编写流处理程序和历史数据处理程序。
4)生产支持
两者都可以在各自的集群框架中运行,但是Storm可以在Mesos上运行, 而Spark Streaming可以在YARN和Mesos上运行。
Storm已经出现好多年了,而且自从2011年开始就在Twitter内部生产环境中使用,还有其他一些公司。
Spark Streaming优缺点
优点:
Spark Streaming的真正优势(Storm绝对比不上的),是它属于Spark生态技术栈中,因此Spark Streaming可以和Spark Core、Spark SQL无缝整合,而这也就意味着,我们可以对实时处理出来的中间数据,立即在程序中无缝进行延迟批处理、交互式查询等操作,这个特点大大增强了Spark Streaming的优势和功能。
缺点:
延迟。500毫秒已经被广泛认为是最小批次大小,这个相对storm来说,还是大很多。所以实际场景中应注意该问题,就像标题分类场景,设定的0.5s一批次,加上处理时间,分类接口会占用1s的响应时间。实时要求高的可选择使用其他框架。
应用场景:
实时性要求高,用storm。
实时性要求不高、在计算过程中需要复杂的转换操作或交互式查询的操作,用 Spark Streaming。
21.2 架构及运行流程
21.2.1 架构
Spark Streaming使用“微批次”的架构,把流试计算当成一系列连接的小规模批处理来对待,Spark Streaming从各种输入源中读取数据,并把数据分成小组的批次,新的批次按均匀的时间间隔创建出来,在每个时间区间开始的时候,一个新的批次就创建出来,在该区间内收到的数据都会被添加到这个批次中,在时间区间结束时,批次停止增长。时间区间的大小是由批次间隔这个参数决定的,批次间隔一般设在500毫秒到几秒之间,由应用开发者配置,每个输出批次都会形成一个RDD,以Spark作业的方式处理并生成其他的RDD。并能将处理结果按批次的方式传给外部系统。
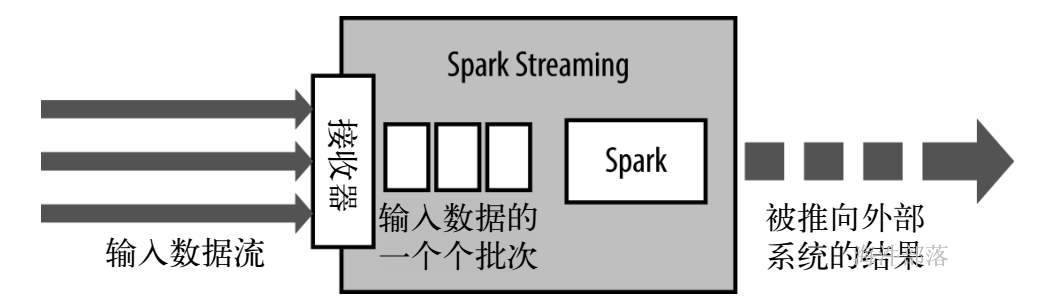
在本地运行Spark Streaming程序时,请勿使用“ local”或“ local [1]”作为主URL。这两种方式均意味着仅一个线程将用于本地运行任务。如果您使用的是基于接收器的输入DStream(例如套接字,Kafka,Flume等),则将使用单个线程来运行接收器,而不会留下任何线程来处理接收到的数据。因此,在本地运行时,请始终使用“ local [ n ]”作为主URL,其中n >要运行的接收器数量。
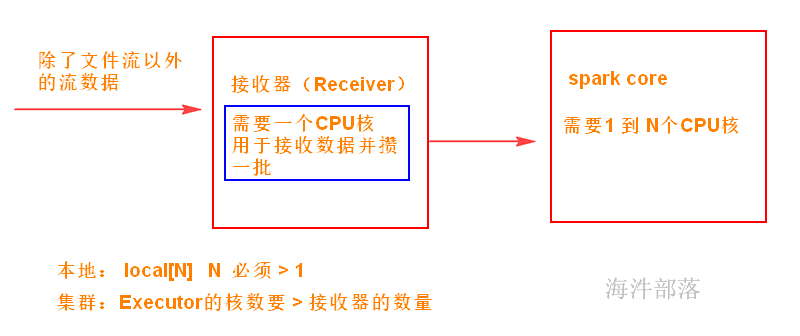
21.2.2 运行流程
SparkStreaming 分为Driver端 和 Client端。
Driver端为StreamingContext实例,包括JobScheduler 、DStreamGraph 等;
Client端为 ReceiverSupervisor 和 Receiver。
SparkStreaming 进行流数据处理的大概步骤:
1)启动流处理引擎;
2)接收及存储流数据;
3)处理流数据;
4)输出处理结果;
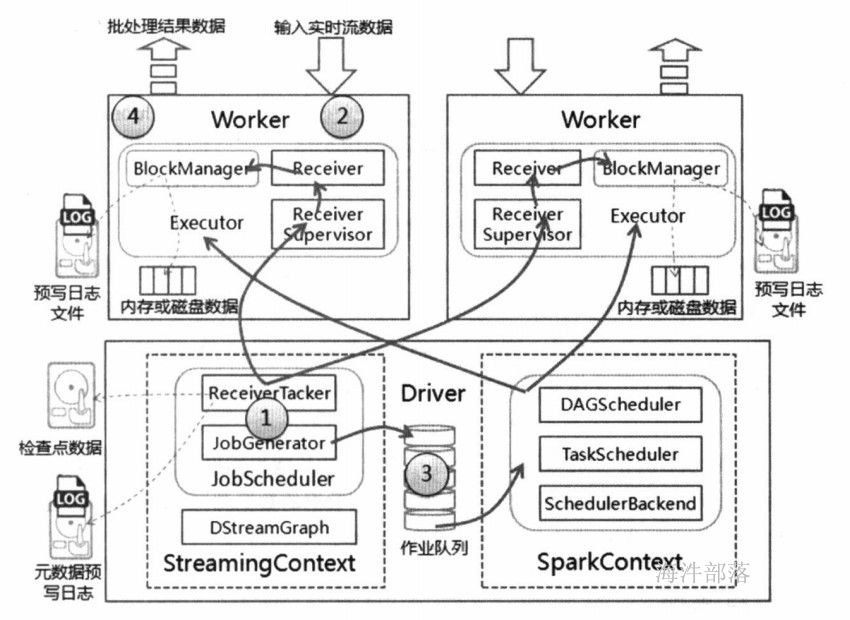
StreamingContext 初始化时,会初始化JobScheduler 、DStreamGraph 实例。其中:
DStreamGraph:存放DStream 间的依赖关系,就像RDD的依赖关系一样;
JobScheduler:JobScheduler 是SparkStreaming 的 Job 总调度者。它 包括 ReceiverTracker 和 JobGenerator。
ReceiverTacker:它负责启动、管理各个executor的 流数据接收器(Receiver)及管理各个Receiver 接收到的数据。当ReceiverTacker启动过程中,会初始化executor 的 流数据接收管理器(ReceiverSupervisor),再由它启动流数据接收器(Receiver)。
JobGenerator:它是批处理作业生成器,内部维护一个定时器,定时处理批次的数据生成作业。
step2:接收及存储流数据;
当Receiver 启动后,连续不断的接收实时流数据,根据传过来的数据大小进行判断,如果数据小,就攒多条数据成一块,进行块存储;如果数据大,则一条数据成一块,进行块存储。
块存储时会根据是否设置预写日志文件分成两种方式:
1)不设置预写日志文件,就直接写入对应Worker的内存或磁盘。
2)设置预写日志文件,会同时写入对应Worker的内存或磁盘 和 容错文件系统(比如hdfs),设置预写日志文件主要是为了容错,在当前节点出故障后,还可以恢复。
数据存储完毕后,ReceiverSupervisor 会将数据存储的元信息(streamId、数据位置、数据条数、数据 size 等信息)上报给 Driver端的 ReceiverTacker。ReceiverTacker 维护收到的元数据信息。
step3:处理流数据;
在 StreamingContext 的 JobGenerator 中维护一个定时器,该定时器在批处理时间到来时会进行生成作业的操作。在操作中进行如下操作:
1)通知 ReceiverTacker 将接收到到的数据进行提交,在提交时采用 synchronize 关键字进行处理,保证每条数据被划入一个且只被划入一个批次中。
2)要求 DStreamGraph 根据 DStream 依赖关系生成作业序列 Seq[Job]。
3)从 ReceiverTacker 中获取本批次数据的元数据。
4)把批处理时间、作业序列 Seq[Job] 和本批次数据的元数据包装为 JobSet。调用 JobScheduler.submitJobSet(JobSet) 提交给 JobScheduler,JobScheduler 将把这些作业放到 作业队列,Spark 核心 在从作业队列中取出执行作业任务。由于中间有 队列,所以速度非常快。
5)当提交本批次作业结束,根据 是否设置checkpoint,如果设置checkpoint,SparkStreaming 对整个系统做checkpoint。
step4:输出处理结果
由于数据的处理有Spark核心来完成,因此处理的结果会从Spark核心中直接输出至外部系统,如数据库或者文件系统等,同时输出的数据也可以直接被外部系统所使用。由于实时流数据的数据源源不断的流入,Spark会周而复始的进行数据的计算,相应也会持续输出处理结果。
21.3 DStream
21.3.1 DStream 输入源
基本输入源:
文件系统 和 Socket。
高级输入源:
| Source | Artifact |
|---|---|
| Kafka | spark-streaming-kafka_2.11 |
| Flume | spark-streaming-flume_2.11 |
| Kinesis | spark-streaming-kinesis-asl_2.11 |
| spark-streaming-twitter_2.11 | |
| ZeroMQ | spark-streaming-zeromq_2.11 |
| MQTT | spark-streaming-mqtt_2.11 |
21.3.2 DStream 转换操作
21.3.2.1 DStream 无状态转换操作
对于DStream 无状态转换操作而言,不会记录历史状态信息,每次对新的批次数据进行处理时,只会记录当前批次数据的状态。
OLDDStream -> NEWDStream
| 转换 | 描述 |
|---|---|
| map(func) | 源 DStream的每个元素通过函数func返回一个新的DStream |
| flatMap(func) | 类似与map操作,不同的是每个输入元素可以被映射出0或者更多的输出元素 |
| filter(func) | 在源DStream上选择func函数返回仅为true的元素,最终返回一个新的DStream |
| repartition(numPartitions) | 通过输入的参数numPartitions的值来改变DStream的分区大小 |
| union(otherStream) | 返回一个包含源DStream与其他 DStream的元素合并后的新DStream |
| count() | 对源DStream内部的所含有的RDD的元素数量进行计数,返回一个内部的RDD只包含一个元素的DStreaam |
| reduce(func) | 使用函数func(有两个参数并返回一个结果)将源DStream 中每个RDD的元素进行聚合操作,返回一个内部所包含的RDD只有一个元素的新DStream。 |
| countByValue() | 计算DStream中每个RDD内的元素出现的频次并返回新的DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素出现的频次。 |
| reduceByKey(func, [numTasks]) | 当一个类型为(K,V)键值对的DStream被调用的时候,返回类型为类型为(K,V)键值对的新 DStream,其中每个键的值V都是使用聚合函数func汇总。注意:默认情况下,使用 Spark的默认并行度提交任务(本地模式下并行度为2,集群模式下位8),可以通过配置numTasks设置不同的并行任务数。 |
| join(otherStream, [numTasks]) | 当被调用类型分别为(K,V)和(K,W)键值对的2个DStream时,返回类型为(K,(V,W))键值对的一个新 DSTREAM。 |
| cogroup(otherStream, [numTasks]) | 当被调用的两个DStream分别含有(K, V) 和(K, W)键值对时,返回一个(K, Seq[V], Seq[W])类型的新的DStream。 |
| transform(func) | 通过对源DStream的每RDD应用RDD-to-RDD函数返回一个新的DStream,这可以用来在DStream做任意RDD操作。 |
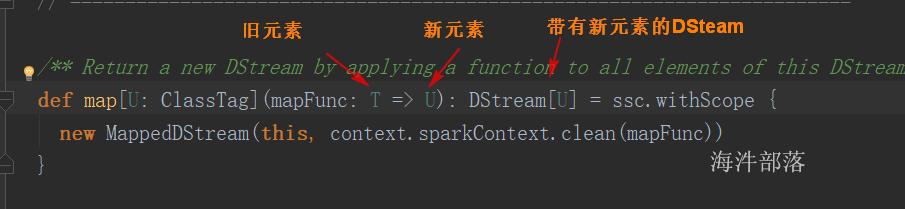
val dstream2 = dstream1.flatMap(.split(" ")).map((,1)).reduceByKey(_ + _)
// 通过 transform 将 dstream 转成 rdd, 然后 通过rdd 的 转换进行单词统计,然后把最终的rdd 在转换成 dstream.
val dstream2 = dstream1.transform(rdd =>{
val name = “hehe” // driver端运行
println(s“name:\${name}”) // driver端运行
rddnew = rdd.flatMap(.split(" ")).map((,1)).reduceByKey(_ + _)
rddnew
})
在无状态转换算子里面:
transform(func) 是个特殊的算子,它函数内部是 RDD;
而其他的算子内部是对应的元素类型,跟RDD算子里面的类型是一样的。
21.3.2.2 DStream 有状态转换操作
DStream 有状态转换操作包括 滑动窗口转换操作 和 updateStateByKey 操作。
1)滑动窗口转换操作
对于窗口操作,批处理间隔、窗口间隔和滑动间隔是非常重要的三个时间概念,是理解窗口操作的关键所在。
批处理间隔:
在Spark Streaming中,数据处理是按批进行的,而数据采集是逐条进行的,因此在Spark Streaming中会先设置好批处理间隔(batch duration),当超过批处理间隔的时候就会把采集到的数据汇总起来成为一批数据交给系统去处理。
窗口间隔:
对于窗口操作而言,在其窗口内部会有N个批处理数据,批处理数据的大小由窗口间隔(window duration)决定,而窗口间隔指的就是窗口的持续时间,在窗口操作中,只有窗口的长度满足了才会触发批数据的处理。
滑动间隔(slide duration):
它指的是经过多长时间窗口滑动一次形成新的窗口,滑动窗口默认情况下和批次间隔的相同,而窗口间隔一般设置的要比它们两个大。在这里必须注意的一点是滑动间隔和窗口间隔的大小一定得设置为批处理间隔的整数倍。
滑动间隔 == 窗口间隔,正好不重复,也不漏数据。
滑动间隔 > 窗口间隔,会漏数据。
滑动间隔、窗口间隔 一定是批处理间隔的整数倍。
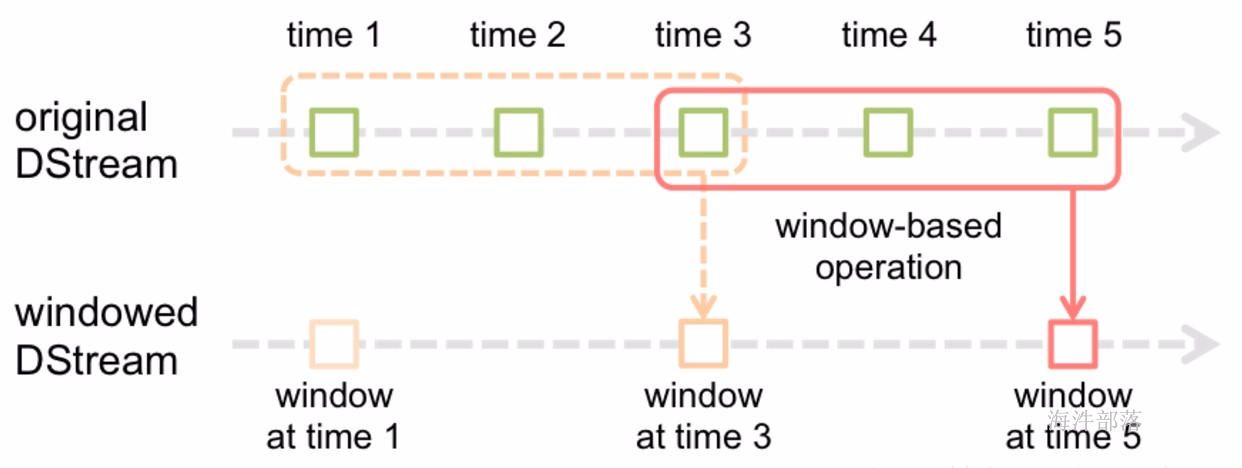
Spark Streaming 还提供了窗口的计算,它允许你通过滑动窗口对数据进行转换,窗口转换操作如下:
| 转换 | 描述 |
|---|---|
| window(windowLength, slideInterval) | 返回一个基于源DStream的窗口批次计算后得到新的DStream。 |
| countByWindow(windowLength,slideInterval) | 返回基于滑动窗口的DStream中的元素的数量。 |
| reduceByWindow(func, windowLength,slideInterval) | 基于滑动窗口对源DStream中的元素进行聚合操作,得到一个新的DStream。 |
| reduceByKeyAndWindow(func,windowLength,slideInterval, [numTasks]) | 基于滑动窗口对(K,V)键值对类型的DStream中的值按K使用聚合函数func进行聚合操作,得到一个新的DStream。可以进行repartition操作。 |
| reduceByKeyAndWindow(func,invFunc,windowLength, slideInterval, [numTasks]) | 更加高效的reduceByKeyAndWindow,每个窗口的reduce值,是基于前窗口的reduce值进行增量计算得到的;它会对进入滑动窗口的新数据进行reduce操作(func),并对离开窗口的老数据进行“逆向reduce” 操作(invFunc)。但是,只能用于“可逆的reduce函数”必须启用“检查点”才能使用此操作 |
| countByValueAndWindow(windowLength,slideInterval, [numTasks]) | 基于滑动窗口计算源DStream中每个RDD内每个元素出现的频次并返回DStream[(K,Long)],其中K是RDD中元素的类型,Long是元素频次。与countByValue一样,reduce任务的数量可以通过一个可选参数进行配置。 |
reduceByKeyAndWindow
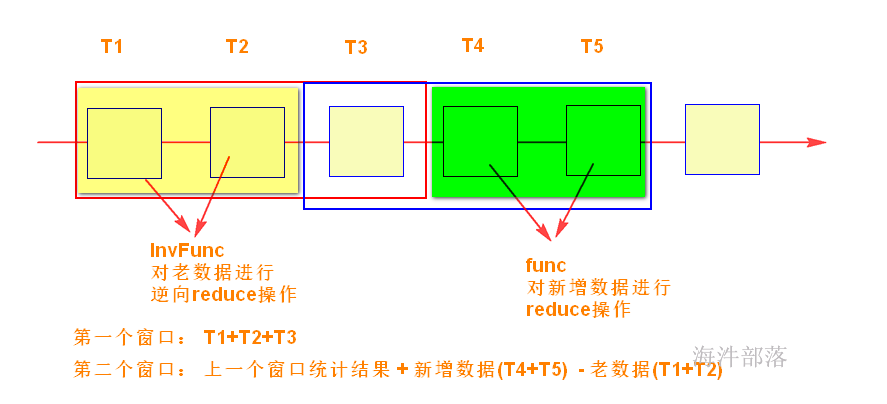
UpdateStateByKey 原语用于记录历史记录,Word Count 示例中就用到了该特性。若不用 UpdateStateByKey 来更新状态,那么每次数据进来后分析完成,结果输出后将不再保存。如输入:hello world,结果则为:(hello,1)(world,1),然后输入 hello spark,结果则为 (hello,1)(spark,1)。也就是不会保留上一次数据处理的结果。
使用 UpdateStateByKey 原语用于需要记录的 State,可以为任意类型,如上例中即为 Optional类型。
返回一个新状态的DStream,其中每个键的状态是根据键的前一个状态和键的新值应用给定函数func后的更新。这个方法可以被用来维持每个键的任何状态数据。
21.3.3 DStream 输出操作
Spark Streaming允许DStream的数据被输出到外部系统,如数据库或文件系统。由于输出操作实际上使transformation操作后的数据可以通过外部系统被使用,同时输出操作触发所有DStream的transformation操作的实际执行(类似于RDD操作)。以下表列出了目前主要的输出操作:
| 转换 | 描述 |
|---|---|
| print() | 在Driver中打印出DStream中数据的前10个元素。 |
| saveAsTextFiles(prefix, [suffix]) | 将DStream中的内容以文本的形式保存为文本文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
| saveAsObjectFiles(prefix, [suffix]) | 将DStream中的内容按对象序列化并且以SequenceFile的格式保存。其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
| saveAsHadoopFiles(prefix, [suffix]) | 将DStream中的内容以文本的形式保存为Hadoop文件,其中每次批处理间隔内产生的文件以prefix-TIME_IN_MS[.suffix]的方式命名。 |
| foreachRDD(func) | 最基本的输出操作,将func函数应用于DStream中的RDD上,这个操作会输出数据到外部系统,比如保存RDD到文件或者网络数据库等。需要注意的是func函数是在运行该streaming应用的Driver进程里执行的。 |
foreachRDD 是个非常强大的输出算子。

它可以把SparkStreaming的程序完全用 rdd的处理方式处理。
// dstream 转换
val dstream2 = dstream1.flatMap(.split(" ")).map((,1)).reduceByKey(_ + _)
// 将上面的 SparkStreaming的程序完全用 rdd的处理方式处理
dstream1.foreacheRDD(rdd => {
val rddNew = rdd.flatMap(.split(" ")).map((,1)).reduceByKey(_ + _)
rddNew.foreach(打印一波)
})
21.4 SparkStreaming程序
21.4.1 socket 创建DStream
21.4.1.1 java 版
package com.hainiuxy.sparkstreaming;
import org.apache.spark.SparkConf;
import org.apache.spark.api.java.JavaPairRDD;
import org.apache.spark.api.java.function.FlatMapFunction;
import org.apache.spark.api.java.function.Function2;
import org.apache.spark.api.java.function.PairFunction;
import org.apache.spark.api.java.function.VoidFunction2;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.Time;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaPairDStream;
import org.apache.spark.streaming.api.java.JavaReceiverInputDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import scala.Tuple2;
import java.util.Arrays;
import java.util.Iterator;
class SparkStreamingSocketForJava {
public static void main(String[] args) throws InterruptedException {
SparkConf sparkConf = new SparkConf();
sparkConf.setAppName("SparkStreamingSocketForJava");
sparkConf.setMaster("local[2]");
// 创建StreamingContext对象
// sparkStreaming流数据进行分段时,每5秒分一段
JavaStreamingContext javaStreamingContext = new JavaStreamingContext(sparkConf, Durations.seconds(5));
// 通过socket流创建DStream
JavaReceiverInputDStream<String> lines = javaStreamingContext.socketTextStream("localhost", 6666);
// DStream[String]
// "a b a" --> "a", "b", "a"
JavaDStream<String> flatMap = lines.flatMap(new FlatMapFunction<String, String>() {
@Override
public Iterator<String> call(String t) throws Exception {
return Arrays.asList(t.split(" ")).iterator();
}
});
// "a", "b", "a" --> (a,1),(b,1),(a,1)
JavaPairDStream<String, Integer> mapToPair = flatMap.mapToPair(new PairFunction<String, String, Integer>() {
@Override
public Tuple2<String, Integer> call(String t) throws Exception {
return new Tuple2<String,Integer>(t,1);
}
});
// (a,1),(b,1) (a,1)--> (a,2),(b,1)
JavaPairDStream<String, Integer> reduceByKey = mapToPair.reduceByKey(new Function2<Integer, Integer, Integer>() {
@Override
public Integer call(Integer v1, Integer v2) throws Exception {
return v1 + v2;
}
});
reduceByKey.foreachRDD(new VoidFunction2<JavaPairRDD<String,Integer>,Time>() {
@Override
public void call(JavaPairRDD<String, Integer> v1, Time v2) throws Exception {
System.out.println("count time:" + v2 + "," + v1.collect());
}
});
// 启动流式计算
javaStreamingContext.start();
// driver将阻塞在这里,直到流式应用意外退出
javaStreamingContext.awaitTermination();
}
}21.4.1.2 scala版
package com.hainiuxy.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
object SparkStreamingSocket {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setAppName("SparkStreamingSocket").setMaster("local[2]")
val ssc = new StreamingContext(conf, Durations.seconds(5))
// 该计算方式的缓存默认级别:StorageLevel.MEMORY_AND_DISK_SER_2
// 从socket端接收一行数据,数据是按照空格分隔的
val inputDS: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 6666)
val flatMapDS: DStream[String] = inputDS.flatMap(_.split(" "))
val pairDS: DStream[(String, Int)] = flatMapDS.map((_,1))
val reduceByKeyDS: DStream[(String, Int)] = pairDS.reduceByKey(_ + _)
reduceByKeyDS.foreachRDD((r,t) =>{
println(s"count time:${t}, ${r.collect().toList}")
})
ssc.start()
ssc.awaitTermination()
}
}a 程序测试
需要 使用nc 命令来启动Socket,作为server端;而sparkStreaming程序作为 client 端。
linux 使用:
1)安装nc:yum install nc
2)执行命令启动Socket服务端: nc -lkp 6666
其中:-l:代表启动监听模式,也就是作为socket服务端; -p:监听的端口; -k:多次监听

windows 使用ncat.exe 工具 :
1)解压ncat.exe 工具
2)执行命令启动socket服务端:ncat.exe -lkp 6666
3)启动SparkStreaming程序,作为客户端,在server端输入数据,客户端监听到就开始运算
程序计算结果
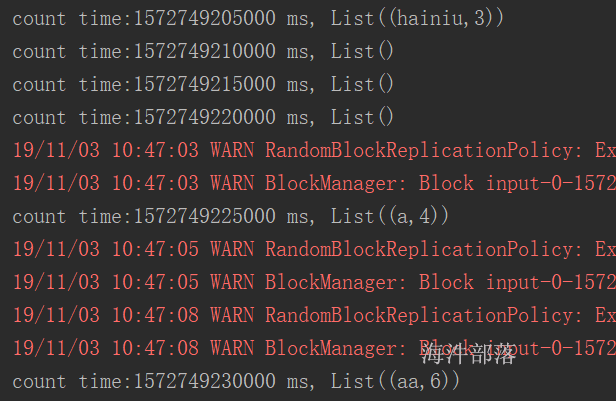
b 查看 webui
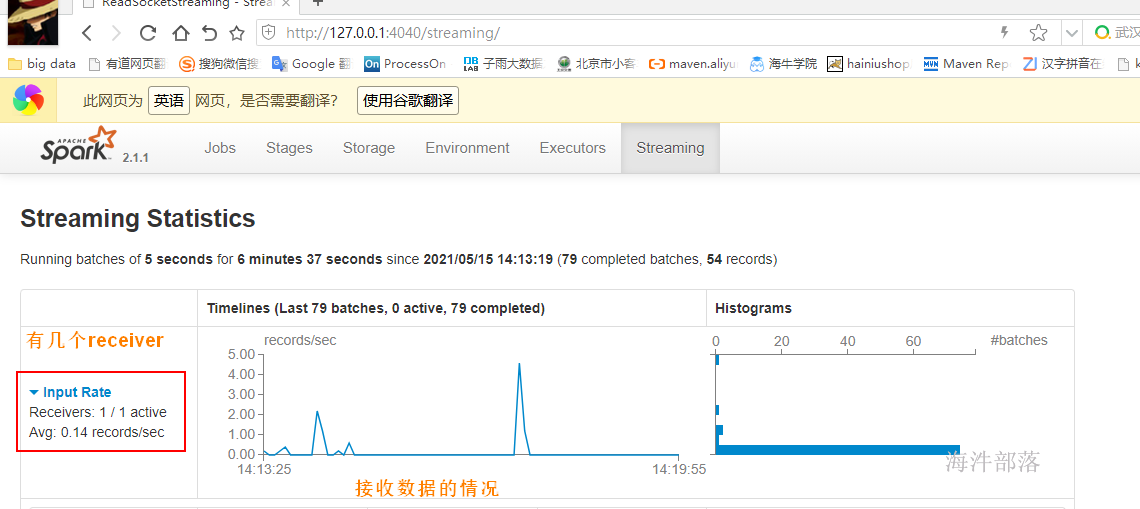
c 用 transform 改写
上面的写法是DStream –> DStream,我们也可以用transform 实现 DStream –>RDD–> DStream
// 下面的DStream 转换可以用RDD转换替代
val reduceByKeyDS: DStream[(String, Int)] = inputDS.transform(rdd => {
val reduceByKey: RDD[(String, Int)] = rdd.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
reduceByKey
})
// val flatMapDS: DStream[String] = inputDS.flatMap(_.split(" "))
// val pairDS: DStream[(String, Int)] = flatMapDS.map((_,1))
// val reduceByKeyDS: DStream[(String, Int)] = pairDS.reduceByKey(_ + _)
reduceByKeyDS.foreachRDD((r,t) =>{
println(s"count time:${t}, ${r.collect().toList}")
})d 用 foreachRDD 改写
当然,我们也可以用 foreachRDD 实现 将流式计算 完全用批处理的方式写
// val flatMapDS: DStream[String] = inputDS.flatMap(_.split(" "))
// val pairDS: DStream[(String, Int)] = flatMapDS.map((_,1))
// val reduceByKeyDS: DStream[(String, Int)] = pairDS.reduceByKey(_ + _)
// reduceByKeyDS.foreachRDD((r,t) =>{
// println(s"count time:${t}, ${r.collect().toList}")
// })
inputDS.foreachRDD((rdd,t) =>{
val s1 = "aa"
println(s1)
val reduceByKey: RDD[(String, Int)] = rdd.flatMap(_.split(" ")).map((_, 1)).reduceByKey(_ + _)
println(s"count time:${t}, ${reduceByKey.collect().toList}")
})e DStream 的 transform 和 foreachRDD 的异同点
相同点:
1)transform和foreachRDD都可以进行RDD转换,可让写spark-streaming程序像写spark-core一样。比如RDD转成DataSet或DatFrame进行spark-sql的操作,操作方便。
2)只有 transform和foreachRDD 算子里的函数执行分driver端运行和executor端运行;DStream 的其他算子的函数都是在executor端运行。
区别:
1)transform 是转换算子,foreachRDD是输出算子。
2)transform 可以将旧RDD转成新RDD,然后返回DStream,执行DStream的行动操作。
而 foreachRDD 本身是DStream的行动操作,它需要将所有的DStream 操作的代码转成RDD操作,直到最后。
DStream Driver端执行的代码与executor 端执行的代码示例

21.4.2 updateStateByKey
java updateStateByKey方法 使用代码示例:
V2:上次数据
返回结果本次汇总数据,也就是下次的V2数据
scala代码:
package com.hainiu.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
object ReadSocketStreamingWithUpdate {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("ReadSocketStreamingWithUpdate")
val checkpointPath:String = "/tmp/sparkstreaming/check_upate"
// 创建StreamingContext对象,每5秒赞一批数据触发运算
val ssc: StreamingContext = new StreamingContext(conf, Durations.seconds(5))
// 设置 checkpoint
ssc.checkpoint(checkpointPath)
// 创建socket流
// receiver接收socket流的存储缓存机制: StorageLevel.MEMORY_AND_DISK_SER_2
val inputDS: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 6666)
val ds2: DStream[(String, Int)] = inputDS.flatMap(_.split(" ")).map((_,1))
// 利用updateStateByKey 实现有状态的转换
val ds3: DStream[(String, Int)] = ds2.updateStateByKey((seq: Seq[Int], lastOption: Option[Int]) => {
var sum: Int = 0
// 统计本批次的结果
for (num <- seq) {
sum += num
}
// 获取上一批次的结果
val lastValue: Int = if (lastOption.isDefined) lastOption.get else 0
// 本批次结果+上一批次结果
val nowValue = sum + lastValue
Some(nowValue)
})
ds3.foreachRDD((rdd, time) =>{
println(s"time:${time}, data:${rdd.collect().toBuffer}")
})
ssc.start()
ssc.awaitTermination()
}
}结果:
第一次执行代码
打印日志
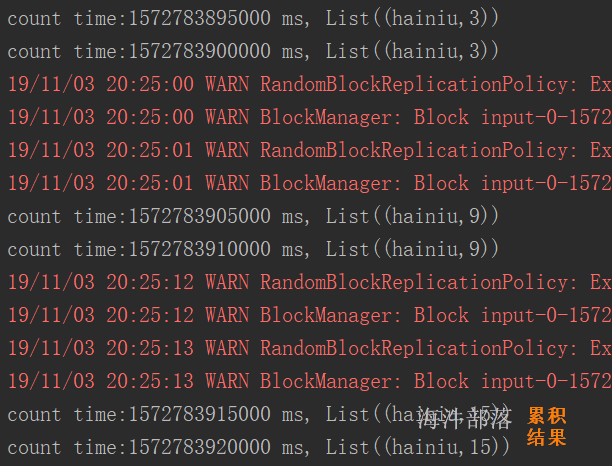
第二次执行代码:
发现上次的数据并没有加载进来,说明只接收了socket流,并没有加载checkpoint的数据。

21.4.3 streaming用checkpoint恢复历史数据
通过StreamingContext.getOrCreate()
该方法优先使用checkpoint 检查点的数据创建StreamingContext;如果checkpoint没有数据,则将通过调用提供的“ creatingFunc”来创建StreamingContext。
代码:
package com.hainiu.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
object ReadSocketStreamingWithUpdate2 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("ReadSocketStreamingWithUpdate2")
val checkpointPath:String = "/tmp/sparkstreaming/check_upate2"
// 当checkpoint目录没有数据时,会执行函数创建StreamingContext对象
// 当checkpoint目录有数据时,会从checkpoint恢复StreamingContext对象, 同时StreamingContext对象记录着处理的socket流
val ssc: StreamingContext = StreamingContext.getOrCreate(checkpointPath, () => {
// 创建StreamingContext对象,每5秒赞一批数据触发运算
val ssc: StreamingContext = new StreamingContext(conf, Durations.seconds(5))
// 设置 checkpoint
ssc.checkpoint(checkpointPath)
// 创建socket流
// receiver接收socket流的存储缓存机制: StorageLevel.MEMORY_AND_DISK_SER_2
val inputDS: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 6666)
val ds2: DStream[(String, Int)] = inputDS.flatMap(_.split(" ")).map((_,1))
// 利用updateStateByKey 实现有状态的转换
val ds3: DStream[(String, Int)] = ds2.updateStateByKey((seq: Seq[Int], lastOption: Option[Int]) => {
var sum: Int = 0
// 统计本批次的结果
for (num <- seq) {
sum += num
}
// 获取上一批次的结果
val lastValue: Int = if (lastOption.isDefined) lastOption.get else 0
// 本批次结果+上一批次结果
val nowValue = sum + lastValue
Some(nowValue)
})
ds3.foreachRDD((rdd, time) =>{
println(s"time:${time}, data:${rdd.collect().toBuffer}")
})
ssc
})
ssc.start()
ssc.awaitTermination()
}
}删除checkpoint 目录,第一次启动程序
运行日志:
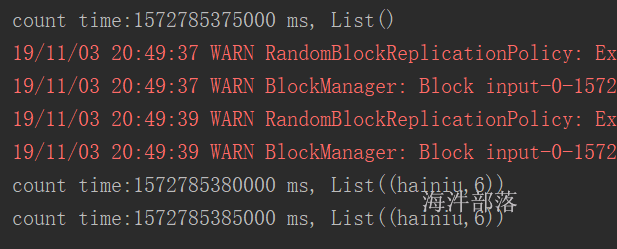
第二次启动程序
运行日志:
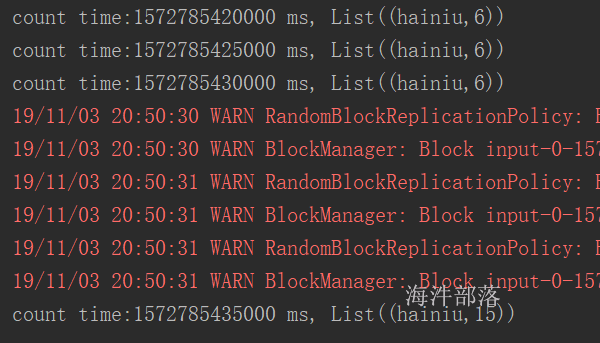
说明先加载checkpoint的数据,然后接收的socket 的流数据。
上面的代码,getOrCreate() 中 包含了很多代码,可读性差,可以将函数封装个函数,直接调用函数。
package com.hainiu.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
object ReadSocketStreamingWithUpdate3 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("ReadSocketStreamingWithUpdate3")
val checkpointPath:String = "/tmp/sparkstreaming/check_upate3"
// 把函数抽出来
val createStreamingContext:()=>StreamingContext = () => {
// 创建StreamingContext对象,每5秒赞一批数据触发运算
val ssc: StreamingContext = new StreamingContext(conf, Durations.seconds(5))
// 设置 checkpoint
ssc.checkpoint(checkpointPath)
// 创建socket流
// receiver接收socket流的存储缓存机制: StorageLevel.MEMORY_AND_DISK_SER_2
val inputDS: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 6666)
val ds2: DStream[(String, Int)] = inputDS.flatMap(_.split(" ")).map((_,1))
// 利用updateStateByKey 实现有状态的转换
val ds3: DStream[(String, Int)] = ds2.updateStateByKey((seq: Seq[Int], lastOption: Option[Int]) => {
var sum: Int = 0
// 统计本批次的结果
for (num <- seq) {
sum += num
}
// 获取上一批次的结果
val lastValue: Int = if (lastOption.isDefined) lastOption.get else 0
// 本批次结果+上一批次结果
val nowValue = sum + lastValue
Some(nowValue)
})
ds3.foreachRDD((rdd, time) =>{
println(s"time:${time}, data:${rdd.collect().toBuffer}")
})
ssc
}
// 当checkpoint目录没有数据时,会执行函数创建StreamingContext对象
// 当checkpoint目录有数据时,会从checkpoint恢复StreamingContext对象, 同时StreamingContext对象记录着处理的socket流
val ssc: StreamingContext = StreamingContext.getOrCreate(checkpointPath, createStreamingContext)
ssc.start()
ssc.awaitTermination()
}
}注意事项:
1)当已生成这个任务的checkpoint时,修改StreamingContext的端口不生效,因为是恢复已存在的checkpoint中的StreamingContext,rdd里的函数可以改。
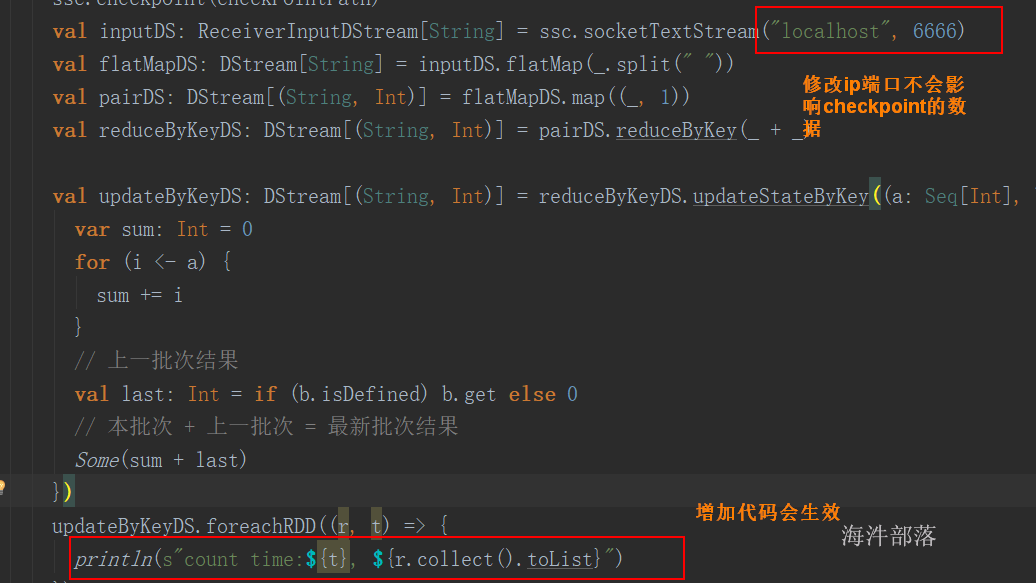
第一次时,从 socket 创建流
当关闭后,第二次时,会创建两个流, 一个是从checkpoint, 一个是从 socket,两个流冲突。
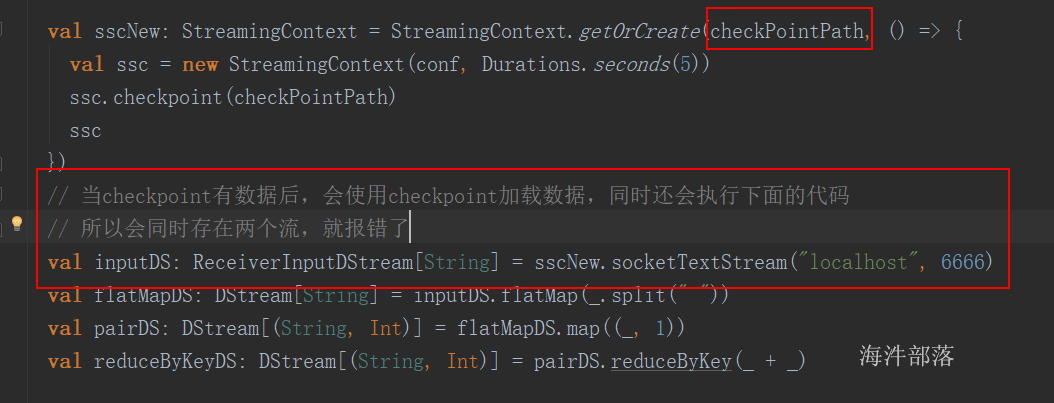
21.4.4 updateStateByKey只使用最近更新的值
背景:
把流式数据每批次计算的结果持久到MySQL数据库。
用 updateStateByKey,会保留之前批次的数据,更新时,如果每次都要把所有 单词 做更新,效率太低。
如何能只将当前批次的数据做更新,这就需要 批次数据中带有状态,来区分是本次更新的数据还是以前的数据。
代码:
package com.hainiu.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
object ReadSocketStreamingWithUpdate4 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("ReadSocketStreamingWithUpdate4")
val checkpointPath:String = "/tmp/sparkstreaming/check_upate4"
// 把函数抽出来
val createStreamingContext:()=>StreamingContext = () => {
// 创建StreamingContext对象,每5秒赞一批数据触发运算
val ssc: StreamingContext = new StreamingContext(conf, Durations.seconds(5))
// 设置 checkpoint
ssc.checkpoint(checkpointPath)
// 创建socket流
// receiver接收socket流的存储缓存机制: StorageLevel.MEMORY_AND_DISK_SER_2
val inputDS: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 6666)
val ds2: DStream[(String, ValueAndStateBean)] = inputDS.flatMap(_.split(" ")).map((_,ValueAndStateBean(1)))
// 利用updateStateByKey 实现有状态的转换
val ds3: DStream[(String, ValueAndStateBean)] = ds2.updateStateByKey((seq: Seq[ValueAndStateBean], lastOption: Option[ValueAndStateBean]) => {
var sum: Int = 0
// 统计本批次的结果
for (bean <- seq) {
sum += bean.num
}
// 获取上一批次的结果
val lastValue: Int = if (lastOption.isDefined) lastOption.get.num else 0
// 本批次结果+上一批次结果
val nowValue = sum + lastValue
// 本批次没有不更新(后面会筛选掉)
if(sum == 0){
Some(ValueAndStateBean(nowValue, false))
}else{
// 本批次有更新(后面会保留)
Some(ValueAndStateBean(nowValue, true))
}
})
ds3.foreachRDD((rdd, time) =>{
// 筛选ValueAndStateBean里面的isUpdate=true的留下
// 本批次有的写入,本批次没有的不写入
val filterRdd: RDD[(String, ValueAndStateBean)] = rdd.filter(_._2.isUpdate)
println(s"time:${time}, 写入MySQL的data:${filterRdd.collect().toBuffer}")
})
ssc
}
// 当checkpoint目录没有数据时,会执行函数创建StreamingContext对象
// 当checkpoint目录有数据时,会从checkpoint恢复StreamingContext对象, 同时StreamingContext对象记录着处理的socket流
val ssc: StreamingContext = StreamingContext.getOrCreate(checkpointPath, createStreamingContext)
ssc.start()
ssc.awaitTermination()
}
}
// num: 数值, isUpdate: 是否更新
case class ValueAndStateBean(val num:Int, val isUpdate:Boolean = false)批次数据:

运行结果:
21.4.5 window 操作
sparkStreaming 支持 window 操作,当你需要跨批次去处理时就可以用,比如:统计过去10分钟的数据做均值、top(热词、热搜等)。
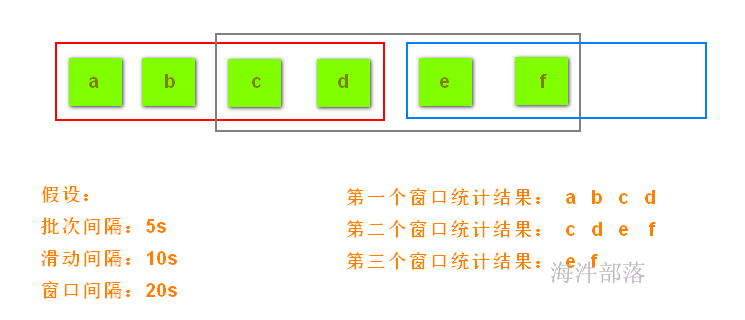
21.4.5.1 window 操作代码
package com.hainiu.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
object ReadSocketStreamingWindow {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("ReadSocketStreamingWindow")
// 批次间隔5秒,5秒触发批次运算
val ssc: StreamingContext = new StreamingContext(conf, Durations.seconds(5))
val inputDS: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 6666)
// window ---> countByValue, 窗口攒的数据多
val windowAndReduceDS: DStream[(String, Long)] = inputDS.flatMap(_.split(" ")).window(Durations.seconds(20), Durations.seconds(10)).countByValue()
// countByValue--> window 和 map--> reduceByKey--> window 一样
// 窗口攒的数据少
// 要点:window 操作前的数据要少,这样缓存占用少,效率高
//val windowAndReduceDS: DStream[(String, Long)] = inputDS.flatMap(_.split(" ")).countByValue().window(Durations.seconds(20), Durations.seconds(10)).reduceByKey(_ + _)
// countByValueAndWindow 底层调用的是 reduceByKeyAndWindow(有逆向reduce函数,需要保存上一个窗口的数据,所以需要checkpoint)
//val windowAndReduceDS: DStream[(String, Long)] = inputDS.flatMap(_.split(" ")).countByValueAndWindow(Durations.seconds(20), Durations.seconds(10))
// val reduceDS: DStream[(String, Int)] = inputDS.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)
//
// // 将reduceDS 的数据 攒20秒的窗口数据, 每10秒滑动窗口
// // 由于要缓存20秒窗口的数据,所以有缓存: StorageLevel.MEMORY_ONLY_SER
// val windowDS: DStream[(String, Int)] = reduceDS.window(Durations.seconds(20), Durations.seconds(10))
// // 每10秒触发运算
// val windowAndReduceDS: DStream[(String, Int)] = windowDS.reduceByKey(_ + _)
windowAndReduceDS.foreachRDD((rdd, time) =>{
// 每10秒触发输出
println(s"time:${time}, data:${rdd.collect().toBuffer}")
})
ssc.start()
ssc.awaitTermination()
}
}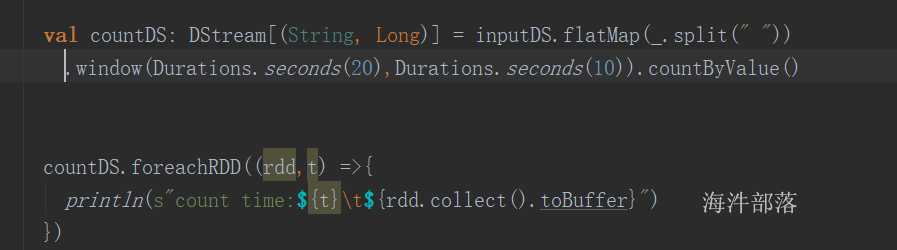
21.4.5.2 使用 countByValueAndWindow 函数统计窗口内数据
// 方案1:每10秒钟窗口,攒一批数据,对这批数据进行统计,需要内存来攒数据
// 该方案后面使用的不是window函数,所以可以没有checkpoint
val pairDS: DStream[(String, Long)] = flatMapDS.window(Durations.seconds(20),Durations.seconds(10)).countByValue()
// 方案2:每10秒钟,在窗口中统计,实际上两个的结果一样。
// 该方案countByValueAndWindow 函数底层其实是调用的 reduceByKeyAndWindow函数,所以它需要 设置checkpoint
val pairDS: DStream[(String, Long)] = flatMapDS.countByValueAndWindow(Durations.seconds(20),Durations.seconds(10))开启checkpoint的window操作
package com.hainiu.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
// 带有checkpoint的window
object ReadSocketStreamingWindow2 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("ReadSocketStreamingWindow2")
val checkpointPath:String = "/tmp/sparkstreaming/window_check"
val ssc: StreamingContext = StreamingContext.getOrCreate(checkpointPath, () => {
// 批次间隔5秒,5秒触发批次运算
val ssc: StreamingContext = new StreamingContext(conf, Durations.seconds(5))
// 设置checkpoint
ssc.checkpoint(checkpointPath)
val inputDS: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 6666)
// 攒20秒的窗口数据运算
// countByValueAndWindow 底层调用的是 reduceByKeyAndWindow(有逆向reduce函数,
// 需要保存上一个窗口的数据,所以需要checkpoint)
val windowAndReduceDS: DStream[(String, Long)] = inputDS.flatMap(_.split(" "))
.countByValueAndWindow(Durations.seconds(20), Durations.seconds(10))
windowAndReduceDS.foreachRDD((rdd, time) => {
// 每10秒触发输出
println(s"time:${time}, data:${rdd.collect().toBuffer}")
})
ssc
})
ssc.start()
ssc.awaitTermination()
}
}发送的数据:

计算结果:
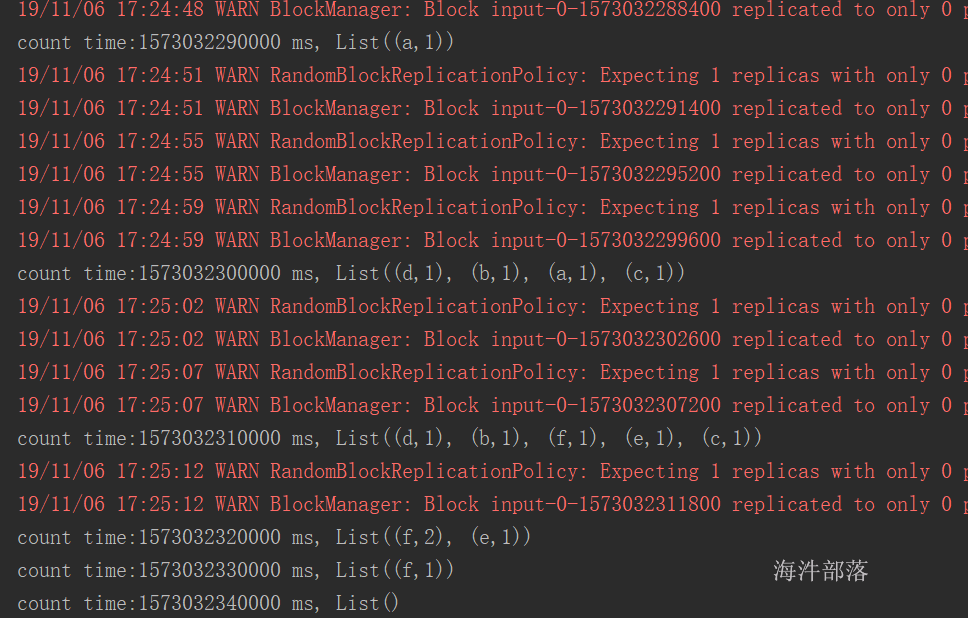
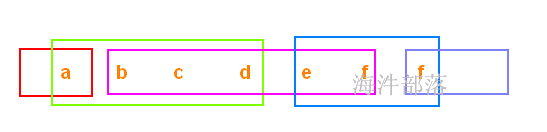
21.4.5.3 用 reduceByKeyAndWindow 统计窗口内的数据
package com.hainiu.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
// 带有checkpoint的window
object ReadSocketStreamingWindow2 {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("ReadSocketStreamingWindow2")
val checkpointPath:String = "/tmp/sparkstreaming/window_check2"
val ssc: StreamingContext = StreamingContext.getOrCreate(checkpointPath, () => {
// 批次间隔5秒,5秒触发批次运算
val ssc: StreamingContext = new StreamingContext(conf, Durations.seconds(5))
// 设置checkpoint
ssc.checkpoint(checkpointPath)
val inputDS: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 6666)
// 攒20秒的窗口数据运算
// countByValueAndWindow 底层调用的是 reduceByKeyAndWindow(有逆向reduce函数,
// 需要保存上一个窗口的数据,所以需要checkpoint)
// val windowAndReduceDS: DStream[(String, Long)] = inputDS.flatMap(_.split(" "))
// .countByValueAndWindow(Durations.seconds(20), Durations.seconds(10))
val windowAndReduceDS: DStream[(String, Int)] = inputDS.flatMap(_.split(" ")).map((_,1))
.reduceByKeyAndWindow(_ + _, _ - _, Durations.seconds(20), Durations.seconds(10))
.filter(_._2 > 0)
windowAndReduceDS.foreachRDD((rdd, time) => {
// 每10秒触发输出
println(s"time:${time}, data:${rdd.collect().toBuffer}")
})
ssc
})
ssc.start()
ssc.awaitTermination()
}
}发送的数据:

计算结果:
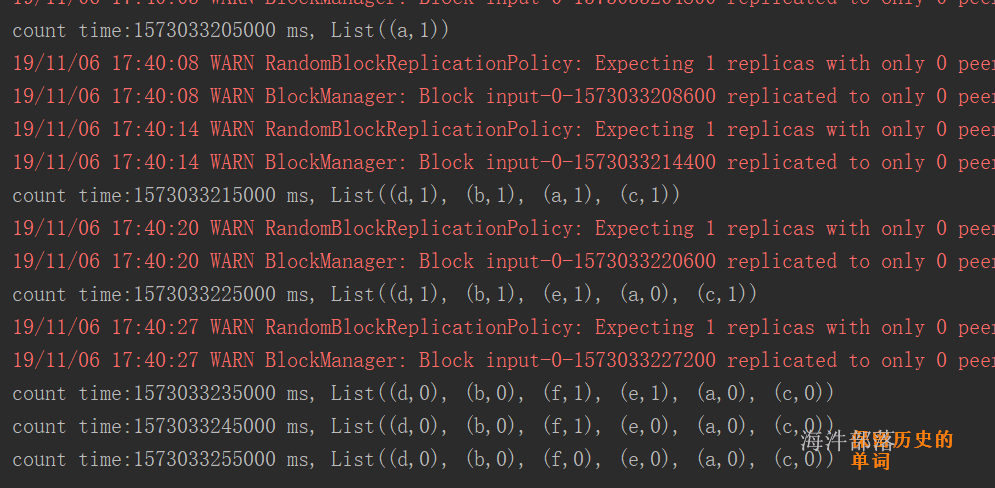
countByValueAndWindow 函数底层调用的也是 reduceByKeyAndWindow函数,那为什么countByValueAndWindow 函数 没有保留历史的单词?
21.4.5 SparkStreaming 何时使用缓存?何时开启检查点?
分析sparkStreaming 什么时候使用缓存?
1)DStream 和 RDD相似,如果DStream中的数据将被多次计算(例如,对同一数据进行多次操作),这将很有用。可以调用 cache()或 persist() 方法缓存。
2)对于基于窗口的操作reduceByWindow和 reduceByKeyAndWindow和基于状态的操作updateStateByKey,由于窗口的操作生成的DStream会自动保存在内存中,而无需开发人员调用persist()。
3)如果需要计算DStream 以外的数据,可以通过streamingContext.remember获取指定窗口的数据,获取的数据会自动保存在内存中。
分析 sparkStreaming 什么时候开启检查点checkpoint?
1)有状态转换的用法 -如果在应用程序中使用updateStateByKey或reduceByKeyAndWindow(带有反函数),则必须提供checkpoint目录以允许定期进行RDD的checkpoint。
2)从运行应用程序的驱动程序故障中恢复,checkpoint用于恢复进度信息。
包括:
配置:用于创建流应用程序的配置。
DStream 操作:定义流应用程序的一组 DStream 操作。
不完整的批次:作业已排队但尚未完成的批次。
21.4.6 SparkStreamingFile
fileStream是Spark Streaming Basic Source的一种,用于“近实时”地分析HDFS(或者与HDFS API兼容的文件系统)指定目录中新写入的文件,目录中的文件需要满足以下约束条件:
1)这些文件格式必须相同,如:统一为文本文件;
2)这些文件在目录中的创建形式比较特殊:必须以原子方式被“移动”或“重命名”至目录中;
3)一旦文件被“移动”或“重命名”至目录中,文件不可以被改变,例如:追加至这些文件的数据可能不会被处理。
directory:指定待分析文件的目录;
filter:用户指定的文件过滤器,用于过滤目录中的文件;
newFilesOnly:应用程序启动时,目录中可能已经存在一些文件,如果newFilesOnly值为true,表示忽略这些文件;如果newFilesOnly值为false,表示需要分析这些文件;
conf:用户指定的Hadoop相关的配置属性;
重要参数:设置能读取到修改时间为多长时间范围内的文件
sparkConf.set(“spark.streaming.fileStream.minRememberDuration”,“2592000s”) // 一个月
package com.hainiu.sparkstreaming
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.Path
import org.apache.hadoop.io.{LongWritable, Text}
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
object ReadFileStreaming {
def main(args: Array[String]): Unit = {
// 文件流没有receiver接收,所以local[1]也可以运行
val conf: SparkConf = new SparkConf().setMaster("local[1]").setAppName("ReadFileStreaming")
//重要参数:设置能读取到修改时间为多长时间范围内的文件
conf.set("spark.streaming.fileStream.minRememberDuration","2592000s") // 一个月
// 创建StreamingContext对象,每5秒赞一批数据触发运算
val ssc: StreamingContext = new StreamingContext(conf, Durations.seconds(5))
val inputDir:String = "/tmp/sparkstreaming/input_file"
// 创建文件流
// directory: String, : 输入目录
// filter: Path => Boolean,: 文件筛选条件 筛选.txt结尾的文件
// newFilesOnly: Boolean, false: 在启动程序前的文件可以让程序检测到 true: 启动程序后放入的文件
// conf: Configuration
val inputDS: InputDStream[(LongWritable, Text)] = ssc.fileStream[LongWritable, Text, TextInputFormat](inputDir,
(inputPath: Path) => inputPath.toString.endsWith(".txt"),
true,
new Configuration())
// dstream 的转换
val reduceByKeyDS: DStream[(String, Int)] = inputDS.flatMap(_._2.toString.split(" ")).map((_,1)).reduceByKey(_ + _)
reduceByKeyDS.foreachRDD((rdd, time) =>{
// 在driver端运行的
val arr: Array[(String, Int)] = rdd.collect()
println(s"time:${time}, data:${arr.toBuffer}")
})
// 启动Streamingcontext
ssc.start()
// 阻塞一直运行下去
ssc.awaitTermination()
}
}输入数据:
运行结果:

注意:
如果设置 newFilesOnly=true, 那执行时,先启动程序,再创建新文件,把新文件放到监控目录下,程序扫描时看的是修改时间。
21.4.7 spark-streaming-socket cogroup spark-streaming-file
socket 流和文件流 join,只有一个批次的数据才能 join 到一起
代码
package com.hainiu.sparkstreaming
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.Path
import org.apache.hadoop.io.{LongWritable, Text}
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
// 文件流joinsocket流
object FileJoinSocketStreaming {
def main(args: Array[String]): Unit = {
// 文件流没有receiver接收,所以local[1]也可以运行
val conf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("FileJoinSocketStreaming")
//重要参数:设置能读取到修改时间为多长时间范围内的文件
conf.set("spark.streaming.fileStream.minRememberDuration","2592000s") // 一个月
// 创建StreamingContext对象,每5秒赞一批数据触发运算
val ssc: StreamingContext = new StreamingContext(conf, Durations.seconds(5))
//CN 中国
val inputDir:String = "/tmp/sparkstreaming/input_file2"
// 创建文件流
// directory: String, : 输入目录
// filter: Path => Boolean,: 文件筛选条件
// newFilesOnly: Boolean, false: 在启动程序前的文件可以让程序检测到 true: 启动程序后放入的文件
// conf: Configuration
val inputFileDS: InputDStream[(LongWritable, Text)] = ssc.fileStream[LongWritable, Text, TextInputFormat](inputDir,
(inputPath: Path) => inputPath.toString.endsWith(".txt"),
false,
new Configuration())
val fileDS: DStream[(String, String)] = inputFileDS.map(f => {
val line: String = f._2.toString
val arr: Array[String] = line.split(" ")
(arr(0), arr(1))
})
// 读socket流
// CN CN CN
val socketInputDS: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 6666)
val socketDS: DStream[(String, Int)] = socketInputDS.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)
// val cogroupDS: DStream[(String, (Iterable[Int], Iterable[String]))] = socketDS.cogroup(fileDS)
//
// cogroupDS.foreachRDD((rdd, time) =>{
// val arr: Array[(String, (Iterable[Int], Iterable[String]))] = rdd.collect()
// for(t <- arr){
// println(s"time:${time}, data:${t}")
// }
//
// })
// innerjoin
// 两个流join,把同一批次的数据join到一起
val joinDS: DStream[(String, (Int, String))] = socketDS.join(fileDS)
joinDS.foreachRDD((rdd,time)=>{
val arr: Array[(String, (Int, String))] = rdd.collect()
for(t <- arr){
println(s"time:${time}, data:${t}")
}
})
// 启动Streamingcontext
ssc.start()
// 阻塞一直运行下去
ssc.awaitTermination()
}
}测试方法:
一个filestream

一个socketstream

在10秒内,生成流数据,进行cogroup。
先生成文件,然后开启socket,发送数据,再启动程序,此时会接收到socket数据,将接收的socket数据与文件的数据进行join。
cogroup结果

在10秒内,生成流数据,进行join
// innerjoin
// 两个流join,把同一批次的数据join到一起
val joinDS: DStream[(String, (Int, String))] = socketDS.join(fileDS)
joinDS.foreachRDD((rdd,time)=>{
val arr: Array[(String, (Int, String))] = rdd.collect()
for(t <- arr){
println(s"countryCode:${t._1}, countryName:${t._2._1}, countryCount:${t._2._2}")
}
})运行结果:

21.4.8 多receiver源union的方式
当数据源多时,有多个数据源就有多个DStream,每个DStream生成自己的任务,为了提高运行效率,可以将多个数据源的流数据union在一起,进而达到减少task的目的。
每个socket 源,都需要有一个receiver接收数据,一个receiver 需要一个CPU核,运行的时候还需要CPU核。
也可以通过本地修改CPU核数,看是否能运行任务


通过 StreamingContext 的 union 方法把多个receiver 源 union到一起。

1)先union,再处理
package com.hainiu.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
import scala.collection.mutable.ListBuffer
// 两个socket union
// 先union,再处理
object SocketUnionStreaming {
def main(args: Array[String]): Unit = {
// 每个socket一个receiver,至少3个cup核
val conf: SparkConf = new SparkConf().setMaster("local[3]").setAppName("SocketUnionStreaming")
// 创建StreamingContext对象,每5秒赞一批数据触发运算
val ssc: StreamingContext = new StreamingContext(conf, Durations.seconds(5))
// CN CN CN
val socketDS1: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 6666)
// CN RU RU
val socketDS2: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 7777)
// 第一种情况,两个流数据格式是一致的,可以直接union
// 要两个流在同一批里面
// socketDS1.union(socketDS2)
val arr: ListBuffer[DStream[String]] = new ListBuffer[DStream[String]]
arr += socketDS1
arr += socketDS2
val unionDS: DStream[String] = ssc.union(arr)
val reduceDS: DStream[(String, Int)] = unionDS.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)
reduceDS.foreachRDD((rdd, time) =>{
println(s"time:${time}, data:${rdd.collect().toBuffer}")
})
// 启动Streamingcontext
ssc.start()
// 阻塞一直运行下去
ssc.awaitTermination()
}
}
// 先加工,再union,然后再处理2)先加工,再union,然后再处理
package com.hainiu.sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
import scala.collection.mutable.ListBuffer
// 两个socket union
// 先加工,再union,然后再处理
object SocketUnionStreaming2 {
def main(args: Array[String]): Unit = {
// 每个socket一个receiver,至少3个cup核
val conf: SparkConf = new SparkConf().setMaster("local[3]").setAppName("SocketUnionStreaming2")
// 创建StreamingContext对象,每5秒赞一批数据触发运算
val ssc: StreamingContext = new StreamingContext(conf, Durations.seconds(5))
// CN CN CN
val socketDS1: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 6666)
// CN#RU#RU
val socketDS2: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 7777)
// 第一种情况,两个流数据格式是不一致一致的,先加工再union
// 要两个流在同一批里面
val flatMapDS1: DStream[String] = socketDS1.flatMap(_.split(" "))
val flatMapDS2: DStream[String] = socketDS2.flatMap(_.split("#"))
val arr: ListBuffer[DStream[String]] = new ListBuffer[DStream[String]]
arr += flatMapDS1
arr += flatMapDS2
val unionDS: DStream[String] = ssc.union(arr)
val reduceDS: DStream[(String, Int)] = unionDS.map((_,1)).reduceByKey(_ + _)
reduceDS.foreachRDD((rdd, time) =>{
println(s"time:${time}, data:${rdd.collect().toBuffer}")
})
// 启动Streamingcontext
ssc.start()
// 阻塞一直运行下去
ssc.awaitTermination()
}
}测试:

先发socket, 启动程序,保证两个socket流在同一批里面
运行结果:

21.4.9 SparkStreaming输出到HDFS
socket 源如何分区?
当从socket 源接收数据时,receiver 会创建数据块。每blockInterval毫秒生成一个新的数据块。在batchInterval期间创建了N个数据块,其中N = batchInterval / blockInterval。
blockInterval 默认是200ms,如果 batchInterval 设置为 2s,理论这个批次会产生 10个分区。如果某个blockInterval 时间内没有数据,则这个blockInterval 时间 就没有产生数据块。也就是说,开启socket源的sparkStreaming程序,如果socket端不喂数据,那这个批次就不会产生数据块,进而分区数是0。

小文件就会带来一系列的问题:
小文件多会占用很大的namenode的元数据空间,下游使用小文件的JOB会产生很多个partition,如果是mr任务就会有很多个map,如果是spark任务就会有很多个task。
如何解决写出小文件问题?
4种方法:
1)增加批次间隔的大小。(不建议使用)
失去了流式计算的意义。
2)使用批处理任务进行小文件的合并。(不建议使用)
需要新开个任务将多个小文件合并成大文件。
3)使用coalesce 减少分区数,进而减少输出小文件的个数。
4)使用HDFS的append方式,追加写入文件中。
package com.hainiu.sparkstreaming
import java.text.SimpleDateFormat
import java.util.Date
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FSDataOutputStream, FileSystem, Path}
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Durations, StreamingContext}
import scala.collection.mutable.ListBuffer
object SocketStreamingSaveHDFS {
def main(args: Array[String]): Unit = {
// 每个socket一个receiver,至少3个cup核
val conf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("SocketStreamingSaveHDFS")
// 创建StreamingContext对象,每5秒赞一批数据触发运算
val ssc: StreamingContext = new StreamingContext(conf, Durations.seconds(5))
// CN CN CN
val inputDS: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 6666)
val reduceDS: DStream[(String, Int)] = inputDS.flatMap(_.split(" ")).map((_,1)).reduceByKey(_ + _)
reduceDS.foreachRDD((rdd, time) =>{
if(!rdd.isEmpty()){
// 将一个批次的多个分区减少到2个
val coalesceRdd: RDD[(String, Int)] = rdd.coalesce(2)
val rdd3: RDD[String] = coalesceRdd.mapPartitionsWithIndex((index, it) => {
// 一个分区创建hdfs写入流, 一条一条写
// 一小时写入一个文件
val fs: FileSystem = FileSystem.get(new Configuration())
val format: SimpleDateFormat = new SimpleDateFormat("yyyyMMddhh")
val hourPath: String = format.format(new Date())
// 设置文件名
// val hdfsFile: String = s"/tmp/sparkstreaming/output_hdfs/${hourPath}/data_${index}"
val hdfsFile: String = s"/user/panniu/spark/output_hdfs/${hourPath}/data_${index}"
var fsdos: FSDataOutputStream = null
try {
val hdfsPath = new Path(hdfsFile)
val isExists: Boolean = fs.exists(hdfsPath)
// 如果文件存在追加写入,文件不存在创建并写入
fsdos = if (isExists) fs.append(hdfsPath) else fs.create(hdfsPath)
it.foreach(f => {
// 一条一条写
fsdos.write(s"${f._1}\t${f._2}\n".getBytes("utf-8"))
})
} catch {
case e: Exception => e.printStackTrace()
} finally {
// 关闭流
fsdos.close()
}
ListBuffer[String]().iterator
})
// 用于触发任务
rdd3.foreach((f) => ())
}
})
// 启动Streamingcontext
ssc.start()
// 阻塞一直运行下去
ssc.awaitTermination()
}
}上面的这个代码,windows本地不支持追加写入,需要写入到集群hdfs上。

操作步骤:
1)把集群/usr/local/hadoop/etc/hadoop目录下的 hdfs-site.xml core-site.xml 放到 本地工程的 资源目录下
2)手动创建hdfs目录及设置权限777
hadoop fs -chmod 777 /user/panniu/spark/output_hdfs
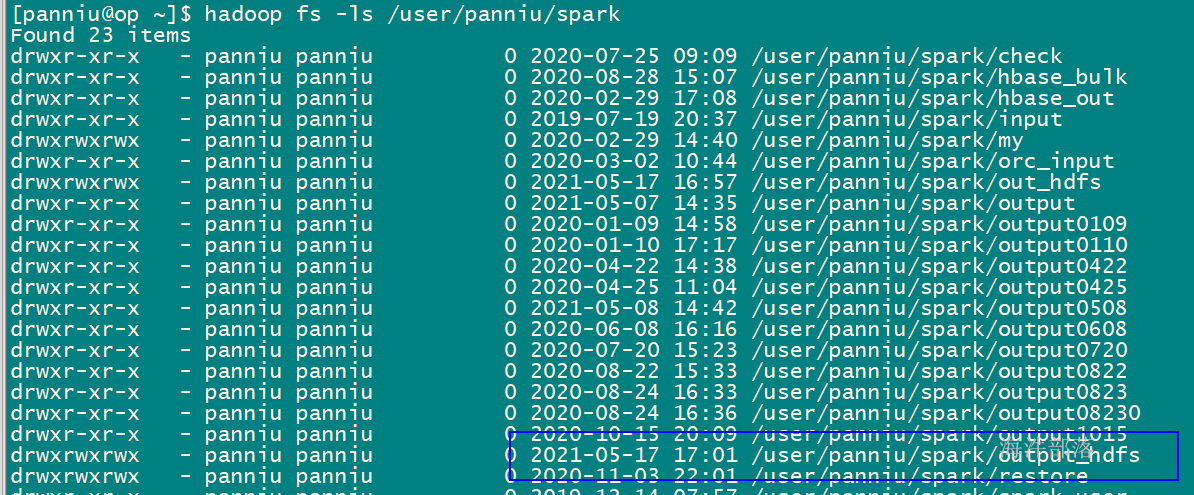
4)修改windows 的hosts 配置集群host
结果:
输入:
输出:

除了本练习以外,需要把资源目录下的 hdfs-site.xml core-site.xml 删除掉。
22 kafka分布式消息队列
22.1 概述
Kafka是由LinkedIn开发的一个分布式的消息系统。它是一款开源的、轻量级的、分布式、可分区和具有复制备份的(Replicated)、基于ZooKeeper的协调管理的分布式流平台的功能强大的消息系统。与传统的消息系统相比,KafKa能够很好的处理活跃的流数据,使得数据在各个子系统中高性能、低延迟地不停流转。
Kafka使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark都支持与Kafka集成。
22.1.1 特性
1)以时间复杂度为O(1)的方式(顺序读写)提供消息持久化能力,对TB级以上数据也能保证正常时间复杂度的访问性能;
2)高吞吐率。即使在非常廉价的商用机器上也能做到单机支持每秒100000条以上消息的传输;
3)支持Kafka Server间的消息分区,及分布式消费,同时保证每个Partition内的消息顺序传输;
4)同时支持离线数据处理(因为消息可以保存默认是168小时)和实时数据处理;
5)支持在线水平扩展;
22.1.2 为什么使用消息队列
解耦、扩展性、缓冲、灵活性 & 峰值处理能力、顺序保证、异步通信、冗余、可恢复性
22.2 基本的kafka系统术语
broker:
Kafka以集群方式运行,集群中每个服务器称为broker;
主题(Topic):
每条发布到Kafka集群的消息都有一个类别,这个类别被称为Topic;
分区(Partition):
topic中的数据分割为一个或多个partition,每个topic至少有一个partition;
partition中的数据是有序的,如果topic有多个partition,消费数据时就不能保证数据的顺序;
生产者(Producer):
生产者即数据的发布者,该角色将消息发布到Kafka的topic中;
消费者(Consumer):
消费者可以从broker中读取数据。消费者可以消费多个topic中的数据。
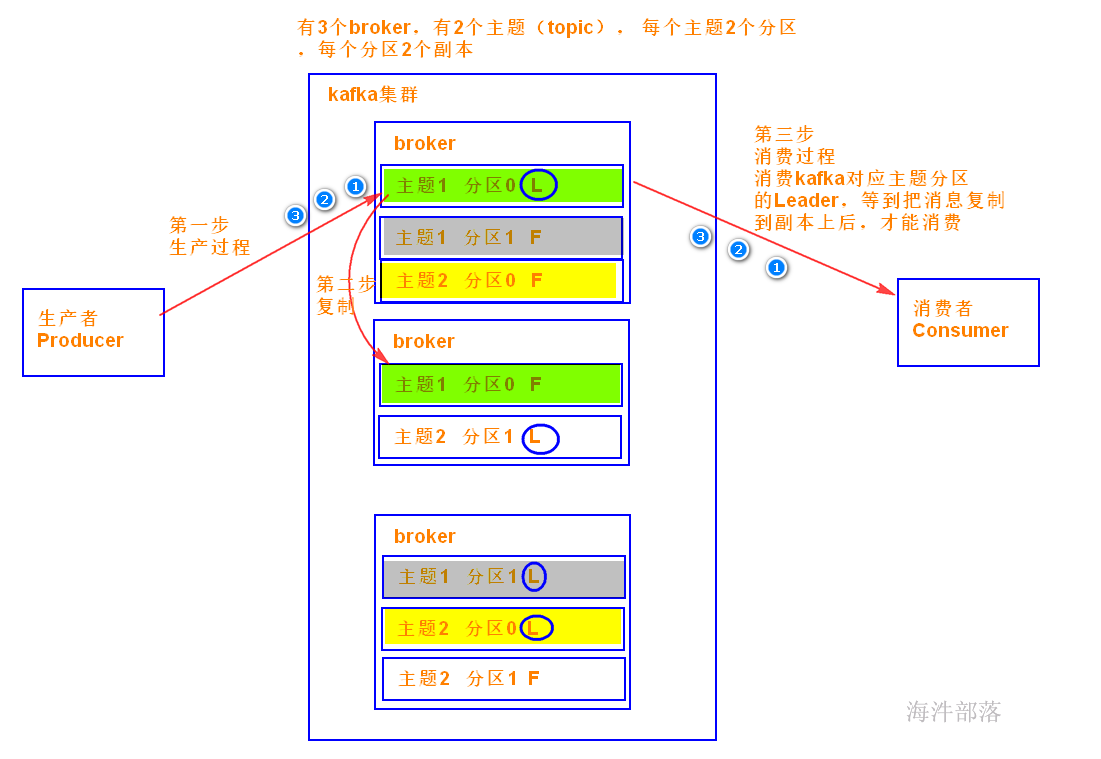
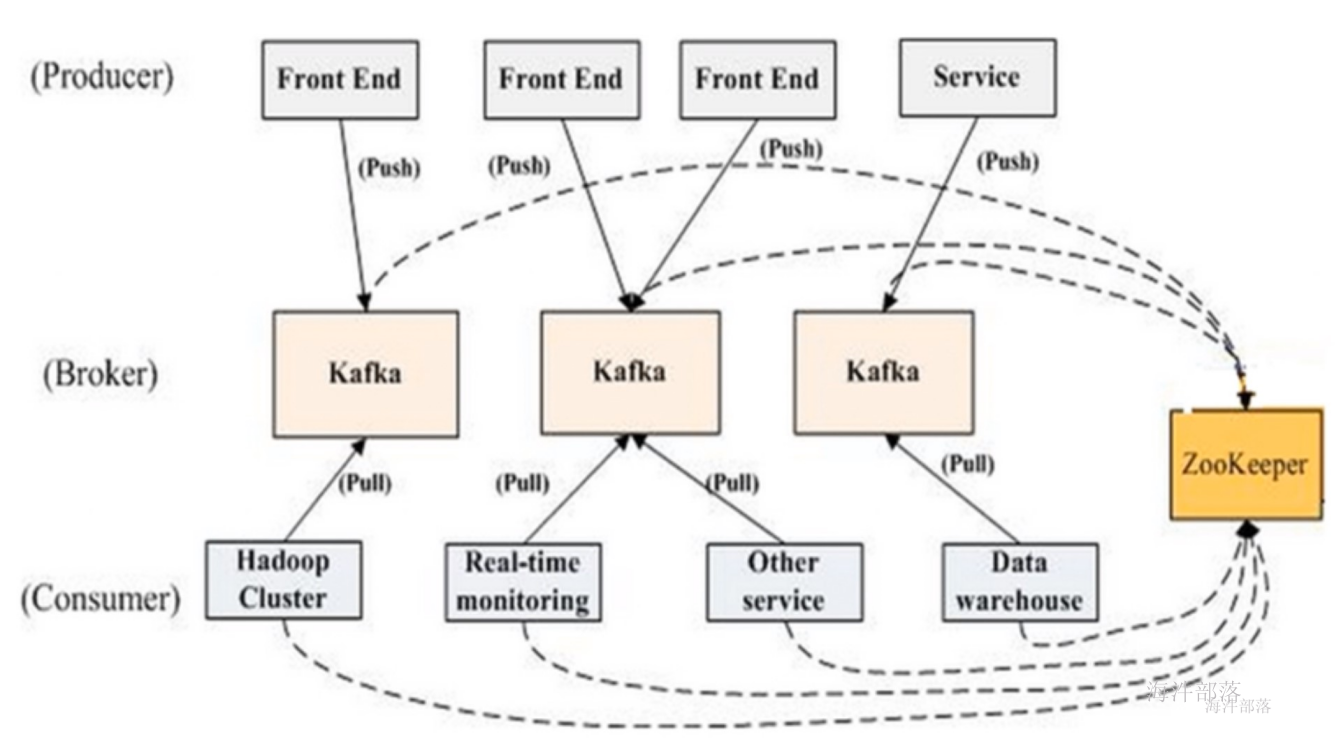
22.4 基本原理
22.4.1 分区与副本
每个topic 有一个或多个分区,每个分区在物理上对应一个文件夹,分区命令规则:主题名称—分区编号,(分区编号从0开始)
任何发布到分区的消息会直接追加到日志文件(分区目录下以.log为文件名后缀的数据文件)的尾部,而每条消息在日志中的位置都会对应一个按顺序递增的偏移量。偏移量是一个分区下严格有序的逻辑值,它并不表示消息在磁盘上的物理位置。
为了能快速查找到对应offset的数据,需要两个索引文件:
.index 结尾:根据有序的offset进行查找;
.timeindex 结尾: 根据有序的时间戳进行查找;

leader处理所有的针对这个partition的读写请求,而followers被动复制leader的结果。如果这个leader失效了,其中的一个follower将会自动的变成新的leader。每个broker自己所管理的partition的可以是leader,同时又是其他broker所管理partitions的followers,kafka通过这种方式来达到负载均衡。
一般情况下partition的数量大于等于broker的数量,并且所有partition的leader均匀分布在broker上。
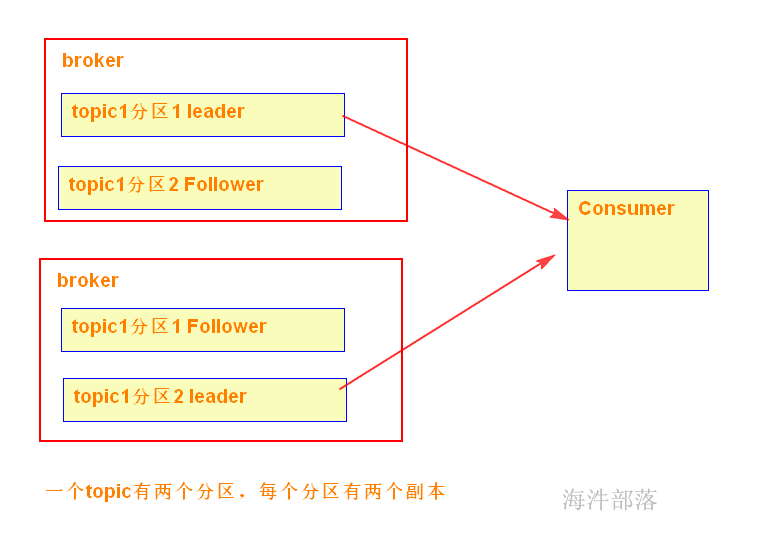
分区能增,不能减;
副本能增,也能减;
22.4.2 消息生产
Producer将消息发布到它指定的topic中,并负责决定发布到哪个分区
主要两种方式:
1)round-robin做简单的负载均;
2)根据消息中的某一个关键字来进行区分;
Producer根据指定的partition方法(round-robin、hash等),将消息发布到指定topic的partition里面。
22.4.3 消费与消费者组
Kafka提供了一种consumer的抽象概念:Consumer Group。
一个消费组可以有多个消费实例,这个实例可以是进程,也可以是线程。
同一Topic 的一条消息,只能被同一个 Consumer Group 的一个 Consumer 消费;
但 多个Consumer Group可同时消费这一消息。
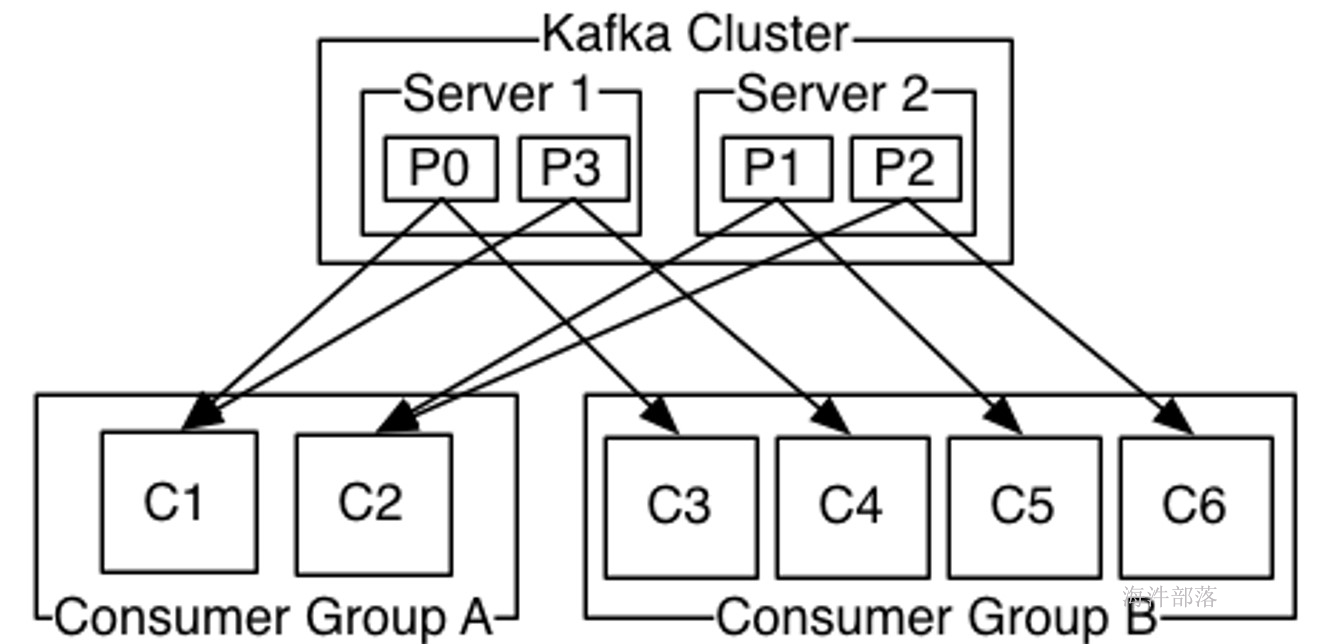
1)如果consumer比partition多,是浪费,因为kafka的设计是在一个partition上是不允许并发的,所以consumer数不要大于partition数;
2)如果consumer比partition少,一个consumer会对应于多个partitions,这里主要合理分配consumer数和partition数,否则会导致partition里面的数据被取的不均匀,最好partiton数目是consumer数目的整数倍;
3)如果consumer从多个partition读到数据,不保证数据间的顺序性,kafka只保证在一个partition上数据是有序的,但多个partition,根据你读的顺序会有所不同;
消费者多于partition
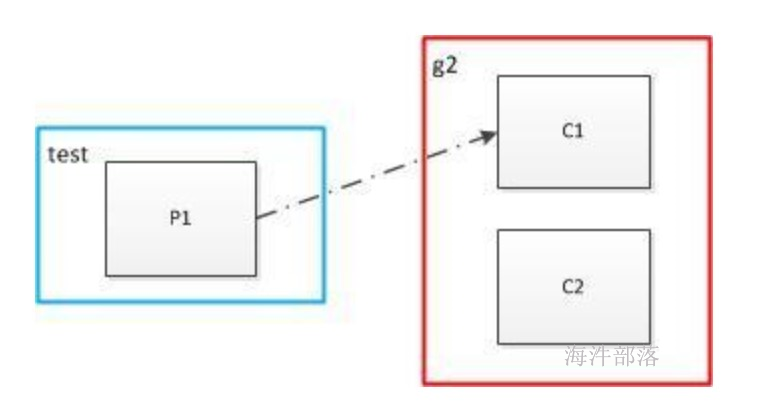
消费者少于和等于partition
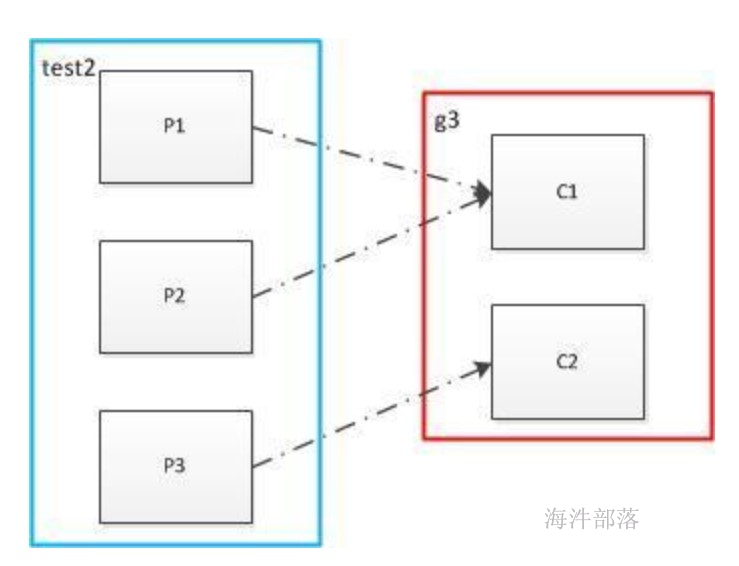
多个消费者组
每个消费者组的某一个消费实例能消费同一同一个消息。

22.4.4 消费顺序
Kafka通过Topic中partition概念实现并行消费;
Kafka可以同时提供顺序性保证和多个consumer同时消费时的负载均衡;
实现的原理是通过将一个topic中的每个partition分配给一个consumer group中的不同consumer实例;
通过这种方式:
Kafka只在partition的范围内保证消息消费的局部顺序性,不能在同一个topic中的多个partition中保证总的消费顺序性;
22.4.5 kafka优化
kafka同hdfs一样实现了软件raid,支持多磁盘并且不做raid,就是为了充分利用多磁盘并发读写,又保证每个磁盘连续读写的特性。
合理设置topic的partition数量,保证并发度。
Jvm内存不宜过大4G左右即可
建议JVM Heap不要太大,在4GB以内就可以。JVM太大,导致Full GC产生的“stop the world”时间过长,导致broker和zk之间的session超时。
JVM也不能过小,否则会导致频繁地触发gc操作,也影响Kafka的吞吐量。
如何为Kafka集群选择合适的Topic/Partitions数量
1)越多的分区可以提供更高的吞吐量,因为一个Partitions可以对应一个Consumer,Partitions越多吞吐量越高,也就是Consumer会并行读取Partitions。
2)分区多了会消耗更多的系统资源比如文件的句柄,broker会为每个Partitions分配一个文件目录,目录中分索引文件和数据文件。所以分区多了需要打开的文件自然就多了。
3)更多分区会导致更高的不可用性,在有副本的情况下更多的分区会导致更多的复制操作,在brokers宕机时也需要恢复更多的Partition。
4)越多的分区可能增加端对端的延时,因为producer发布消息后consumer需要等待所有partition完成复本复制之后才能得到该消息,分区越多说明复制所花费的时间越长,因为从一个broker到别一个broker复制数据是由一个线程来完成的。
5)越多的Partition意味着需要客户端分配更多的内存,比如一个topic有2000个分区,当只有一个consumer时,则这个consumer需要在内存中记住这2000个分区信息。
日志保留策略设置
log.retention.hours:日志保留时间,默认7天;
log.segment.bytes:段文件配置1GB,有利于快速回收磁盘空间,重启kafka加载也会加快(不需要扫描过多的小文件);
文件刷盘策略
为了大幅度提高producer写入吞吐量,需要定期批量写文件。建议配置:
log.flush.interval.messages=10000(每当producer写入10000条消息时,刷数据到磁盘)
log.flush.interval.ms=1000(每间隔1秒钟时间,刷数据到磁盘)
网络和io操作线程配置优化
一般num.network.threads主要处理网络io,读写缓冲区数据,基本没有io等待,配置线程数量为cpu核数加1。
num.network.threads=xxx (broker处理消息的最大线程数)
num.io.threads(主要进行磁盘io操作,高峰期可能有些io等待,因此配置需要大些。配置线程数量为cpu核数2倍,最大不超过3倍)
queued.max.requests=5000 (加入队列的最大请求数,超过该值,network thread阻塞)
socket.send.buffer.bytes=1024000 (server使用的send buffer大小)
socket.receive.buffer.bytes=1024000 (server使用的receive buffer大小)
配置参数:
| 参数 | 说明(解释) |
|---|---|
| broker.id =0 | 每一个broker在集群中的唯一表示,要求是正数。当该服务器的IP地址发生改变时,broker.id没有变化,则不会影响consumers的消息情况 |
| log.dirs=/data/kafka-logs | kafka数据的存放地址,多个地址的话用逗号分割,多个目录分布在不同磁盘上可以提高读写性能 /data/kafka-logs-1,/data/kafka-logs-2 |
| port =9092 | broker server服务端口 |
| message.max.bytes =6525000 | 表示消息体的最大大小,单位是字节 |
| num.network.threads =4 | broker处理消息的最大线程数,一般情况下数量为cpu核数 |
| num.io.threads =8 | broker处理磁盘IO的线程数,数值为cpu核数2倍 |
| background.threads =4 | 一些后台任务处理的线程数,例如过期消息文件的删除等,一般情况下不需要去做修改 |
| queued.max.requests =500 | 等待IO线程处理的请求队列最大数,若是等待IO的请求超过这个数值,那么会停止接受外部消息,应该是一种自我保护机制。 |
| host.name | broker的主机地址,若是设置了,那么会绑定到这个地址上,若是没有,会绑定到所有的接口上,并将其中之一发送到ZK,一般不设置 |
| socket.send.buffer.bytes=100*1024 | socket的发送缓冲区,socket的调优参数SO_SNDBUFF |
| socket.receive.buffer.bytes =100*1024 | socket的接受缓冲区,socket的调优参数SO_RCVBUFF |
| socket.request.max.bytes =10010241024 | socket请求的最大数值,防止serverOOM,message.max.bytes必然要小于socket.request.max.bytes,会被topic创建时的指定参数覆盖 |
| log.segment.bytes =102410241024 | topic的分区是以一堆segment文件存储的,这个控制每个segment的大小,会被topic创建时的指定参数覆盖 |
| log.roll.hours =24*7 | 这个参数会在日志segment没有达到log.segment.bytes设置的大小,也会强制新建一个segment会被 topic创建时的指定参数覆盖 |
| log.cleanup.policy = delete | 日志清理策略选择有:delete和compact主要针对过期数据的处理,或是日志文件达到限制的额度,会被 topic创建时的指定参数覆盖 |
| log.retention.minutes=300或log.retention.hours=24 | 数据文件保留多长时间, 存储的最大时间超过这个时间会根据log.cleanup.policy设置数据清除策略log.retention.bytes和log.retention.minutes或log.retention.hours任意一个达到要求,都会执行删除 有2删除数据文件方式:按照文件大小删除:log.retention.bytes 按照2中不同时间粒度删除:分别为分钟,小时 |
| log.retention.bytes=-1 | topic每个分区的最大文件大小,一个topic的大小限制 = 分区数*log.retention.bytes。-1没有大小限log.retention.bytes和log.retention.minutes任意一个达到要求,都会执行删除,会被topic创建时的指定参数覆盖 |
| log.retention.check.interval.ms=5minutes | 文件大小检查的周期时间,是否处罚 log.cleanup.policy中设置的策略 |
| log.cleaner.enable=false | 是否开启日志清理 |
| log.cleaner.threads = 2 | 日志清理运行的线程数 |
| log.cleaner.io.max.bytes.per.second=None | 日志清理时候处理的最大大小 |
| log.cleaner.dedupe.buffer.size=50010241024 | 日志清理去重时候的缓存空间,在空间允许的情况下,越大越好 |
| log.cleaner.io.buffer.size=512*1024 | 日志清理时候用到的IO块大小一般不需要修改 |
| log.cleaner.io.buffer.load.factor =0.9 | 日志清理中hash表的扩大因子一般不需要修改 |
| log.cleaner.backoff.ms =15000 | 检查是否处罚日志清理的间隔 |
| log.cleaner.min.cleanable.ratio=0.5 | 日志清理的频率控制,越大意味着更高效的清理,同时会存在一些空间上的浪费,会被topic创建时的指定参数覆盖 |
| log.cleaner.delete.retention.ms =1day | 对于压缩的日志保留的最长时间,也是客户端消费消息的最长时间,同log.retention.minutes的区别在于一个控制未压缩数据,一个控制压缩后的数据。会被topic创建时的指定参数覆盖 |
| log.index.size.max.bytes =1010241024 | 对于segment日志的索引文件大小限制,会被topic创建时的指定参数覆盖 |
| log.index.interval.bytes =4096 | 当执行一个fetch操作后,需要一定的空间来扫描最近的offset大小,设置越大,代表扫描速度越快,但是也更好内存,一般情况下不需要搭理这个参数 |
| log.flush.interval.messages=None例如log.flush.interval.messages=1000表示每当消息记录数达到1000时flush一次数据到磁盘 | log文件”sync”到磁盘之前累积的消息条数,因为磁盘IO操作是一个慢操作,但又是一个”数据可靠性“的必要手段,所以此参数的设置,需要在"数据可靠性"与”性能“之间做必要的权衡.如果此值过大,将会导致每次”fsync"的时间较长(IO阻塞),如果此值过小,将会导致“fsync”的次数较多,这也意味着整体的client请求有一定的延迟.物理server故障,将会导致没有fsync的消息丢失. |
| log.flush.scheduler.interval.ms =3000 | 检查是否需要固化到硬盘的时间间隔 |
| log.flush.interval.ms = None例如:log.flush.interval.ms=1000表示每间隔1000毫秒flush一次数据到磁盘 | 仅仅通过interval来控制消息的磁盘写入时机,是不足的.此参数用于控制“fsync”的时间间隔,如果消息量始终没有达到阀值,但是离上一次磁盘同步的时间间隔达到阀值,也将触发. |
| log.delete.delay.ms =60000 | 文件在索引中清除后保留的时间一般不需要去修改 |
| log.flush.offset.checkpoint.interval.ms =60000 | 控制上次固化硬盘的时间点,以便于数据恢复一般不需要去修改 |
| auto.create.topics.enable =true | 是否允许自动创建topic,若是false,就需要通过命令创建topic |
| default.replication.factor =1 | 是否允许自动创建topic,若是false,就需要通过命令创建topic |
| num.partitions =1 | 每个topic的分区个数,若是在topic创建时候没有指定的话会被topic创建时的指定参数覆盖 |
| 以下是kafka中Leader,replicas配置参数 | |
| controller.socket.timeout.ms =30000 | partition leader与replicas之间通讯时,socket的超时时间 |
| controller.message.queue.size=10 | partition leader与replicas数据同步时,消息的队列尺寸 |
| replica.lag.time.max.ms =10000 | 如果leader发现flower超过10秒没有向它发起fech请求,那么leader考虑这个flower是不是程序出了点问题或者资源紧张调度不过来,它太慢了,不希望它拖慢后面的进度,就把它从ISR中移除。 |
| replica.lag.max.messages =4000 | 如果follower落后与leader太多,将会认为此follower[或者说partition relicas]已经失效,相差4000条就移除##通常,在follower与leader通讯时,因为网络延迟或者链接断开,总会导致replicas中消息同步滞后##如果消息之后太多,leader将认为此follower网络延迟较大或者消息吞吐能力有限,将会把此replicas迁移##到其他follower中.##在broker数量较少,或者网络不足的环境中,建议提高此值. |
| replica.socket.timeout.ms=30*1000 | follower与leader之间的socket超时时间 |
| replica.socket.receive.buffer.bytes=64*1024 | leader复制时候的socket缓存大小 |
| replica.fetch.max.bytes =1024*1024 | replicas每次获取数据的最大大小 |
| replica.fetch.wait.max.ms =500 | replicas同leader之间通信的最大等待时间,失败了会重试 |
| replica.fetch.min.bytes =1 | fetch的最小数据尺寸,如果leader中尚未同步的数据不足此值,将会阻塞,直到满足条件 |
| num.replica.fetchers=1 | leader进行复制的线程数,增大这个数值会增加follower的IO |
| replica.high.watermark.checkpoint.interval.ms =5000 | 每个replica检查是否将最高水位进行固化的频率 |
| controlled.shutdown.enable =false | 是否允许控制器关闭broker ,若是设置为true,会关闭所有在这个broker上的leader,并转移到其他broker |
| controlled.shutdown.max.retries =3 | 控制器关闭的尝试次数 |
| controlled.shutdown.retry.backoff.ms =5000 | 每次关闭尝试的时间间隔 |
| leader.imbalance.per.broker.percentage =10 | leader的不平衡比例,若是超过这个数值,会对分区进行重新的平衡 |
| leader.imbalance.check.interval.seconds =300 | 检查leader是否不平衡的时间间隔 |
| offset.metadata.max.bytes | 客户端保留offset信息的最大空间大小 |
| kafka中zookeeper参数配置 | |
| zookeeper.connect = localhost:2181 | zookeeper集群的地址,可以是多个,多个之间用逗号分割hostname1:port1,hostname2:port2,hostname3:port3 |
| zookeeper.session.timeout.ms=6000 | ZooKeeper的最大超时时间,就是心跳的间隔,若是没有反映,那么认为已经死了,不易过大 |
| zookeeper.connection.timeout.ms =6000 | ZooKeeper的连接超时时间 |
| zookeeper.sync.time.ms =2000 | ZooKeeper集群中leader和follower之间的同步实际那 |
22.5 kafka安装
安装规划:
kafka 是集群需要 zookeeper,在zookeeper 集群对应的节点上 安装kafka集群。
nn1.hadoop
nn2.hadoop
s1.hadoop
如果之前安装过,需要删除掉zookeeper 中已经存在的kafka 的数据目录 和 每台机器磁盘上的 kafka-logs 目录


./ssh_root_zookeeper.sh tar -xzf /tmp/kafka_2.11-0.10.2.1.tgz -C /usr/local
./ssh_root_zookeeper.sh ln -s /usr/local/kafka_2.11-0.10.2.1 /usr/local/kafka
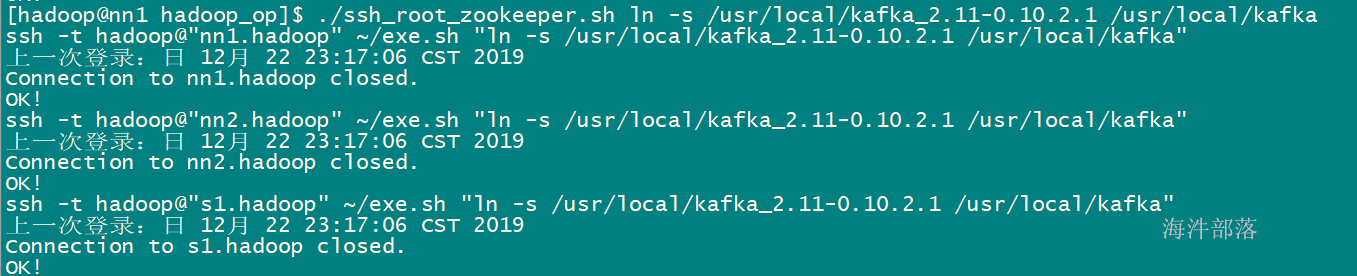
./ssh_root_zookeeper.sh chown -R hadoop:hadoop /usr/local/kafka_2.11-0.10.2.1
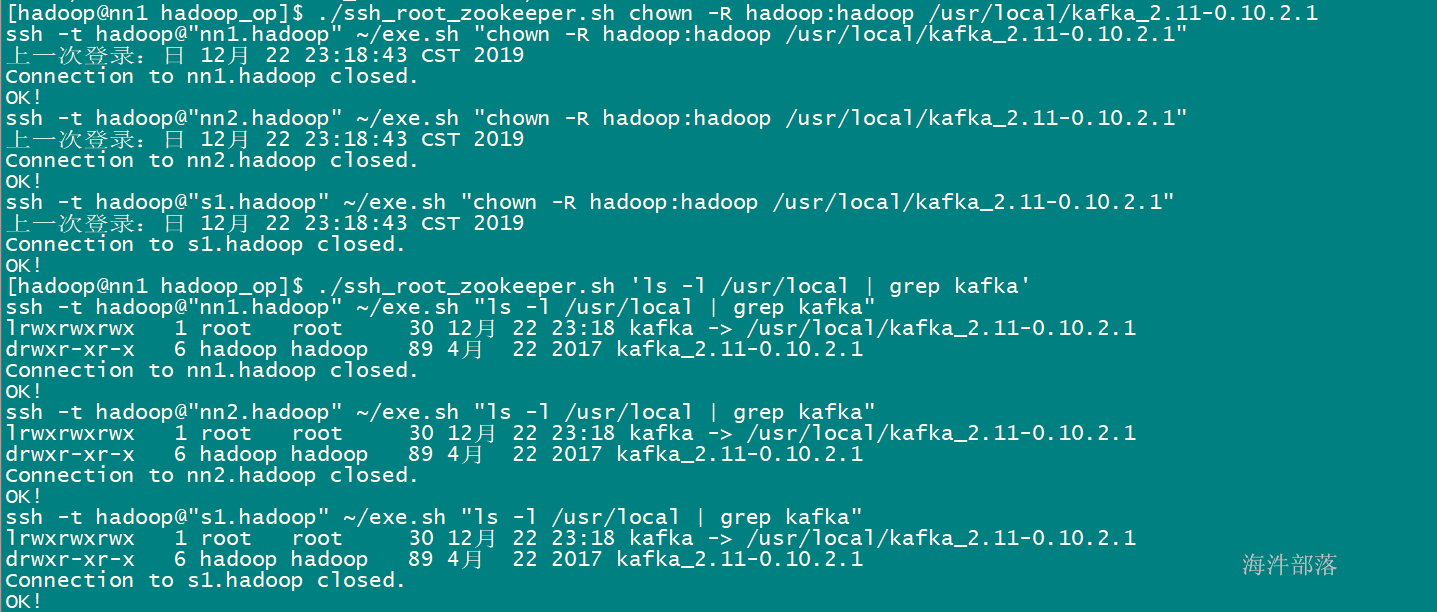
定义端口

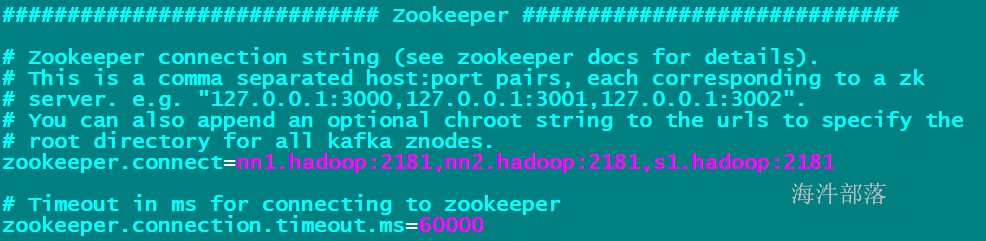
教室集群配置





./scp_all_zookeeper.sh /usr/local/kafka/config/server.properties /usr/local/kafka/config
./scp_all_zookeeper.sh /usr/local/kafka/config/producer.properties /usr/local/kafka/config
./scp_all_zookeeper.sh /usr/local/kafka/config/consumer.properties /usr/local/kafka/config

./ssh_all_zookeeper.sh /usr/local/zookeeper/bin/zkServer.sh start
启动kafka
./ssh_all_zookeeper.sh “nohup /usr/local/kafka/bin/kafka-server-start.sh /usr/local/kafka/config/server.properties > /tmp/kafka_logs 2>&1 &”
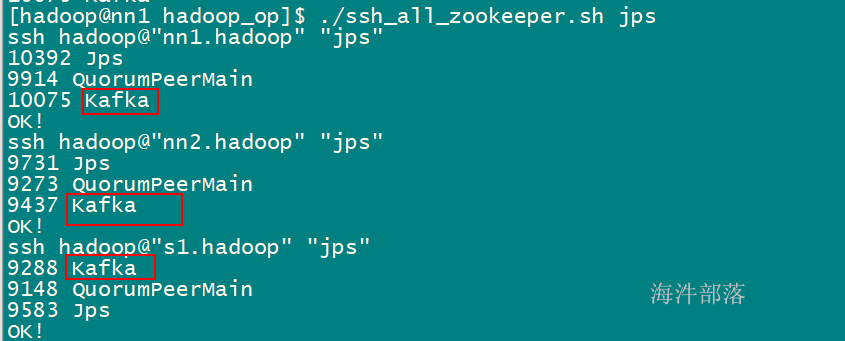
/usr/local/kafka/bin/kafka-topics.sh –create –replication-factor 2 –partitions 2 –topic hainiu_test –zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181
这里指定了2个副本,2个分区,topic名为hainiu_test,并且指定zookeeper地址

/usr/local/zookeeper/bin/zkCli.sh -server nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181
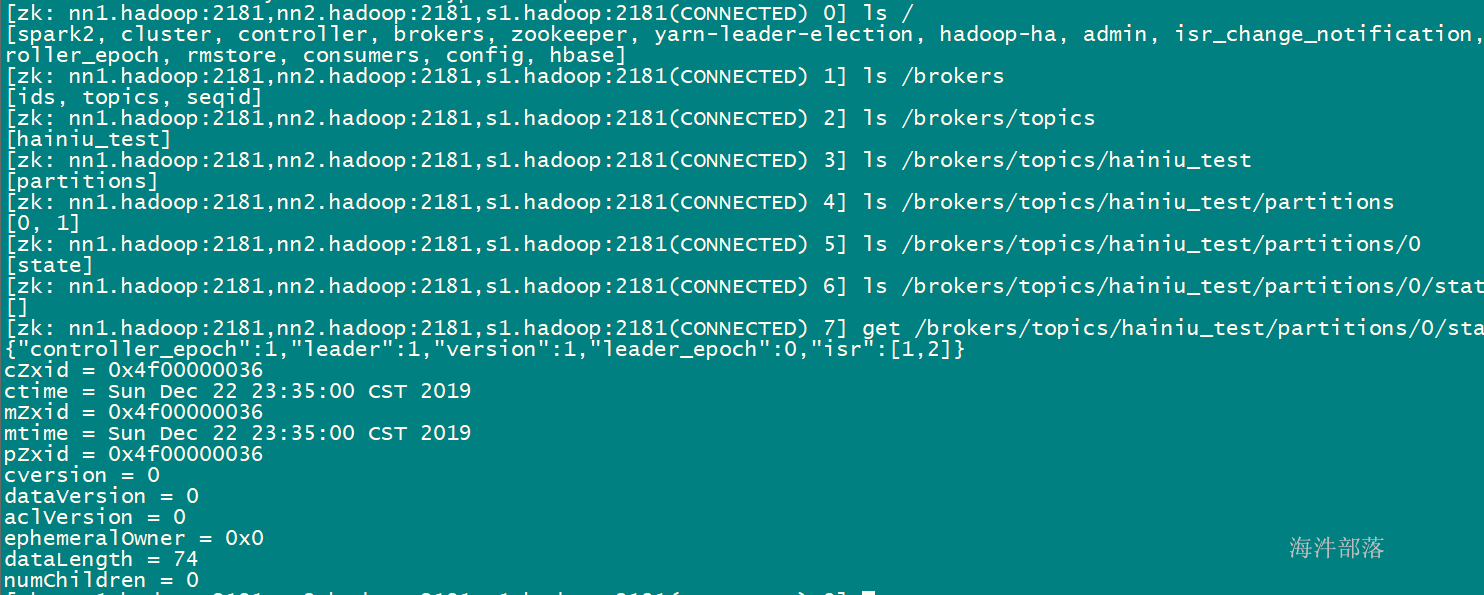
/usr/local/kafka/bin/kafka-topics.sh –list –zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181

/usr/local/kafka/bin/kafka-topics.sh –describe –zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 –topic hainiu_test

/usr/local/kafka/bin/kafka-console-producer.sh –broker-list nn1.hadoop:9092,nn2.hadoop:9092,s1.hadoop:9092 –topic hainiu_test

/usr/local/kafka/bin/kafka-console-consumer.sh –zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 –topic hainiu_test

/usr/local/kafka/bin/kafka-consumer-groups.sh –zookeeper nn1.hadoop:2181 –list

/usr/local/kafka/bin/kafka-consumer-groups.sh –zookeeper nn1.hadoop:2181 –group group1 –describe
消费的topic名称、partition id、consumer group最后一次提交的offset、最后提交的生产消息offset、消费offset与生产offset之间的差值、当前消费topic-partition的group成员id
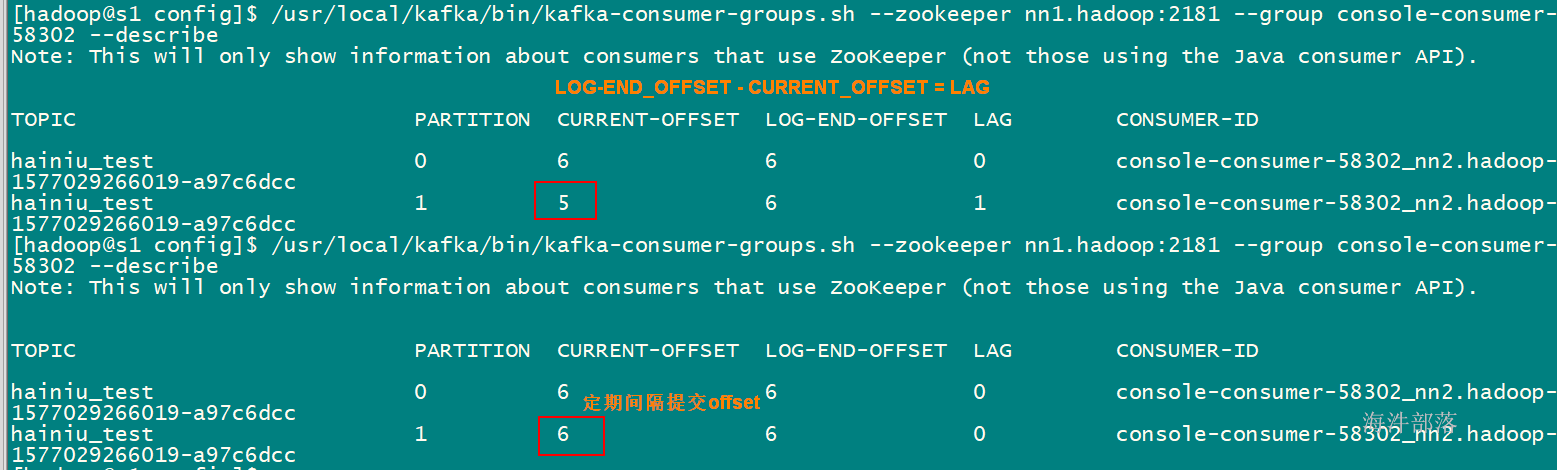
当增加新分区后,需要重启producer 才能识别新增加的分区。
/usr/local/kafka/bin/kafka-topics.sh –alter –zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 –topic hainiu_test –partitions 3
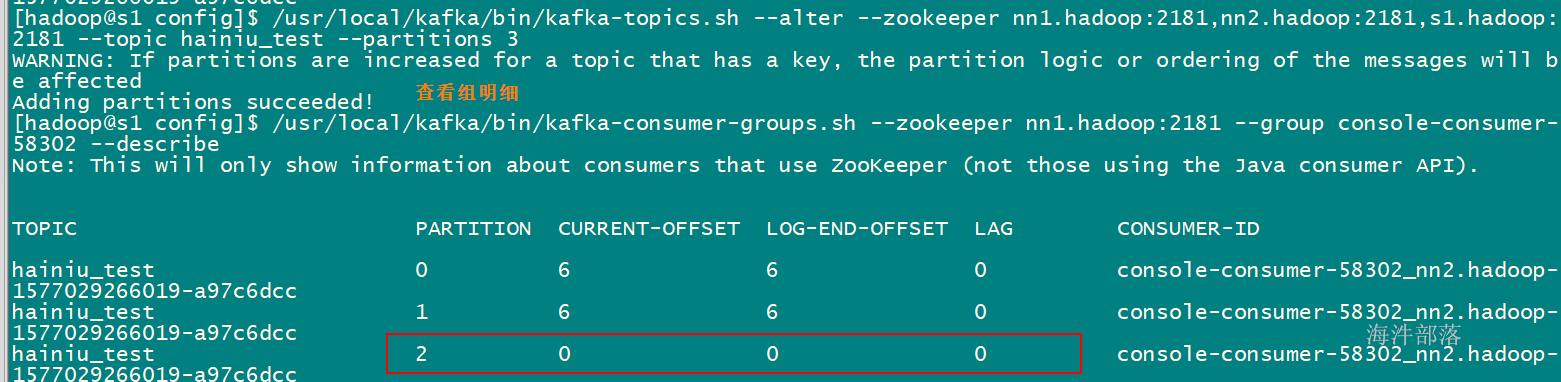


/usr/local/kafka/bin/kafka-reassign-partitions.sh –zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 –reassignment-json-file /home/hadoop/topic.json –execute

/usr/local/kafka/bin/kafka-topics.sh –describe –zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 –topic hainiu_test

/usr/local/kafka/bin/kafka-reassign-partitions.sh –zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 –reassignment-json-file /home/hadoop/topic.json –verify

使用下面这个json
{"partitions":[{"topic":"hainiu_test","partition":0,"replicas":[0,1,2]},{"topic":"hainiu_test","partition":1,"replicas":[0,1,2]},{"topic":"hainiu_test","partition":2,"replicas":[0,1,2]}],"version":1}格式化后:
{
"partitions":
[
{
"topic": "hainiu_test",
"partition": 0,
"replicas": [0,1,2] //副本所在brokerID,就是在server.properties中配置的broker.id
},
{
"topic": "hainiu_test",
"partition": 1,
"replicas": [0,1,2]
},
{
"topic": "hainiu_test",
"partition": 2,
"replicas": [0,1,2]
}
],
"version":1
}删除topic
/usr/local/kafka/bin/kafka-topics.sh –delete –zookeeper nn1.hadoop:2181,nn2.hadoop:2181,s1.hadoop:2181 –topic hainiu_test

删除kafka存储目录(server.properties文件log.dirs配置,默认为“/data/kafka-logs”)相关topic目录
删除zookeeper “/brokers/topics/”目录下相关topic节点
停止kafka服务
./ssh_all_zookeeper.sh /usr/local/kafka/bin/kafka-server-stop.sh
22.6 kafka-manager的安装与使用
安装在nn1.hadoop
通过kafka-manager 来管理 kafka。
1)先解压到/usr/local目录下
2)创建软链接
ln -s /usr/local/kafka-manager-1.3.3.7 /usr/local/kafka-manager
3)修改所属用户为hadoop
4)修改配置文件
vim /usr/local/kafka-manager/conf/application.conf

6)启动
指定配置启动并指定端口为9999
nohup /usr/local/kafka-manager/bin/kafka-manager -Dconfig.file=/usr/local/kafka-manager/conf/application.conf -Dhttp.port=9999 > /usr/local/kafka-manager/logs/kafka-manager.log 2>&1 &
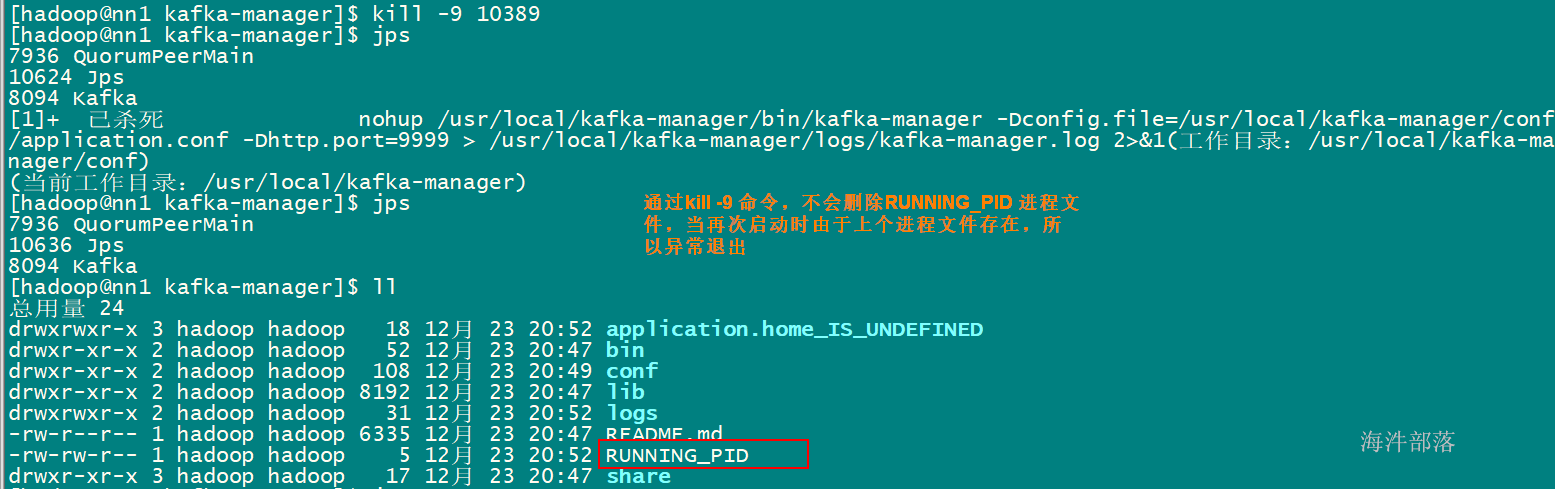
http://blog.csdn.net/isea533/article/details/73727485
7).海牛kafka-manager服务访问地址 http://nn2.hadoop:9999
22.7 kafka开发之通过broker消费kafka数据

添加pom依赖,之前添加过:
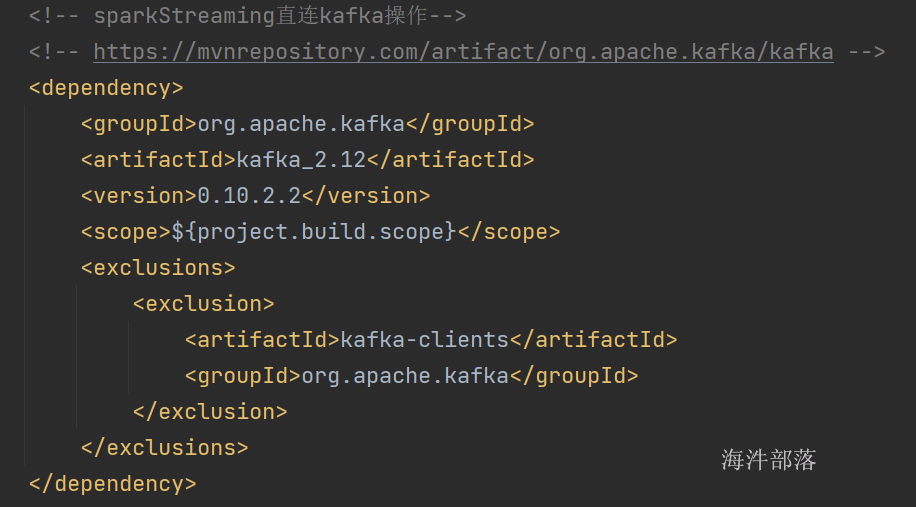
22.7.1 写入kafka数据用自带的StringSerializer
auto.offset.reset值含义解释
| auto.offset.reset值 | 说明 | |
|---|---|---|
| 分区下有已提交offset | 分区无提交的offset | |
| earliest | 从提交的offset开始消费 | 从头开始消费 |
| latest | 从提交的offset开始消费 | 消费新产生的该分区下的数据 |
| none | 从提交的offset开始消费 | 抛异常 |
代码:
package com.hainiu.kafka
import java.util.Properties
import kafka.consumer._
import kafka.message.MessageAndMetadata
import org.apache.kafka.clients.consumer.{ConsumerRecords, KafkaConsumer}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.{StringDeserializer, StringSerializer}
import scala.actors.Actor
import scala.collection.mutable
class HainiuKafkaProducerBroker extends Actor {
var topic: String = _
var producer: KafkaProducer[String, String] = _
def this(topic: String) = {
this()
this.topic = topic
// 根据配置初始化 KafkaProducer// 根据配置初始化 KafkaProducer
val props = new Properties()
// broker地址
props.put("bootstrap.servers", "nn1.hadoop:9092,nn2.hadoop:9092,s1.hadoop:9092")
props.put("key.serializer", classOf[StringSerializer].getName)
props.put("value.serializer", classOf[StringSerializer].getName)
this.producer = new KafkaProducer[String, String](props)
}
override def act(): Unit = {
var num: Int = 1
while (true) {
val msg = s"hainiu_${num}"
println(s"send: ${msg}")
this.producer.send(new ProducerRecord[String, String](this.topic, msg))
num += 1
if (num > 10) {
num = 1
}
Thread.sleep(1000)
}
}
}
class HainiuKafkaConsumerBroker extends Actor {
var topic:String = _
// 利用kafka的高级api消费
var consumer:KafkaConsumer[String,String] = _
def this(topic: String) = {
this()
this.topic = topic
val pro = new Properties()
// 更高级的api,直接读broker
pro.put("bootstrap.servers", "nn1.hadoop:9092,nn2.hadoop:9092,s1.hadoop:9092")
//每个consumer在消费数据的时候指定自己属于那个consumerGroup
pro.put("group.id", "group102")
//consumer读取的策略
pro.put("auto.offset.reset", "latest")
//是否自动提交offset
pro.put("enable.auto.commit", "true")
//多长时间提交一次
pro.put("auto.commit.interval.ms", "1000")
//使用String的序列化工具把二进制转成String类型
pro.put("key.deserializer", classOf[StringDeserializer].getName)
//使用自定义的序列化工具把二进制转成String类型
pro.put("value.deserializer", classOf[StringDeserializer].getName)
this.consumer = new KafkaConsumer[String, String](pro)
//指定consumer读取topic中的那一个partition,这个叫做分配方式
this.consumer.assign(java.util.Arrays.asList(new TopicPartition(topic,0)))
//指定consumer读取topic中所有的partition,这个叫做订阅方式
// this.consumer.subscribe(java.util.Arrays.asList(topic))
}
override def act(): Unit = {
while(true){
// Iterable[ConsumerRecord[K, V]]
val records: ConsumerRecords[String, String] = this.consumer.poll(100)
// 通过隐式转换把java的 Iterable 转成 scala的 Iterable
import scala.collection.convert.wrapAll._
for(record <- records){
val topicName: String = record.topic()
val partition: Int = record.partition()
val offset: Long = record.offset()
val msg: String = record.value()
println(s"receive: ${msg}\t${topicName}\t${partition}\t${offset}")
}
}
}
}
object HainiuKafkaBrokerTest {
def main(args: Array[String]): Unit = {
val topic: String = "hainiu_t1"
new HainiuKafkaProducerBroker(topic).start()
new HainiuKafkaConsumerBroker(topic).start()
}
}测试:
1) 消费策略:订阅模式, 读取策略:earliest , 换消费者组
2)消费策略:订阅模式, 读取策略:laster, 换消费者组
2)消费策略:分配模式, 读取策略:laster, 不换消费者组
22.7.2 写入kafka数据自定义序列化与反序列化
1)自定义序列化类 java版
序列化需要实现 org.apache.kafka.common.serialization.Serializer
package com.hainiu.kafka;
import org.apache.kafka.common.serialization.Serializer;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.util.Map;
// 自定义序列化类,把KafkaData对象序列化成byte[]
public class KafkaDataSerializer implements Serializer<KafkaData> {
public void configure(Map<String, ?> configs, boolean isKey) {
}
public byte[] serialize(String topic, KafkaData data) {
if(data == null){
return null;
}
ByteArrayOutputStream bos = null;
ObjectOutputStream oos = null;
try{
bos = new ByteArrayOutputStream();
oos = new ObjectOutputStream(bos);
oos.writeObject(data);
}catch (Exception e){
e.printStackTrace();
}finally {
try {
oos.close();
bos.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return bos.toByteArray();
}
public void close() {
}
}2)自定义反序列化类 java版
package com.hainiu.kafka;
import org.apache.kafka.common.serialization.Deserializer;
import java.io.ByteArrayInputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.util.Map;
// 定义反序列化类,用于把byte[] 反序列化成kafkaData对象
public class KafkaDataDeserializer implements Deserializer<KafkaData> {
public void configure(Map<String, ?> configs, boolean isKey) {
}
public KafkaData deserialize(String topic, byte[] data) {
if(data == null){
return null;
}
ByteArrayInputStream bis = null;
ObjectInputStream ois = null;
Object obj = null;
try{
bis = new ByteArrayInputStream(data);
ois = new ObjectInputStream(bis);
obj = ois.readObject();
}catch (Exception e){
e.printStackTrace();
}finally {
try {
ois.close();
bis.close();
} catch (IOException e) {
e.printStackTrace();
}
}
return (KafkaData) obj;
}
public void close() {
}
}3)生产消费程序
package com.hainiu.kafka
import java.util.Properties
import javakafka.{KafkaDataDeserializer, KafkaDataSerializer}
import kafka.consumer._
import kafka.message.MessageAndMetadata
import org.apache.kafka.clients.consumer.{ConsumerRecords, KafkaConsumer}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.{StringDeserializer, StringSerializer}
import scala.actors.Actor
import scala.collection.mutable
// 定义样例类,发送样例类到kafka
case class KafkaData(val data:String)
class HainiuKafkaProducerBrokerSer extends Actor {
var topic: String = _
var producer: KafkaProducer[String, KafkaData] = _
def this(topic: String) = {
this()
this.topic = topic
// 根据配置初始化 KafkaProducer// 根据配置初始化 KafkaProducer
val props = new Properties()
// broker地址
props.put("bootstrap.servers", "nn1.hadoop:9092,nn2.hadoop:9092,s1.hadoop:9092")
props.put("key.serializer", classOf[StringSerializer].getName)
props.put("value.serializer", classOf[KafkaDataSerializer].getName)
this.producer = new KafkaProducer[String, KafkaData](props)
}
override def act(): Unit = {
var num: Int = 1
while (true) {
val msg = KafkaData(s"hainiu_${num}")
println(s"send: ${msg}")
this.producer.send(new ProducerRecord[String, KafkaData](this.topic, msg))
num += 1
if (num > 10) {
num = 1
}
Thread.sleep(1000)
}
}
}
class HainiuKafkaConsumerBrokerSer extends Actor {
var topic:String = _
// 利用kafka的高级api消费
var consumer:KafkaConsumer[String,KafkaData] = _
def this(topic: String) = {
this()
this.topic = topic
val pro = new Properties()
// 更高级的api,直接读broker
pro.put("bootstrap.servers", "nn1.hadoop:9092,nn2.hadoop:9092,s1.hadoop:9092")
//每个consumer在消费数据的时候指定自己属于那个consumerGroup
pro.put("group.id", "group103")
//consumer读取的策略
pro.put("auto.offset.reset", "latest")
//是否自动提交offset
pro.put("enable.auto.commit", "true")
//多长时间提交一次
pro.put("auto.commit.interval.ms", "1000")
//使用String的序列化工具把二进制转成String类型
pro.put("key.deserializer", classOf[StringDeserializer].getName)
//使用自定义的序列化工具把二进制转成String类型
pro.put("value.deserializer", classOf[KafkaDataDeserializer].getName)
this.consumer = new KafkaConsumer[String, KafkaData](pro)
//指定consumer读取topic中的那一个partition,这个叫做分配方式
//this.consumer.assign(java.util.Arrays.asList(new TopicPartition(topic,0)))
//指定consumer读取topic中所有的partition,这个叫做订阅方式
this.consumer.subscribe(java.util.Arrays.asList(topic))
}
override def act(): Unit = {
while(true){
// Iterable[ConsumerRecord[K, V]]
val records: ConsumerRecords[String, KafkaData] = this.consumer.poll(100)
// 通过隐式转换把java的 Iterable 转成 scala的 Iterable
import scala.collection.convert.wrapAll._
for(record <- records){
val topicName: String = record.topic()
val partition: Int = record.partition()
val offset: Long = record.offset()
val msg: KafkaData = record.value()
println(s"receive: ${msg}\t${topicName}\t${partition}\t${offset}")
}
}
}
}
object HainiuKafkaBrokerSerTest {
def main(args: Array[String]): Unit = {
val topic: String = "hainiu_t2"
new HainiuKafkaProducerBrokerSer(topic).start()
new HainiuKafkaConsumerBrokerSer(topic).start()
}
}创建新的topic
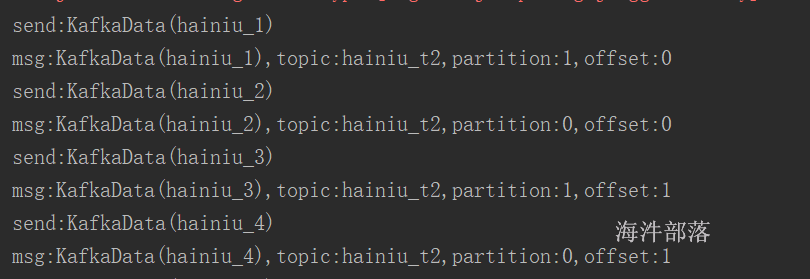
22.7.3 生产消费特定partition
实现需求:
生产根据写入数据的数字,偶数分区0,奇数分区1。
消费通过分配模式只消费分区0 的数据。
1)KafkaProducer 发送时自定义分区
package javakafka;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
public class ProducerPartitioner implements Partitioner{
@Override
public int partition(String topic, Object key, byte[] keyBytes,
Object value, byte[] valueBytes, Cluster cluster) {
// 生产根据写入数据的数字,偶数分区0,奇数分区1
String data = (String)value;
// data:hainiu_n
String[] arr = data.split("_");
int num = Integer.parseInt(arr[1]);
if(num % 2 == 0){
return 0;
}
return 1;
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}2)KafkaProducer 参数增加自定义partitioner.class
// 根据配置初始化 KafkaProducer
val props = new Properties()
props.put("bootstrap.servers", "nn1.hadoop:9092,nn2.hadoop:9092,s1.hadoop:9092")
props.put("key.serializer", classOf[StringSerializer].getName())
// 设置 序列化类为自定义 HainiuKafkaSerializer
props.put("value.serializer", classOf[HainiuKafkaSerializer].getName())
// 设置指定的数据放到指定的分区
props.put("partitioner.class", classOf[ProducerPartitioner].getName)
this.producer = new KafkaProducer[String,KafkaData](props)3)KafkaConsumer 设置分配方式接收
//指定consumer读取topic中的那一个partition,这个叫做分配方式
// 只接收0分区的数据
this.consumer.assign(java.util.Arrays.asList(new TopicPartition(topic,0)))4)全部代码如下
package com.hainiu.kafka
import java.util.Properties
import javakafka.ProducerPartitioner
import kafka.consumer._
import kafka.message.MessageAndMetadata
import org.apache.kafka.clients.consumer.{ConsumerRecords, KafkaConsumer}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerConfig, ProducerRecord}
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.{StringDeserializer, StringSerializer}
import scala.actors.Actor
import scala.collection.mutable
class HainiuKafkaProducerBrokerPartitioner extends Actor {
var topic: String = _
var producer: KafkaProducer[String, String] = _
def this(topic: String) = {
this()
this.topic = topic
// 根据配置初始化 KafkaProducer// 根据配置初始化 KafkaProducer
val props = new Properties()
// broker地址
props.put("bootstrap.servers", "nn1.hadoop:9092,nn2.hadoop:9092,s1.hadoop:9092")
props.put("key.serializer", classOf[StringSerializer].getName)
props.put("value.serializer", classOf[StringSerializer].getName)
// 设置自定义partitionclass
// 发送时就按照定义的算法进行发送
props.put(ProducerConfig.PARTITIONER_CLASS_CONFIG, classOf[ProducerPartitioner].getName)
this.producer = new KafkaProducer[String, String](props)
}
override def act(): Unit = {
var num: Int = 1
while (true) {
val msg = s"hainiu_${num}"
println(s"send: ${msg}")
this.producer.send(new ProducerRecord[String, String](this.topic, msg))
num += 1
if (num > 10) {
num = 1
}
Thread.sleep(1000)
}
}
}
class HainiuKafkaConsumerBrokerPartitioner extends Actor {
var topic:String = _
// 利用kafka的高级api消费
var consumer:KafkaConsumer[String,String] = _
def this(topic: String) = {
this()
this.topic = topic
val pro = new Properties()
// 更高级的api,直接读broker
pro.put("bootstrap.servers", "nn1.hadoop:9092,nn2.hadoop:9092,s1.hadoop:9092")
//每个consumer在消费数据的时候指定自己属于那个consumerGroup
pro.put("group.id", "group103")
//consumer读取的策略
pro.put("auto.offset.reset", "earliest")
//是否自动提交offset
pro.put("enable.auto.commit", "true")
//多长时间提交一次
pro.put("auto.commit.interval.ms", "1000")
//使用String的序列化工具把二进制转成String类型
pro.put("key.deserializer", classOf[StringDeserializer].getName)
//使用自定义的序列化工具把二进制转成String类型
pro.put("value.deserializer", classOf[StringDeserializer].getName)
this.consumer = new KafkaConsumer[String, String](pro)
//指定consumer读取topic中的那一个partition,这个叫做分配方式
this.consumer.assign(java.util.Arrays.asList(new TopicPartition(topic,0)))
//指定consumer读取topic中所有的partition,这个叫做订阅方式
// this.consumer.subscribe(java.util.Arrays.asList(topic))
}
override def act(): Unit = {
while(true){
// Iterable[ConsumerRecord[K, V]]
val records: ConsumerRecords[String, String] = this.consumer.poll(100)
// 通过隐式转换把java的 Iterable 转成 scala的 Iterable
import scala.collection.convert.wrapAll._
for(record <- records){
val topicName: String = record.topic()
val partition: Int = record.partition()
val offset: Long = record.offset()
val msg: String = record.value()
println(s"receive: ${msg}\t${topicName}\t${partition}\t${offset}")
}
}
}
}
object HainiuKafkaBrokerTestPartitioner {
def main(args: Array[String]): Unit = {
val topic: String = "hainiu_t3"
new HainiuKafkaProducerBrokerPartitioner(topic).start()
new HainiuKafkaConsumerBrokerPartitioner(topic).start()
}
}结果只接收分区0 的数据
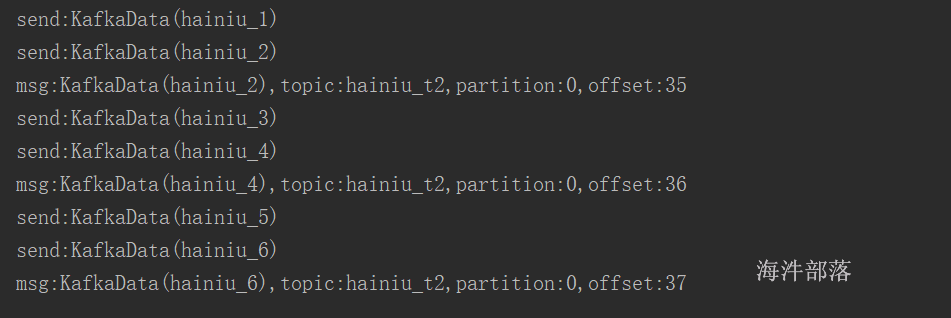
5)生产者写kafka源码分析
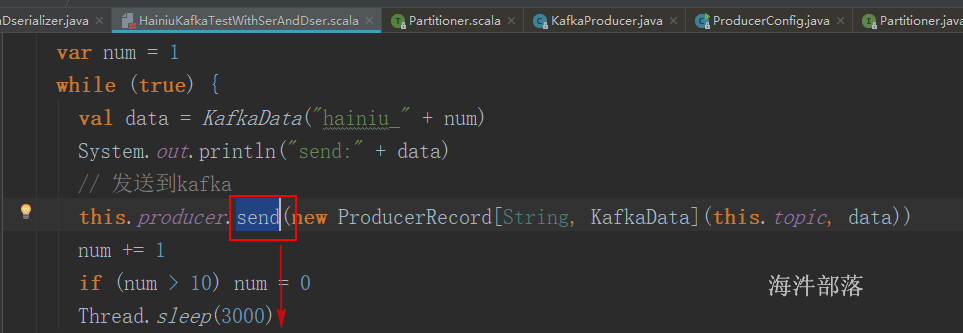
1)给消费组1设置groupid 为 group60,然后消费输出时增加groupid,这样到哪个组消费的。同时启动生产和消费。

22.8 spark-streaming-kafka
sparkStreaming 读kafka,有两种方式,一种读zookeeper(现有版本已抛弃),一种读broker,也就是kafka直连流方式。
1)位置策略
Spark Streaming 中提供了如下三种位置策略,用于指定 Kafka 主题分区与 Spark 执行程序 Executors 之间的分配关系:
PreferConsistent : 它将在所有的 Executors 上均匀分配分区;
PreferBrokers : 当 Spark 的 Executor 与 Kafka Broker 在同一机器上时可以选择该选项,它优先将该 Broker 上的首领分区分配给该机器上的 Executor;
PreferFixed : 可以指定主题分区与特定主机的映射关系,显示地将分区分配到特定的主机,其构造器如下:
@Experimental
def PreferFixed(hostMap: collection.Map[TopicPartition, String]): LocationStrategy =
new PreferFixed(new ju.HashMap[TopicPartition, String](hostMap.asJava))
@Experimental
def PreferFixed(hostMap: ju.Map[TopicPartition, String]): LocationStrategy =
new PreferFixed(hostMap)2)消费策略
订阅和分配。
订阅:可订阅一个主题所有分区或多个主题所有分区。
分配:可消费指定主题分区数据。
Spark Streaming 提供了两种主题订阅方式,分别为 Subscribe 和 SubscribePattern。后者可以使用正则匹配订阅主题的名称。其构造器分别如下:
/**
\* @param topics 需要订阅的主题的集合
\* @param Kafka 消费者参数
\* @param offsets(可选): 在初始启动时开始的偏移量。如果没有,则将使用保存的偏移量或 auto.offset.reset 属性的值
*/
def Subscribe[K, V](
topics: ju.Collection[jl.String],
kafkaParams: ju.Map[String, Object],
offsets: ju.Map[TopicPartition, jl.Long]): ConsumerStrategy[K, V] = { ... }
/**
\* @param pattern需要订阅的正则
\* @param Kafka 消费者参数
\* @param offsets(可选): 在初始启动时开始的偏移量。如果没有,则将使用保存的偏移量或 auto.offset.reset 属性的值
*/
def SubscribePattern[K, V](
pattern: ju.regex.Pattern,
kafkaParams: collection.Map[String, Object],
offsets: collection.Map[TopicPartition, Long]): ConsumerStrategy[K, V] = { ... }3)程序代码
package com.hainiu.kafka
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Durations, StreamingContext}
import scala.collection.mutable
import scala.collection.mutable.ListBuffer
object ReadKafkaStream {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[*]").setAppName("ReadKafkaStream")
val topics:String = "hainiu_sk"
// 读取kafka的配置
val kafkaParams = new mutable.HashMap[String,Object]()
kafkaParams += "bootstrap.servers" -> "nn1.hadoop:9092,nn2.hadoop:9092,s1.hadoop:9092"
kafkaParams += "group.id" -> "group105"
kafkaParams += "key.deserializer" -> classOf[StringDeserializer].getName
kafkaParams += "value.deserializer" -> classOf[StringDeserializer].getName
kafkaParams += "auto.offset.reset" -> "earliest"
kafkaParams += "enable.auto.commit" -> "true"
val ssc: StreamingContext = new StreamingContext(conf, Durations.seconds(5))
// 设置位置策略
val locationStrategy: LocationStrategy = LocationStrategies.PreferConsistent
// 设置消费策略
// 订阅策略
// val consumerStategy: ConsumerStrategy[String, String] = ConsumerStrategies.Subscribe[String,String](topics.split(",").toSet, kafkaParams)
// 只订阅0和1分区的数据
val p0: TopicPartition = new TopicPartition("hainiu_sk", 0)
val p1: TopicPartition = new TopicPartition("hainiu_sk", 1)
val partitions: ListBuffer[TopicPartition] = new ListBuffer[TopicPartition]
partitions += p0
partitions += p1
val consumerStategy: ConsumerStrategy[String, String] = ConsumerStrategies.Assign[String, String](partitions, kafkaParams)
// 通过KafkaUtils工具类创建kafka直连流
val kafkaDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(ssc,locationStrategy, consumerStategy)
// 如果想看到kafka消费的offset信息,那就得从kafka流获取,如果通过流转换后,元数据信息就看不见了
val kafkaDS2: DStream[ConsumerRecord[String, String]] = kafkaDS.transform((kafkaRdd) => {
println(s"kafka直连流的rdd分区数:${kafkaRdd.getNumPartitions}")
// kafka流底层就是kafkaRDD, kafkaRdd 实现了 HasOffsetRanges
val ranges: HasOffsetRanges = kafkaRdd.asInstanceOf[HasOffsetRanges]
val arr: Array[OffsetRange] = ranges.offsetRanges
for (offsetRange <- arr) {
val topic: String = offsetRange.topic
val partition: Int = offsetRange.partition
// 当前批次从哪个分区的哪个offset开始消费
val offset: Long = offsetRange.fromOffset
println(s"消费的offset信息:${topic}\t${partition}\t${offset}")
}
kafkaRdd
})
// 当一个sparkStreaming程序消费多个topic时,可以通过下面的这行代码拿到消息对应的topic,
// 后面就可以通过topic去判断和处理
// kafkaDS.map(f => (s"${f.topic()}-${f.partition()}", f.value()))
val reduceDS: DStream[(String, Int)] = kafkaDS2.flatMap(_.value().split(" ")).map((_,1)).reduceByKey(_ + _)
reduceDS.foreachRDD((rdd, time)=>{
println(s"转换后的rdd分区数:${rdd.getNumPartitions}")
println(s"time:${time}, data:${rdd.collect().toBuffer}")
})
ssc.start()
ssc.awaitTermination()
}
}测试:
创建新的topic: hainiu_sk
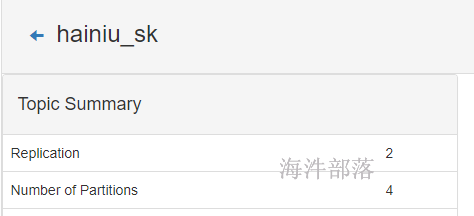

分配策略:
22.9 SparkStreaming-kafka高级开发
需求:
1、SparkStreaming多DirectStream方式去对接kaka数据源
2、更新广播变量替代cogroup fileStream达到更改配置的目的
3、累加器重置
规划 kafka topic有4个分区,sparkStreaming也有分区,采用分配模式。
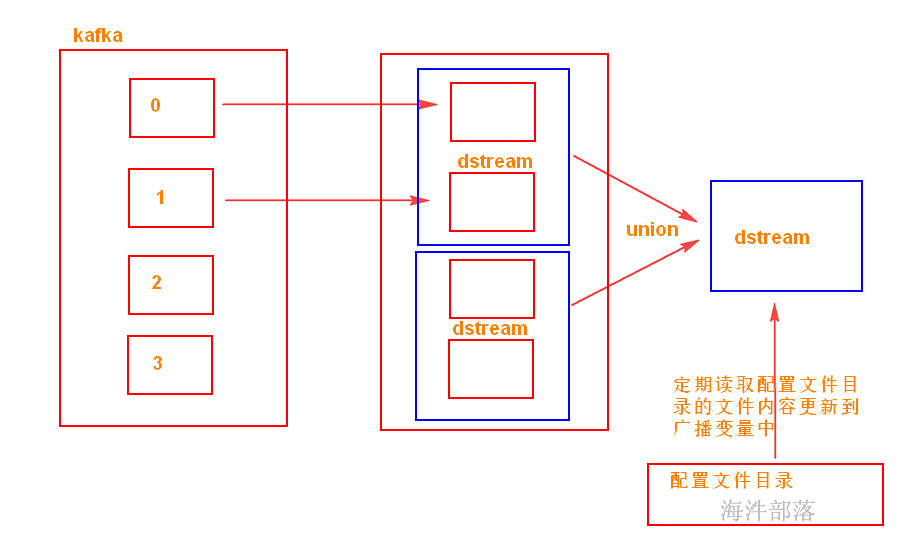
package com.hainiu.kafka
import java.io.{BufferedReader, InputStreamReader}
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileStatus, FileSystem, Path}
import org.apache.kafka.clients.consumer.ConsumerRecord
import org.apache.kafka.common.TopicPartition
import org.apache.kafka.common.serialization.StringDeserializer
import org.apache.spark.SparkConf
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.streaming.dstream.{DStream, InputDStream}
import org.apache.spark.streaming.kafka010._
import org.apache.spark.streaming.{Durations, StreamingContext}
import org.apache.spark.util.LongAccumulator
import scala.collection.mutable
import scala.collection.mutable.ListBuffer
import scala.util.control.Breaks
object KafkaStreamJoinFileByBroadUpdateConfig {
def main(args: Array[String]): Unit = {
// kafka 4个分区需要4个CPU核直连处理 + driver端需要1个1CPU核处理逻辑 = 5 (至少)
val conf: SparkConf = new SparkConf().setMaster("local[5]").setAppName("KafkaStreamJoinFileByBroadUpdateConfig")
val topics:String = "hainiu_sk2"
// 读取kafka的配置
val kafkaParams = new mutable.HashMap[String,Object]()
kafkaParams += "bootstrap.servers" -> "nn1.hadoop:9092,nn2.hadoop:9092,s1.hadoop:9092"
kafkaParams += "group.id" -> "group105"
kafkaParams += "key.deserializer" -> classOf[StringDeserializer].getName
kafkaParams += "value.deserializer" -> classOf[StringDeserializer].getName
kafkaParams += "auto.offset.reset" -> "earliest"
kafkaParams += "enable.auto.commit" -> "true"
val ssc: StreamingContext = new StreamingContext(conf, Durations.seconds(5))
// 设置位置策略
val locationStrategy: LocationStrategy = LocationStrategies.PreferConsistent
// 装多个kafka流
val kafkaDSs: ListBuffer[InputDStream[ConsumerRecord[String, String]]] = new ListBuffer[InputDStream[ConsumerRecord[String, String]]]
// 创建两个kafka流
for(i <- 0 until 2){
// i=0, 创建 分区0,1的流
// i=1, 创建 分区2,3的流
val tps: ListBuffer[TopicPartition] = new ListBuffer[TopicPartition]
for(j <- i * 2 until i * 2 + 2){
// 设置消费策略
val tp: TopicPartition = new TopicPartition(topics, j)
tps += tp
}
val consumerStategy: ConsumerStrategy[String, String] = ConsumerStrategies.Assign[String, String](tps, kafkaParams)
// 通过KafkaUtils工具类创建kafka直连流
val kafkaDS: InputDStream[ConsumerRecord[String, String]] = KafkaUtils.createDirectStream(ssc,locationStrategy, consumerStategy)
kafkaDSs += kafkaDS
}
// 将两个流union
val unionDS: DStream[ConsumerRecord[String, String]] = ssc.union(kafkaDSs)
// 获取kafka流wordcount
val reduceDS: DStream[(String, Int)] = unionDS.flatMap(_.value().split(" ")).map((_,1)).reduceByKey(_ + _)
// 定义广播变量(用于存储配置文件内容)
var broad: Broadcast[mutable.HashMap[String, String]] = ssc.sparkContext.broadcast(new mutable.HashMap[String,String])
// 定义匹配上的累加器
val matchAcc: LongAccumulator = ssc.sparkContext.longAccumulator
// 定义没匹配上的累加器
val notMatchAcc: LongAccumulator = ssc.sparkContext.longAccumulator
// 配置文件更新间隔时间(10秒)
val configUpdateIntervalTime:Long = 10000L
// 配置更新完成时间
var configUpdateOverTime:Long = 0
reduceDS.foreachRDD((rdd, time)=>{
if(! rdd.isEmpty()){
// 如果广播变量数据为空,加载广播变量
// 或者 到了更新配置的间隔时间时,重新读取文件加载到广播变量
if(broad.value.isEmpty || System.currentTimeMillis() - configUpdateOverTime >= configUpdateIntervalTime){
val configMap = new mutable.HashMap[String,String]
//读取hdfs指定目录下所有文件内容加载到configMap
val configDir:String = "/tmp/sparkstreaming/input_updateSparkBroadCast"
val fs: FileSystem = FileSystem.get(new Configuration())
val fileStatusArr: Array[FileStatus] = fs.listStatus(new Path(configDir))
for(file <- fileStatusArr){
var reader: BufferedReader = null
try{
reader = new BufferedReader(new InputStreamReader(fs.open(file.getPath)))
val breaks: Breaks = new Breaks
breaks.breakable(
while(true){
val line = reader.readLine()
if(line == null){
breaks.break()
}
val arr: Array[String] = line.split("\t")
val code: String = arr(0)
val name: String = arr(1)
configMap += (code-> name)
}
)
}catch {
case e:Exception => e.printStackTrace()
}finally {
reader.close()
}
}
// 更新广播变量(清空,重新赋值)
broad.unpersist()
broad = ssc.sparkContext.broadcast(configMap)
println(s"更新后的配置:${configMap}")
// 设置更新完成时间
configUpdateOverTime = System.currentTimeMillis()
}
// rdd的转换
rdd.foreachPartition(it =>{
// 一个分区获取广播变量的数据
val map: mutable.HashMap[String, String] = broad.value
// 一个一个的join
it.foreach(f =>{
val countryCode: String = f._1
val option: Option[String] = map.get(countryCode)
if(option == None){
// 没join上
notMatchAcc.add(1L)
println(s"notmatch data==>time:${time},countryCode:${countryCode}")
}else{
// join上
matchAcc.add(1L)
val countryName: String = option.get
println(s"match data==>time:${time},countryCode:${countryCode}, countryName:${countryName}, count:${f._2}")
}
})
})
// 一个批次处理完事输出累加器
println(s"time:${time}==>matchAcc:${matchAcc.value}")
println(s"time:${time}==>notMatchAcc:${notMatchAcc.value}")
// 输出完清空累加器
matchAcc.reset()
notMatchAcc.reset()
}
})
ssc.start()
ssc.awaitTermination()
}
}测试:
1)命令行启动kafka producer
输入数据:

往字典目录添加字典文件,只要是"分割的,放在这个目录里面就可以更新到广播变量

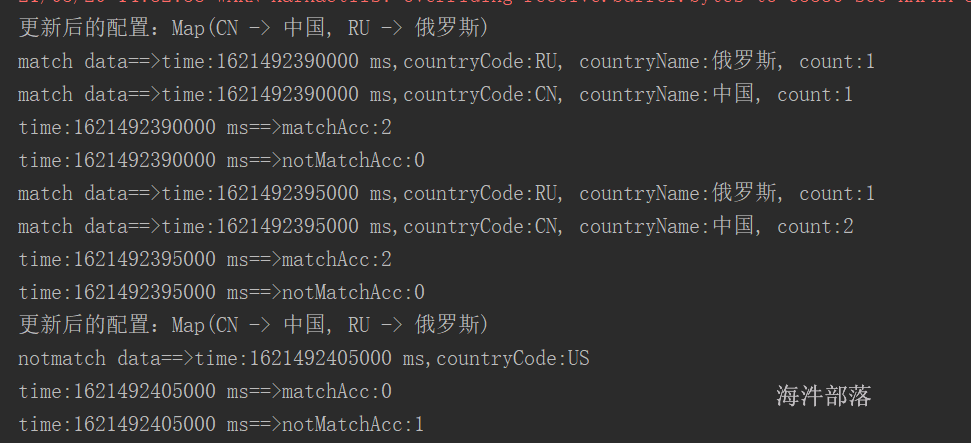
22.10 sparkStreaming-kafka的offset管理
22.10.1 receiver方式 vs 直连方式
sparkStreaming-kafka 的 receiver 方式
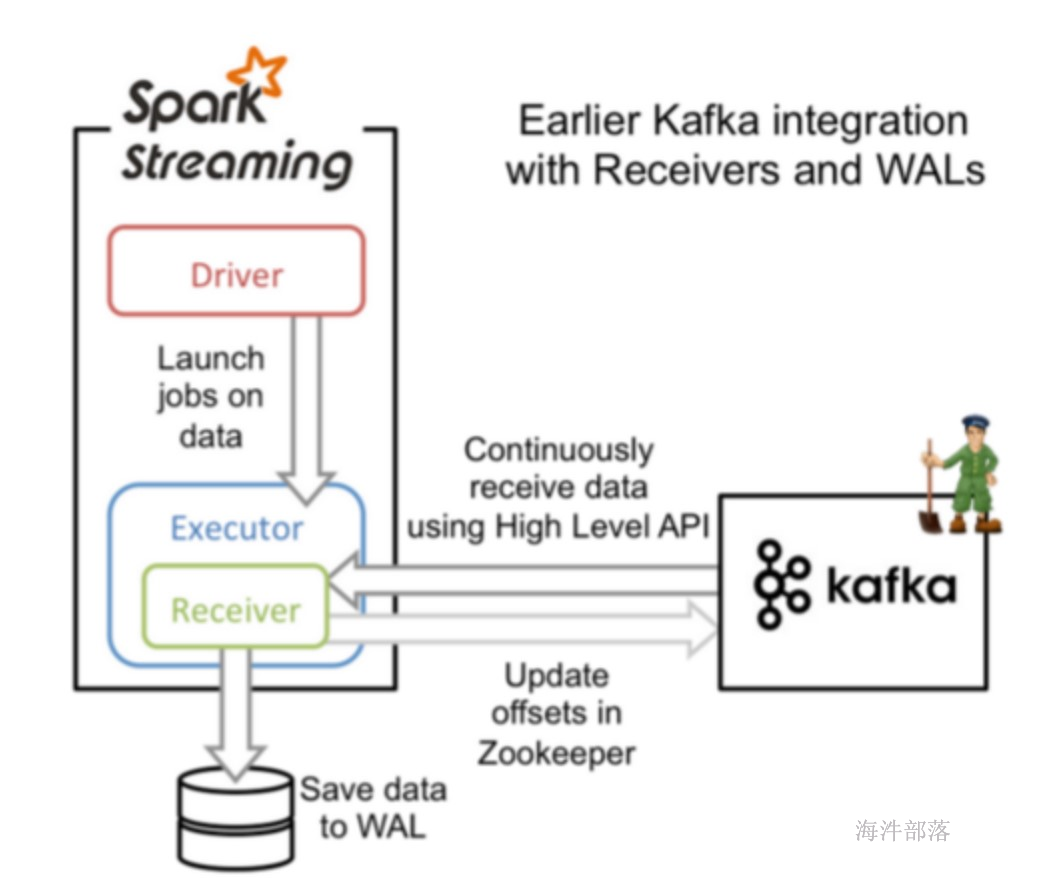
sparkStreaming-kafka 的 Direct 方式
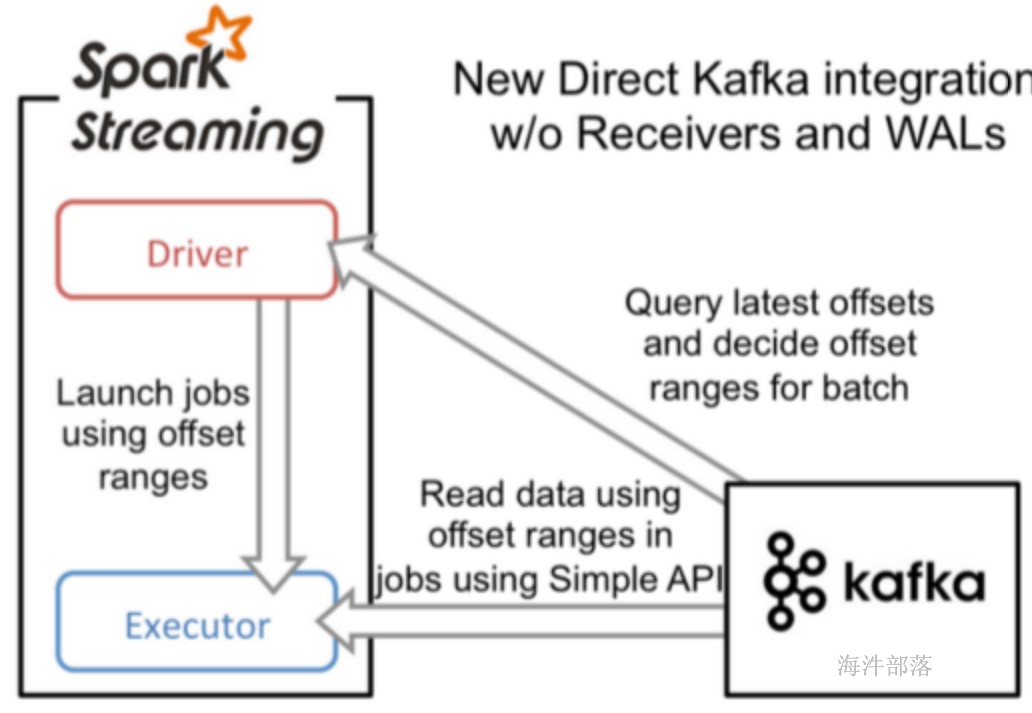
receiver 和 direct 方式有什么区别?
receiver 方式:
receiver把固定间隔的数据放在内存中,使用kafka高级的API,自动维护偏移量,达到固定的时间一起处理每个批次的offset数据,效率低且容易丢数据,因为数据在内存中,为了容错,还得加入预写日志。
Direct 直连方式:
会周期性地查询Kafka,获得每个topic+partition的最新的offset,从而定义每个batch的offset的范围。当处理数据的job启动时,就会使用Kafka的简单consumer api来获取Kafka指定offset范围的数据。
此种方式相当于直接连接到kafka的分区上(无需receiver,也不需要预写日志),一个RDD的分区对应一个Kafka的分区,使用Kafka底层的API去读取数据,效率高。
流式计算有三种容错语义,分别是:
at-most-once(最多一次):每条记录将被处理一次或根本不处理。
at-least-once(至少一次):每条记录将被处理一次或多次。这比最多一次强,因为它确保不会丢失任何数据。但可能有重复。
Exactly once(只处理一次):每条记录只会被处理一次 - 不会丢失任何数据,也不会多次处理数据。这显然是三者中最强的保证。
SparkStreaming直连kafka可以保证时效最强语义,但需要我们自己去维护偏移量(现在比较流行的方式是手动把offset维护到第三方存储,比如zookeeper、MySQL等。)。
如果想实现最强语义,需要做到以下几点:
1)kafka源支持重复读取。
2)SparkStreaming的输出要支持幂等性或事务。
幂等性:输出多次的操作内容是一样的。
事务:将输出和维护offset放在一个事务中,要么都成功,要么都失败。
3)需要我们自己手动去维护消费的offset。
总结下来就是:
直连kafka,kafka的offset 由 开发者自己维护,获取要消费的offset,进行消费处理,处理完成后,自行维护offset,输出要支持幂等性或事务。
http://spark.apache.org/docs/2.1.1/streaming-kafka-integration.html
例子见如下代码
22.10.2 receiver方式管理offset
代码:SparkStreamingKafkaStream
目前被直连方式替代,代码看看即可。
22.10.3 direct方式管理offset
22.10.3.1手动提交offset到kafka
代码:SparkStreamingKafkaOffsetNotAutoCommit
代码逻辑:

说明:
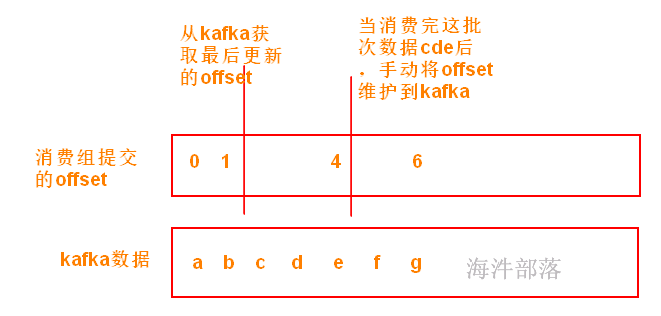
结果:
22.10.3.2手动提交offset到zookeeper(外部存储系统)
代码:SparkStreamingKafkaOffsetZKForeachRDD
代码逻辑:

说明:

结果:
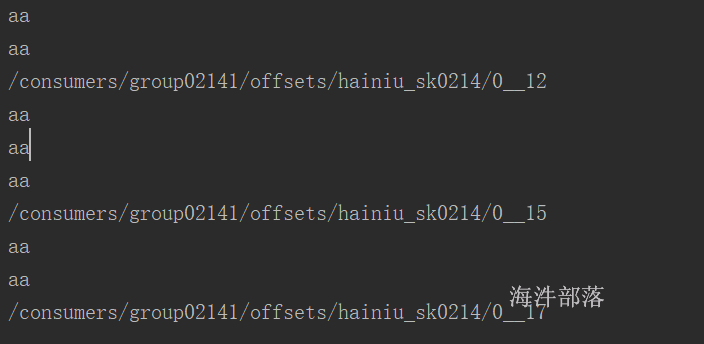
22.10.3.3 解决数据丢失的时候,程序启动问题
Kafka的数据默认保存7天,如果zookeeper里维护的是7天前数据的消费offset,当启动程序时会报错,如何解决?
说明:
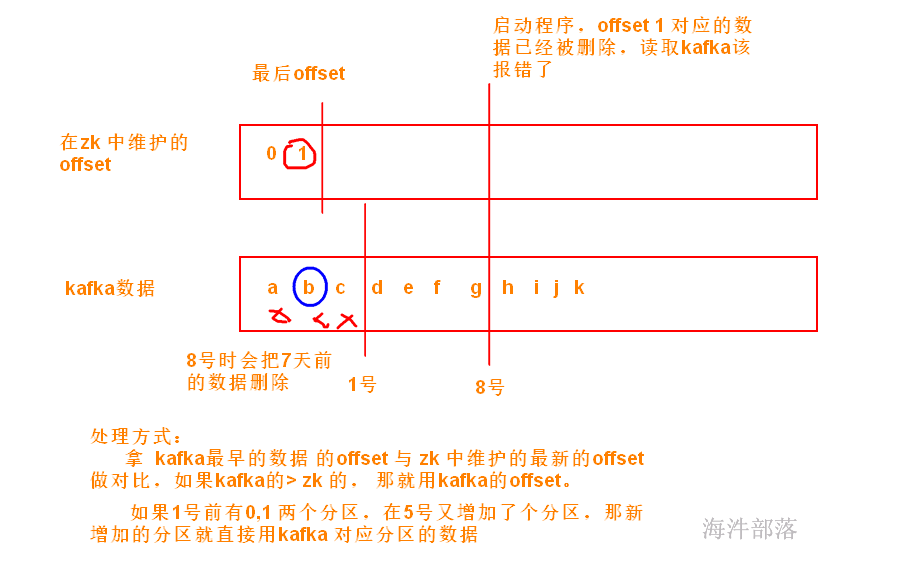
代码逻辑:

调试方式:


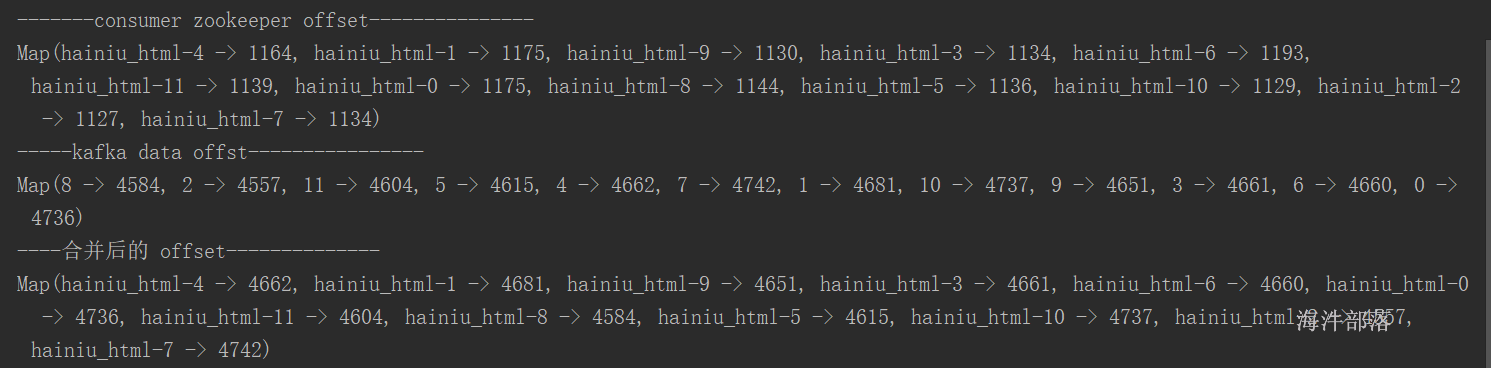
SparkStreamingKafkaOffsetZKRecoveryNew 是解决 zookeeper分区数 小于 kafka数据分区数

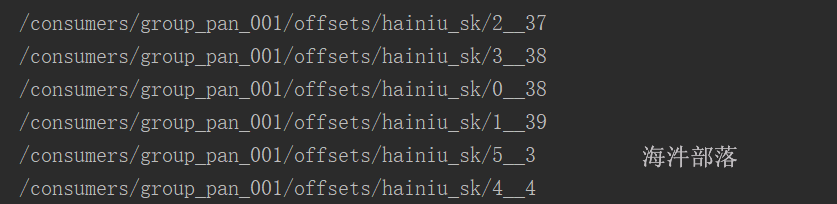

23 Spark优化汇总
由于大多数Spark计算的内存性质,Spark程序可能会受到集群中任何资源(CPU,网络带宽或内存)的瓶颈。Spark优化主要是围绕着这几个瓶颈展开,优化方式包括序列化调优、内存调优等。
23.1 数据序列化
在任何分布式系统中,序列化都是扮演着一个重要的角色的。如果使用的序列化技术,在执行序列化操作的时候很慢,或者是序列化后的数据还是很大,那么会让分布式应用程序的性能下降很多。所以,进行Spark性能优化的第一步,就是进行序列化的性能优化。
Spark 旨在便利性(允许您在操作中使用任何 Java 类型)和性能之间取得平衡。它提供了两个序列化库:
Java 序列化机制:
默认情况下,spark使用此种机制。
默认情况下,Spark使用Java自身的ObjectInputStream和ObjectOutputStream机制进行对象的序列化。而且Java序列化机制是提供了自定义序列化支持的,只要你实现Serializable接口即可实现自己的更高性能的序列化算法。Java序列化机制的速度比较慢,而且序列化后的数据占用的内存空间比较大。
Kryo 序列化机制:
Spark也支持使用Kryo类库来进行序列化。Kryo序列化机制比Java序列化机制更快,而且序列化后的数据占用的空间更小,通常比Java序列化的数据占用的空间要小10倍。Kryo序列化机制之所以不是默认序列化机制的原因是,有些类型它也不一定能够进行序列化;此外,如果你要得到最佳的性能,Kryo还要求你在Spark应用程序中,对所有你需要序列化的类型都进行注册。
如何使用Kryo 序列化机制

优化Kryo 类库的使用
1)优化缓存大小
如果注册的要序列化的自定义的类型,本身特别大,比如包含了超过100个field。那么就会导致要序列化的对象过大。此时就需要对Kryo本身进行优化。因为Kryo内部的缓存可能不够存放那么大的class对象。此时就需要调用SparkConf.set()方法,设置spark.kryoserializer.buffer.max参数的值,将其调大。
默认情况下它的值是64,就是说最大能缓存64M的对象,然后进行序列化。可以在必要时将其调大。
2)预先注册自定义类型
使用自定义类型时需要预先注册好要序列化的自定义的类。
在什么场景下使用Kryo 序列化类库?
1)从 Spark 2.0.0 开始,在内部使用 Kryo 序列化程序来对具有简单类型、简单类型数组或字符串类型的 RDD 进行shuffle。
2)在你的算子中使用了别人实现写的且没有实现Serializable,比如hadoop的Text。
3)算子函数使用到了外部的大对象情况。比如我们在外部自定义了一个Map对象,里面包含了100m的数据。然后,在算子函数里面,使用到了这个外部的大对象。此时用广播变量替代大对象。
23.2 内存调优
23.2.1 内存都花费在哪了
1)每个Java对象,都有一个对象头,会占用16个字节,主要是包括了一些对象的元信息,比如指向它的类的指针。如果一个对象本身很小,比如就包括了一个int类型的field,那么它的对象头实际上比对象自己还要大。
JAVA对象 = 对象头 + 实例数据 + 对象填充(补余用的,用于保证对象所占空间是8个字节的整数倍)
2)Java的String对象,会比它内部的原始数据,要多出40个字节。因为它内部使用char数组来保存内部的字符序列的,并且还得保存诸如数组长度之类的信息。而且因为String使用的是UTF-16编码,所以每个字符会占用2个字节。比如,包含10个字符的String,会占用60个字节。
3)Java中的集合类型,比如HashMap和LinkedList,内部使用的是链表数据结构,所以对链表中的每一个数据,都使用了Entry对象来包装。Entry对象不仅有对象头,还有指向下一个Entry的指针,通常占用8个字节。
4)元素类型为原始数据类型(比如int)的集合,内部通常会使用原始数据类型的包装类型,比如用Integer来存储元素。
下面将从 Spark 中内存管理的概述开始,然后我们讨论可以采取的特定策略,以更有效地使用内存。特别是,我们将描述如何确定对象的内存使用情况,以及如何改进它——通过更改数据结构或以序列化格式存储数据。然后我们将介绍调整 Spark 的缓存大小和 Java 垃圾收集器。
23.2.2 内存管理
Spark的内存可以大体归为两类:execution(运行内存)和storage(存储内存),前者包括shuffles、joins、sorts和aggregations所需内存,后者包括cache和节点间数据传输所需内存;
Spark1.6及以后,引入的统一内存管理机制,与静态内存管理的区别在于存储内存和执行内存共享同一块空间,可以动态占用对方的空闲区域,提供更好的性能。此种方式使得我们不需要修改内存比例。
23.2.3 如何判断你的程序消耗了多少内存?
这里有一个非常简单的办法来判断,你的spark程序消耗了多少内存。
1)首先,自己设置RDD的并行度,有下列方法:
a) 在parallelize()、textFile()等方法中,传入第二个参数,设置RDD的task 或 partition的数量;
b) 用SparkConf.set()方法,设置一个参数,spark.default.parallelism,可以统一设置这个application所有RDD的partition数量。
2)其次,在程序中将RDD cache到内存中,调用RDD.cache()方法即可。
3)最后,观察web ui

val cacheRdd = rdd.cache() //应该根据这个地方cache的结果,进行内存的调节
cacheRdd.count()
23.2.4 优化数据结构
减少内存消耗的第一种方法是避免Java语法特性中所导致的额外内存的开销,比如基于指针的Java数据结构,以及包装类型。
有一个关键的问题,就是优化什么数据结构?其实主要就是优化你的算子函数,内部使用到的局部数据,或者是算子函数外部的数据。都可以进行数据结构的优化。优化之后,都会减少其对内存的消耗和占用。
优化方法:
1)能用数组取代,就不用集合。比如:用Array代替List。
2)能用字符串取代,就不用数组或集合。
3)能用int型取代,就不要用字符串;比如:Map的key可以用int取代字符串。
23.2.5 对多次使用的RDD进行持久化或Checkpoint
RDD 持久化:
如果程序中,对某一个RDD,基于它进行了多次transformation或者action操作。那么就非常有必要对其进行持久化操作,以避免对一个RDD反复进行计算。
此外,如果RDD的持久化数据可能会丢失的(因为使用cache的时候),还要保证高性能,那么可以对RDD进行Checkpoint操作。
checkpoint:
checkpoint的意思就是建立检查点,类似于快照,当DAG计算过程出现问题了就可以从这个快照中恢复,当然我们也可以通过cache或者persist将中间的计算结果放到内存或者磁盘中,但也未必完全可靠,假如内存或者硬盘坏了,也会导致spark从头再根据rdd计算一遍,所以就有了checkpoint,其中checkpoint的作用就是将DAG中比较重要的中间数据做一个检查点将结果存储到一个高可用的地方比如HDFS。
使用方法:

23.2.6 选择带有序列化的持久化级别
除了对多次使用的RDD进行持久化操作之外,还可以进一步优化其性能。如果RDD数据持久化到内存或磁盘时,如果内存不够就可能只缓存RDD的部分数据。
为了提高效率,可以采取序列化持久到内存,这样内存占用少。比如MEMORY_ONLY_SER、MEMORY_AND_DISK_SER等。
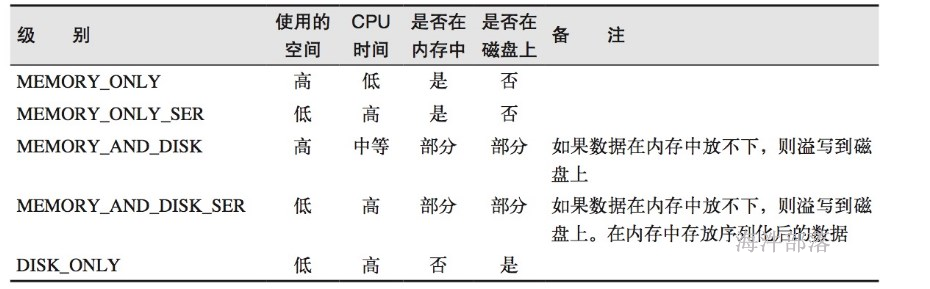
对于序列化的持久化级别,还可以使用Kryo序列化进一步优化,这样,可以获得更快的序列化速度,并且占用更小的内存空间。
23.2.7 JVM调优
23.2.6.1 Java虚拟机垃圾回收调优的背景
如果在持久化RDD的时候,持久化了大量的数据,那么Java虚拟机的垃圾回收就可能成为一个性能瓶颈。因为Java虚拟机会定期进行垃圾回收,此时就会追踪所有的java对象,并且在垃圾回收时,找到那些已经不在使用的对象,然后清理旧的对象,来给新的对象腾出内存空间。
垃圾回收的性能开销,是跟内存中的对象的数量,成正比的。所以,对于垃圾回收的性能问题,首先要做的就是,使用更高效的数据结构,比如array和string;其次就是在持久化rdd时,使用序列化的持久化级别,而且用Kryo序列化类库,这样,每个partition就只是一个对象——一个字节数组。
我们可以对垃圾回收进行监测,包括多久进行一次垃圾回收,以及每次垃圾回收耗费的时间。只要在spark-submit脚本中,增加一个配置即可,–conf “spark.executor.extraJavaOptions=-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps”。
但是要记住,这里虽然会打印出Java虚拟机的垃圾回收的相关信息,但是是输出到了worker上的日志中,而不是driver的日志中。
其实完全可以通过SparkUI(4040端口)来观察每个stage的垃圾回收的情况。
spark.executor.extraJavaOptions是配置executor的jvm参数
spark.driver.extraJavaOptions是配置driver的jvm参数
23.2.6.3 垃圾回收机制
首先,Eden区域和Survivor1区域用于存放对象,Survivor2区域备用。创建的对象,首先放入Eden区域和Survivor1区域,如果Eden区域满了,那么就会触发一次Minor GC,进行年轻代的垃圾回收。Eden和Survivor1区域中存活的对象,会被移动到Survivor2区域中。然后Survivor1和Survivor2的角色调换,Survivor1变成了备用。
如果一个对象,在年轻代中,撑过了多次垃圾回收,都没有被回收掉,那么会被认为是长时间存活的,此时就会被移入老年代。此外,如果在将Eden和Survivor1中的存活对象,尝试放入Survivor2中时,发现Survivor2放满了,那么会直接放入老年代。此时就出现了,短时间存活的对象,进入老年代的问题。
如果老年代的空间满了,那么就会触发Full GC,进行老年代的垃圾回收操作。
23.2.6.4 高级垃圾回收调优
Spark如果发现,在task执行期间,大量full gc发生了,那么说明,年轻代的Eden区域,给的空间不够大。此时可以执行一些操作来优化垃圾回收行为:
1)包括降低存储内存的比例(spark.memory.storageFraction),给年轻代更多的空间,来存放短时间存活的对象;
2)当大对象很多,但minorGC少,说明大对象都进入了老年代,此时给Eden区域分配更大的空间,使用-Xmn(年轻代的heap大小)即可,通常建议给Eden区域,预计大小的4/3;
3)如果使用的是HDFS文件,那么很好估计Eden区域大小,如果每个executor有4个task,然后每个hdfs压缩块解压缩后是该压缩块大小的3倍,每个hdfs块的大小是128M,那么Eden区域的预计大小就是:4 * 3 * 128MB,然后呢,再通过-Xmn参数,将Eden区域大小设置为4 * 3 * 128* 4/3。
23.2.6.5 最后一点总结
根据经验来看,对于垃圾回收的调优,因为jvm的调优是非常复杂和敏感的。除非真的到了万不得已的地步,并且,自己本身又对jvm相关的技术很了解,那么此时进行Eden区域的调节是可以的。
一些高级的参数:
-XX:SurvivorRatio=4:
设置年轻代中Eden区与Survivor区的大小比值。如果值为4,那么就是Eden跟两个Survivor的比例是4:2,也就是说每个Survivor占据的年轻代的比例是1/6,所以,你其实也可以尝试调大Survivor区域的大小。
-XX:NewRatio=4:
调节新生代和老年代的比例。如果为4,则年轻代与年老代所占比值为1:4,年轻代占整个堆栈的1/5。
其它设置内存大小的参数:
-Xms:为jvm启动时分配的内存,比如-Xms200m,表示分配200M。
-Xmx:为jvm运行过程中分配的最大内存,比如-Xms500m,表示jvm进程最多只能够占用500M内存。
-Xmn:年轻代的heap大小
-Xss:为jvm启动的每个线程分配的内存大小
23.2 常用shuffle优化
shuffle是一个涉及到CPU(序列化反序列化)、网络IO(跨节点数据传输)以及磁盘IO(shuffle中间结果落盘)的操作。
优化思路:
减少shuffle的数据量,减少shuffle的次数
具体方式:
1)能不shuffle的时候尽量不要shuffle数据,可以使用mapjoin(广播变量);
2)能用reducerByKey就不要用groupByKey,因为reducerByKey会在shuffle前进行本地聚合,可以使在shuffle过程中减少磁盘IO;
3)spark2.0后已经没有HashShuffleManager,只有SortShuffleManager,SortShuffleManager内部有3种shuffle操作,可适应小中大集群。
4)参数调节:
spark.reducer.maxSizeInFlight:reduce task的拉取缓存,默认48m
spark.shuffle.file.buffer:map task的写磁盘缓存,默认32k
spark.shuffle.io.maxRetries:拉取失败的最大重试次数,默认3次
spark.shuffle.io.retryWait:拉取失败的重试间隔,默认5s

23.3 提高并行度(资源足够的情况下)
在执行任务过程中,Spark集群的资源并不一定会被充分利用到,所以要尽量设置合理的并行度,来充分地利用集群的资源。才能充分提高Spark应用程序的性能。
Spark会自动设置以文件作为输入源的RDD的并行度,依据其大小,比如HDFS,就会给每一个block创建一个partition,也依据这个设置并行度。对于reduceByKey等会发生shuffle的操作,就使用并行度最大的父RDD的并行度即可。
1)使用textFile()、parallelize()方法时的第二个参数设置并行度;
2)使用 coalesce 或 repartition 设置并行度;
3)使用像 reduceByKey的第二个参数设置并行度;
4)使用spark.default.parallelism参数,来设置统一的并行度。Spark官方的推荐是,给集群中的每个cpu core设置2\~3个task。
比如说,spark-submit设置了executor数量是10个,每个executor要求分配2个core,那么application总共会有20个core。此时可以设置new SparkConf().set(“spark.default.parallelism”, “60”)来设置合理的并行度,从而充分利用资源。
推荐:一个CPU核对应2-3个task数。
任务运行数量与资源分配:
Task被执行的并行度 = Executor数目 * 每个Executor核数(=core总个数)
当 executor数=2, 每个executor核数=1, task被执行的并行度= 2 * 1 = 2, 8个task就需要迭代4次。
当 executor数=2, 每个executor核数=2, task被执行的并行度= 2 * 2 = 4, 8个task就需要迭代2次。
因为一个job会划分很多个阶段,所以没必要把所有阶段的task都占有一个CPU核,这样会极大的浪费资源。
分配资源时,尽量task数能整除开 task被执行的并行度,这样不会有CPU核空转。
比如 6 executor数=2, 每个executor核数=3, task被执行的并行度= 2 * 3 = 6, 那执行一次后,就有4个核空转,浪费资源。
23.4 广播共享数据
如果你的算子函数中,使用到了特别大的数据,那么这个时候,推荐将该数据进行广播。这样的话,就不至于将一个大数据拷贝到每一个task上去。而是给每个节点拷贝一份,然后节点上的task共享该数据。
这样就可以减少大数据在节点上的内存消耗。并且可以减少数据到节点的网络传输消耗。
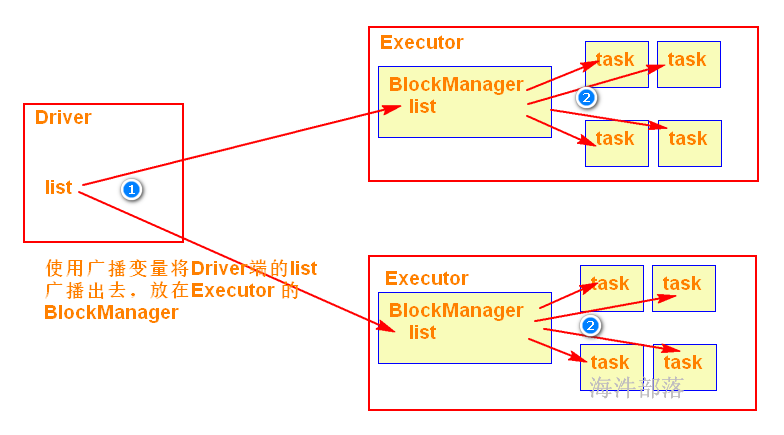
23.5 数据本地化
数据本地化对于Spark Job性能有着巨大的影响。如果数据以及要计算它的代码是在一起的,那么性能当然会非常高。但是,如果数据和计算它的代码是分开的,那么其中之一必须到另外一方的机器上。通常来说,移动代码到其他节点,会比移动数据到代码所在的节点上去,速度要快得多,因为代码比较小。Spark也正是基于这个数据本地化的原则来构建task调度算法的。
数据本地化,指的是数据离计算它的代码有多近。基于数据距离代码的距离,有几种数据本地化级别:
PROCESS_LOCAL:
进程本地化。数据和计算它的代码在同一个JVM进程中。
NODE_LOCAL:
节点本地化。数据和计算它的代码在一个节点上,但是不在一个进程中,比如在不同的executor进程中,但是尽量在读取文件(HDFS文件的block)所在的机器上
NO_PREF:
对于task来说,数据从哪里获取都一样,没有好坏之分,比如从数据库中获取数据。
RACK_LOCAL:
机架本地化。数据和计算它的代码在一个机架上。
ANY:
数据和task可能在集群中的任何地方,而且不在一个机架中,性能最差。

Spark默认会等待一会儿,来期望task要处理的数据所在的节点上的executor空闲出一个cpu,从而将task分配过去。只要超过了时间,那么Spark就会将task分配到其他任意一个空闲的executor上。
可以设置参数,spark.locality系列参数,来调节Spark等待task可以进行数据本地化的时间。
spark.locality.wait(3000毫秒) spark.locality.wait.process spark.locality.wait.node spark.locality.wait.rack
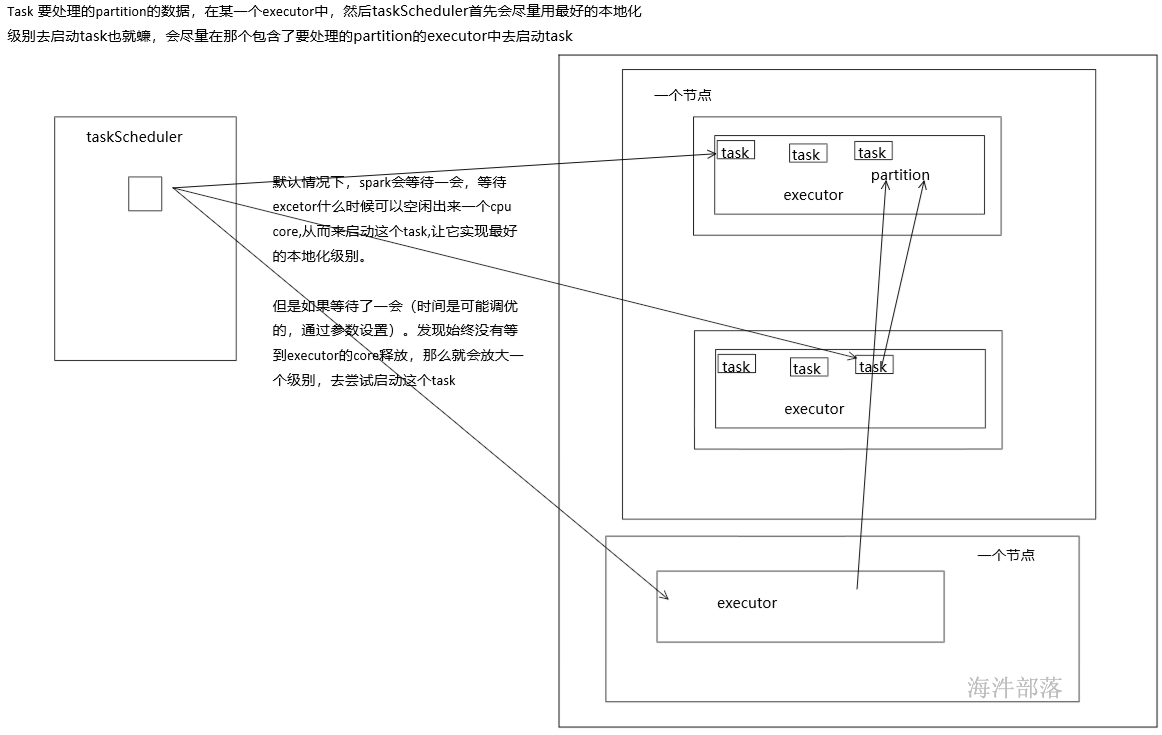
23.6 数据倾斜
1)可以用hive进行发生倾斜的key做聚合
2)进行数据的清洗,把发生倾斜的刨除,用单独的程序去算倾斜的key
方法是打上随机前缀先聚合一次,然后去掉随机前缀再聚合一次。适用场景groupby
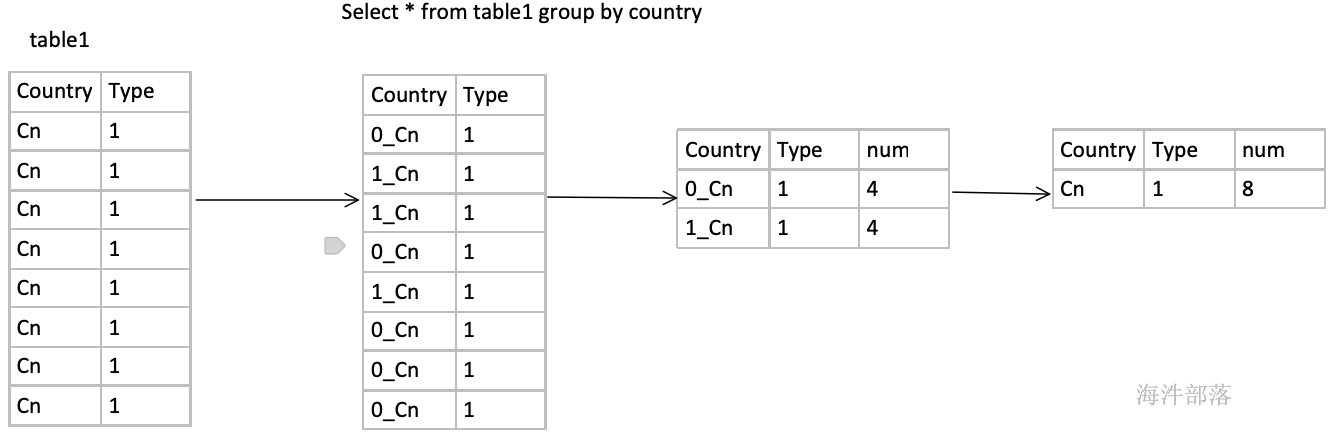
适用场景join
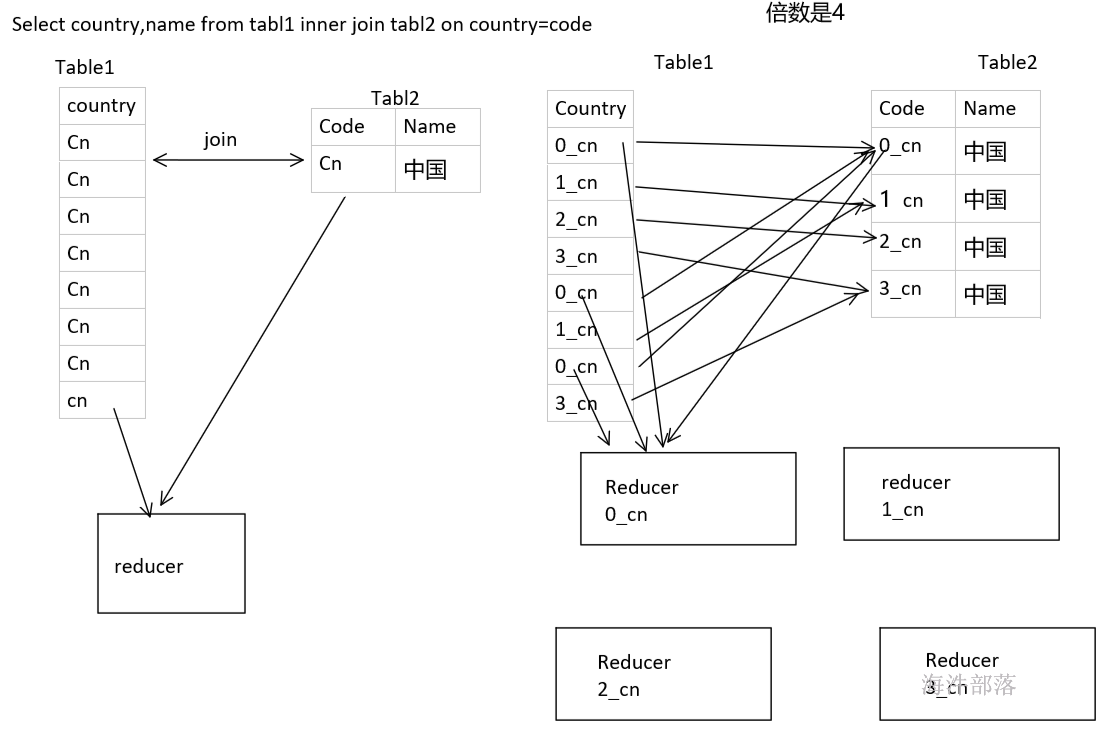
24 spark-streaming优化
Streaming应用程序中获得最佳性能,需要考虑两件事:
1)通过有效使用群集资源减少每批数据的处理时间。
2)设置正确的批处理大小,使得数据处理跟上数据摄取的速度。
24.1 带有receiver的数据接收并行度调优——多个DStream
通过网络接收数据时(比如Kafka、Flume),会将数据反序列化,并存储在Spark的内存中。如果数据接收成为系统的瓶颈,那么可以考虑并行化数据接收。每一个输入DStream都会在某个Worker的Executor上启动一个Receiver,该Receiver接收一个数据流。因此可以通过创建多个输入DStream,并且配置它们接收数据源不同的分区数据,达到接收多个数据流的效果。比如说,一个接收两个Kafka Topic的输入DStream,可以被拆分为两个输入DStream,每个分别接收一个topic的数据。这样就会创建两个Receiver,从而并行地接收数据,进而提升吞吐量。多个DStream可以使用union算子进行聚合,从而形成一个DStream。然后后续的transformation算子操作都针对该一个聚合后的DStream即可。
注意这种增加receiver的方法不适合DirectStream直连模式,因直连模式不需要Receiver。
val numStreams = 5
// 每个topic 创建流,流多receiver就多
val kafkaStreams = (1 to numStreams).map { i => KafkaUtils.createStream(...) }
val unifiedStream = streamingContext.union(kafkaStreams)
unifiedStream.print()设置socket的revicer

24.2 带有receiver的数据接收并行度调优——blockinterval
数据接收并行度调优,除了创建更多输入DStream和Receiver以外,还可以考虑调节block interval。通过参数,spark.streaming.blockInterval,可以设置block interval,默认是200ms。对于大多数Receiver来说,都会将数据切分为一个一个的block。而每个batch中的block数量,则决定了该batch对应的RDD的partition的数量,以及针对该RDD执行transformation操作时,创建的task的数量。每个batch对应的task数量是大约估计的,即batch interval / block interval。
例如说,batch interval为2s,block interval为200ms,会创建10个task。如果你认为每个batch的task数量太少,即低于每台机器的cpu core数量,那么就说明batch的task数量是不够的,因为所有的cpu资源无法完全被利用起来。要为batch增加block的数量,那么就减小block interval。然而,推荐的block interval最小值是50ms,如果低于这个数值,那么大量task的启动时间,可能会变成一个性能开销点。
现在是没有数据接收,所以receiver就是skipped,那这个task的并行度其实是根据任务的cpu core来定,默认情况下,当然可以通过设置spark.streaming.blockInterval来自己指定任务数。
receiver task的并行度是由bacth inerval/block interval决定,初始没有数据的时候,task的数量是由 cpu core来定,随着数据量越来越大,task的数量也在增加,当数据量达到一定规模,task数就能达到 bacth inerval/block interval 数量。
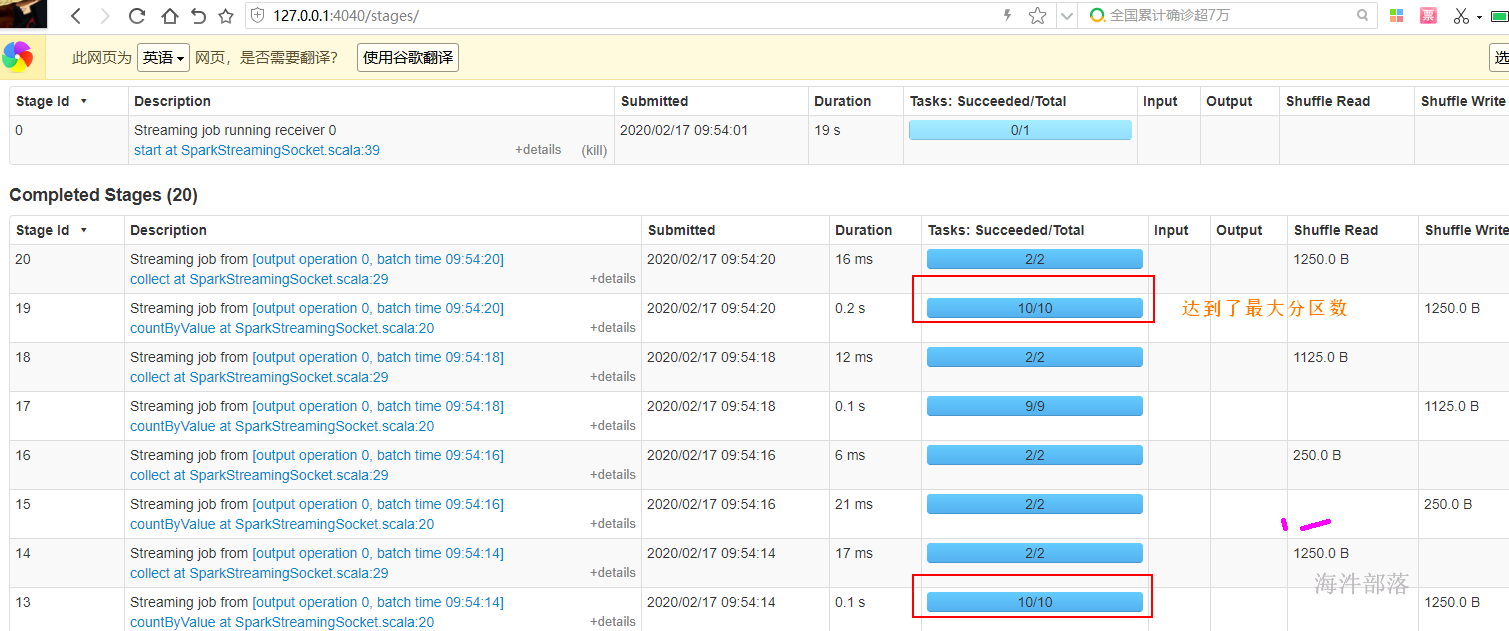
24.3 数据接收并行度调优——task
如果每秒钟启动的task过于多,比如每秒钟启动50个,那么发送这些task去Worker节点上的Executor的性能开销,会比较大,而且此时基本就很难达到毫秒级的延迟了。当然也要结合优化你的数据结构,尽量减少序列化后task的大小(注意:使用Kryo序列化只能优化shuffle数据不能用来序列化task),从而减少发送这些task到各个Worker节点上的Executor的时间。可以将每个batch的处理时间减少100毫秒。
24.4 数据处理并行度调优
如果在计算的任何stage中使用的并行task的数量没有足够多,那么集群资源是无法被充分利用的。举例来说,对于分布式的reduce操作,比如reduceByKey和reduceByKeyAndWindow,默认的并行task的数量是由spark.default.parallelism参数决定的。你可以在reduceByKey等操作中,传入第二个参数,手动指定该操作的并行度,也可以调节全局的spark.default.parallelism参数。
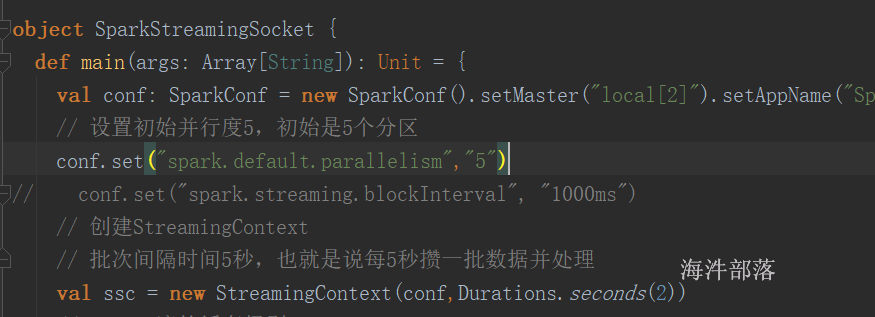
24.5 数据序列化调优
数据序列化造成的系统开销可以由序列化格式来减小。在流传输过程中,有两种类型的数据需要序列化:
1)输入数据:
默认情况下,接收到的输入数据,是存储在Executor的内存中的,使用的持久化级别是StorageLevel.MEMORY_AND_DISK_SER_2。这意味着,数据被序列化为字节从而减小GC开销,并且会复制其它executor进行失败的容错。因此,数据首先会存储在内存中,然后在内存不足时会溢写到磁盘上,从而为流式计算来保存所有需要的数据。这里的序列化有明显的性能开销——Receiver必须反序列化从网络接收到的数据,然后再使用Spark的序列化格式序列化数据。
2)流式计算操作生成的持久化RDD:
流式计算操作生成的持久化RDD,可能会持久化到内存中。例如,窗口操作默认就会将数据持久化在内存中,因为这些数据后面可能会在多个窗口中被使用,并被处理多次。流式计算操作生成的RDD的默认持久化级别是StorageLevel.MEMORY_ONLY_SER ,默认就会减小GC开销。
在上述的场景中,使用Kryo序列化类库可以减小CPU和内存的性能开销。使用Kryo时,一定要考虑注册自定义的类,并且禁用对应引用的tracking(spark.kryo.referenceTracking)。
| spark.kryo.referenceTracking | true | 当用Kryo序列化时,跟踪是否引用同一对象。如果你的对象图有环,这是必须的设置。如果他们包含相同对象的多个副本,这个设置对效率是有用的。如果你知道不在这两个场景,那么可以禁用它以提高效率 |
|---|---|---|
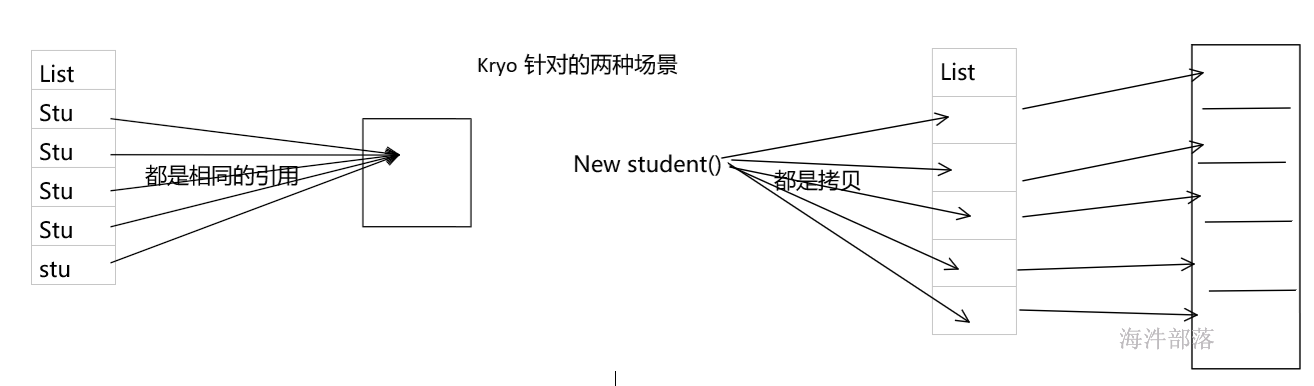
24.6 batch interval调优(最重要)
如果想让一个运行在集群上的Spark Streaming应用程序可以稳定,它就必须尽可能快地处理接收到的数据。换句话说,批量数据的处理速度应与生成它们的速度一样快。对于一个应用来说,可以通过观察Spark UI上的batch处理时间来定。batch处理时间必须小于batch interval时间。
基于流式计算的本质,batch interval对于,在固定集群资源条件下,应用能保持的数据接收速率,会有巨大的影响。例如,在WordCount例子中,对于一个特定的数据接收速率,应用业务可以保证每2秒打印一次单词计数,而不是每500ms。因此batch interval需要被设置得,让预期的数据接收速率可以在生产环境中保持住。
为你的应用计算正确的batch大小的比较好的方法,是在一个很保守的batch interval,比如5\~10s,以很慢的数据接收速率进行测试。要检查应用是否跟得上这个数据速率,可以检查每个batch的处理时间的延迟,如果处理时间与batch interval基本吻合,那么应用就是稳定的。否则,如果batch调度的延迟持续增长,那么就意味应用无法跟得上这个速率,也就是不稳定的。因此你要想有一个稳定的配置,可以尝试提升数据处理的速度,或者增加batch interval。记住,由于临时性的数据增长导致的暂时的延迟增长,可以合理的,只要延迟情况可以在短时间内恢复即可。
测试代码
package sparkstreaming
import org.apache.spark.SparkConf
import org.apache.spark.rdd.RDD
import org.apache.spark.streaming.dstream.{DStream, ReceiverInputDStream}
import org.apache.spark.streaming.{Duration, Durations, StreamingContext}
object SparkStreamingSocket {
def main(args: Array[String]): Unit = {
val conf: SparkConf = new SparkConf().setMaster("local[2]").setAppName("SparkStreamingSocket")
// 设置初始并行度5,初始是5个分区
// conf.set("spark.default.parallelism","5")
// conf.set("spark.streaming.blockInterval", "1000ms")
// 创建StreamingContext
// 批次间隔时间5秒,也就是说每5秒攒一批数据并处理
val ssc = new StreamingContext(conf,Durations.seconds(5))
// socket流的缓存级别: storageLevel: StorageLevel = StorageLevel.MEMORY_AND_DISK_SER_2
val inputDS: ReceiverInputDStream[String] = ssc.socketTextStream("localhost", 6666)
// DStream 转换操作
val reduceByKeyDS: DStream[(String, Long)] = inputDS.countByValue()
reduceByKeyDS.foreachRDD((rdd,t) =>{
// 使每批次数据处理达到2s以上
Thread.sleep(2000)
println(s"count time:${t}\t${rdd.collect().toBuffer}")
})
// 启动流式计算
ssc.start()
// 阻塞一直运行下去,除非异常退出或关闭
ssc.awaitTermination()
}
}
提升数据处理的速度,本例是把延时2s取消。
24.7 内存调优
Spark Streaming应用需要的集群内存资源,是由使用的transformation操作类型决定的。举例来说,如果想要使用一个窗口长度为10分钟的window操作,那么集群就必须有足够的内存来保存10分钟内的数据。如果想要使用updateStateByKey来维护许多key的state,那么你的内存资源就必须足够大。反过来说,如果想要做一个简单的map-filter-store操作,那么需要使用的内存就很少。
通常来说,通过Receiver接收到的数据,会使用StorageLevel.MEMORY_AND_DISK_SER_2持久化级别来进行存储,因此无法保存在内存中的数据会溢写到磁盘上。而溢写到磁盘上,是会降低应用的性能的。因此,通常是建议为应用提供它需要的足够的内存资源。建议在一个小规模的场景下测试内存的使用量,并进行评估。
内存调优的另外一个方面是垃圾回收。对于流式应用程序,如果要获得低延迟,肯定不想要有因为JVM垃圾回收导致的长时间延迟。
减少存储空间的方式:
1)DStream的持久化:输入数据和某些操作生产的中间RDD,默认持久化时都会序列化为字节。与非序列化的方式相比,这会降低内存和GC开销。使用Kryo序列化机制可以进一步减少内存使用和GC开销。
2)进一步降低内存使用率,可以对数据进行压缩,由spark.rdd.compress参数控制(默认false)。
如何让数据保存时间更长:
默认情况下,所有输入数据和通过DStream transformation操作生成的持久化RDD,会自动被清理。Spark Streaming会决定何时清理这些数据,Spark Streaming会根据使用的transformaction来决定何时清理数据。举个例子,如果你使用一个10分钟的窗口,那么程序会保留10分钟的数据,然后自动的清理老数据。当然你可以通过设置streamingContext.remember参数来让数据保留更长的时间。当然你的内存得足够,还有业务需要的情况下,这才可这么做。


