watermark和join
1.structured操作
查询操作分为以下几种类型
- 1.弱类型操作如:select
,where,groupBy 使用api的方式 - 2.强类型操作如:map
,filter,flatMap 使用方法的形式操作 - 3.弱类型中还有不仅仅可以使用sql还可以使用字段形式操作
- 4.使用sql进行操作 sql方式
1.1 api操作
使用sql方法的形式进行操作,但是并不好操作,建议大家使用sql方式
代码案例如下,同sparksql的api方式
整体代码如下:
package com.hainiu.spark
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
object TestSource {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("test source").getOrCreate()
import session.implicits._
val df = session.readStream
.format("kafka")
.option("kafka.bootstrap.servers","kafka1-89796:9092")
.option("kafka.group.id","hainiu")
.option("subscribe","topic_hainiu")
.option("startingOffsets","latest")
.load()
val ds = df.selectExpr("cast(key as string)", "cast(value as string)")
//1 zhangsan 20
val ds1 = ds.select("value").as[String]
.map(t=>{
val strs = t.split(" ")
(strs(0),strs(1),strs(2))
}).toDF("id","name","age")
//age count
val ds2 = ds1.groupBy("age").count()
ds2.writeStream
.option("truncate","false")
.format("console")
.outputMode("complete")
.start()
.awaitTermination()
}
}执行结果如下:

如果出现程序异常退出

这个问题是spark的内存不足问题

1.2 rdd方式操作
使用类似于rdd上面的代码,比如filter和flatMap等操作,强类型操作
可以调用rdd上面的处理的方法,但是不能完全以rdd形式进行编程,ds.rdd这个编程方式是离线编程,对于持续性的聚合查询不能保存中间的结果的状态
package com.hainiu.spark
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
object TestSource {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("test source").getOrCreate()
import session.implicits._
val df = session.readStream
.format("kafka")
.option("kafka.bootstrap.servers","kafka1-89796:9092")
.option("kafka.group.id","hainiu")
.option("subscribe","topic_hainiu")
.option("startingOffsets","latest")
.load()
val ds = df.selectExpr("cast(key as string)", "cast(value as string)")
//1 zhangsan 20
//rdd --> a a -> a 2
// a a -> a,2
// a a => a,2 a a -> a,4
val ds1 = ds.select("value").as[String]
val ds2 = ds1.map(t=>{
val strs = t.split(" ")
(strs(0),strs(1),strs(2))
}).map(_._3)
.groupBy("value")
.count()
ds2.writeStream
.option("truncate","false")
.format("console")
.outputMode("complete")
.start()
.awaitTermination()
}
}
这种方式操作中,表的字段会出现问题,有时候会自己变化,使用起来也比较笨重,比如刚才我们看到的student的数据在dataset中处理完毕以后id字段变成了value
1.3 使用类的字段并且是sql思想做操作
import org.apache.spark.sql.expressions.scalalang.typed
ds.groupByKey(_.deviceType).agg(typed.avg(_.signal)) 可以引入typed工具,实现在dataSet的对象基础上进行字段形式的计算处理
整体代码如下:
val df1: Dataset[Student] = df.selectExpr("cast(value as string)")
.as[String]
.map(t => {
val strs = t.split(",")
Student(strs(0).toInt, strs(1), strs(2).toInt)
})
import org.apache.spark.sql.expressions.scalalang.typed
df1.groupByKey(_.id).agg(typed.avg(_.id))
.writeStream.outputMode("update")
.format("console")
.option("truncate",false)
.start()
.awaitTermination()groupBykey在sql对象是可以按照指定字段进行分组的,并且可以直接使用聚合agg(),其中聚合的时候可以直接使用类的字段,并且这种类型的操作也是sql的思想,属于弱类型操作的一种
作为了解使用
1.4 sql形式操作
这种方式完全使用sql的思想和sql语句进行编程,不用考虑方法编程过程中的副作用,纯sql编程更加灵活,可读性更高
val df1 = df.selectExpr("cast(value as string)")
.as[String]
.map(t => {
val strs = t.split(",")
Student(strs(0).toInt, strs(1), strs(2).toInt)
})
df1.createTempView("student")
spark.sql(
"""
|select count(*),id from student
|group by id
|""".stripMargin)
.writeStream.outputMode("update")
.format("console")
.option("truncate",false)
.start()
.awaitTermination()推荐这种方式
1.5 判断是否是流式操作
df.isStreaming整体代码如下:
val spark = SparkSession.builder()
.config("spark.sql.shuffle.partitions",2) //设置少量分区数,默认分区格式200个
.appName("test read")
.master("local[*]")
.getOrCreate()
val df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "s1.hadoop:9092")
.option("subscribePattern", "topic_42")
.option("kafka.group.id", "group_hainiu")
.option("startingOffsets", "latest")
.load()
import spark.implicits._
import org.apache.spark.sql.functions._
val df1: Dataset[Student] = df.selectExpr("cast(value as string)")
.as[String]
.map(t => {
val strs = t.split(",")
Student(strs(0).toInt, strs(1), strs(2).toInt)
})
println(df1.isStreaming)可以查看打印结果为true
val spark = SparkSession.builder()
.config("spark.sql.shuffle.partitions",2) //设置少量分区数,默认分区格式200个
.appName("test read")
.master("local[*]")
.getOrCreate()
import spark.implicits._
val d = spark.read.json("data/student.json")
println(d.isStreaming)查看打印结果为false
2.窗口操作
2.1事件时间窗口操作
滑动事件时间窗口上的聚合与结构化流式处理非常简单,与分组聚合非常相似。在分组聚合中,为用户指定的分组列中的每个唯一值维护聚合值(例如计数)。对于基于窗口的聚合,将为行的事件时间所在的每个窗口维护聚合值。让我们用一个例子来理解这一点。
之前的wordcount的数据流进行修改,并且流现在包含行以及生成行的时间。我们希望在10分钟内统计单词,每5分钟更新一次,而不是运行单词计数。也就是说,在10分钟窗口12:00-12:10、12:05-12:15、12:10-12:20等之间接收的单词计数。请注意,12:00-12:10 表示在12:00之后但在12:10之前到达的数据。现在,想想12:07收到的一个词。该单词应增加对应于两个窗口12:00-12:10和12:05-12:15的计数。因此,计数将通过分组键(即单词)和窗口(可以从事件时间计算)进行索引。
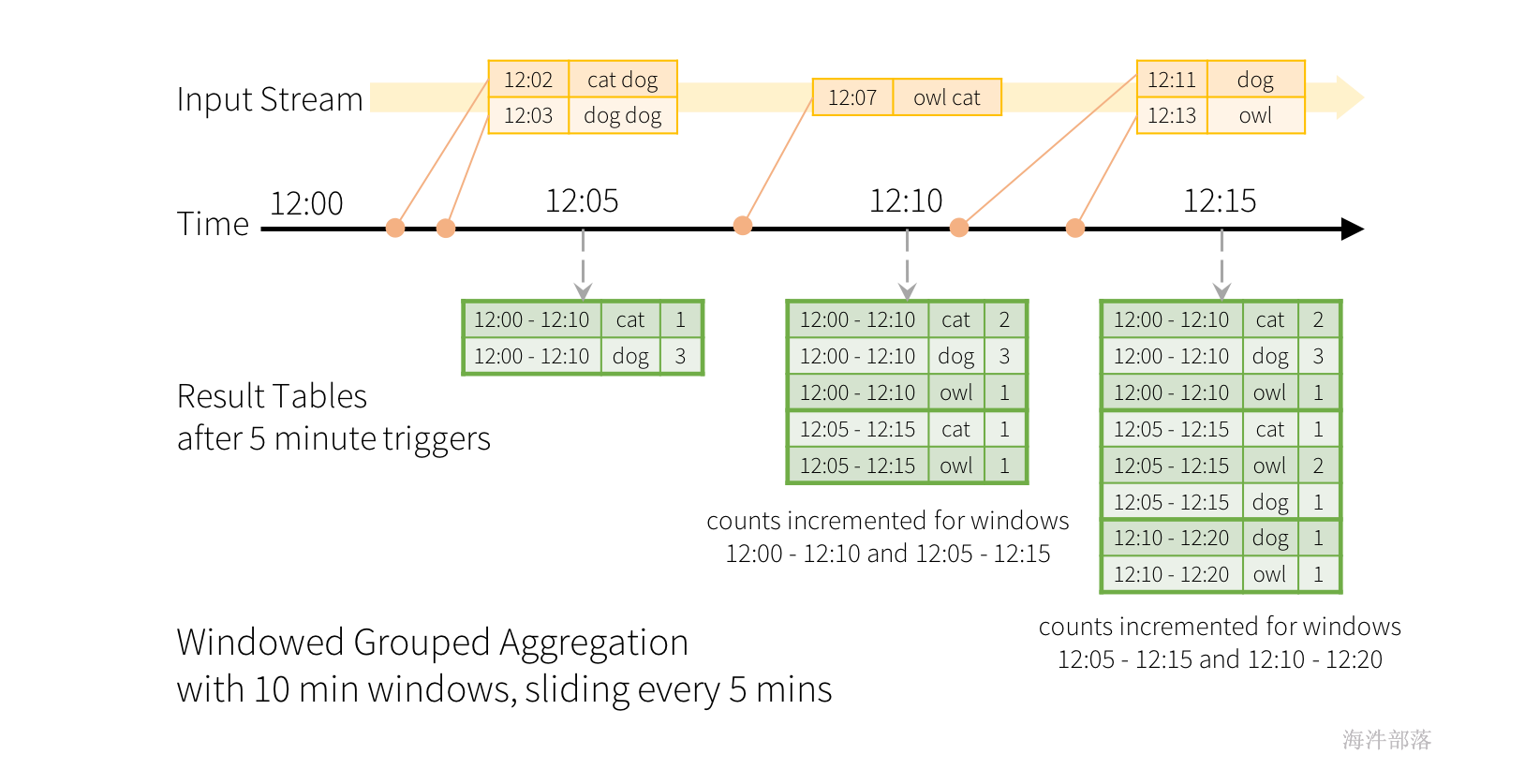
其中窗口设置代码如下:
import spark.implicits._
val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = words.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word"
).count()其中 window($"timestamp", "10 minutes", "5 minutes") 设定计算窗口的大小
$"word"是分组的字段,标识在这个窗口的范围内进行按照word进行分组求出聚合的count值
在上面的案例中我们使用数据携带的事件时间,这个时间准确性特别高,因为确定性的标识数据的产生时间就可以在计算的时候,避免数据乱序所带来的不便和数据因为延迟而出现的计算差错 ,而且计算的数据结果时间和当前系统的时间完全无关
系统时间窗口的整体代码:
package com.hainiu.spark
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.expressions.javalang.typed
import org.apache.spark.sql.functions.window
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.types.{IntegerType, StringType, StructField, StructType}
import java.text.SimpleDateFormat
import java.util.Date
object TestSource {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("test source").getOrCreate()
import session.implicits._
val df = session.readStream
.format("kafka")
.option("kafka.bootstrap.servers","kafka1-89796:9092")
.option("kafka.group.id","hainiu")
.option("subscribe","topic_hainiu")
.option("startingOffsets","latest")
.load()
//kafka --> hello
val ds = df.selectExpr("cast(key as string)", "cast(value as string)")
val ds2 = ds.select("value").as[String]
.map(t=> {
val datef = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss")
val time = datef.format(new Date)
(time, t)
}).toDF("tm","word")
.groupBy(
window($"tm","5 seconds")
,$"word")
.count()
ds2.writeStream
.option("truncate","false")
.format("console")
.outputMode("complete")
.start()
.awaitTermination()
}
}
在kafka中输入单词
hello
hello hello
hello
hello
world
模拟数据
# 在data文件夹下面创建word.txt,输入如下内容
# 模拟上图中的数据
2023-02-13 12:02:10 cat dog
2023-02-13 12:03:10 dog dog
2023-02-13 12:07:10 owl cat
2023-02-13 12:11:10 dog
2023-02-13 12:13:10 owl整体代码如下:
package com.hainiu.structure
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.types.{IntegerType, StringType, StructType}
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* 读取text文件
*/
object TestSource {
def main(args: Array[String]): Unit = {
val spark = SparkSession.builder()
.config("spark.sql.shuffle.partitions",2) //设置少量分区数,默认分区格式200个
.appName("test read")
.master("local[*]")
.getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
val df = spark.readStream
.text("data/text")
df.as[String].flatMap(t=>{
val strs = t.split(" ")
val date = strs.head //日期
val timestamp = strs.tail.head //小时分钟
val all_date = date+" "+timestamp //组装整体时间
//将每个单词和时间进行匹配
strs.tail.tail.map((_,all_date))
}).toDF("word","timestamp")
.groupBy(
window($"timestamp","10 minutes","5 minutes"),$"word"
)
.agg(count($"word"))
.orderBy($"window")
.writeStream
.format("console")
.outputMode("complete")
.option("truncate","false")
.start()
.awaitTermination()
}
}结果如下:

2.2 窗口生成
上面的案例中第一个窗口的初始化时间是11.55开始的,但是我们的数据并没有这个时间点的数据,那么窗口的开始和结束时间是如何进行设定的呢?
源码在 org.apache.spark.sql.catalyst.analysis.TimeWindowing这个类中
* maxNumOverlapping <- ceil(windowDuration / slideDuration)
* for (i <- 0 until maxNumOverlapping)
* windowId <- ceil((timestamp - startTime) / slideDuration)
* windowStart <- windowId * slideDuration + (i - maxNumOverlapping) * slideDuration + startTime
* windowEnd <- windowStart + windowDuration
* return windowStart, windowEnd
*
* This behaves as follows for the given parameters for the time: 12:05. The valid windows are
* marked with a +, and invalid ones are marked with a x. The invalid ones are filtered using the
* Filter operator.
* window: 12m, slide: 5m, start: 0m :: window: 12m, slide: 5m, start: 2m
* 11:55 - 12:07 + 11:52 - 12:04 x
* 12:00 - 12:12 + 11:57 - 12:09 +
* 12:05 - 12:17 + 12:02 - 12:14 +这段描述代码的意思如下:
maxNumOverlapping <- ceil(windowDuration / slideDuration)
计算总共重叠的窗口个数:ceil(windowDuration / slideDuration) = maxNumOverlapping;
从0开始迭代到maxNumOverlapping,计算Window;
在真实的实现中,区分了滚动窗口和滑动窗口:
- 如果是滚动窗口,其maxNumOverlapping就是1,直接转换成Window返回即可;
- 如果是滑动窗口,其maxNumOverlapping>1,需要基于
Expand算子整合多个Window,达到一次input映射到多个Window的目的;
首先使用事件的 开始时间和start-times也就是0ms进行减法得出间隔时间,然后根据间隔时间除以slideDuration主要目的是想要将时间变成滑动大小的整数倍,去除参与时间,windowStart <- windowId slideDuration + (i - maxNumOverlapping) slideDuration + startTime然后根据时间进行推断,得出开始时间
比如我们的第一个数据是
2023-02-13 12:02:10 cat dog然后根据时间戳得出 1676260930000
然后使用这个时间和5分钟进行相除得出 windowId = 5587537
windowId slideDuration + (i - maxNumOverlapping) slideDuration + startTime 根据格式进行计算得出
i从0开始,到1结束 maxNumOverlapping大小为2
scala> 5587537*5*60*1000L
res5: Long = 1676261100000
scala> 5587534*5*60*1000L
res6: Long = 1676260500000所以 1676261100000- 2*5*60*1000+ startTime = 1676260500000
所以开始时间为2023-02-13 11:55:00
产生的窗口分别为
| 开始时间 | 结束时间 |
|---|---|
| 2023-02-13 11:55:00 | 2023-02-13 12:05:00 |
| 2023-02-13 12:00:00 | 2023-02-13 12:10:00 |
| 2023-02-13 12:05:00 | 2023-02-13 12:15:00 |
但是因为第一个窗口没有数据所以是无效窗口,没有任何计算

2.3 迟到数据
按照事件时间进行处理数据会出现迟到数据的情况
现在考虑一下,如果其中一个事件延迟到达应用程序,会发生什么情况。例如,例如,在12:04(即事件时间)生成的单词可以在12:11被应用程序接收。应用程序应使用时间12:04而不是12:11更新窗口12:00-12:10的旧计数。这自然发生在我们基于窗口的分组中——结构化流可以长期保持部分聚合的中间状态,以便后期数据可以正确更新旧窗口的聚合,如下所示。
全量模式
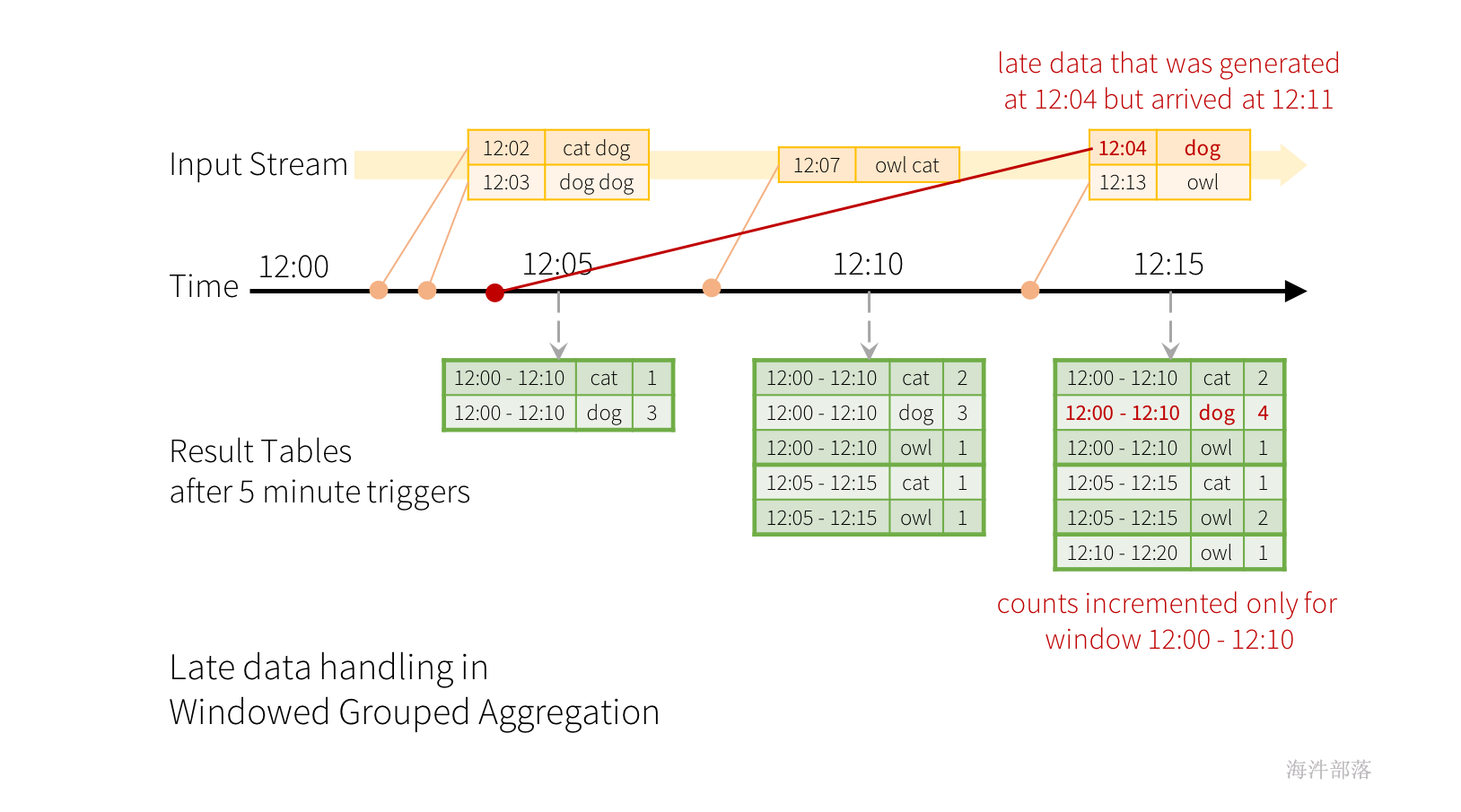
例如上面数据顺序,如果计算是按照五分钟进行滑动进行计算的,12:00 - 12:05的数据会直接进行计算,这个时候只有 12:02 cat dog 12:03 dog dog ,这个时候12:07的数据到来了,计算是按照数据进行推进的,只有数据到了时间才会向下推,窗口才会计算,但是这个数据已经计算完了,这个时候在12:10的以后时间又来了一个带有12:04 的数据dog,这个时候没有任何地方可去
然而,要连续几天运行此查询,系统必须绑定它累积的内存中间状态的数量。这意味着系统需要知道何时可以将旧聚合从内存状态中删除,因为应用程序将不再接收该聚合的延迟数据。为了实现这一点,在Spark 2.1中,我们引入了watermark,它使引擎能够自动跟踪数据中的当前事件时间,并尝试相应地清理旧状态。可以通过指定事件时间列和数据在事件时间方面的预期延迟阈值来定义查询的水印。对于在时间T结束的特定窗口,引擎将保持状态并允许后期数据更新状态,直到(引擎看到的最大事件时间-后期阈值>T)。换言之,阈值内的后期数据将被聚合,但阈值之后的数据将开始被丢弃。让我们用一个例子来理解这一点。我们可以使用withWatermark()在前面的示例中定义水印,如下所示。
import spark.implicits._
val words = ... // streaming DataFrame of schema { timestamp: Timestamp, word: String }
// Group the data by window and word and compute the count of each group
val windowedCounts = words
.withWatermark("timestamp", "10 minutes")
.groupBy(
window($"timestamp", "10 minutes", "5 minutes"),
$"word")
.count() 在本例中,我们将根据列“timestamp”的值定义查询的水印,并将“10分钟”定义为数据允许延迟的阈值。则引擎将在结果表中保持更新窗口计数,直到窗口早于水印,它比“时间戳”列中的当前事件时间滞后10分钟。这是一个例子。
更新模式
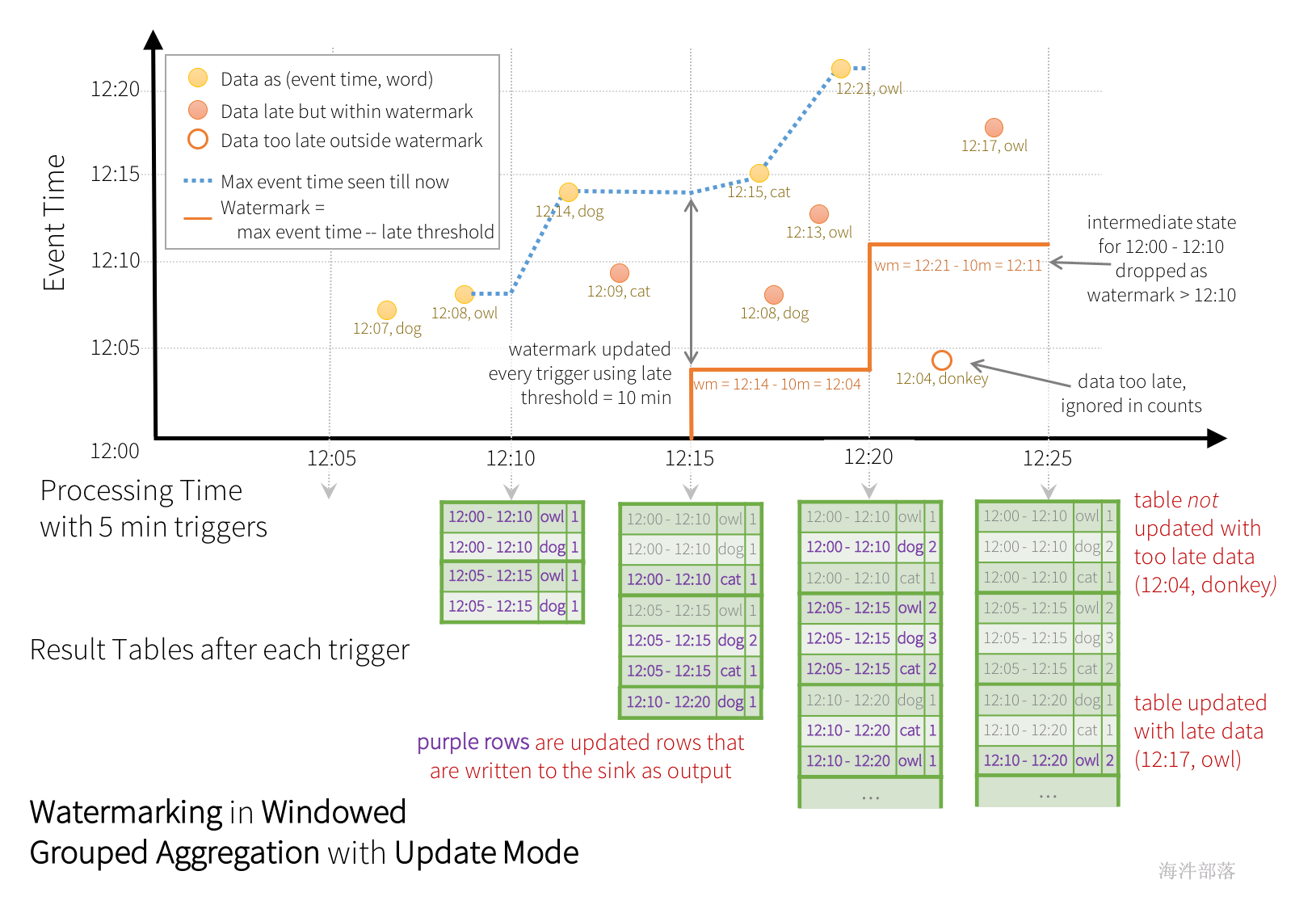
下面是追加模式
如上数据是按照批次进行执行的,那么滑动时间是五分钟,所以滑动的五分钟会计算一次结果,这个事件时间是按照当前五分钟一个整体中最大的时间戳进行赋值的,watermark也是
如图所示,引擎跟踪的最大事件时间是蓝色虚线,每个触发器开始时设置为(最大事件时间-“10分钟”)的水印是红线。例如,当引擎观察数据(12:14,dog)时,它将下一个触发器的水印设置为12:04。此水印允许引擎在额外的10分钟内保持中间状态,以允许对后期数据进行计数。例如,数据(12:09,cat)出现故障和延迟,并且出现在窗口12:00-12:10和12:05-12:15中。由于它仍在触发器中的水印12:04之前,因此引擎仍将中间计数保持为状态,并正确更新相关窗口的计数。然而,当水印更新到12:11时,窗口(12:00-12:10)的中间状态被清除,所有后续数据(例如(12:04,donkey))被认为“太迟了”,因此被忽略。请注意,在每次触发后,更新的计数(即紫色行)将被写入接收器作为触发输出,如更新模式所指示的。
请注意,在非流数据集上使用withWatermark是不行的。由于水印不会以任何方式影响任何批次查询,因此我们将直接忽略它。
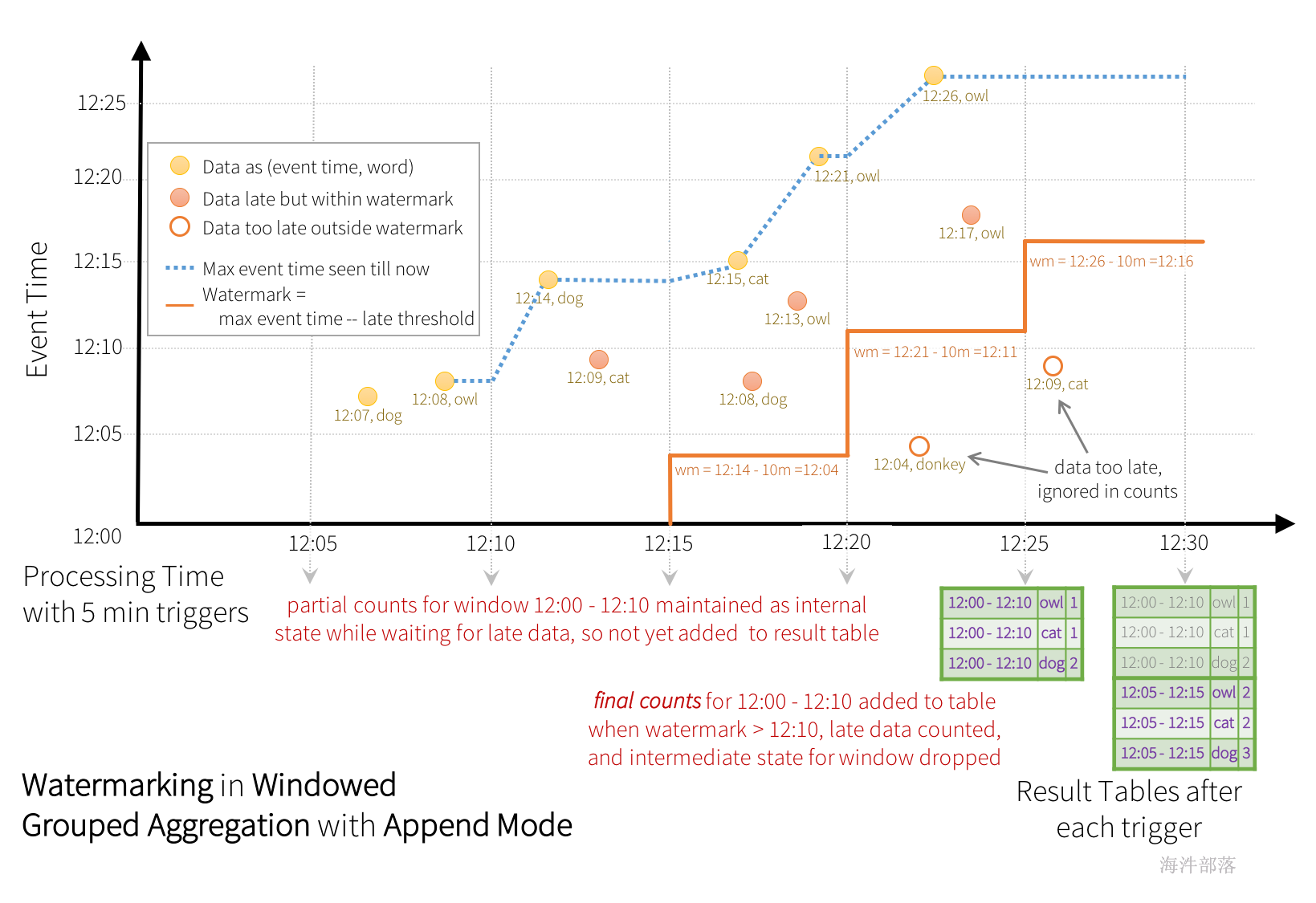
与前面的更新模式类似,引擎为每个窗口保持中间计数。但是,部分计数不会更新到结果表,也不会写入接收器。引擎等待“10分钟”以计算延迟日期,然后删除窗口<水印的中间状态,并将最终计数附加到结果表/接收器。例如,只有在水印更新为12:11之后,窗口12:00-12:10的最终计数才会附加到结果表。
比如上图中的数据,在12.20进行计算触发的时候是因为12.21的数据到了,这个时候窗口闭合,但是闭合的时候整个流中最大的数据是12.21,watermark延迟时间是10分钟,那么当前最大的watermark是12.11,这个时候小于这个值的数据才会被写出到外部存储中
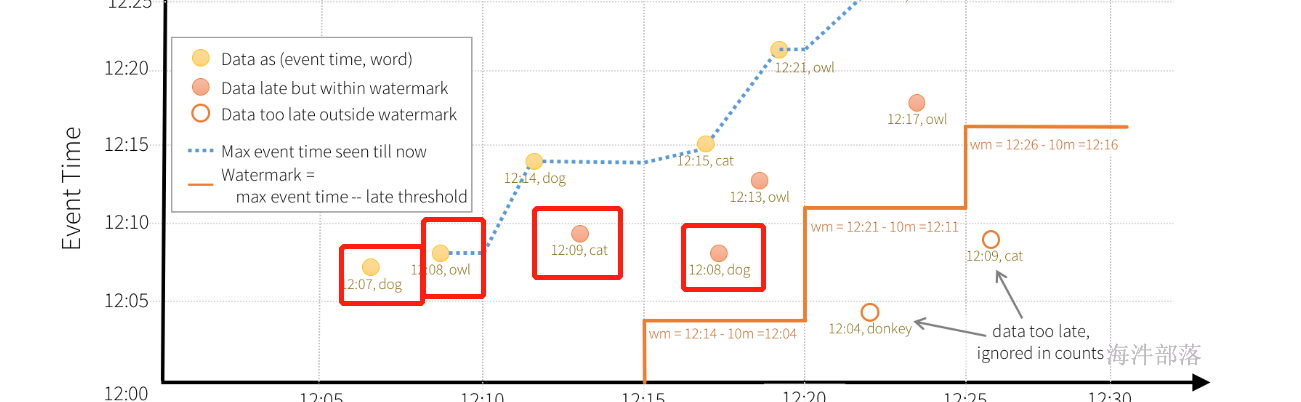
比如上图的四个数据
2.4 不同的输出模式下,迟到数据的处理是不同的
-
outputMode 必须为appende或update。complete 模式要求保留所有聚合数据,因此不能使用水印来删除中间状态。
-
聚合必须具有事件时间列或事件时间列上的窗口。
-
必须在与聚合中使用的时间戳列相同的列上调用withWatermark。例如,df.withWatermark(“time”,“1 min”).groupBy(“time2”).count()在追加输出模式下无效,因为水印是在与聚合列不同的列上定义的。
- 必须在聚合之前调用withWatermark才能使用水印。例如,df.groupBy(“time”).count().withWatermark(“时间”,“1分钟”)在追加输出模式下无效。
2.4.1 complete模式下的延迟数据
在complete模式下数据会全部都输出
2023-04-12 12:07:00 dog
2023-04-12 12:08:00 owl
2023-04-12 12:14:00 dog
2023-04-12 12:09:00 cat
2023-04-12 12:15:00 cat
2023-04-12 12:13:00 owl
2023-04-12 12:08:00 dog
2023-04-12 12:21:00 owl
2023-04-12 12:17:00 owl
2023-04-12 12:04:00 donkey
2023-04-12 12:26:00 owl整体代码如下:
package com.hainiu.spark
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.window
import java.sql.Timestamp
object TestWaterMark {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("watermark")
conf.setMaster("local[*]")
val session = SparkSession.builder().config(conf).getOrCreate()
import session.implicits._
val df = session.readStream.format("socket")
.option("port", 6666)
.option("host", "nn1")
.load()
//tcp --> 2023-04-13 10:10:10 hello world
val df1 = df.as[String].flatMap(t => {
val strs = t.split(" ")
val date = strs(0) + " " + strs(1)
strs.tail.tail.map((Timestamp.valueOf(date), _))
}).toDF("time", "word")
df1
.withWatermark("time","10 minutes")
.groupBy(
window($"time","10 minutes","5 minutes")
,$"word"
).count()
.orderBy($"window")
.writeStream
.option("truncate","false")
.outputMode("complete")
.format("console")
.start()
.awaitTermination()
}
}
结果数据如下:
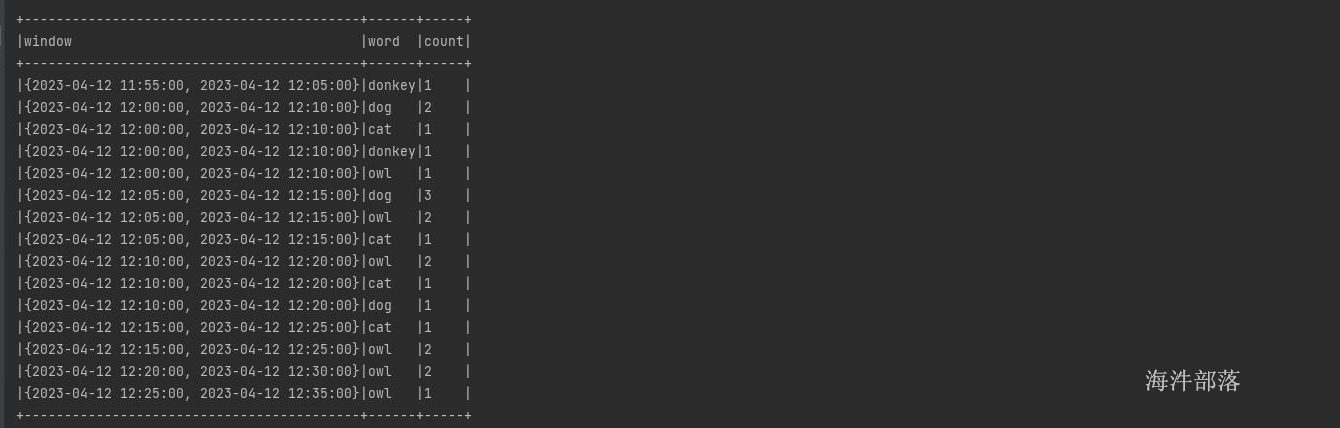
全量模式下watermark不起作用,全量输出
在输入数据第一个数据是12.07的时候开始的窗口时间是11.55
输入的第一个数据是
2023-04-12 12:07:00
* maxNumOverlapping <- ceil(windowDuration / slideDuration)
* for (i <- 0 until maxNumOverlapping)
* windowId <- ceil((timestamp - startTime) / slideDuration)
* windowStart <- windowId * slideDuration + (i - maxNumOverlapping) * slideDuration + startTime
* windowEnd <- windowStart + windowDuration
* return windowStart, windowEnd
*
windowDuration 10 minutes
slideDuration 5 minutes
maxNumOverlapping = 2
timestamp = 1681272420000 startTime = 0
windowId = 5604242
windowId * slideDuration + (i - maxNumOverlapping) * slideDuration + startTime
5604242 * 5*1000*60 0 - 2 5*60*1000 0
1681272000000 --> 2023-04-12 12:00:00
窗口的开始时间
因为后续出来一个donkey 12:04的数据
所以增加前面的窗口11:55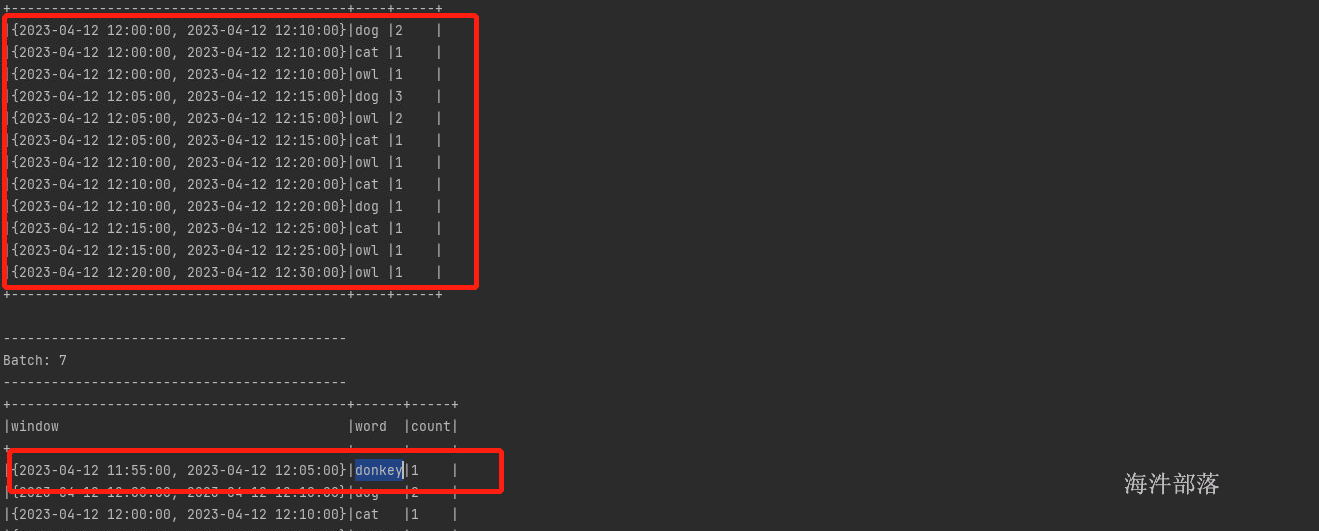
2.4.2 update模式下的延迟数据
在update模式下,只会显示出来变化和新增的数据
.outputMode("update")// 注释掉这个排序代码,排序在更新模式下是不可以使用的
// .orderBy($"window")代码整体不变,但是输出模式变化为update
package com.hainiu.spark
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.window
import java.sql.Timestamp
object TestWaterMark {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("watermark")
conf.setMaster("local[*]")
val session = SparkSession.builder().config(conf).getOrCreate()
import session.implicits._
val df = session.readStream.format("socket")
.option("port", 6666)
.option("host", "nn1")
.load()
//tcp --> 2023-04-13 10:10:10 hello world
val df1 = df.as[String].flatMap(t => {
val strs = t.split(" ")
val date = strs(0) + " " + strs(1)
strs.tail.tail.map((Timestamp.valueOf(date), _))
}).toDF("time", "word")
df1
.withWatermark("time","10 minutes")
.groupBy(
window($"time","10 minutes","5 minutes")
,$"word"
).count()
// .orderBy($"window")
.writeStream
.option("truncate","false")
.outputMode("update")
.format("console")
.start()
.awaitTermination()
}
}输入数据依旧同上
2023-04-12 12:07:00 dog
2023-04-12 12:08:00 owl
2023-04-12 12:14:00 dog
2023-04-12 12:09:00 cat
2023-04-12 12:15:00 cat
2023-04-12 12:13:00 owl
2023-04-12 12:08:00 dog
2023-04-12 12:21:00 owl
2023-04-12 12:17:00 owl
2023-04-12 12:04:00 donkey
2023-04-12 12:26:00 owl第一次的结果
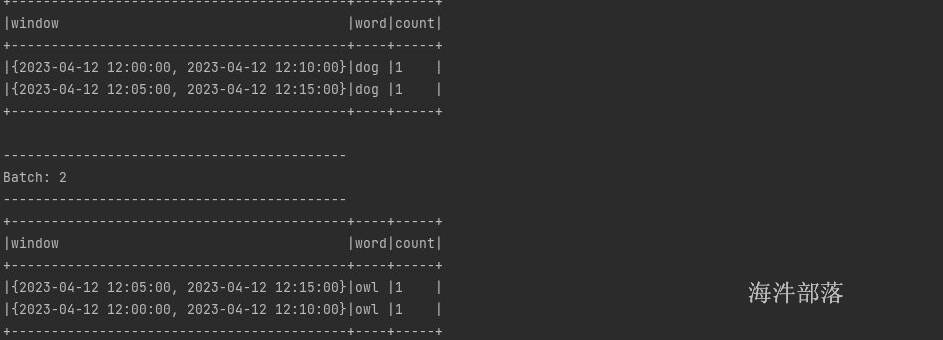
第二次结果
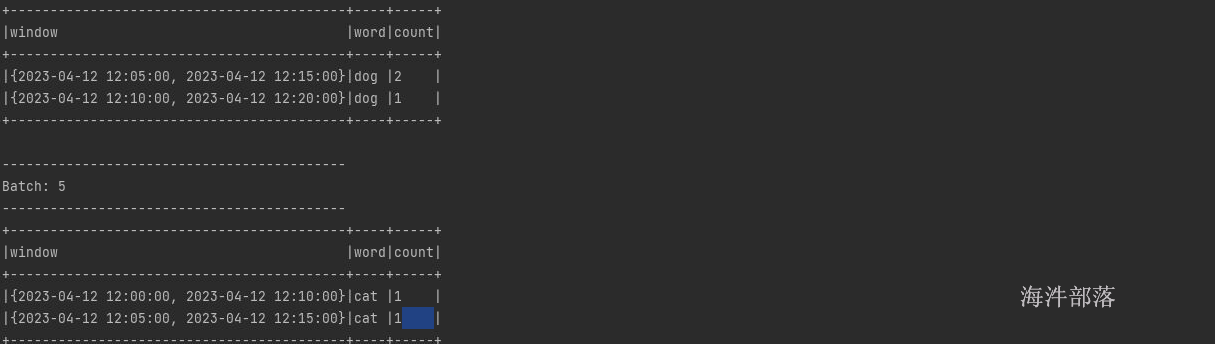
第三次结果
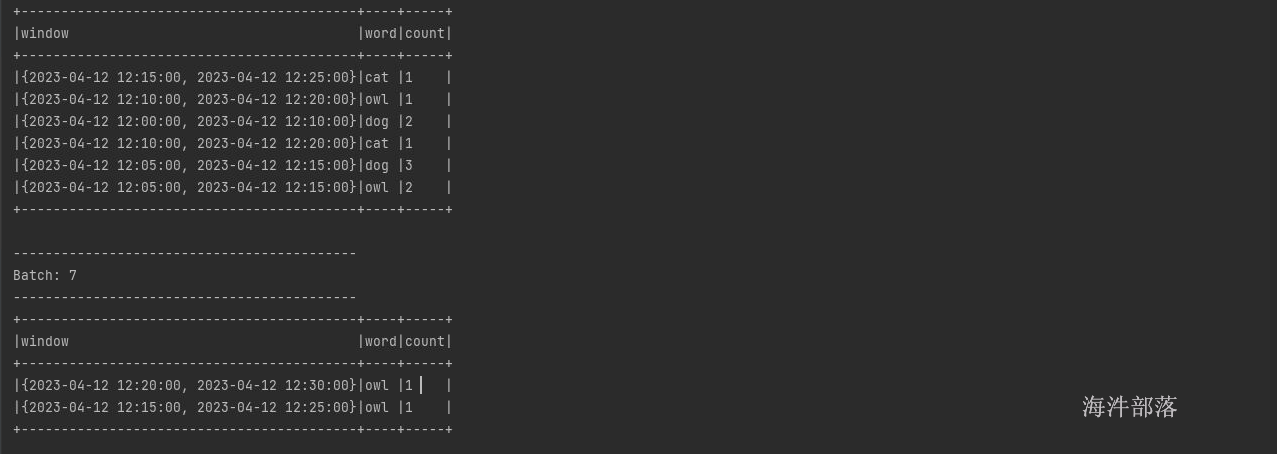
第四次结果重点是没有donkey,因为12.04的数据过期了
最大的事件时间12.21 watermark是10分钟 当前闭合窗口小于12.11的就会被删除
只有donkey位于 12:00-12:10的窗口中,其他的数据不仅仅在这个窗口中

2.4.3 append模式下的延迟数据
这个模式中也需要将排序进行去掉,因为必须是全量模式才可以排序
追加模式中必须保证数据后续不会再被更新才会输出结果,所以刚开始的时候不会看到任何的结果
代码如下:
package com.hainiu.spark
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.window
import java.sql.Timestamp
object TestWaterMark {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("watermark")
conf.setMaster("local[*]")
val session = SparkSession.builder().config(conf).getOrCreate()
import session.implicits._
val df = session.readStream.format("socket")
.option("port", 6666)
.option("host", "nn1")
.load()
//tcp --> 2023-04-13 10:10:10 hello world
val df1 = df.as[String].flatMap(t => {
val strs = t.split(" ")
val date = strs(0) + " " + strs(1)
strs.tail.tail.map((Timestamp.valueOf(date), _))
}).toDF("time", "word")
df1
.withWatermark("time","10 minutes")
.groupBy(
window($"time","10 minutes","5 minutes")
,$"word"
).count()
// .orderBy($"window")
.writeStream
.option("truncate","false")
.outputMode("append")
.format("console")
.start()
.awaitTermination()
}
}输入数据如下:
2023-04-12 12:07:00 dog
2023-04-12 12:08:00 owl
2023-04-12 12:14:00 dog
2023-04-12 12:09:00 cat
2023-04-12 12:15:00 cat
2023-04-12 12:13:00 owl
2023-04-12 12:08:00 dog
2023-04-12 12:21:00 owl
2023-04-12 12:17:00 owl
2023-04-12 12:04:00 donkey
2023-04-12 12:26:00 owl12.21的数据使得12:00-12:10的窗口闭合了
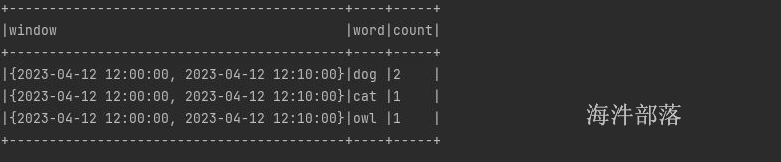
12.26的数据让12:05-12:15的窗口闭合了

2.4.4 带有watermark的聚合保证
-
水印延迟(使用水印设置)为“2小时”,保证引擎不会丢弃任何延迟时间小于2小时的数据。换言之,在此之前处理的最新数据(以事件时间计)落后2小时以内的任何数据都保证被聚合。
- 然而,担保仅在一个方向上严格。延迟超过2小时的数据不保证被丢弃;它可以聚合也可以不聚合。数据越延迟,引擎处理数据的丢失可能性就越小。
3. join
3.1 static join
spark2.0以后Structured Streaming开始支持流和静态表之间的join
join方式如下
val staticDf = spark.read. ...
val streamingDf = spark.readStream. ...
streamingDf.join(staticDf, "type") // inner equi-join with a static DF
streamingDf.join(staticDf, "type", "left_outer") // left outer join with a static DF3.1.1内连接
首先准备数据
# 静态表数据,data/dept.txt 输入如下数据
1,销售部,北京
2,公关部,上海
# 启动nc并且输入如下流式数据
1,zhangsan,20,1
2,lisi,30,2
3,wangwu,32,1
4,zhaosi,35,2
5,guangkun,40,3整体代码如下:
package com.hainiu.spark
import org.apache.spark.sql.SparkSession
object TestJoinWithStatic {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("join").getOrCreate()
import session.implicits._
val deptDF = session.read.textFile("data/dept")
.map(t=>{
val strs = t.split(",")
(strs(0),strs(1),strs(2))
}).toDF("deptno","dname","location")
val empDF = session.readStream.format("socket")
.option("host", "nn1")
.option("port", 6666)
.load().as[String]
.map(t=>{
val strs = t.split(",")
(strs(0), strs(1), strs(2),strs(3))
}).toDF("id","name","age","deptno")
val joinDF = empDF.join(deptDF, Seq("deptno"),"leftOuter")
//aggregate complete append(watermark) update
//normal append update
joinDF.writeStream
.format("console")
.option("truncate","false")
.outputMode("append")
.start()
.awaitTermination()
}
}
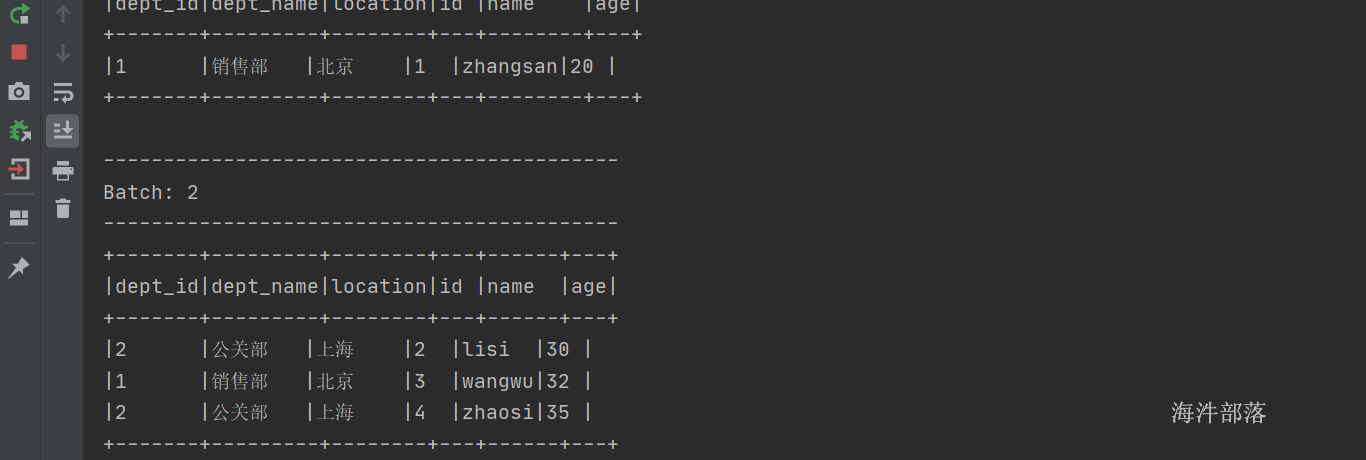
输入数据结果如上
3.1.2 外连接
修改代码
val frame = emp.join(dept,$"dept_id","left_outer")增加join方式
可选的join有以下几种常用的
inner[默认的] leftouter rightouter left_semi full继续数据上面数据
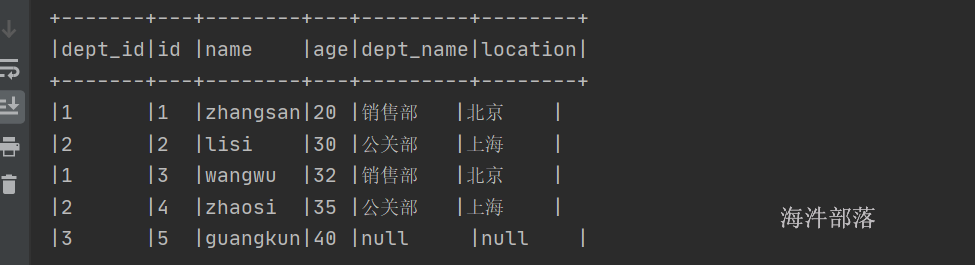
可以发现左侧的数据全部显示,与普通的表格的join相同
但是上述的数据为了能够将数据进行join,主要的原理就是将静态的表进行内存中缓存起来,然后将另一个流中的数据和内存表中的数据进行join
3.2 流join
在Spark 2.3中,我们增加了对流-流连接的支持,也就是说,可以连接两个流dataSet/dataFrame。在两个数据流之间生成连接结果的挑战是,在任何时间点,数据集的视图对于连接的双方都是不完整的,这使得在输入之间查找匹配变得更加困难。从一个输入流接收的任何行都可以与来自另一输入流的任何未来的、尚未接收的行相匹配。因此,对于两个输入流,我们将过去的输入缓冲为流状态,以便我们可以将每个未来的输入与过去的输入进行匹配,从而生成合并结果。此外,与流聚合类似,我们自动处理延迟的无序数据,并可以使用水印限制状态。
支持任何类型的列上的内部连接以及任何类型的连接条件。然而,随着流的运行,流状态的大小将无限增长,因为所有过去的输入都必须保存,因为任何新输入都可以与过去的任何输入相匹配。为了避免无边界状态,必须定义额外的连接条件,以便无限期的旧输入不能与未来的输入匹配,因此可以从状态中清除。换句话说,必须在连接中执行以下附加步骤。
-
1.在两个输入上定义水印延迟,以便引擎知道输入的延迟程度(类似于流聚合)
- 2.定义两个输入之间的事件时间约束,以便引擎可以确定何时不需要一个输入的旧行(即不满足时间约束)来匹配另一个输入。该约束可以通过以下两种方式之一定义。
- 增加时间范围 (e.g.
...JOIN ON leftTime BETWEEN rightTime AND rightTime + INTERVAL 1 HOUR), - 增加窗口形式的join (e.g.
...JOIN ON leftTimeWindow = rightTimeWindow).
- 增加时间范围 (e.g.
假设我们希望将一个广告流(当广告显示时)与另一个用户点击广告流相结合,在用户点击的时候进行关联。要允许此流流连接中的状态清理,您必须指定水印延迟和时间限制,如下所示。
-
水印延迟:例如,广告和相应的点击可能会在活动时间延迟最多2小时或3小时。
- 事件时间范围条件:例如,在相应广告后0秒到1小时的时间范围内可以发生点击。
3.2.1 没有watermark的join
在做流的join的时候不支持update模式,append模式是可以的
首先准备数据
# 启动nc 6666 输入如下数据
1,销售部,北京,2023-01-13 10:15:00
2,公关部,上海,2023-01-13 10:20:00
3,物流部,广州,2023-01-13 10:50:00
# 启动nc 7777并且输入如下流式数据
1,zhangsan,20,1,2023-01-13 10:10:00
2,lisi,30,2,2023-01-13 10:15:00
3,wangwu,32,1,2023-01-13 10:20:00
4,zhaosi,35,2,2023-01-13 10:25:00
5,guangkun,40,3,2023-01-13 10:30:00val frame = emp.join(dept,Seq("dept_id"),"left_outer")如果没有指定watermark那么不能使用外连接
整体代码如下:
package com.hainiu.spark
import org.apache.spark.sql.SparkSession
object TestJoinWithoutWatermark {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().appName("join").master("local[*]").getOrCreate()
import session.implicits._
val df1 = session.readStream.format("socket")
.option("host", "nn1")
.option("port", 6666)
.load().as[String]
.map(t=>{
val strs = t.split(",")
(strs(0),strs(1),strs(2),strs(3))
}).toDF("deptno","dname","location","time")
val df2 = session.readStream.format("socket")
.option("host", "nn1")
.option("port", 7777)
.load().as[String]
.map(t => {
val strs = t.split(",")
(strs(0), strs(1), strs(2), strs(3),strs(4))
}).toDF("id", "name", "age","deptno","time")
df1.join(df2,"deptno")
.writeStream
.option("truncate","false")
.format("console")
.outputMode("append")
.start()
.awaitTermination()
}
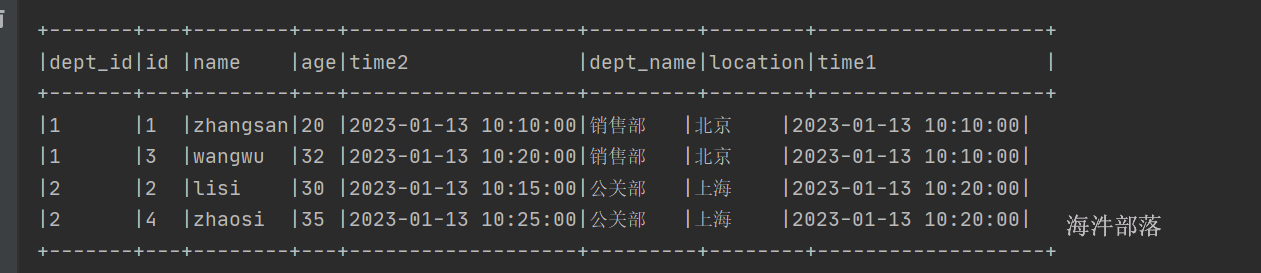
}
join的速度比较慢,为了能够让数据join在一起必须全部都保存起来,所以缓存的数据会比较多
3.2.2 带有watermark的join
这个时候需要设定join的范围时间和watermark的时间,watermark规定了在多久以后数据会丢失,join设定的范围主要是为了设定什么样子的数据可以join到一起
逻辑设定如下:
import org.apache.spark.sql.functions.expr
val impressions = spark.readStream. ...
val clicks = spark.readStream. ...
// Apply watermarks on event-time columns
val impressionsWithWatermark = impressions.withWatermark("impressionTime", "2 hours")
val clicksWithWatermark = clicks.withWatermark("clickTime", "3 hours")
// Join with event-time constraints
impressionsWithWatermark.join(
clicksWithWatermark,
expr("""
clickAdId = impressionAdId AND
clickTime >= impressionTime AND
clickTime <= impressionTime + interval 1 hour
""")
)整体代码如下:
package com.hainiu.structure
import java.sql.Timestamp
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object TestJoin {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("testjoin")
conf.setMaster("local[*]")
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
val dept = spark.readStream.format("socket").option("host", "op.hadoop")
.option("port", 6666)
.load().as[String]
.map(t=>{
val strs = t.split(",")
(strs(0),strs(1),strs(2),Timestamp.valueOf(strs(3)))
}).toDF("dept_id","dept_name","location","time1")
.withWatermark("time1","20 seconds")
val emp = spark.readStream.format("socket").option("host", "op.hadoop")
.option("port", 7777)
.load().as[String]
.map(t=>{
val strs = t.split(",")
(strs(0),strs(1),strs(2),strs(3),Timestamp.valueOf(strs(4)))
}).toDF("id","name","age","dept_id","time2")
.withWatermark("time2","10 seconds")
import org.apache.spark.sql.functions._
val frame = emp.join(dept,emp("dept_id")===dept("dept_id") and expr(
"""
| time1 >= time2 - interval 10 seconds
| AND
| time1 <= time2 + interval 10 seconds
|""".stripMargin))
frame.writeStream.format("console")
.outputMode("append")
.option("truncate",false)
.start()
.awaitTermination()
}
}
# 启动nc 6666 输入如下数据
1,销售部,北京,2023-01-13 10:15:10
# 启动nc 7777并且输入如下流式数据
1,zhangsan,20,1,2023-01-13 10:15:10
3,wangwu,32,1,2023-01-13 10:15:20
5,guangkun,40,1,2023-01-13 10:15:30这个时候发现数据展示必须符合时间条件dept在emp的-10到+10秒范围内


这个时候输入
5,guangkun,40,1,2023-01-13 10:15:30
发现没有数据输出

因为不仅仅需要考虑到join的范围还需要知道数据必须在watermark失效之前,因为输入了
5,guangkun,40,1,2023-01-13 10:15:30
这个时候超过了10秒,之前的部门数据丢失了
3.2.3 带有状态的外连接
外链接的时候必须加上watermark,因为要保留一侧表中的数据然后进行处理,所以必须加上watermark
整体代码
package com.hainiu.spark
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.expr
import java.sql.Timestamp
object TestJoinWithoutWatermark {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().appName("join").master("local[*]").getOrCreate()
import session.implicits._
val df1 = session.readStream.format("socket")
.option("host", "nn1")
.option("port", 6666)
.load().as[String]
.map(t=>{
val strs = t.split(",")
(strs(0),strs(1),strs(2),Timestamp.valueOf(strs(3)))
}).toDF("deptno","dname","location","time1")
.withWatermark("time1","20 seconds")
val df2 = session.readStream.format("socket")
.option("host", "nn1")
.option("port", 7777)
.load().as[String]
.map(t => {
val strs = t.split(",")
(strs(0), strs(1), strs(2), strs(3),Timestamp.valueOf(strs(4)))
}).toDF("id", "name", "age","deptno","time2")
.withWatermark("time2","20 seconds")
df1.join(df2,df1("deptno")===df2("deptno")
and expr(
"""
|time1 <= time2 + interval 10 seconds
|and
|time1 >= time2 - interval 10 seconds
|""".stripMargin),"leftOuter"
)
.writeStream
.option("truncate","false")
.format("console")
.outputMode("append")
.start()
.awaitTermination()
}
}
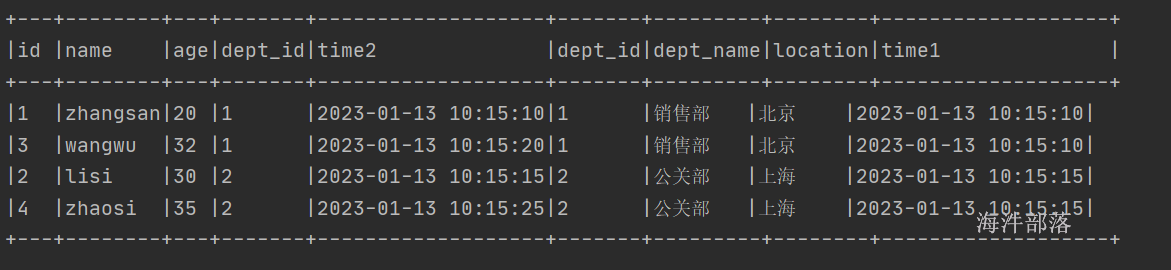
只需要修改连接方式就可以了,要人为推进时间,因为数据的计算和事件时间是相关的
注意事项
关于如何生成外部结果,有几个重要的特征需要注意。
外部NULL结果将以取决于指定水印延迟和时间范围条件的延迟生成。这是因为引擎必须等待这么长时间,以确保没有匹配,并且将来不会再有匹配。
在微批处理引擎中的当前实现中,水印在微批结束时被提前,下一个微批处理使用更新的水印来清理状态并输出外部结果。由于我们仅在有新数据要处理时才触发微批处理,因此如果流中没有接收到新数据,则外部结果的生成可能会延迟。简而言之,如果被连接的两个输入流中的任何一个在一段时间内没有接收到数据,则外部(两种情况,左侧或右侧)输出可能会延迟。
3.3 join支持
-
join可以多次使用,比如
df1.join(df2, ...).join(df3, ...).join(df4, ....). - join操作能够使用的输出模式只有append,其他模式并不支持
- 在join之前不能使用聚合
- 不能够使用mapGroupsWithState 和flatMapGroupsWithState 在join之前
4.流式去重
4.1 不带watermark的去重
我们可以使用事件中的唯一标识符对数据流中的记录进行重复数据消除。这与使用唯一标识符列的静态重复数据消除完全相同。查询将存储以前记录中所需的数据量,以便可以过滤重复记录。与聚合类似,您可以使用带或不带水印的重复数据消除。
带水印-如果重复记录到达的时间有上限,则可以在事件时间列上定义水印,并使用guid和事件时间列进行重复数据消除。查询将使用水印从过去的记录中删除旧的状态数据,这些记录预计不会再获得任何重复数据。这限制了查询必须保持的状态量。
没有水印-由于重复记录可能到达的时间没有界限,因此查询将所有过去记录中的数据存储为状态。
代码如下:
val streamingDf = spark.readStream. ... // columns: guid, eventTime, ...
// Without watermark using guid column
streamingDf.dropDuplicates("guid")
// With watermark using guid and eventTime columns
streamingDf
.withWatermark("eventTime", "10 seconds")
.dropDuplicates("guid", "eventTime")# 首先创建文件 data/score/score.txt
# 输入如下内容
1,zhangsan,20
2,lisi,30
3,wangwu,40
1,zhaosi,39整体代码如下:
package com.hainiu.spark
import org.apache.spark.sql.SparkSession
object TestDistinct {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("distinct").getOrCreate()
import session.implicits._
session.readStream.format("text")
.load("data/distinct")
.as[String]
.map(t=>{
val strs = t.split(",")
(strs(0),strs(1),strs(2))
}).toDF("id","name","age")
.dropDuplicates("id")
.writeStream
.format("console")
.outputMode("append")
.start()
.awaitTermination()
}
}
输出结果如上图,根据id可以去重掉
4.2 带有watermark的去重
这个去重不是说之前的数据会按照watermark消失
watermark可以过滤掉过期的数据,但是去重永久可以去重
# 启动nc 输入如下内容
1,zhangsan,20,2023-01-13 10:10:10
2,lisi,30,2023-01-13 10:10:15
3,zhaosi,35,2023-01-13 10:10:20
1,wangwu,20,2023-01-13 10:10:50整体代码如下:
package com.hainiu.spark
import org.apache.spark.sql.SparkSession
import java.sql.Timestamp
object TestDistinctWithWatermark {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().appName("distinct").master("local[*]").getOrCreate()
import session.implicits._
session.readStream.format("socket")
.option("host","nn1")
.option("port",6666)
.load().as[String]
.map(t=>{
val strs = t.split(",")
(strs(0),strs(1),strs(2),Timestamp.valueOf(strs(3)))
}).toDF("id","name","age","ts")
.withWatermark("ts","10 seconds")
.dropDuplicates("id")
.writeStream
.format("console")
.outputMode("append")
.start()
.awaitTermination()
}
}

继续输入4,liuneng,35,2023-01-13 10:10:10
虽然4的id没出现过,所以本应该显示的数据,但是因为过期数据不会被处理,所以没有任何的展示

5.不同watermark的处理策略
流式查询可以有多个输入流,这些输入流被联合或连接在一起。每个输入流可以具有不同的延迟数据阈值,这对于有状态操作是需要容忍的。可以在每个输入流上使用withWatermarks(“eventTime”,延迟)指定这些阈值。例如,考虑在inputStream1和inputStream2之间具有流流连接的查询。
inputStream1.withWatermark("eventTime1", "1 hour")
.join(
inputStream2.withWatermark("eventTime2", "2 hours"),
joinCondition) 在执行查询时,结构化流单独跟踪每个输入流中看到的最大事件时间,根据相应的延迟计算水印,并选择一个全局水印用于有状态操作。默认情况下,选择最小值作为全局水印,因为它可以确保如果其中一个流落后于其他流(例如,其中一个由于上游故障而停止接收数据),则不会因太晚而意外丢弃数据。换句话说,全局水印将以最慢流的速度安全地移动,查询输出将相应地延迟。
然而,在某些情况下,我们可能希望获得更快的结果,即使这意味着从最慢的流中删除数据。从Spark 2.4开始,可以通过将SQL配置Spark.SQL.streaming.multipleWatermarkPolicy设置为max(默认值为min),将多重水印策略设置为选择最大值作为全局水印。这使得全局水印以最快的速度移动。然而,作为一个副作用,来自较慢流的数据将被大量丢弃。因此,使用min是最优的选择。
测试 如下:
package com.hainiu.structure
import java.sql.Timestamp
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.Trigger
object TestDistinct {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("testjoin")
conf.setMaster("local[*]")
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
val ds1 = spark.readStream.format("socket")
.option("host", "nn1")
.option("port", 6666)
.load()
.as[String]
.map(t=>{
val strs = t.split(",")
(strs(0),Timestamp.valueOf(strs(1)))
}).toDF("word","ts1")
.withWatermark("ts1","10 seconds")
val ds2 = spark.readStream.format("socket")
.option("host", "nn1")
.option("port", 7777)
.load()
.as[String]
.map(t=>{
val strs = t.split(",")
(strs(0),Timestamp.valueOf(strs(1)))
}).toDF("word","ts2")
.withWatermark("ts2","5 seconds")
import org.apache.spark.sql.functions._
ds1.join(ds2,ds1("word") === ds2("word") and expr(
"""
| ts1 >= ts2 - interval 10 seconds
| AND
| ts1 <= ts2 + interval 10 seconds
|""".stripMargin))
.writeStream
.outputMode("append")
.format("console")
.start()
.awaitTermination()
}
}分别做以下输入
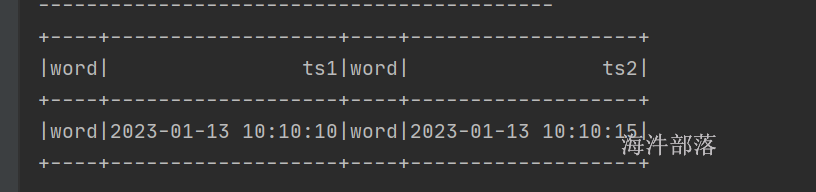
nc -l -k -p 7777
word,2023-01-13 10:10:15nc -k -l -p 6666
word,2023-01-13 10:10:15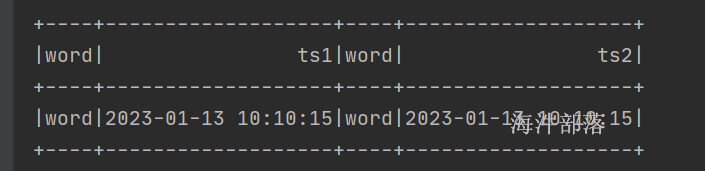
这个时候继续输入数据
nc -k -l -p 6666
word,2023-01-13 10:10:30
word,2023-01-13 10:10:10如果watermark是按照最大时间进行下推的,那么会发现输入word,2023-01-13 10:10:15关联不到数据,但是发现数据还是输出了
因为一侧时间下推一侧数据没有任何变化,所以按照最小时间戳进行推算
这个时候继续输入数据
nc -k -l -p 7777
word,2023-01-13 10:10:30
word,2023-01-13 10:10:10发现之前超时的数据被删除了,因为这一侧数据也下推了

可以设置参数配置
conf.set("spark.sql.streaming.multipleWatermarkPolicy","max")默认值为min


