YARN
1.yarn的概述
大数据的组成部分两个,分别是分布式存储和分布式计算
hdfs解决的部分是分布式存储
yarn解决的是分布式计算,但是在hadoop1.x版本中的时候是没有yarn的,后续为了灵活和负载均衡的操作才出现了yarn资源管理平台
问题1:什么是资源
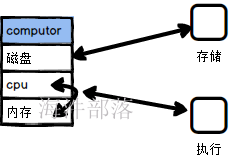
问题2:yarn是解决什么问题的
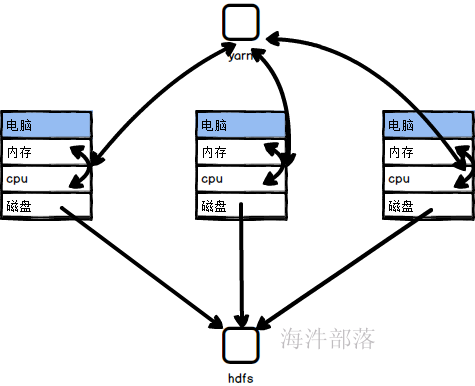
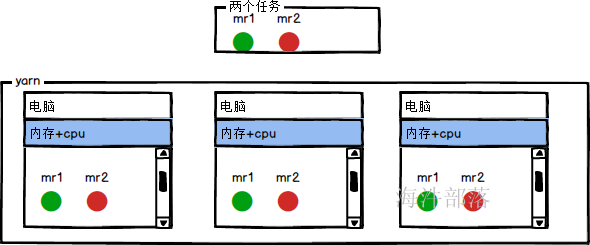
问题3:mapreduce是什么
mr只是运行在yarn资源中的一个框架而已
hadoop1.x的资源管理
首先看旧的mr的架构
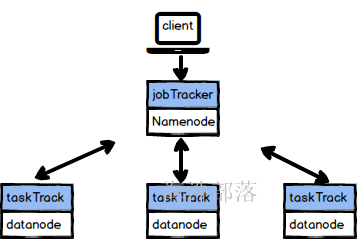
结构
一个 Hadoop 集群可分解为两个抽象实体:MapReduce 计算引擎和分布式文件系统。当一个客户端向一个 Hadoop 集群发出一个请求时,此请求由 JobTracker 管理。JobTracker 与 NameNode 联合将任务分发到离它所处理的数据尽可能近的位置。然后JobTracker 将 Map 和 Reduce 任务安排到一个或多个 TaskTracker 上的可用插槽中。TaskTracker 与 DataNode一起对来自 DataNode 的数据执行 Map 和 Reduce 任务。当 Map 和 Reduce 任务完成时,TaskTracker 会告知 JobTracker,后者确定所有任务何时完成并最终告知客户作业已完成。
缺点
在hadoop1.x的资源管理中资源管理是通过JobTracker进行管理的,并且任务提交到集群中的时候要需要监控执行和调度,都是一个节点完成的,压力过大,并且单点会出现故障,而且这个架构只使用与mr的程序,在一个公司中的资源管理架构只有一个就够了,并不需要多个种类,原来的集群在运行不同任务的时候需要不同的集群进行支持,比如flink集群 spark集群 mr的集群,这样通用性不强
举个栗子
比如yarn是一个景点
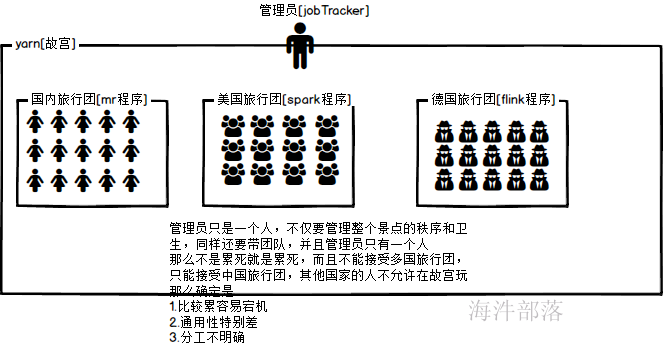
所以yarn出现了,解决了hadoop1.x版本资源管理的病态
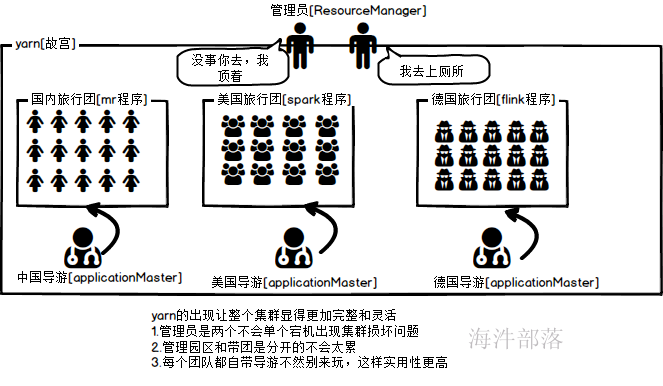
YARN通过将资源管理和应用程序管理分剥离开,分别由ResouceManager和ApplicationMaster负责。
YARN具有向后兼容性,用户在MRv1上运行的作业,无需任何修改即可运行在YARN之上。
YARN支持多种计算框架,比如 mapreduce、spark、flink。
框架升级更容易,框架不需要部署到集群的各个结点,而是被封装成一个用户程序库(lib)存放在客户端,当需要对计算框架进行升级时,只需升级用户程序库即可。
2.yarn的结构
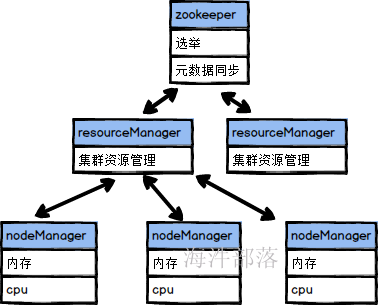
所以yarn的结构也是主从结构的
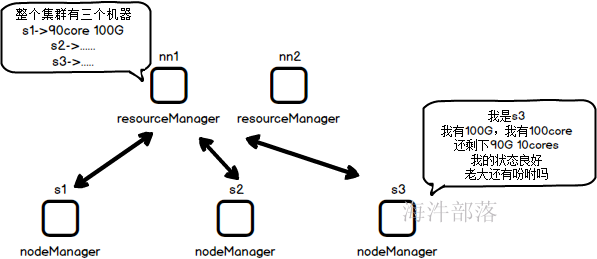
ResourceManager(RM)
RM是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager,ASM),通俗讲是用于管理NodeManager节点的资源,包括cup、内存等。
NodeManager(NM)
NM是每个节点上的资源和任务管理器,一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;另一方面,它接收并处理来自AM的Container启动/停止等各种请求。
3.双节点RM的HA
问题:一般的主从集群都会为了防止集群的单节点的故障而使用双主从的热备方式,那么如果一个节点宕机另一个节点从事服务是怎么知道集群中有多少资源已经当前运行的任务有哪些,并且执行的情况如何呢?
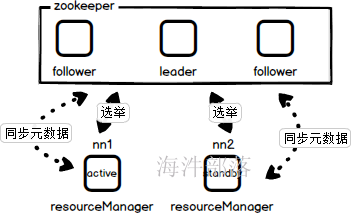
和hdfs相同,通过独享锁可以选举出来整个集群的active节点和standby节点
同时active节点在运行的时候也会写出元数据到zookeeper中,那么从节点在从事服务的时候就可以读取其中的元数据了
4.resourceManager的搭建
首先配置yarn-env.sh中的内容
#设置内存占比,yarn的内存为256M
source /etc/profile
JAVA=$JAVA_HOME/bin/java
JAVA_HEAP_MAX=-Xmx256m
YARN_HEAPSIZE=256
export YARN_RESOURCEMANAGER_HEAPSIZE=256设置yarn-site.xml中的配置,记得更改ip设置是nn1和nn2
<!-- RM1 configs start -->
<property>
<name>yarn.resourcemanager.address.rm1</name>
<value>nn1:8032</value>
<description>ResourceManager 对客户端暴露的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>nn1</value>
<description>ResourceManager主机名</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm1</name>
<value>nn1:8030</value>
<description>ResourceManager 对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等。</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm1</name>
<value>nn1:8089</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>nn1:8088</value>
<description>ResourceManager对外web ui地址。用户可通过该地址在浏览器中查看集群各类信息。</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm1</name>
<value>nn1:8031</value>
<description>ResourceManager 对NodeManager暴露的地址.。NodeManager通过该地址向RM汇报心跳,领取任务等。</description>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm1</name>
<value>nn1:8033</value>
<description>ResourceManager 对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令等</description>
</property>
<!-- RM1 configs end -->
<!-- RM2 configs start -->
<property>
<name>yarn.resourcemanager.address.rm2</name>
<value>nn2:8032</value>
<description>ResourceManager 对客户端暴露的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>nn2</value>
<description>ResourceManager主机名</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm2</name>
<value>nn2:8030</value>
<description>ResourceManager 对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资>源等。</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm2</name>
<value>nn2:8089</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>nn2:8088</value>
<description>ResourceManager对外web ui地址。用户可通过该地址在浏览器中查看集群各类信息。</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm2</name>
<value>nn2:8031</value>
<description>ResourceManager 对NodeManager暴露的地址.。NodeManager通过该地址向RM汇报心跳,领取任务等。</description>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm2</name>
<value>nn2:8033</value>
<description>ResourceManager 对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令等</description>
</property>
<!-- RM2 configs end -->启动resourceManager
#分发配置文件到每个机器中
scp_all.sh /usr/local/hadoop/etc/hadoop/yarn-env.sh /usr/local/hadoop/etc/hadoop/
scp_all.sh /usr/local/hadoop/etc/hadoop/yarn-site.xml /usr/local/hadoop/etc/hadoop/
# 在nn1和nn2两台启动resourceManager
yarn --daemon start resourcemanager查看监控页面
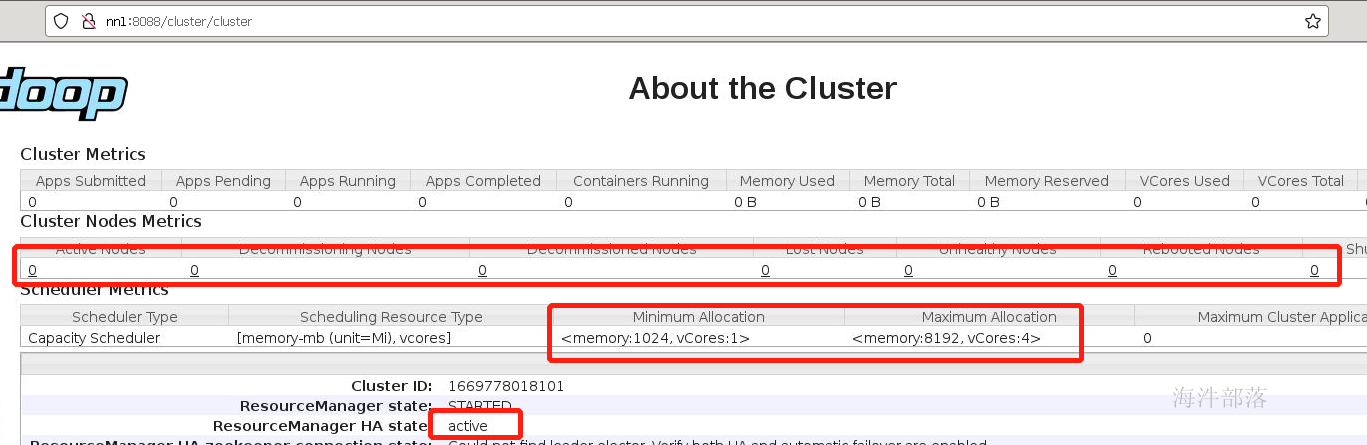
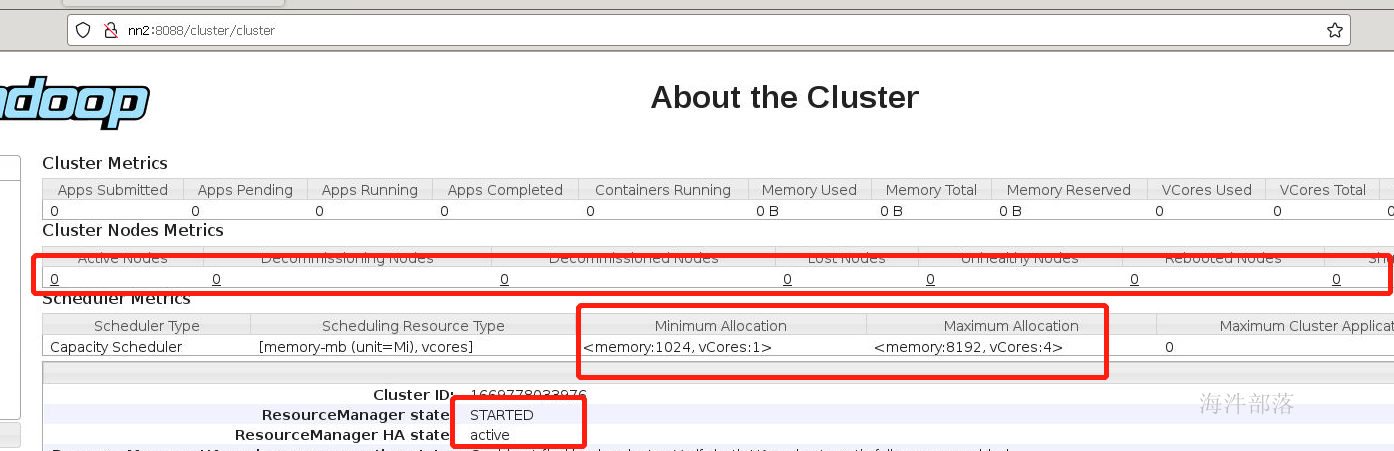
我们可以看到启动了两个resourceManager,但是两个节点都是active状态的,因为没有人选举出来,并且子节点个数全部为0,资源也没有进行设定
5.HA的搭建
yarn-site.xml中增加如下配置
<!-- yarn ha start -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
<description>是否开启yarn ha</description>
</property>
<property>
<name>yarn.resourcemanager.ha.automatic-failover.embedded</name>
<value>true</value>
<description>ha状态切换为自动切换</description>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
<description>RMs的逻辑id列表</description>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>nn1:2181,nn2:2181,s1:2181</value>
<description>ha状态的存储地址</description>
</property>
<!-- yarn ha end -->
<!-- 元数据存储共享 -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>pseudo-yarn-rm-cluster</value>
<description>集群的Id</description>
</property>
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
<description>默认值为false,也就是说resourcemanager挂了相应的正在运行的任务在rm恢复后不能重新启动</description>
</property>
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
<description>配置RM状态信息存储方式3有两种,一种是FileSystemRMStateStore,另一种是MemoryRMStateStore,还有一种目前较为主流的是zkstore</description>
</property>
<property>
<name>yarn.resourcemanager.zk.state-store.address</name>
<value>nn1:2181,nn2:2181,s1:2181</value>
<description>当使用ZK存储时,指定在ZK上的存储地址。</description>
</property>
<!-- 元数据存储共享 -->#千万记得切换为hadoop用户
su - hadoop
#启动zookeeper
ssh_all_zk.sh /usr/local/zookeeper/bin/zkServer.sh start
# nn1和nn2重启resourceManager
yarn --daemon stop resourcemanager
yarn --daemon start resourcemanager查看监控页面的8088端口可以查看状态
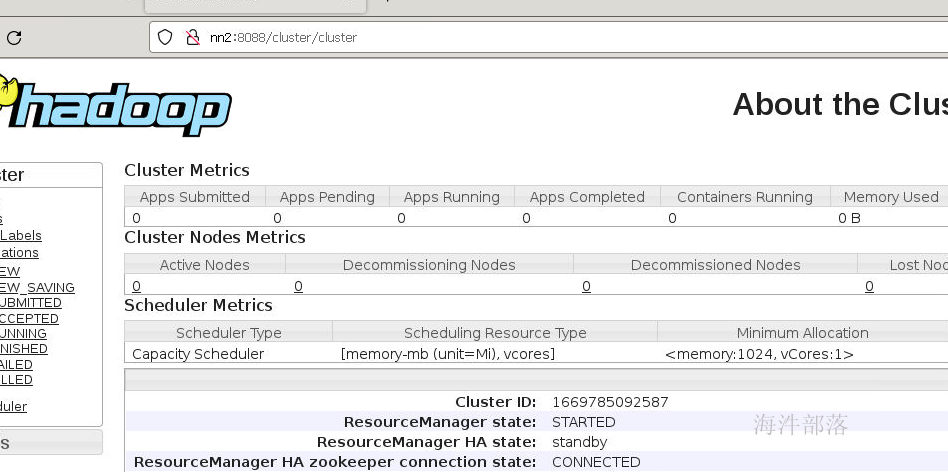
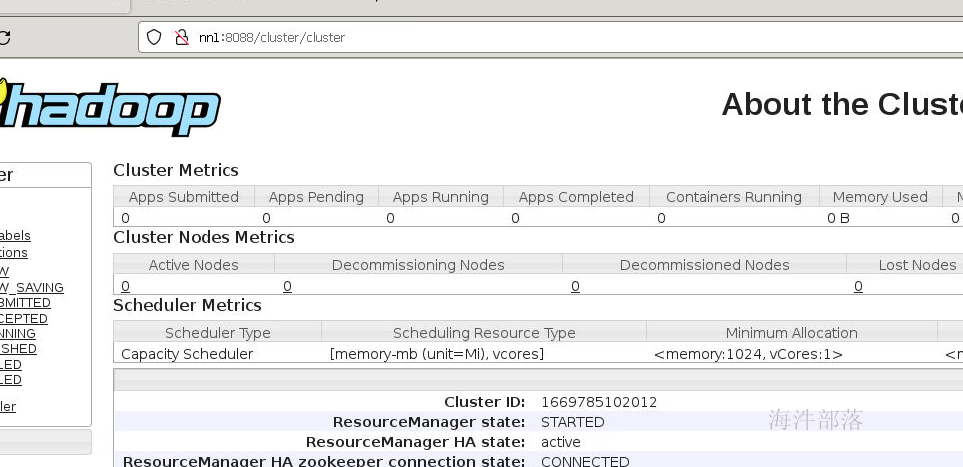
可以看到状态的切换,一个为active一个为standby
查看zookeeper中的状态

yarn-leader-election是选举的文件夹
rmstore是两个resourceManager进行同步元数据的文件夹

显示为rm1也就是nn1为active状态

这个文件夹中存储的数据是元数据信息
在hadoop3.x版本中resourceManager也可以搭建三份
基于namenode的三台的搭建的机器实现
yarn-site.xml中增加如下配置
<!-- RM1 configs start -->
<property>
<name>yarn.resourcemanager.address.rm3</name>
<value>nn3:8032</value>
<description>ResourceManager 对客户端暴露的地址。客户端通过该地址向RM提交应用程序,杀死应用程序等</description>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm3</name>
<value>nn3</value>
<description>ResourceManager主机名</description>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address.rm3</name>
<value>nn3:8030</value>
<description>ResourceManager 对ApplicationMaster暴露的访问地址。ApplicationMaster通过该地址向RM申请资源、释放资源等。</description>
</property>
<property>
<name>yarn.resourcemanager.webapp.https.address.rm3</name>
<value>nn3:8089</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm3</name>
<value>nn3:8088</value>
<description>ResourceManager对外web ui地址。用户可通过该地址在浏览器中查看集群各类信息。</description>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address.rm3</name>
<value>nn3:8031</value>
<description>ResourceManager 对NodeManager暴露的地址.。NodeManager通过该地址向RM汇报心跳,领取任务等。</description>
</property>
<property>
<name>yarn.resourcemanager.admin.address.rm3</name>
<value>nn3:8033</value>
<description>ResourceManager 对管理员暴露的访问地址。管理员通过该地址向RM发送管理命令等</description>
</property>
<!--下面的集群列表需要更改 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2,rm3</value>
<description>RMs的逻辑id列表</description>
</property>
#分发yarn-site.xml给每个机器
#nn1节点分发给所有机器
scp_all.sh /usr/local/hadoop/etc/hadoop/yarn-site.xml /usr/local/hadoop/etc/hadoop
#并且把关于yarn的所有配置文件给nn3机器分发一份
scp /usr/local/hadoop/etc/hadoop/yarn-site.xml hadoop@nn3:/usr/local/hadoop/etc/hadoop/
scp /usr/local/hadoop/etc/hadoop/mapred-site.xml hadoop@nn3:/usr/local/hadoop/etc/hadoop/
scp /usr/local/hadoop/etc/hadoop/yarn-env.sh hadoop@nn3:/usr/local/hadoop/etc/hadoop/
scp /usr/local/hadoop/etc/hadoop/fair-scheduler.xml hadoop@nn3:/usr/local/hadoop/etc/hadoop/
#在nn3机器上启动resourceManager
yarn --daemon start resourcemanager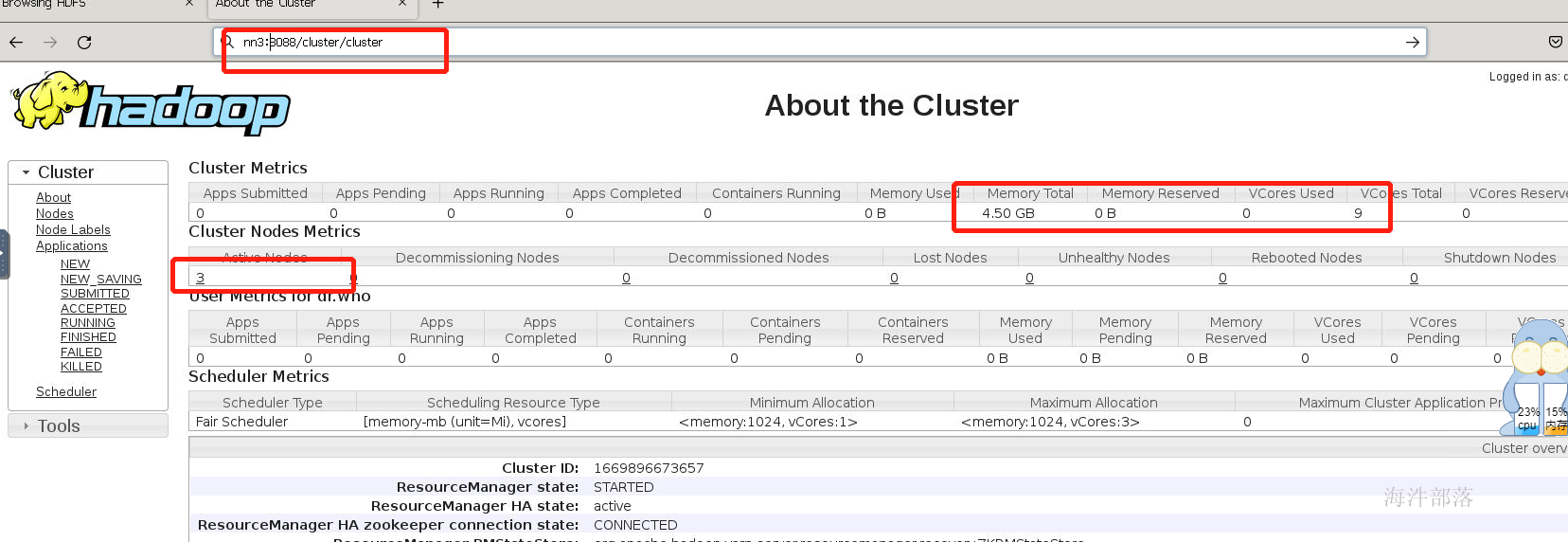
6.nodeManager的搭建
现在resourcemanager已经启动但是,我们发现没有任何节点和任何资源

现在我们搭建nodeManager,每个机器上面的nodeManager可以托管自己节点的内存和cpu和运行情况汇报给resourceManager
配置yarn-site.xml中的内容
<!-- nodeManager基础配置 -->
<property>
<name>yarn.nodemanager.local-dirs</name>
<value>/data/yarn/local</value>
<description>中间结果存放位置,存放执行Container所需的数据如可执行程序或jar包,配置文件等和运行过程中产生的临时数据</description>
</property>
<property>
<name>yarn.nodemanager.log-dirs</name>
<value>/data/yarn/logs</value>
<description>Container运行日志存放地址(可配置多个目录)</description>
</property>
<property>
<name>yarn.nodemanager.address</name>
<value>0.0.0.0:9103</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
<description>NodeManager上运行的附属服务。需配置成mapreduce_shuffle,才可运行MapReduce程序</description>
</property>
<property>
<name>yarn.nodemanager.webapp.address</name>
<value>0.0.0.0:8042</value>
</property>
<property>
<name>yarn.nodemanager.localizer.address</name>
<value>0.0.0.0:8040</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>mapreduce.shuffle.port</name>
<value>23080</value>
</property>
<!-- nodeManager基础配置 -->#分发yarn-site.xml到各个机器中
scp_all.sh /usr/local/hadoop/etc/hadoop/yarn-site.xml /usr/local/hadoop/etc/hadoop/
#启动三个机器的所有nodemanager
yarn --workers --daemon start nodemanager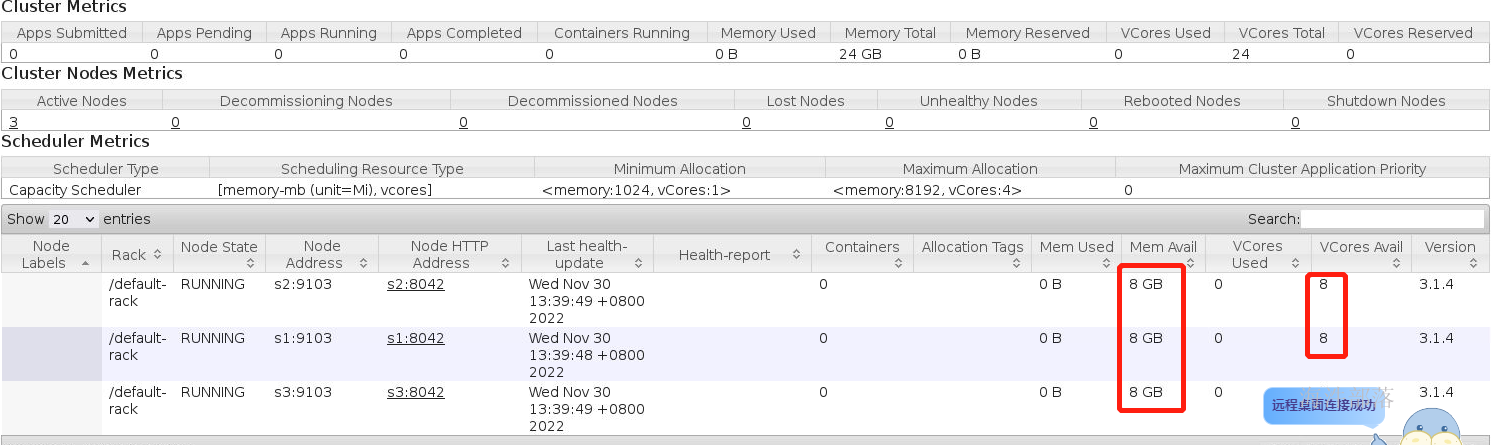
这个时候资源可以显示整个集群三个机器的内存情况和cpu核数情况
但是资源设置明显不对
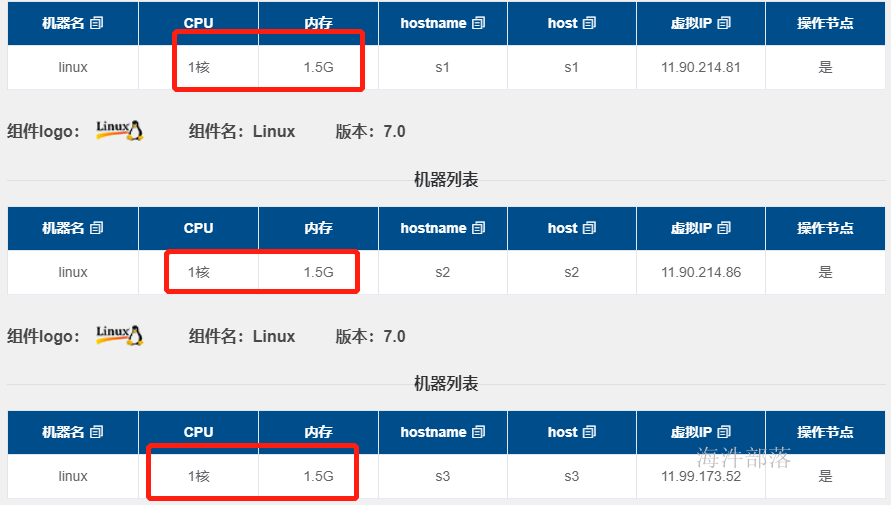
每个机器只能是1core和1.5G为什么显示的是8G 8core,明显集群中能够使用到的资源远大于整个集群的资源
所以我们需要设置一下集群中的内存和cpu
7.集群资源限定
在设置集群资源之前我们先引入一个问题
问题1:什么是资源?

内存:一块和磁盘一样的存储区域,但是这个区域速度更快,数据存储粒度更小,适合做计算和数据加载,任何要执行的数据都要先加载到内存中,所以内存是任何应用程序运行至关重要的一个部分,也是决定因素
cpu:提供很多物理的cpu核能够执行计算,核数越多那么同时执行计算的能力越大
问题2:资源的占用和隔离
举个栗子:比如cpu是老师,内存是教室
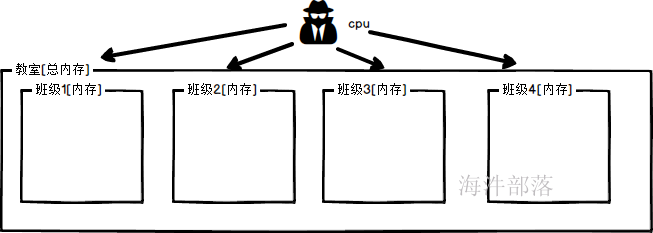
如果在一个学校中,教室的资源是有限的,一个班级占用的资源是独享的,如果教室不够了那么是不可以增加新的教室的,如果老师的资源不够了,其实无所谓,因为一个老师可以带多个班级
这就映射到一个机器中的资源,内存是计算的根本,如果内存不够了那么程序运行的时候需要加载的内容不能加载就无法运行,并且内存的占用是真的独占,但是cpu的核数是可以大家共享的,一个core可以执行多个应用程序,只不过大家需要抢占cpu核,这样程序多了会使得运行速度变慢,但是不至于运行不了
就比如我们的计算机,我的计算机是8core,但是后台却可以运行特别多的应用
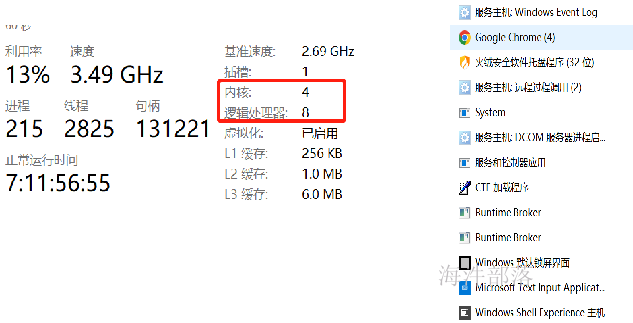
现在我们开始设计我们的集群的内存和cpu核数
内存的设计必须是按照实际大小,允许运行的任务能够占用的资源最多不能超过物理内存大小
但是如果运行的时候内存真的不足怎么办呢?在windows和linux中存在虚拟内存技术,如果运行时候内存中的数据太多可以溢写到磁盘中,做部分缓冲,但是提交的任务内存必须小于实际剩余内存,不然任务无法提交
但是cpu核数不能按照实际设计,比如我们存在三个core,我们如果只允许执行三个程序,对于集群的资源是极大的浪费的,所以我们设计的核数要超过真正的物理核数,这种核叫做虚拟核,其实指的是允许最大提交的任务的数量
可以设置虚核
配置yarn-site.xml中的资源设定配置
<!-- nodeMananger资源限定 start -->
<property>
<name>yarn.scheduler.minimum-allocation-vcores</name>
<value>1</value>
<description>单个任务可申请的最小虚拟CPU个数</description>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-vcores</name>
<value>3</value>
<description>单个任务可申请的最大虚拟CPU个数,此参数对应yarn.nodemanager.resource.cpu-vcores,建议最大为一个物理CPU的数量</description>
</property>
<property>
<name>yarn.nodemanager.resource.memory-mb</name>
<value>1536</value>
</property>
<property>
<name>yarn.scheduler.maximum-allocation-mb</name>
<value>1024</value>
<description>单个任务可申请的最多物理内存量</description>
</property>
<property>
<name>yarn.nodemanager.resource.cpu-vcores</name>
<value>3</value>
<description>该节点上YARN可使用的虚拟CPU个数,一个物理CPU对应3个虚拟CPU</description>
</property>
<!-- 重要开始 end -->
<!-- 关闭内存检测 -->
<property>
<name>yarn.nodemanager.vmem-check-enabled</name>
<value>false</value>
<description>虚拟内存检测,默认是True</description>
</property>
<property>
<name>yarn.nodemanager.pmem-check-enabled</name>
<value>false</value>
<description>物理内存检测,默认是True</description>
</property>
<property>
<name>yarn.application.classpath</name>
<value>
$HADOOP_CONF_DIR,
$HADOOP_COMMON_HOME/share/hadoop/common/*,
$HADOOP_COMMON_HOME/share/hadoop/common/lib/*,
$HADOOP_COMMON_HOME/share/hadoop/hdfs/*,
$HADOOP_COMMON_HOME/share/hadoop/hdfs/lib/*,
$HADOOP_COMMON_HOME/share/hadoop/mapreduce/*,
$HADOOP_COMMON_HOME/share/hadoop/mapreduce/lib/*,
$HADOOP_COMMON_HOME/share/hadoop/yarn/*,
$HADOOP_COMMON_HOME/share/hadoop/yarn/lib/*
</value>
</property>
<!-- nodeMananger资源限定 start -->#配置yarn-site.xml中的内容
#分发配置到多个集群节点中
scp_all.sh /usr/local/hadoop/etc/hadoop/yarn-site.xml /usr/local/hadoop/etc/hadoop/
#重启整个yarn集群
stop-yarn.sh
start-yarn.sh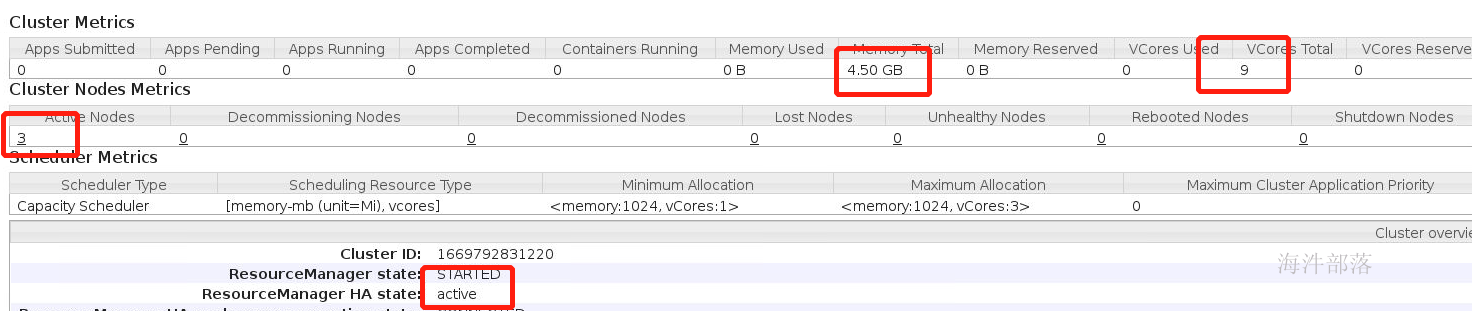
启动后发现集群中的资源发生了变化
8.任务测试
现在集群已经搭建完毕,我们提交一个mapreduce任务进行任务的运行,测试集群
在hadoop的安装包中存在已经准备好的代码包

路径 /usr/local/hadoop/share/hadoop/mapreduce
但是mapreduce程序不能直接执行需要进行配置mapred-site.xml
<!--运行模式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
<description>运行模式</description>
</property>
<!--运行模式 -->
<!--资源限定 -->
<property>
<name>yarn.app.mapreduce.am.resource.mb</name>
<value>1024</value>
<description>MR ApplicationMaster yarn申请的内存量</description>
</property>
<property>
<name>yarn.app.mapreduce.am.command-opts</name>
<value>-Xmx256m</value>
<description>jvm使用内存</description>
</property>
<property>
<name>mapreduce.map.memory.mb</name>
<value>1024</value>
<description>每个Map Task yarn申请内存</description>
</property>
<property>
<name>mapreduce.reduce.memory.mb</name>
<value>1024</value>
<description>每个Reduce Task yarn申请内存</description>
</property>
<property>
<name>yarn.app.mapreduce.am.resource.cpu-vcores</name>
<value>1</value>
<description>MR ApplicationMaster占用的虚拟CPU个数,此参数对应yarn.nodemanager.resource.cpu-vcores,建议最大为一个物理CPU的数量</description>
</property>
<property>
<name>mapreduce.reduce.java.opts</name>
<value>-Xmx256m</value>
<description>reduce jvm实际内存</description>
</property>
<property>
<name>mapreduce.map.java.opts</name>
<value>-Xmx256m</value>
<description>map jvm实际内存</description>
</property>
<property>
<name>mapreduce.map.cpu.vcores</name>
<value>1</value>
<description>每个map Task需要的虚拟cpu数</description>
</property>
<property>
<name>mapreduce.reduce.cpu.vcores</name>
<value>1</value>
<description>每个Reduce Task需要的虚拟cpu数</description>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>/usr/local/hadoop/etc/hadoop,/usr/local/hadoop/share/hadoop/common/*,/usr/local/hadoop/share/hadoop/common/lib/*,/usr/local/hadoop/share/hadoop/hdfs/*,/usr/local/hadoop/share/hadoop/hdfs/lib/*,/usr/local/hadoop/share/hadoop/mapreduce/*,/usr/local/hadoop/share/hadoop/mapreduce/lib/*,/usr/local/hadoop/share/hadoop/yarn/*,/usr/local/hadoop/share/hadoop/yarn/lib/*,/usr/local/hadoop/lib/*,/usr/local/hbase/lib/*</value>
<description>运行mr程序所使用的虚拟机运行时的classpath</description>
</property>
<!--资源限定 -->#分发到不同的节点
scp_all.sh /usr/local/hadoop/etc/hadoop/mapred-site.xml /usr/local/hadoop/etc/hadoop/#启动hdfs
start-dfs.sh
#本次创建测试文件
echo 'hello tom hello jack hello hainiu' >> wordcount.txt
echo 'hello tom hello jack hello hainiu' >> wordcount.txt
echo 'hello tom hello jack hello hainiu' >> wordcount.txt
echo 'hello tom hello jack hello hainiu' >> wordcount.txt
#上传文件到hdfs中
hdfs dfs -put wordcount.txt /
#查看文件
hdfs dfs -ls /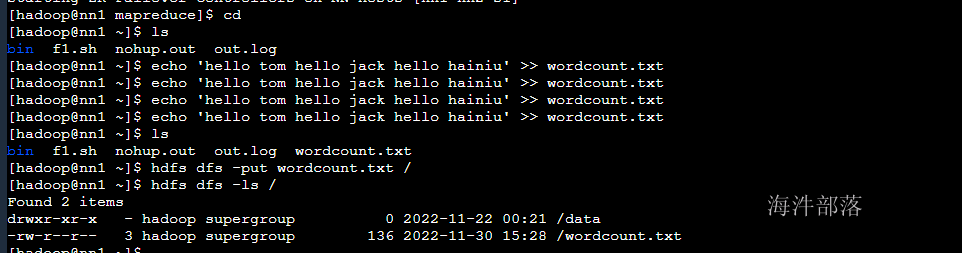
#提交代码到集群中
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar \
wordcount \
hdfs的输入路径
hdfs的输出路径
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar wordcount /wordcount.txt /res
9.yarn的资源调度
yarn中存在很多资源了,那么在提交任务的时候在需要资源的情况下是如何分配资源的呢?
在公司中很多个部门,一起都需要资源,那么是怎么进行资源划分的呢?
带着这两个问题我们开始进入到调度器的配置环节
调度器
在提交任务到yarn集群中的时候,多个任务的调度顺序和资源分配管理都是又调度器完成的
调度器的种类
- 先进先出,顺序调度(FIFO[first in first out])
- 容量(Capacity Scheduler)
- 公平(Fair Scheduler)
在hadoop3.x版本中默认调度器是容量调度器,CDH版本中调度器是公平调度器
9.1.FIFO调度器
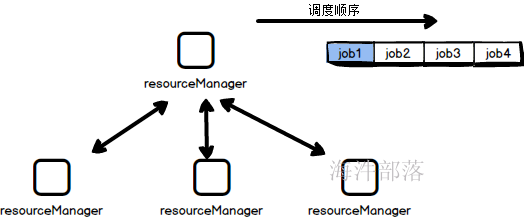
非常好理解,当客户端提交多个任务的时候,按照顺序进行资源分配
9.2.容量调度器
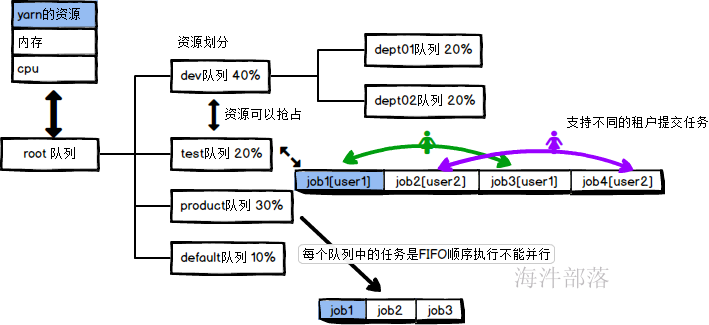
队列以分层方式组织资源,设计了多层级别的资源限制条件以更好的让多用户共享一个Hadoop集群,比如队列资源限制、用户资源限制、用户应用程序数目限制。队列里的应用以FIFO方式调度,每个队列可设定一定比例的资源最低保证和使用上限,同时,每个用户也可以设定一定的资源使用上限以防止资源滥用。而当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列。
可以划分资源队列,不同队列可以给不同的部门使用,是的资源产生隔离
队列间的优先级保证是按照资源的利用率低保证的,运行的任务所需资源/应该分配的资源
队列间中的任务优先级是按照时间顺序和任务的权重分配的
多个队列中的任务可以并行执行但是单个队列中的任务不可以
特性
Capacity调度器具有以下的几个特性:
- 层次化的队列设计,这种层次化的队列设计保证了子队列可以使用父队列设置的全部资源。这样通过层次化的管理,更容易合理分配和限制资源的使用。
- 容量保证,队列上都会设置一个资源的占比,这样可以保证每个队列都不会占用整个集群的资源。
- 安全,每个队列有严格的访问控制。用户只能向自己的队列里面提交任务,而且不能修改或者访问其他队列的任务。
- 弹性分配,空闲的资源可以被分配给任何队列。当多个队列出现争用的时候,则会按照比例进行平衡。
- 多租户租用,通过队列的容量限制,多个用户就可以共享同一个集群,同时保证每个队列分配到自己的容量,提高利用率。
- 操作性,yarn支持动态修改调整容量、权限等的分配,可以在运行时直接修改。还提供给管理员界面,来显示当前的队列状况。管理员可以在运行时,添加一个队列;但是不能删除一个队列。管理员还可以在运行时暂停某个队列,这样可以保证当前的队列在执行过程中,集群不会接收其他的任务。如果一个队列被设置成了stopped,那么就不能向他或者子队列上提交任务了。
- 基于资源的调度,协调不同资源需求的应用程序,比如内存、CPU、磁盘等等。
9.3.公平调度器
公平调度器是由facebook发明的,原理和容量调度器差不多,但是单个队列中的任务是可以并行执行的
所以公司中使用公平调度器的方式最多
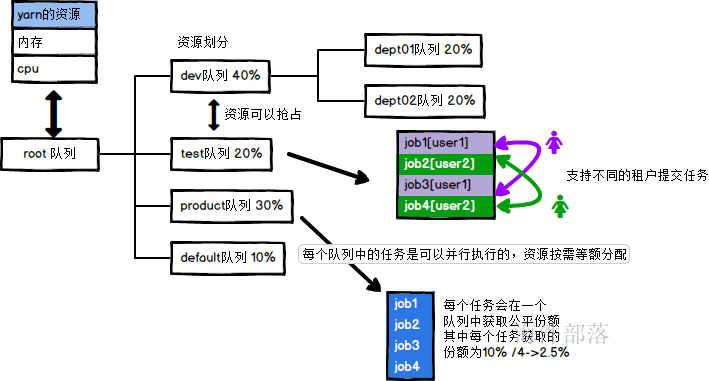
特点
1.可以配置多个队列
2.每个队列可以单独设置资源分配方式比如:FIFO FAIR
3.队列间可以实现资源相互抢占
4.队列中的任务会获取公平一致的资源
5.调度规则是按照资源紧缺程度进行优先级设定的

资源的均匀分配规则
1.资源池的资源分配过程

2.任务资源分配过程
A>普通任务分配
比如一个队列中存在资源是100个,分别提交四个任务
job0 -->10
job1 -->20
job2 -->30
job3 -->40
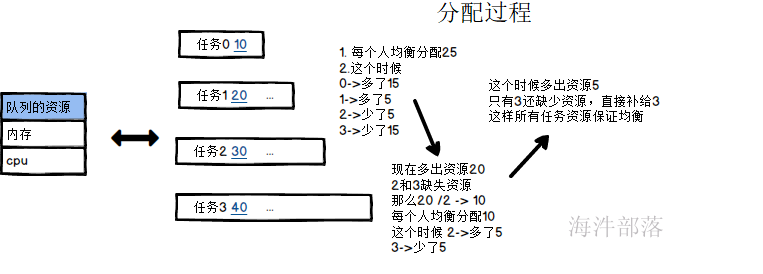
简单任务分配的资源和队列资源分配规则相同
B>带有权重的任务分配资源过程
在开发过程中提交任务是可以设置任务的优先级和权重的,保证任务的优先顺序,这个和KTV点歌相似
比如一个队列中存在资源是100个,分别提交四个任务
job0 -->10 job0权重为 10
job1 -->20 job1权重为 2
job2 -->30 job2权重为 5
job3 -->40 job3权重为 10
计算规则

9.4 公平调度器的配置
yarn-site.xml中增加如下配置
<!-- scheduler begin -->
<property>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.fair.FairScheduler</value>
<description>调度器实现类</description>
</property>
<property>
<name>yarn.scheduler.fair.allocation.file</name>
<value>fair-scheduler.xml</value>
<description>自定义XML配置文件所在位置,该文件主要用于描述各个队列的属性,比如资源量、权重等</description>
</property>
<property>
<name>yarn.scheduler.fair.user-as-default-queue</name>
<value>true</value>
<description>当应用程序未指定队列名时,是否指定用户名作为应用程序所在的队列名。如果设置为false或者未设置,所有未知队列的应用程序将被提交到default队列中,默认值为true</description>
</property>
<property>
<name>yarn.scheduler.fair.preemption</name>
<value>true</value>
<description>是否支持抢占</description>
</property>
<property>
<name>yarn.scheduler.fair.sizebasedweight</name>
<value>false</value>
<description>在一个队列内部分配资源时,默认情况下,采用公平轮询的方法将资源分配各各个应用程序,而该参数则提供了外一种资源分配方式:按照应用程序资源需求数目分配资源,即需求资源数量越多,分配的资源越多。默认情况下,该参数值为false</description>
</property>
<property>
<name>yarn.scheduler.increment-allocation-mb</name>
<value>256</value>
<description>内存规整化单位,默认是1024,这意味着,如果一个Container请求资源是700mB,则将被调度器规整化为 (700mB / 256mb) * 256mb=768mb</description>
</property>
<property>
<name>yarn.scheduler.assignmultiple</name>
<value>true</value>
<description>是否启动批量分配功能。当一个节点出现大量资源时,可以一次分配完成,也可以多次分配完成。默认情况下,参数值为false</description>
</property>
<property>
<name>yarn.scheduler.fair.max.assign</name>
<value>10</value>
<description>如果开启批量分配功能,可指定一次分配的container数目。默认情况下,该参数值为-1,表示不限制</description>
</property>
<property>
<name>yarn.scheduler.fair.allow-undeclared-pools</name>
<value>false</value>
<description>如果提交的队列名不存在,Scheduler会自动创建一个该队列,默认开启</description>
</property>
<!-- scheduler end -->增加fair-scheduler.xml
<?xml version="1.0"?>
<allocations>
<queue name="hainiu">
<minResources>512 mb,1 vcores</minResources>
<maxResources>6140 mb,3 vcores</maxResources>
<maxRunningApps>50</maxRunningApps>
<weight>2.0</weight>
<schedulingPolicy>fair</schedulingPolicy>
<!--可向队列中提交应用程序的用户或用户组列表,默认情况下为“*”,表示任何用户均可以向该队列提交应用程序。-->
<aclSubmitApps>hainiu</aclSubmitApps>
<!--一个队列的管理员可管理该队列中的资源和应用程序,比如可杀死任意应用程序-->
<aclAdministerApps>hainiu</aclAdministerApps>
</queue>
<queue name="default">
<weight>1.0</weight>
<aclSubmitApps>*</aclSubmitApps>
<aclAdministerApps>*</aclAdministerApps>
</queue>
<!-- user节点只有一个子节点 -->
<user name="root">
<aclSubmitApps>*</aclSubmitApps>
<aclAdministerApps>*</aclAdministerApps>
<maxRunningApps>10</maxRunningApps>
</user>
<!-- 用户的maxRunningJobs属性的默认值 -->
<userMaxAppsDefault>50</userMaxAppsDefault>
<!-- 队列的schedulingMode属性的默认值 默认是fair-->
<defaultQueueSchedulingPolicy>fair</defaultQueueSchedulingPolicy>
<!-- 如果一个队列在该段时间内使用的资源量低于fair共享资源量,则开始抢占其他队列的资源。-->
<fairSharePreemptionTimeout>60</fairSharePreemptionTimeout>
<!-- 如果一个队列在该段时间内使用的资源量低于最小共享资源量,则开始抢占其他队列的资源。 -->
<defaultMinSharePreemptionTimeout>60</defaultMinSharePreemptionTimeout>
<queuePlacementPolicy>
<rule name="specified" create="false" />
<rule name="user" create="false" />
<rule name="reject" />
</queuePlacementPolicy>
</allocations>
分发文件重启yarn
#关闭yarn
stop-yarn.sh
#分发文件
scp_all.sh /usr/local/hadoop/etc/hadoop/fair-scheduler.xml /usr/local/hadoop/etc/hadoop/
scp_all.sh /usr/local/hadoop/etc/hadoop/yarn-site.xml /usr/local/hadoop/etc/hadoop/
#重启yarn
start-yarn.sh打开监控页面查看

点击调度器可以查看队列信息

点开每个队列可以查看队列信息
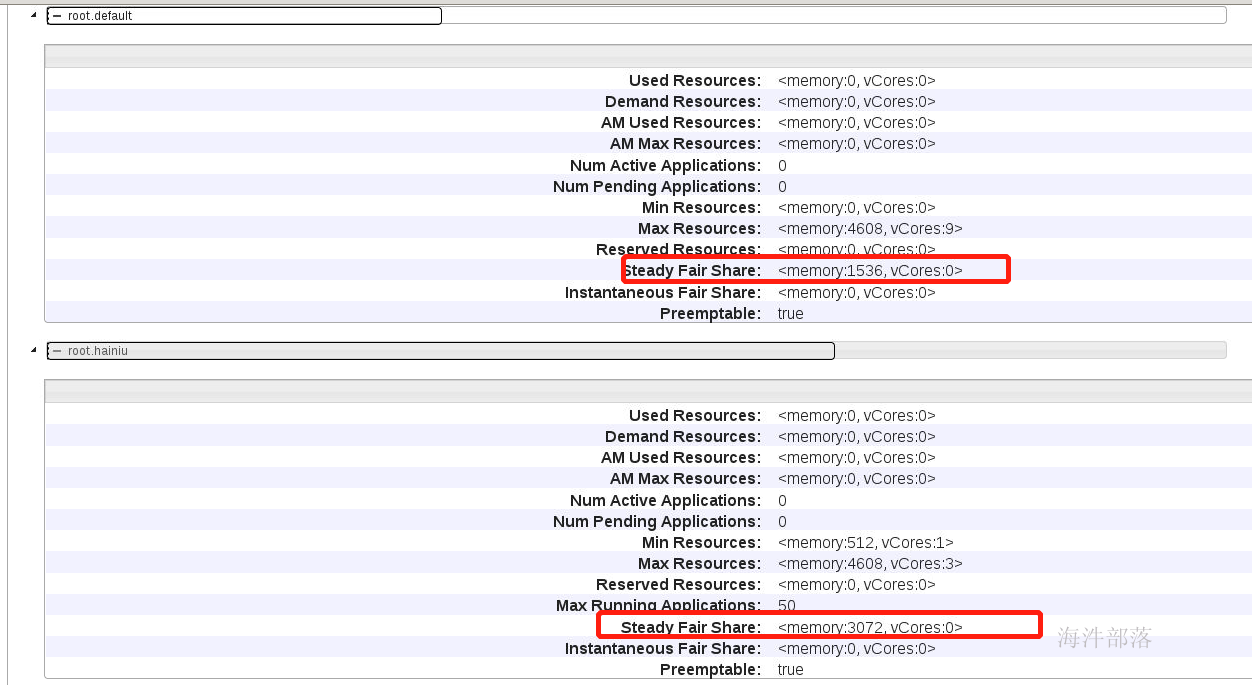
队列的权重比是2:1
#提交任务测试
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar wordcount /wordcount.txt /res11
必须指定队列才可以,因为我们的策略是reject

增加命令提交
#提交任务测试
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.4.jar wordcount -Dmapreduce.job.queuename=root.hainiu /wordcount.txt /res11
10.yarn的任务提交流程
通过以上的讲解我们知道了,yarn的资源的调度原理,但是这只是一个简单的任务调度过程,我们提出两个问题
问题1:任务的资源分配流程是什么呢?
问题2:不同的任务在yarn上面执行的时候是怎么进行资源隔离的呢?
带着上面的两个问题我们引出yarn中的组件
10.1 yarn的组件
ResourceManager(RM)
RM是一个全局的资源管理器,负责整个系统的资源管理和分配。它主要由两个组件构成:调度器(Scheduler)和应用程序管理器(Applications Manager,ASM),通俗讲是用于管理NodeManager节点的资源,包括cup、内存等。
Scheduler(调度器)
调度器根据容量、队列等限制条件(如每个队列分配一定的资源,最多执行一定数量的作业等),将系统中的资源分配给各个正在运行的应用程序;在资源紧张的情况下,可以kill掉优先级低的,来运行优先级高的任务。
Applications Manager(应用程序管理器)
负责管理整个系统中所有应用程序,包括应用程序提交、与调度器协商资源以启动ApplicationMaster、监控ApplicationMaster运行状态并在失败时重新启动它等。
ApplicationMaster(AM)
ApplicationMaster 管理在YARN内运行的每个应用程序实例。每个应用程序对应一个ApplicationMaster。ApplicationMaster 负责协调来自 ResourceManager 的资源,并通过 NodeManager 监视容器的执行和资源使用(CPU、内存等的资源分配),通俗讲是管理发起的任务,随着任务创建而创建,任务的完成而结束。NodeManager(NM)
NM是每个节点上的资源和任务管理器,一方面,它会定时地向RM汇报本节点上的资源使用情况和各个Container的运行状态;另一方面,它接收并处理来自AM的Container启动/停止等各种请求。
Container
Container是YARN中的资源抽象,它封装了某个节点上的多维度资源,如内存、CPU、磁盘、网络等,当AM向RM申请资源时,RM为AM返回的资源便是用Container表示的。YARN会为每个任务分配一个Container,且该任务只能使用该Container中描述的资源。
举个栗子
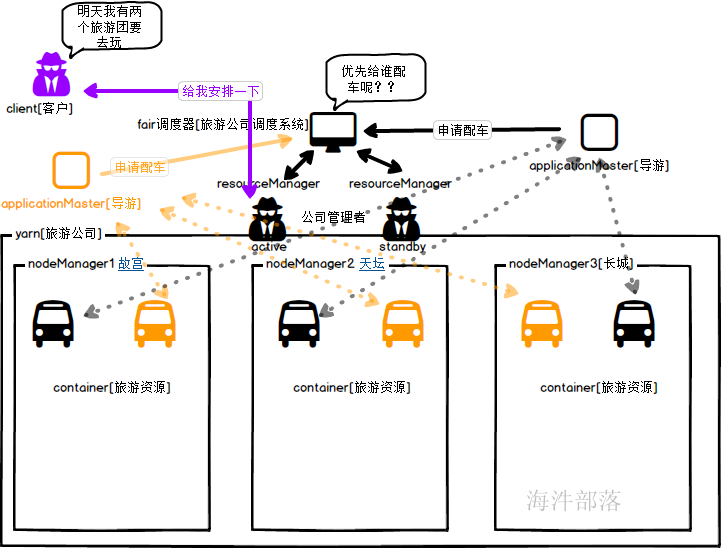
resoucerManager像是一个旅游公司的领导,可以管理故宫,天坛,长城三个旅游景点的资源
nodeManager是手下的员工分别管理自己的节点的资源
client提交任务的客户端,像是一个要联系旅游的客户
scheduler调度器,像是公司的调度系统,优先安排哪个旅游团玩呢
applicationMaster应用的管理者,像是给每个旅游团配置的导游,每个旅游团都是单独的导游
container就是资源的封装容器,像是公司的旅行车
10.2yarn资源分配流程
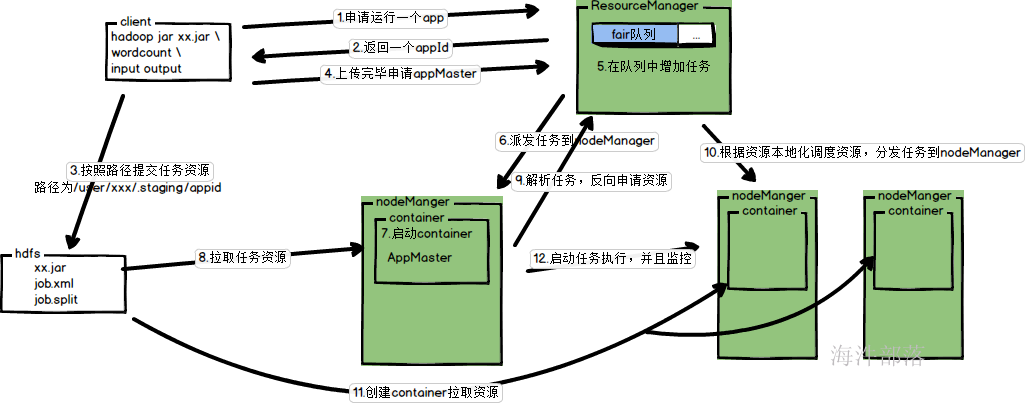
1.client提交任务,申请运行一个任务
2.RM返回一个appid
3.client开始组合上传路径,上传资源
4.上传完毕通知RM
5.RM将任务放入到任务队列
6.RM分发任务到nodeManager中
7.nodeManager启动container
8.拉取任务资源,启动AM
9.AM启动完毕和RM注册,并且解析代码,申请资源
10.RM根据AM的计算结果,尽量以数据本地化的方式分发资源
11.nodeManager启动container,并且拉取资源
12.appMaster启动container中的任务执行
13.执行完毕任务回收资源
执行任务查看资源分配情况
<!--在yarn-site.xml中配置,执行的任务文件应该上传到/user的用户目录下 -->
<property>
<name>yarn.app.mapreduce.am.staging-dir</name>
<value>/user</value>
</property>
<property>
<name>yarn.app.mapreduce.am.scheduler.connection.wait.interval-ms</name>
<value>5000</value>
</property>

提交任务

任务的资源上传
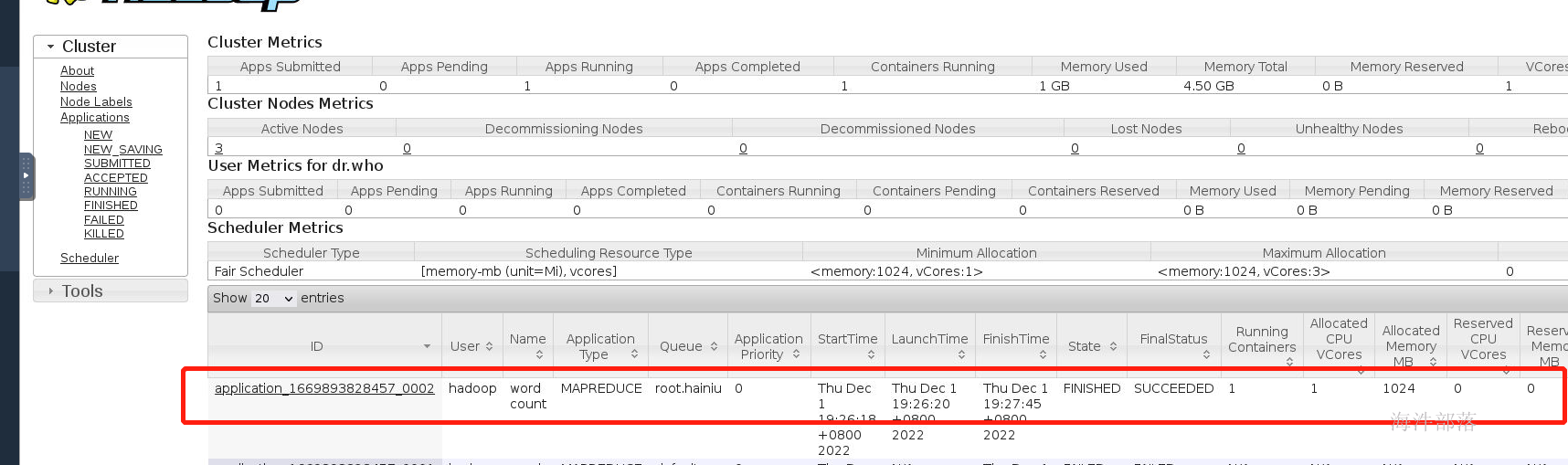
任务执行的appMaster的任务运行进程

yarnchild就是任务执行的container的进程

11.日志聚合和历史服务器
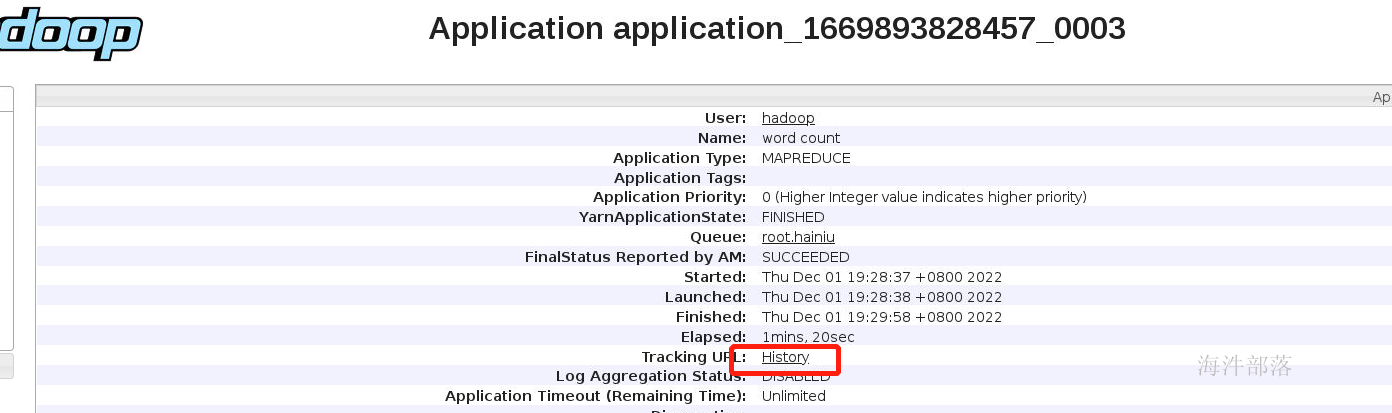
在运行完毕程序以后我们可以看到进程中出现了History按钮,可以查看运行历史日志,但是无法点击
这个时候我们需要配置历史服务器
mapred-site.xml中配置信息
<property>
<name>mapreduce.jobhistory.address</name>
<value>nn1:10020</value>
<description>MapReduce JobHistory Server地址</description>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>nn1:19888</value>
<description>MapReduce JobHistory Server Web UI地址</description>
</property>
<property>
<name>mapreduce.jobhistory.intermediate-done-dir</name>
<value>/data/mapred/tmp</value>
<description>MapReduce作业产生的日志存放位置</description>
</property>
<property>
<name>mapreduce.jobhistory.done-dir</name>
<value>/data/mapred/done</value>
<description>MR JobHistory Server管理的日志的存放位置</description>
</property>
<property>
<name>mapreduce.job.userlog.retain.hours</name>
<value>48</value>
</property>虽然配置了历史服务器,但是还不能看到日志,因为运行的日志需要聚合操作
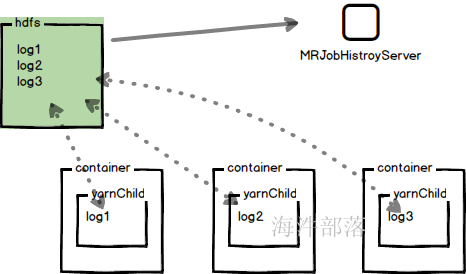
我们需要将各个服务器的日志聚合到hdfs中,然后开启日志服务器才能看到日志信息
yarn-site.xml中配置如下参数进行日志聚合
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
<description>是否启用日志聚集功能</description>
</property>
<property>
<name>yarn.nodemanager.remote-app-log-dir</name>
<value>/tmp/app-logs</value>
<description>当应用程序运行结束后,日志被转移到的HDFS目录(启用日志聚集功能时有效)</description>
</property>
<!--目录相关 end -->
<!-- 其它 -->
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>1209600</value>
<description>nodemanager上所有Container的运行日志在HDFS中的保存时间,保留半个月</description>
</property>#分发配置文件到所有机器中
scp_all.sh /usr/local/hadoop/etc/hadoop/yarn-site.xml /usr/local/hadoop/etc/hadoop/
scp_all.sh /usr/local/hadoop/etc/hadoop/mapred-site.xml /usr/local/hadoop/etc/hadoop/
#重启yarn
stop-yarn.sh
start-yarn.sh
#启动日志服务器
mapred --daemon start historyserver
这样我们就可以看到聚合以后的日志了
12.web proxy代理服务器
现在我们可以在程序运行的时候通过applicationMaster按钮进入到程序运行页面,直接访问applicatMaster的监控,也可以放入jobHistory历史服务器,但是这样的访问是不安全的,我们需要开启web proxy
web proxy
Web应用程序代理是YARN的一部分。默认情况下,它将作为资源管理器(RM)的一部分运行,但可以配置为在独立模式下运行。代理的原因是通过YARN降低基于Web的攻击的可能性。
在YARN中,Application Master(AM)有责任提供Web UI并将该链接发送给RM。这开辟了许多潜在的问题。RM作为受信任的用户运行,访问该网址的人会对其进行处理,并将其提供的链接视为受信任的,而实际上AM作为不受信任的用户运行,并且它为RM提供的链接可以指向恶意或其他任何东西。Web应用程序代理通过警告不属于给定应用程序的用户连接到不受信任的站点来降低此风险。
除此之外,代理还尝试减少恶意AM可能对用户造成的影响。它主要通过从用户剥离cookie,并用提供登录用户的用户名的单个cookie替换它们来实现。这是因为大多数基于Web的身份验证系统将基于cookie识别用户。通过将此cookie提供给不受信任的应用程序,它可以开启漏洞利用的可能性。如果cookie设计得恰当,那么潜力应该相当小,但这只是为了减少潜在的攻击向量。
yarn-site.xml中配置如下参数
<property>
<name>yarn.web-proxy.address</name>
<value>nn1:8041</value>
</property>#分发文件
scp_all.sh /usr/local/hadoop/etc/hadoop/yarn-site.xml /usr/local/hadoop/etc/hadoop/
#重启yarn
stop-yarn.sh
start-yarn.sh注意:hadoop3.x中的webproxy是自带的不需要配置
13.yarn常用命令
#集群列表查看
yarn node -list -all
#队列情况
yarn queue -status <queue>
#列出所有Application
yarn application -list
#参数过滤 -appStates [ALL、NEW、NEW_SAVING、SUBMITTED、ACCEPTED、RUNNING、FINISHED、FAILED、KILLED]
#杀死进程
yarn application -kill
#查看日志
yarn logs -applicationId
#查看container列表
yarn container -list <ApplicationAttemptId>
