sink部分
1.查询限制
-
流数据集尚不支持多个流聚合(即流DF上的聚合链)。
-
流式数据集不支持限制和获取前N行。
-
不支持流数据集上的distinct操作。
-
只有在complete输出模式下才支持排序操作。
-
count()-无法从流数据集中返回单个计数。请使用ds.groupBy.count,它返回包含运行计数的流数据集。
-
foreach()-改用ds.writeStream.foreach(…)
- show()- 不能直接使用需要使用 format("console")
如果使用则会报出 operation XYZ is not supported with streaming DataFrames/Datasets异常
2.全局水印限制
在追加模式下,如果有状态操作发出的行早于当前水印加上允许的延迟记录,则在下游有状态操作中,它们将是“延迟行”(因为Spark使用全局水印)。请注意,这些行可能会被丢弃。这是全局水印的一个限制,可能会导致正确性问题。
Spark将检查查询的逻辑计划,并在Spark检测到这种模式时记录警告。
以下任何状态操作之后的任何状态操作都可能出现此问题:
-
附加模式下的流聚合
-
流流外部连接
-
追加模式下的mapGroupsWithState和flatMapGroupsWithStates(取决于状态函数的实现)
- 由于Spark无法检查mapGroupsWithState/flatMapGroupsWithState的状态函数,因此如果运算符使用追加模式,Spark假设状态函数会发出延迟行。
Spark提供了两种方法来检查有状态运算符上的延迟行数:
-
在Spark UI上:在SQL选项卡的查询执行详细信息页面中检查有状态运算符节点中的度量
- 在流式查询侦听器上:选中QueryProcessEvent中“stateOperators”中的“numRowsDroppedByWatermark”。
sql页面

structured streaming页面

3.输出
一旦定义了最终结果DataFrame/Dataset,剩下的就是开始流计算。为此必须使用通过Dataset.writeStream()返回的DataStreamWriter进行数据输出,其中下面几个关于输出的设置比较重要
-
输出接收器的详细信息:数据格式、位置等。
-
输出模式:指定写入输出接收器的内容。
-
查询名称:可以选择指定查询的唯一名称以进行标识。
-
触发间隔:可以选择指定触发间隔。如果未指定,系统将在上一处理完成后立即检查新数据的可用性。如果由于先前的处理尚未完成而错过了触发时间,则系统将立即触发处理。
- 检查点位置:对于可以保证端到端容错的某些输出接收器,请指定系统将写入所有检查点信息的位置。这应该是HDFS文件系统中的一个目录
3.1 输出模式
-
append模式(默认)-这是默认模式,其中只有自上次触发以来添加到结果表的新行将被输出到接收器。只有那些添加到结果表中的行永远不会更改的查询才支持这一点。因此,这种模式保证每一行只输出一次(假设容错接收器)。例如,只有select、where、map、flatMap、filter、join等的查询将支持追加模式。
-
complete 模式-每次触发后,整个结果表都将输出到接收器。聚合查询支持此功能。
- update 模式-(从Spark 2.1.1开始可用)只有结果表中自上次触发后更新的行将被输出到接收器
每种操作支持的模式如下:
| Query Type | Supported Output Modes | Notes | |
|---|---|---|---|
| Queries with aggregation | Aggregation on event-time with watermark | Append, Update, Complete | Append mode uses watermark to drop old aggregation state. But the output of a windowed aggregation is delayed the late threshold specified in withWatermark() as by the modes semantics, rows can be added to the Result Table only once after they are finalized (i.e. after watermark is crossed). See the Late Data section for more details. Update mode uses watermark to drop old aggregation state. Complete mode does not drop old aggregation state since by definition this mode preserves all data in the Result Table. |
| Other aggregations | Complete, Update | Since no watermark is defined (only defined in other category), old aggregation state is not dropped. Append mode is not supported as aggregates can update thus violating the semantics of this mode. | |
Queries with mapGroupsWithState |
Update | Aggregations not allowed in a query with mapGroupsWithState. |
|
Queries with flatMapGroupsWithState |
Append operation mode | Append | Aggregations are allowed after flatMapGroupsWithState. |
| Update operation mode | Update | Aggregations not allowed in a query with flatMapGroupsWithState. |
|
Queries with joins |
Append | Update and Complete mode not supported yet. See the support matrix in the Join Operations section for more details on what types of joins are supported. | |
| Other queries | Append, Update | Complete mode not supported as it is infeasible to keep all unaggregated data in the Result Table. |
3.2 输出位置
首先创建源文件
# 创建 data/user文件夹,创建user.txt
1,zhangsan,20,male
2,lisi,30,female
3,zhaosi,25,male
4,wangwu,32,female3.2.1文件
整体代码如下:
文本输出不能够是多列数据,必须是一列才可以
package com.hainiu.structure
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
object TestSink1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("testjoin")
conf.setMaster("local[*]")
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
val df = spark.readStream.text("data/user")
.as[String]
.map(t => {
val strs = t.split(",")
(strs(0), strs(1), strs(2), strs(3))
}).toDF("id", "name", "age", "gender")
.withColumn("all",concat_ws(" ",$"id",$"name",$"age",$"gender"))
.selectExpr("all")
df.writeStream.format("text")
.outputMode("append")
.option("truncate",false)
.option("path","data/sink/text")
.option("checkpointLocation", "data/ckpt")
.start()
.awaitTermination()
}
}分别修改输出文件的方式
package com.hainiu.structure
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.Trigger
object TestSink1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("testjoin")
conf.setMaster("local[*]")
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
val df = spark.readStream.text("data/user")
.as[String]
.map(t => {
val strs = t.split(",")
(strs(0), strs(1), strs(2), strs(3))
}).toDF("id", "name", "age", "gender")
df.writeStream.format("json")
.outputMode("append")
.option("truncate",false)
.option("path","data/sink/json")
.option("checkpointLocation", "data/ckpt/json")
.trigger(Trigger.ProcessingTime(0))
.start()
.awaitTermination()
}
} df.writeStream.format("orc")
.outputMode("append")
.option("truncate",false)
.option("path","data/sink/orc")
.option("checkpointLocation", "data/ckpt/orc")
.trigger(Trigger.ProcessingTime(0))
.start()
.awaitTermination() df.writeStream.format("parquet")
.outputMode("append")
.option("truncate",false)
.option("path","data/sink/parquet")
.option("checkpointLocation", "data/ckpt/parquet")
.trigger(Trigger.ProcessingTime(0))
.start()
.awaitTermination() df.writeStream.format("csv")
.outputMode("append")
.option("truncate",false)
.option("path","data/sink/csv")
.option("checkpointLocation", "data/ckpt/csv")
.trigger(Trigger.ProcessingTime(0))
.start()
.awaitTermination()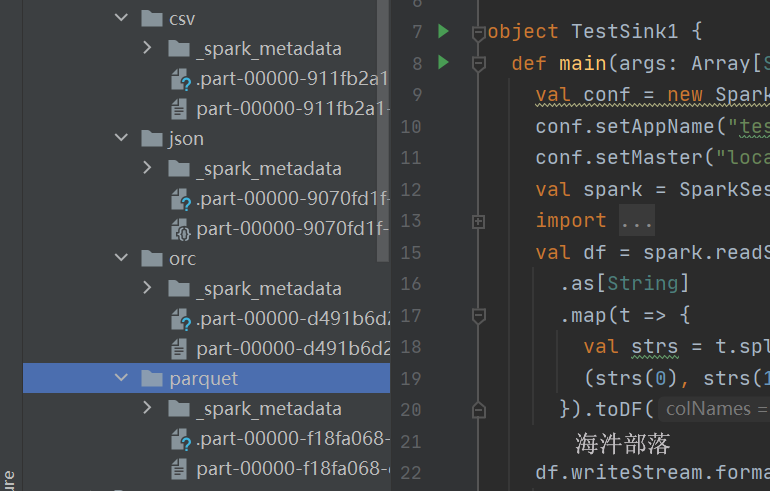
输出结果如上图,其中需要设定ckpt路径,并且路径不同
文件输出不支持 complete和update操作,只支持append操作
3.2.2 kafka
kafka sink中需要指定value列才可以
首先准备kafka的环境
启动完毕开始创建topic
kafka-topics.sh --bootstrap-server kafka1-46793:9092 --create --topic topic_hainiu --partitions 3 --replication-factor 2整体代码如下:
package com.hainiu.spark
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.functions.concat_ws
object TestKafkaSink {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("kafka").getOrCreate()
import session.implicits._
session.readStream.format("socket")
.option("host","nn1")
.option("port",6666)
.load().as[String]
.map(t=>{
val strs = t.split(" ")
(strs(0),strs(1),strs(2))
}).toDF("id","name","age")
//kafka --> key value
.withColumn("value",concat_ws(" ",$"id",$"name",$"age"))
.select("value")
.selectExpr("cast(value as string)")
.writeStream
.format("kafka")
.outputMode("update")
.option("kafka.bootstrap.servers","kafka1-46793:9092")
.option("topic","topic_hainiu")
.option("checkpointLocation","data/ckpt/kafka1")
.start()
.awaitTermination()
}
}#消费kafka的数据
kafka-console-consumer.sh --bootstrap-server kafka1-46793:9092 --topic topic_hainiu
# 在socket中输入数据查看kafka的信息
分别设置输出模式 update和complete
df.writeStream
.outputMode("update")
.format("kafka")
.trigger(Trigger.ProcessingTime(0))
.option("kafka.bootstrap.servers", "s1.hadoop:9092") // kafka 配置
.option("topic", "topic_42") // kafka 主题
.option("checkpointLocation", "data/ckpt/kafka") // 必须指定 checkpoint 目录
.start()
.awaitTermination()complete肯定不好用,聚合才可以使用
记住每次必须设置删除断点

其中追加和更新操作都可以使用
聚合操作
使用append模式进行聚合的时候需要加上watermark,为了演示方便我们选择update和complete模式
整体代码如下:
package com.hainiu.structure
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FileSystem, Path}
import org.apache.spark.SparkConf
import org.apache.spark.sql.SparkSession
import org.apache.spark.sql.streaming.Trigger
object TestSink1 {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("testjoin")
conf.setMaster("local[*]")
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
val df = spark.readStream
.format("socket")
.option("host","op.hadoop")
.option("port",6666)
.load()
.as[String]
.map(t => {
val strs = t.split(",")
(strs(0), strs(1), strs(2), strs(3))
}).toDF("id", "name", "age", "gender")
.groupBy("gender").count()
.withColumn("value",concat_ws(" ",$"gender",$"count"))
.selectExpr("cast(value as string)")
val fs = FileSystem.get(new Configuration())
fs.listStatus(new Path("data/ckpt")).foreach(path=>{
fs.delete(path.getPath)
})
df.writeStream
.outputMode("update")
.format("kafka")
.trigger(Trigger.ProcessingTime(0))
.option("kafka.bootstrap.servers", "s1.hadoop:9092") // kafka 配置
.option("topic", "topic_42") // kafka 主题
.option("checkpointLocation", "data/ckpt/kafka") // 必须指定 checkpoint 目录
.start()
.awaitTermination()
}
}分别设计模式为update和complete展示结果如下

只展示变化的数据

全量展示
3.2.3 foreach
这个输出比较灵活可以指定任意输出数据位置
在foreach方法中能够获取到每个数据,然后进行数据的处理,所以这个时候我们可以定义任何的位置进行数据的存储,简单的存储到文件中,或者选择其他存储方式,比如存储到redis或者mysql中
引入依赖
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.4</version>
</dependency>基于hdfs存储数据所以启动hdfs
# 登录nn1机器
ssh_all_zk.sh /usr/local/zookeeper/bin/zkServer.sh start
start-dfs.sh
# 启动hdfs存储到hdfs中
# 首先准备配置文件
# 下载hdfs的配置文件core-site.xml 和 hdfs-site.xml
# 放入到src/main/resources中
# 因为只有hdfs是支持追加的
# 可以远程发送文件到项目中
# 去远程桌面中找到ip和项目地址
ip addr
# 选择ip
11.99.173.36
# 然后发送文件到项目中 在nn1中
scp /usr/local/hadoop/etc/hadoop/core-site.xml root@11.99.173.36:/headless/workspace/structure_streaming/src/main/resources/
scp /usr/local/hadoop/etc/hadoop/hdfs-site.xml root@11.99.173.36:/headless/workspace/structure_streaming/src/main/resources/
需求:存储socket中的数据到hdfs中,并且按照小时进行存储数据
整体代码如下:
package com.hainiu.spark
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FSDataOutputStream, FileSystem, Path}
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.{ForeachWriter, Row, SparkSession}
import java.io.PrintWriter
import java.text.SimpleDateFormat
import java.util.Date
object TestSink2Hdfs {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().appName("hdfs sink").master("local[*]").getOrCreate()
val df = session.readStream.format("socket")
.option("host", "nn1")
.option("port", 6666)
.load()
df.repartition(2).writeStream.foreach(new ForeachWriter[Row] {
//修改分区
var fs:FileSystem = null
var stream: FSDataOutputStream = null
var pw:PrintWriter = null
override def open(partitionId: Long, epochId: Long): Boolean = {
//打开
fs = FileSystem.get(new Configuration())
val dff = new SimpleDateFormat("yyyy/MM/dd/HH")
val date_str = dff.format(new Date)
val all_path = "/structed_sink/"+date_str+"/"+partitionId+".txt"
val path = new Path(all_path)
if(fs.exists(path)){
stream = fs.append(path)
}else{
stream = fs.create(path)
}
pw = new PrintWriter(stream, true)
true
}
override def process(value: Row): Unit = {
//处理数据
val line = value.getAs[String]("value")
pw.println(line)
}
override def close(errorOrNull: Throwable): Unit = {
//关闭
pw.close()
stream.close()
fs.close()
}
})
.option("checkpointLocation","/tmp/ckpt1234")
.trigger(Trigger.ProcessingTime("5 seconds"))
.start()
.awaitTermination()
}
}
.trigger(Trigger.ProcessingTime("5 seconds"))
一定要设定触发时间,因为太频繁的链接hdfs会出现错误和异常
.option("checkpointLocation", "/tmp/ckpt1")
设定断点位置,不然会一直找本地路径
3.2.4 foreachBatch
代码如下:
package com.hainiu.structure
import org.apache.spark.SparkConf
import org.apache.spark.sql.streaming.{StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
object TestForeach {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("testjoin")
conf.setMaster("local[*]")
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
val df = spark.readStream
.format("socket")
.option("host","op.hadoop")
.option("port",6666)
.load()
.as[String]
.map(t => {
val strs = t.split(",")
(strs(0), strs(1), strs(2), strs(3))
}).toDF("id", "name", "age", "gender")
df.withColumn("all",concat_ws(" ",$"id",$"name",$"age",$"gender"))
.select("all")
.repartition(2)
.writeStream
.option("checkpointLocation", "/tmp/ckpt1")
.foreachBatch((df:DataFrame,batchid:Long)=>{
//batchid是批次id
//使用df的api直接进行存储
println(batchid)
df.write.text(s"/tmp/res/res_${batchid}")
}).trigger(Trigger.ProcessingTime("5 seconds"))
.start()
.awaitTermination()
}
}
df.write.text(s"/tmp/res/res_${batchid}")修改批次id作为路径使用
.foreachBatch((df:DataFrame,batchid:Long)=>一定要设定函数的类型,不然会出现类型冲突
3.2.5 存储数据到mysql中
首先引入依赖关系
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.49</version>
</dependency>在mysql中创建表
create table hainiudb.word_count(word varchar(50),count int,primary key(word));foreachBatch 代码如下:
package com.hainiu.structure
import java.util.Properties
import org.apache.spark.SparkConf
import org.apache.spark.sql.streaming.{StreamingQuery, Trigger}
import org.apache.spark.sql.{DataFrame, Dataset, SaveMode, SparkSession}
object TestForeach {
def main(args: Array[String]): Unit = {
val conf = new SparkConf()
conf.setAppName("testjoin")
conf.setMaster("local[*]")
val spark = SparkSession.builder().config(conf).getOrCreate()
import spark.implicits._
import org.apache.spark.sql.functions._
val df = spark.readStream
.format("socket")
.option("host","op.hadoop")
.option("port",6666)
.load()
.as[String]
.toDF("word")
.groupBy("word")
.count()
.writeStream
.option("checkpointLocation", "/tmp/ckpt2")
.outputMode("complete")
.foreachBatch((df:DataFrame,batchid:Long)=>{
val pro = new Properties()
pro.put("user","root")
pro.put("password","123456")
df.write.mode(SaveMode.Overwrite).jdbc("jdbc:mysql://localhost:3306/hainiudb","word_count",pro)
}).trigger(Trigger.ProcessingTime("5 seconds"))
.start()
.awaitTermination()
}
}
记得删除断点数据
df.write.mode(SaveMode.Overwrite)插入模式为覆盖
# 启动nc 输入如下数据
hello world
hello world
hello world
hello world
hello world
hello world查看输出数据结果

使用foreach方式
整体代码如下:
package com.hainiu.spark
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.fs.{FSDataOutputStream, FileSystem, Path}
import org.apache.spark.sql.streaming.Trigger
import org.apache.spark.sql.{DataFrame, ForeachWriter, Row, SaveMode, SparkSession}
import java.io.PrintWriter
import java.sql.{Connection, DriverManager, PreparedStatement}
import java.text.SimpleDateFormat
import java.util.{Date, Properties}
object TestSink2Hdfs {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().appName("hdfs sink").master("local[*]").getOrCreate()
import session.implicits._
val df = session.readStream.format("socket")
.option("host", "nn1")
.option("port", 6666)
.load().as[String]
.flatMap(t=>{
val strs = t.split(" ")
strs
}).toDF("word")
.groupBy("word")
.count()
df.writeStream.foreach(new ForeachWriter[Row] {
var con:Connection =null
var prp:PreparedStatement = null
override def open(partitionId: Long, epochId: Long): Boolean = {
con = DriverManager.getConnection("jdbc:mysql://11.138.24.87:3306/hainiu", "root", "hainiu")
prp = con.prepareStatement("replace into wordcount(word,count) values(?,?)")
con != null
}
override def process(value: Row): Unit = {
val word = value.getAs[String]("word")
val count = value.getAs[Long]("count")
prp.setString(1,word)
prp.setLong(2,count)
prp.execute()
prp.clearParameters()
}
override def close(errorOrNull: Throwable): Unit = {
prp.close()
con.close()
}
})
.option("checkpointLocation","/tmp/ckpt_mysql1")
.outputMode("complete")
.trigger(Trigger.ProcessingTime("5 seconds"))
.start()
.awaitTermination()
}
}
prp = connection.prepareStatement("replace into word_count(word,count) values
主键重复则替换内容
输入数据后结果如下

3.2.6 console
代码设计
df.writeStream
.outputMode("append")
.format("console")
.start()
.awaitTermination()上面案例中一致使用console输出,请看上面的操作
3.2.7 memory
内存表主要是将数据放入到内存中一张虚拟表,可以保存数据多次查询
# 启动nc 6666端口
1,销售部,北京
2,公关部,东莞
# 启动nc 7777端口
1,zhangsan,20,1
2,lisi,30,2将第一个流中的数据进行存储到内存表中,形成动态内存表,使用流与其join
整体代码如下:
package com.hainiu.spark
import org.apache.spark.sql.SparkSession
object TestMemorySink {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("memory sink").getOrCreate()
import session.implicits._
val df1 = session.readStream.format("socket")
.option("host", "nn1")
.option("port", 6666)
.load().as[String]
.map(t=>{
val strs = t.split(",")
(strs(0),strs(1),strs(2))
}).toDF("deptno","dname","location")
df1.writeStream.format("memory")
.outputMode("append")
.queryName("dept")
.option("checkpointLocation","/tmp/ckpt222")
.start()
val df2 = session.readStream.format("socket")
.option("host", "nn1")
.option("port", 7777)
.load().as[String]
.map(t => {
val strs = t.split(",")
(strs(0), strs(1), strs(2),strs(3))
}).toDF("id", "name", "age","deptno")
.createTempView("emp")
session.sql(
"""
|select * from emp a join dept b on a.deptno = b.deptno
|""".stripMargin)
.writeStream.format("console")
.option("checkpointLocation","/tmp/ckpt333")
.outputMode("append")
.start()
.awaitTermination()
}
}输入数据后结果如下:


4.状态编程函数
mapGroupsWithState
以wordcount为案例,在内存中存储单词的数量,然后每个批次进行累加
package com.hainiu.spark
import org.apache.spark.sql.streaming.GroupState
import org.apache.spark.sql.{Row, SparkSession}
object TestMapGroupsWithState {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("memory sink").getOrCreate()
import session.implicits._
val df1 = session.readStream.format("socket")
.option("host", "nn1")
.option("port", 6666)
.load().as[String]
.flatMap(_.split(" "))
.toDF("word")
.groupByKey(t=>{
t.getAs[String]("word")
}).mapGroupsWithState((k:String,values:Iterator[Row],state:GroupState[Int])=>{
val current = values.size
val last = state.getOption.getOrElse(0)
val total = current+last
state.update(total)
(k,total)
}).writeStream
.format("console")
.outputMode("update")
.option("checkpointLocation","/tmp/ckpt_group3")
.start()
.awaitTermination()
}
}
输入数据
hello world
hello world
hello world
hello world
hello world
hello world
hello world
hello world
hello world结果数据如下:

flatMapGroupsWithState
整体代码:
package com.hainiu.spark
import org.apache.spark.sql.streaming.{GroupState, GroupStateTimeout, OutputMode}
import org.apache.spark.sql.{Row, SparkSession}
object TestMapGroupsWithState {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().master("local[*]").appName("memory sink").getOrCreate()
import session.implicits._
val df1 = session.readStream.format("socket")
.option("host", "nn1")
.option("port", 6666)
.load().as[String]
.flatMap(_.split(" "))
.toDF("word")
.groupByKey(t=>{
t.getAs[String]("word")
})
.flatMapGroupsWithState(OutputMode.Update(),GroupStateTimeout.NoTimeout())(
(k:String,values:Iterator[Row],state:GroupState[Int])=>{
val current = values.size
val last = state.getOption.getOrElse(0)
val total = current+last
state.update(total)
Iterator((k,total))
}
)
.writeStream
.format("console")
.outputMode("update")
.option("checkpointLocation","/tmp/ckpt_group4")
.start()
.awaitTermination()
}
}
结果如下:

5.失败恢复
如果发生故障或故意关闭,可以恢复上一个查询的先前进度和状态,并在其停止时继续。这是使用检查点和预写日志完成的。我们可以使用检查点位置配置查询,查询将保存所有进度信息(即每个触发器中处理的偏移范围)和正在运行的聚合(例如,快速示例中的单词计数)到检查点位置。此检查点位置必须是HDFS兼容文件系统中的路径,并且可以设置为
aggDF
.writeStream
.outputMode("complete")
.option("checkpointLocation", "path/to/HDFS/dir")
.format("memory")
.start()代码失败重启的时候要注意不能大量修改代码的逻辑
请参照官网进行设置
6.触发器
Continuous processing是Spark 2.3中引入的一种新的实验性流式执行模式,可实现低(~1毫秒)端到端延迟,并至少保证一次容错。将其与默认的微批处理引擎进行比较,该引擎可以实现精确的一次保证,但延迟最多可达100毫秒。对于某些类型的查询(如下所述),我们可以选择在不修改应用程序逻辑(即不更改DataFrame/Dataset操作)的情况下执行它们的模式。
要在连续处理模式下运行受支持的查询,只需指定一个连续触发器,并将所需的检查点间隔作为参数。例如
import org.apache.spark.sql.streaming.Trigger
spark
.readStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("subscribe", "topic1")
.load()
.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)")
.writeStream
.format("kafka")
.option("kafka.bootstrap.servers", "host1:port1,host2:port2")
.option("topic", "topic1")
.trigger(Trigger.Continuous("1 second")) // only change in query
.start()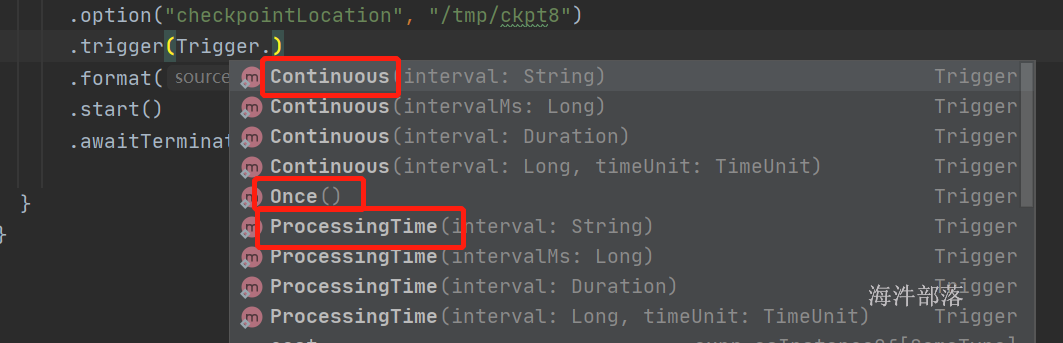
通过源码我们可以知道查询的间隔可以任意指定
- 没有显示的设定触发器, 表示使用 micro-batch mode, 尽可能快的处理每个批次的数据. 如果无数据可用, 则处于阻塞状态, 等待数据流入
- ProcessingTime查询会在微批处理模式下执行, 其中微批处理将以用户指定的间隔执行. 1. 如果以前的微批处理在间隔内完成, 则引擎会等待间隔结束, 然后开启下一个微批次 2. 如果前一个微批处理在一个间隔内没有完成(即错过了间隔边界), 则下个微批处理会在上一个完成之后立即启动(不会等待下一个间隔边界) 3. 如果没有新数据可用, 则不会启动微批次. 适用于流式数据的批处理作业
-
Once 查询将在所有可用数据上执行一次微批次处理, 然后自行停止. 如果你希望定期启动集群, 然后处理集群关闭期间产生的数据, 然后再关闭集群. 这种情况下很有用. 它可以显著的降低成本. 一般用于非实时的数据分析
- Continuous以最低的延迟进行数据处理
代码设置如下:
val df1 = df.writeStream
.outputMode("append")
.format("console")
.start()
val df1 = df.writeStream
.outputMode("append")
.format("console")
.trigger(Trigger.ProcessingTime("2 seconds"))
.start
valdf1 = df.writeStream
.outputMode("append")
.format("console")
.trigger(Trigger.Once())
.start()
val df1 = df.writeStream
.outputMode("append")
.format("console")
.trigger(Trigger.Continuous("1 seconds"))
.start

