回在这个位置
加上这个了吗?
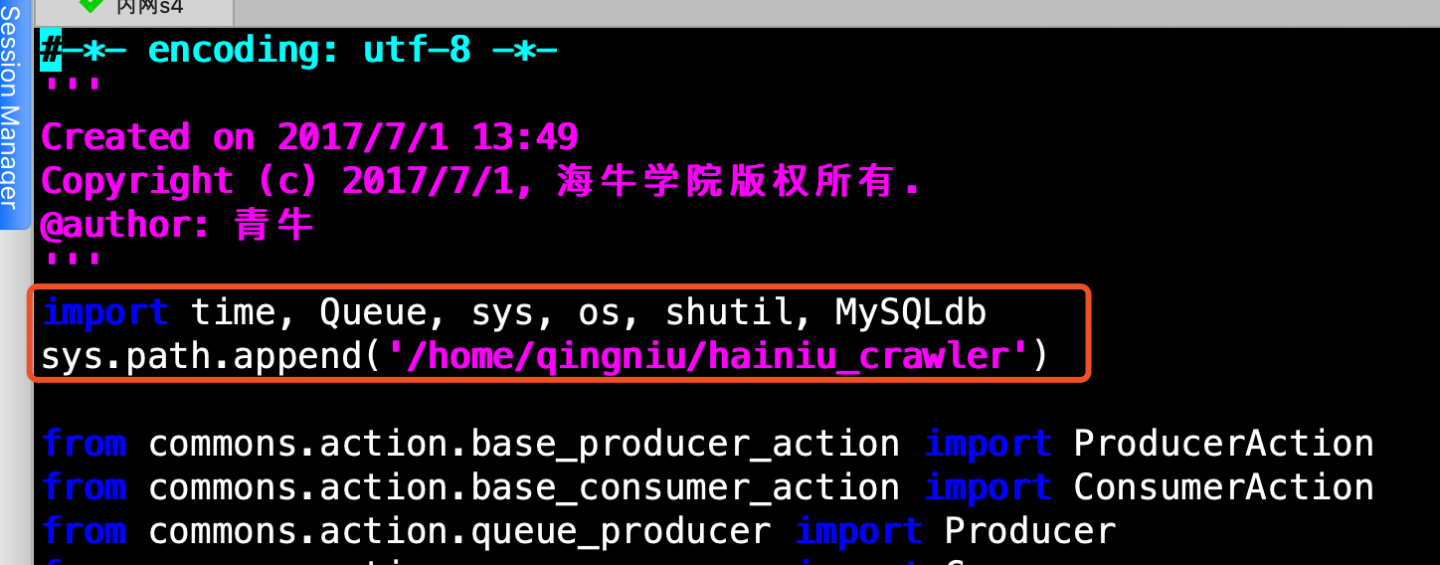
import time, Queue, sys, os, shutil, MySQLdb sys.path.append('/home/hadoop/hainiu_crawler')
1.mapreduce不就是一个可以并发的大find吗
2.不用汇集到一个目录里面,使用mr的多目录输入
FileInputFormat.setInputPaths(job, inputPaths);
zkfc监控自己机器的nn状态,如果自己机器的nn挂了,那将通知别一个机器的zkfc把它所在机器的nn变成active,那这个过程就说明两台机器的zkfc中有联系的。比如掉电这种幻想中的操作,活着zkfc就让自己机器的nn变成active了,并且在zk中向世界公布这个状态。
执行journalctl -xe看一下是什么错误
@LUNLI mysqlclient装了吗?我看你报错提示里面有mysql
@wwwzhangnanwc 给你咱们线下班python数据分析课程的视频 https://pan.baidu.com/s/1j4OtcqTVw003Q7PDBuYuCg 密码: pili
setuptools没装对?
@wwwzhangnanwc 你说py那些数据分析工具啊?那些是数据分析方面的课程,咱们是数据开发的课程。
这个mx安装可能是网络的问题
把其它机器的那个文件拷贝过去试试
上传的过程中当然不能移动了,不过可以使用flume直接读access日志,然后flume自己实现文件小时切分,这样就不用接住crontab了,你可以问一下潘老师。 公司集群使用flume,以后脚本的方式指定要抛弃。 不同的数据源,可以配置不同的flume-agent实现。 其实你问这3个问题都能用flume解决
pycharm是管理员模式打开的吗?
不存在你说的第二种方案,ODS层是直接上传就完事了。用hive和mr都可以到ETL从ODS到DWD。hive做脏数据统计麻烦,mr可以用counter做脏数据统计。写mr的方式好,这样可以既出数据又做了脏数据统计。
复杂的字段格式转换现有函数不能完成时需要自己定制一个udf,hive大小表join满足条件自动的优化成semijoin所以不用特意写个udf。